hm){
+ System.out.print(name+"的牌: ");
+ for (Integer t:ts){
+ System.out.print(hm.get(t)+" ");
+ }
+ System.out.println();
+
+ }
+}
+```
\ No newline at end of file
diff --git "a/docs/01.Java/07.Java-\345\244\232\347\272\277\347\250\213/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260/02.JUC\345\255\246\344\271\240\347\254\224\350\256\260.md" "b/docs/01.Java/07.Java-\345\244\232\347\272\277\347\250\213/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260/02.JUC\345\255\246\344\271\240\347\254\224\350\256\260.md"
new file mode 100644
index 00000000..028d800b
--- /dev/null
+++ "b/docs/01.Java/07.Java-\345\244\232\347\272\277\347\250\213/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260/02.JUC\345\255\246\344\271\240\347\254\224\350\256\260.md"
@@ -0,0 +1,657 @@
+---
+title: JUC学习笔记(一)
+permalink: /java/se/thread/study-note
+date: 2021-05-15 18:09:11
+---
+
+# JUC
+
+
+
+
+
+- [一 简介](#%E4%B8%80-%E7%AE%80%E4%BB%8B)
+ - [什么是JUC](#%E4%BB%80%E4%B9%88%E6%98%AFjuc)
+ - [进程和线程](#%E8%BF%9B%E7%A8%8B%E5%92%8C%E7%BA%BF%E7%A8%8B)
+- [二 Lock锁](#%E4%BA%8C-lock%E9%94%81)
+ - [synchronized锁](#synchronized%E9%94%81)
+ - [Lock 锁](#lock-%E9%94%81)
+ - [区别](#%E5%8C%BA%E5%88%AB)
+- [三 生产者和消费者](#%E4%B8%89-%E7%94%9F%E4%BA%A7%E8%80%85%E5%92%8C%E6%B6%88%E8%B4%B9%E8%80%85)
+ - [synchroinzed](#synchroinzed)
+ - [lock](#lock)
+ - [按照线程顺序执行](#%E6%8C%89%E7%85%A7%E7%BA%BF%E7%A8%8B%E9%A1%BA%E5%BA%8F%E6%89%A7%E8%A1%8C)
+
+
+
+
+
+狂神JUC视频教程:https://www.bilibili.com/video/BV1B7411L7tE
+
+
+
+## 一 简介
+
+
+
+### 什么是JUC
+
+JUC是java.util.concurrent 的简写,在并发编程中使用的工具类。
+
+在jdk官方手册中可以看到juc相关的jar包有三个。
+
+用中文概括一下,JUC的意思就是java并发编程工具包
+
+实现多线程有三种方式:Thread、Runnable、Callable,其中Callable就位于concurrent包下
+
+### 进程和线程
+
+> 进程 / 线程是什么?
+
+进程:进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。
+
+线程:通常在一个进程中可以包含若干个线程,当然一个进程中至少有一个线程,不然没有存在的意义,线程可以利用进程所有拥有的资源。在引入线程的操作系统中,通常都是把进程作为分配资源的基本单位,而把线程作为独立运行和独立调度的基本单位,由于线程比进程小,基本上不拥有系统资源, 故对它的调度所付出的开销就会小得多,能更高效的提高系统多个程序间并发执行的程度。
+
+白话:
+
+进程:就是操作系统中运行的一个程序,QQ.exe,music.exe,word.exe ,这就是多个进程
+
+线程:每个进程中都存在一个或者多个线程,比如用word写文章时,就会有一个线程默默帮你定时自动保存。
+
+> 并发 / 并行是什么?
+
+做并发编程之前,必须首先理解什么是并发,什么是并行。
+
+并发和并行是两个非常容易混淆的概念。它们都可以表示两个或多个任务一起执行,但是偏重点有点不同。并发偏重于多个任务交替执行,而多个任务之间有可能还是串行的。并发是逻辑上的同时发生(simultaneous),而并行是物理上的同时发生。然而并行的偏重点在于”同时执行”。
+
+严格意义上来说,并行的多个任务是真实的同时执行,而对于并发来说,这个过程只是交替的,一会运行任务一,一会儿又运行任务二,系统会不停地在两者间切换。但对于外部观察者来说,即使多个任务是串行并发的,也会造成是多个任务并行执行的错觉。
+
+实际上,如果系统内只有一个CPU,而现在而使用多线程或者多线程任务,那么真实环境中这些任务不可能真实并行的,毕竟一个CPU一次只能执行一条指令,这种情况下多线程或者多线程任务就是并发的,而不是并行,操作系统会不停的切换任务。真正的并发也只能够出现在拥有多个CPU的系统中(多核CPU)。
+
+**并发的动机**:在计算能力恒定的情况下处理更多的任务, 就像我们的大脑, 计算能力相对恒定, 要在一天中处理更多的问题, 我们就必须具备多任务的能力. 现实工作中有很多事情可能会中断你的当前任务, 处理这种多任务的能力就是你的并发能力。
+
+**并行的动机**:用更多的CPU核心更快的完成任务. 就像一个团队, 一个脑袋不够用了, 一个团队来一起处理 一个任务。
+
+例子:
+你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
+你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。 (不一定是
+同时的)
+你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
+所以并发编程的目标是充分的利用处理器的每一个核,以达到最高的处理性能。
+
+
+
+> 线程的状态
+
+Java的线程有6种状态:可以分析源码:
+
+```java
+public enum State {
+ //线程刚创建
+ NEW,
+
+ //在JVM中正在运行的线程
+ RUNNABLE,
+
+ //线程处于阻塞状态,等待监视锁,可以重新进行同步代码块中执行
+ BLOCKED,
+
+ //等待状态
+ WAITING,
+
+ //调用sleep() join() wait()方法可能导致线程处于等待状态
+ TIMED_WAITING,
+
+ //线程执行完毕,已经退出
+ TERMINATED;
+}
+```
+
+
+
+> wait / sleep 的区别
+
+**1、来自不同的类**
+
+这两个方法来自不同的类分别是,sleep来自Thread类,和wait来自Object类。
+
+sleep是Thread的静态类方法,谁调用的谁去睡觉,即使在a线程里调用了b的sleep方法,实际上还是a去睡觉,要让b线程睡觉要在b的代码中调用sleep。
+
+**2、有没有释放锁(释放资源)**
+
+最主要是sleep方法没有释放锁
+
+而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
+
+
+
+sleep是线程被调用时,占着cpu去睡觉,其他线程不能占用cpu,os认为该线程正在工作,不会让出系统资源,wait是进入等待池等待,让出系统资源,其他线程可以占用cpu。
+
+
+
+sleep(100L)是占用cpu,线程休眠100毫秒,其他进程不能再占用cpu资源,wait(100L)是进入等待池中等待,交出cpu等系统资源供其他进程使用,在这100毫秒中,该线程可以被其他线程notify,但不同的是其他在等待池中的线程不被notify不会出来,但这个线程在等待100毫秒后会自动进入就绪队列等待系统分配资源,换句话说,sleep(100)在100毫秒后肯定会运行,但wait在100毫秒后还有等待os调用分配资源,所以wait100的停止运行时间是不确定的,但至少是100毫秒。
+就是说sleep有时间限制的就像闹钟一样到时候就叫了,而wait是无限期的除非用户主动notify。
+
+**3、使用范围不同**
+
+wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用
+
+```java
+synchronized(x){
+ //或者wait()
+ x.notify()
+}
+```
+
+**4、是否需要捕获异常**
+
+sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
+
+## 二 Lock锁
+
+### synchronized锁
+
+```java
+public class SaleTicketTest1 {
+ /*
+ * 题目:三个售票员 卖出 30张票
+ * 多线程编程的企业级套路:
+ * 1. 在高内聚低耦合的前提下, 线程 操作(对外暴露的调用方法) 资源类
+ */
+
+ public static void main(String[] args) {
+ Ticket ticket = new Ticket();
+
+ new Thread(new Runnable() {
+ @Override
+ public void run() {
+ for (int i = 1; i <= 40; i++) {
+ ticket.saleTicket();
+ }
+ }
+ }, "A").start();
+
+ new Thread(new Runnable() {
+ @Override
+ public void run() {
+ for (int i = 1; i <=40; i++) {
+ ticket.saleTicket();
+ }
+ }
+ }, "B").start();
+
+ new Thread(new Runnable() {
+ @Override
+ public void run() {
+ for (int i = 1; i <= 40; i++) {
+ ticket.saleTicket();
+ }
+ }
+ }, "C").start();
+
+ }
+
+}
+
+class Ticket { // 资源类
+ private int number = 30;
+
+ public synchronized void saleTicket() {
+ if (number > 0) {
+ System.out.println(Thread.currentThread().getName() + "卖出第 " + (number--) + "票,还剩下:" + number);
+ }
+ }
+}
+```
+
+### Lock 锁
+
+```java
+public class SaleTicketTest2 {
+ public static void main(String[] args) {
+ Ticket2 ticket2 = new Ticket2();
+
+ new Thread(() -> {
+ for (int i = 1; i <= 40; i++) {
+ ticket2.saleTicket();
+ }
+ }, "A").start();
+
+ new Thread(() -> {
+ for (int i = 1; i <= 40; i++) {
+ ticket2.saleTicket();
+ }
+ }, "B").start();
+
+ new Thread(() -> {
+ for (int i = 1; i <= 40; i++) {
+ ticket2.saleTicket();
+ }
+ }, "C").start();
+
+ }
+}
+
+class Ticket2 { // 资源类
+ private Lock lock = new ReentrantLock();
+
+ private int number = 30;
+
+ public void saleTicket() {
+ lock.lock();
+
+ try {
+ if (number > 0) {
+ System.out.println(Thread.currentThread().getName() + "卖出第 " + (number--) + "票,还剩下:" + number);
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ lock.unlock();
+ }
+
+ }
+}
+```
+
+### 区别
+
+1. 首先synchronized是java内置关键字,在jvm层面,Lock是个java类;
+2. synchronized无法判断是否获取锁的状态,Lock可以判断是否获取到锁;
+3. synchronized会自动释放锁(a 线程执行完同步代码会释放锁 ;b 线程执行过程中发生异常会释放
+锁),Lock需在finally中手工释放锁(unlock()方法释放锁),否则容易造成线程死锁;
+4. 用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1
+阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以
+不用一直等待就结束了;
+5. synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平(两者皆可)
+6. Lock锁适合大量同步的代码的同步问题,synchronized锁适合代码少量的同步问题。
+
+## 三 生产者和消费者
+
+### synchroinzed
+
+生产者和消费者 synchroinzed 版
+
+```java
+public class ProducerConsumer {
+ /**
+ * 题目:现在两个线程,可以操作初始值为0的一个变量
+ * 实现一个线程对该变量 + 1,一个线程对该变量 -1
+ * 实现交替10次
+ *
+ * 诀窍:
+ * 1. 高内聚低耦合的前提下,线程操作资源类
+ * 2. 判断 、干活、通知
+ */
+
+ public static void main(String[] args) {
+ Data data = new Data();
+
+ //A线程增加
+ new Thread(() -> {
+ for (int i = 1; i <= 10; i++) {
+ try {
+ data.increment();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }, "A").start();
+
+ //B线程减少
+ new Thread(() -> {
+ for (int i = 1; i <= 10; i++) {
+ try {
+ data.decrement();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }, "B").start();
+ }
+}
+
+class Data {
+ private int number = 0;
+
+ public synchronized void increment() throws InterruptedException {
+ // 判断该不该这个线程做
+ if (number != 0) {
+ this.wait();
+ }
+ // 干活
+ number++;
+ System.out.println(Thread.currentThread().getName() + "\t" + number);
+ // 通知
+ this.notifyAll();
+ }
+
+ public synchronized void decrement() throws InterruptedException {
+ // 判断该不该这个线程做
+ if (number == 0) {
+ this.wait();
+ }
+ // 干活
+ number--;
+ System.out.println(Thread.currentThread().getName() + "\t" + number);
+ // 通知
+ this.notifyAll();
+ }
+
+}
+```
+
+问题升级:防止虚假唤醒,4个线程,两个加,两个减
+
+【重点】if 和 while
+
+```java
+public class ProducerConsumerPlus {
+ /**
+ * 题目:现在四个线程,可以操作初始值为0的一个变量
+ * 实现两个线程对该变量 + 1,两个线程对该变量 -1
+ * 实现交替10次
+ *
+ * 诀窍:
+ * 1. 高内聚低耦合的前提下,线程操作资源类
+ * 2. 判断 、干活、通知
+ * 3. 多线程交互中,必须要防止多线程的虚假唤醒,即(判断不能用if,只能用while)
+ */
+
+ public static void main(String[] args) {
+ Data2 data = new Data2();
+
+ //A线程增加
+ new Thread(() -> {
+ for (int i = 1; i <= 10; i++) {
+ try {
+ data.increment();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }, "A").start();
+
+ //B线程减少
+ new Thread(() -> {
+ for (int i = 1; i <= 10; i++) {
+ try {
+ data.decrement();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }, "B").start();
+
+ new Thread(() -> {
+ for (int i = 1; i <= 10; i++) {
+ try {
+ data.increment();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }, "C").start();
+
+ new Thread(() -> {
+ for (int i = 1; i <= 10; i++) {
+ try {
+ data.decrement();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }, "D").start();
+ }
+}
+
+class Data2 {
+ private int number = 0;
+
+ public synchronized void increment() throws InterruptedException {
+ // 判断该不该这个线程做
+ while (number != 0) {
+ this.wait();
+ }
+ // 干活
+ number++;
+ System.out.println(Thread.currentThread().getName() + "\t" + number);
+ // 通知
+ this.notifyAll();
+ }
+
+ public synchronized void decrement() throws InterruptedException {
+ // 判断该不该这个线程做
+ while (number == 0) {
+ this.wait();
+ }
+ // 干活
+ number--;
+ System.out.println(Thread.currentThread().getName() + "\t" + number);
+ // 通知
+ this.notifyAll();
+ }
+
+}
+```
+
+
+
+### lock
+
+
+
+```java
+public class ProducerConsumerPlus {
+ /**
+ * 题目:现在四个线程,可以操作初始值为0的一个变量
+ * 实现两个线程对该变量 + 1,两个线程对该变量 -1
+ * 实现交替10次
+ *
+ * 诀窍:
+ * 1. 高内聚低耦合的前提下,线程操作资源类
+ * 2. 判断 、干活、通知
+ * 3. 多线程交互中,必须要防止多线程的虚假唤醒,即(判断不能用if,只能用while)
+ */
+
+ public static void main(String[] args) {
+ Data2 data = new Data2();
+
+ //A线程增加
+ new Thread(() -> {
+ for (int i = 1; i <= 10; i++) {
+ try {
+ data.increment();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }, "A").start();
+
+ //B线程减少
+ new Thread(() -> {
+ for (int i = 1; i <= 10; i++) {
+ try {
+ data.decrement();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }, "B").start();
+
+ new Thread(() -> {
+ for (int i = 1; i <= 10; i++) {
+ try {
+ data.increment();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }, "C").start();
+
+ new Thread(() -> {
+ for (int i = 1; i <= 10; i++) {
+ try {
+ data.decrement();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }, "D").start();
+ }
+}
+
+class Data2 {
+ private int number = 0;
+ private Lock lock = new ReentrantLock();
+ private Condition condition = lock.newCondition();
+
+ public void increment() throws InterruptedException {
+
+ lock.lock();
+ try {
+ // 判断该不该这个线程做
+ while (number != 0) {
+ condition.await();
+ }
+ // 干活
+ number++;
+ System.out.println(Thread.currentThread().getName() + "\t" + number);
+ // 通知
+ condition.signalAll();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ } finally {
+ lock.unlock();
+ }
+ }
+
+ public void decrement() throws InterruptedException {
+ lock.lock();
+ try {
+ // 判断该不该这个线程做
+ while (number == 0) {
+ condition.await();
+ }
+ // 干活
+ number--;
+ System.out.println(Thread.currentThread().getName() + "\t" + number);
+ // 通知
+ condition.signalAll();
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ lock.unlock();
+ }
+ }
+
+}
+```
+
+以上写的程序并不会按照ABCD线程顺序,只会按照 “生产” “消费”顺序
+
+### 按照线程顺序执行
+
+精确通知顺序访问
+
+```java
+public class c {
+ /**
+ * 题目:多线程之间按顺序调用,实现 A->B->C
+ * 重点:标志位
+ */
+
+ public static void main(String[] args) {
+ Resources resources = new Resources();
+
+ new Thread(() -> {
+ for (int i = 1; i <= 10; i++) {
+ resources.a();
+ }
+
+ }, "A").start();
+
+ new Thread(() -> {
+ for (int i = 1; i <= 10; i++) {
+ resources.b();
+ }
+
+ }, "B").start();
+
+ new Thread(() -> {
+ for (int i = 1; i <= 10; i++) {
+ resources.c();
+ }
+
+ }, "C").start();
+
+ }
+}
+
+class Resources {
+ private int number = 1; // 1A 2B 3C
+ private Lock lock = new ReentrantLock();
+ private Condition condition1 = lock.newCondition();
+ private Condition condition2 = lock.newCondition();
+ private Condition condition3 = lock.newCondition();
+
+ public void a() {
+ lock.lock();
+ try {
+ // 判断
+ while (number != 1) {
+ condition1.await();
+ }
+ // 干活
+ System.out.println(Thread.currentThread().getName());
+ // 通知,指定的干活!
+ number = 2;
+ condition2.signal();
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ lock.unlock();
+ }
+ }
+
+ public void b() {
+ lock.lock();
+ try {
+ // 判断
+ while (number != 2) {
+ condition2.await();
+ }
+ // 干活
+ System.out.println(Thread.currentThread().getName() );
+
+ // 通知,指定的干活!
+ number = 3;
+ condition3.signal();
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ lock.unlock();
+ }
+ }
+
+ public void c() {
+ lock.lock();
+ try {
+ // 判断
+ while (number != 3) {
+ condition3.await();
+ }
+ // 干活
+ System.out.println(Thread.currentThread().getName());
+
+ // 通知,指定的干活!
+ number = 1;
+ condition1.signal();
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ lock.unlock();
+ }
+ }
+}
+```
\ No newline at end of file
diff --git "a/docs/01.Java/07.Java-\345\244\232\347\272\277\347\250\213/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260/03.JUC-\345\205\253\351\224\201.md" "b/docs/01.Java/07.Java-\345\244\232\347\272\277\347\250\213/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260/03.JUC-\345\205\253\351\224\201.md"
new file mode 100644
index 00000000..3deb624f
--- /dev/null
+++ "b/docs/01.Java/07.Java-\345\244\232\347\272\277\347\250\213/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260/03.JUC-\345\205\253\351\224\201.md"
@@ -0,0 +1,500 @@
+---
+title: JUC学习笔记-8锁的现象
+permalink: /java/se/thread/study-note/3
+date: 2021-05-16 11:01:20
+---
+
+# 8锁的现象
+
+
+
+
+
+- [问题一](#%E9%97%AE%E9%A2%98%E4%B8%80)
+- [问题二](#%E9%97%AE%E9%A2%98%E4%BA%8C)
+- [问题三](#%E9%97%AE%E9%A2%98%E4%B8%89)
+- [问题四](#%E9%97%AE%E9%A2%98%E5%9B%9B)
+- [问题五](#%E9%97%AE%E9%A2%98%E4%BA%94)
+- [问题六](#%E9%97%AE%E9%A2%98%E5%85%AD)
+- [问题七](#%E9%97%AE%E9%A2%98%E4%B8%83)
+- [问题八](#%E9%97%AE%E9%A2%98%E5%85%AB)
+- [小结](#%E5%B0%8F%E7%BB%93)
+
+
+
+
+
+## 问题一
+
+1、标准访问,请问先打印邮件还是短信?
+
+```java
+package com.oddfar.lock8;
+
+import java.util.concurrent.TimeUnit;
+
+public class A {
+ /**
+ * 多线程的8锁
+ * 1、标准访问,请问先打印邮件还是短信?
+ */
+ public static void main(String[] args) throws InterruptedException {
+ Phone phone = new Phone();
+ new Thread(() -> {
+ try {
+ phone.sendEmail();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "A").start();
+
+ //休眠一秒
+ //Thread.sleep(1000);
+ TimeUnit.SECONDS.sleep(1);
+
+ new Thread(() -> {
+ try {
+ phone.sendSMS();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "B").start();
+
+ }
+}
+
+class Phone {
+ public synchronized void sendEmail(){
+ System.out.println("sendEmail");
+ }
+
+ public synchronized void sendSMS(){
+ System.out.println("sendSMS");
+ }
+}
+
+```
+
+答案:sendEmail
+
+结论:被synchronized修饰的方法,锁的对象是方法的调用者。因为两个方法的调用者是同一个,所以两个方法用的是同一个锁,先调用方法的先执行。
+
+
+
+## 问题二
+
+2、邮件方法暂停4秒钟,请问先打印邮件还是短信?
+
+```java
+package com.oddfar.lock8;
+
+import java.util.concurrent.TimeUnit;
+
+public class B {
+ /**
+ * 多线程的8锁
+ * 2、邮件方法暂停4秒钟,请问先打印邮件还是短信?
+ */
+ public static void main(String[] args) throws InterruptedException {
+ Phone2 phone = new Phone2();
+ new Thread(() -> {
+ try {
+ phone.sendEmail();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "A").start();
+
+ TimeUnit.SECONDS.sleep(1);
+
+ new Thread(() -> {
+ try {
+ phone.sendSMS();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "B").start();
+
+ }
+}
+
+class Phone2 {
+ public synchronized void sendEmail() throws Exception {
+ TimeUnit.SECONDS.sleep(4);
+ System.out.println("sendEmail");
+ }
+
+ public synchronized void sendSMS(){
+ System.out.println("sendSMS");
+ }
+}
+```
+
+答案:sendEmail
+
+结论:被synchronized修饰的方法,锁的对象是方法的调用者。因为两个方法的调用者是同一个,所以两个方法用的是同一个锁,先调用方法的先执行,第二个方法只有在第一个方法执行完释放锁之后才能执行。
+
+## 问题三
+
+3、新增一个普通方法hello()不加锁,请问先打印邮件还是hello?
+
+```java
+package com.oddfar.lock8;
+
+import java.util.concurrent.TimeUnit;
+
+/**
+ * @author zhiyuan
+ */
+public class C {
+ /**
+ * 多线程的8锁
+ * 3、新增一个普通方法hello()不加锁,请问先打印邮件还是hello?
+ */
+ public static void main(String[] args) throws InterruptedException {
+ Phone3 phone = new Phone3();
+ new Thread(() -> {
+ try {
+ phone.sendEmail();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "A").start();
+
+ TimeUnit.SECONDS.sleep(1);
+
+ new Thread(() -> {
+ try {
+ phone.hello();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "B").start();
+
+ }
+}
+
+class Phone3 {
+ public synchronized void sendEmail() throws Exception {
+ TimeUnit.SECONDS.sleep(4);
+ System.out.println("sendEmail");
+ }
+
+ // 没有 synchronized,没有 static 就是普通方式
+ public void hello() {
+ System.out.println("Hello");
+ }
+}
+```
+
+答案:Hello
+
+结论:如果一个方法没有被synchronized修饰,不是同步方法,不受锁的影响,所以不需要等待。
+
+## 问题四
+
+4、两个手机,一个手机发邮件,另一个发短信,请问先执行sendEmail 还是 sendSMS
+
+```java
+package com.oddfar.lock8;
+
+import java.util.concurrent.TimeUnit;
+
+public class D {
+ /**
+ * 多线程的8锁
+ * 4、两个手机,请问先执行sendEmail 还是 sendSMS
+ */
+ public static void main(String[] args) throws InterruptedException {
+ Phone4 phone = new Phone4();
+ Phone4 phone2 = new Phone4();
+
+ new Thread(() -> {
+ try {
+ phone.sendEmail();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "A").start();
+
+ TimeUnit.SECONDS.sleep(1);
+
+ new Thread(() -> {
+ try {
+ phone2.sendSMS();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "B").start();
+
+ }
+}
+
+class Phone4 {
+ public synchronized void sendEmail() throws Exception {
+ TimeUnit.SECONDS.sleep(4);
+ System.out.println("sendEmail");
+ }
+
+ public synchronized void sendSMS() {
+ System.out.println("sendSMS");
+ }
+}
+```
+
+
+
+答案:先执行“sendSMS”
+
+结论:被synchronized修饰的方法,锁的对象是方法的调用者。用了两个对象调用各自的方法,所以两个方法的调用者不是同一个,于是两个方法用的不是同一个锁,后调用的方法不需要等待先调用的方法。
+
+## 问题五
+
+5、两个静态同步方法,同一部手机,请问先打印邮件还是短信?
+
+```java
+package com.oddfar.lock8;
+
+import java.util.concurrent.TimeUnit;
+
+public class E {
+ /**
+ * 多线程的8锁
+ * 5、两个静态同步方法,同一部手机,请问先打印邮件还是短信?
+ */
+ public static void main(String[] args) throws InterruptedException {
+ Phone5 phone = new Phone5();
+
+ new Thread(() -> {
+ try {
+ phone.sendEmail();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "A").start();
+
+ TimeUnit.SECONDS.sleep(1);
+
+ new Thread(() -> {
+ try {
+ phone.sendSMS();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "B").start();
+
+ }
+}
+
+class Phone5 {
+ public static synchronized void sendEmail() throws Exception {
+ TimeUnit.SECONDS.sleep(4);
+ System.out.println("sendEmail");
+ }
+
+ public static synchronized void sendSMS() {
+ System.out.println("sendSMS");
+ }
+}
+```
+
+
+
+答案:先执行“sendEmail”
+
+结论:被synchronized和static修饰的方法,锁的对象是类的class模板对象,这个则全局唯一!两个方法都被static修饰了,所以两个方法用的是同一个锁,后调用的方法需要等待先调用的方法。
+
+## 问题六
+
+6、两个静态同步方法,2部手机,一个手机发邮件,另一个发短信,请问先打印邮件还是短信?
+
+```java
+package com.oddfar.lock8;
+
+import java.util.concurrent.TimeUnit;
+
+/**
+ * @author zhiyuan
+ */
+public class F {
+ /**
+ * 多线程的8锁
+ * 6、两个静态同步方法,2部手机,一个手机发邮件,另一个发短信,请问先打印邮件还是短信?
+ */
+ public static void main(String[] args) throws InterruptedException {
+ Phone6 phone = new Phone6();
+
+ Phone6 phone2 = new Phone6();
+
+ new Thread(() -> {
+ try {
+ phone.sendEmail();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "A").start();
+
+ TimeUnit.SECONDS.sleep(1);
+
+ new Thread(() -> {
+ try {
+ phone2.sendSMS();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "B").start();
+
+ }
+}
+
+class Phone6 {
+ public static synchronized void sendEmail() throws Exception {
+ TimeUnit.SECONDS.sleep(4);
+ System.out.println("sendEmail");
+ }
+
+ public static synchronized void sendSMS() {
+ System.out.println("sendSMS");
+ }
+}
+```
+
+答案:先输出“sendEmail”
+
+结论:被synchronized和static修饰的方法,锁的对象就是Class模板对象,这个则全局唯一!所以说这里是同一个
+
+## 问题七
+
+7、一个普通同步方法,一个静态同步方法,同一部手机,请问先打印邮件还是短信?
+
+```java
+package com.oddfar.lock8;
+
+import java.util.concurrent.TimeUnit;
+
+public class G {
+ /**
+ * 多线程的8锁
+ * 7、一个普通同步方法,一个静态同步方法,同一部手机,请问先打印邮件还是短信?
+ */
+ public static void main(String[] args) throws InterruptedException {
+ Phone7 phone = new Phone7();
+
+ new Thread(() -> {
+ try {
+ phone.sendEmail();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "A").start();
+
+ TimeUnit.SECONDS.sleep(1);
+
+ new Thread(() -> {
+ try {
+ phone.sendSMS();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "B").start();
+
+ }
+}
+
+class Phone7 {
+ public static synchronized void sendEmail() throws Exception {
+ TimeUnit.SECONDS.sleep(4);
+ System.out.println("sendEmail");
+ }
+
+ public synchronized void sendSMS() {
+ System.out.println("sendSMS");
+ }
+}
+```
+
+答案:先执行“sendSMS”
+
+结论:synchronized 锁的是这个调用的对象。被synchronized和static修饰的方法,锁的是这个类的Class模板 。这里是两个锁!
+
+## 问题八
+
+8、一个普通同步方法,一个静态同步方法,2部手机,一个发邮件,一个发短信,请问哪个先执行?
+
+```java
+package com.oddfar.lock8;
+
+import java.util.concurrent.TimeUnit;
+
+/**
+ * @author zhiyuan
+ */
+public class H {
+ /**
+ * 多线程的8锁
+ * 8、一个普通同步方法,一个静态同步方法,2部手机,一个发邮件,一个发短信,请问先打印邮件还是短信?
+ */
+ public static void main(String[] args) throws InterruptedException {
+ Phone8 phone = new Phone8();
+ Phone8 phone2 = new Phone8();
+
+ new Thread(() -> {
+ try {
+ phone.sendEmail();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "A").start();
+
+ TimeUnit.SECONDS.sleep(1);
+
+ new Thread(() -> {
+ try {
+ phone2.sendSMS();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }, "B").start();
+
+ }
+}
+
+class Phone8 {
+ public static synchronized void sendEmail() throws Exception {
+ TimeUnit.SECONDS.sleep(4);
+ System.out.println("sendEmail");
+ }
+
+ public synchronized void sendSMS() {
+ System.out.println("sendSMS");
+ }
+}
+```
+
+答案:sendSMS
+
+结论:被synchronized和static修饰的方法,锁的对象是类的class对象。仅被synchronized修饰的方法,锁的对象是方法的调用者。即便是用同一个对象调用两个方法,锁的对象也不是同一个,所以两个方法用的不是同一个锁,后调用的方法不需要等待先调用的方法。
+
+## 小结
+
+1、new this 调用的这个对象,是一个具体的对象!
+
+2、static class 唯一的一个模板!
+
+一个对象里面如果有多个synchronized方法,某个时刻内,只要一个线程去调用其中一个synchronized 方法了,其他的线程都要等待,换句话说,在某个时刻内,只能有唯一一个线程去访问这些 synchronized方法,锁的是当前对象this,被锁定后,其他的线程都不能进入到当前对象的其他的 synchronized方法
+
+加个普通方法后发现和同步锁无关,换成两个对象后,不是同一把锁,情况变化
+
+都换成静态同步方法后,情况又变化了。所有的非静态的同步方法用的都是同一把锁(锁的class模板)
+
+**具体的表现为以下三种形式:**
+
+- 对于普通同步方法,锁的是当前实例对象
+
+- 对于静态同步方法,锁的是当前的Class对象。
+
+- 对于同步方法块,锁是synchronized括号里面的配置对象
+
+当一个线程试图访问同步代码块时,他首先必须得到锁,退出或者是抛出异常时必须释放锁,也就是说 如果一个实例对象的非静态同步方法获取锁后,该实例对象的其他非静态同步方法必须等待获取锁的方法释放锁后才能获取锁,可以是别的实例对象非非静态同步方法因为跟该实例对象的非静态同步方法用 的是不同的锁,所以必须等待该实例对象已经获取锁的非静态同步方法释放锁就可以获取他们自己的 锁。
+
+所有的静态同步方法用的也是同一把锁(类对象本身) ,这两把锁的是两个不同的对象,所以静态的同步方法与非静态的同步方法之间是不会有竞争条件的,但是一旦一个静态同步方法获取锁后,其他的静态同步方法都必须等待该方法释放锁后才能获取锁,而不是同一个实例对象的静态同步方法之间,还是不同的实例对象的静态同步方法之间,只要他们用一个的是同一个类的实例对象。
\ No newline at end of file
diff --git "a/docs/01.Java/07.Java-\345\244\232\347\272\277\347\250\213/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260/04.JUC\345\255\246\344\271\240\347\254\224\350\256\260.md" "b/docs/01.Java/07.Java-\345\244\232\347\272\277\347\250\213/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260/04.JUC\345\255\246\344\271\240\347\254\224\350\256\260.md"
new file mode 100644
index 00000000..5d277684
--- /dev/null
+++ "b/docs/01.Java/07.Java-\345\244\232\347\272\277\347\250\213/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260/04.JUC\345\255\246\344\271\240\347\254\224\350\256\260.md"
@@ -0,0 +1,630 @@
+---
+title: JUC学习笔记(二)
+permalink: /java/se/thread/study-note/4
+date: 2021-05-16 14:49:33
+---
+
+
+
+
+
+- [六 多线程下集合类的不安全](#%E5%85%AD-%E5%A4%9A%E7%BA%BF%E7%A8%8B%E4%B8%8B%E9%9B%86%E5%90%88%E7%B1%BB%E7%9A%84%E4%B8%8D%E5%AE%89%E5%85%A8)
+ - [list](#list)
+ - [set](#set)
+ - [map](#map)
+- [七 Callable](#%E4%B8%83-callable)
+ - [基础入门](#%E5%9F%BA%E7%A1%80%E5%85%A5%E9%97%A8)
+ - [多个线程调用](#%E5%A4%9A%E4%B8%AA%E7%BA%BF%E7%A8%8B%E8%B0%83%E7%94%A8)
+ - [参考资料](#%E5%8F%82%E8%80%83%E8%B5%84%E6%96%99)
+- [八 常用辅助类](#%E5%85%AB-%E5%B8%B8%E7%94%A8%E8%BE%85%E5%8A%A9%E7%B1%BB)
+ - [CountDownLatch](#countdownlatch)
+ - [CyclicBarrier](#cyclicbarrier)
+ - [Semaphore](#semaphore)
+- [九 读写锁](#%E4%B9%9D-%E8%AF%BB%E5%86%99%E9%94%81)
+- [十 阻塞队列](#%E5%8D%81-%E9%98%BB%E5%A1%9E%E9%98%9F%E5%88%97)
+ - [阻塞队列简介](#%E9%98%BB%E5%A1%9E%E9%98%9F%E5%88%97%E7%AE%80%E4%BB%8B)
+ - [阻塞队列的用处](#%E9%98%BB%E5%A1%9E%E9%98%9F%E5%88%97%E7%9A%84%E7%94%A8%E5%A4%84)
+ - [接口架构图](#%E6%8E%A5%E5%8F%A3%E6%9E%B6%E6%9E%84%E5%9B%BE)
+ - [API的使用](#api%E7%9A%84%E4%BD%BF%E7%94%A8)
+
+
+
+## 六 多线程下集合类的不安全
+
+### list
+
+多线程下
+
+```java
+public class ListTest {
+ public static void main(String[] args) {
+ List list = new ArrayList<>();
+ // 对比3个线程 和 30个线程,看区别
+ for (int i = 1; i <= 30; i++) {
+ new Thread(() -> {
+ list.add(UUID.randomUUID().toString().substring(0, 8));
+ System.out.println(list);
+ }, String.valueOf(i)).start();
+ }
+ }
+}
+```
+
+运行报错:`java.util.ConcurrentModificationException`
+
+导致原因:add 方法没有加锁
+
+解决方案:
+
+```java
+/**
+ * 换一个集合类
+ * 1、List list = new Vector<>(); JDK1.0 就存在了!
+ * 2、List list = Collections.synchronizedList(new ArrayList<>());
+ * 3、List list = new CopyOnWriteArrayList<>();
+ */
+public class ListTest {
+ public static void main(String[] args) {
+
+ List list = new CopyOnWriteArrayList<>();
+
+ for (int i = 1; i <= 30; i++) {
+ new Thread(() -> {
+ list.add(UUID.randomUUID().toString().substring(0, 8));
+ System.out.println(list);
+ }, String.valueOf(i)).start();
+ }
+ }
+}
+```
+
+**写入时复制(CopyOnWrite)思想**
+
+写入时复制(CopyOnWrite,简称COW)思想是计算机程序设计领域中的一种优化策略。其核心思想是,如果有多个调用者(Callers)同时要求相同的资源(如内存或者是磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者视图修改资源内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的(transparently)。此做法主要的优点是如果调用者没有修改资源,就不会有副本 (private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
+
+**CopyOnWriteArrayList为什么并发安全且性能比Vector好**
+
+Vector是增删改查方法都加了synchronized,保证同步,但是每个方法执行的时候都要去获得锁,性能就会大大下降,而CopyOnWriteArrayList 只是在增删改上加锁,但是读不加锁,在读方面的性能就好于Vector,CopyOnWriteArrayList支持读多写少的并发情况。
+
+### set
+
+
+
+```java
+/**
+ * 1、Set set = Collections.synchronizedSet(new HashSet<>());
+ * 2、Set set = new CopyOnWriteArraySet();
+ */
+public class SetTest {
+ public static void main(String[] args) {
+
+ Set set = new CopyOnWriteArraySet();
+
+ for (int i = 1; i <= 30; i++) {
+ new Thread(() -> {
+ set.add(UUID.randomUUID().toString().substring(0, 8));
+ System.out.println(set);
+ }, String.valueOf(i)).start();
+ }
+ }
+}
+```
+
+### map
+
+hashMap底层是数组+链表+红黑树
+
+```java
+Map map = new HashMap<>();
+// 等价于
+Map map = new HashMap<>(16,0.75);
+// 工作中,常常会自己根据业务来写参数,提高效率
+```
+
+map不安全测试:
+
+```java
+public class MapSet {
+ public static void main(String[] args) {
+ Map map = new HashMap<>();
+
+ for (int i = 1; i <= 30; i++) {
+ new Thread(() -> {
+ map.put(Thread.currentThread().getName(),
+ UUID.randomUUID().toString().substring(0, 8));
+ System.out.println(map);
+ }, String.valueOf(i)).start();
+ }
+ }
+}
+```
+
+解决:
+
+```java
+Map map = new ConcurrentHashMap<>();
+```
+
+## 七 Callable
+
+我们已经知道Java中常用的两种线程实现方式:分别是继承Thread类和实现Runnable接口。
+
+
+
+从上图中,我们可以看到,第三种实现Callable接口的线程,而且还带有返回值的。我们来对比下实现Runnable和实现Callable接口的两种方式不同点:
+
+1:需要实现的方法名称不一样:一个run方法,一个call方法
+
+2:返回值不同:一个void无返回值,一个带有返回值的。其中返回值的类型和泛型V是一致的。
+
+3:异常:一个无需抛出异常,一个需要抛出异常。
+
+### 基础入门
+
+```java
+public class CallableDemo {
+ public static void main(String[] args) throws Exception {
+ MyThread myThread = new MyThread();
+ FutureTask futureTask = new FutureTask(myThread); // 适配类
+ Thread t1 = new Thread(futureTask, "A"); // 调用执行
+ t1.start();
+ Integer result = (Integer) futureTask.get(); // 获取返回值
+ System.out.println(result);
+ }
+}
+
+class MyThread implements Callable {
+ @Override
+ public Integer call() throws Exception {
+ System.out.println("call 被调用");
+ return 1024;
+ }
+}
+```
+
+
+
+### 多个线程调用
+
+```java
+public class CallableDemo {
+ public static void main(String[] args) throws Exception {
+ MyThread myThread = new MyThread();
+ FutureTask futureTask = new FutureTask(myThread); // 适配类
+
+ new Thread(futureTask, "A").start(); // 调用执行
+ // 第二次调用执行,在同一个futureTask对象,不输出结果,可理解为“缓存”
+ new Thread(futureTask, "B").start();
+
+ //get 方法获得返回结果! 一般放在最后一行!否则可能会阻塞
+ Integer result = (Integer) futureTask.get(); // 获取返回值
+ System.out.println(result);
+ }
+}
+
+class MyThread implements Callable {
+ @Override
+ public Integer call() throws Exception {
+ System.out.println(Thread.currentThread().getName() + "\tcall 被调用");
+ TimeUnit.SECONDS.sleep(2);
+ return 1024;
+ }
+}
+```
+
+### 参考资料
+
+- https://baijiahao.baidu.com/s?id=1666820818587296272
+
+## 八 常用辅助类
+
+### CountDownLatch
+
+“倒计时锁存器”
+
+例如,执行完6个线程输出执行完毕
+
+```java
+public class CountDownLatchDemo {
+ public static void main(String[] args) throws InterruptedException {
+ // 计数器
+ CountDownLatch countDownLatch = new CountDownLatch(6);
+ for (int i = 1; i <= 6; i++) {
+ new Thread(() -> {
+ System.out.println(Thread.currentThread().getName() + "\tStart");
+ countDownLatch.countDown(); // 计数器-1
+ }, String.valueOf(i)).start();
+ }
+ //阻塞等待计数器归零
+ countDownLatch.await();
+ System.out.println(Thread.currentThread().getName() + "\tEnd");
+ }
+
+}
+```
+
+
+
+CountDownLatch 主要有两个方法,当一个或多个线程调用 `await` 方法时,这些线程会阻塞
+
+其他线程调用`CountDown()`方法会将计数器减1(调用CountDown方法的线程不会阻塞)
+
+当计数器变为0时,await 方法阻塞的线程会被唤醒,继续执行
+
+
+
+### CyclicBarrier
+
+翻译:CyclicBarrier 篱栅
+
+作用:和上面的减法相反,这里是加法,好比集齐7个龙珠召唤神龙,或者人到齐了再开会!
