Cross-platform semantic memory for AI coding agents.





- 🌐 All Platforms, One Memory — memories flow across Claude Code, OpenClaw, OpenCode, and Codex CLI. A conversation in one agent becomes searchable context in all others — no extra setup
- 👥 For Agent Users, install a plugin and get persistent memory with zero effort; for Agent Developers, use the full CLI and Python API to build memory and harness engineering into your own agents
- 📄 Markdown is the source of truth — inspired by OpenClaw. Your memories are just
.mdfiles — human-readable, editable, version-controllable. Milvus is a "shadow index": a derived, rebuildable cache - 🔍 Progressive retrieval, hybrid search, smart dedup, live sync — 3-layer recall (search → expand → transcript); dense vector + BM25 sparse + RRF reranking; SHA-256 content hashing skips unchanged content; file watcher auto-indexes in real time
Pick your platform, install the plugin, and you're done. Each plugin captures conversations automatically and provides semantic recall with zero configuration.
# Install
/plugin marketplace add zilliztech/memsearch
/plugin install memsearch
# Restart Claude Code to activate the pluginAfter restarting, just chat with Claude Code as usual. The plugin captures every conversation turn automatically.
Verify it's working — after a few conversations, check your memory files:
ls .memsearch/memory/ # you should see daily .md files
cat .memsearch/memory/$(date +%Y-%m-%d).mdRecall memories — two ways to trigger:
/memory-recall what did we discuss about Redis?
Or just ask naturally — Claude auto-invokes the skill when it senses the question needs history:
We discussed Redis caching before, what was the TTL we chose?
# Install from ClawHub
openclaw plugins install clawhub:memsearch
openclaw gateway restartAfter installing, chat in TUI as usual. The plugin captures each turn automatically.
Verify it's working — memory files are stored in your agent's workspace:
# For the main agent:
ls ~/.openclaw/workspace/.memsearch/memory/
# For other agents (e.g. work):
ls ~/.openclaw/workspace-work/.memsearch/memory/Recall memories — two ways to trigger:
/memory-recall what was the batch size limit we set?
Or just ask naturally — the LLM auto-invokes memory tools when it senses the question needs history:
We discussed batch size limits before, what did we decide?
🔧 For OpenCode Users
// In ~/.config/opencode/opencode.json
{ "plugin": ["@zilliz/memsearch-opencode"] }After installing, chat in TUI as usual. A background daemon captures conversations.
Verify it's working:
ls .memsearch/memory/ # daily .md files appear after a few conversationsRecall memories — two ways to trigger:
/memory-recall what did we discuss about authentication?
Or just ask naturally — the LLM auto-invokes memory tools when it senses the question needs history:
We discussed the authentication flow before, what was the approach?
🔧 For Codex CLI Users
# Install
bash memsearch/plugins/codex/scripts/install.sh
codex --yolo # needed for ONNX model network accessAfter installing, chat as usual. Hooks capture and summarize each turn.
Verify it's working:
ls .memsearch/memory/Recall memories — use the skill:
$memory-recall what did we discuss about deployment?
All plugins share the same memsearch backend. Configure once, works everywhere.
Defaults to ONNX bge-m3 — runs locally on CPU, no API key, no cost. On first launch the model (~558 MB) is downloaded from HuggingFace Hub.
