![]()

LLM Traffic Simulator - A lightweight, high-performance LLM API simulator for load testing, CI/CD, and local development.
LLMSim replicates realistic LLM API behavior without running actual models. It solves common challenges when testing LLM-integrated applications:
- Cost: Real API calls during load tests are expensive
- Rate Limits: Production APIs prevent realistic load testing
- Reproducibility: Real models produce variable responses
- Traffic Realism: LLM responses have unique characteristics (streaming, variable latency, token-based billing)
- Multi-Provider API Support - OpenAI Chat Completions and OpenResponses APIs
- Realistic Latency Simulation - Time-to-first-token (TTFT) and inter-token delays with normal distribution
- Streaming Support - Server-Sent Events (SSE) for both OpenAI and OpenResponses streaming formats
- Accurate Token Counting - Uses tiktoken-rs (OpenAI's tokenizer implementation)
- Error Injection - Rate limits (429), server errors (500/503), timeouts
- Multiple Response Generators - Lorem ipsum, echo, fixed, random, sequence
- Model-Specific Profiles - GPT-5, GPT-4, Claude, Gemini latency profiles
- Real-time Stats Dashboard - TUI dashboard with live metrics (requests, tokens, latency, errors)
- Stats API - JSON endpoint for programmatic access to server metrics
cargo install llmsim
# Include the optional terminal dashboard
cargo install llmsim --features tui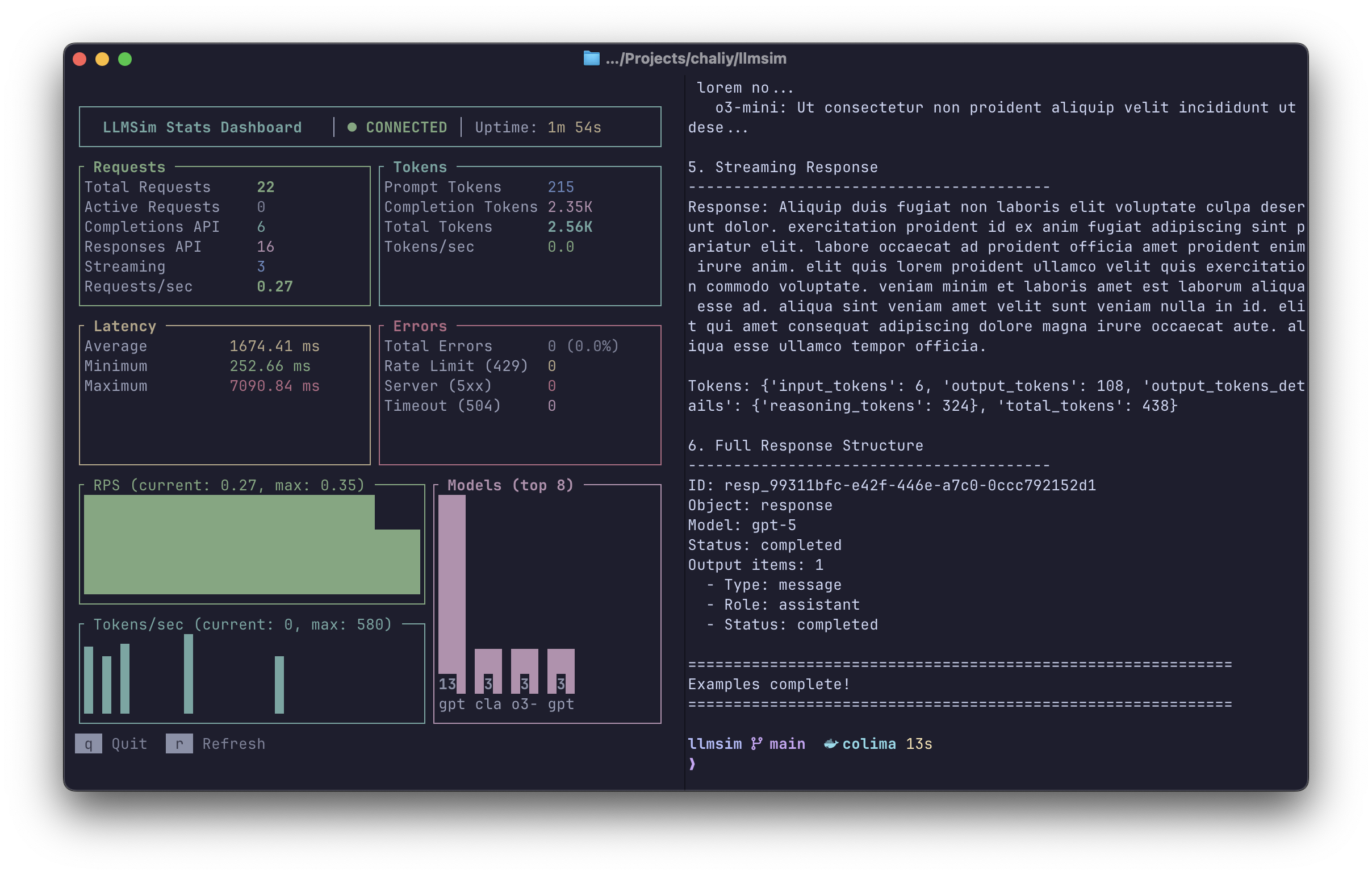
# Start with defaults (port 8080, lorem generator)
llmsim serve
# Start with real-time stats dashboard (TUI)
# Requires installing/building with `--features tui`
llmsim serve --tui
# All options
llmsim serve \
--port 8080 \
--host 0.0.0.0 \
--generator lorem \
--target-tokens 150 \
--tui
# Using config file
llmsim serve --config config.tomlThe --tui flag launches an interactive terminal dashboard showing real-time metrics:
- Requests: Total, active, streaming vs non-streaming, requests/sec
- Tokens: Prompt, completion, total, tokens/sec
- Latency: Average, min, max response times
- Errors: Total errors, rate limits (429), server errors (5xx), timeouts
- Charts: RPS and token rate sparklines, model distribution
Controls: q to quit, r to force refresh.