+
+```java
+public class CyclicBarrierDemo {
+ public static void main(String[] args) {
+ // CyclicBarrier(int parties, Runnable barrierAction)
+ CyclicBarrier cyclicBarrier = new CyclicBarrier(7, () -> {
+ System.out.println("召唤神龙成功");
+ });
+
+ for (int i = 1; i <= 7; i++) {
+ final int tempInt = i;
+ new Thread(() -> {
+ System.out.println(Thread.currentThread().getName() +
+ "收集了第" + tempInt + "颗龙珠");
+
+ try {
+ cyclicBarrier.await(); // 等待
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ } catch (BrokenBarrierException e) {
+ e.printStackTrace();
+ }
+
+ }).start();
+ }
+ }
+}
+```
+
+
+
+### Semaphore
+
+翻译:Semaphore 信号量;信号灯;信号
+
+举个“抢车位”的例子
+
+```java
+public class SemaphoreDemo {
+ public static void main(String[] args) {
+ // 模拟资源类,有3个空车位
+ Semaphore semaphore = new Semaphore(3);
+ for (int i = 1; i <= 6; i++) { // 模拟6个车
+ new Thread(() -> {
+ try {
+ semaphore.acquire(); // acquire 得到
+ System.out.println(Thread.currentThread().getName() + " 抢到了车位");
+ TimeUnit.SECONDS.sleep(3); // 停3秒钟
+ System.out.println(Thread.currentThread().getName() + " 离开了车位");
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ } finally {
+ semaphore.release(); // 释放这个位置
+ }
+ }, String.valueOf(i)).start();
+ }
+
+ }
+}
+```
+
+在信号量上我们定义两种操作:
+
+- acquire(获取)
+
+ 当一个线程调用 acquire 操作时,他要么通过成功获取信号量(信号量-1)
+
+ 要么一直等下去,直到有线程释放信号量,或超时
+
+- release (释放)
+
+ 会将信号量的值 + 1,然后唤醒等待的线程
+
+
+
+信号量主要用于两个目的:一个是用于多个共享资源的互斥使用,另一个用于并发线程数的控制。
+
+## 九 读写锁
+
+**ReadWriteLock**
+
+独占锁(写锁):指该锁一次只能被一个线程锁持有。对于ReentranrLock和 Synchronized 而言都是独占锁。
+
+共享锁(读锁):该锁可被多个线程所持有。
+
+对于ReentrantReadWriteLock其读锁时共享锁,写锁是独占锁,读锁的共享锁可保证并发读是非常高效的。
+
+```java
+public class ReadWriteLockDemo {
+ /**
+ * 多个线程同时读一个资源类没有任何问题,所以为了满足并发量,读取共享资源应该可以同时进行。
+ * 但是,如果有一个线程想去写共享资源,就不应该再有其他线程可以对该资源进行读或写。
+ * 1. 读-读 可以共存
+ * 2. 读-写 不能共存
+ * 3. 写-写 不能共存
+ */
+ public static void main(String[] args) {
+ MyCacheLock myCache = new MyCacheLock();
+ // 写
+ for (int i = 1; i <= 5; i++) {
+ final int tempInt = i;
+ new Thread(() -> {
+ myCache.put(tempInt + "", tempInt + "");
+ }, String.valueOf(i)).start();
+ }
+
+ // 读
+ for (int i = 1; i <= 5; i++) {
+ final int tempInt = i;
+ new Thread(() -> {
+ myCache.get(tempInt + "");
+ }, String.valueOf(i)).start();
+ }
+ }
+
+}
+
+// 测试发现问题: 写入的时候,还没写入完成,会存在其他的写入!造成问题
+class MyCache {
+ private volatile Map map = new HashMap<>();
+
+ public void put(String key, Object value) {
+ System.out.println(Thread.currentThread().getName() + " 写入" + key);
+ map.put(key, value);
+ System.out.println(Thread.currentThread().getName() + " 写入成功!");
+ }
+
+ public void get(String key) {
+ System.out.println(Thread.currentThread().getName() + " 读取" + key);
+ Object result = map.get(key);
+ System.out.println(Thread.currentThread().getName() + " 读取结果:" + result);
+ }
+}
+
+// 加锁
+class MyCacheLock {
+ private volatile Map map = new HashMap<>();
+ private ReadWriteLock readWriteLock = new ReentrantReadWriteLock(); // 读写锁
+
+ public void put(String key, Object value) {
+ // 写锁
+ readWriteLock.writeLock().lock();
+ try {
+ System.out.println(Thread.currentThread().getName() + " 写入" + key);
+ map.put(key, value);
+ System.out.println(Thread.currentThread().getName() + " 写入成功!");
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ //解锁
+ readWriteLock.writeLock().unlock();
+ }
+ }
+
+ public void get(String key) {
+ // 读锁
+ readWriteLock.readLock().lock();
+ try {
+ System.out.println(Thread.currentThread().getName() + " 读取" + key);
+ Object result = map.get(key);
+ System.out.println(Thread.currentThread().getName() + " 读取结果:" + result);
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ readWriteLock.readLock().unlock();
+ }
+ }
+}
+```
+
+## 十 阻塞队列
+
+```java
+Interface BlockingQueue
+```
+
+### 阻塞队列简介
+
+阻塞:必须要阻塞、不得不阻塞
+
+阻塞队列是一个队列,在数据结构中起的作用如下图:
+
+
+
+当队列是空的,从队列中**获取**元素的操作将会被阻塞。
+
+当队列是满的,从队列中**添加**元素的操作将会被阻塞。
+
+试图从空的队列中获取元素的线程将会被阻塞,直到其他线程往空的队列插入新的元素。
+
+试图向已满的队列中添加新元素的线程将会被阻塞,直到其他线程从队列中移除一个或多个元素或者完全清空,使队列变得空闲起来并后续新增。
+
+### 阻塞队列的用处
+
+在多线程领域:所谓阻塞,在某些情况下会挂起线程(即阻塞),一旦条件满足,被挂起的线程又会自 动被唤起。
+
+为什么需要 BlockingQueue?
+
+好处是我们不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,因为这一切BlockingQueue 都 给你一手包办了。
+
+在 concurrent 包发布以前,在多线程环境下,我们每个程序员都必须自己去控制这些细节,尤其还要兼顾效率和线程安全,而这会给我们的程序带来不小的复杂度。
+
+### 接口架构图
+
+
+
+- ArrayBlockingQueue
+
+ 由数组结构组成的有界阻塞队列。
+
+- LinkedBlockingQueue
+
+ 由链表结构组成的有界(默认值为:integer.MAX_VALUE)阻塞队列。
+
+- PriorityBlockingQueue
+
+ 支持优先级排序的无界阻塞队列
+
+- DelayQueue
+
+ 使用优先级队列实现的延迟无界阻塞队列。
+
+- SynchronousQueue
+
+ 不存储元素的阻塞队列,也即单个元素的队列。
+
+- LinkedTransferQueue
+
+ 由链表组成的无界阻塞队列
+
+- LinkedBlockingDeque
+
+ 由链表组成的双向阻塞队列。
+
+
+
+### API的使用
+
+| 方法\处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
+| ------------- | --------- | ---------- | -------- | ------------------ |
+| 插入方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
+| 移除方法 | remove() | poll() | take() | poll(time,unit) |
+| 检查方法 | element() | peek() | 不可用 | 不可用 |
+
+解释:
+
+- 抛出异常
+
+当阻塞队列满时,再往队列里add插入元素会抛出 `IllegalStateException: Queue full`
+
+当阻塞队列空时,再往队列里remove移除元素会抛 NoSuchElementException`
+
+- 返回特殊值
+
+插入方法,成功返回true,失败则false
+
+移除方法,成功返回队列元素,队列里没有则返回null
+
+- 一直阻塞
+
+当阻塞队列满时,生产者线程继续往队列里put元素,队列会一直阻塞生产者线程直到put数据或响应中断退出
+
+当阻塞队列空时,消费者线程从队列里take元素,队列会一直阻塞消费者线程直到队列可用
+
+- 超时退出
+
+当阻塞队列满时,队列会阻塞生产者线程一定时间,超过限时后生产者线程会退出
+
+
+
+**抛出异常**
+
+```java
+package com.oddfar.bq;
+
+import java.util.concurrent.ArrayBlockingQueue;
+
+/**
+ * @author zhiyuan
+ */
+public class BlockingQueueDemo {
+
+ public static void main(String[] args) {
+ // 队列大小
+ ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);
+ System.out.println(blockingQueue.add("a"));
+ System.out.println(blockingQueue.add("b"));
+ System.out.println(blockingQueue.add("c"));
+
+ //java.lang.IllegalStateException: Queue full
+// System.out.println(blockingQueue.add("d"));
+
+ System.out.println("首元素:" + blockingQueue.element()); // 检测队列队首元素!
+ // public E remove() 返回值E,就是移除的值
+ System.out.println(blockingQueue.remove()); //a
+ System.out.println(blockingQueue.remove()); //b
+ System.out.println(blockingQueue.remove()); //c
+ // java.util.NoSuchElementException
+// System.out.println(blockingQueue.remove());
+
+ }
+}
+```
+
+**返回特殊值**
+
+```java
+public class BlockingQueueDemo2 {
+ public static void main(String[] args) {
+ // 队列大小
+ ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);
+
+ System.out.println(blockingQueue.offer("a")); // true
+ System.out.println(blockingQueue.offer("b")); // true
+ System.out.println(blockingQueue.offer("c")); // true
+ //System.out.println(blockingQueue.offer("d")); // false
+
+ System.out.println("首元素:" + blockingQueue.peek()); // 检测队列队首元素!
+
+ // public E poll()
+ System.out.println(blockingQueue.poll()); // a
+ System.out.println(blockingQueue.poll()); // b
+ System.out.println(blockingQueue.poll()); // c
+ System.out.println(blockingQueue.poll()); // null
+ }
+}
+```
+
+**一直阻塞**
+
+```java
+public class BlockingQueueDemo3 {
+ public static void main(String[] args) throws InterruptedException {
+ // 队列大小
+ ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);
+
+ // 一直阻塞
+ blockingQueue.put("a");
+ blockingQueue.put("b");
+ blockingQueue.put("c");
+// blockingQueue.put("d");
+ System.out.println(blockingQueue.take()); // a
+ System.out.println(blockingQueue.take()); // b
+ System.out.println(blockingQueue.take()); // c
+ System.out.println(blockingQueue.take()); // 阻塞不停止等待
+ }
+}
+```
+
+**超时退出**
+
+```java
+public class BlockingQueueDemo4 {
+ public static void main(String[] args) throws InterruptedException {
+ // 队列大小
+ ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);
+
+ // 一直阻塞
+ blockingQueue.put("a");
+ blockingQueue.put("b");
+ blockingQueue.put("c");
+ blockingQueue.offer("d",2L, TimeUnit.SECONDS); // 等待2秒超时退出
+
+ System.out.println(blockingQueue.take()); // a
+ System.out.println(blockingQueue.take()); // b
+ System.out.println(blockingQueue.take()); // c
+ System.out.println(blockingQueue.take()); // 阻塞不停止等待
+ }
+}
+```
\ No newline at end of file
diff --git "a/docs/01.Java/07.Java-\345\244\232\347\272\277\347\250\213/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260.md" "b/docs/01.Java/07.Java-\345\244\232\347\272\277\347\250\213/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260.md"
new file mode 100644
index 00000000..0aa6c156
--- /dev/null
+++ "b/docs/01.Java/07.Java-\345\244\232\347\272\277\347\250\213/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260/05.JUC\345\255\246\344\271\240\347\254\224\350\256\260.md"
@@ -0,0 +1,18 @@
+---
+title: JUC学习笔记(三)
+permalink: /java/se/thread/study-note/5
+date: 2021-05-17 18:01:25
+---
+
+
+
+
+
+- [十 线程池](#%E5%8D%81-%E7%BA%BF%E7%A8%8B%E6%B1%A0)
+
+
+
+## 十 线程池
+
+待补充
+
diff --git "a/docs/01.Java/20.JavaWeb/01.\345\237\272\346\234\254\346\246\202\345\277\265.md" "b/docs/01.Java/20.JavaWeb/01.\345\237\272\346\234\254\346\246\202\345\277\265.md"
new file mode 100644
index 00000000..a8da5cfb
--- /dev/null
+++ "b/docs/01.Java/20.JavaWeb/01.\345\237\272\346\234\254\346\246\202\345\277\265.md"
@@ -0,0 +1,170 @@
+---
+title: 基本概念
+permalink: /javaweb/basic-concepts
+categories:
+ - java
+ - java-web
+date: 2021-05-15 18:09:11
+---
+
+JavaWeb笔记转载于狂神笔记,稍修改了点内容
+
+## 1、基本概念
+
+### 1.1、前言
+
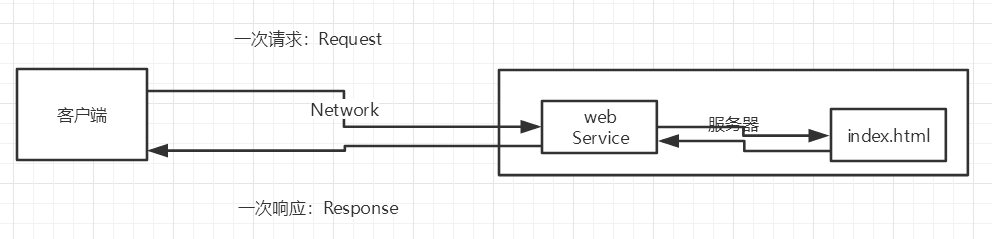
+web开发:
+
+- web,网页的意思 , www.baidu.com
+- 静态web
+ - html,css
+ - 提供给所有人看的数据始终不会发生变化!
+- 动态web
+ - 淘宝,几乎是所有的网站;
+ - 提供给所有人看的数据始终会发生变化,每个人在不同的时间,不同的地点看到的信息各不相同!
+ - 技术栈:Servlet/JSP,ASP,PHP
+
+在Java中,动态web资源开发的技术统称为JavaWeb;
+
+### 1.2、web应用程序
+
+web应用程序:可以提供浏览器访问的程序;
+
+- a.html、b.html......多个web资源,这些web资源可以被外界访问,对外界提供服务;
+- 你们能访问到的任何一个页面或者资源,都存在于这个世界的某一个角落的计算机上。
+- URL
+- 这个统一的web资源会被放在同一个文件夹下,web应用程序-->Tomcat:服务器
+- 一个web应用由多部分组成 (静态web,动态web)
+ - html,css,js
+ - jsp,servlet
+ - Java程序
+ - jar包
+ - 配置文件 (Properties)
+
+web应用程序编写完毕后,若想提供给外界访问:需要一个服务器来统一管理;
+
+### 1.3、静态web
+
+- *.htm, *.html,这些都是网页的后缀,如果服务器上一直存在这些东西,我们就可以直接进行读取。通络;
+
+
+
+- 静态web存在的缺点
+ - Web页面无法动态更新,所有用户看到都是同一个页面
+ - 轮播图,点击特效:伪动态
+ - JavaScript [实际开发中,它用的最多]
+ - VBScript
+ - 它无法和数据库交互(数据无法持久化,用户无法交互)
+
+
+
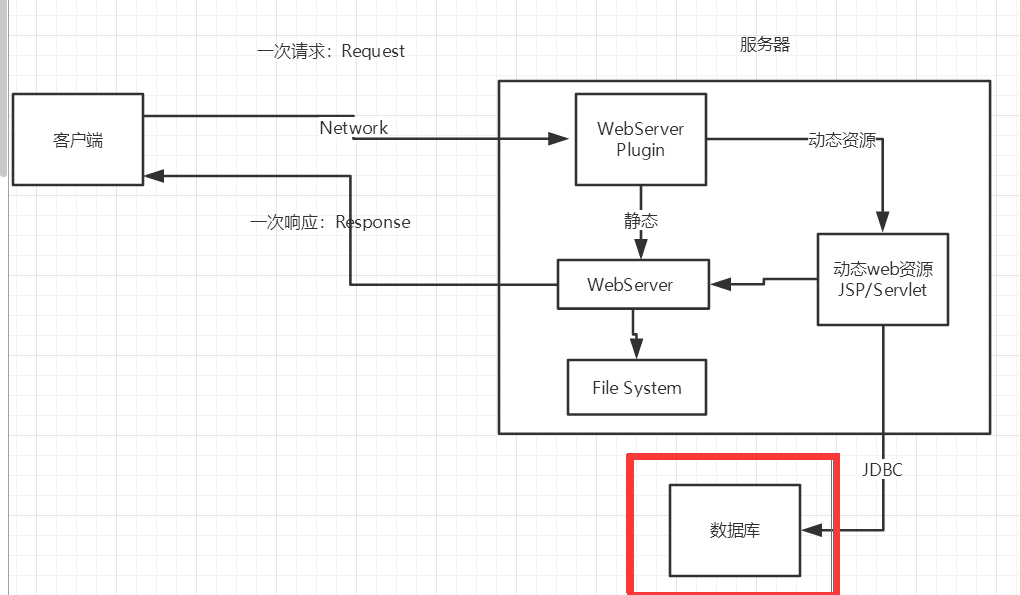
+### 1.4、动态web
+
+页面会动态展示: “Web的页面展示的效果因人而异”;
+
+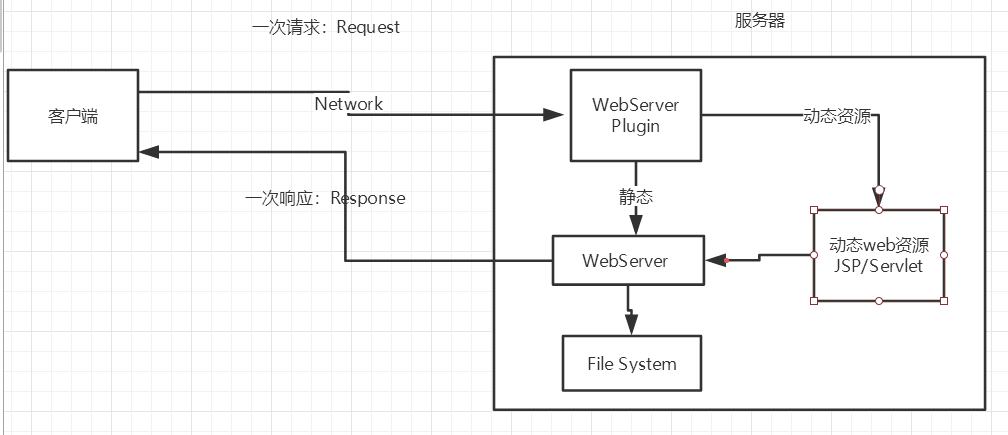
+
+缺点:
+
+- 加入服务器的动态web资源出现了错误,我们需要重新编写我们的**后台程序**,重新发布;
+ - 停机维护
+
+优点:
+
+- Web页面可以动态更新,所有用户看到都不是同一个页面
+- 它可以与数据库交互 (数据持久化:注册,商品信息,用户信息........)
+
+
+
+
+## 2、web服务器
+
+### 2.1、技术讲解
+
+**ASP:**
+
+- 微软:国内最早流行的就是ASP;
+
+- 在HTML中嵌入了VB的脚本, ASP + COM;
+
+- 在ASP开发中,基本一个页面都有几千行的业务代码,页面极其换乱
+
+- 维护成本高!
+
+- C#
+
+- IIS
+
+ ```html
+
+
+
+
+
+
+ <%
+ System.out.println("hello")
+ %>
+
+
+
+
+ ```
+
+
+
+**php:**
+
+- PHP开发速度很快,功能很强大,跨平台,代码很简单 (70% , WP)
+- 无法承载大访问量的情况(局限性)
+
+
+
+**JSP/Servlet : **
+
+B/S:浏览和服务器
+
+C/S: 客户端和服务器
+
+- sun公司主推的B/S架构
+- 基于Java语言的 (所有的大公司,或者一些开源的组件,都是用Java写的)
+- 可以承载三高问题带来的影响;
+- 语法像ASP , ASP-->JSP , 加强市场强度;
+
+
+
+.....
+
+
+
+### 2.2、web服务器
+
+服务器是一种被动的操作,用来处理用户的一些请求和给用户一些响应信息;
+
+
+
+**IIS**
+
+微软的; ASP...,Windows中自带的
+
+**Tomcat**
+
+
+
+面向百度编程;
+
+Tomcat是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,最新的Servlet 和JSP 规范总是能在Tomcat 中得到体现,因为Tomcat 技术先进、性能稳定,而且**免费**,因而深受Java 爱好者的喜爱并得到了部分软件开发商的认可,成为目前比较流行的Web 应用服务器。
+
+Tomcat 服务器是一个免费的开放源代码的Web 应用服务器,属于轻量级应用[服务器](https://baike.baidu.com/item/服务器),在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP 程序的首选。对于一个Java初学web的人来说,它是最佳的选择
+
+Tomcat 实际上运行JSP 页面和Servlet。Tomcat最新版本为**9.0。**
+
+....
+
+**工作3-5年之后,可以尝试手写Tomcat服务器;**
+
+下载tomcat:
+
+1. 安装 or 解压
+2. 了解配置文件及目录结构
+3. 这个东西的作用
\ No newline at end of file
diff --git a/docs/01.Java/20.JavaWeb/02.Tomcat.md b/docs/01.Java/20.JavaWeb/02.Tomcat.md
new file mode 100644
index 00000000..5ab2b1eb
--- /dev/null
+++ b/docs/01.Java/20.JavaWeb/02.Tomcat.md
@@ -0,0 +1,124 @@
+---
+title: Tomcat
+permalink: /javaweb/tomcat
+categories:
+ - java
+ - java-web
+date: 2021-05-09 12:09:00
+---
+
+# 3、Tomcat
+
+## 3.1、 安装tomcat
+
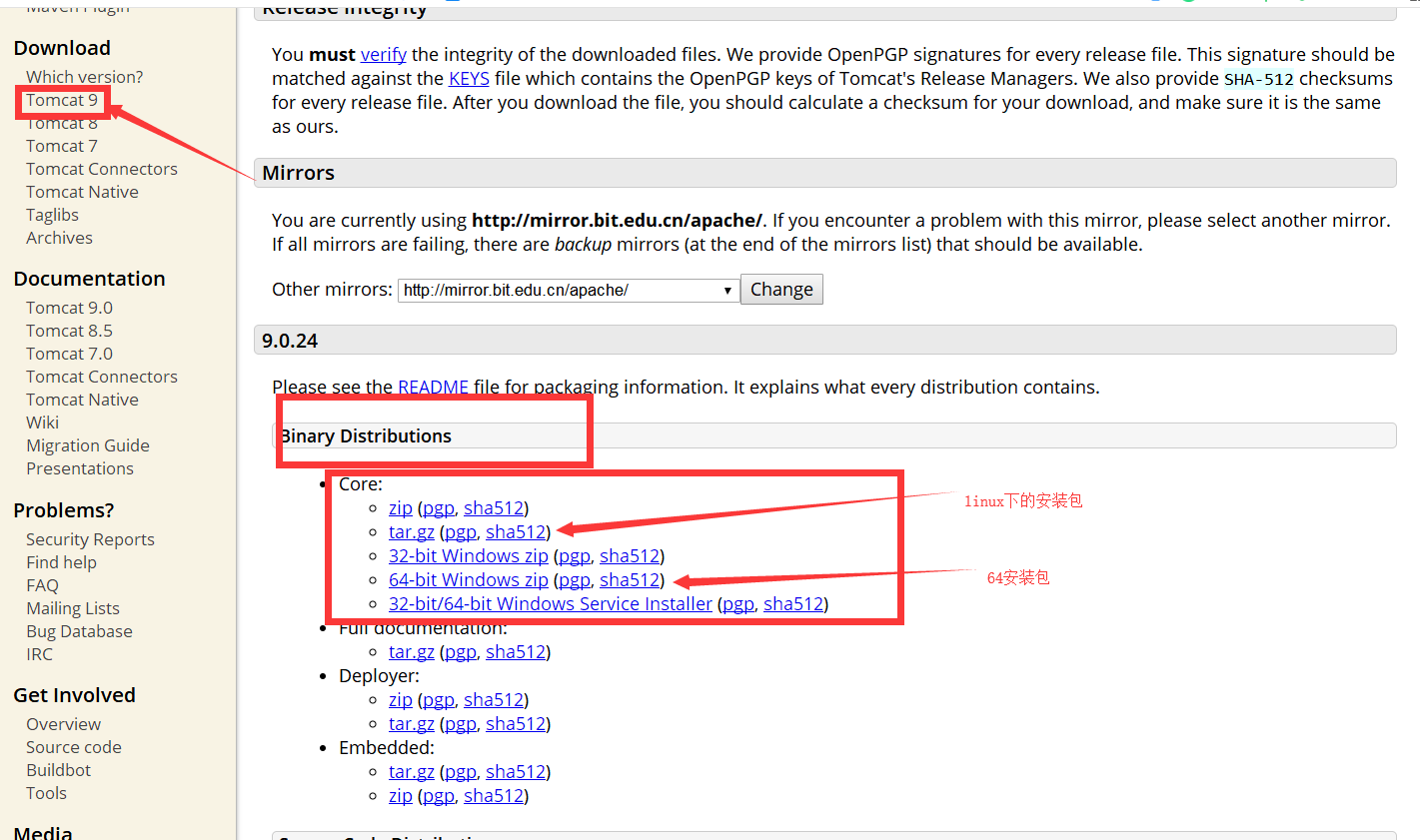
+tomcat官网:http://tomcat.apache.org/
+
+
+
+
+
+
+
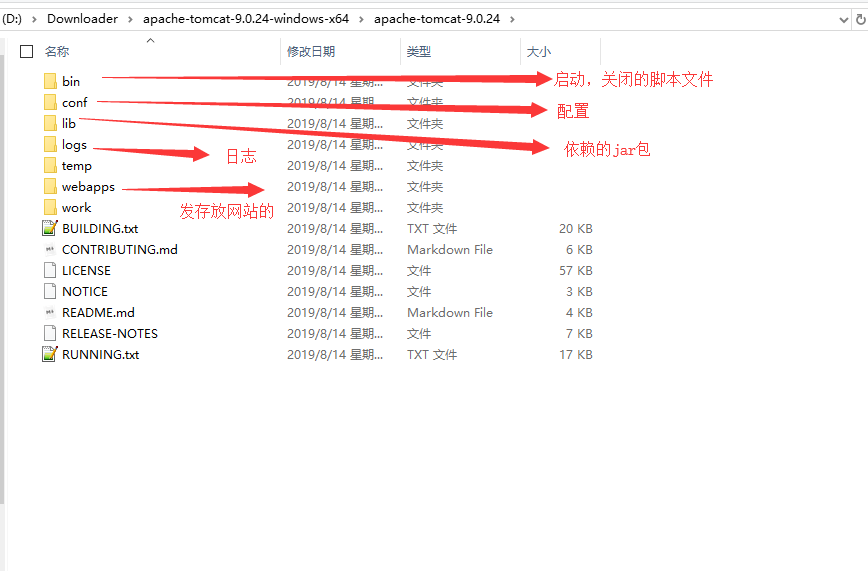
+## 3.2、Tomcat启动和配置
+
+文件夹作用:
+
+
+
+**启动。关闭Tomcat**
+
+
+
+访问测试:http://localhost:8080/
+
+可能遇到的问题:
+
+1. Java环境变量没有配置
+2. 闪退问题:需要配置兼容性
+3. 乱码问题:配置文件中设置
+
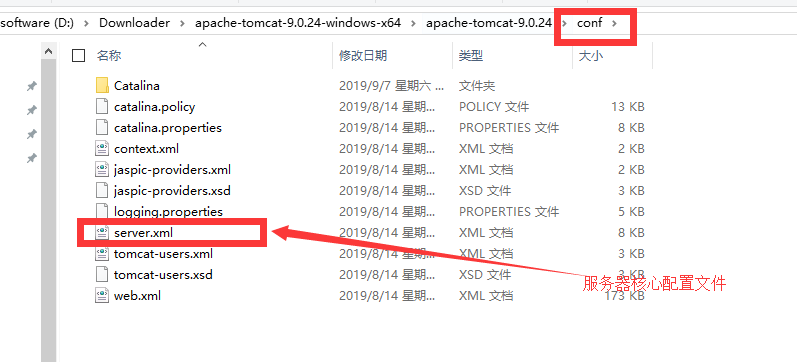
+## 3.3、配置
+
+
+
+可以配置启动的端口号
+
+- tomcat的默认端口号为:8080
+- mysql:3306
+- http:80
+- https:443
+
+```xml
+
+```
+可以配置主机的名称
+
+- 默认的主机名为:localhost->127.0.0.1
+- 默认网站应用存放的位置为:webapps
+
+```xml
+
+```
+### 高难度面试题:
+
+请你谈谈网站是如何进行访问的!
+
+1. 输入一个域名;回车
+
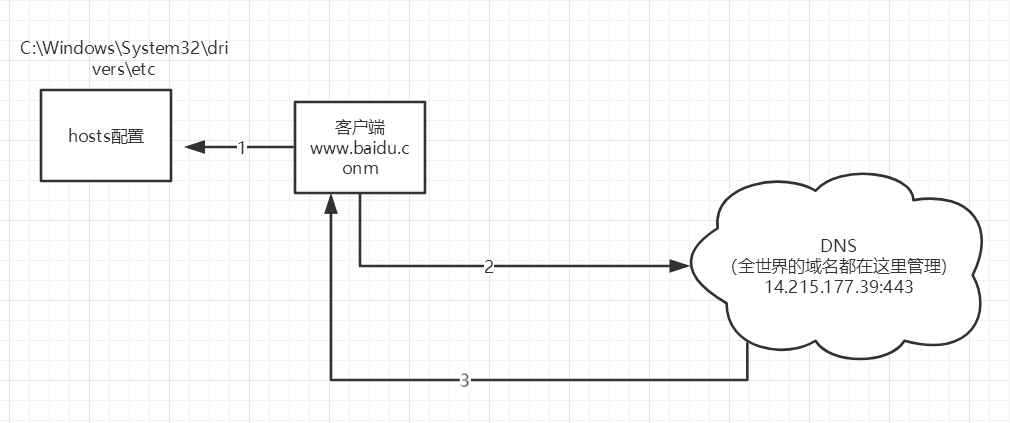
+2. 检查本机的 C:\Windows\System32\drivers\etc\hosts配置文件下有没有这个域名映射;
+
+ 1. 有:直接返回对应的ip地址,这个地址中,有我们需要访问的web程序,可以直接访问
+
+ ```java
+ 127.0.0.1 www.qinjiang.com
+ ```
+
+ 2. 没有:去DNS服务器找,找到的话就返回,找不到就返回找不到;
+
+ 
+
+4. 可以配置一下环境变量(可选性)
+
+## 3.4、发布一个web网站
+
+不会就先模仿
+
+- 将自己写的网站,放到服务器(Tomcat)中指定的web应用的文件夹(webapps)下,就可以访问了
+
+网站应该有的结构
+
+```java
+--webapps :Tomcat服务器的web目录
+ -ROOT
+ -kuangstudy :网站的目录名
+ - WEB-INF
+ -classes : java程序
+ -lib:web应用所依赖的jar包
+ -web.xml :网站配置文件
+ - index.html 默认的首页
+ - static
+ -css
+ -style.css
+ -js
+ -img
+ -.....
+```
+
+
+
+HTTP协议 : 面试
+
+Maven:构建工具
+
+- Maven安装包
+
+Servlet 入门
+
+- HelloWorld!
+- Servlet配置
+- 原理
+
+
diff --git a/docs/01.Java/20.JavaWeb/03.Http.md b/docs/01.Java/20.JavaWeb/03.Http.md
new file mode 100644
index 00000000..6028794b
--- /dev/null
+++ b/docs/01.Java/20.JavaWeb/03.Http.md
@@ -0,0 +1,124 @@
+---
+title: Http
+permalink: /javaweb/http
+date: 2021-05-06 14:38:43
+categories:
+ - java
+ - java-web
+---
+
+
+# 4、Http
+
+## 4.1、什么是HTTP
+
+HTTP(超文本传输协议)是一个简单的请求-响应协议,它通常运行在TCP之上。
+
+- 文本:html,字符串,~ ….
+- 超文本:图片,音乐,视频,定位,地图…….
+- 80
+
+Https:安全的
+
+- 443
+
+## 4.2、两个时代
+
+- http1.0
+
+ - HTTP/1.0:客户端可以与web服务器连接后,只能获得一个web资源,断开连接
+
+- http2.0
+
+ - HTTP/1.1:客户端可以与web服务器连接后,可以获得多个web资源。‘
+
+
+
+## 4.3、Http请求
+
+- 客户端---发请求(Request)---服务器
+
+百度:
+
+```java
+Request URL:https://www.baidu.com/ 请求地址
+Request Method:GET get方法/post方法
+Status Code:200 OK 状态码:200
+Remote(远程) Address:14.215.177.39:443
+```
+
+```java
+Accept:text/html
+Accept-Encoding:gzip, deflate, br
+Accept-Language:zh-CN,zh;q=0.9 语言
+Cache-Control:max-age=0
+Connection:keep-alive
+```
+
+### 1、请求行
+
+- 请求行中的请求方式:GET
+- 请求方式:**Get,Post**,HEAD,DELETE,PUT,TRACT…
+ - get:请求能够携带的参数比较少,大小有限制,会在浏览器的URL地址栏显示数据内容,不安全,但高效
+ - post:请求能够携带的参数没有限制,大小没有限制,不会在浏览器的URL地址栏显示数据内容,安全,但不高效。
+
+### 2、消息头
+
+```java
+Accept:告诉浏览器,它所支持的数据类型
+Accept-Encoding:支持哪种编码格式 GBK UTF-8 GB2312 ISO8859-1
+Accept-Language:告诉浏览器,它的语言环境
+Cache-Control:缓存控制
+Connection:告诉浏览器,请求完成是断开还是保持连接
+HOST:主机..../.
+```
+
+## 4.4、Http响应
+
+- 服务器---响应-----客户端
+
+百度:
+
+```java
+Cache-Control:private 缓存控制
+Connection:Keep-Alive 连接
+Content-Encoding:gzip 编码
+Content-Type:text/html 类型
+```
+
+### 1.响应体
+
+```java
+Accept:告诉浏览器,它所支持的数据类型
+Accept-Encoding:支持哪种编码格式 GBK UTF-8 GB2312 ISO8859-1
+Accept-Language:告诉浏览器,它的语言环境
+Cache-Control:缓存控制
+Connection:告诉浏览器,请求完成是断开还是保持连接
+HOST:主机..../.
+Refresh:告诉客户端,多久刷新一次;
+Location:让网页重新定位;
+```
+
+### 2、响应状态码
+
+200:请求响应成功 200
+
+3xx:请求重定向
+
+- 重定向:你重新到我给你新位置去;
+
+4xx:找不到资源 404
+
+- 资源不存在;
+
+5xx:服务器代码错误 500 502:网关错误
+
+
+
+**常见面试题:**
+
+当你的浏览器中地址栏输入地址并回车的一瞬间到页面能够展示回来,经历了什么?
+
+
+
+
diff --git a/docs/01.Java/20.JavaWeb/04.Maven.md b/docs/01.Java/20.JavaWeb/04.Maven.md
new file mode 100644
index 00000000..e548f806
--- /dev/null
+++ b/docs/01.Java/20.JavaWeb/04.Maven.md
@@ -0,0 +1,343 @@
+---
+title: Maven
+permalink: /javaweb/maven
+date: 2021-05-06 14:38:43
+categories:
+ - java
+ - java-web
+---
+
+# 5、Maven
+
+**我为什么要学习这个技术?**
+
+1. 在Javaweb开发中,需要使用大量的jar包,我们手动去导入;
+
+2. 如何能够让一个东西自动帮我导入和配置这个jar包。
+
+ 由此,Maven诞生了!
+
+
+
+## 5.1 Maven项目架构管理工具
+
+我们目前用来就是方便导入jar包的!
+
+Maven的核心思想:**约定大于配置**
+
+- 有约束,不要去违反。
+
+Maven会规定好你该如何去编写我们的Java代码,必须要按照这个规范来;
+
+## 5.2 下载安装Maven
+
+官网;https://maven.apache.org/
+
+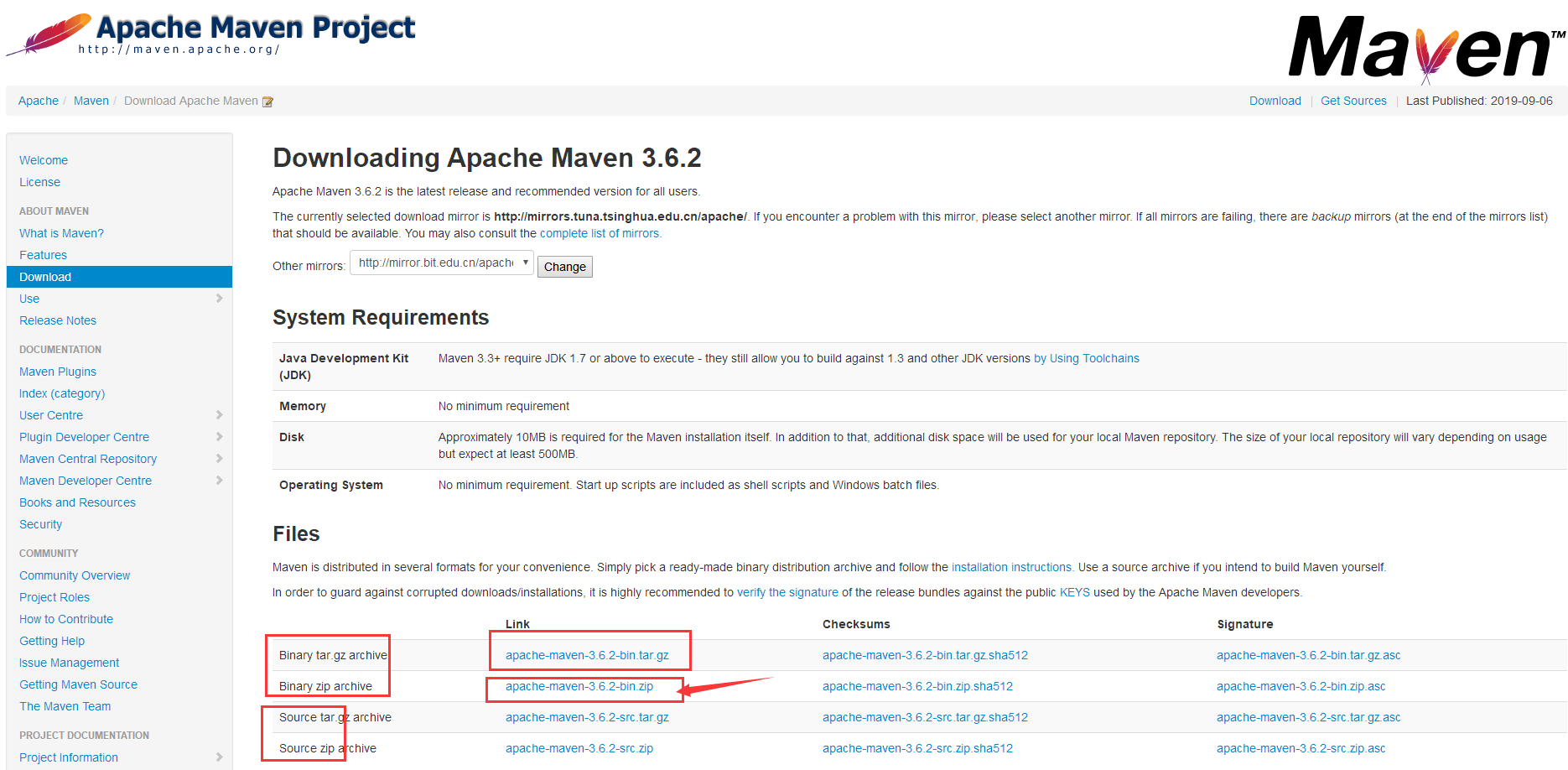
+
+下载完成后,解压即可;
+
+小狂神友情建议:电脑上的所有环境都放在一个文件夹下,方便管理;
+
+
+
+## 5.3 配置环境变量
+
+在我们的系统环境变量中
+
+配置如下配置:
+
+- M2_HOME maven目录下的bin目录
+- MAVEN_HOME maven的目录
+- 在系统的path中配置 %MAVEN_HOME%\bin
+
+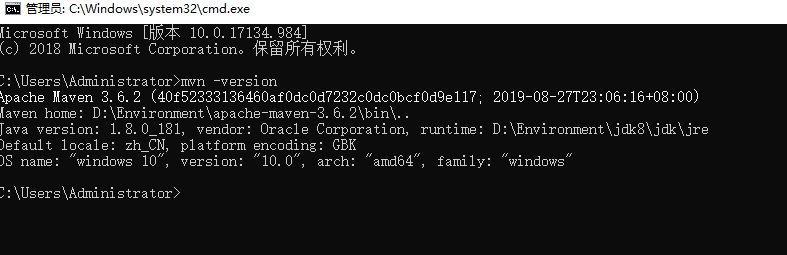
+
+测试Maven是否安装成功,保证必须配置完毕!
