讨论内容
现在很多公司对前端或全栈的要求已经变了。
以前做一个后台管理系统、博客系统、商城系统,就能证明自己会页面、接口、数据库和基础业务流程。但现在只会这些已经很难拉开差距。尤其是 AI 应用越来越多之后,公司更希望候选人不只是会写业务代码,还能理解 AI 产品怎么落地:用户输入怎么变成任务,Agent 怎么拆分和调度,模型输出怎么结构化,历史内容怎么召回,生成结果怎么质检,系统出问题怎么观测和回滚。
所以我打算开发一个 AI 自媒体创作平台。
它表面上是一个给创作者使用的内容生产工具,可以服务公众号、抖音、小红书、头条等内容场景。但从技术实现上看,它真正训练的是 AI 全栈能力:复杂富文本编辑器、Supervisor 多 Agent 编排、BAML 结构化输出、短期记忆、长期记忆、RAG、GraphRAG、质量门禁、任务队列、监控告警和发布复盘。
这个项目不是简单接一个大模型接口,然后让 AI 返回一篇文章。它要做的是一套完整的 AI 创作工作台:用户在类 Cursor 的三栏界面里管理素材、写文章、和 AI 协作;系统在后端通过 Agent 拆解任务、召回记忆、生成内容、检查质量、失败回流;最后把用户修改行为、爆文分析结果和发布复盘沉淀成长期记忆,让下一次创作更贴近当前 Workspace 的风格。
做完这个项目,能讲的就不再是我写了几个页面、几个接口,而是我做过一个完整的 AI 全栈项目,里面同时包含复杂前端、后端工程和 AI 工程化能力。
通过这个项目,可以学到这些适合写进简历,也适合面试展开讲的能力:
- 如何基于 Tiptap 实现一个类飞书、类 Notion 的强富文本编辑器,包括块编辑、Slash Command、选区 AI 改写、评论批注、版本对比、流式插入和内容导出
- 如何设计 Supervisor 多 Agent 架构,让不同 Agent 分别负责意图识别、素材分析、选题规划、正文生成、去 AI 味、原创检查、合规检查和复盘写回
- 如何实现短期记忆,让系统记住当前任务状态、上下文、工具结果和生成进度
- 如何实现长期记忆,让系统沉淀用户风格、历史偏好、禁用表达、高质量内容模式和发布复盘结论
- 如何用 BAML 和 Zod 把模型输出变成稳定的结构化数据,而不是只返回一段不可控文本
- 如何用 RAG 和 GraphRAG 让历史文章、用户画像、主题实体和内容关系参与生成
- 如何做 AI 质量门禁,包括去 AI 味、原创检查、合规检查、事实风险检查和失败回流
- 如何用 Langfuse、Promptfoo、OpenTelemetry、Prometheus、Grafana 和 Sentry 做 AI 应用的观测、评测和错误追踪
这个项目的优势不是做了一个创作平台,而是它能同时覆盖复杂前端和 AI 工程化两条线。前端有富文本编辑器、三栏工作台、流式交互和 Agent 执行面板,后端有任务队列、数据隔离、对象存储、监控告警和可观测,AI 层有 Agent 编排、记忆系统、RAG、GraphRAG、结构化输出和质量评测。
技术栈围绕 AI 全栈能力来设计
这个项目不是普通前后端 CRUD,所以技术栈不能只围绕页面、接口和数据库展开,而是要覆盖复杂编辑器、Agent 编排、长短期记忆、异步任务、质量评测、监控告警和后续商业化扩展。
前端技术栈
| 技术 |
用途 |
Next.js |
前端主框架,负责应用路由、页面组织、服务端渲染和工作台入口 |
React |
构建编辑器、任务面板、Agent 时间线、配置面板等复杂交互 |
TypeScript |
保证组件、接口、编辑器状态、AI 事件和表单数据的类型安全 |
Tailwind CSS |
统一页面样式、响应式布局和设计规范 |
shadcn/ui |
快速构建按钮、弹窗、表单、菜单、Tabs、Dialog 等基础组件 |
Tiptap |
构建类飞书、类 Notion 的强富文本编辑器,是前端核心技术之一 |
ProseMirror |
Tiptap 底层能力,支撑文档结构、节点、插件、选区和编辑行为扩展 |
React Flow |
展示 Agent 执行链路、任务流转、节点状态和可视化流程 |
TanStack Query |
管理接口请求、缓存、任务状态、轮询和异步数据同步 |
Zod |
校验前端表单、接口响应、AI 流式事件和配置数据 |
React Hook Form |
处理问卷、配置项、发布设置和记忆编辑等复杂表单 |
Zustand |
管理工作台局部状态,比如当前文档、右侧面板、选区、任务状态 |
SSE |
接收 AI 流式输出,实时展示生成内容、执行步骤和 Agent 日志 |
WebSocket |
后续用于协同编辑、实时通知和任务状态推送 |
Yjs |
后续支持多人协同编辑、冲突合并和实时文档同步 |
Sentry |
前端异常监控,追踪页面崩溃、编辑器错误、接口失败和用户操作路径 |
前端的核心不是做几个页面,而是做一个真正能承载内容生产的 AI 工作台。Tiptap 负责文档编辑,右侧 AI 面板负责 Agent 协作,React Flow 可以展示任务执行链路,SSE 负责把 AI 生成结果流式写入编辑器。这个组合比普通表单页面更有技术辨识度。
后端技术栈
| 技术 |
用途 |
NestJS |
后端主框架,负责业务服务、AI 网关、任务调度、数据管理和第三方服务接入 |
Fastify Adapter |
提升 NestJS 性能,适合高并发、流式响应和插件化扩展 |
TypeScript |
统一后端 DTO、Schema、任务数据、Agent 输出和数据库类型 |
PostgreSQL |
主数据库,存储用户、Workspace、文章、任务、记忆、质检报告和模型调用记录 |
Drizzle ORM |
管理数据库 Schema、SQL 查询和迁移,保持类型安全和 SQL 可控 |
PostgreSQL RLS |
实现用户级、Workspace 级数据隔离,提升多租户安全性 |
Redis / Valkey |
缓存、限流、任务状态、幂等控制和队列底座 |
BullMQ |
异步任务队列,处理批量生成、embedding、图片生成、导出、复盘和失败重试 |
MinIO / S3 |
存储素材、附件、截图、封面图、正文配图和导出文件 |
JWT / Auth.js |
处理用户登录态、鉴权和前后端身份传递 |
SSE |
向前端推送 AI 流式生成内容、任务进度和 Agent 执行日志 |
WebSocket |
后续支持实时通知、协同编辑状态和任务进度同步 |
Pino / Winston |
结构化日志,记录 traceId、userId、workspaceId、taskId、耗时和错误信息 |
Docker |
统一本地开发环境和部署环境 |
GitHub Actions |
自动化构建、测试、类型检查、Lint 和部署流程 |
后端的重点不是堆接口,而是把 AI 创作过程抽象成稳定的任务系统。用户每一次成稿、改写、素材分析、批量生成、复盘,都应该有任务状态、执行轨迹、失败原因、重试入口、耗时统计和成本记录。
监控与可观测技术栈
| 技术 |
用途 |
Prometheus |
采集接口、队列、任务、数据库连接、模型调用等指标 |
Grafana |
