A simple yet powerful dictionary web application with autocomplete and spell-checking features, leveraging advanced data structures and algorithms. Built using Java and Spring Boot for a University DSA Project.

- Autocomplete: Quickly find words as you type using a Trie data structure.
- Spell-checking: Identify and correct spelling errors using BK trees.
- Efficient Sorting: Words are sorted using a custom QuickSort algorithm.
- Query History Management: Utilizes an LRU Cache to efficiently manage and store recent search queries.
- Offline Support: Works seamlessly without an internet connection.
- Modern UI: Beautiful web interface using custom CSS and JavaScript to ensure a polished and engaging user experience.
- Backend: Java, Spring Boot
- Frontend: HTML (with Thymeleaf), CSS, JavaScript
- Java 21 (should work with other versions too)
- Maven (only if building)
-
Download the JAR files from the releases page:
dictionary-app-web.jarfor the web applicationdictionary-app-cli.jarfor the CLI interface
-
Run the web application JAR: Navigate to the directory containing the .jar files.
java -jar dictionary-app-web.jar
If it didn't autostart, Open your browser and navigate to
http://localhost:8080 -
Run the CLI JAR:
java -jar dictionary-app-cli.jar
-
Download Files from Releases:
- Go to the releases page.
- Download the following files:
dictionary-app-web.jar(for the web application)run-dictionary-app.bat(batch script to start the web application)
-
Prepare the Directory:
- Create a new directory on your system or use an existing one.
- Move both downloaded files (
dictionary-app-web.jarandrun-dictionary-app.bat) into this directory.
-
Run the Web Application:
- Double-click on
run-dictionary-app.batto start the web application. This script will automatically execute the JAR file and open the application.
- Double-click on
-
Access the Application:
- Open your browser and navigate to
http://localhost:8080to start using the web application (if it didn't autostart).
- Open your browser and navigate to
- Clone the repository:
git clone https://github.com/thebooleanguy/dictionary-app.git cd dictionary-app
-
Build and run the application:
./mvnw spring-boot:run
-
Access the application: Open your browser and navigate to
http://localhost:8080if it didn't autostart.
-
Import Project into Your IDE:
-
IntelliJ IDEA:
- Open IntelliJ IDEA.
- Select
File>Open.... - Navigate to the directory where you cloned the repository and select it.
- IntelliJ IDEA will recognize it as a Maven project and automatically import it.
-
NetBeans:
- Open NetBeans.
- Select
File>Open Project.... - Navigate to the directory where you cloned the repository and select the
dictionary-appfolder. - NetBeans will detect the project as a Maven project and import it.
-
-
Build the Project:
-
IntelliJ IDEA:
- Go to
Build>Build Projector use the shortcutCtrl + F9.
- Go to
-
NetBeans:
- Right-click on the project in the
Projectswindow and selectBuild.
- Right-click on the project in the
-
-
Run the Application:
-
IntelliJ IDEA:
- Click the green
Runbutton or right-click on the main application class (e.g.,DictionaryWebAppApplication.java) and selectRun 'DictionaryWebAppApplication'.
- Click the green
-
NetBeans:
- Right-click on the project in the
Projectswindow and selectRun.
- Right-click on the project in the
-
dictionary-app/
├── src/
│ └── main/
│ ├── java/com/thebooleanguy/dictionary/
│ │ ├── controller/ # Spring Boot controllers (e.g., DictionaryController) which handle HTTP requests and responses.
│ │ ├── model/ # Data models (e.g., Word, SearchResult)
│ │ ├── service/ # Service layers (e.g., DictionaryService) that handle business logic and interact with data structures.
│ │ ├── util/ # Utility classes (e.g., DictionaryFileLoader for parsing datasets).
│ │ ├── DictionaryCLI.java # CLI interface independent of Spring Boot.
│ │ ├── DictionaryWebAppApplication.java # The main class that runs the Spring Boot application.