+
+## 5.4 阿里云镜像
+
+
+
+- 镜像:mirrors
+ - 作用:加速我们的下载
+- 国内建议使用阿里云的镜像
+
+```xml
+
+ nexus-aliyun
+ *,!jeecg,!jeecg-snapshots
+ Nexus aliyun
+ http://maven.aliyun.com/nexus/content/groups/public
+
+```
+
+## 5.5 本地仓库
+
+在本地的仓库,远程仓库;
+
+**建立一个本地仓库:**localRepository
+
+```xml
+D:\Environment\apache-maven-3.6.2\maven-repo
+```
+
+## 5.6、在IDEA中使用Maven
+
+1. 启动IDEA
+
+2. 创建一个MavenWeb项目
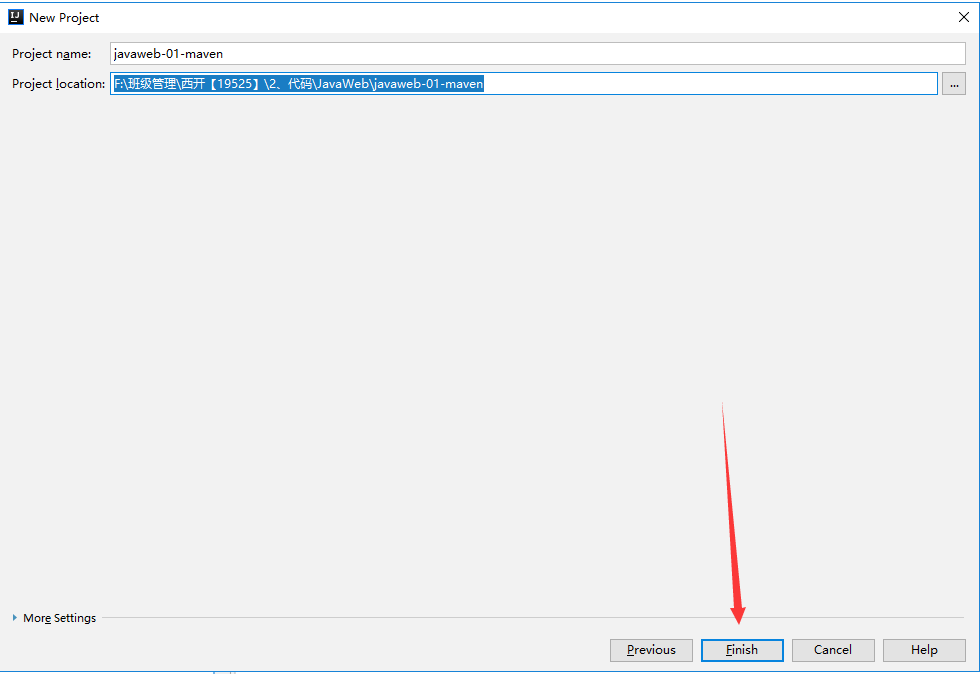
+
+ 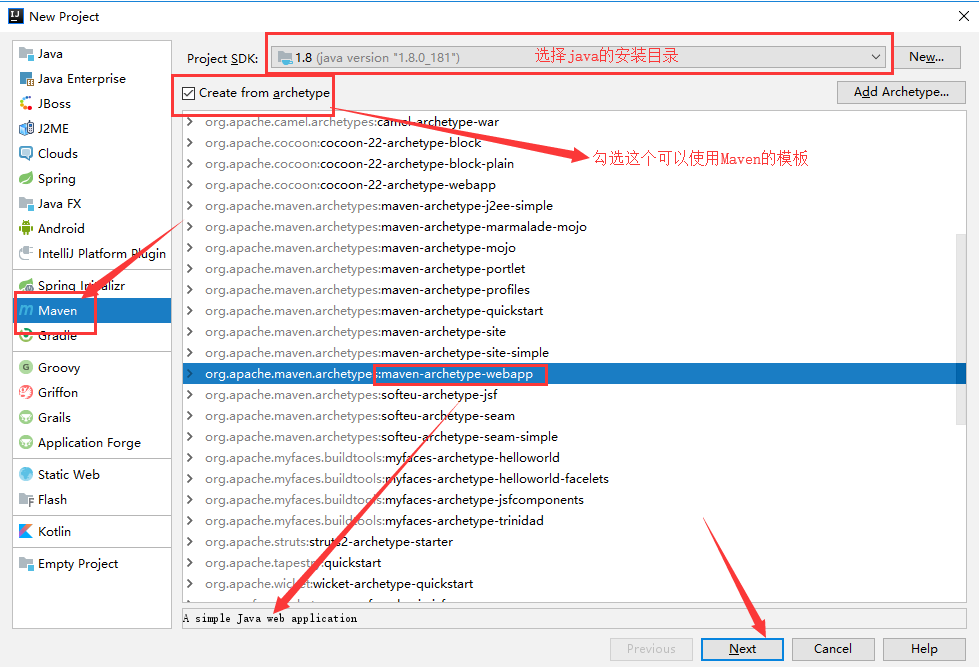
+
+ 
+
+ 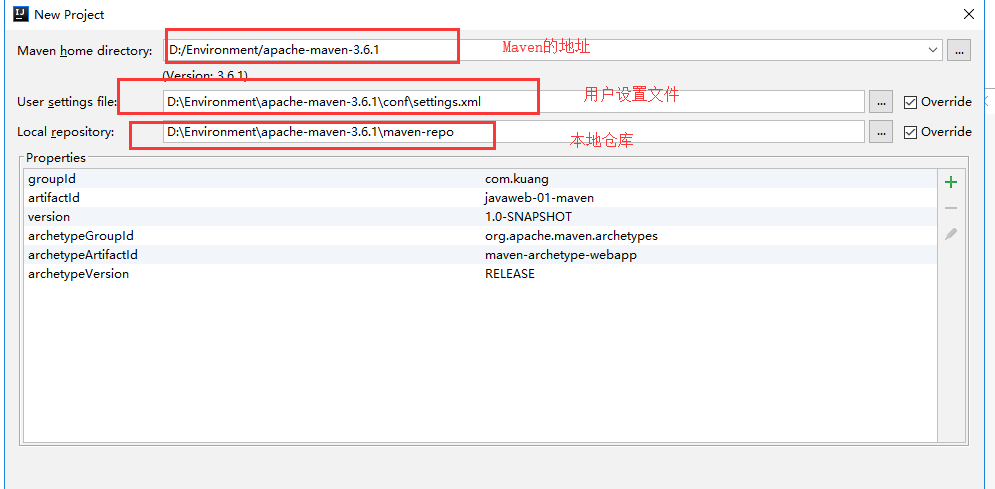
+
+ 
+
+ 
+
+3. 等待项目初始化完毕
+
+ 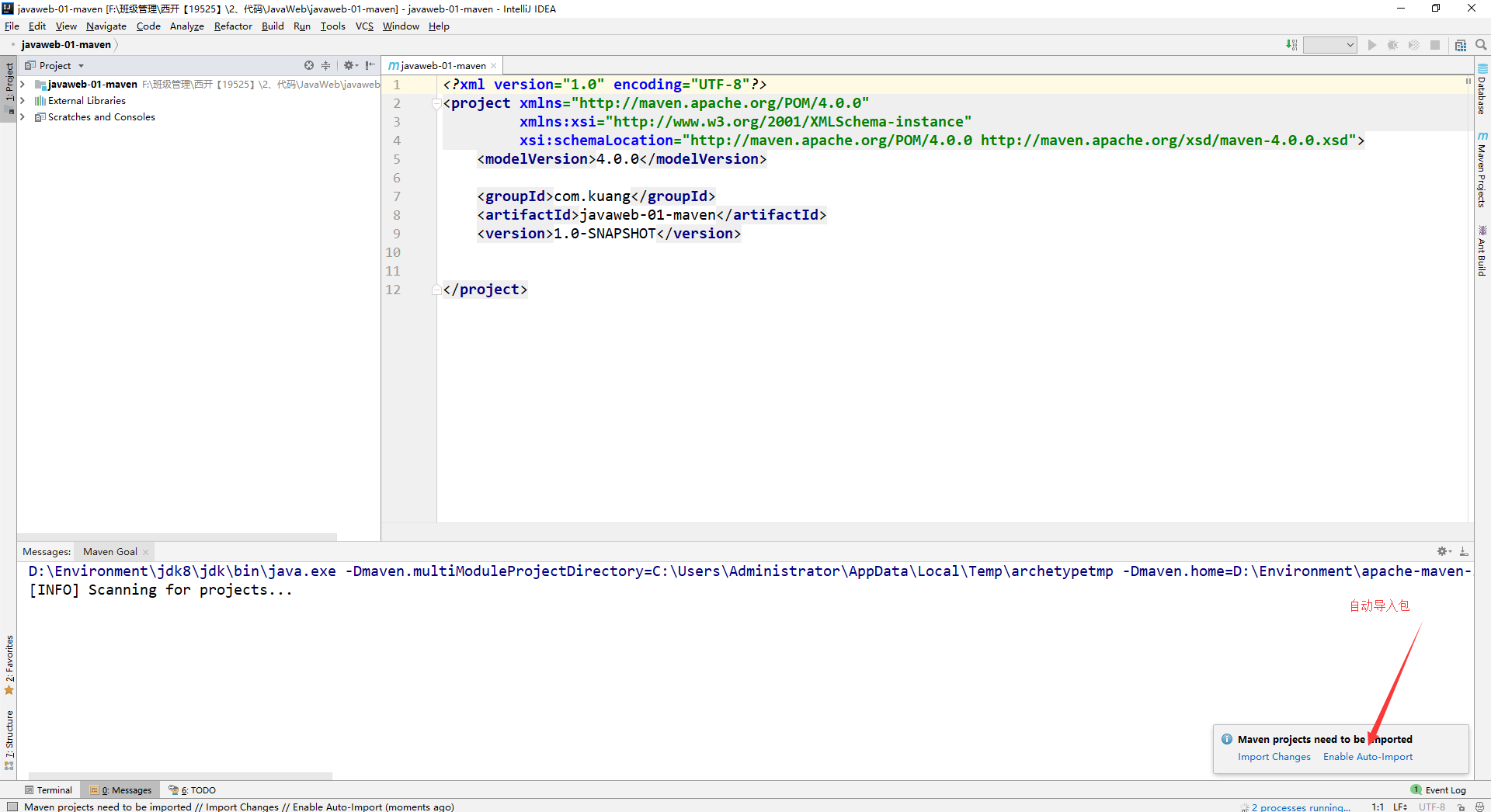
+
+ 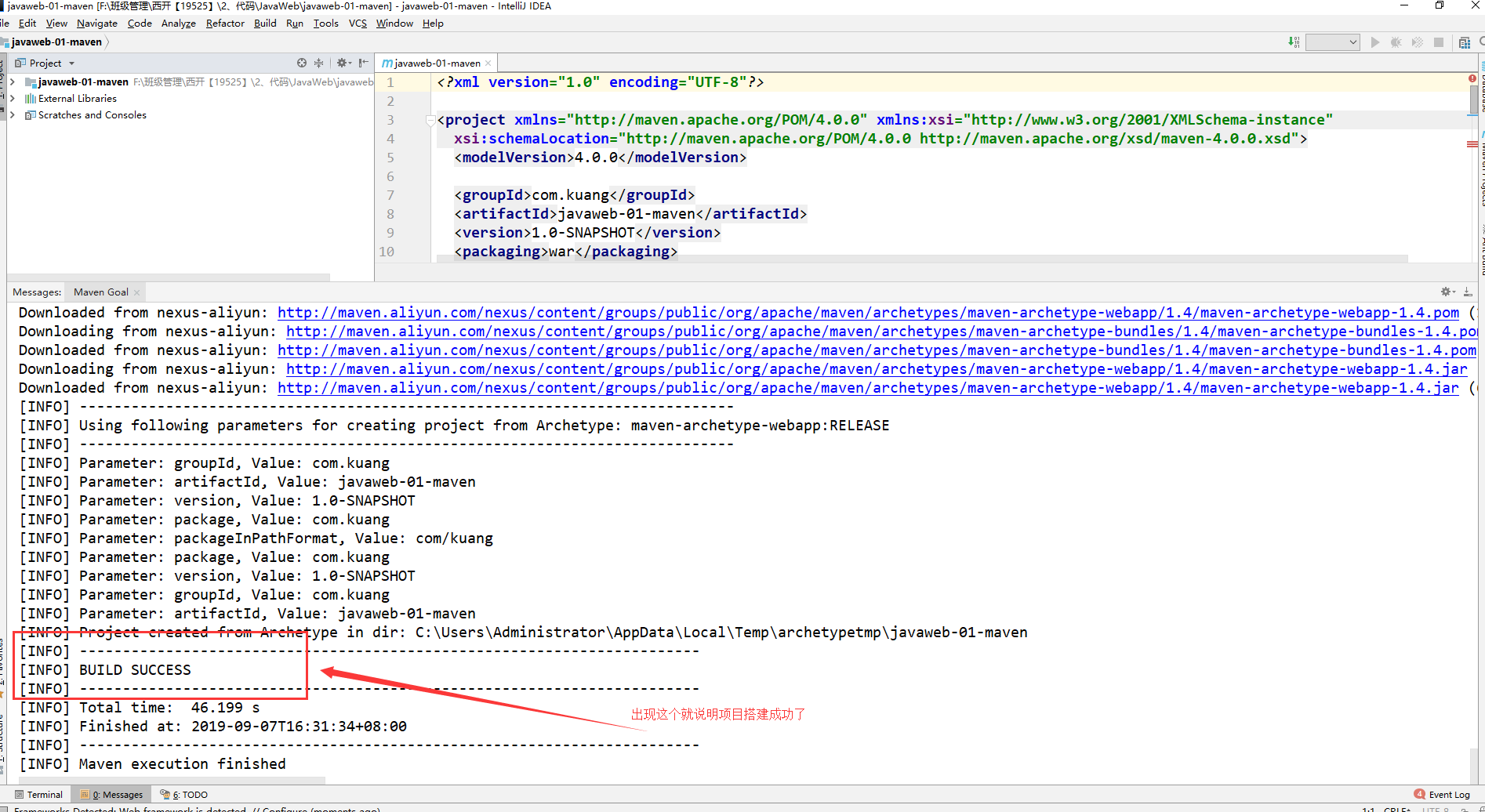
+
+4. 观察maven仓库中多了什么东西?
+
+5. IDEA中的Maven设置
+
+ 注意:IDEA项目创建成功后,看一眼Maven的配置
+
+ 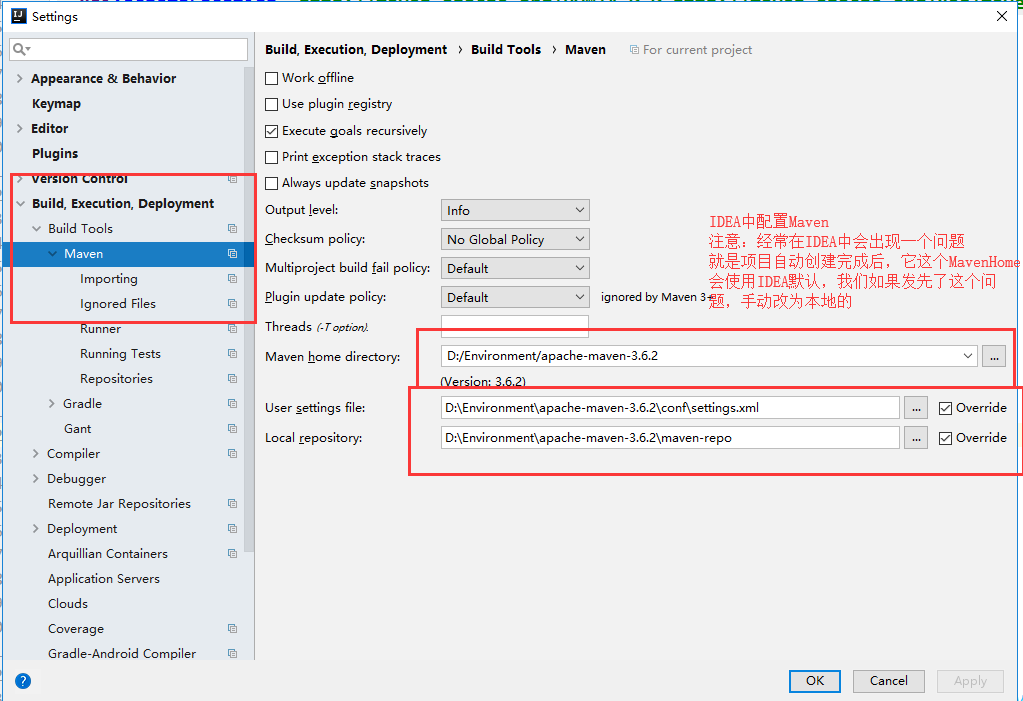
+
+ 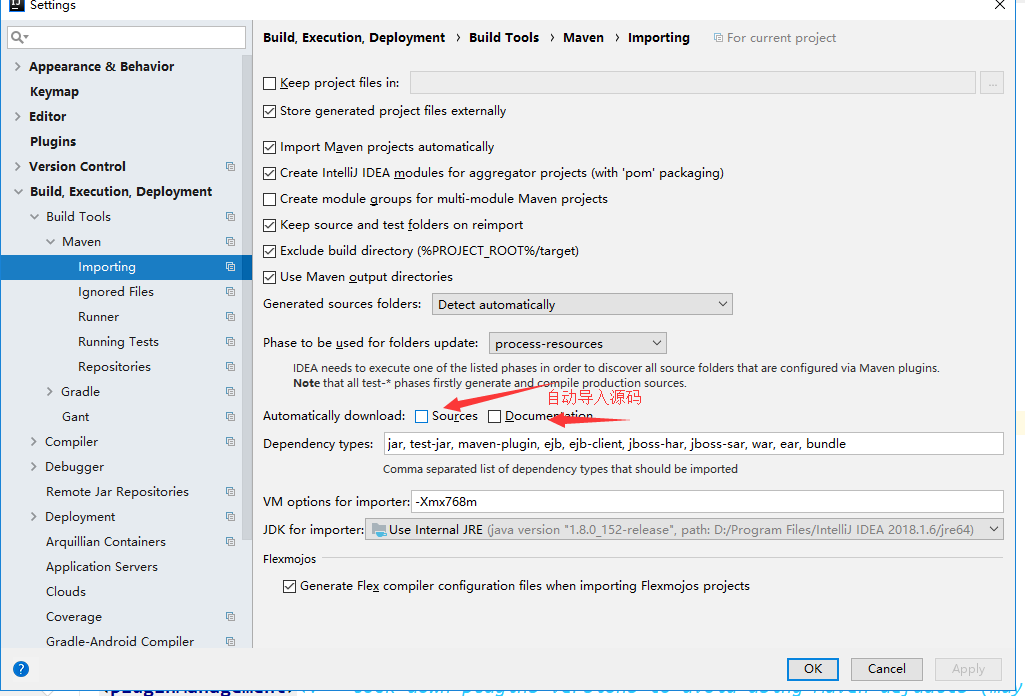
+
+6. 到这里,Maven在IDEA中的配置和使用就OK了!
+
+## 5.7、创建一个普通的Maven项目
+
+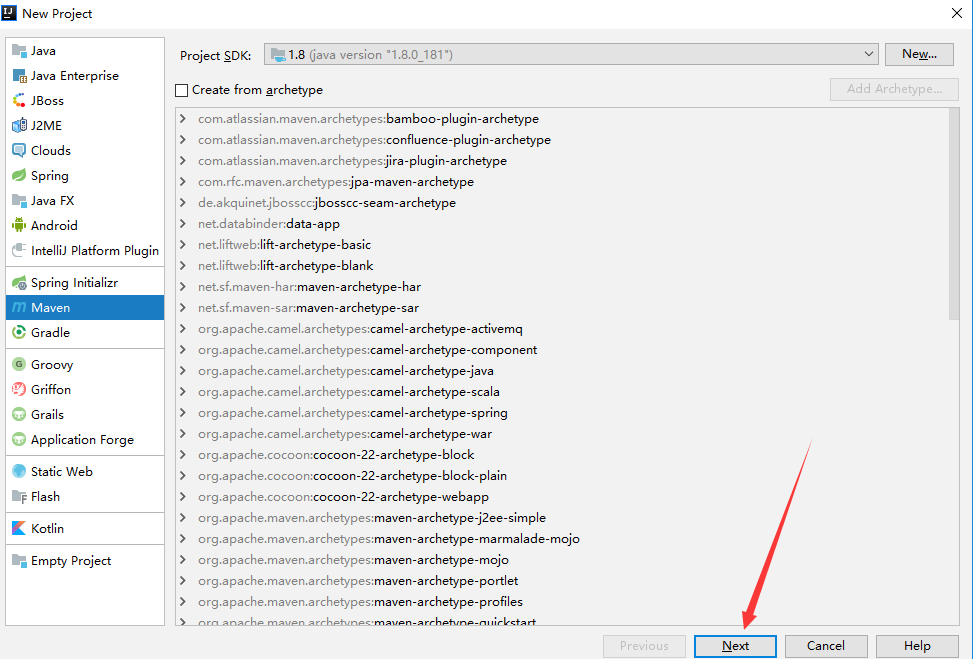
+
+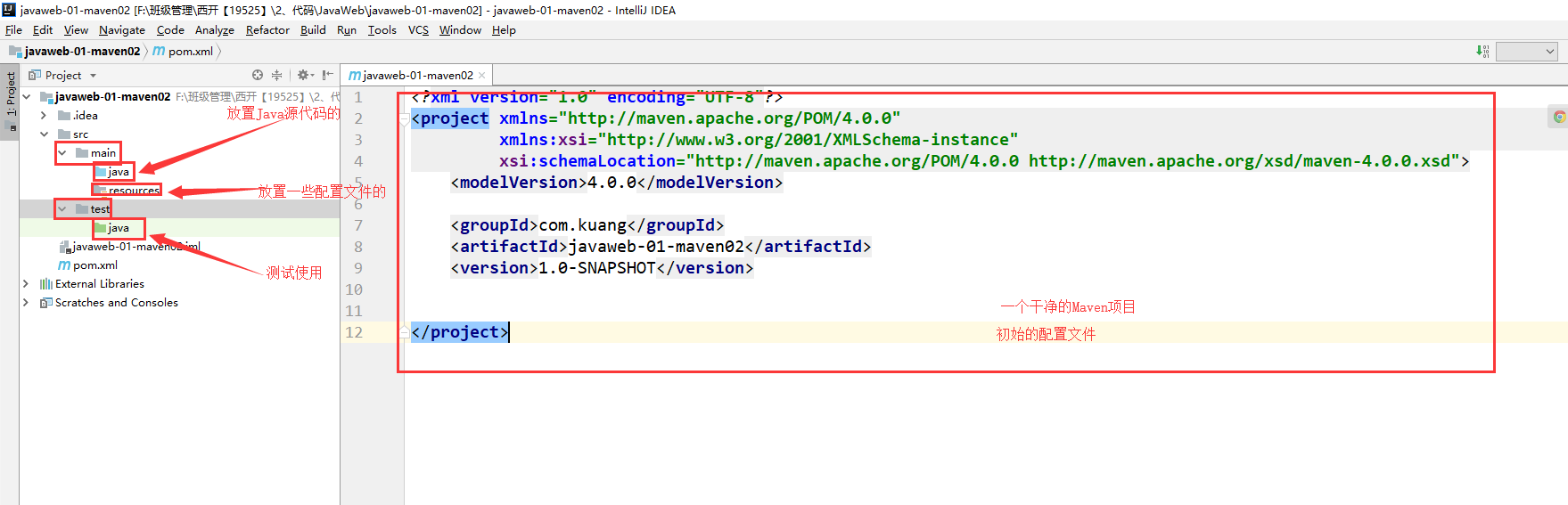
+
+这个只有在Web应用下才会有!
+
+
+
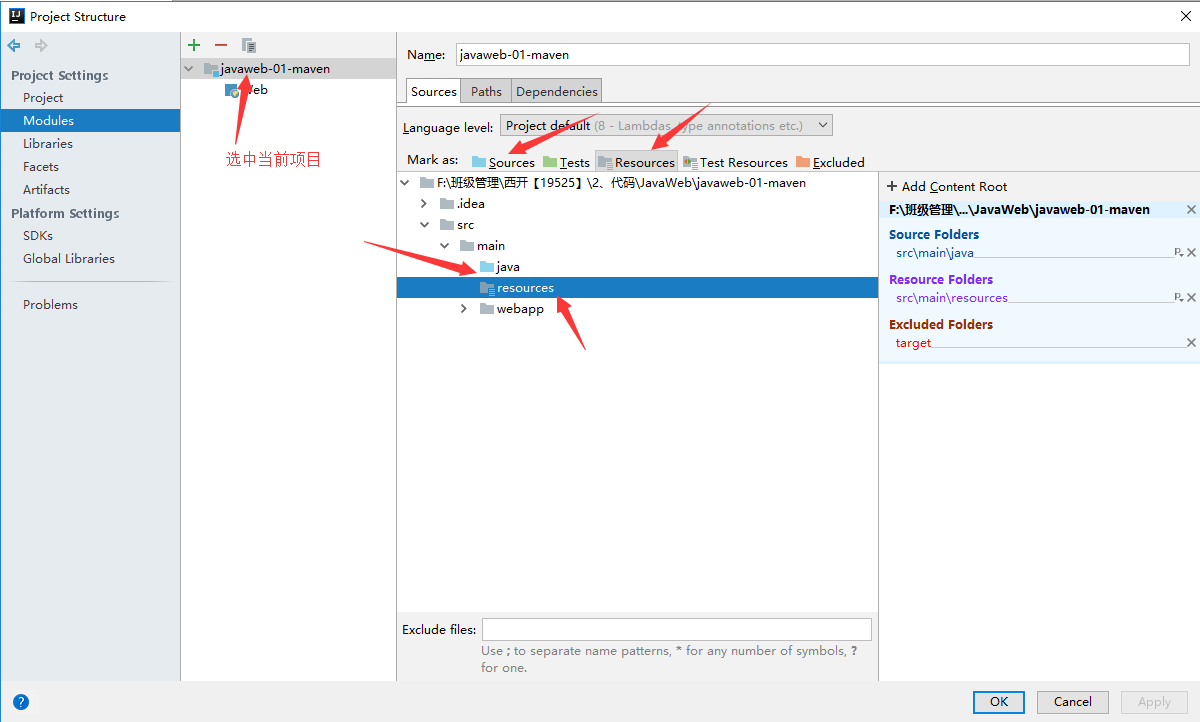
+## 5.8 标记文件夹功能
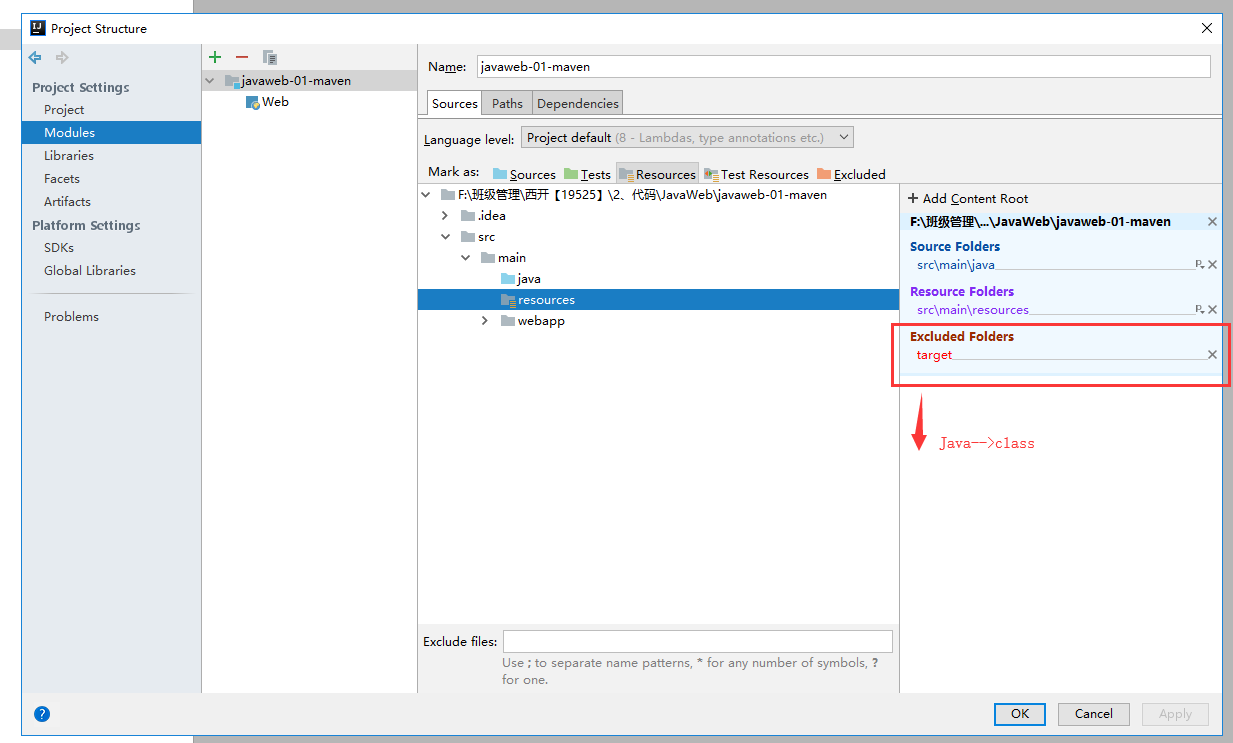
+
+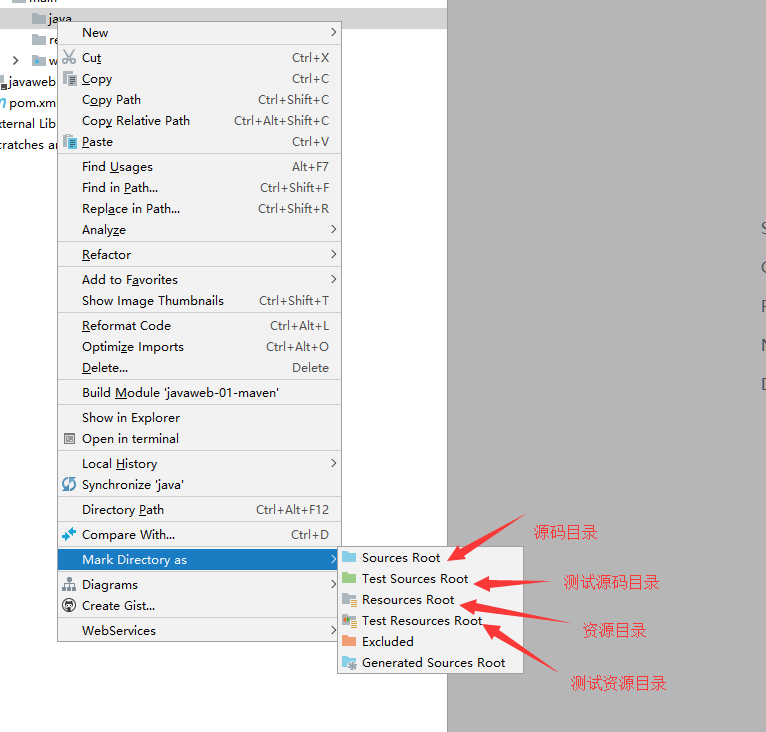
+
+
+
+
+
+
+
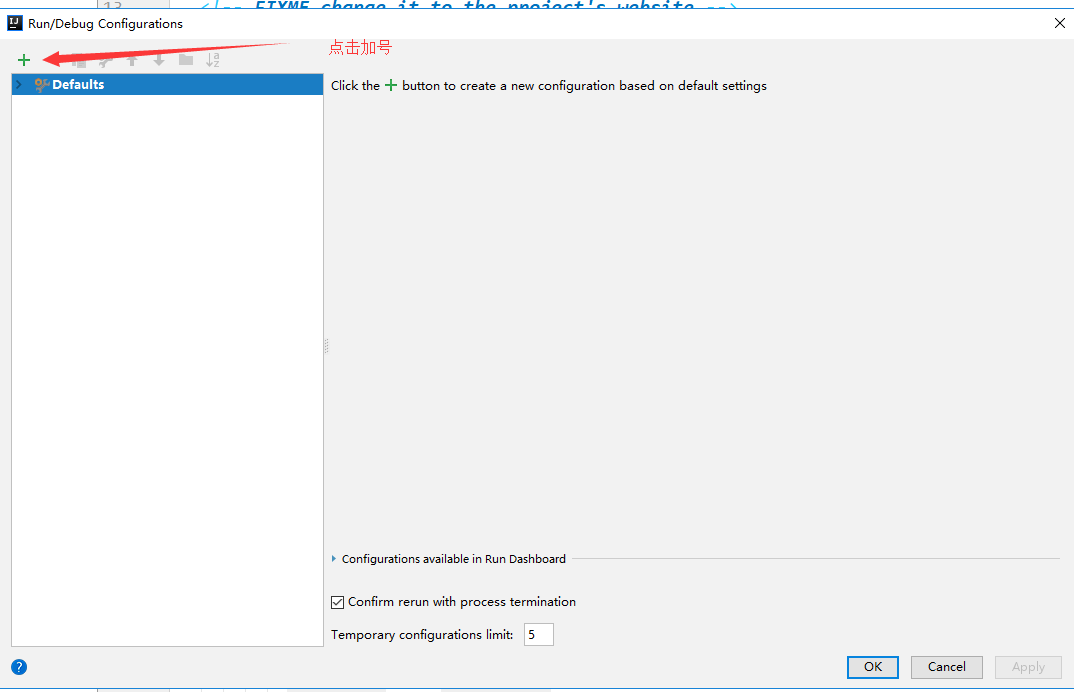
+## 5.9 在 IDEA中配置Tomcat
+
+
+
+
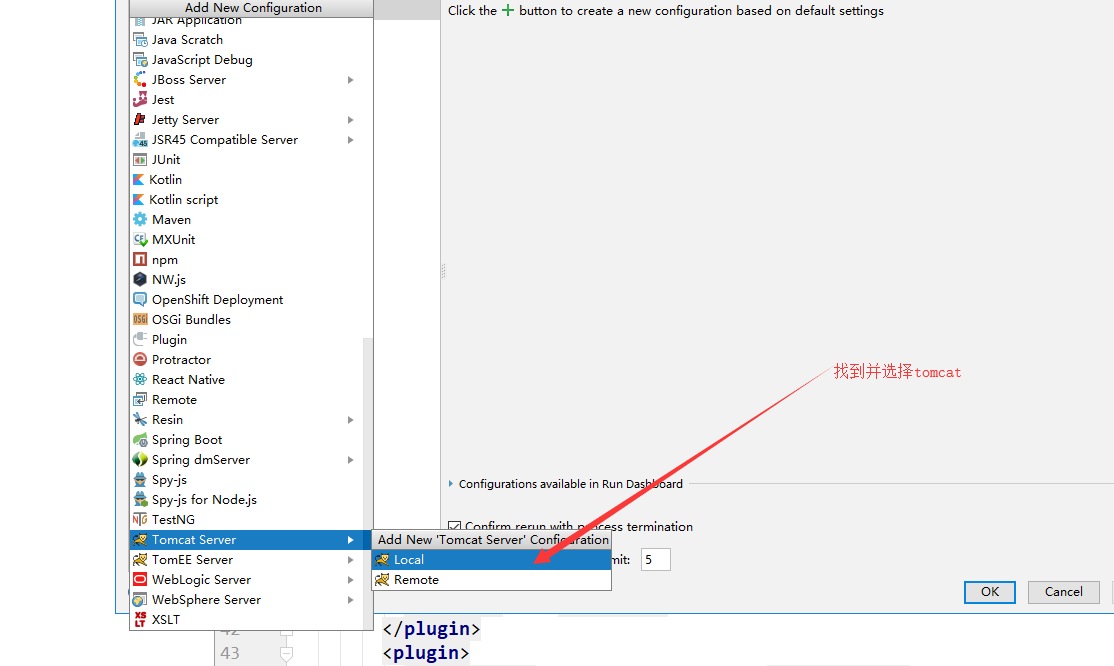
+
+
+
+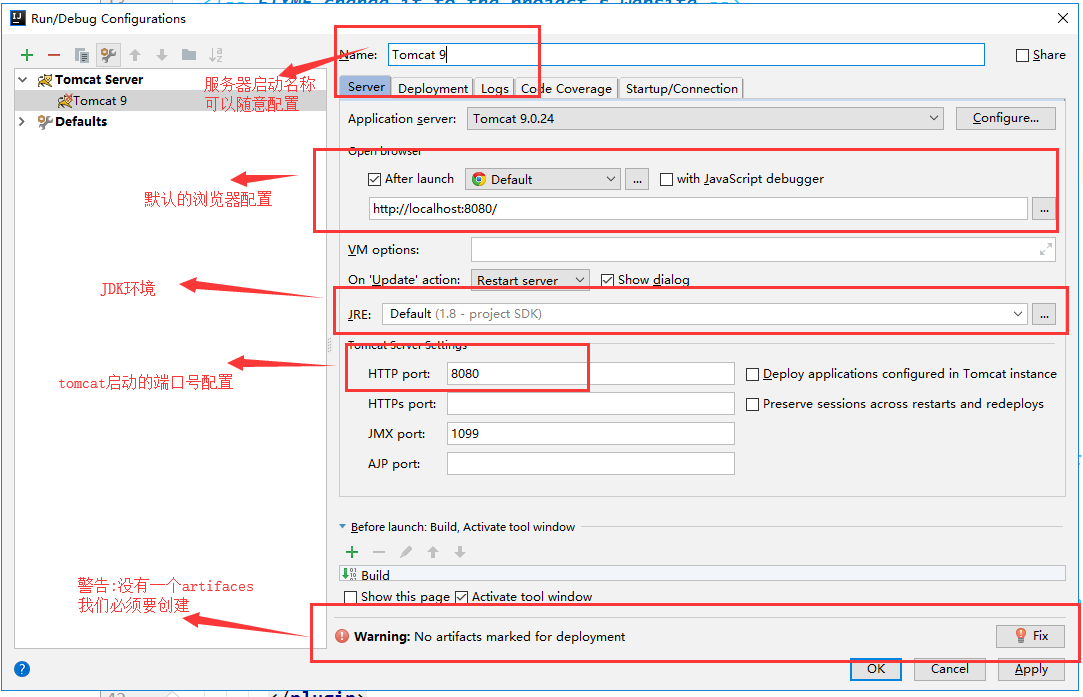
+
+解决警告问题
+
+必须要的配置:**为什么会有这个问题:我们访问一个网站,需要指定一个文件夹名字;**
+
+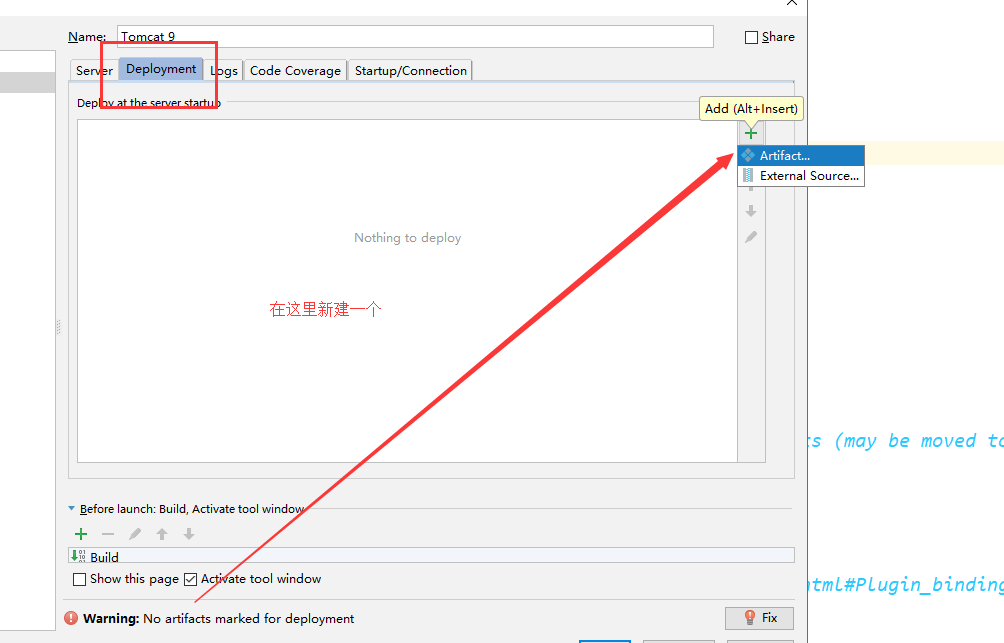
+
+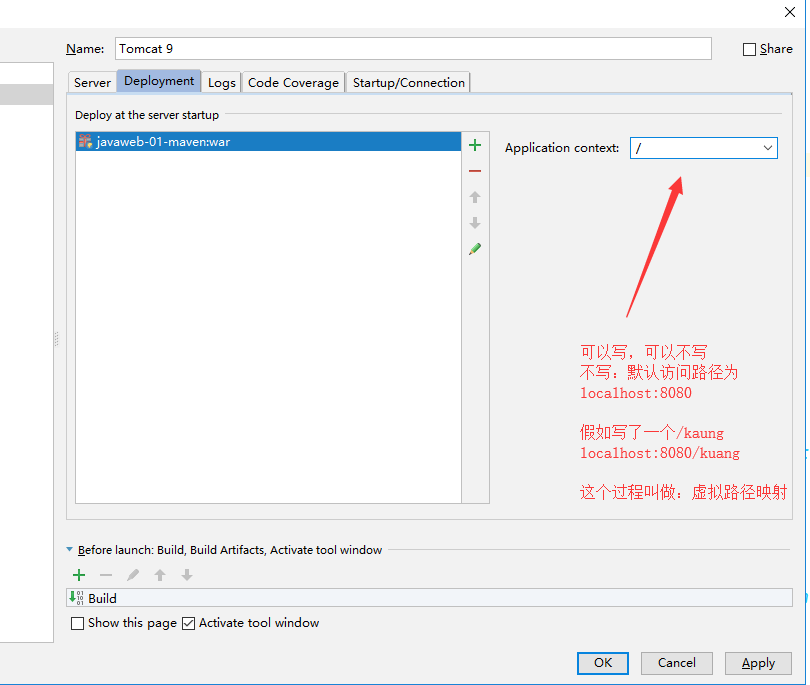
+
+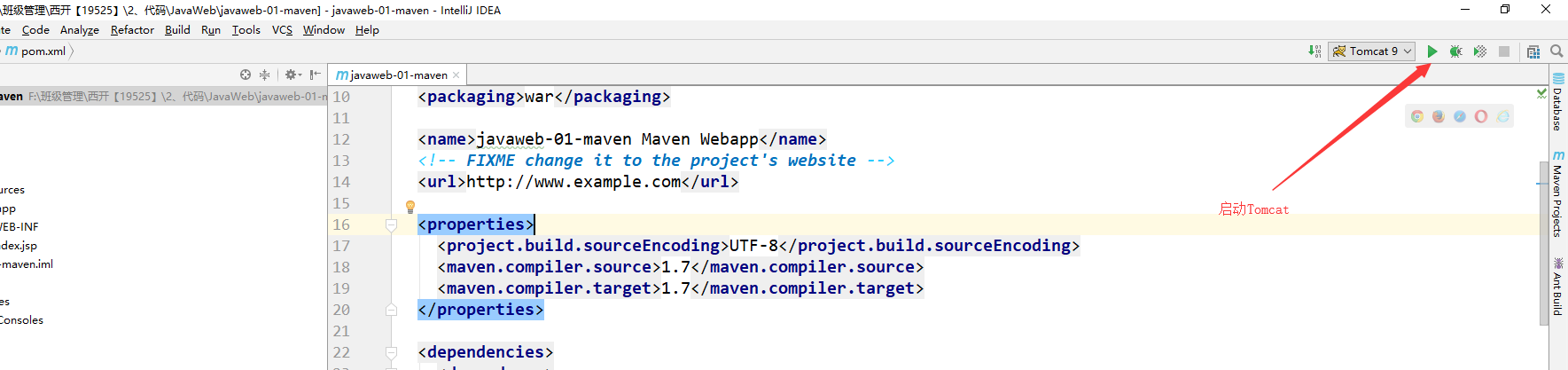
+
+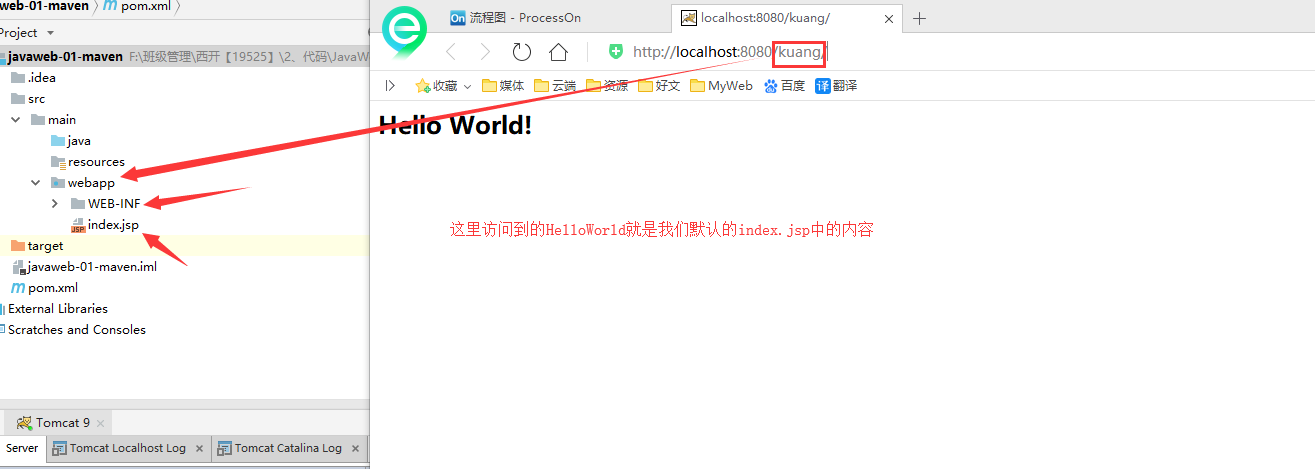
+
+## 5.10 pom文件
+
+pom.xml 是Maven的核心配置文件
+
+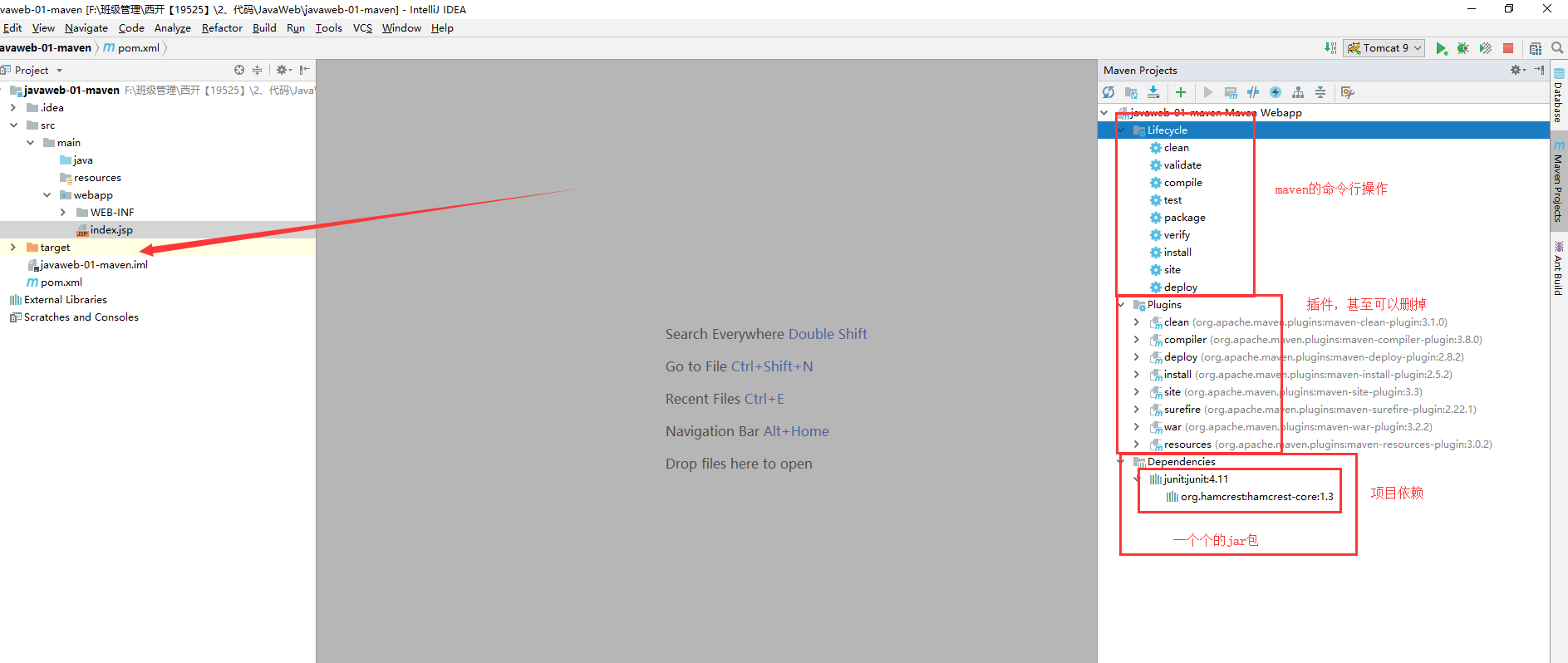
+
+```xml
+
+
+
+
+ 4.0.0
+
+
+ com.kuang
+ javaweb-01-maven
+ 1.0-SNAPSHOT
+
+ war
+
+
+
+
+
+ UTF-8
+
+ 1.8
+ 1.8
+
+
+
+
+
+
+ junit
+ junit
+ 4.11
+
+
+
+
+
+ javaweb-01-maven
+
+
+
+ maven-clean-plugin
+ 3.1.0
+
+
+
+ maven-resources-plugin
+ 3.0.2
+
+
+ maven-compiler-plugin
+ 3.8.0
+
+
+ maven-surefire-plugin
+ 2.22.1
+
+
+ maven-war-plugin
+ 3.2.2
+
+
+ maven-install-plugin
+ 2.5.2
+
+
+ maven-deploy-plugin
+ 2.8.2
+
+
+
+
+
+
+```
+
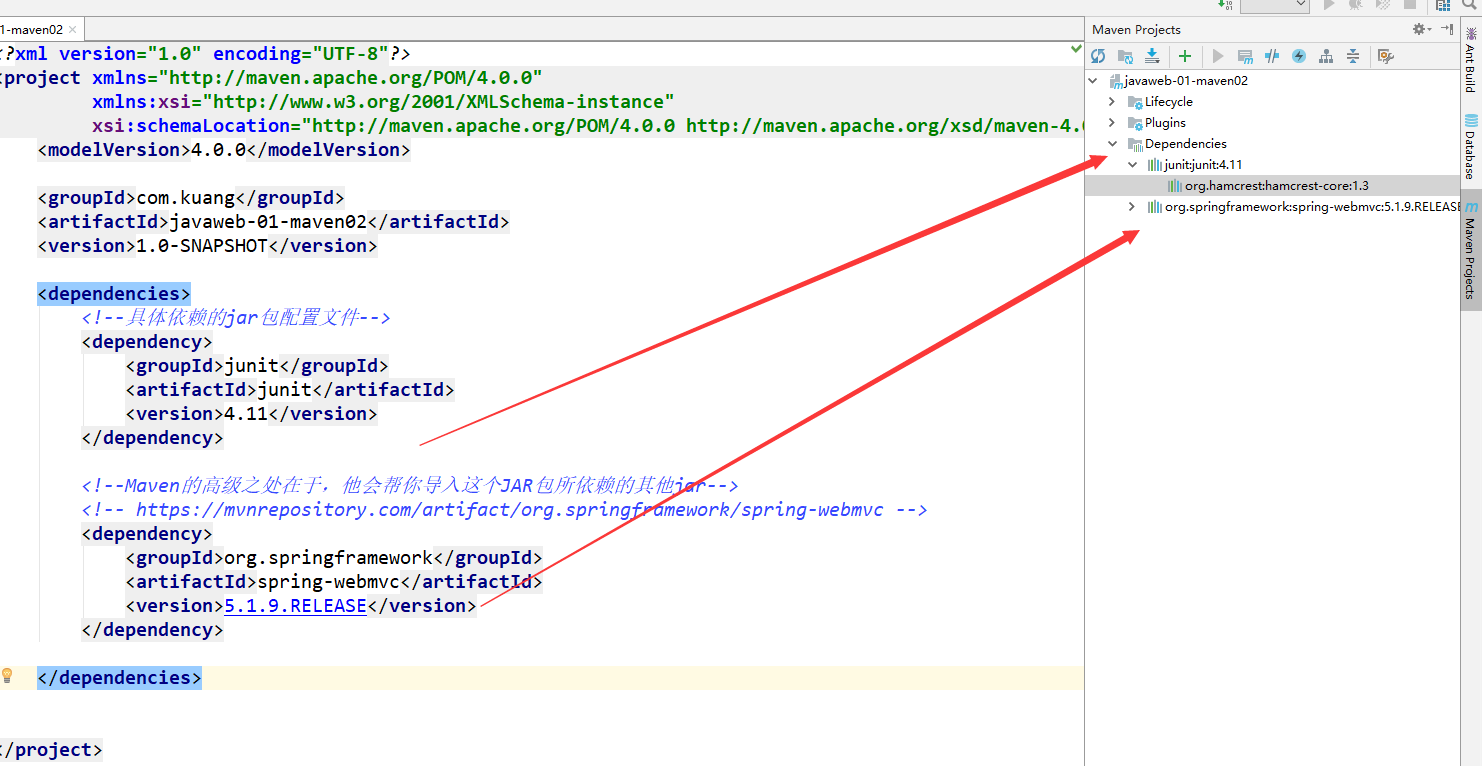
+
+
+
+
+maven由于他的约定大于配置,我们之后可以能遇到我们写的配置文件,无法被导出或者生效的问题,解决方案:
+
+```xml
+
+
+
+
+ src/main/resources
+
+ **/*.properties
+ **/*.xml
+
+ true
+
+
+ src/main/java
+
+ **/*.properties
+ **/*.xml
+
+ true
+
+
+
+```
+
+
+
+## 5.12 IDEA操作
+
+
+
+
+
+
+
+
+
+## 5.13 解决遇到的问题
+
+1. Maven 3.6.2
+
+ 解决方法:降级为3.6.1
+
+ 
+
+2. Tomcat闪退
+
+
+
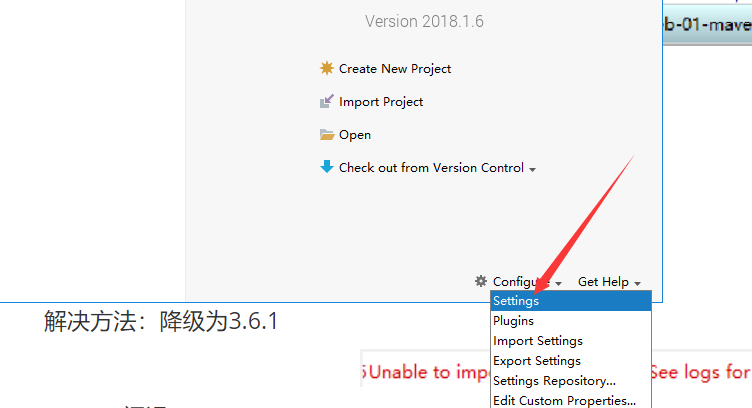
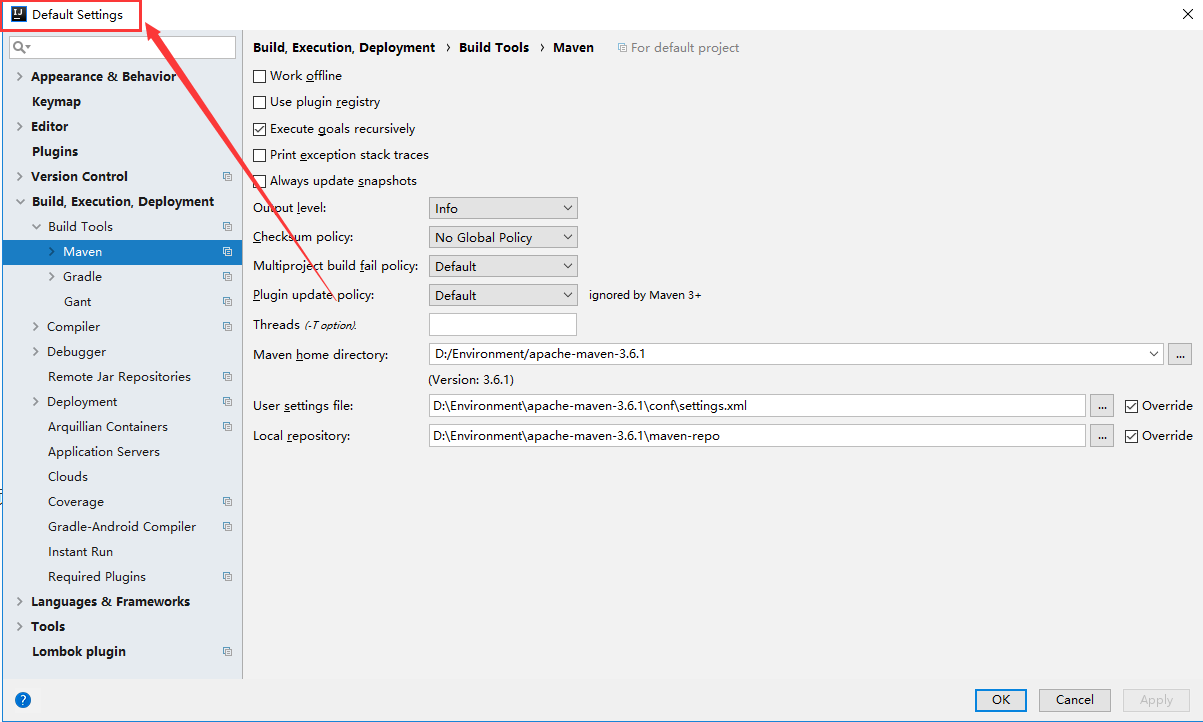
+3. IDEA中每次都要重复配置Maven
+ 在IDEA中的全局默认配置中去配置
+
+ 
+
+ 
+
+4. Maven项目中Tomcat无法配置
+
+5. maven默认web项目中的web.xml版本问题
+
+ 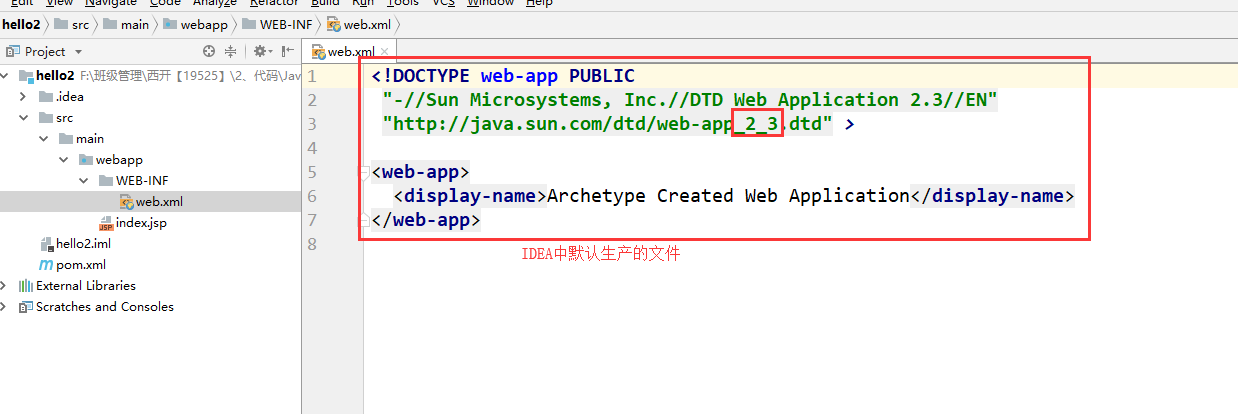
+
+6. 替换为webapp4.0版本和tomcat一致
+
+ ```xml
+
+
+
+
+
+
+ ```
+
+
+
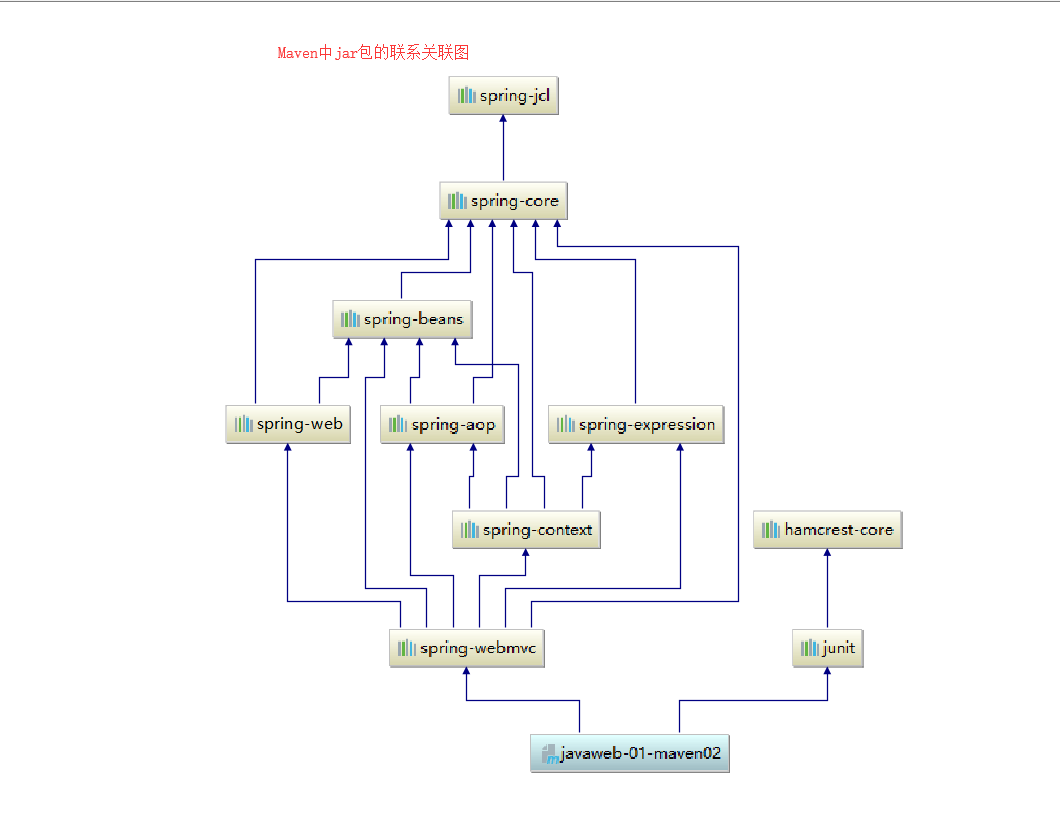
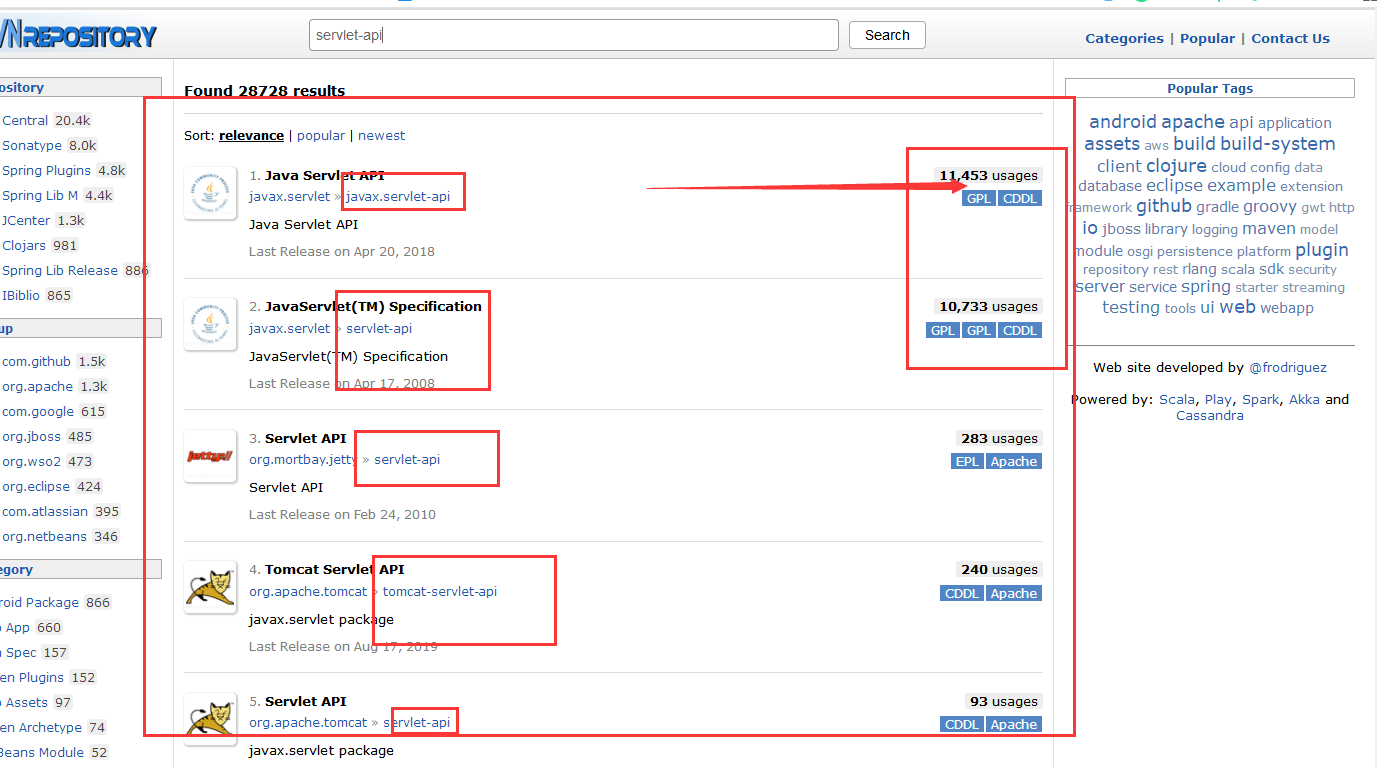
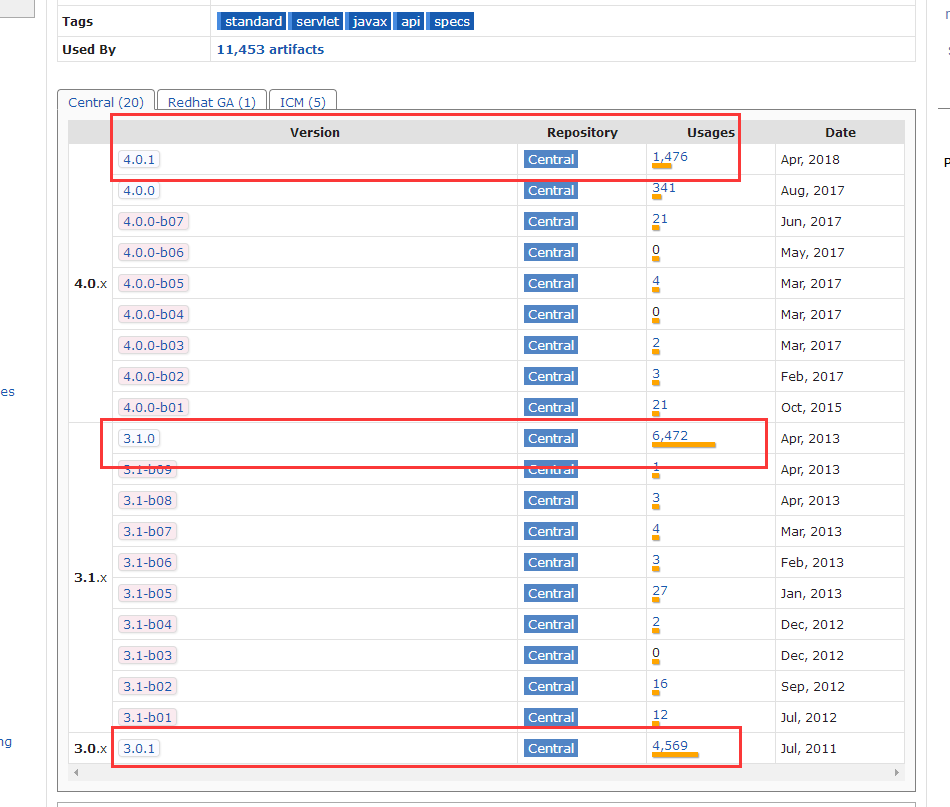
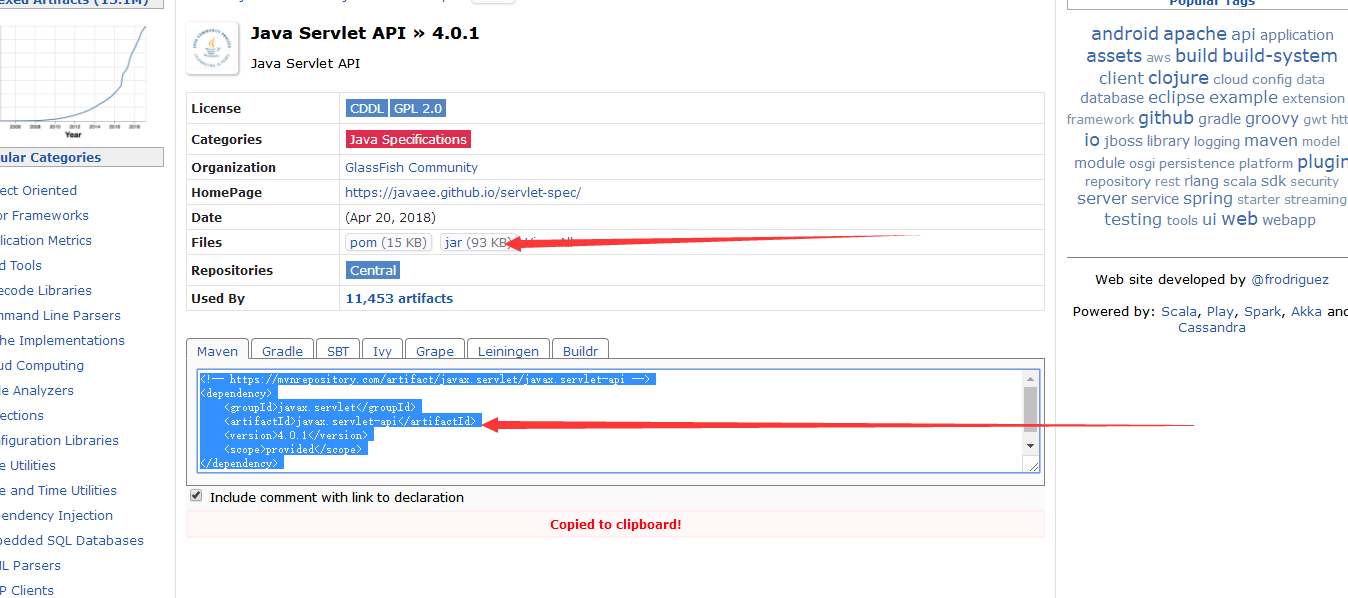
+7. Maven仓库的使用
+
+ 地址:https://mvnrepository.com/
+
+ 
+
+ 
+
+ 
+
+ 
+
+
diff --git "a/docs/01.Java/20.JavaWeb/20.\346\200\273\350\247\210.md" "b/docs/01.Java/20.JavaWeb/20.\346\200\273\350\247\210.md"
new file mode 100644
index 00000000..e25598c3
--- /dev/null
+++ "b/docs/01.Java/20.JavaWeb/20.\346\200\273\350\247\210.md"
@@ -0,0 +1,2054 @@
+---
+title: java-web总览
+permalink: /javaweb/overview
+author:
+ name: 致远
+ link: https://oddfar.com
+categories:
+ - java
+ - java-web
+categoryText: java
+date: 2021-05-07 18:09:11
+---
+
+
+# JavaWeb
+
+
+## 6、Servlet
+
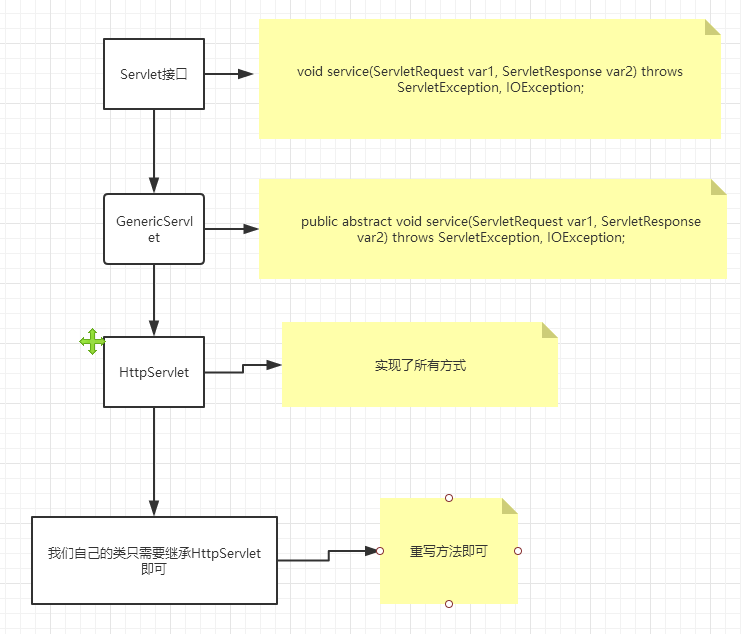
+### 6.1、Servlet简介
+
+- Servlet就是sun公司开发动态web的一门技术
+- Sun在这些API中提供一个接口叫做:Servlet,如果你想开发一个Servlet程序,只需要完成两个小步骤:
+ - 编写一个类,实现Servlet接口
+ - 把开发好的Java类部署到web服务器中。
+
+**把实现了Servlet接口的Java程序叫做,Servlet**
+
+### 6.2、HelloServlet
+
+Serlvet接口Sun公司有两个默认的实现类:HttpServlet,GenericServlet
+
+
+
+1. 构建一个普通的Maven项目,删掉里面的src目录,以后我们的学习就在这个项目里面建立Moudel;这个空的工程就是Maven主工程;
+
+2. 关于Maven父子工程的理解:
+
+ 父项目中会有
+
+ ```xml
+
+ servlet-01
+
+ ```
+
+ 子项目会有
+
+ ```xml
+
+ javaweb-02-servlet
+ com.kuang
+ 1.0-SNAPSHOT
+
+ ```
+
+ 父项目中的java子项目可以直接使用
+
+ ```java
+ son extends father
+ ```
+
+3. Maven环境优化
+
+ 1. 修改web.xml为最新的
+ 2. 将maven的结构搭建完整
+
+4. 编写一个Servlet程序
+
+ 
+
+ 1. 编写一个普通类
+
+ 2. 实现Servlet接口,这里我们直接继承HttpServlet
+
+ ```java
+ public class HelloServlet extends HttpServlet {
+
+ //由于get或者post只是请求实现的不同的方式,可以相互调用,业务逻辑都一样;
+ @Override
+ protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+ //ServletOutputStream outputStream = resp.getOutputStream();
+ PrintWriter writer = resp.getWriter(); //响应流
+ writer.print("Hello,Serlvet");
+ }
+
+ @Override
+ protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+ doGet(req, resp);
+ }
+ }
+
+ ```
+
+5. 编写Servlet的映射
+
+ 为什么需要映射:我们写的是JAVA程序,但是要通过浏览器访问,而浏览器需要连接web服务器,所以我们需要再web服务中注册我们写的Servlet,还需给他一个浏览器能够访问的路径;
+
+ ```xml
+
+
+
+ hello
+ com.kuang.servlet.HelloServlet
+
+
+
+ hello
+ /hello
+
+
+ ```
+
+
+
+6. 配置Tomcat
+
+ 注意:配置项目发布的路径就可以了
+
+7. 启动测试,OK!
+
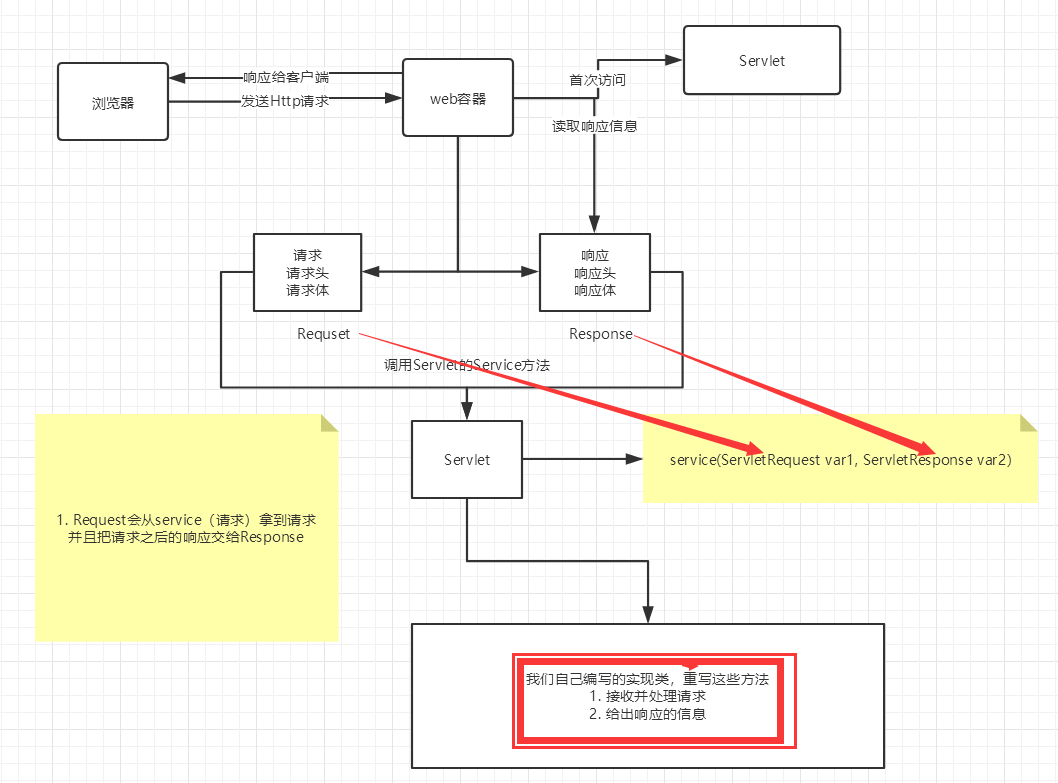
+### 6.3、Servlet原理
+
+Servlet是由Web服务器调用,web服务器在收到浏览器请求之后,会:
+
+
+
+### 6.4、Mapping问题
+
+1. 一个Servlet可以指定一个映射路径
+
+ ```xml
+
+ hello
+ /hello
+
+ ```
+
+2. 一个Servlet可以指定多个映射路径
+
+ ```xml
+
+ hello
+ /hello
+
+
+ hello
+ /hello2
+
+
+ hello
+ /hello3
+
+
+ hello
+ /hello4
+
+
+ hello
+ /hello5
+
+
+ ```
+
+3. 一个Servlet可以指定通用映射路径
+
+ ```xml
+
+ hello
+ /hello/*
+
+ ```
+
+4. 默认请求路径
+
+ ```xml
+
+
+ hello
+ /*
+
+ ```
+
+5. 指定一些后缀或者前缀等等….
+
+ ```xml
+
+
+
+ hello
+ *.qinjiang
+
+ ```
+
+6. 优先级问题
+ 指定了固有的映射路径优先级最高,如果找不到就会走默认的处理请求;
+
+ ```xml
+
+
+ error
+ com.kuang.servlet.ErrorServlet
+
+
+ error
+ /*
+
+
+ ```
+
+
+
+### 6.5、ServletContext
+
+web容器在启动的时候,它会为每个web程序都创建一个对应的ServletContext对象,它代表了当前的web应用;
+
+#### 1、共享数据
+
+我在这个Servlet中保存的数据,可以在另外一个servlet中拿到;
+
+```java
+public class HelloServlet extends HttpServlet {
+ @Override
+ protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+
+ //this.getInitParameter() 初始化参数
+ //this.getServletConfig() Servlet配置
+ //this.getServletContext() Servlet上下文
+ ServletContext context = this.getServletContext();
+
+ String username = "秦疆"; //数据
+ context.setAttribute("username",username); //将一个数据保存在了ServletContext中,名字为:username 。值 username
+
+ }
+
+}
+
+```
+
+```java
+public class GetServlet extends HttpServlet {
+ @Override
+ protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+ ServletContext context = this.getServletContext();
+ String username = (String) context.getAttribute("username");
+
+ resp.setContentType("text/html");
+ resp.setCharacterEncoding("utf-8");
+ resp.getWriter().print("名字"+username);
+
+ }
+
+ @Override
+ protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+ doGet(req, resp);
+ }
+}
+
+```
+
+```XML
+
+ hello
+ com.kuang.servlet.HelloServlet
+
+
+ hello
+ /hello
+
+
+
+
+ getc
+ com.kuang.servlet.GetServlet
+
+
+ getc
+ /getc
+
+```
+
+测试访问结果;
+
+
+
+#### 2、获取初始化参数
+
+```xml
+
+
+ url
+ jdbc:mysql://localhost:3306/mybatis
+
+```
+
+```java
+protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+ ServletContext context = this.getServletContext();
+ String url = context.getInitParameter("url");
+ resp.getWriter().print(url);
+}
+```
+
+#### 3、请求转发
+
+```java
+@Override
+protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+ ServletContext context = this.getServletContext();
+ System.out.println("进入了ServletDemo04");
+ //RequestDispatcher requestDispatcher = context.getRequestDispatcher("/gp"); //转发的请求路径
+ //requestDispatcher.forward(req,resp); //调用forward实现请求转发;
+ context.getRequestDispatcher("/gp").forward(req,resp);
+}
+```
+
+
+
+#### 4、读取资源文件
+
+Properties
+
+- 在java目录下新建properties
+- 在resources目录下新建properties
+
+发现:都被打包到了同一个路径下:classes,我们俗称这个路径为classpath:
+
+思路:需要一个文件流;
+
+```properties
+username=root12312
+password=zxczxczxc
+```
+
+```java
+public class ServletDemo05 extends HttpServlet {
+ @Override
+ protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+
+ InputStream is = this.getServletContext().getResourceAsStream("/WEB-INF/classes/com/kuang/servlet/aa.properties");
+
+ Properties prop = new Properties();
+ prop.load(is);
+ String user = prop.getProperty("username");
+ String pwd = prop.getProperty("password");
+
+ resp.getWriter().print(user+":"+pwd);
+
+ }
+
+ @Override
+ protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+ doGet(req, resp);
+ }
+}
+
+```
+
+访问测试即可ok;
+
+### 6.6、HttpServletResponse
+
+web服务器接收到客户端的http请求,针对这个请求,分别创建一个代表请求的HttpServletRequest对象,代表响应的一个HttpServletResponse;
+
+- 如果要获取客户端请求过来的参数:找HttpServletRequest
+- 如果要给客户端响应一些信息:找HttpServletResponse
+
+#### 1、简单分类
+
+负责向浏览器发送数据的方法
+
+```java
+ServletOutputStream getOutputStream() throws IOException;
+PrintWriter getWriter() throws IOException;
+```
+
+负责向浏览器发送响应头的方法
+
+```java
+ void setCharacterEncoding(String var1);
+
+ void setContentLength(int var1);
+
+ void setContentLengthLong(long var1);
+
+ void setContentType(String var1);
+
+ void setDateHeader(String var1, long var2);
+
+ void addDateHeader(String var1, long var2);
+
+ void setHeader(String var1, String var2);
+
+ void addHeader(String var1, String var2);
+
+ void setIntHeader(String var1, int var2);
+
+ void addIntHeader(String var1, int var2);
+```
+
+响应的状态码
+
+```java
+ int SC_CONTINUE = 100;
+ int SC_SWITCHING_PROTOCOLS = 101;
+ int SC_OK = 200;
+ int SC_CREATED = 201;
+ int SC_ACCEPTED = 202;
+ int SC_NON_AUTHORITATIVE_INFORMATION = 203;
+ int SC_NO_CONTENT = 204;
+ int SC_RESET_CONTENT = 205;
+ int SC_PARTIAL_CONTENT = 206;
+ int SC_MULTIPLE_CHOICES = 300;
+ int SC_MOVED_PERMANENTLY = 301;
+ int SC_MOVED_TEMPORARILY = 302;
+ int SC_FOUND = 302;
+ int SC_SEE_OTHER = 303;
+ int SC_NOT_MODIFIED = 304;
+ int SC_USE_PROXY = 305;
+ int SC_TEMPORARY_REDIRECT = 307;
+ int SC_BAD_REQUEST = 400;
+ int SC_UNAUTHORIZED = 401;
+ int SC_PAYMENT_REQUIRED = 402;
+ int SC_FORBIDDEN = 403;
+ int SC_NOT_FOUND = 404;
+ int SC_METHOD_NOT_ALLOWED = 405;
+ int SC_NOT_ACCEPTABLE = 406;
+ int SC_PROXY_AUTHENTICATION_REQUIRED = 407;
+ int SC_REQUEST_TIMEOUT = 408;
+ int SC_CONFLICT = 409;
+ int SC_GONE = 410;
+ int SC_LENGTH_REQUIRED = 411;
+ int SC_PRECONDITION_FAILED = 412;
+ int SC_REQUEST_ENTITY_TOO_LARGE = 413;
+ int SC_REQUEST_URI_TOO_LONG = 414;
+ int SC_UNSUPPORTED_MEDIA_TYPE = 415;
+ int SC_REQUESTED_RANGE_NOT_SATISFIABLE = 416;
+ int SC_EXPECTATION_FAILED = 417;
+ int SC_INTERNAL_SERVER_ERROR = 500;
+ int SC_NOT_IMPLEMENTED = 501;
+ int SC_BAD_GATEWAY = 502;
+ int SC_SERVICE_UNAVAILABLE = 503;
+ int SC_GATEWAY_TIMEOUT = 504;
+ int SC_HTTP_VERSION_NOT_SUPPORTED = 505;
+```
+
+#### 2、下载文件
+
+1. 向浏览器输出消息 (一直在讲,就不说了)
+2. 下载文件
+ 1. 要获取下载文件的路径
+ 2. 下载的文件名是啥?
+ 3. 设置想办法让浏览器能够支持下载我们需要的东西
+ 4. 获取下载文件的输入流
+ 5. 创建缓冲区
+ 6. 获取OutputStream对象
+ 7. 将FileOutputStream流写入到buffer缓冲区
+ 8. 使用OutputStream将缓冲区中的数据输出到客户端!
+
+```java
+@Override
+protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+ // 1. 要获取下载文件的路径
+ String realPath = "F:\\班级管理\\西开【19525】\\2、代码\\JavaWeb\\javaweb-02-servlet\\response\\target\\classes\\秦疆.png";
+ System.out.println("下载文件的路径:"+realPath);
+ // 2. 下载的文件名是啥?
+ String fileName = realPath.substring(realPath.lastIndexOf("\\") + 1);
+ // 3. 设置想办法让浏览器能够支持(Content-Disposition)下载我们需要的东西,中文文件名URLEncoder.encode编码,否则有可能乱码
+ resp.setHeader("Content-Disposition","attachment;filename="+URLEncoder.encode(fileName,"UTF-8"));
+ // 4. 获取下载文件的输入流
+ FileInputStream in = new FileInputStream(realPath);
+ // 5. 创建缓冲区
+ int len = 0;
+ byte[] buffer = new byte[1024];
+ // 6. 获取OutputStream对象
+ ServletOutputStream out = resp.getOutputStream();
+ // 7. 将FileOutputStream流写入到buffer缓冲区,使用OutputStream将缓冲区中的数据输出到客户端!
+ while ((len=in.read(buffer))>0){
+ out.write(buffer,0,len);
+ }
+
+ in.close();
+ out.close();
+}
+```
+
+#### 3、验证码功能
+
+验证怎么来的?
