DenseNet
DenseNet (Dense Convolutional Network), which connects each layer to every other layer in a feed-forward fashion. Whereas traditional convolutional networks with L layers have L connections - one between each layer and its subsequent layer - our network has L(L+1)/2 direct connections. For each layer, the feature-maps of all preceding layers are used as inputs, and its own feature-maps are used as inputs into all subsequent layers.
DenseNets have several compelling advantages:
- They alleviate the vanishing-gradient problem,
- Strengthen feature propagation,
- Encourage feature reuse
- Substantially reduce the number of parameters.
The framework is as follows:
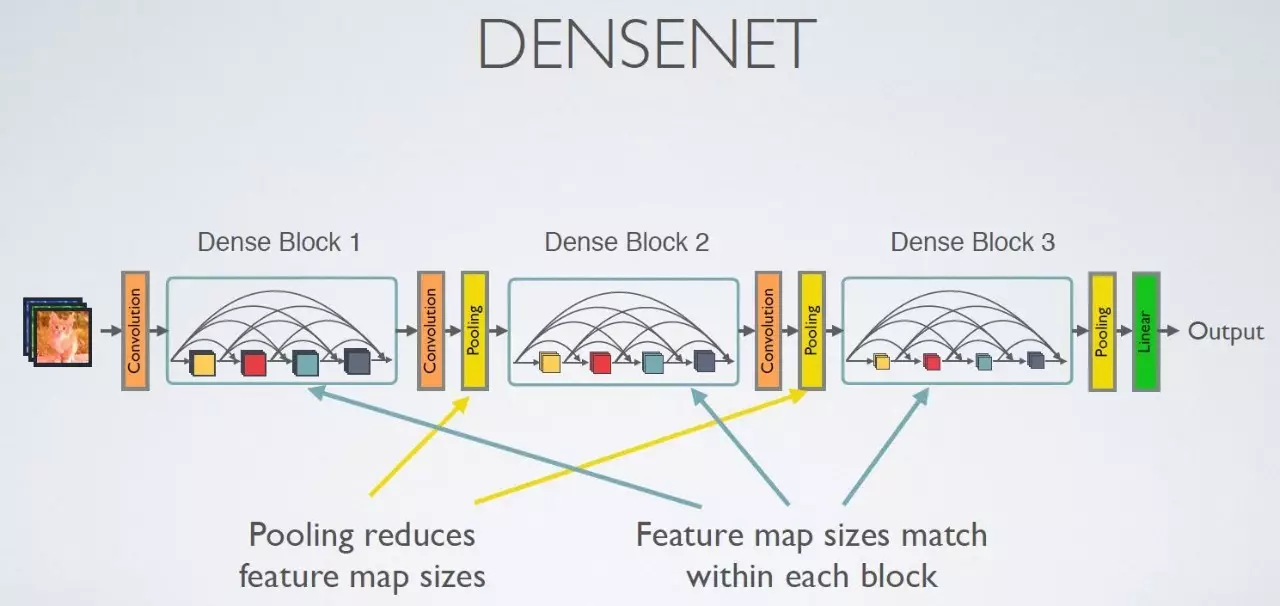
In our implementation, we use a specific version of DenseNet (Tiramisu). There are different variations of it, and we use its 103-layer version. But the basic structure could be illustrated as follows:

See linked Jégou et. al's paper for details.
Reference:
- Huang, Gao, et al. "Densely connected convolutional networks." Proceedings of the IEEE conference on computer vision and pattern recognition. Vol. 1. No. 2. 2017.
- Jégou, Simon, et al. "The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation." Computer Vision and Pattern Recognition Workshops (CVPRW), 2017 IEEE Conference on. IEEE, 2017. (https://arxiv.org/abs/1611.09326)