r=>{if(typeof r[e]=="undefined")return;let n=[r.location,e].join(":");return t.set(n,lunr.tokenizer.table=[]),r[e]}}function Re(t,e){let[r,n]=[new Set(t),new Set(e)];return[...new Set([...r].filter(i=>!n.has(i)))]}var U=class{constructor({config:e,docs:r,options:n}){let i=Oe(this.table=new Map);this.map=ie(r),this.options=n,this.index=lunr(function(){this.metadataWhitelist=["position"],this.b(0),e.lang.length===1&&e.lang[0]!=="en"?this.use(lunr[e.lang[0]]):e.lang.length>1&&this.use(lunr.multiLanguage(...e.lang)),this.tokenizer=ae,lunr.tokenizer.separator=new RegExp(e.separator),lunr.segmenter="TinySegmenter"in lunr?new lunr.TinySegmenter:void 0;let s=Re(["trimmer","stopWordFilter","stemmer"],e.pipeline);for(let o of e.lang.map(a=>a==="en"?lunr:lunr[a]))for(let a of s)this.pipeline.remove(o[a]),this.searchPipeline.remove(o[a]);this.ref("location");for(let[o,a]of Object.entries(e.fields))this.field(o,B(_({},a),{extractor:i(o)}));for(let o of r)this.add(o,{boost:o.boost})})}search(e){if(e=e.replace(new RegExp("\\p{sc=Han}+","gu"),s=>[...fe(s,this.index.invertedIndex)].join("* ")),e=ce(e),!e)return{items:[]};let r=le(e).filter(s=>s.presence!==lunr.Query.presence.PROHIBITED),n=this.index.search(e).reduce((s,{ref:o,score:a,matchData:u})=>{let c=this.map.get(o);if(typeof c!="undefined"){c=_({},c),c.tags&&(c.tags=[...c.tags]);let f=he(r,Object.keys(u.metadata));for(let l of this.index.fields){if(typeof c[l]=="undefined")continue;let m=[];for(let d of Object.values(u.metadata))typeof d[l]!="undefined"&&m.push(...d[l].position);if(!m.length)continue;let x=this.table.get([c.location,l].join(":")),v=Array.isArray(c[l])?q:oe;c[l]=v(c[l],x,m,l!=="text")}let g=+!c.parent+Object.values(f).filter(l=>l).length/Object.keys(f).length;s.push(B(_({},c),{score:a*(1+K(g,2)),terms:f}))}return s},[]).sort((s,o)=>o.score-s.score).reduce((s,o)=>{let a=this.map.get(o.location);if(typeof a!="undefined"){let u=a.parent?a.parent.location:a.location;s.set(u,[...s.get(u)||[],o])}return s},new Map);for(let[s,o]of n)if(!o.find(a=>a.location===s)){let a=this.map.get(s);o.push(B(_({},a),{score:0,terms:{}}))}let i;if(this.options.suggest){let s=this.index.query(o=>{for(let a of r)o.term(a.term,{fields:["title"],presence:lunr.Query.presence.REQUIRED,wildcard:lunr.Query.wildcard.TRAILING})});i=s.length?Object.keys(s[0].matchData.metadata):[]}return _({items:[...n.values()]},typeof i!="undefined"&&{suggest:i})}};var de;function Ie(t){return W(this,null,function*(){let e="../lunr";if(typeof parent!="undefined"&&"IFrameWorker"in parent){let n=ne("script[src]"),[i]=n.src.split("/worker");e=e.replace("..",i)}let r=[];for(let n of t.lang){switch(n){case"ja":r.push(`${e}/tinyseg.js`);break;case"hi":case"th":r.push(`${e}/wordcut.js`);break}n!=="en"&&r.push(`${e}/min/lunr.${n}.min.js`)}t.lang.length>1&&r.push(`${e}/min/lunr.multi.min.js`),r.length&&(yield importScripts(`${e}/min/lunr.stemmer.support.min.js`,...r))})}function Fe(t){return W(this,null,function*(){switch(t.type){case 0:return yield Ie(t.data.config),de=new U(t.data),{type:1};case 2:let e=t.data;try{return{type:3,data:de.search(e)}}catch(r){return console.warn(`Invalid query: ${e} \u2013 see https://bit.ly/2s3ChXG`),console.warn(r),{type:3,data:{items:[]}}}default:throw new TypeError("Invalid message type")}})}self.lunr=Y.default;Y.default.utils.warn=console.warn;addEventListener("message",t=>W(void 0,null,function*(){postMessage(yield Fe(t.data))}));})();
diff --git a/assets/stylesheets/main.12320a83.min.css b/assets/stylesheets/main.12320a83.min.css
new file mode 100644
index 000000000..b33c69021
--- /dev/null
+++ b/assets/stylesheets/main.12320a83.min.css
@@ -0,0 +1 @@
+@charset "UTF-8";html{-webkit-text-size-adjust:none;-moz-text-size-adjust:none;text-size-adjust:none;box-sizing:border-box}*,:after,:before{box-sizing:inherit}@media (prefers-reduced-motion){*,:after,:before{transition:none!important}}body{margin:0}a,button,input,label{-webkit-tap-highlight-color:transparent}a{color:inherit;text-decoration:none}hr{border:0;box-sizing:initial;display:block;height:.05rem;overflow:visible;padding:0}small{font-size:80%}sub,sup{line-height:1em}img{border-style:none}table{border-collapse:initial;border-spacing:0}td,th{font-weight:400;vertical-align:top}button{background:#0000;border:0;font-family:inherit;font-size:inherit;margin:0;padding:0}input{border:0;outline:none}:root{--md-primary-fg-color:#4051b5;--md-primary-fg-color--light:#5d6cc0;--md-primary-fg-color--dark:#303fa1;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3;--md-accent-fg-color:#526cfe;--md-accent-fg-color--transparent:#526cfe1a;--md-accent-bg-color:#fff;--md-accent-bg-color--light:#ffffffb3}[data-md-color-scheme=default]{color-scheme:light}[data-md-color-scheme=default] img[src$="#gh-dark-mode-only"],[data-md-color-scheme=default] img[src$="#only-dark"]{display:none}:root,[data-md-color-scheme=default]{--md-hue:225deg;--md-default-fg-color:#000000de;--md-default-fg-color--light:#0000008a;--md-default-fg-color--lighter:#00000052;--md-default-fg-color--lightest:#00000012;--md-default-bg-color:#fff;--md-default-bg-color--light:#ffffffb3;--md-default-bg-color--lighter:#ffffff4d;--md-default-bg-color--lightest:#ffffff1f;--md-code-fg-color:#36464e;--md-code-bg-color:#f5f5f5;--md-code-bg-color--light:#f5f5f5b3;--md-code-bg-color--lighter:#f5f5f54d;--md-code-hl-color:#4287ff;--md-code-hl-color--light:#4287ff1a;--md-code-hl-number-color:#d52a2a;--md-code-hl-special-color:#db1457;--md-code-hl-function-color:#a846b9;--md-code-hl-constant-color:#6e59d9;--md-code-hl-keyword-color:#3f6ec6;--md-code-hl-string-color:#1c7d4d;--md-code-hl-name-color:var(--md-code-fg-color);--md-code-hl-operator-color:var(--md-default-fg-color--light);--md-code-hl-punctuation-color:var(--md-default-fg-color--light);--md-code-hl-comment-color:var(--md-default-fg-color--light);--md-code-hl-generic-color:var(--md-default-fg-color--light);--md-code-hl-variable-color:var(--md-default-fg-color--light);--md-typeset-color:var(--md-default-fg-color);--md-typeset-a-color:var(--md-primary-fg-color);--md-typeset-del-color:#f5503d26;--md-typeset-ins-color:#0bd57026;--md-typeset-kbd-color:#fafafa;--md-typeset-kbd-accent-color:#fff;--md-typeset-kbd-border-color:#b8b8b8;--md-typeset-mark-color:#ffff0080;--md-typeset-table-color:#0000001f;--md-typeset-table-color--light:rgba(0,0,0,.035);--md-admonition-fg-color:var(--md-default-fg-color);--md-admonition-bg-color:var(--md-default-bg-color);--md-warning-fg-color:#000000de;--md-warning-bg-color:#ff9;--md-footer-fg-color:#fff;--md-footer-fg-color--light:#ffffffb3;--md-footer-fg-color--lighter:#ffffff73;--md-footer-bg-color:#000000de;--md-footer-bg-color--dark:#00000052;--md-shadow-z1:0 0.2rem 0.5rem #0000000d,0 0 0.05rem #0000001a;--md-shadow-z2:0 0.2rem 0.5rem #0000001a,0 0 0.05rem #00000040;--md-shadow-z3:0 0.2rem 0.5rem #0003,0 0 0.05rem #00000059}.md-icon svg{fill:currentcolor;display:block;height:1.2rem;width:1.2rem}body{-webkit-font-smoothing:antialiased;-moz-osx-font-smoothing:grayscale;--md-text-font-family:var(--md-text-font,_),-apple-system,BlinkMacSystemFont,Helvetica,Arial,sans-serif;--md-code-font-family:var(--md-code-font,_),SFMono-Regular,Consolas,Menlo,monospace}aside,body,input{font-feature-settings:"kern","liga";color:var(--md-typeset-color);font-family:var(--md-text-font-family)}code,kbd,pre{font-feature-settings:"kern";font-family:var(--md-code-font-family)}:root{--md-typeset-table-sort-icon:url('data:image/svg+xml;charset=utf-8,');--md-typeset-table-sort-icon--asc:url('data:image/svg+xml;charset=utf-8,');--md-typeset-table-sort-icon--desc:url('data:image/svg+xml;charset=utf-8,')}.md-typeset{-webkit-print-color-adjust:exact;color-adjust:exact;font-size:.8rem;line-height:1.6}@media print{.md-typeset{font-size:.68rem}}.md-typeset blockquote,.md-typeset dl,.md-typeset figure,.md-typeset ol,.md-typeset pre,.md-typeset ul{margin-bottom:1em;margin-top:1em}.md-typeset h1{color:var(--md-default-fg-color--light);font-size:2em;line-height:1.3;margin:0 0 1.25em}.md-typeset h1,.md-typeset h2{font-weight:300;letter-spacing:-.01em}.md-typeset h2{font-size:1.5625em;line-height:1.4;margin:1.6em 0 .64em}.md-typeset h3{font-size:1.25em;font-weight:400;letter-spacing:-.01em;line-height:1.5;margin:1.6em 0 .8em}.md-typeset h2+h3{margin-top:.8em}.md-typeset h4{font-weight:700;letter-spacing:-.01em;margin:1em 0}.md-typeset h5,.md-typeset h6{color:var(--md-default-fg-color--light);font-size:.8em;font-weight:700;letter-spacing:-.01em;margin:1.25em 0}.md-typeset h5{text-transform:uppercase}.md-typeset hr{border-bottom:.05rem solid var(--md-default-fg-color--lightest);display:flow-root;margin:1.5em 0}.md-typeset a{color:var(--md-typeset-a-color);word-break:break-word}.md-typeset a,.md-typeset a:before{transition:color 125ms}.md-typeset a:focus,.md-typeset a:hover{color:var(--md-accent-fg-color)}.md-typeset a:focus code,.md-typeset a:hover code{background-color:var(--md-accent-fg-color--transparent);color:var(--md-accent-fg-color)}.md-typeset a code{color:var(--md-typeset-a-color)}.md-typeset a.focus-visible{outline-color:var(--md-accent-fg-color);outline-offset:.2rem}.md-typeset code,.md-typeset kbd,.md-typeset pre{color:var(--md-code-fg-color);direction:ltr;font-variant-ligatures:none;transition:background-color 125ms}@media print{.md-typeset code,.md-typeset kbd,.md-typeset pre{white-space:pre-wrap}}.md-typeset code{background-color:var(--md-code-bg-color);border-radius:.1rem;-webkit-box-decoration-break:clone;box-decoration-break:clone;font-size:.85em;padding:0 .2941176471em;transition:color 125ms,background-color 125ms;word-break:break-word}.md-typeset code:not(.focus-visible){-webkit-tap-highlight-color:transparent;outline:none}.md-typeset pre{display:flow-root;line-height:1.4;position:relative}.md-typeset pre>code{-webkit-box-decoration-break:slice;box-decoration-break:slice;box-shadow:none;display:block;margin:0;outline-color:var(--md-accent-fg-color);overflow:auto;padding:.7720588235em 1.1764705882em;scrollbar-color:var(--md-default-fg-color--lighter) #0000;scrollbar-width:thin;touch-action:auto;word-break:normal}.md-typeset pre>code:hover{scrollbar-color:var(--md-accent-fg-color) #0000}.md-typeset pre>code::-webkit-scrollbar{height:.2rem;width:.2rem}.md-typeset pre>code::-webkit-scrollbar-thumb{background-color:var(--md-default-fg-color--lighter)}.md-typeset pre>code::-webkit-scrollbar-thumb:hover{background-color:var(--md-accent-fg-color)}.md-typeset kbd{background-color:var(--md-typeset-kbd-color);border-radius:.1rem;box-shadow:0 .1rem 0 .05rem var(--md-typeset-kbd-border-color),0 .1rem 0 var(--md-typeset-kbd-border-color),0 -.1rem .2rem var(--md-typeset-kbd-accent-color) inset;color:var(--md-default-fg-color);display:inline-block;font-size:.75em;padding:0 .6666666667em;vertical-align:text-top;word-break:break-word}.md-typeset mark{background-color:var(--md-typeset-mark-color);-webkit-box-decoration-break:clone;box-decoration-break:clone;color:inherit;word-break:break-word}.md-typeset abbr{cursor:help;text-decoration:none}.md-typeset [data-preview],.md-typeset abbr{border-bottom:.05rem dotted var(--md-default-fg-color--light)}.md-typeset small{opacity:.75}[dir=ltr] .md-typeset sub,[dir=ltr] .md-typeset sup{margin-left:.078125em}[dir=rtl] .md-typeset sub,[dir=rtl] .md-typeset sup{margin-right:.078125em}[dir=ltr] .md-typeset blockquote{padding-left:.6rem}[dir=rtl] .md-typeset blockquote{padding-right:.6rem}[dir=ltr] .md-typeset blockquote{border-left:.2rem solid var(--md-default-fg-color--lighter)}[dir=rtl] .md-typeset blockquote{border-right:.2rem solid var(--md-default-fg-color--lighter)}.md-typeset blockquote{color:var(--md-default-fg-color--light);margin-left:0;margin-right:0}.md-typeset ul{list-style-type:disc}.md-typeset ul[type]{list-style-type:revert-layer}[dir=ltr] .md-typeset ol,[dir=ltr] .md-typeset ul{margin-left:.625em}[dir=rtl] .md-typeset ol,[dir=rtl] .md-typeset ul{margin-right:.625em}.md-typeset ol,.md-typeset ul{padding:0}.md-typeset ol:not([hidden]),.md-typeset ul:not([hidden]){display:flow-root}.md-typeset ol ol,.md-typeset ul ol{list-style-type:lower-alpha}.md-typeset ol ol ol,.md-typeset ul ol ol{list-style-type:lower-roman}.md-typeset ol ol ol ol,.md-typeset ul ol ol ol{list-style-type:upper-alpha}.md-typeset ol ol ol ol ol,.md-typeset ul ol ol ol ol{list-style-type:upper-roman}.md-typeset ol[type],.md-typeset ul[type]{list-style-type:revert-layer}[dir=ltr] .md-typeset ol li,[dir=ltr] .md-typeset ul li{margin-left:1.25em}[dir=rtl] .md-typeset ol li,[dir=rtl] .md-typeset ul li{margin-right:1.25em}.md-typeset ol li,.md-typeset ul li{margin-bottom:.5em}.md-typeset ol li blockquote,.md-typeset ol li p,.md-typeset ul li blockquote,.md-typeset ul li p{margin:.5em 0}.md-typeset ol li:last-child,.md-typeset ul li:last-child{margin-bottom:0}[dir=ltr] .md-typeset ol li ol,[dir=ltr] .md-typeset ol li ul,[dir=ltr] .md-typeset ul li ol,[dir=ltr] .md-typeset ul li ul{margin-left:.625em}[dir=rtl] .md-typeset ol li ol,[dir=rtl] .md-typeset ol li ul,[dir=rtl] .md-typeset ul li ol,[dir=rtl] .md-typeset ul li ul{margin-right:.625em}.md-typeset ol li ol,.md-typeset ol li ul,.md-typeset ul li ol,.md-typeset ul li ul{margin-bottom:.5em;margin-top:.5em}[dir=ltr] .md-typeset dd{margin-left:1.875em}[dir=rtl] .md-typeset dd{margin-right:1.875em}.md-typeset dd{margin-bottom:1.5em;margin-top:1em}.md-typeset img,.md-typeset svg,.md-typeset video{height:auto;max-width:100%}.md-typeset img[align=left]{margin:1em 1em 1em 0}.md-typeset img[align=right]{margin:1em 0 1em 1em}.md-typeset img[align]:only-child{margin-top:0}.md-typeset figure{display:flow-root;margin:1em auto;max-width:100%;text-align:center;width:-moz-fit-content;width:fit-content}.md-typeset figure img{display:block;margin:0 auto}.md-typeset figcaption{font-style:italic;margin:1em auto;max-width:24rem}.md-typeset iframe{max-width:100%}.md-typeset table:not([class]){background-color:var(--md-default-bg-color);border:.05rem solid var(--md-typeset-table-color);border-radius:.1rem;display:inline-block;font-size:.64rem;max-width:100%;overflow:auto;touch-action:auto}@media print{.md-typeset table:not([class]){display:table}}.md-typeset table:not([class])+*{margin-top:1.5em}.md-typeset table:not([class]) td>:first-child,.md-typeset table:not([class]) th>:first-child{margin-top:0}.md-typeset table:not([class]) td>:last-child,.md-typeset table:not([class]) th>:last-child{margin-bottom:0}.md-typeset table:not([class]) td:not([align]),.md-typeset table:not([class]) th:not([align]){text-align:left}[dir=rtl] .md-typeset table:not([class]) td:not([align]),[dir=rtl] .md-typeset table:not([class]) th:not([align]){text-align:right}.md-typeset table:not([class]) th{font-weight:700;min-width:5rem;padding:.9375em 1.25em;vertical-align:top}.md-typeset table:not([class]) td{border-top:.05rem solid var(--md-typeset-table-color);padding:.9375em 1.25em;vertical-align:top}.md-typeset table:not([class]) tbody tr{transition:background-color 125ms}.md-typeset table:not([class]) tbody tr:hover{background-color:var(--md-typeset-table-color--light);box-shadow:0 .05rem 0 var(--md-default-bg-color) inset}.md-typeset table:not([class]) a{word-break:normal}.md-typeset table th[role=columnheader]{cursor:pointer}[dir=ltr] .md-typeset table th[role=columnheader]:after{margin-left:.5em}[dir=rtl] .md-typeset table th[role=columnheader]:after{margin-right:.5em}.md-typeset table th[role=columnheader]:after{content:"";display:inline-block;height:1.2em;-webkit-mask-image:var(--md-typeset-table-sort-icon);mask-image:var(--md-typeset-table-sort-icon);-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;transition:background-color 125ms;vertical-align:text-bottom;width:1.2em}.md-typeset table th[role=columnheader]:hover:after{background-color:var(--md-default-fg-color--lighter)}.md-typeset table th[role=columnheader][aria-sort=ascending]:after{background-color:var(--md-default-fg-color--light);-webkit-mask-image:var(--md-typeset-table-sort-icon--asc);mask-image:var(--md-typeset-table-sort-icon--asc)}.md-typeset table th[role=columnheader][aria-sort=descending]:after{background-color:var(--md-default-fg-color--light);-webkit-mask-image:var(--md-typeset-table-sort-icon--desc);mask-image:var(--md-typeset-table-sort-icon--desc)}.md-typeset__scrollwrap{margin:1em -.8rem;overflow-x:auto;touch-action:auto}.md-typeset__table{display:inline-block;margin-bottom:.5em;padding:0 .8rem}@media print{.md-typeset__table{display:block}}html .md-typeset__table table{display:table;margin:0;overflow:hidden;width:100%}@media screen and (max-width:44.984375em){.md-content__inner>pre{margin:1em -.8rem}.md-content__inner>pre code{border-radius:0}}.md-typeset .md-author{border-radius:100%;display:block;flex-shrink:0;height:1.6rem;overflow:hidden;position:relative;transition:color 125ms,transform 125ms;width:1.6rem}.md-typeset .md-author img{display:block}.md-typeset .md-author--more{background:var(--md-default-fg-color--lightest);color:var(--md-default-fg-color--lighter);font-size:.6rem;font-weight:700;line-height:1.6rem;text-align:center}.md-typeset .md-author--long{height:2.4rem;width:2.4rem}.md-typeset a.md-author{transform:scale(1)}.md-typeset a.md-author img{border-radius:100%;filter:grayscale(100%) opacity(75%);transition:filter 125ms}.md-typeset a.md-author:focus,.md-typeset a.md-author:hover{transform:scale(1.1);z-index:1}.md-typeset a.md-author:focus img,.md-typeset a.md-author:hover img{filter:grayscale(0)}.md-banner{background-color:var(--md-footer-bg-color);color:var(--md-footer-fg-color);overflow:auto}@media print{.md-banner{display:none}}.md-banner--warning{background-color:var(--md-warning-bg-color);color:var(--md-warning-fg-color)}.md-banner__inner{font-size:.7rem;margin:.6rem auto;padding:0 .8rem}[dir=ltr] .md-banner__button{float:right}[dir=rtl] .md-banner__button{float:left}.md-banner__button{color:inherit;cursor:pointer;transition:opacity .25s}.no-js .md-banner__button{display:none}.md-banner__button:hover{opacity:.7}html{font-size:125%;height:100%;overflow-x:hidden}@media screen and (min-width:100em){html{font-size:137.5%}}@media screen and (min-width:125em){html{font-size:150%}}body{background-color:var(--md-default-bg-color);display:flex;flex-direction:column;font-size:.5rem;min-height:100%;position:relative;width:100%}@media print{body{display:block}}@media screen and (max-width:59.984375em){body[data-md-scrolllock]{position:fixed}}.md-grid{margin-left:auto;margin-right:auto;max-width:61rem}.md-container{display:flex;flex-direction:column;flex-grow:1}@media print{.md-container{display:block}}.md-main{flex-grow:1}.md-main__inner{display:flex;height:100%;margin-top:1.5rem}.md-ellipsis{overflow:hidden;text-overflow:ellipsis}.md-toggle{display:none}.md-option{height:0;opacity:0;position:absolute;width:0}.md-option:checked+label:not([hidden]){display:block}.md-option.focus-visible+label{outline-color:var(--md-accent-fg-color);outline-style:auto}.md-skip{background-color:var(--md-default-fg-color);border-radius:.1rem;color:var(--md-default-bg-color);font-size:.64rem;margin:.5rem;opacity:0;outline-color:var(--md-accent-fg-color);padding:.3rem .5rem;position:fixed;transform:translateY(.4rem);z-index:-1}.md-skip:focus{opacity:1;transform:translateY(0);transition:transform .25s cubic-bezier(.4,0,.2,1),opacity 175ms 75ms;z-index:10}@page{margin:25mm}:root{--md-clipboard-icon:url('data:image/svg+xml;charset=utf-8,')}.md-clipboard{border-radius:.1rem;color:var(--md-default-fg-color--lightest);cursor:pointer;height:1.5em;outline-color:var(--md-accent-fg-color);outline-offset:.1rem;transition:color .25s;width:1.5em;z-index:1}@media print{.md-clipboard{display:none}}.md-clipboard:not(.focus-visible){-webkit-tap-highlight-color:transparent;outline:none}:hover>.md-clipboard{color:var(--md-default-fg-color--light)}.md-clipboard:focus,.md-clipboard:hover{color:var(--md-accent-fg-color)}.md-clipboard:after{background-color:currentcolor;content:"";display:block;height:1.125em;margin:0 auto;-webkit-mask-image:var(--md-clipboard-icon);mask-image:var(--md-clipboard-icon);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;width:1.125em}.md-clipboard--inline{cursor:pointer}.md-clipboard--inline code{transition:color .25s,background-color .25s}.md-clipboard--inline:focus code,.md-clipboard--inline:hover code{background-color:var(--md-accent-fg-color--transparent);color:var(--md-accent-fg-color)}:root{--md-code-select-icon:url('data:image/svg+xml;charset=utf-8,');--md-code-copy-icon:url('data:image/svg+xml;charset=utf-8,')}.md-typeset .md-code__content{display:grid}.md-code__nav{background-color:var(--md-code-bg-color--lighter);border-radius:.1rem;display:flex;gap:.2rem;padding:.2rem;position:absolute;right:.25em;top:.25em;transition:background-color .25s;z-index:1}:hover>.md-code__nav{background-color:var(--md-code-bg-color--light)}.md-code__button{color:var(--md-default-fg-color--lightest);cursor:pointer;display:block;height:1.5em;outline-color:var(--md-accent-fg-color);outline-offset:.1rem;transition:color .25s;width:1.5em}:hover>*>.md-code__button{color:var(--md-default-fg-color--light)}.md-code__button.focus-visible,.md-code__button:hover{color:var(--md-accent-fg-color)}.md-code__button--active{color:var(--md-default-fg-color)!important}.md-code__button:after{background-color:currentcolor;content:"";display:block;height:1.125em;margin:0 auto;-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;width:1.125em}.md-code__button[data-md-type=select]:after{-webkit-mask-image:var(--md-code-select-icon);mask-image:var(--md-code-select-icon)}.md-code__button[data-md-type=copy]:after{-webkit-mask-image:var(--md-code-copy-icon);mask-image:var(--md-code-copy-icon)}@keyframes consent{0%{opacity:0;transform:translateY(100%)}to{opacity:1;transform:translateY(0)}}@keyframes overlay{0%{opacity:0}to{opacity:1}}.md-consent__overlay{animation:overlay .25s both;-webkit-backdrop-filter:blur(.1rem);backdrop-filter:blur(.1rem);background-color:#0000008a;height:100%;opacity:1;position:fixed;top:0;width:100%;z-index:5}.md-consent__inner{animation:consent .5s cubic-bezier(.1,.7,.1,1) both;background-color:var(--md-default-bg-color);border:0;border-radius:.1rem;bottom:0;box-shadow:0 0 .2rem #0000001a,0 .2rem .4rem #0003;max-height:100%;overflow:auto;padding:0;position:fixed;width:100%;z-index:5}.md-consent__form{padding:.8rem}.md-consent__settings{display:none;margin:1em 0}input:checked+.md-consent__settings{display:block}.md-consent__controls{margin-bottom:.8rem}.md-typeset .md-consent__controls .md-button{display:inline}@media screen and (max-width:44.984375em){.md-typeset .md-consent__controls .md-button{display:block;margin-top:.4rem;text-align:center;width:100%}}.md-consent label{cursor:pointer}.md-content{flex-grow:1;min-width:0}.md-content__inner{margin:0 .8rem 1.2rem;padding-top:.6rem}@media screen and (min-width:76.25em){[dir=ltr] .md-sidebar--primary:not([hidden])~.md-content>.md-content__inner{margin-left:1.2rem}[dir=ltr] .md-sidebar--secondary:not([hidden])~.md-content>.md-content__inner,[dir=rtl] .md-sidebar--primary:not([hidden])~.md-content>.md-content__inner{margin-right:1.2rem}[dir=rtl] .md-sidebar--secondary:not([hidden])~.md-content>.md-content__inner{margin-left:1.2rem}}.md-content__inner:before{content:"";display:block;height:.4rem}.md-content__inner>:last-child{margin-bottom:0}[dir=ltr] .md-content__button{float:right}[dir=rtl] .md-content__button{float:left}[dir=ltr] .md-content__button{margin-left:.4rem}[dir=rtl] .md-content__button{margin-right:.4rem}.md-content__button{margin:.4rem 0;padding:0}@media print{.md-content__button{display:none}}.md-typeset .md-content__button{color:var(--md-default-fg-color--lighter)}.md-content__button svg{display:inline;vertical-align:top}[dir=rtl] .md-content__button svg{transform:scaleX(-1)}[dir=ltr] .md-dialog{right:.8rem}[dir=rtl] .md-dialog{left:.8rem}.md-dialog{background-color:var(--md-default-fg-color);border-radius:.1rem;bottom:.8rem;box-shadow:var(--md-shadow-z3);min-width:11.1rem;opacity:0;padding:.4rem .6rem;pointer-events:none;position:fixed;transform:translateY(100%);transition:transform 0ms .4s,opacity .4s;z-index:4}@media print{.md-dialog{display:none}}.md-dialog--active{opacity:1;pointer-events:auto;transform:translateY(0);transition:transform .4s cubic-bezier(.075,.85,.175,1),opacity .4s}.md-dialog__inner{color:var(--md-default-bg-color);font-size:.7rem}.md-feedback{margin:2em 0 1em;text-align:center}.md-feedback fieldset{border:none;margin:0;padding:0}.md-feedback__title{font-weight:700;margin:1em auto}.md-feedback__inner{position:relative}.md-feedback__list{display:flex;flex-wrap:wrap;place-content:baseline center;position:relative}.md-feedback__list:hover .md-icon:not(:disabled){color:var(--md-default-fg-color--lighter)}:disabled .md-feedback__list{min-height:1.8rem}.md-feedback__icon{color:var(--md-default-fg-color--light);cursor:pointer;flex-shrink:0;margin:0 .1rem;transition:color 125ms}.md-feedback__icon:not(:disabled).md-icon:hover{color:var(--md-accent-fg-color)}.md-feedback__icon:disabled{color:var(--md-default-fg-color--lightest);pointer-events:none}.md-feedback__note{opacity:0;position:relative;transform:translateY(.4rem);transition:transform .4s cubic-bezier(.1,.7,.1,1),opacity .15s}.md-feedback__note>*{margin:0 auto;max-width:16rem}:disabled .md-feedback__note{opacity:1;transform:translateY(0)}@media print{.md-feedback{display:none}}.md-footer{background-color:var(--md-footer-bg-color);color:var(--md-footer-fg-color)}@media print{.md-footer{display:none}}.md-footer__inner{justify-content:space-between;overflow:auto;padding:.2rem}.md-footer__inner:not([hidden]){display:flex}.md-footer__link{align-items:end;display:flex;flex-grow:0.01;margin-bottom:.4rem;margin-top:1rem;max-width:100%;outline-color:var(--md-accent-fg-color);overflow:hidden;transition:opacity .25s}.md-footer__link:focus,.md-footer__link:hover{opacity:.7}[dir=rtl] .md-footer__link svg{transform:scaleX(-1)}@media screen and (max-width:44.984375em){.md-footer__link--prev{flex-shrink:0}.md-footer__link--prev .md-footer__title{display:none}}[dir=ltr] .md-footer__link--next{margin-left:auto}[dir=rtl] .md-footer__link--next{margin-right:auto}.md-footer__link--next{text-align:right}[dir=rtl] .md-footer__link--next{text-align:left}.md-footer__title{flex-grow:1;font-size:.9rem;margin-bottom:.7rem;max-width:calc(100% - 2.4rem);padding:0 1rem;white-space:nowrap}.md-footer__button{margin:.2rem;padding:.4rem}.md-footer__direction{font-size:.64rem;opacity:.7}.md-footer-meta{background-color:var(--md-footer-bg-color--dark)}.md-footer-meta__inner{display:flex;flex-wrap:wrap;justify-content:space-between;padding:.2rem}html .md-footer-meta.md-typeset a{color:var(--md-footer-fg-color--light)}html .md-footer-meta.md-typeset a:focus,html .md-footer-meta.md-typeset a:hover{color:var(--md-footer-fg-color)}.md-copyright{color:var(--md-footer-fg-color--lighter);font-size:.64rem;margin:auto .6rem;padding:.4rem 0;width:100%}@media screen and (min-width:45em){.md-copyright{width:auto}}.md-copyright__highlight{color:var(--md-footer-fg-color--light)}.md-social{display:inline-flex;gap:.2rem;margin:0 .4rem;padding:.2rem 0 .6rem}@media screen and (min-width:45em){.md-social{padding:.6rem 0}}.md-social__link{display:inline-block;height:1.6rem;text-align:center;width:1.6rem}.md-social__link:before{line-height:1.9}.md-social__link svg{fill:currentcolor;max-height:.8rem;vertical-align:-25%}.md-typeset .md-button{border:.1rem solid;border-radius:.1rem;color:var(--md-primary-fg-color);cursor:pointer;display:inline-block;font-weight:700;padding:.625em 2em;transition:color 125ms,background-color 125ms,border-color 125ms}.md-typeset .md-button--primary{background-color:var(--md-primary-fg-color);border-color:var(--md-primary-fg-color);color:var(--md-primary-bg-color)}.md-typeset .md-button:focus,.md-typeset .md-button:hover{background-color:var(--md-accent-fg-color);border-color:var(--md-accent-fg-color);color:var(--md-accent-bg-color)}[dir=ltr] .md-typeset .md-input{border-top-left-radius:.1rem}[dir=ltr] .md-typeset .md-input,[dir=rtl] .md-typeset .md-input{border-top-right-radius:.1rem}[dir=rtl] .md-typeset .md-input{border-top-left-radius:.1rem}.md-typeset .md-input{border-bottom:.1rem solid var(--md-default-fg-color--lighter);box-shadow:var(--md-shadow-z1);font-size:.8rem;height:1.8rem;padding:0 .6rem;transition:border .25s,box-shadow .25s}.md-typeset .md-input:focus,.md-typeset .md-input:hover{border-bottom-color:var(--md-accent-fg-color);box-shadow:var(--md-shadow-z2)}.md-typeset .md-input--stretch{width:100%}.md-header{background-color:var(--md-primary-fg-color);box-shadow:0 0 .2rem #0000,0 .2rem .4rem #0000;color:var(--md-primary-bg-color);display:block;left:0;position:sticky;right:0;top:0;z-index:4}@media print{.md-header{display:none}}.md-header[hidden]{transform:translateY(-100%);transition:transform .25s cubic-bezier(.8,0,.6,1),box-shadow .25s}.md-header--shadow{box-shadow:0 0 .2rem #0000001a,0 .2rem .4rem #0003;transition:transform .25s cubic-bezier(.1,.7,.1,1),box-shadow .25s}.md-header__inner{align-items:center;display:flex;padding:0 .2rem}.md-header__button{color:currentcolor;cursor:pointer;margin:.2rem;outline-color:var(--md-accent-fg-color);padding:.4rem;position:relative;transition:opacity .25s;vertical-align:middle;z-index:1}.md-header__button:hover{opacity:.7}.md-header__button:not([hidden]){display:inline-block}.md-header__button:not(.focus-visible){-webkit-tap-highlight-color:transparent;outline:none}.md-header__button.md-logo{margin:.2rem;padding:.4rem}@media screen and (max-width:76.234375em){.md-header__button.md-logo{display:none}}.md-header__button.md-logo img,.md-header__button.md-logo svg{fill:currentcolor;display:block;height:1.2rem;width:auto}@media screen and (min-width:60em){.md-header__button[for=__search]{display:none}}.no-js .md-header__button[for=__search]{display:none}[dir=rtl] .md-header__button[for=__search] svg{transform:scaleX(-1)}@media screen and (min-width:76.25em){.md-header__button[for=__drawer]{display:none}}.md-header__topic{display:flex;max-width:100%;position:absolute;transition:transform .4s cubic-bezier(.1,.7,.1,1),opacity .15s;white-space:nowrap}.md-header__topic+.md-header__topic{opacity:0;pointer-events:none;transform:translateX(1.25rem);transition:transform .4s cubic-bezier(1,.7,.1,.1),opacity .15s;z-index:-1}[dir=rtl] .md-header__topic+.md-header__topic{transform:translateX(-1.25rem)}.md-header__topic:first-child{font-weight:700}[dir=ltr] .md-header__title{margin-left:1rem;margin-right:.4rem}[dir=rtl] .md-header__title{margin-left:.4rem;margin-right:1rem}.md-header__title{flex-grow:1;font-size:.9rem;height:2.4rem;line-height:2.4rem}.md-header__title--active .md-header__topic{opacity:0;pointer-events:none;transform:translateX(-1.25rem);transition:transform .4s cubic-bezier(1,.7,.1,.1),opacity .15s;z-index:-1}[dir=rtl] .md-header__title--active .md-header__topic{transform:translateX(1.25rem)}.md-header__title--active .md-header__topic+.md-header__topic{opacity:1;pointer-events:auto;transform:translateX(0);transition:transform .4s cubic-bezier(.1,.7,.1,1),opacity .15s;z-index:0}.md-header__title>.md-header__ellipsis{height:100%;position:relative;width:100%}.md-header__option{display:flex;flex-shrink:0;max-width:100%;transition:max-width 0ms .25s,opacity .25s .25s;white-space:nowrap}[data-md-toggle=search]:checked~.md-header .md-header__option{max-width:0;opacity:0;transition:max-width 0ms,opacity 0ms}.md-header__option>input{bottom:0}.md-header__source{display:none}@media screen and (min-width:60em){[dir=ltr] .md-header__source{margin-left:1rem}[dir=rtl] .md-header__source{margin-right:1rem}.md-header__source{display:block;max-width:11.7rem;width:11.7rem}}@media screen and (min-width:76.25em){[dir=ltr] .md-header__source{margin-left:1.4rem}[dir=rtl] .md-header__source{margin-right:1.4rem}}.md-meta{color:var(--md-default-fg-color--light);font-size:.7rem;line-height:1.3}.md-meta__list{display:inline-flex;flex-wrap:wrap;list-style:none;margin:0;padding:0}.md-meta__item:not(:last-child):after{content:"·";margin-left:.2rem;margin-right:.2rem}.md-meta__link{color:var(--md-typeset-a-color)}.md-meta__link:focus,.md-meta__link:hover{color:var(--md-accent-fg-color)}.md-draft{background-color:#ff1744;border-radius:.125em;color:#fff;display:inline-block;font-weight:700;padding-left:.5714285714em;padding-right:.5714285714em}:root{--md-nav-icon--prev:url('data:image/svg+xml;charset=utf-8,');--md-nav-icon--next:url('data:image/svg+xml;charset=utf-8,');--md-toc-icon:url('data:image/svg+xml;charset=utf-8,')}.md-nav{font-size:.7rem;line-height:1.3}.md-nav__title{color:var(--md-default-fg-color--light);display:block;font-weight:700;overflow:hidden;padding:0 .6rem;text-overflow:ellipsis}.md-nav__title .md-nav__button{display:none}.md-nav__title .md-nav__button img{height:100%;width:auto}.md-nav__title .md-nav__button.md-logo img,.md-nav__title .md-nav__button.md-logo svg{fill:currentcolor;display:block;height:2.4rem;max-width:100%;object-fit:contain;width:auto}.md-nav__list{list-style:none;margin:0;padding:0}.md-nav__link{align-items:flex-start;display:flex;gap:.4rem;margin-top:.625em;scroll-snap-align:start;transition:color 125ms}.md-nav__link--passed,.md-nav__link--passed code{color:var(--md-default-fg-color--light)}.md-nav__item .md-nav__link--active,.md-nav__item .md-nav__link--active code{color:var(--md-typeset-a-color)}.md-nav__link .md-ellipsis{position:relative}.md-nav__link .md-ellipsis code{word-break:normal}[dir=ltr] .md-nav__link .md-icon:last-child{margin-left:auto}[dir=rtl] .md-nav__link .md-icon:last-child{margin-right:auto}.md-nav__link .md-typeset{font-size:.7rem;line-height:1.3}.md-nav__link svg{fill:currentcolor;flex-shrink:0;height:1.3em;position:relative}.md-nav__link[for]:focus,.md-nav__link[for]:hover,.md-nav__link[href]:focus,.md-nav__link[href]:hover{color:var(--md-accent-fg-color);cursor:pointer}.md-nav__link[for]:focus code,.md-nav__link[for]:hover code,.md-nav__link[href]:focus code,.md-nav__link[href]:hover code{background-color:var(--md-accent-fg-color--transparent);color:var(--md-accent-fg-color)}.md-nav__link.focus-visible{outline-color:var(--md-accent-fg-color);outline-offset:.2rem}.md-nav--primary .md-nav__link[for=__toc]{display:none}.md-nav--primary .md-nav__link[for=__toc] .md-icon:after{background-color:currentcolor;display:block;height:100%;-webkit-mask-image:var(--md-toc-icon);mask-image:var(--md-toc-icon);width:100%}.md-nav--primary .md-nav__link[for=__toc]~.md-nav{display:none}.md-nav__container>.md-nav__link{margin-top:0}.md-nav__container>.md-nav__link:first-child{flex-grow:1;min-width:0}.md-nav__icon{flex-shrink:0}.md-nav__source{display:none}@media screen and (max-width:76.234375em){.md-nav--primary,.md-nav--primary .md-nav{background-color:var(--md-default-bg-color);display:flex;flex-direction:column;height:100%;left:0;position:absolute;right:0;top:0;z-index:1}.md-nav--primary .md-nav__item,.md-nav--primary .md-nav__title{font-size:.8rem;line-height:1.5}.md-nav--primary .md-nav__title{background-color:var(--md-default-fg-color--lightest);color:var(--md-default-fg-color--light);cursor:pointer;height:5.6rem;line-height:2.4rem;padding:3rem .8rem .2rem;position:relative;white-space:nowrap}[dir=ltr] .md-nav--primary .md-nav__title .md-nav__icon{left:.4rem}[dir=rtl] .md-nav--primary .md-nav__title .md-nav__icon{right:.4rem}.md-nav--primary .md-nav__title .md-nav__icon{display:block;height:1.2rem;margin:.2rem;position:absolute;top:.4rem;width:1.2rem}.md-nav--primary .md-nav__title .md-nav__icon:after{background-color:currentcolor;content:"";display:block;height:100%;-webkit-mask-image:var(--md-nav-icon--prev);mask-image:var(--md-nav-icon--prev);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;width:100%}.md-nav--primary .md-nav__title~.md-nav__list{background-color:var(--md-default-bg-color);box-shadow:0 .05rem 0 var(--md-default-fg-color--lightest) inset;overflow-y:auto;scroll-snap-type:y mandatory;touch-action:pan-y}.md-nav--primary .md-nav__title~.md-nav__list>:first-child{border-top:0}.md-nav--primary .md-nav__title[for=__drawer]{background-color:var(--md-primary-fg-color);color:var(--md-primary-bg-color);font-weight:700}.md-nav--primary .md-nav__title .md-logo{display:block;left:.2rem;margin:.2rem;padding:.4rem;position:absolute;right:.2rem;top:.2rem}.md-nav--primary .md-nav__list{flex:1}.md-nav--primary .md-nav__item{border-top:.05rem solid var(--md-default-fg-color--lightest)}.md-nav--primary .md-nav__item--active>.md-nav__link{color:var(--md-typeset-a-color)}.md-nav--primary .md-nav__item--active>.md-nav__link:focus,.md-nav--primary .md-nav__item--active>.md-nav__link:hover{color:var(--md-accent-fg-color)}.md-nav--primary .md-nav__link{margin-top:0;padding:.6rem .8rem}.md-nav--primary .md-nav__link svg{margin-top:.1em}.md-nav--primary .md-nav__link>.md-nav__link{padding:0}[dir=ltr] .md-nav--primary .md-nav__link .md-nav__icon{margin-right:-.2rem}[dir=rtl] .md-nav--primary .md-nav__link .md-nav__icon{margin-left:-.2rem}.md-nav--primary .md-nav__link .md-nav__icon{font-size:1.2rem;height:1.2rem;width:1.2rem}.md-nav--primary .md-nav__link .md-nav__icon:after{background-color:currentcolor;content:"";display:block;height:100%;-webkit-mask-image:var(--md-nav-icon--next);mask-image:var(--md-nav-icon--next);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;width:100%}[dir=rtl] .md-nav--primary .md-nav__icon:after{transform:scale(-1)}.md-nav--primary .md-nav--secondary .md-nav{background-color:initial;position:static}[dir=ltr] .md-nav--primary .md-nav--secondary .md-nav .md-nav__link{padding-left:1.4rem}[dir=rtl] .md-nav--primary .md-nav--secondary .md-nav .md-nav__link{padding-right:1.4rem}[dir=ltr] .md-nav--primary .md-nav--secondary .md-nav .md-nav .md-nav__link{padding-left:2rem}[dir=rtl] .md-nav--primary .md-nav--secondary .md-nav .md-nav .md-nav__link{padding-right:2rem}[dir=ltr] .md-nav--primary .md-nav--secondary .md-nav .md-nav .md-nav .md-nav__link{padding-left:2.6rem}[dir=rtl] .md-nav--primary .md-nav--secondary .md-nav .md-nav .md-nav .md-nav__link{padding-right:2.6rem}[dir=ltr] .md-nav--primary .md-nav--secondary .md-nav .md-nav .md-nav .md-nav .md-nav__link{padding-left:3.2rem}[dir=rtl] .md-nav--primary .md-nav--secondary .md-nav .md-nav .md-nav .md-nav .md-nav__link{padding-right:3.2rem}.md-nav--secondary{background-color:initial}.md-nav__toggle~.md-nav{display:flex;opacity:0;transform:translateX(100%);transition:transform .25s cubic-bezier(.8,0,.6,1),opacity 125ms 50ms}[dir=rtl] .md-nav__toggle~.md-nav{transform:translateX(-100%)}.md-nav__toggle:checked~.md-nav{opacity:1;transform:translateX(0);transition:transform .25s cubic-bezier(.4,0,.2,1),opacity 125ms 125ms}.md-nav__toggle:checked~.md-nav>.md-nav__list{-webkit-backface-visibility:hidden;backface-visibility:hidden}}@media screen and (max-width:59.984375em){.md-nav--primary .md-nav__link[for=__toc]{display:flex}.md-nav--primary .md-nav__link[for=__toc] .md-icon:after{content:""}.md-nav--primary .md-nav__link[for=__toc]+.md-nav__link{display:none}.md-nav--primary .md-nav__link[for=__toc]~.md-nav{display:flex}.md-nav__source{background-color:var(--md-primary-fg-color--dark);color:var(--md-primary-bg-color);display:block;padding:0 .2rem}}@media screen and (min-width:60em) and (max-width:76.234375em){.md-nav--integrated .md-nav__link[for=__toc]{display:flex}.md-nav--integrated .md-nav__link[for=__toc] .md-icon:after{content:""}.md-nav--integrated .md-nav__link[for=__toc]+.md-nav__link{display:none}.md-nav--integrated .md-nav__link[for=__toc]~.md-nav{display:flex}}@media screen and (min-width:60em){.md-nav{margin-bottom:-.4rem}.md-nav--secondary .md-nav__title{background:var(--md-default-bg-color);box-shadow:0 0 .4rem .4rem var(--md-default-bg-color);position:sticky;top:0;z-index:1}.md-nav--secondary .md-nav__title[for=__toc]{scroll-snap-align:start}.md-nav--secondary .md-nav__title .md-nav__icon{display:none}[dir=ltr] .md-nav--secondary .md-nav__list{padding-left:.6rem}[dir=rtl] .md-nav--secondary .md-nav__list{padding-right:.6rem}.md-nav--secondary .md-nav__list{padding-bottom:.4rem}[dir=ltr] .md-nav--secondary .md-nav__item>.md-nav__link{margin-right:.4rem}[dir=rtl] .md-nav--secondary .md-nav__item>.md-nav__link{margin-left:.4rem}}@media screen and (min-width:76.25em){.md-nav{margin-bottom:-.4rem;transition:max-height .25s cubic-bezier(.86,0,.07,1)}.md-nav--primary .md-nav__title{background:var(--md-default-bg-color);box-shadow:0 0 .4rem .4rem var(--md-default-bg-color);position:sticky;top:0;z-index:1}.md-nav--primary .md-nav__title[for=__drawer]{scroll-snap-align:start}.md-nav--primary .md-nav__title .md-nav__icon{display:none}[dir=ltr] .md-nav--primary .md-nav__list{padding-left:.6rem}[dir=rtl] .md-nav--primary .md-nav__list{padding-right:.6rem}.md-nav--primary .md-nav__list{padding-bottom:.4rem}[dir=ltr] .md-nav--primary .md-nav__item>.md-nav__link{margin-right:.4rem}[dir=rtl] .md-nav--primary .md-nav__item>.md-nav__link{margin-left:.4rem}.md-nav__toggle~.md-nav{display:grid;grid-template-rows:0fr;opacity:0;transition:grid-template-rows .25s cubic-bezier(.86,0,.07,1),opacity .25s,visibility 0ms .25s;visibility:collapse}.md-nav__toggle~.md-nav>.md-nav__list{overflow:hidden}.md-nav__toggle.md-toggle--indeterminate~.md-nav,.md-nav__toggle:checked~.md-nav{grid-template-rows:1fr;opacity:1;transition:grid-template-rows .25s cubic-bezier(.86,0,.07,1),opacity .15s .1s,visibility 0ms;visibility:visible}.md-nav__toggle.md-toggle--indeterminate~.md-nav{transition:none}.md-nav__item--nested>.md-nav>.md-nav__title{display:none}.md-nav__item--section{display:block;margin:1.25em 0}.md-nav__item--section:last-child{margin-bottom:0}.md-nav__item--section>.md-nav__link{font-weight:700}.md-nav__item--section>.md-nav__link[for]{color:var(--md-default-fg-color--light)}.md-nav__item--section>.md-nav__link:not(.md-nav__container){pointer-events:none}.md-nav__item--section>.md-nav__link .md-icon,.md-nav__item--section>.md-nav__link>[for]{display:none}[dir=ltr] .md-nav__item--section>.md-nav{margin-left:-.6rem}[dir=rtl] .md-nav__item--section>.md-nav{margin-right:-.6rem}.md-nav__item--section>.md-nav{display:block;opacity:1;visibility:visible}.md-nav__item--section>.md-nav>.md-nav__list>.md-nav__item{padding:0}.md-nav__icon{border-radius:100%;height:.9rem;transition:background-color .25s;width:.9rem}.md-nav__icon:hover{background-color:var(--md-accent-fg-color--transparent)}.md-nav__icon:after{background-color:currentcolor;border-radius:100%;content:"";display:inline-block;height:100%;-webkit-mask-image:var(--md-nav-icon--next);mask-image:var(--md-nav-icon--next);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;transition:transform .25s;vertical-align:-.1rem;width:100%}[dir=rtl] .md-nav__icon:after{transform:rotate(180deg)}.md-nav__item--nested .md-nav__toggle:checked~.md-nav__link .md-nav__icon:after,.md-nav__item--nested .md-toggle--indeterminate~.md-nav__link .md-nav__icon:after{transform:rotate(90deg)}.md-nav--lifted>.md-nav__list>.md-nav__item,.md-nav--lifted>.md-nav__title{display:none}.md-nav--lifted>.md-nav__list>.md-nav__item--active{display:block}.md-nav--lifted>.md-nav__list>.md-nav__item--active>.md-nav__link{background:var(--md-default-bg-color);box-shadow:0 0 .4rem .4rem var(--md-default-bg-color);margin-top:0;position:sticky;top:0;z-index:1}.md-nav--lifted>.md-nav__list>.md-nav__item--active>.md-nav__link:not(.md-nav__container){pointer-events:none}.md-nav--lifted>.md-nav__list>.md-nav__item--active.md-nav__item--section{margin:0}[dir=ltr] .md-nav--lifted>.md-nav__list>.md-nav__item>.md-nav:not(.md-nav--secondary){margin-left:-.6rem}[dir=rtl] .md-nav--lifted>.md-nav__list>.md-nav__item>.md-nav:not(.md-nav--secondary){margin-right:-.6rem}.md-nav--lifted>.md-nav__list>.md-nav__item>[for]{color:var(--md-default-fg-color--light)}.md-nav--lifted .md-nav[data-md-level="1"]{grid-template-rows:1fr;opacity:1;visibility:visible}[dir=ltr] .md-nav--integrated>.md-nav__list>.md-nav__item--active .md-nav--secondary{border-left:.05rem solid var(--md-primary-fg-color)}[dir=rtl] .md-nav--integrated>.md-nav__list>.md-nav__item--active .md-nav--secondary{border-right:.05rem solid var(--md-primary-fg-color)}.md-nav--integrated>.md-nav__list>.md-nav__item--active .md-nav--secondary{display:block;margin-bottom:1.25em;opacity:1;visibility:visible}.md-nav--integrated>.md-nav__list>.md-nav__item--active .md-nav--secondary>.md-nav__list{overflow:visible;padding-bottom:0}.md-nav--integrated>.md-nav__list>.md-nav__item--active .md-nav--secondary>.md-nav__title{display:none}}.md-pagination{font-size:.8rem;font-weight:700;gap:.4rem}.md-pagination,.md-pagination>*{align-items:center;display:flex;justify-content:center}.md-pagination>*{border-radius:.2rem;height:1.8rem;min-width:1.8rem;text-align:center}.md-pagination__current{background-color:var(--md-default-fg-color--lightest);color:var(--md-default-fg-color--light)}.md-pagination__link{transition:color 125ms,background-color 125ms}.md-pagination__link:focus,.md-pagination__link:hover{background-color:var(--md-accent-fg-color--transparent);color:var(--md-accent-fg-color)}.md-pagination__link:focus svg,.md-pagination__link:hover svg{color:var(--md-accent-fg-color)}.md-pagination__link.focus-visible{outline-color:var(--md-accent-fg-color);outline-offset:.2rem}.md-pagination__link svg{fill:currentcolor;color:var(--md-default-fg-color--lighter);display:block;max-height:100%;width:1.2rem}:root{--md-path-icon:url('data:image/svg+xml;charset=utf-8,')}.md-path{font-size:.7rem;margin:0 .8rem;overflow:auto;padding-top:1.2rem}.md-path:not([hidden]){display:block}@media screen and (min-width:76.25em){.md-path{margin:0 1.2rem}}.md-path__list{align-items:center;display:flex;gap:.2rem;list-style:none;margin:0;padding:0}.md-path__item:not(:first-child){display:inline-flex;gap:.2rem;white-space:nowrap}.md-path__item:not(:first-child):before{background-color:var(--md-default-fg-color--lighter);content:"";display:inline;height:.8rem;-webkit-mask-image:var(--md-path-icon);mask-image:var(--md-path-icon);width:.8rem}.md-path__link{align-items:center;color:var(--md-default-fg-color--light);display:flex}.md-path__link:focus,.md-path__link:hover{color:var(--md-accent-fg-color)}:root{--md-post-pin-icon:url('data:image/svg+xml;charset=utf-8,')}.md-post__back{border-bottom:.05rem solid var(--md-default-fg-color--lightest);margin-bottom:1.2rem;padding-bottom:1.2rem}@media screen and (max-width:76.234375em){.md-post__back{display:none}}[dir=rtl] .md-post__back svg{transform:scaleX(-1)}.md-post__authors{display:flex;flex-direction:column;gap:.6rem;margin:0 .6rem 1.2rem}.md-post .md-post__meta a{transition:color 125ms}.md-post .md-post__meta a:focus,.md-post .md-post__meta a:hover{color:var(--md-accent-fg-color)}.md-post__title{color:var(--md-default-fg-color--light);font-weight:700}.md-post--excerpt{margin-bottom:3.2rem}.md-post--excerpt .md-post__header{align-items:center;display:flex;gap:.6rem;min-height:1.6rem}.md-post--excerpt .md-post__authors{align-items:center;display:inline-flex;flex-direction:row;gap:.2rem;margin:0;min-height:2.4rem}[dir=ltr] .md-post--excerpt .md-post__meta .md-meta__list{margin-right:.4rem}[dir=rtl] .md-post--excerpt .md-post__meta .md-meta__list{margin-left:.4rem}.md-post--excerpt .md-post__content>:first-child{--md-scroll-margin:6rem;margin-top:0}.md-post>.md-nav--secondary{margin:1em 0}.md-pin{background:var(--md-default-fg-color--lightest);border-radius:1rem;margin-top:-.05rem;padding:.2rem}.md-pin:after{background-color:currentcolor;content:"";display:block;height:.6rem;margin:0 auto;-webkit-mask-image:var(--md-post-pin-icon);mask-image:var(--md-post-pin-icon);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;width:.6rem}.md-profile{align-items:center;display:flex;font-size:.7rem;gap:.6rem;line-height:1.4;width:100%}.md-profile__description{flex-grow:1}.md-content--post{display:flex}@media screen and (max-width:76.234375em){.md-content--post{flex-flow:column-reverse}}.md-content--post>.md-content__inner{min-width:0}@media screen and (min-width:76.25em){[dir=ltr] .md-content--post>.md-content__inner{margin-left:1.2rem}[dir=rtl] .md-content--post>.md-content__inner{margin-right:1.2rem}}@media screen and (max-width:76.234375em){.md-sidebar.md-sidebar--post{padding:0;position:static;width:100%}.md-sidebar.md-sidebar--post .md-sidebar__scrollwrap{overflow:visible}.md-sidebar.md-sidebar--post .md-sidebar__inner{padding:0}.md-sidebar.md-sidebar--post .md-post__meta{margin-left:.6rem;margin-right:.6rem}.md-sidebar.md-sidebar--post .md-nav__item{border:none;display:inline}.md-sidebar.md-sidebar--post .md-nav__list{display:inline-flex;flex-wrap:wrap;gap:.6rem;padding-bottom:.6rem;padding-top:.6rem}.md-sidebar.md-sidebar--post .md-nav__link{padding:0}.md-sidebar.md-sidebar--post .md-nav{height:auto;margin-bottom:0;position:static}}:root{--md-progress-value:0;--md-progress-delay:400ms}.md-progress{background:var(--md-primary-bg-color);height:.075rem;opacity:min(clamp(0,var(--md-progress-value),1),clamp(0,100 - var(--md-progress-value),1));position:fixed;top:0;transform:scaleX(calc(var(--md-progress-value)*1%));transform-origin:left;transition:transform .5s cubic-bezier(.19,1,.22,1),opacity .25s var(--md-progress-delay);width:100%;z-index:4}:root{--md-search-result-icon:url('data:image/svg+xml;charset=utf-8,')}.md-search{position:relative}@media screen and (min-width:60em){.md-search{padding:.2rem 0}}.no-js .md-search{display:none}.md-search__overlay{opacity:0;z-index:1}@media screen and (max-width:59.984375em){[dir=ltr] .md-search__overlay{left:-2.2rem}[dir=rtl] .md-search__overlay{right:-2.2rem}.md-search__overlay{background-color:var(--md-default-bg-color);border-radius:1rem;height:2rem;overflow:hidden;pointer-events:none;position:absolute;top:-1rem;transform-origin:center;transition:transform .3s .1s,opacity .2s .2s;width:2rem}[data-md-toggle=search]:checked~.md-header .md-search__overlay{opacity:1;transition:transform .4s,opacity .1s}}@media screen and (min-width:60em){[dir=ltr] .md-search__overlay{left:0}[dir=rtl] .md-search__overlay{right:0}.md-search__overlay{background-color:#0000008a;cursor:pointer;height:0;position:fixed;top:0;transition:width 0ms .25s,height 0ms .25s,opacity .25s;width:0}[data-md-toggle=search]:checked~.md-header .md-search__overlay{height:200vh;opacity:1;transition:width 0ms,height 0ms,opacity .25s;width:100%}}@media screen and (max-width:29.984375em){[data-md-toggle=search]:checked~.md-header .md-search__overlay{transform:scale(45)}}@media screen and (min-width:30em) and (max-width:44.984375em){[data-md-toggle=search]:checked~.md-header .md-search__overlay{transform:scale(60)}}@media screen and (min-width:45em) and (max-width:59.984375em){[data-md-toggle=search]:checked~.md-header .md-search__overlay{transform:scale(75)}}.md-search__inner{-webkit-backface-visibility:hidden;backface-visibility:hidden}@media screen and (max-width:59.984375em){[dir=ltr] .md-search__inner{left:0}[dir=rtl] .md-search__inner{right:0}.md-search__inner{height:0;opacity:0;overflow:hidden;position:fixed;top:0;transform:translateX(5%);transition:width 0ms .3s,height 0ms .3s,transform .15s cubic-bezier(.4,0,.2,1) .15s,opacity .15s .15s;width:0;z-index:2}[dir=rtl] .md-search__inner{transform:translateX(-5%)}[data-md-toggle=search]:checked~.md-header .md-search__inner{height:100%;opacity:1;transform:translateX(0);transition:width 0ms 0ms,height 0ms 0ms,transform .15s cubic-bezier(.1,.7,.1,1) .15s,opacity .15s .15s;width:100%}}@media screen and (min-width:60em){[dir=ltr] .md-search__inner{float:right}[dir=rtl] .md-search__inner{float:left}.md-search__inner{padding:.1rem 0;position:relative;transition:width .25s cubic-bezier(.1,.7,.1,1);width:11.7rem}}@media screen and (min-width:60em) and (max-width:76.234375em){[data-md-toggle=search]:checked~.md-header .md-search__inner{width:23.4rem}}@media screen and (min-width:76.25em){[data-md-toggle=search]:checked~.md-header .md-search__inner{width:34.4rem}}.md-search__form{background-color:var(--md-default-bg-color);box-shadow:0 0 .6rem #0000;height:2.4rem;position:relative;transition:color .25s,background-color .25s;z-index:2}@media screen and (min-width:60em){.md-search__form{background-color:#00000042;border-radius:.1rem;height:1.8rem}.md-search__form:hover{background-color:#ffffff1f}}[data-md-toggle=search]:checked~.md-header .md-search__form{background-color:var(--md-default-bg-color);border-radius:.1rem .1rem 0 0;box-shadow:0 0 .6rem #00000012;color:var(--md-default-fg-color)}[dir=ltr] .md-search__input{padding-left:3.6rem;padding-right:2.2rem}[dir=rtl] .md-search__input{padding-left:2.2rem;padding-right:3.6rem}.md-search__input{background:#0000;font-size:.9rem;height:100%;position:relative;text-overflow:ellipsis;width:100%;z-index:2}.md-search__input::placeholder{transition:color .25s}.md-search__input::placeholder,.md-search__input~.md-search__icon{color:var(--md-default-fg-color--light)}.md-search__input::-ms-clear{display:none}@media screen and (max-width:59.984375em){.md-search__input{font-size:.9rem;height:2.4rem;width:100%}}@media screen and (min-width:60em){[dir=ltr] .md-search__input{padding-left:2.2rem}[dir=rtl] .md-search__input{padding-right:2.2rem}.md-search__input{color:inherit;font-size:.8rem}.md-search__input::placeholder{color:var(--md-primary-bg-color--light)}.md-search__input+.md-search__icon{color:var(--md-primary-bg-color)}[data-md-toggle=search]:checked~.md-header .md-search__input{text-overflow:clip}[data-md-toggle=search]:checked~.md-header .md-search__input+.md-search__icon{color:var(--md-default-fg-color--light)}[data-md-toggle=search]:checked~.md-header .md-search__input::placeholder{color:#0000}}.md-search__icon{cursor:pointer;display:inline-block;height:1.2rem;transition:color .25s,opacity .25s;width:1.2rem}.md-search__icon:hover{opacity:.7}[dir=ltr] .md-search__icon[for=__search]{left:.5rem}[dir=rtl] .md-search__icon[for=__search]{right:.5rem}.md-search__icon[for=__search]{position:absolute;top:.3rem;z-index:2}[dir=rtl] .md-search__icon[for=__search] svg{transform:scaleX(-1)}@media screen and (max-width:59.984375em){[dir=ltr] .md-search__icon[for=__search]{left:.8rem}[dir=rtl] .md-search__icon[for=__search]{right:.8rem}.md-search__icon[for=__search]{top:.6rem}.md-search__icon[for=__search] svg:first-child{display:none}}@media screen and (min-width:60em){.md-search__icon[for=__search]{pointer-events:none}.md-search__icon[for=__search] svg:last-child{display:none}}[dir=ltr] .md-search__options{right:.5rem}[dir=rtl] .md-search__options{left:.5rem}.md-search__options{pointer-events:none;position:absolute;top:.3rem;z-index:2}@media screen and (max-width:59.984375em){[dir=ltr] .md-search__options{right:.8rem}[dir=rtl] .md-search__options{left:.8rem}.md-search__options{top:.6rem}}[dir=ltr] .md-search__options>.md-icon{margin-left:.2rem}[dir=rtl] .md-search__options>.md-icon{margin-right:.2rem}.md-search__options>.md-icon{color:var(--md-default-fg-color--light);opacity:0;transform:scale(.75);transition:transform .15s cubic-bezier(.1,.7,.1,1),opacity .15s}.md-search__options>.md-icon:not(.focus-visible){-webkit-tap-highlight-color:transparent;outline:none}[data-md-toggle=search]:checked~.md-header .md-search__input:valid~.md-search__options>.md-icon{opacity:1;pointer-events:auto;transform:scale(1)}[data-md-toggle=search]:checked~.md-header .md-search__input:valid~.md-search__options>.md-icon:hover{opacity:.7}[dir=ltr] .md-search__suggest{padding-left:3.6rem;padding-right:2.2rem}[dir=rtl] .md-search__suggest{padding-left:2.2rem;padding-right:3.6rem}.md-search__suggest{align-items:center;color:var(--md-default-fg-color--lighter);display:flex;font-size:.9rem;height:100%;opacity:0;position:absolute;top:0;transition:opacity 50ms;white-space:nowrap;width:100%}@media screen and (min-width:60em){[dir=ltr] .md-search__suggest{padding-left:2.2rem}[dir=rtl] .md-search__suggest{padding-right:2.2rem}.md-search__suggest{font-size:.8rem}}[data-md-toggle=search]:checked~.md-header .md-search__suggest{opacity:1;transition:opacity .3s .1s}[dir=ltr] .md-search__output{border-bottom-left-radius:.1rem}[dir=ltr] .md-search__output,[dir=rtl] .md-search__output{border-bottom-right-radius:.1rem}[dir=rtl] .md-search__output{border-bottom-left-radius:.1rem}.md-search__output{overflow:hidden;position:absolute;width:100%;z-index:1}@media screen and (max-width:59.984375em){.md-search__output{bottom:0;top:2.4rem}}@media screen and (min-width:60em){.md-search__output{opacity:0;top:1.9rem;transition:opacity .4s}[data-md-toggle=search]:checked~.md-header .md-search__output{box-shadow:var(--md-shadow-z3);opacity:1}}.md-search__scrollwrap{-webkit-backface-visibility:hidden;backface-visibility:hidden;background-color:var(--md-default-bg-color);height:100%;overflow-y:auto;touch-action:pan-y}@media (-webkit-max-device-pixel-ratio:1),(max-resolution:1dppx){.md-search__scrollwrap{transform:translateZ(0)}}@media screen and (min-width:60em) and (max-width:76.234375em){.md-search__scrollwrap{width:23.4rem}}@media screen and (min-width:76.25em){.md-search__scrollwrap{width:34.4rem}}@media screen and (min-width:60em){.md-search__scrollwrap{max-height:0;scrollbar-color:var(--md-default-fg-color--lighter) #0000;scrollbar-width:thin}[data-md-toggle=search]:checked~.md-header .md-search__scrollwrap{max-height:75vh}.md-search__scrollwrap:hover{scrollbar-color:var(--md-accent-fg-color) #0000}.md-search__scrollwrap::-webkit-scrollbar{height:.2rem;width:.2rem}.md-search__scrollwrap::-webkit-scrollbar-thumb{background-color:var(--md-default-fg-color--lighter)}.md-search__scrollwrap::-webkit-scrollbar-thumb:hover{background-color:var(--md-accent-fg-color)}}.md-search-result{color:var(--md-default-fg-color);word-break:break-word}.md-search-result__meta{background-color:var(--md-default-fg-color--lightest);color:var(--md-default-fg-color--light);font-size:.64rem;line-height:1.8rem;padding:0 .8rem;scroll-snap-align:start}@media screen and (min-width:60em){[dir=ltr] .md-search-result__meta{padding-left:2.2rem}[dir=rtl] .md-search-result__meta{padding-right:2.2rem}}.md-search-result__list{list-style:none;margin:0;padding:0;-webkit-user-select:none;user-select:none}.md-search-result__item{box-shadow:0 -.05rem var(--md-default-fg-color--lightest)}.md-search-result__item:first-child{box-shadow:none}.md-search-result__link{display:block;outline:none;scroll-snap-align:start;transition:background-color .25s}.md-search-result__link:focus,.md-search-result__link:hover{background-color:var(--md-accent-fg-color--transparent)}.md-search-result__link:last-child p:last-child{margin-bottom:.6rem}.md-search-result__more>summary{cursor:pointer;display:block;outline:none;position:sticky;scroll-snap-align:start;top:0;z-index:1}.md-search-result__more>summary::marker{display:none}.md-search-result__more>summary::-webkit-details-marker{display:none}.md-search-result__more>summary>div{color:var(--md-typeset-a-color);font-size:.64rem;padding:.75em .8rem;transition:color .25s,background-color .25s}@media screen and (min-width:60em){[dir=ltr] .md-search-result__more>summary>div{padding-left:2.2rem}[dir=rtl] .md-search-result__more>summary>div{padding-right:2.2rem}}.md-search-result__more>summary:focus>div,.md-search-result__more>summary:hover>div{background-color:var(--md-accent-fg-color--transparent);color:var(--md-accent-fg-color)}.md-search-result__more[open]>summary{background-color:var(--md-default-bg-color)}.md-search-result__article{overflow:hidden;padding:0 .8rem;position:relative}@media screen and (min-width:60em){[dir=ltr] .md-search-result__article{padding-left:2.2rem}[dir=rtl] .md-search-result__article{padding-right:2.2rem}}[dir=ltr] .md-search-result__icon{left:0}[dir=rtl] .md-search-result__icon{right:0}.md-search-result__icon{color:var(--md-default-fg-color--light);height:1.2rem;margin:.5rem;position:absolute;width:1.2rem}@media screen and (max-width:59.984375em){.md-search-result__icon{display:none}}.md-search-result__icon:after{background-color:currentcolor;content:"";display:inline-block;height:100%;-webkit-mask-image:var(--md-search-result-icon);mask-image:var(--md-search-result-icon);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;width:100%}[dir=rtl] .md-search-result__icon:after{transform:scaleX(-1)}.md-search-result .md-typeset{color:var(--md-default-fg-color--light);font-size:.64rem;line-height:1.6}.md-search-result .md-typeset h1{color:var(--md-default-fg-color);font-size:.8rem;font-weight:400;line-height:1.4;margin:.55rem 0}.md-search-result .md-typeset h1 mark{text-decoration:none}.md-search-result .md-typeset h2{color:var(--md-default-fg-color);font-size:.64rem;font-weight:700;line-height:1.6;margin:.5em 0}.md-search-result .md-typeset h2 mark{text-decoration:none}.md-search-result__terms{color:var(--md-default-fg-color);display:block;font-size:.64rem;font-style:italic;margin:.5em 0}.md-search-result mark{background-color:initial;color:var(--md-accent-fg-color);text-decoration:underline}.md-select{position:relative;z-index:1}.md-select__inner{background-color:var(--md-default-bg-color);border-radius:.1rem;box-shadow:var(--md-shadow-z2);color:var(--md-default-fg-color);left:50%;margin-top:.2rem;max-height:0;opacity:0;position:absolute;top:calc(100% - .2rem);transform:translate3d(-50%,.3rem,0);transition:transform .25s 375ms,opacity .25s .25s,max-height 0ms .5s}.md-select:focus-within .md-select__inner,.md-select:hover .md-select__inner{max-height:10rem;opacity:1;transform:translate3d(-50%,0,0);transition:transform .25s cubic-bezier(.1,.7,.1,1),opacity .25s,max-height 0ms}.md-select__inner:after{border-bottom:.2rem solid #0000;border-bottom-color:var(--md-default-bg-color);border-left:.2rem solid #0000;border-right:.2rem solid #0000;border-top:0;content:"";height:0;left:50%;margin-left:-.2rem;margin-top:-.2rem;position:absolute;top:0;width:0}.md-select__list{border-radius:.1rem;font-size:.8rem;list-style-type:none;margin:0;max-height:inherit;overflow:auto;padding:0}.md-select__item{line-height:1.8rem}[dir=ltr] .md-select__link{padding-left:.6rem;padding-right:1.2rem}[dir=rtl] .md-select__link{padding-left:1.2rem;padding-right:.6rem}.md-select__link{cursor:pointer;display:block;outline:none;scroll-snap-align:start;transition:background-color .25s,color .25s;width:100%}.md-select__link:focus,.md-select__link:hover{color:var(--md-accent-fg-color)}.md-select__link:focus{background-color:var(--md-default-fg-color--lightest)}.md-sidebar{align-self:flex-start;flex-shrink:0;padding:1.2rem 0;position:sticky;top:2.4rem;width:12.1rem}@media print{.md-sidebar{display:none}}@media screen and (max-width:76.234375em){[dir=ltr] .md-sidebar--primary{left:-12.1rem}[dir=rtl] .md-sidebar--primary{right:-12.1rem}.md-sidebar--primary{background-color:var(--md-default-bg-color);display:block;height:100%;position:fixed;top:0;transform:translateX(0);transition:transform .25s cubic-bezier(.4,0,.2,1),box-shadow .25s;width:12.1rem;z-index:5}[data-md-toggle=drawer]:checked~.md-container .md-sidebar--primary{box-shadow:var(--md-shadow-z3);transform:translateX(12.1rem)}[dir=rtl] [data-md-toggle=drawer]:checked~.md-container .md-sidebar--primary{transform:translateX(-12.1rem)}.md-sidebar--primary .md-sidebar__scrollwrap{bottom:0;left:0;margin:0;overflow:hidden;position:absolute;right:0;scroll-snap-type:none;top:0}}@media screen and (min-width:76.25em){.md-sidebar{height:0}.no-js .md-sidebar{height:auto}.md-header--lifted~.md-container .md-sidebar{top:4.8rem}}.md-sidebar--secondary{display:none;order:2}@media screen and (min-width:60em){.md-sidebar--secondary{height:0}.no-js .md-sidebar--secondary{height:auto}.md-sidebar--secondary:not([hidden]){display:block}.md-sidebar--secondary .md-sidebar__scrollwrap{touch-action:pan-y}}.md-sidebar__scrollwrap{scrollbar-gutter:stable;-webkit-backface-visibility:hidden;backface-visibility:hidden;margin:0 .2rem;overflow-y:auto;scrollbar-color:var(--md-default-fg-color--lighter) #0000;scrollbar-width:thin}.md-sidebar__scrollwrap::-webkit-scrollbar{height:.2rem;width:.2rem}.md-sidebar__scrollwrap:focus-within,.md-sidebar__scrollwrap:hover{scrollbar-color:var(--md-accent-fg-color) #0000}.md-sidebar__scrollwrap:focus-within::-webkit-scrollbar-thumb,.md-sidebar__scrollwrap:hover::-webkit-scrollbar-thumb{background-color:var(--md-default-fg-color--lighter)}.md-sidebar__scrollwrap:focus-within::-webkit-scrollbar-thumb:hover,.md-sidebar__scrollwrap:hover::-webkit-scrollbar-thumb:hover{background-color:var(--md-accent-fg-color)}@supports selector(::-webkit-scrollbar){.md-sidebar__scrollwrap{scrollbar-gutter:auto}[dir=ltr] .md-sidebar__inner{padding-right:calc(100% - 11.5rem)}[dir=rtl] .md-sidebar__inner{padding-left:calc(100% - 11.5rem)}}@media screen and (max-width:76.234375em){.md-overlay{background-color:#0000008a;height:0;opacity:0;position:fixed;top:0;transition:width 0ms .25s,height 0ms .25s,opacity .25s;width:0;z-index:5}[data-md-toggle=drawer]:checked~.md-overlay{height:100%;opacity:1;transition:width 0ms,height 0ms,opacity .25s;width:100%}}@keyframes facts{0%{height:0}to{height:.65rem}}@keyframes fact{0%{opacity:0;transform:translateY(100%)}50%{opacity:0}to{opacity:1;transform:translateY(0)}}:root{--md-source-forks-icon:url('data:image/svg+xml;charset=utf-8,');--md-source-repositories-icon:url('data:image/svg+xml;charset=utf-8,');--md-source-stars-icon:url('data:image/svg+xml;charset=utf-8,');--md-source-version-icon:url('data:image/svg+xml;charset=utf-8,')}.md-source{-webkit-backface-visibility:hidden;backface-visibility:hidden;display:block;font-size:.65rem;line-height:1.2;outline-color:var(--md-accent-fg-color);transition:opacity .25s;white-space:nowrap}.md-source:hover{opacity:.7}.md-source__icon{display:inline-block;height:2.4rem;vertical-align:middle;width:2rem}[dir=ltr] .md-source__icon svg{margin-left:.6rem}[dir=rtl] .md-source__icon svg{margin-right:.6rem}.md-source__icon svg{margin-top:.6rem}[dir=ltr] .md-source__icon+.md-source__repository{padding-left:2rem}[dir=rtl] .md-source__icon+.md-source__repository{padding-right:2rem}[dir=ltr] .md-source__icon+.md-source__repository{margin-left:-2rem}[dir=rtl] .md-source__icon+.md-source__repository{margin-right:-2rem}[dir=ltr] .md-source__repository{margin-left:.6rem}[dir=rtl] .md-source__repository{margin-right:.6rem}.md-source__repository{display:inline-block;max-width:calc(100% - 1.2rem);overflow:hidden;text-overflow:ellipsis;vertical-align:middle}.md-source__facts{display:flex;font-size:.55rem;gap:.4rem;list-style-type:none;margin:.1rem 0 0;opacity:.75;overflow:hidden;padding:0;width:100%}.md-source__repository--active .md-source__facts{animation:facts .25s ease-in}.md-source__fact{overflow:hidden;text-overflow:ellipsis}.md-source__repository--active .md-source__fact{animation:fact .4s ease-out}[dir=ltr] .md-source__fact:before{margin-right:.1rem}[dir=rtl] .md-source__fact:before{margin-left:.1rem}.md-source__fact:before{background-color:currentcolor;content:"";display:inline-block;height:.6rem;-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;vertical-align:text-top;width:.6rem}.md-source__fact:nth-child(1n+2){flex-shrink:0}.md-source__fact--version:before{-webkit-mask-image:var(--md-source-version-icon);mask-image:var(--md-source-version-icon)}.md-source__fact--stars:before{-webkit-mask-image:var(--md-source-stars-icon);mask-image:var(--md-source-stars-icon)}.md-source__fact--forks:before{-webkit-mask-image:var(--md-source-forks-icon);mask-image:var(--md-source-forks-icon)}.md-source__fact--repositories:before{-webkit-mask-image:var(--md-source-repositories-icon);mask-image:var(--md-source-repositories-icon)}.md-source-file{margin:1em 0}[dir=ltr] .md-source-file__fact{margin-right:.6rem}[dir=rtl] .md-source-file__fact{margin-left:.6rem}.md-source-file__fact{align-items:center;color:var(--md-default-fg-color--light);display:inline-flex;font-size:.68rem;gap:.3rem}.md-source-file__fact .md-icon{flex-shrink:0;margin-bottom:.05rem}[dir=ltr] .md-source-file__fact .md-author{float:left}[dir=rtl] .md-source-file__fact .md-author{float:right}.md-source-file__fact .md-author{margin-right:.2rem}.md-source-file__fact svg{width:.9rem}:root{--md-status:url('data:image/svg+xml;charset=utf-8,');--md-status--new:url('data:image/svg+xml;charset=utf-8,');--md-status--deprecated:url('data:image/svg+xml;charset=utf-8,');--md-status--encrypted:url('data:image/svg+xml;charset=utf-8,')}.md-status:after{background-color:var(--md-default-fg-color--light);content:"";display:inline-block;height:1.125em;-webkit-mask-image:var(--md-status);mask-image:var(--md-status);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;vertical-align:text-bottom;width:1.125em}.md-status:hover:after{background-color:currentcolor}.md-status--new:after{-webkit-mask-image:var(--md-status--new);mask-image:var(--md-status--new)}.md-status--deprecated:after{-webkit-mask-image:var(--md-status--deprecated);mask-image:var(--md-status--deprecated)}.md-status--encrypted:after{-webkit-mask-image:var(--md-status--encrypted);mask-image:var(--md-status--encrypted)}.md-tabs{background-color:var(--md-primary-fg-color);color:var(--md-primary-bg-color);display:block;line-height:1.3;overflow:auto;width:100%;z-index:3}@media print{.md-tabs{display:none}}@media screen and (max-width:76.234375em){.md-tabs{display:none}}.md-tabs[hidden]{pointer-events:none}[dir=ltr] .md-tabs__list{margin-left:.2rem}[dir=rtl] .md-tabs__list{margin-right:.2rem}.md-tabs__list{contain:content;display:flex;list-style:none;margin:0;overflow:auto;padding:0;scrollbar-width:none;white-space:nowrap}.md-tabs__list::-webkit-scrollbar{display:none}.md-tabs__item{height:2.4rem;padding-left:.6rem;padding-right:.6rem}.md-tabs__item--active .md-tabs__link{color:inherit;opacity:1}.md-tabs__link{-webkit-backface-visibility:hidden;backface-visibility:hidden;display:flex;font-size:.7rem;margin-top:.8rem;opacity:.7;outline-color:var(--md-accent-fg-color);outline-offset:.2rem;transition:transform .4s cubic-bezier(.1,.7,.1,1),opacity .25s}.md-tabs__link:focus,.md-tabs__link:hover{color:inherit;opacity:1}[dir=ltr] .md-tabs__link svg{margin-right:.4rem}[dir=rtl] .md-tabs__link svg{margin-left:.4rem}.md-tabs__link svg{fill:currentcolor;height:1.3em}.md-tabs__item:nth-child(2) .md-tabs__link{transition-delay:20ms}.md-tabs__item:nth-child(3) .md-tabs__link{transition-delay:40ms}.md-tabs__item:nth-child(4) .md-tabs__link{transition-delay:60ms}.md-tabs__item:nth-child(5) .md-tabs__link{transition-delay:80ms}.md-tabs__item:nth-child(6) .md-tabs__link{transition-delay:.1s}.md-tabs__item:nth-child(7) .md-tabs__link{transition-delay:.12s}.md-tabs__item:nth-child(8) .md-tabs__link{transition-delay:.14s}.md-tabs__item:nth-child(9) .md-tabs__link{transition-delay:.16s}.md-tabs__item:nth-child(10) .md-tabs__link{transition-delay:.18s}.md-tabs__item:nth-child(11) .md-tabs__link{transition-delay:.2s}.md-tabs__item:nth-child(12) .md-tabs__link{transition-delay:.22s}.md-tabs__item:nth-child(13) .md-tabs__link{transition-delay:.24s}.md-tabs__item:nth-child(14) .md-tabs__link{transition-delay:.26s}.md-tabs__item:nth-child(15) .md-tabs__link{transition-delay:.28s}.md-tabs__item:nth-child(16) .md-tabs__link{transition-delay:.3s}.md-tabs[hidden] .md-tabs__link{opacity:0;transform:translateY(50%);transition:transform 0ms .1s,opacity .1s}:root{--md-tag-icon:url('data:image/svg+xml;charset=utf-8,')}.md-typeset .md-tags:not([hidden]){display:inline-flex;flex-wrap:wrap;gap:.5em;margin-bottom:.75em;margin-top:-.125em}.md-typeset .md-tag{align-items:center;background:var(--md-default-fg-color--lightest);border-radius:2.4rem;display:inline-flex;font-size:.64rem;font-size:min(.8em,.64rem);font-weight:700;gap:.5em;letter-spacing:normal;line-height:1.6;padding:.3125em .78125em}.md-typeset .md-tag[href]{-webkit-tap-highlight-color:transparent;color:inherit;outline:none;transition:color 125ms,background-color 125ms}.md-typeset .md-tag[href]:focus,.md-typeset .md-tag[href]:hover{background-color:var(--md-accent-fg-color);color:var(--md-accent-bg-color)}[id]>.md-typeset .md-tag{vertical-align:text-top}.md-typeset .md-tag-shadow{opacity:.5}.md-typeset .md-tag-icon:before{background-color:var(--md-default-fg-color--lighter);content:"";display:inline-block;height:1.2em;-webkit-mask-image:var(--md-tag-icon);mask-image:var(--md-tag-icon);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;transition:background-color 125ms;vertical-align:text-bottom;width:1.2em}.md-typeset .md-tag-icon[href]:focus:before,.md-typeset .md-tag-icon[href]:hover:before{background-color:var(--md-accent-bg-color)}@keyframes pulse{0%{transform:scale(.95)}75%{transform:scale(1)}to{transform:scale(.95)}}:root{--md-annotation-bg-icon:url('data:image/svg+xml;charset=utf-8,');--md-annotation-icon:url('data:image/svg+xml;charset=utf-8,')}.md-tooltip{-webkit-backface-visibility:hidden;backface-visibility:hidden;background-color:var(--md-default-bg-color);border-radius:.1rem;box-shadow:var(--md-shadow-z2);color:var(--md-default-fg-color);font-family:var(--md-text-font-family);left:clamp(var(--md-tooltip-0,0rem) + .8rem,var(--md-tooltip-x),100vw + var(--md-tooltip-0,0rem) + .8rem - var(--md-tooltip-width) - 2 * .8rem);max-width:calc(100vw - 1.6rem);opacity:0;position:absolute;top:var(--md-tooltip-y);transform:translateY(-.4rem);transition:transform 0ms .25s,opacity .25s,z-index .25s;width:var(--md-tooltip-width);z-index:0}.md-tooltip--active{opacity:1;transform:translateY(0);transition:transform .25s cubic-bezier(.1,.7,.1,1),opacity .25s,z-index 0ms;z-index:2}.md-tooltip--inline{font-weight:700;-webkit-user-select:none;user-select:none;width:auto}.md-tooltip--inline:not(.md-tooltip--active){transform:translateY(.2rem) scale(.9)}.md-tooltip--inline .md-tooltip__inner{font-size:.5rem;padding:.2rem .4rem}[hidden]+.md-tooltip--inline{display:none}.focus-visible>.md-tooltip,.md-tooltip:target{outline:var(--md-accent-fg-color) auto}.md-tooltip__inner{font-size:.64rem;padding:.8rem}.md-tooltip__inner.md-typeset>:first-child{margin-top:0}.md-tooltip__inner.md-typeset>:last-child{margin-bottom:0}.md-annotation{font-style:normal;font-weight:400;outline:none;text-align:initial;vertical-align:text-bottom;white-space:normal}[dir=rtl] .md-annotation{direction:rtl}code .md-annotation{font-family:var(--md-code-font-family);font-size:inherit}.md-annotation:not([hidden]){display:inline-block;line-height:1.25}.md-annotation__index{border-radius:.01px;cursor:pointer;display:inline-block;margin-left:.4ch;margin-right:.4ch;outline:none;overflow:hidden;position:relative;-webkit-user-select:none;user-select:none;vertical-align:text-top;z-index:0}.md-annotation .md-annotation__index{transition:z-index .25s}@media screen{.md-annotation__index{width:2.2ch}[data-md-visible]>.md-annotation__index{animation:pulse 2s infinite}.md-annotation__index:before{background:var(--md-default-bg-color);-webkit-mask-image:var(--md-annotation-bg-icon);mask-image:var(--md-annotation-bg-icon)}.md-annotation__index:after,.md-annotation__index:before{content:"";height:2.2ch;-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;position:absolute;top:-.1ch;width:2.2ch;z-index:-1}.md-annotation__index:after{background-color:var(--md-default-fg-color--lighter);-webkit-mask-image:var(--md-annotation-icon);mask-image:var(--md-annotation-icon);transform:scale(1.0001);transition:background-color .25s,transform .25s}.md-tooltip--active+.md-annotation__index:after{transform:rotate(45deg)}.md-tooltip--active+.md-annotation__index:after,:hover>.md-annotation__index:after{background-color:var(--md-accent-fg-color)}}.md-tooltip--active+.md-annotation__index{animation-play-state:paused;transition-duration:0ms;z-index:2}.md-annotation__index [data-md-annotation-id]{display:inline-block}@media print{.md-annotation__index [data-md-annotation-id]{background:var(--md-default-fg-color--lighter);border-radius:2ch;color:var(--md-default-bg-color);font-weight:700;padding:0 .6ch;white-space:nowrap}.md-annotation__index [data-md-annotation-id]:after{content:attr(data-md-annotation-id)}}.md-typeset .md-annotation-list{counter-reset:xxx;list-style:none}.md-typeset .md-annotation-list li{position:relative}[dir=ltr] .md-typeset .md-annotation-list li:before{left:-2.125em}[dir=rtl] .md-typeset .md-annotation-list li:before{right:-2.125em}.md-typeset .md-annotation-list li:before{background:var(--md-default-fg-color--lighter);border-radius:2ch;color:var(--md-default-bg-color);content:counter(xxx);counter-increment:xxx;font-size:.8875em;font-weight:700;height:2ch;line-height:1.25;min-width:2ch;padding:0 .6ch;position:absolute;text-align:center;top:.25em}:root{--md-tooltip-width:20rem;--md-tooltip-tail:0.3rem}.md-tooltip2{-webkit-backface-visibility:hidden;backface-visibility:hidden;color:var(--md-default-fg-color);font-family:var(--md-text-font-family);opacity:0;pointer-events:none;position:absolute;top:calc(var(--md-tooltip-host-y) + var(--md-tooltip-y));transform:translateY(-.4rem);transform-origin:calc(var(--md-tooltip-host-x) + var(--md-tooltip-x)) 0;transition:transform 0ms .25s,opacity .25s,z-index .25s;width:100%;z-index:0}.md-tooltip2:before{border-left:var(--md-tooltip-tail) solid #0000;border-right:var(--md-tooltip-tail) solid #0000;content:"";display:block;left:clamp(1.5 * .8rem,var(--md-tooltip-host-x) + var(--md-tooltip-x) - var(--md-tooltip-tail),100vw - 2 * var(--md-tooltip-tail) - 1.5 * .8rem);position:absolute;z-index:1}.md-tooltip2--top:before{border-top:var(--md-tooltip-tail) solid var(--md-default-bg-color);bottom:calc(var(--md-tooltip-tail)*-1 + .025rem);filter:drop-shadow(0 1px 0 hsla(0,0%,0%,.05))}.md-tooltip2--bottom:before{border-bottom:var(--md-tooltip-tail) solid var(--md-default-bg-color);filter:drop-shadow(0 -1px 0 hsla(0,0%,0%,.05));top:calc(var(--md-tooltip-tail)*-1 + .025rem)}.md-tooltip2--active{opacity:1;transform:translateY(0);transition:transform .4s cubic-bezier(0,1,.5,1),opacity .25s,z-index 0ms;z-index:2}.md-tooltip2__inner{scrollbar-gutter:stable;background-color:var(--md-default-bg-color);border-radius:.1rem;box-shadow:var(--md-shadow-z2);left:clamp(.8rem,var(--md-tooltip-host-x) - .8rem,100vw - var(--md-tooltip-width) - .8rem);max-height:40vh;max-width:calc(100vw - 1.6rem);position:relative;scrollbar-width:thin}.md-tooltip2__inner::-webkit-scrollbar{height:.2rem;width:.2rem}.md-tooltip2__inner::-webkit-scrollbar-thumb{background-color:var(--md-default-fg-color--lighter)}.md-tooltip2__inner::-webkit-scrollbar-thumb:hover{background-color:var(--md-accent-fg-color)}[role=dialog]>.md-tooltip2__inner{font-size:.64rem;overflow:auto;padding:0 .8rem;pointer-events:auto;width:var(--md-tooltip-width)}[role=dialog]>.md-tooltip2__inner:after,[role=dialog]>.md-tooltip2__inner:before{content:"";display:block;height:.8rem;position:sticky;width:100%;z-index:10}[role=dialog]>.md-tooltip2__inner:before{background:linear-gradient(var(--md-default-bg-color),#0000 75%);top:0}[role=dialog]>.md-tooltip2__inner:after{background:linear-gradient(#0000,var(--md-default-bg-color) 75%);bottom:0}[role=tooltip]>.md-tooltip2__inner{font-size:.5rem;font-weight:700;left:clamp(.8rem,var(--md-tooltip-host-x) + var(--md-tooltip-x) - var(--md-tooltip-width)/2,100vw - var(--md-tooltip-width) - .8rem);max-width:min(100vw - 2 * .8rem,400px);padding:.2rem .4rem;-webkit-user-select:none;user-select:none;width:-moz-fit-content;width:fit-content}.md-tooltip2__inner.md-typeset>:first-child{margin-top:0}.md-tooltip2__inner.md-typeset>:last-child{margin-bottom:0}[dir=ltr] .md-top{margin-left:50%}[dir=rtl] .md-top{margin-right:50%}.md-top{background-color:var(--md-default-bg-color);border-radius:1.6rem;box-shadow:var(--md-shadow-z2);color:var(--md-default-fg-color--light);cursor:pointer;display:block;font-size:.7rem;outline:none;padding:.4rem .8rem;position:fixed;top:3.2rem;transform:translate(-50%);transition:color 125ms,background-color 125ms,transform 125ms cubic-bezier(.4,0,.2,1),opacity 125ms;z-index:2}@media print{.md-top{display:none}}[dir=rtl] .md-top{transform:translate(50%)}.md-top[hidden]{opacity:0;pointer-events:none;transform:translate(-50%,.2rem);transition-duration:0ms}[dir=rtl] .md-top[hidden]{transform:translate(50%,.2rem)}.md-top:focus,.md-top:hover{background-color:var(--md-accent-fg-color);color:var(--md-accent-bg-color)}.md-top svg{display:inline-block;vertical-align:-.5em}@keyframes hoverfix{0%{pointer-events:none}}:root{--md-version-icon:url('data:image/svg+xml;charset=utf-8,')}.md-version{flex-shrink:0;font-size:.8rem;height:2.4rem}[dir=ltr] .md-version__current{margin-left:1.4rem;margin-right:.4rem}[dir=rtl] .md-version__current{margin-left:.4rem;margin-right:1.4rem}.md-version__current{color:inherit;cursor:pointer;outline:none;position:relative;top:.05rem}[dir=ltr] .md-version__current:after{margin-left:.4rem}[dir=rtl] .md-version__current:after{margin-right:.4rem}.md-version__current:after{background-color:currentcolor;content:"";display:inline-block;height:.6rem;-webkit-mask-image:var(--md-version-icon);mask-image:var(--md-version-icon);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;width:.4rem}.md-version__alias{margin-left:.3rem;opacity:.7}.md-version__list{background-color:var(--md-default-bg-color);border-radius:.1rem;box-shadow:var(--md-shadow-z2);color:var(--md-default-fg-color);list-style-type:none;margin:.2rem .8rem;max-height:0;opacity:0;overflow:auto;padding:0;position:absolute;scroll-snap-type:y mandatory;top:.15rem;transition:max-height 0ms .5s,opacity .25s .25s;z-index:3}.md-version:focus-within .md-version__list,.md-version:hover .md-version__list{max-height:10rem;opacity:1;transition:max-height 0ms,opacity .25s}@media (hover:none),(pointer:coarse){.md-version:hover .md-version__list{animation:hoverfix .25s forwards}.md-version:focus-within .md-version__list{animation:none}}.md-version__item{line-height:1.8rem}[dir=ltr] .md-version__link{padding-left:.6rem;padding-right:1.2rem}[dir=rtl] .md-version__link{padding-left:1.2rem;padding-right:.6rem}.md-version__link{cursor:pointer;display:block;outline:none;scroll-snap-align:start;transition:color .25s,background-color .25s;white-space:nowrap;width:100%}.md-version__link:focus,.md-version__link:hover{color:var(--md-accent-fg-color)}.md-version__link:focus{background-color:var(--md-default-fg-color--lightest)}:root{--md-admonition-icon--note:url('data:image/svg+xml;charset=utf-8,');--md-admonition-icon--abstract:url('data:image/svg+xml;charset=utf-8,');--md-admonition-icon--info:url('data:image/svg+xml;charset=utf-8,');--md-admonition-icon--tip:url('data:image/svg+xml;charset=utf-8,');--md-admonition-icon--success:url('data:image/svg+xml;charset=utf-8,');--md-admonition-icon--question:url('data:image/svg+xml;charset=utf-8,');--md-admonition-icon--warning:url('data:image/svg+xml;charset=utf-8,');--md-admonition-icon--failure:url('data:image/svg+xml;charset=utf-8,');--md-admonition-icon--danger:url('data:image/svg+xml;charset=utf-8,');--md-admonition-icon--bug:url('data:image/svg+xml;charset=utf-8,');--md-admonition-icon--example:url('data:image/svg+xml;charset=utf-8,');--md-admonition-icon--quote:url('data:image/svg+xml;charset=utf-8,')}.md-typeset .admonition,.md-typeset details{background-color:var(--md-admonition-bg-color);border:.075rem solid #448aff;border-radius:.2rem;box-shadow:var(--md-shadow-z1);color:var(--md-admonition-fg-color);display:flow-root;font-size:.64rem;margin:1.5625em 0;padding:0 .6rem;page-break-inside:avoid;transition:box-shadow 125ms}@media print{.md-typeset .admonition,.md-typeset details{box-shadow:none}}.md-typeset .admonition:focus-within,.md-typeset details:focus-within{box-shadow:0 0 0 .2rem #448aff1a}.md-typeset .admonition>*,.md-typeset details>*{box-sizing:border-box}.md-typeset .admonition .admonition,.md-typeset .admonition details,.md-typeset details .admonition,.md-typeset details details{margin-bottom:1em;margin-top:1em}.md-typeset .admonition .md-typeset__scrollwrap,.md-typeset details .md-typeset__scrollwrap{margin:1em -.6rem}.md-typeset .admonition .md-typeset__table,.md-typeset details .md-typeset__table{padding:0 .6rem}.md-typeset .admonition>.tabbed-set:only-child,.md-typeset details>.tabbed-set:only-child{margin-top:0}html .md-typeset .admonition>:last-child,html .md-typeset details>:last-child{margin-bottom:.6rem}[dir=ltr] .md-typeset .admonition-title,[dir=ltr] .md-typeset summary{padding-left:2rem;padding-right:.6rem}[dir=rtl] .md-typeset .admonition-title,[dir=rtl] .md-typeset summary{padding-left:.6rem;padding-right:2rem}[dir=ltr] .md-typeset .admonition-title,[dir=ltr] .md-typeset summary{border-left-width:.2rem}[dir=rtl] .md-typeset .admonition-title,[dir=rtl] .md-typeset summary{border-right-width:.2rem}[dir=ltr] .md-typeset .admonition-title,[dir=ltr] .md-typeset summary{border-top-left-radius:.1rem}[dir=ltr] .md-typeset .admonition-title,[dir=ltr] .md-typeset summary,[dir=rtl] .md-typeset .admonition-title,[dir=rtl] .md-typeset summary{border-top-right-radius:.1rem}[dir=rtl] .md-typeset .admonition-title,[dir=rtl] .md-typeset summary{border-top-left-radius:.1rem}.md-typeset .admonition-title,.md-typeset summary{background-color:#448aff1a;border:none;font-weight:700;margin:0 -.6rem;padding-bottom:.4rem;padding-top:.4rem;position:relative}html .md-typeset .admonition-title:last-child,html .md-typeset summary:last-child{margin-bottom:0}[dir=ltr] .md-typeset .admonition-title:before,[dir=ltr] .md-typeset summary:before{left:.6rem}[dir=rtl] .md-typeset .admonition-title:before,[dir=rtl] .md-typeset summary:before{right:.6rem}.md-typeset .admonition-title:before,.md-typeset summary:before{background-color:#448aff;content:"";height:1rem;-webkit-mask-image:var(--md-admonition-icon--note);mask-image:var(--md-admonition-icon--note);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;position:absolute;top:.625em;width:1rem}.md-typeset .admonition-title code,.md-typeset summary code{box-shadow:0 0 0 .05rem var(--md-default-fg-color--lightest)}.md-typeset .admonition.note,.md-typeset details.note{border-color:#448aff}.md-typeset .admonition.note:focus-within,.md-typeset details.note:focus-within{box-shadow:0 0 0 .2rem #448aff1a}.md-typeset .note>.admonition-title,.md-typeset .note>summary{background-color:#448aff1a}.md-typeset .note>.admonition-title:before,.md-typeset .note>summary:before{background-color:#448aff;-webkit-mask-image:var(--md-admonition-icon--note);mask-image:var(--md-admonition-icon--note)}.md-typeset .note>.admonition-title:after,.md-typeset .note>summary:after{color:#448aff}.md-typeset .admonition.abstract,.md-typeset details.abstract{border-color:#00b0ff}.md-typeset .admonition.abstract:focus-within,.md-typeset details.abstract:focus-within{box-shadow:0 0 0 .2rem #00b0ff1a}.md-typeset .abstract>.admonition-title,.md-typeset .abstract>summary{background-color:#00b0ff1a}.md-typeset .abstract>.admonition-title:before,.md-typeset .abstract>summary:before{background-color:#00b0ff;-webkit-mask-image:var(--md-admonition-icon--abstract);mask-image:var(--md-admonition-icon--abstract)}.md-typeset .abstract>.admonition-title:after,.md-typeset .abstract>summary:after{color:#00b0ff}.md-typeset .admonition.info,.md-typeset details.info{border-color:#00b8d4}.md-typeset .admonition.info:focus-within,.md-typeset details.info:focus-within{box-shadow:0 0 0 .2rem #00b8d41a}.md-typeset .info>.admonition-title,.md-typeset .info>summary{background-color:#00b8d41a}.md-typeset .info>.admonition-title:before,.md-typeset .info>summary:before{background-color:#00b8d4;-webkit-mask-image:var(--md-admonition-icon--info);mask-image:var(--md-admonition-icon--info)}.md-typeset .info>.admonition-title:after,.md-typeset .info>summary:after{color:#00b8d4}.md-typeset .admonition.tip,.md-typeset details.tip{border-color:#00bfa5}.md-typeset .admonition.tip:focus-within,.md-typeset details.tip:focus-within{box-shadow:0 0 0 .2rem #00bfa51a}.md-typeset .tip>.admonition-title,.md-typeset .tip>summary{background-color:#00bfa51a}.md-typeset .tip>.admonition-title:before,.md-typeset .tip>summary:before{background-color:#00bfa5;-webkit-mask-image:var(--md-admonition-icon--tip);mask-image:var(--md-admonition-icon--tip)}.md-typeset .tip>.admonition-title:after,.md-typeset .tip>summary:after{color:#00bfa5}.md-typeset .admonition.success,.md-typeset details.success{border-color:#00c853}.md-typeset .admonition.success:focus-within,.md-typeset details.success:focus-within{box-shadow:0 0 0 .2rem #00c8531a}.md-typeset .success>.admonition-title,.md-typeset .success>summary{background-color:#00c8531a}.md-typeset .success>.admonition-title:before,.md-typeset .success>summary:before{background-color:#00c853;-webkit-mask-image:var(--md-admonition-icon--success);mask-image:var(--md-admonition-icon--success)}.md-typeset .success>.admonition-title:after,.md-typeset .success>summary:after{color:#00c853}.md-typeset .admonition.question,.md-typeset details.question{border-color:#64dd17}.md-typeset .admonition.question:focus-within,.md-typeset details.question:focus-within{box-shadow:0 0 0 .2rem #64dd171a}.md-typeset .question>.admonition-title,.md-typeset .question>summary{background-color:#64dd171a}.md-typeset .question>.admonition-title:before,.md-typeset .question>summary:before{background-color:#64dd17;-webkit-mask-image:var(--md-admonition-icon--question);mask-image:var(--md-admonition-icon--question)}.md-typeset .question>.admonition-title:after,.md-typeset .question>summary:after{color:#64dd17}.md-typeset .admonition.warning,.md-typeset details.warning{border-color:#ff9100}.md-typeset .admonition.warning:focus-within,.md-typeset details.warning:focus-within{box-shadow:0 0 0 .2rem #ff91001a}.md-typeset .warning>.admonition-title,.md-typeset .warning>summary{background-color:#ff91001a}.md-typeset .warning>.admonition-title:before,.md-typeset .warning>summary:before{background-color:#ff9100;-webkit-mask-image:var(--md-admonition-icon--warning);mask-image:var(--md-admonition-icon--warning)}.md-typeset .warning>.admonition-title:after,.md-typeset .warning>summary:after{color:#ff9100}.md-typeset .admonition.failure,.md-typeset details.failure{border-color:#ff5252}.md-typeset .admonition.failure:focus-within,.md-typeset details.failure:focus-within{box-shadow:0 0 0 .2rem #ff52521a}.md-typeset .failure>.admonition-title,.md-typeset .failure>summary{background-color:#ff52521a}.md-typeset .failure>.admonition-title:before,.md-typeset .failure>summary:before{background-color:#ff5252;-webkit-mask-image:var(--md-admonition-icon--failure);mask-image:var(--md-admonition-icon--failure)}.md-typeset .failure>.admonition-title:after,.md-typeset .failure>summary:after{color:#ff5252}.md-typeset .admonition.danger,.md-typeset details.danger{border-color:#ff1744}.md-typeset .admonition.danger:focus-within,.md-typeset details.danger:focus-within{box-shadow:0 0 0 .2rem #ff17441a}.md-typeset .danger>.admonition-title,.md-typeset .danger>summary{background-color:#ff17441a}.md-typeset .danger>.admonition-title:before,.md-typeset .danger>summary:before{background-color:#ff1744;-webkit-mask-image:var(--md-admonition-icon--danger);mask-image:var(--md-admonition-icon--danger)}.md-typeset .danger>.admonition-title:after,.md-typeset .danger>summary:after{color:#ff1744}.md-typeset .admonition.bug,.md-typeset details.bug{border-color:#f50057}.md-typeset .admonition.bug:focus-within,.md-typeset details.bug:focus-within{box-shadow:0 0 0 .2rem #f500571a}.md-typeset .bug>.admonition-title,.md-typeset .bug>summary{background-color:#f500571a}.md-typeset .bug>.admonition-title:before,.md-typeset .bug>summary:before{background-color:#f50057;-webkit-mask-image:var(--md-admonition-icon--bug);mask-image:var(--md-admonition-icon--bug)}.md-typeset .bug>.admonition-title:after,.md-typeset .bug>summary:after{color:#f50057}.md-typeset .admonition.example,.md-typeset details.example{border-color:#7c4dff}.md-typeset .admonition.example:focus-within,.md-typeset details.example:focus-within{box-shadow:0 0 0 .2rem #7c4dff1a}.md-typeset .example>.admonition-title,.md-typeset .example>summary{background-color:#7c4dff1a}.md-typeset .example>.admonition-title:before,.md-typeset .example>summary:before{background-color:#7c4dff;-webkit-mask-image:var(--md-admonition-icon--example);mask-image:var(--md-admonition-icon--example)}.md-typeset .example>.admonition-title:after,.md-typeset .example>summary:after{color:#7c4dff}.md-typeset .admonition.quote,.md-typeset details.quote{border-color:#9e9e9e}.md-typeset .admonition.quote:focus-within,.md-typeset details.quote:focus-within{box-shadow:0 0 0 .2rem #9e9e9e1a}.md-typeset .quote>.admonition-title,.md-typeset .quote>summary{background-color:#9e9e9e1a}.md-typeset .quote>.admonition-title:before,.md-typeset .quote>summary:before{background-color:#9e9e9e;-webkit-mask-image:var(--md-admonition-icon--quote);mask-image:var(--md-admonition-icon--quote)}.md-typeset .quote>.admonition-title:after,.md-typeset .quote>summary:after{color:#9e9e9e}:root{--md-footnotes-icon:url('data:image/svg+xml;charset=utf-8,')}.md-typeset .footnote{color:var(--md-default-fg-color--light);font-size:.64rem}[dir=ltr] .md-typeset .footnote>ol{margin-left:0}[dir=rtl] .md-typeset .footnote>ol{margin-right:0}.md-typeset .footnote>ol>li{transition:color 125ms}.md-typeset .footnote>ol>li:target{color:var(--md-default-fg-color)}.md-typeset .footnote>ol>li:focus-within .footnote-backref{opacity:1;transform:translateX(0);transition:none}.md-typeset .footnote>ol>li:hover .footnote-backref,.md-typeset .footnote>ol>li:target .footnote-backref{opacity:1;transform:translateX(0)}.md-typeset .footnote>ol>li>:first-child{margin-top:0}.md-typeset .footnote-ref{font-size:.75em;font-weight:700}html .md-typeset .footnote-ref{outline-offset:.1rem}.md-typeset [id^="fnref:"]:target>.footnote-ref{outline:auto}.md-typeset .footnote-backref{color:var(--md-typeset-a-color);display:inline-block;font-size:0;opacity:0;transform:translateX(.25rem);transition:color .25s,transform .25s .25s,opacity 125ms .25s;vertical-align:text-bottom}@media print{.md-typeset .footnote-backref{color:var(--md-typeset-a-color);opacity:1;transform:translateX(0)}}[dir=rtl] .md-typeset .footnote-backref{transform:translateX(-.25rem)}.md-typeset .footnote-backref:hover{color:var(--md-accent-fg-color)}.md-typeset .footnote-backref:before{background-color:currentcolor;content:"";display:inline-block;height:.8rem;-webkit-mask-image:var(--md-footnotes-icon);mask-image:var(--md-footnotes-icon);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;width:.8rem}[dir=rtl] .md-typeset .footnote-backref:before svg{transform:scaleX(-1)}[dir=ltr] .md-typeset .headerlink{margin-left:.5rem}[dir=rtl] .md-typeset .headerlink{margin-right:.5rem}.md-typeset .headerlink{color:var(--md-default-fg-color--lighter);display:inline-block;opacity:0;transition:color .25s,opacity 125ms}@media print{.md-typeset .headerlink{display:none}}.md-typeset .headerlink:focus,.md-typeset :hover>.headerlink,.md-typeset :target>.headerlink{opacity:1;transition:color .25s,opacity 125ms}.md-typeset .headerlink:focus,.md-typeset .headerlink:hover,.md-typeset :target>.headerlink{color:var(--md-accent-fg-color)}.md-typeset :target{--md-scroll-margin:3.6rem;--md-scroll-offset:0rem;scroll-margin-top:calc(var(--md-scroll-margin) - var(--md-scroll-offset))}@media screen and (min-width:76.25em){.md-header--lifted~.md-container .md-typeset :target{--md-scroll-margin:6rem}}.md-typeset h1:target,.md-typeset h2:target,.md-typeset h3:target{--md-scroll-offset:0.2rem}.md-typeset h4:target{--md-scroll-offset:0.15rem}.md-typeset div.arithmatex{overflow:auto}@media screen and (max-width:44.984375em){.md-typeset div.arithmatex{margin:0 -.8rem}.md-typeset div.arithmatex>*{width:min-content}}.md-typeset div.arithmatex>*{margin-left:auto!important;margin-right:auto!important;padding:0 .8rem;touch-action:auto}.md-typeset div.arithmatex>* mjx-container{margin:0!important}.md-typeset div.arithmatex mjx-assistive-mml{height:0}.md-typeset del.critic{background-color:var(--md-typeset-del-color)}.md-typeset del.critic,.md-typeset ins.critic{-webkit-box-decoration-break:clone;box-decoration-break:clone}.md-typeset ins.critic{background-color:var(--md-typeset-ins-color)}.md-typeset .critic.comment{-webkit-box-decoration-break:clone;box-decoration-break:clone;color:var(--md-code-hl-comment-color)}.md-typeset .critic.comment:before{content:"/* "}.md-typeset .critic.comment:after{content:" */"}.md-typeset .critic.block{box-shadow:none;display:block;margin:1em 0;overflow:auto;padding-left:.8rem;padding-right:.8rem}.md-typeset .critic.block>:first-child{margin-top:.5em}.md-typeset .critic.block>:last-child{margin-bottom:.5em}:root{--md-details-icon:url('data:image/svg+xml;charset=utf-8,')}.md-typeset details{display:flow-root;overflow:visible;padding-top:0}.md-typeset