+
+- 前端实现
+- 后端实现,需要用到 Java 的图片类,生产一个图片
+
+```java
+package com.kuang.servlet;
+
+import javax.imageio.ImageIO;
+import javax.servlet.ServletException;
+import javax.servlet.http.HttpServlet;
+import javax.servlet.http.HttpServletRequest;
+import javax.servlet.http.HttpServletResponse;
+import java.awt.*;
+import java.awt.image.BufferedImage;
+import java.io.IOException;
+import java.util.Random;
+
+public class ImageServlet extends HttpServlet {
+
+ @Override
+ protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+
+ //如何让浏览器3秒自动刷新一次;
+ resp.setHeader("refresh","3");
+
+ //在内存中创建一个图片
+ BufferedImage image = new BufferedImage(80,20,BufferedImage.TYPE_INT_RGB);
+ //得到图片
+ Graphics2D g = (Graphics2D) image.getGraphics(); //笔
+ //设置图片的背景颜色
+ g.setColor(Color.white);
+ g.fillRect(0,0,80,20);
+ //给图片写数据
+ g.setColor(Color.BLUE);
+ g.setFont(new Font(null,Font.BOLD,20));
+ g.drawString(makeNum(),0,20);
+
+ //告诉浏览器,这个请求用图片的方式打开
+ resp.setContentType("image/jpeg");
+ //网站存在缓存,不让浏览器缓存
+ resp.setDateHeader("expires",-1);
+ resp.setHeader("Cache-Control","no-cache");
+ resp.setHeader("Pragma","no-cache");
+
+ //把图片写给浏览器
+ ImageIO.write(image,"jpg", resp.getOutputStream());
+
+ }
+
+ //生成随机数
+ private String makeNum(){
+ Random random = new Random();
+ String num = random.nextInt(9999999) + "";
+ StringBuffer sb = new StringBuffer();
+ for (int i = 0; i < 7-num.length() ; i++) {
+ sb.append("0");
+ }
+ num = sb.toString() + num;
+ return num;
+ }
+
+
+ @Override
+ protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+ doGet(req, resp);
+ }
+}
+
+```
+
+#### 4、实现重定向
+
+
+
+B一个web资源收到客户端A请求后,B他会通知A客户端去访问另外一个web资源C,这个过程叫重定向
+
+常见场景:
+
+- 用户登录
+
+```java
+void sendRedirect(String var1) throws IOException;
+```
+
+测试:
+
+```java
+@Override
+protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+
+ /*
+ resp.setHeader("Location","/r/img");
+ resp.setStatus(302);
+ */
+ resp.sendRedirect("/r/img");//重定向
+}
+```
+
+面试题:请你聊聊重定向和转发的区别?
+
+相同点
+
+- 页面都会实现跳转
+
+不同点
+
+- 请求转发的时候,url不会产生变化
+- 重定向时候,url地址栏会发生变化;
+
+
+
+#### 5、简单实现登录重定向
+
+```jsp
+<%--这里提交的路径,需要寻找到项目的路径--%>
+<%--${pageContext.request.contextPath}代表当前的项目--%>
+
+
+
+```
+
+```JAVA
+
+ @Override
+ protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+ //处理请求
+ String username = req.getParameter("username");
+ String password = req.getParameter("password");
+
+ System.out.println(username+":"+password);
+
+ //重定向时候一定要注意,路径问题,否则404;
+ resp.sendRedirect("/r/success.jsp");
+ }
+
+```
+
+```xml
+
+ requset
+ com.kuang.servlet.RequestTest
+
+
+ requset
+ /login
+
+```
+
+```jsp
+<%@ page contentType="text/html;charset=UTF-8" language="java" %>
+
+
+ Title
+
+
+
+Success
+
+
+
+
+```
+
+### 6.7、HttpServletRequest
+
+HttpServletRequest代表客户端的请求,用户通过Http协议访问服务器,HTTP请求中的所有信息会被封装到HttpServletRequest,通过这个HttpServletRequest的方法,获得客户端的所有信息;
+
+
+
+
+
+#### 获取参数,请求转发
+
+
+
+```java
+@Override
+protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+
+ req.setCharacterEncoding("utf-8");
+ resp.setCharacterEncoding("utf-8");
+
+ String username = req.getParameter("username");
+ String password = req.getParameter("password");
+ String[] hobbys = req.getParameterValues("hobbys");
+ System.out.println("=============================");
+ //后台接收中文乱码问题
+ System.out.println(username);
+ System.out.println(password);
+ System.out.println(Arrays.toString(hobbys));
+ System.out.println("=============================");
+
+
+ System.out.println(req.getContextPath());
+ //通过请求转发
+ //这里的 / 代表当前的web应用
+ req.getRequestDispatcher("/success.jsp").forward(req,resp);
+
+}
+```
+
+**面试题:请你聊聊重定向和转发的区别?**
+
+相同点
+
+- 页面都会实现跳转
+
+不同点
+
+- 请求转发的时候,url不会产生变化 307
+- 重定向时候,url地址栏会发生变化; 302
+
+
+
+## 7、Cookie、Session
+
+### 7.1、会话
+
+**会话**:用户打开一个浏览器,点击了很多超链接,访问多个web资源,关闭浏览器,这个过程可以称之为会话;
+
+**有状态会话**:一个同学来过教室,下次再来教室,我们会知道这个同学,曾经来过,称之为有状态会话;
+
+**你能怎么证明你是西开的学生?**
+
+你 西开
+
+1. 发票 西开给你发票
+2. 学校登记 西开标记你来过了
+
+**一个网站,怎么证明你来过?**
+
+客户端 服务端
+
+1. 服务端给客户端一个 信件,客户端下次访问服务端带上信件就可以了; cookie
+2. 服务器登记你来过了,下次你来的时候我来匹配你; seesion
+
+
+
+### 7.2、保存会话的两种技术
+
+**cookie**
+
+- 客户端技术 (响应,请求)
+
+**session**
+
+- 服务器技术,利用这个技术,可以保存用户的会话信息? 我们可以把信息或者数据放在Session中!
+
+
+
+常见常见:网站登录之后,你下次不用再登录了,第二次访问直接就上去了!
+
+### 7.3、Cookie
+
+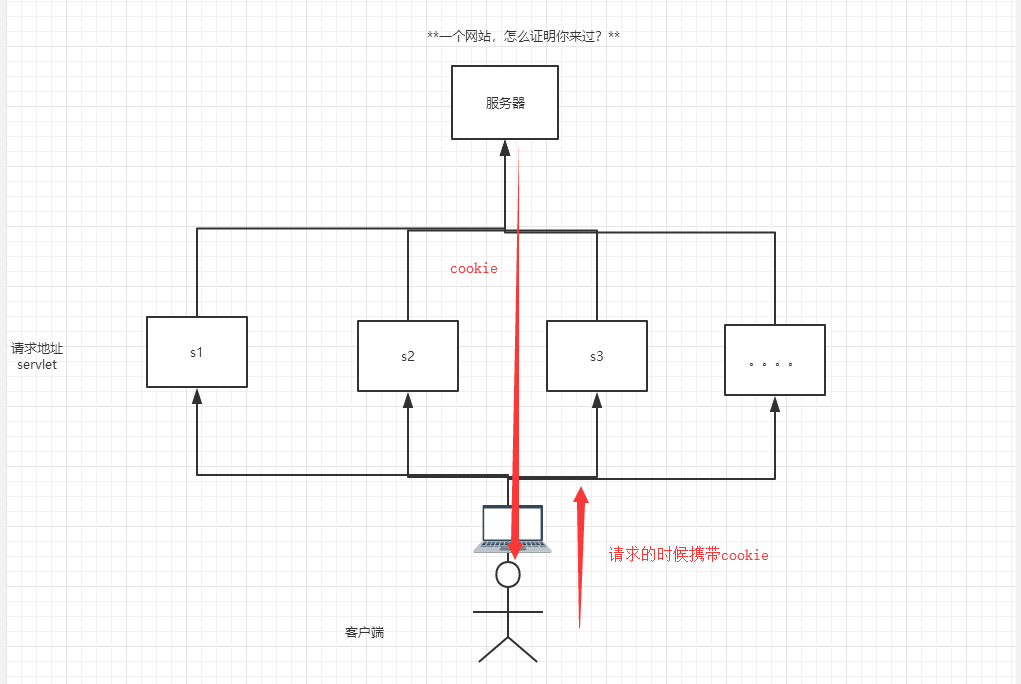
+
+1. 从请求中拿到cookie信息
+2. 服务器响应给客户端cookie
+
+```java
+Cookie[] cookies = req.getCookies(); //获得Cookie
+cookie.getName(); //获得cookie中的key
+cookie.getValue(); //获得cookie中的vlaue
+new Cookie("lastLoginTime", System.currentTimeMillis()+""); //新建一个cookie
+cookie.setMaxAge(24*60*60); //设置cookie的有效期
+resp.addCookie(cookie); //响应给客户端一个cookie
+```
+
+**cookie:一般会保存在本地的 用户目录下 appdata;**
+
+
+
+一个网站cookie是否存在上限!**聊聊细节问题**
+
+- 一个Cookie只能保存一个信息;
+- 一个web站点可以给浏览器发送多个cookie,最多存放20个cookie;
+- Cookie大小有限制4kb;
+- 300个cookie浏览器上限
+
+
+
+**删除Cookie;**
+
+- 不设置有效期,关闭浏览器,自动失效;
+- 设置有效期时间为 0 ;
+
+
+
+**编码解码:**
+
+```java
+URLEncoder.encode("秦疆","utf-8")
+URLDecoder.decode(cookie.getValue(),"UTF-8")
+```
+
+
+
+### 7.4、Session(重点)
+
+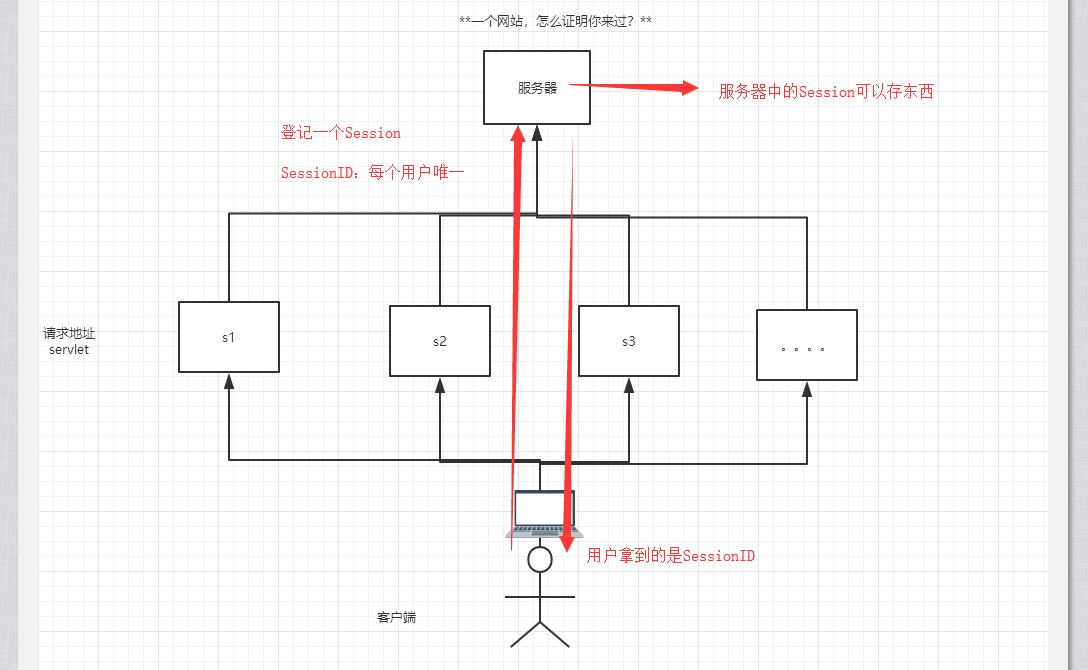
+
+什么是Session:
+
+- 服务器会给每一个用户(浏览器)创建一个Seesion对象;
+- 一个Seesion独占一个浏览器,只要浏览器没有关闭,这个Session就存在;
+- 用户登录之后,整个网站它都可以访问!--> 保存用户的信息;保存购物车的信息…..
+
+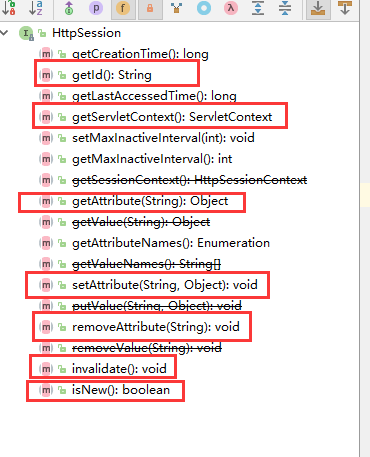
+
+Session和cookie的区别:
+
+- Cookie是把用户的数据写给用户的浏览器,浏览器保存 (可以保存多个)
+- Session把用户的数据写到用户独占Session中,服务器端保存 (保存重要的信息,减少服务器资源的浪费)
+- Session对象由服务创建;
+
+
+
+使用场景:
+
+- 保存一个登录用户的信息;
+- 购物车信息;
+- 在整个网站中经常会使用的数据,我们将它保存在Session中;
+
+
+
+使用Session:
+
+```java
+package com.kuang.servlet;
+
+import com.kuang.pojo.Person;
+
+import javax.servlet.ServletException;
+import javax.servlet.http.*;
+import java.io.IOException;
+
+public class SessionDemo01 extends HttpServlet {
+ @Override
+ protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+
+ //解决乱码问题
+ req.setCharacterEncoding("UTF-8");
+ resp.setCharacterEncoding("UTF-8");
+ resp.setContentType("text/html;charset=utf-8");
+
+ //得到Session
+ HttpSession session = req.getSession();
+ //给Session中存东西
+ session.setAttribute("name",new Person("秦疆",1));
+ //获取Session的ID
+ String sessionId = session.getId();
+
+ //判断Session是不是新创建
+ if (session.isNew()){
+ resp.getWriter().write("session创建成功,ID:"+sessionId);
+ }else {
+ resp.getWriter().write("session以及在服务器中存在了,ID:"+sessionId);
+ }
+
+ //Session创建的时候做了什么事情;
+// Cookie cookie = new Cookie("JSESSIONID",sessionId);
+// resp.addCookie(cookie);
+
+ }
+
+ @Override
+ protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
+ doGet(req, resp);
+ }
+}
+
+//得到Session
+HttpSession session = req.getSession();
+
+Person person = (Person) session.getAttribute("name");
+
+System.out.println(person.toString());
+
+HttpSession session = req.getSession();
+session.removeAttribute("name");
+//手动注销Session
+session.invalidate();
+```
+
+
+
+**会话自动过期:web.xml配置**
+
+```xml
+
+
+
+ 15
+
+```
+
+
+
+
+
+
+
+## 8、JSP
+
+### 8.1、什么是JSP
+
+Java Server Pages : Java服务器端页面,也和Servlet一样,用于动态Web技术!
+
+最大的特点:
+
+- 写JSP就像在写HTML
+- 区别:
+ - HTML只给用户提供静态的数据
+ - JSP页面中可以嵌入JAVA代码,为用户提供动态数据;
+
+
+
+### 8.2、JSP原理
+
+思路:JSP到底怎么执行的!
+
+- 代码层面没有任何问题
+
+- 服务器内部工作
+
+ tomcat中有一个work目录;
+
+ IDEA中使用Tomcat的会在IDEA的tomcat中生产一个work目录
+
+ 
+
+ 我电脑的地址:
+
+ ```java
+ C:\Users\Administrator\.IntelliJIdea2018.1\system\tomcat\Unnamed_javaweb-session-cookie\work\Catalina\localhost\ROOT\org\apache\jsp
+ ```
+
+ 发现页面转变成了Java程序!
+
+ 
+
+
+
+**浏览器向服务器发送请求,不管访问什么资源,其实都是在访问Servlet!**
+
+JSP最终也会被转换成为一个Java类!
+
+**JSP 本质上就是一个Servlet**
+
+```java
+//初始化
+ public void _jspInit() {
+
+ }
+//销毁
+ public void _jspDestroy() {
+ }
+//JSPService
+ public void _jspService(.HttpServletRequest request,HttpServletResponse response)
+
+```
+
+1. 判断请求
+
+2. 内置一些对象
+
+ ```java
+ final javax.servlet.jsp.PageContext pageContext; //页面上下文
+ javax.servlet.http.HttpSession session = null; //session
+ final javax.servlet.ServletContext application; //applicationContext
+ final javax.servlet.ServletConfig config; //config
+ javax.servlet.jsp.JspWriter out = null; //out
+ final java.lang.Object page = this; //page:当前
+ HttpServletRequest request //请求
+ HttpServletResponse response //响应
+ ```
+
+3. 输出页面前增加的代码
+
+ ```java
+ response.setContentType("text/html"); //设置响应的页面类型
+ pageContext = _jspxFactory.getPageContext(this, request, response,
+ null, true, 8192, true);
+ _jspx_page_context = pageContext;
+ application = pageContext.getServletContext();
+ config = pageContext.getServletConfig();
+ session = pageContext.getSession();
+ out = pageContext.getOut();
+ _jspx_out = out;
+ ```
+
+4. 以上的这些个对象我们可以在JSP页面中直接使用!
+
+
+
+
+
+在JSP页面中;
+
+只要是 JAVA代码就会原封不动的输出;
+
+如果是HTML代码,就会被转换为:
+
+```java
+out.write("\r\n");
+```
+
+这样的格式,输出到前端!
+
+
+
+### 8.3、JSP基础语法
+
+任何语言都有自己的语法,JAVA中有,。 JSP 作为java技术的一种应用,它拥有一些自己扩充的语法(了解,知道即可!),Java所有语法都支持!
+
+
+
+#### **JSP表达式**
+
+```jsp
+ <%--JSP表达式
+ 作用:用来将程序的输出,输出到客户端
+ <%= 变量或者表达式%>
+ --%>
+ <%= new java.util.Date()%>
+```
+
+
+
+#### **jsp脚本片段**
+
+```jsp
+
+ <%--jsp脚本片段--%>
+ <%
+ int sum = 0;
+ for (int i = 1; i <=100 ; i++) {
+ sum+=i;
+ }
+ out.println("Sum="+sum+"
");
+ %>
+
+```
+
+
+
+**脚本片段的再实现**
+
+```jsp
+ <%
+ int x = 10;
+ out.println(x);
+ %>
+ 这是一个JSP文档
+ <%
+ int y = 2;
+ out.println(y);
+ %>
+
+
+
+
+ <%--在代码嵌入HTML元素--%>
+ <%
+ for (int i = 0; i < 5; i++) {
+ %>
+ Hello,World <%=i%>
+ <%
+ }
+ %>
+```
+
+
+
+#### JSP声明
+
+```jsp
+ <%!
+ static {
+ System.out.println("Loading Servlet!");
+ }
+
+ private int globalVar = 0;
+
+ public void kuang(){
+ System.out.println("进入了方法Kuang!");
+ }
+ %>
+```
+
+
+
+JSP声明:会被编译到JSP生成Java的类中!其他的,就会被生成到_jspService方法中!
+
+在JSP,嵌入Java代码即可!
+
+```jsp
+<%%>
+<%=%>
+<%!%>
+
+<%--注释--%>
+```
+
+JSP的注释,不会在客户端显示,HTML就会!
+
+
+
+### 8.4、JSP指令
+
+```jsp
+<%@page args.... %>
+<%@include file=""%>
+
+<%--@include会将两个页面合二为一--%>
+
+<%@include file="common/header.jsp"%>
+网页主体
+
+<%@include file="common/footer.jsp"%>
+
+
+
+
+<%--jSP标签
+ jsp:include:拼接页面,本质还是三个
+ --%>
+
+网页主体
+
+
+```
+
+
+
+### 8.5、9大内置对象
+
+- PageContext 存东西
+- Request 存东西
+- Response
+- Session 存东西
+- Application 【SerlvetContext】 存东西
+- config 【SerlvetConfig】
+- out
+- page ,不用了解
+- exception
+
+```java
+pageContext.setAttribute("name1","秦疆1号"); //保存的数据只在一个页面中有效
+request.setAttribute("name2","秦疆2号"); //保存的数据只在一次请求中有效,请求转发会携带这个数据
+session.setAttribute("name3","秦疆3号"); //保存的数据只在一次会话中有效,从打开浏览器到关闭浏览器
+application.setAttribute("name4","秦疆4号"); //保存的数据只在服务器中有效,从打开服务器到关闭服务器
+```
+
+request:客户端向服务器发送请求,产生的数据,用户看完就没用了,比如:新闻,用户看完没用的!
+
+session:客户端向服务器发送请求,产生的数据,用户用完一会还有用,比如:购物车;
+
+application:客户端向服务器发送请求,产生的数据,一个用户用完了,其他用户还可能使用,比如:聊天数据;
+
+### 8.6、JSP标签、JSTL标签、EL表达式
+
+```xml
+
+
+ javax.servlet.jsp.jstl
+ jstl-api
+ 1.2
+
+
+
+ taglibs
+ standard
+ 1.1.2
+
+
+```
+
+EL表达式: ${ }
+
+- **获取数据**
+- **执行运算**
+- **获取web开发的常用对象**
+
+
+
+**JSP标签**
+
+```jsp
+<%--jsp:include--%>
+
+<%--
+http://localhost:8080/jsptag.jsp?name=kuangshen&age=12
+--%>
+
+
+
+
+
+```
+
+
+
+**JSTL表达式**
+
+JSTL标签库的使用就是为了弥补HTML标签的不足;它自定义许多标签,可以供我们使用,标签的功能和Java代码一样!
+
+**格式化标签**
+
+**SQL标签**
+
+**XML 标签**
+
+**核心标签** (掌握部分)
+
+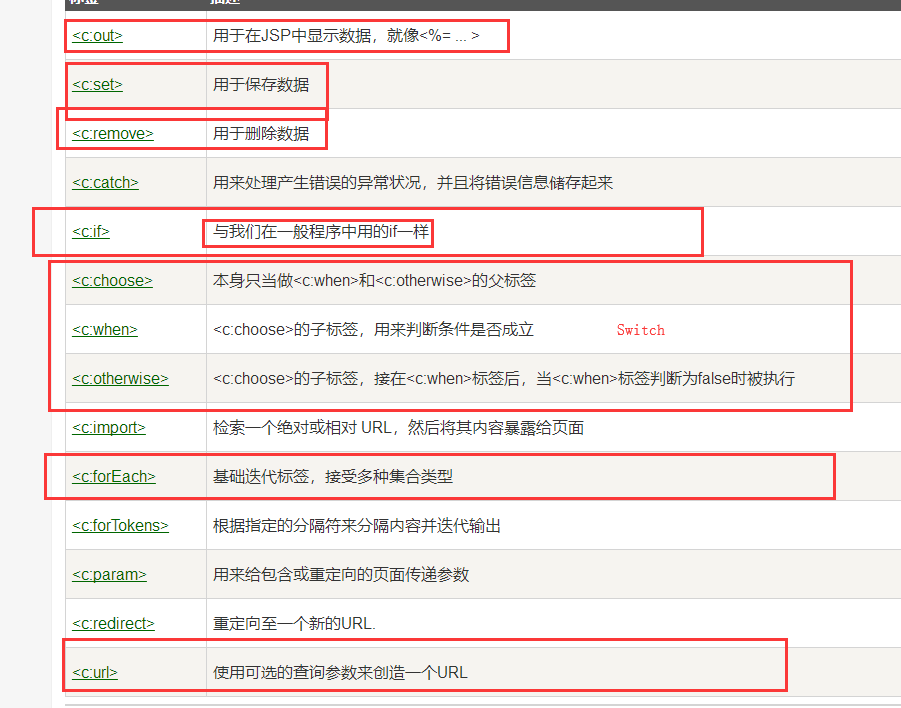
+
+**JSTL标签库使用步骤**
+
+- 引入对应的 taglib
+- 使用其中的方法
+- **在Tomcat 也需要引入 jstl的包,否则会报错:JSTL解析错误**
+
+c:if
+
+```jsp
+
+ Title
+
+
+
+
+if测试
+
+
+
+
+
+<%--判断如果提交的用户名是管理员,则登录成功--%>
+
+
+
+
+<%--自闭合标签--%>
+
+
+
+```
+
+c:choose c:when
+
+```jsp
+
+
+<%--定义一个变量score,值为85--%>
+
+
+
+
+ 你的成绩为优秀
+
+
+ 你的成绩为一般
+
+
+ 你的成绩为良好
+
+
+ 你的成绩为不及格
+
+
+
+
+```
+
+c:forEach
+
+```jsp
+<%
+
+ ArrayList people = new ArrayList<>();
+ people.add(0,"张三");
+ people.add(1,"李四");
+ people.add(2,"王五");
+ people.add(3,"赵六");
+ people.add(4,"田六");
+ request.setAttribute("list",people);
+%>
+
+
+<%--
+var , 每一次遍历出来的变量
+items, 要遍历的对象
+begin, 哪里开始
+end, 到哪里
+step, 步长
+--%>
+
+
+
+
+
+
+
+
+
+
+```
+
+## 9、JavaBean
+
+实体类
+
+JavaBean有特定的写法:
+
+- 必须要有一个无参构造
+- 属性必须私有化
+- 必须有对应的get/set方法;
+
+一般用来和数据库的字段做映射 ORM;
+
+ORM :对象关系映射
+
+- 表--->类
+- 字段-->属性
+- 行记录---->对象
+
+**people表**
+
+| id | name | age | address |
+| ---- | ------- | ---- | ------- |
+| 1 | 秦疆1号 | 3 | 西安 |
+| 2 | 秦疆2号 | 18 | 西安 |
+| 3 | 秦疆3号 | 100 | 西安 |
+
+```java
+class People{
+ private int id;
+ private String name;
+ private int id;
+ private String address;
+}
+
+class A{
+ new People(1,"秦疆1号",3,"西安");
+ new People(2,"秦疆2号",3,"西安");
+ new People(3,"秦疆3号",3,"西安");
+}
+```
+
+
+
+- 过滤器
+- 文件上传
+- 邮件发送
+- JDBC 复习 : 如何使用JDBC , JDBC crud, jdbc 事务
+
+
+
+## 10、MVC三层架构
+
+什么是MVC: Model view Controller 模型、视图、控制器
+
+### 10.1、早些年
+
+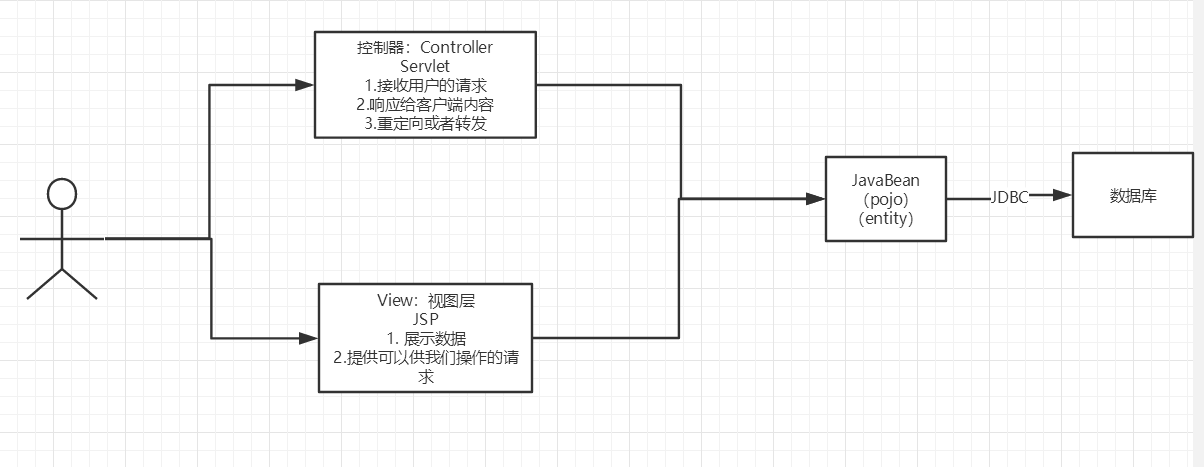
+
+用户直接访问控制层,控制层就可以直接操作数据库;
+
+```java
+servlet--CRUD-->数据库
+弊端:程序十分臃肿,不利于维护
+servlet的代码中:处理请求、响应、视图跳转、处理JDBC、处理业务代码、处理逻辑代码
+
+架构:没有什么是加一层解决不了的!
+程序猿调用
+|
+JDBC
+|
+Mysql Oracle SqlServer ....
+```
+
+### 10.2、MVC三层架构
+
+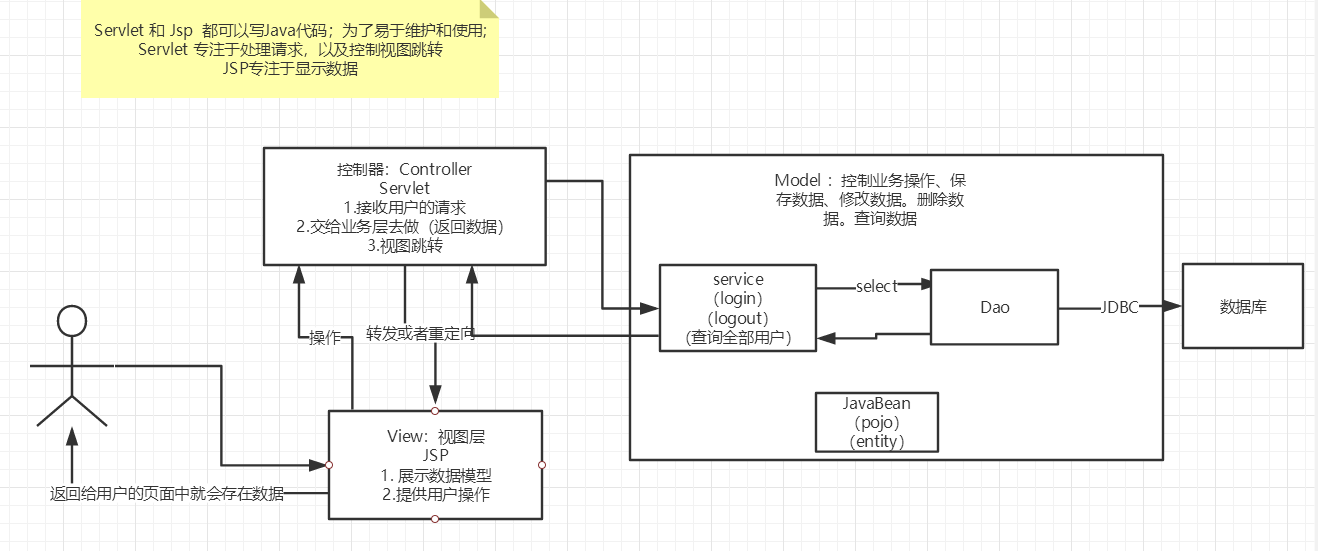
+
+
+
+Model
+
+- 业务处理 :业务逻辑(Service)
+- 数据持久层:CRUD (Dao)
+
+View
+
+- 展示数据
+- 提供链接发起Servlet请求 (a,form,img…)
+
+Controller (Servlet)
+
+- 接收用户的请求 :(req:请求参数、Session信息….)
+
+- 交给业务层处理对应的代码
+
+- 控制视图的跳转
+
+ ```java
+ 登录--->接收用户的登录请求--->处理用户的请求(获取用户登录的参数,username,password)---->交给业务层处理登录业务(判断用户名密码是否正确:事务)--->Dao层查询用户名和密码是否正确-->数据库
+ ```
+
+
+
+## 11、Filter (重点)
+
+Filter:过滤器 ,用来过滤网站的数据;
+
+- 处理中文乱码
+- 登录验证….
+
+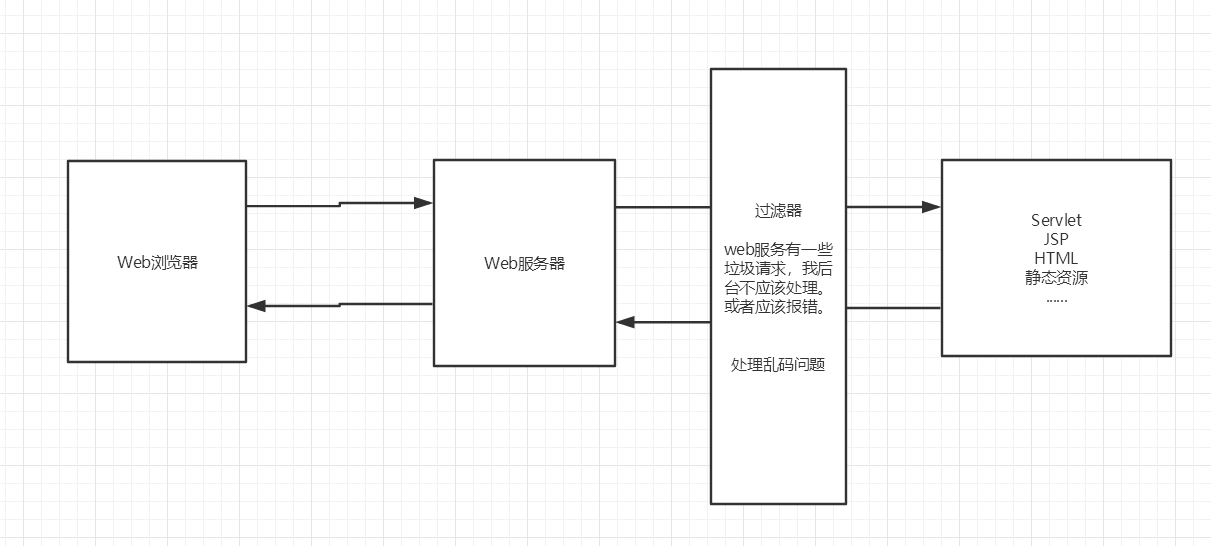
+
+Filter开发步骤:
+
+1. 导包
+
+2. 编写过滤器
+
+ 1. 导包不要错
+
+ 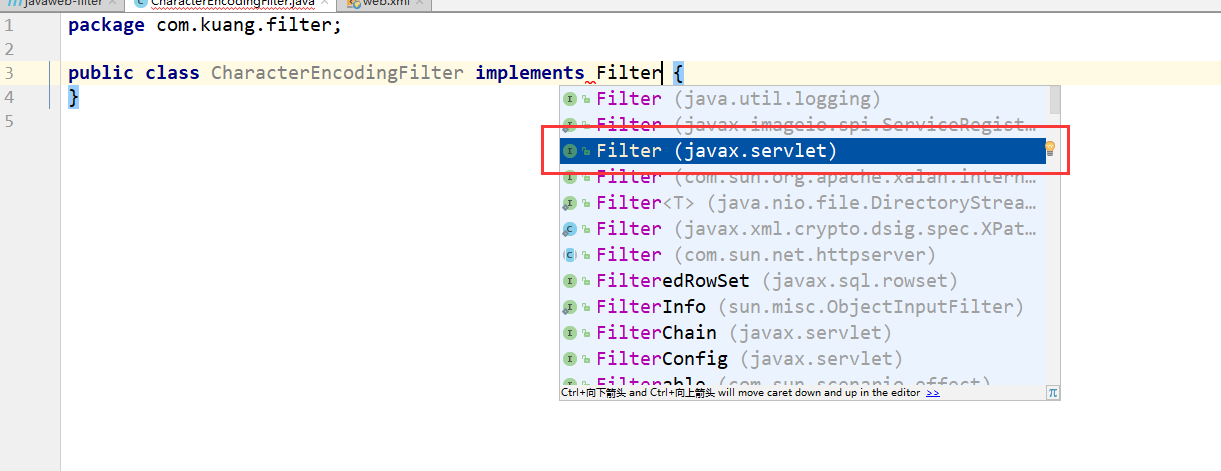
+
+ 实现Filter接口,重写对应的方法即可
+
+ ```java
+ public class CharacterEncodingFilter implements Filter {
+
+ //初始化:web服务器启动,就以及初始化了,随时等待过滤对象出现!
+ public void init(FilterConfig filterConfig) throws ServletException {
+ System.out.println("CharacterEncodingFilter初始化");
+ }
+
+ //Chain : 链
+ /*
+ 1. 过滤中的所有代码,在过滤特定请求的时候都会执行
+ 2. 必须要让过滤器继续同行
+ chain.doFilter(request,response);
+ */
+ public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
+ request.setCharacterEncoding("utf-8");
+ response.setCharacterEncoding("utf-8");
+ response.setContentType("text/html;charset=UTF-8");
+
+ System.out.println("CharacterEncodingFilter执行前....");
+ chain.doFilter(request,response); //让我们的请求继续走,如果不写,程序到这里就被拦截停止!
+ System.out.println("CharacterEncodingFilter执行后....");
+ }
+
+ //销毁:web服务器关闭的时候,过滤会销毁
+ public void destroy() {
+ System.out.println("CharacterEncodingFilter销毁");
+ }
+ }
+
+ ```
+
+3. 在web.xml中配置 Filter
+
+ ```xml
+
+ CharacterEncodingFilter
+ com.kuang.filter.CharacterEncodingFilter
+
+
+ CharacterEncodingFilter
+
+ /servlet/*
+
+
+ ```
+
+
+
+## 12、监听器
+
+实现一个监听器的接口;(有N种)
+
+1. 编写一个监听器
+
+ 实现监听器的接口…
+
+ ```java
+ //统计网站在线人数 : 统计session
+ public class OnlineCountListener implements HttpSessionListener {
+
+ //创建session监听: 看你的一举一动
+ //一旦创建Session就会触发一次这个事件!
+ public void sessionCreated(HttpSessionEvent se) {
+ ServletContext ctx = se.getSession().getServletContext();
+
+ System.out.println(se.getSession().getId());
+
+ Integer onlineCount = (Integer) ctx.getAttribute("OnlineCount");
+
+ if (onlineCount==null){
+ onlineCount = new Integer(1);
+ }else {
+ int count = onlineCount.intValue();
+ onlineCount = new Integer(count+1);
+ }
+
+ ctx.setAttribute("OnlineCount",onlineCount);
+
+ }
+
+ //销毁session监听
+ //一旦销毁Session就会触发一次这个事件!
+ public void sessionDestroyed(HttpSessionEvent se) {
+ ServletContext ctx = se.getSession().getServletContext();
+
+ Integer onlineCount = (Integer) ctx.getAttribute("OnlineCount");
+
+ if (onlineCount==null){
+ onlineCount = new Integer(0);
+ }else {
+ int count = onlineCount.intValue();
+ onlineCount = new Integer(count-1);
+ }
+
+ ctx.setAttribute("OnlineCount",onlineCount);
+
+ }
+
+
+ /*
+ Session销毁:
+ 1. 手动销毁 getSession().invalidate();
+ 2. 自动销毁
+ */
+ }
+
+ ```
+
+2. web.xml中注册监听器
+
+ ```xml
+
+
+ com.kuang.listener.OnlineCountListener
+
+ ```
+
+3. 看情况是否使用!
+
+
+
+## 13、过滤器、监听器常见应用
+
+**监听器:GUI编程中经常使用;**
+
+```java
+public class TestPanel {
+ public static void main(String[] args) {
+ Frame frame = new Frame("中秋节快乐"); //新建一个窗体
+ Panel panel = new Panel(null); //面板
+ frame.setLayout(null); //设置窗体的布局
+
+ frame.setBounds(300,300,500,500);
+ frame.setBackground(new Color(0,0,255)); //设置背景颜色
+
+ panel.setBounds(50,50,300,300);
+ panel.setBackground(new Color(0,255,0)); //设置背景颜色
+
+ frame.add(panel);
+
+ frame.setVisible(true);
+
+ //监听事件,监听关闭事件
+ frame.addWindowListener(new WindowAdapter() {
+ @Override
+ public void windowClosing(WindowEvent e) {
+ super.windowClosing(e);
+ }
+ });
+
+
+ }
+}
+```
+
+
+
+用户登录之后才能进入主页!用户注销后就不能进入主页了!
+
+1. 用户登录之后,向Sesison中放入用户的数据
+
+2. 进入主页的时候要判断用户是否已经登录;要求:在过滤器中实现!
+
+ ```java
+ HttpServletRequest request = (HttpServletRequest) req;
+ HttpServletResponse response = (HttpServletResponse) resp;
+
+ if (request.getSession().getAttribute(Constant.USER_SESSION)==null){
+ response.sendRedirect("/error.jsp");
+ }
+
+ chain.doFilter(request,response);
+ ```
+
+
+
+
+## 14、JDBC
+
+什么是JDBC : Java连接数据库!
