Project motivation:
- Including side-information in MDP RL framework
- Uncertainty Modeling by applying high-level stochastic processes (Ito' calculos, SDE, etc.)
- Applying cutting-edge techniques from DRL domain, such as: trust-regions, PPO to ACKTR and more.
https://www.youtube.com/watch?v=SKhTeI_TRno
from https://finance.yahoo.com/quote/%5EGSPC?p=^GSPC or from https://www.kaggle.com/janiobachmann/s-p-500-time-series-forecasting-with-prophet/data
we use value-based RL ( ddpg algo. has also a Policy netork model ) - the goal of the agent is to optimize the value function V(s) which is defined as a function that tells us the maximum expected future reward the agent shall get at each state. The value of each state is the total amount of the reward an RL agent can expect to collect over the future, from a particular state. we use TD (Temporal Difference) method to calculate value (probability of action) base on current and next state: TD In plain English, means maximum future reward for this state and action (s,a) is the immediate reward r plus maximum future reward for the next state

the model get updated every few days.
As illustrated in below figure The agent will use the above value function to select which state to choose at each step. The agent will always take the state with the biggest value.
model input :
- historical stock data
- historicsl market data
- investment status, and reward and value function
model output(action prediction):
- buy-entry to a new trade
- hold-do nothing
- sell-exit last trade

market env is essentially a time-series data-frame (RNNs work well with time-series data)
The policy network outputs an action daily the market returns the rewards of such actions (the profit) and all this data ( status, amount of money gain or lost), sent to policy network to train

there are 3 possible actions that the agent can take, hold, buy, sell there is a zero-market impact hypothesis, which essentially states that the agent’s action can never be significant enough to affect the market env. and the ai_agent will assign score for each action and state
State : Current situation returned by the environment.
this Q-learning implementation applied to (short-term) stock trading. The model uses t-day windows of close prices as features to determine if the best action to take at a given time is to buy, sell or hold.
Reward shaping is a technique inspired by animal training where supplemental rewards are provided to make a problem easier to learn. There is usually an obvious natural reward for any problem. For games, this is usually a win or loss. For financial problems, the reward is usually profit. Reward shaping augments the natural reward signal by adding additional rewards for making progress toward a good solution.
learning is based on immediate and long-term reward To make the model perform well in long-term, we need to take into account not only the immediate rewards but also the future rewards we are going to get.
In order to do this, we are going to have a ‘discount rate’ or ‘gamma’. If gamma=0 then agent will only learn to consider current rewards. if gamma=1 then agent will make it strive for a long-term high reward. This way the agent will learn to maximize the discounted future reward based on the given state.
the model is not very good at making decisions in long-term , but is quite good at predicting peaks and troughs.
Epsilon, aka exploration rate, this is the rate in which an agent randomly decides its action rather than prediction. epsilon_min, used to let the agent explore a minimum percent of randomness epsilon_decay- used to decrease the number of explorations as it gets good at trading.
-
Install python 3.7
- Anaconda, Python, IPython, and Jupyter notebooks
- Installing packages
condaenvironments
-
Install on Virtualenv (pip packages are defined on requirements.txt):
# Create a virtual environment
virtualenv -p /usr/local/bin/python3 venv
or
python -m venv venv
# activate the virtual environment.
source venv/bin/activate
# create requirements.txt
pip freeze > requirements.txt
# install packages
pip install -r requirements.txt
-
Download data
- training and test csv files from Yahoo! Finance
- put in
files/input/
-
Bring other features if u have
-
Train model. for good results run:
- with minimum 20,000 episodes (takes 24 hours on 2 ghz machine)
- on all data (or on 2011 which is interesting year)
- with GPU https://www.paperspace.com
- with dockerfile
-
Docker create image
- docker build -t app:1.0 .
- wait few minutes on 1st attempt to make this image(later it will be faster)
-
Docker run container(2 options)
- docker run -it /bin/bash
- python rl_dqn.py -na 'test_sinus' -ne 2000 -nf 20 -nn 64 -nb 20 (340min@t2, 225min@c5, profit161%)
- python backtest.py -na 'test_sinus' -nm 'model_ep2000' -tf 0. (profit : y$, z buys, z sells)
- python rl_dqn.py -na '^GSPC_2011' -ne 20000 -nf 20 -nn 64 -nb 20 (1440min@pc, x min@c5, profit x%)
- python backtest.py -na '^GSPC_2011' -nm 'model_ep20000' -tf 0. (profit : %125.664 , Total hold/buy/sell/notvalid trades: 0 / 55 / 55 / 123)
- or....
