![]()
The local operations layer for long-running AI agents.
Coding, ops, research, automation — any agent that runs for hours on the same workspace.
Profiles before commands · Checkpoints before risky work · Durable history after the chat is gone.




Landing · Quickstart · What Helm does · Workflows · Docs · 한국어
pip install helm-agent-ops
helm init --path ~/.helm/workspace
export HELM_WORKSPACE=~/.helm/workspaceRun your first inspection under a declared risk profile:
helm profile run inspect_local --task-name "first look" -- git status --short
helm status --brief
helm dashboardThe first command produces a guarded execution record. The second shows what just happened in plain English. The third lays out the workspace state on one page.
No PyPI? Use the bootstrap installer:
curl -fsSL https://raw.githubusercontent.com/JDeun/Helm/main/install.sh | bash
Long-running AI agents drift. They forget prior decisions, execute risky actions before you can stop them, and leave behind a chat log nobody can audit a week later — regardless of whether the agent is editing code, running ops, organizing notes, browsing sites, or chaining tool calls.
Helm is a thin, file-backed operations layer that sits around your existing agent runtime. It does not replace your agent. It makes the agent's work boundable, recoverable, and reviewable.
| Without Helm | With Helm |
|---|---|
| Risky commands run as soon as the agent decides | Commands run under a declared execution profile with a guard check |
| Multi-step or multi-file changes leave you guessing what happened | Checkpoint created before the work; visible rollback point |
| "What did the agent do yesterday?" → scroll the chat | Local task ledger, command log, dashboard, markdown report |
| Context lives in the chat window | File-backed memory + ranked retrieval rehydrates the next session |
| Skill rules live in prompts | SKILL.md + contract.json enforce policy at run time |
If your agent only runs one-off demos, you do not need Helm. If you run it for hours on the same workspace — coding, ops, knowledge capture, or any mix — you do.
|
|
|

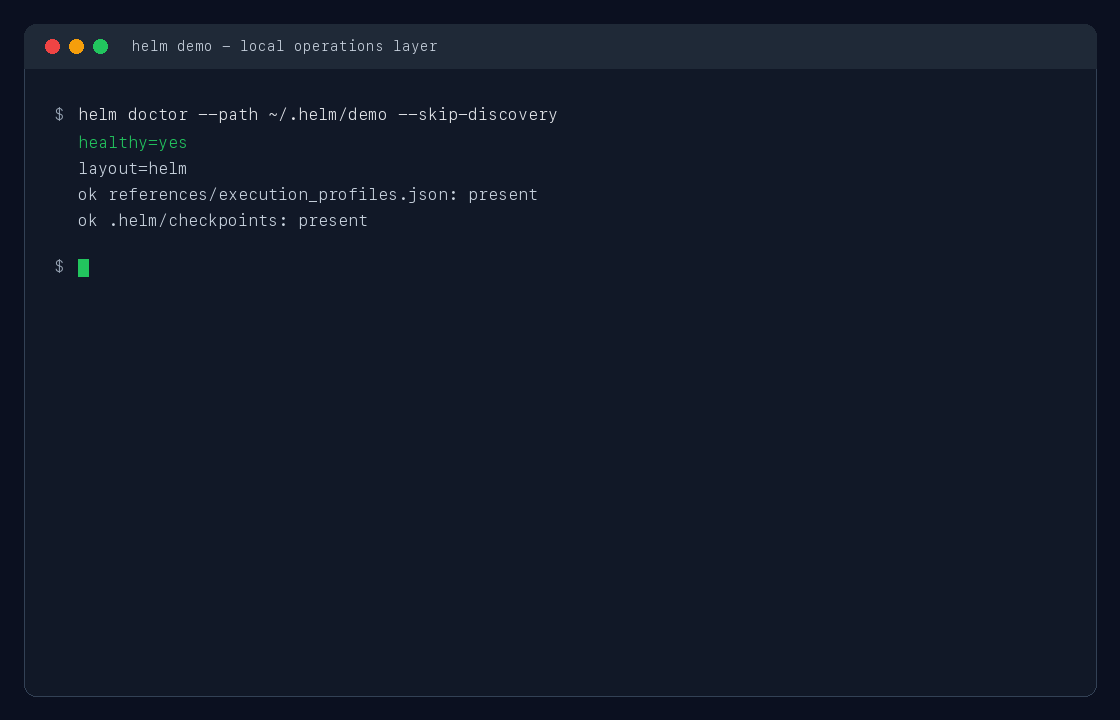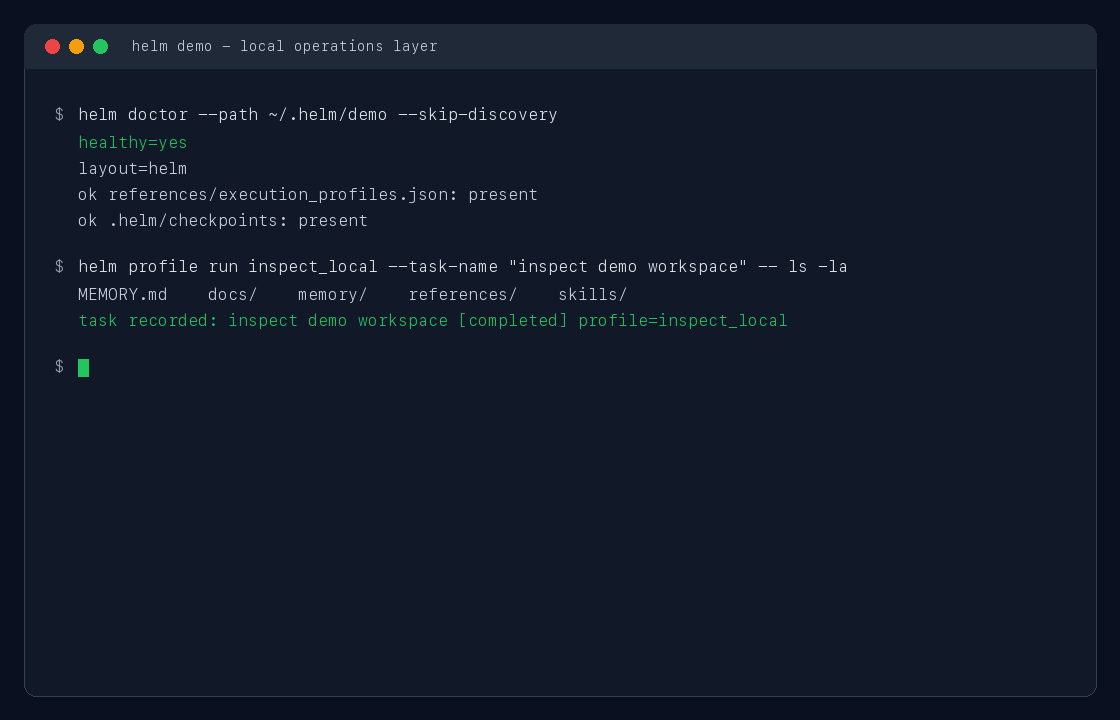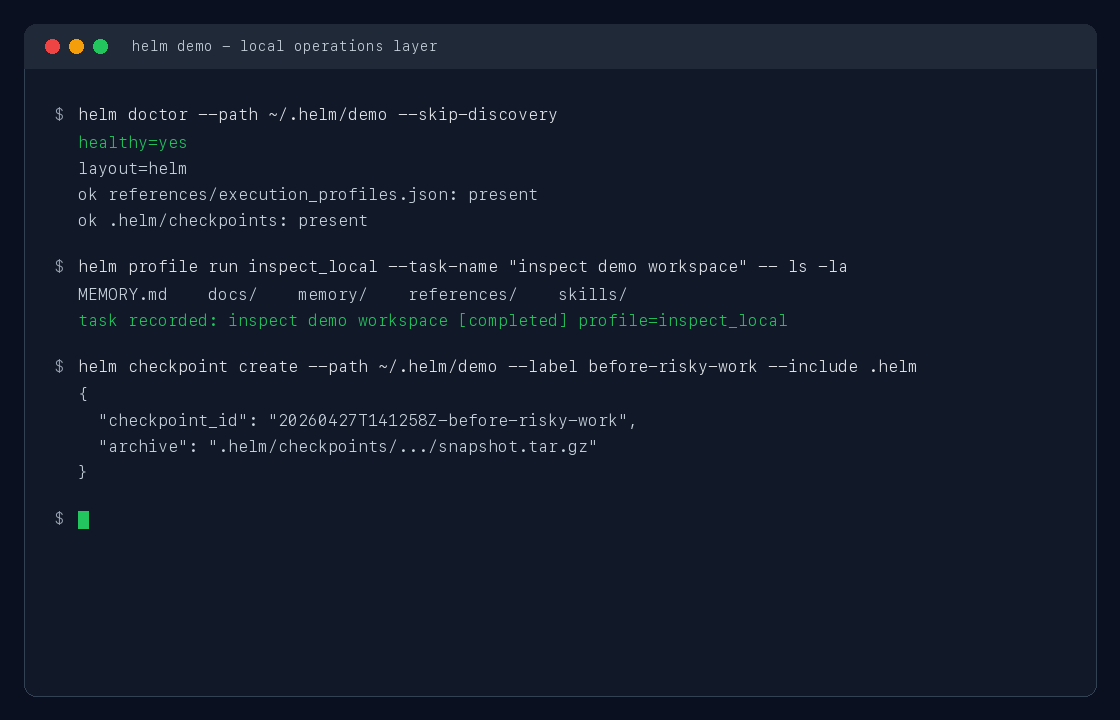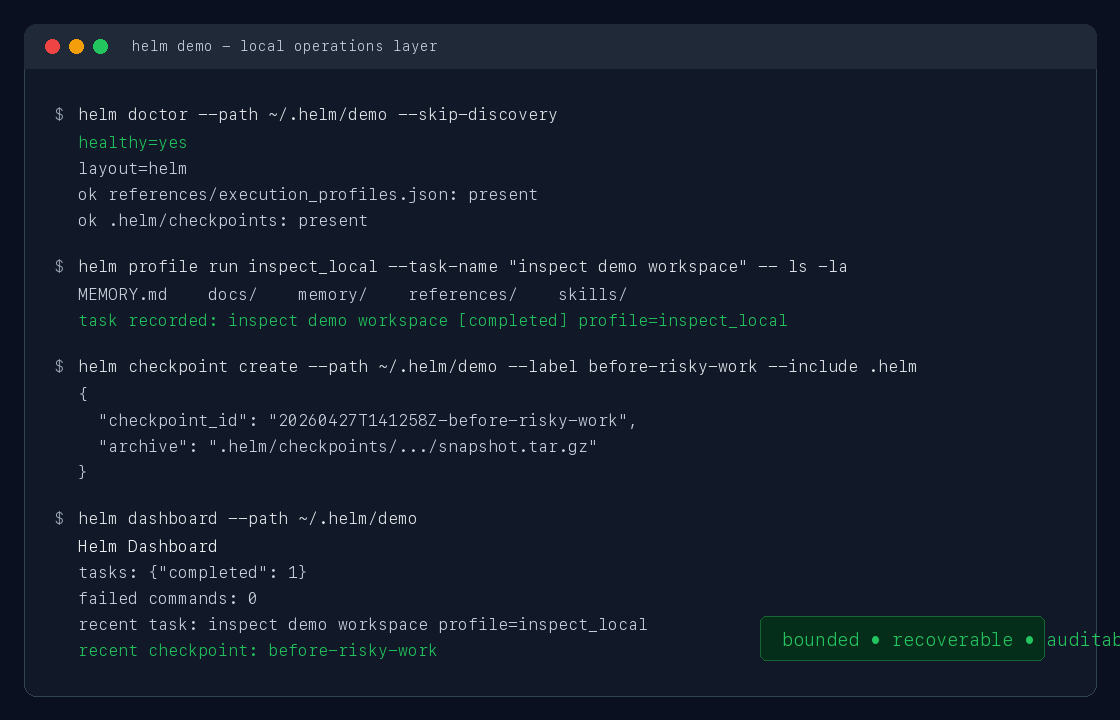
helm profile run inspect_local --task-name "inspect current repository" -- git status --short
helm checkpoint create --label before-risky-work --include $HELM_WORKSPACE
helm report --format markdown
helm dashboardEach command leaves a structured record on disk: task ledger, command log, checkpoint record, dashboard summary. None of it requires the agent to remember anything.
Inspect the workspace
helm doctor
helm status --brief