+
+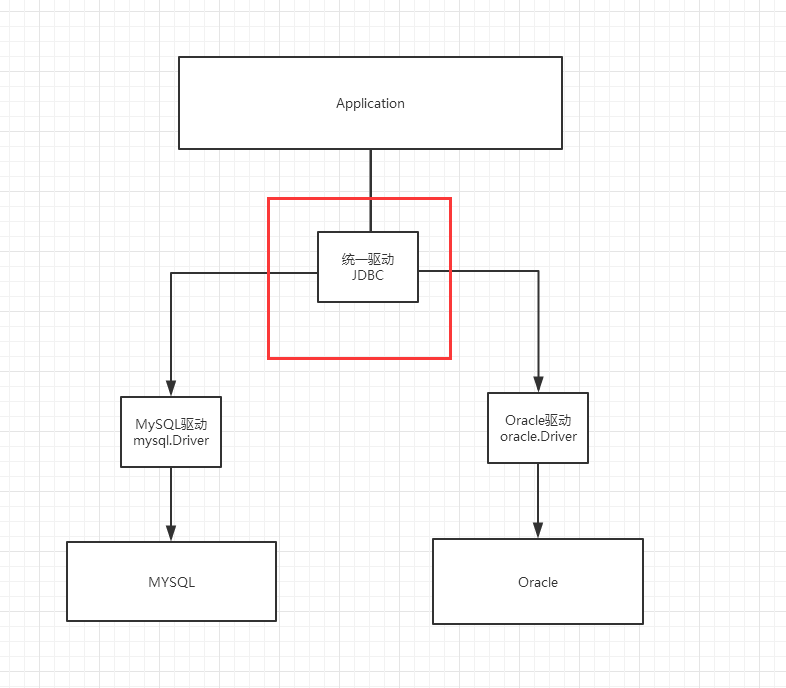
+
+需要jar包的支持:
+
+- java.sql
+- javax.sql
+- mysql-conneter-java… 连接驱动(必须要导入)
+
+
+
+**实验环境搭建**
+
+```sql
+
+CREATE TABLE users(
+ id INT PRIMARY KEY,
+ `name` VARCHAR(40),
+ `password` VARCHAR(40),
+ email VARCHAR(60),
+ birthday DATE
+);
+
+INSERT INTO users(id,`name`,`password`,email,birthday)
+VALUES(1,'张三','123456','zs@qq.com','2000-01-01');
+INSERT INTO users(id,`name`,`password`,email,birthday)
+VALUES(2,'李四','123456','ls@qq.com','2000-01-01');
+INSERT INTO users(id,`name`,`password`,email,birthday)
+VALUES(3,'王五','123456','ww@qq.com','2000-01-01');
+
+
+SELECT * FROM users;
+
+```
+
+
+
+导入数据库依赖
+
+```xml
+
+
+ mysql
+ mysql-connector-java
+ 5.1.47
+
+```
+
+IDEA中连接数据库:
+
+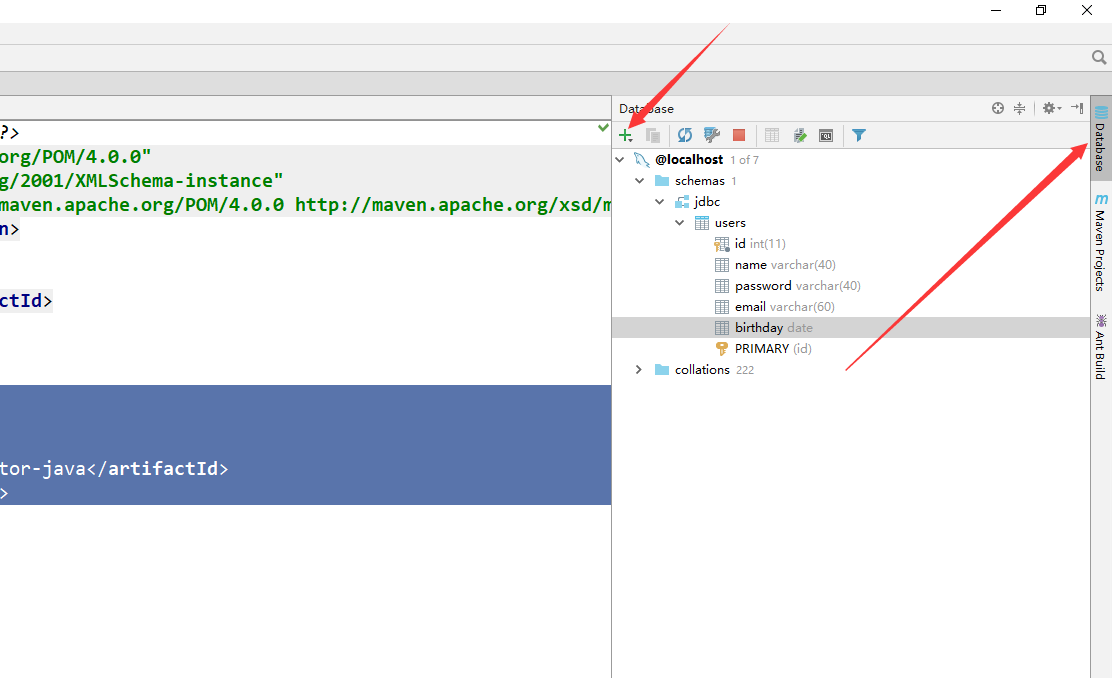
+
+
+
+**JDBC 固定步骤:**
+
+1. 加载驱动
+2. 连接数据库,代表数据库
+3. 向数据库发送SQL的对象Statement : CRUD
+4. 编写SQL (根据业务,不同的SQL)
+5. 执行SQL
+6. 关闭连接
+
+```java
+public class TestJdbc {
+ public static void main(String[] args) throws ClassNotFoundException, SQLException {
+ //配置信息
+ //useUnicode=true&characterEncoding=utf-8 解决中文乱码
+ String url="jdbc:mysql://localhost:3306/jdbc?useUnicode=true&characterEncoding=utf-8";
+ String username = "root";
+ String password = "123456";
+
+ //1.加载驱动
+ Class.forName("com.mysql.jdbc.Driver");
+ //2.连接数据库,代表数据库
+ Connection connection = DriverManager.getConnection(url, username, password);
+
+ //3.向数据库发送SQL的对象Statement,PreparedStatement : CRUD
+ Statement statement = connection.createStatement();
+
+ //4.编写SQL
+ String sql = "select * from users";
+
+ //5.执行查询SQL,返回一个 ResultSet : 结果集
+ ResultSet rs = statement.executeQuery(sql);
+
+ while (rs.next()){
+ System.out.println("id="+rs.getObject("id"));
+ System.out.println("name="+rs.getObject("name"));
+ System.out.println("password="+rs.getObject("password"));
+ System.out.println("email="+rs.getObject("email"));
+ System.out.println("birthday="+rs.getObject("birthday"));
+ }
+
+ //6.关闭连接,释放资源(一定要做) 先开后关
+ rs.close();
+ statement.close();
+ connection.close();
+ }
+}
+
+```
+
+
+
+**预编译SQL**
+
+```java
+public class TestJDBC2 {
+ public static void main(String[] args) throws Exception {
+ //配置信息
+ //useUnicode=true&characterEncoding=utf-8 解决中文乱码
+ String url="jdbc:mysql://localhost:3306/jdbc?useUnicode=true&characterEncoding=utf-8";
+ String username = "root";
+ String password = "123456";
+
+ //1.加载驱动
+ Class.forName("com.mysql.jdbc.Driver");
+ //2.连接数据库,代表数据库
+ Connection connection = DriverManager.getConnection(url, username, password);
+
+ //3.编写SQL
+ String sql = "insert into users(id, name, password, email, birthday) values (?,?,?,?,?);";
+
+ //4.预编译
+ PreparedStatement preparedStatement = connection.prepareStatement(sql);
+
+ preparedStatement.setInt(1,2);//给第一个占位符? 的值赋值为1;
+ preparedStatement.setString(2,"狂神说Java");//给第二个占位符? 的值赋值为狂神说Java;
+ preparedStatement.setString(3,"123456");//给第三个占位符? 的值赋值为123456;
+ preparedStatement.setString(4,"24736743@qq.com");//给第四个占位符? 的值赋值为1;
+ preparedStatement.setDate(5,new Date(new java.util.Date().getTime()));//给第五个占位符? 的值赋值为new Date(new java.util.Date().getTime());
+
+ //5.执行SQL
+ int i = preparedStatement.executeUpdate();
+
+ if (i>0){
+ System.out.println("插入成功@");
+ }
+
+ //6.关闭连接,释放资源(一定要做) 先开后关
+ preparedStatement.close();
+ connection.close();
+ }
+}
+
+```
+
+
+
+**事务**
+
+要么都成功,要么都失败!
+
+ACID原则:保证数据的安全。
+
+```java
+开启事务
+事务提交 commit()
+事务回滚 rollback()
+关闭事务
+
+转账:
+A:1000
+B:1000
+
+A(900) --100--> B(1100)
+```
+
+
+
+**Junit单元测试**
+
+依赖
+
+```xml
+
+
+ junit
+ junit
+ 4.12
+
+```
+
+简单使用
+
+@Test注解只有在方法上有效,只要加了这个注解的方法,就可以直接运行!
+
+```java
+@Test
+public void test(){
+ System.out.println("Hello");
+}
+```
+
+
+
+失败的时候是红色:
+
+
+
+
+
+**搭建一个环境**
+
+```sql
+CREATE TABLE account(
+ id INT PRIMARY KEY AUTO_INCREMENT,
+ `name` VARCHAR(40),
+ money FLOAT
+);
+
+INSERT INTO account(`name`,money) VALUES('A',1000);
+INSERT INTO account(`name`,money) VALUES('B',1000);
+INSERT INTO account(`name`,money) VALUES('C',1000);
+```
+
+```java
+ @Test
+ public void test() {
+ //配置信息
+ //useUnicode=true&characterEncoding=utf-8 解决中文乱码
+ String url="jdbc:mysql://localhost:3306/jdbc?useUnicode=true&characterEncoding=utf-8";
+ String username = "root";
+ String password = "123456";
+
+ Connection connection = null;
+
+ //1.加载驱动
+ try {
+ Class.forName("com.mysql.jdbc.Driver");
+ //2.连接数据库,代表数据库
+ connection = DriverManager.getConnection(url, username, password);
+
+ //3.通知数据库开启事务,false 开启
+ connection.setAutoCommit(false);
+
+ String sql = "update account set money = money-100 where name = 'A'";
+ connection.prepareStatement(sql).executeUpdate();
+
+ //制造错误
+ //int i = 1/0;
+
+ String sql2 = "update account set money = money+100 where name = 'B'";
+ connection.prepareStatement(sql2).executeUpdate();
+
+ connection.commit();//以上两条SQL都执行成功了,就提交事务!
+ System.out.println("success");
+ } catch (Exception e) {
+ try {
+ //如果出现异常,就通知数据库回滚事务
+ connection.rollback();
+ } catch (SQLException e1) {
+ e1.printStackTrace();
+ }
+ e.printStackTrace();
+ }finally {
+ try {
+ connection.close();
+ } catch (SQLException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+```
+
+## 15、数据库连接池
+
+**概念:其实就是一个容器(集合),存放数据库连接的容器。**
+当系统初始化好后,容器被创建,容器中会申请一些连接对象,当用户来访问数据库时,从容器中获取连接对象,用户访问完之后,会将连接对象归还给容器。
+**好处:**
+
+1. 节约资源
+2. 用户访问高效
+
+**实现:**
+标准接口:`DataSource javax.sql`包下的
+
+1. 方法:
+
+>获取连接:`getConnection()`
+>归还连接:`Connection.close()`。
+>如果连接对象Connection是从连接池中获取的,那么调用`Connection.close()`方法,则不会再关闭连接了。而是归还连接
+
+2. 一般我们不去实现它,有数据库厂商来实现
+
+>1. C3P0:数据库连接池技术
+>2. Druid:数据库连接池实现技术,由阿里巴巴提供的
+
+
+**C3P0:数据库连接池技术**
+
+- 步骤:
+
+1. 导入jar包 (两个) c3p0-0.9.5.2.jar mchange-commons-java-0.2.12.jar ,
+ *不要忘记导入数据库驱动 `jar` 包*
+2. 定义配置文件:
+
+>名称: `c3p0.properties` 或者 `c3p0-config.xml`
+>路径:直接将文件放在src目录下即可。
+
+3. 创建核心对象 数据库连接池对象 `ComboPooledDataSource()`
+4. 获取连接:`getConnection()`
+
+- 代码:
+
+```java
+//1.创建数据库连接池对象
+DataSource ds = new ComboPooledDataSource();
+//2. 获取连接对象
+Connection conn = ds.getConnection();
+```
+
+**Druid:数据库连接池实现技术,由阿里巴巴提供的**
+
+- 步骤:
+
+1. 导入jar包 `druid-1.0.9.jar`
+2. 定义配置文件:
+ * 是`properties`形式的*
+ * 可以叫任意名称,可以放在任意目录下*
+3. 加载配置文件。`Properties`
+4. 获取数据库连接池对象:通过工厂来来获取 `DruidDataSourceFactory()`
+5. 获取连接:`getConnection()`
+
+- 代码:
+
+```
+//3.加载配置文件
+Properties pro = new Properties();
+InputStream is = DruidDemo.class.getClassLoader().getResourceAsStream("druid.properties");
+pro.load(is);
+//4.获取连接池对象
+DataSource ds = DruidDataSourceFactory.createDataSource(pro);
+//5.获取连接
+Connection conn = ds.getConnection();
+```
+
+**定义工具类**
+
+1. 定义一个类 JDBCUtils
+2. 提供静态代码块加载配置文件,初始化连接池对象
+3. 提供方法
+
+> 1. 获取连接方法:通过数据库连接池获取连接
+> 2. 释放资源
+> 3. 获取连接池的方法
+
+
+**代码:**
+
+```Java
+public class JDBCUtils {
+
+ //1.定义成员变量 DataSource
+ private static DataSource ds ;
+
+ static{
+ try {
+ //1.加载配置文件
+ Properties pro = new Properties();
+ pro.load(JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties"));
+ //2.获取DataSource
+ ds = DruidDataSourceFactory.createDataSource(pro);
+ } catch (IOException e) {
+ e.printStackTrace();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+
+ /**
+ * 获取连接
+ */
+ public static Connection getConnection() throws SQLException {
+ return ds.getConnection();
+ }
+
+ /**
+ * 释放资源
+ */
+ public static void close(Statement stmt,Connection conn){
+ /* if(stmt != null){
+ try {
+ stmt.close();
+ } catch (SQLException e) {
+ e.printStackTrace();
+ }
+ }
+
+ if(conn != null){
+ try {
+ conn.close();//归还连接
+ } catch (SQLException e) {
+ e.printStackTrace();
+ }
+ }*/
+
+ close(null,stmt,conn);
+ }
+
+
+ public static void close(ResultSet rs , Statement stmt, Connection conn){
+
+ if(rs != null){
+ try {
+ rs.close();
+ } catch (SQLException e) {
+ e.printStackTrace();
+ }
+ }
+ if(stmt != null){
+ try {
+ stmt.close();
+ } catch (SQLException e) {
+ e.printStackTrace();
+ }
+ }
+
+ if(conn != null){
+ try {
+ conn.close();//归还连接
+ } catch (SQLException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+
+ /**
+ * 获取连接池方法
+ */
+
+ public static DataSource getDataSource(){
+ return ds;
+ }
+}
+```
\ No newline at end of file
diff --git "a/docs/02.Web/01.Html5/02.\346\200\273\350\247\210.md" "b/docs/02.Web/01.Html5/02.\346\200\273\350\247\210.md"
new file mode 100644
index 00000000..4f35a28c
--- /dev/null
+++ "b/docs/02.Web/01.Html5/02.\346\200\273\350\247\210.md"
@@ -0,0 +1,13 @@
+---
+title: 总览
+permalink: /html5/overview
+date: 2021-05-09 09:50:58
+---
+
+
+
+
+
+# 总览
+
+html5
\ No newline at end of file
diff --git "a/docs/02.Web/02.CSS/02.\346\200\273\350\247\210.md" "b/docs/02.Web/02.CSS/02.\346\200\273\350\247\210.md"
new file mode 100644
index 00000000..b9969cf2
--- /dev/null
+++ "b/docs/02.Web/02.CSS/02.\346\200\273\350\247\210.md"
@@ -0,0 +1,16 @@
+---
+title: 总览
+permalink: /css/overview
+categories:
+ - java
+ - java-web
+date: 2021-05-09 09:53:16
+---
+
+
+
+
+
+# 总览
+
+css
\ No newline at end of file
diff --git "a/docs/02.Web/03.JavaScript/02.\346\200\273\350\247\210.md" "b/docs/02.Web/03.JavaScript/02.\346\200\273\350\247\210.md"
new file mode 100644
index 00000000..f23a8340
--- /dev/null
+++ "b/docs/02.Web/03.JavaScript/02.\346\200\273\350\247\210.md"
@@ -0,0 +1,14 @@
+---
+title: 总览
+permalink: /javascript/overview
+date: 2021-05-09 09:53:35
+---
+
+
+
+
+
+# 总览
+
+JavaScript
+
diff --git "a/docs/02.Web/10.vue/02.\346\200\273\350\247\210.md" "b/docs/02.Web/10.vue/02.\346\200\273\350\247\210.md"
new file mode 100644
index 00000000..5f47d9fa
--- /dev/null
+++ "b/docs/02.Web/10.vue/02.\346\200\273\350\247\210.md"
@@ -0,0 +1,14 @@
+---
+title: 总览
+permalink: /vue/overview
+date: 2021-05-09 09:53:35
+---
+
+
+
+
+
+# 总览
+
+vue
+
diff --git "a/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/02.MySQL - \345\211\215\350\250\200.md" "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/02.MySQL - \345\211\215\350\250\200.md"
new file mode 100644
index 00000000..d2064489
--- /dev/null
+++ "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/02.MySQL - \345\211\215\350\250\200.md"
@@ -0,0 +1,42 @@
+---
+title: MySQL - 前言
+permalink: /mysql/preface/
+date: 2021-05-20 09:55:12
+---
+
+**MySQL入门:**
+
+MySQL基础笔记可看 [菜鸟教程](https://www.runoob.com/mysql/mysql-tutorial.html)
+
+mysql基础视频教程 bilibili 上搜即可
+
+---
+
+**MySQL进阶:**
+
+- **尚硅谷MySQL数据库高级**
+
+ 视频:https://www.bilibili.com/video/BV1KW411u7vy
+
+ 笔记链接:https://pan.baidu.com/s/1GUzPFVG3Je9uT419rHE8MQ
+
+ 提取码:ybfi
+
+- **黑马程序员2020最新MySQL高级教程**
+
+ 视频:https://www.bilibili.com/video/BV1UQ4y1P7Xr
+
+ 笔记:https://gitee.com/yooome/netty-study
+
+
+
+
+我刚开始看的是尚硅谷的,看了一半跑去看黑马的了
+
+这两教程内容都差不多,黑马的更多一些
+
+
+
+推荐书籍:《深入浅出mysql》
+
+视频内容围绕着这本书上内容讲的
\ No newline at end of file
diff --git "a/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/04.MySQL - \351\200\273\350\276\221\346\236\266\346\236\204.md" "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/04.MySQL - \351\200\273\350\276\221\346\236\266\346\236\204.md"
new file mode 100644
index 00000000..a9d1c852
--- /dev/null
+++ "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/04.MySQL - \351\200\273\350\276\221\346\236\266\346\236\204.md"
@@ -0,0 +1,435 @@
+---
+title: MySQL - 逻辑架构简介
+permalink: /mysql/logic-framework/
+date: 2021-05-20 09:55:12
+---
+
+
+
+
+
+- [Mysql 逻辑架构简介](#mysql-%E9%80%BB%E8%BE%91%E6%9E%B6%E6%9E%84%E7%AE%80%E4%BB%8B)
+ - [整体架构图](#%E6%95%B4%E4%BD%93%E6%9E%B6%E6%9E%84%E5%9B%BE)
+ - [连接层](#%E8%BF%9E%E6%8E%A5%E5%B1%82)
+ - [服务层](#%E6%9C%8D%E5%8A%A1%E5%B1%82)
+ - [引擎层](#%E5%BC%95%E6%93%8E%E5%B1%82)
+ - [存储层](#%E5%AD%98%E5%82%A8%E5%B1%82)
+ - [show profile](#show-profile)
+ - [大致的查询流程](#%E5%A4%A7%E8%87%B4%E7%9A%84%E6%9F%A5%E8%AF%A2%E6%B5%81%E7%A8%8B)
+ - [SQL的执行顺序](#sql%E7%9A%84%E6%89%A7%E8%A1%8C%E9%A1%BA%E5%BA%8F)
+- [存储引擎](#%E5%AD%98%E5%82%A8%E5%BC%95%E6%93%8E)
+ - [存储引擎概述](#%E5%AD%98%E5%82%A8%E5%BC%95%E6%93%8E%E6%A6%82%E8%BF%B0)
+ - [各种存储引擎特性](#%E5%90%84%E7%A7%8D%E5%AD%98%E5%82%A8%E5%BC%95%E6%93%8E%E7%89%B9%E6%80%A7)
+ - [InnoDB](#innodb)
+ - [MyISAM](#myisam)
+ - [MEMORY](#memory)
+ - [MERGE](#merge)
+- [SQL 预热](#sql-%E9%A2%84%E7%83%AD)
+
+
+
+
+
+## Mysql 逻辑架构简介
+
+### 整体架构图
+
+
+
+和其它数据库相比,MySQL 有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎的架构上,插件式的存储引擎架构将查询处理和其它的系统任务以及数据的存储提取相分离。这种架构可 以根据业务的需求和实际需要选择合适的存储引擎。
+
+**各层介绍:**
+
+#### 连接层
+
+最上层是一些客户端和连接服务,包含本地 sock 通信和大多数基于客户端/服务端工具实现的类似于 tcp/ip 的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证 安全接入的客户端提供线程。同样在该层上可以实现基于 SSL 的安全链接。服务器也会为安全接入的每个客户端验 证它所具有的操作权限。
+
+#### 服务层
+
+- Management Serveices & Utilities
+
+ 系统管理和控制工具
+
+- SQL Interface
+
+ SQL 接口。接受用户的 SQL 命令,并且返回用户需要查询的结果。比如 select from 就是调用 SQL Interface
+
+- Parser
+
+ 解析器。 SQL 命令传递到解析器的时候会被解析器验证和解析
+
+- Optimizer
+
+ 查询优化器。 SQL 语句在查询之前会使用查询优化器对查询进行优化,比如有 where 条件时,优化器来决定先投影还是先过滤。
+
+- Cache 和 Buffer
+
+ 查询缓存。如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key 缓存, 权限缓存等
+
+ 注:mysql 8.X 取消了查询缓存
+
+#### 引擎层
+
+存储引擎层,存储引擎真正的负责了 MySQL 中数据的存储和提取,服务器通过 API 与存储引擎进行通信。不同 的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。
+
+#### 存储层
+
+数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
+
+
+
+### show profile
+
+利用 show profile 可以查看 sql 的执行周期!
+
+**开启 profile**
+
+查看 profile 是否开启:show variables like '%profiling%'
+
+```sh
+mysql> show variables like '%profiling%';
++------------------------+-------+
+| Variable_name | Value |
++------------------------+-------+
+| have_profiling | YES |
+| profiling | OFF |
+| profiling_history_size | 15 |
++------------------------+-------+
+3 rows in set (0.01 sec)
+```
+
+如果没有开启,可以执行 set profiling=1 开启!
+
+**使用 profile**
+
+执行 `show profiles;` 命令,可以查看最近的几次查询。
+
+根据 `Query_ID`,可以进一步执行 `show profile cpu,block io for query Query_id` 来查看 sql 的具体执行步骤。
+
+
+
+### 大致的查询流程
+
+mysql 的查询流程大致是:
+
+mysql 客户端通过协议与 mysql 服务器建连接,发送查询语句,先检查查询缓存,如果命中,直接返回结果, 否则进行语句解析,也就是说,在解析查询之前,服务器会先访问查询缓存(query cache)——它存储 SELECT 语句以及 相应的查询结果集。如果某个查询结果已经位于缓存中,服务器就不会再对查询进行解析、优化、以及执行。它仅仅将缓存中的结果返回给用户即可,这将大大提高系统的性能。
+
+语法解析器和预处理:首先 mysql 通过关键字将 SQL 语句进行解析,并生成一颗对应的“解析树”。mysql 解析器将使用 mysql 语法规则验证和解析查询;预处理器则根据一些 mysql 规则进一步检查解析数是否合法。
+
+查询优化器当解析树被认为是合法的了,并且由优化器将其转化成执行计划。一条查询可以有很多种执行方式, 最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
+
+然后,mysql 默认使用的 BTREE 索引,并且一个大致方向是:无论怎么折腾 sql,至少在目前来说,mysql 最多只用到表中的一个索引。
+
+
+
+### SQL的执行顺序
+
+手写的顺序:
+
+
+
+真正执行的顺序:
+
+ 随着 Mysql 版本的更新换代,其优化器也在不断的升级,优化器会分析不同执行顺序产生的性能消耗不同而动 态调整执行顺序。下面是经常出现的查询顺序:
+
+
+
+
+
+
+
+## 存储引擎
+
+### 存储引擎概述
+
+和大多数的数据库不同, MySQL中有一个存储引擎的概念, 针对不同的存储需求可以选择最优的存储引擎。
+
+ 存储引擎就是存储数据,建立索引,更新查询数据等等技术的实现方式 。存储引擎是基于表的,而不是基于库的。所以存储引擎也可被称为表类型。
+
+ Oracle,SqlServer等数据库只有一种存储引擎。MySQL提供了插件式的存储引擎架构。所以MySQL存在多种存储引擎,可以根据需要使用相应引擎,或者编写存储引擎。
+
+ MySQL5.0支持的存储引擎包含 : InnoDB 、MyISAM 、BDB、MEMORY、MERGE、EXAMPLE、NDB Cluster、ARCHIVE、CSV、BLACKHOLE、FEDERATED等,其中InnoDB和BDB提供事务安全表,其他存储引擎是非事务安全表。
+
+通过指令查询当前数据库支持的存储引擎 :
+
+```sql
+show engines
+```
+
+
+
+
+
+创建新表时如果不指定存储引擎,那么系统就会使用默认的存储引擎,MySQL5.5之前的默认存储引擎是MyISAM,5.5之后就改为了InnoDB。
+
+查看Mysql数据库默认的存储引擎 , 指令 :
+
+```sql
+show variables like '%storage_engine%' ;
+```
+
+
+
+### 各种存储引擎特性
+
+下面重点介绍几种常用的存储引擎, 并对比各个存储引擎之间的区别, 如下表所示 :
+
+| 特点 | InnoDB | MyISAM | MEMORY | MERGE | NDB |
+| ------------ | -------------------- | -------- | ------ | ----- | ---- |
+| 存储限制 | 64TB | 有 | 有 | 没有 | 有 |
+| 事务安全 | **支持** | | | | |
+| 锁机制 | **行锁(适合高并发)** | **表锁** | 表锁 | 表锁 | 行锁 |
+| B树索引 | 支持 | 支持 | 支持 | 支持 | 支持 |
+| 哈希索引 | | | 支持 | | |
+| 全文索引 | 支持(5.6版本之后) | 支持 | | | |
+| 集群索引 | 支持 | | | | |
+| 数据索引 | 支持 | | 支持 | | 支持 |
+| 索引缓存 | 支持 | 支持 | 支持 | 支持 | 支持 |
+| 数据可压缩 | | 支持 | | | |
+| 空间使用 | 高 | 低 | N/A | 低 | 低 |
+| 内存使用 | 高 | 低 | 中等 | 低 | 高 |
+| 批量插入速度 | 低 | 高 | 高 | 高 | 高 |
+| 支持外键 | **支持** | | | | |
+
+下面我们将重点介绍最长使用的两种存储引擎: InnoDB、MyISAM , 另外两种 MEMORY、MERGE , 了解即可。
+
+#### InnoDB
+
+InnoDB 存储引擎是 Mysql 的默认存储引擎。
+
+InnoDB存储引擎提供了具有提交、回滚、崩溃恢复能力的事务安全。但是对比 MyISAM 的存储引擎,InnoDB 写的处理效率差一些,并且会占用更多的磁盘空间以保留数据和索引。
+
+InnoDB 存储引擎不同于其他存储引擎的特点 :
+
+- 事务控制
+
+ **
+
+ ```sql
+ create table goods_innodb(
+ id int NOT NULL AUTO_INCREMENT,
+ name varchar(20) NOT NULL,
+ primary key(id)
+ )ENGINE=innodb DEFAULT CHARSET=utf8;
+ ```
+
+ ```sql
+ #1
+ start transaction;
+ #2
+ insert into goods_innodb(id,name)values(null,'Meta20');
+ #3
+ commit;
+ ```
+
+ 
+
+ 测试发现在 InnoDB 中是存在事务的 ;
+
+- 外键约束
+
+ MySQL支持外键的存储引擎只有 InnoDB , 在创建外键的时候, 要求父表必须有对应的索引 ,子表在创建外键的时候,也会自动的创建对应的索引。
+
+ 下面两张表中 , country_innodb 是父表 , country_id 为主键索引,city_innodb 表是子表,country_id 字段为外键,对应于 country_innodb 表的主键 country_id 。
+
+ ```sql
+ create table country_innodb(
+ country_id int NOT NULL AUTO_INCREMENT,
+ country_name varchar(100) NOT NULL,
+ primary key(country_id)
+ )ENGINE=InnoDB DEFAULT CHARSET=utf8;
+
+
+ create table city_innodb(
+ city_id int NOT NULL AUTO_INCREMENT,
+ city_name varchar(50) NOT NULL,
+ country_id int NOT NULL,
+ primary key(city_id),
+ key idx_fk_country_id(country_id),
+ CONSTRAINT `fk_city_country` FOREIGN KEY(country_id) REFERENCES country_innodb(country_id) ON DELETE RESTRICT ON UPDATE CASCADE
+ )ENGINE=InnoDB DEFAULT CHARSET=utf8;
+
+
+
+ insert into country_innodb values(null,'China'),(null,'America'),(null,'Japan');
+ insert into city_innodb values(null,'Xian',1),(null,'NewYork',2),(null,'BeiJing',1);
+
+ ```
+
+ 在创建索引时, 可以指定在删除、更新父表时,对子表进行的相应操作,包括 RESTRICT、CASCADE、SET NULL 和 NO ACTION。
+
+ RESTRICT 和NO ACTION 相同, 是指限制在子表有关联记录的情况下, 父表不能更新;
+
+ CASCADE 表示父表在更新或者删除时,更新或者删除子表对应的记录;
+
+ SET NULL 则表示父表在更新或者删除的时候,子表的对应字段被SET NULL 。
+
+ 针对上面创建的两个表, 子表的外键指定是ON DELETE RESTRICT ON UPDATE CASCADE 方式的, 那么在主表删除记录的时候, 如果子表有对应记录, 则不允许删除, 主表在更新记录的时候, 如果子表有对应记录, 则子表对应更新 。
+
+
+
+ 表中数据如下图所示 :
+
+ 
+
+ 查看外键信息
+
+ ```sql
+ show create table city_innodb ;
+ ```
+
+ 
+
+ 删除 country_id为 1 的 country 数据,有外键时会删除失败
+
+ 
+
+ 更新主表country表的字段 country_id 时
+
+ ```sql
+ update country_innodb set country_id = 100 where country_id = 1;
+ ```
+
+ 
+
+ 更新后, 子表的数据信息为 :
+
+ 
+
+
+
+- **存储方式**
+
+ InnoDB 存储表和索引有以下两种方式 :
+
+ ①. 使用共享表空间存储, 这种方式创建的表的表结构保存在 `.frm`文件中, 数据和索引保存在 innodb_data_home_dir 和 innodb_data_file_path 定义的表空间中,可以是多个文件。
+
+ ②. 使用多表空间存储, 这种方式创建的表的表结构仍然存在 `.frm` 文件中,但是每个表的数据和索引单独保存在 `.ibd` 中。
+
+ 
+
+
+
+#### MyISAM
+
+MyISAM 不支持事务、也不支持外键,其优势是访问的速度快,对事务的完整性没有要求或者以SELECT、INSERT为主的应用基本上都可以使用这个引擎来创建表 。有以下两个比较重要的特点:
+
+- 不支持事务
+
+ ```sql
+ create table goods_myisam(
+ id int NOT NULL AUTO_INCREMENT,
+ name varchar(20) NOT NULL,
+ primary key(id)
+ )ENGINE=myisam DEFAULT CHARSET=utf8;
+ ```
+
+ 
+
+ 通过测试,我们发现,在MyISAM存储引擎中,是没有事务控制的 ;
+
+
+
+- 文件存储方式
+
+ 每个MyISAM在磁盘上存储成3个文件,其文件名都和表名相同,但拓展名分别是 :
+
+ .frm (存储表定义);
+
+ .MYD(MYData , 存储数据);
+
+ .MYI(MYIndex , 存储索引);
+
+ 
+
+
+
+#### MEMORY
+
+ Memory存储引擎将表的数据存放在内存中。每个MEMORY表实际对应一个磁盘文件,格式是.frm ,该文件中只存储表的结构,而其数据文件,都是存储在内存中,这样有利于数据的快速处理,提高整个表的效率。MEMORY 类型的表访问非常地快,因为他的数据是存放在内存中的,并且默认使用HASH索引 , 但是服务一旦关闭,表中的数据就会丢失。
+
+#### MERGE
+
+ MERGE存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,MERGE表本身并没有存储数据,对MERGE类型的表可以进行查询、更新、删除操作,这些操作实际上是对内部的MyISAM表进行的。
+
+ 对于MERGE类型表的插入操作,是通过INSERT_METHOD子句定义插入的表,可以有3个不同的值,使用FIRST 或 LAST 值使得插入操作被相应地作用在第一或者最后一个表上,不定义这个子句或者定义为NO,表示不能对这个MERGE表执行插入操作。
+
+ 可以对MERGE表进行DROP操作,但是这个操作只是删除MERGE表的定义,对内部的表是没有任何影响的。
+
+
+
+
+
+**下面是一个创建和使用MERGE表的示例 :**
+
+1). 创建3个测试表 order_1990, order_1991, order_all , 其中 order_all 是前两个表的 MERGE 表 :
+
+```sql
+create table order_1990(
+ order_id int ,
+ order_money double(10,2),
+ order_address varchar(50),
+ primary key (order_id)
+)engine = myisam default charset=utf8;
+
+
+create table order_1991(
+ order_id int ,
+ order_money double(10,2),
+ order_address varchar(50),
+ primary key (order_id)
+)engine = myisam default charset=utf8;
+
+
+create table order_all(
+ order_id int ,
+ order_money double(10,2),
+ order_address varchar(50),
+ primary key (order_id)
+)engine = merge union = (order_1990,order_1991) INSERT_METHOD=LAST default charset=utf8;
+```
+
+2). 分别向两张表中插入记录
+
+```sql
+insert into order_1990 values(1,100.0,'北京');
+insert into order_1990 values(2,100.0,'上海');
+
+insert into order_1991 values(10,200.0,'北京');
+insert into order_1991 values(11,200.0,'上海');
+```
+
+3). 查询3张表中的数据。
+
+order_1990中的数据 :
+
+
+
+order_1991中的数据 :
+
+
+
+order_all中的数据 :
+
+
+
+4). 往order_all中插入一条记录 ,由于在MERGE表定义时,INSERT_METHOD 选择的是LAST,那么插入的数据会想最后一张表中插入。
+
+```sql
+insert into order_all values(100,10000.0,'西安');
+```
+
+
+
+
+
+## SQL 预热
+
+常见的 Join 查询图
+
+
+
+
+
+
+
diff --git "a/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/06.MySQL - \347\264\242\345\274\225.md" "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/06.MySQL - \347\264\242\345\274\225.md"
new file mode 100644
index 00000000..5ebcbe2b
--- /dev/null
+++ "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/06.MySQL - \347\264\242\345\274\225.md"
@@ -0,0 +1,436 @@
+---
+title: MySQL - 索引介绍
+permalink: /mysql/index/
+date: 2021-05-20 20:51:46
+---
+
+
+
+
+
+- [索引的概念](#%E7%B4%A2%E5%BC%95%E7%9A%84%E6%A6%82%E5%BF%B5)
+- [推荐文章](#%E6%8E%A8%E8%8D%90%E6%96%87%E7%AB%A0)
+- [索引结构](#%E7%B4%A2%E5%BC%95%E7%BB%93%E6%9E%84)
+ - [Btree 索引结构](#btree-%E7%B4%A2%E5%BC%95%E7%BB%93%E6%9E%84)
+ - [演变过程](#%E6%BC%94%E5%8F%98%E8%BF%87%E7%A8%8B)
+ - [其他](#%E5%85%B6%E4%BB%96)
+ - [B+tree 结构](#btree-%E7%BB%93%E6%9E%84)
+ - [MySQL中的B+Tree](#mysql%E4%B8%AD%E7%9A%84btree)
+ - [聚簇索引和非聚簇索引](#%E8%81%9A%E7%B0%87%E7%B4%A2%E5%BC%95%E5%92%8C%E9%9D%9E%E8%81%9A%E7%B0%87%E7%B4%A2%E5%BC%95)
+ - [时间复杂度](#%E6%97%B6%E9%97%B4%E5%A4%8D%E6%9D%82%E5%BA%A6)
+- [索引分类](#%E7%B4%A2%E5%BC%95%E5%88%86%E7%B1%BB)
+ - [单值索引](#%E5%8D%95%E5%80%BC%E7%B4%A2%E5%BC%95)
+ - [唯一索引](#%E5%94%AF%E4%B8%80%E7%B4%A2%E5%BC%95)
+ - [复合索引](#%E5%A4%8D%E5%90%88%E7%B4%A2%E5%BC%95)
+ - [主键索引](#%E4%B8%BB%E9%94%AE%E7%B4%A2%E5%BC%95)
+ - [索引基本语法](#%E7%B4%A2%E5%BC%95%E5%9F%BA%E6%9C%AC%E8%AF%AD%E6%B3%95)
+- [索引设计原则](#%E7%B4%A2%E5%BC%95%E8%AE%BE%E8%AE%A1%E5%8E%9F%E5%88%99)
+
+
+
+## 索引的概念
+
+索引(Index)是帮助 MySQL 高效获取数据的数据结构,可以简单理解为**排好序的快速查找数据结构**。
+
+在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引
+
+
+
+
+
+
+
+左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找快速获取到相应数据。
+
+一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。索引是数据库中用来提高性能的最常用的工具。
+
+
+
+**索引优缺点**
+
+优势:
+
+- 提高数据检索的效率,降低数据库的IO成本。
+- 数据排序,降低CPU消耗
+
+劣势:
+
+- 虽然索引大大提高了查询速度,同时却会降低更新表的速度
+
+ 如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因更新所带来的键值变化后的索引信息。
+
+- 索引本质也是一张表,保存着索引字段和指向实际记录的指针,所以也要占用数据库空间,一般而言,索引表占用的空间是数据表的1.5倍
+
+
+
+
+
+## 推荐文章
+
+- [MySQL 索引原理 图文讲解](https://zhuanlan.zhihu.com/p/359306500)
+
+ 涉及到树相关数据结构知识。
+
+- [BTree和B+Tree](https://www.jianshu.com/p/ac12d2c83708)
+
+ 详细介绍
+
+## 索引结构
+
+### Btree 索引结构
+
+黑马教程:https://www.bilibili.com/video/BV1UQ4y1P7Xr?p=6
+
+**Btree又可以写成B-tree**(B-Tree,并不是B“减”树,横杠为连接符,容易被误导)
+
+BTree又叫多路平衡搜索树,一颗 **m** 叉的BTree特性如下:
+
+- 树中每个节点最多包含m个孩子。
+- 除根节点与叶子节点外,每个节点至少有 [ceil(m/2)] 个孩子。
+- 若根节点不是叶子节点,则至少有两个孩子。
+- 所有的叶子节点都在同一层。
+- 每个非叶子节点由 n 个 key 与 n+1 个指针组成,其中 [ceil(m/2)-1] <= n <= m-1
+
+celi():向上取整,例如celi(2.5)=3
+
+
+
+#### 演变过程
+
+以5叉 BTree 为例,key的数量:公式推导 [ceil(m/2)-1] <= n <= m-1。所以 2 <= n <=4 。
+
+当 n>4 时,中间节点分裂到父节点,两边节点分裂。
+
+插入 C N G A H E K Q M F W L T Z D P R X Y S 数据为例。(插入时,按照ABCD..顺序)
+
+1). 插入前4个字母 C N G A
+
+
+
+2). 插入H,n>4,中间元素G字母向上分裂到新的节点
+
+
+
+3). 插入E,K,Q不需要分裂
+
+
+
+4). 插入M,中间元素M字母向上分裂到父节点G
+
+(M 在 K、N中间,BTree最多含有n-1个key,这里即4个key,5个指针)
+
+
+
+5). 插入F,W,L,T不需要分裂
+
+
+
+6). 插入Z,中间元素T向上分裂到父节点中
+
+(插入Z后是,NQTWZ,把中间T提出来,方便更快的查询,所以不提出Z)
+
+
+
+7). 插入D,中间元素D向上分裂到父节点中。然后插入P,R,X,Y不需要分裂
+
+
+
+8). 最后插入S(R后面),NPQR节点n>5,中间节点Q向上分裂,但分裂后父节点DGMT的n>5,中间节点M向上分裂
+
+
+
+到此,该BTREE树就已经构建完成了, BTREE树 和 二叉树 相比, 查询数据的效率更高, 因为对于相同的数据量来说,BTREE的层级结构比二叉树小,因此搜索速度快。
+
+
+
+#### 其他
+
+
+
+**初始化介绍**
+
+
+
+一颗 b 树,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色 所示),
+
+如磁盘块 1 包含数据项 17 和 35,包含指针 P1、P2、P3,
+P1 表示小于 17 的磁盘块,P2 表示在 17 和 35 之间的磁盘块,P3 表示大于 35 的磁盘块。
+真实的数据存在于叶子节点即 3、5、9、10、13、15、28、29、36、60、75、79、90、99。
+非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如 17、35 并不真实存在于数据表中
+
+**查找过程**
+
+如果要查找数据项 29,那么首先会把磁盘块 1 由磁盘加载到内存,此时发生一次 IO,在内存中用二分查找确定 29 在 17 和 35 之间,锁定磁盘块 1 的 P2 指针,内存时间因为非常短(相比磁盘的 IO)可以忽略不计,通过磁盘块 1 的 P2 指针的磁盘地址把磁盘块 3 由磁盘加载到内存,发生第二次 IO,29 在 26 和 30 之间,锁定磁盘块 3 的 P2 指 针,通过指针加载磁盘块 8 到内存,发生第三次 IO,同时内存中做二分查找找到 29,结束查询,总计三次 IO。
+
+
+
+真实的情况是,3 层的 b+树可以表示上百万的数据,如果上百万的数据查找只需要三次 IO,性能提高将是巨大的, 如果没有索引,每个数据项都要发生一次 IO,那么总共需要百万次的 IO,显然成本非常非常高。
+
+
+
+### B+tree 结构
+
+
+
+B+Tree为BTree的变种,B+Tree与BTree的区别为:
+
+1). n叉B+Tree最多含有n个key,而BTree最多含有n-1个key。
+
+2). B+Tree的叶子节点保存所有的key信息,依key大小顺序排列。
+
+3). 所有的非叶子节点都可以看作是key的索引部分。
+
+
+
+- B-树的关键字和记录是放在一起的,叶子节点可以看作外部节点,不包含任何信息;B+树的非叶子节点中只有关键字和指向下一个节点的索引,记录只放在叶子节点中。
+- 在 B-树中,越靠近根节点的记录查找时间越快,只要找到关键字即可确定记录的存在;而 B+树中每个记录的查找时间基本是一样的,都需要从根节点走到叶子节点,而且在叶子节点中还要再比较关键字。从这个角度看 B- 树的性能好像要比 B+树好,而在实际应用中却是 B+树的性能要好些。因为 B+树的非叶子节点不存放实际的数据, 这样每个节点可容纳的元素个数比 B-树多,树高比 B-树小,这样带来的好处是减少磁盘访问次数。尽管 B+树找到 一个记录所需的比较次数要比 B-树多,但是一次磁盘访问的时间相当于成百上千次内存比较的时间,因此实际中 B+树的性能可能还会好些,而且 B+树的叶子节点使用指针连接在一起,方便顺序遍历(例如查看一个目录下的所有 文件,一个表中的所有记录等),这也是很多数据库和文件系统使用 B+树的缘故。
+
+**为什么B+树比 B-树更适合索引?**
+
+- B+树的磁盘读写代价更低
+
+ B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对 B 树更小。如果把所有同一内部结点 的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就 越多。相对来说 IO 读写次数也就降低了。
+
+- B+树的查询效率更加稳定
+
+ 由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须 走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
+
+### MySQL中的B+Tree
+
+MySql索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。
+
+MySQL中的 B+Tree 索引结构示意图:
+
+
+
+
+
+### 聚簇索引和非聚簇索引
+
+聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。术语‘聚簇’表示数据行和相邻的键值聚簇的存储 在一起。如下图,左侧的索引就是聚簇索引,因为数据行在磁盘的排列和索引排序保持一致。
+
+
+
+
+
+**聚簇索引的好处**
+
+按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不不用从多 个数据块中提取数据,所以节省了大量的 io 操作。
+
+**聚簇索引的限制**
+
+对于 mysql 数据库目前只有 innodb 数据引擎支持聚簇索引,而 Myisam 并不支持聚簇索引。
+
+由于数据物理存储排序方式只能有一种,所以每个 Mysql 的表只能有一个聚簇索引。一般情况下就是该表的主键。
+
+为了充分利用聚簇索引的聚簇的特性,所以 innodb 表的主键列尽量选用有序的顺序 id,而不建议用无序的 id,比如 uuid 这种。
+
+### 时间复杂度
+
+同一问题可用不同算法解决,而一个算法的质量优劣将影响到算法乃至程序的效率。算法分析的目的在于选择合适算法和改进算法。
+
+时间复杂度是指执行算法所需要的计算工作量,用大 O 表示记为:O(…)
+
+
+
+
+
+## 索引分类
+
+### 单值索引
+
+概念:即一个索引只包含单个列,一个表可以有多个单列索引
+
+- 所表一起创建
+
+ ```sql
+ CREATE TABLE customer (
+ id INT (10) UNSIGNED AUTO_INCREMENT,
+ customer_no VARCHAR (200),
+ customer_name VARCHAR (200),
+ PRIMARY KEY (id),
+ KEY (customer_name) #this
+ );
+ ```
+
+- 单独建单值索引
+
+ ```sql
+ CREATE INDEX idx_customer_name
+ ON customer (customer_name);
+ ```
+
+### 唯一索引
+
+概念:索引列的值必须唯一,但允许有空值
+
+- 随表一起创建
+
+ ```sql
+ CREATE TABLE customer (
+ id INT (10) UNSIGNED AUTO_INCREMENT,
+ customer_no VARCHAR (200),
+ customer_name VARCHAR (200),
+ PRIMARY KEY (id),
+ KEY (customer_name),
+ UNIQUE (customer_no) #this
+ );
+ ```
+
+- 单独建唯一索引:
+
+ ```sql
+ CREATE UNIQUE INDEX idx_customer_no
+ ON customer (customer_no);
+ ```
+
+
+
+### 复合索引
+
+概念:即一个索引包含多个列
+
+- 随表一起建索引
+
+ ```sql
+ CREATE TABLE customer (
+ id INT (10) UNSIGNED AUTO_INCREMENT,
+ customer_no VARCHAR (200),
+ customer_name VARCHAR (200),
+ PRIMARY KEY (id),
+ KEY (customer_name),
+ UNIQUE (customer_name),
+ KEY (customer_no, customer_name) #this
+ );
+ ```
+
