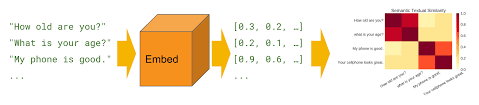
Sentence Similarity is the task of determining how similar two texts are, or to what extent they express the same meaning. Sentence similarity models convert input texts into vectors (embeddings) that capture semantic information and calculate how close (similar) they are between them. This task is particularly useful for information retrieval and clustering/grouping.
This project was initially done back in 2017 and uses the traditional methods of solving the challenge. Today. the same problems can be solved using deep learning models especially BERT models (introduced in 2018).
TODO: Add LLMs and compare BERT models with LLMs to detect the best model for the given data.
Store the documents on a document object store. Checked alternatives of AWS S3 buckets. Here is a list of different S3 bucket alternatives. Recommended to choose AWS for the high availability, better support and past experience. S3 buckets are slower than MongoDB but would cost significantly less and the time difference should be comparable. The bucketID would be the document UUID. Every file in the bucket would contain the paragraphID and the document would be split based on paragraphs.
Note: The models would also be stored in s3 buckets.
For fast search retrieval, we need to find the document that contains the most similar information for the query quickly. This database would be used for retrieval. Elasticsearch/Solr is great for retrieving nearest neighbours using cosine distances using dense vector fields/embeddings. Eg. Solr Reference Link, ElasticVue Reference Link.
Note: Each application information would be stored on a separate elasticsearch index.
The elasticsearch would contain the data about each paragraph by creating the embedding of each of the paragraphs
textId (UUID) (Primary Key) - Unique ID of the text
paragraph (string) - paragraph string
applicationId (UUID) - Unique ID of the application
paragraphId (UUID) - Unique ID of the paragraph
documentId (UUID) - ID of the document being recommended
paragraphEmbedding (dense vector) - embedding of the current query
model (string) - Name of the model used to embed the query
We can either use DynamoDB (for AWS systems) or mongoDB. The data for the embedding microservice will be stored in at least two database tables. The first database would store information about the query and the embedding, whereas the second datastore would store the recommendation information.
Database used to store the embedding information about the query itself and the basic information generating regarding the embedding such as its embedding, model used to generate the embedding, datetime, etc.
queryId (UUID) (Primary Key) - Unique ID of the query
applicationId (UUID) - Unique ID of the application
userId (UUID) - Unique user ID
query (string) - Query string
queryEmbedding (dense vector) - embedding of the current query
model (string) - Name of the model used to embed the query
datetimeCreated (timestamp) - created timestamp
datetimeDeleted (timestamp) - deleted timestamp
Database used to store the recommendation provided by the system and the acceptance. It would only store the recommendations that are demonstrated to the frontend user. Eg. if we are showing the top 3 results, it should store all 3 results. It would also be updated based on the feedback of the user.
recommendationId (UUID) (Primary Key) - Unique recommendation ID
queryId (UUID) (Indexing) - Unique ID of the query
applicationId (UUID) (Indexing) - Id of the application, the user is trying to find information about.
userId (UUID) - User ID
query (string) - The entire query string
recommendation (string) - The entire recommendation string
documentId (UUID) - The ID of the stored document in the s3 bucket
paragraphId (UUID) - The ID of the paragraph stored
rank (int) - The position of the recommendation. Eg if it was the highest match then rank would be 1 and if we are showing top 3 results then the lowest **recommendation would have rank 3.
rerankingModel (string) - The name of the model that is used for reranking the recommendations
score (float) - score for matching by the model while reranking
status (ENUM) - RECOMMENDED/ACCEPTED/REJECTED
datetimeCreated (timestamp) - created timestamp
datetimeUpdated (timestamp) - updated timestamp
datetimeDeleted (timestamp) - deleted timestamp.
The document data would be stored in S3 buckets with the applicationID being the outer bucket and the documentID being buckets inside the applicationID. Each documentID would then store multiple paragraphs with each paragraphID as the key and the paragraph data as the object.
The model would be trained on past query and correct predictions using the recommendations database and the past data already existing in voiceflow. The embedding of the documents will be created and stored in the elasticsearch based on this model.
Everytime the application documents need to be updated, it would need to be handled by a lambda which would upload the new documents to the s3 buckets. Every document that is updated, would trigger a lambda with the new document ID and the elasticsearch would be updated with the new embeddings
Periodically (once every 3 months), the ES would need to be completely changed by the new retrained ML model and the embeddings would be updated.
There are multiple ways we can generate document embeddings:
- TF-IDF (paragraph embeddings)
- Bert Model embeddings (paragraph embeddings)
- Use a LLM to generate embeddings for the paragraph completely
The embeddings would be updated with the use of a lambda that would asynchronously create the embeddings for a document and update the DynamoDB/mongoDB table.
Bi-encoder BERT models Used bi-encoder bert models to convert paragraphs directly to embeddings and store the embeddings. Although, this comes with a cost such as we would need to reduce the paragraphs to much smaller size to accommodate with BERT models small input token size. Also the difference in size between queries and the paragraph might not produce the most optimal accuracy but would still be more accurate than the TF-IDF.
Once the document paragraphs are retrieved (approximately top 10) we would need to rerank the paragraphs in the documents based on a bert cross-encoder model and then use the highest ranked paragraph for generating the answer. We would use the BERT Libraries encoder to perform this activity. It is the cheapest and easiest library to use for BERT models based on pytorch. HuggingFace library provides thousands of models to choose from. It also makes it super easy to fine-tune the model
bi_encoder = SentenceTransformer(bi_enc,use_auth_token=auth_token)