│ │ └── dataStructure/ # Contains data structures and algorithms.
│ │ ├── algorithms/ # Algorithms (e.g., QuickSort, LevenshteinDistance)
│ │ └── structures/ # Data structures (e.g., Trie, BKTree, LRUCache, HashMap)
│ └── resources/ # Contains application resources.
│ │ ├── static/ # Static resources (e.g., CSS, JS) for styling and scripting.
│ │ └── templates/ # Thymeleaf templates (e.g., index.html, cachedView.html) used for rendering web pages dynamically.
│ └── test/ # Contains tests for the implemented data structures and algorithms
├── scripts # Contains miscellaneous scripts (e.g., python script used to generate word dataset, wrapper scripts to launch .jar)
├── .gitignore # Git ignore file
├── LICENSE # License file
├── pom.xml # Maven project file
└── README.md # Readme file
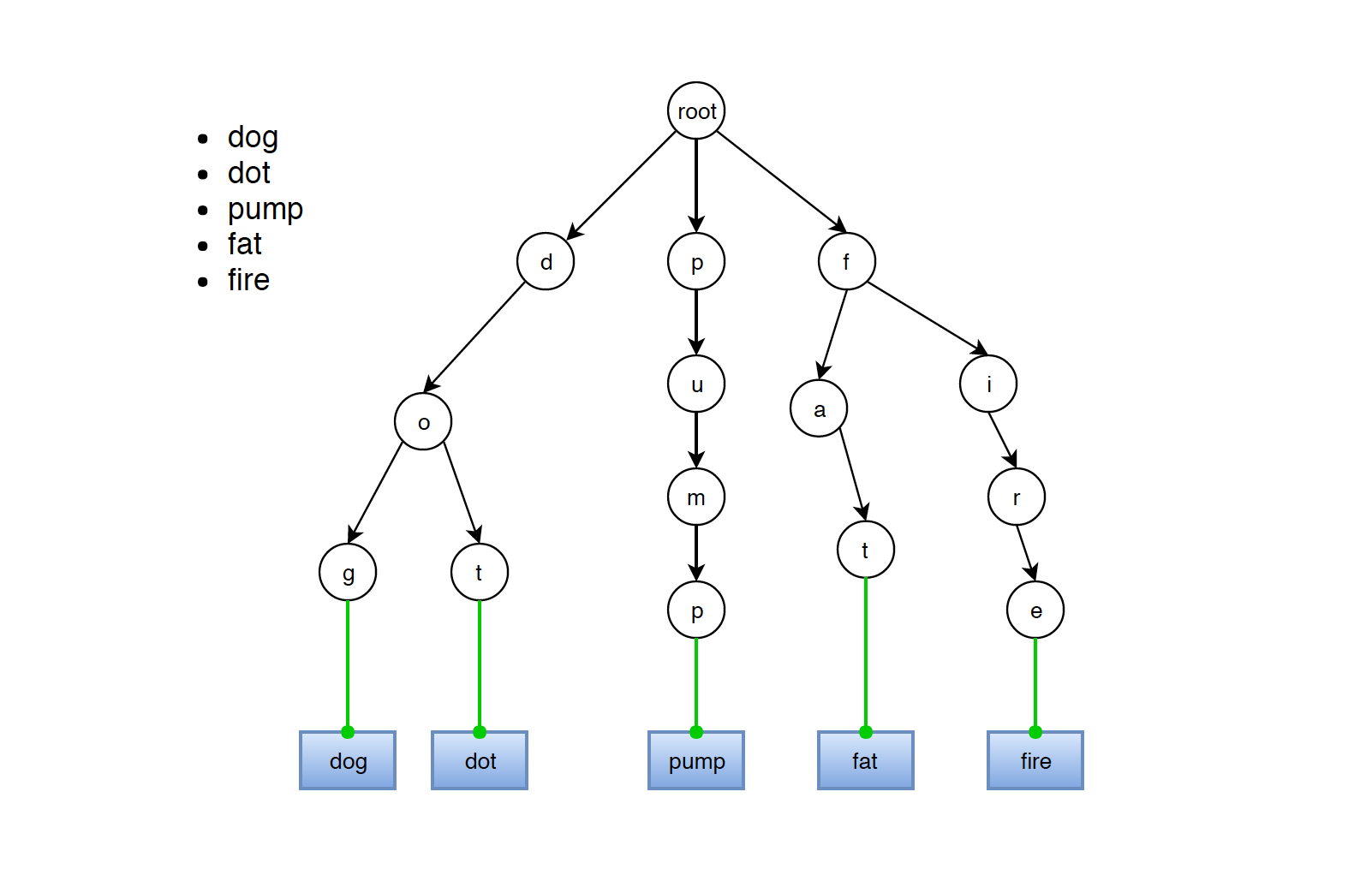
- Description: A tree-like data structure for efficient retrieval of words with autocomplete functionality.