+- 单独建索引:
+
+ ```sql
+ CREATE INDEX idx_no_name
+ ON customer (customer_no, customer_name);
+ ```
+
+
+
+### 主键索引
+
+概念:设定为主键后数据库会自动建立索引,innodb为聚簇索引
+
+- 随表一起建索引
+
+ ```sql
+ CREATE TABLE customer (
+ id INT (10) UNSIGNED AUTO_INCREMENT,
+ customer_no VARCHAR (200),
+ customer_name VARCHAR (200),
+ PRIMARY KEY (id) #this
+ );
+ ```
+
+- 单独建主键索引:
+
+ ```sql
+ ALTER TABLE customer ADD PRIMARY KEY customer(customer_no);
+ ```
+
+- 删除主键索引
+
+ ```sql
+ ALTER TABLE customer drop PRIMARY KEY ;
+ ```
+
+- 修改建主键索引
+
+ 必须先删除掉(drop)原索引,再新建(add)索引
+
+
+
+### 索引基本语法
+
+- 创建
+
+ ```sql
+ CREATE [UNIQUE] INDEX [indexName]
+ ON table_name(column))
+ ```
+
+ 示例 : 为city表中的city_name字段创建索引 ;
+
+ 
+
+- 删除
+
+ ```sql
+ DROP INDEX index_name ON tbl_name;
+ ```
+
+- 查看
+
+ ```sql
+ show index from table_name;
+ ```
+
+- AlTER
+
+ ```
+ 1). alter table tb_name add primary key(column_list);
+
+ 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
+
+ 2). alter table tb_name add unique index_name(column_list);
+
+ 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)
+
+ 3). alter table tb_name add index index_name(column_list);
+
+ 添加普通索引, 索引值可以出现多次。
+
+ 4). alter table tb_name add fulltext index_name(column_list);
+
+ 该语句指定了索引为FULLTEXT, 用于全文索引
+
+ ```
+
+
+
+
+## 索引设计原则
+
+
+
+索引的设计可以遵循一些已有的原则,创建索引的时候请尽量考虑符合这些原则,便于提升索引的使用效率,更高效的使用索引。
+
+- 对查询频次较高,且数据量比较大的表建立索引。
+
+- 索引字段的选择,最佳候选列应当从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用、过滤效果最好的列的组合。
+
+- 使用唯一索引,区分度越高,使用索引的效率越高。
+
+- 索引可以有效的提升查询数据的效率,但索引数量不是多多益善,索引越多,维护索引的代价自然也就水涨船高。对于插入、更新、删除等DML操作比较频繁的表来说,索引过多,会引入相当高的维护代价,降低DML操作的效率,增加相应操作的时间消耗。另外索引过多的话,MySQL也会犯选择困难病,虽然最终仍然会找到一个可用的索引,但无疑提高了选择的代价。
+
+- 使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率,也可以提升总体的访问效率。假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,相应的可以有效的提升MySQL访问索引的I/O效率。
+
+- 利用最左前缀,N个列组合而成的组合索引,那么相当于是创建了N个索引,如果查询时where子句中使用了组成该索引的前几个字段,那么这条查询SQL可以利用组合索引来提升查询效率。
+
+
+
+ 创建复合索引
+
+ ```sql
+ CREATE INDEX idx_name_email_status ON tb_seller(NAME,email,STATUS);
+ ```
+
+ 就相当于
+
+ 对 name 创建索引 ;
+ 对 name , email 创建了索引 ;
+ 对 name , email, status 创建了索引 ;
+
+**不适合创建索引的情况**
+
+- 表记录太少
+- 经常增删改的表或者字段
+- Where 条件里用不到的字段不创建索引
+- 过滤性不好的不适合建索引
+
diff --git "a/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/10.MySQL - \344\274\230\345\214\226SQL\346\243\200\346\265\213\346\255\245\351\252\244.md" "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/10.MySQL - \344\274\230\345\214\226SQL\346\243\200\346\265\213\346\255\245\351\252\244.md"
new file mode 100644
index 00000000..8093105d
--- /dev/null
+++ "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/10.MySQL - \344\274\230\345\214\226SQL\346\243\200\346\265\213\346\255\245\351\252\244.md"
@@ -0,0 +1,590 @@
+---
+title: MySQL - 优化SQL检测步骤
+permalink: /mysql/optimize-sql-check/
+date: 2021-05-20 20:51:46
+---
+
+# 优化SQL步骤
+
+
+
+
+
+- [查看SQL执行频率](#%E6%9F%A5%E7%9C%8Bsql%E6%89%A7%E8%A1%8C%E9%A2%91%E7%8E%87)
+- [定位低效率执行SQL](#%E5%AE%9A%E4%BD%8D%E4%BD%8E%E6%95%88%E7%8E%87%E6%89%A7%E8%A1%8Csql)
+- [explain分析执行计划](#explain%E5%88%86%E6%9E%90%E6%89%A7%E8%A1%8C%E8%AE%A1%E5%88%92)
+ - [环境准备](#%E7%8E%AF%E5%A2%83%E5%87%86%E5%A4%87)
+ - [explain 之 id](#explain-%E4%B9%8B-id)
+ - [explain 之 select_type](#explain-%E4%B9%8B-select_type)
+ - [explain 之 table](#explain-%E4%B9%8B-table)
+ - [explain 之 type](#explain-%E4%B9%8B-type)
+ - [explain 之 key](#explain-%E4%B9%8B-key)
+ - [explain 之 rows](#explain-%E4%B9%8B-rows)
+ - [explain 之 extra](#explain-%E4%B9%8B-extra)
+- [show profile分析SQL](#show-profile%E5%88%86%E6%9E%90sql)
+- [trace分析优化器执行计划](#trace%E5%88%86%E6%9E%90%E4%BC%98%E5%8C%96%E5%99%A8%E6%89%A7%E8%A1%8C%E8%AE%A1%E5%88%92)
+
+
+
+
+
+在应用的的开发过程中,由于初期数据量小,开发人员写 SQL 语句时更重视功能上的实现,但是当应用系统正式上线后,随着生产数据量的急剧增长,很多 SQL 语句开始逐渐显露出性能问题,对生产的影响也越来越大,此时这些有问题的 SQL 语句就成为整个系统性能的瓶颈,因此我们必须要对它们进行优化,本章将详细介绍在 MySQL 中优化 SQL 语句的方法。
+
+当面对一个有 SQL 性能问题的数据库时,我们应该从何处入手来进行系统的分析,使得能够尽快定位问题 SQL 并尽快解决问题。
+
+
+
+## 查看SQL执行频率
+
+MySQL 客户端连接成功后,通过 `show [session|global] status` 命令可以提供服务器状态信息。
+
+show [session|global] status 可以根据需要加上参数“session”或者“global”来显示 session 级(当前连接)的计结果和 global 级(自数据库上次启动至今)的统计结果。如果不写,默认使用参数是“session”。
+
+下面的命令显示了当前 session 中所有统计参数的值:
+
+```sql
+show status like 'Com_______';
+```
+
+Com_xxx 表示每个 xxx 语句执行的次数
+
+
+
+```sql
+show status like 'Innodb_rows_%';
+```
+
+我们通常比较关心的是以下几个统计参数
+
+| 参数 | 含义 |
+| :------------------- | ------------------------------------------------------------ |
+| Com_select | 执行 select 操作的次数,一次查询只累加 1。 |
+| Com_insert | 执行 INSERT 操作的次数,对于批量插入的 INSERT 操作,只累加一次。 |
+| Com_update | 执行 UPDATE 操作的次数。 |
+| Com_delete | 执行 DELETE 操作的次数。 |
+| Innodb_rows_read | select 查询返回的行数。 |
+| Innodb_rows_inserted | 执行 INSERT 操作插入的行数。 |
+| Innodb_rows_updated | 执行 UPDATE 操作更新的行数。 |
+| Innodb_rows_deleted | 执行 DELETE 操作删除的行数。 |
+| Connections | 试图连接 MySQL 服务器的次数。 |
+| Uptime | 服务器工作时间。 |
+| Slow_queries | 慢查询的次数。 |
+
+Com_*** : 这些参数对于所有存储引擎的表操作都会进行累计。
+
+Innodb_*** : 这几个参数只是针对InnoDB 存储引擎的,累加的算法也略有不同。
+
+## 定位低效率执行SQL
+
+
+
+- 慢查询日志
+
+ 通过慢查询日志定位那些执行效率较低的 SQL 语句,用 log-slow-queries[file_name] 选项启动时,mysqld 写一个包含所有执行时间超过 long_query_time 秒的 SQL 语句的日志文件。具体可以查看日志管理的相关部分。
+
+- show processlist
+
+ 慢查询日志在查询结束以后才纪录,所以在应用反映执行效率出现问题的时候查询慢查询日志并不能定位问题,可以使用 `show processlist` 命令查看当前MySQL在进行的线程,包括线程的状态、是否锁表等,可以实时地查看 SQL 的执行情况,同时对一些锁表操作进行优化。
+
+
+
+1) id列,用户登录mysql时,系统分配的"connection_id",可以使用函数connection_id()查看
+
+2) user列,显示当前用户。如果不是root,这个命令就只显示用户权限范围的sql语句
+
+3) host列,显示这个语句是从哪个ip的哪个端口上发的,可以用来跟踪出现问题语句的用户
+
+4) db列,显示这个进程目前连接的是哪个数据库
+
+5) command列,显示当前连接的执行的命令,一般取值为休眠(sleep),查询(query),连接(connect)等
+
+6) time列,显示这个状态持续的时间,单位是秒
+
+7) state列,显示使用当前连接的sql语句的状态,很重要的列。state描述的是语句执行中的某一个状态。一个sql语句,以查询为例,可能需要经过copying to tmp table、sorting result、sending data等状态才可以完成
+
+8) info列,显示这个sql语句,是判断问题语句的一个重要依据
+
+## explain分析执行计划
+
+通过 EXPLAIN 或者 DESC命令获取 MySQL 如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
+
+```sql
+explain select * from tb_item where id = 1;
+```
+
+
+
+
+
+
+
+| 字段 | 含义 |
+| ------------- | ------------------------------------------------------------ |
+| id | select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。 |
+| select_type | 表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或者后面的查询语句)、SUBQUERY(子查询中的第一个 SELECT)等 |
+| table | 输出结果集的表 |
+| type | 表示表的连接类型,性能由好到差的连接类型为( system ---> const -----> eq_ref ------> ref -------> ref_or_null----> index_merge ---> index_subquery -----> range -----> index ------> all ) |
+| possible_keys | 表示查询时,可能使用的索引 |
+| key | 表示实际使用的索引 |
+| key_len | 索引字段的长度 |
+| rows | 扫描行的数量 |
+| extra | 执行情况的说明和描述 |
+
+### 环境准备
+
+
+
+```sql
+CREATE TABLE `t_role` (
+ `id` VARCHAR(32) NOT NULL,
+ `role_name` VARCHAR(255) DEFAULT NULL,
+ `role_code` VARCHAR(255) DEFAULT NULL,
+ `description` VARCHAR(255) DEFAULT NULL,
+ PRIMARY KEY (`id`),
+ UNIQUE KEY `unique_role_name` (`role_name`)
+) ENGINE=INNODB DEFAULT CHARSET=utf8;
+
+CREATE TABLE `t_user` (
+ `id` VARCHAR(32) NOT NULL,
+ `username` VARCHAR(45) NOT NULL,
+ `password` VARCHAR(96) NOT NULL,
+ `name` VARCHAR(45) NOT NULL,
+ PRIMARY KEY (`id`),
+ UNIQUE KEY `unique_user_username` (`username`)
+) ENGINE=INNODB DEFAULT CHARSET=utf8;
+
+CREATE TABLE `user_role` (
+ `id` INT(11) NOT NULL AUTO_INCREMENT ,
+ `user_id` VARCHAR(32) DEFAULT NULL,
+ `role_id` VARCHAR(32) DEFAULT NULL,
+ PRIMARY KEY (`id`),
+ KEY `fk_ur_user_id` (`user_id`),
+ KEY `fk_ur_role_id` (`role_id`),
+ CONSTRAINT `fk_ur_role_id` FOREIGN KEY (`role_id`) REFERENCES `t_role` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
+ CONSTRAINT `fk_ur_user_id` FOREIGN KEY (`user_id`) REFERENCES `t_user` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
+) ENGINE=INNODB DEFAULT CHARSET=utf8;
+
+INSERT INTO `t_user` (`id`, `username`, `password`, `name`) VALUES('1','super','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','超级管理员');
+INSERT INTO `t_user` (`id`, `username`, `password`, `name`) VALUES('2','admin','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','系统管理员');
+INSERT INTO `t_user` (`id`, `username`, `password`, `name`) VALUES('3','itcast','$2a$10$8qmaHgUFUAmPR5pOuWhYWOr291WJYjHelUlYn07k5ELF8ZCrW0Cui','test02');
+INSERT INTO `t_user` (`id`, `username`, `password`, `name`) VALUES('4','stu1','$2a$10$pLtt2KDAFpwTWLjNsmTEi.oU1yOZyIn9XkziK/y/spH5rftCpUMZa','学生1');
+INSERT INTO `t_user` (`id`, `username`, `password`, `name`) VALUES('5','stu2','$2a$10$nxPKkYSez7uz2YQYUnwhR.z57km3yqKn3Hr/p1FR6ZKgc18u.Tvqm','学生2');
+INSERT INTO `t_user` (`id`, `username`, `password`, `name`) VALUES('6','t1','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','老师1');
+
+INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('5','学生','student','学生');
+INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('7','老师','teacher','老师');
+INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('8','教学管理员','teachmanager','教学管理员');
+INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('9','管理员','admin','管理员');
+INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('10','超级管理员','super','超级管理员');
+
+INSERT INTO user_role(id,user_id,role_id) VALUES(NULL, '1', '5'),(NULL, '1', '7'),(NULL, '2', '8'),(NULL, '3', '9'),(NULL, '4', '8'),(NULL, '5', '10') ;
+
+```
+
+### explain 之 id
+
+id 字段是 select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。id 情况有三种
+
+1) id 相同表示加载表的顺序是从上到下。
+
+```sql
+explain select * from t_role r, t_user u, user_role ur where r.id = ur.role_id and u.id = ur.user_id ;
+```
+
+
+
+2) id 不同id值越大,优先级越高,越先被执行。
+
+```sql
+EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'))
+```
+
+
+
+3) id 有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大,优先级越高,越先执行。
+
+```sql
+EXPLAIN SELECT * FROM t_role r , (SELECT * FROM user_role ur WHERE ur.`user_id` = '2') a WHERE r.id = a.role_id ;
+```
+
+
+
+### explain 之 select_type
+
+表示 SELECT 的类型,常见的取值,如下表所示:
+
+| select_type | 含义 |
+| ------------ | ------------------------------------------------------------ |
+| SIMPLE | 简单的select查询,查询中不包含子查询或者UNION |
+| PRIMARY | 查询中若包含任何复杂的子查询,最外层查询标记为该标识 |
+| SUBQUERY | 在SELECT 或 WHERE 列表中包含了子查询 |
+| DERIVED | 在FROM 列表中包含的子查询,被标记为 DERIVED(衍生) MYSQL会递归执行这些子查询,把结果放在临时表中 |
+| UNION | 若第二个SELECT出现在UNION之后,则标记为UNION ; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为 : DERIVED |
+| UNION RESULT | 从UNION表获取结果的SELECT |
+
+- SIMPLE
+
+ SIMPLE 代表单表查询
+
+ ```sql
+ EXPLAIN SELECT * FROM t_user;
+ ```
+
+ 
+
+
+
+- PRIMARY、SUBQUERY
+
+ 在 SELECT 或 WHERE 列表中包含了子查询。最外层查询则被标记为 Primary。
+
+ ```sql
+ explain select * from t_user where id = (select id from user_role where role_id='9' );
+ ```
+
+ 
+
+- DERIVED
+
+ 在 FROM 列表中包含的子查询被标记为 DERIVED(衍生),MySQL 会递归执行这些子查询, 把结果放在临时表里。
+
+ ```sql
+ explain select a.* from (select * from t_user where id in('1','2') ) a;
+ ```
+
+ mysql 5.7 中为 `simple`
+
+ 
+
+
+
+ mysql 5.6 中:
+
+ 
+
+
+
+- union
+
+ ```sql
+ explain select * from t_user where id='1' union select * from t_user where id='2';
+ ```
+
+ 
+
+
+
+### explain 之 table
+
+展示这一行的数据是关于哪一张表的
+
+没有与之关系的表为 NULL
+
+
+
+
+
+### explain 之 type
+
+type 显示的是访问类型,是较为重要的一个指标,可取值为:
+
+| type | 含义 |
+| ------ | ------------------------------------------------------------ |
+| NULL | MySQL不访问任何表,索引,直接返回结果 |
+| system | 表只有一行记录(等于系统表),这是const类型的特例,一般不会出现 |
+| const | 表示通过索引一次就找到了,const 用于比较primary key 或者 unique 索引。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL 就能将该查询转换为一个常亮。const于将 "主键" 或 "唯一" 索引的所有部分与常量值进行比较 |
+| eq_ref | 类似ref,区别在于使用的是唯一索引,使用主键的关联查询,关联查询出的记录只有一条。常见于主键或唯一索引扫描 |
+| ref | 非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,返回所有匹配某个单独值的所有行(多个) |
+| range | 只检索给定返回的行,使用一个索引来选择行。 where 之后出现 between , < , > , in 等操作。 |
+| index | index 与 ALL的区别为 index 类型只是遍历了索引树, 通常比ALL 快, ALL 是遍历数据文件。 |
+| all | 将遍历全表以找到匹配的行 |
+
+结果值从最好到最坏以此是:
+
+- NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
+
+- system > const > eq_ref > ref > range > index > ALL
+
+一般来说, 我们需要保证查询至少达到 range 级别, 最好达到ref
+
+### explain 之 key
+
+
+
+- possible_keys :
+
+ 显示可能应用在这张表的索引, 一个或多个。
+
+- key
+
+ 实际使用的索引, 如果为NULL, 则没有使用索引。
+
+- key_len
+
+ 表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下, 长度越短越好 。
+
+### explain 之 rows
+
+扫描行的数量。
+
+### explain 之 extra
+
+其他的额外的执行计划信息,在该列展示 。
+
+| extra | 含义 |
+| ---------------- | ------------------------------------------------------------ |
+| using filesort | 说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取, 称为 “文件排序”, 效率低。 |
+| using temporary | 使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于 order by 和 group by; 效率低 |
+| using index | 表示相应的select操作使用了覆盖索引, 避免访问表的数据行, 效率不错。 |
+
+## show profile分析SQL
+
+Mysql从5.0.37版本开始增加了对 show profiles 和 show profile 语句的支持。
+
+show profiles 能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。
+
+通过 have_profiling 参数,能够看到当前MySQL是否支持profile:
+
+
+
+默认profiling是关闭的,可以通过set语句在Session级别开启profiling:
+
+
+
+```sql
+set profiling=1; //开启profiling 开关;
+```
+
+通过profile,我们能够更清楚地了解SQL执行的过程。
+
+我们可以执行一系列的操作:
+
+```sql
+show databases;
+
+use db01;
+
+show tables;
+
+select * from tb_item where id < 5;
+
+select count(*) from tb_item;
+```
+
+执行完上述命令之后,再执行 `show profiles` 指令, 来查看SQL语句执行的耗时:
+
+
+
+通过 `show profile for query query_id` 语句查看该SQL执行过程中每个线程的状态和消耗的时间
+
+
+
+TIP:Sending data 状态表示 MySQL 线程开始访问数据行并把结果返回给客户端,而不仅仅是返回个客户端。由于在 Sending data 状态下,MySQL 线程往往需要做大量的磁盘读取操作,所以经常是整各查询中耗时最长的状态。
+
+在获取到最消耗时间的线程状态后,MySQL支持进一步选择all、cpu、block io 、context switch、page faults等明细类型类查看MySQL在使用什么资源上耗费了过高的时间。例如,选择查看CPU的耗费时间 :
+
+
+
+| 字段 | 含义 |
+| ---------- | ------------------------------ |
+| Status | sql 语句执行的状态 |
+| Duration | sql 执行过程中每一个步骤的耗时 |
+| CPU_user | 当前用户占有的cpu |
+| CPU_system | 系统占有的cpu |
+
+## trace分析优化器执行计划
+
+MySQL5.6提供了对SQL的跟踪trace, 通过trace文件能够进一步了解为什么优化器选择A计划, 而不是选择B计划。
+
+打开trace , 设置格式为 JSON,并设置trace最大能够使用的内存大小,避免解析过程中因为默认内存过小而不能够完整展示。
+
+```sql
+SET optimizer_trace="enabled=on",end_markers_in_json=on;
+set optimizer_trace_max_mem_size=1000000;
+```
+
+执行SQL语句 :
+
+```sql
+select * from tb_item where id < 4;
+```
+
+最后, 检查 information_schema.optimizer_trace 就可以知道MySQL是如何执行SQL的 :
+
+```sql
+select * from information_schema.optimizer_trace\G;
+```
+
+```json
+*************************** 1. row ***************************
+QUERY: select * from tb_item where id < 4
+TRACE: {
+ "steps": [
+ {
+ "join_preparation": {
+ "select#": 1,
+ "steps": [
+ {
+ "expanded_query": "/* select#1 */ select `tb_item`.`id` AS `id`,`tb_item`.`title` AS `title`,`tb_item`.`price` AS `price`,`tb_item`.`num` AS `num`,`tb_item`.`categoryid` AS `categoryid`,`tb_item`.`status` AS `status`,`tb_item`.`sellerid` AS `sellerid`,`tb_item`.`createtime` AS `createtime`,`tb_item`.`updatetime` AS `updatetime` from `tb_item` where (`tb_item`.`id` < 4)"
+ }
+ ] /* steps */
+ } /* join_preparation */
+ },
+ {
+ "join_optimization": {
+ "select#": 1,
+ "steps": [
+ {
+ "condition_processing": {
+ "condition": "WHERE",
+ "original_condition": "(`tb_item`.`id` < 4)",
+ "steps": [
+ {
+ "transformation": "equality_propagation",
+ "resulting_condition": "(`tb_item`.`id` < 4)"
+ },
+ {
+ "transformation": "constant_propagation",
+ "resulting_condition": "(`tb_item`.`id` < 4)"
+ },
+ {
+ "transformation": "trivial_condition_removal",
+ "resulting_condition": "(`tb_item`.`id` < 4)"
+ }
+ ] /* steps */
+ } /* condition_processing */
+ },
+ {
+ "table_dependencies": [
+ {
+ "table": "`tb_item`",
+ "row_may_be_null": false,
+ "map_bit": 0,
+ "depends_on_map_bits": [
+ ] /* depends_on_map_bits */
+ }
+ ] /* table_dependencies */
+ },
+ {
+ "ref_optimizer_key_uses": [
+ ] /* ref_optimizer_key_uses */
+ },
+ {
+ "rows_estimation": [
+ {
+ "table": "`tb_item`",
+ "range_analysis": {
+ "table_scan": {
+ "rows": 9816098,
+ "cost": 2.04e6
+ } /* table_scan */,
+ "potential_range_indices": [
+ {
+ "index": "PRIMARY",
+ "usable": true,
+ "key_parts": [
+ "id"
+ ] /* key_parts */
+ }
+ ] /* potential_range_indices */,
+ "setup_range_conditions": [
+ ] /* setup_range_conditions */,
+ "group_index_range": {
+ "chosen": false,
+ "cause": "not_group_by_or_distinct"
+ } /* group_index_range */,
+ "analyzing_range_alternatives": {
+ "range_scan_alternatives": [
+ {
+ "index": "PRIMARY",
+ "ranges": [
+ "id < 4"
+ ] /* ranges */,
+ "index_dives_for_eq_ranges": true,
+ "rowid_ordered": true,
+ "using_mrr": false,
+ "index_only": false,
+ "rows": 3,
+ "cost": 1.6154,
+ "chosen": true
+ }
+ ] /* range_scan_alternatives */,
+ "analyzing_roworder_intersect": {
+ "usable": false,
+ "cause": "too_few_roworder_scans"
+ } /* analyzing_roworder_intersect */
+ } /* analyzing_range_alternatives */,
+ "chosen_range_access_summary": {
+ "range_access_plan": {
+ "type": "range_scan",
+ "index": "PRIMARY",
+ "rows": 3,
+ "ranges": [
+ "id < 4"
+ ] /* ranges */
+ } /* range_access_plan */,
+ "rows_for_plan": 3,
+ "cost_for_plan": 1.6154,
+ "chosen": true
+ } /* chosen_range_access_summary */
+ } /* range_analysis */
+ }
+ ] /* rows_estimation */
+ },
+ {
+ "considered_execution_plans": [
+ {
+ "plan_prefix": [
+ ] /* plan_prefix */,
+ "table": "`tb_item`",
+ "best_access_path": {
+ "considered_access_paths": [
+ {
+ "access_type": "range",
+ "rows": 3,
+ "cost": 2.2154,
+ "chosen": true
+ }
+ ] /* considered_access_paths */
+ } /* best_access_path */,
+ "cost_for_plan": 2.2154,
+ "rows_for_plan": 3,
+ "chosen": true
+ }
+ ] /* considered_execution_plans */
+ },
+ {
+ "attaching_conditions_to_tables": {
+ "original_condition": "(`tb_item`.`id` < 4)",
+ "attached_conditions_computation": [
+ ] /* attached_conditions_computation */,
+ "attached_conditions_summary": [
+ {
+ "table": "`tb_item`",
+ "attached": "(`tb_item`.`id` < 4)"
+ }
+ ] /* attached_conditions_summary */
+ } /* attaching_conditions_to_tables */
+ },
+ {
+ "refine_plan": [
+ {
+ "table": "`tb_item`",
+ "access_type": "range"
+ }
+ ] /* refine_plan */
+ }
+ ] /* steps */
+ } /* join_optimization */
+ },
+ {
+ "join_execution": {
+ "select#": 1,
+ "steps": [
+ ] /* steps */
+ } /* join_execution */
+ }
+ ] /* steps */
+}
+```
+
diff --git "a/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/12.MySQL - \347\264\242\345\274\225\347\232\204\344\275\277\347\224\250.md" "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/12.MySQL - \347\264\242\345\274\225\347\232\204\344\275\277\347\224\250.md"
new file mode 100644
index 00000000..37c2cc4f
--- /dev/null
+++ "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/12.MySQL - \347\264\242\345\274\225\347\232\204\344\275\277\347\224\250.md"
@@ -0,0 +1,349 @@
+---
+title: MySQL - 索引的使用
+permalink: /mysql/index-use/
+date: 2021-05-20 20:51:46
+---
+
+
+
+
+
+- [索引的使用](#%E7%B4%A2%E5%BC%95%E7%9A%84%E4%BD%BF%E7%94%A8)
+ - [验证索引提升查询效率](#%E9%AA%8C%E8%AF%81%E7%B4%A2%E5%BC%95%E6%8F%90%E5%8D%87%E6%9F%A5%E8%AF%A2%E6%95%88%E7%8E%87)
+ - [准备环境](#%E5%87%86%E5%A4%87%E7%8E%AF%E5%A2%83)
+ - [避免索引失效](#%E9%81%BF%E5%85%8D%E7%B4%A2%E5%BC%95%E5%A4%B1%E6%95%88)
+ - [查看索引使用情况](#%E6%9F%A5%E7%9C%8B%E7%B4%A2%E5%BC%95%E4%BD%BF%E7%94%A8%E6%83%85%E5%86%B5)
+ - [练习](#%E7%BB%83%E4%B9%A0)
+
+
+
+
+
+# 索引的使用
+
+
+
+索引是数据库优化最常用也是最重要的手段之一, 通过索引通常可以帮助用户解决大多数的MySQL的性能优化问题。
+
+
+
+## 验证索引提升查询效率
+
+在我们准备的表结构 tb_item 中, 一共存储了 300 万记录;
+
+1). 根据ID查询
+
+```sql
+select * from tb_item where id = 1999\G;
+```
+
+
+
+查询速度很快, 接近0s , 主要的原因是因为id为主键, 有索引;
+
+
+
+
+
+2). 根据 title 进行精确查询
+
+```sql
+select * from tb_item where title = 'iphoneX 移动3G 32G941'\G;
+```
+
+
+
+查看SQL语句的执行计划 :
+
+
+
+
+
+处理方案 , 针对title字段, 创建索引 :
+
+```sql
+create index idx_item_title on tb_item(title);
+```
+
+
+
+
+
+索引创建完成之后,再次进行查询 :
+
+
+
+通过 explain , 查看执行计划,执行SQL时使用了刚才创建的索引
+
+
+
+
+
+## 准备环境
+
+```sql
+create table `tb_seller` (
+ `sellerid` varchar (100),
+ `name` varchar (100),
+ `nickname` varchar (50),
+ `password` varchar (60),
+ `status` varchar (1),
+ `address` varchar (100),
+ `createtime` datetime,
+ primary key(`sellerid`)
+)engine=innodb default charset=utf8mb4;
+
+insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('alibaba','阿里巴巴','阿里小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
+insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('baidu','百度科技有限公司','百度小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
+insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('huawei','华为科技有限公司','华为小店','e10adc3949ba59abbe56e057f20f883e','0','北京市','2088-01-01 12:00:00');
+insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('itcast','传智播客教育科技有限公司','传智播客','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
+insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('itheima','黑马程序员','黑马程序员','e10adc3949ba59abbe56e057f20f883e','0','北京市','2088-01-01 12:00:00');
+insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('luoji','罗技科技有限公司','罗技小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
+insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('oppo','OPPO科技有限公司','OPPO官方旗舰店','e10adc3949ba59abbe56e057f20f883e','0','北京市','2088-01-01 12:00:00');
+insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('ourpalm','掌趣科技股份有限公司','掌趣小店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
+insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('qiandu','千度科技','千度小店','e10adc3949ba59abbe56e057f20f883e','2','北京市','2088-01-01 12:00:00');
+insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('sina','新浪科技有限公司','新浪官方旗舰店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
+insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('xiaomi','小米科技','小米官方旗舰店','e10adc3949ba59abbe56e057f20f883e','1','西安市','2088-01-01 12:00:00');
+insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('yijia','宜家家居','宜家家居旗舰店','e10adc3949ba59abbe56e057f20f883e','1','北京市','2088-01-01 12:00:00');
+
+
+create index idx_seller_name_sta_addr on tb_seller(name,status,address);
+```
+
+## 避免索引失效
+
+**1). 全值匹配 ,对索引中所有列都指定具体值。**
+
+该情况下,索引生效,执行效率高。
+
+```sql
+explain select * from tb_seller where name='小米科技' and status='1' and address='北京市'\G;
+```
+
+
+
+**2). 最左前缀法则**
+
+如果索引了多列(复合索引),要遵守最左前缀法则。指的是查询从索引的最左前列开始,并且不跳过索引中的列。
+
+
+
+匹配最左前缀法则,走索引:
+
+
+
+违法最左前缀法则 , 索引失效:
+
+
+
+如果符合最左法则,但是出现跳跃某一列,只有最左列索引生效:
+
+
+
+
+
+**3). 范围查询,不能使用索引 。**
+
+
+
+根据前面的两个字段name , status 查询是走索引的, 但是最后一个条件address 没有用到索引。
+
+
+
+**4). 不要在索引列上进行运算操作,否则索引将失效。**
+
+
+
+**5). 字符串不加单引号,造成索引失效。**
+
+
+
+在查询时,没有对字符串加单引号,MySQL的查询优化器,会自动的进行类型转换,造成索引失效。
+
+**6). 尽量使用覆盖索引,避免select ***
+
+尽量使用覆盖索引(只访问索引的查询(索引列完全包含查询列)),减少select * 。
+
+
+
+如果查询列,超出索引列,也会降低性能。
+
+
+
+**Extra:**
+
+- using index
+
+ 使用覆盖索引的时候就会出现
+
+- using where
+
+ 在查找使用索引的情况下,需要回表去查询所需的数据
+
+- using index condition
+
+ 查找使用了索引,但是需要回表查询数据
+
+- using index ; using where
+
+ 查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据
+
+
+
+**7). 用or分割开的条件, 如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。**
+
+示例,name字段是索引列 , 而createtime不是索引列,中间是or进行连接是不走索引的 :
+
+```sql
+explain select * from tb_seller where name='黑马程序员' or createtime = '2088-01-01 12:00:00'\G;
+```
+
+
+
+
+
+**8). 以%开头的Like模糊查询,索引失效。**
+
+如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
+
+```sql
+explain select * from tb_seller where name like "%黑马程序员";
+```
+
+
+
+解决方案 :
+
+通过覆盖索引来解决 (不用 select *)
+
+
+
+**9). 如果MySQL评估使用索引比全表更慢,则不使用索引。**
+
+我们先给 address 创建索引
+
+```sql
+create index idx_seller_address on tb_seller(address);
+```
+
+在我们表 tb_seller 中,12条地区数据其中11个是北京市
+
+查北京地区的走全表扫描
+
+
+
+
+
+使用覆盖查询会走索引
+
+```sql
+ explain select address from tb_seller where address='北京市';
+```
+
+**10). is NULL , is NOT NULL 有时索引失效。**
+
+和上一条(9)差不多。
+
+
+
+**11). in 走索引, not in 索引失效。**
+
+在mysql 5.6中
+
+
+
+
+
+个人理解:not in 判断不存在的,需要对表进行大部分数据扫描,类似于第九条
+
+
+
+mysql 5.7中都不失效:
+
+
+
+**12). 单列索引和复合索引。**
+
+尽量使用复合索引,而少使用单列索引 。
+
+创建复合索引
+
+```sql
+create index idx_name_sta_address on tb_seller(name, status, address);
+
+--就相当于创建了三个索引 :
+-- name
+-- name + status
+-- name + status + address
+```
+
+
+
+创建单列索引
+
+```sql
+create index idx_seller_name on tb_seller(name);
+create index idx_seller_status on tb_seller(status);
+create index idx_seller_address on tb_seller(address);
+```
+
+数据库会选择一个最优的索引(辨识度最高索引)来使用,并不会使用全部索引 。
+
+## 查看索引使用情况
+
+```sql
+show status like 'Handler_read%'; --当前会话级别
+
+show global status like 'Handler_read%'; --全局级别
+```
+
+
+
+- Handler_read_first
+
+ 索引中第一条被读的次数。如果较高,表示服务器正执行大量全索引扫描(这个值越低越好)。
+
+- Handler_read_key
+
+ 如果索引正在工作,这个值代表一个行被索引值读的次数,如果值越低,表示索引得到的性能改善不高,因为索引不经常使用(这个值越高越好)。
+
+- Handler_read_next
+
+ 按照键顺序读下一行的请求数。如果你用范围约束或如果执行索引扫描来查询索引列,该值增加。
+
+- Handler_read_prev
+
+ 按照键顺序读前一行的请求数。该读方法主要用于优化ORDER BY ... DESC。
+
+- Handler_read_rnd
+
+ 根据固定位置读一行的请求数。如果你正执行大量查询并需要对结果进行排序该值较高。你可能使用了大量需要MySQL扫描整个表的查询或你的连接没有正确使用键。这个值较高,意味着运行效率低,应该建立索引来补救。
+
+- Handler_read_rnd_next
+
+ 在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值较高。通常说明你的表索引不正确或写入的查询没有利用索引。
+
+
+
+## 练习
+
+假设 index(a,b,c);
+
+| Where 语句 | 索引是否被使用 |
+| ------------------------------------------------------- | ------------------------------------------ |
+| where a = 3 | Y,使用到 a |
+| where a = 3 and b = 5 | Y,使用到 a,b |
+| where a = 3 and b = 5 and c = 4 | Y,使用到 a,b,c |
+| where b = 3 或者 where b = 3 and c = 4 或者 where c = 4 | N(第二条,左前缀法则) |
+| where a = 3 and c = 5 | 使用到 a, 但是 c 不可以,b 中间断了 |
+| where a = 3 and b > 4 and c = 5 | 使用到 a 和 b, c 不能用在范围之后,b 断了 |
+| where a is null and b is not null | is null 支持索引 但是 is not null 不支持 |
+| where a <> 3 | 不能使用索引 |
+| where abs(a) =3 | 不能使用索引 |
+| where a = 3 and b like 'kk%' and c = 4 | Y,使用到 a,b,c |
+| where a = 3 and b like '%kk' and c = 4 | Y,只用到 a |
+| where a = 3 and b like '%kk%' and c = 4 | Y,只用到 a |
+| where a = 3 and b like 'k%kk%' and c = 4 | Y,使用到 a,b,c |
+
+
+
diff --git "a/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/14.MySQL - SQL\344\274\230\345\214\226.md" "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/14.MySQL - SQL\344\274\230\345\214\226.md"
new file mode 100644
index 00000000..30edc08f
--- /dev/null
+++ "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/14.MySQL - SQL\344\274\230\345\214\226.md"
@@ -0,0 +1,431 @@
+---
+title: MySQL - SQL语句优化
+permalink: /mysql/sql-optimize/
+date: 2021-05-23 14:08:28
+---
+
+
+
+
+
+- [大批量插入数据时](#%E5%A4%A7%E6%89%B9%E9%87%8F%E6%8F%92%E5%85%A5%E6%95%B0%E6%8D%AE%E6%97%B6)
+- [优化insert语句](#%E4%BC%98%E5%8C%96insert%E8%AF%AD%E5%8F%A5)
+- [优化order by语句](#%E4%BC%98%E5%8C%96order-by%E8%AF%AD%E5%8F%A5)
+ - [环境准备](#%E7%8E%AF%E5%A2%83%E5%87%86%E5%A4%87)
+ - [两种排序方式](#%E4%B8%A4%E7%A7%8D%E6%8E%92%E5%BA%8F%E6%96%B9%E5%BC%8F)
+ - [Filesort 的优化](#filesort-%E7%9A%84%E4%BC%98%E5%8C%96)
+- [优化group by 语句](#%E4%BC%98%E5%8C%96group-by-%E8%AF%AD%E5%8F%A5)
+- [优化嵌套查询](#%E4%BC%98%E5%8C%96%E5%B5%8C%E5%A5%97%E6%9F%A5%E8%AF%A2)
+- [优化OR条件](#%E4%BC%98%E5%8C%96or%E6%9D%A1%E4%BB%B6)
+- [优化分页查询](#%E4%BC%98%E5%8C%96%E5%88%86%E9%A1%B5%E6%9F%A5%E8%AF%A2)
+- [使用SQL提示](#%E4%BD%BF%E7%94%A8sql%E6%8F%90%E7%A4%BA)
+
+
+
+## 大批量插入数据时
+
+环境准备:
+
+```sql
+CREATE TABLE `tb_user_2` (
+ `id` int(11) NOT NULL AUTO_INCREMENT,
+ `username` varchar(45) NOT NULL,
+ `password` varchar(96) NOT NULL,
