Boilerplate files
cd
SRC_REPO=https://github.com/GoogleCloudPlatform/mlops-on-gcp
kpt pkg get $SRC_REPO/workshops/mlep-qwiklabs/tfserving-gke-autoscaling tfserving-gke
cd tfserving-gkeProject config
gcloud config set compute/zone us-central1-f
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=cluster-1Cluster creation call
gcloud beta container clusters create $CLUSTER_NAME \
--cluster-version=latest \
--machine-type=n1-standard-4 \
--enable-autoscaling \
--min-nodes=1 \
--max-nodes=3 \
--num-nodes=1 New cluster credentials retrieval
gcloud container clusters get-credentials $CLUSTER_NAME
Model needs to be in
SavedModelformat and in a storage bucket of the project.
Create storage bucket
export MODEL_BUCKET=${PROJECT_ID}-bucket
gsutil mb gs://${MODEL_BUCKET}Copying public model to new bucket
gsutil cp -r gs://workshop-datasets/models/resnet_101 gs://${MODEL_BUCKET}
Create configmap
First you will create a Kubernetes ConfigMap that points to the location of the ResNet101 model in your storage bucket.
configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: tfserving-configs
data:
MODEL_NAME: image_classifier
MODEL_PATH: gs://qwiklabs-gcp-03-4b91a600a7a2-bucket/resnet_101 # here update model bucketthen,
kubectl apply -f tf-serving/configmap.yaml
Create TF serving deployment
Then, you will create a Kubernetes Deployment using a standard TensorFlow Serving image from Docker Hub.
using the base file at tf-serving/deployment.yaml:
...
spec:
containers:
- name: tf-serving
image: "tensorflow/serving"
args:
- "--model_name=$(MODEL_NAME)"
- "--model_base_path=$(MODEL_PATH)"
envFrom:
- configMapRef:
name: tfserving-configs
...This conf file is set to start with one replica and CPU and RAM resources:
...
apiVersion: apps/v1
kind: Deployment
metadata:
name: image-classifier
namespace: default
labels:
app: image-classifier
spec:
replicas: 1
...At start, each replica requests 3 CPUs and 4 Gigabytes of RAM. Your cluster is configured with n1-standard-4 nodes that have 4 virtual CPUs and 15GB or RAM. It means that only a single replica can run on a node.
Deploy call
kubectl apply -f tf-serving/deployment.yaml
Get deployments
kubectl get deployments
When the deployment is ready, you will create a Kubernetes Service to expose the deployment through a load balancer.
Using cat tf-serving/service.yaml base image.
Notice that the service is of type LoadBalancer and that it exposes two ports: 8500 and 8501. By default, Tensorflow Serving uses port 8500 for the gRPC interface and port 8501 for the REST interface.
...
spec:
type: LoadBalancer
ports:
- port: 8500
protocol: TCP
name: tf-serving-grpc
- port: 8501
protocol: TCP
name: tf-serving-http
selector:
app: image-classifier
...Service creation call
kubectl apply -f tf-serving/service.yaml
Get service
kubectl get svc image-classifier
The final step is to add Horizontal Pod Autoscaler (HPA). The below command configures HPA to start a new replica of TensorFlow Serving whenever the mean CPU utilization across all already running replicas reaches 60%. HPA will attempt to create up to 4 replicas and and scale down to 1 replica.
kubectl autoscale deployment image-classifier \
--cpu-percent=60 \
--min=1 \
--max=4 Check status
kubectl get hpa
Test observation
EXTERNAL_IP=[YOUR_SERVICE_IP]
curl -d @locust/request-body.json -X POST http://${EXTERNAL_IP}:8501/v1/models/image_classifier:predictThe response returned by the model includes the list of 5 most likely labels with the associated probabilities. The response should look similar to the one below:

Install utility
pip3 install locust==1.4.1 then, export PATH=~/.local/bin:$PATH
Test install
locust -V
Starting load test
The locust folder contains the Locust script that generates prediction requests against the ResNet101 model. The script uses the same request body you used previously to verify the TensorFlow Serving deployment. The script is configured to progressively increase the number of simulated users that send prediction requests to the ResNet101 model. After reaching the maximum number of configured users, the script stops generating the load. The number of users is adjusted every 60s.
cd locust
locust -f tasks.py \
--headless \
--host http://${EXTERNAL_IP}:8501Go to GKE Dashboard
You should see the page similar to one below:

Two lines on the CPU line chart in the upper left part of the page show the requested and the currently utilized CPUs. As the load increases, the number of requested CPUs will increase in steps of 3 as new replicas are started. The number of used CPUs will be a ragged curve representing the current utilization averaged across all allocated CPU resources. The CPU line chart shows data delayed by about 60 seconds.
Note that you need to click on the Refresh button on the top menu to see the updates.
The Managed pods widget shows the currrent number of replicas. At the beginning of the test it will show one replica:

Soon you will see two pods. One running and one in the unschedulable state:

