Content analysis is the process of making sense out of visual, textual, and audio content. Textual analysis is a subset of content analysis which focuses on the written and spoken word. Until recently, most social science treatments of textual data has focused on close readings by humans of text. However, social scientists have adopted methods from the fields of natural language processing and machine learning to integrate automated textual analysis methods into social science practice. Grimmer and Stewart (2013) provide a detailed outline of automated textual analysis methods within the social sciences, with a specific focus on political text.
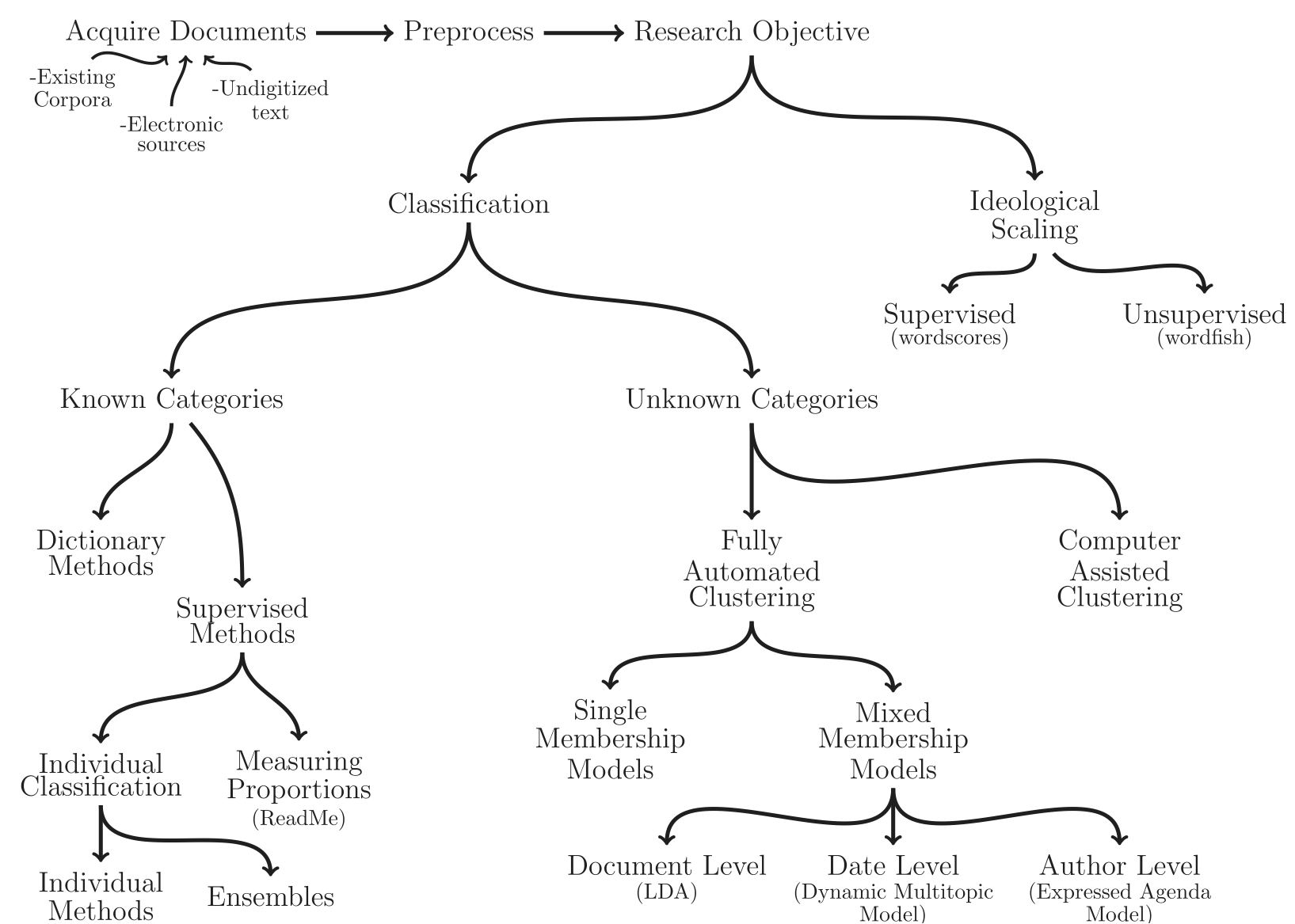
Source: Grimmer and Stewart (2013)
In this workshop we will learn how to deal with text data sets using automated methods. We'll focus first on how to handle text on very basic level, then move to basic searching of text using keyword searches and regular expressions. We'll talk about preprocessing for larger-scale text analysis and conclude with machine learning methods of textual analysis, including supervised classification and topic modeling.
As an example for these methods, we'll be using data and methods drawn from a collaborative research project designed by a group of computer scientists and educational psychologists at the University of Wisconsin-Madison. The project focused on how to understand and combat cyberbullying by using the digital traces of bullying on Twitter. We use this example to connect text analysis to current research in education.