
Mentat Mail lets you send emails to LLM APIs and receive their responses in your inbox. For most use cases, I prefer it to using ChatGPT or Claude's interfaces. See below for some usage examples, or check out this blog post for more.
Especially with the rise of test-time compute / chain-of-thought models, I don't want to sit around in those interfaces waiting for a response. Email is a much nicer interface, and I'm in there all day already.
Jeff Weinstein summarizes the case well in this post:
Email is a surprisingly pleasant medium for AI agents:
- turn-based, async
- no new thing to login to
- manage N, very different agents at once
- add links+files
- web+mobile
- my shortcut keys work
- good for short or long inputs+replies
Plus, I can search across all my agent interactions regardless of LLM provider, I can loop other people into the thread easily, and I can even have different agents interact with each other.
Right now, you'll need to deploy Mentat Mail yourself — it's pretty simple. If you're potentially interested in a hosted version where you can just sign up for an account and start emailing with LLMs, drop your email on mentatmail.com. I'm thinking about productionizing it.
Warning
Mentat Mail is currently a hack project. I don't make any guarantees about its stability, security, or robustness. Use at your own risk!
If you want to read more about the project, you can check out the blog post.
Here I am making a request to OpenAI’s o1 model, which can take awhile. I can drop an email, walk away, and when I come back the response is in my inbox:
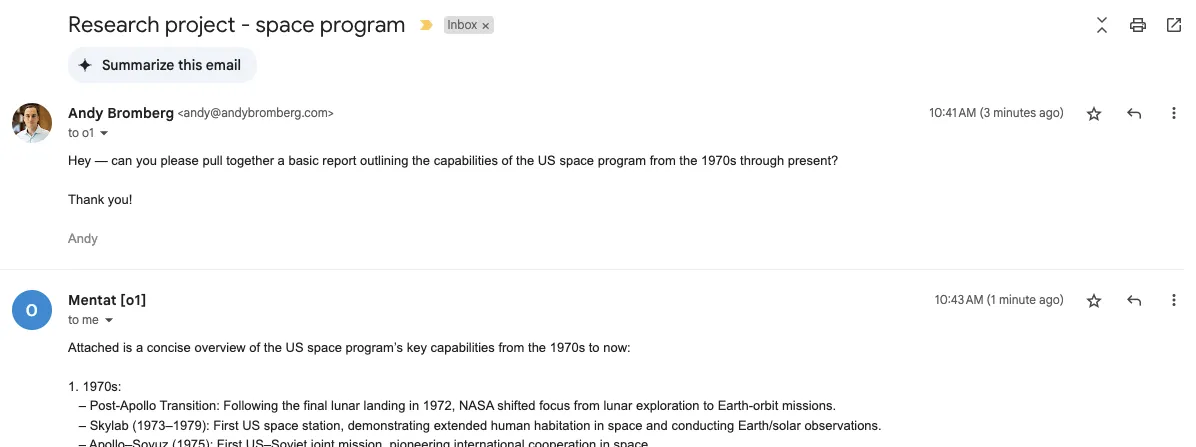
It also processes multiple requests concurrently, so you can make an o1 request, then fire off some faster requests (e.g. GPT-4o mini or Claude) while the first one is running running.