- How It Works:
- Words are inserted into the Trie, creating nodes for each character in the word.
- Searches are performed by traversing nodes corresponding to the characters of the word.
- Supports efficient prefix searches and autocomplete features.
- Usage: Useful for implementing features like word suggestions and prefix-based searches.
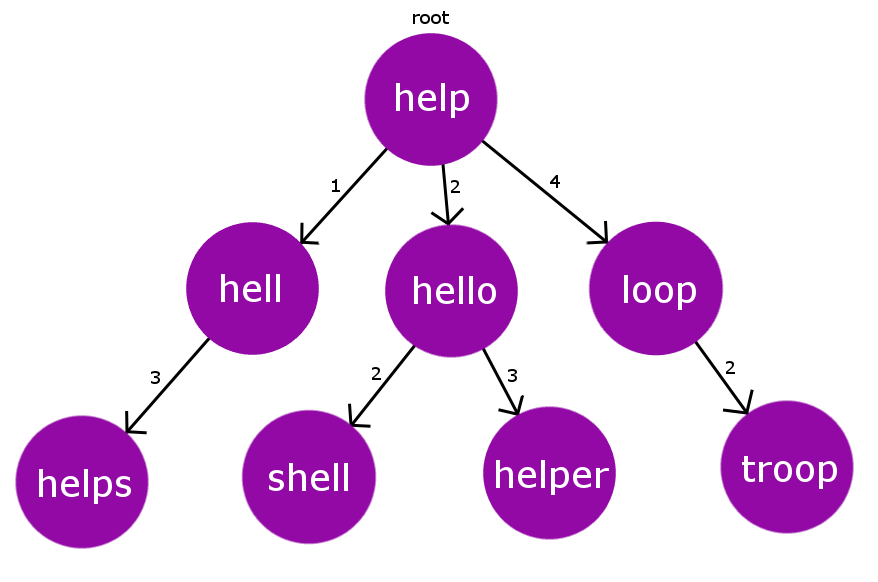
- Description: Used for approximate string matching. Finds words similar to a given word based on the Levenshtein distance (edit distance).
- How It Works:
- Words are added to the tree based on their distance from existing words using the Levenshtein distance.
- During the search, nodes within a specified distance are explored to find approximate matches.
- Usage: Ideal for spell-checking and fuzzy search functionalities.
- Description: The application uses an LRU (Least Recently Used) Cache to efficiently manage and store recent search queries. This ensures that only the most recent queries are kept, optimizing performance and memory usage.
- Components:
- LinkedList: Manages the order of entries, with the most recently used queries at the head and the least recently used queries at the tail.
- HashMap: Provides fast access to cache entries, mapping query strings to their corresponding nodes in the
LinkedList.
- How It Works:
- When a new search query is performed, the cache checks if the query is already present. If it is, the entry is moved to the front of the
LinkedList. - If the query is not present and the cache is full, the oldest entry (at the tail of the
LinkedList) is removed to make room for the new query. The corresponding entry in theHashMapis also removed. - The
LinkedListmaintains the order of entries, ensuring that the least recently used queries are evicted when the cache exceeds its capacity.
