继续进行下一步,执行命令runtest.bat,会报错Unable to make field private final byte[] java.lang.String.value accessible: module java.base does not "opens java.lang" to unnamed module @4ed07f8c。通常在jdk9及以上会遇到该问题。
// 存储每个顶点的信息和该顶点所有边的信息。 classNode { public List<Edge> edges = newArrayList<>(); } // 存储每条边的信息(也可以用链表表示,用链表Node中的边只需用头节点存储即可) classEdge { int n, w; publicEdge(int node, int weight) { n = node; w = weight; } }
public Node[] createGraph(int[][] matrix, int n) { Node[] graph = newNode[n]; for (inti=0; i < n; i++) { graph[i] = newNode(); } for (inti=0; i < matrix.length; i++) { intweight= matrix[i][0], from = matrix[i][1], to = matrix[i][2]; graph[from].edges.add(newEdge(to, weight)); } return graph; }
+
c++版本
+
1 2 3 4 5
// 定义边数据结构,存储边到达的下一个顶点和权重 structEdge { int n, w; }; // 邻接表表示图,可以用两个vector表示,也可以用一个存储vector的数组表示 vector<vector<Edge>> g(n); // vector<Edge> g[n];
classTrie { booleanisEnd=false; Trie[] next = newTrie[26];
publicTrie() { } publicvoidinsert(String word) { if (search(word)) { return; } char[] words = word.toCharArray(); Triecur=this; for (char ch : words) { intindex= ch - 'a'; if (cur.next[index] == null) { cur.next[index] = newTrie(); } cur = cur.next[index]; } cur.isEnd = true; } publicbooleansearch(String word) { Triecur=this; char[] words = word.toCharArray(); for (char ch : words) { intindex= ch - 'a'; if (cur.next[index] == null) { returnfalse; } cur = cur.next[index]; } return cur.isEnd; } publicbooleanstartsWith(String prefix) { Triecur=this; char[] words = prefix.toCharArray(); for (char ch : words) { intindex= ch - 'a'; if (cur.next[index] == null) { returnfalse; } cur = cur.next[index]; } returntrue; } }
/** * Your Trie object will be instantiated and called as such: * Trie obj = new Trie(); * obj.insert(word); * boolean param_2 = obj.search(word); * boolean param_3 = obj.startsWith(prefix); */
classTrie { public: vector<Trie*> next; bool is_end; Trie() : next(26), is_end(false) {} // c++需要手动释放内存,因为next数组中的指针是new出来的,否则会造成内存泄漏 // 虽然算法题是一次运行,基本不会出现内存泄漏,但是在笔试面试中尽可能完善,所以需要手动释放 ~Trie() { for (auto &p : next) { if (p != nullptr) { delete p; } } } voidinsert(string word){ if (search(word)) { return; } Trie *cur = this; for (auto &ch : word) { int index = ch - 'a'; if (cur->next[index] == nullptr) { // 这里进行了new操作申请了空间,需要在析构函数中释放掉 cur->next[index] = newTrie(); } cur = cur->next[index]; } cur->is_end = true; } boolsearch(string word){ Trie *cur = this; for (auto &ch : word) { int index = ch - 'a'; if (cur->next[index] == nullptr) { returnfalse; } cur = cur->next[index]; } return cur->is_end; } boolstartsWith(string prefix){ Trie *cur = this; for (auto &ch : prefix) { int index = ch - 'a'; if (cur->next[index] == nullptr) { returnfalse; } cur = cur->next[index]; } returntrue; } };