memsearch config set embedding.provider onnx # default — local, free
memsearch config set embedding.provider openai # needs OPENAI_API_KEY
memsearch config set embedding.provider ollama # local, any modelAll providers and models: Configuration — Embedding Provider
Just change milvus_uri (and optionally milvus_token) to switch between deployment modes:
Milvus Lite (default) — zero config, single file. Great for getting started:
# Works out of the box, no setup needed
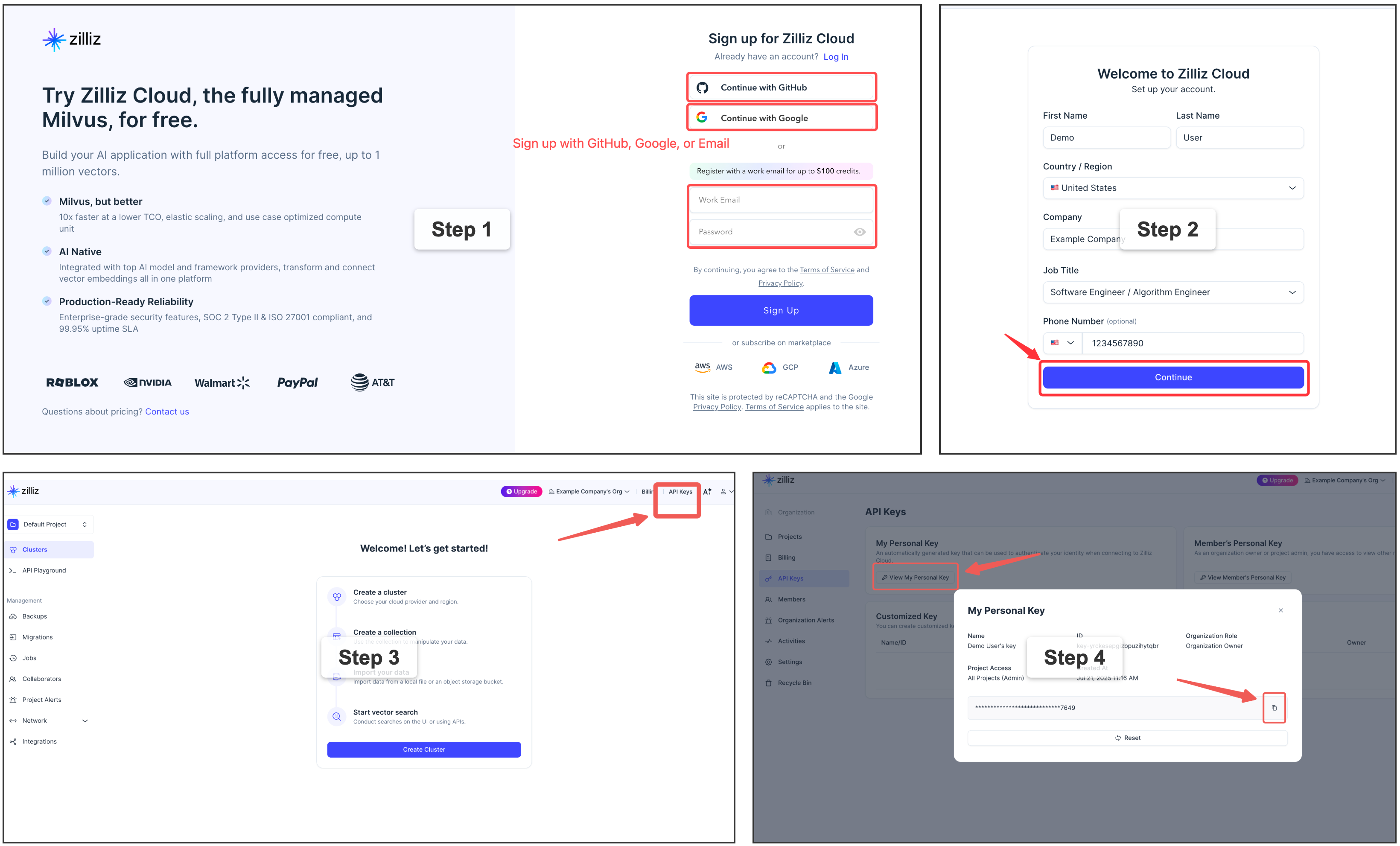
memsearch config get milvus.uri # → ~/.memsearch/milvus.db⭐ Zilliz Cloud (recommended) — fully managed, free tier available — sign up 👇:
memsearch config set milvus.uri "https://in03-xxx.api.gcp-us-west1.zillizcloud.com"
memsearch config set milvus.token "your-api-key"⭐ Sign up for a free Zilliz Cloud cluster
You can sign up on Zilliz Cloud to get a free cluster and API key.
Self-hosted Milvus Server (Docker) — for advanced users
For multi-user or team environments with a dedicated Milvus instance. Requires Docker. See the official installation guide.
memsearch config set milvus.uri http://localhost:19530📖 Full configuration guide: Configuration · Platform comparison
Beyond ready-to-use plugins, memsearch provides a complete CLI and Python API for building memory into your own agents. Whether you're adding persistent context to a custom agent, building a memory-augmented RAG pipeline, or doing harness engineering — the same core engine that powers the plugins is available as a library.
