Up to 86% fewer FLOPs · accuracy kept · 18 benchmark datasets · no GPU required

Compress any PyTorch model with one function call. dNATY uses multi-objective evolutionary search (NSGA-II) guided by episodic memory to find smaller, faster architectures — automatically, on a standard CPU.
pip install dnatyWebsite · Docs · Benchmarks · Changelog
import torch.nn as nn
from dnaty import compress
from dnaty.experiments.fast_dataset import FastDataset
# 1. Your model — any nn.Module with Linear layers
model = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 512), nn.ReLU(),
nn.Linear(512, 256), nn.ReLU(),
nn.Linear(256, 10)
)
# 2. Load dataset (cached in RAM — zero I/O across generations)
ds = FastDataset("MNIST", device="cpu", train_subset=10_000)
# 3. Compress
result = compress(model, ds, target_flops=0.5, n_generations=30)
print(result.summary())
# CompressResult | arch=[301, 153, 128] | FLOPs -46.5% (1,133,056 → 605,802)
# | params -46.5% (536K → 286K) | acc=0.9859The compressed model is a regular nn.Module — drop it into your existing pipeline:
result.model # nn.Module, ready for inference
result.accuracy # 0.9859
result.flops_reduction_pct # 46.5
result.arch # [301, 153, 128] ← hidden layer sizes found
# Save / reload
result.save("compressed.pt")
result = dnaty.load("compressed.pt")
# Export to ONNX for edge deployment (no PyTorch needed on the device)
result.export_onnx("model.onnx", input_shape=(784,))
# Measure real CPU latency on your machine
print(result.benchmark_latency((784,))) # p50/p95/p99 ms + fpsThe problem: most models ship larger than they need to be. That means slower inference, higher cloud bills, and models too heavy for edge devices (cameras, drones, robots, industrial boxes). Shrinking them by hand is days of trial-and-error with no guarantee you found the best size/accuracy trade-off.
What you get with dNATY:
- Smaller, cheaper models — 23–86% fewer FLOPs across 18 benchmark datasets, accuracy kept
- No GPU — the search runs on CPU in minutes, so it works in CI and on the hardware you already have
- No manual architecture design — point it at a model + dataset, get a deployable
nn.Moduleback - One function call —
compress(model, dataset); export to.pt/.onnx
Runtimes optimize execution of a fixed architecture. dNATY optimizes the architecture itself, upstream of any runtime. You don't choose between them — you chain them: compress() → export_onnx() → load into TensorRT / TFLite / ONNX Runtime. The savings stack.
| Method | What it does | Catch |
|---|---|---|
| Quantization | Lower-precision weights (fp32→int8) | Same architecture & op count. Stack it on top of dNATY. |
| Pruning | Zeroes individual weights | Needs sparse runtimes to actually run faster; manual tuning |
| Distillation | Trains a small student model | You design the student + write the training loop |
| DARTS | Gradient-based architecture search | Needs a GPU + hours of config |
| Random NAS | Random architecture sampling | No memory — re-tries bad ideas |
| dNATY | Evolves a smaller architecture, memory-guided | CPU-only, one call |
The engine is episodic memory-guided evolutionary search: operators that helped in past generations get sampled more often, so it converges 1.6× faster than random NAS — no gradients, no GPU.
All numbers measured on a standard desktop CPU, validation accuracy on a held-out 20% split, reproducible from scripts in this repo. Full tables, configs, and caveats: dnaty.org/benchmarks.