展示监控看板,观察接口耗时、错误率、队列堆积、任务失败率和模型成本 |
Sentry Frontend / Backend |
追踪前端页面异常、编辑器错误、NestJS 异常、队列任务失败和第三方服务报错 |
OpenTelemetry |
串联前端请求、后端接口、数据库、队列、外部服务和模型调用链路 |
NestJS Terminus |
健康检查,检测数据库、Redis、对象存储、队列和外部模型服务状态 |
Prometheus Client |
在 NestJS 中暴露自定义指标,如任务数量、Agent 节点耗时、模型调用次数 |
Structured Logging |
记录结构化日志,方便按 traceId、taskId、agentName、workspaceId 排查问题 |
AI 应用最怕的问题不是接口简单报错,而是任务卡住、Agent 死循环、模型输出不稳定、队列堆积、成本异常、生成质量退化。所以这个项目从一开始就要设计监控、日志、Trace、评测和告警。
AI 与 Agent 技术栈
| 技术 |
用途 |
LangGraph |
Agent 编排框架,实现 Supervisor、多 Agent、状态流转、回流和中断恢复 |
Supervisor 架构 |
统一调度多个 Agent,决定任务路由、执行顺序、失败回流和最终输出 |
Multi-Agent |
将意图识别、素材分析、选题规划、正文生成、质检、记忆写回拆成不同 Agent |
BAML |
让模型稳定输出结构化数据,如意图、任务书、大纲、质检报告、记忆条目 |
Zod |
对模型输出做最终校验,保证进入业务系统的数据稳定可靠 |
RAG |
召回历史文章、素材片段、用户画像和知识内容,增强生成上下文 |
GraphRAG |
基于实体和关系做多跳召回,让长期记忆和历史内容更精准参与生成 |
pgvector |
在 PostgreSQL 中做向量检索,用于语义相似召回 |
PostgreSQL FTS |
做关键词检索,适合主题、品牌、术语、标题等精确命中 |
pg_trgm |
做字面近似匹配,适合原创检查、标题重复和相似表达识别 |
Apache AGE |
在 PostgreSQL 内做图关系查询,支撑 GraphRAG 的实体多跳扩展 |
Langfuse |
记录 Prompt、模型输入输出、Token、成本、延迟和 Agent 节点表现 |
Promptfoo |
做 Prompt 回归测试、LLM 评测、质量门禁测试和红队测试 |
LiteLLM |
可选,用于统一接入多模型厂商,做 fallback、限流和成本控制 |
记忆系统技术栈
| 技术 |
用途 |
LangGraph Checkpointer |
保存当前会话、当前任务和中间状态,用于短期记忆 |
PostgresSaver |
将短期记忆持久化到 PostgreSQL,支持任务中断恢复 |
LangGraph Store |
保存跨会话、跨任务的长期记忆对象 |
PostgreSQL |
存储记忆条目、实体、关系、版本、权限、命中记录和生命周期状态 |
pgvector |
根据语义相似度召回长期记忆 |
FTS |
根据关键词召回主题、标签、实体和历史内容 |
pg_trgm |
处理近似文本匹配、重复表达识别和原创风险辅助判断 |
Apache AGE |
做实体关系图谱和多跳扩展,支撑 GraphRAG |
BAML |
从对话、编辑行为、复盘结果中提炼结构化记忆 |
Zod |
校验记忆对象结构,避免脏数据进入长期记忆库 |
BullMQ |
异步处理 embedding、记忆写入、反思、合并、衰减和索引重建 |
Langfuse |
追踪每次生成使用了哪些记忆,以及记忆召回是否有效 |
记忆系统是这个项目和普通 AI 写作 Demo 拉开差距的关键。普通 Demo 每次都是重新问模型,而这个项目要让系统能够记住当前任务、沉淀长期偏好,并且知道什么时候该遗忘、什么时候该更新、什么时候该让用户确认。
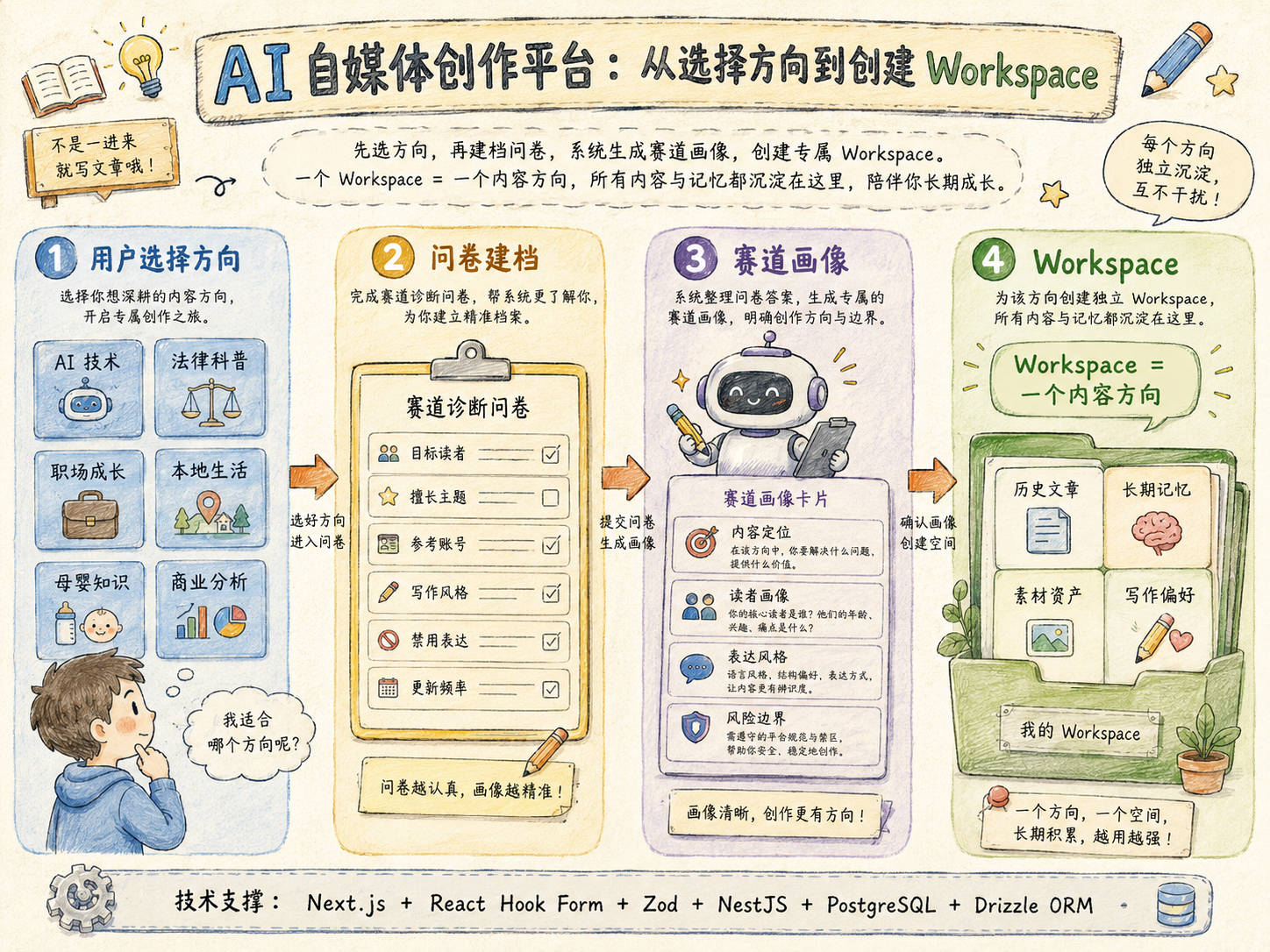
项目从选择方向开始,而不是直接写文章
项目的第一步不是让用户直接写文章,而是让用户先选择一个内容方向。比如 AI 技术、法律科普、职场成长、本地生活、母婴知识、商业分析等。系统会根据这个方向创建一个 Workspace,一个 Workspace 就代表一个独立的内容赛道。
后续所有历史文章、参考素材、长期记忆、写作偏好、选题策略和复盘结论,都会沉淀在这个 Workspace 下面。这样可以避免今天写 AI 技术,明天写生活种草,后天又写法律科普,最后所有风格、素材和记忆混在一起,导致系统越用越乱。
创建 Workspace 时,用户需要完成一组选择题和基础配置,比如目标读者是谁、擅长什么主题、每周能投入多少时间、参考哪些账号、喜欢什么表达风格、禁用哪些表达、希望内容偏观点还是教程、风险边界是什么。
这些不是普通问卷,而是后续 Agent 执行的基础上下文。目标读者会影响选题规划,表达风格会影响正文生成,禁用表达会进入长期记忆,风险边界会影响合规检查,参考账号会影响 Research Agent 的结构分析方向。
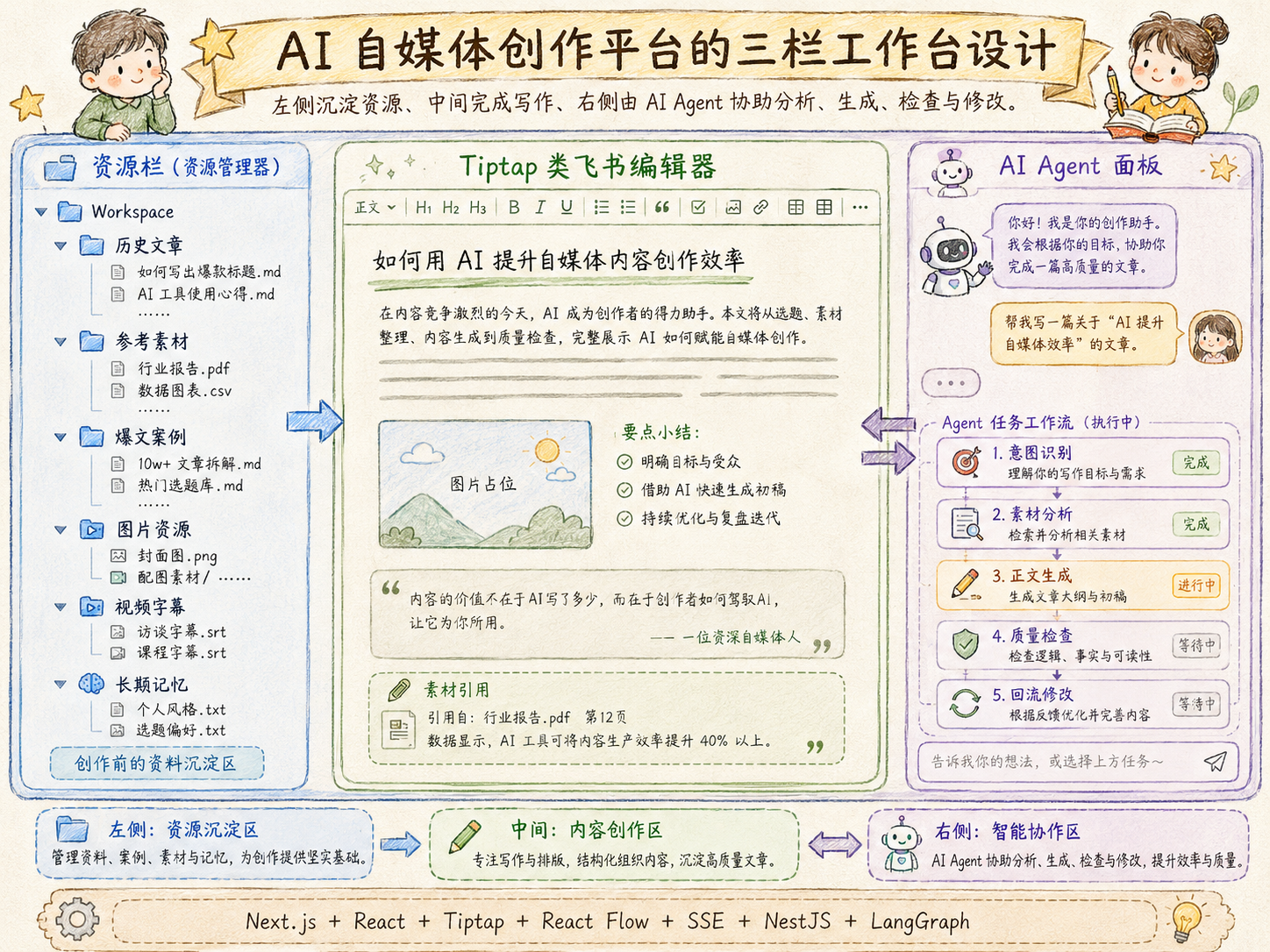
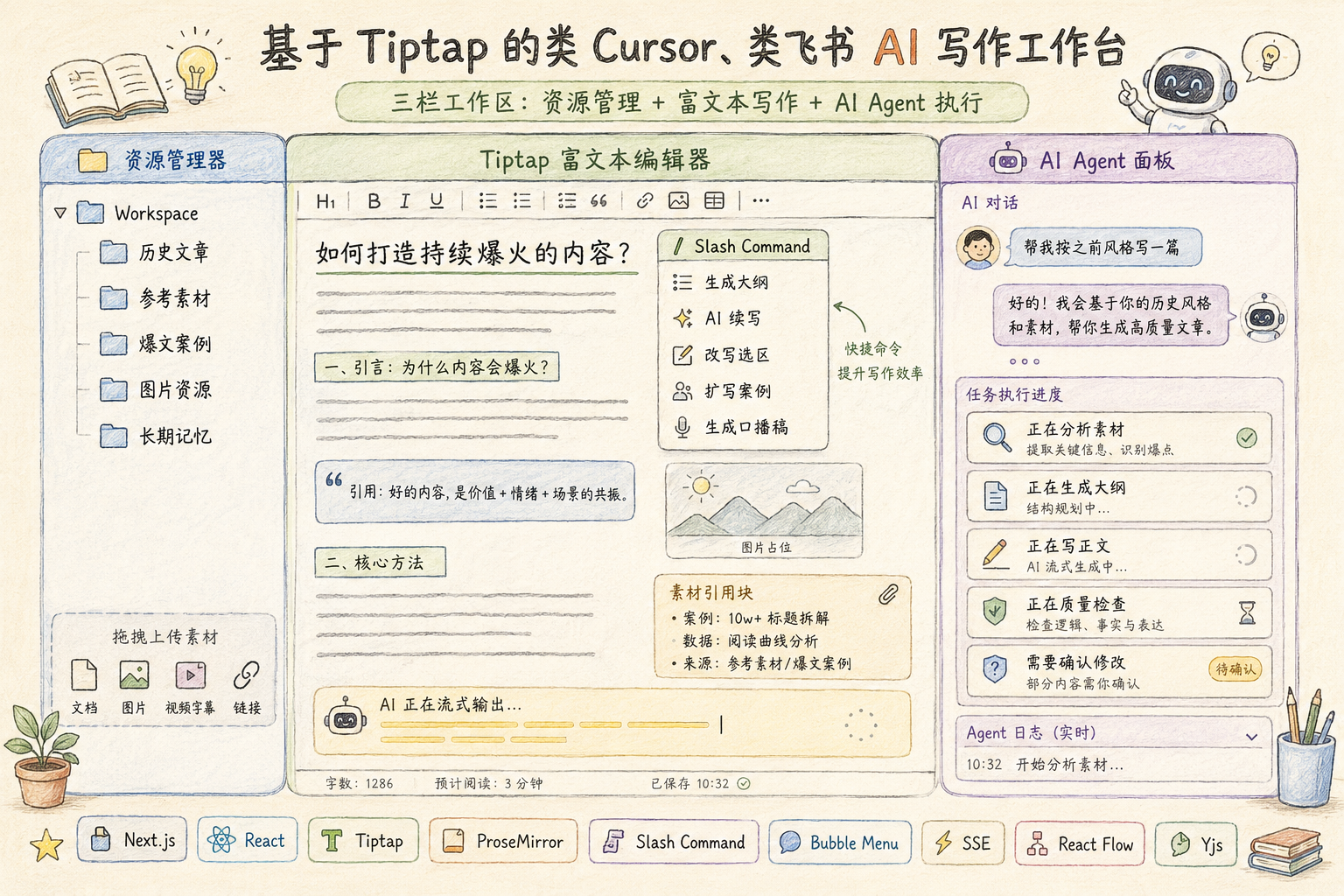
三栏工作台让 AI 协作更像真实生产环境
Workspace 创建完成后,用户会进入一个类似 Cursor 的三栏工作台。
左侧是资源栏,用来管理当前内容方向下的文章、素材、参考案例、历史公众号内容、图片、视频字幕和记忆条目;中间是 Tiptap 编辑器,用来写作和修改内容;右侧是 AI Agent 面板,用来发起创作任务、查看 AI 执行过程、确认修改建议和追踪任务状态。
这个设计的好处是,用户不是在一个孤立的聊天框里和 AI 对话,而是在一个真实工作区里完成内容生产。左侧提供素材和上下文,中间承载最终内容,右侧负责 AI 协作和任务执行。
它既有 Cursor 的工作区感,也有飞书文档的编辑体验。用户可以一边看素材,一边写文章,一边让 AI 分析、改写、续写或质检。
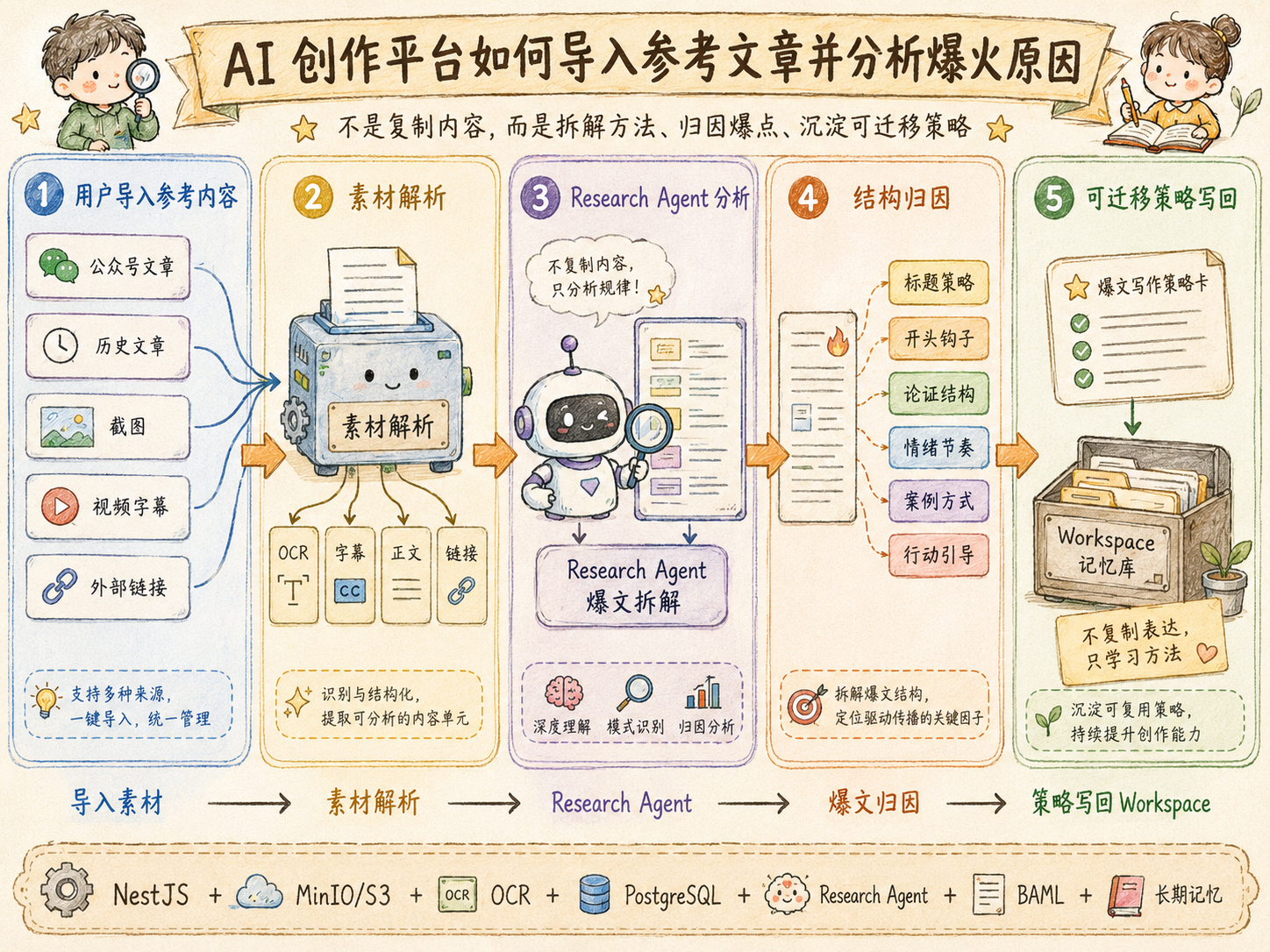
参考文章不是用来照抄,而是用来分析方法
进入工作台后,用户可以先导入参考内容。参考内容可以是自己以前写过的公众号文章,也可以是其他公众号的爆文、外部链接、截图、文件、视频字幕或小红书、头条、抖音里的文案。
系统导入这些内容不是为了照抄,而是为了分析它为什么有效。
比如系统会分析标题为什么能吸引点击,开头是不是制造了真实场景,中间是用案例推动还是用观点推动,情绪节奏是怎么变化的,结尾有没有行动引导,整篇内容是教程型、观点型、故事型还是清单型。
Research Agent 会把这些内容拆成可复用的写作策略,而不是复制原文表达。
技术上,链接、正文、文件、截图和视频字幕会先进入素材解析链路。普通文本可以直接解析,截图可以通过 OCR 转成文字,视频字幕可以作为文本资产保存。素材正文、摘要、标签、来源和授权状态会写入 PostgreSQL,文件本体放在 MinIO 或 S3。
随后 Research Agent 使用 BAML 产出结构化分析结果,比如标题策略、开头策略、论证结构、情绪节奏、案例模式和可迁移规则。这些高价值结论还可以由 Memory Agent 判断是否写入长期记忆,供后续创作复用。