/** * Your Trie object will be instantiated and called as such: * Trie* obj = new Trie(); * obj->insert(word); * bool param_2 = obj->search(word); * bool param_3 = obj->startsWith(prefix); */
/** * Your MedianFinder object will be instantiated and called as such: * MedianFinder obj = new MedianFinder(); * obj.addNum(num); * double param_2 = obj.findMedian(); */
publicintnumDecodings(char[] chs, int i) { if (i == chs.length) { return1; } if (chs[i] == '0') { return0; } intret= numDecodings(chs, i + 1); if (chs[i] == '1') { if (i + 1 < chs.length) { ret += numDecodings(chs, i + 2); } } if (chs[i] == '2') { if (i + 1 < chs.length && chs[i + 1] < '7') { ret += numDecodings(chs, i + 2); } } return ret; } }
intgetIsland(vector<vector<int>> &m, int N, int M){ int ret = 0; for (int i = 0; i < N; i++) { for (int j = 0; j < M; j++) { if (m[i][j] == 1) { ret++; dfs(m, i, j, N, M); } } } return ret; }
voiddfs(vector<vector<int>> &m, int i, int j, int N, int M){ if (i < 0 || i >= N || j < 0 || j >= M || m[i][j] == 0) { return; } m[i][j] = 2; dfs(m, i - 1, j, N, M); dfs(m, i, j - 1, N, M); dfs(m, i + 1, j, N, M); dfs(m, i, j + 1, N, M); }
/** * Your LRUCache object will be instantiated and called as such: * var obj = new LRUCache(capacity) * var param_1 = obj.get(key) * obj.put(key,value) */
voidremoveNode(Node *temp){ temp->prev->next = temp->next; temp->next->prev = temp->prev; } intget(int key){ if (!hash.count(key)) { return-1; } auto temp = hash[key]; removeNode(temp); addNodeToHead(temp); return temp->val; } voidput(int key, int value){ if (hash.count(key)) { auto temp = hash[key]; temp->val = value; removeNode(temp); addNodeToHead(temp); } else { auto temp = newNode(key, value); hash[key] = temp; addNodeToHead(temp); if (hash.size() > size) { auto removed = dummyTail->prev; removeNode(removed); hash.erase(removed->key); delete removed; } } } };
/** * Your LRUCache object will be instantiated and called as such: * LRUCache* obj = new LRUCache(capacity); * int param_1 = obj->get(key); * obj->put(key,value); */