┌──────────────────────────────────────────────────────────────┐
│ 🧑💻 For Agent Users (Plugins) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌────────┐ ┌──────┐ │
│ │ Claude │ │ OpenClaw │ │ OpenCode │ │ Codex │ │ Your │ │
│ │ Code │ │ Plugin │ │ Plugin │ │ Plugin │ │ App │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ └───┬────┘ └──┬───┘ │
│ └─────────────┴────────────┴───────────┴────────┘ │
├────────────────────────────┬─────────────────────────────────┤
│ 🛠️ For Agent Developers │ Build your own with ↓ │
│ ┌─────────────────────────┴──────────────────────────────┐ │
│ │ memsearch CLI / Python API │ │
│ │ index · search · expand · watch · compact │ │
│ └─────────────────────────┬──────────────────────────────┘ │
│ ┌─────────────────────────┴──────────────────────────────┐ │
│ │ Core: Chunker → Embedder → Milvus │ │
│ │ Hybrid Search (BM25 + Dense + RRF) │ │
│ └────────────────────────────────────────────────────────┘ │
├──────────────────────────────────────────────────────────────┤
│ 📄 Markdown Files (Source of Truth) │
│ memory/2026-03-27.md · memory/2026-03-26.md · ... │
└──────────────────────────────────────────────────────────────┘
Plugins sit on top of the CLI/API layer. The API handles indexing, searching, and Milvus sync. Markdown files are always the source of truth — Milvus is a rebuildable shadow index. Everything below the plugin layer is what you use as an agent developer.
Capture — after each conversation turn:
User asks question → Agent responds → Stop hook fires
│
┌────────────────────┘
▼
Parse last turn
│
▼
LLM summarizes (haiku)
"- User asked about X."
"- Claude did Y."
│
▼
Append to memory/2026-03-27.md
with <!-- session:UUID --> anchor
│
▼
memsearch index → Milvus
Recall — 3-layer progressive search:
User: "What did we discuss about batch size?"
│
▼
L1 memsearch search "batch size" → ranked chunks
│ (need more?)
▼
L2 memsearch expand <chunk_hash> → full .md section
│ (need original?)
▼
L3 parse-transcript <session.jsonl> → raw dialogue
Plugins append ──→ .md files ←── human editable
│
▼
memsearch watch (live watcher)
│
detects file change
│
▼
re-chunk changed .md
│
hash each chunk (SHA-256)
│
┌───────────┴───────────┐
▼ ▼
hash unchanged? hash is new/changed?
→ skip (no API call) → embed → upsert to Milvus
│ │
└───────────┬───────────┘
▼
┌──────────────────┐
│ Milvus (shadow) │
│ always in sync │
│ rebuildable │
└──────────────────┘
# pip
pip install memsearch
# or uv (recommended)
uv add memsearchOptional embedding providers
pip install "memsearch[onnx]" # Local ONNX (recommended, no API key)
# or: uv add "memsearch[onnx]"
# Other options: [openai], [google], [voyage], [ollama], [local], [all]from memsearch import MemSearch
mem = MemSearch(paths=["./memory"])
await mem.index() # index markdown files
results = await mem.search("Redis config", top_k=3) # semantic search
scoped = await mem.search("pricing", top_k=3, source_prefix="./memory/product")
print(results[0]["content"], results[0]["score"]) # content + similarityFull example — agent with memory (OpenAI) — click to expand
import asyncio
from datetime import date
from pathlib import Path
from openai import OpenAI
from memsearch import MemSearch
MEMORY_DIR = "./memory"
llm = OpenAI() # your LLM client
mem = MemSearch(paths=[MEMORY_DIR]) # memsearch handles the rest
def save_memory(content: str):
"""Append a note to today's memory log (OpenClaw-style daily markdown)."""
p = Path(MEMORY_DIR) / f"{date.today()}.md"
p.parent.mkdir(parents=True, exist_ok=True)
with open(p, "a") as f:
f.write(f"\n{content}\n")
async def agent_chat(user_input: str) -> str:
# 1. Recall — search past memories for relevant context
memories = await mem.search(user_input, top_k=3)
context = "\n".join(f"- {m['content'][:200]}" for m in memories)
# 2. Think — call LLM with memory context
resp = llm.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": f"You have these memories:\n{context}"},
{"role": "user", "content": user_input},
],
)
answer = resp.choices[0].message.content
# 3. Remember — save this exchange and index it
save_memory(f"## {user_input}\n{answer}")
await mem.index()
return answer
async def main():
# Seed some knowledge
save_memory("## Team\n- Alice: frontend lead\n- Bob: backend lead")
save_memory("## Decision\nWe chose Redis for caching over Memcached.")