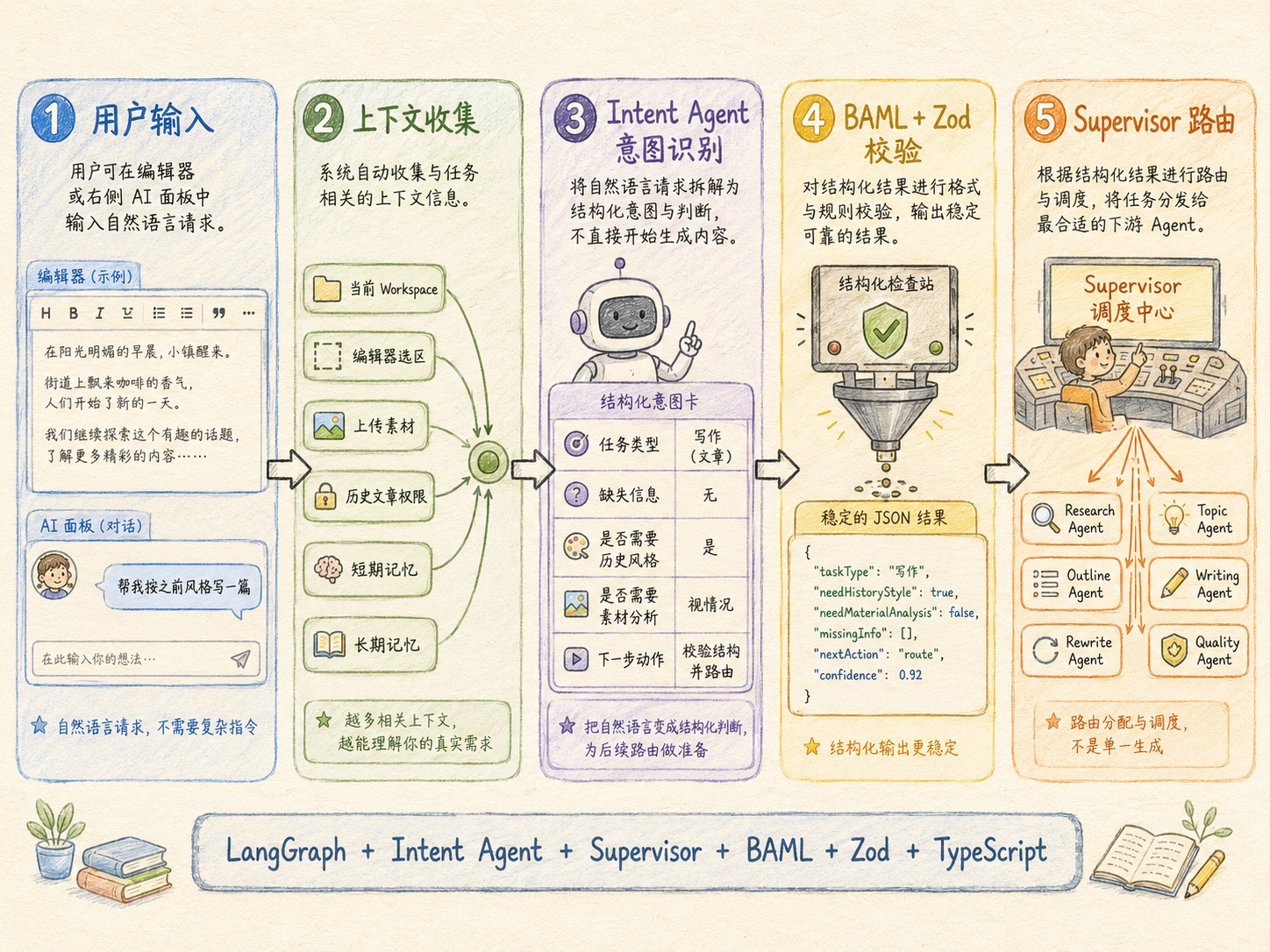
用户输入后先做意图识别,再由 Supervisor 调度 Agent
当用户正式开始写文章时,可以直接在 Tiptap 编辑器里输入需求,也可以选中某一段文字后在右侧 AI 面板里要求改写、扩写、压缩或换成另一个平台的表达方式。
比如用户可以说帮我写一篇 AI Agent 的公众号文章,也可以选中开头说这里太像 AI 了,帮我改得自然一点。
这时系统不会直接把输入丢给大模型,而是先由 Intent Agent 做意图识别。它会综合用户输入、当前编辑器选区、当前 Workspace、历史文章授权状态、上传素材、短期记忆和长期记忆,判断用户到底是要成稿、改写、爆文分析、批量选题、多平台转换还是复盘。
Intent Agent 不直接生成文章,而是用 BAML 输出结构化意图,再交给 Zod 校验。只有结构稳定,Supervisor 才能继续调度,而不是靠模型随口说的一段自然语言猜下一步该做什么。
Supervisor 相当于整个 Agent 系统的调度中心。它会根据意图结果决定下一步调用哪个 Agent。如果信息不完整,就先追问用户;如果需要分析参考文章,就调用 Research Agent;如果要生成选题,就调用 Topic Agent;如果要写正文,就调用 Outline Agent 和 Writing Agent;如果只是局部修改,就调用 Rewrite Agent;如果生成完成,就调用 Quality Agent 做质量检查。
流式输出和 Agent 可视化让执行过程可感知
在 Agent 执行过程中,前端会持续展示任务进度。右侧 AI 面板不是简单聊天,而是一个 Agent 执行窗口,能够显示当前节点、执行日志、AI 产出、需要用户确认的建议和失败原因。
中间的 Tiptap 编辑器会接收 SSE 流式内容,像 Cursor 写代码一样逐步把正文插入文档中。React Flow 可以用来展示任务链路,让用户看到意图识别、素材分析、大纲生成、正文生成、质量检查、回流修改这些节点的执行状态。
这一层的技术重点是流式交互和复杂编辑器。Tiptap 负责文档结构和内容编辑,ProseMirror 负责底层节点、选区和插件系统,Slash Command 负责快捷命令,Bubble Menu 负责选中文本后的 AI 操作,SSE 负责后端向前端持续推送内容,React Flow 负责 Agent 节点可视化。
后续如果接入 Yjs,还可以支持多人协同编辑、评论批注、版本对比和实时同步,让这个工作台进一步接近飞书、Notion、Cursor 这类复杂产品体验。
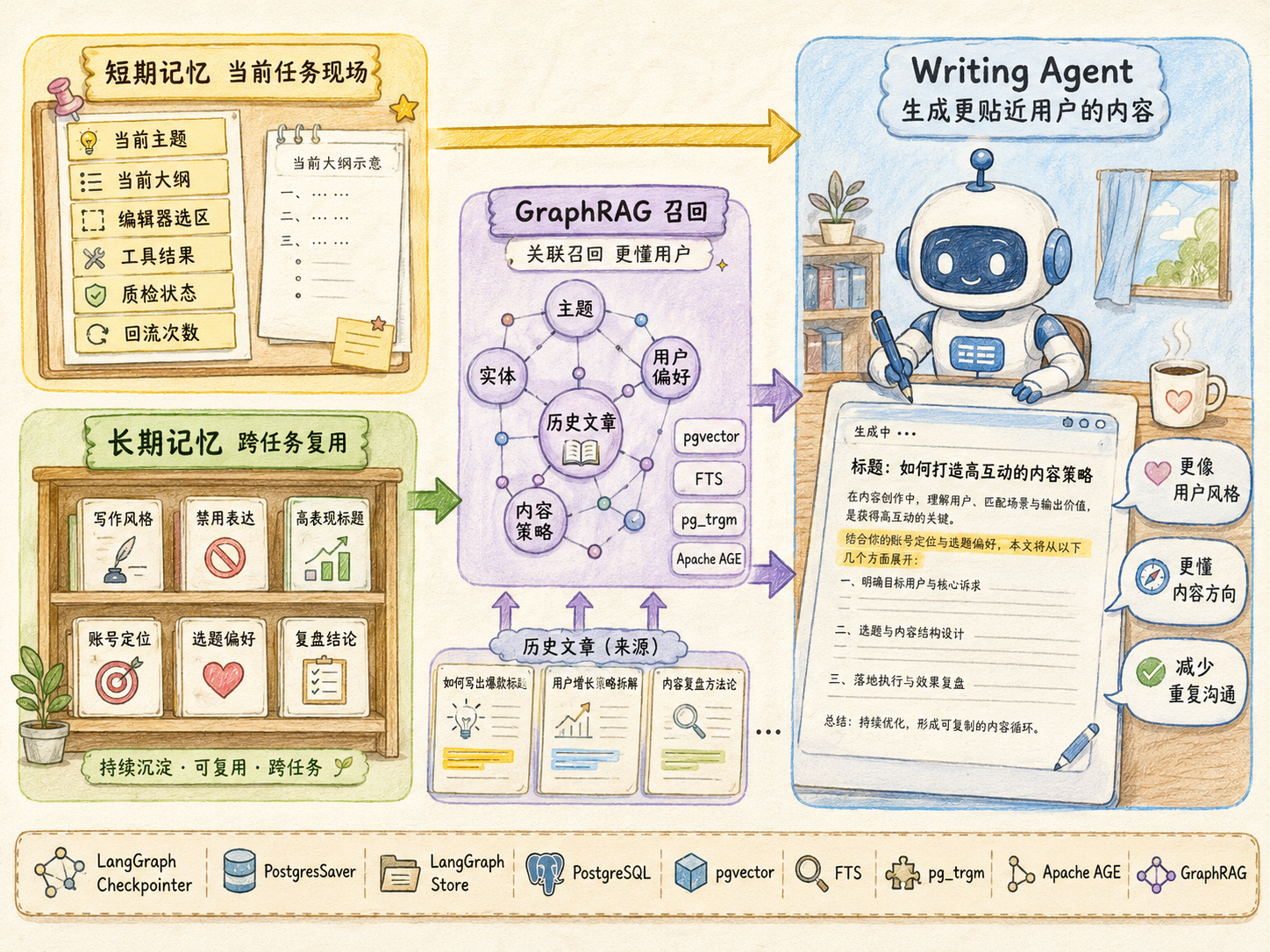
长短期记忆让系统既不断片,也能越用越懂用户
内容生成时,系统会同时使用短期记忆和长期记忆。
短期记忆负责当前任务不断片。比如当前主题是什么、大纲生成到了哪里、哪些段落已经写完、当前编辑器选区是什么、工具调用结果是什么、质检是否通过、已经回流几次。短期记忆可以通过 LangGraph Checkpointer 和 PostgresSaver 存到 PostgreSQL,保证任务中断后还能恢复。
长期记忆负责让系统越来越懂这个 Workspace。它会保存用户写作风格、禁用表达、常用结构、历史高表现标题、选题偏好、复盘结论和参考文章分析出的可迁移策略。长期记忆不会把所有聊天记录都塞进去,而是通过 Memory Agent 提炼,再用 BAML 结构化和 Zod 校验,最后写入 PostgreSQL。
当 Writing Agent 生成内容时,系统会通过 RAG 和 GraphRAG 召回相关上下文。pgvector 负责语义相似召回,PostgreSQL FTS 负责关键词和主题命中,pg_trgm 负责相似标题和相似表达识别,Apache AGE 或递归 CTE 负责实体关系多跳扩展。GraphRAG 会把历史文章、长期记忆、主题实体、用户偏好和内容策略重新排序、压缩,再注入给 Writing Agent。
这样内容生成不是每次从零开始,而是基于当前 Workspace 的长期积累持续优化。
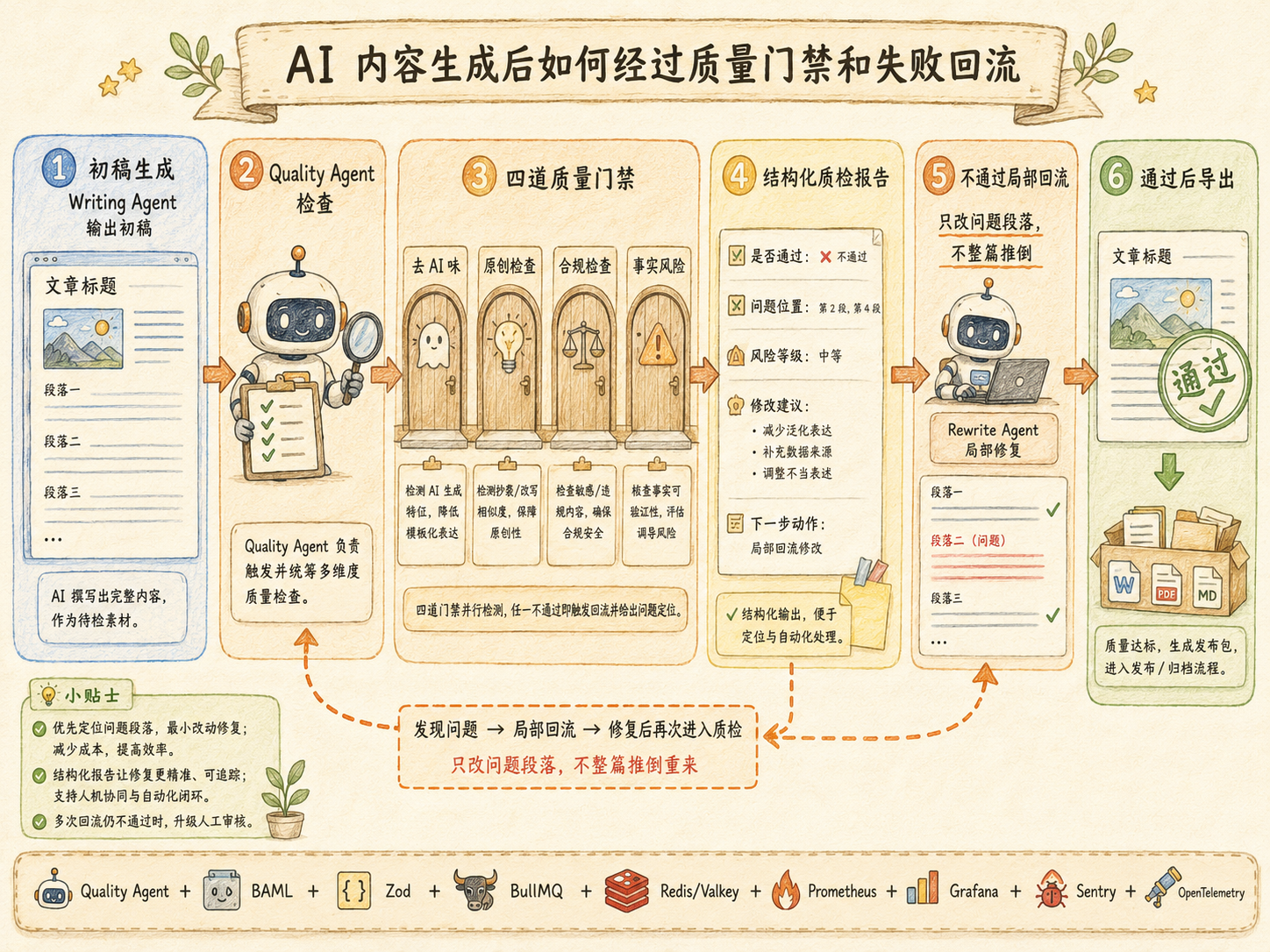
质量门禁让内容不是生成完就交付
生成完成后,内容不会直接交付,而是进入质量门禁。Quality Agent 会检查去 AI 味、原创风险、合规风险、事实风险和风格一致性。
比如它会判断开头是不是模板化,表达是不是太空,是否和参考文章过于相似,是否出现未经证实的事实,是否触碰平台风险边界。
如果质量门禁不通过,系统不会简单整篇重写,而是根据问题位置做局部回流。比如开头太生硬,就只回流开头;某个案例太空,就让 Rewrite Agent 补案例;某个事实不稳,就要求补充来源或降低语气;某段相似度太高,就只改相似段落。
这样可以保留已经写好的内容,不会因为一次检查失败把整篇推倒重来。
批量任务也会走同样逻辑。用户可以一次提交多个选题,BullMQ 会把它拆成父任务和多个子任务,每篇文章独立生成、独立质检、独立重试。一篇失败不会阻塞其他文章。Redis 或 Valkey 负责队列、限流、缓存和幂等控制,Prometheus 和 Grafana 监控任务耗时、失败率、队列堆积和模型调用成本,Sentry 和 OpenTelemetry 负责异常追踪和链路追踪。
通过质检后还要复盘,把经验写回长期记忆
通过质检后,内容会回到 Tiptap 编辑器中。用户可以继续手动编辑,也可以选中文本继续让 AI 局部优化。系统还可以生成正文配图占位块、封面图占位块、标题候选、摘要、多平台版本和发布检查清单。
最终内容可以导出为 Markdown、HTML,或者进一步适配公众号、抖音、小红书、头条等平台发布包。
发布或使用之后,系统会进入复盘阶段。Review Agent 会结合用户修改行为、质检结果、发布数据和历史表现,生成复盘建议。Memory Agent 会判断哪些结论值得写回长期记忆,比如某类标题表现更好,某种开头更容易被保留,某些表达被反复删除,某个账号更适合强观点结构。
写回前还会经过持久性价值、结构化程度、个性化价值三层筛选,避免长期记忆变成垃圾堆。
最终,这个项目形成的是一个完整闭环:用户先选择方向并创建 Workspace,再导入参考文章和历史内容,系统分析爆火原因并沉淀策略;用户在类 Cursor 的三栏工作台中写作,左侧管理素材,中间用 Tiptap 编辑正文,右侧通过 AI Agent 发起任务;后端通过 NestJS 和 LangGraph 调度多个 Agent,结合短期记忆、长期记忆、RAG 和 GraphRAG 生成内容,再经过质量门禁、失败回流、发布导出和复盘写回,让系统随着使用不断理解当前内容方向和用户风格。
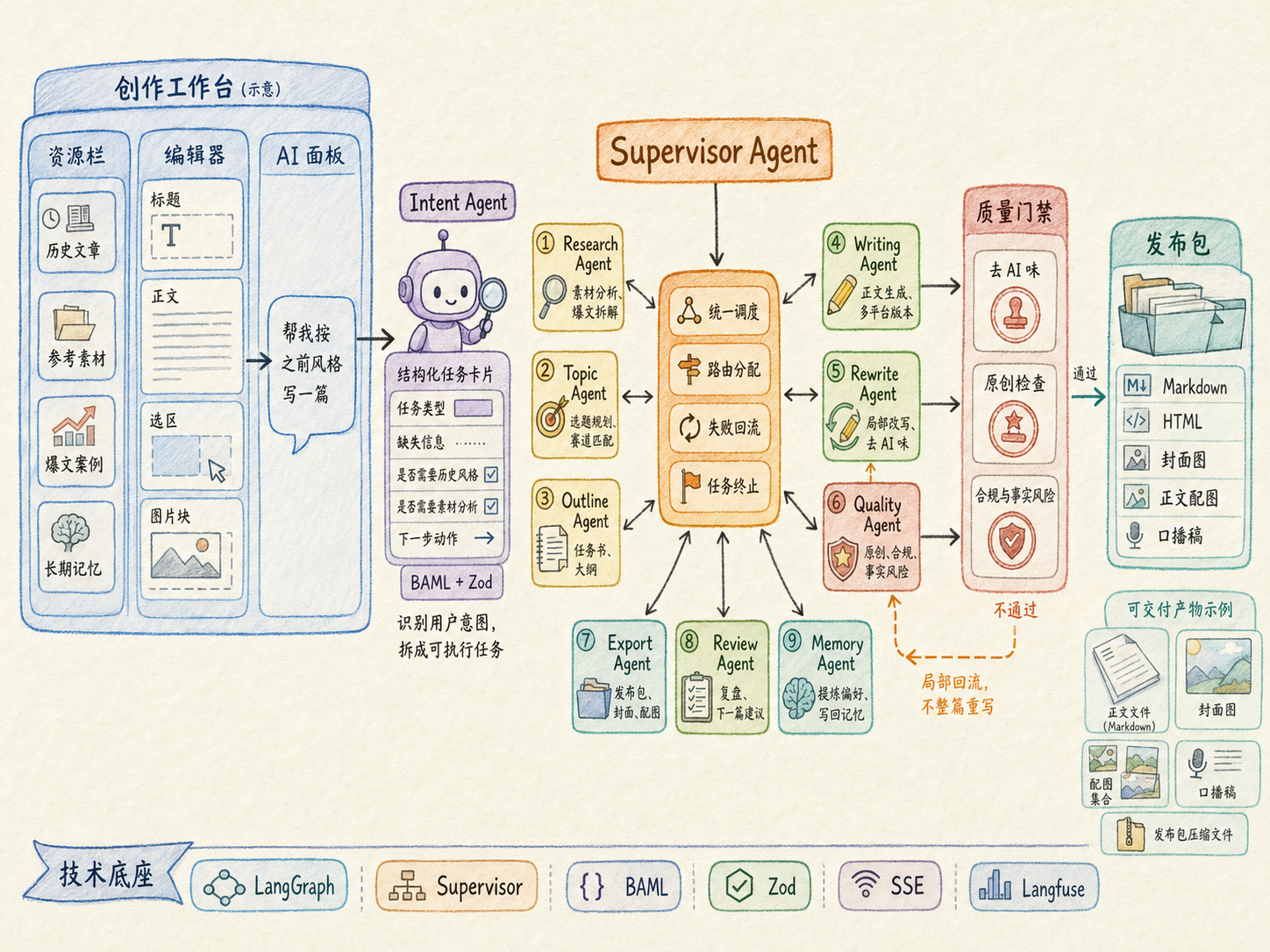
Agent 分工不是功能堆叠,而是让任务链路可控
这个项目里的 Agent 不是页面上的功能按钮,也不是让用户手动选择的角色列表,而是服务端内部的一套执行体系。用户只需要在右侧 AI 面板里输入一句自然语言,比如帮我分析这篇爆文、帮我按之前风格写一篇、把这段改自然一点,系统会先判断用户真实意图,再由 Supervisor 调度不同 Agent 完成分析、选题、写作、质检、回流、导出和记忆写回。
