Update: We are excited to share that MOISE+MARL was accepted at AAMAS 2025 in the Learning and Adaptation track. See you in Detroit!
MOISE+MARL is a MARL framework designed to integrate organizational concepts—such as roles, missions, and goals—into the learning process. By embedding these structures directly into standard MARL algorithms, MOISE+MARL enables more interpretable, efficient coordination among agents, helping them discover and follow well-defined organizational patterns while still adapting to complex or dynamic environments.
This repository provides an implementation of the MOISE+MARL framework, compatible with MARLlib algorithms and PettingZoo environments.
A JAX-based version of MOISE+MARL is currently under development to support environments and algorithms from JaxMARL.
| Environment | Reference | README | Summary |
|---|---|---|---|
| 🔴 MPE | Paper | Source | Communication-oriented tasks in a multi-agent particle world |
| 🍲 Overcooked | Paper | Source | Fully-cooperative human–AI coordination tasks based on the Overcooked video game |
| 🎆 Warehouse Management | Novel | Source | Fully-cooperative, partially-observable multiplayer management game |
| 👾 SMAX | Novel | Source | Simplified cooperative StarCraft micromanagement environment |
| 🧮 STORM: Spatial-Temporal Representations of Matrix Games | Paper | Source | Matrix games represented as grid-based scenarios |
| 🧭 JaxNav | Paper | Source | 2D geometric navigation for differential drive robots |
| 🪙 3rd CAGE Challenge | Paper | Source | Cyberdefense tasks against malware in a drone swarm scenario |
We employ CleanRL implementations of MARL algorithms, preserving CleanRL’s single-file philosophy. Our JAX-based algorithms follow the same CleanRL approach, consistent with JaxMARL.
| Algorithm | Reference | README |
|---|---|---|
| MAPPO | Paper | Source |
| COMA | Paper | Source |
| QMIX | Paper | Source |
| MADDPG | Paper | Source |
| IQL | Paper | Source |
| VDN | Paper | Source |
| IPPO | Paper | Source |
| TransfQMIX | Paper | Source |
| SHAQ | Paper | Source |
| PQN-VDN | Paper | Source |
To install dependencies for both MARLlib algorithms and PettingZoo environments:
cd marllib_moise_marl
./install.shTo install dependencies for JaxMARL-based algorithms and environments:
pip install -e .[jaxmarl]If you encounter JAX or JaxMARL-specific issues, please ensure a proper JaxMARL installation. For details, refer to the JaxMARL documentation.
Check you are able to activate the mma conda environment typing:
source ~/miniconda/etc/profile.d/conda.sh
conda activate mma
Then, from the MOISE+MARL project root, enter:
cd marllib_moise_marl/test_scenarios/
clear ; ./clean.sh ; python overcooked.py
If the 'overcooked-ai' rendered interface is dislayed, then your installation is likely completed.

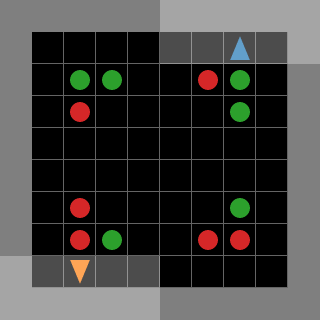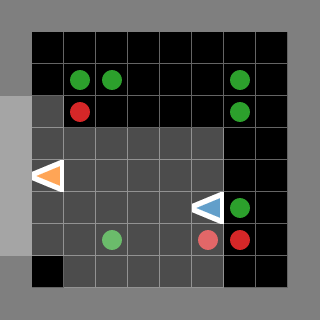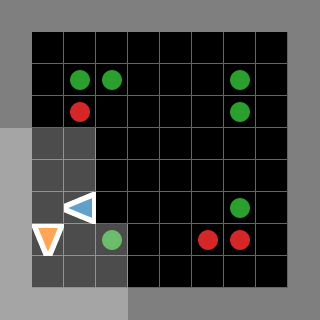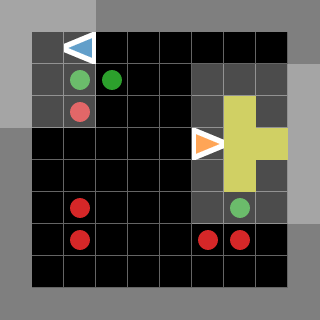



Examples of rendered environments as animated GIFs (some are adapted from [JaxMARL](https://github.com/FLAIROx/JaxMARL))
To train and test a MARL algorithm on a specific environment, look at the test_scenarios folder containing typical examples showing how to use MMA for various environments.
Notes:
- Incomplete training sessions are automatically saved as checkpoints.
- Checkpoints contain the latest training data
- Recorded environments are saved as mp4 video if 'record_env' is enabled.
For example, to train/test agents using MAPPO on the Overcooked AI environment:
clear ; ./clean.sh ; python overcooked.pyThe MOISE+MARL API (MMA) provides a series of classes and modified MARLlib functions. You can first implement a label_manager to handle observations and actions so you can conveniently use them to create roles and goals logics aftewards. Then, you can create an organizational_model that you can inject in the marllib.make_env function to make your organizational model effective during training.
MMA also features the Trajectory-based Evaluation in MOISE+MARL (TEMM) method, accessed via the TEMM class. This function takes a joint-policy model and produces a new MOISE+MARL model augmented with inferred organizational specifications with unsupervised learning techniques.