- docker run -na 'test_sinus' -ne 2000 -nf 20 -nn 64 -nb 20 (300 min)
-
See 3 plots generated
- episode vs profits
- episode vs trades
- episode vs epsilon
-
Back-test last model created in files/output/ on any stock
python backtest.py
Some examples of results on test sets:
-!^GSPC 2015 -S&P 500, 2015. Profit of $431.04.
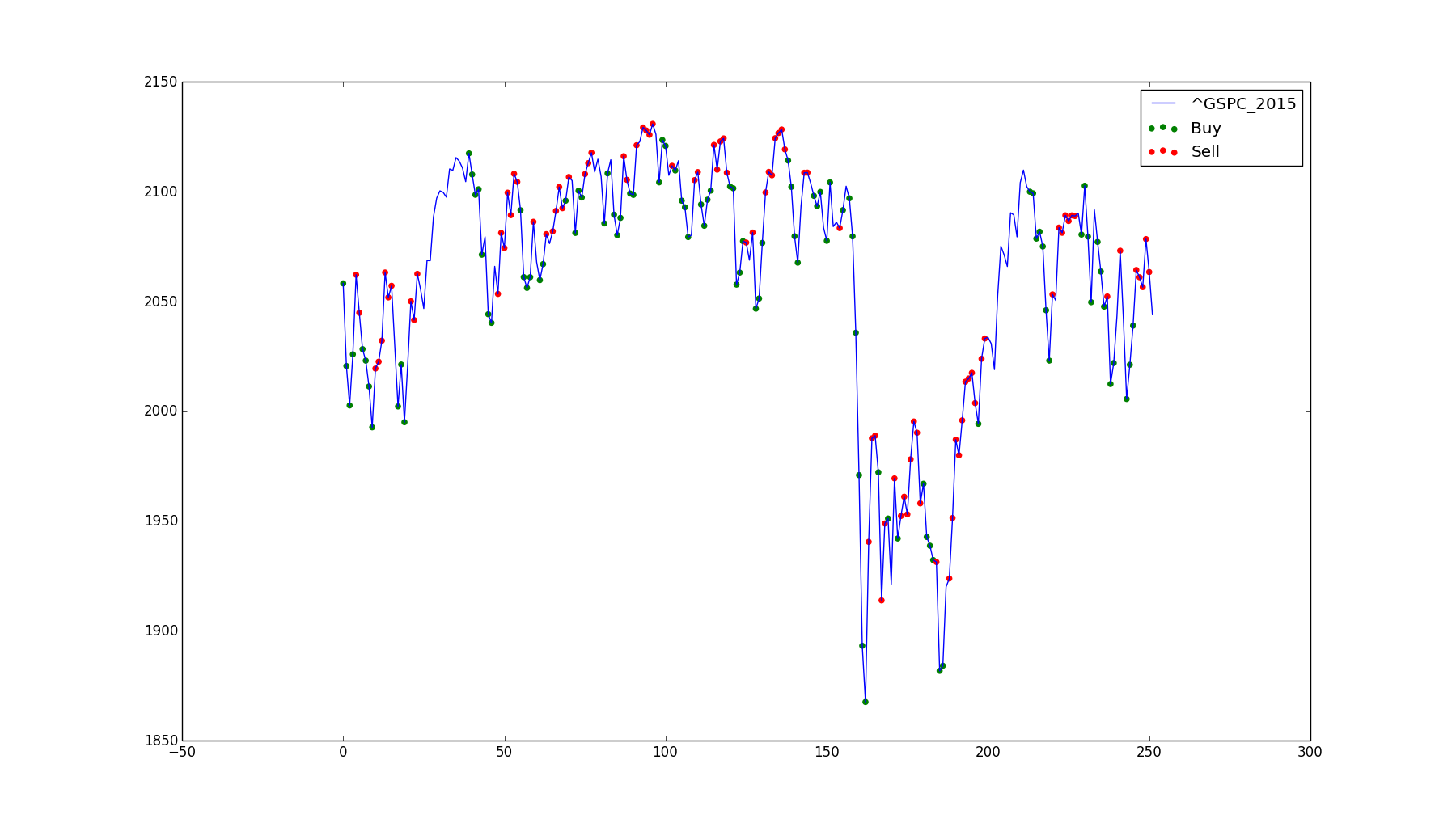{kind=link}
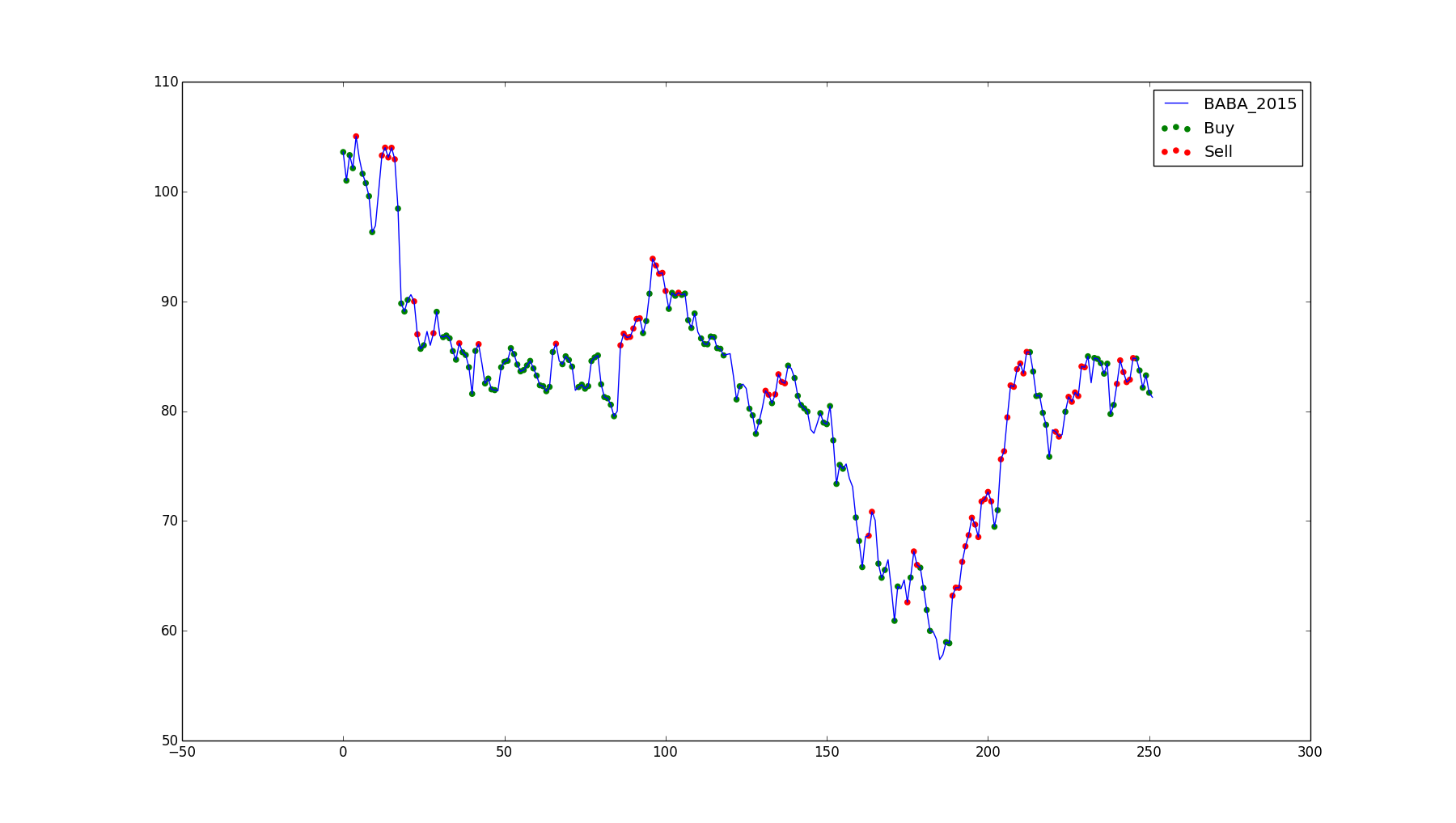 Alibaba Group Holding Ltd, 2015. Loss of $351.59.