这套设计的重点不是为了显得复杂,而是为了让 AI 创作过程变得可控。每个 Agent 都有明确输入、明确输出、置信度、证据和下一步动作。这样系统才能知道什么时候继续生成,什么时候追问用户,什么时候局部回流,什么时候进入人工确认,什么时候可以导出。
| Agent |
主要职责 |
关键输入 |
输出结果 |
| Intent Agent |
识别用户意图,判断是成稿、改写、爆文分析、批量选题、多平台转换还是复盘 |
用户输入、Tiptap 选区、当前 Workspace、上传素材、短期记忆 |
结构化意图、缺失字段、下一步动作 |
| Supervisor Agent |
统一调度任务,决定追问、继续、回流、终止或人工确认 |
Intent 结果、任务状态、回流次数、质检结果 |
Agent 路由结果、执行计划、回流决策 |
| Research Agent |
分析参考文章、爆文、截图、链接、视频字幕,提炼可迁移策略 |
参考内容、历史文章、OCR 文本、素材摘要 |
标题策略、开头方式、结构归因、爆火原因 |
| Topic Agent |
根据赛道画像、历史内容和长期记忆生成选题 |
Workspace 画像、问卷结果、历史表现、长期记忆 |
选题候选、推荐理由、适合平台、风险提示 |
| Outline Agent |
把选题变成任务书和大纲 |
选题、素材摘要、用户风格、平台要求 |
任务书、大纲、写作约束 |
| Writing Agent |
生成正文和多平台版本 |
大纲、任务书、RAG、GraphRAG、长短期记忆 |
初稿、分段正文、公众号版、口播稿、小红书版 |
| Rewrite Agent |
做局部改写、扩写、压缩、润色、去 AI 味 |
Tiptap 选区、用户修改要求、质检报告 |
局部替换内容、修改说明 |
| Quality Agent |
做去 AI 味、原创、合规、事实风险和风格一致性检查 |
初稿、参考来源、风险边界、记忆约束 |
质检报告、问题位置、风险等级、修改建议 |
| Memory Agent |
判断哪些信息值得写入长期记忆 |
用户修改行为、爆文分析结果、质检结果、复盘报告 |
记忆候选、证据、置信度、记忆类型 |
| Review Agent |
根据发布数据和用户修改行为生成复盘建议 |
发布数据、用户修改、历史表现、质检结果 |
复盘报告、下一篇行动建议 |
| Export Agent |
生成发布包和多平台内容 |
最终正文、封面、配图、平台要求 |
Markdown、HTML、封面图、正文配图、口播稿 |
用户输入不会直接进入大模型,而是先经过 Intent Agent,再由 Supervisor 调度多个 Agent,最后进入质量门禁、发布导出和记忆写回。
短期记忆保存任务现场,长期记忆沉淀用户资产
短期记忆负责当前任务不断片。比如用户正在写一篇公众号文章,系统要知道当前主题是什么、大纲生成到哪一步、哪些段落已经写完、Tiptap 当前选区在哪里、调用过哪些工具、质检失败了几次、下一步应该继续写还是回流修改。这些信息大多只服务当前任务,不适合全部写进长期记忆。
短期记忆可以理解成任务现场。它主要存在于 LangGraph State 里,再通过 Checkpointer 和 PostgresSaver 持久化到 PostgreSQL。这样即使页面刷新、请求超时、队列重试,系统也能恢复到之前的执行状态。
短期记忆主要保存这些内容:
| 内容 |
作用 |
| 当前需求 |
记录用户这一次到底要写什么、改什么、分析什么 |
| 当前 Workspace |
限定当前内容方向,避免跨赛道污染 |
| 编辑器上下文 |
保存 Tiptap 文档内容、选区位置、被选中的段落 |
| 当前大纲 |
保存任务书、大纲、已确认结构 |
| 已生成内容 |
保存标题候选、正文块、素材引用块 |
| 工具结果 |
保存素材解析、OCR、RAG、GraphRAG、质检等结果 |
| 质检状态 |
保存是否通过、失败原因、修改建议 |
| 回流次数 |
防止 Agent 因为质量问题无限重试 |
| 下一步动作 |
判断继续生成、局部改写、质检、导出还是追问用户 |
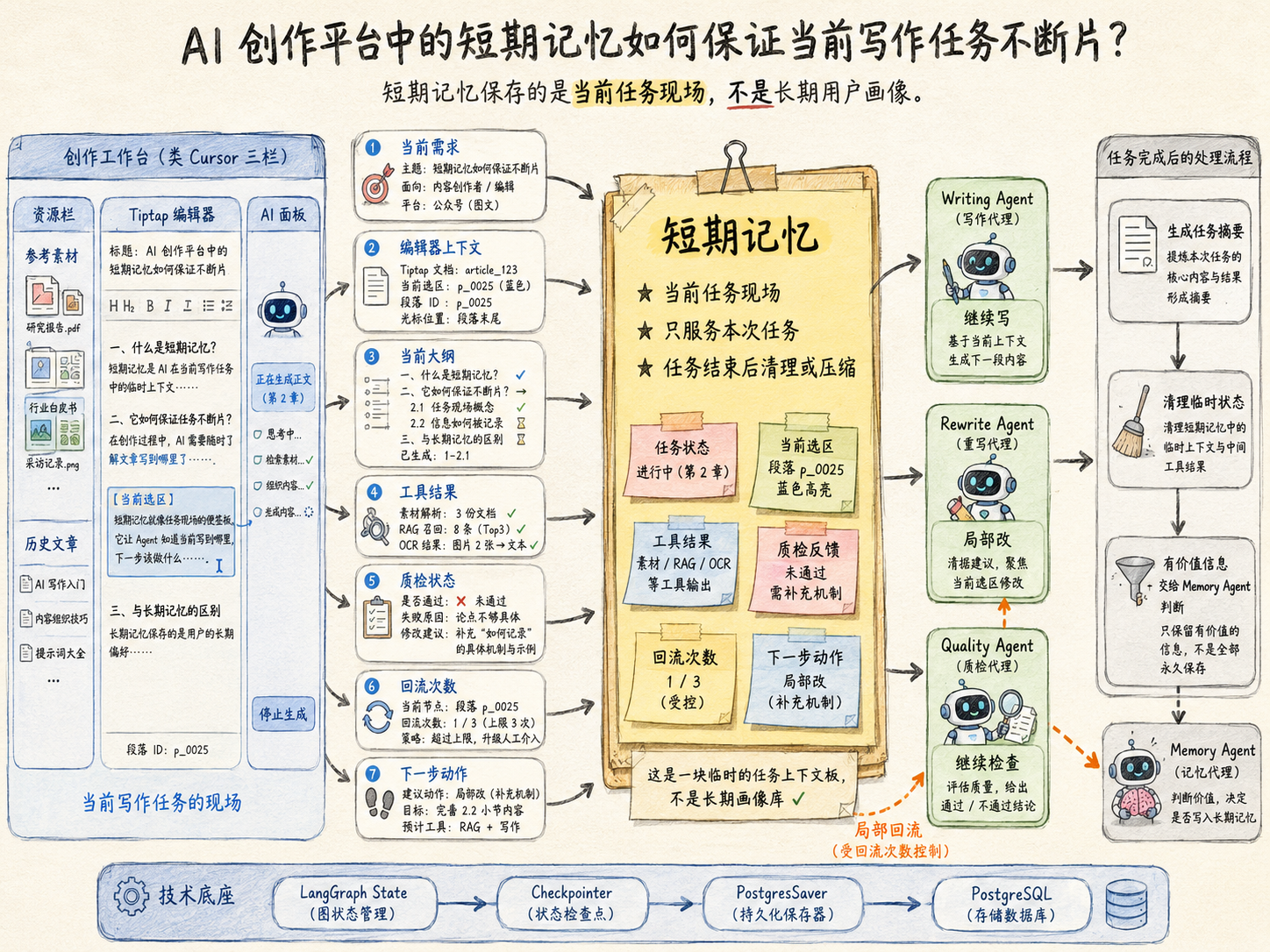
长期记忆负责跨任务复用。它保存的不是当前文章写到哪一步,而是未来还会反复用到的东西,比如用户写作风格、禁用表达、标题偏好、常用结构、历史决策、爆文分析结论、复盘策略和当前 Workspace 的长期内容方向。
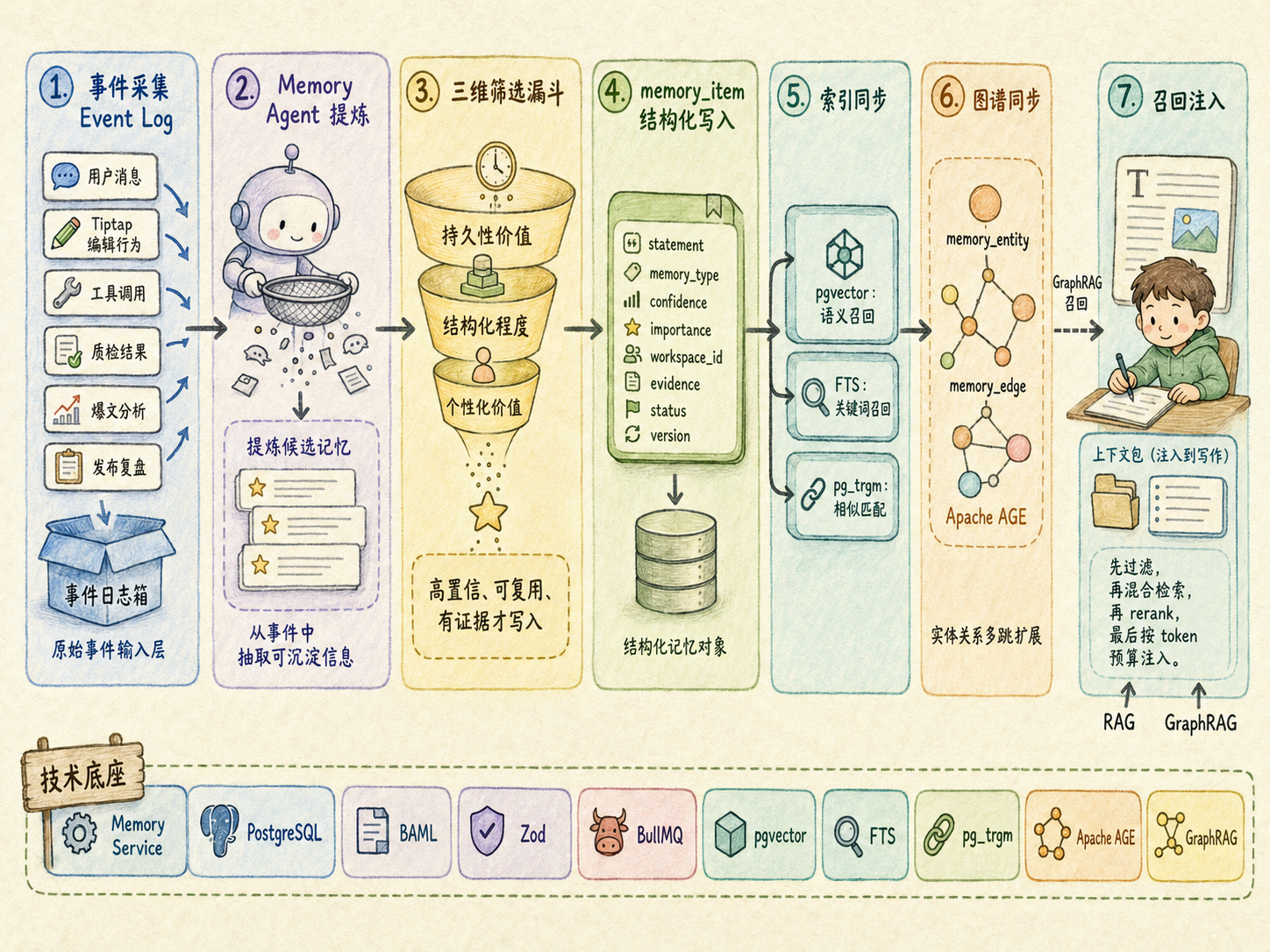
长期记忆不能简单做成聊天记录存档,也不能只做一个向量库。真正可落地的架构应该是 Memory Service:先采集事件,再提炼候选记忆,再过筛选漏斗,再写入结构化记忆对象,最后异步维护向量索引、全文索引、近似文本索引和图谱关系。
长期记忆写入流程可以拆成五步:
- 用户行为、Agent 输出、质检结果、发布复盘先进入 Event Log。比如用户连续删除模板化开头,Research Agent 分析出某篇爆文的标题策略,Quality Agent 发现某段内容 AI 味过重,Review Agent 发现某类选题阅读更好,这些都先成为原始事件。
- Memory Agent 从事件中提炼候选记忆。候选记忆不能直接入库,而是要判断它是不是未来还会用到,能不能结构化成规则、偏好、实体或关系,是否体现当前用户或 Workspace 的独特习惯。
- 通过筛选后,长期记忆写入 memory_item,保存 statement、memory_type、confidence、importance、workspace_id、evidence、status、version 等字段。
- 写入后异步完成索引和图谱同步。写作偏好、风格模式、爆文策略适合生成 embedding;禁用词、固定规则、平台风险边界适合做关键词和结构化字段;主题、平台、内容支柱、品牌、账号适合抽取成实体;实体之间的关系进入 memory_edge,并同步到 Apache AGE 或递归 CTE 支撑 GraphRAG 多跳召回。
- 下一次生成时,Memory Service 先按 workspace_id、memory_type、status、scope 过滤,再通过 pgvector、FTS、pg_trgm 和 GraphRAG 混合召回,最后按 token 预算打包给 Writing Agent。
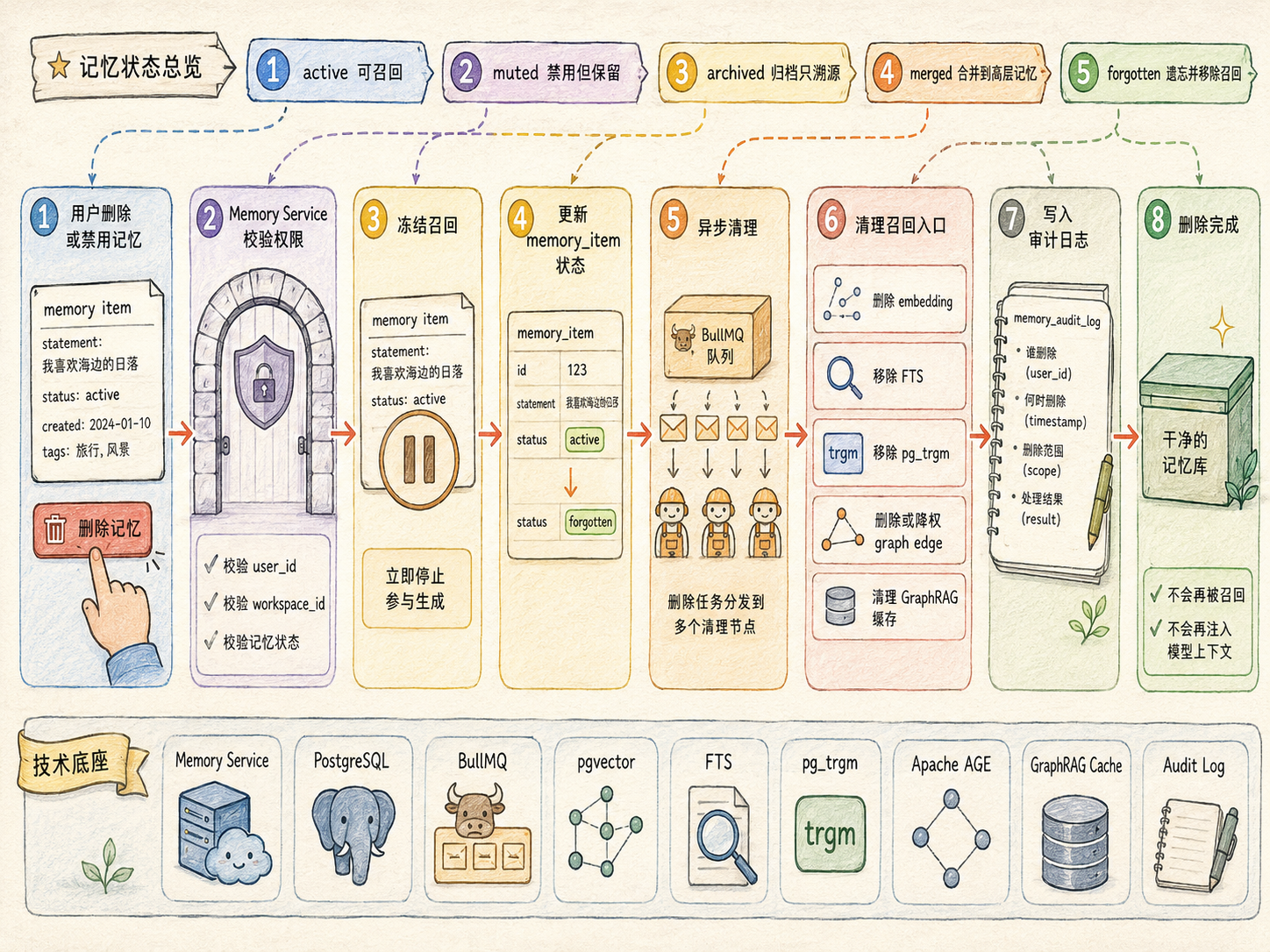
记忆清除不是删一行数据,而是清掉所有召回入口
记忆清除也必须设计清楚。用户删除一条记忆,不是把 memory_item 表里的一行删掉就结束,因为这条记忆可能已经进入 embedding、全文索引、近似文本索引、图谱边、召回缓存和任务日志。如果只删主表,系统后续仍然可能通过向量索引或图谱关系召回旧偏好,这会造成记忆残留。
所以记忆清除要分成几种动作:
| 操作 |
适用场景 |
系统行为 |
| 禁用 muted |
用户暂时不想让这条记忆参与生成 |