+ `name` varchar(45) NOT NULL,
+ `birthday` datetime DEFAULT NULL,
+ `sex` char(1) DEFAULT NULL,
+ `email` varchar(45) DEFAULT NULL,
+ `phone` varchar(45) DEFAULT NULL,
+ `qq` varchar(32) DEFAULT NULL,
+ `status` varchar(32) NOT NULL COMMENT '用户状态',
+ `create_time` datetime NOT NULL,
+ `update_time` datetime DEFAULT NULL,
+ PRIMARY KEY (`id`),
+ UNIQUE KEY `unique_user_username` (`username`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
+```
+
+当使用 `load` 命令导入数据的时候,适当的设置可以提高导入的效率。
+
+
+
+对于 InnoDB 类型的表,有以下几种方式可以提高导入的效率:
+
+**1) 主键顺序插入**
+
+因为InnoDB类型的表是按照主键的顺序保存的,所以将导入的数据按照主键的顺序排列,可以有效的提高导入数据的效率。如果InnoDB表没有主键,那么系统会自动默认创建一个内部列作为主键,所以如果可以给表创建一个主键,将可以利用这点,来提高导入数据的效率。
+
+> 脚本文件介绍 :
+>
+> sql1.log ----> 主键有序
+>
+> sql2.log ----> 主键无序
+
+
+
+插入ID顺序排列数据:
+
+
+
+插入ID无序排列数据:
+
+
+
+
+
+**2) 关闭唯一性校验**
+
+在导入数据前执行 SET UNIQUE_CHECKS=0,关闭唯一性校验
+
+在导入结束后执行SET UNIQUE_CHECKS=1,恢复唯一性校验,可以提高导入的效率。
+
+
+
+
+
+**3) 手动提交事务**
+
+建议在导入前执行 SET AUTOCOMMIT=0,关闭自动提交
+
+导入结束后再执行 SET AUTOCOMMIT=1,打开自动提交,也可以提高导入的效率。
+
+
+
+
+
+> load执行可能会报错
+
+The used command is not allowed with this MySQL version
+
+错误的原因是没有开启 local_infile 模块。
+
+**解决方法:**
+
+首先看一下 local_infile 模块是否打开:
+
+```msyql
+show global variables like 'local_infile';
+```
+
+显示如下:
+
+
+
+然后可以发现这个模块已经启用了:
+
+
+
+
+
+之后重启一下Mysql服务即可
+
+## 优化insert语句
+
+
+
+1.)如果需要同时对一张表插入很多行数据时,应该尽量使用多个值表的insert语句,这种方式将大大的缩减客户端与数据库之间的连接、关闭等消耗。使得效率比分开执行的单个insert语句快。
+
+- 原始方式为:
+
+ ```sql
+ insert into tb_test values(1,'Tom');
+ insert into tb_test values(2,'Cat');
+ insert into tb_test values(3,'Jerry');
+ ```
+
+ 优化后的方案为 :
+
+ ```sql
+ insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
+ ```
+
+
+2.)在事务中进行数据插入。
+
+```sql
+start transaction;
+insert into tb_test values(1,'Tom');
+insert into tb_test values(2,'Cat');
+insert into tb_test values(3,'Jerry');
+commit;
+```
+
+3.)数据有序插入
+
+- 原
+
+ ```sql
+ insert into tb_test values(4,'Tim');
+ insert into tb_test values(1,'Tom');
+ insert into tb_test values(3,'Jerry');
+ insert into tb_test values(5,'Rose');
+ insert into tb_test values(2,'Cat');
+ ```
+
+- 优化后
+
+ ```sql
+ insert into tb_test values(1,'Tom');
+ insert into tb_test values(2,'Cat');
+ insert into tb_test values(3,'Jerry');
+ insert into tb_test values(4,'Tim');
+ insert into tb_test values(5,'Rose');
+ ```
+
+
+
+## 优化order by语句
+
+### 环境准备
+
+```SQL
+CREATE TABLE `emp` (
+ `id` int(11) NOT NULL AUTO_INCREMENT,
+ `name` varchar(100) NOT NULL,
+ `age` int(3) NOT NULL,
+ `salary` int(11) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+
+insert into `emp` (`id`, `name`, `age`, `salary`) values('1','Tom','25','2300');
+insert into `emp` (`id`, `name`, `age`, `salary`) values('2','Jerry','30','3500');
+insert into `emp` (`id`, `name`, `age`, `salary`) values('3','Luci','25','2800');
+insert into `emp` (`id`, `name`, `age`, `salary`) values('4','Jay','36','3500');
+insert into `emp` (`id`, `name`, `age`, `salary`) values('5','Tom2','21','2200');
+insert into `emp` (`id`, `name`, `age`, `salary`) values('6','Jerry2','31','3300');
+insert into `emp` (`id`, `name`, `age`, `salary`) values('7','Luci2','26','2700');
+insert into `emp` (`id`, `name`, `age`, `salary`) values('8','Jay2','33','3500');
+insert into `emp` (`id`, `name`, `age`, `salary`) values('9','Tom3','23','2400');
+insert into `emp` (`id`, `name`, `age`, `salary`) values('10','Jerry3','32','3100');
+insert into `emp` (`id`, `name`, `age`, `salary`) values('11','Luci3','26','2900');
+insert into `emp` (`id`, `name`, `age`, `salary`) values('12','Jay3','37','4500');
+
+create index idx_emp_age_salary on emp(age,salary);
+```
+
+### 两种排序方式
+
+1). 第一种是通过对返回数据进行排序,也就是通常说的 filesort 排序
+
+不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
+
+
+
+2). 第二种通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高。
+
+
+
+多字段排序
+
+
+
+
+
+了解了MySQL的排序方式,优化目标就清晰了:尽量减少额外的排序,通过索引直接返回有序数据。where 条件和Order by 使用相同的索引,并且Order By 的顺序和索引顺序相同, 并且Order by 的字段都是升序,或者都是降序。否则肯定需要额外的操作,这样就会出现 FileSort。
+
+
+
+### Filesort 的优化
+
+通过创建合适的索引,能够减少 Filesort 的出现,但是在某些情况下,条件限制不能让 Filesort 消失,那就需要加快 Filesort的排序操作。对于Filesort ,MySQL 有两种排序算法:
+
+1) 两次扫描算法 :MySQL4.1 之前,使用该方式排序。首先根据条件取出排序字段和行指针信息,然后在排序区 sort buffer 中排序,如果sort buffer不够,则在临时表 temporary table 中存储排序结果。完成排序之后,再根据行指针回表读取记录,该操作可能会导致大量随机I/O操作。
+
+2)一次扫描算法:一次性取出满足条件的所有字段,然后在排序区 sort buffer 中排序后直接输出结果集。排序时内存开销较大,但是排序效率比两次扫描算法要高。
+
+
+
+MySQL 通过比较系统变量 max_length_for_sort_data 的大小和 Query 语句取出的字段总大小, 来判定是否那种排序算法,如果 max_length_for_sort_data 更大,那么使用第二种优化之后的算法;否则使用第一种。
+
+可以适当提高 sort_buffer_size 和 max_length_for_sort_data 系统变量,来增大排序区的大小,提高排序的效率。
+
+
+
+
+
+## 优化group by 语句
+
+由于 GROUP BY 实际上也同样会进行排序操作,而且与 ORDER BY 相比,GROUP BY 主要只是多了排序之后的分组操作。当然,如果在分组的时候还使用了其他的一些聚合函数,那么还需要一些聚合函数的计算。所以,在GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引。
+
+如果查询包含 group by 但是想要避免排序结果的消耗, 则可以执行order by null 禁止排序。如下 :
+
+```sql
+drop index idx_emp_age_salary on emp; -- 删除之前创建的索引
+
+explain select age,count(*) from emp group by age;
+```
+
+
+
+优化后
+
+```sql
+explain select age,count(*) from emp group by age order by null;
+```
+
+
+
+从上面的例子可以看出,第一个SQL语句需要进行"filesort",而第二个SQL由于 `order by null` 不需要进行 "filesort", 而上文提过 Filesort 往往非常耗费时间。
+
+
+
+创建索引 :
+
+```SQL
+create index idx_emp_age_salary on emp(age,salary);
+```
+
+
+
+
+
+**但是在 mysql 5.7 中:**
+
+
+
+
+
+## 优化嵌套查询
+
+Mysql4.1版本之后,开始支持SQL的子查询。这个技术可以使用SELECT语句来创建一个单列的查询结果,然后把这个结果作为过滤条件用在另一个查询中。使用子查询可以一次性的完成很多逻辑上需要多个步骤才能完成的SQL操作,同时也可以避免事务或者表锁死,并且写起来也很容易。但是,有些情况下,子查询是可以被更高效的连接(JOIN)替代。
+
+示例 ,查找有角色的所有的用户信息 :
+
+```SQL
+ explain select * from t_user where id in (select user_id from user_role );
+```
+
+执行计划为 :
+
+
+
+优化后 :
+
+```SQL
+explain select * from t_user u , user_role ur where u.id = ur.user_id;
+```
+
+
+
+连接(Join)查询之所以更有效率一些 ,是因为MySQL不需要在内存中创建临时表来完成这个逻辑上需要两个步骤的查询工作。
+
+在 mysql 5.7 中
+
+
+
+
+
+## 优化OR条件
+
+对于包含OR的查询子句,如果要利用索引,则OR之间的每个条件列都必须用到索引 , 而且不能使用到复合索引; 如果没有索引,则应该考虑增加索引。
+
+获取 emp 表中的所有的索引 :
+
+
+
+示例 :
+
+```SQL
+explain select * from emp where id = 1 or age = 30;
+```
+
+
+
+
+
+建议使用 union 替换 or :
+
+
+
+我们来比较下重要指标,发现主要差别是 type 和 ref 这两项
+
+type 显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
+
+```
+system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
+```
+
+UNION 语句的 type 值为 ref,OR 语句的 type 值为 range,可以看到这是一个很明显的差距
+
+UNION 语句的 ref 值为 const,OR 语句的 type 值为 null,const 表示是常量值引用,非常快
+
+这两项的差距就说明了 UNION 要优于 OR 。
+
+在 mysql 8.0 中,默认优化了,具体自行测试。
+
+
+
+## 优化分页查询
+
+一般分页查询时,通过创建覆盖索引能够比较好地提高性能。一个常见又非常头疼的问题就是 limit 2000000,10 ,此时需要MySQL排序前2000010 记录,仅仅返回2000000 - 2000010 的记录,其他记录丢弃,查询排序的代价非常大 。
+
+
+
+**优化思路一**
+
+在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容。
+
+
+
+
+
+**优化思路二**
+
+该方案适用于主键自增的表,可以把Limit 查询转换成某个位置的查询 。
+
+
+
+
+
+## 使用SQL提示
+
+SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
+
+
+
+**USE INDEX**
+
+在查询语句中表名的后面,添加 use index 来提供希望MySQL去参考的索引列表,就可以让MySQL不再考虑其他可用的索引。
+
+```
+create index idx_seller_name on tb_seller(name);
+```
+
+
+
+
+
+**IGNORE INDEX**
+
+如果用户只是单纯的想让MySQL忽略一个或者多个索引,则可以使用 ignore index 作为 hint 。
+
+```
+ explain select * from tb_seller ignore index(idx_seller_name) where name = '小米科技';
+```
+
+
+
+
+
+**FORCE INDEX**
+
+为强制MySQL使用一个特定的索引,可在查询中使用 force index 作为hint 。
+
+``` SQL
+create index idx_seller_address on tb_seller(address);
+```
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/16.MySQL - \347\274\223\345\255\230\346\237\245\350\257\242.md" "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/16.MySQL - \347\274\223\345\255\230\346\237\245\350\257\242.md"
new file mode 100644
index 00000000..6453e72a
--- /dev/null
+++ "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/16.MySQL - \347\274\223\345\255\230\346\237\245\350\257\242.md"
@@ -0,0 +1,163 @@
+---
+title: MySQL - 缓存查询
+permalink: /mysql/cache-query/
+date: 2021-05-24 15:10:03
+---
+
+
+
+
+
+- [概述](#%E6%A6%82%E8%BF%B0)
+- [查询缓存配置](#%E6%9F%A5%E8%AF%A2%E7%BC%93%E5%AD%98%E9%85%8D%E7%BD%AE)
+- [开启查询缓存](#%E5%BC%80%E5%90%AF%E6%9F%A5%E8%AF%A2%E7%BC%93%E5%AD%98)
+- [查询缓存SELECT选项](#%E6%9F%A5%E8%AF%A2%E7%BC%93%E5%AD%98select%E9%80%89%E9%A1%B9)
+- [查询缓存失效的情况](#%E6%9F%A5%E8%AF%A2%E7%BC%93%E5%AD%98%E5%A4%B1%E6%95%88%E7%9A%84%E6%83%85%E5%86%B5)
+
+
+
+## 概述
+
+开启Mysql的查询缓存,当执行完全相同的SQL语句的时候,服务器就会直接从缓存中读取结果,当数据被修改,之前的缓存会失效,修改比较频繁的表不适合做查询缓存。
+
+
+
+ 
+
+1. 客户端发送一条查询给服务器;
+2. 服务器先会检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果。否则进入下一阶段;
+3. 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划;
+4. MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询;
+5. 将结果返回给客户端。
+
+## 查询缓存配置
+
+- 查看当前的MySQL数据库是否支持查询缓存:
+
+```SQL
+SHOW VARIABLES LIKE 'have_query_cache';
+```
+
+
+
+在Mysql8,已经取消了查询缓存
+
+
+
+- 查看当前MySQL是否开启了查询缓存 :
+
+```SQL
+SHOW VARIABLES LIKE 'query_cache_type';
+```
+
+
+
+- 查看查询缓存的占用大小 :
+
+```SQL
+SHOW VARIABLES LIKE 'query_cache_size';
+```
+
+
+
+- 查看查询缓存的状态变量:
+
+```SQL
+SHOW STATUS LIKE 'Qcache%';
+```
+
+
+
+各个变量的含义如下:
+
+| 参数 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| Qcache_free_blocks | 查询缓存中的可用内存块数 |
+| Qcache_free_memory | 查询缓存的可用内存量 |
+| Qcache_hits | 查询缓存命中数 |
+| Qcache_inserts | 添加到查询缓存的查询数 |
+| Qcache_lowmen_prunes | 由于内存不足而从查询缓存中删除的查询数 |
+| Qcache_not_cached | 非缓存查询的数量(由于 query_cache_type 设置而无法缓存或未缓存) |
+| Qcache_queries_in_cache | 查询缓存中注册的查询数 |
+| Qcache_total_blocks | 查询缓存中的块总数 |
+
+
+
+## 开启查询缓存
+
+MySQL的查询缓存默认是关闭的,需要手动配置参数 query_cache_type , 来开启查询缓存。
+
+query_cache_type 该参数的可取值有三个 :
+
+| 值 | 含义 |
+| ----------- | ------------------------------------------------------------ |
+| OFF 或 0 | 查询缓存功能关闭 |
+| ON 或 1 | 查询缓存功能打开,SELECT的结果符合缓存条件即会缓存,否则,不予缓存,显式指定 SQL_NO_CACHE,不予缓存 |
+| DEMAND 或 2 | 查询缓存功能按需进行,显式指定 SQL_CACHE 的SELECT语句才会缓存;其它均不予缓存 |
+
+在 `/usr/my.cnf` 配置中(宝塔在 `/etc/my.cnf` ),增加以下配置 :
+
+```properties
+# 开启mysql的查询缓存
+query_cache_type=1
+```
+
+配置完毕之后,重启服务既可生效 , `service mysqld restart `;
+
+然后就可以在命令行执行SQL语句进行验证 ,执行一条比较耗时的SQL语句,然后再多执行几次,查看后面几次的执行时间;获取通过查看查询缓存的缓存命中数,来判定是否走查询缓存。
+
+## 查询缓存SELECT选项
+
+可以在 SELECT 语句中指定两个与查询缓存相关的选项 :
+
+- SQL_CACHE
+
+ 如果查询结果是可缓存的,并且 query_cache_type 系统变量的值为 ON 或 DEMAND ,则缓存查询结果 。
+
+- SQL_NO_CACHE
+
+ 服务器不使用查询缓存。它既不检查查询缓存,也不检查结果是否已缓存,也不缓存查询结果。
+
+例子:
+
+```SQL
+SELECT SQL_CACHE id, name FROM customer;
+SELECT SQL_NO_CACHE id, name FROM customer;
+```
+
+
+
+## 查询缓存失效的情况
+
+1) SQL 语句不一致的情况, 要想命中查询缓存,查询的SQL语句必须一致。
+
+```SQL
+-- SQL1 :
+select count(*) from tb_item;
+-- SQL2 :
+Select count(*) from tb_item;
+```
+
+2) 当查询语句中有一些不确定的时,则不会缓存。如 : now() , current_date() , curdate() , curtime() , rand() , uuid() , user() , database() 。
+
+```SQL
+select * from tb_item where updatetime < now() limit 1;
+select user();
+select database();
+```
+
+3) 不使用任何表查询语句。
+
+```SQL
+select 'A';
+```
+
+4) 查询 mysql, information_schema或 performance_schema 系统数据库中的表时,不会走查询缓存。
+
+```SQL
+select * from information_schema.engines;
+```
+
+5) 在存储的函数,触发器或事件的主体内执行的查询。
+
+6) 如果表更改,则使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除。这包括使用`MERGE`映射到已更改表的表的查询。一个表可以被许多类型的语句,如被改变 INSERT, UPDATE, DELETE, TRUNCATE TABLE, ALTER TABLE, DROP TABLE,或 DROP DATABASE 。
\ No newline at end of file
diff --git "a/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/18.MySQL - \345\206\205\345\255\230\347\256\241\347\220\206.md" "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/18.MySQL - \345\206\205\345\255\230\347\256\241\347\220\206.md"
new file mode 100644
index 00000000..b0bb8553
--- /dev/null
+++ "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/18.MySQL - \345\206\205\345\255\230\347\256\241\347\220\206.md"
@@ -0,0 +1,89 @@
+---
+title: MySQL - 内存管理
+permalink: /mysql/memory-management/
+date: 2021-05-24 15:46:46
+---
+
+
+
+
+
+- [Mysql内存管理及优化](#mysql%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86%E5%8F%8A%E4%BC%98%E5%8C%96)
+ - [内存优化原则](#%E5%86%85%E5%AD%98%E4%BC%98%E5%8C%96%E5%8E%9F%E5%88%99)
+ - [MyISAM 内存优化](#myisam-%E5%86%85%E5%AD%98%E4%BC%98%E5%8C%96)
+ - [InnoDB 内存优化](#innodb-%E5%86%85%E5%AD%98%E4%BC%98%E5%8C%96)
+
+
+
+# Mysql内存管理及优化
+
+## 内存优化原则
+
+1) 将尽量多的内存分配给MySQL做缓存,但要给操作系统和其他程序预留足够内存。
+
+2) MyISAM 存储引擎的数据文件读取依赖于操作系统自身的IO缓存,因此,如果有MyISAM表,就要预留更多的内存给操作系统做IO缓存。
+
+3) 排序区、连接区等缓存是分配给每个数据库会话(session)专用的,其默认值的设置要根据最大连接数合理分配,如果设置太大,不但浪费资源,而且在并发连接较高时会导致物理内存耗尽。
+
+
+
+## MyISAM 内存优化
+
+了解即可,我们平时用的都是 InnoDB
+
+
+
+myisam存储引擎使用 key_buffer 缓存索引块,加速myisam索引的读写速度。对于myisam表的数据块,mysql没有特别的缓存机制,完全依赖于操作系统的IO缓存。
+
+
+
+- key_buffer_size
+
+key_buffer_size决定MyISAM索引块缓存区的大小,直接影响到MyISAM表的存取效率。可以在MySQL参数文件中设置key_buffer_size的值,对于一般MyISAM数据库,建议至少将1/4可用内存分配给key_buffer_size。
+
+在 `/usr/my.cnf` 中做如下配置:
+
+```properties
+key_buffer_size=512M
+```
+
+```sql
+SHOW VARIABLES LIKE 'key_buffer_size' -- 查看大小
+```
+
+- read_buffer_size
+
+如果需要经常顺序扫描myisam表,可以通过增大read_buffer_size的值来改善性能。但需要注意的是read_buffer_size是每个session独占的,如果默认值设置太大,就会造成内存浪费。
+
+
+
+- read_rnd_buffer_size
+
+对于需要做排序的myisam表的查询,如带有order by子句的sql,适当增加 read_rnd_buffer_size 的值,可以改善此类的sql性能。但需要注意的是 read_rnd_buffer_size 是每个session独占的,如果默认值设置太大,就会造成内存浪费。
+
+
+
+## InnoDB 内存优化
+
+innodb用一块内存区做IO缓存池,该缓存池不仅用来缓存innodb的索引块,而且也用来缓存innodb的数据块。
+
+
+
+- innodb_buffer_pool_size
+
+该变量决定了 innodb 存储引擎表数据和索引数据的最大缓存区大小。在保证操作系统及其他程序有足够内存可用的情况下,innodb_buffer_pool_size 的值越大,缓存命中率越高,访问InnoDB表需要的磁盘I/O 就越少,性能也就越高。
+
+```properties
+innodb_buffer_pool_size=512M
+```
+
+
+
+- innodb_log_buffer_size
+
+决定了 Innodb 重做日志缓存的大小,对于可能产生大量更新记录的大事务,增加innodb_log_buffer_size的大小,可以避免innodb在事务提交前就执行不必要的日志写入磁盘操作。
+
+```properties
+innodb_log_buffer_size=10M
+```
+
diff --git "a/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/20.MySQL - \345\271\266\345\217\221\345\217\202\346\225\260.md" "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/20.MySQL - \345\271\266\345\217\221\345\217\202\346\225\260.md"
new file mode 100644
index 00000000..e3dcc16d
--- /dev/null
+++ "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/20.MySQL - \345\271\266\345\217\221\345\217\202\346\225\260.md"
@@ -0,0 +1,58 @@
+---
+title: MySQL - 并发参数
+permalink: /mysql/concurrent-parameter/
+date: 2021-05-24 16:13:14
+---
+
+
+
+
+
+- [max_connections](#max_connections)
+- [back_log](#back_log)
+- [table_open_cache](#table_open_cache)
+- [thread_cache_size](#thread_cache_size)
+- [innodb_lock_wait_timeout](#innodb_lock_wait_timeout)
+
+
+
+
+
+从实现上来说,MySQL Server 是多线程结构,包括后台线程和客户服务线程。多线程可以有效利用服务器资源,提高数据库的并发性能。在Mysql中,控制并发连接和线程的主要参数包括 max_connections、back_log、thread_cache_size、table_open_cahce。
+
+## max_connections
+
+采用max_connections 控制允许连接到MySQL数据库的最大数量,默认值是 151。如果状态变量 connection_errors_max_connections 不为零,并且一直增长,则说明不断有连接请求因数据库连接数已达到允许最大值而失败,这是可以考虑增大max_connections 的值。
+
+Mysql 最大可支持的连接数,取决于很多因素,包括给定操作系统平台的线程库的质量、内存大小、每个连接的负荷、CPU的处理速度,期望的响应时间等。在Linux 平台下,性能好的服务器,支持 500-1000 个连接不是难事,需要根据服务器性能进行评估设定。
+
+
+
+## back_log
+
+back_log 参数控制MySQL监听TCP端口时设置的积压请求栈大小。如果MySql的连接数达到 max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即 back_log,如果等待连接的数量超过back_log,将不被授予连接资源,将会报错。5.6.6 版本之前默认值为 50 , 之后的版本默认为 50 + (max_connections / 5), 但最大不超过900。
+
+如果需要数据库在较短的时间内处理大量连接请求, 可以考虑适当增大 back_log 的值。
+
+
+
+## table_open_cache
+
+该参数用来控制所有SQL语句执行线程可打开表缓存的数量, 而在执行SQL语句时,每一个SQL执行线程至少要打开 1 个表缓存。该参数的值应该根据设置的最大连接数 max_connections 以及每个连接执行关联查询中涉及的表的最大数量来设定 :max_connections x N ;
+
+```sql
+SHOW VARIABLES LIKE 'table_open_cache' -- 查看大小
+```
+
+
+
+## thread_cache_size
+
+为了加快连接数据库的速度,MySQL 会缓存一定数量的客户服务线程以备重用,通过参数 thread_cache_size 可控制 MySQL 缓存客户服务线程的数量。
+
+
+
+## innodb_lock_wait_timeout
+
+该参数是用来设置InnoDB 事务等待行锁的时间,默认值是50ms , 可以根据需要进行动态设置。对于需要快速反馈的业务系统来说,可以将行锁的等待时间调小,以避免事务长时间挂起; 对于后台运行的批量处理程序来说, 可以将行锁的等待时间调大, 以避免发生大的回滚操作。
+
diff --git "a/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/22.MySQL - \351\224\201\351\227\256\351\242\230.md" "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/22.MySQL - \351\224\201\351\227\256\351\242\230.md"
new file mode 100644
index 00000000..40ceb5be
--- /dev/null
+++ "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/22.MySQL - \351\224\201\351\227\256\351\242\230.md"
@@ -0,0 +1,523 @@
+---
+title: MySQL - 锁问题
+permalink: /mysql/lock-question/
+date: 2021-05-24 16:15:57
+---
+
+
+
+
+
+- [简介](#%E7%AE%80%E4%BB%8B)
+- [MyISAM 表锁](#myisam-%E8%A1%A8%E9%94%81)
+ - [如何加表锁](#%E5%A6%82%E4%BD%95%E5%8A%A0%E8%A1%A8%E9%94%81)
+ - [读锁案例](#%E8%AF%BB%E9%94%81%E6%A1%88%E4%BE%8B)
+ - [写锁案例](#%E5%86%99%E9%94%81%E6%A1%88%E4%BE%8B)
+ - [结论](#%E7%BB%93%E8%AE%BA)
+ - [查看锁的争用情况](#%E6%9F%A5%E7%9C%8B%E9%94%81%E7%9A%84%E4%BA%89%E7%94%A8%E6%83%85%E5%86%B5)
+- [InnoDB 行锁](#innodb-%E8%A1%8C%E9%94%81)
+ - [行锁介绍](#%E8%A1%8C%E9%94%81%E4%BB%8B%E7%BB%8D)
+ - [背景知识](#%E8%83%8C%E6%99%AF%E7%9F%A5%E8%AF%86)
+ - [InnoDB 的行锁模式](#innodb-%E7%9A%84%E8%A1%8C%E9%94%81%E6%A8%A1%E5%BC%8F)
+ - [行锁基本演示](#%E8%A1%8C%E9%94%81%E5%9F%BA%E6%9C%AC%E6%BC%94%E7%A4%BA)
+ - [无索引行锁升级为表锁](#%E6%97%A0%E7%B4%A2%E5%BC%95%E8%A1%8C%E9%94%81%E5%8D%87%E7%BA%A7%E4%B8%BA%E8%A1%A8%E9%94%81)
+ - [间隙锁危害](#%E9%97%B4%E9%9A%99%E9%94%81%E5%8D%B1%E5%AE%B3)
+ - [InnoDB 行锁争用情况](#innodb-%E8%A1%8C%E9%94%81%E4%BA%89%E7%94%A8%E6%83%85%E5%86%B5)
+ - [总结](#%E6%80%BB%E7%BB%93)
+
+
+
+
+
+## 简介
+
+- **锁概述**
+
+锁是计算机协调多个进程或线程并发访问某一资源的机制(避免争抢)。
+
+在数据库中,除传统的计算资源(如 CPU、RAM、I/O 等)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。从这个角度来说,锁对数据库而言显得尤其重要,也更加复杂。
+
+
+
+- **锁分类:**
+
+从对数据操作的粒度分 :
+
+1) 表锁:操作时,会锁定整个表。
+
+2) 行锁:操作时,会锁定当前操作行。
+
+从对数据操作的类型分:
+
+1) 读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响。
+
+2) 写锁(排它锁):当前操作没有完成之前,它会阻断其他写锁和读锁。
+
+
+
+- **Mysql 锁**
+
+相对其他数据库而言,MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制。
+
+下表中罗列出了各存储引擎对锁的支持情况:
+
+| 存储引擎 | 表级锁 | 行级锁 | 页面锁 |
+| -------- | ------ | ------ | ------ |
+| MyISAM | 支持 | 不支持 | 不支持 |
+| InnoDB | 支持 | 支持 | 不支持 |
+| MEMORY | 支持 | 不支持 | 不支持 |
+| BDB | 支持 | 不支持 | 支持 |
+
+MySQL这3种锁的特性可大致归纳如下 :
+
+| 锁类型 | 特点 |
+| ------ | ------------------------------------------------------------ |
+| 表级锁 | 偏向MyISAM 存储引擎,开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。 |
+| 行级锁 | 偏向InnoDB 存储引擎,开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。 |
+| 页面锁 | 开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。 |
+
+从上述特点可见,很难笼统地说哪种锁更好,只能就具体应用的特点来说哪种锁更合适!仅从锁的角度来说:表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如Web 应用;而行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并查询的应用,如一些在线事务处理(OLTP)系统。
+
+
+
+
+## MyISAM 表锁
+
+MyISAM 存储引擎只支持表锁,这也是MySQL开始几个版本中唯一支持的锁类型。
+
+
+
+### 如何加表锁
+
+MyISAM 在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行更新操作(UPDATE、DELETE、INSERT 等)前,会自动给涉及的表加写锁,这个过程并不需要用户干预,因此,用户一般不需要直接用 LOCK TABLE 命令给 MyISAM 表显式加锁。
+
+```SQL
+lock table table_name read; --加读锁
+
+lock table table_name writ; --加写锁
+```
+
+
+
+### 读锁案例
+
+准备环境
+
+```SQL
+create database demo_03 default charset=utf8mb4;
+
+use demo_03;
+
+CREATE TABLE `tb_book` (
+ `id` INT(11) auto_increment,
+ `name` VARCHAR(50) DEFAULT NULL,
+ `publish_time` DATE DEFAULT NULL,
+ `status` CHAR(1) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ENGINE=myisam DEFAULT CHARSET=utf8 ;
+
+INSERT INTO tb_book (id, name, publish_time, status) VALUES(NULL,'java编程思想','2088-08-01','1');
+INSERT INTO tb_book (id, name, publish_time, status) VALUES(NULL,'solr编程思想','2088-08-08','0');
+
+
+
+CREATE TABLE `tb_user` (
+ `id` INT(11) auto_increment,
+ `name` VARCHAR(50) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ENGINE=myisam DEFAULT CHARSET=utf8 ;
+
+INSERT INTO tb_user (id, name) VALUES(NULL,'令狐冲');
+INSERT INTO tb_user (id, name) VALUES(NULL,'田伯光');
+
+```
+
+
+
+客户端 一 :
+
+1)加 tb_book 表的读锁
+
+```sql
+lock table tb_book read;
+```
+
+
+
+2) 执行查询操作
+
+```sql
+select * from tb_book;
+```
+
+
+
+可以正常执行 , 查询出数据。
+
+客户端 二 :
+
+3) 执行查询操作
+
+```sql
+select * from tb_book;
+```
+
+
+
+
+
+客户端 一 :
+
+4)查询未锁定的表
+
+```sql
+select name from tb_seller;
+```
+
+
+
+客户端 二 :
+
+5)查询未锁定的表
+
+```sql
+select name from tb_seller;
+```
+
+
+
+可以正常查询出未锁定的表;
+
+
+
+客户端 一 :
+
+6) 执行插入操作
+
+```sql
+insert into tb_book values(null,'Mysql高级','2088-01-01','1');
+```
+
+
+
+执行插入, 直接报错 , 由于当前tb_book 获得的是 读锁, 不能执行更新操作。
+
+
+
+客户端 二 :
+
+7) 执行插入操作
+
+```sql
+insert into tb_book values(null,'Mysql高级','2088-01-01','1');
+```
+
+
+
+
+
+当在客户端一中释放锁指令 unlock tables 后 , 客户端二中的 inesrt 语句 , 立即执行 ;
+
+### 写锁案例
+
+客户端 一 :
+
+1)给 tb_book 表的写锁
+
+```sql
+lock table tb_book write ;
+```
+
+2)执行查询操作
+
+```sql
+select * from tb_book ;
+```
+
+
+
+查询操作执行成功;
+
+3)执行更新操作
+
+```sql
+update tb_book set name = 'java编程思想(第二版)' where id = 1;
+```
+
+
+
+更新操作执行成功 ;
+
+
+
+客户端 二 :
+
+4)执行查询操作
+
+```
+select * from tb_book ;
+```
+
+
+
+
+
+当在客户端一中释放锁指令 unlock tables 后 , 客户端二中的 select 语句 , 立即执行 ;
+
+
+
+
+
+### 结论
+
+锁模式的相互兼容性如表中所示:
+
+
+
+由上表可见:
+
+ 1) 对MyISAM 表的读操作,不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写请求;
+
+ 2) 对MyISAM 表的写操作,会都阻塞其他用户对同一表的读和写操作;
+
+ 简而言之,就是读锁会阻塞写,但是不会阻塞读。而写锁,则既会阻塞读,又会阻塞写。
+
+
+
+此外,MyISAM 的读写锁调度是写优先,这也是MyISAM不适合做写为主的表的存储引擎的原因。因为写锁后,其他线程不能做任何操作,大量的更新会使查询很难得到锁,从而造成永远阻塞。
+
+### 查看锁的争用情况
+
+``` sql
+show open tables;
+```
+
+
+
+In_user : 表当前被查询使用的次数。如果该数为零,则表是打开的,但是当前没有被使用。
+
+Name_locked:表名称是否被锁定。名称锁定用于取消表或对表进行重命名等操作。
+
+
+
+```sql
+show status like 'Table_locks%';
+```
+
+
+
+Table_locks_immediate : 指的是能够立即获得表级锁的次数,每立即获取锁,值加1。
+
+Table_locks_waited : 指的是不能立即获取表级锁而需要等待的次数,每等待一次,该值加1,此值高说明存在着较为严重的表级锁争用情况。
+
+## InnoDB 行锁
+
+### 行锁介绍
+
+行锁特点 :偏向InnoDB 存储引擎,开销大,加锁慢;会出现死锁;锁定力度最小,发生锁冲突的概率最低,并发度也最高。
+
+InnoDB 与 MyISAM 的最大不同有两点:一是支持事务;二是采用了行级锁。
+
+
+
+### 背景知识
+
+**事务及其ACID属性**
+
+事务是由一组SQL语句组成的逻辑处理单元。
+
+事务具有以下4个特性,简称为事务ACID属性。
+
+| ACID属性 | 含义 |
+| -------------------- | ------------------------------------------------------------ |
+| 原子性(Atomicity) | 事务是一个原子操作单元,其对数据的修改,要么全部成功,要么全部失败。 |
+| 一致性(Consistent) | 在事务开始和完成时,数据都必须保持一致状态。 |
+| 隔离性(Isolation) | 数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的 “独立” 环境下运行。 |
+| 持久性(Durable) | 事务完成之后,对于数据的修改是永久的。 |
+
+
+
+**并发事务处理带来的问题**
+
+| 问题 | 含义 |
+| ---------------------------------- | ------------------------------------------------------------ |
+| 丢失更新(Lost Update) | 当两个或多个事务选择同一行,最初的事务修改的值,会被后面的事务修改的值覆盖。 |
+| 脏读(Dirty Reads) | 当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。 |
+| 不可重复读(Non-Repeatable Reads) | 一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现和以前读出的数据不一致。 |
+| 幻读(Phantom Reads) | 一个事务按照相同的查询条件重新读取以前查询过的数据,却发现其他事务插入了满足其查询条件的新数据。 |
+
+
+
+**事务隔离级别**
+
+为了解决上述提到的事务并发问题,数据库提供一定的事务隔离机制来解决这个问题。数据库的事务隔离越严格,并发副作用越小,但付出的代价也就越大,因为事务隔离实质上就是使用事务在一定程度上“串行化” 进行,这显然与“并发” 是矛盾的。
+
+数据库的隔离级别有4个,由低到高依次为 Read uncommitted、Read committed、Repeatable read、Serializable,这四个级别可以逐个解决 脏写、脏读、不可重复读、幻读 这几类问题。
+
+| 隔离级别 | 丢失更新 | 脏读 | 不可重复读 | 幻读 |
+| ----------------------- | -------- | ---- | ---------- | ---- |
+| Read uncommitted | × | √ | √ | √ |
+| Read committed | × | × | √ | √ |
+| Repeatable read(默认) | × | × | × | √ |
+| Serializable | × | × | × | × |
+
+备注 : √ 代表可能出现 , × 代表不会出现 。
+
+Mysql 的数据库的默认隔离级别为 Repeatable read , 查看方式:
+
+```sql
+show variables like 'tx_isolation';
+```
+
+
+
+
+
+### InnoDB 的行锁模式
+
+InnoDB 实现了以下两种类型的行锁。
+
+- 共享锁(S):又称为读锁,简称 `S` 锁,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
+- 排他锁(X):又称为写锁,简称 `X` 锁,排他锁就是不能与其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁,但是获取排他锁的事务是可以对数据就行读取和修改。
+
+对于 UPDATE、DELETE、INSERT 语句,InnoDB 会自动给涉及数据集加 排他锁(X)
+
+对于普通SELECT语句,InnoDB不会加任何锁;
+
+
+
+可以通过以下语句显示给记录集加共享锁或排他锁 。
+
+```sql
+-- 共享锁(S)
+SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE
+-- 排他锁(X)
+SELECT * FROM table_name WHERE ... FOR UPDATE
+```
+
+### 行锁基本演示
+
+准备 sql
+
+```sql
+create table test_innodb_lock(
+ id int(11),
+ name varchar(16),
+ sex varchar(1)
+)engine = innodb default charset=utf8;
+
+insert into test_innodb_lock values(1,'100','1');
+insert into test_innodb_lock values(3,'3','1');
+insert into test_innodb_lock values(4,'400','0');
+insert into test_innodb_lock values(5,'500','1');
+insert into test_innodb_lock values(6,'600','0');
+insert into test_innodb_lock values(7,'700','0');
+insert into test_innodb_lock values(8,'800','1');
+insert into test_innodb_lock values(9,'900','1');
+insert into test_innodb_lock values(1,'200','0');
+
+create index idx_test_innodb_lock_id on test_innodb_lock(id);
+create index idx_test_innodb_lock_name on test_innodb_lock(name);
+```
+
+开启两个会话
+
+| Session-1 | Session-2 |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 关闭自动提交功能 | 关闭自动提交功能 |
+| 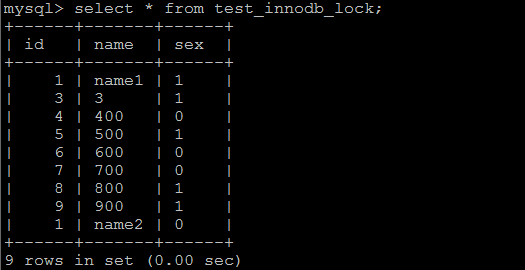可以正常的查询出全部的数据 | 可以正常的查询出全部的数据 |
+| 查询id 为3的数据 ; | 获取id为3的数据 ; |
+| 更新id为3的数据,但是不提交; |  更新id为3 的数据, 出于等待状态 |
+| 通过commit, 提交事务 |  解除阻塞,更新正常进行 |
+| 以上, 操作的都是同一行的数据,接下来,演示不同行的数据 : | |
+|  更新id为3数据,正常的获取到行锁 ,执行更新 |  由于与 Session-1 操作不是同一行,获取当前行锁,执行更新; |
+
+### 无索引行锁升级为表锁
+
+如果不通过索引条件检索数据,那么InnoDB将对表中的所有记录加锁,实际效果跟表锁一样。
+
+```sql
+ --查看当前表的索引 :
+ show index from test_innodb_lock ;
+```
+
+
+
+| Session-1 | Session-2 |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 关闭事务的自动提交 | 关闭事务的自动提交 |
+| 执行更新语句 | 执行更新语句, 但处于阻塞状态 |
+| 提交事务 | 解除阻塞,执行更新成功 |
+| | 执行提交操作 |
+
+由于执行更新时,name字段本来为varchar类型, 我们是作为数字类型使用,存在类型转换,索引失效,最终行锁变为表锁 ;
+
+
+
+### 间隙锁危害
+
+当我们用范围条件,而不是使用相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据进行加锁; 对于键值在条件范围内但并不存在的记录,叫做 "间隙(GAP)" , InnoDB也会对这个 "间隙" 加锁,这种锁机制就是所谓的 间隙锁(Next-Key锁) 。
+
+示例 :
+
+| Session-1 | Session-2 |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 关闭事务自动提交 ! | 关闭事务自动提交 |
+| 根据id范围更新数据 | |
+| | 插入id为2的记录, 出于阻塞状态! |
+| 提交事务 | |
+| | 解除阻塞 , 执行插入操作 |
+| | 提交事务 |
+
+
+
+### InnoDB 行锁争用情况
+
+```sql
+show status like 'innodb_row_lock%';
+```
+
+
+
+- Innodb_row_lock_current_waits
+
+ 当前正在等待锁定的数量
+
+- Innodb_row_lock_time
+
+ 从系统启动到现在锁定总时间长度
+
+- Innodb_row_lock_time_avg
+
+ 每次等待所花平均时长
+
+- Innodb_row_lock_time_max
+
+ 从系统启动到现在等待最长的一次所花的时间
+
+- Innodb_row_lock_waits
+
+ 系统启动后到现在总共等待的次数
+
+当等待的次数很高,而且每次等待的时长也不小的时候,我们就需要分析系统中为什么会有如此多的等待,然后根据分析结果着手制定优化计划。
+
+
+
+
+
+### 总结
+
+InnoDB存储引擎由于实现了行级锁定,虽然在锁定机制的实现方面带来了性能损耗可能比表锁会更高一些,但是在整体并发处理能力方面要远远由于MyISAM的表锁的。当系统并发量较高的时候,InnoDB的整体性能和MyISAM相比就会有比较明显的优势。
+
+但是,InnoDB的行级锁同样也有其脆弱的一面,当我们使用不当的时候,可能会让InnoDB的整体性能表现不仅不能比MyISAM高,甚至可能会更差。
+
+
+
+优化建议:
+
+- 尽可能让所有数据检索都能通过索引来完成,避免无索引行锁升级为表锁。
+- 合理设计索引,尽量缩小锁的范围
+- 尽可能减少索引条件,及索引范围,避免间隙锁
+- 尽量控制事务大小,减少锁定资源量和时间长度
+- 尽可使用低级别事务隔离(但是需要业务层面满足需求)
+
diff --git "a/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/24.MySQL - \345\270\270\347\224\250sql\346\212\200\345\267\247.md" "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/24.MySQL - \345\270\270\347\224\250sql\346\212\200\345\267\247.md"
new file mode 100644
index 00000000..f04c817c
--- /dev/null
+++ "b/docs/03.\346\225\260\346\215\256\345\272\223/05.MySQL/24.MySQL - \345\270\270\347\224\250sql\346\212\200\345\267\247.md"
@@ -0,0 +1,176 @@
+---
+title: MySQL - 常用sql技巧
+permalink: /mysql/common-use-sql-skill/
+date: 2021-05-24 19:06:10
+---
+
+
+
+
+
+- [SQL执行顺序](#sql%E6%89%A7%E8%A1%8C%E9%A1%BA%E5%BA%8F)
+- [正则表达式使用](#%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F%E4%BD%BF%E7%94%A8)
+- [MySQL 常用函数](#mysql-%E5%B8%B8%E7%94%A8%E5%87%BD%E6%95%B0)
+
+
+
+
+
+## SQL执行顺序
+
+编写顺序
+
+```SQL
+SELECT DISTINCT
+