/** * @param {string} word * @return {void} */ Trie.prototype.insert = function(word) { let temp = this; for (let i = 0; i < word.length; i++) { const c = word[i]; // 原来不存在才创建,否则会丢失原有的数据 if (!temp.next.get(c)) { temp.next.set(c, newTrie()); } temp = temp.next.get(c); } temp.end = true; };
/** * @param {string} word * @return {boolean} */ Trie.prototype.search = function(word) { let temp = this; for (let c of word) { // 获取下一个节点 const node = temp.next.get(c); // 如果没有则说明没有添加过 if (!node) { returnfalse; } temp = node; } // 如果end为true说明添加的是这个单词,否则只能说明以这个单词为前缀 return temp.end; };
/** * @param {string} prefix * @return {boolean} */ Trie.prototype.startsWith = function(prefix) { let temp = this; for (let c of prefix) { const node = temp.next.get(c); if (!node) { returnfalse; } temp = node; } returntrue; };
/** * Your Trie object will be instantiated and called as such: * var obj = new Trie() * obj.insert(word) * var param_2 = obj.search(word) * var param_3 = obj.startsWith(prefix) */
/** * Your MinStack object will be instantiated and called as such: * var obj = new MinStack() * obj.push(val) * obj.pop() * var param_3 = obj.top() * var param_4 = obj.getMin() */
classSolution { public: voidnextPermutation(vector<int>& nums){ if (nums.size() <= 1) return; int i = nums.size() - 2, j = i + 1, k = j; for (; i >= 0; i--, j--) { if (nums[i] < nums[j]) break; } // 如果 i >= 0 说明不是最后一个排列,可以继续向下寻找,否则说明是最后一个排列,则直接跳过 // 执行后续步骤就会回到第一个排列 if (i >= 0) { for (; k >= j; k--) { if (nums[i] < nums[k]) break; } swap(nums[i], nums[k]); } for (int a = j, b = nums.size() - 1; a < b; a++, b--) { swap(nums[a], nums[b]); } } };
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | recordDate | date | | temperature | int | +---------------+---------+ id 是该表具有唯一值的列。 该表包含特定日期的温度信息
+-------------+------+ | Column Name | Type | +-------------+------+ | x | int | | y | int | | z | int | +-------------+------+ 在 SQL 中,(x, y, z)是该表的主键列。 该表的每一行包含三个线段的长度。
+
对每三个线段报告它们是否可以形成一个三角形。
+
以 任意顺序 返回结果表。
+
查询结果格式如下所示。
+
示例 1:
+
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
输入: Triangle 表: +----+----+----+ | x | y | z | +----+----+----+ | 13 | 15 | 30 | | 10 | 20 | 15 | +----+----+----+ 输出: +----+----+----+----------+ | x | y | z | triangle | +----+----+----+----------+ | 13 | 15 | 30 | No | | 10 | 20 | 15 | Yes | +----+----+----+----------+
+
解析(case when条件判断)
+
题目不难,很容易理解。问题在于如何判断并且输出YesorNo。
+
这里使用case when进行判断。
+
1 2 3 4 5 6
select x, y, z, case when x + y > z and x + z > y and y + z > x then'Yes' else'No' end'triangle' from triangle;