details[open]>summary:after{transform:rotate(90deg)}.md-typeset details:not([open]){box-shadow:none;padding-bottom:0}.md-typeset details:not([open])>summary{border-radius:.1rem}[dir=ltr] .md-typeset summary{padding-right:1.8rem}[dir=rtl] .md-typeset summary{padding-left:1.8rem}[dir=ltr] .md-typeset summary{border-top-left-radius:.1rem}[dir=ltr] .md-typeset summary,[dir=rtl] .md-typeset summary{border-top-right-radius:.1rem}[dir=rtl] .md-typeset summary{border-top-left-radius:.1rem}.md-typeset summary{cursor:pointer;display:block;min-height:1rem;overflow:hidden}.md-typeset summary.focus-visible{outline-color:var(--md-accent-fg-color);outline-offset:.2rem}.md-typeset summary:not(.focus-visible){-webkit-tap-highlight-color:transparent;outline:none}[dir=ltr] .md-typeset summary:after{right:.4rem}[dir=rtl] .md-typeset summary:after{left:.4rem}.md-typeset summary:after{background-color:currentcolor;content:"";height:1rem;-webkit-mask-image:var(--md-details-icon);mask-image:var(--md-details-icon);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;position:absolute;top:.625em;transform:rotate(0deg);transition:transform .25s;width:1rem}[dir=rtl] .md-typeset summary:after{transform:rotate(180deg)}.md-typeset summary::marker{display:none}.md-typeset summary::-webkit-details-marker{display:none}.md-typeset .emojione,.md-typeset .gemoji,.md-typeset .twemoji{--md-icon-size:1.125em;display:inline-flex;height:var(--md-icon-size);vertical-align:text-top}.md-typeset .emojione svg,.md-typeset .gemoji svg,.md-typeset .twemoji svg{fill:currentcolor;max-height:100%;width:var(--md-icon-size)}.md-typeset .lg,.md-typeset .xl,.md-typeset .xxl,.md-typeset .xxxl{vertical-align:text-bottom}.md-typeset .middle{vertical-align:middle}.md-typeset .lg{--md-icon-size:1.5em}.md-typeset .xl{--md-icon-size:2.25em}.md-typeset .xxl{--md-icon-size:3em}.md-typeset .xxxl{--md-icon-size:4em}.highlight .o,.highlight .ow{color:var(--md-code-hl-operator-color)}.highlight .p{color:var(--md-code-hl-punctuation-color)}.highlight .cpf,.highlight .l,.highlight .s,.highlight .s1,.highlight .s2,.highlight .sb,.highlight .sc,.highlight .si,.highlight .ss{color:var(--md-code-hl-string-color)}.highlight .cp,.highlight .se,.highlight .sh,.highlight .sr,.highlight .sx{color:var(--md-code-hl-special-color)}.highlight .il,.highlight .m,.highlight .mb,.highlight .mf,.highlight .mh,.highlight .mi,.highlight .mo{color:var(--md-code-hl-number-color)}.highlight .k,.highlight .kd,.highlight .kn,.highlight .kp,.highlight .kr,.highlight .kt{color:var(--md-code-hl-keyword-color)}.highlight .kc,.highlight .n{color:var(--md-code-hl-name-color)}.highlight .bp,.highlight .nb,.highlight .no{color:var(--md-code-hl-constant-color)}.highlight .nc,.highlight .ne,.highlight .nf,.highlight .nn{color:var(--md-code-hl-function-color)}.highlight .nd,.highlight .ni,.highlight .nl,.highlight .nt{color:var(--md-code-hl-keyword-color)}.highlight .c,.highlight .c1,.highlight .ch,.highlight .cm,.highlight .cs,.highlight .sd{color:var(--md-code-hl-comment-color)}.highlight .na,.highlight .nv,.highlight .vc,.highlight .vg,.highlight .vi{color:var(--md-code-hl-variable-color)}.highlight .ge,.highlight .gh,.highlight .go,.highlight .gp,.highlight .gr,.highlight .gs,.highlight .gt,.highlight .gu{color:var(--md-code-hl-generic-color)}.highlight .gd,.highlight .gi{border-radius:.1rem;margin:0 -.125em;padding:0 .125em}.highlight .gd{background-color:var(--md-typeset-del-color)}.highlight .gi{background-color:var(--md-typeset-ins-color)}.highlight .hll{background-color:var(--md-code-hl-color--light);box-shadow:2px 0 0 0 var(--md-code-hl-color) inset;display:block;margin:0 -1.1764705882em;padding:0 1.1764705882em}.highlight span.filename{background-color:var(--md-code-bg-color);border-bottom:.05rem solid var(--md-default-fg-color--lightest);border-top-left-radius:.1rem;border-top-right-radius:.1rem;display:flow-root;font-size:.85em;font-weight:700;margin-top:1em;padding:.6617647059em 1.1764705882em;position:relative}.highlight span.filename+pre{margin-top:0}.highlight span.filename+pre>code{border-top-left-radius:0;border-top-right-radius:0}.highlight [data-linenos]:before{background-color:var(--md-code-bg-color);box-shadow:-.05rem 0 var(--md-default-fg-color--lightest) inset;color:var(--md-default-fg-color--light);content:attr(data-linenos);float:left;left:-1.1764705882em;margin-left:-1.1764705882em;margin-right:1.1764705882em;padding-left:1.1764705882em;position:sticky;-webkit-user-select:none;user-select:none;z-index:3}.highlight code a[id]{position:absolute;visibility:hidden}.highlight code[data-md-copying]{display:initial}.highlight code[data-md-copying] .hll{display:contents}.highlight code[data-md-copying] .md-annotation{display:none}.highlighttable{display:flow-root}.highlighttable tbody,.highlighttable td{display:block;padding:0}.highlighttable tr{display:flex}.highlighttable pre{margin:0}.highlighttable th.filename{flex-grow:1;padding:0;text-align:left}.highlighttable th.filename span.filename{margin-top:0}.highlighttable .linenos{background-color:var(--md-code-bg-color);border-bottom-left-radius:.1rem;border-top-left-radius:.1rem;font-size:.85em;padding:.7720588235em 0 .7720588235em 1.1764705882em;-webkit-user-select:none;user-select:none}.highlighttable .linenodiv{box-shadow:-.05rem 0 var(--md-default-fg-color--lightest) inset}.highlighttable .linenodiv pre{color:var(--md-default-fg-color--light);text-align:right}.highlighttable .linenodiv span[class]{padding-right:.5882352941em}.highlighttable .code{flex:1;min-width:0}.linenodiv a{color:inherit}.md-typeset .highlighttable{direction:ltr;margin:1em 0}.md-typeset .highlighttable>tbody>tr>.code>div>pre>code{border-bottom-left-radius:0;border-top-left-radius:0}.md-typeset .highlight+.result{border:.05rem solid var(--md-code-bg-color);border-bottom-left-radius:.1rem;border-bottom-right-radius:.1rem;border-top-width:.1rem;margin-top:-1.125em;overflow:visible;padding:0 1em}.md-typeset .highlight+.result:after{clear:both;content:"";display:block}@media screen and (max-width:44.984375em){.md-content__inner>.highlight{margin:1em -.8rem}.md-content__inner>.highlight>.filename,.md-content__inner>.highlight>.highlighttable>tbody>tr>.code>div>pre>code,.md-content__inner>.highlight>.highlighttable>tbody>tr>.filename span.filename,.md-content__inner>.highlight>.highlighttable>tbody>tr>.linenos,.md-content__inner>.highlight>pre>code{border-radius:0}.md-content__inner>.highlight+.result{border-left-width:0;border-radius:0;border-right-width:0;margin-left:-.8rem;margin-right:-.8rem}}.md-typeset .keys kbd:after,.md-typeset .keys kbd:before{-moz-osx-font-smoothing:initial;-webkit-font-smoothing:initial;color:inherit;margin:0;position:relative}.md-typeset .keys span{color:var(--md-default-fg-color--light);padding:0 .2em}.md-typeset .keys .key-alt:before,.md-typeset .keys .key-left-alt:before,.md-typeset .keys .key-right-alt:before{content:"⎇";padding-right:.4em}.md-typeset .keys .key-command:before,.md-typeset .keys .key-left-command:before,.md-typeset .keys .key-right-command:before{content:"⌘";padding-right:.4em}.md-typeset .keys .key-control:before,.md-typeset .keys .key-left-control:before,.md-typeset .keys .key-right-control:before{content:"⌃";padding-right:.4em}.md-typeset .keys .key-left-meta:before,.md-typeset .keys .key-meta:before,.md-typeset .keys .key-right-meta:before{content:"◆";padding-right:.4em}.md-typeset .keys .key-left-option:before,.md-typeset .keys .key-option:before,.md-typeset .keys .key-right-option:before{content:"⌥";padding-right:.4em}.md-typeset .keys .key-left-shift:before,.md-typeset .keys .key-right-shift:before,.md-typeset .keys .key-shift:before{content:"⇧";padding-right:.4em}.md-typeset .keys .key-left-super:before,.md-typeset .keys .key-right-super:before,.md-typeset .keys .key-super:before{content:"❖";padding-right:.4em}.md-typeset .keys .key-left-windows:before,.md-typeset .keys .key-right-windows:before,.md-typeset .keys .key-windows:before{content:"⊞";padding-right:.4em}.md-typeset .keys .key-arrow-down:before{content:"↓";padding-right:.4em}.md-typeset .keys .key-arrow-left:before{content:"←";padding-right:.4em}.md-typeset .keys .key-arrow-right:before{content:"→";padding-right:.4em}.md-typeset .keys .key-arrow-up:before{content:"↑";padding-right:.4em}.md-typeset .keys .key-backspace:before{content:"⌫";padding-right:.4em}.md-typeset .keys .key-backtab:before{content:"⇤";padding-right:.4em}.md-typeset .keys .key-caps-lock:before{content:"⇪";padding-right:.4em}.md-typeset .keys .key-clear:before{content:"⌧";padding-right:.4em}.md-typeset .keys .key-context-menu:before{content:"☰";padding-right:.4em}.md-typeset .keys .key-delete:before{content:"⌦";padding-right:.4em}.md-typeset .keys .key-eject:before{content:"⏏";padding-right:.4em}.md-typeset .keys .key-end:before{content:"⤓";padding-right:.4em}.md-typeset .keys .key-escape:before{content:"⎋";padding-right:.4em}.md-typeset .keys .key-home:before{content:"⤒";padding-right:.4em}.md-typeset .keys .key-insert:before{content:"⎀";padding-right:.4em}.md-typeset .keys .key-page-down:before{content:"⇟";padding-right:.4em}.md-typeset .keys .key-page-up:before{content:"⇞";padding-right:.4em}.md-typeset .keys .key-print-screen:before{content:"⎙";padding-right:.4em}.md-typeset .keys .key-tab:after{content:"⇥";padding-left:.4em}.md-typeset .keys .key-num-enter:after{content:"⌤";padding-left:.4em}.md-typeset .keys .key-enter:after{content:"⏎";padding-left:.4em}:root{--md-tabbed-icon--prev:url('data:image/svg+xml;charset=utf-8,');--md-tabbed-icon--next:url('data:image/svg+xml;charset=utf-8,')}.md-typeset .tabbed-set{border-radius:.1rem;display:flex;flex-flow:column wrap;margin:1em 0;position:relative}.md-typeset .tabbed-set>input{height:0;opacity:0;position:absolute;width:0}.md-typeset .tabbed-set>input:target{--md-scroll-offset:0.625em}.md-typeset .tabbed-set>input.focus-visible~.tabbed-labels:before{background-color:var(--md-accent-fg-color)}.md-typeset .tabbed-labels{-ms-overflow-style:none;box-shadow:0 -.05rem var(--md-default-fg-color--lightest) inset;display:flex;max-width:100%;overflow:auto;scrollbar-width:none}@media print{.md-typeset .tabbed-labels{display:contents}}@media screen{.js .md-typeset .tabbed-labels{position:relative}.js .md-typeset .tabbed-labels:before{background:var(--md-default-fg-color);bottom:0;content:"";display:block;height:2px;left:0;position:absolute;transform:translateX(var(--md-indicator-x));transition:width 225ms,background-color .25s,transform .25s;transition-timing-function:cubic-bezier(.4,0,.2,1);width:var(--md-indicator-width)}}.md-typeset .tabbed-labels::-webkit-scrollbar{display:none}.md-typeset .tabbed-labels>label{border-bottom:.1rem solid #0000;border-radius:.1rem .1rem 0 0;color:var(--md-default-fg-color--light);cursor:pointer;flex-shrink:0;font-size:.64rem;font-weight:700;padding:.78125em 1.25em .625em;scroll-margin-inline-start:1rem;transition:background-color .25s,color .25s;white-space:nowrap;width:auto}@media print{.md-typeset .tabbed-labels>label:first-child{order:1}.md-typeset .tabbed-labels>label:nth-child(2){order:2}.md-typeset .tabbed-labels>label:nth-child(3){order:3}.md-typeset .tabbed-labels>label:nth-child(4){order:4}.md-typeset .tabbed-labels>label:nth-child(5){order:5}.md-typeset .tabbed-labels>label:nth-child(6){order:6}.md-typeset .tabbed-labels>label:nth-child(7){order:7}.md-typeset .tabbed-labels>label:nth-child(8){order:8}.md-typeset .tabbed-labels>label:nth-child(9){order:9}.md-typeset .tabbed-labels>label:nth-child(10){order:10}.md-typeset .tabbed-labels>label:nth-child(11){order:11}.md-typeset .tabbed-labels>label:nth-child(12){order:12}.md-typeset .tabbed-labels>label:nth-child(13){order:13}.md-typeset .tabbed-labels>label:nth-child(14){order:14}.md-typeset .tabbed-labels>label:nth-child(15){order:15}.md-typeset .tabbed-labels>label:nth-child(16){order:16}.md-typeset .tabbed-labels>label:nth-child(17){order:17}.md-typeset .tabbed-labels>label:nth-child(18){order:18}.md-typeset .tabbed-labels>label:nth-child(19){order:19}.md-typeset .tabbed-labels>label:nth-child(20){order:20}}.md-typeset .tabbed-labels>label:hover{color:var(--md-default-fg-color)}.md-typeset .tabbed-labels>label>[href]:first-child{color:inherit}.md-typeset .tabbed-labels--linked>label{padding:0}.md-typeset .tabbed-labels--linked>label>a{display:block;padding:.78125em 1.25em .625em}.md-typeset .tabbed-content{width:100%}@media print{.md-typeset .tabbed-content{display:contents}}.md-typeset .tabbed-block{display:none}@media print{.md-typeset .tabbed-block{display:block}.md-typeset .tabbed-block:first-child{order:1}.md-typeset .tabbed-block:nth-child(2){order:2}.md-typeset .tabbed-block:nth-child(3){order:3}.md-typeset .tabbed-block:nth-child(4){order:4}.md-typeset .tabbed-block:nth-child(5){order:5}.md-typeset .tabbed-block:nth-child(6){order:6}.md-typeset .tabbed-block:nth-child(7){order:7}.md-typeset .tabbed-block:nth-child(8){order:8}.md-typeset .tabbed-block:nth-child(9){order:9}.md-typeset .tabbed-block:nth-child(10){order:10}.md-typeset .tabbed-block:nth-child(11){order:11}.md-typeset .tabbed-block:nth-child(12){order:12}.md-typeset .tabbed-block:nth-child(13){order:13}.md-typeset .tabbed-block:nth-child(14){order:14}.md-typeset .tabbed-block:nth-child(15){order:15}.md-typeset .tabbed-block:nth-child(16){order:16}.md-typeset .tabbed-block:nth-child(17){order:17}.md-typeset .tabbed-block:nth-child(18){order:18}.md-typeset .tabbed-block:nth-child(19){order:19}.md-typeset .tabbed-block:nth-child(20){order:20}}.md-typeset .tabbed-block>.highlight:first-child>pre,.md-typeset .tabbed-block>pre:first-child{margin:0}.md-typeset .tabbed-block>.highlight:first-child>pre>code,.md-typeset .tabbed-block>pre:first-child>code{border-top-left-radius:0;border-top-right-radius:0}.md-typeset .tabbed-block>.highlight:first-child>.filename{border-top-left-radius:0;border-top-right-radius:0;margin:0}.md-typeset .tabbed-block>.highlight:first-child>.highlighttable{margin:0}.md-typeset .tabbed-block>.highlight:first-child>.highlighttable>tbody>tr>.filename span.filename,.md-typeset .tabbed-block>.highlight:first-child>.highlighttable>tbody>tr>.linenos{border-top-left-radius:0;border-top-right-radius:0;margin:0}.md-typeset .tabbed-block>.highlight:first-child>.highlighttable>tbody>tr>.code>div>pre>code{border-top-left-radius:0;border-top-right-radius:0}.md-typeset .tabbed-block>.highlight:first-child+.result{margin-top:-.125em}.md-typeset .tabbed-block>.tabbed-set{margin:0}.md-typeset .tabbed-button{align-self:center;border-radius:100%;color:var(--md-default-fg-color--light);cursor:pointer;display:block;height:.9rem;margin-top:.1rem;pointer-events:auto;transition:background-color .25s;width:.9rem}.md-typeset .tabbed-button:hover{background-color:var(--md-accent-fg-color--transparent);color:var(--md-accent-fg-color)}.md-typeset .tabbed-button:after{background-color:currentcolor;content:"";display:block;height:100%;-webkit-mask-image:var(--md-tabbed-icon--prev);mask-image:var(--md-tabbed-icon--prev);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;transition:background-color .25s,transform .25s;width:100%}.md-typeset .tabbed-control{background:linear-gradient(to right,var(--md-default-bg-color) 60%,#0000);display:flex;height:1.9rem;justify-content:start;pointer-events:none;position:absolute;transition:opacity 125ms;width:1.2rem}[dir=rtl] .md-typeset .tabbed-control{transform:rotate(180deg)}.md-typeset .tabbed-control[hidden]{opacity:0}.md-typeset .tabbed-control--next{background:linear-gradient(to left,var(--md-default-bg-color) 60%,#0000);justify-content:end;right:0}.md-typeset .tabbed-control--next .tabbed-button:after{-webkit-mask-image:var(--md-tabbed-icon--next);mask-image:var(--md-tabbed-icon--next)}@media screen and (max-width:44.984375em){[dir=ltr] .md-content__inner>.tabbed-set .tabbed-labels{padding-left:.8rem}[dir=rtl] .md-content__inner>.tabbed-set .tabbed-labels{padding-right:.8rem}.md-content__inner>.tabbed-set .tabbed-labels{margin:0 -.8rem;max-width:100vw;scroll-padding-inline-start:.8rem}[dir=ltr] .md-content__inner>.tabbed-set .tabbed-labels:after{padding-right:.8rem}[dir=rtl] .md-content__inner>.tabbed-set .tabbed-labels:after{padding-left:.8rem}.md-content__inner>.tabbed-set .tabbed-labels:after{content:""}[dir=ltr] .md-content__inner>.tabbed-set .tabbed-labels~.tabbed-control--prev{padding-left:.8rem}[dir=rtl] .md-content__inner>.tabbed-set .tabbed-labels~.tabbed-control--prev{padding-right:.8rem}[dir=ltr] .md-content__inner>.tabbed-set .tabbed-labels~.tabbed-control--prev{margin-left:-.8rem}[dir=rtl] .md-content__inner>.tabbed-set .tabbed-labels~.tabbed-control--prev{margin-right:-.8rem}.md-content__inner>.tabbed-set .tabbed-labels~.tabbed-control--prev{width:2rem}[dir=ltr] .md-content__inner>.tabbed-set .tabbed-labels~.tabbed-control--next{padding-right:.8rem}[dir=rtl] .md-content__inner>.tabbed-set .tabbed-labels~.tabbed-control--next{padding-left:.8rem}[dir=ltr] .md-content__inner>.tabbed-set .tabbed-labels~.tabbed-control--next{margin-right:-.8rem}[dir=rtl] .md-content__inner>.tabbed-set .tabbed-labels~.tabbed-control--next{margin-left:-.8rem}.md-content__inner>.tabbed-set .tabbed-labels~.tabbed-control--next{width:2rem}}@media screen{.md-typeset .tabbed-set>input:first-child:checked~.tabbed-labels>:first-child,.md-typeset .tabbed-set>input:nth-child(10):checked~.tabbed-labels>:nth-child(10),.md-typeset .tabbed-set>input:nth-child(11):checked~.tabbed-labels>:nth-child(11),.md-typeset .tabbed-set>input:nth-child(12):checked~.tabbed-labels>:nth-child(12),.md-typeset .tabbed-set>input:nth-child(13):checked~.tabbed-labels>:nth-child(13),.md-typeset .tabbed-set>input:nth-child(14):checked~.tabbed-labels>:nth-child(14),.md-typeset .tabbed-set>input:nth-child(15):checked~.tabbed-labels>:nth-child(15),.md-typeset .tabbed-set>input:nth-child(16):checked~.tabbed-labels>:nth-child(16),.md-typeset .tabbed-set>input:nth-child(17):checked~.tabbed-labels>:nth-child(17),.md-typeset .tabbed-set>input:nth-child(18):checked~.tabbed-labels>:nth-child(18),.md-typeset .tabbed-set>input:nth-child(19):checked~.tabbed-labels>:nth-child(19),.md-typeset .tabbed-set>input:nth-child(2):checked~.tabbed-labels>:nth-child(2),.md-typeset .tabbed-set>input:nth-child(20):checked~.tabbed-labels>:nth-child(20),.md-typeset .tabbed-set>input:nth-child(3):checked~.tabbed-labels>:nth-child(3),.md-typeset .tabbed-set>input:nth-child(4):checked~.tabbed-labels>:nth-child(4),.md-typeset .tabbed-set>input:nth-child(5):checked~.tabbed-labels>:nth-child(5),.md-typeset .tabbed-set>input:nth-child(6):checked~.tabbed-labels>:nth-child(6),.md-typeset .tabbed-set>input:nth-child(7):checked~.tabbed-labels>:nth-child(7),.md-typeset .tabbed-set>input:nth-child(8):checked~.tabbed-labels>:nth-child(8),.md-typeset .tabbed-set>input:nth-child(9):checked~.tabbed-labels>:nth-child(9){color:var(--md-default-fg-color)}.md-typeset .no-js .tabbed-set>input:first-child:checked~.tabbed-labels>:first-child,.md-typeset .no-js .tabbed-set>input:nth-child(10):checked~.tabbed-labels>:nth-child(10),.md-typeset .no-js .tabbed-set>input:nth-child(11):checked~.tabbed-labels>:nth-child(11),.md-typeset .no-js .tabbed-set>input:nth-child(12):checked~.tabbed-labels>:nth-child(12),.md-typeset .no-js .tabbed-set>input:nth-child(13):checked~.tabbed-labels>:nth-child(13),.md-typeset .no-js .tabbed-set>input:nth-child(14):checked~.tabbed-labels>:nth-child(14),.md-typeset .no-js .tabbed-set>input:nth-child(15):checked~.tabbed-labels>:nth-child(15),.md-typeset .no-js .tabbed-set>input:nth-child(16):checked~.tabbed-labels>:nth-child(16),.md-typeset .no-js .tabbed-set>input:nth-child(17):checked~.tabbed-labels>:nth-child(17),.md-typeset .no-js .tabbed-set>input:nth-child(18):checked~.tabbed-labels>:nth-child(18),.md-typeset .no-js .tabbed-set>input:nth-child(19):checked~.tabbed-labels>:nth-child(19),.md-typeset .no-js .tabbed-set>input:nth-child(2):checked~.tabbed-labels>:nth-child(2),.md-typeset .no-js .tabbed-set>input:nth-child(20):checked~.tabbed-labels>:nth-child(20),.md-typeset .no-js .tabbed-set>input:nth-child(3):checked~.tabbed-labels>:nth-child(3),.md-typeset .no-js .tabbed-set>input:nth-child(4):checked~.tabbed-labels>:nth-child(4),.md-typeset .no-js .tabbed-set>input:nth-child(5):checked~.tabbed-labels>:nth-child(5),.md-typeset .no-js .tabbed-set>input:nth-child(6):checked~.tabbed-labels>:nth-child(6),.md-typeset .no-js .tabbed-set>input:nth-child(7):checked~.tabbed-labels>:nth-child(7),.md-typeset .no-js .tabbed-set>input:nth-child(8):checked~.tabbed-labels>:nth-child(8),.md-typeset .no-js .tabbed-set>input:nth-child(9):checked~.tabbed-labels>:nth-child(9),.md-typeset [role=dialog] .tabbed-set>input:first-child:checked~.tabbed-labels>:first-child,.md-typeset [role=dialog] .tabbed-set>input:nth-child(10):checked~.tabbed-labels>:nth-child(10),.md-typeset [role=dialog] .tabbed-set>input:nth-child(11):checked~.tabbed-labels>:nth-child(11),.md-typeset [role=dialog] .tabbed-set>input:nth-child(12):checked~.tabbed-labels>:nth-child(12),.md-typeset [role=dialog] .tabbed-set>input:nth-child(13):checked~.tabbed-labels>:nth-child(13),.md-typeset [role=dialog] .tabbed-set>input:nth-child(14):checked~.tabbed-labels>:nth-child(14),.md-typeset [role=dialog] .tabbed-set>input:nth-child(15):checked~.tabbed-labels>:nth-child(15),.md-typeset [role=dialog] .tabbed-set>input:nth-child(16):checked~.tabbed-labels>:nth-child(16),.md-typeset [role=dialog] .tabbed-set>input:nth-child(17):checked~.tabbed-labels>:nth-child(17),.md-typeset [role=dialog] .tabbed-set>input:nth-child(18):checked~.tabbed-labels>:nth-child(18),.md-typeset [role=dialog] .tabbed-set>input:nth-child(19):checked~.tabbed-labels>:nth-child(19),.md-typeset [role=dialog] .tabbed-set>input:nth-child(2):checked~.tabbed-labels>:nth-child(2),.md-typeset [role=dialog] .tabbed-set>input:nth-child(20):checked~.tabbed-labels>:nth-child(20),.md-typeset [role=dialog] .tabbed-set>input:nth-child(3):checked~.tabbed-labels>:nth-child(3),.md-typeset [role=dialog] .tabbed-set>input:nth-child(4):checked~.tabbed-labels>:nth-child(4),.md-typeset [role=dialog] .tabbed-set>input:nth-child(5):checked~.tabbed-labels>:nth-child(5),.md-typeset [role=dialog] .tabbed-set>input:nth-child(6):checked~.tabbed-labels>:nth-child(6),.md-typeset [role=dialog] .tabbed-set>input:nth-child(7):checked~.tabbed-labels>:nth-child(7),.md-typeset [role=dialog] .tabbed-set>input:nth-child(8):checked~.tabbed-labels>:nth-child(8),.md-typeset [role=dialog] .tabbed-set>input:nth-child(9):checked~.tabbed-labels>:nth-child(9),.no-js .md-typeset .tabbed-set>input:first-child:checked~.tabbed-labels>:first-child,.no-js .md-typeset .tabbed-set>input:nth-child(10):checked~.tabbed-labels>:nth-child(10),.no-js .md-typeset .tabbed-set>input:nth-child(11):checked~.tabbed-labels>:nth-child(11),.no-js .md-typeset .tabbed-set>input:nth-child(12):checked~.tabbed-labels>:nth-child(12),.no-js .md-typeset .tabbed-set>input:nth-child(13):checked~.tabbed-labels>:nth-child(13),.no-js .md-typeset .tabbed-set>input:nth-child(14):checked~.tabbed-labels>:nth-child(14),.no-js .md-typeset .tabbed-set>input:nth-child(15):checked~.tabbed-labels>:nth-child(15),.no-js .md-typeset .tabbed-set>input:nth-child(16):checked~.tabbed-labels>:nth-child(16),.no-js .md-typeset .tabbed-set>input:nth-child(17):checked~.tabbed-labels>:nth-child(17),.no-js .md-typeset .tabbed-set>input:nth-child(18):checked~.tabbed-labels>:nth-child(18),.no-js .md-typeset .tabbed-set>input:nth-child(19):checked~.tabbed-labels>:nth-child(19),.no-js .md-typeset .tabbed-set>input:nth-child(2):checked~.tabbed-labels>:nth-child(2),.no-js .md-typeset .tabbed-set>input:nth-child(20):checked~.tabbed-labels>:nth-child(20),.no-js .md-typeset .tabbed-set>input:nth-child(3):checked~.tabbed-labels>:nth-child(3),.no-js .md-typeset .tabbed-set>input:nth-child(4):checked~.tabbed-labels>:nth-child(4),.no-js .md-typeset .tabbed-set>input:nth-child(5):checked~.tabbed-labels>:nth-child(5),.no-js .md-typeset .tabbed-set>input:nth-child(6):checked~.tabbed-labels>:nth-child(6),.no-js .md-typeset .tabbed-set>input:nth-child(7):checked~.tabbed-labels>:nth-child(7),.no-js .md-typeset .tabbed-set>input:nth-child(8):checked~.tabbed-labels>:nth-child(8),.no-js .md-typeset .tabbed-set>input:nth-child(9):checked~.tabbed-labels>:nth-child(9),[role=dialog] .md-typeset .tabbed-set>input:first-child:checked~.tabbed-labels>:first-child,[role=dialog] .md-typeset .tabbed-set>input:nth-child(10):checked~.tabbed-labels>:nth-child(10),[role=dialog] .md-typeset .tabbed-set>input:nth-child(11):checked~.tabbed-labels>:nth-child(11),[role=dialog] .md-typeset .tabbed-set>input:nth-child(12):checked~.tabbed-labels>:nth-child(12),[role=dialog] .md-typeset .tabbed-set>input:nth-child(13):checked~.tabbed-labels>:nth-child(13),[role=dialog] .md-typeset .tabbed-set>input:nth-child(14):checked~.tabbed-labels>:nth-child(14),[role=dialog] .md-typeset .tabbed-set>input:nth-child(15):checked~.tabbed-labels>:nth-child(15),[role=dialog] .md-typeset .tabbed-set>input:nth-child(16):checked~.tabbed-labels>:nth-child(16),[role=dialog] .md-typeset .tabbed-set>input:nth-child(17):checked~.tabbed-labels>:nth-child(17),[role=dialog] .md-typeset .tabbed-set>input:nth-child(18):checked~.tabbed-labels>:nth-child(18),[role=dialog] .md-typeset .tabbed-set>input:nth-child(19):checked~.tabbed-labels>:nth-child(19),[role=dialog] .md-typeset .tabbed-set>input:nth-child(2):checked~.tabbed-labels>:nth-child(2),[role=dialog] .md-typeset .tabbed-set>input:nth-child(20):checked~.tabbed-labels>:nth-child(20),[role=dialog] .md-typeset .tabbed-set>input:nth-child(3):checked~.tabbed-labels>:nth-child(3),[role=dialog] .md-typeset .tabbed-set>input:nth-child(4):checked~.tabbed-labels>:nth-child(4),[role=dialog] .md-typeset .tabbed-set>input:nth-child(5):checked~.tabbed-labels>:nth-child(5),[role=dialog] .md-typeset .tabbed-set>input:nth-child(6):checked~.tabbed-labels>:nth-child(6),[role=dialog] .md-typeset .tabbed-set>input:nth-child(7):checked~.tabbed-labels>:nth-child(7),[role=dialog] .md-typeset .tabbed-set>input:nth-child(8):checked~.tabbed-labels>:nth-child(8),[role=dialog] .md-typeset .tabbed-set>input:nth-child(9):checked~.tabbed-labels>:nth-child(9){border-color:var(--md-default-fg-color)}}.md-typeset .tabbed-set>input:first-child.focus-visible~.tabbed-labels>:first-child,.md-typeset .tabbed-set>input:nth-child(10).focus-visible~.tabbed-labels>:nth-child(10),.md-typeset .tabbed-set>input:nth-child(11).focus-visible~.tabbed-labels>:nth-child(11),.md-typeset .tabbed-set>input:nth-child(12).focus-visible~.tabbed-labels>:nth-child(12),.md-typeset .tabbed-set>input:nth-child(13).focus-visible~.tabbed-labels>:nth-child(13),.md-typeset .tabbed-set>input:nth-child(14).focus-visible~.tabbed-labels>:nth-child(14),.md-typeset .tabbed-set>input:nth-child(15).focus-visible~.tabbed-labels>:nth-child(15),.md-typeset .tabbed-set>input:nth-child(16).focus-visible~.tabbed-labels>:nth-child(16),.md-typeset .tabbed-set>input:nth-child(17).focus-visible~.tabbed-labels>:nth-child(17),.md-typeset .tabbed-set>input:nth-child(18).focus-visible~.tabbed-labels>:nth-child(18),.md-typeset .tabbed-set>input:nth-child(19).focus-visible~.tabbed-labels>:nth-child(19),.md-typeset .tabbed-set>input:nth-child(2).focus-visible~.tabbed-labels>:nth-child(2),.md-typeset .tabbed-set>input:nth-child(20).focus-visible~.tabbed-labels>:nth-child(20),.md-typeset .tabbed-set>input:nth-child(3).focus-visible~.tabbed-labels>:nth-child(3),.md-typeset .tabbed-set>input:nth-child(4).focus-visible~.tabbed-labels>:nth-child(4),.md-typeset .tabbed-set>input:nth-child(5).focus-visible~.tabbed-labels>:nth-child(5),.md-typeset .tabbed-set>input:nth-child(6).focus-visible~.tabbed-labels>:nth-child(6),.md-typeset .tabbed-set>input:nth-child(7).focus-visible~.tabbed-labels>:nth-child(7),.md-typeset .tabbed-set>input:nth-child(8).focus-visible~.tabbed-labels>:nth-child(8),.md-typeset .tabbed-set>input:nth-child(9).focus-visible~.tabbed-labels>:nth-child(9){color:var(--md-accent-fg-color)}.md-typeset .tabbed-set>input:first-child:checked~.tabbed-content>:first-child,.md-typeset .tabbed-set>input:nth-child(10):checked~.tabbed-content>:nth-child(10),.md-typeset .tabbed-set>input:nth-child(11):checked~.tabbed-content>:nth-child(11),.md-typeset .tabbed-set>input:nth-child(12):checked~.tabbed-content>:nth-child(12),.md-typeset .tabbed-set>input:nth-child(13):checked~.tabbed-content>:nth-child(13),.md-typeset .tabbed-set>input:nth-child(14):checked~.tabbed-content>:nth-child(14),.md-typeset .tabbed-set>input:nth-child(15):checked~.tabbed-content>:nth-child(15),.md-typeset .tabbed-set>input:nth-child(16):checked~.tabbed-content>:nth-child(16),.md-typeset .tabbed-set>input:nth-child(17):checked~.tabbed-content>:nth-child(17),.md-typeset .tabbed-set>input:nth-child(18):checked~.tabbed-content>:nth-child(18),.md-typeset .tabbed-set>input:nth-child(19):checked~.tabbed-content>:nth-child(19),.md-typeset .tabbed-set>input:nth-child(2):checked~.tabbed-content>:nth-child(2),.md-typeset .tabbed-set>input:nth-child(20):checked~.tabbed-content>:nth-child(20),.md-typeset .tabbed-set>input:nth-child(3):checked~.tabbed-content>:nth-child(3),.md-typeset .tabbed-set>input:nth-child(4):checked~.tabbed-content>:nth-child(4),.md-typeset .tabbed-set>input:nth-child(5):checked~.tabbed-content>:nth-child(5),.md-typeset .tabbed-set>input:nth-child(6):checked~.tabbed-content>:nth-child(6),.md-typeset .tabbed-set>input:nth-child(7):checked~.tabbed-content>:nth-child(7),.md-typeset .tabbed-set>input:nth-child(8):checked~.tabbed-content>:nth-child(8),.md-typeset .tabbed-set>input:nth-child(9):checked~.tabbed-content>:nth-child(9){display:block}:root{--md-tasklist-icon:url('data:image/svg+xml;charset=utf-8,');--md-tasklist-icon--checked:url('data:image/svg+xml;charset=utf-8,')}.md-typeset .task-list-item{list-style-type:none;position:relative}[dir=ltr] .md-typeset .task-list-item [type=checkbox]{left:-2em}[dir=rtl] .md-typeset .task-list-item [type=checkbox]{right:-2em}.md-typeset .task-list-item [type=checkbox]{position:absolute;top:.45em}.md-typeset .task-list-control [type=checkbox]{opacity:0;z-index:-1}[dir=ltr] .md-typeset .task-list-indicator:before{left:-1.5em}[dir=rtl] .md-typeset .task-list-indicator:before{right:-1.5em}.md-typeset .task-list-indicator:before{background-color:var(--md-default-fg-color--lightest);content:"";height:1.25em;-webkit-mask-image:var(--md-tasklist-icon);mask-image:var(--md-tasklist-icon);-webkit-mask-position:center;mask-position:center;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:contain;mask-size:contain;position:absolute;top:.15em;width:1.25em}.md-typeset [type=checkbox]:checked+.task-list-indicator:before{background-color:#00e676;-webkit-mask-image:var(--md-tasklist-icon--checked);mask-image:var(--md-tasklist-icon--checked)}@media print{.giscus,[id=__comments]{display:none}}:root>*{--md-mermaid-font-family:var(--md-text-font-family),sans-serif;--md-mermaid-edge-color:var(--md-code-fg-color);--md-mermaid-node-bg-color:var(--md-accent-fg-color--transparent);--md-mermaid-node-fg-color:var(--md-accent-fg-color);--md-mermaid-label-bg-color:var(--md-default-bg-color);--md-mermaid-label-fg-color:var(--md-code-fg-color);--md-mermaid-sequence-actor-bg-color:var(--md-mermaid-label-bg-color);--md-mermaid-sequence-actor-fg-color:var(--md-mermaid-label-fg-color);--md-mermaid-sequence-actor-border-color:var(--md-mermaid-node-fg-color);--md-mermaid-sequence-actor-line-color:var(--md-default-fg-color--lighter);--md-mermaid-sequence-actorman-bg-color:var(--md-mermaid-label-bg-color);--md-mermaid-sequence-actorman-line-color:var(--md-mermaid-node-fg-color);--md-mermaid-sequence-box-bg-color:var(--md-mermaid-node-bg-color);--md-mermaid-sequence-box-fg-color:var(--md-mermaid-edge-color);--md-mermaid-sequence-label-bg-color:var(--md-mermaid-node-bg-color);--md-mermaid-sequence-label-fg-color:var(--md-mermaid-node-fg-color);--md-mermaid-sequence-loop-bg-color:var(--md-mermaid-node-bg-color);--md-mermaid-sequence-loop-fg-color:var(--md-mermaid-edge-color);--md-mermaid-sequence-loop-border-color:var(--md-mermaid-node-fg-color);--md-mermaid-sequence-message-fg-color:var(--md-mermaid-edge-color);--md-mermaid-sequence-message-line-color:var(--md-mermaid-edge-color);--md-mermaid-sequence-note-bg-color:var(--md-mermaid-label-bg-color);--md-mermaid-sequence-note-fg-color:var(--md-mermaid-edge-color);--md-mermaid-sequence-note-border-color:var(--md-mermaid-label-fg-color);--md-mermaid-sequence-number-bg-color:var(--md-mermaid-node-fg-color);--md-mermaid-sequence-number-fg-color:var(--md-accent-bg-color)}.mermaid{line-height:normal;margin:1em 0}.md-typeset .grid{grid-gap:.4rem;display:grid;grid-template-columns:repeat(auto-fit,minmax(min(100%,16rem),1fr));margin:1em 0}.md-typeset .grid.cards>ol,.md-typeset .grid.cards>ul{display:contents}.md-typeset .grid.cards>ol>li,.md-typeset .grid.cards>ul>li,.md-typeset .grid>.card{border:.05rem solid var(--md-default-fg-color--lightest);border-radius:.1rem;display:block;margin:0;padding:.8rem;transition:border .25s,box-shadow .25s}.md-typeset .grid.cards>ol>li:focus-within,.md-typeset .grid.cards>ol>li:hover,.md-typeset .grid.cards>ul>li:focus-within,.md-typeset .grid.cards>ul>li:hover,.md-typeset .grid>.card:focus-within,.md-typeset .grid>.card:hover{border-color:#0000;box-shadow:var(--md-shadow-z2)}.md-typeset .grid.cards>ol>li>hr,.md-typeset .grid.cards>ul>li>hr,.md-typeset .grid>.card>hr{margin-bottom:1em;margin-top:1em}.md-typeset .grid.cards>ol>li>:first-child,.md-typeset .grid.cards>ul>li>:first-child,.md-typeset .grid>.card>:first-child{margin-top:0}.md-typeset .grid.cards>ol>li>:last-child,.md-typeset .grid.cards>ul>li>:last-child,.md-typeset .grid>.card>:last-child{margin-bottom:0}.md-typeset .grid>*,.md-typeset .grid>.admonition,.md-typeset .grid>.highlight>*,.md-typeset .grid>.highlighttable,.md-typeset .grid>.md-typeset details,.md-typeset .grid>details,.md-typeset .grid>pre{margin-bottom:0;margin-top:0}.md-typeset .grid>.highlight>pre:only-child,.md-typeset .grid>.highlight>pre>code,.md-typeset .grid>.highlighttable,.md-typeset .grid>.highlighttable>tbody,.md-typeset .grid>.highlighttable>tbody>tr,.md-typeset .grid>.highlighttable>tbody>tr>.code,.md-typeset .grid>.highlighttable>tbody>tr>.code>.highlight,.md-typeset .grid>.highlighttable>tbody>tr>.code>.highlight>pre,.md-typeset .grid>.highlighttable>tbody>tr>.code>.highlight>pre>code{height:100%}.md-typeset .grid>.tabbed-set{margin-bottom:0;margin-top:0}@media screen and (min-width:45em){[dir=ltr] .md-typeset .inline{float:left}[dir=rtl] .md-typeset .inline{float:right}[dir=ltr] .md-typeset .inline{margin-right:.8rem}[dir=rtl] .md-typeset .inline{margin-left:.8rem}.md-typeset .inline{margin-bottom:.8rem;margin-top:0;width:11.7rem}[dir=ltr] .md-typeset .inline.end{float:right}[dir=rtl] .md-typeset .inline.end{float:left}[dir=ltr] .md-typeset .inline.end{margin-left:.8rem;margin-right:0}[dir=rtl] .md-typeset .inline.end{margin-left:0;margin-right:.8rem}}
\ No newline at end of file
diff --git a/assets/stylesheets/palette.ab4e12ef.min.css b/assets/stylesheets/palette.ab4e12ef.min.css
new file mode 100644
index 000000000..75aaf8425
--- /dev/null
+++ b/assets/stylesheets/palette.ab4e12ef.min.css
@@ -0,0 +1 @@
+@media screen{[data-md-color-scheme=slate]{--md-default-fg-color:hsla(var(--md-hue),15%,90%,0.82);--md-default-fg-color--light:hsla(var(--md-hue),15%,90%,0.56);--md-default-fg-color--lighter:hsla(var(--md-hue),15%,90%,0.32);--md-default-fg-color--lightest:hsla(var(--md-hue),15%,90%,0.12);--md-default-bg-color:hsla(var(--md-hue),15%,14%,1);--md-default-bg-color--light:hsla(var(--md-hue),15%,14%,0.54);--md-default-bg-color--lighter:hsla(var(--md-hue),15%,14%,0.26);--md-default-bg-color--lightest:hsla(var(--md-hue),15%,14%,0.07);--md-code-fg-color:hsla(var(--md-hue),18%,86%,0.82);--md-code-bg-color:hsla(var(--md-hue),15%,18%,1);--md-code-bg-color--light:hsla(var(--md-hue),15%,18%,0.9);--md-code-bg-color--lighter:hsla(var(--md-hue),15%,18%,0.54);--md-code-hl-color:#2977ff;--md-code-hl-color--light:#2977ff1a;--md-code-hl-number-color:#e6695b;--md-code-hl-special-color:#f06090;--md-code-hl-function-color:#c973d9;--md-code-hl-constant-color:#9383e2;--md-code-hl-keyword-color:#6791e0;--md-code-hl-string-color:#2fb170;--md-code-hl-name-color:var(--md-code-fg-color);--md-code-hl-operator-color:var(--md-default-fg-color--light);--md-code-hl-punctuation-color:var(--md-default-fg-color--light);--md-code-hl-comment-color:var(--md-default-fg-color--light);--md-code-hl-generic-color:var(--md-default-fg-color--light);--md-code-hl-variable-color:var(--md-default-fg-color--light);--md-typeset-color:var(--md-default-fg-color);--md-typeset-a-color:var(--md-primary-fg-color);--md-typeset-kbd-color:hsla(var(--md-hue),15%,90%,0.12);--md-typeset-kbd-accent-color:hsla(var(--md-hue),15%,90%,0.2);--md-typeset-kbd-border-color:hsla(var(--md-hue),15%,14%,1);--md-typeset-mark-color:#4287ff4d;--md-typeset-table-color:hsla(var(--md-hue),15%,95%,0.12);--md-typeset-table-color--light:hsla(var(--md-hue),15%,95%,0.035);--md-admonition-fg-color:var(--md-default-fg-color);--md-admonition-bg-color:var(--md-default-bg-color);--md-footer-bg-color:hsla(var(--md-hue),15%,10%,0.87);--md-footer-bg-color--dark:hsla(var(--md-hue),15%,8%,1);--md-shadow-z1:0 0.2rem 0.5rem #0000000d,0 0 0.05rem #0000001a;--md-shadow-z2:0 0.2rem 0.5rem #00000040,0 0 0.05rem #00000040;--md-shadow-z3:0 0.2rem 0.5rem #0006,0 0 0.05rem #00000059;color-scheme:dark}[data-md-color-scheme=slate] img[src$="#gh-light-mode-only"],[data-md-color-scheme=slate] img[src$="#only-light"]{display:none}[data-md-color-scheme=slate][data-md-color-primary=pink]{--md-typeset-a-color:#ed5487}[data-md-color-scheme=slate][data-md-color-primary=purple]{--md-typeset-a-color:#c46fd3}[data-md-color-scheme=slate][data-md-color-primary=deep-purple]{--md-typeset-a-color:#a47bea}[data-md-color-scheme=slate][data-md-color-primary=indigo]{--md-typeset-a-color:#5488e8}[data-md-color-scheme=slate][data-md-color-primary=teal]{--md-typeset-a-color:#00ccb8}[data-md-color-scheme=slate][data-md-color-primary=green]{--md-typeset-a-color:#71c174}[data-md-color-scheme=slate][data-md-color-primary=deep-orange]{--md-typeset-a-color:#ff764d}[data-md-color-scheme=slate][data-md-color-primary=brown]{--md-typeset-a-color:#c1775c}[data-md-color-scheme=slate][data-md-color-primary=black],[data-md-color-scheme=slate][data-md-color-primary=blue-grey],[data-md-color-scheme=slate][data-md-color-primary=grey],[data-md-color-scheme=slate][data-md-color-primary=white]{--md-typeset-a-color:#5e8bde}[data-md-color-switching] *,[data-md-color-switching] :after,[data-md-color-switching] :before{transition-duration:0ms!important}}[data-md-color-accent=red]{--md-accent-fg-color:#ff1947;--md-accent-fg-color--transparent:#ff19471a;--md-accent-bg-color:#fff;--md-accent-bg-color--light:#ffffffb3}[data-md-color-accent=pink]{--md-accent-fg-color:#f50056;--md-accent-fg-color--transparent:#f500561a;--md-accent-bg-color:#fff;--md-accent-bg-color--light:#ffffffb3}[data-md-color-accent=purple]{--md-accent-fg-color:#df41fb;--md-accent-fg-color--transparent:#df41fb1a;--md-accent-bg-color:#fff;--md-accent-bg-color--light:#ffffffb3}[data-md-color-accent=deep-purple]{--md-accent-fg-color:#7c4dff;--md-accent-fg-color--transparent:#7c4dff1a;--md-accent-bg-color:#fff;--md-accent-bg-color--light:#ffffffb3}[data-md-color-accent=indigo]{--md-accent-fg-color:#526cfe;--md-accent-fg-color--transparent:#526cfe1a;--md-accent-bg-color:#fff;--md-accent-bg-color--light:#ffffffb3}[data-md-color-accent=blue]{--md-accent-fg-color:#4287ff;--md-accent-fg-color--transparent:#4287ff1a;--md-accent-bg-color:#fff;--md-accent-bg-color--light:#ffffffb3}[data-md-color-accent=light-blue]{--md-accent-fg-color:#0091eb;--md-accent-fg-color--transparent:#0091eb1a;--md-accent-bg-color:#fff;--md-accent-bg-color--light:#ffffffb3}[data-md-color-accent=cyan]{--md-accent-fg-color:#00bad6;--md-accent-fg-color--transparent:#00bad61a;--md-accent-bg-color:#fff;--md-accent-bg-color--light:#ffffffb3}[data-md-color-accent=teal]{--md-accent-fg-color:#00bda4;--md-accent-fg-color--transparent:#00bda41a;--md-accent-bg-color:#fff;--md-accent-bg-color--light:#ffffffb3}[data-md-color-accent=green]{--md-accent-fg-color:#00c753;--md-accent-fg-color--transparent:#00c7531a;--md-accent-bg-color:#fff;--md-accent-bg-color--light:#ffffffb3}[data-md-color-accent=light-green]{--md-accent-fg-color:#63de17;--md-accent-fg-color--transparent:#63de171a;--md-accent-bg-color:#fff;--md-accent-bg-color--light:#ffffffb3}[data-md-color-accent=lime]{--md-accent-fg-color:#b0eb00;--md-accent-fg-color--transparent:#b0eb001a;--md-accent-bg-color:#000000de;--md-accent-bg-color--light:#0000008a}[data-md-color-accent=yellow]{--md-accent-fg-color:#ffd500;--md-accent-fg-color--transparent:#ffd5001a;--md-accent-bg-color:#000000de;--md-accent-bg-color--light:#0000008a}[data-md-color-accent=amber]{--md-accent-fg-color:#fa0;--md-accent-fg-color--transparent:#ffaa001a;--md-accent-bg-color:#000000de;--md-accent-bg-color--light:#0000008a}[data-md-color-accent=orange]{--md-accent-fg-color:#ff9100;--md-accent-fg-color--transparent:#ff91001a;--md-accent-bg-color:#000000de;--md-accent-bg-color--light:#0000008a}[data-md-color-accent=deep-orange]{--md-accent-fg-color:#ff6e42;--md-accent-fg-color--transparent:#ff6e421a;--md-accent-bg-color:#fff;--md-accent-bg-color--light:#ffffffb3}[data-md-color-primary=red]{--md-primary-fg-color:#ef5552;--md-primary-fg-color--light:#e57171;--md-primary-fg-color--dark:#e53734;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3}[data-md-color-primary=pink]{--md-primary-fg-color:#e92063;--md-primary-fg-color--light:#ec417a;--md-primary-fg-color--dark:#c3185d;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3}[data-md-color-primary=purple]{--md-primary-fg-color:#ab47bd;--md-primary-fg-color--light:#bb69c9;--md-primary-fg-color--dark:#8c24a8;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3}[data-md-color-primary=deep-purple]{--md-primary-fg-color:#7e56c2;--md-primary-fg-color--light:#9574cd;--md-primary-fg-color--dark:#673ab6;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3}[data-md-color-primary=indigo]{--md-primary-fg-color:#4051b5;--md-primary-fg-color--light:#5d6cc0;--md-primary-fg-color--dark:#303fa1;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3}[data-md-color-primary=blue]{--md-primary-fg-color:#2094f3;--md-primary-fg-color--light:#42a5f5;--md-primary-fg-color--dark:#1975d2;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3}[data-md-color-primary=light-blue]{--md-primary-fg-color:#02a6f2;--md-primary-fg-color--light:#28b5f6;--md-primary-fg-color--dark:#0287cf;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3}[data-md-color-primary=cyan]{--md-primary-fg-color:#00bdd6;--md-primary-fg-color--light:#25c5da;--md-primary-fg-color--dark:#0097a8;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3}[data-md-color-primary=teal]{--md-primary-fg-color:#009485;--md-primary-fg-color--light:#26a699;--md-primary-fg-color--dark:#007a6c;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3}[data-md-color-primary=green]{--md-primary-fg-color:#4cae4f;--md-primary-fg-color--light:#68bb6c;--md-primary-fg-color--dark:#398e3d;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3}[data-md-color-primary=light-green]{--md-primary-fg-color:#8bc34b;--md-primary-fg-color--light:#9ccc66;--md-primary-fg-color--dark:#689f38;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3}[data-md-color-primary=lime]{--md-primary-fg-color:#cbdc38;--md-primary-fg-color--light:#d3e156;--md-primary-fg-color--dark:#b0b52c;--md-primary-bg-color:#000000de;--md-primary-bg-color--light:#0000008a}[data-md-color-primary=yellow]{--md-primary-fg-color:#ffec3d;--md-primary-fg-color--light:#ffee57;--md-primary-fg-color--dark:#fbc02d;--md-primary-bg-color:#000000de;--md-primary-bg-color--light:#0000008a}[data-md-color-primary=amber]{--md-primary-fg-color:#ffc105;--md-primary-fg-color--light:#ffc929;--md-primary-fg-color--dark:#ffa200;--md-primary-bg-color:#000000de;--md-primary-bg-color--light:#0000008a}[data-md-color-primary=orange]{--md-primary-fg-color:#ffa724;--md-primary-fg-color--light:#ffa724;--md-primary-fg-color--dark:#fa8900;--md-primary-bg-color:#000000de;--md-primary-bg-color--light:#0000008a}[data-md-color-primary=deep-orange]{--md-primary-fg-color:#ff6e42;--md-primary-fg-color--light:#ff8a66;--md-primary-fg-color--dark:#f4511f;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3}[data-md-color-primary=brown]{--md-primary-fg-color:#795649;--md-primary-fg-color--light:#8d6e62;--md-primary-fg-color--dark:#5d4037;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3}[data-md-color-primary=grey]{--md-primary-fg-color:#757575;--md-primary-fg-color--light:#9e9e9e;--md-primary-fg-color--dark:#616161;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3;--md-typeset-a-color:#4051b5}[data-md-color-primary=blue-grey]{--md-primary-fg-color:#546d78;--md-primary-fg-color--light:#607c8a;--md-primary-fg-color--dark:#455a63;--md-primary-bg-color:#fff;--md-primary-bg-color--light:#ffffffb3;--md-typeset-a-color:#4051b5}[data-md-color-primary=light-green]:not([data-md-color-scheme=slate]){--md-typeset-a-color:#72ad2e}[data-md-color-primary=lime]:not([data-md-color-scheme=slate]){--md-typeset-a-color:#8b990a}[data-md-color-primary=yellow]:not([data-md-color-scheme=slate]){--md-typeset-a-color:#b8a500}[data-md-color-primary=amber]:not([data-md-color-scheme=slate]){--md-typeset-a-color:#d19d00}[data-md-color-primary=orange]:not([data-md-color-scheme=slate]){--md-typeset-a-color:#e68a00}[data-md-color-primary=white]{--md-primary-fg-color:hsla(var(--md-hue),0%,100%,1);--md-primary-fg-color--light:hsla(var(--md-hue),0%,100%,0.7);--md-primary-fg-color--dark:hsla(var(--md-hue),0%,0%,0.07);--md-primary-bg-color:hsla(var(--md-hue),0%,0%,0.87);--md-primary-bg-color--light:hsla(var(--md-hue),0%,0%,0.54);--md-typeset-a-color:#4051b5}[data-md-color-primary=white] .md-button{color:var(--md-typeset-a-color)}[data-md-color-primary=white] .md-button--primary{background-color:var(--md-typeset-a-color);border-color:var(--md-typeset-a-color);color:hsla(var(--md-hue),0%,100%,1)}@media screen and (min-width:60em){[data-md-color-primary=white] .md-search__form{background-color:hsla(var(--md-hue),0%,0%,.07)}[data-md-color-primary=white] .md-search__form:hover{background-color:hsla(var(--md-hue),0%,0%,.32)}[data-md-color-primary=white] .md-search__input+.md-search__icon{color:hsla(var(--md-hue),0%,0%,.87)}}@media screen and (min-width:76.25em){[data-md-color-primary=white] .md-tabs{border-bottom:.05rem solid #00000012}}[data-md-color-primary=black]{--md-primary-fg-color:hsla(var(--md-hue),15%,9%,1);--md-primary-fg-color--light:hsla(var(--md-hue),15%,9%,0.54);--md-primary-fg-color--dark:hsla(var(--md-hue),15%,9%,1);--md-primary-bg-color:hsla(var(--md-hue),15%,100%,1);--md-primary-bg-color--light:hsla(var(--md-hue),15%,100%,0.7);--md-typeset-a-color:#4051b5}[data-md-color-primary=black] .md-button{color:var(--md-typeset-a-color)}[data-md-color-primary=black] .md-button--primary{background-color:var(--md-typeset-a-color);border-color:var(--md-typeset-a-color);color:hsla(var(--md-hue),0%,100%,1)}[data-md-color-primary=black] .md-header{background-color:hsla(var(--md-hue),15%,9%,1)}@media screen and (max-width:59.984375em){[data-md-color-primary=black] .md-nav__source{background-color:hsla(var(--md-hue),15%,11%,.87)}}@media screen and (max-width:76.234375em){html [data-md-color-primary=black] .md-nav--primary .md-nav__title[for=__drawer]{background-color:hsla(var(--md-hue),15%,9%,1)}}@media screen and (min-width:76.25em){[data-md-color-primary=black] .md-tabs{background-color:hsla(var(--md-hue),15%,9%,1)}}
\ No newline at end of file
diff --git a/communicating-your-work/index.html b/communicating-your-work/index.html
new file mode 100644
index 000000000..9a335cf8a
--- /dev/null
+++ b/communicating-your-work/index.html
@@ -0,0 +1,1138 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Communicating your work - Zero to Mastery Data Science and Machine Learning Bootcamp
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+Communicating and Sharing Your Work as a Data Scientist/Machine Learning Engineer
+This article is nearly 3000 words long but you can summarise it in 3.