use llmsim::{
openai::{ChatCompletionRequest, Message},
generator::LoremGenerator,
latency::LatencyProfile,
};
// Create a latency profile
let latency = LatencyProfile::gpt5();
// Count tokens
let tokens = llmsim::count_tokens("Hello, world!", "gpt-5").unwrap();
// Generate responses
let generator = LoremGenerator::new(100);
let response = generator.generate(&request);| Endpoint | Method | Description |
|---|---|---|
/openai/v1/chat/completions |
POST | Chat completions (streaming & non-streaming) |
/openai/v1/models |
GET | List available models |
/openai/v1/models/{model_id} |
GET | Get specific model details |
/openai/v1/responses |
POST | Responses API (streaming & non-streaming) |
When using OpenAI SDKs, set the base URL to http://localhost:8080/openai/v1.
OpenResponses is an open-source specification for building multi-provider, interoperable LLM interfaces.
| Endpoint | Method | Description |
|---|---|---|
/openresponses/v1/responses |
POST | Create response (streaming & non-streaming) |
| Endpoint | Method | Description |
|---|---|---|
/health |
GET | Health check |
/llmsim/stats |
GET | Real-time server statistics (JSON) |
[server]
port = 8080
host = "0.0.0.0"
[latency]
profile = "gpt5"
# Custom values (optional):
# ttft_mean_ms = 600
# ttft_stddev_ms = 150
# tbt_mean_ms = 40
# tbt_stddev_ms = 12
[response]
generator = "lorem"
target_tokens = 100
[errors]
rate_limit_rate = 0.01
server_error_rate = 0.001
timeout_rate = 0.0
timeout_after_ms = 30000
[models]
available = [
"gpt-5",
"gpt-5-mini",
"gpt-4o",
"claude-opus",
]Note: The config file format moved from YAML to TOML in this release. To migrate an existing
config.yaml, replace section headers likeserver:with[server], changekey: valuetokey = value, quote strings, and convert lists. Seebenchmarks/config/*.tomlfor working examples.
| Family | Models |
|---|---|
| GPT-5 | gpt-5, gpt-5-pro, gpt-5-mini, gpt-5-nano, gpt-5-codex, gpt-5.1, gpt-5.2, gpt-5.3-codex, gpt-5.4, gpt-5.5 |
| O-Series | o1, o1-mini, o3, o3-mini, o4-mini |
| GPT-4 | gpt-4, gpt-4-turbo, gpt-4o, gpt-4o-mini, gpt-4.1 |
| Claude | claude-opus, claude-sonnet, claude-haiku (with 4.x versions through Opus 4.7 and Sonnet 4.6) |
| Gemini | gemini-2.0-flash, gemini-2.5-pro, gemini-3 and gemini-3.1 previews |
| Profile | TTFT Mean | TBT Mean |
|---|---|---|
| gpt-5 | 600ms | 40ms |
| gpt-5-mini | 300ms | 20ms |
| gpt-4 | 800ms | 50ms |
| gpt-4o | 400ms | 25ms |
| o-series | 2000ms | 30ms |
| claude-opus | 1000ms | 60ms |
| claude-sonnet | 500ms | 30ms |
| claude-haiku | 200ms | 15ms |
| instant | 0ms | 0ms |
| fast | 10ms | 1ms |
- Load Testing - Simulate thousands of concurrent LLM requests
- CI/CD Pipelines - Fast, deterministic tests for LLM integrations
- Local Development - Develop without API keys or costs
- Chaos Engineering - Test behavior under failure scenarios
- Cost Estimation - Estimate token usage before production
- Rust 1.83+ (for building from source)
- OR Docker
MIT License - see LICENSE for details.
See CONTRIBUTING.md for contribution guidelines.