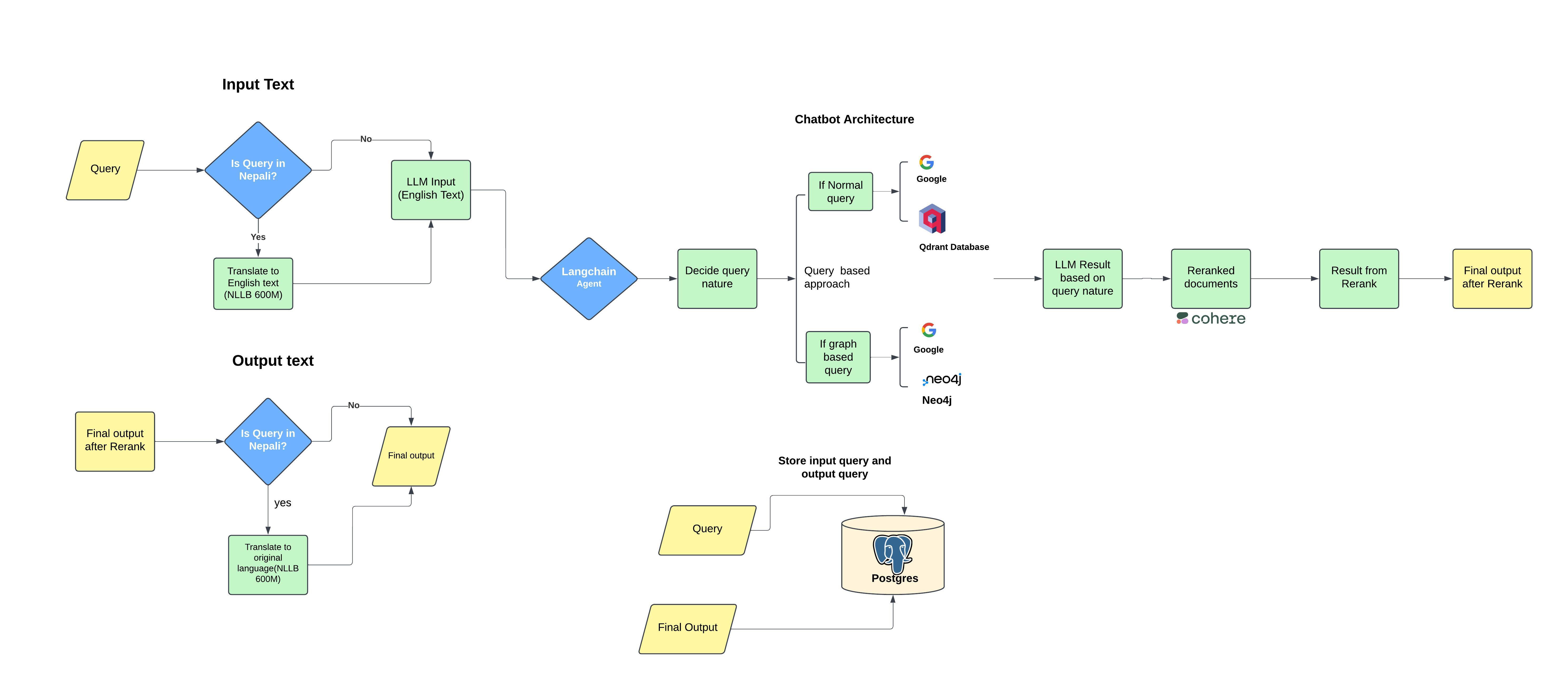
The History of Nepal Chatbot is an intelligent conversational agent designed to provide users with accurate, in-depth, and engaging information about the history of Nepal. It integrates multiple advanced technologies and tools to ensure high-quality responses, leveraging retrieval-augmented generation (RAG) techniques, knowledge graphs, and internet-based searches.
- Knowledge Sources:
- Qdrant: For dense retrieval using embeddings.
- Knowledge Graph (Neo4j): To explore relationships among historical entities.