+3 words in the form of a question.
+Whenever you're communicating your work, ask yourself, "Who's it for?".
+That's your start. Build upon it. Dig deeper. Got an idea of who your work is for? What questions will they have? What needs do they have? What concerns can you address before they arise?
+You'll never be able to fully answer these questions but it pays to think about them in advance.
+Having a conversation with your potential audience is a warm up for the actual conversation.
+Communicating your work is an unsolved challenge. But that's what makes it fun. What may make complete sense in your head could be a complete mystery to someone else.
+If you want your message to be heard, it's not enough for you to deliver it in a way someone can hear it. You have to deliver it in a way it can be understood.
+Imagine a man yelling in the middle of the street. His message can be heard. But no matter what he's talking about, it's unlikely it'll be understood.
+Let's break this down.
+After asking yourself, "Who's it for?", you'll start to realise there are two main audiences for your work. Those on your team, your boss, your manager, the people you sit next to and those who aren't, your clients, your customers, your fans. These can be broken down further and have plenty of overlaps but they're where we'll start.
+You'll also start to realise, your work isn't for everyone. A beginner's mistake is thinking too broadly. A message which appeals to everyone may convey information but it'll lack substance. You want the gut punch reaction.
+To begin, let's pretend you've asked yourself, "Who's it for?", and your answer is someone you work with, your teammates, your manager, someone on the internet reading about your latest technical project.
+Communicating with people on your team
+All non-technical problems are communication problems. Often, you'll find these harder to solve than the technical problems. Technical problems, unless bounded by the laws of physics, have a finite solution. Communication problems don't.
+What do they need to know?
+After asking yourself, "Who's it for?", a question you should follow up with is, "What do they need to know?".
+What your teammate may need to know might be different to what your manager needs to know.
+When answering this for yourself, lean on the side of excess. Write it down for later. The worst case is, you figure out what's not needed.
+
+
+
+ |
+
+
+
+
+| Start with "Who's it for?" and follow it up with "What do they need to know?". When answering these questions, write your questions and answers down. Writing helps to clear your thinking. It also gives you a resource you can refer to later. |
+
+
+
+The Project Manager, Boss, Senior, Lead
+Your project manager, Amber, has a mission. Aside from taking care of you and the team, she's determined to keep the project running on time and on budget.
+This translates to: keeping obstacles out of your way.
+So her questions will often come in some form of "What's holding you back?".
+It should go without saying, honesty is your best friend here. Life happens. When challenges come up, Amber should know about them.
+That's what Amber is there for. She's there to help oversee and figure out the challenges, she's there to connect you with people who might be able to help.
+When preparing a report, align it to the questions and concerns Amber may have. If you’ve asked yourself, “What does Amber need to know?”, start with the answers.
+
+
+
+ |
+
+
+
+
+| Your bosses primary job is to take care of you and challenging you (if not, get a new boss). After this, it's in their best interest for projects to run on budget and time. This means keeping obstacles out of your way. If something is holding you back, you should let them know. |
+
+
+
+The People You're Working With, Sitting Next to, in the Group Chat
+It saddens me how many communication channels there are now. Most of them encourage communicating too often. Unless it's an emergency, "Now" is often never the best time.
+Projects you work on will have arbitrarily long timelines, with many milestones, plans and steps. Keep in mind the longer the timescale, the worse humans are at dealing with them.
+Break it down. Days and weeks are much easier units of time to understand.
+
+
+
+ |
+
+
+
+
+| Example of how a 6-month project becomes a day-by-day project. |
+
+
+
+What are you working on this week? Write it down, share it with the team. This not only consolidates your thinking, it gives your team an opportunity to ask questions and offer advice.
+Set a reminder for the end of each day. Have it ask, "What did you work on today?". Your response doesn't have to be long but it should be written down.
+You could use the following template.
+What I worked on today (1-3 points on what you did):
+
+- What's working?
+- What's not working?
+- What could be improved?
+
+What I'm working on next:
+
+- What's your next course of action? (based on the above)
+- Why?
+- What's holding you back?
+
+After you've written down answers, you should share them with your team.
+The beauty of a daily reflection like this is you've got a history, a playbook, a thought process. Plus, this style of communication is far better than little bits and pieces scattered throughout the day.
+You may be tempted to hold something back because it's not perfect, not fully thought out, but that's what your teammates are for. To help you figure it out. The same goes for the reverse. Help each other.
+Relate these daily and weekly communications back to the overall project goal. A 6-month project seems like a lot to begin with but breaking it down week by week, day by day, helps you and the people around you know what's going on.
+Take note of questions which arise. If a question gets asked more than 3 times, it should be documented somewhere for others to reference.
+You'll see some of the communication points for the people you're sitting with crossover with your project manager and vice versa. You're smart enough to figure out when to use each.
+Start the job before you have it
+It can be hard to communicate with a project manager, boss or teammates if you don't have a job. And if you've recently learned some skills through an online course, it can be tempting to jump straight into the next one.
+But what are you really chasing?
+Are you after more certificates or more skills?
+No matter how good the course, you can assume the skills you learn there will be commoditised. That means, many other people will have gone through the same course, acquired the skills and then will be looking for similar jobs to what you are.
+If Janet posts a job vacancy and receives 673 applicants through an online form, you can imagine how hard it is for your resume to stand out.
+This isn't to say you shouldn't apply through an online form but if you're really serious about getting a role somewhere, start the job before you have it.
+How?
+By working on and sharing your own projects which relate to the role you're applying for.
+I call this the weekend project principle. During the week you're building foundational skills through various courses. But on the weekend, you design your own projects, projects inline with the role you're after and work on them.
+Let’s see it in practice.
+Melissa and Henry apply for a data scientist role. They both make it through to interviews and are sitting with Janet. Janet looks at both their resumes and notices they've both done similar style courses.
+She asks Joe if he's worked on any of his own projects and he tells her, no he's only had a chance to work on coursework but has plenty of ideas.
+She asks Melissa the same. She pulls out her phone and tells Janet she's built a small app to help read food labels. Her daughter can't have gluten and got confused every time she tried to figure out what was in the food she was eating. The app isn't perfect but Melissa tells the story of how her daughter has figured out a few foods she should avoid and a few others which are fine.
+If you were Janet, who would you lean towards?
+Working on your own projects helps you build specific knowledge, they're what compound knowledge into skill, skill which can't be taught in courses.
+What should you work on?
+The hard part is you've unlimited options. The best part is you've got unlimited options.
+One method is to find the ideal company and ideal role you're going for. And then do your research.
+What does a person in that position day-to-day? Figure it out and then replicate it. Design yourself a 6-week project based on what you find.
+Why 6-weeks? The worst case is, if it doesn't work out, it's only 6 weeks. The best case is, you'll surprise yourself at what you can accomplish in 42-days.
+If you're still stuck, follow your interests. Use the same timeline except this time, choose something which excites you and see where it goes. Remember, the worst case is, after 6-weeks, you'll know whether to pursue it (another 6 weeks) or move onto the next thing.
+Now instead of only having a collection of certificates, you've got a story to tell. You've got evidence of you trying to put what you've learned into practice (exactly what you'll be doing in a job).
+And if you're wondering where the evidence comes from, it comes from you documenting your work.
+Where?
+On your own blog.
+Why a blog?
+We've discussed this before but it's worth repeating. Writing down what you're working on, helps solidify your thinking. It also helps others learn what you’ve figured out.
+You could start with a post per week detailing how your 6-week project is going, what you've figured out, what you're doing next. Again, your project doesn't have to be perfect, none are, and your writing doesn't have to be perfect either.
+By the end of the 6-weeks, you'll have a series of articles detailing your work.
+Something you can point to and say, "This is what I've done."
+If you're looking for resources to start a blog, Devblog by Hashnode and fast_template by the fast.ai team are both free and require almost zero setup. Medium is the next best place.
+Share your articles on Twitter, LinkedIn or even better, send them directly to the person in charge of hiring for the role you're after. You're crafty enough to find them.
+Communicating with those outside your team
+When answering "Who's it for?” results in someone who doesn't think like you, customers, clients, fans, it's also important to follow up with "What do they need to know?".
+A reminder: The line between people on your team and outside your team isn’t set in stone. The goal of these exercises and techniques are to get you thinking from the perspective of the person you are trying to communicate with.
+Clients, Customers & Fans
+I made a presentation for a board meeting once. We were there to present our results on a recent software proof of concept to some executives. Being an engineer, my presentation slides were clogged with detailed text, barely large enough to read. It contained every detail of the project, the techniques used, theories, code, acronyms with no definition. The presentation looked great to other engineers but caused the executives to squint, lean in and ignore everything being said in an attempt to read them.
+Once we made it through to the end, a slide with a visual appeared, to which, I palmed off as unnecessary but immediately sparked the interest of the executives.
+"What's that?", one asked.
+We spent the next 45-minutes discussing that one slide in detail. The slide which to me, didn’t matter.
+The lesson here is what you think is important may be the opposite to others. And what's obvious to you could be amazing to others.
+Knowing this, you'll start to realise, unless they directly tell you, figuring out what your clients, customers and fans want to know is a challenge.
+There's a simple solution to this.
+Ask.
+Most people have a lot to offer but rarely volunteer it. Ask if what you're saying is clear, ask if there is anything else they'd like to see.
+You may get something left of field or things you're not sure of. In these cases, it's up to you to address them before they become larger issues.
+Don't forget, sometimes the best answer is "I don't know, but I'll figure it out and get back to you," or "that's not what we're focused on for now..." (then bringing it back to what you are focused on).
+What story are you telling?
+You're going to underestimate and overestimate your work at the same time. This is a good thing. No one is going to care as much about your work as you. It's up to you to be your own biggest fan and harshest critique at the same time.
+
+
+
+ |
+
+
+
+
+| The first step of any creation is to make something you're proud of. The next step is to figure out how you could improve it. In other words, being your own biggest fan and harshest critique at the same time. |
+
+
+
+When sharing your work, you could drop the facts in. Nothing but a list of exactly what you did. But everyone else can do that too.
+Working what you've done into a story, sharing what worked, what didn't, why you went one direction and not another is hard. But that's exactly why it's worth it.
+I will say it until I go hoarse, how you deliver your message will depend on who your audience is.
+Being specific is brave, put it in writing and here's what I've done
+Starting with "Who's it for?", and following up with, "What do they need to know?", means you're going to have to be specific. And being specific means having to say, “It's not for you" to a lot of people. Doing this takes courage but it also means the ones who do receive your message will engage with it more.
+You'll get lost in thought but found in the words. Writing is nature's way of showing how sloppy your thinking is. Break your larger projects down into a series of sub projects.
+What's on today? What's on this week? Tell yourself, tell your team.
+Take advantage of Cunningham's Law: Sometimes the best way to figure out the right answer isn't to ask a question, it's to put the wrong answer out there.
+Finally, remind yourself, you're not going for perfection. You're going for progress. Going for perfection gets in the way of progress.
+You know you should have your own blog, you know you should be building specific knowledge by working on your own your projects, you know you should be documenting what you've been working on.
+The upside of being able to say, "Here's what I've done", far outweighs the downside of potentially being wrong.
+Recommended Further Reading and Resources
+This article was inspired by experience and a handful of other resources worth your time.
+
+- Basecamp’s guide to internal communication – if you're working on a team, this should be required reading for everyone.
+- You Should Blog by Jeremy Howard from fast.ai – The fast.ai team not only teach amazing artificial intelligence and other technical skills, they teach you how to communicate them. The best thing is, they live and breath what they teach.
+- How to Start Your Own Machine Learning Projects by Daniel Bourke – After learning foundational skills using courses, one of the hardest things to do next is to use the skills you've learned in your own projects. This article by yours truly gives a deeper breakdown into how to approach your own projects.
+- Why you (yes, you) should blog by Rachel Thomas from fast.ai – Rachel Thomas not only has incredible technical skills, she's a phenomenal communicator. If you aren't convinced to start your own blog yet, this article will have you writing in no time.
+- Fast Template by fast.ai – Starting a blog should be required for everyone learning some kind of skill. Fast Template by the fast.ai team makes it free and easy.
+- Devblog by Hasnode – Your own blog, your own domain, readers ready to go, you own your content (automatic backups on GitHub), all ready to go. Start writing.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Notebook last run (end-to-end): 2024-10-30 11:54:38.504966
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
pandas version: 2.2.2
+NumPy version: 2.1.1
+matplotlib version: 3.9.2
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] 'bluebook-for-bulldozers' dataset exists, feel free to proceed!
+[INFO] Current dataset dir: ../data/bluebook-for-bulldozers
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Files/folders available in ../data/bluebook-for-bulldozers:
+
+
+
+
+
Out[11]:
+
+
['random_forest_benchmark_test.csv',
+ 'Valid.csv',
+ 'median_benchmark.csv',
+ 'Valid.zip',
+ 'TrainAndValid.7z',
+ 'Test.csv',
+ 'predictions.csv',
+ 'Train.7z',
+ 'TrainAndValid_object_values_as_categories.parquet',
+ 'test_predictions.csv',
+ 'ValidSolution.csv',
+ 'train_tmp.csv',
+ 'Machine_Appendix.csv',
+ 'Train.csv',
+ 'Valid.7z',
+ 'TrainAndValid_object_values_as_categories.csv',
+ 'TrainAndValid_object_values_as_categories_and_missing_values_filled.parquet',
+ 'Data Dictionary.xlsx',
+ 'TrainAndValid.csv',
+ 'Train.zip',
+ 'TrainAndValid.zip']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
/var/folders/c4/qj4gdk190td18bqvjjh0p3p00000gn/T/ipykernel_20423/1127193594.py:2: DtypeWarning: Columns (13,39,40,41) have mixed types. Specify dtype option on import or set low_memory=False.
+ df = pd.read_csv(filepath_or_buffer="../data/bluebook-for-bulldozers/TrainAndValid.csv")
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
<class 'pandas.core.frame.DataFrame'>
+RangeIndex: 412698 entries, 0 to 412697
+Data columns (total 53 columns):
+ # Column Non-Null Count Dtype
+--- ------ -------------- -----
+ 0 SalesID 412698 non-null int64
+ 1 SalePrice 412698 non-null float64
+ 2 MachineID 412698 non-null int64
+ 3 ModelID 412698 non-null int64
+ 4 datasource 412698 non-null int64
+ 5 auctioneerID 392562 non-null float64
+ 6 YearMade 412698 non-null int64
+ 7 MachineHoursCurrentMeter 147504 non-null float64
+ 8 UsageBand 73670 non-null object
+ 9 saledate 412698 non-null object
+ 10 fiModelDesc 412698 non-null object
+ 11 fiBaseModel 412698 non-null object
+ 12 fiSecondaryDesc 271971 non-null object
+ 13 fiModelSeries 58667 non-null object
+ 14 fiModelDescriptor 74816 non-null object
+ 15 ProductSize 196093 non-null object
+ 16 fiProductClassDesc 412698 non-null object
+ 17 state 412698 non-null object
+ 18 ProductGroup 412698 non-null object
+ 19 ProductGroupDesc 412698 non-null object
+ 20 Drive_System 107087 non-null object
+ 21 Enclosure 412364 non-null object
+ 22 Forks 197715 non-null object
+ 23 Pad_Type 81096 non-null object
+ 24 Ride_Control 152728 non-null object
+ 25 Stick 81096 non-null object
+ 26 Transmission 188007 non-null object
+ 27 Turbocharged 81096 non-null object
+ 28 Blade_Extension 25983 non-null object
+ 29 Blade_Width 25983 non-null object
+ 30 Enclosure_Type 25983 non-null object
+ 31 Engine_Horsepower 25983 non-null object
+ 32 Hydraulics 330133 non-null object
+ 33 Pushblock 25983 non-null object
+ 34 Ripper 106945 non-null object
+ 35 Scarifier 25994 non-null object
+ 36 Tip_Control 25983 non-null object
+ 37 Tire_Size 97638 non-null object
+ 38 Coupler 220679 non-null object
+ 39 Coupler_System 44974 non-null object
+ 40 Grouser_Tracks 44875 non-null object
+ 41 Hydraulics_Flow 44875 non-null object
+ 42 Track_Type 102193 non-null object
+ 43 Undercarriage_Pad_Width 102916 non-null object
+ 44 Stick_Length 102261 non-null object
+ 45 Thumb 102332 non-null object
+ 46 Pattern_Changer 102261 non-null object
+ 47 Grouser_Type 102193 non-null object
+ 48 Backhoe_Mounting 80712 non-null object
+ 49 Blade_Type 81875 non-null object
+ 50 Travel_Controls 81877 non-null object
+ 51 Differential_Type 71564 non-null object
+ 52 Steering_Controls 71522 non-null object
+dtypes: float64(3), int64(5), object(45)
+memory usage: 166.9+ MB
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[15]:
+
+
0 11/16/2006 0:00
+1 3/26/2004 0:00
+2 2/26/2004 0:00
+3 5/19/2011 0:00
+4 7/23/2009 0:00
+5 12/18/2008 0:00
+6 8/26/2004 0:00
+7 11/17/2005 0:00
+8 8/27/2009 0:00
+9 8/9/2007 0:00
+Name: saledate, dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
<class 'pandas.core.frame.DataFrame'>
+RangeIndex: 412698 entries, 0 to 412697
+Data columns (total 53 columns):
+ # Column Non-Null Count Dtype
+--- ------ -------------- -----
+ 0 SalesID 412698 non-null int64
+ 1 SalePrice 412698 non-null float64
+ 2 MachineID 412698 non-null int64
+ 3 ModelID 412698 non-null int64
+ 4 datasource 412698 non-null int64
+ 5 auctioneerID 392562 non-null float64
+ 6 YearMade 412698 non-null int64
+ 7 MachineHoursCurrentMeter 147504 non-null float64
+ 8 UsageBand 73670 non-null object
+ 9 saledate 412698 non-null datetime64[ns]
+ 10 fiModelDesc 412698 non-null object
+ 11 fiBaseModel 412698 non-null object
+ 12 fiSecondaryDesc 271971 non-null object
+ 13 fiModelSeries 58667 non-null object
+ 14 fiModelDescriptor 74816 non-null object
+ 15 ProductSize 196093 non-null object
+ 16 fiProductClassDesc 412698 non-null object
+ 17 state 412698 non-null object
+ 18 ProductGroup 412698 non-null object
+ 19 ProductGroupDesc 412698 non-null object
+ 20 Drive_System 107087 non-null object
+ 21 Enclosure 412364 non-null object
+ 22 Forks 197715 non-null object
+ 23 Pad_Type 81096 non-null object
+ 24 Ride_Control 152728 non-null object
+ 25 Stick 81096 non-null object
+ 26 Transmission 188007 non-null object
+ 27 Turbocharged 81096 non-null object
+ 28 Blade_Extension 25983 non-null object
+ 29 Blade_Width 25983 non-null object
+ 30 Enclosure_Type 25983 non-null object
+ 31 Engine_Horsepower 25983 non-null object
+ 32 Hydraulics 330133 non-null object
+ 33 Pushblock 25983 non-null object
+ 34 Ripper 106945 non-null object
+ 35 Scarifier 25994 non-null object
+ 36 Tip_Control 25983 non-null object
+ 37 Tire_Size 97638 non-null object
+ 38 Coupler 220679 non-null object
+ 39 Coupler_System 44974 non-null object
+ 40 Grouser_Tracks 44875 non-null object
+ 41 Hydraulics_Flow 44875 non-null object
+ 42 Track_Type 102193 non-null object
+ 43 Undercarriage_Pad_Width 102916 non-null object
+ 44 Stick_Length 102261 non-null object
+ 45 Thumb 102332 non-null object
+ 46 Pattern_Changer 102261 non-null object
+ 47 Grouser_Type 102193 non-null object
+ 48 Backhoe_Mounting 80712 non-null object
+ 49 Blade_Type 81875 non-null object
+ 50 Travel_Controls 81877 non-null object
+ 51 Differential_Type 71564 non-null object
+ 52 Steering_Controls 71522 non-null object
+dtypes: datetime64[ns](1), float64(3), int64(5), object(44)
+memory usage: 166.9+ MB
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[19]:
+
+
0 2006-11-16
+1 2004-03-26
+2 2004-02-26
+3 2011-05-19
+4 2009-07-23
+5 2008-12-18
+6 2004-08-26
+7 2005-11-17
+8 2009-08-27
+9 2007-08-09
+Name: saledate, dtype: datetime64[ns]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[21]:
+
+
(205615 1989-01-17
+ 274835 1989-01-31
+ 141296 1989-01-31
+ 212552 1989-01-31
+ 62755 1989-01-31
+ 54653 1989-01-31
+ 81383 1989-01-31
+ 204924 1989-01-31
+ 135376 1989-01-31
+ 113390 1989-01-31
+ Name: saledate, dtype: datetime64[ns],
+ 409202 2012-04-28
+ 408976 2012-04-28
+ 411695 2012-04-28
+ 411319 2012-04-28
+ 408889 2012-04-28
+ 410879 2012-04-28
+ 412476 2012-04-28
+ 411927 2012-04-28
+ 407124 2012-04-28
+ 409203 2012-04-28
+ Name: saledate, dtype: datetime64[ns])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[24]:
+
+
+
+
+
+
+ |
+SalePrice |
+saleYear |
+saleMonth |
+saleDay |
+saleDayofweek |
+saleDayofyear |
+
+
+
+
+| 205615 |
+9500.0 |
+1989 |
+1 |
+17 |
+1 |
+17 |
+
+
+| 274835 |
+14000.0 |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+| 141296 |
+50000.0 |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+| 212552 |
+16000.0 |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+| 62755 |
+22000.0 |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[27]:
+
+
state
+Florida 67320
+Texas 53110
+California 29761
+Washington 16222
+Georgia 14633
+Maryland 13322
+Mississippi 13240
+Ohio 12369
+Illinois 11540
+Colorado 11529
+Name: count, dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+/var/folders/c4/qj4gdk190td18bqvjjh0p3p00000gn/T/ipykernel_20423/2824176890.py in ?()
+ 1 # This won't work since we've got missing numbers and categories
+ 2 from sklearn.ensemble import RandomForestRegressor
+ 3
+ 4 model = RandomForestRegressor(n_jobs=-1)
+----> 5 model.fit(X=df_tmp.drop("SalePrice", axis=1), # use all columns except SalePrice as X input
+ 6 y=df_tmp.SalePrice) # use SalePrice column as y input
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(estimator, *args, **kwargs)
+ 1469 skip_parameter_validation=(
+ 1470 prefer_skip_nested_validation or global_skip_validation
+ 1471 )
+ 1472 ):
+-> 1473 return fit_method(estimator, *args, **kwargs)
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X, y, sample_weight)
+ 359 # Validate or convert input data
+ 360 if issparse(y):
+ 361 raise ValueError("sparse multilabel-indicator for y is not supported.")
+ 362
+--> 363 X, y = self._validate_data(
+ 364 X,
+ 365 y,
+ 366 multi_output=True,
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)
+ 646 if "estimator" not in check_y_params:
+ 647 check_y_params = {**default_check_params, **check_y_params}
+ 648 y = check_array(y, input_name="y", **check_y_params)
+ 649 else:
+--> 650 X, y = check_X_y(X, y, **check_params)
+ 651 out = X, y
+ 652
+ 653 if not no_val_X and check_params.get("ensure_2d", True):
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(X, y, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, estimator)
+ 1297 raise ValueError(
+ 1298 f"{estimator_name} requires y to be passed, but the target y is None"
+ 1299 )
+ 1300
+-> 1301 X = check_array(
+ 1302 X,
+ 1303 accept_sparse=accept_sparse,
+ 1304 accept_large_sparse=accept_large_sparse,
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)
+ 1009 )
+ 1010 array = xp.astype(array, dtype, copy=False)
+ 1011 else:
+ 1012 array = _asarray_with_order(array, order=order, dtype=dtype, xp=xp)
+-> 1013 except ComplexWarning as complex_warning:
+ 1014 raise ValueError(
+ 1015 "Complex data not supported\n{}\n".format(array)
+ 1016 ) from complex_warning
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/_array_api.py in ?(array, dtype, order, copy, xp, device)
+ 747 # Use NumPy API to support order
+ 748 if copy is True:
+ 749 array = numpy.array(array, order=order, dtype=dtype)
+ 750 else:
+--> 751 array = numpy.asarray(array, order=order, dtype=dtype)
+ 752
+ 753 # At this point array is a NumPy ndarray. We convert it to an array
+ 754 # container that is consistent with the input's namespace.
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/core/generic.py in ?(self, dtype, copy)
+ 2149 def __array__(
+ 2150 self, dtype: npt.DTypeLike | None = None, copy: bool_t | None = None
+ 2151 ) -> np.ndarray:
+ 2152 values = self._values
+-> 2153 arr = np.asarray(values, dtype=dtype)
+ 2154 if (
+ 2155 astype_is_view(values.dtype, arr.dtype)
+ 2156 and using_copy_on_write()
+
+ValueError: could not convert string to float: 'Low'
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
<class 'pandas.core.frame.DataFrame'>
+Index: 412698 entries, 205615 to 409203
+Data columns (total 57 columns):
+ # Column Non-Null Count Dtype
+--- ------ -------------- -----
+ 0 SalesID 412698 non-null int64
+ 1 SalePrice 412698 non-null float64
+ 2 MachineID 412698 non-null int64
+ 3 ModelID 412698 non-null int64
+ 4 datasource 412698 non-null int64
+ 5 auctioneerID 392562 non-null float64
+ 6 YearMade 412698 non-null int64
+ 7 MachineHoursCurrentMeter 147504 non-null float64
+ 8 UsageBand 73670 non-null object
+ 9 fiModelDesc 412698 non-null object
+ 10 fiBaseModel 412698 non-null object
+ 11 fiSecondaryDesc 271971 non-null object
+ 12 fiModelSeries 58667 non-null object
+ 13 fiModelDescriptor 74816 non-null object
+ 14 ProductSize 196093 non-null object
+ 15 fiProductClassDesc 412698 non-null object
+ 16 state 412698 non-null object
+ 17 ProductGroup 412698 non-null object
+ 18 ProductGroupDesc 412698 non-null object
+ 19 Drive_System 107087 non-null object
+ 20 Enclosure 412364 non-null object
+ 21 Forks 197715 non-null object
+ 22 Pad_Type 81096 non-null object
+ 23 Ride_Control 152728 non-null object
+ 24 Stick 81096 non-null object
+ 25 Transmission 188007 non-null object
+ 26 Turbocharged 81096 non-null object
+ 27 Blade_Extension 25983 non-null object
+ 28 Blade_Width 25983 non-null object
+ 29 Enclosure_Type 25983 non-null object
+ 30 Engine_Horsepower 25983 non-null object
+ 31 Hydraulics 330133 non-null object
+ 32 Pushblock 25983 non-null object
+ 33 Ripper 106945 non-null object
+ 34 Scarifier 25994 non-null object
+ 35 Tip_Control 25983 non-null object
+ 36 Tire_Size 97638 non-null object
+ 37 Coupler 220679 non-null object
+ 38 Coupler_System 44974 non-null object
+ 39 Grouser_Tracks 44875 non-null object
+ 40 Hydraulics_Flow 44875 non-null object
+ 41 Track_Type 102193 non-null object
+ 42 Undercarriage_Pad_Width 102916 non-null object
+ 43 Stick_Length 102261 non-null object
+ 44 Thumb 102332 non-null object
+ 45 Pattern_Changer 102261 non-null object
+ 46 Grouser_Type 102193 non-null object
+ 47 Backhoe_Mounting 80712 non-null object
+ 48 Blade_Type 81875 non-null object
+ 49 Travel_Controls 81877 non-null object
+ 50 Differential_Type 71564 non-null object
+ 51 Steering_Controls 71522 non-null object
+ 52 saleYear 412698 non-null int32
+ 53 saleMonth 412698 non-null int32
+ 54 saleDay 412698 non-null int32
+ 55 saleDayofweek 412698 non-null int32
+ 56 saleDayofyear 412698 non-null int32
+dtypes: float64(3), int32(5), int64(5), object(44)
+memory usage: 174.7+ MB
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[31]:
+
+
+
+
+
+
+ |
+SalesID |
+SalePrice |
+MachineID |
+ModelID |
+datasource |
+auctioneerID |
+YearMade |
+MachineHoursCurrentMeter |
+UsageBand |
+fiModelDesc |
+... |
+Backhoe_Mounting |
+Blade_Type |
+Travel_Controls |
+Differential_Type |
+Steering_Controls |
+saleYear |
+saleMonth |
+saleDay |
+saleDayofweek |
+saleDayofyear |
+
+
+
+
+| 205615 |
+False |
+False |
+False |
+False |
+False |
+False |
+False |
+True |
+True |
+False |
+... |
+False |
+False |
+False |
+True |
+True |
+False |
+False |
+False |
+False |
+False |
+
+
+| 274835 |
+False |
+False |
+False |
+False |
+False |
+False |
+False |
+True |
+True |
+False |
+... |
+True |
+True |
+True |
+False |
+False |
+False |
+False |
+False |
+False |
+False |
+
+
+| 141296 |
+False |
+False |
+False |
+False |
+False |
+False |
+False |
+True |
+True |
+False |
+... |
+False |
+False |
+False |
+True |
+True |
+False |
+False |
+False |
+False |
+False |
+
+
+| 212552 |
+False |
+False |
+False |
+False |
+False |
+False |
+False |
+True |
+True |
+False |
+... |
+True |
+True |
+True |
+False |
+False |
+False |
+False |
+False |
+False |
+False |
+
+
+| 62755 |
+False |
+False |
+False |
+False |
+False |
+False |
+False |
+True |
+True |
+False |
+... |
+False |
+False |
+False |
+True |
+True |
+False |
+False |
+False |
+False |
+False |
+
+
+
+
5 rows × 57 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[32]:
+
+
SalesID 0
+SalePrice 0
+MachineID 0
+ModelID 0
+datasource 0
+auctioneerID 20136
+YearMade 0
+MachineHoursCurrentMeter 265194
+UsageBand 339028
+fiModelDesc 0
+fiBaseModel 0
+fiSecondaryDesc 140727
+fiModelSeries 354031
+fiModelDescriptor 337882
+ProductSize 216605
+fiProductClassDesc 0
+state 0
+ProductGroup 0
+ProductGroupDesc 0
+Drive_System 305611
+Enclosure 334
+Forks 214983
+Pad_Type 331602
+Ride_Control 259970
+Stick 331602
+Transmission 224691
+Turbocharged 331602
+Blade_Extension 386715
+Blade_Width 386715
+Enclosure_Type 386715
+Engine_Horsepower 386715
+Hydraulics 82565
+Pushblock 386715
+Ripper 305753
+Scarifier 386704
+Tip_Control 386715
+Tire_Size 315060
+Coupler 192019
+Coupler_System 367724
+Grouser_Tracks 367823
+Hydraulics_Flow 367823
+Track_Type 310505
+Undercarriage_Pad_Width 309782
+Stick_Length 310437
+Thumb 310366
+Pattern_Changer 310437
+Grouser_Type 310505
+Backhoe_Mounting 331986
+Blade_Type 330823
+Travel_Controls 330821
+Differential_Type 341134
+Steering_Controls 341176
+saleYear 0
+saleMonth 0
+saleDay 0
+saleDayofweek 0
+saleDayofyear 0
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[33]:
+
+
(dtype('O'), 'object')
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
This is a key: key1
+This is a value: hello
+This is a key: key2
+This is a value: world!
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Column name: fiModelDesc | Column dtype: object | Example value: ['35ZTS'] | Example value dtype: string
+Column name: fiBaseModel | Column dtype: object | Example value: ['PC75'] | Example value dtype: string
+Column name: fiProductClassDesc | Column dtype: object | Example value: ['Backhoe Loader - 14.0 to 15.0 Ft Standard Digging Depth'] | Example value dtype: string
+Column name: state | Column dtype: object | Example value: ['Florida'] | Example value dtype: string
+Column name: ProductGroup | Column dtype: object | Example value: ['TTT'] | Example value dtype: string
+Column name: ProductGroupDesc | Column dtype: object | Example value: ['Track Excavators'] | Example value dtype: string
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Column name: UsageBand | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: fiModelDesc | Column dtype: object | Example value: ['590SUPER MII'] | Example value dtype: string
+Column name: fiBaseModel | Column dtype: object | Example value: ['580'] | Example value dtype: string
+Column name: fiSecondaryDesc | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: fiModelSeries | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: fiModelDescriptor | Column dtype: object | Example value: ['H'] | Example value dtype: string
+Column name: ProductSize | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: fiProductClassDesc | Column dtype: object | Example value: ['Track Type Tractor, Dozer - 75.0 to 85.0 Horsepower'] | Example value dtype: string
+Column name: state | Column dtype: object | Example value: ['Florida'] | Example value dtype: string
+Column name: ProductGroup | Column dtype: object | Example value: ['TEX'] | Example value dtype: string
+Column name: ProductGroupDesc | Column dtype: object | Example value: ['Skid Steer Loaders'] | Example value dtype: string
+Column name: Drive_System | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Enclosure | Column dtype: object | Example value: ['EROPS'] | Example value dtype: string
+Column name: Forks | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Pad_Type | Column dtype: object | Example value: ['None or Unspecified'] | Example value dtype: string
+Column name: Ride_Control | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Stick | Column dtype: object | Example value: ['Extended'] | Example value dtype: string
+Column name: Transmission | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Turbocharged | Column dtype: object | Example value: ['None or Unspecified'] | Example value dtype: string
+Column name: Blade_Extension | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Blade_Width | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Enclosure_Type | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Engine_Horsepower | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Hydraulics | Column dtype: object | Example value: ['Standard'] | Example value dtype: string
+Column name: Pushblock | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Ripper | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Scarifier | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Tip_Control | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Tire_Size | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Coupler | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Coupler_System | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Grouser_Tracks | Column dtype: object | Example value: ['None or Unspecified'] | Example value dtype: string
+Column name: Hydraulics_Flow | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Track_Type | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Undercarriage_Pad_Width | Column dtype: object | Example value: ['20 inch'] | Example value dtype: string
+Column name: Stick_Length | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Thumb | Column dtype: object | Example value: ['None or Unspecified'] | Example value dtype: string
+Column name: Pattern_Changer | Column dtype: object | Example value: ['None or Unspecified'] | Example value dtype: string
+Column name: Grouser_Type | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Backhoe_Mounting | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Blade_Type | Column dtype: object | Example value: ['Straight'] | Example value dtype: string
+Column name: Travel_Controls | Column dtype: object | Example value: ['None or Unspecified'] | Example value dtype: string
+Column name: Differential_Type | Column dtype: object | Example value: [nan] | Example value dtype: empty
+Column name: Steering_Controls | Column dtype: object | Example value: [nan] | Example value dtype: empty
+
+[INFO] Total number of object type columns: 44
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
<class 'pandas.core.frame.DataFrame'>
+Index: 412698 entries, 205615 to 409203
+Data columns (total 57 columns):
+ # Column Non-Null Count Dtype
+--- ------ -------------- -----
+ 0 SalesID 412698 non-null int64
+ 1 SalePrice 412698 non-null float64
+ 2 MachineID 412698 non-null int64
+ 3 ModelID 412698 non-null int64
+ 4 datasource 412698 non-null int64
+ 5 auctioneerID 392562 non-null float64
+ 6 YearMade 412698 non-null int64
+ 7 MachineHoursCurrentMeter 147504 non-null float64
+ 8 UsageBand 73670 non-null category
+ 9 fiModelDesc 412698 non-null category
+ 10 fiBaseModel 412698 non-null category
+ 11 fiSecondaryDesc 271971 non-null category
+ 12 fiModelSeries 58667 non-null category
+ 13 fiModelDescriptor 74816 non-null category
+ 14 ProductSize 196093 non-null category
+ 15 fiProductClassDesc 412698 non-null category
+ 16 state 412698 non-null category
+ 17 ProductGroup 412698 non-null category
+ 18 ProductGroupDesc 412698 non-null category
+ 19 Drive_System 107087 non-null category
+ 20 Enclosure 412364 non-null category
+ 21 Forks 197715 non-null category
+ 22 Pad_Type 81096 non-null category
+ 23 Ride_Control 152728 non-null category
+ 24 Stick 81096 non-null category
+ 25 Transmission 188007 non-null category
+ 26 Turbocharged 81096 non-null category
+ 27 Blade_Extension 25983 non-null category
+ 28 Blade_Width 25983 non-null category
+ 29 Enclosure_Type 25983 non-null category
+ 30 Engine_Horsepower 25983 non-null category
+ 31 Hydraulics 330133 non-null category
+ 32 Pushblock 25983 non-null category
+ 33 Ripper 106945 non-null category
+ 34 Scarifier 25994 non-null category
+ 35 Tip_Control 25983 non-null category
+ 36 Tire_Size 97638 non-null category
+ 37 Coupler 220679 non-null category
+ 38 Coupler_System 44974 non-null category
+ 39 Grouser_Tracks 44875 non-null category
+ 40 Hydraulics_Flow 44875 non-null category
+ 41 Track_Type 102193 non-null category
+ 42 Undercarriage_Pad_Width 102916 non-null category
+ 43 Stick_Length 102261 non-null category
+ 44 Thumb 102332 non-null category
+ 45 Pattern_Changer 102261 non-null category
+ 46 Grouser_Type 102193 non-null category
+ 47 Backhoe_Mounting 80712 non-null category
+ 48 Blade_Type 81875 non-null category
+ 49 Travel_Controls 81877 non-null category
+ 50 Differential_Type 71564 non-null category
+ 51 Steering_Controls 71522 non-null category
+ 52 saleYear 412698 non-null int32
+ 53 saleMonth 412698 non-null int32
+ 54 saleDay 412698 non-null int32
+ 55 saleDayofweek 412698 non-null int32
+ 56 saleDayofyear 412698 non-null int32
+dtypes: category(44), float64(3), int32(5), int64(5)
+memory usage: 55.4 MB
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[41]:
+
+
CategoricalDtype(categories=['Alabama', 'Alaska', 'Arizona', 'Arkansas', 'California',
+ 'Colorado', 'Connecticut', 'Delaware', 'Florida', 'Georgia',
+ 'Hawaii', 'Idaho', 'Illinois', 'Indiana', 'Iowa', 'Kansas',
+ 'Kentucky', 'Louisiana', 'Maine', 'Maryland',
+ 'Massachusetts', 'Michigan', 'Minnesota', 'Mississippi',
+ 'Missouri', 'Montana', 'Nebraska', 'Nevada', 'New Hampshire',
+ 'New Jersey', 'New Mexico', 'New York', 'North Carolina',
+ 'North Dakota', 'Ohio', 'Oklahoma', 'Oregon', 'Pennsylvania',
+ 'Puerto Rico', 'Rhode Island', 'South Carolina',
+ 'South Dakota', 'Tennessee', 'Texas', 'Unspecified', 'Utah',
+ 'Vermont', 'Virginia', 'Washington', 'Washington DC',
+ 'West Virginia', 'Wisconsin', 'Wyoming'],
+, ordered=False, categories_dtype=object)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[42]:
+
+
Index(['Alabama', 'Alaska', 'Arizona', 'Arkansas', 'California', 'Colorado',
+ 'Connecticut', 'Delaware', 'Florida', 'Georgia', 'Hawaii', 'Idaho',
+ 'Illinois', 'Indiana', 'Iowa', 'Kansas', 'Kentucky', 'Louisiana',
+ 'Maine', 'Maryland', 'Massachusetts', 'Michigan', 'Minnesota',
+ 'Mississippi', 'Missouri', 'Montana', 'Nebraska', 'Nevada',
+ 'New Hampshire', 'New Jersey', 'New Mexico', 'New York',
+ 'North Carolina', 'North Dakota', 'Ohio', 'Oklahoma', 'Oregon',
+ 'Pennsylvania', 'Puerto Rico', 'Rhode Island', 'South Carolina',
+ 'South Dakota', 'Tennessee', 'Texas', 'Unspecified', 'Utah', 'Vermont',
+ 'Virginia', 'Washington', 'Washington DC', 'West Virginia', 'Wisconsin',
+ 'Wyoming'],
+ dtype='object')
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[43]:
+
+
205615 43
+274835 8
+141296 8
+212552 8
+62755 8
+ ..