不参与召回,但保留内容和证据 |
| 归档 archived |
记忆过期、不常用,但还需要溯源 |
默认不参与生成,只在搜索和复盘时可见 |
| 合并 merged |
多条记忆表达重复 |
合并到更高层记忆,旧记忆保留指针 |
| 软删除 forgotten |
用户删除普通记忆 |
从召回、索引、图谱中移除,保留审计记录 |
| 硬删除 hard delete |
用户要求彻底删除、隐私删除或清空 Workspace |
删除正文、向量、索引、图边、缓存和可恢复内容 |
| 清空短期记忆 |
当前任务结束或取消 |
删除 checkpoint 临时状态,只保留必要任务摘要 |
| 清空 Workspace 记忆 |
用户删除某个内容方向 |
删除该 workspace 下的 memory、embedding、entity、edge、cache 和检索记录 |
长期记忆删除应该由 Memory Service 发起。流程是先校验 user_id 和 workspace_id 权限,再把记忆标记为 forgotten,马上冻结它的召回能力。随后投递后台删除任务,删除 embedding,移除 FTS 和 pg_trgm 索引,删除或降权相关 memory_edge,清理 GraphRAG 子图缓存和召回缓存,最后写入 audit log。
这样才能保证删除动作不是表面删除,而是真正从所有召回入口里移除。
如果是硬删除,还需要进一步清理证据片段、实体绑定、孤立实体、只由该记忆支撑的图谱边,以及日志和观测系统里的敏感 payload。这样用户才不会出现我已经删除了,但系统下一次还记得的体验问题。
长期记忆需要更新、冲突处理和冷热分层
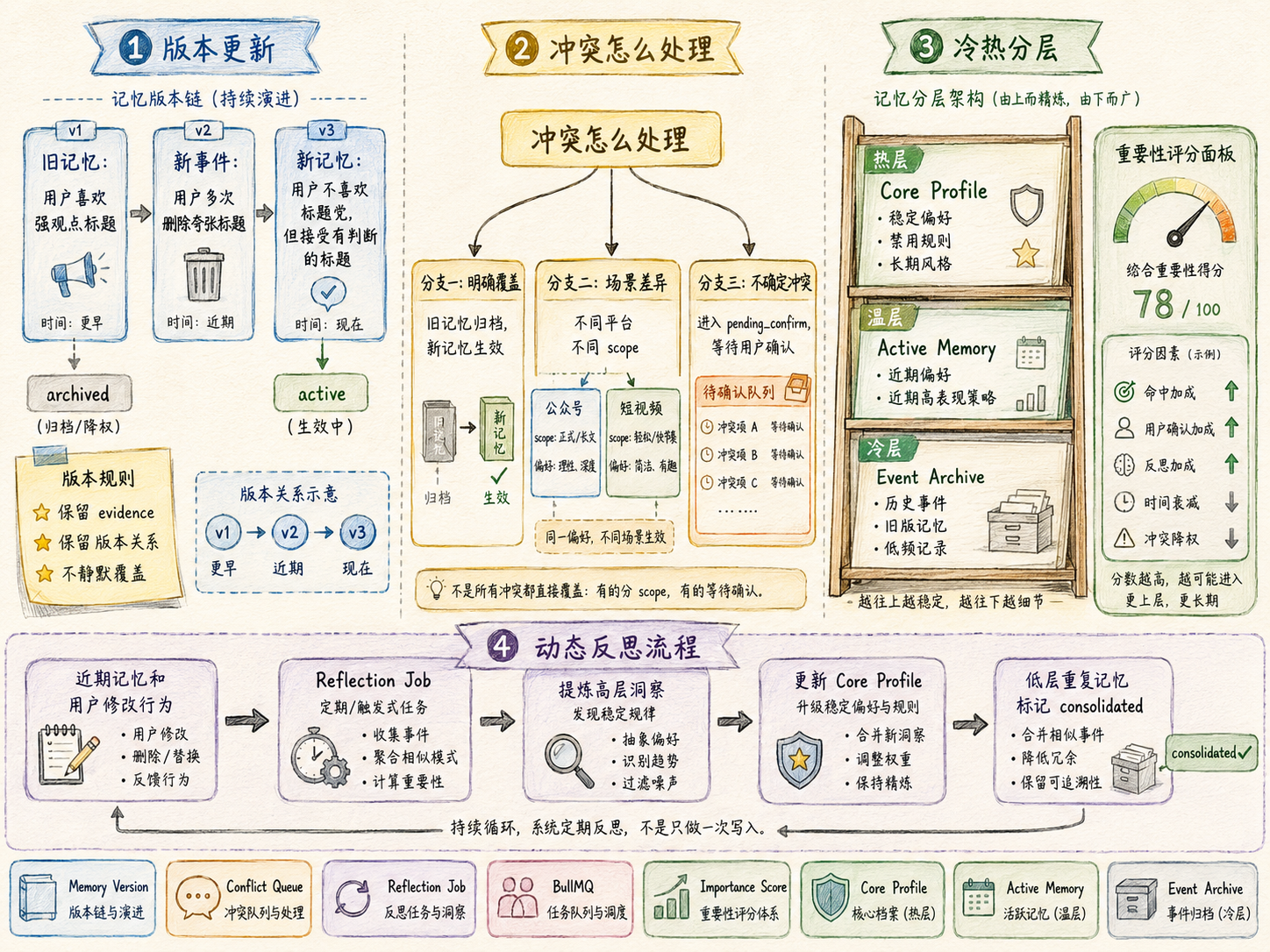
长期记忆还需要更新和冲突处理。因为用户偏好会变化,不能把第一次写入的规则永久当成真理。
比如用户早期喜欢标题强一点,后来又多次删除夸张标题,这时候系统不应该简单覆盖旧记忆,而是要建立版本链:旧记忆降权或归档,新记忆变成 active,两条记忆都保留证据和适用场景。
冲突可以分三类处理:
| 冲突类型 |
处理方式 |
| 明确覆盖 |
用户直接说以后不要这样写,旧记忆归档,新记忆生效 |
| 场景差异 |
公众号可以强观点,小红书要轻一点,两条记忆都保留,但 scope 不同 |
| 不确定冲突 |
系统无法判断时进入 pending_confirm,让用户确认 |
这样可以避免一次临时修改推翻长期偏好,也避免旧偏好一直污染新任务。
长期记忆还要做冷热分层:
| 层级 |
保存内容 |
召回策略 |
| 热层 Core Profile |
稳定画像、强偏好、禁用规则 |
优先召回,不自动衰减 |
| 温层 Active Memory |
近期偏好、近期高表现策略 |
按任务相关性召回 |
| 冷层 Event Archive |
旧版本、历史事件、低频记录 |
默认不注入,只用于搜索、复盘和溯源 |
这套机制能让长期记忆保持干净,不会越存越乱。真正稳定的偏好会进入 Core Profile,近期变化会留在 Active Memory,旧版和低频信息会进入 Event Archive。系统既能记住用户,也能在用户偏好变化时及时调整。
记忆最终要回到创作链路里,而不是停留在架构设计上
这套记忆系统真正有价值的地方,不是后台多了几张表,也不是多做了一层向量检索,而是它能在每一次创作任务中真正发挥作用。
当用户在右侧 AI 面板里说按我之前的风格写一篇时,系统不会直接把所有历史文章塞给模型,而是先由 Intent Agent 判断这次任务是否需要历史风格、是否需要参考历史稿、是否需要召回长期记忆。随后 Memory Service 会根据当前 workspace_id、任务类型、平台类型和用户权限,筛选出真正相关的记忆。
比如写公众号长文时,系统会优先召回这些内容:
- 当前 Workspace 的内容定位
- 用户稳定的写作风格
- 用户明确禁用的表达方式
- 历史高表现标题和开头结构
- 最近复盘得到的内容策略
- 参考文章分析后沉淀的可迁移方法
如果只是对 Tiptap 里选中的一段文字做局部改写,就不需要召回大量历史文章,只需要读取当前选区、短期记忆里的上下文、相关风格约束和禁用表达。这样可以避免上下文过大,也避免模型被无关记忆干扰。
记忆召回后,系统还需要把它变成可解释的上下文包,而不是黑箱注入。前端可以在 AI 面板里展示本次使用了哪些记忆,比如参考了你的写作风格、命中了禁用表达规则、使用了历史高表现结构、参考了某篇爆文分析策略。这样用户能知道 AI 为什么这样写,也能手动关闭、编辑或删除某条记忆。
这一步很重要。因为记忆系统如果不可解释,用户就会觉得系统在偷偷使用历史信息;如果记忆不可管理,旧偏好就会一直污染新内容。所以这个项目里的记忆必须让用户可查看、可编辑、可禁用、可删除,并且每次召回都要有记录。
从工程实现上,每次 Agent 调用 Memory Service 后,都要写入 memory_retrieval_log,记录这次任务召回了哪些记忆、命中了哪些实体、GraphRAG 扩展了几跳、最终注入了哪些上下文、生成结果是否被用户接受。后续 Langfuse 可以追踪记忆是否真的提升了生成质量,Promptfoo 可以用固定测试集验证改了记忆策略后,文章风格有没有跑偏。
这样记忆系统才不是一个静态资料库,而是一个可以被观测、被评估、被修正的长期能力。
总结
这个项目不是一个普通 AI 写作 Demo,而是一个覆盖复杂前端、后端工程和 AI 工程化的 AI 全栈项目。
前端有类 Cursor 的三栏工作台、Tiptap 富文本编辑器、选区 AI 改写、流式输出和 Agent 执行可视化。后端有 NestJS、PostgreSQL、Drizzle、BullMQ、对象存储、监控告警和可观测。AI 层有 Supervisor 多 Agent、BAML 结构化输出、短期记忆、长期记忆、RAG、GraphRAG、质量门禁、失败回流和复盘写回。
它最有价值的地方,是把一次性生成变成了一个长期协作系统。
用户创建 Workspace,系统通过问卷建立初始画像;用户导入历史文章和参考爆文,Research Agent 提炼可迁移策略;用户在 Tiptap 编辑器里写作,Intent Agent 和 Supervisor 负责理解任务并调度 Agent;短期记忆保证当前任务不断片,长期记忆和 GraphRAG 负责召回历史风格和内容策略;Quality Agent 做质量门禁和失败回流;用户修改、发布复盘和内容表现再由 Memory Agent 写回长期记忆。
短期记忆让这一篇文章写得不断片,长期记忆让下一篇文章更像这个用户,GraphRAG 让历史内容和主题关系真正参与生成,质量门禁保证内容不是生成完就直接交付。
这就是这个项目和普通 AI 写作工具最大的区别。普通 Demo 只能证明模型能生成内容,而这个项目能证明我们掌握了 AI 全栈产品里更核心的能力:复杂编辑器、Agent 编排、结构化输出、长短期记忆、GraphRAG 召回、质量评测、失败回流、用户可控和持续进化。
讨论内容
现在很多公司对前端或全栈的要求已经变了。