- When a new search query is performed, the cache checks if the query is already present. If it is, the entry is moved to the front of the
- Benefits:
- Performance: Constant time complexity for insertions, deletions, and look-ups due to the combination of
LinkedListandHashMap. - Memory Management: Optimizes memory usage by retaining only a fixed number of recent queries.
- User Experience: Provides quick access to recent searches without affecting application responsiveness.
- Performance: Constant time complexity for insertions, deletions, and look-ups due to the combination of

- Description: Measures the difference between two sequences by calculating the minimum number of single-character edits (insertions, deletions, or substitutions) required to transform one sequence into the other.
- Usage: Used by the BK Tree to find approximate matches based on edit distance.
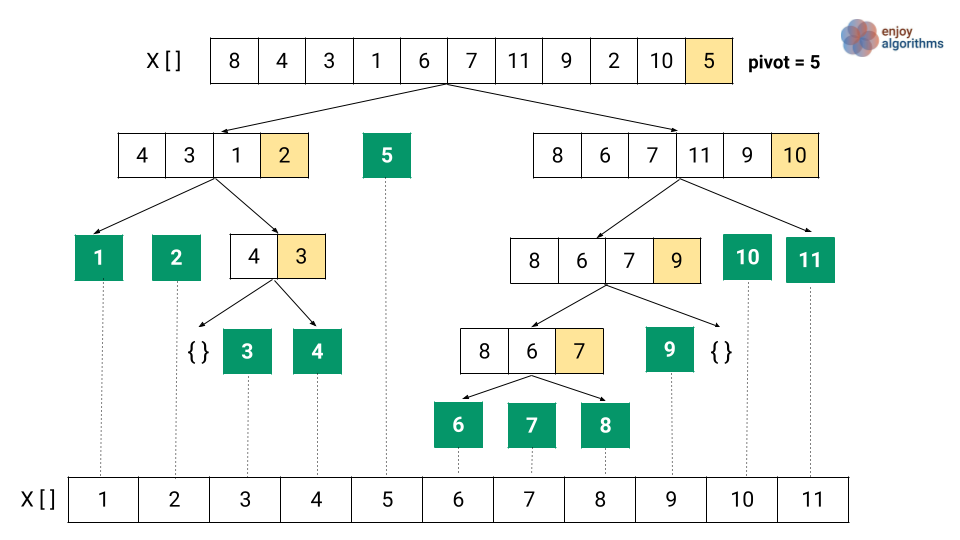
- Description: A highly efficient sorting algorithm using a divide-and-conquer approach to sort lists.
- How It Works:
- The list is divided into sublists based on a pivot element.
- Elements are rearranged so that elements greater than the pivot are on one side, and elements less than the pivot are on the other side.
- Recursively applies the same process to sublists.
- Usage: Utilized in the BK Tree and Trie implementations to sort results by frequency in descending order.
- Insertion/Search/Prefix Search: O(L) — Linear time complexity based on the length of the word, effectively constant time due to the fixed number of possible characters (26 for English alphabet).
- Insertion/Search: O(N * D) — Linear time complexity with respect to the number of entries (N) and average distance computation time (D).
- Computation: O(m * n) — Linear time complexity relative to the length of the words being compared.
- Average Case: O(n log n) — Efficient linearithmic time complexity for sorting elements.
- Worst Case: O(n^2) — Quadratic time complexity in cases of poor pivot selection.
- Insertion/Deletion/Lookup: O(1) — Constant time complexity using HashMap and LinkedList.
This project is a collaborative effort with contributions from the following team members:
- E.A.S.V. Edirisinghe (COHNDSE241F-051)
- W.A.T.S. Abeyrathna (COHNDSE241F-064)
- H.M.A.K. Chandrasiri (COHNDSE241F-093)