+410879 4
+412476 4
+411927 4
+407124 4
+409203 4
+Length: 412698, dtype: int8
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Target state category number 43 maps to: Texas
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[46]:
+
+
+
+
+
+
+ |
+SalesID |
+SalePrice |
+MachineID |
+ModelID |
+datasource |
+auctioneerID |
+YearMade |
+MachineHoursCurrentMeter |
+UsageBand |
+fiModelDesc |
+... |
+Backhoe_Mounting |
+Blade_Type |
+Travel_Controls |
+Differential_Type |
+Steering_Controls |
+saleYear |
+saleMonth |
+saleDay |
+saleDayofweek |
+saleDayofyear |
+
+
+
+
+| 0 |
+1646770 |
+9500.0 |
+1126363 |
+8434 |
+132 |
+18.0 |
+1974 |
+NaN |
+NaN |
+TD20 |
+... |
+None or Unspecified |
+Straight |
+None or Unspecified |
+NaN |
+NaN |
+1989 |
+1 |
+17 |
+1 |
+17 |
+
+
+| 1 |
+1821514 |
+14000.0 |
+1194089 |
+10150 |
+132 |
+99.0 |
+1980 |
+NaN |
+NaN |
+A66 |
+... |
+NaN |
+NaN |
+NaN |
+Standard |
+Conventional |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+| 2 |
+1505138 |
+50000.0 |
+1473654 |
+4139 |
+132 |
+99.0 |
+1978 |
+NaN |
+NaN |
+D7G |
+... |
+None or Unspecified |
+Straight |
+None or Unspecified |
+NaN |
+NaN |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+| 3 |
+1671174 |
+16000.0 |
+1327630 |
+8591 |
+132 |
+99.0 |
+1980 |
+NaN |
+NaN |
+A62 |
+... |
+NaN |
+NaN |
+NaN |
+Standard |
+Conventional |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+| 4 |
+1329056 |
+22000.0 |
+1336053 |
+4089 |
+132 |
+99.0 |
+1984 |
+NaN |
+NaN |
+D3B |
+... |
+None or Unspecified |
+PAT |
+Lever |
+NaN |
+NaN |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+
+
5 rows × 57 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
<class 'pandas.core.frame.DataFrame'>
+RangeIndex: 412698 entries, 0 to 412697
+Data columns (total 57 columns):
+ # Column Non-Null Count Dtype
+--- ------ -------------- -----
+ 0 SalesID 412698 non-null int64
+ 1 SalePrice 412698 non-null float64
+ 2 MachineID 412698 non-null int64
+ 3 ModelID 412698 non-null int64
+ 4 datasource 412698 non-null int64
+ 5 auctioneerID 392562 non-null float64
+ 6 YearMade 412698 non-null int64
+ 7 MachineHoursCurrentMeter 147504 non-null float64
+ 8 UsageBand 73670 non-null object
+ 9 fiModelDesc 412698 non-null object
+ 10 fiBaseModel 412698 non-null object
+ 11 fiSecondaryDesc 271971 non-null object
+ 12 fiModelSeries 58667 non-null object
+ 13 fiModelDescriptor 74816 non-null object
+ 14 ProductSize 196093 non-null object
+ 15 fiProductClassDesc 412698 non-null object
+ 16 state 412698 non-null object
+ 17 ProductGroup 412698 non-null object
+ 18 ProductGroupDesc 412698 non-null object
+ 19 Drive_System 107087 non-null object
+ 20 Enclosure 412364 non-null object
+ 21 Forks 197715 non-null object
+ 22 Pad_Type 81096 non-null object
+ 23 Ride_Control 152728 non-null object
+ 24 Stick 81096 non-null object
+ 25 Transmission 188007 non-null object
+ 26 Turbocharged 81096 non-null object
+ 27 Blade_Extension 25983 non-null object
+ 28 Blade_Width 25983 non-null object
+ 29 Enclosure_Type 25983 non-null object
+ 30 Engine_Horsepower 25983 non-null object
+ 31 Hydraulics 330133 non-null object
+ 32 Pushblock 25983 non-null object
+ 33 Ripper 106945 non-null object
+ 34 Scarifier 25994 non-null object
+ 35 Tip_Control 25983 non-null object
+ 36 Tire_Size 97638 non-null object
+ 37 Coupler 220679 non-null object
+ 38 Coupler_System 44974 non-null object
+ 39 Grouser_Tracks 44875 non-null object
+ 40 Hydraulics_Flow 44875 non-null object
+ 41 Track_Type 102193 non-null object
+ 42 Undercarriage_Pad_Width 102916 non-null object
+ 43 Stick_Length 102261 non-null object
+ 44 Thumb 102332 non-null object
+ 45 Pattern_Changer 102261 non-null object
+ 46 Grouser_Type 102193 non-null object
+ 47 Backhoe_Mounting 80712 non-null object
+ 48 Blade_Type 81875 non-null object
+ 49 Travel_Controls 81877 non-null object
+ 50 Differential_Type 71564 non-null object
+ 51 Steering_Controls 71522 non-null object
+ 52 saleYear 412698 non-null int64
+ 53 saleMonth 412698 non-null int64
+ 54 saleDay 412698 non-null int64
+ 55 saleDayofweek 412698 non-null int64
+ 56 saleDayofyear 412698 non-null int64
+dtypes: float64(3), int64(10), object(44)
+memory usage: 179.5+ MB
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
<class 'pandas.core.frame.DataFrame'>
+RangeIndex: 412698 entries, 0 to 412697
+Data columns (total 57 columns):
+ # Column Non-Null Count Dtype
+--- ------ -------------- -----
+ 0 SalesID 412698 non-null int64
+ 1 SalePrice 412698 non-null float64
+ 2 MachineID 412698 non-null int64
+ 3 ModelID 412698 non-null int64
+ 4 datasource 412698 non-null int64
+ 5 auctioneerID 392562 non-null float64
+ 6 YearMade 412698 non-null int64
+ 7 MachineHoursCurrentMeter 147504 non-null float64
+ 8 UsageBand 73670 non-null category
+ 9 fiModelDesc 412698 non-null category
+ 10 fiBaseModel 412698 non-null category
+ 11 fiSecondaryDesc 271971 non-null category
+ 12 fiModelSeries 58667 non-null category
+ 13 fiModelDescriptor 74816 non-null category
+ 14 ProductSize 196093 non-null category
+ 15 fiProductClassDesc 412698 non-null category
+ 16 state 412698 non-null category
+ 17 ProductGroup 412698 non-null category
+ 18 ProductGroupDesc 412698 non-null category
+ 19 Drive_System 107087 non-null category
+ 20 Enclosure 412364 non-null category
+ 21 Forks 197715 non-null category
+ 22 Pad_Type 81096 non-null category
+ 23 Ride_Control 152728 non-null category
+ 24 Stick 81096 non-null category
+ 25 Transmission 188007 non-null category
+ 26 Turbocharged 81096 non-null category
+ 27 Blade_Extension 25983 non-null category
+ 28 Blade_Width 25983 non-null category
+ 29 Enclosure_Type 25983 non-null category
+ 30 Engine_Horsepower 25983 non-null category
+ 31 Hydraulics 330133 non-null category
+ 32 Pushblock 25983 non-null category
+ 33 Ripper 106945 non-null category
+ 34 Scarifier 25994 non-null category
+ 35 Tip_Control 25983 non-null category
+ 36 Tire_Size 97638 non-null category
+ 37 Coupler 220679 non-null category
+ 38 Coupler_System 44974 non-null category
+ 39 Grouser_Tracks 44875 non-null category
+ 40 Hydraulics_Flow 44875 non-null category
+ 41 Track_Type 102193 non-null category
+ 42 Undercarriage_Pad_Width 102916 non-null category
+ 43 Stick_Length 102261 non-null category
+ 44 Thumb 102332 non-null category
+ 45 Pattern_Changer 102261 non-null category
+ 46 Grouser_Type 102193 non-null category
+ 47 Backhoe_Mounting 80712 non-null category
+ 48 Blade_Type 81875 non-null category
+ 49 Travel_Controls 81877 non-null category
+ 50 Differential_Type 71564 non-null category
+ 51 Steering_Controls 71522 non-null category
+ 52 saleYear 412698 non-null int64
+ 53 saleMonth 412698 non-null int64
+ 54 saleDay 412698 non-null int64
+ 55 saleDayofweek 412698 non-null int64
+ 56 saleDayofyear 412698 non-null int64
+dtypes: category(44), float64(3), int64(10)
+memory usage: 60.1 MB
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[51]:
+
+
Blade_Width 386715
+Engine_Horsepower 386715
+Tip_Control 386715
+Pushblock 386715
+Blade_Extension 386715
+Enclosure_Type 386715
+Scarifier 386704
+Hydraulics_Flow 367823
+Grouser_Tracks 367823
+Coupler_System 367724
+fiModelSeries 354031
+Steering_Controls 341176
+Differential_Type 341134
+UsageBand 339028
+fiModelDescriptor 337882
+Backhoe_Mounting 331986
+Stick 331602
+Turbocharged 331602
+Pad_Type 331602
+Blade_Type 330823
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Column name: SalesID | Column dtype: int64 | Example value: [1748586] | Example value dtype: integer
+Column name: SalePrice | Column dtype: float64 | Example value: [13000.] | Example value dtype: floating
+Column name: MachineID | Column dtype: int64 | Example value: [1441940] | Example value dtype: integer
+Column name: ModelID | Column dtype: int64 | Example value: [1333] | Example value dtype: integer
+Column name: datasource | Column dtype: int64 | Example value: [132] | Example value dtype: integer
+Column name: auctioneerID | Column dtype: float64 | Example value: [2.] | Example value dtype: floating
+Column name: YearMade | Column dtype: int64 | Example value: [1000] | Example value dtype: integer
+Column name: MachineHoursCurrentMeter | Column dtype: float64 | Example value: [nan] | Example value dtype: floating
+Column name: saleYear | Column dtype: int64 | Example value: [2010] | Example value dtype: integer
+Column name: saleMonth | Column dtype: int64 | Example value: [6] | Example value dtype: integer
+Column name: saleDay | Column dtype: int64 | Example value: [16] | Example value dtype: integer
+Column name: saleDayofweek | Column dtype: int64 | Example value: [3] | Example value dtype: integer
+Column name: saleDayofyear | Column dtype: int64 | Example value: [285] | Example value dtype: integer
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Column name: SalesID | Has missing values: False
+Column name: SalePrice | Has missing values: False
+Column name: MachineID | Has missing values: False
+Column name: ModelID | Has missing values: False
+Column name: datasource | Has missing values: False
+Column name: auctioneerID | Has missing values: True
+Column name: YearMade | Has missing values: False
+Column name: MachineHoursCurrentMeter | Has missing values: True
+Column name: saleYear | Has missing values: False
+Column name: saleMonth | Has missing values: False
+Column name: saleDay | Has missing values: False
+Column name: saleDayofweek | Has missing values: False
+Column name: saleDayofyear | Has missing values: False
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[55]:
+
+
+
+
+
+
+ |
+SalesID |
+SalePrice |
+MachineID |
+ModelID |
+datasource |
+auctioneerID |
+YearMade |
+MachineHoursCurrentMeter |
+UsageBand |
+fiModelDesc |
+... |
+Travel_Controls |
+Differential_Type |
+Steering_Controls |
+saleYear |
+saleMonth |
+saleDay |
+saleDayofweek |
+saleDayofyear |
+auctioneerID_is_missing |
+MachineHoursCurrentMeter_is_missing |
+
+
+
+
+| 150110 |
+1631531 |
+35000.0 |
+1267456 |
+4794 |
+132 |
+2.0 |
+1998 |
+0.0 |
+NaN |
+710D |
+... |
+NaN |
+NaN |
+NaN |
+2003 |
+9 |
+11 |
+3 |
+254 |
+0 |
+1 |
+
+
+| 111297 |
+1327658 |
+15000.0 |
+1185021 |
+4112 |
+132 |
+99.0 |
+1980 |
+0.0 |
+NaN |
+D5B |
+... |
+None or Unspecified |
+NaN |
+NaN |
+2001 |
+5 |
+8 |
+1 |
+128 |
+0 |
+1 |
+
+
+| 177121 |
+1432179 |
+52000.0 |
+788654 |
+1263 |
+132 |
+1.0 |
+1997 |
+0.0 |
+NaN |
+330BL |
+... |
+NaN |
+NaN |
+NaN |
+2005 |
+2 |
+15 |
+1 |
+46 |
+0 |
+1 |
+
+
+| 138512 |
+1440179 |
+27000.0 |
+790577 |
+3547 |
+132 |
+7.0 |
+1999 |
+0.0 |
+NaN |
+426C |
+... |
+NaN |
+NaN |
+NaN |
+2002 |
+12 |
+6 |
+4 |
+340 |
+0 |
+1 |
+
+
+| 69375 |
+1473901 |
+67500.0 |
+196530 |
+3823 |
+132 |
+6.0 |
+1991 |
+0.0 |
+NaN |
+950F |
+... |
+NaN |
+Standard |
+Conventional |
+1998 |
+8 |
+27 |
+3 |
+239 |
+0 |
+1 |
+
+
+
+
5 rows × 59 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Column name: SalesID | Has missing values: False
+Column name: SalePrice | Has missing values: False
+Column name: MachineID | Has missing values: False
+Column name: ModelID | Has missing values: False
+Column name: datasource | Has missing values: False
+Column name: auctioneerID | Has missing values: False
+Column name: YearMade | Has missing values: False
+Column name: MachineHoursCurrentMeter | Has missing values: False
+Column name: saleYear | Has missing values: False
+Column name: saleMonth | Has missing values: False
+Column name: saleDay | Has missing values: False
+Column name: saleDayofweek | Has missing values: False
+Column name: saleDayofyear | Has missing values: False
+Column name: auctioneerID_is_missing | Has missing values: False
+Column name: MachineHoursCurrentMeter_is_missing | Has missing values: False
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[57]:
+
+
auctioneerID_is_missing
+0 392562
+1 20136
+Name: count, dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Columns which are not numeric:
+Column name: UsageBand | Column dtype: category
+Column name: fiModelDesc | Column dtype: category
+Column name: fiBaseModel | Column dtype: category
+Column name: fiSecondaryDesc | Column dtype: category
+Column name: fiModelSeries | Column dtype: category
+Column name: fiModelDescriptor | Column dtype: category
+Column name: ProductSize | Column dtype: category
+Column name: fiProductClassDesc | Column dtype: category
+Column name: state | Column dtype: category
+Column name: ProductGroup | Column dtype: category
+Column name: ProductGroupDesc | Column dtype: category
+Column name: Drive_System | Column dtype: category
+Column name: Enclosure | Column dtype: category
+Column name: Forks | Column dtype: category
+Column name: Pad_Type | Column dtype: category
+Column name: Ride_Control | Column dtype: category
+Column name: Stick | Column dtype: category
+Column name: Transmission | Column dtype: category
+Column name: Turbocharged | Column dtype: category
+Column name: Blade_Extension | Column dtype: category
+Column name: Blade_Width | Column dtype: category
+Column name: Enclosure_Type | Column dtype: category
+Column name: Engine_Horsepower | Column dtype: category
+Column name: Hydraulics | Column dtype: category
+Column name: Pushblock | Column dtype: category
+Column name: Ripper | Column dtype: category
+Column name: Scarifier | Column dtype: category
+Column name: Tip_Control | Column dtype: category
+Column name: Tire_Size | Column dtype: category
+Column name: Coupler | Column dtype: category
+Column name: Coupler_System | Column dtype: category
+Column name: Grouser_Tracks | Column dtype: category
+Column name: Hydraulics_Flow | Column dtype: category
+Column name: Track_Type | Column dtype: category
+Column name: Undercarriage_Pad_Width | Column dtype: category
+Column name: Stick_Length | Column dtype: category
+Column name: Thumb | Column dtype: category
+Column name: Pattern_Changer | Column dtype: category
+Column name: Grouser_Type | Column dtype: category
+Column name: Backhoe_Mounting | Column dtype: category
+Column name: Blade_Type | Column dtype: category
+Column name: Travel_Controls | Column dtype: category
+Column name: Differential_Type | Column dtype: category
+Column name: Steering_Controls | Column dtype: category
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[60]:
+
+
+
+
+
+
+ |
+SalesID |
+SalePrice |
+MachineID |
+ModelID |
+datasource |
+auctioneerID |
+YearMade |
+MachineHoursCurrentMeter |
+UsageBand |
+fiModelDesc |
+... |
+Undercarriage_Pad_Width_is_missing |
+Stick_Length_is_missing |
+Thumb_is_missing |
+Pattern_Changer_is_missing |
+Grouser_Type_is_missing |
+Backhoe_Mounting_is_missing |
+Blade_Type_is_missing |
+Travel_Controls_is_missing |
+Differential_Type_is_missing |
+Steering_Controls_is_missing |
+
+
+
+
+| 232167 |
+2412660 |
+53000.0 |
+1144729 |
+607 |
+136 |
+1.0 |
+2000 |
+0.0 |
+0 |
+4823 |
+... |
+1 |
+1 |
+1 |
+1 |
+1 |
+1 |
+1 |
+1 |
+0 |
+0 |
+
+
+| 398100 |
+1221746 |
+18500.0 |
+1047245 |
+2759 |
+121 |
+3.0 |
+1000 |
+319.0 |
+2 |
+2224 |
+... |
+1 |
+1 |
+1 |
+1 |
+1 |
+0 |
+0 |
+0 |
+1 |
+1 |
+
+
+| 363820 |
+2502559 |
+31000.0 |
+1333542 |
+3172 |
+149 |
+1.0 |
+2007 |
+1149.0 |
+3 |
+1081 |
+... |
+1 |
+1 |
+1 |
+1 |
+1 |
+1 |
+1 |
+1 |
+1 |
+1 |
+
+
+| 322230 |
+2432752 |
+7500.0 |
+1537457 |
+36033 |
+136 |
+1.0 |
+2003 |
+0.0 |
+0 |
+4259 |
+... |
+1 |
+1 |
+1 |
+1 |
+1 |
+1 |
+1 |
+1 |
+1 |
+1 |
+
+
+| 10401 |
+1356581 |
+26000.0 |
+1394933 |
+4090 |
+132 |
+1.0 |
+1988 |
+0.0 |
+0 |
+2121 |
+... |
+1 |
+1 |
+1 |
+1 |
+1 |
+0 |
+0 |
+0 |
+1 |
+1 |
+
+
+
+
5 rows × 103 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
0 -> nan
+1 -> High
+2 -> Low
+3 -> Medium
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
1 -> Alabama
+2 -> Alaska
+3 -> Arizona
+4 -> Arkansas
+5 -> California
+6 -> Colorado
+7 -> Connecticut
+8 -> Delaware
+9 -> Florida
+10 -> Georgia
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Total missing values: 0 - Woohoo! Let's build a model!
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Total missing values: 0 - Woohoo! Let's build a model!
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
CPU times: user 1.06 s, sys: 2.37 s, total: 3.43 s
+Wall time: 976 ms
+
+
+
+
+
Out[67]:
+
+
RandomForestRegressor(n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Model score on 1000 samples: 0.9563062437082765
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
CPU times: user 10min 21s, sys: 8min 31s, total: 18min 53s
+Wall time: 3min 24s
+
+
+
+
+
Out[69]:
+
+
RandomForestRegressor(n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Model score on 412698 samples: 0.9875710658782831
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Number of samples in training DataFrame: 401125
+[INFO] Number of samples in validation DataFrame: 11573
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[72]:
+
+
+
+
+
+
+ |
+SalesID |
+SalePrice |
+MachineID |
+ModelID |
+datasource |
+auctioneerID |
+YearMade |
+MachineHoursCurrentMeter |
+UsageBand |
+saledate |
+... |
+Undercarriage_Pad_Width |
+Stick_Length |
+Thumb |
+Pattern_Changer |
+Grouser_Type |
+Backhoe_Mounting |
+Blade_Type |
+Travel_Controls |
+Differential_Type |
+Steering_Controls |
+
+
+
+
+| 118276 |
+1457333 |
+58000 |
+1434146 |
+4147 |
+132 |
+1.0 |
+1980 |
+NaN |
+NaN |
+1990-05-03 |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+None or Unspecified |
+Straight |
+None or Unspecified |
+NaN |
+NaN |
+
+
+| 149220 |
+1522457 |
+37000 |
+1473616 |
+4199 |
+132 |
+2.0 |
+1992 |
+NaN |
+NaN |
+1996-11-16 |
+... |
+None or Unspecified |
+None or Unspecified |
+None or Unspecified |
+None or Unspecified |
+Double |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+
+
+| 118159 |
+1457054 |
+19250 |
+1503681 |
+4147 |
+132 |
+99.0 |
+1979 |
+NaN |
+NaN |
+2009-10-01 |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+None or Unspecified |
+Semi U |
+None or Unspecified |
+NaN |
+NaN |
+
+
+| 28240 |
+1258591 |
+8250 |
+1459934 |
+6788 |
+132 |
+6.0 |
+1971 |
+NaN |
+NaN |
+1990-04-18 |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+
+
+| 396348 |
+6282780 |
+41600 |
+1916198 |
+14272 |
+149 |
+99.0 |
+2003 |
+NaN |
+NaN |
+2011-11-09 |
+... |
+None or Unspecified |
+None or Unspecified |
+None or Unspecified |
+None or Unspecified |
+Double |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+
+
+
+
5 rows × 53 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[73]:
+
+
+
+
+
+
+ |
+SalesID |
+MachineID |
+ModelID |
+datasource |
+auctioneerID |
+YearMade |
+MachineHoursCurrentMeter |
+UsageBand |
+saledate |
+fiModelDesc |
+... |
+Stick_Length |
+Thumb |
+Pattern_Changer |
+Grouser_Type |
+Backhoe_Mounting |
+Blade_Type |
+Travel_Controls |
+Differential_Type |
+Steering_Controls |
+SalePrice |
+
+
+
+
+| 7504 |
+4325208 |
+2306826 |
+4840 |
+172 |
+1 |
+1987 |
+9540.0 |
+Low |
+2012-03-22 |
+850B |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+None or Unspecified |
+Straight |
+None or Unspecified |
+NaN |
+NaN |
+10000.0 |
+
+
+| 4853 |
+6282223 |
+1482307 |
+28842 |
+149 |
+0 |
+2004 |
+NaN |
+NaN |
+2012-02-23 |
+80C |
+... |
+None or Unspecified |
+None or Unspecified |
+None or Unspecified |
+Double |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+27000.0 |
+
+
+| 28 |
+6269818 |
+1791122 |
+7257 |
+149 |
+99 |
+1978 |
+48.0 |
+Low |
+2012-01-11 |
+910 |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+Standard |
+Conventional |
+10600.0 |
+
+
+| 7451 |
+1226478 |
+205898 |
+1269 |
+121 |
+3 |
+2004 |
+9333.0 |
+Medium |
+2012-03-22 |
+330CL |
+... |
+None or Unspecified |
+Hydraulic |
+Yes |
+Double |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+90000.0 |
+
+
+| 693 |
+1223479 |
+143807 |
+3538 |
+121 |
+3 |
+1997 |
+2154.0 |
+Low |
+2012-01-27 |
+416C |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+19500.0 |
+
+
+
+
5 rows × 53 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[75]:
+
+
+
+
+
+
+ |
+saleYear |
+saleMonth |
+saleDay |
+saleDayofweek |
+saleDayofyear |
+
+
+
+
+| 319998 |
+2010 |
+4 |
+22 |
+3 |
+112 |
+
+
+| 133509 |
+2003 |
+2 |
+20 |
+3 |
+51 |
+
+
+| 291200 |
+2008 |
+5 |
+23 |
+4 |
+144 |
+
+
+| 280146 |
+2006 |
+3 |
+18 |
+5 |
+77 |
+
+
+| 335509 |
+2008 |
+4 |
+29 |
+1 |
+120 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+/var/folders/c4/qj4gdk190td18bqvjjh0p3p00000gn/T/ipykernel_20423/150598518.py in ?()
+ 9 # Create a model
+ 10 model = RandomForestRegressor(n_jobs=-1)
+ 11
+ 12 # Fit a model to the training data only
+---> 13 model.fit(X=X_train,
+ 14 y=y_train)
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(estimator, *args, **kwargs)
+ 1469 skip_parameter_validation=(
+ 1470 prefer_skip_nested_validation or global_skip_validation
+ 1471 )
+ 1472 ):
+-> 1473 return fit_method(estimator, *args, **kwargs)
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X, y, sample_weight)
+ 359 # Validate or convert input data
+ 360 if issparse(y):
+ 361 raise ValueError("sparse multilabel-indicator for y is not supported.")
+ 362
+--> 363 X, y = self._validate_data(
+ 364 X,
+ 365 y,
+ 366 multi_output=True,
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)
+ 646 if "estimator" not in check_y_params:
+ 647 check_y_params = {**default_check_params, **check_y_params}
+ 648 y = check_array(y, input_name="y", **check_y_params)
+ 649 else:
+--> 650 X, y = check_X_y(X, y, **check_params)
+ 651 out = X, y
+ 652
+ 653 if not no_val_X and check_params.get("ensure_2d", True):
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(X, y, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, estimator)
+ 1297 raise ValueError(
+ 1298 f"{estimator_name} requires y to be passed, but the target y is None"
+ 1299 )
+ 1300
+-> 1301 X = check_array(
+ 1302 X,
+ 1303 accept_sparse=accept_sparse,
+ 1304 accept_large_sparse=accept_large_sparse,
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)
+ 1009 )
+ 1010 array = xp.astype(array, dtype, copy=False)
+ 1011 else:
+ 1012 array = _asarray_with_order(array, order=order, dtype=dtype, xp=xp)
+-> 1013 except ComplexWarning as complex_warning:
+ 1014 raise ValueError(
+ 1015 "Complex data not supported\n{}\n".format(array)
+ 1016 ) from complex_warning
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/_array_api.py in ?(array, dtype, order, copy, xp, device)
+ 747 # Use NumPy API to support order
+ 748 if copy is True:
+ 749 array = numpy.array(array, order=order, dtype=dtype)
+ 750 else:
+--> 751 array = numpy.asarray(array, order=order, dtype=dtype)
+ 752
+ 753 # At this point array is a NumPy ndarray. We convert it to an array
+ 754 # container that is consistent with the input's namespace.
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/core/generic.py in ?(self, dtype, copy)
+ 2149 def __array__(
+ 2150 self, dtype: npt.DTypeLike | None = None, copy: bool_t | None = None
+ 2151 ) -> np.ndarray:
+ 2152 values = self._values
+-> 2153 arr = np.asarray(values, dtype=dtype)
+ 2154 if (
+ 2155 astype_is_view(values.dtype, arr.dtype)
+ 2156 and using_copy_on_write()
+
+ValueError: could not convert string to float: 'Medium'
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Numeric features: ['SalesID', 'MachineID', 'ModelID', 'datasource', 'auctioneerID', 'YearMade', 'MachineHoursCurrentMeter', 'saleYear', 'saleMonth', 'saleDay', 'saleDayofweek', 'saleDayofyear']
+[INFO] Categorical features: ['UsageBand', 'fiModelDesc', 'fiBaseModel', 'fiSecondaryDesc', 'fiModelSeries', 'fiModelDescriptor', 'ProductSize', 'fiProductClassDesc', 'state', 'ProductGroup']...
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[79]:
+
+
+
+
+
+
+ |
+SalesID |
+MachineID |
+ModelID |
+datasource |
+auctioneerID |
+YearMade |
+MachineHoursCurrentMeter |
+UsageBand |
+fiModelDesc |
+fiBaseModel |
+... |
+Backhoe_Mounting |
+Blade_Type |
+Travel_Controls |
+Differential_Type |
+Steering_Controls |
+saleYear |
+saleMonth |
+saleDay |
+saleDayofweek |
+saleDayofyear |
+
+
+
+
+| 205615 |
+1646770 |
+1126363 |
+8434 |
+132 |
+18.0 |
+1974 |
+NaN |
+NaN |
+TD20 |
+TD20 |
+... |
+None or Unspecified |
+Straight |
+None or Unspecified |
+NaN |
+NaN |
+1989 |
+1 |
+17 |
+1 |
+17 |
+
+
+| 92803 |
+1404019 |
+1169900 |
+7110 |
+132 |
+99.0 |
+1986 |
+NaN |
+NaN |
+416 |
+416 |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+| 98346 |
+1415646 |
+1262088 |
+3357 |
+132 |
+99.0 |
+1975 |
+NaN |
+NaN |
+12G |
+12 |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+| 169297 |
+1596358 |
+1433229 |
+8247 |
+132 |
+99.0 |
+1978 |
+NaN |
+NaN |
+644 |
+644 |
+... |
+NaN |
+NaN |
+NaN |
+Standard |
+Conventional |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+| 274835 |
+1821514 |
+1194089 |
+10150 |
+132 |
+99.0 |
+1980 |
+NaN |
+NaN |
+A66 |
+A66 |
+... |
+NaN |
+NaN |
+NaN |
+Standard |
+Conventional |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+
+
5 rows × 56 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[80]:
+
+
+
+
+
+
+ |
+SalesID |
+MachineID |
+ModelID |
+datasource |
+auctioneerID |
+YearMade |
+MachineHoursCurrentMeter |
+UsageBand |
+fiModelDesc |
+fiBaseModel |
+... |
+Backhoe_Mounting |
+Blade_Type |
+Travel_Controls |
+Differential_Type |
+Steering_Controls |
+saleYear |
+saleMonth |
+saleDay |
+saleDayofweek |
+saleDayofyear |
+
+
+
+
+| 205615 |
+1646770 |
+1126363 |
+8434 |
+132 |
+18.0 |
+1974 |
+NaN |
+3.0 |
+4536.0 |
+1734.0 |
+... |
+0.0 |
+7.0 |
+5.0 |
+4.0 |
+5.0 |
+1989 |
+1 |
+17 |
+1 |
+17 |
+
+
+| 92803 |
+1404019 |
+1169900 |
+7110 |
+132 |
+99.0 |
+1986 |
+NaN |
+3.0 |
+734.0 |
+242.0 |
+... |
+2.0 |
+10.0 |
+7.0 |
+4.0 |
+5.0 |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+| 98346 |
+1415646 |
+1262088 |
+3357 |
+132 |
+99.0 |
+1975 |
+NaN |
+3.0 |
+81.0 |
+18.0 |
+... |
+2.0 |
+10.0 |
+7.0 |
+4.0 |
+5.0 |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+| 169297 |
+1596358 |
+1433229 |
+8247 |
+132 |
+99.0 |
+1978 |
+NaN |
+3.0 |
+1157.0 |
+348.0 |
+... |
+2.0 |
+10.0 |
+7.0 |
+3.0 |
+1.0 |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+| 274835 |
+1821514 |
+1194089 |
+10150 |
+132 |
+99.0 |
+1980 |
+NaN |
+3.0 |
+1799.0 |
+556.0 |
+... |
+2.0 |
+10.0 |
+7.0 |
+3.0 |
+1.0 |
+1989 |
+1 |
+31 |
+1 |
+31 |
+
+
+
+
5 rows × 56 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[81]:
+
+
Engine_Horsepower 375906
+Blade_Extension 375906
+Tip_Control 375906
+Pushblock 375906
+Enclosure_Type 375906
+Blade_Width 375906
+Scarifier 375895
+Hydraulics_Flow 357763
+Grouser_Tracks 357763
+Coupler_System 357667
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[82]:
+
+
UsageBand 0
+fiModelDesc 0
+Pushblock 0
+Ripper 0
+Scarifier 0
+Tip_Control 0
+Tire_Size 0
+Coupler 0
+Coupler_System 0
+Grouser_Tracks 0
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[83]:
+
+
[array(['High', 'Low', 'Medium', 'nan'], dtype=object),
+ array(['100C', '104', '1066', ..., 'ZX800LC', 'ZX80LCK', 'ZX850H'],
+ dtype=object),
+ array(['10', '100', '104', ..., 'ZX80', 'ZX800', 'ZX850'], dtype=object)]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[84]:
+
+
{0: 'High', 1: 'Low', 2: 'Medium', 3: 'nan'}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[85]:
+
+
+
+
+
+
+ |
+UsageBand |
+fiModelDesc |
+fiBaseModel |
+fiSecondaryDesc |
+fiModelSeries |
+fiModelDescriptor |
+ProductSize |
+fiProductClassDesc |
+state |
+ProductGroup |
+... |
+Undercarriage_Pad_Width |
+Stick_Length |
+Thumb |
+Pattern_Changer |
+Grouser_Type |
+Backhoe_Mounting |
+Blade_Type |
+Travel_Controls |
+Differential_Type |
+Steering_Controls |
+
+
+
+
+| 214315 |
+nan |
+160CLC |
+160 |
+C |
+nan |
+LC |
+Small |
+Hydraulic Excavator, Track - 14.0 to 16.0 Metr... |
+Alabama |
+TEX |
+... |
+28 inch |
+None or Unspecified |
+None or Unspecified |
+None or Unspecified |
+Triple |
+nan |
+nan |
+nan |
+nan |
+nan |
+
+
+| 96782 |
+nan |
+D4H |
+D4 |
+H |
+nan |
+nan |
+nan |
+Track Type Tractor, Dozer - 85.0 to 105.0 Hors... |
+California |
+TTT |
+... |
+nan |
+nan |
+nan |
+nan |
+nan |
+None or Unspecified |
+PAT |
+None or Unspecified |
+nan |
+nan |
+
+
+| 224604 |
+nan |
+140G |
+140 |
+G |
+nan |
+nan |
+nan |
+Motorgrader - 145.0 to 170.0 Horsepower |
+Missouri |
+MG |
+... |
+nan |
+nan |
+nan |
+nan |
+nan |
+nan |
+nan |
+nan |
+nan |
+nan |
+
+
+| 310524 |
+High |
+966E |
+966 |
+E |
+nan |
+nan |
+Medium |
+Wheel Loader - 200.0 to 225.0 Horsepower |
+Michigan |
+WL |
+... |
+nan |
+nan |
+nan |
+nan |
+nan |
+nan |
+nan |
+nan |
+Standard |
+Conventional |
+
+
+| 156716 |
+nan |
+650H |
+650 |
+H |
+nan |
+nan |
+nan |
+Track Type Tractor, Dozer - 85.0 to 105.0 Hors... |
+Florida |
+TTT |
+... |
+nan |
+nan |
+nan |
+nan |
+nan |
+None or Unspecified |
+PAT |
+None or Unspecified |
+nan |
+nan |
+
+
+
+
5 rows × 44 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
CPU times: user 8min 54s, sys: 6min 26s, total: 15min 20s
+Wall time: 2min 40s
+
+
+
+
+
Out[86]:
+
+
RandomForestRegressor(n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+<timed eval> in ?()
+ 1 'Could not get source, probably due dynamically evaluated source code.'
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(self, X, y, sample_weight)
+ 844 """
+ 845
+ 846 from .metrics import r2_score
+ 847
+--> 848 y_pred = self.predict(X)
+ 849 return r2_score(y, y_pred, sample_weight=sample_weight)
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X)
+ 1059 The predicted values.
+ 1060 """
+ 1061 check_is_fitted(self)
+ 1062 # Check data
+-> 1063 X = self._validate_X_predict(X)
+ 1064
+ 1065 # Assign chunk of trees to jobs
+ 1066 n_jobs, _, _ = _partition_estimators(self.n_estimators, self.n_jobs)
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X)
+ 637 force_all_finite = "allow-nan"
+ 638 else:
+ 639 force_all_finite = True
+ 640
+--> 641 X = self._validate_data(
+ 642 X,
+ 643 dtype=DTYPE,
+ 644 accept_sparse="csr",
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)
+ 629 out = y
+ 630 else:
+ 631 out = X, y
+ 632 elif not no_val_X and no_val_y:
+--> 633 out = check_array(X, input_name="X", **check_params)
+ 634 elif no_val_X and not no_val_y:
+ 635 out = _check_y(y, **check_params)
+ 636 else:
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)
+ 1009 )
+ 1010 array = xp.astype(array, dtype, copy=False)
+ 1011 else:
+ 1012 array = _asarray_with_order(array, order=order, dtype=dtype, xp=xp)
+-> 1013 except ComplexWarning as complex_warning:
+ 1014 raise ValueError(
+ 1015 "Complex data not supported\n{}\n".format(array)
+ 1016 ) from complex_warning
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/_array_api.py in ?(array, dtype, order, copy, xp, device)
+ 747 # Use NumPy API to support order
+ 748 if copy is True:
+ 749 array = numpy.array(array, order=order, dtype=dtype)
+ 750 else:
+--> 751 array = numpy.asarray(array, order=order, dtype=dtype)
+ 752
+ 753 # At this point array is a NumPy ndarray. We convert it to an array
+ 754 # container that is consistent with the input's namespace.
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/core/generic.py in ?(self, dtype, copy)
+ 2149 def __array__(
+ 2150 self, dtype: npt.DTypeLike | None = None, copy: bool_t | None = None
+ 2151 ) -> np.ndarray:
+ 2152 values = self._values
+-> 2153 arr = np.asarray(values, dtype=dtype)
+ 2154 if (
+ 2155 astype_is_view(values.dtype, arr.dtype)
+ 2156 and using_copy_on_write()
+
+ValueError: could not convert string to float: 'Low'
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
CPU times: user 766 ms, sys: 3.54 s, total: 4.3 s
+Wall time: 1.27 s
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
CPU times: user 17.6 s, sys: 19.2 s, total: 36.8 s
+Wall time: 7.42 s
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[94]:
+
+
{'Training MAE': np.float64(1596.4113176025767),
+ 'Valid MAE': np.float64(6172.124644142976),
+ 'Training RMSLE': np.float64(0.08546822305943352),
+ 'Valid RMSLE': np.float64(0.2576977236694938),
+ 'Training R^2': 0.9872786621410867,
+ 'Valid R^2': 0.8700295442271035}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
CPU times: user 19.2 s, sys: 18.5 s, total: 37.6 s
+Wall time: 7.53 s
+
+
+
+
+
Out[95]:
+
+
RandomForestRegressor(max_samples=10000, n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[96]:
+
+
{'Training MAE': np.float64(5605.344206319725),
+ 'Valid MAE': np.float64(7176.1651147786515),
+ 'Training RMSLE': np.float64(0.26030112528907273),
+ 'Valid RMSLE': np.float64(0.2935839690284876),
+ 'Training R^2': 0.858111849057448,
+ 'Valid R^2': 0.828549722372896}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Fitting 3 folds for each of 20 candidates, totalling 60 fits
+[CV 1/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=1, min_samples_split=3, n_estimators=160;, score=0.539 total time= 21.6s
+[CV 2/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=1, min_samples_split=3, n_estimators=160;, score=0.720 total time= 23.0s
+[CV 3/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=1, min_samples_split=3, n_estimators=160;, score=0.596 total time= 22.2s
+[CV 1/3] END max_depth=10, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=60;, score=0.491 total time= 3.3s
+[CV 2/3] END max_depth=10, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=60;, score=0.655 total time= 3.4s
+[CV 3/3] END max_depth=10, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=60;, score=0.614 total time= 3.3s
+[CV 1/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=8, n_estimators=130;, score=0.520 total time= 6.7s
+[CV 2/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=8, n_estimators=130;, score=0.702 total time= 6.6s
+[CV 3/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=8, n_estimators=130;, score=0.636 total time= 6.6s
+[CV 1/3] END max_depth=20, max_features=sqrt, max_samples=10000, min_samples_leaf=8, min_samples_split=9, n_estimators=30;, score=0.512 total time= 3.0s
+[CV 2/3] END max_depth=20, max_features=sqrt, max_samples=10000, min_samples_leaf=8, min_samples_split=9, n_estimators=30;, score=0.703 total time= 2.7s
+[CV 3/3] END max_depth=20, max_features=sqrt, max_samples=10000, min_samples_leaf=8, min_samples_split=9, n_estimators=30;, score=0.636 total time= 2.7s
+[CV 1/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=3, n_estimators=100;, score=0.541 total time= 9.9s
+[CV 2/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=3, n_estimators=100;, score=0.745 total time= 11.1s
+[CV 3/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=3, n_estimators=100;, score=0.632 total time= 10.2s
+[CV 1/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=3, min_samples_split=8, n_estimators=50;, score=0.529 total time= 6.1s
+[CV 2/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=3, min_samples_split=8, n_estimators=50;, score=0.713 total time= 5.5s
+[CV 3/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=3, min_samples_split=8, n_estimators=50;, score=0.625 total time= 5.2s
+[CV 1/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=4, min_samples_split=6, n_estimators=170;, score=0.532 total time= 13.9s
+[CV 2/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=4, min_samples_split=6, n_estimators=170;, score=0.712 total time= 14.6s
+[CV 3/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=4, min_samples_split=6, n_estimators=170;, score=0.631 total time= 14.2s
+[CV 1/3] END max_depth=20, max_features=0.5, max_samples=10000, min_samples_leaf=1, min_samples_split=5, n_estimators=40;, score=0.545 total time= 6.6s
+[CV 2/3] END max_depth=20, max_features=0.5, max_samples=10000, min_samples_leaf=1, min_samples_split=5, n_estimators=40;, score=0.767 total time= 6.5s
+[CV 3/3] END max_depth=20, max_features=0.5, max_samples=10000, min_samples_leaf=1, min_samples_split=5, n_estimators=40;, score=0.619 total time= 6.2s
+[CV 1/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=120;, score=0.518 total time= 6.0s
+[CV 2/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=120;, score=0.703 total time= 6.4s
+[CV 3/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=120;, score=0.637 total time= 6.2s
+[CV 1/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=9, n_estimators=120;, score=0.533 total time= 10.7s
+[CV 2/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=9, n_estimators=120;, score=0.708 total time= 13.7s
+[CV 3/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=9, n_estimators=120;, score=0.628 total time= 10.5s
+[CV 1/3] END max_depth=20, max_features=1.0, max_samples=10000, min_samples_leaf=2, min_samples_split=7, n_estimators=90;, score=0.542 total time= 20.0s
+[CV 2/3] END max_depth=20, max_features=1.0, max_samples=10000, min_samples_leaf=2, min_samples_split=7, n_estimators=90;, score=0.756 total time= 19.9s
+[CV 3/3] END max_depth=20, max_features=1.0, max_samples=10000, min_samples_leaf=2, min_samples_split=7, n_estimators=90;, score=0.611 total time= 17.1s
+[CV 1/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=8, min_samples_split=8, n_estimators=190;, score=0.524 total time= 9.1s
+[CV 2/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=8, min_samples_split=8, n_estimators=190;, score=0.706 total time= 8.7s
+[CV 3/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=8, min_samples_split=8, n_estimators=190;, score=0.637 total time= 8.6s
+[CV 1/3] END max_depth=None, max_features=1.0, max_samples=10000, min_samples_leaf=5, min_samples_split=8, n_estimators=70;, score=0.539 total time= 16.0s
+[CV 2/3] END max_depth=None, max_features=1.0, max_samples=10000, min_samples_leaf=5, min_samples_split=8, n_estimators=70;, score=0.754 total time= 14.8s
+[CV 3/3] END max_depth=None, max_features=1.0, max_samples=10000, min_samples_leaf=5, min_samples_split=8, n_estimators=70;, score=0.615 total time= 14.2s
+[CV 1/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=1, min_samples_split=9, n_estimators=60;, score=0.548 total time= 9.3s
+[CV 2/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=1, min_samples_split=9, n_estimators=60;, score=0.766 total time= 8.6s
+[CV 3/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=1, min_samples_split=9, n_estimators=60;, score=0.623 total time= 9.0s
+[CV 1/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=170;, score=0.535 total time= 23.8s
+[CV 2/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=170;, score=0.715 total time= 25.5s
+[CV 3/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=170;, score=0.595 total time= 27.2s
+[CV 1/3] END max_depth=20, max_features=0.5, max_samples=10000, min_samples_leaf=2, min_samples_split=3, n_estimators=80;, score=0.544 total time= 12.0s
+[CV 2/3] END max_depth=20, max_features=0.5, max_samples=10000, min_samples_leaf=2, min_samples_split=3, n_estimators=80;, score=0.764 total time= 11.5s
+[CV 3/3] END max_depth=20, max_features=0.5, max_samples=10000, min_samples_leaf=2, min_samples_split=3, n_estimators=80;, score=0.642 total time= 10.4s
+[CV 1/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=6, min_samples_split=7, n_estimators=70;, score=0.538 total time= 8.2s
+[CV 2/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=6, min_samples_split=7, n_estimators=70;, score=0.752 total time= 8.4s
+[CV 3/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=6, min_samples_split=7, n_estimators=70;, score=0.640 total time= 8.5s
+[CV 1/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=90;, score=0.537 total time= 9.8s
+[CV 2/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=90;, score=0.747 total time= 9.5s
+[CV 3/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=90;, score=0.630 total time= 9.7s
+[CV 1/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=2, min_samples_split=8, n_estimators=180;, score=0.536 total time= 28.3s
+[CV 2/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=2, min_samples_split=8, n_estimators=180;, score=0.721 total time= 28.6s
+[CV 3/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=2, min_samples_split=8, n_estimators=180;, score=0.597 total time= 28.1s
+[CV 1/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=2, min_samples_split=3, n_estimators=150;, score=0.539 total time= 9.0s
+[CV 2/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=2, min_samples_split=3, n_estimators=150;, score=0.733 total time= 10.7s
+[CV 3/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=2, min_samples_split=3, n_estimators=150;, score=0.643 total time= 8.9s
+CPU times: user 8min 6s, sys: 25min 58s, total: 34min 4s
+Wall time: 11min 54s
+
+
+
+
+
Out[97]:
+
+
RandomizedSearchCV(cv=3, estimator=RandomForestRegressor(), n_iter=20,
+ param_distributions={'max_depth': [None, 10, 20],
+ 'max_features': [0.5, 1.0, 'sqrt'],
+ 'max_samples': [10000],
+ 'min_samples_leaf': array([1, 2, 3, 4, 5, 6, 7, 8, 9]),
+ 'min_samples_split': array([2, 3, 4, 5, 6, 7, 8, 9]),
+ 'n_estimators': array([ 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130,
+ 140, 150, 160, 170, 180, 190])},
+ verbose=3)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.RandomizedSearchCV(cv=3, estimator=RandomForestRegressor(), n_iter=20,
+ param_distributions={'max_depth': [None, 10, 20],
+ 'max_features': [0.5, 1.0, 'sqrt'],
+ 'max_samples': [10000],
+ 'min_samples_leaf': array([1, 2, 3, 4, 5, 6, 7, 8, 9]),
+ 'min_samples_split': array([2, 3, 4, 5, 6, 7, 8, 9]),
+ 'n_estimators': array([ 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130,
+ 140, 150, 160, 170, 180, 190])},
+ verbose=3)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[113]:
+
+
{'n_estimators': np.int64(80),
+ 'min_samples_split': np.int64(3),
+ 'min_samples_leaf': np.int64(2),
+ 'max_samples': 10000,
+ 'max_features': 0.5,
+ 'max_depth': 20}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[114]:
+
+
{'Training MAE': np.float64(5804.886346446167),
+ 'Valid MAE': np.float64(7271.010705137403),
+ 'Training RMSLE': np.float64(0.2668477962708691),
+ 'Valid RMSLE': np.float64(0.2985683128197976),
+ 'Training R^2': 0.8494436266937344,
+ 'Valid R^2': 0.8280568050158131}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
CPU times: user 4min 6s, sys: 4min 34s, total: 8min 40s
+Wall time: 2min
+
+
+
+
+
Out[115]:
+
+
RandomForestRegressor(max_features=0.5, min_samples_split=5, n_estimators=90,
+ n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
CPU times: user 28.8 s, sys: 37.4 s, total: 1min 6s
+Wall time: 14.5 s
+
+
+
+
+
Out[116]:
+
+
{'Training MAE': np.float64(1955.980118634043),
+ 'Valid MAE': np.float64(5979.47564414195),
+ 'Training RMSLE': np.float64(0.10224456852444506),
+ 'Valid RMSLE': np.float64(0.24733387014318542),
+ 'Training R^2': 0.9809704227866279,
+ 'Valid R^2': 0.8810497144604977}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
CPU times: user 2min, sys: 1min 58s, total: 3min 58s
+Wall time: 44.9 s
+
+
+
+
+
Out[117]:
+
+
RandomForestRegressor(max_features=0.5, min_samples_split=5, n_estimators=45,
+ n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
CPU times: user 14.6 s, sys: 23.7 s, total: 38.3 s
+Wall time: 9.59 s
+
+
+
+
+
Out[118]:
+
+
{'Training MAE': np.float64(1989.0544948757317),
+ 'Valid MAE': np.float64(6029.137329100962),
+ 'Training RMSLE': np.float64(0.10373049008046713),
+ 'Valid RMSLE': np.float64(0.24897544966690316),
+ 'Training R^2': 0.9802744452357592,
+ 'Valid R^2': 0.8788749110488039}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[119]:
+
+
+
+
+
+
+ |
+Training MAE |
+Valid MAE |
+Training RMSLE |
+Valid RMSLE |
+Training R^2 |
+Valid R^2 |
+model_name |
+
+
+
+
+| 1 |
+5804.886346 |
+7271.010705 |
+0.266848 |
+0.298568 |
+0.849444 |
+0.828057 |
+random_search_model |
+
+
+| 0 |
+5605.344206 |
+7176.165115 |
+0.260301 |
+0.293584 |
+0.858112 |
+0.828550 |
+default_model |
+
+
+| 3 |
+1989.054495 |
+6029.137329 |
+0.103730 |
+0.248975 |
+0.980274 |
+0.878875 |
+fast_model |
+
+
+| 2 |
+1955.980119 |
+5979.475644 |
+0.102245 |
+0.247334 |
+0.980970 |
+0.881050 |
+ideal_model |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[121]:
+
+
['randomforest_regressor_best_RMSLE.pkl']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[122]:
+
+
RandomForestRegressor(max_features=0.5, min_samples_split=5, n_estimators=90,
+ n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[123]:
+
+
{'Training MAE': np.float64(1955.9801186340424),
+ 'Valid MAE': np.float64(5979.47564414195),
+ 'Training RMSLE': np.float64(0.10224456852444506),
+ 'Valid RMSLE': np.float64(0.24733387014318542),
+ 'Training R^2': 0.9809704227866279,
+ 'Valid R^2': 0.8810497144604977}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Model results are close!
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[126]:
+
+
+
+
+
+
+ |
+SalesID |
+MachineID |
+ModelID |
+datasource |
+auctioneerID |
+YearMade |
+MachineHoursCurrentMeter |
+UsageBand |
+saledate |
+fiModelDesc |
+... |
+Undercarriage_Pad_Width |
+Stick_Length |
+Thumb |
+Pattern_Changer |
+Grouser_Type |
+Backhoe_Mounting |
+Blade_Type |
+Travel_Controls |
+Differential_Type |
+Steering_Controls |
+
+
+
+
+| 0 |
+1227829 |
+1006309 |
+3168 |
+121 |
+3 |
+1999 |
+3688.0 |
+Low |
+2012-05-03 |
+580G |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+
+
+| 1 |
+1227844 |
+1022817 |
+7271 |
+121 |
+3 |
+1000 |
+28555.0 |
+High |
+2012-05-10 |
+936 |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+Standard |
+Conventional |
+
+
+| 2 |
+1227847 |
+1031560 |
+22805 |
+121 |
+3 |
+2004 |
+6038.0 |
+Medium |
+2012-05-10 |
+EC210BLC |
+... |
+None or Unspecified |
+9' 6" |
+Manual |
+None or Unspecified |
+Double |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+
+
+| 3 |
+1227848 |
+56204 |
+1269 |
+121 |
+3 |
+2006 |
+8940.0 |
+High |
+2012-05-10 |
+330CL |
+... |
+None or Unspecified |
+None or Unspecified |
+Manual |
+Yes |
+Triple |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+
+
+| 4 |
+1227863 |
+1053887 |
+22312 |
+121 |
+3 |
+2005 |
+2286.0 |
+Low |
+2012-05-10 |
+650K |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+None or Unspecified |
+PAT |
+None or Unspecified |
+NaN |
+NaN |
+
+
+
+
5 rows × 52 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+Cell In[127], line 2
+ 1 # Let's see how the model goes predicting on the test data
+----> 2 test_preds = best_model.predict(X=test_df)
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py:1063, in ForestRegressor.predict(self, X)
+ 1061 check_is_fitted(self)
+ 1062 # Check data
+-> 1063 X = self._validate_X_predict(X)
+ 1065 # Assign chunk of trees to jobs
+ 1066 n_jobs, _, _ = _partition_estimators(self.n_estimators, self.n_jobs)
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py:641, in BaseForest._validate_X_predict(self, X)
+ 638 else:
+ 639 force_all_finite = True
+--> 641 X = self._validate_data(
+ 642 X,
+ 643 dtype=DTYPE,
+ 644 accept_sparse="csr",
+ 645 reset=False,
+ 646 force_all_finite=force_all_finite,
+ 647 )
+ 648 if issparse(X) and (X.indices.dtype != np.intc or X.indptr.dtype != np.intc):
+ 649 raise ValueError("No support for np.int64 index based sparse matrices")
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py:608, in BaseEstimator._validate_data(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)
+ 537 def _validate_data(
+ 538 self,
+ 539 X="no_validation",
+ (...)
+ 544 **check_params,
+ 545 ):
+ 546 """Validate input data and set or check the `n_features_in_` attribute.
+ 547
+ 548 Parameters
+ (...)
+ 606 validated.
+ 607 """
+--> 608 self._check_feature_names(X, reset=reset)
+ 610 if y is None and self._get_tags()["requires_y"]:
+ 611 raise ValueError(
+ 612 f"This {self.__class__.__name__} estimator "
+ 613 "requires y to be passed, but the target y is None."
+ 614 )
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py:535, in BaseEstimator._check_feature_names(self, X, reset)
+ 530 if not missing_names and not unexpected_names:
+ 531 message += (
+ 532 "Feature names must be in the same order as they were in fit.\n"
+ 533 )
+--> 535 raise ValueError(message)
+
+ValueError: The feature names should match those that were passed during fit.
+Feature names unseen at fit time:
+- saledate
+Feature names seen at fit time, yet now missing:
+- saleDay
+- saleDayofweek
+- saleDayofyear
+- saleMonth
+- saleYear
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[128]:
+
+
+
+
+
+
+ |
+SalesID |
+MachineID |
+ModelID |
+datasource |
+auctioneerID |
+YearMade |
+MachineHoursCurrentMeter |
+UsageBand |
+fiModelDesc |
+fiBaseModel |
+... |
+Backhoe_Mounting |
+Blade_Type |
+Travel_Controls |
+Differential_Type |
+Steering_Controls |
+saleYear |
+saleMonth |
+saleDay |
+saleDayofweek |
+saleDayofyear |
+
+
+
+
+| 0 |
+1227829 |
+1006309 |
+3168 |
+121 |
+3 |
+1999 |
+3688.0 |
+Low |
+580G |
+580 |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+2012 |
+5 |
+3 |
+3 |
+124 |
+
+
+| 1 |
+1227844 |
+1022817 |
+7271 |
+121 |
+3 |
+1000 |
+28555.0 |
+High |
+936 |
+936 |
+... |
+NaN |
+NaN |
+NaN |
+Standard |
+Conventional |
+2012 |
+5 |
+10 |
+3 |
+131 |
+
+
+| 2 |
+1227847 |
+1031560 |
+22805 |
+121 |
+3 |
+2004 |
+6038.0 |
+Medium |
+EC210BLC |
+EC210 |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+2012 |
+5 |
+10 |
+3 |
+131 |
+
+
+| 3 |
+1227848 |
+56204 |
+1269 |
+121 |
+3 |
+2006 |
+8940.0 |
+High |
+330CL |
+330 |
+... |
+NaN |
+NaN |
+NaN |
+NaN |
+NaN |
+2012 |
+5 |
+10 |
+3 |
+131 |
+
+
+| 4 |
+1227863 |
+1053887 |
+22312 |
+121 |
+3 |
+2005 |
+2286.0 |
+Low |
+650K |
+650 |
+... |
+None or Unspecified |
+PAT |
+None or Unspecified |
+NaN |
+NaN |
+2012 |
+5 |
+10 |
+3 |
+131 |
+
+
+
+
5 rows × 56 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+/var/folders/c4/qj4gdk190td18bqvjjh0p3p00000gn/T/ipykernel_20423/2042912174.py in ?()
+ 1 # Try to predict with model
+----> 2 test_preds = best_model.predict(test_df)
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X)
+ 1059 The predicted values.
+ 1060 """
+ 1061 check_is_fitted(self)
+ 1062 # Check data
+-> 1063 X = self._validate_X_predict(X)
+ 1064
+ 1065 # Assign chunk of trees to jobs
+ 1066 n_jobs, _, _ = _partition_estimators(self.n_estimators, self.n_jobs)
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X)
+ 637 force_all_finite = "allow-nan"
+ 638 else:
+ 639 force_all_finite = True
+ 640
+--> 641 X = self._validate_data(
+ 642 X,
+ 643 dtype=DTYPE,
+ 644 accept_sparse="csr",
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)
+ 629 out = y
+ 630 else:
+ 631 out = X, y
+ 632 elif not no_val_X and no_val_y:
+--> 633 out = check_array(X, input_name="X", **check_params)
+ 634 elif no_val_X and not no_val_y:
+ 635 out = _check_y(y, **check_params)
+ 636 else:
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)
+ 1009 )
+ 1010 array = xp.astype(array, dtype, copy=False)
+ 1011 else:
+ 1012 array = _asarray_with_order(array, order=order, dtype=dtype, xp=xp)
+-> 1013 except ComplexWarning as complex_warning:
+ 1014 raise ValueError(
+ 1015 "Complex data not supported\n{}\n".format(array)
+ 1016 ) from complex_warning
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/_array_api.py in ?(array, dtype, order, copy, xp, device)
+ 747 # Use NumPy API to support order
+ 748 if copy is True:
+ 749 array = numpy.array(array, order=order, dtype=dtype)
+ 750 else:
+--> 751 array = numpy.asarray(array, order=order, dtype=dtype)
+ 752
+ 753 # At this point array is a NumPy ndarray. We convert it to an array
+ 754 # container that is consistent with the input's namespace.