await mem.index() # or mem.watch() to auto-index in the background
# Agent can now recall those memories
print(await agent_chat("Who is our frontend lead?"))
print(await agent_chat("What caching solution did we pick?"))
asyncio.run(main())Anthropic Claude example — click to expand
pip install memsearch anthropicimport asyncio
from datetime import date
from pathlib import Path
from anthropic import Anthropic
from memsearch import MemSearch
MEMORY_DIR = "./memory"
llm = Anthropic()
mem = MemSearch(paths=[MEMORY_DIR])
def save_memory(content: str):
p = Path(MEMORY_DIR) / f"{date.today()}.md"
p.parent.mkdir(parents=True, exist_ok=True)
with open(p, "a") as f:
f.write(f"\n{content}\n")
async def agent_chat(user_input: str) -> str:
# 1. Recall
memories = await mem.search(user_input, top_k=3)
context = "\n".join(f"- {m['content'][:200]}" for m in memories)
# 2. Think — call Claude with memory context
resp = llm.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=1024,
system=f"You have these memories:\n{context}",
messages=[{"role": "user", "content": user_input}],
)
answer = resp.content[0].text
# 3. Remember
save_memory(f"## {user_input}\n{answer}")
await mem.index()
return answer
async def main():
save_memory("## Team\n- Alice: frontend lead\n- Bob: backend lead")
await mem.index()
print(await agent_chat("Who is our frontend lead?"))
asyncio.run(main())Ollama (fully local, no API key) — click to expand
pip install "memsearch[ollama]"
ollama pull nomic-embed-text # embedding model
ollama pull llama3.2 # chat modelimport asyncio
from datetime import date
from pathlib import Path
from ollama import chat
from memsearch import MemSearch
MEMORY_DIR = "./memory"
mem = MemSearch(paths=[MEMORY_DIR], embedding_provider="ollama")
def save_memory(content: str):
p = Path(MEMORY_DIR) / f"{date.today()}.md"
p.parent.mkdir(parents=True, exist_ok=True)
with open(p, "a") as f:
f.write(f"\n{content}\n")
async def agent_chat(user_input: str) -> str:
# 1. Recall
memories = await mem.search(user_input, top_k=3)
context = "\n".join(f"- {m['content'][:200]}" for m in memories)
# 2. Think — call Ollama locally
resp = chat(
model="llama3.2",
messages=[
{"role": "system", "content": f"You have these memories:\n{context}"},
{"role": "user", "content": user_input},
],
)
answer = resp.message.content
# 3. Remember
save_memory(f"## {user_input}\n{answer}")
await mem.index()
return answer
async def main():
save_memory("## Team\n- Alice: frontend lead\n- Bob: backend lead")
await mem.index()
print(await agent_chat("Who is our frontend lead?"))
asyncio.run(main())📖 Full Python API reference: Python API docs
Setup:
memsearch config init # interactive setup wizard
memsearch config set embedding.provider onnx # switch embedding provider
memsearch config set milvus.uri http://localhost:19530 # switch Milvus backendIndex & Search:
memsearch index ./memory/ # index markdown files
memsearch index ./memory/ ./notes/ --force # re-embed everything
memsearch search "Redis caching" # hybrid search (BM25 + vector)
memsearch search "auth flow" --top-k 10 --json-output # JSON for scripting
memsearch expand <chunk_hash> # show full section around a chunkLive Sync & Maintenance:
memsearch watch ./memory/ # live file watcher (auto-index on change)
memsearch compact # LLM-powered chunk summarization
memsearch stats # show indexed chunk count
memsearch reset --yes # drop all indexed data and rebuild📖 Full CLI reference with all flags: CLI docs
Embedding and Milvus backend settings → Configuration (all platforms)
Settings priority: Built-in defaults → ~/.memsearch/config.toml → .memsearch.toml → CLI flags.
📖 Full config guide: Configuration
- 📖 Documentation — full guides, API reference, and architecture details
- 🔌 Platform Plugins — Claude Code, OpenClaw, OpenCode, Codex CLI
- 💡 Design Philosophy — why markdown, why Milvus, competitor comparison
- 🦞 OpenClaw — the memory architecture that inspired memsearch
- 🗄️ Milvus | Zilliz Cloud — the vector database powering memsearch
Bug reports, feature requests, and pull requests are welcome! See the Contributing Guide for development setup, testing, and plugin development instructions. For questions and discussions, join us on Discord.