以前做一个后台管理系统、博客系统、商城系统,就能证明自己会页面、接口、数据库和基础业务流程。但现在只会这些已经很难拉开差距。尤其是 AI 应用越来越多之后,公司更希望候选人不只是会写业务代码,还能理解 AI 产品怎么落地:用户输入怎么变成任务,Agent 怎么拆分和调度,模型输出怎么结构化,历史内容怎么召回,生成结果怎么质检,系统出问题怎么观测和回滚。
所以我打算开发一个 AI 自媒体创作平台。
它表面上是一个给创作者使用的内容生产工具,可以服务公众号、抖音、小红书、头条等内容场景。但从技术实现上看,它真正训练的是 AI 全栈能力:复杂富文本编辑器、Supervisor 多 Agent 编排、BAML 结构化输出、短期记忆、长期记忆、RAG、GraphRAG、质量门禁、任务队列、监控告警和发布复盘。
这个项目不是简单接一个大模型接口,然后让 AI 返回一篇文章。它要做的是一套完整的 AI 创作工作台:用户在类 Cursor 的三栏界面里管理素材、写文章、和 AI 协作;系统在后端通过 Agent 拆解任务、召回记忆、生成内容、检查质量、失败回流;最后把用户修改行为、爆文分析结果和发布复盘沉淀成长期记忆,让下一次创作更贴近当前 Workspace 的风格。
做完这个项目,能讲的就不再是我写了几个页面、几个接口,而是我做过一个完整的 AI 全栈项目,里面同时包含复杂前端、后端工程和 AI 工程化能力。
通过这个项目,可以学到这些适合写进简历,也适合面试展开讲的能力:
这个项目的优势不是做了一个创作平台,而是它能同时覆盖复杂前端和 AI 工程化两条线。前端有富文本编辑器、三栏工作台、流式交互和 Agent 执行面板,后端有任务队列、数据隔离、对象存储、监控告警和可观测,AI 层有 Agent 编排、记忆系统、RAG、GraphRAG、结构化输出和质量评测。
技术栈围绕 AI 全栈能力来设计
这个项目不是普通前后端 CRUD,所以技术栈不能只围绕页面、接口和数据库展开,而是要覆盖复杂编辑器、Agent 编排、长短期记忆、异步任务、质量评测、监控告警和后续商业化扩展。
前端技术栈
Next.jsReactTypeScriptTailwind CSSshadcn/uiTiptapProseMirrorReact FlowTanStack QueryZodReact Hook FormZustandSSEWebSocketYjsSentry前端的核心不是做几个页面,而是做一个真正能承载内容生产的 AI 工作台。Tiptap 负责文档编辑,右侧 AI 面板负责 Agent 协作,React Flow 可以展示任务执行链路,SSE 负责把 AI 生成结果流式写入编辑器。这个组合比普通表单页面更有技术辨识度。
后端技术栈
NestJSFastify AdapterTypeScriptPostgreSQLDrizzle ORMPostgreSQL RLSRedis / ValkeyBullMQMinIO / S3JWT / Auth.jsSSEWebSocketPino / WinstonDockerGitHub Actions后端的重点不是堆接口,而是把 AI 创作过程抽象成稳定的任务系统。用户每一次成稿、改写、素材分析、批量生成、复盘,都应该有任务状态、执行轨迹、失败原因、重试入口、耗时统计和成本记录。
监控与可观测技术栈
PrometheusGrafanaSentry Frontend / BackendOpenTelemetryNestJS TerminusPrometheus ClientStructured LoggingAI 应用最怕的问题不是接口简单报错,而是任务卡住、Agent 死循环、模型输出不稳定、队列堆积、成本异常、生成质量退化。所以这个项目从一开始就要设计监控、日志、Trace、评测和告警。
AI 与 Agent 技术栈
LangGraphSupervisor 架构Multi-AgentBAMLZodRAGGraphRAGpgvectorPostgreSQL FTSpg_trgmApache AGELangfusePromptfooLiteLLM记忆系统技术栈
LangGraph CheckpointerPostgresSaverLangGraph StorePostgreSQLpgvectorFTSpg_trgmApache AGEBAMLZodBullMQLangfuse记忆系统是这个项目和普通 AI 写作 Demo 拉开差距的关键。普通 Demo 每次都是重新问模型,而这个项目要让系统能够记住当前任务、沉淀长期偏好,并且知道什么时候该遗忘、什么时候该更新、什么时候该让用户确认。
项目从选择方向开始,而不是直接写文章
项目的第一步不是让用户直接写文章,而是让用户先选择一个内容方向。比如 AI 技术、法律科普、职场成长、本地生活、母婴知识、商业分析等。系统会根据这个方向创建一个 Workspace,一个 Workspace 就代表一个独立的内容赛道。
后续所有历史文章、参考素材、长期记忆、写作偏好、选题策略和复盘结论,都会沉淀在这个 Workspace 下面。这样可以避免今天写 AI 技术,明天写生活种草,后天又写法律科普,最后所有风格、素材和记忆混在一起,导致系统越用越乱。
创建 Workspace 时,用户需要完成一组选择题和基础配置,比如目标读者是谁、擅长什么主题、每周能投入多少时间、参考哪些账号、喜欢什么表达风格、禁用哪些表达、希望内容偏观点还是教程、风险边界是什么。
这些不是普通问卷,而是后续 Agent 执行的基础上下文。目标读者会影响选题规划,表达风格会影响正文生成,禁用表达会进入长期记忆,风险边界会影响合规检查,参考账号会影响 Research Agent 的结构分析方向。
三栏工作台让 AI 协作更像真实生产环境
Workspace 创建完成后,用户会进入一个类似 Cursor 的三栏工作台。
左侧是资源栏,用来管理当前内容方向下的文章、素材、参考案例、历史公众号内容、图片、视频字幕和记忆条目;中间是 Tiptap 编辑器,用来写作和修改内容;右侧是 AI Agent 面板,用来发起创作任务、查看 AI 执行过程、确认修改建议和追踪任务状态。
这个设计的好处是,用户不是在一个孤立的聊天框里和 AI 对话,而是在一个真实工作区里完成内容生产。左侧提供素材和上下文,中间承载最终内容,右侧负责 AI 协作和任务执行。
它既有 Cursor 的工作区感,也有飞书文档的编辑体验。用户可以一边看素材,一边写文章,一边让 AI 分析、改写、续写或质检。
参考文章不是用来照抄,而是用来分析方法
进入工作台后,用户可以先导入参考内容。参考内容可以是自己以前写过的公众号文章,也可以是其他公众号的爆文、外部链接、截图、文件、视频字幕或小红书、头条、抖音里的文案。
系统导入这些内容不是为了照抄,而是为了分析它为什么有效。
比如系统会分析标题为什么能吸引点击,开头是不是制造了真实场景,中间是用案例推动还是用观点推动,情绪节奏是怎么变化的,结尾有没有行动引导,整篇内容是教程型、观点型、故事型还是清单型。
Research Agent 会把这些内容拆成可复用的写作策略,而不是复制原文表达。
技术上,链接、正文、文件、截图和视频字幕会先进入素材解析链路。普通文本可以直接解析,截图可以通过 OCR 转成文字,视频字幕可以作为文本资产保存。素材正文、摘要、标签、来源和授权状态会写入 PostgreSQL,文件本体放在 MinIO 或 S3。