+
619.只出现一次的最大数字
+
MyNumbers 表:
+
1 2 3 4 5 6 7
+-------------+------+ | Column Name | Type | +-------------+------+ | num | int | +-------------+------+ 该表可能包含重复项(换句话说,在SQL中,该表没有主键)。 这张表的每一行都含有一个整数。
select s.product_id, p.product_name from Sales s innerjoin Product p on s.product_id = p.product_id groupby s.product_id havingcount(s.sale_date between'2019-01-01'and'2019-03-31'ornull) =count(*);
+
其中count(s.sale_date between '2019-01-01' and '2019-03-31' or null)中的or null是固定写法,不写的话等价于count(*)。也可以写成count(if(s.sale_date between '2019-01-01' and '2019-03-31', 1, null))
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | start_date | date | | end_date | date | | price | int | +---------------+---------+ (product_id,start_date,end_date) 是 prices 表的主键(具有唯一值的列的组合)。 prices 表的每一行表示的是某个产品在一段时期内的价格。 每个产品的对应时间段是不会重叠的,这也意味着同一个产品的价格时段不会出现交叉。
+
表:UnitsSold
+
1 2 3 4 5 6 7 8 9
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | purchase_date | date | | units | int | +---------------+---------+ 该表可能包含重复数据。 该表的每一行表示的是每种产品的出售日期,单位和产品 id。
select p.product_id , round(ifnull(sum(units * price) /sum(units), 0), 2) average_price from Prices p leftjoin UnitsSold u on u.product_id = p.product_id where u.purchase_date between p.start_date and p.end_date or u.purchase_date isnull groupby p.product_id;
+
1280.学生们参加各科测试的次数
+
学生表: Students
+
1 2 3 4 5 6 7 8
+---------------+---------+ | Column Name | Type | +---------------+---------+ | student_id | int | | student_name | varchar | +---------------+---------+ 在 SQL 中,主键为 student_id(学生ID)。 该表内的每一行都记录有学校一名学生的信息。
+
科目表: Subjects
+
1 2 3 4 5 6 7
+--------------+---------+ | Column Name | Type | +--------------+---------+ | subject_name | varchar | +--------------+---------+ 在 SQL 中,主键为 subject_name(科目名称)。 每一行记录学校的一门科目名称。
+
考试表: Examinations
+
1 2 3 4 5 6 7 8 9
+--------------+---------+ | Column Name | Type | +--------------+---------+ | student_id | int | | subject_name | varchar | +--------------+---------+ 这个表可能包含重复数据(换句话说,在 SQL 中,这个表没有主键)。 学生表里的一个学生修读科目表里的每一门科目。 这张考试表的每一行记录就表示学生表里的某个学生参加了一次科目表里某门科目的测试。
select employee_id, department_id from Employee groupby employee_id havingcount(*) =1 union select employee_id, department_id from Employee where primary_flag ='Y';
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | num | varchar | +-------------+---------+ 在 SQL 中,id 是该表的主键。 id 是一个自增列。