I can attach an image to the email and the AI will parse it:

I can loop the AI on an existing thread and have it use the prior context to answer a question:
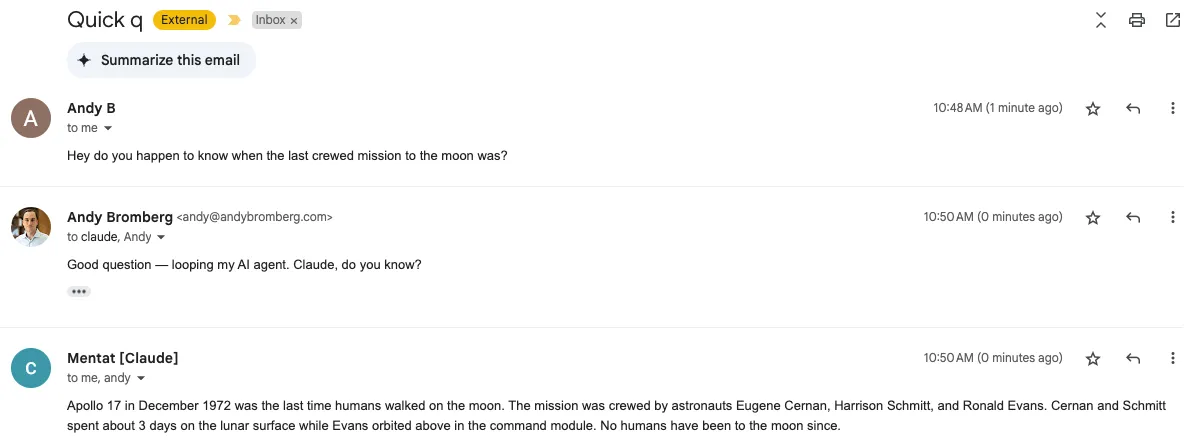
(Or I can forward the thread to an agent and it’ll reply just to me.)
I can set up two agents to play off each other, both responding on the thread:
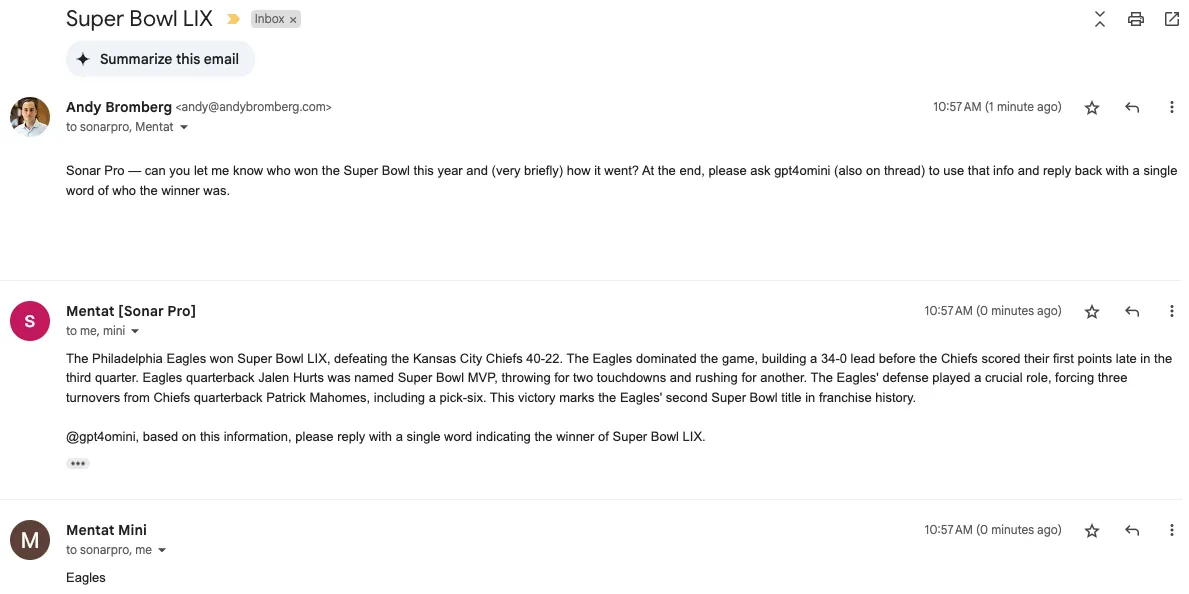
You should be able to deploy this yourself for free (as of February 2025), only paying for your usage of your preferred LLM API(s).
Render offers a free tier that can be used for hosting the server. Note that requests on that free tier will typically take an extra minute because they sleep your project after 15 minutes of inactivity; their $7/month plan will save you from this.
SendGrid also offers a free tier of 100 free (outbound — from the AI to you) emails per day. ~$20/month gets you thousands per day.
-
Click this button to deploy to Render (or, of course, you can clone and deploy to your own server or locally):
(I have no affiliation with Render, I've just found it easy to deploy on and the free tier terms work for this project.)