随后 Research Agent 使用 BAML 产出结构化分析结果,比如标题策略、开头策略、论证结构、情绪节奏、案例模式和可迁移规则。这些高价值结论还可以由 Memory Agent 判断是否写入长期记忆,供后续创作复用。
用户输入后先做意图识别,再由 Supervisor 调度 Agent
当用户正式开始写文章时,可以直接在 Tiptap 编辑器里输入需求,也可以选中某一段文字后在右侧 AI 面板里要求改写、扩写、压缩或换成另一个平台的表达方式。
比如用户可以说帮我写一篇 AI Agent 的公众号文章,也可以选中开头说这里太像 AI 了,帮我改得自然一点。
这时系统不会直接把输入丢给大模型,而是先由 Intent Agent 做意图识别。它会综合用户输入、当前编辑器选区、当前 Workspace、历史文章授权状态、上传素材、短期记忆和长期记忆,判断用户到底是要成稿、改写、爆文分析、批量选题、多平台转换还是复盘。
Intent Agent 不直接生成文章,而是用 BAML 输出结构化意图,再交给 Zod 校验。只有结构稳定,Supervisor 才能继续调度,而不是靠模型随口说的一段自然语言猜下一步该做什么。
Supervisor 相当于整个 Agent 系统的调度中心。它会根据意图结果决定下一步调用哪个 Agent。如果信息不完整,就先追问用户;如果需要分析参考文章,就调用 Research Agent;如果要生成选题,就调用 Topic Agent;如果要写正文,就调用 Outline Agent 和 Writing Agent;如果只是局部修改,就调用 Rewrite Agent;如果生成完成,就调用 Quality Agent 做质量检查。
流式输出和 Agent 可视化让执行过程可感知
在 Agent 执行过程中,前端会持续展示任务进度。右侧 AI 面板不是简单聊天,而是一个 Agent 执行窗口,能够显示当前节点、执行日志、AI 产出、需要用户确认的建议和失败原因。
中间的 Tiptap 编辑器会接收 SSE 流式内容,像 Cursor 写代码一样逐步把正文插入文档中。React Flow 可以用来展示任务链路,让用户看到意图识别、素材分析、大纲生成、正文生成、质量检查、回流修改这些节点的执行状态。
这一层的技术重点是流式交互和复杂编辑器。Tiptap 负责文档结构和内容编辑,ProseMirror 负责底层节点、选区和插件系统,Slash Command 负责快捷命令,Bubble Menu 负责选中文本后的 AI 操作,SSE 负责后端向前端持续推送内容,React Flow 负责 Agent 节点可视化。
后续如果接入 Yjs,还可以支持多人协同编辑、评论批注、版本对比和实时同步,让这个工作台进一步接近飞书、Notion、Cursor 这类复杂产品体验。
长短期记忆让系统既不断片,也能越用越懂用户
内容生成时,系统会同时使用短期记忆和长期记忆。
短期记忆负责当前任务不断片。比如当前主题是什么、大纲生成到了哪里、哪些段落已经写完、当前编辑器选区是什么、工具调用结果是什么、质检是否通过、已经回流几次。短期记忆可以通过 LangGraph Checkpointer 和 PostgresSaver 存到 PostgreSQL,保证任务中断后还能恢复。
长期记忆负责让系统越来越懂这个 Workspace。它会保存用户写作风格、禁用表达、常用结构、历史高表现标题、选题偏好、复盘结论和参考文章分析出的可迁移策略。长期记忆不会把所有聊天记录都塞进去,而是通过 Memory Agent 提炼,再用 BAML 结构化和 Zod 校验,最后写入 PostgreSQL。
当 Writing Agent 生成内容时,系统会通过 RAG 和 GraphRAG 召回相关上下文。pgvector 负责语义相似召回,PostgreSQL FTS 负责关键词和主题命中,pg_trgm 负责相似标题和相似表达识别,Apache AGE 或递归 CTE 负责实体关系多跳扩展。GraphRAG 会把历史文章、长期记忆、主题实体、用户偏好和内容策略重新排序、压缩,再注入给 Writing Agent。
这样内容生成不是每次从零开始,而是基于当前 Workspace 的长期积累持续优化。
质量门禁让内容不是生成完就交付
生成完成后,内容不会直接交付,而是进入质量门禁。Quality Agent 会检查去 AI 味、原创风险、合规风险、事实风险和风格一致性。
比如它会判断开头是不是模板化,表达是不是太空,是否和参考文章过于相似,是否出现未经证实的事实,是否触碰平台风险边界。
如果质量门禁不通过,系统不会简单整篇重写,而是根据问题位置做局部回流。比如开头太生硬,就只回流开头;某个案例太空,就让 Rewrite Agent 补案例;某个事实不稳,就要求补充来源或降低语气;某段相似度太高,就只改相似段落。
这样可以保留已经写好的内容,不会因为一次检查失败把整篇推倒重来。
批量任务也会走同样逻辑。用户可以一次提交多个选题,BullMQ 会把它拆成父任务和多个子任务,每篇文章独立生成、独立质检、独立重试。一篇失败不会阻塞其他文章。Redis 或 Valkey 负责队列、限流、缓存和幂等控制,Prometheus 和 Grafana 监控任务耗时、失败率、队列堆积和模型调用成本,Sentry 和 OpenTelemetry 负责异常追踪和链路追踪。
通过质检后还要复盘,把经验写回长期记忆
通过质检后,内容会回到 Tiptap 编辑器中。用户可以继续手动编辑,也可以选中文本继续让 AI 局部优化。系统还可以生成正文配图占位块、封面图占位块、标题候选、摘要、多平台版本和发布检查清单。
最终内容可以导出为 Markdown、HTML,或者进一步适配公众号、抖音、小红书、头条等平台发布包。
发布或使用之后,系统会进入复盘阶段。Review Agent 会结合用户修改行为、质检结果、发布数据和历史表现,生成复盘建议。Memory Agent 会判断哪些结论值得写回长期记忆,比如某类标题表现更好,某种开头更容易被保留,某些表达被反复删除,某个账号更适合强观点结构。
写回前还会经过持久性价值、结构化程度、个性化价值三层筛选,避免长期记忆变成垃圾堆。
最终,这个项目形成的是一个完整闭环:用户先选择方向并创建 Workspace,再导入参考文章和历史内容,系统分析爆火原因并沉淀策略;用户在类 Cursor 的三栏工作台中写作,左侧管理素材,中间用 Tiptap 编辑正文,右侧通过 AI Agent 发起任务;后端通过 NestJS 和 LangGraph 调度多个 Agent,结合短期记忆、长期记忆、RAG 和 GraphRAG 生成内容,再经过质量门禁、失败回流、发布导出和复盘写回,让系统随着使用不断理解当前内容方向和用户风格。
Agent 分工不是功能堆叠,而是让任务链路可控
这个项目里的 Agent 不是页面上的功能按钮,也不是让用户手动选择的角色列表,而是服务端内部的一套执行体系。用户只需要在右侧 AI 面板里输入一句自然语言,比如帮我分析这篇爆文、帮我按之前风格写一篇、把这段改自然一点,系统会先判断用户真实意图,再由 Supervisor 调度不同 Agent 完成分析、选题、写作、质检、回流、导出和记忆写回。