selectdistinct num ConsecutiveNums from ( select * , row_number() over (partitionby num orderby id) id1 , row_number() over (orderby id) id2 from Logs ) tmp_logs groupby id2 - id1, num havingcount(*) >=3;
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | student | varchar | +-------------+---------+ id 是该表的主键(唯一值)列。 该表的每一行都表示学生的姓名和 ID。 id 是一个连续的增量。
select row_number() over (orderby id) id , student from ( select id +1 id , student from Seat wheremod(id, 2) =1 union select id -1 id , student from Seat wheremod(id, 2) =0 ) t orderby id;
+
在看了别人提交的代码后,学习到了一种更为巧妙的方法。
+
1 2 3 4
SELECT RANK() OVER (ORDERBY (id -1) ^1) AS id, student FROM seat
select product_id, year first_year, quantity, price from ( select * , rank() over (partitionby product_id orderbyyear) rownum from Sales ) t where rownum =1;
+
1321.餐馆营业额变化增长
+
表: Customer
+
1 2 3 4 5 6 7 8 9 10 11 12
+---------------+---------+ | Column Name | Type | +---------------+---------+ | customer_id | int | | name | varchar | | visited_on | date | | amount | int | +---------------+---------+ 在 SQL 中,(customer_id, visited_on) 是该表的主键。 该表包含一家餐馆的顾客交易数据。 visited_on 表示 (customer_id) 的顾客在 visited_on 那天访问了餐馆。 amount 是一个顾客某一天的消费总额。
+---------------+---------+ | Column Name | Type | +---------------+---------+ | movie_id | int | | title | varchar | +---------------+---------+ movie_id 是这个表的主键(具有唯一值的列)。 title 是电影的名字。
+
表:Users
+
1 2 3 4 5 6 7
+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | int | | name | varchar | +---------------+---------+ user_id 是表的主键(具有唯一值的列)。
+
表:MovieRating
+
1 2 3 4 5 6 7 8 9 10 11
+---------------+---------+ | Column Name | Type | +---------------+---------+ | movie_id | int | | user_id | int | | rating | int | | created_at | date | +---------------+---------+ (movie_id, user_id) 是这个表的主键(具有唯一值的列的组合)。 这个表包含用户在其评论中对电影的评分 rating 。 created_at 是用户的点评日期。
+
请你编写一个解决方案:
+
+
查找评论电影数量最多的用户名。如果出现平局,返回字典序较小的用户名。
+
查找在 February 2020平均评分最高
+的电影名称。如果出现平局,返回字典序较小的电影名称。
# Write your MySQL query statement below SELECT ROUND(AVG(a.player_id ISNOTNULL), 2) fraction FROM ( SELECT player_id, MIN(event_date) event_date FROM Activity GROUPBY player_id ) t_login LEFTJOIN Activity a ON DATEDIFF(a.event_date, t_login.event_date) =1 AND t_login.player_id = a.player_id;
+
1164.指定日期的产品价格
+
产品数据表: Products
+
1 2 3 4 5 6 7 8 9
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | new_price | int | | change_date | date | +---------------+---------+ (product_id, change_date) 是此表的主键(具有唯一值的列组合)。 这张表的每一行分别记录了 某产品 在某个日期 更改后 的新价格。