Recall that only one TensorFlow Serving pod can fit on a single cluster node. The pod stays in the unschedulable state while GKE autoscaler creates a new node. After both pods are in the running state you can verify that a new node has been created in the default node pool by opening the node pool dashboard in another browser tab.
https://console.cloud.google.com/kubernetes/nodepool/us-central1-f/cluster-1/default-pool
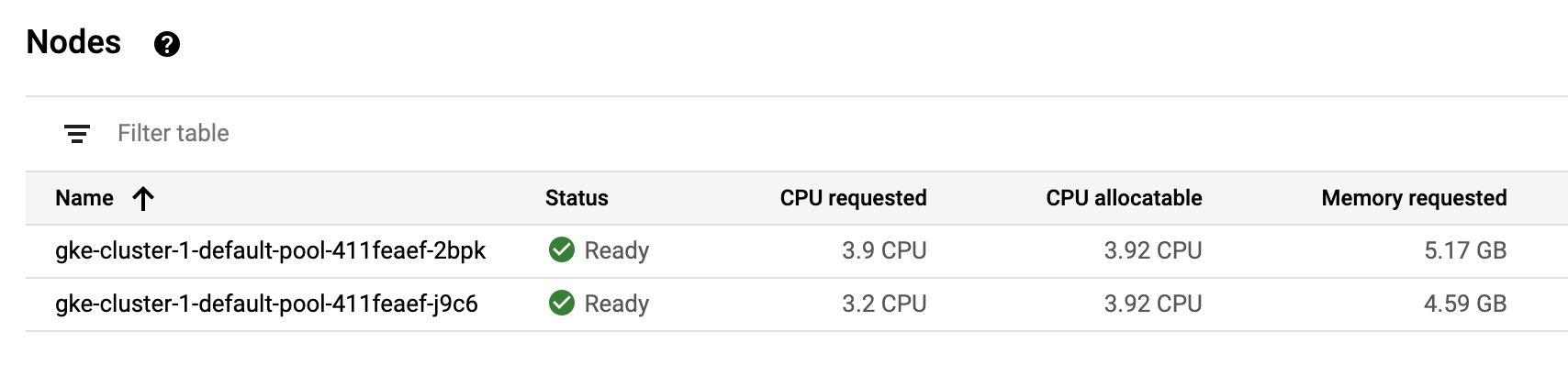
At some point the forth replica is scheduled:
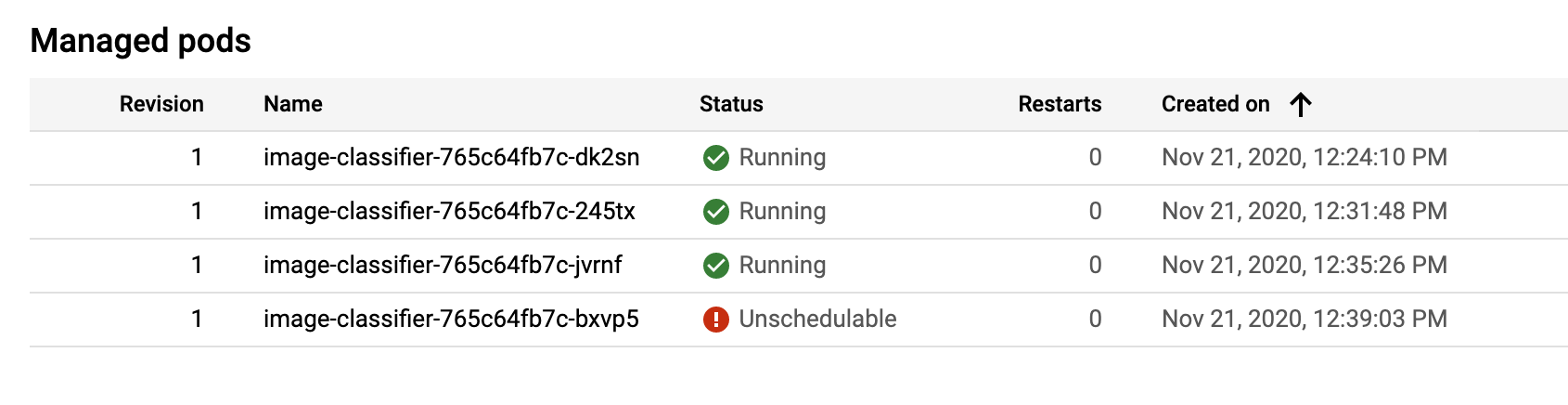
The forth replica will not transition to the running state as the GKE autoscaler was configured to create a maximum of three nodes.
After about 15 minutes, the script stops sending requests. As a result, the number of TensorFlow Serving replicas will also go down.
By default, the HPA will wait for 5 minutes before triggering the downscaling operation so you will need to wait at least 5 minutes to observe this behavior.
As the number of replicas goes down, the GKE autoscaler starts removing nodes from the default node pool.
For the purposes of scaling down, the autoscaler calculates the group's recommended target size based on peak load over the last 10 minutes. These last 10 minutes are referred to as the stabilization period. So be patient. It will take over 15 minutes after the script stopped generating predictions to see the changes in the size of the default node pool.
kpt pkg get download directories.