这套设计的重点不是为了显得复杂,而是为了让 AI 创作过程变得可控。每个 Agent 都有明确输入、明确输出、置信度、证据和下一步动作。这样系统才能知道什么时候继续生成,什么时候追问用户,什么时候局部回流,什么时候进入人工确认,什么时候可以导出。
用户输入不会直接进入大模型,而是先经过 Intent Agent,再由 Supervisor 调度多个 Agent,最后进入质量门禁、发布导出和记忆写回。
短期记忆保存任务现场,长期记忆沉淀用户资产
短期记忆负责当前任务不断片。比如用户正在写一篇公众号文章,系统要知道当前主题是什么、大纲生成到哪一步、哪些段落已经写完、Tiptap 当前选区在哪里、调用过哪些工具、质检失败了几次、下一步应该继续写还是回流修改。这些信息大多只服务当前任务,不适合全部写进长期记忆。
短期记忆可以理解成任务现场。它主要存在于 LangGraph State 里,再通过 Checkpointer 和 PostgresSaver 持久化到 PostgreSQL。这样即使页面刷新、请求超时、队列重试,系统也能恢复到之前的执行状态。
短期记忆主要保存这些内容:
长期记忆负责跨任务复用。它保存的不是当前文章写到哪一步,而是未来还会反复用到的东西,比如用户写作风格、禁用表达、标题偏好、常用结构、历史决策、爆文分析结论、复盘策略和当前 Workspace 的长期内容方向。
长期记忆不能简单做成聊天记录存档,也不能只做一个向量库。真正可落地的架构应该是 Memory Service:先采集事件,再提炼候选记忆,再过筛选漏斗,再写入结构化记忆对象,最后异步维护向量索引、全文索引、近似文本索引和图谱关系。
长期记忆写入流程可以拆成五步:
记忆清除不是删一行数据,而是清掉所有召回入口
记忆清除也必须设计清楚。用户删除一条记忆,不是把 memory_item 表里的一行删掉就结束,因为这条记忆可能已经进入 embedding、全文索引、近似文本索引、图谱边、召回缓存和任务日志。如果只删主表,系统后续仍然可能通过向量索引或图谱关系召回旧偏好,这会造成记忆残留。
所以记忆清除要分成几种动作:
长期记忆删除应该由 Memory Service 发起。流程是先校验 user_id 和 workspace_id 权限,再把记忆标记为 forgotten,马上冻结它的召回能力。随后投递后台删除任务,删除 embedding,移除 FTS 和 pg_trgm 索引,删除或降权相关 memory_edge,清理 GraphRAG 子图缓存和召回缓存,最后写入 audit log。
这样才能保证删除动作不是表面删除,而是真正从所有召回入口里移除。
如果是硬删除,还需要进一步清理证据片段、实体绑定、孤立实体、只由该记忆支撑的图谱边,以及日志和观测系统里的敏感 payload。这样用户才不会出现我已经删除了,但系统下一次还记得的体验问题。
长期记忆需要更新、冲突处理和冷热分层
长期记忆还需要更新和冲突处理。因为用户偏好会变化,不能把第一次写入的规则永久当成真理。
比如用户早期喜欢标题强一点,后来又多次删除夸张标题,这时候系统不应该简单覆盖旧记忆,而是要建立版本链:旧记忆降权或归档,新记忆变成 active,两条记忆都保留证据和适用场景。
冲突可以分三类处理:
这样可以避免一次临时修改推翻长期偏好,也避免旧偏好一直污染新任务。
长期记忆还要做冷热分层:
这套机制能让长期记忆保持干净,不会越存越乱。真正稳定的偏好会进入 Core Profile,近期变化会留在 Active Memory,旧版和低频信息会进入 Event Archive。系统既能记住用户,也能在用户偏好变化时及时调整。
记忆最终要回到创作链路里,而不是停留在架构设计上
这套记忆系统真正有价值的地方,不是后台多了几张表,也不是多做了一层向量检索,而是它能在每一次创作任务中真正发挥作用。
当用户在右侧 AI 面板里说按我之前的风格写一篇时,系统不会直接把所有历史文章塞给模型,而是先由 Intent Agent 判断这次任务是否需要历史风格、是否需要参考历史稿、是否需要召回长期记忆。随后 Memory Service 会根据当前 workspace_id、任务类型、平台类型和用户权限,筛选出真正相关的记忆。
比如写公众号长文时,系统会优先召回这些内容:
如果只是对 Tiptap 里选中的一段文字做局部改写,就不需要召回大量历史文章,只需要读取当前选区、短期记忆里的上下文、相关风格约束和禁用表达。这样可以避免上下文过大,也避免模型被无关记忆干扰。
记忆召回后,系统还需要把它变成可解释的上下文包,而不是黑箱注入。前端可以在 AI 面板里展示本次使用了哪些记忆,比如参考了你的写作风格、命中了禁用表达规则、使用了历史高表现结构、参考了某篇爆文分析策略。这样用户能知道 AI 为什么这样写,也能手动关闭、编辑或删除某条记忆。
这一步很重要。因为记忆系统如果不可解释,用户就会觉得系统在偷偷使用历史信息;如果记忆不可管理,旧偏好就会一直污染新内容。所以这个项目里的记忆必须让用户可查看、可编辑、可禁用、可删除,并且每次召回都要有记录。
从工程实现上,每次 Agent 调用 Memory Service 后,都要写入 memory_retrieval_log,记录这次任务召回了哪些记忆、命中了哪些实体、GraphRAG 扩展了几跳、最终注入了哪些上下文、生成结果是否被用户接受。后续 Langfuse 可以追踪记忆是否真的提升了生成质量,Promptfoo 可以用固定测试集验证改了记忆策略后,文章风格有没有跑偏。
这样记忆系统才不是一个静态资料库,而是一个可以被观测、被评估、被修正的长期能力。
总结
这个项目不是一个普通 AI 写作 Demo,而是一个覆盖复杂前端、后端工程和 AI 工程化的 AI 全栈项目。
前端有类 Cursor 的三栏工作台、Tiptap 富文本编辑器、选区 AI 改写、流式输出和 Agent 执行可视化。后端有 NestJS、PostgreSQL、Drizzle、BullMQ、对象存储、监控告警和可观测。AI 层有 Supervisor 多 Agent、BAML 结构化输出、短期记忆、长期记忆、RAG、GraphRAG、质量门禁、失败回流和复盘写回。
它最有价值的地方,是把一次性生成变成了一个长期协作系统。
用户创建 Workspace,系统通过问卷建立初始画像;用户导入历史文章和参考爆文,Research Agent 提炼可迁移策略;用户在 Tiptap 编辑器里写作,Intent Agent 和 Supervisor 负责理解任务并调度 Agent;短期记忆保证当前任务不断片,长期记忆和 GraphRAG 负责召回历史风格和内容策略;Quality Agent 做质量门禁和失败回流;用户修改、发布复盘和内容表现再由 Memory Agent 写回长期记忆。
短期记忆让这一篇文章写得不断片,长期记忆让下一篇文章更像这个用户,GraphRAG 让历史内容和主题关系真正参与生成,质量门禁保证内容不是生成完就直接交付。
这就是这个项目和普通 AI 写作工具最大的区别。普通 Demo 只能证明模型能生成内容,而这个项目能证明我们掌握了 AI 全栈产品里更核心的能力:复杂编辑器、Agent 编排、结构化输出、长短期记忆、GraphRAG 召回、质量评测、失败回流、用户可控和持续进化。