-
Sign up for a SendGrid account. You'll need to take three steps:
- verify your domain for sending. You can either use a single-purpose standalone domain, or a subdomain of one of your existing domains. For example, I used
agent.andybromberg.com. SendGrid will walk you through adding the necessary DNS records. - go to Settings -> Inbound Parse. Click "Add Host & URL," leave the subdomain field empty, and select your domain (which may be a subdomain itself, like
agent.andybromberg.comin my case). Then in the Destination URL field, enter your server's address +/inbound. If you've publicly deployed it on Render, this will be something likehttps://[your-render-project-name].onrender.com/inbound. - go to Settings -> API Keys and create a new Full Access API key
- verify your domain for sending. You can either use a single-purpose standalone domain, or a subdomain of one of your existing domains. For example, I used
-
Sign up for whatever LLM API you want to use — right now, Mentat Mail supports OpenAI, Anthropic, Perplexity, and Google Gemini, although you could trivially add any others that are supported by LiteLLM. Get an API key from the LLM provider.
-
Go into your Render project settings and set the environment variables — the API key(s) for your LLM provider(s) the SendGrid API key. There are three env variables that need a little more explanation:
WHITELISTED_EMAILSshould include the email address you want your AI agents to accept requests from. You can also include a wildcard, like*@yourdomain.comor*. Any email address that is not whitelisted will be rejected, which means that other people can't send emails to your AI agents (costing you money). Note: I recommend adding your agent email domain (e.g.*@agent.andybromberg.com) — this way, your agents can talk to each other if relevant.MODEL_ALIASESis a JSON string that maps aliases to models. This is optional, and allows you to set a custom email address for your agent and have it respond as a specific model. For example, say you wanted[email protected]to respond to theopenai/gpt-4o-minimodel. You could setMODEL_ALIASESto{"jeeves": {"model": "openai/gpt-4o-mini", "name": "Jeeves", "provider": "openai"}}.SYSTEM_PROMPTis a string that will be added to the system prompt of your agent. This is optional, but can be useful if you want to set a specific behavior for your agent. The default one works fine, but I have customized mine quite a bit. This works like "custom instructions" in AI sites/apps.
-
Redeploy on Render with those new environment variables, and you should be good to go! Just send an email from a whitelisted email address to
[email protected]and it should reply! Or you can send too1@,o3mini@,claude@,geminiflash@,sonarpro@(Perplexity), and more (as long as you have the correct API key in your env). It will automatically dispatch the request to the corresponding model.

Mentat Mail supports any AI model that is supported by LiteLLM (which is an amazing project!). All you need to do is add the model to model_mapping in the config.py file, and add an environment variable for the API key if necessary. The environment variable should be in the format [PROVIDER_NAME]_API_KEY.
If you're testing locally:
- Set up a SendGrid account, other than setting up the Inbound Parse.
- Copy the
.env.examplefile to.envand set the environment variables there as discussed above. - Install dependencies:
pip3 install -r requirements.txt - Run the application:
python3 app.py - Use a service like ngrok to create a public URL that would look something like
https://[your-ngrok-subdomain].ngrok.app/ - Go to your SendGrid dashboard and set the Inbound Parse URL to your ngrok URL with
/inboundappended. - Send an email from a whitelisted email address to an agent email address, and it should reply!
- Core flow of email receiving, parsing, and replying
- Handles image attachments
- Multiple agents can talk to each other without looping forever
- Concurrent handling of multiple requests
- Supports multiple LLM providers (OpenAI, Anthropic, Perplexity, Gemini)
- Whitelisting only specific email addresses to trigger the agent
- Custom system prompt to control behavior of the agents
- Custom system prompts for each model instead of global
- Better handling of email formatting (rich text formatting, math formatting, quoted text, splitting threads into individual messages...)
- Better / broader attachment handling
- Agent should be able to visit links and use them as context
- Integrations into other systems (e.g. putting things on my to-do list)
- More clear error responses (e.g. if user isn't whitelisted but is on a thread with someone who is)
- Voice notes / audio processing
Please feel free to submit issues and pull requests!
This project is licensed under the GNU General Public License v3.0 - see the LICENSE file for details.
Mentat Mail is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.