Alibaba Group Holding Ltd, 2015. Loss of $351.59.
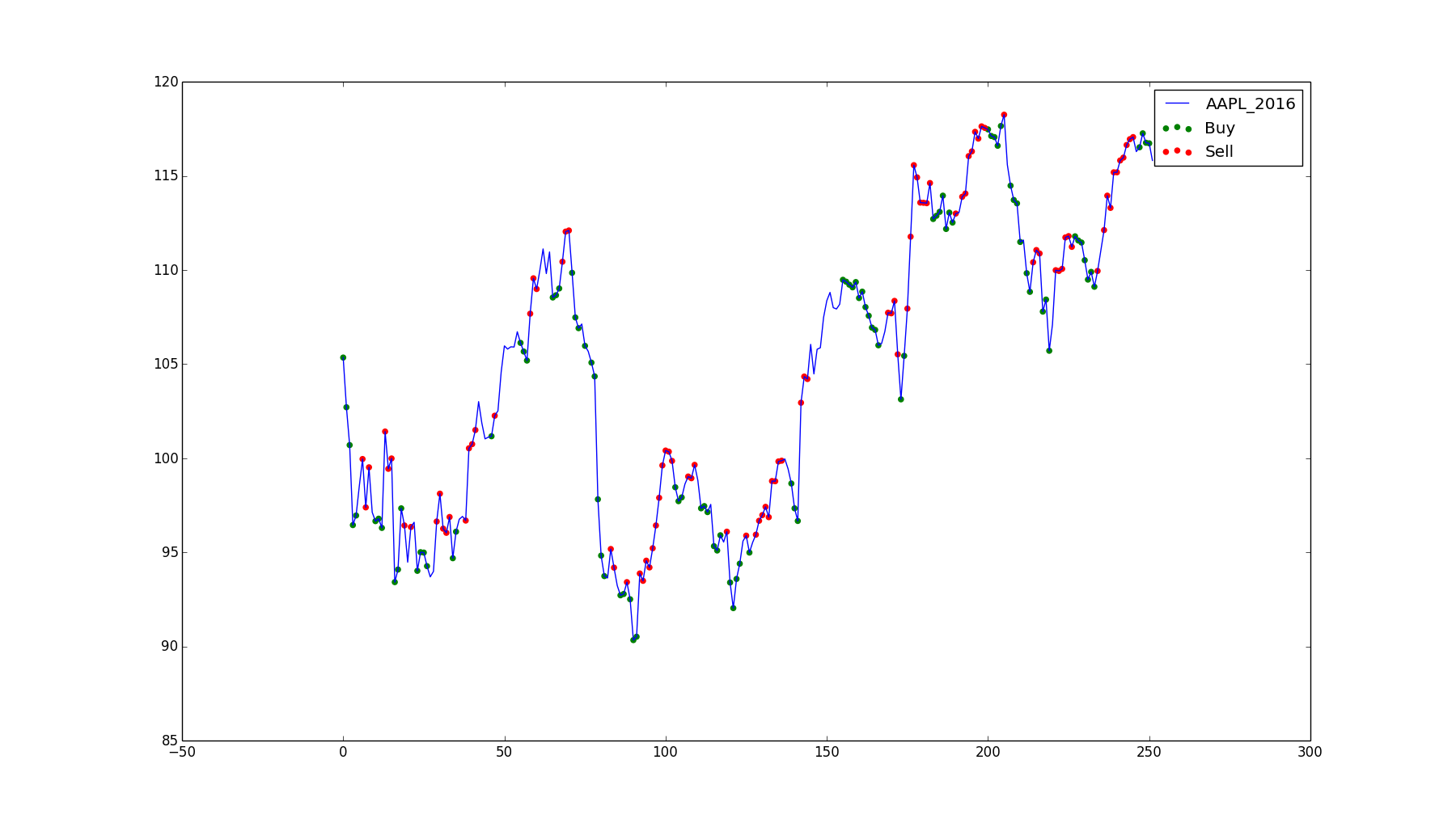 Apple, Inc, 2016. Profit of $162.73.
Apple, Inc, 2016. Profit of $162.73.