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/core/generic.py in ?(self, dtype, copy)
+ 2149 def __array__(
+ 2150 self, dtype: npt.DTypeLike | None = None, copy: bool_t | None = None
+ 2151 ) -> np.ndarray:
+ 2152 values = self._values
+-> 2153 arr = np.asarray(values, dtype=dtype)
+ 2154 if (
+ 2155 astype_is_view(values.dtype, arr.dtype)
+ 2156 and using_copy_on_write()
+
+ValueError: could not convert string to float: 'Low'
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
<class 'pandas.core.frame.DataFrame'>
+RangeIndex: 12457 entries, 0 to 12456
+Data columns (total 56 columns):
+ # Column Non-Null Count Dtype
+--- ------ -------------- -----
+ 0 SalesID 12457 non-null int64
+ 1 MachineID 12457 non-null int64
+ 2 ModelID 12457 non-null int64
+ 3 datasource 12457 non-null int64
+ 4 auctioneerID 12457 non-null int64
+ 5 YearMade 12457 non-null int64
+ 6 MachineHoursCurrentMeter 2129 non-null float64
+ 7 UsageBand 12457 non-null float64
+ 8 fiModelDesc 12349 non-null float64
+ 9 fiBaseModel 12431 non-null float64
+ 10 fiSecondaryDesc 12449 non-null float64
+ 11 fiModelSeries 12456 non-null float64
+ 12 fiModelDescriptor 12452 non-null float64
+ 13 ProductSize 12457 non-null float64
+ 14 fiProductClassDesc 12457 non-null float64
+ 15 state 12457 non-null float64
+ 16 ProductGroup 12457 non-null float64
+ 17 ProductGroupDesc 12457 non-null float64
+ 18 Drive_System 12457 non-null float64
+ 19 Enclosure 12457 non-null float64
+ 20 Forks 12457 non-null float64
+ 21 Pad_Type 12457 non-null float64
+ 22 Ride_Control 12457 non-null float64
+ 23 Stick 12457 non-null float64
+ 24 Transmission 12457 non-null float64
+ 25 Turbocharged 12457 non-null float64
+ 26 Blade_Extension 12457 non-null float64
+ 27 Blade_Width 12457 non-null float64
+ 28 Enclosure_Type 12457 non-null float64
+ 29 Engine_Horsepower 12457 non-null float64
+ 30 Hydraulics 12457 non-null float64
+ 31 Pushblock 12457 non-null float64
+ 32 Ripper 12457 non-null float64
+ 33 Scarifier 12457 non-null float64
+ 34 Tip_Control 12457 non-null float64
+ 35 Tire_Size 12457 non-null float64
+ 36 Coupler 12457 non-null float64
+ 37 Coupler_System 12457 non-null float64
+ 38 Grouser_Tracks 12457 non-null float64
+ 39 Hydraulics_Flow 12457 non-null float64
+ 40 Track_Type 12457 non-null float64
+ 41 Undercarriage_Pad_Width 12457 non-null float64
+ 42 Stick_Length 12457 non-null float64
+ 43 Thumb 12457 non-null float64
+ 44 Pattern_Changer 12457 non-null float64
+ 45 Grouser_Type 12457 non-null float64
+ 46 Backhoe_Mounting 12457 non-null float64
+ 47 Blade_Type 12457 non-null float64
+ 48 Travel_Controls 12457 non-null float64
+ 49 Differential_Type 12457 non-null float64
+ 50 Steering_Controls 12457 non-null float64
+ 51 saleYear 12457 non-null int32
+ 52 saleMonth 12457 non-null int32
+ 53 saleDay 12457 non-null int32
+ 54 saleDayofweek 12457 non-null int32
+ 55 saleDayofyear 12457 non-null int32
+dtypes: float64(45), int32(5), int64(6)
+memory usage: 5.1 MB
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[132]:
+
+
array([14384.79497354, 31377.65862841, 48589.23540965, 95857.57194966,
+ 26910.53992304, 29401.41534392, 27061.53819945, 20377.23364598,
+ 17325.67857143, 33646.67768959])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[133]:
+
+
((12457,), (12457, 56))
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[134]:
+
+
+
+
+
+
+ |
+SalesID |
+SalePrice |
+
+
+
+
+| 6517 |
+6304619 |
+78522.550705 |
+
+
+| 922 |
+1231204 |
+13500.628307 |
+
+
+| 6859 |
+6311050 |
+10891.180556 |
+
+
+| 6634 |
+6307731 |
+28503.776455 |
+
+
+| 8882 |
+6447290 |
+50641.411817 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[136]:
+
+
[{'SalesID': 1229148,
+ 'MachineID': 1042578,
+ 'ModelID': 9579,
+ 'datasource': 121,
+ 'auctioneerID': 3,
+ 'YearMade': 2004,
+ 'MachineHoursCurrentMeter': 3290.0,
+ 'UsageBand': 'Medium',
+ 'fiModelDesc': 'S250',
+ 'fiBaseModel': 'S250',
+ 'fiSecondaryDesc': 'nan',
+ 'fiModelSeries': 'nan',
+ 'fiModelDescriptor': 'nan',
+ 'ProductSize': 'nan',
+ 'fiProductClassDesc': 'Skid Steer Loader - 2201.0 to 2701.0 Lb Operating Capacity',
+ 'state': 'Missouri',
+ 'ProductGroup': 'SSL',
+ 'ProductGroupDesc': 'Skid Steer Loaders',
+ 'Drive_System': 'nan',
+ 'Enclosure': 'EROPS',
+ 'Forks': 'None or Unspecified',
+ 'Pad_Type': 'nan',
+ 'Ride_Control': 'nan',
+ 'Stick': 'nan',
+ 'Transmission': 'nan',
+ 'Turbocharged': 'nan',
+ 'Blade_Extension': 'nan',
+ 'Blade_Width': 'nan',
+ 'Enclosure_Type': 'nan',
+ 'Engine_Horsepower': 'nan',
+ 'Hydraulics': 'Auxiliary',
+ 'Pushblock': 'nan',
+ 'Ripper': 'nan',
+ 'Scarifier': 'nan',
+ 'Tip_Control': 'nan',
+ 'Tire_Size': 'nan',
+ 'Coupler': 'Hydraulic',
+ 'Coupler_System': 'Yes',
+ 'Grouser_Tracks': 'None or Unspecified',
+ 'Hydraulics_Flow': 'Standard',
+ 'Track_Type': 'nan',
+ 'Undercarriage_Pad_Width': 'nan',
+ 'Stick_Length': 'nan',
+ 'Thumb': 'nan',
+ 'Pattern_Changer': 'nan',
+ 'Grouser_Type': 'nan',
+ 'Backhoe_Mounting': 'nan',
+ 'Blade_Type': 'nan',
+ 'Travel_Controls': 'nan',
+ 'Differential_Type': 'nan',
+ 'Steering_Controls': 'nan',
+ 'saleYear': 2012,
+ 'saleMonth': 6,
+ 'saleDay': 15,
+ 'saleDayofweek': 4,
+ 'saleDayofyear': 167}]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[137]:
+
+
array([13519.31657848])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[139]:
+
+
+
+
+
+
+ |
+SalesID |
+MachineID |
+ModelID |
+datasource |
+auctioneerID |
+YearMade |
+MachineHoursCurrentMeter |
+UsageBand |
+fiModelDesc |
+fiBaseModel |
+... |
+Backhoe_Mounting |
+Blade_Type |
+Travel_Controls |
+Differential_Type |
+Steering_Controls |
+saleYear |
+saleMonth |
+saleDay |
+saleDayofweek |
+saleDayofyear |
+
+
+
+
+| 0 |
+NaN |
+8504 |
+NaN |
+NaN |
+NaN |
+2004 |
+11770.0 |
+High |
+D6RXL |
+D6 |
+... |
+None or Unspecified |
+Semi U |
+NaN |
+NaN |
+Command Control |
+2024 |
+6 |
+7 |
+5 |
+159 |
+
+
+
+
1 rows × 56 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[140]:
+
+
+
+
+
+
+ |
+SalesID |
+MachineID |
+ModelID |
+datasource |
+auctioneerID |
+YearMade |
+MachineHoursCurrentMeter |
+UsageBand |
+fiModelDesc |
+fiBaseModel |
+... |
+Backhoe_Mounting |
+Blade_Type |
+Travel_Controls |
+Differential_Type |
+Steering_Controls |
+saleYear |
+saleMonth |
+saleDay |
+saleDayofweek |
+saleDayofyear |
+
+
+
+
+| 0 |
+NaN |
+8504 |
+NaN |
+NaN |
+NaN |
+2004 |
+11770.0 |
+0.0 |
+2308.0 |
+703.0 |
+... |
+0.0 |
+6.0 |
+7.0 |
+4.0 |
+0.0 |
+2024 |
+6 |
+7 |
+5 |
+159 |
+
+
+
+
1 rows × 56 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Predicted sale price of custom sample: $51474.96
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Model MAE on custom sample: 21125.040564373892
+[INFO] Model RMSLE on custom sample: 0.3438638042344433
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[143]:
+
+
array([3.78948522e-02, 2.70954102e-02, 5.85804002e-02, 1.79438322e-03,
+ 5.25621132e-03, 1.92040831e-01, 6.71461619e-03, 1.42137572e-03,
+ 4.79324438e-02, 4.73967258e-02, 4.12235661e-02, 4.75379381e-03,
+ 2.55283197e-02, 1.60578799e-01, 5.08919397e-02, 8.34245434e-03,
+ 3.43077232e-03, 4.16871935e-03, 1.45645185e-03, 6.32089976e-02,
+ 1.93106853e-03, 7.91189110e-04, 2.16468186e-03, 2.42755109e-04,
+ 1.44729959e-03, 1.10292279e-04, 4.69525167e-03, 4.70046399e-03,
+ 2.18877572e-03, 4.03668217e-03, 4.46781002e-03, 2.86947732e-03,
+ 5.20668987e-03, 3.50894384e-03, 1.75215277e-03, 1.16769900e-02,
+ 1.84682779e-03, 2.08450645e-02, 1.17370327e-02, 5.26785421e-03,
+ 2.07101299e-03, 1.36424627e-03, 1.60680297e-03, 9.71604299e-04,
+ 7.85735364e-04, 7.29302663e-04, 6.74283032e-04, 3.28828690e-03,
+ 2.83781098e-03, 3.92432694e-04, 4.73081800e-04, 7.26042221e-02,
+ 5.42512552e-03, 8.54840059e-03, 4.42773246e-03, 1.26015531e-02])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Number of feature importance values: 56
+[INFO] Number of features in training dataset: 56
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[145]:
+
+
+
+
+
+
+ |
+feature_names |
+feature_importance |
+
+
+
+
+| 5 |
+YearMade |
+0.192041 |
+
+
+| 13 |
+ProductSize |
+0.160579 |
+
+
+| 51 |
+saleYear |
+0.072604 |
+
+
+| 19 |
+Enclosure |
+0.063209 |
+
+
+| 2 |
+ModelID |
+0.058580 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Unique ProductSize values: ['Medium' nan 'Compact' 'Small' 'Large' 'Large / Medium' 'Mini']
+[INFO] Unique Enclosure values: ['OROPS' 'EROPS' 'EROPS w AC' nan 'EROPS AC' 'NO ROPS'
+ 'None or Unspecified']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Number of samples in training DataFrame: 401125
+[INFO] Number of samples in validation DataFrame: 11573
+
+
+
+
+
Out[244]:
+
+
{'Training MAE': np.float64(1951.2971558280735),
+ 'Valid MAE': np.float64(5964.025764507629),
+ 'Training RMSLE': np.float64(0.101909965049995),
+ 'Valid RMSLE': np.float64(0.24697812443315573),
+ 'Training R^2': 0.9810825663665007,
+ 'Valid R^2': 0.8809697755766817}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[247]:
+
+
{'Training MAE': np.float64(1951.4776197781914),
+ 'Valid MAE': np.float64(5974.931566226864),
+ 'Training RMSLE': np.float64(0.10196097739473307),
+ 'Valid RMSLE': np.float64(0.24760612684722114),
+ 'Training R^2': 0.9811027965058758,
+ 'Valid R^2': 0.8807288353268701}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Fitting HistGradientBoostingRegressor model with pipeline...
+[INFO] Evaluating HistGradientBoostingRegressor model with pipeline...
+
+Pipeline HistGradientBoostingRegressor Scores:
+
+
+
+
+
Out[148]:
+
+
{'Training MAE': np.float64(5638.6121797753785),
+ 'Valid MAE': np.float64(7264.258786098576),
+ 'Training RMSLE': np.float64(0.2691456681483351),
+ 'Valid RMSLE': np.float64(0.30482586120872424),
+ 'Training R^2': 0.8646511348082063,
+ 'Valid R^2': 0.8319021596407035}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Fitting model with one hot encoded values...
+[INFO] Evaluating model with one hot encoded values...
+[INFO] Pipeline with one hot encoding scores:
+CPU times: user 29min, sys: 23min 12s, total: 52min 13s
+Wall time: 9min 14s
+
+
+
+
+
Out[7]:
+
+
{'Training MAE': np.float64(2133.748251811842),
+ 'Valid MAE': np.float64(6176.810802667383),
+ 'Training RMSLE': np.float64(0.11021214524792695),
+ 'Valid RMSLE': np.float64(0.2539881442090813),
+ 'Training R^2': 0.9759312990258391,
+ 'Valid R^2': 0.870741470996933}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Last updated: 2024-04-26 01:26:48.838163
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] TensorFlow has GPU available to use. Woohoo!! Computing will be sped up!
+[INFO] Accessible devices:
+[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Mounted at /content/drive
+[INFO] Copying Dog Vision files from Google Drive to local directory...
+[INFO] Source dir: drive/MyDrive/tensorflow/dog_vision_data -> Target dir: dog_vision_data
+[INFO] Good to go!
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
dog_vision_data/
+ lists.tar
+ images.tar
+ annotation.tar
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[8]:
+
+
['.config',
+ 'dog_vision_data',
+ 'file_list.mat',
+ 'drive',
+ 'train_list.mat',
+ 'Images',
+ 'Annotation',
+ 'test_list.mat',
+ 'sample_data']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[9]:
+
+
({'__header__': b'MATLAB 5.0 MAT-file, Platform: GLNXA64, Created on: Sun Oct 9 08:36:13 2011',
+ '__version__': '1.0',
+ '__globals__': [],
+ 'file_list': array([[array(['n02085620-Chihuahua/n02085620_5927.jpg'], dtype='<U38')],
+ [array(['n02085620-Chihuahua/n02085620_4441.jpg'], dtype='<U38')],
+ [array(['n02085620-Chihuahua/n02085620_1502.jpg'], dtype='<U38')],
+ ...,
+ [array(['n02116738-African_hunting_dog/n02116738_6754.jpg'], dtype='<U48')],
+ [array(['n02116738-African_hunting_dog/n02116738_9333.jpg'], dtype='<U48')],
+ [array(['n02116738-African_hunting_dog/n02116738_2503.jpg'], dtype='<U48')]],
+ dtype=object),
+ 'annotation_list': array([[array(['n02085620-Chihuahua/n02085620_5927'], dtype='<U34')],
+ [array(['n02085620-Chihuahua/n02085620_4441'], dtype='<U34')],
+ [array(['n02085620-Chihuahua/n02085620_1502'], dtype='<U34')],
+ ...,
+ [array(['n02116738-African_hunting_dog/n02116738_6754'], dtype='<U44')],
+ [array(['n02116738-African_hunting_dog/n02116738_9333'], dtype='<U44')],
+ [array(['n02116738-African_hunting_dog/n02116738_2503'], dtype='<U44')]],
+ dtype=object),
+ 'labels': array([[ 1],
+ [ 1],
+ [ 1],
+ ...,
+ [120],
+ [120],
+ [120]], dtype=uint8)},
+ dict)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[10]:
+
+
dict_keys(['__header__', '__version__', '__globals__', 'file_list', 'annotation_list', 'labels'])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Number of files in training list: 12000
+Number of files in testing list: 8580
+Number of files in full list: 20580
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[12]:
+
+
array([[array(['n02085620-Chihuahua/n02085620_5927.jpg'], dtype='<U38')],
+ [array(['n02085620-Chihuahua/n02085620_4441.jpg'], dtype='<U38')],
+ [array(['n02085620-Chihuahua/n02085620_1502.jpg'], dtype='<U38')],
+ ...,
+ [array(['n02116738-African_hunting_dog/n02116738_6754.jpg'], dtype='<U48')],
+ [array(['n02116738-African_hunting_dog/n02116738_9333.jpg'], dtype='<U48')],
+ [array(['n02116738-African_hunting_dog/n02116738_2503.jpg'], dtype='<U48')]],
+ dtype=object)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[13]:
+
+
'n02085620-Chihuahua/n02085620_5927.jpg'
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[15]:
+
+
['n02094258-Norwich_terrier/n02094258_439.jpg',
+ 'n02113624-toy_poodle/n02113624_3624.jpg',
+ 'n02102973-Irish_water_spaniel/n02102973_3635.jpg',
+ 'n02102318-cocker_spaniel/n02102318_2048.jpg',
+ 'n02098286-West_Highland_white_terrier/n02098286_1261.jpg',
+ 'n02088238-basset/n02088238_10095.jpg',
+ 'n02108915-French_bulldog/n02108915_9457.jpg',
+ 'n02098286-West_Highland_white_terrier/n02098286_5979.jpg',
+ 'n02109047-Great_Dane/n02109047_31274.jpg',
+ 'n02095889-Sealyham_terrier/n02095889_760.jpg']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[18]:
+
+
['n02111129-Leonberg',
+ 'n02102973-Irish_water_spaniel',
+ 'n02110806-basenji',
+ 'n02105251-briard',
+ 'n02093991-Irish_terrier',
+ 'n02099267-flat-coated_retriever',
+ 'n02110627-affenpinscher',
+ 'n02112137-chow',
+ 'n02094114-Norfolk_terrier',
+ 'n02095570-Lakeland_terrier']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Number of subfolders in Annotation directory: 120
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[20]:
+
+
'n02085620-Chihuahua/n02085620_5927.jpg'
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[21]:
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[22]:
+
+
['n02111129-Leonberg',
+ 'n02102973-Irish_water_spaniel',
+ 'n02110806-basenji',
+ 'n02105251-briard',
+ 'n02093991-Irish_terrier',
+ 'n02099267-flat-coated_retriever',
+ 'n02110627-affenpinscher',
+ 'n02112137-chow',
+ 'n02094114-Norfolk_terrier',
+ 'n02095570-Lakeland_terrier']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[24]:
+
+
[('n02111129-Leonberg', 'leonberg'),
+ ('n02102973-Irish_water_spaniel', 'irish_water_spaniel'),
+ ('n02110806-basenji', 'basenji'),
+ ('n02105251-briard', 'briard'),
+ ('n02093991-Irish_terrier', 'irish_terrier'),
+ ('n02099267-flat-coated_retriever', 'flat_coated_retriever'),
+ ('n02110627-affenpinscher', 'affenpinscher'),
+ ('n02112137-chow', 'chow'),
+ ('n02094114-Norfolk_terrier', 'norfolk_terrier'),
+ ('n02095570-Lakeland_terrier', 'lakeland_terrier')]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[25]:
+
+
['affenpinscher',
+ 'afghan_hound',
+ 'african_hunting_dog',
+ 'airedale',
+ 'american_staffordshire_terrier',
+ 'appenzeller',
+ 'australian_terrier',
+ 'basenji',
+ 'basset',
+ 'beagle']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[28]:
+
+
[{'class_name': 'n02111129-Leonberg', 'image_count': 210},
+ {'class_name': 'n02102973-Irish_water_spaniel', 'image_count': 150},
+ {'class_name': 'n02110806-basenji', 'image_count': 209}]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[29]:
+
+
+
+
+
+
+
+ |
+class_name |
+image_count |
+
+
+
+
+| 116 |
+n02085936-Maltese_dog |
+252 |
+
+
+| 53 |
+n02088094-Afghan_hound |
+239 |
+
+
+| 111 |
+n02092002-Scottish_deerhound |
+232 |
+
+
+| 103 |
+n02112018-Pomeranian |
+219 |
+
+
+| 54 |
+n02107683-Bernese_mountain_dog |
+218 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[30]:
+
+
+
+
+
+
+
+ |
+class_name |
+image_count |
+
+
+
+
+| 116 |
+maltese_dog |
+252 |
+
+
+| 53 |
+afghan_hound |
+239 |
+
+
+| 111 |
+scottish_deerhound |
+232 |
+
+
+| 103 |
+pomeranian |
+219 |
+
+
+| 54 |
+bernese_mountain_dog |
+218 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[32]:
+
+
+
+
+
+
+
+ |
+image_count |
+
+
+
+
+| count |
+120.000000 |
+
+
+| mean |
+171.500000 |
+
+
+| std |
+23.220898 |
+
+
+| min |
+148.000000 |
+
+
+| 25% |
+152.750000 |
+
+
+| 50% |
+159.500000 |
+
+
+| 75% |
+186.250000 |
+
+
+| max |
+252.000000 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Directory images_split/train is exists.
+Directory images_split/test is exists.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[34]:
+
+
['images_split/train/affenpinscher',
+ 'images_split/train/afghan_hound',
+ 'images_split/train/african_hunting_dog',
+ 'images_split/train/airedale',
+ 'images_split/train/american_staffordshire_terrier',
+ 'images_split/train/appenzeller',
+ 'images_split/train/australian_terrier',
+ 'images_split/train/basenji',
+ 'images_split/train/basset',
+ 'images_split/train/beagle']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
0%| | 0/12000 [00:00<?, ?it/s]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
0%| | 0/8580 [00:00<?, ?it/s]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Number of images in images_split/train: 12000
+Number of images in images_split/test: 8580
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[41]:
+
+
['test', 'train_10_percent', 'train']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Original number of training image paths: 12000
+Number of 10% training image paths: 1200
+First 5 random 10% training image paths:
+
+
+
+
+
Out[42]:
+
+
[PosixPath('images_split/train/miniature_pinscher/n02107312_2706.jpg'),
+ PosixPath('images_split/train/irish_wolfhound/n02090721_272.jpg'),
+ PosixPath('images_split/train/greater_swiss_mountain_dog/n02107574_3274.jpg'),
+ PosixPath('images_split/train/italian_greyhound/n02091032_3763.jpg'),
+ PosixPath('images_split/train/bloodhound/n02088466_7962.jpg')]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
0%| | 0/1200 [00:00<?, ?it/s]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[44]:
+
+
+
+
+
+
+
+ |
+class_name |
+image_count |
+
+
+
+
+| 33 |
+labrador_retriever |
+3 |
+
+
+| 23 |
+welsh_springer_spaniel |
+4 |
+
+
+| 61 |
+great_dane |
+4 |
+
+
+| 64 |
+curly_coated_retriever |
+4 |
+
+
+| 100 |
+sussex_spaniel |
+5 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Found 1200 files belonging to 120 classes.
+Found 12000 files belonging to 120 classes.
+Found 8580 files belonging to 120 classes.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[48]:
+
+
<_PrefetchDataset element_spec=(TensorSpec(shape=(None, 224, 224, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 120), dtype=tf.float32, name=None))>
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[49]:
+
+
(TensorShape([32, 224, 224, 3]), TensorShape([32, 120]))
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Single image tensor:
+[[[196.61607 174.61607 160.61607 ]
+ [197.84822 175.84822 161.84822 ]
+ [200. 178. 164. ]
+ ...
+ [ 60.095097 79.75804 45.769207]
+ [ 61.83293 71.22575 63.288315]
+ [ 77.65755 83.65755 81.65755 ]]
+
+ [[196. 174. 160. ]
+ [197.83876 175.83876 161.83876 ]
+ [199.07945 177.07945 163.07945 ]
+ ...
+ [ 94.573715 110.55229 83.59694 ]
+ [125.869865 135.26268 127.33472 ]
+ [122.579605 128.5796 126.579605]]
+
+ [[195.73691 173.73691 159.73691 ]
+ [196.896 174.896 160.896 ]
+ [199. 177. 163. ]
+ ...
+ [ 26.679413 38.759026 20.500835]
+ [ 24.372307 31.440136 26.675896]
+ [ 20.214453 26.214453 24.214453]]
+
+ ...
+
+ [[ 61.57369 70.18976 104.72547 ]
+ [189.91965 199.61607 213.28572 ]
+ [247.26637 255. 252.70387 ]
+ ...
+ [113.40158 83.40158 57.40158 ]
+ [110.75214 78.75214 53.752136]
+ [107.37048 75.37048 50.370483]]
+
+ [[ 61.27007 69.88614 104.42185 ]
+ [188.93079 198.62721 212.29686 ]
+ [246.33257 255. 251.77007 ]
+ ...
+ [110.88623 80.88623 54.88623 ]
+ [102.763245 70.763245 45.763245]
+ [ 99.457634 67.457634 42.457638]]
+
+ [[ 60.25893 68.875 103.41071 ]
+ [188.58261 198.27904 211.94868 ]
+ [245.93112 254.6097 251.36862 ]
+ ...
+ [105.02222 75.02222 49.022217]
+ [109.11186 77.11186 52.111866]
+ [106.56936 74.56936 49.56936 ]]]
+
+Single label tensor: [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
+ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
+ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
+ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.
+ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
+Single sample class name: schipperke
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[53]:
+
+
['images_split/train/boston_bull/n02096585_1753.jpg',
+ 'images_split/train/kerry_blue_terrier/n02093859_855.jpg',
+ 'images_split/train/border_terrier/n02093754_2281.jpg',
+ 'images_split/train/rottweiler/n02106550_11823.jpg',
+ 'images_split/train/airedale/n02096051_5884.jpg']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[54]:
+
+
['affenpinscher',
+ 'afghan_hound',
+ 'african_hunting_dog',
+ 'airedale',
+ 'american_staffordshire_terrier']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/efficientnet_v2/efficientnetv2-b0.h5
+29403144/29403144 [==============================] - 0s 0us/step
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Number of layers in base_model: 273
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+<ipython-input-62-5e9b29e6f858> in <cell line: 2>()
+ 1 # Create a base model with 120 output classes
+----> 2 base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(
+ 3 include_top=True,
+ 4 include_preprocessing=True,
+ 5 weights="imagenet",
+
+/usr/local/lib/python3.10/dist-packages/keras/src/applications/efficientnet_v2.py in EfficientNetV2B0(include_top, weights, input_tensor, input_shape, pooling, classes, classifier_activation, include_preprocessing)
+ 1128 include_preprocessing=True,
+ 1129 ):
+-> 1130 return EfficientNetV2(
+ 1131 width_coefficient=1.0,
+ 1132 depth_coefficient=1.0,
+
+/usr/local/lib/python3.10/dist-packages/keras/src/applications/efficientnet_v2.py in EfficientNetV2(width_coefficient, depth_coefficient, default_size, dropout_rate, drop_connect_rate, depth_divisor, min_depth, bn_momentum, activation, blocks_args, model_name, include_top, weights, input_tensor, input_shape, pooling, classes, classifier_activation, include_preprocessing)
+ 932
+ 933 if weights == "imagenet" and include_top and classes != 1000:
+--> 934 raise ValueError(
+ 935 "If using `weights` as `'imagenet'` with `include_top`"
+ 936 " as true, `classes` should be 1000"
+
+ValueError: If using `weights` as `'imagenet'` with `include_top` as true, `classes` should be 1000Received: classes=120
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/efficientnet_v2/efficientnetv2-b0_notop.h5
+24274472/24274472 [==============================] - 0s 0us/step
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Number of layers in base_model: 270
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Model efficientnetv2-b0 parameter counts:
+Total parameters: 5919312
+Trainable parameters: 5858704
+Non-trainable parameters: 60608
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Model efficientnetv2-b0 parameter counts:
+Total parameters: 5919312.0
+Trainable parameters: 0.0
+Non-trainable parameters: 5919312
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+<ipython-input-69-957d897dc1dc> in <cell line: 2>()
+ 1 # Extract features from a single image using our base model
+----> 2 feature_extraction = base_model(image_batch[0])
+ 3 feature_extraction
+
+/usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py in error_handler(*args, **kwargs)
+ 68 # To get the full stack trace, call:
+ 69 # `tf.debugging.disable_traceback_filtering()`
+---> 70 raise e.with_traceback(filtered_tb) from None
+ 71 finally:
+ 72 del filtered_tb
+
+/usr/local/lib/python3.10/dist-packages/keras/src/engine/input_spec.py in assert_input_compatibility(input_spec, inputs, layer_name)
+ 296 if spec_dim is not None and dim is not None:
+ 297 if spec_dim != dim:
+--> 298 raise ValueError(
+ 299 f'Input {input_index} of layer "{layer_name}" is '
+ 300 "incompatible with the layer: "
+
+ValueError: Input 0 of layer "efficientnetv2-b0" is incompatible with the layer: expected shape=(None, 224, 224, 3), found shape=(224, 224, 3)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Shape of image without batch: (224, 224, 3)
+Shape of image with batch: (1, 224, 224, 3)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[71]:
+
+
<tf.Tensor: shape=(1, 7, 7, 1280), dtype=float32, numpy=
+array([[[[-2.19177201e-01, -3.44185606e-02, -1.40321642e-01, ...,
+ -1.44454449e-01, -2.73809850e-01, -7.41252452e-02],
+ [-8.69670734e-02, -6.48750067e-02, -2.14546964e-01, ...,
+ -4.57209721e-02, -2.77900100e-01, -8.20885971e-02],
+ [-2.76872963e-01, -8.26781020e-02, -3.85153107e-02, ...,
+ -2.72128999e-01, -2.52802134e-01, -2.28105962e-01],
+ ...,
+ [-1.01604000e-01, -3.55145968e-02, -2.23027021e-01, ...,
+ -2.26227805e-01, -8.61771777e-02, -1.60450727e-01],
+ [-5.87608740e-02, -4.65543661e-03, -1.06193267e-01, ...,
+ -2.87548676e-02, -9.06914026e-02, -1.82624385e-01],
+ [-6.27618432e-02, -1.38620799e-03, 1.52704502e-02, ...,
+ -7.85450079e-03, -1.84584558e-01, -2.62404829e-01]],
+
+ [[-2.17334151e-01, -1.10280879e-01, -2.74605274e-01, ...,
+ -2.22405165e-01, -2.74738282e-01, -1.01998925e-01],
+ [-1.40700653e-01, -1.66820198e-01, -2.77449101e-01, ...,
+ 2.40375683e-01, -2.77627349e-01, -9.07808691e-02],
+ [-2.40916476e-01, -2.00582087e-01, -2.38370374e-01, ...,
+ -8.27576742e-02, -2.78428614e-01, -1.23056054e-01],
+ ...,
+ [-2.67296195e-01, -5.43131726e-03, -6.44061863e-02, ...,
+ -3.34720500e-02, -1.55141622e-01, -3.23073938e-02],
+ [-2.66513556e-01, -2.09966358e-02, -1.50375053e-01, ...,
+ -6.29274473e-02, -2.69798309e-01, -2.74081439e-01],
+ [-8.39830115e-02, -1.58605091e-02, -2.78447241e-01, ...,
+ -1.43555822e-02, -2.77474761e-01, 1.37483165e-01]],
+
+ [[-2.15840712e-01, 4.50323820e-01, -7.51058161e-02, ...,
+ -2.43637279e-01, -2.75048614e-01, -6.00421876e-02],
+ [-2.39066556e-01, -2.25066260e-01, -4.89832312e-02, ...,
+ -2.77957618e-01, -1.14677951e-01, -2.69968715e-02],
+ [-1.60943881e-01, -2.12972730e-01, -1.08622171e-01, ...,
+ -2.78464079e-01, -1.95970193e-01, -2.92074662e-02],
+ ...,
+ [-2.67642140e-01, -7.13412274e-10, -2.47387841e-01, ...,
+ -1.27752789e-03, 1.69062471e+00, -1.07747754e-02],
+ [-2.69456387e-01, -3.02123808e-05, -2.19904676e-01, ...,
+ -1.19841937e-02, 6.54936790e-01, 4.92877871e-01],
+ [-1.83339473e-02, -9.84105989e-02, -2.77752399e-01, ...,
+ -9.53171253e-02, -2.76987553e-01, -1.81873620e-01]],
+
+ ...,
+
+ [[-6.59235120e-02, -1.64803467e-03, -1.58951283e-01, ...,
+ -1.34164095e-01, -6.30896613e-02, -7.77927637e-02],
+ [-1.83377475e-01, -4.98497509e-04, -1.57654762e-01, ...,
+ -4.48885784e-02, -1.06884383e-01, -2.78372377e-01],
+ [-2.45749369e-01, -9.95399058e-03, -1.79216102e-01, ...,
+ -1.02837617e-02, -1.84168354e-01, -1.70697242e-01],
+ ...,
+ [ 2.22050592e-01, -2.04384560e-04, -1.46467671e-01, ...,
+ -2.65387502e-02, -1.85434178e-01, -9.71652716e-02],
+ [ 1.52228832e+00, -3.39617883e-03, -3.22414264e-02, ...,
+ -1.19287046e-02, -1.46435276e-01, -8.73169452e-02],
+ [-1.89164400e-01, -5.49114570e-02, -2.05218419e-01, ...,
+ -1.32163316e-01, -1.48950770e-01, -1.18042991e-01]],
+
+ [[-2.16520607e-01, -7.84920622e-03, -1.43650264e-01, ...,
+ -1.73660204e-01, -4.83706780e-02, -3.76228467e-02],
+ [-2.78293848e-01, -6.24539470e-03, -2.28590608e-01, ...,
+ -2.06465453e-01, -1.93291768e-01, -9.23046917e-02],
+ [-2.40500003e-01, -2.73558766e-01, -1.58736348e-01, ...,
+ -4.13209312e-02, -2.64240265e-01, -3.26484852e-02],
+ ...,
+ [-2.31358394e-01, -2.72292078e-01, -6.80670887e-02, ...,
+ -2.16453914e-02, -2.71368980e-01, -3.88960652e-02],
+ [-2.45319903e-01, -2.78179497e-01, -6.18890636e-02, ...,
+ -1.86282583e-02, -2.23804727e-01, -2.72233319e-02],
+ [-2.31111392e-01, -2.37449735e-01, -5.13911694e-02, ...,
+ -4.55225781e-02, -2.74753064e-01, -3.51530202e-02]],
+
+ [[-3.96142267e-02, -1.39998682e-02, -9.56050456e-02, ...,
+ -2.33392462e-01, -1.83407709e-01, -4.99856956e-02],
+ [-2.60713607e-01, -3.96164991e-02, -1.29626304e-01, ...,
+ -2.78417081e-01, -2.78285533e-01, -7.70441368e-02],
+ [-8.02241415e-02, -2.30456606e-01, -1.13508031e-01, ...,
+ -5.45607917e-02, -2.71063268e-01, -2.75666509e-02],
+ ...,
+ [-9.41052362e-02, -2.42691532e-01, -5.48249595e-02, ...,
+ -2.13044193e-02, -2.63691694e-01, -9.28506851e-02],
+ [-9.08804908e-02, -2.40457997e-01, -7.88932368e-02, ...,
+ -3.80579121e-02, -2.71065891e-01, -4.05692160e-02],
+ [-1.26358300e-01, -2.17053503e-01, -7.44825602e-02, ...,
+ -5.66985942e-02, -2.75216103e-01, -6.91162944e-02]]]],
+ dtype=float32)>
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[72]:
+
+
TensorShape([1, 7, 7, 1280])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[74]:
+
+
<tf.Tensor: shape=(1, 1280), dtype=float32, numpy=
+array([[-0.11521906, -0.04476562, -0.12476546, ..., -0.09118073,
+ -0.08420841, -0.07769417]], dtype=float32)>
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[75]:
+
+
TensorShape([1, 1280])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Input -> feature extraction reduction factor: 2.4
+Feature extraction -> feature vector reduction factor: 49.0
+Input -> feature extraction -> feature vector reduction factor: 117.6
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Model efficientnetv2-b0 parameter counts:
+Total parameters: 5919312.0
+Trainable parameters: 0.0
+Non-trainable parameters: 5919312
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[79]:
+
+
<tf.Tensor: shape=(1, 1280), dtype=float32, numpy=
+array([[-0.11521906, -0.04476562, -0.12476546, ..., -0.09118073,
+ -0.08420841, -0.07769417]], dtype=float32)>
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Model: "sequential"
+_________________________________________________________________
+ Layer (type) Output Shape Param #
+=================================================================
+ efficientnetv2-b0 (Functio (None, 1280) 5919312
+ nal)
+
+ dense (Dense) (None, 120) 153720
+
+=================================================================
+Total params: 6073032 (23.17 MB)
+Trainable params: 153720 (600.47 KB)
+Non-trainable params: 5919312 (22.58 MB)
+_________________________________________________________________
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[84]:
+
+
<tf.Tensor: shape=(1, 120), dtype=float32, numpy=
+array([[0.00783153, 0.01119391, 0.00476165, 0.0072348 , 0.00766934,
+ 0.00753752, 0.00522398, 0.02337082, 0.00579716, 0.00539333,
+ 0.00549823, 0.01011768, 0.00610076, 0.0109506 , 0.00540159,
+ 0.0079683 , 0.01227358, 0.01056393, 0.00507148, 0.00996652,
+ 0.00604106, 0.00729022, 0.0155036 , 0.00745004, 0.00628229,
+ 0.00796217, 0.00905823, 0.00712278, 0.01243507, 0.006427 ,
+ 0.00602891, 0.01276839, 0.00652441, 0.00842482, 0.01247454,
+ 0.00749902, 0.01086363, 0.007803 , 0.0058652 , 0.00474356,
+ 0.00902809, 0.00715358, 0.00981051, 0.00444271, 0.01031628,
+ 0.00691859, 0.00699083, 0.0065892 , 0.00966169, 0.01177148,
+ 0.00908043, 0.00729699, 0.00496712, 0.00509035, 0.00584058,
+ 0.01068885, 0.00817651, 0.00602052, 0.00901201, 0.01008151,
+ 0.00495409, 0.01285929, 0.00480146, 0.0108622 , 0.01421483,
+ 0.00814719, 0.00910061, 0.00798947, 0.00789293, 0.00636969,
+ 0.00656019, 0.01309155, 0.00754355, 0.00702062, 0.00485884,
+ 0.00958675, 0.01086809, 0.00682202, 0.00923016, 0.00856321,
+ 0.00482627, 0.01234931, 0.01140433, 0.00771413, 0.01140642,
+ 0.00382939, 0.00891482, 0.00409833, 0.00771865, 0.00652135,
+ 0.00668143, 0.00935989, 0.00784146, 0.00751913, 0.00785116,
+ 0.00794632, 0.0079146 , 0.00798953, 0.01011222, 0.01318719,
+ 0.00721227, 0.00736159, 0.01369175, 0.01087009, 0.00510072,
+ 0.00843218, 0.00451756, 0.00966478, 0.01013771, 0.00715721,
+ 0.00367131, 0.00825834, 0.00832634, 0.01225684, 0.00724481,
+ 0.00670675, 0.00536995, 0.01070637, 0.00937007, 0.00998812]],
+ dtype=float32)>
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Highest value index: 7 (basenji)
+Prediction probability: 0.023370817303657532
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Predicted value: 7
+Actual value: 95
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Sequential model predicted label: basenji
+Ground truth label: schipperke
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Model: "functional_model"
+_________________________________________________________________
+ Layer (type) Output Shape Param #
+=================================================================
+ input_4 (InputLayer) [(None, 224, 224, 3)] 0
+
+ efficientnetv2-b0 (Functio (None, 1280) 5919312
+ nal)
+
+ output_layer (Dense) (None, 120) 153720
+
+=================================================================
+Total params: 6073032 (23.17 MB)
+Trainable params: 153720 (600.47 KB)
+Non-trainable params: 5919312 (22.58 MB)
+_________________________________________________________________
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Model: "model"
+_________________________________________________________________
+ Layer (type) Output Shape Param #
+=================================================================
+ input_layer (InputLayer) [(None, 224, 224, 3)] 0
+
+ efficientnetv2-b0 (Functio (None, 1280) 5919312
+ nal)
+
+ output_layer (Dense) (None, 120) 153720
+
+=================================================================
+Total params: 6073032 (23.17 MB)
+Trainable params: 153720 (600.47 KB)
+Non-trainable params: 5919312 (22.58 MB)
+_________________________________________________________________
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
input_layer True
+efficientnetv2-b0 False
+output_layer True
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Model: "model_0"
+_________________________________________________________________
+ Layer (type) Output Shape Param #
+=================================================================
+ input_layer (InputLayer) [(None, 224, 224, 3)] 0
+
+ efficientnetv2-b0 (Functio (None, 1280) 5919312
+ nal)
+
+ output_layer (Dense) (None, 120) 153720
+
+=================================================================
+Total params: 6073032 (23.17 MB)
+Trainable params: 153720 (600.47 KB)
+Non-trainable params: 5919312 (22.58 MB)
+_________________________________________________________________
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[95]:
+
+
<keras.src.optimizers.adam.Adam at 0x7f3bb4107040>
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[96]:
+
+
<tf.Tensor: shape=(120,), dtype=float32, numpy=
+array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
+ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
+ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
+ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
+ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
+ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,
+ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
+ 0.], dtype=float32)>
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[97]:
+
+
<keras.src.losses.CategoricalCrossentropy at 0x7f3bb4107430>
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Epoch 1/5
+38/38 [==============================] - 27s 482ms/step - loss: 3.9758 - accuracy: 0.3000 - val_loss: 3.0500 - val_accuracy: 0.5415
+Epoch 2/5
+38/38 [==============================] - 14s 379ms/step - loss: 2.0531 - accuracy: 0.8008 - val_loss: 1.8650 - val_accuracy: 0.7041
+Epoch 3/5
+38/38 [==============================] - 14s 375ms/step - loss: 1.0491 - accuracy: 0.9025 - val_loss: 1.3060 - val_accuracy: 0.7548
+Epoch 4/5
+38/38 [==============================] - 14s 373ms/step - loss: 0.6138 - accuracy: 0.9483 - val_loss: 1.0317 - val_accuracy: 0.7910
+Epoch 5/5
+38/38 [==============================] - 14s 373ms/step - loss: 0.4157 - accuracy: 0.9683 - val_loss: 0.8927 - val_accuracy: 0.8044
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Epoch 1/5
+38/38 [==============================] - 22s 418ms/step - loss: 3.9263 - accuracy: 0.3225 - val_loss: 2.9969 - val_accuracy: 0.5549
+Epoch 2/5
+38/38 [==============================] - 14s 379ms/step - loss: 1.9899 - accuracy: 0.7900 - val_loss: 1.8436 - val_accuracy: 0.7063
+Epoch 3/5
+38/38 [==============================] - 14s 380ms/step - loss: 1.0152 - accuracy: 0.9058 - val_loss: 1.2817 - val_accuracy: 0.7702
+Epoch 4/5
+38/38 [==============================] - 14s 376ms/step - loss: 0.5997 - accuracy: 0.9483 - val_loss: 1.0173 - val_accuracy: 0.7945
+Epoch 5/5
+38/38 [==============================] - 14s 374ms/step - loss: 0.4040 - accuracy: 0.9708 - val_loss: 0.8792 - val_accuracy: 0.8107
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[102]:
+
+
{'loss': [3.926330089569092,
+ 1.9898805618286133,
+ 1.0152279138565063,
+ 0.599678099155426,
+ 0.4040333032608032],
+ 'accuracy': [0.32249999046325684,
+ 0.7900000214576721,
+ 0.9058333039283752,
+ 0.9483333230018616,
+ 0.9708333611488342],
+ 'val_loss': [2.996889591217041,
+ 1.8436286449432373,
+ 1.2817054986953735,
+ 1.0173338651657104,
+ 0.8792150616645813],
+ 'val_accuracy': [0.5548951029777527,
+ 0.7062937021255493,
+ 0.7701631784439087,
+ 0.7945221662521362,
+ 0.8107225894927979]}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
269/269 [==============================] - 13s 47ms/step - loss: 0.8792 - accuracy: 0.8107
+
+
+
+
+
Out[104]:
+
+
[0.8792150616645813, 0.8107225894927979]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Epoch 1/5
+375/375 [==============================] - 43s 84ms/step - loss: 1.2725 - accuracy: 0.7607 - val_loss: 0.4849 - val_accuracy: 0.8756
+Epoch 2/5
+375/375 [==============================] - 30s 80ms/step - loss: 0.3667 - accuracy: 0.9013 - val_loss: 0.4041 - val_accuracy: 0.8770
+Epoch 3/5
+375/375 [==============================] - 30s 79ms/step - loss: 0.2641 - accuracy: 0.9287 - val_loss: 0.3731 - val_accuracy: 0.8832
+Epoch 4/5
+375/375 [==============================] - 30s 80ms/step - loss: 0.2043 - accuracy: 0.9483 - val_loss: 0.3708 - val_accuracy: 0.8819
+Epoch 5/5
+375/375 [==============================] - 30s 80ms/step - loss: 0.1606 - accuracy: 0.9633 - val_loss: 0.3753 - val_accuracy: 0.8767
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
269/269 [==============================] - 12s 46ms/step - loss: 0.3753 - accuracy: 0.8767
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
269/269 [==============================] - 13s 44ms/step
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] Random test index: 1824
+[INFO] Random test pred sample shape: (120,)
+[INFO] Random test pred sample argmax: 24
+[INFO] Random test pred sample label: brittany_spaniel
+[INFO] Random test pred sample max prediction probability: 0.9248308539390564
+[INFO] Random test pred sample prediction probability values:
+[3.0155065e-06 4.2946940e-05 3.2878995e-06 3.1306336e-05 1.7298260e-06
+ 1.3368123e-05 2.8498230e-06 6.8758955e-06 2.6828552e-06 4.6089318e-04
+ 9.8374185e-06 1.9263330e-06 7.6487186e-07 6.1217276e-04 1.2198443e-06
+ 5.9309714e-06 2.4797799e-05 2.5847612e-06 4.9912862e-05 3.1809162e-07
+ 1.0326848e-06 2.7293386e-06 2.1035332e-06 5.2793930e-06 9.2483085e-01
+ 2.6070888e-06 1.6410323e-06 1.4008251e-06 2.0515323e-05 2.1309786e-05
+ 1.4602327e-06 3.8456672e-04 7.4974610e-05 4.4831428e-05 5.5091264e-06
+ 2.1345174e-07 2.9732748e-06 5.5520386e-06 8.7954652e-07 1.6277906e-03
+ 5.3978354e-02 9.6090174e-05 9.6672220e-06 4.4037843e-06 2.5557700e-05
+ 6.3994042e-07 1.6738920e-06 4.6715216e-04 4.1448075e-06 6.4118845e-05
+ 2.0398900e-06 3.6135450e-06 4.4963690e-05 2.8406910e-05 3.4689847e-07
+ 6.2964758e-04 9.1336078e-05 5.2363583e-05 1.2731762e-06 2.4212743e-06
+ 1.5872080e-06 6.3476455e-06 6.2880179e-07 6.6757898e-06 1.6635622e-06
+ 4.3550008e-07 2.3698403e-05 1.4149221e-05 3.8156581e-05 1.0464001e-05
+ 5.0107906e-06 1.7395665e-06 2.8848885e-07 4.2622072e-05 3.2712339e-07
+ 1.8591476e-07 2.2874669e-05 7.9814470e-07 2.3121322e-05 1.6275973e-06
+ 4.6186727e-07 7.6188849e-07 3.2468931e-06 3.1449999e-05 2.9600946e-05
+ 3.8992380e-06 2.8564186e-06 4.1459539e-06 6.0877244e-07 2.5443229e-05
+ 5.4467969e-06 5.4184858e-07 2.8361776e-04 9.0548929e-05 8.8840829e-07
+ 9.1714105e-07 1.9990568e-07 1.7958368e-05 7.7042150e-06 2.4126435e-05
+ 1.9759838e-05 8.2941342e-06 2.5857928e-05 6.1904398e-06 1.4601937e-06
+ 1.5800337e-05 6.0928446e-06 5.0209674e-05 1.4067524e-05 2.3544631e-05
+ 1.4134421e-06 9.8844721e-05 9.1535941e-05 2.4448002e-03 5.8540131e-06
+ 1.2547853e-02 1.3779800e-05 8.0164841e-07 2.5093528e-05 3.7180773e-05]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[115]:
+
+
+
+
+
+
+
+ |
+test_pred_label |
+test_pred_prob |
+test_pred_class_name |
+test_truth_label |
+test_truth_class_name |
+correct |
+
+
+
+
+| 0 |
+0 |
+0.974350 |
+affenpinscher |
+0 |
+affenpinscher |
+True |
+
+
+| 1 |
+0 |
+0.694450 |
+affenpinscher |
+0 |
+affenpinscher |
+True |
+
+
+| 2 |
+0 |
+0.993829 |
+affenpinscher |
+0 |
+affenpinscher |
+True |
+
+
+| 3 |
+44 |
+0.691742 |
+flat_coated_retriever |
+0 |
+affenpinscher |
+False |
+
+
+| 4 |
+0 |
+0.989754 |
+affenpinscher |
+0 |
+affenpinscher |
+True |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[116]:
+
+
+
+
+
+
+
+ |
+test_truth_class_name |
+correct |
+
+
+
+
+| 10 |
+bedlington_terrier |
+1.000000 |
+
+
+| 62 |
+keeshond |
+1.000000 |
+
+
+| 30 |
+chow |
+0.989583 |
+
+
+| 92 |
+saint_bernard |
+0.985714 |
+
+
+| 2 |
+african_hunting_dog |
+0.985507 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[118]:
+
+
+
+
+
+
+
+ |
+test_truth_class_name |
+correct |
+
+
+
+
+| 104 |
+staffordshire_bullterrier |
+0.672727 |
+
+
+| 76 |
+miniature_poodle |
+0.654545 |
+
+
+| 90 |
+rhodesian_ridgeback |
+0.638889 |
+
+
+| 71 |
+malamute |
+0.615385 |
+
+
+| 101 |
+siberian_husky |
+0.271739 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[119]:
+
+
+
+
+
+
+
+ |
+test_pred_label |
+test_pred_prob |
+test_pred_class_name |
+test_truth_label |
+test_truth_class_name |
+correct |
+
+
+
+
+| 2727 |
+75 |
+0.997043 |
+miniature_pinscher |
+38 |
+doberman |
+False |
+
+
+| 5480 |
+44 |
+0.995325 |
+flat_coated_retriever |
+78 |
+newfoundland |
+False |
+
+
+| 6884 |
+54 |
+0.994142 |
+groenendael |
+95 |
+schipperke |
+False |
+
+
+| 4155 |
+55 |
+0.987126 |
+ibizan_hound |
+60 |
+italian_greyhound |
+False |
+
+
+| 1715 |
+85 |
+0.984834 |
+pekinese |
+22 |
+brabancon_griffon |
+False |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[120]:
+
+
Index([2001, 1715, 8112, 1642, 5480, 6383, 7363, 4155, 7895, 4105], dtype='int64')
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
269/269 [==============================] - 15s 47ms/step - loss: 0.3753 - accuracy: 0.8767
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
--2024-04-26 01:43:26-- https://github.com/mrdbourke/zero-to-mastery-ml/raw/master/images/dog-photos.zip
+Resolving github.com (github.com)... 140.82.113.4
+Connecting to github.com (github.com)|140.82.113.4|:443... connected.
+HTTP request sent, awaiting response... 302 Found
+Location: https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/images/dog-photos.zip [following]
+--2024-04-26 01:43:26-- https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/images/dog-photos.zip
+Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...
+Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
+HTTP request sent, awaiting response... 200 OK
+Length: 1091355 (1.0M) [application/zip]
+Saving to: ‘dog-photos.zip’
+
+dog-photos.zip 100%[===================>] 1.04M --.-KB/s in 0.05s
+
+2024-04-26 01:43:27 (21.6 MB/s) - ‘dog-photos.zip’ saved [1091355/1091355]
+
+Archive: dog-photos.zip
+ inflating: dog-photo-4.jpeg
+ inflating: dog-photo-1.jpeg
+ inflating: dog-photo-2.jpeg
+ inflating: dog-photo-3.jpeg
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+IndexError Traceback (most recent call last)
+<ipython-input-129-336b90293288> in <cell line: 2>()
+ 1 # Try and make a prediction on the first dog image
+----> 2 loaded_model.predict("dog-photo-1.jpeg")
+
+/usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py in error_handler(*args, **kwargs)
+ 68 # To get the full stack trace, call:
+ 69 # `tf.debugging.disable_traceback_filtering()`
+---> 70 raise e.with_traceback(filtered_tb) from None
+ 71 finally:
+ 72 del filtered_tb
+
+/usr/local/lib/python3.10/dist-packages/tensorflow/python/framework/tensor_shape.py in __getitem__(self, key)
+ 960 else:
+ 961 if self._v2_behavior:
+--> 962 return self._dims[key]
+ 963 else:
+ 964 return self.dims[key]
+
+IndexError: tuple index out of range
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[130]:
+
+
(PIL.Image.Image, <PIL.Image.Image image mode=RGB size=224x224>)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+<ipython-input-132-bd82d1e41fed> in <cell line: 2>()
+ 1 # Make a prediction on our custom image tensor
+----> 2 loaded_model.predict(custom_image_tensor)
+
+/usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py in error_handler(*args, **kwargs)
+ 68 # To get the full stack trace, call:
+ 69 # `tf.debugging.disable_traceback_filtering()`
+---> 70 raise e.with_traceback(filtered_tb) from None
+ 71 finally:
+ 72 del filtered_tb
+
+/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py in tf__predict_function(iterator)
+ 13 try:
+ 14 do_return = True
+---> 15 retval_ = ag__.converted_call(ag__.ld(step_function), (ag__.ld(self), ag__.ld(iterator)), None, fscope)
+ 16 except:
+ 17 do_return = False
+
+ValueError: in user code:
+
+ File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py", line 2440, in predict_function *
+ return step_function(self, iterator)
+ File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py", line 2425, in step_function **
+ outputs = model.distribute_strategy.run(run_step, args=(data,))
+ File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py", line 2413, in run_step **
+ outputs = model.predict_step(data)
+ File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py", line 2381, in predict_step
+ return self(x, training=False)
+ File "/usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py", line 70, in error_handler
+ raise e.with_traceback(filtered_tb) from None
+ File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/input_spec.py", line 298, in assert_input_compatibility
+ raise ValueError(
+
+ ValueError: Input 0 of layer "model_1" is incompatible with the layer: expected shape=(None, 224, 224, 3), found shape=(32, 224, 3)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Shape of custom image tensor: (1, 224, 224, 3)
+Shape of custom image tensor: (1, 224, 224, 3)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
1/1 [==============================] - 2s 2s/step
+
+
+
+
+
Out[134]:
+
+
array([[1.83611644e-06, 3.09535017e-06, 3.86047805e-06, 3.19048486e-05,
+ 1.66974694e-03, 1.27542022e-04, 7.03033629e-06, 1.19856362e-04,
+ 1.01050091e-05, 3.87266744e-04, 6.44192414e-06, 1.67636438e-06,
+ 8.94749770e-04, 5.01931618e-06, 1.60283549e-03, 9.41093604e-05,
+ 4.67637838e-05, 8.51367513e-05, 5.67736897e-05, 6.14693909e-06,
+ 2.67342989e-06, 1.47549901e-04, 4.17501433e-05, 3.90995192e-05,
+ 9.50478498e-05, 1.47656752e-02, 3.08718845e-05, 1.58209339e-04,
+ 8.39364156e-03, 1.17800606e-03, 2.69454729e-04, 1.02170045e-04,
+ 7.42143384e-05, 8.22680071e-04, 1.73064705e-04, 8.98789040e-06,
+ 6.77722392e-06, 2.46034167e-03, 1.21447938e-05, 3.06540052e-04,
+ 1.12927992e-04, 1.30907722e-06, 1.19819895e-04, 3.28008295e-03,
+ 4.22435085e-04, 2.56334723e-04, 6.35078293e-04, 6.96951101e-05,
+ 1.82968670e-05, 6.66733533e-02, 1.65604251e-06, 4.85742465e-04,
+ 3.82422912e-03, 4.36909148e-04, 1.34899176e-06, 4.04351122e-05,
+ 2.30197293e-05, 7.29483800e-05, 1.31009811e-05, 1.30437169e-04,
+ 1.27625071e-05, 3.21804691e-06, 6.78410470e-06, 3.72191658e-03,
+ 9.23305777e-07, 4.05427454e-06, 1.32554891e-02, 8.34832132e-01,
+ 1.84010264e-06, 5.39118366e-04, 2.44915718e-05, 1.35658804e-04,
+ 9.53144918e-04, 3.80869096e-05, 3.43683018e-06, 3.57066506e-06,
+ 2.41459438e-05, 2.93612948e-06, 1.27533756e-04, 2.15716864e-05,
+ 3.21038242e-05, 7.87725276e-06, 1.70349504e-05, 4.27997729e-05,
+ 5.72475437e-06, 1.81680916e-05, 1.28094471e-04, 7.12008550e-05,
+ 8.24760180e-04, 6.14038622e-03, 4.27179504e-03, 3.55221750e-03,
+ 1.20739173e-03, 4.15856484e-04, 1.61429329e-04, 1.58363022e-04,
+ 3.78229856e-06, 1.03004022e-05, 2.00551622e-05, 1.21213234e-04,
+ 2.68000053e-06, 1.00253812e-04, 4.04065868e-05, 9.84299404e-05,
+ 1.29673525e-03, 3.07669543e-05, 1.62672077e-05, 1.17529435e-05,
+ 3.74953932e-04, 4.74653389e-05, 1.00191637e-05, 1.36496616e-04,
+ 3.76833777e-05, 1.55215133e-02, 2.33796614e-04, 1.01105807e-05,
+ 8.56942424e-05, 1.37508148e-04, 3.79100857e-06, 1.04301716e-05]],
+ dtype=float32)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Predicted class label: 67
+Predicted class name: labrador_retriever
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
1/1 [==============================] - 0s 27ms/step
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
1/1 [==============================] - 0s 28ms/step
+1/1 [==============================] - 0s 26ms/step
+1/1 [==============================] - 0s 25ms/step
+1/1 [==============================] - 0s 28ms/step
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 12.2/12.2 MB 34.0 MB/s eta 0:00:00
+ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 91.9/91.9 kB 12.9 MB/s eta 0:00:00
+ Preparing metadata (setup.py) ... done
+ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 314.4/314.4 kB 33.7 MB/s eta 0:00:00
+ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 75.6/75.6 kB 10.1 MB/s eta 0:00:00
+ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 141.1/141.1 kB 18.2 MB/s eta 0:00:00
+ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.8/8.8 MB 91.6 MB/s eta 0:00:00
+ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 47.2/47.2 kB 4.3 MB/s eta 0:00:00
+ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 60.8/60.8 kB 8.8 MB/s eta 0:00:00
+ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 129.9/129.9 kB 16.6 MB/s eta 0:00:00
+ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 77.9/77.9 kB 9.8 MB/s eta 0:00:00
+ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 58.3/58.3 kB 8.3 MB/s eta 0:00:00
+ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 71.9/71.9 kB 9.7 MB/s eta 0:00:00
+ Building wheel for ffmpy (setup.py) ... done
+ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
+spacy 3.7.4 requires typer<0.10.0,>=0.3.0, but you have typer 0.12.3 which is incompatible.