使用group by 和 count判断唯一和不唯一这两个条件。分别求出满足两个条件的信息,然后进行过滤。
+
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# Write your MySQL query statement below SELECT ROUND(SUM(tiv_2016), 2) tiv_2016 FROM Insurance WHERE CONCAT(lat, lon) IN ( SELECT CONCAT(lat, lon) FROM Insurance GROUPBY lat, lon HAVINGCOUNT(*) =1 ) AND tiv_2015 IN ( SELECT tiv_2015 FROM Insurance GROUPBY tiv_2015 HAVINGCOUNT(*) >1 )
+
❗注意:以下写法是错误的
+
1 2 3 4 5 6 7 8 9 10 11 12 13
# Write your MySQL query statement below SELECT ROUND(SUM(tiv_2016), 2) tiv_2016 FROM ( SELECTSUM(tiv_2016) tiv_2016 FROM ( SELECT* FROM Insurance GROUPBY lat, lon HAVINGCOUNT(*) =1 ) T1 GROUPBY tiv_2015 HAVINGCOUNT(*) >1 ) T2
drop table if exists actor; CREATE TABLE actor ( actor_id smallint(5) NOT NULL PRIMARY KEY, first_name varchar(45) NOT NULL, last_name varchar(45) NOT NULL, last_update DATETIME NOT NULL); insert into actor values ('3', 'WD', 'GUINESS', '2006-02-15 12:34:33');
+
对于表actor插入如下数据,如果数据已经存在,请忽略(不支持使用replace操作)
+
+
+
+
actor_id
+
first_name
+
last_name
+
last_update
+
+
+
+
+
'3'
+
'ED'
+
'CHASE'
+
'2006-02-15 12:34:33'
+
+
+
+
解析
+
1 2 3 4 5 6
# mysql中常用的三种插入数据的语句: # insertinto表示插入数据,数据库会检查主键,如果出现重复会报错; # replace into表示插入替换数据,需求表中有PrimaryKey, # 或者unique索引,如果数据库已经存在数据,则用新数据替换,如果没有数据效果则和insertinto一样; # insert ignore表示,如果中已经存在相同的记录,则忽略当前新数据; insert ignore into actor values("3","ED","CHASE","2006-02-15 12:34:33");
SELECTDATE(oo.event_time) dt, od.product_id FROM tb_order_detail od INNERJOIN tb_order_overall oo ON od.order_id = oo.order_id INNERJOIN tb_product_info pi ON od.product_id = pi.product_id WHERE pi.shop_id =901 ANDDATE(oo.event_time) BETWEEN'2021-09-25'AND'2021-10-03'
WITH t_all AS ( SELECT uid, MAX(out_time) last_dt, MIN(out_time) first_dt, MAX(MAX(out_time)) OVER () today FROM tb_user_log GROUPBY uid ), t_grade AS ( SELECT uid, CASE WHEN DATEDIFF(today, last_dt) <=6AND DATEDIFF(today, first_dt) >6THEN'忠实用户' WHEN DATEDIFF(today, first_dt) <=6THEN'新晋用户' WHEN DATEDIFF(today, last_dt) >29THEN'流失用户' ELSE'沉睡用户' END user_grade FROM t_all )
SELECT user_grade, ROUND(COUNT(uid) /SUM(COUNT(user_grade)) OVER (), 2) ratio FROM t_grade GROUPBY user_grade ORDERBY ratio DESC
mathjax: tags:none# or 'ams' or 'all' single_dollars:true# enable single dollar signs as in-line math delimiters cjk_width:0.9# relative CJK char width normal_width:0.6# relative normal (monospace) width append_css:true# add CSS to every page every_page:true# if true, every page will be rendered by mathjax regardless the `mathjax` setting in Front-matter of each article