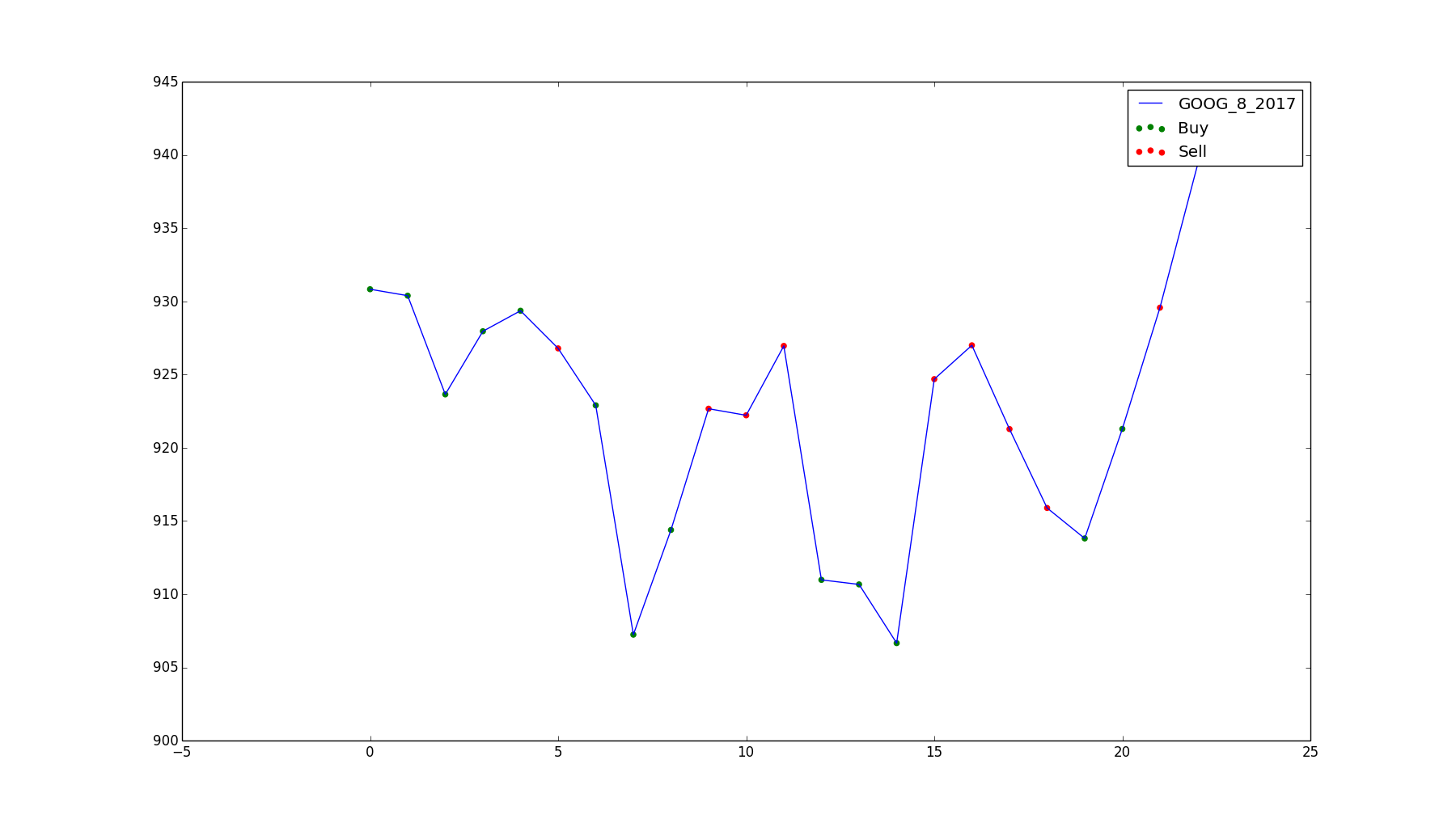 Google, Inc, August 2017. Profit of $19.37.
Google, Inc, August 2017. Profit of $19.37.
Deep Q-Learning with Keras and Gym - balance CartPole game with Q-learning
https://quantdare.com/deep-reinforcement-trading/
paper of Deep Q network by deep mind
paper Capturing Financial markets to apply Deep RL
https://github.com/notadamking/tensortrade/tree/master/tensortrade