helm dashboardRun a command under a declared profile
helm profile run inspect_local --task-name "inspect repository state" -- git status --short
helm profile run workspace_edit --task-name "tighten typing in api/" -- ruff check api/Adopt existing systems as context sources
helm survey
helm onboard --use-detected --dry-run
helm onboard --use-detectedCheck rollback and recent state
helm checkpoint-recommend
helm checkpoint list
helm task list --status running
helm task doctor
helm report --format markdownQuery durable context with inspectable ranking
helm context --mode decisions --explain-ranking --json
helm context --mode timeline --since 2026-05-01
helm context --mode entity --entity project_helm
helm context --mode reflect-candidatesRun a privacy boundary preflight
helm privacy scan --text "Contact alice@example.com" --json
helm privacy tokenize --scope task-123 --text "Contact alice@example.com"Review stale skill claims
helm skill-lifecycle negative-claims --persist
helm skill-lifecycle revalidation-due
helm skill-lifecycle revalidate-claim \
--skill old-skill \
--claim-id sha256:abc123 \
--status resolved \
--note "command now exists"Probe model health
helm health state --json
helm health select --jsonEvery command also accepts
--path /custom/workspaceif you do not want to use$HELM_WORKSPACE. The demo workspace atexamples/demo-workspaceis safe to point at.