13 public datasets (n_generations=30, n_pop=15) — top rows:
| Dataset | Samples | FLOPs ↓ | Val acc | Domain |
|---|---|---|---|---|
| Electrical Fault Detect | 12,001 | −86.0% | 99.04% | smart grid sensors |
| Dry Bean Quality | 13,611 | −83.4% | 92.43% | agricultural IoT |
| Predictive Maint. (AI4I) | 10,000 | −83.1% | 96.70% | factory IoT |
| Breast Cancer (UCI) | 569 | −72.6% | 100.0% | clinical tabular |
| Credit Card Fraud (full) | 284,807 | −64.0% | 99.96% | financial anomaly |
| Network Intrusion (NSL-KDD) | 31,490 | −56.3% | 99.46% | edge security |
| HAR Sensors (UCI) | 10,299 | −46.8% | 99.17% | wearables · robotics |
| MNIST (full 70K) | 70,000 | −41.8% | 98.68% | vision · digits |
5 market-grade synthetic domains (n_generations=15, n_pop=12, deterministic feature-correlated labels):
| Dataset | Samples | FLOPs ↓ | Val acc |
|---|---|---|---|
| Telecom Churn Prediction | 35,000 | −64.6% | 99.94% |
| IoT Sensor Anomaly Detection | 50,000 | −61.4% | 99.18% |
| Financial Fraud Detection | 100,000 | −60.3% | 99.31% |
| E-commerce Purchase Propensity | 80,000 | −49.9% | 98.03% |
| Healthcare Risk Stratification | 25,000 | −23.3% | 93.74% |
Compression scales with how oversized the model is — dNATY finds the right size, it doesn't force a fixed cut. Lean models get small cuts (that's correct Pareto behavior, not a bug).
Continual learning (Split-MNIST, 5 tasks, 3 seeds)
| Method | Backward Transfer (BWT) | |
|---|---|---|
| dNATY (balanced replay) | −0.145 | 6.9× less forgetting |
| EWC | −0.999 | near-total forgetting |
| MLP (no CL) | −0.998 | baseline |
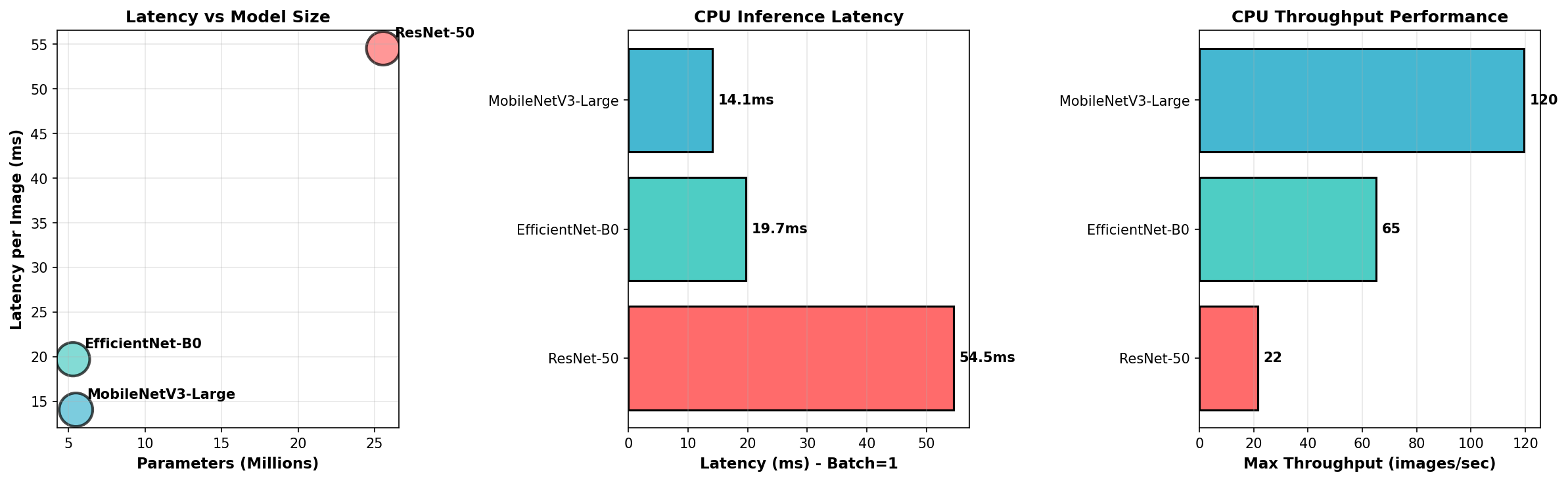
Reproduce: python scripts/prove_it.py (NAS vs random) · python scripts/benchmark_market_real.py (market datasets)
| You want to… | Use |
|---|---|
| Compress a tabular/sensor MLP | compress(model, data, target_flops=0.5) |
| Compress a small CNN trained from scratch | compress_cnn(model, loader) (early access — CIFAR-scale classification) |
| Compress the head of a pretrained backbone | compress_with_backbone(resnet, loader, finetune_backbone=True) |
| Thin out conv layers too | prune_conv_channels(model, amount=0.3) |
| Deploy without PyTorch on the device | result.export_onnx("m.onnx", input_shape=...) |
| Save / reload | result.save("m.pt") / dnaty.load("m.pt") |
| Detect data drift in production | DriftDetector().fit(X_train) + ProductionTracker(model, detector) |
| Profile compute before deciding | count_flops(model, input_shape) / flops_by_layer(...) |
Supported backbones for compress_with_backbone: ResNet, MobileNetV2/V3, EfficientNet, VGG, DenseNet, ViT, and custom models with an fc/classifier/head attribute.