Here is an environment-agnostic skeleton code showing the underlying principles of MMA.
from marllib import marl
from mma_wrapper.label_manager import label_manager
from mma_wrapper.organizational_model import deontic_specification, organizational_model, structural_specifications, functional_specifications, deontic_specifications, time_constraint_type
from mma_wrapper.TEMM import TEMM
from mma_wrapper.organizational_specification_logic import role_logic, goal_factory, role_factory, goal_logic
from mma_wrapper.utils import label, observation, action, trajectory
from simple_env import simple_env
env = simple_env_v3.env(render_mode="human")
# Implement the observation/action label manager
class simple_label_manager(label_manager):
def one_hot_encode_observation(self, observation: Any, agent: str = None) -> 'observation':
...
return one_hot_encoded_observation
def one_hot_decode_observation(self, observation: observation, agent: str = None) -> Any:
...
return extracted_values
def one_hot_encode_action(self, action: Any, agent: str = None) -> action:
...
return encoded_action
def one_hot_decode_action(self, action: action, agent: str = None) -> Any:
...
return decoded_action
...
# Create some custom script rules
def role1_fun(trajectory: trajectory, observation: label, agent_name: str, label_manager: label_manager) -> label:
# print("Leader adversary")
data = label_manager.one_hot_decode_observation(
observation=observation, agent=agent_name)
...
return action
def role2_fun(trajectory: trajectory, observation: label, agent_name: str, label_manager: label_manager) -> label:
# print("Leader adversary")
data = label_manager.one_hot_decode_observation(
observation=observation, agent=agent_name)
...
return action
simple_label_mngr = simple_label_manager()
# Define a MOISE+MARL model
simple_model = organizational_model(
structural_specifications(
roles={
"role_1": role_logic(label_manager=simple_label_mngr).registrer_script_rule(role1_fun),
"role_2": role_logic(label_manager=simple_label_mngr).registrer_script_rule(role2_fun),
"role_3": role_logic(label_manager=simple_label_mngr).register_pattern_rule("[#any,#any](0,*)[o1,a1](1,1)", "o2", [("a1", 1), "a2", 1])
},
role_inheritance_relations={}, root_groups={}),
functional_specifications=functional_specifications(
goals={}, social_scheme={}, mission_preferences=[]),
deontic_specifications=deontic_specifications(permissions=[], obligations=[
deontic_specification("role_1", ["agent_0"], [], time_constraint_type.ANY),
deontic_specification("role_2", ["agent_1", "agent_2"], [], time_constraint_type.ANY)
]))
# prepare env
env = marl.make_env(environment_name="mpe",
map_name="simple_world_comm", organizational_model=simple_model)
# initialize algorithm with appointed hyper-parameters
# (here 'test' for debuging)
mappo = marl.algos.mappo(hyperparam_source="test")
# build agent model based on env + algorithms + user preference
model = marl.build_model(
env, mappo, {"core_arch": "mlp", "encode_layer": "128-256"})
# start training
mappo.fit(env, model, stop={'episode_reward_mean': 6000, 'timesteps_total': 20000000}, local_mode=False, num_gpus=0, num_gpus_per_worker=0,
num_workers=1, share_policy='group', checkpoint_freq=20)
# rendering from given checkpoint
mappo.render(env, model,
restore_path={
'params_path': "./exp_results/.../params.json",
'model_path': "./exp_results/.../checkpoint_000020/checkpoint-20",
# generates rendered mp4 videos
'record_env': True,
# runs the default rendering mechanism
'render_env': True
},
local_mode=True,
share_policy="group",
stop_timesteps=1,
timesteps_total=1,
checkpoint_freq=1,
stop_iters=1,
checkpoint_end=True)
@inproceedings{soule2024moise_marl,
title = {An Organizationally-Oriented Approach to Enhancing Explainability and Control in Multi-Agent Reinforcement Learning},
author = {Soulé, Julien and Jamont, Jean-Paul and Occello, Michel and Traonouez, Louis-Marie and Théron, Paul},
booktitle = {Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems (AAMAS)},
year = {2024},
series = {AAMAS '24},
pages = {XXX--XXX}, % TBD
publisher = {International Foundation for Autonomous Agents and Multiagent Systems},
address = {Detroit, USA},
month = {May},
abstract = {Multi-Agent Reinforcement Learning can lead to the development of collaborative agent behaviors that show similarities with organizational concepts. Pushing forward this perspective, we introduce a novel framework that explicitly incorporates organizational roles and goals from the $\mathcal{M}OISE^+$ model into the MARL process, guiding agents to satisfy corresponding organizational constraints. By structuring training with roles and goals, we aim to enhance both the explainability and control of agent behaviors at the organizational level, whereas much of the literature primarily focuses on individual agents. Additionally, our framework includes a post-training analysis method to infer implicit roles and goals, offering insights into emergent agent behaviors. This framework has been applied across various MARL environments and algorithms, demonstrating coherence between predefined organizational specifications and those inferred from trained agents.},
keywords = {Multi-Agent Reinforcement Learning, Organizational Explainability, Organizational Control},
}
There are a number of other libraries which inspired this work, we encourage you to take a look!
- ROMA: https://github.com/TonghanWang/ROMA
- Roco: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5060074
- CORD: https://arxiv.org/abs/2501.02221
- TarMAC: https://arxiv.org/abs/1810.11187
- Feudal Multi-Agent Hierarchies for Cooperative Reinforcement Learning : https://arxiv.org/abs/1901.08492