Current release: v0.10.0 — released 2026-05-22. Everything new ships in shadow mode by default — decisions are logged but not enforced until you opt in.
- Failure signature classification — every failure event normalizes to
{component, tool, profile, error_class, target, fingerprint}so the same failure is recognizable across runs. - Profile → tool-group grants — each execution profile exposes only the tools it should; runner records the grant in every ledger row.
- Repeated-failure policy transitions — same-fingerprint, patch-failed, same-skill, and credential-invalid-grant patterns automatically pick a next action (stop / decompose / repair / re-auth).
- Patch-first edit policy + validation gates — file edits prefer patch operations; per-extension validation commands run after writes.
- Task-state control container — Forge's "Control Flow Is Not Memory" principle: required-steps, completed-steps, blockers, approvals, and recovered messages live as structured state, not transcript content.
- Trace recorder → trace replay → skill candidate — every run produces a JSON trace; recurring success patterns surface as skill drafts; recurring failures surface as repair candidates.
- Profile pause / resume — secret-token-gated hard stop per profile, gated by
OPENCLAW_PAUSE_GATE. - Browser work verifier — pre-flight decision (
allow_single_session,block_mutation,require_user_login,require_confirmation,pause_profile,require_cleanup_evidence) with a runner-side enforcement gate. - Model repair + synthetic respond hooks — library entry points for small-model fallback proxies; gated by
HELM_MODEL_REPAIRandHELM_SYNTHETIC_RESPOND. - Shadow-mode reporter —
helm shadow-report --since 14d --with-recommendationsaggregates 14 days of signals and emitsready_to_enforce / needs_more_data / caution / no_signalper feature.
See the full v0.10.0 notes and the 13-document docs/harness-engineering/ directory for the design.
Helm runs in a dedicated workspace, treating existing systems as read-only context sources first.
- Helm state lives under
.helm/inside the workspace. - Profiles, notes, policies, and skill rules stay as explicit files.
- OpenClaw, Hermes, and notes vaults can be adopted instead of overwritten.
- JSONL is the append-only source of truth; SQLite is a query index.
| Category | Better for | Helm adds |
|---|---|---|
| Agent frameworks (LangChain, AutoGen, etc.) | prompts, planners, tool loops, agent graphs | profiles, guard decisions, checkpoints, task ledgers |
| Observability (Langfuse, Helicone, etc.) | hosted traces, service metrics | pre-execution policy + local recovery state |
| Evaluation (DeepEval, Phoenix, etc.) | scoring model output | operational history around repeated human-agent work |
| Shell wrappers (cmd helpers) | command convenience | workspace state, memory capture, reports, recovery discipline |
See deeper comparisons in docs/comparisons/.
| Get started | Core concepts | Advanced |
|---|---|---|
Helm's design follows the findings in Harness Design Determines Operational Stability in Small Language Models, which experimentally studies how planning, verification, and recovery harnesses affect operational stability.
Cite Helm:
@software{helm_2026,
title = {Helm: A stability-first operations layer for long-lived agent workspaces},
author = {Cho, Yong Eun},
year = {2026},
url = {https://github.com/JDeun/Helm},
version = {0.10.0}
}See CITATION.cff for the machine-readable form.
Issues and pull requests welcome.
- Read
CONTRIBUTING.mdbefore opening a PR. - Run the test suite:
python -m pytest -q(currently 1,372 tests). - Run the release checks:
python scripts/release_version_check.py --version <next>. - Security reports: see
SECURITY.md.
- Latest: v0.10.0 — harness-engineering layer (2026-05-22)
- Previous: v0.9.6, v0.9.5, v0.9.0
- Full changelog:
CHANGELOG.md· older release notes
Helm ships only the public operations layer. It does not include:
- Private memory contents
- Personal agent overlays
- Credentials or secrets
- Raw task content from any specific workspace
- Live connector tokens
The repository is safe to fork, clone, and inspect.