- Google Search: To supplement responses with up-to-date information.
- Conversation Handling:
- Session-based interactions using LangChain.
- Stores old conversations for context-aware responses.
- Custom Agent:
- Orchestrates workflows to retrieve and synthesize data seamlessly.
- Data Persistence:
- Query and response storage in PostgreSQL with session IDs and timestamps.
- Fully Dockerized architecture for ease of deployment.
- Integration of multiple services:
- Ollama for language modeling.
- LangChain for query handling.
- PostgreSQL for database storage.
- Neo4j for graph-based data representation.
- Qdrant for vector-based search.
- Multi-source validation:
- Google Search validates outputs from Qdrant and Neo4j.
- Replaces inconsistent or outdated information with Google search results.
- Session Management:
- Tracks and retains user sessions for enhanced interaction.
- Time-Stamped Logs:
- Maintains a history of interactions for user reviews and analytics.
- Ollama: Language model for generating human-like responses.
- LangChain: Manages interaction workflows and context handling.
- Qdrant: Vector database for document retrieval.
- Neo4j: Graph database for entity relationships.
- PostgreSQL: Stores query-response pairs with session data.
- Docker: Containers for all components, ensuring portability and scalability.
- Google Search API: Provides supplementary information and validation.
- Docker
- Docker Compose
-
Clone the repository:
git clone <repository_url> cd <repository_directory>
-
Create a
.envfile for environment variables. Example:- Take reference from env_description which will be required to run this entire project,
-
Build and start the Docker containers:
docker-compose up --build
-
Access the chatbot service via the designated API endpoint or UI (if available).
- Step 1: Parse the document. Use preprocessing/parse.py which will parse the document using llama parse and store it in markdown format
- Step 2: Then to extract the document and chunk them use cmd/extraction_script.py which will chunk the parsed document.
- Step 3: To push to the qdrant database and perform embedding and perform hybrid search use cmd/hybrid_search_script.py
- Step 4: To push to the neo4j database and perform embedding and perform retrieveral from graph database use cmd/ neo4j_graph_script.py
- Step 5: To run agent use agents/custom_agent.py
- Llama3.2 3B
- langchain agent
- neo4j
- embedding model (mxbai-embed-large)
- sparse embedding (Qdrant/bm25)
- NLLB 600M from ctranslate2
- rerank cohere
-
Ask Historical Questions:
- Example: "What is the significance of the Battle of Kirtipur?"
- The chatbot will retrieve information from Qdrant, Neo4j, and validate with Google Search.
-
Explore Relationships:
- Example: "What was the relationship between Prithvi Narayan Shah and the British East India Company?"
-
Session Continuity:
- Engage in conversations where the chatbot retains the context of previous queries.
- Endpoint:
/api/chat - Method:
POST - Payload:
{ "query": "What is the history of Lumbini?", "session_id": "12345" }
- Endpoint:
/api/conversations - Method:
GET - Query Parameters:
session_id: Session identifier
-
User Query:
- Input query received via API or UI.
-
Retrieval:
- Query sent to Qdrant for vector-based search.
- Query sent to Neo4j for graph traversal.
-
Validation and Augmentation:
- Google Search API validates and supplements retrieved data.
-
Response Generation:
- Data synthesized using Ollama and LangChain.
- Response stored in PostgreSQL with session ID and timestamp.
-
Final Output:
- Context-aware and validated response delivered to the user.
- Interactive Visualizations:
- Timelines, maps, and graphs for richer user experiences.
- Voice Integration:
- Enable voice-based queries and responses.
- AI-Driven Insights:
- Predictive analytics and insights about historical trends.
Contributions are welcome! Please follow the steps below:
- Fork the repository.
- Create a new branch:
git checkout -b feature-branch-name
- Commit your changes and open a pull request.
This project is licensed under the MIT License. See the LICENSE file for details.
- The creators of Ollama, LangChain, Qdrant, Neo4j, and PostgreSQL for providing robust tools.
- Google Search API for real-time supplementary information.
For any issues or queries, please contact [[email protected]].