+weasel 0.3.4 requires typer<0.10.0,>=0.3.0, but you have typer 0.12.3 which is incompatible.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Notebook last updated: 2024-09-24 13:29:26.771285
+
+NumPy version: 2.1.1
+pandas version: 2.2.2
+matplotlib version: 3.9.2
+Scikit-Learn version: 1.5.1
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[3]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+target |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+1 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+1 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[4]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+target |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+1 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+1 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[5]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+target |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+1 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 5 |
+57 |
+1 |
+0 |
+140 |
+192 |
+0 |
+1 |
+148 |
+0 |
+0.4 |
+1 |
+0 |
+1 |
+1 |
+
+
+| 6 |
+56 |
+0 |
+1 |
+140 |
+294 |
+0 |
+0 |
+153 |
+0 |
+1.3 |
+1 |
+0 |
+2 |
+1 |
+
+
+| 7 |
+44 |
+1 |
+1 |
+120 |
+263 |
+0 |
+1 |
+173 |
+0 |
+0.0 |
+2 |
+0 |
+3 |
+1 |
+
+
+| 8 |
+52 |
+1 |
+2 |
+172 |
+199 |
+1 |
+1 |
+162 |
+0 |
+0.5 |
+2 |
+0 |
+3 |
+1 |
+
+
+| 9 |
+57 |
+1 |
+2 |
+150 |
+168 |
+0 |
+1 |
+174 |
+0 |
+1.6 |
+2 |
+0 |
+2 |
+1 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[6]:
+
+
target
+1 165
+0 138
+Name: count, dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[7]:
+
+
target
+1 0.544554
+0 0.455446
+Name: proportion, dtype: float64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
<class 'pandas.core.frame.DataFrame'>
+RangeIndex: 303 entries, 0 to 302
+Data columns (total 14 columns):
+ # Column Non-Null Count Dtype
+--- ------ -------------- -----
+ 0 age 303 non-null int64
+ 1 sex 303 non-null int64
+ 2 cp 303 non-null int64
+ 3 trestbps 303 non-null int64
+ 4 chol 303 non-null int64
+ 5 fbs 303 non-null int64
+ 6 restecg 303 non-null int64
+ 7 thalach 303 non-null int64
+ 8 exang 303 non-null int64
+ 9 oldpeak 303 non-null float64
+ 10 slope 303 non-null int64
+ 11 ca 303 non-null int64
+ 12 thal 303 non-null int64
+ 13 target 303 non-null int64
+dtypes: float64(1), int64(13)
+memory usage: 33.3 KB
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[10]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+target |
+
+
+
+
+| count |
+303.000000 |
+303.000000 |
+303.000000 |
+303.000000 |
+303.000000 |
+303.000000 |
+303.000000 |
+303.000000 |
+303.000000 |
+303.000000 |
+303.000000 |
+303.000000 |
+303.000000 |
+303.000000 |
+
+
+| mean |
+54.366337 |
+0.683168 |
+0.966997 |
+131.623762 |
+246.264026 |
+0.148515 |
+0.528053 |
+149.646865 |
+0.326733 |
+1.039604 |
+1.399340 |
+0.729373 |
+2.313531 |
+0.544554 |
+
+
+| std |
+9.082101 |
+0.466011 |
+1.032052 |
+17.538143 |
+51.830751 |
+0.356198 |
+0.525860 |
+22.905161 |
+0.469794 |
+1.161075 |
+0.616226 |
+1.022606 |
+0.612277 |
+0.498835 |
+
+
+| min |
+29.000000 |
+0.000000 |
+0.000000 |
+94.000000 |
+126.000000 |
+0.000000 |
+0.000000 |
+71.000000 |
+0.000000 |
+0.000000 |
+0.000000 |
+0.000000 |
+0.000000 |
+0.000000 |
+
+
+| 25% |
+47.500000 |
+0.000000 |
+0.000000 |
+120.000000 |
+211.000000 |
+0.000000 |
+0.000000 |
+133.500000 |
+0.000000 |
+0.000000 |
+1.000000 |
+0.000000 |
+2.000000 |
+0.000000 |
+
+
+| 50% |
+55.000000 |
+1.000000 |
+1.000000 |
+130.000000 |
+240.000000 |
+0.000000 |
+1.000000 |
+153.000000 |
+0.000000 |
+0.800000 |
+1.000000 |
+0.000000 |
+2.000000 |
+1.000000 |
+
+
+| 75% |
+61.000000 |
+1.000000 |
+2.000000 |
+140.000000 |
+274.500000 |
+0.000000 |
+1.000000 |
+166.000000 |
+1.000000 |
+1.600000 |
+2.000000 |
+1.000000 |
+3.000000 |
+1.000000 |
+
+
+| max |
+77.000000 |
+1.000000 |
+3.000000 |
+200.000000 |
+564.000000 |
+1.000000 |
+2.000000 |
+202.000000 |
+1.000000 |
+6.200000 |
+2.000000 |
+4.000000 |
+3.000000 |
+1.000000 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[11]:
+
+
sex
+1 207
+0 96
+Name: count, dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[12]:
+
+
+
+
+
+
+| sex |
+0 |
+1 |
+
+
+| target |
+ |
+ |
+
+
+
+
+| 0 |
+24 |
+114 |
+
+
+| 1 |
+72 |
+93 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[17]:
+
+
+
+
+
+
+| target |
+0 |
+1 |
+
+
+| cp |
+ |
+ |
+
+
+
+
+| 0 |
+104 |
+39 |
+
+
+| 1 |
+9 |
+41 |
+
+
+| 2 |
+18 |
+69 |
+
+
+| 3 |
+7 |
+16 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[19]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+target |
+
+
+
+
+| age |
+1.000000 |
+-0.098447 |
+-0.068653 |
+0.279351 |
+0.213678 |
+0.121308 |
+-0.116211 |
+-0.398522 |
+0.096801 |
+0.210013 |
+-0.168814 |
+0.276326 |
+0.068001 |
+-0.225439 |
+
+
+| sex |
+-0.098447 |
+1.000000 |
+-0.049353 |
+-0.056769 |
+-0.197912 |
+0.045032 |
+-0.058196 |
+-0.044020 |
+0.141664 |
+0.096093 |
+-0.030711 |
+0.118261 |
+0.210041 |
+-0.280937 |
+
+
+| cp |
+-0.068653 |
+-0.049353 |
+1.000000 |
+0.047608 |
+-0.076904 |
+0.094444 |
+0.044421 |
+0.295762 |
+-0.394280 |
+-0.149230 |
+0.119717 |
+-0.181053 |
+-0.161736 |
+0.433798 |
+
+
+| trestbps |
+0.279351 |
+-0.056769 |
+0.047608 |
+1.000000 |
+0.123174 |
+0.177531 |
+-0.114103 |
+-0.046698 |
+0.067616 |
+0.193216 |
+-0.121475 |
+0.101389 |
+0.062210 |
+-0.144931 |
+
+
+| chol |
+0.213678 |
+-0.197912 |
+-0.076904 |
+0.123174 |
+1.000000 |
+0.013294 |
+-0.151040 |
+-0.009940 |
+0.067023 |
+0.053952 |
+-0.004038 |
+0.070511 |
+0.098803 |
+-0.085239 |
+
+
+| fbs |
+0.121308 |
+0.045032 |
+0.094444 |
+0.177531 |
+0.013294 |
+1.000000 |
+-0.084189 |
+-0.008567 |
+0.025665 |
+0.005747 |
+-0.059894 |
+0.137979 |
+-0.032019 |
+-0.028046 |
+
+
+| restecg |
+-0.116211 |
+-0.058196 |
+0.044421 |
+-0.114103 |
+-0.151040 |
+-0.084189 |
+1.000000 |
+0.044123 |
+-0.070733 |
+-0.058770 |
+0.093045 |
+-0.072042 |
+-0.011981 |
+0.137230 |
+
+
+| thalach |
+-0.398522 |
+-0.044020 |
+0.295762 |
+-0.046698 |
+-0.009940 |
+-0.008567 |
+0.044123 |
+1.000000 |
+-0.378812 |
+-0.344187 |
+0.386784 |
+-0.213177 |
+-0.096439 |
+0.421741 |
+
+
+| exang |
+0.096801 |
+0.141664 |
+-0.394280 |
+0.067616 |
+0.067023 |
+0.025665 |
+-0.070733 |
+-0.378812 |
+1.000000 |
+0.288223 |
+-0.257748 |
+0.115739 |
+0.206754 |
+-0.436757 |
+
+
+| oldpeak |
+0.210013 |
+0.096093 |
+-0.149230 |
+0.193216 |
+0.053952 |
+0.005747 |
+-0.058770 |
+-0.344187 |
+0.288223 |
+1.000000 |
+-0.577537 |
+0.222682 |
+0.210244 |
+-0.430696 |
+
+
+| slope |
+-0.168814 |
+-0.030711 |
+0.119717 |
+-0.121475 |
+-0.004038 |
+-0.059894 |
+0.093045 |
+0.386784 |
+-0.257748 |
+-0.577537 |
+1.000000 |
+-0.080155 |
+-0.104764 |
+0.345877 |
+
+
+| ca |
+0.276326 |
+0.118261 |
+-0.181053 |
+0.101389 |
+0.070511 |
+0.137979 |
+-0.072042 |
+-0.213177 |
+0.115739 |
+0.222682 |
+-0.080155 |
+1.000000 |
+0.151832 |
+-0.391724 |
+
+
+| thal |
+0.068001 |
+0.210041 |
+-0.161736 |
+0.062210 |
+0.098803 |
+-0.032019 |
+-0.011981 |
+-0.096439 |
+0.206754 |
+0.210244 |
+-0.104764 |
+0.151832 |
+1.000000 |
+-0.344029 |
+
+
+| target |
+-0.225439 |
+-0.280937 |
+0.433798 |
+-0.144931 |
+-0.085239 |
+-0.028046 |
+0.137230 |
+0.421741 |
+-0.436757 |
+-0.430696 |
+0.345877 |
+-0.391724 |
+-0.344029 |
+1.000000 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[21]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+target |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+1 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+1 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[23]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[24]:
+
+
(array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]),
+ numpy.ndarray)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[26]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+
+
+
+
+| 132 |
+42 |
+1 |
+1 |
+120 |
+295 |
+0 |
+1 |
+162 |
+0 |
+0.0 |
+2 |
+0 |
+2 |
+
+
+| 202 |
+58 |
+1 |
+0 |
+150 |
+270 |
+0 |
+0 |
+111 |
+1 |
+0.8 |
+2 |
+0 |
+3 |
+
+
+| 196 |
+46 |
+1 |
+2 |
+150 |
+231 |
+0 |
+1 |
+147 |
+0 |
+3.6 |
+1 |
+0 |
+2 |
+
+
+| 75 |
+55 |
+0 |
+1 |
+135 |
+250 |
+0 |
+0 |
+161 |
+0 |
+1.4 |
+1 |
+0 |
+2 |
+
+
+| 176 |
+60 |
+1 |
+0 |
+117 |
+230 |
+1 |
+1 |
+160 |
+1 |
+1.4 |
+2 |
+2 |
+3 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[27]:
+
+
(array([1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1,
+ 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0,
+ 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1,
+ 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0,
+ 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0,
+ 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1,
+ 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1,
+ 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0,
+ 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 1,
+ 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1,
+ 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1]),
+ 242)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[28]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+
+
+
+
+| 179 |
+57 |
+1 |
+0 |
+150 |
+276 |
+0 |
+0 |
+112 |
+1 |
+0.6 |
+1 |
+1 |
+1 |
+
+
+| 228 |
+59 |
+1 |
+3 |
+170 |
+288 |
+0 |
+0 |
+159 |
+0 |
+0.2 |
+1 |
+0 |
+3 |
+
+
+| 111 |
+57 |
+1 |
+2 |
+150 |
+126 |
+1 |
+1 |
+173 |
+0 |
+0.2 |
+2 |
+1 |
+3 |
+
+
+| 246 |
+56 |
+0 |
+0 |
+134 |
+409 |
+0 |
+0 |
+150 |
+1 |
+1.9 |
+1 |
+2 |
+3 |
+
+
+| 60 |
+71 |
+0 |
+2 |
+110 |
+265 |
+1 |
+0 |
+130 |
+0 |
+0.0 |
+2 |
+1 |
+2 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[29]:
+
+
(array([0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0,
+ 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0]),
+ 61)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
/Users/daniel/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/linear_model/_logistic.py:469: ConvergenceWarning: lbfgs failed to converge (status=1):
+STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
+
+Increase the number of iterations (max_iter) or scale the data as shown in:
+ https://scikit-learn.org/stable/modules/preprocessing.html
+Please also refer to the documentation for alternative solver options:
+ https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
+ n_iter_i = _check_optimize_result(
+
+
+
+
+
Out[31]:
+
+
{'KNN': 0.6885245901639344,
+ 'Logistic Regression': 0.8852459016393442,
+ 'Random Forest': 0.8360655737704918}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[34]:
+
+
[1.0,
+ 0.8099173553719008,
+ 0.7727272727272727,
+ 0.743801652892562,
+ 0.7603305785123967,
+ 0.7520661157024794,
+ 0.743801652892562,
+ 0.7231404958677686,
+ 0.71900826446281,
+ 0.6942148760330579,
+ 0.7272727272727273,
+ 0.6983471074380165,
+ 0.6900826446280992,
+ 0.6942148760330579,
+ 0.6859504132231405,
+ 0.6735537190082644,
+ 0.6859504132231405,
+ 0.6652892561983471,
+ 0.6818181818181818,
+ 0.6694214876033058]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Maximum KNN score on the test data: 75.41%
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Fitting 5 folds for each of 20 candidates, totalling 100 fits
+CPU times: user 160 ms, sys: 7.51 ms, total: 168 ms
+Wall time: 193 ms
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[39]:
+
+
{'solver': 'liblinear', 'C': np.float64(0.23357214690901212)}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Fitting 5 folds for each of 20 candidates, totalling 100 fits
+CPU times: user 21.6 s, sys: 144 ms, total: 21.8 s
+Wall time: 22.1 s
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[50]:
+
+
{'n_estimators': np.int64(210),
+ 'min_samples_split': np.int64(4),
+ 'min_samples_leaf': np.int64(19),
+ 'max_depth': 3}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Fitting 5 folds for each of 20 candidates, totalling 100 fits
+CPU times: user 161 ms, sys: 2.41 ms, total: 163 ms
+Wall time: 212 ms
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[44]:
+
+
{'C': np.float64(0.23357214690901212), 'solver': 'liblinear'}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[47]:
+
+
array([0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0,
+ 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[48]:
+
+
array([0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0,
+ 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
precision recall f1-score support
+
+ 0 0.89 0.86 0.88 29
+ 1 0.88 0.91 0.89 32
+
+ accuracy 0.89 61
+ macro avg 0.89 0.88 0.88 61
+weighted avg 0.89 0.89 0.89 61
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[52]:
+
+
{'C': np.float64(0.23357214690901212), 'solver': 'liblinear'}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
CPU times: user 9.91 ms, sys: 1.35 ms, total: 11.3 ms
+Wall time: 9.75 ms
+
+
+
+
+
Out[54]:
+
+
array([0.81967213, 0.90163934, 0.8852459 , 0.88333333, 0.75 ])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[55]:
+
+
np.float64(0.8479781420765027)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[56]:
+
+
np.float64(0.8215873015873015)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[57]:
+
+
np.float64(0.9272727272727274)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[58]:
+
+
np.float64(0.8705403543192143)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[61]:
+
+
array([[ 0.00369922, -0.90424094, 0.67472825, -0.0116134 , -0.00170364,
+ 0.04787688, 0.33490202, 0.02472938, -0.6312041 , -0.57590972,
+ 0.47095153, -0.65165346, -0.69984212]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[62]:
+
+
{'age': np.float64(0.0036992219987868977),
+ 'sex': np.float64(-0.9042409356586161),
+ 'cp': np.float64(0.6747282473934053),
+ 'trestbps': np.float64(-0.011613399733807518),
+ 'chol': np.float64(-0.0017036437157196944),
+ 'fbs': np.float64(0.0478768767697894),
+ 'restecg': np.float64(0.3349020243959257),
+ 'thalach': np.float64(0.02472938207178759),
+ 'exang': np.float64(-0.6312040952883138),
+ 'oldpeak': np.float64(-0.575909718275565),
+ 'slope': np.float64(0.4709515257844554),
+ 'ca': np.float64(-0.6516534575992304),
+ 'thal': np.float64(-0.6998421177365038)}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[81]:
+
+
+
+
+
+
+| target |
+0 |
+1 |
+
+
+| sex |
+ |
+ |
+
+
+
+
+| 0 |
+24 |
+72 |
+
+
+| 1 |
+114 |
+93 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[82]:
+
+
+
+
+
+
+| target |
+0 |
+1 |
+
+
+| slope |
+ |
+ |
+
+
+
+
+| 0 |
+12 |
+9 |
+
+
+| 1 |
+91 |
+49 |
+
+
+| 2 |
+35 |
+107 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+Welcome to the Zero to Mastery Data Science and Machine Learning Bootcamp!
+This webpage contains all of the materials for the Zero to Mastery Data Science and Machine Learning Bootcamp.
+Quick Links
+
+Contents
+The following contents are listed in suggested chronological order.
+But feel free to mix in match in anyway you feel fit.
+
+
+
+| Section |
+Resource |
+Description |
+
+
+
+
+| 00 |
+A 6 step framework for approaching machine learning projects |
+A guideline for different kinds of machine learning projects and how to break them down into smaller steps. |
+
+
+| 01 |
+Introduction to NumPy |
+NumPy stands for Numerical Python. It's one of the most used Python libraries for numerical processing (which is what much of data science and machine learning is). |
+
+
+| 02 |
+Introduction to pandas |
+pandas is a Python library for manipulating and analysing data. You can imagine pandas as a programmatic form of an Excel spreadsheet. |
+
+
+| 03 |
+Introduction to Matplotlib |
+Matplotlib helps to visualize data. You can create plots and graphs programmatically based on various data sources. |
+
+
+| 04 |
+Introduction to Scikit-Learn |
+Scikit-Learn or sklearn is full of data processing techniques as well as pre-built machine learning algorithms for many different tasks. |
+
+
+| 05 |
+Milestone Project 1: End-to-end Heart Disease Classification |
+Here we'll put together everything we've gone through in the previous sections to create a machine learning model that is capable of classifying if someone has heart disease or not based on their health characteristics. We'll start with a raw dataset and work through performing an exploratory data analysis (EDA) on it before trying out several different machine learning models to see which performs best. |
+
+
+| 06 |
+Introduction to TensorFlow/Keras and Deep Learning |
+TensorFlow/Keras are deep learning frameworks written in Python. Originally created by Google and are now open-source. These frameworks allow you to build and train neural networks, one of the most powerful kinds of machine learning models. In this section we'll learn about deep learning and TensorFlow/Keras by building Dog Vision 🐶👁️, a neural network to identify dog breeds in images. |
+
+
+| 07 |
+Communicating your work |
+One of the most important parts of machine learning and any software project is communicating what you've found/done. This module takes the learnings from the previous sections and gives tips and tricks on how you can communicate your work to others. |
+
+
+
+If you have any questions, leave an issue/discussion on the course GitHub.
+Author
+Daniel Bourke
+Last update: 24 September 2024
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Last updated: 2024-09-06 13:12:51.657220
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
matplotlib version: 3.9.2
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[13]:
+
+
(matplotlib.figure.Figure, matplotlib.axes._axes.Axes)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[16]:
+
+
array([0. , 0.1010101 , 0.2020202 , 0.3030303 , 0.4040404 ,
+ 0.50505051, 0.60606061, 0.70707071, 0.80808081, 0.90909091])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[28]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+$4,000.00 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+$5,000.00 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+$7,000.00 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+$22,000.00 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+$3,500.00 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+$4,500.00 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+$7,500.00 |
+
+
+| 7 |
+Honda |
+Blue |
+54738 |
+4 |
+$7,000.00 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+$6,250.00 |
+
+
+| 9 |
+Nissan |
+White |
+31600 |
+4 |
+$9,700.00 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[29]:
+
+
2025-01-01 1.724020
+2025-01-02 -0.530374
+2025-01-03 2.247190
+2025-01-04 0.077367
+2025-01-05 -1.035777
+ ...
+2027-09-23 -1.467224
+2027-09-24 -0.588671
+2027-09-25 -0.394004
+2027-09-26 1.327045
+2027-09-27 -0.160190
+Freq: D, Length: 1000, dtype: float64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[30]:
+
+
2025-01-01 1.724020
+2025-01-02 1.193646
+2025-01-03 3.440836
+2025-01-04 3.518203
+2025-01-05 2.482426
+ ...
+2027-09-23 32.888806
+2027-09-24 32.300135
+2027-09-25 31.906130
+2027-09-26 33.233175
+2027-09-27 33.072985
+Freq: D, Length: 1000, dtype: float64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[32]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+400000 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+500000 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+700000 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+2200000 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+350000 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+450000 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+750000 |
+
+
+| 7 |
+Honda |
+Blue |
+54738 |
+4 |
+700000 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+625000 |
+
+
+| 9 |
+Nissan |
+White |
+31600 |
+4 |
+970000 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[33]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+4000 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+5000 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+7000 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+22000 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+3500 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+4500 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+7500 |
+
+
+| 7 |
+Honda |
+Blue |
+54738 |
+4 |
+7000 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+6250 |
+
+
+| 9 |
+Nissan |
+White |
+31600 |
+4 |
+9700 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[34]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+Sale Date |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+4000 |
+2024-01-01 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+5000 |
+2024-01-02 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+7000 |
+2024-01-03 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+22000 |
+2024-01-04 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+3500 |
+2024-01-05 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+4500 |
+2024-01-06 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+7500 |
+2024-01-07 |
+
+
+| 7 |
+Honda |
+Blue |
+54738 |
+4 |
+7000 |
+2024-01-08 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+6250 |
+2024-01-09 |
+
+
+| 9 |
+Nissan |
+White |
+31600 |
+4 |
+9700 |
+2024-01-10 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[35]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+Sale Date |
+Total Sales |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+4000 |
+2024-01-01 |
+4000 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+5000 |
+2024-01-02 |
+9000 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+7000 |
+2024-01-03 |
+16000 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+22000 |
+2024-01-04 |
+38000 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+3500 |
+2024-01-05 |
+41500 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+4500 |
+2024-01-06 |
+46000 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+7500 |
+2024-01-07 |
+53500 |
+
+
+| 7 |
+Honda |
+Blue |
+54738 |
+4 |
+7000 |
+2024-01-08 |
+60500 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+6250 |
+2024-01-09 |
+66750 |
+
+
+| 9 |
+Nissan |
+White |
+31600 |
+4 |
+9700 |
+2024-01-10 |
+76450 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[39]:
+
+
array([[0.63664747, 0.11886476, 0.96687683, 0.62490457],
+ [0.9623542 , 0.75100119, 0.08098382, 0.83857796],
+ [0.49430885, 0.00545069, 0.89374991, 0.99877205],
+ [0.89788013, 0.15844467, 0.50083739, 0.72846574],
+ [0.51719877, 0.00978263, 0.74440314, 0.70385373],
+ [0.17211921, 0.42804418, 0.16401737, 0.66153094],
+ [0.39768996, 0.00628579, 0.71681382, 0.83828817],
+ [0.75507146, 0.73571561, 0.30901804, 0.4720662 ],
+ [0.46070935, 0.93093698, 0.01335433, 0.91765471],
+ [0.77798775, 0.70517195, 0.05298553, 0.68972541]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[40]:
+
+
+
+
+
+
+ |
+a |
+b |
+c |
+d |
+
+
+
+
+| 0 |
+0.636647 |
+0.118865 |
+0.966877 |
+0.624905 |
+
+
+| 1 |
+0.962354 |
+0.751001 |
+0.080984 |
+0.838578 |
+
+
+| 2 |
+0.494309 |
+0.005451 |
+0.893750 |
+0.998772 |
+
+
+| 3 |
+0.897880 |
+0.158445 |
+0.500837 |
+0.728466 |
+
+
+| 4 |
+0.517199 |
+0.009783 |
+0.744403 |
+0.703854 |
+
+
+| 5 |
+0.172119 |
+0.428044 |
+0.164017 |
+0.661531 |
+
+
+| 6 |
+0.397690 |
+0.006286 |
+0.716814 |
+0.838288 |
+
+
+| 7 |
+0.755071 |
+0.735716 |
+0.309018 |
+0.472066 |
+
+
+| 8 |
+0.460709 |
+0.930937 |
+0.013354 |
+0.917655 |
+
+
+| 9 |
+0.777988 |
+0.705172 |
+0.052986 |
+0.689725 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[48]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+target |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+1 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+1 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[50]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+target |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+1 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+1 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[52]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+target |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+1 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 5 |
+57 |
+1 |
+0 |
+140 |
+192 |
+0 |
+1 |
+148 |
+0 |
+0.4 |
+1 |
+0 |
+1 |
+1 |
+
+
+| 6 |
+56 |
+0 |
+1 |
+140 |
+294 |
+0 |
+0 |
+153 |
+0 |
+1.3 |
+1 |
+0 |
+2 |
+1 |
+
+
+| ... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+
+
+| 297 |
+59 |
+1 |
+0 |
+164 |
+176 |
+1 |
+0 |
+90 |
+0 |
+1.0 |
+1 |
+2 |
+1 |
+0 |
+
+
+| 298 |
+57 |
+0 |
+0 |
+140 |
+241 |
+0 |
+1 |
+123 |
+1 |
+0.2 |
+1 |
+0 |
+3 |
+0 |
+
+
+| 300 |
+68 |
+1 |
+0 |
+144 |
+193 |
+1 |
+1 |
+141 |
+0 |
+3.4 |
+1 |
+2 |
+3 |
+0 |
+
+
+| 301 |
+57 |
+1 |
+0 |
+130 |
+131 |
+0 |
+1 |
+115 |
+1 |
+1.2 |
+1 |
+1 |
+3 |
+0 |
+
+
+| 302 |
+57 |
+0 |
+1 |
+130 |
+236 |
+0 |
+0 |
+174 |
+0 |
+0.0 |
+1 |
+1 |
+2 |
+0 |
+
+
+
+
208 rows × 14 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[60]:
+
+
['Solarize_Light2',
+ '_classic_test_patch',
+ '_mpl-gallery',
+ '_mpl-gallery-nogrid',
+ 'bmh',
+ 'classic',
+ 'dark_background',
+ 'fast',
+ 'fivethirtyeight',
+ 'ggplot',
+ 'grayscale',
+ 'seaborn-v0_8',
+ 'seaborn-v0_8-bright',
+ 'seaborn-v0_8-colorblind',
+ 'seaborn-v0_8-dark',
+ 'seaborn-v0_8-dark-palette',
+ 'seaborn-v0_8-darkgrid',
+ 'seaborn-v0_8-deep',
+ 'seaborn-v0_8-muted',
+ 'seaborn-v0_8-notebook',
+ 'seaborn-v0_8-paper',
+ 'seaborn-v0_8-pastel',
+ 'seaborn-v0_8-poster',
+ 'seaborn-v0_8-talk',
+ 'seaborn-v0_8-ticks',
+ 'seaborn-v0_8-white',
+ 'seaborn-v0_8-whitegrid',
+ 'tableau-colorblind10']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[72]:
+
+
array([[ 1.17212975, 0.46563975, -1.90589871, -1.19235958],
+ [-0.63717099, -0.08598952, -0.14465387, 0.54449588],
+ [-1.60294003, 0.96718789, -0.13203246, 0.37619322],
+ [-1.08186882, -1.7225243 , -1.91029832, -1.42247578],
+ [-0.22936709, 1.79289551, 0.24236151, -0.11114891],
+ [-0.22966661, -0.04768414, 0.74157096, -1.71206472],
+ [-0.15221366, -0.34325158, 0.96609502, -1.03521241],
+ [ 1.09157697, -0.77361491, 0.35805583, 0.91628358],
+ [ 0.15352594, -1.22128756, -0.45763768, -1.3302614 ],
+ [-0.86535615, -0.4931282 , -0.43404157, 0.55973627]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[73]:
+
+
+
+
+
+
+ |
+a |
+b |
+c |
+d |
+
+
+
+
+| 0 |
+1.172130 |
+0.465640 |
+-1.905899 |
+-1.192360 |
+
+
+| 1 |
+-0.637171 |
+-0.085990 |
+-0.144654 |
+0.544496 |
+
+
+| 2 |
+-1.602940 |
+0.967188 |
+-0.132032 |
+0.376193 |
+
+
+| 3 |
+-1.081869 |
+-1.722524 |
+-1.910298 |
+-1.422476 |
+
+
+| 4 |
+-0.229367 |
+1.792896 |
+0.242362 |
+-0.111149 |
+
+
+| 5 |
+-0.229667 |
+-0.047684 |
+0.741571 |
+-1.712065 |
+
+
+| 6 |
+-0.152214 |
+-0.343252 |
+0.966095 |
+-1.035212 |
+
+
+| 7 |
+1.091577 |
+-0.773615 |
+0.358056 |
+0.916284 |
+
+
+| 8 |
+0.153526 |
+-1.221288 |
+-0.457638 |
+-1.330261 |
+
+
+| 9 |
+-0.865356 |
+-0.493128 |
+-0.434042 |
+0.559736 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[74]:
+
+
matplotlib.axes._axes.Axes
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[82]:
+
+
{'eps': 'Encapsulated Postscript',
+ 'jpg': 'Joint Photographic Experts Group',
+ 'jpeg': 'Joint Photographic Experts Group',
+ 'pdf': 'Portable Document Format',
+ 'pgf': 'PGF code for LaTeX',
+ 'png': 'Portable Network Graphics',
+ 'ps': 'Postscript',
+ 'raw': 'Raw RGBA bitmap',
+ 'rgba': 'Raw RGBA bitmap',
+ 'svg': 'Scalable Vector Graphics',
+ 'svgz': 'Scalable Vector Graphics',
+ 'tif': 'Tagged Image File Format',
+ 'tiff': 'Tagged Image File Format',
+ 'webp': 'WebP Image Format'}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[83]:
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Last updated: 2024-09-05 13:15:36.894029
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[4]:
+
+
((3,), 1, dtype('int64'), 3, numpy.ndarray)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[5]:
+
+
((2, 3), 2, dtype('float64'), 6, numpy.ndarray)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[6]:
+
+
((2, 3, 3), 3, dtype('int64'), 18, numpy.ndarray)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[8]:
+
+
array([[1. , 2. , 3.3],
+ [4. , 5. , 6.5]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[9]:
+
+
array([[[ 1, 2, 3],
+ [ 4, 5, 6],
+ [ 7, 8, 9]],
+
+ [[10, 11, 12],
+ [13, 14, 15],
+ [16, 17, 18]]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[10]:
+
+
+
+
+
+
+ |
+a |
+b |
+c |
+
+
+
+
+| 0 |
+5 |
+8 |
+0 |
+
+
+| 1 |
+3 |
+3 |
+2 |
+
+
+| 2 |
+1 |
+6 |
+7 |
+
+
+| 3 |
+7 |
+3 |
+9 |
+
+
+| 4 |
+6 |
+6 |
+7 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[11]:
+
+
array([[1. , 2. , 3.3],
+ [4. , 5. , 6.5]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[12]:
+
+
+
+
+
+
+ |
+0 |
+1 |
+2 |
+
+
+
+
+| 0 |
+1.0 |
+2.0 |
+3.3 |
+
+
+| 1 |
+4.0 |
+5.0 |
+6.5 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[14]:
+
+
(array([1, 2, 3]), dtype('int64'))
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[15]:
+
+
array([[1., 1.],
+ [1., 1.],
+ [1., 1.],
+ [1., 1.],
+ [1., 1.],
+ [1., 1.],
+ [1., 1.],
+ [1., 1.],
+ [1., 1.],
+ [1., 1.]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[17]:
+
+
array([[1, 1],
+ [1, 1],
+ [1, 1],
+ [1, 1],
+ [1, 1],
+ [1, 1],
+ [1, 1],
+ [1, 1],
+ [1, 1],
+ [1, 1]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[18]:
+
+
array([[[0., 0., 0.],
+ [0., 0., 0.],
+ [0., 0., 0.]],
+
+ [[0., 0., 0.],
+ [0., 0., 0.],
+ [0., 0., 0.]],
+
+ [[0., 0., 0.],
+ [0., 0., 0.],
+ [0., 0., 0.]],
+
+ [[0., 0., 0.],
+ [0., 0., 0.],
+ [0., 0., 0.]],
+
+ [[0., 0., 0.],
+ [0., 0., 0.],
+ [0., 0., 0.]]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[20]:
+
+
array([0, 2, 4, 6, 8])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[21]:
+
+
array([[8, 7, 6],
+ [4, 2, 7],
+ [6, 0, 6],
+ [0, 8, 5],
+ [6, 2, 9]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[22]:
+
+
array([[0.47811645, 0.49437395, 0.09426995],
+ [0.80062461, 0.41609157, 0.45268566],
+ [0.24531914, 0.56982162, 0.36856519],
+ [0.32292926, 0.03760924, 0.13312765],
+ [0.66844485, 0.88781517, 0.21807957]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[23]:
+
+
array([[0.96868201, 0.87777028, 0.21900062],
+ [0.88225041, 0.73815918, 0.83321165],
+ [0.14038979, 0.79643185, 0.2741666 ],
+ [0.48166491, 0.74364069, 0.75385132],
+ [0.58920305, 0.43270563, 0.42922598]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[24]:
+
+
array([[0.90225603, 0.76253433, 0.84856067],
+ [0.8961939 , 0.37019149, 0.00568981],
+ [0.78797133, 0.07953581, 0.99870521],
+ [0.07481087, 0.74846133, 0.0788899 ],
+ [0.40156115, 0.80716411, 0.37204142]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[25]:
+
+
array([[0.80767414, 0.62863218, 0.32492877],
+ [0.71402148, 0.06601142, 0.16626604],
+ [0.81986587, 0.75875945, 0.73266779],
+ [0.4233863 , 0.52077358, 0.21571921],
+ [0.75862881, 0.65817717, 0.74667541]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[26]:
+
+
array([[5, 0, 3],
+ [3, 7, 9],
+ [3, 5, 2],
+ [4, 7, 6],
+ [8, 8, 1]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[27]:
+
+
array([[6, 7, 7],
+ [8, 1, 5],
+ [9, 8, 9],
+ [4, 3, 0],
+ [3, 5, 0]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[28]:
+
+
array([[5, 0, 3],
+ [3, 7, 9],
+ [3, 5, 2],
+ [4, 7, 6],
+ [8, 8, 1]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[29]:
+
+
+
+
+
+
+ |
+0 |
+1 |
+2 |
+
+
+
+
+| 0 |
+5 |
+0 |
+3 |
+
+
+| 1 |
+3 |
+7 |
+9 |
+
+
+| 2 |
+3 |
+5 |
+2 |
+
+
+| 3 |
+4 |
+7 |
+6 |
+
+
+| 4 |
+8 |
+8 |
+1 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[32]:
+
+
array([[1. , 2. , 3.3],
+ [4. , 5. , 6.5]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[33]:
+
+
array([[[ 1, 2, 3],
+ [ 4, 5, 6],
+ [ 7, 8, 9]],
+
+ [[10, 11, 12],
+ [13, 14, 15],
+ [16, 17, 18]]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[35]:
+
+
array([1. , 2. , 3.3])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[36]:
+
+
array([[1, 2, 3],
+ [4, 5, 6],
+ [7, 8, 9]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[37]:
+
+
array([4. , 5. , 6.5])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[38]:
+
+
array([[[ 1, 2],
+ [ 4, 5]],
+
+ [[10, 11],
+ [13, 14]]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[39]:
+
+
array([[[[6, 7, 7, 8, 1],
+ [5, 9, 8, 9, 4],
+ [3, 0, 3, 5, 0],
+ [2, 3, 8, 1, 3]],
+
+ [[3, 3, 7, 0, 1],
+ [9, 9, 0, 4, 7],
+ [3, 2, 7, 2, 0],
+ [0, 4, 5, 5, 6]],
+
+ [[8, 4, 1, 4, 9],
+ [8, 1, 1, 7, 9],
+ [9, 3, 6, 7, 2],
+ [0, 3, 5, 9, 4]]],
+
+
+ [[[4, 6, 4, 4, 3],
+ [4, 4, 8, 4, 3],
+ [7, 5, 5, 0, 1],
+ [5, 9, 3, 0, 5]],
+
+ [[0, 1, 2, 4, 2],
+ [0, 3, 2, 0, 7],
+ [5, 9, 0, 2, 7],
+ [2, 9, 2, 3, 3]],
+
+ [[2, 3, 4, 1, 2],
+ [9, 1, 4, 6, 8],
+ [2, 3, 0, 0, 6],
+ [0, 6, 3, 3, 8]]]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[41]:
+
+
array([[[[6, 7, 7, 8],
+ [5, 9, 8, 9],
+ [3, 0, 3, 5],
+ [2, 3, 8, 1]],
+
+ [[3, 3, 7, 0],
+ [9, 9, 0, 4],
+ [3, 2, 7, 2],
+ [0, 4, 5, 5]],
+
+ [[8, 4, 1, 4],
+ [8, 1, 1, 7],
+ [9, 3, 6, 7],
+ [0, 3, 5, 9]]],
+
+
+ [[[4, 6, 4, 4],
+ [4, 4, 8, 4],
+ [7, 5, 5, 0],
+ [5, 9, 3, 0]],
+
+ [[0, 1, 2, 4],
+ [0, 3, 2, 0],
+ [5, 9, 0, 2],
+ [2, 9, 2, 3]],
+
+ [[2, 3, 4, 1],
+ [9, 1, 4, 6],
+ [2, 3, 0, 0],
+ [0, 6, 3, 3]]]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[47]:
+
+
array([[ 1. , 4. , 9.9],
+ [ 4. , 10. , 19.5]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+Cell In[49], line 2
+ 1 # This will error as the arrays have a different number of dimensions (2, 3) vs. (2, 3, 3)
+----> 2 a2 * a3
+
+ValueError: operands could not be broadcast together with shapes (2,3) (2,3,3)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[50]:
+
+
array([[[ 1, 2, 3],
+ [ 4, 5, 6],
+ [ 7, 8, 9]],
+
+ [[10, 11, 12],
+ [13, 14, 15],
+ [16, 17, 18]]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[54]:
+
+
array([[1. , 2. , 3.3],
+ [4. , 5. , 6.5]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[55]:
+
+
array([[2. , 4. , 6.3],
+ [5. , 7. , 9.5]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[56]:
+
+
array([[3. , 4. , 5.3],
+ [6. , 7. , 8.5]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+Cell In[57], line 2
+ 1 # Raises an error because there's a shape mismatch (2, 3) vs. (2, 3, 3)
+----> 2 a2 + a3
+
+ValueError: operands could not be broadcast together with shapes (2,3) (2,3,3)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[59]:
+
+
array([[1., 1., 1.],
+ [4., 2., 2.]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[63]:
+
+
array([0. , 0.69314718, 1.09861229])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[64]:
+
+
array([ 2.71828183, 7.3890561 , 20.08553692])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[67]:
+
+
(100000, numpy.ndarray)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
3.93 ms ± 145 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
+20.5 μs ± 698 ns per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[70]:
+
+
[8, 9, 1, 0, 0, 6, 2, 8, 6, 3]
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
419 μs ± 6.74 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
+2.72 ms ± 118 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[72]:
+
+
array([[1. , 2. , 3.3],
+ [4. , 5. , 6.5]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[73]:
+
+
np.float64(3.6333333333333333)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[76]:
+
+
np.float64(1.8226964152656422)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[77]:
+
+
np.float64(3.3222222222222224)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[78]:
+
+
np.float64(1.8226964152656422)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[79]:
+
+
(np.float64(4296133.472222221), np.float64(8.0))
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[80]:
+
+
(np.float64(2072.711623024829), np.float64(2.8284271247461903))
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[81]:
+
+
np.float64(2072.711623024829)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[84]:
+
+
array([[1. , 2. , 3.3],
+ [4. , 5. , 6.5]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+Cell In[86], line 1
+----> 1 a2 + a3
+
+ValueError: operands could not be broadcast together with shapes (2,3) (2,3,3)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[87]:
+
+
array([[[ 2. , 3. , 4. ],
+ [ 6. , 7. , 8. ],
+ [10.3, 11.3, 12.3]],
+
+ [[14. , 15. , 16. ],
+ [18. , 19. , 20. ],
+ [22.5, 23.5, 24.5]]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[89]:
+
+
array([[1. , 4. ],
+ [2. , 5. ],
+ [3.3, 6.5]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[90]:
+
+
array([[1. , 4. ],
+ [2. , 5. ],
+ [3.3, 6.5]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[92]:
+
+
array([[[0.59816399, 0.17370251, 0.49752936],
+ [0.51231935, 0.41529741, 0.44150892],
+ [0.96844105, 0.23242417, 0.90336451]],
+
+ [[0.35172075, 0.56481088, 0.57771134],
+ [0.73115238, 0.88762934, 0.37368847],
+ [0.35104994, 0.11873224, 0.72324236]],
+
+ [[0.93202688, 0.09600718, 0.4330638 ],
+ [0.71979707, 0.06689016, 0.20815443],
+ [0.55415679, 0.08416165, 0.88953996]],
+
+ [[0.00301345, 0.30163886, 0.12337636],
+ [0.13435611, 0.51987339, 0.05418991],
+ [0.11426417, 0.19005404, 0.61364183]],
+
+ [[0.23385887, 0.13555752, 0.32546415],
+ [0.81922614, 0.94551446, 0.12975713],
+ [0.35431267, 0.37758386, 0.07987885]]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[94]:
+
+
array([[[0.59816399, 0.35172075, 0.93202688, 0.00301345, 0.23385887],
+ [0.51231935, 0.73115238, 0.71979707, 0.13435611, 0.81922614],
+ [0.96844105, 0.35104994, 0.55415679, 0.11426417, 0.35431267]],
+
+ [[0.17370251, 0.56481088, 0.09600718, 0.30163886, 0.13555752],
+ [0.41529741, 0.88762934, 0.06689016, 0.51987339, 0.94551446],
+ [0.23242417, 0.11873224, 0.08416165, 0.19005404, 0.37758386]],
+
+ [[0.49752936, 0.57771134, 0.4330638 , 0.12337636, 0.32546415],
+ [0.44150892, 0.37368847, 0.20815443, 0.05418991, 0.12975713],
+ [0.90336451, 0.72324236, 0.88953996, 0.61364183, 0.07987885]]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[97]:
+
+
array([[[ True, True, True, True, True],
+ [ True, True, True, True, True],
+ [ True, True, True, True, True]],
+
+ [[ True, True, True, True, True],
+ [ True, True, True, True, True],
+ [ True, True, True, True, True]],
+
+ [[ True, True, True, True, True],
+ [ True, True, True, True, True],
+ [ True, True, True, True, True]]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[99]:
+
+
array([[5, 0, 3],
+ [3, 7, 9],
+ [3, 5, 2]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[100]:
+
+
array([[4, 7],
+ [6, 8],
+ [8, 1]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[101]:
+
+
array([[ 44, 38],
+ [126, 86],
+ [ 58, 63]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[102]:
+
+
array([[ 44, 38],
+ [126, 86],
+ [ 58, 63]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[103]:
+
+
array([[5, 0, 3],
+ [3, 7, 9],
+ [3, 5, 2],
+ [4, 7, 6]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[104]:
+
+
array([[8, 8, 1],
+ [6, 7, 7],
+ [8, 1, 5],
+ [9, 8, 9]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+Cell In[105], line 2
+ 1 # This will fail as the inner dimensions of the matrices do not match
+----> 2 np.dot(mat3, mat4)
+
+ValueError: shapes (4,3) and (4,3) not aligned: 3 (dim 1) != 4 (dim 0)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[107]:
+
+
array([[118, 96, 77],
+ [145, 110, 137],
+ [148, 137, 130]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[108]:
+
+
array([[40, 0, 3],
+ [18, 49, 63],
+ [24, 5, 10],
+ [36, 56, 54]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[109]:
+
+
array([[12, 15, 0],
+ [ 3, 3, 7],
+ [ 9, 19, 18],
+ [ 4, 6, 12],
+ [ 1, 6, 7]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[110]:
+
+
+
+
+
+
+ |
+Almond butter |
+Peanut butter |
+Cashew butter |
+
+
+
+
+| Mon |
+12 |
+15 |
+0 |
+
+
+| Tues |
+3 |
+3 |
+7 |
+
+
+| Wed |
+9 |
+19 |
+18 |
+
+
+| Thurs |
+4 |
+6 |
+12 |
+
+
+| Fri |
+1 |
+6 |
+7 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+Cell In[114], line 2
+ 1 # Find the total amount of sales for a whole day
+----> 2 total_sales = prices.dot(sales_amounts)
+ 3 total_sales
+
+ValueError: shapes (3,) and (5,3) not aligned: 3 (dim 0) != 5 (dim 0)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[117]:
+
+
array([240, 138, 458, 232, 142])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[119]:
+
+
+
+
+
+
+ |
+Mon |
+Tues |
+Wed |
+Thurs |
+Fri |
+
+
+
+
+| Price |
+240 |
+138 |
+458 |
+232 |
+142 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[120]:
+
+
+
+
+
+
+ |
+Almond butter |
+Peanut butter |
+Cashew butter |
+Total |
+
+
+
+
+| Mon |
+12 |
+15 |
+0 |
+240 |
+
+
+| Tues |
+3 |
+3 |
+7 |
+138 |
+
+
+| Wed |
+9 |
+19 |
+18 |
+458 |
+
+
+| Thurs |
+4 |
+6 |
+12 |
+232 |
+
+
+| Fri |
+1 |
+6 |
+7 |
+142 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[122]:
+
+
array([[1. , 2. , 3.3],
+ [4. , 5. , 6.5]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[123]:
+
+
array([[False, False, False],
+ [False, False, False]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[124]:
+
+
array([[ True, True, False],
+ [False, False, False]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[125]:
+
+
array([False, False, False])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[126]:
+
+
array([ True, True, True])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[127]:
+
+
array([[ True, True, False],
+ [False, False, False]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[128]:
+
+
array([[8, 7, 6],
+ [4, 2, 7],
+ [6, 0, 6],
+ [0, 8, 5],
+ [6, 2, 9]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[129]:
+
+
array([[6, 7, 8],
+ [2, 4, 7],
+ [0, 6, 6],
+ [0, 5, 8],
+ [2, 6, 9]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[130]:
+
+
array([[2, 1, 0],
+ [1, 0, 2],
+ [1, 0, 2],
+ [0, 2, 1],
+ [1, 0, 2]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[134]:
+
+
array([[8, 7, 6],
+ [4, 2, 7],
+ [6, 0, 6],
+ [0, 8, 5],
+ [6, 2, 9]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[135]:
+
+
array([0, 2, 0, 1, 2])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
<class 'numpy.ndarray'>
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[139]:
+
+
array([[[14, 27, 17],
+ [14, 27, 17],
+ [12, 28, 17],
+ ...,
+ [42, 36, 24],
+ [42, 35, 25],
+ [41, 34, 24]],
+
+ [[14, 27, 17],
+ [14, 27, 17],
+ [12, 28, 17],
+ ...,
+ [42, 36, 24],
+ [42, 35, 25],
+ [42, 35, 25]],
+
+ [[13, 26, 16],
+ [14, 27, 17],
+ [12, 28, 17],
+ ...,
+ [42, 36, 24],
+ [42, 35, 25],
+ [42, 35, 25]],
+
+ ...,
+
+ [[47, 32, 27],
+ [48, 33, 28],
+ [48, 33, 26],
+ ...,
+ [ 6, 6, 8],
+ [ 6, 6, 8],
+ [ 6, 6, 8]],
+
+ [[39, 24, 17],
+ [40, 25, 18],
+ [42, 27, 20],
+ ...,
+ [ 6, 6, 8],
+ [ 6, 6, 8],
+ [ 6, 6, 8]],
+
+ [[32, 17, 10],
+ [33, 18, 11],
+ [36, 21, 14],
+ ...,
+ [ 6, 6, 8],
+ [ 6, 6, 8],
+ [ 6, 6, 8]]], dtype=uint8)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[143]:
+
+
array([[[0.70980394, 0.80784315, 0.88235295, 1. ],
+ [0.72156864, 0.8117647 , 0.8862745 , 1. ],
+ [0.7411765 , 0.8156863 , 0.8862745 , 1. ],
+ ...,
+ [0.49803922, 0.6862745 , 0.8392157 , 1. ],
+ [0.49411765, 0.68235296, 0.8392157 , 1. ],
+ [0.49411765, 0.68235296, 0.8352941 , 1. ]],
+
+ [[0.69411767, 0.8039216 , 0.8862745 , 1. ],
+ [0.7019608 , 0.8039216 , 0.88235295, 1. ],
+ [0.7058824 , 0.80784315, 0.88235295, 1. ],
+ ...,
+ [0.5019608 , 0.6862745 , 0.84705883, 1. ],
+ [0.49411765, 0.68235296, 0.84313726, 1. ],
+ [0.49411765, 0.68235296, 0.8392157 , 1. ]],
+
+ [[0.6901961 , 0.8 , 0.88235295, 1. ],
+ [0.69803923, 0.8039216 , 0.88235295, 1. ],
+ [0.7058824 , 0.80784315, 0.88235295, 1. ],
+ ...,
+ [0.5019608 , 0.6862745 , 0.84705883, 1. ],
+ [0.49803922, 0.6862745 , 0.84313726, 1. ],
+ [0.49803922, 0.6862745 , 0.84313726, 1. ]],
+
+ ...,
+
+ [[0.9098039 , 0.81960785, 0.654902 , 1. ],
+ [0.8352941 , 0.7490196 , 0.6509804 , 1. ],
+ [0.72156864, 0.6313726 , 0.5372549 , 1. ],
+ ...,
+ [0.01568628, 0.07058824, 0.02352941, 1. ],
+ [0.03921569, 0.09411765, 0.03529412, 1. ],
+ [0.03921569, 0.09019608, 0.05490196, 1. ]],
+
+ [[0.9137255 , 0.83137256, 0.6784314 , 1. ],
+ [0.8117647 , 0.7294118 , 0.627451 , 1. ],
+ [0.65882355, 0.5686275 , 0.47843137, 1. ],
+ ...,
+ [0.00392157, 0.05490196, 0.03529412, 1. ],
+ [0.03137255, 0.09019608, 0.05490196, 1. ],
+ [0.04705882, 0.10588235, 0.06666667, 1. ]],
+
+ [[0.9137255 , 0.83137256, 0.68235296, 1. ],
+ [0.76862746, 0.68235296, 0.5882353 , 1. ],
+ [0.59607846, 0.5058824 , 0.44313726, 1. ],
+ ...,
+ [0.03921569, 0.10196079, 0.07058824, 1. ],
+ [0.02745098, 0.08235294, 0.05882353, 1. ],
+ [0.05098039, 0.11372549, 0.07058824, 1. ]]], dtype=float32)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Last updated: 2024-09-04 16:09:35.139163
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
pandas version: 2.2.2
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[3]:
+
+
0 BMW
+1 Toyota
+2 Honda
+dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[4]:
+
+
0 Blue
+1 Red
+2 White
+dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[5]:
+
+
+
+
+
+
+ |
+Car type |
+Colour |
+
+
+
+
+| 0 |
+BMW |
+Blue |
+
+
+| 1 |
+Toyota |
+Red |
+
+
+| 2 |
+Honda |
+White |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[7]:
+
+
+
+
+
+
+ |
+Foods |
+Price |
+
+
+
+
+| 0 |
+Almond butter |
+9 |
+
+
+| 1 |
+Eggs |
+6 |
+
+
+| 2 |
+Avocado |
+2 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[8]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+$4,000.00 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+$5,000.00 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+$7,000.00 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+$22,000.00 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+$3,500.00 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+$4,500.00 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+$7,500.00 |
+
+
+| 7 |
+Honda |
+Blue |
+54738 |
+4 |
+$7,000.00 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+$6,250.00 |
+
+
+| 9 |
+Nissan |
+White |
+31600 |
+4 |
+$9,700.00 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[9]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+$4,000.00 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+$5,000.00 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+$7,000.00 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+$22,000.00 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+$3,500.00 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+$4,500.00 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+$7,500.00 |
+
+
+| 7 |
+Honda |
+Blue |
+54738 |
+4 |
+$7,000.00 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+$6,250.00 |
+
+
+| 9 |
+Nissan |
+White |
+31600 |
+4 |
+$9,700.00 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[12]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+target |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+1 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+1 |
+
+
+| ... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+
+
+| 298 |
+57 |
+0 |
+0 |
+140 |
+241 |
+0 |
+1 |
+123 |
+1 |
+0.2 |
+1 |
+0 |
+3 |
+0 |
+
+
+| 299 |
+45 |
+1 |
+3 |
+110 |
+264 |
+0 |
+1 |
+132 |
+0 |
+1.2 |
+1 |
+0 |
+3 |
+0 |
+
+
+| 300 |
+68 |
+1 |
+0 |
+144 |
+193 |
+1 |
+1 |
+141 |
+0 |
+3.4 |
+1 |
+2 |
+3 |
+0 |
+
+
+| 301 |
+57 |
+1 |
+0 |
+130 |
+131 |
+0 |
+1 |
+115 |
+1 |
+1.2 |
+1 |
+1 |
+3 |
+0 |
+
+
+| 302 |
+57 |
+0 |
+1 |
+130 |
+236 |
+0 |
+0 |
+174 |
+0 |
+0.0 |
+1 |
+1 |
+2 |
+0 |
+
+
+
+
303 rows × 14 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[14]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+$4,000.00 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+$5,000.00 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+$7,000.00 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+$22,000.00 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+$3,500.00 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+$4,500.00 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+$7,500.00 |
+
+
+| 7 |
+Honda |
+Blue |
+54738 |
+4 |
+$7,000.00 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+$6,250.00 |
+
+
+| 9 |
+Nissan |
+White |
+31600 |
+4 |
+$9,700.00 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[15]:
+
+
Make object
+Colour object
+Odometer (KM) int64
+Doors int64
+Price object
+dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[16]:
+
+
+
+
+
+
+ |
+Odometer (KM) |
+Doors |
+
+
+
+
+| count |
+10.000000 |
+10.000000 |
+
+
+| mean |
+78601.400000 |
+4.000000 |
+
+
+| std |
+61983.471735 |
+0.471405 |
+
+
+| min |
+11179.000000 |
+3.000000 |
+
+
+| 25% |
+35836.250000 |
+4.000000 |
+
+
+| 50% |
+57369.000000 |
+4.000000 |
+
+
+| 75% |
+96384.500000 |
+4.000000 |
+
+
+| max |
+213095.000000 |
+5.000000 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
<class 'pandas.core.frame.DataFrame'>
+RangeIndex: 10 entries, 0 to 9
+Data columns (total 5 columns):
+ # Column Non-Null Count Dtype
+--- ------ -------------- -----
+ 0 Make 10 non-null object
+ 1 Colour 10 non-null object
+ 2 Odometer (KM) 10 non-null int64
+ 3 Doors 10 non-null int64
+ 4 Price 10 non-null object
+dtypes: int64(2), object(3)
+memory usage: 532.0+ bytes
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[18]:
+
+
Odometer (KM) 78601.4
+Doors 4.0
+dtype: float64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[19]:
+
+
np.float64(5916.666666666667)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[20]:
+
+
Make ToyotaHondaToyotaBMWNissanToyotaHondaHondaToyo...