Full reference with copy-paste recipes: dnaty.org/docs
import torchvision.models as tv
import dnaty
backbone = tv.mobilenet_v2(weights="IMAGENET1K_V1")
dnaty.prune_conv_channels(backbone, amount=0.2) # optional: thin convs first
result = dnaty.compress_with_backbone(
backbone, train_loader,
target_flops=0.4,
finetune_backbone=True, finetune_epochs=10,
)
result.export_onnx("mobilenet_edge.onnx", input_shape=(3, 224, 224))result = compress(model, ds, target_flops=0.5, n_generations=30, seed=42)
# Same seed → identical result. The pytest suite gates every release on this.Strong: MLPs on tabular/sensor data; classifier heads on frozen CNN/ViT backbones; CPU-only environments. Not yet: full convolutional NAS end-to-end (under development — convs are handled by structural pruning today); transformer/LLM compression; models that are already minimal (no fat → little or no cut, and the library warns you when the model would need to grow).
No comparison against OFA or MnasNet is claimed — those target full conv search spaces on GPUs; dNATY targets CPU-only workflows on a different problem slice.
pip install dnaty # stable (recommended)
pip install dnaty==1.1.6 # pin to this release
pip install git+https://github.com/pedrovergueiro/dNaty # latest from sourceRequirements: Python 3.10+, PyTorch 2.0+, NumPy 1.24+
pip install dnaty[dev] # adds pytest, matplotlib, jupyterdNaty/
├── dnaty/
│ ├── compress.py # public API: compress, compress_cnn,
│ │ # compress_with_backbone, prune_conv_channels
│ ├── result.py # CompressResult + load() — save/export/latency
│ ├── evolution/evolver.py # DnatyEvolver / CnnEvolver — NSGA-II search
│ ├── core/ # DynamicMLP, DynamicCNN, Individual, episodic memory
│ ├── operators/ # structural mutation operators (dense + conv)
│ ├── training/local_train.py # fast local trainer
│ ├── monitoring/ # DriftDetector, ProductionTracker
│ ├── utils/flops_counter.py # count_flops, flops_by_layer
│ └── experiments/fast_dataset.py # zero-I/O MNIST/FashionMNIST/CIFAR10 loader
├── scripts/ # prove_it.py, benchmark_market_real.py, ...
└── tests/ # pytest suite (57 tests) — gates every release
Prefer not to run it locally? dnaty.org hosts the same engine with a web UI and REST API — upload a CSV, get a compressed model back. Free tier: 1 training a day, no card.
@software{vergueiro_dnaty_2026,
author = {Vergueiro, Pedro},
title = {dNaty: Dynamic Neuro-Adaptive sYstem with evoluTionarY Learning},
year = {2026},
url = {https://github.com/pedrovergueiro/dNaty},
version = {1.1.6},
license = {BSL-1.1}
}Business Source License 1.1 — free for research, academic work, and personal projects. Commercial use requires a license: dnaty.org/commercial · pedrol.vergueiro@gmail.com