https://javaguide.cn/java/basis/unsafe.html#cas-%E6%93%8D%E4%BD%9C
+CAS 即比较并替换(Compare And
+Swap),是实现并发算法时常用到的一种技术。CAS
+操作包含三个操作数——内存位置、预期原值及新值。执行 CAS
+操作的时候,将内存位置的值与预期原值比较,如果相匹配,那么处理器会自动将该位置值更新为新值,否则,处理器不做任何操作。我们都知道,CAS
+是一条 CPU 的原子指令(cmpxchg
+指令),不会造成所谓的数据不一致问题,Unsafe 提供的 CAS 方法(如
+compareAndSwapObject、compareAndSwapInt、compareAndSwapLong)底层实现即为
+CPU 指令 cmpxchg 。
letdecimal: number = 6; lethex: number = 0xf00d; letbinary: number = 0b1010; letoctal: number = 0o744; letbig: bigint = 100n;
+
boolean
+
1
letisDone: boolean = false;
+
string
+
1 2 3 4 5 6 7 8
letcolor: string = "blue"; color = 'red';
letfullName: string = `Bob Bobbington`; letage: number = 37; letsentence: string = `Hello, my name is ${fullName}. I'll be ${age + 1} years old next month.`;
#!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in cluster100 cluster101 cluster102 do echo ==================== $host ==================== #3. 遍历所有目录发送
for file in$@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname$file); pwd)
#6. 获取当前文件的名称 fname=$(basename$file) ssh $host"mkdir -p $pdir" rsync -av $pdir/$fname$host:$pdir else echo$file does not exists! fi done done
+
jpsall: 查看所有节点的进程,并展示出来。
+
1 2 3 4 5
for host in cluster100 cluster101 cluster102 do echo =============== $host =============== ssh $host jps done
 +
+
 +
+ +
+ +
+ +
+ +
+
 +
+ +
+ +
+ +
+
 +
+








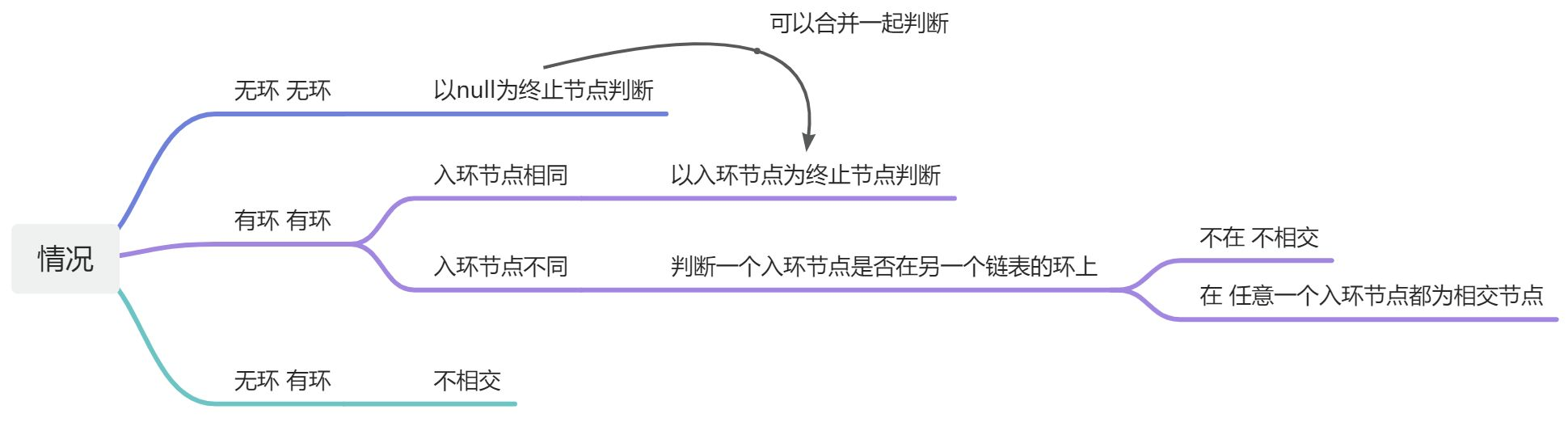
 ❗上述过程要注意:加入孩子节点时一定是先加入右孩子,再加入左孩子,因为栈是后进先出的顺序,所以要后加入左孩子。
❗上述过程要注意:加入孩子节点时一定是先加入右孩子,再加入左孩子,因为栈是后进先出的顺序,所以要后加入左孩子。


 +4. 根节点个数不满足条件
+4. 根节点个数不满足条件 根节点个数为0
+
根节点个数为0
+ +5. 从根节点遍历不能遍历到所有节点
+5. 从根节点遍历不能遍历到所有节点 因此根据上述条件总结出算法流程:
因此根据上述条件总结出算法流程: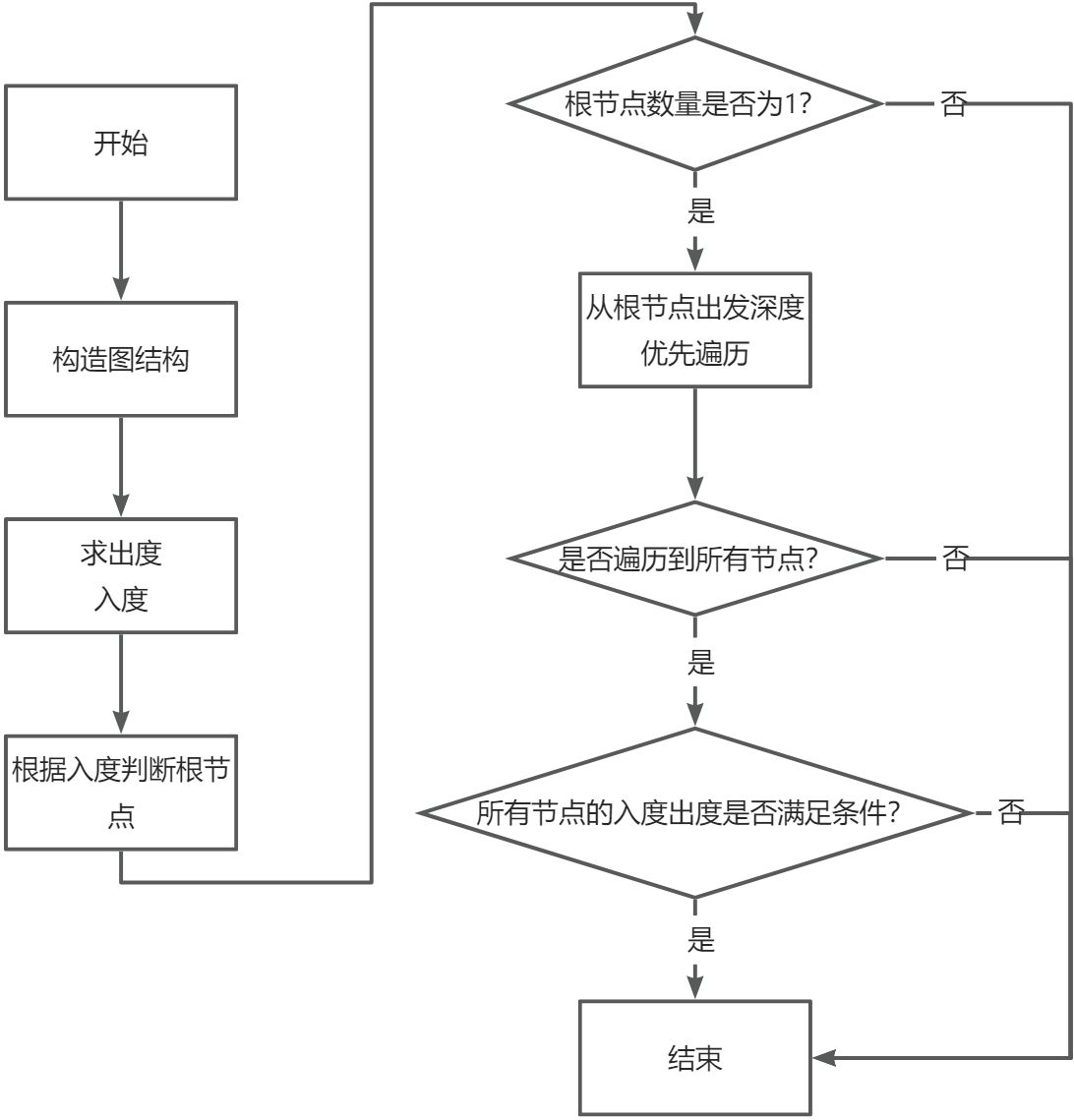




 +
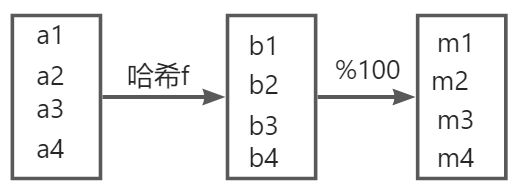
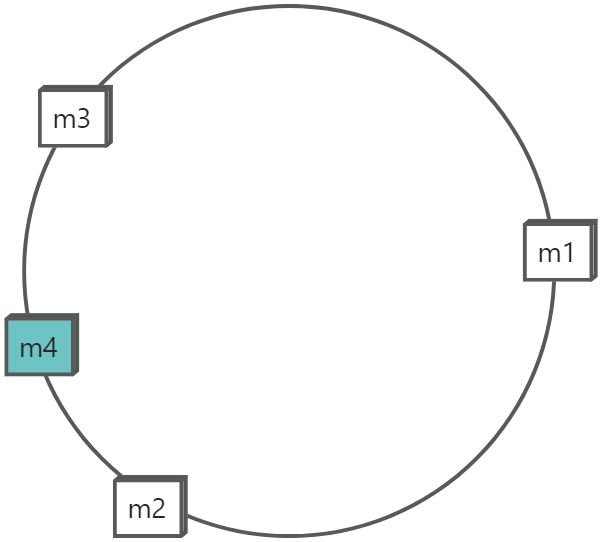
+













 ,移项可得
,移项可得 即
即 ,也就是说从C点和A点出发,以同样的速度行进,会同时到达B即入口节点。
,也就是说从C点和A点出发,以同样的速度行进,会同时到达B即入口节点。
 之间,因此可以遍历一遍,设
之间,因此可以遍历一遍,设

 添加工具,
添加工具, +
+ 按照自己的指令进行设置即可。
+
按照自己的指令进行设置即可。
+ 客户端打印:
客户端打印:
 +
+
 +
+ +
+







 +
+ +
+ +
+ ## 创建模板项目
## 创建模板项目 ## 遇到的问题
## 遇到的问题 +
+
 +
+
 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+
+
+  +
+ +
+ +
+



 +
+ +
+ +
+
 +
+ +
+ +
+
+
+ +
+ +
+
 +
+ +
+ +
+ +
+ +
+ +
+ +
+
 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+