+Colour WhiteRedBlueBlackWhiteGreenBlueBlueWhiteWhite
+Odometer (KM) 786014
+Doors 40
+Price $4,000.00$5,000.00$7,000.00$22,000.00$3,500.00...
+dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[21]:
+
+
Odometer (KM) 786014
+Doors 40
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[23]:
+
+
Index(['Make', 'Colour', 'Odometer (KM)', 'Doors', 'Price'], dtype='object')
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[25]:
+
+
RangeIndex(start=0, stop=10, step=1)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[27]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+$4,000.00 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+$5,000.00 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+$7,000.00 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+$22,000.00 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+$3,500.00 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[28]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+$4,000.00 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+$5,000.00 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+$7,000.00 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+$22,000.00 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+$3,500.00 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+$4,500.00 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+$7,500.00 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[29]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+$4,500.00 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+$7,500.00 |
+
+
+| 7 |
+Honda |
+Blue |
+54738 |
+4 |
+$7,000.00 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+$6,250.00 |
+
+
+| 9 |
+Nissan |
+White |
+31600 |
+4 |
+$9,700.00 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[30]:
+
+
0 cat
+3 dog
+9 bird
+8 snake
+67 ox
+3 lion
+dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[31]:
+
+
3 dog
+3 lion
+dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[33]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+$4,000.00 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+$5,000.00 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+$7,000.00 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+$22,000.00 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+$3,500.00 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+$4,500.00 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+$7,500.00 |
+
+
+| 7 |
+Honda |
+Blue |
+54738 |
+4 |
+$7,000.00 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+$6,250.00 |
+
+
+| 9 |
+Nissan |
+White |
+31600 |
+4 |
+$9,700.00 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[34]:
+
+
Make BMW
+Colour Black
+Odometer (KM) 11179
+Doors 5
+Price $22,000.00
+Name: 3, dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[35]:
+
+
0 cat
+3 dog
+9 bird
+8 snake
+67 ox
+3 lion
+dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[37]:
+
+
Make BMW
+Colour Black
+Odometer (KM) 11179
+Doors 5
+Price $22,000.00
+Name: 3, dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[38]:
+
+
0 cat
+3 dog
+9 bird
+dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[39]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+$4,000.00 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+$5,000.00 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+$7,000.00 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+$22,000.00 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[40]:
+
+
0 White
+1 Red
+2 Blue
+3 Black
+4 White
+5 Green
+6 Blue
+7 Blue
+8 White
+9 White
+Name: Colour, dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[41]:
+
+
0 Toyota
+1 Honda
+2 Toyota
+3 BMW
+4 Nissan
+5 Toyota
+6 Honda
+7 Honda
+8 Toyota
+9 Nissan
+Name: Make, dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[42]:
+
+
0 White
+1 Red
+2 Blue
+3 Black
+4 White
+5 Green
+6 Blue
+7 Blue
+8 White
+9 White
+Name: Colour, dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[43]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+$4,000.00 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+$3,500.00 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[44]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+$4,000.00 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+$7,000.00 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+$4,500.00 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+$6,250.00 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[45]:
+
+
+
+
+
+
+| Doors |
+3 |
+4 |
+5 |
+
+
+| Make |
+ |
+ |
+ |
+
+
+
+
+| BMW |
+0 |
+0 |
+1 |
+
+
+| Honda |
+0 |
+3 |
+0 |
+
+
+| Nissan |
+0 |
+2 |
+0 |
+
+
+| Toyota |
+1 |
+3 |
+0 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[46]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+$4,000.00 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+$5,000.00 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+$7,000.00 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+$22,000.00 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+$3,500.00 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+$4,500.00 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+$7,500.00 |
+
+
+| 7 |
+Honda |
+Blue |
+54738 |
+4 |
+$7,000.00 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+$6,250.00 |
+
+
+| 9 |
+Nissan |
+White |
+31600 |
+4 |
+$9,700.00 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[47]:
+
+
+
+
+
+
+ |
+Odometer (KM) |
+Doors |
+
+
+| Make |
+ |
+ |
+
+
+
+
+| BMW |
+11179.000000 |
+5.00 |
+
+
+| Honda |
+62778.333333 |
+4.00 |
+
+
+| Nissan |
+122347.500000 |
+4.00 |
+
+
+| Toyota |
+85451.250000 |
+3.75 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+TypeError Traceback (most recent call last)
+Cell In[56], line 1
+----> 1 car_sales["Price"].plot()
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/plotting/_core.py:1030, in PlotAccessor.__call__(self, *args, **kwargs)
+ 1027 label_name = label_kw or data.columns
+ 1028 data.columns = label_name
+-> 1030 return plot_backend.plot(data, kind=kind, **kwargs)
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/plotting/_matplotlib/__init__.py:71, in plot(data, kind, **kwargs)
+ 69 kwargs["ax"] = getattr(ax, "left_ax", ax)
+ 70 plot_obj = PLOT_CLASSES[kind](data, **kwargs)
+---> 71 plot_obj.generate()
+ 72 plot_obj.draw()
+ 73 return plot_obj.result
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/plotting/_matplotlib/core.py:499, in MPLPlot.generate(self)
+ 497 @final
+ 498 def generate(self) -> None:
+--> 499 self._compute_plot_data()
+ 500 fig = self.fig
+ 501 self._make_plot(fig)
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/plotting/_matplotlib/core.py:698, in MPLPlot._compute_plot_data(self)
+ 696 # no non-numeric frames or series allowed
+ 697 if is_empty:
+--> 698 raise TypeError("no numeric data to plot")
+ 700 self.data = numeric_data.apply(type(self)._convert_to_ndarray)
+
+TypeError: no numeric data to plot
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
<class 'pandas.core.frame.DataFrame'>
+RangeIndex: 10 entries, 0 to 9
+Data columns (total 5 columns):
+ # Column Non-Null Count Dtype
+--- ------ -------------- -----
+ 0 Make 10 non-null object
+ 1 Colour 10 non-null object
+ 2 Odometer (KM) 10 non-null int64
+ 3 Doors 10 non-null int64
+ 4 Price 10 non-null object
+dtypes: int64(2), object(3)
+memory usage: 532.0+ bytes
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[58]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+400000 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+500000 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+700000 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+2200000 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+350000 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+450000 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+750000 |
+
+
+| 7 |
+Honda |
+Blue |
+54738 |
+4 |
+700000 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+625000 |
+
+
+| 9 |
+Nissan |
+White |
+31600 |
+4 |
+970000 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[59]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+4000 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+5000 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+7000 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+22000 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+3500 |
+
+
+| 5 |
+Toyota |
+Green |
+99213 |
+4 |
+4500 |
+
+
+| 6 |
+Honda |
+Blue |
+45698 |
+4 |
+7500 |
+
+
+| 7 |
+Honda |
+Blue |
+54738 |
+4 |
+7000 |
+
+
+| 8 |
+Toyota |
+White |
+60000 |
+4 |
+6250 |
+
+
+| 9 |
+Nissan |
+White |
+31600 |
+4 |
+9700 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[60]:
+
+
Make object
+Colour object
+Odometer (KM) int64
+Doors int64
+Price int64
+dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[62]:
+
+
0 toyota
+1 honda
+2 toyota
+3 bmw
+4 nissan
+5 toyota
+6 honda
+7 honda
+8 toyota
+9 nissan
+Name: Make, dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[63]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043 |
+4 |
+4000 |
+
+
+| 1 |
+Honda |
+Red |
+87899 |
+4 |
+5000 |
+
+
+| 2 |
+Toyota |
+Blue |
+32549 |
+3 |
+7000 |
+
+
+| 3 |
+BMW |
+Black |
+11179 |
+5 |
+22000 |
+
+
+| 4 |
+Nissan |
+White |
+213095 |
+4 |
+3500 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[64]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+toyota |
+White |
+150043 |
+4 |
+4000 |
+
+
+| 1 |
+honda |
+Red |
+87899 |
+4 |
+5000 |
+
+
+| 2 |
+toyota |
+Blue |
+32549 |
+3 |
+7000 |
+
+
+| 3 |
+bmw |
+Black |
+11179 |
+5 |
+22000 |
+
+
+| 4 |
+nissan |
+White |
+213095 |
+4 |
+3500 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[65]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043.0 |
+4.0 |
+$4,000 |
+
+
+| 1 |
+Honda |
+Red |
+87899.0 |
+4.0 |
+$5,000 |
+
+
+| 2 |
+Toyota |
+Blue |
+NaN |
+3.0 |
+$7,000 |
+
+
+| 3 |
+BMW |
+Black |
+11179.0 |
+5.0 |
+$22,000 |
+
+
+| 4 |
+Nissan |
+White |
+213095.0 |
+4.0 |
+$3,500 |
+
+
+| 5 |
+Toyota |
+Green |
+NaN |
+4.0 |
+$4,500 |
+
+
+| 6 |
+Honda |
+NaN |
+NaN |
+4.0 |
+$7,500 |
+
+
+| 7 |
+Honda |
+Blue |
+NaN |
+4.0 |
+NaN |
+
+
+| 8 |
+Toyota |
+White |
+60000.0 |
+NaN |
+NaN |
+
+
+| 9 |
+NaN |
+White |
+31600.0 |
+4.0 |
+$9,700 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[66]:
+
+
0 150043.000000
+1 87899.000000
+2 92302.666667
+3 11179.000000
+4 213095.000000
+5 92302.666667
+6 92302.666667
+7 92302.666667
+8 60000.000000
+9 31600.000000
+Name: Odometer, dtype: float64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[67]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043.0 |
+4.0 |
+$4,000 |
+
+
+| 1 |
+Honda |
+Red |
+87899.0 |
+4.0 |
+$5,000 |
+
+
+| 2 |
+Toyota |
+Blue |
+NaN |
+3.0 |
+$7,000 |
+
+
+| 3 |
+BMW |
+Black |
+11179.0 |
+5.0 |
+$22,000 |
+
+
+| 4 |
+Nissan |
+White |
+213095.0 |
+4.0 |
+$3,500 |
+
+
+| 5 |
+Toyota |
+Green |
+NaN |
+4.0 |
+$4,500 |
+
+
+| 6 |
+Honda |
+NaN |
+NaN |
+4.0 |
+$7,500 |
+
+
+| 7 |
+Honda |
+Blue |
+NaN |
+4.0 |
+NaN |
+
+
+| 8 |
+Toyota |
+White |
+60000.0 |
+NaN |
+NaN |
+
+
+| 9 |
+NaN |
+White |
+31600.0 |
+4.0 |
+$9,700 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[69]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043.000000 |
+4.0 |
+$4,000 |
+
+
+| 1 |
+Honda |
+Red |
+87899.000000 |
+4.0 |
+$5,000 |
+
+
+| 2 |
+Toyota |
+Blue |
+92302.666667 |
+3.0 |
+$7,000 |
+
+
+| 3 |
+BMW |
+Black |
+11179.000000 |
+5.0 |
+$22,000 |
+
+
+| 4 |
+Nissan |
+White |
+213095.000000 |
+4.0 |
+$3,500 |
+
+
+| 5 |
+Toyota |
+Green |
+92302.666667 |
+4.0 |
+$4,500 |
+
+
+| 6 |
+Honda |
+NaN |
+92302.666667 |
+4.0 |
+$7,500 |
+
+
+| 7 |
+Honda |
+Blue |
+92302.666667 |
+4.0 |
+NaN |
+
+
+| 8 |
+Toyota |
+White |
+60000.000000 |
+NaN |
+NaN |
+
+
+| 9 |
+NaN |
+White |
+31600.000000 |
+4.0 |
+$9,700 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[70]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043.000000 |
+4.0 |
+$4,000 |
+
+
+| 1 |
+Honda |
+Red |
+87899.000000 |
+4.0 |
+$5,000 |
+
+
+| 2 |
+Toyota |
+Blue |
+92302.666667 |
+3.0 |
+$7,000 |
+
+
+| 3 |
+BMW |
+Black |
+11179.000000 |
+5.0 |
+$22,000 |
+
+
+| 4 |
+Nissan |
+White |
+213095.000000 |
+4.0 |
+$3,500 |
+
+
+| 5 |
+Toyota |
+Green |
+92302.666667 |
+4.0 |
+$4,500 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[71]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043.000000 |
+4.0 |
+$4,000 |
+
+
+| 1 |
+Honda |
+Red |
+87899.000000 |
+4.0 |
+$5,000 |
+
+
+| 2 |
+Toyota |
+Blue |
+92302.666667 |
+3.0 |
+$7,000 |
+
+
+| 3 |
+BMW |
+Black |
+11179.000000 |
+5.0 |
+$22,000 |
+
+
+| 4 |
+Nissan |
+White |
+213095.000000 |
+4.0 |
+$3,500 |
+
+
+| 5 |
+Toyota |
+Green |
+92302.666667 |
+4.0 |
+$4,500 |
+
+
+| 6 |
+Honda |
+NaN |
+92302.666667 |
+4.0 |
+$7,500 |
+
+
+| 7 |
+Honda |
+Blue |
+92302.666667 |
+4.0 |
+NaN |
+
+
+| 8 |
+Toyota |
+White |
+60000.000000 |
+NaN |
+NaN |
+
+
+| 9 |
+NaN |
+White |
+31600.000000 |
+4.0 |
+$9,700 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[73]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Toyota |
+White |
+150043.000000 |
+4.0 |
+$4,000 |
+
+
+| 1 |
+Honda |
+Red |
+87899.000000 |
+4.0 |
+$5,000 |
+
+
+| 2 |
+Toyota |
+Blue |
+92302.666667 |
+3.0 |
+$7,000 |
+
+
+| 3 |
+BMW |
+Black |
+11179.000000 |
+5.0 |
+$22,000 |
+
+
+| 4 |
+Nissan |
+White |
+213095.000000 |
+4.0 |
+$3,500 |
+
+
+| 5 |
+Toyota |
+Green |
+92302.666667 |
+4.0 |
+$4,500 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[74]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+Seats |
+
+
+
+
+| 0 |
+toyota |
+White |
+150043 |
+4 |
+4000 |
+5 |
+
+
+| 1 |
+honda |
+Red |
+87899 |
+4 |
+5000 |
+5 |
+
+
+| 2 |
+toyota |
+Blue |
+32549 |
+3 |
+7000 |
+5 |
+
+
+| 3 |
+bmw |
+Black |
+11179 |
+5 |
+22000 |
+5 |
+
+
+| 4 |
+nissan |
+White |
+213095 |
+4 |
+3500 |
+5 |
+
+
+| 5 |
+toyota |
+Green |
+99213 |
+4 |
+4500 |
+5 |
+
+
+| 6 |
+honda |
+Blue |
+45698 |
+4 |
+7500 |
+5 |
+
+
+| 7 |
+honda |
+Blue |
+54738 |
+4 |
+7000 |
+5 |
+
+
+| 8 |
+toyota |
+White |
+60000 |
+4 |
+6250 |
+5 |
+
+
+| 9 |
+nissan |
+White |
+31600 |
+4 |
+9700 |
+5 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[75]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+Seats |
+Engine Size |
+
+
+
+
+| 0 |
+toyota |
+White |
+150043 |
+4 |
+4000 |
+5 |
+1.3 |
+
+
+| 1 |
+honda |
+Red |
+87899 |
+4 |
+5000 |
+5 |
+2.0 |
+
+
+| 2 |
+toyota |
+Blue |
+32549 |
+3 |
+7000 |
+5 |
+3.0 |
+
+
+| 3 |
+bmw |
+Black |
+11179 |
+5 |
+22000 |
+5 |
+4.2 |
+
+
+| 4 |
+nissan |
+White |
+213095 |
+4 |
+3500 |
+5 |
+1.6 |
+
+
+| 5 |
+toyota |
+Green |
+99213 |
+4 |
+4500 |
+5 |
+1.0 |
+
+
+| 6 |
+honda |
+Blue |
+45698 |
+4 |
+7500 |
+5 |
+2.0 |
+
+
+| 7 |
+honda |
+Blue |
+54738 |
+4 |
+7000 |
+5 |
+2.3 |
+
+
+| 8 |
+toyota |
+White |
+60000 |
+4 |
+6250 |
+5 |
+2.0 |
+
+
+| 9 |
+nissan |
+White |
+31600 |
+4 |
+9700 |
+5 |
+3.0 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[76]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+Seats |
+Engine Size |
+Price per KM |
+
+
+
+
+| 0 |
+toyota |
+White |
+150043 |
+4 |
+4000 |
+5 |
+1.3 |
+0.026659 |
+
+
+| 1 |
+honda |
+Red |
+87899 |
+4 |
+5000 |
+5 |
+2.0 |
+0.056883 |
+
+
+| 2 |
+toyota |
+Blue |
+32549 |
+3 |
+7000 |
+5 |
+3.0 |
+0.215060 |
+
+
+| 3 |
+bmw |
+Black |
+11179 |
+5 |
+22000 |
+5 |
+4.2 |
+1.967976 |
+
+
+| 4 |
+nissan |
+White |
+213095 |
+4 |
+3500 |
+5 |
+1.6 |
+0.016425 |
+
+
+| 5 |
+toyota |
+Green |
+99213 |
+4 |
+4500 |
+5 |
+1.0 |
+0.045357 |
+
+
+| 6 |
+honda |
+Blue |
+45698 |
+4 |
+7500 |
+5 |
+2.0 |
+0.164121 |
+
+
+| 7 |
+honda |
+Blue |
+54738 |
+4 |
+7000 |
+5 |
+2.3 |
+0.127882 |
+
+
+| 8 |
+toyota |
+White |
+60000 |
+4 |
+6250 |
+5 |
+2.0 |
+0.104167 |
+
+
+| 9 |
+nissan |
+White |
+31600 |
+4 |
+9700 |
+5 |
+3.0 |
+0.306962 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[77]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+Seats |
+Engine Size |
+Price per KM |
+Number of wheels |
+
+
+
+
+| 0 |
+toyota |
+White |
+150043 |
+4 |
+4000 |
+5 |
+1.3 |
+0.026659 |
+4 |
+
+
+| 1 |
+honda |
+Red |
+87899 |
+4 |
+5000 |
+5 |
+2.0 |
+0.056883 |
+4 |
+
+
+| 2 |
+toyota |
+Blue |
+32549 |
+3 |
+7000 |
+5 |
+3.0 |
+0.215060 |
+4 |
+
+
+| 3 |
+bmw |
+Black |
+11179 |
+5 |
+22000 |
+5 |
+4.2 |
+1.967976 |
+4 |
+
+
+| 4 |
+nissan |
+White |
+213095 |
+4 |
+3500 |
+5 |
+1.6 |
+0.016425 |
+4 |
+
+
+| 5 |
+toyota |
+Green |
+99213 |
+4 |
+4500 |
+5 |
+1.0 |
+0.045357 |
+4 |
+
+
+| 6 |
+honda |
+Blue |
+45698 |
+4 |
+7500 |
+5 |
+2.0 |
+0.164121 |
+4 |
+
+
+| 7 |
+honda |
+Blue |
+54738 |
+4 |
+7000 |
+5 |
+2.3 |
+0.127882 |
+4 |
+
+
+| 8 |
+toyota |
+White |
+60000 |
+4 |
+6250 |
+5 |
+2.0 |
+0.104167 |
+4 |
+
+
+| 9 |
+nissan |
+White |
+31600 |
+4 |
+9700 |
+5 |
+3.0 |
+0.306962 |
+4 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[78]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+Seats |
+Engine Size |
+Price per KM |
+Number of wheels |
+Passed road safety |
+
+
+
+
+| 0 |
+toyota |
+White |
+150043 |
+4 |
+4000 |
+5 |
+1.3 |
+0.026659 |
+4 |
+True |
+
+
+| 1 |
+honda |
+Red |
+87899 |
+4 |
+5000 |
+5 |
+2.0 |
+0.056883 |
+4 |
+True |
+
+
+| 2 |
+toyota |
+Blue |
+32549 |
+3 |
+7000 |
+5 |
+3.0 |
+0.215060 |
+4 |
+True |
+
+
+| 3 |
+bmw |
+Black |
+11179 |
+5 |
+22000 |
+5 |
+4.2 |
+1.967976 |
+4 |
+True |
+
+
+| 4 |
+nissan |
+White |
+213095 |
+4 |
+3500 |
+5 |
+1.6 |
+0.016425 |
+4 |
+True |
+
+
+| 5 |
+toyota |
+Green |
+99213 |
+4 |
+4500 |
+5 |
+1.0 |
+0.045357 |
+4 |
+True |
+
+
+| 6 |
+honda |
+Blue |
+45698 |
+4 |
+7500 |
+5 |
+2.0 |
+0.164121 |
+4 |
+True |
+
+
+| 7 |
+honda |
+Blue |
+54738 |
+4 |
+7000 |
+5 |
+2.3 |
+0.127882 |
+4 |
+True |
+
+
+| 8 |
+toyota |
+White |
+60000 |
+4 |
+6250 |
+5 |
+2.0 |
+0.104167 |
+4 |
+True |
+
+
+| 9 |
+nissan |
+White |
+31600 |
+4 |
+9700 |
+5 |
+3.0 |
+0.306962 |
+4 |
+True |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[79]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+Seats |
+Engine Size |
+Number of wheels |
+Passed road safety |
+
+
+
+
+| 0 |
+toyota |
+White |
+150043 |
+4 |
+4000 |
+5 |
+1.3 |
+4 |
+True |
+
+
+| 1 |
+honda |
+Red |
+87899 |
+4 |
+5000 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 2 |
+toyota |
+Blue |
+32549 |
+3 |
+7000 |
+5 |
+3.0 |
+4 |
+True |
+
+
+| 3 |
+bmw |
+Black |
+11179 |
+5 |
+22000 |
+5 |
+4.2 |
+4 |
+True |
+
+
+| 4 |
+nissan |
+White |
+213095 |
+4 |
+3500 |
+5 |
+1.6 |
+4 |
+True |
+
+
+| 5 |
+toyota |
+Green |
+99213 |
+4 |
+4500 |
+5 |
+1.0 |
+4 |
+True |
+
+
+| 6 |
+honda |
+Blue |
+45698 |
+4 |
+7500 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 7 |
+honda |
+Blue |
+54738 |
+4 |
+7000 |
+5 |
+2.3 |
+4 |
+True |
+
+
+| 8 |
+toyota |
+White |
+60000 |
+4 |
+6250 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 9 |
+nissan |
+White |
+31600 |
+4 |
+9700 |
+5 |
+3.0 |
+4 |
+True |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[80]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+Seats |
+Engine Size |
+Number of wheels |
+Passed road safety |
+
+
+
+
+| 2 |
+toyota |
+Blue |
+32549 |
+3 |
+7000 |
+5 |
+3.0 |
+4 |
+True |
+
+
+| 4 |
+nissan |
+White |
+213095 |
+4 |
+3500 |
+5 |
+1.6 |
+4 |
+True |
+
+
+| 9 |
+nissan |
+White |
+31600 |
+4 |
+9700 |
+5 |
+3.0 |
+4 |
+True |
+
+
+| 1 |
+honda |
+Red |
+87899 |
+4 |
+5000 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 0 |
+toyota |
+White |
+150043 |
+4 |
+4000 |
+5 |
+1.3 |
+4 |
+True |
+
+
+| 8 |
+toyota |
+White |
+60000 |
+4 |
+6250 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 3 |
+bmw |
+Black |
+11179 |
+5 |
+22000 |
+5 |
+4.2 |
+4 |
+True |
+
+
+| 5 |
+toyota |
+Green |
+99213 |
+4 |
+4500 |
+5 |
+1.0 |
+4 |
+True |
+
+
+| 6 |
+honda |
+Blue |
+45698 |
+4 |
+7500 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 7 |
+honda |
+Blue |
+54738 |
+4 |
+7000 |
+5 |
+2.3 |
+4 |
+True |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[81]:
+
+
+
+
+
+
+ |
+index |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+Seats |
+Engine Size |
+Number of wheels |
+Passed road safety |
+
+
+
+
+| 0 |
+2 |
+toyota |
+Blue |
+32549 |
+3 |
+7000 |
+5 |
+3.0 |
+4 |
+True |
+
+
+| 1 |
+4 |
+nissan |
+White |
+213095 |
+4 |
+3500 |
+5 |
+1.6 |
+4 |
+True |
+
+
+| 2 |
+9 |
+nissan |
+White |
+31600 |
+4 |
+9700 |
+5 |
+3.0 |
+4 |
+True |
+
+
+| 3 |
+1 |
+honda |
+Red |
+87899 |
+4 |
+5000 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 4 |
+0 |
+toyota |
+White |
+150043 |
+4 |
+4000 |
+5 |
+1.3 |
+4 |
+True |
+
+
+| 5 |
+8 |
+toyota |
+White |
+60000 |
+4 |
+6250 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 6 |
+3 |
+bmw |
+Black |
+11179 |
+5 |
+22000 |
+5 |
+4.2 |
+4 |
+True |
+
+
+| 7 |
+5 |
+toyota |
+Green |
+99213 |
+4 |
+4500 |
+5 |
+1.0 |
+4 |
+True |
+
+
+| 8 |
+6 |
+honda |
+Blue |
+45698 |
+4 |
+7500 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 9 |
+7 |
+honda |
+Blue |
+54738 |
+4 |
+7000 |
+5 |
+2.3 |
+4 |
+True |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[82]:
+
+
0 93776.875
+1 54936.875
+2 20343.125
+3 6986.875
+4 133184.375
+5 62008.125
+6 28561.250
+7 34211.250
+8 37500.000
+9 19750.000
+Name: Odometer (KM), dtype: float64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[83]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+Seats |
+Engine Size |
+Number of wheels |
+Passed road safety |
+
+
+
+
+| 0 |
+toyota |
+White |
+150043 |
+4 |
+4000 |
+5 |
+1.3 |
+4 |
+True |
+
+
+| 1 |
+honda |
+Red |
+87899 |
+4 |
+5000 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 2 |
+toyota |
+Blue |
+32549 |
+3 |
+7000 |
+5 |
+3.0 |
+4 |
+True |
+
+
+| 3 |
+bmw |
+Black |
+11179 |
+5 |
+22000 |
+5 |
+4.2 |
+4 |
+True |
+
+
+| 4 |
+nissan |
+White |
+213095 |
+4 |
+3500 |
+5 |
+1.6 |
+4 |
+True |
+
+
+| 5 |
+toyota |
+Green |
+99213 |
+4 |
+4500 |
+5 |
+1.0 |
+4 |
+True |
+
+
+| 6 |
+honda |
+Blue |
+45698 |
+4 |
+7500 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 7 |
+honda |
+Blue |
+54738 |
+4 |
+7000 |
+5 |
+2.3 |
+4 |
+True |
+
+
+| 8 |
+toyota |
+White |
+60000 |
+4 |
+6250 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 9 |
+nissan |
+White |
+31600 |
+4 |
+9700 |
+5 |
+3.0 |
+4 |
+True |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[84]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+Seats |
+Engine Size |
+Number of wheels |
+Passed road safety |
+
+
+
+
+| 0 |
+toyota |
+White |
+93776.875 |
+4 |
+4000 |
+5 |
+1.3 |
+4 |
+True |
+
+
+| 1 |
+honda |
+Red |
+54936.875 |
+4 |
+5000 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 2 |
+toyota |
+Blue |
+20343.125 |
+3 |
+7000 |
+5 |
+3.0 |
+4 |
+True |
+
+
+| 3 |
+bmw |
+Black |
+6986.875 |
+5 |
+22000 |
+5 |
+4.2 |
+4 |
+True |
+
+
+| 4 |
+nissan |
+White |
+133184.375 |
+4 |
+3500 |
+5 |
+1.6 |
+4 |
+True |
+
+
+| 5 |
+toyota |
+Green |
+62008.125 |
+4 |
+4500 |
+5 |
+1.0 |
+4 |
+True |
+
+
+| 6 |
+honda |
+Blue |
+28561.250 |
+4 |
+7500 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 7 |
+honda |
+Blue |
+34211.250 |
+4 |
+7000 |
+5 |
+2.3 |
+4 |
+True |
+
+
+| 8 |
+toyota |
+White |
+37500.000 |
+4 |
+6250 |
+5 |
+2.0 |
+4 |
+True |
+
+
+| 9 |
+nissan |
+White |
+19750.000 |
+4 |
+9700 |
+5 |
+3.0 |
+4 |
+True |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Last updated: 2024-09-06 13:30:34.743560
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Using Scikit-Learn version: 1.5.1 (materials in this notebook require this version or newer).
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[3]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+target |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+1 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+1 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[4]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[5]:
+
+
(0 1
+ 1 1
+ 2 1
+ 3 1
+ 4 1
+ Name: target, dtype: int64,
+ target
+ 1 165
+ 0 138
+ Name: count, dtype: int64)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[6]:
+
+
((227, 13), (76, 13), (227,), (76,))
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[8]:
+
+
{'bootstrap': True,
+ 'ccp_alpha': 0.0,
+ 'class_weight': None,
+ 'criterion': 'gini',
+ 'max_depth': None,
+ 'max_features': 'sqrt',
+ 'max_leaf_nodes': None,
+ 'max_samples': None,
+ 'min_impurity_decrease': 0.0,
+ 'min_samples_leaf': 1,
+ 'min_samples_split': 2,
+ 'min_weight_fraction_leaf': 0.0,
+ 'monotonic_cst': None,
+ 'n_estimators': 100,
+ 'n_jobs': None,
+ 'oob_score': False,
+ 'random_state': None,
+ 'verbose': 0,
+ 'warm_start': False}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[9]:
+
+
RandomForestClassifier()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
/Users/daniel/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py:493: UserWarning: X does not have valid feature names, but RandomForestClassifier was fitted with feature names
+ warnings.warn(
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+Cell In[10], line 2
+ 1 # This doesn't work... incorrect shapes
+----> 2 y_label = clf.predict(np.array([0, 2, 3, 4]))
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py:904, in ForestClassifier.predict(self, X)
+ 883 def predict(self, X):
+ 884 """
+ 885 Predict class for X.
+ 886
+ (...)
+ 902 The predicted classes.
+ 903 """
+--> 904 proba = self.predict_proba(X)
+ 906 if self.n_outputs_ == 1:
+ 907 return self.classes_.take(np.argmax(proba, axis=1), axis=0)
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py:946, in ForestClassifier.predict_proba(self, X)
+ 944 check_is_fitted(self)
+ 945 # Check data
+--> 946 X = self._validate_X_predict(X)
+ 948 # Assign chunk of trees to jobs
+ 949 n_jobs, _, _ = _partition_estimators(self.n_estimators, self.n_jobs)
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py:641, in BaseForest._validate_X_predict(self, X)
+ 638 else:
+ 639 force_all_finite = True
+--> 641 X = self._validate_data(
+ 642 X,
+ 643 dtype=DTYPE,
+ 644 accept_sparse="csr",
+ 645 reset=False,
+ 646 force_all_finite=force_all_finite,
+ 647 )
+ 648 if issparse(X) and (X.indices.dtype != np.intc or X.indptr.dtype != np.intc):
+ 649 raise ValueError("No support for np.int64 index based sparse matrices")
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py:633, in BaseEstimator._validate_data(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)
+ 631 out = X, y
+ 632 elif not no_val_X and no_val_y:
+--> 633 out = check_array(X, input_name="X", **check_params)
+ 634 elif no_val_X and not no_val_y:
+ 635 out = _check_y(y, **check_params)
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py:1050, in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)
+ 1043 else:
+ 1044 msg = (
+ 1045 f"Expected 2D array, got 1D array instead:\narray={array}.\n"
+ 1046 "Reshape your data either using array.reshape(-1, 1) if "
+ 1047 "your data has a single feature or array.reshape(1, -1) "
+ 1048 "if it contains a single sample."
+ 1049 )
+-> 1050 raise ValueError(msg)
+ 1052 if dtype_numeric and hasattr(array.dtype, "kind") and array.dtype.kind in "USV":
+ 1053 raise ValueError(
+ 1054 "dtype='numeric' is not compatible with arrays of bytes/strings."
+ 1055 "Convert your data to numeric values explicitly instead."
+ 1056 )
+
+ValueError: Expected 2D array, got 1D array instead:
+array=[0. 2. 3. 4.].
+Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[11]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+
+
+
+
+| 165 |
+67 |
+1 |
+0 |
+160 |
+286 |
+0 |
+0 |
+108 |
+1 |
+1.5 |
+1 |
+3 |
+2 |
+
+
+| 71 |
+51 |
+1 |
+2 |
+94 |
+227 |
+0 |
+1 |
+154 |
+1 |
+0.0 |
+2 |
+1 |
+3 |
+
+
+| 24 |
+40 |
+1 |
+3 |
+140 |
+199 |
+0 |
+1 |
+178 |
+1 |
+1.4 |
+2 |
+0 |
+3 |
+
+
+| 19 |
+69 |
+0 |
+3 |
+140 |
+239 |
+0 |
+1 |
+151 |
+0 |
+1.8 |
+2 |
+2 |
+2 |
+
+
+| 258 |
+62 |
+0 |
+0 |
+150 |
+244 |
+0 |
+1 |
+154 |
+1 |
+1.4 |
+1 |
+0 |
+2 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
The model's accuracy on the training dataset is: 100.0%
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
The model's accuracy on the testing dataset is: 88.16%
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
precision recall f1-score support
+
+ 0 0.87 0.84 0.85 31
+ 1 0.89 0.91 0.90 45
+
+ accuracy 0.88 76
+ macro avg 0.88 0.87 0.88 76
+weighted avg 0.88 0.88 0.88 76
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[16]:
+
+
array([[26, 5],
+ [ 4, 41]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Trying model with 100 estimators...
+Model accuracy on test set: 88.16%
+
+Trying model with 110 estimators...
+Model accuracy on test set: 90.79%
+
+Trying model with 120 estimators...
+Model accuracy on test set: 90.79%
+
+Trying model with 130 estimators...
+Model accuracy on test set: 89.47%
+
+Trying model with 140 estimators...
+Model accuracy on test set: 88.16%
+
+Trying model with 150 estimators...
+Model accuracy on test set: 94.74%
+
+Trying model with 160 estimators...
+Model accuracy on test set: 92.11%
+
+Trying model with 170 estimators...
+Model accuracy on test set: 92.11%
+
+Trying model with 180 estimators...
+Model accuracy on test set: 92.11%
+
+Trying model with 190 estimators...
+Model accuracy on test set: 89.47%
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Trying model with 100 estimators...
+Model accuracy on single test set split: 88.16%
+5-fold cross-validation score: 82.15%
+
+Trying model with 110 estimators...
+Model accuracy on single test set split: 94.74%
+5-fold cross-validation score: 81.17%
+
+Trying model with 120 estimators...
+Model accuracy on single test set split: 88.16%
+5-fold cross-validation score: 83.49%
+
+Trying model with 130 estimators...
+Model accuracy on single test set split: 89.47%
+5-fold cross-validation score: 83.14%
+
+Trying model with 140 estimators...
+Model accuracy on single test set split: 88.16%
+5-fold cross-validation score: 82.48%
+
+Trying model with 150 estimators...
+Model accuracy on single test set split: 90.79%
+5-fold cross-validation score: 80.17%
+
+Trying model with 160 estimators...
+Model accuracy on single test set split: 89.47%
+5-fold cross-validation score: 80.83%
+
+Trying model with 170 estimators...
+Model accuracy on single test set split: 86.84%
+5-fold cross-validation score: 82.16%
+
+Trying model with 180 estimators...
+Model accuracy on single test set split: 92.11%
+5-fold cross-validation score: 81.50%
+
+Trying model with 190 estimators...
+Model accuracy on single test set split: 88.16%
+5-fold cross-validation score: 81.83%
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Fitting 5 folds for each of 10 candidates, totalling 50 fits
+The best parameter values are: {'n_estimators': 120}
+With a score of: 82.82%
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[21]:
+
+
RandomForestClassifier(n_estimators=120)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Best model score on single split of the data: 85.53%
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Loaded pickle model prediction score: 88.16%
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[25]:
+
+
['random_forest_model_1.joblib']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Loaded joblib model prediction score: 88.16%
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[27]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+target |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+1 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+1 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[28]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+
+
+| ... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+
+
+| 298 |
+57 |
+0 |
+0 |
+140 |
+241 |
+0 |
+1 |
+123 |
+1 |
+0.2 |
+1 |
+0 |
+3 |
+
+
+| 299 |
+45 |
+1 |
+3 |
+110 |
+264 |
+0 |
+1 |
+132 |
+0 |
+1.2 |
+1 |
+0 |
+3 |
+
+
+| 300 |
+68 |
+1 |
+0 |
+144 |
+193 |
+1 |
+1 |
+141 |
+0 |
+3.4 |
+1 |
+2 |
+3 |
+
+
+| 301 |
+57 |
+1 |
+0 |
+130 |
+131 |
+0 |
+1 |
+115 |
+1 |
+1.2 |
+1 |
+1 |
+3 |
+
+
+| 302 |
+57 |
+0 |
+1 |
+130 |
+236 |
+0 |
+0 |
+174 |
+0 |
+0.0 |
+1 |
+1 |
+2 |
+
+
+
+
303 rows × 13 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[29]:
+
+
0 1
+1 1
+2 1
+3 1
+4 1
+ ..
+298 0
+299 0
+300 0
+301 0
+302 0
+Name: target, Length: 303, dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[30]:
+
+
((242, 13), (61, 13), (242,), (61,))
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[33]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Honda |
+White |
+35431 |
+4 |
+15323 |
+
+
+| 1 |
+BMW |
+Blue |
+192714 |
+5 |
+19943 |
+
+
+| 2 |
+Honda |
+White |
+84714 |
+4 |
+28343 |
+
+
+| 3 |
+Toyota |
+White |
+154365 |
+4 |
+13434 |
+
+
+| 4 |
+Nissan |
+Blue |
+181577 |
+3 |
+14043 |
+
+
+| ... |
+... |
+... |
+... |
+... |
+... |
+
+
+| 995 |
+Toyota |
+Black |
+35820 |
+4 |
+32042 |
+
+
+| 996 |
+Nissan |
+White |
+155144 |
+3 |
+5716 |
+
+
+| 997 |
+Nissan |
+Blue |
+66604 |
+4 |
+31570 |
+
+
+| 998 |
+Honda |
+White |
+215883 |
+4 |
+4001 |
+
+
+| 999 |
+Toyota |
+Blue |
+248360 |
+4 |
+12732 |
+
+
+
+
1000 rows × 5 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[34]:
+
+
Make object
+Colour object
+Odometer (KM) int64
+Doors int64
+Price int64
+dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+/var/folders/c4/qj4gdk190td18bqvjjh0p3p00000gn/T/ipykernel_23180/1044518071.py in ?()
+ 1 # Try to predict with random forest on price column (doesn't work)
+ 2 from sklearn.ensemble import RandomForestRegressor
+ 3
+ 4 model = RandomForestRegressor()
+----> 5 model.fit(X_train, y_train)
+ 6 model.score(X_test, y_test)
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(estimator, *args, **kwargs)
+ 1469 skip_parameter_validation=(
+ 1470 prefer_skip_nested_validation or global_skip_validation
+ 1471 )
+ 1472 ):
+-> 1473 return fit_method(estimator, *args, **kwargs)
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X, y, sample_weight)
+ 359 # Validate or convert input data
+ 360 if issparse(y):
+ 361 raise ValueError("sparse multilabel-indicator for y is not supported.")
+ 362
+--> 363 X, y = self._validate_data(
+ 364 X,
+ 365 y,
+ 366 multi_output=True,
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)
+ 646 if "estimator" not in check_y_params:
+ 647 check_y_params = {**default_check_params, **check_y_params}
+ 648 y = check_array(y, input_name="y", **check_y_params)
+ 649 else:
+--> 650 X, y = check_X_y(X, y, **check_params)
+ 651 out = X, y
+ 652
+ 653 if not no_val_X and check_params.get("ensure_2d", True):
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(X, y, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, estimator)
+ 1297 raise ValueError(
+ 1298 f"{estimator_name} requires y to be passed, but the target y is None"
+ 1299 )
+ 1300
+-> 1301 X = check_array(
+ 1302 X,
+ 1303 accept_sparse=accept_sparse,
+ 1304 accept_large_sparse=accept_large_sparse,
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)
+ 1009 )
+ 1010 array = xp.astype(array, dtype, copy=False)
+ 1011 else:
+ 1012 array = _asarray_with_order(array, order=order, dtype=dtype, xp=xp)
+-> 1013 except ComplexWarning as complex_warning:
+ 1014 raise ValueError(
+ 1015 "Complex data not supported\n{}\n".format(array)
+ 1016 ) from complex_warning
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/_array_api.py in ?(array, dtype, order, copy, xp, device)
+ 747 # Use NumPy API to support order
+ 748 if copy is True:
+ 749 array = numpy.array(array, order=order, dtype=dtype)
+ 750 else:
+--> 751 array = numpy.asarray(array, order=order, dtype=dtype)
+ 752
+ 753 # At this point array is a NumPy ndarray. We convert it to an array
+ 754 # container that is consistent with the input's namespace.
+
+~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/core/generic.py in ?(self, dtype, copy)
+ 2149 def __array__(
+ 2150 self, dtype: npt.DTypeLike | None = None, copy: bool_t | None = None
+ 2151 ) -> np.ndarray:
+ 2152 values = self._values
+-> 2153 arr = np.asarray(values, dtype=dtype)
+ 2154 if (
+ 2155 astype_is_view(values.dtype, arr.dtype)
+ 2156 and using_copy_on_write()
+
+ValueError: could not convert string to float: 'Honda'
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[37]:
+
+
array([[0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,
+ 0.00000e+00, 3.54310e+04],
+ [1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
+ 1.00000e+00, 1.92714e+05],
+ [0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,
+ 0.00000e+00, 8.47140e+04],
+ ...,
+ [0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 1.00000e+00,
+ 0.00000e+00, 6.66040e+04],
+ [0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,
+ 0.00000e+00, 2.15883e+05],
+ [0.00000e+00, 0.00000e+00, 0.00000e+00, ..., 1.00000e+00,
+ 0.00000e+00, 2.48360e+05]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[38]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+
+
+
+
+| 0 |
+Honda |
+White |
+35431 |
+4 |
+
+
+| 1 |
+BMW |
+Blue |
+192714 |
+5 |
+
+
+| 2 |
+Honda |
+White |
+84714 |
+4 |
+
+
+| 3 |
+Toyota |
+White |
+154365 |
+4 |
+
+
+| 4 |
+Nissan |
+Blue |
+181577 |
+3 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[39]:
+
+
array([0.0000e+00, 1.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
+ 0.0000e+00, 0.0000e+00, 0.0000e+00, 1.0000e+00, 0.0000e+00,
+ 1.0000e+00, 0.0000e+00, 3.5431e+04])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[40]:
+
+
Make Honda
+Colour White
+Odometer (KM) 35431
+Doors 4
+Name: 0, dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[41]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Honda |
+White |
+35431 |
+4 |
+15323 |
+
+
+| 1 |
+BMW |
+Blue |
+192714 |
+5 |
+19943 |
+
+
+| 2 |
+Honda |
+White |
+84714 |
+4 |
+28343 |
+
+
+| 3 |
+Toyota |
+White |
+154365 |
+4 |
+13434 |
+
+
+| 4 |
+Nissan |
+Blue |
+181577 |
+3 |
+14043 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[42]:
+
+
+
+
+
+
+ |
+Doors |
+Make_BMW |
+Make_Honda |
+Make_Nissan |
+Make_Toyota |
+Colour_Black |
+Colour_Blue |
+Colour_Green |
+Colour_Red |
+Colour_White |
+
+
+
+
+| 0 |
+4 |
+False |
+True |
+False |
+False |
+False |
+False |
+False |
+False |
+True |
+
+
+| 1 |
+5 |
+True |
+False |
+False |
+False |
+False |
+True |
+False |
+False |
+False |
+
+
+| 2 |
+4 |
+False |
+True |
+False |
+False |
+False |
+False |
+False |
+False |
+True |
+
+
+| 3 |
+4 |
+False |
+False |
+False |
+True |
+False |
+False |
+False |
+False |
+True |
+
+
+| 4 |
+3 |
+False |
+False |
+True |
+False |
+False |
+True |
+False |
+False |
+False |
+
+
+| ... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+
+
+| 995 |
+4 |
+False |
+False |
+False |
+True |
+True |
+False |
+False |
+False |
+False |
+
+
+| 996 |
+3 |
+False |
+False |
+True |
+False |
+False |
+False |
+False |
+False |
+True |
+
+
+| 997 |
+4 |
+False |
+False |
+True |
+False |
+False |
+True |
+False |
+False |
+False |
+
+
+| 998 |
+4 |
+False |
+True |
+False |
+False |
+False |
+False |
+False |
+False |
+True |
+
+
+| 999 |
+4 |
+False |
+False |
+False |
+True |
+False |
+True |
+False |
+False |
+False |
+
+
+
+
1000 rows × 10 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[43]:
+
+
+
+
+
+
+ |
+Make_BMW |
+Make_Honda |
+Make_Nissan |
+Make_Toyota |
+Colour_Black |
+Colour_Blue |
+Colour_Green |
+Colour_Red |
+Colour_White |
+Doors_3 |
+Doors_4 |
+Doors_5 |
+
+
+
+
+| 0 |
+0.0 |
+1.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+1.0 |
+0.0 |
+
+
+| 1 |
+1.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+
+
+| 2 |
+0.0 |
+1.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+1.0 |
+0.0 |
+
+
+| 3 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+1.0 |
+0.0 |
+
+
+| 4 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+0.0 |
+
+
+| ... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+... |
+
+
+| 995 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+1.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+
+
+| 996 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+1.0 |
+0.0 |
+0.0 |
+
+
+| 997 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+
+
+| 998 |
+0.0 |
+1.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+1.0 |
+0.0 |
+
+
+| 999 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+1.0 |
+0.0 |
+0.0 |
+0.0 |
+0.0 |
+1.0 |
+0.0 |
+
+
+
+
1000 rows × 12 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[47]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Honda |
+White |
+35431.0 |
+4.0 |
+15323.0 |
+
+
+| 1 |
+BMW |
+Blue |
+192714.0 |
+5.0 |
+19943.0 |
+
+
+| 2 |
+Honda |
+White |
+84714.0 |
+4.0 |
+28343.0 |
+
+
+| 3 |
+Toyota |
+White |
+154365.0 |
+4.0 |
+13434.0 |
+
+
+| 4 |
+Nissan |
+Blue |
+181577.0 |
+3.0 |
+14043.0 |
+
+
+| 5 |
+Honda |
+Red |
+42652.0 |
+4.0 |
+23883.0 |
+
+
+| 6 |
+Toyota |
+Blue |
+163453.0 |
+4.0 |
+8473.0 |
+
+
+| 7 |
+Honda |
+White |
+NaN |
+4.0 |
+20306.0 |
+
+
+| 8 |
+NaN |
+White |
+130538.0 |
+4.0 |
+9374.0 |
+
+
+| 9 |
+Honda |
+Blue |
+51029.0 |
+4.0 |
+26683.0 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[48]:
+
+
Make 49
+Colour 50
+Odometer (KM) 50
+Doors 50
+Price 50
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Number of missing X values:
+Make 49
+Colour 50
+Odometer (KM) 50
+Doors 50
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Number of missing y values: 50
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[51]:
+
+
array([[0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 0.00000e+00,
+ 0.00000e+00, 3.54310e+04],
+ [1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 1.00000e+00,
+ 0.00000e+00, 1.92714e+05],
+ [0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 0.00000e+00,
+ 0.00000e+00, 8.47140e+04],
+ ...,
+ [0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 0.00000e+00,
+ 0.00000e+00, 6.66040e+04],
+ [0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 0.00000e+00,
+ 0.00000e+00, 2.15883e+05],
+ [0.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
+ 0.00000e+00, 2.48360e+05]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+---------------------------------------------------------------------------
+ValueError Traceback (most recent call last)
+Cell In[52], line 8
+ 6 # Fit and score a model
+ 7 model = RandomForestRegressor()
+----> 8 model.fit(X_train, y_train)
+ 9 model.score(X_test, y_test)
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py:1473, in _fit_context.<locals>.decorator.<locals>.wrapper(estimator, *args, **kwargs)
+ 1466 estimator._validate_params()
+ 1468 with config_context(
+ 1469 skip_parameter_validation=(
+ 1470 prefer_skip_nested_validation or global_skip_validation
+ 1471 )
+ 1472 ):
+-> 1473 return fit_method(estimator, *args, **kwargs)
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py:363, in BaseForest.fit(self, X, y, sample_weight)
+ 360 if issparse(y):
+ 361 raise ValueError("sparse multilabel-indicator for y is not supported.")
+--> 363 X, y = self._validate_data(
+ 364 X,
+ 365 y,
+ 366 multi_output=True,
+ 367 accept_sparse="csc",
+ 368 dtype=DTYPE,
+ 369 force_all_finite=False,
+ 370 )
+ 371 # _compute_missing_values_in_feature_mask checks if X has missing values and
+ 372 # will raise an error if the underlying tree base estimator can't handle missing
+ 373 # values. Only the criterion is required to determine if the tree supports
+ 374 # missing values.
+ 375 estimator = type(self.estimator)(criterion=self.criterion)
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py:650, in BaseEstimator._validate_data(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)
+ 648 y = check_array(y, input_name="y", **check_y_params)
+ 649 else:
+--> 650 X, y = check_X_y(X, y, **check_params)
+ 651 out = X, y
+ 653 if not no_val_X and check_params.get("ensure_2d", True):
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py:1318, in check_X_y(X, y, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, estimator)
+ 1297 raise ValueError(
+ 1298 f"{estimator_name} requires y to be passed, but the target y is None"
+ 1299 )
+ 1301 X = check_array(
+ 1302 X,
+ 1303 accept_sparse=accept_sparse,
+ (...)
+ 1315 input_name="X",
+ 1316 )
+-> 1318 y = _check_y(y, multi_output=multi_output, y_numeric=y_numeric, estimator=estimator)
+ 1320 check_consistent_length(X, y)
+ 1322 return X, y
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py:1328, in _check_y(y, multi_output, y_numeric, estimator)
+ 1326 """Isolated part of check_X_y dedicated to y validation"""
+ 1327 if multi_output:
+-> 1328 y = check_array(
+ 1329 y,
+ 1330 accept_sparse="csr",
+ 1331 force_all_finite=True,
+ 1332 ensure_2d=False,
+ 1333 dtype=None,
+ 1334 input_name="y",
+ 1335 estimator=estimator,
+ 1336 )
+ 1337 else:
+ 1338 estimator_name = _check_estimator_name(estimator)
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py:1064, in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)
+ 1058 raise ValueError(
+ 1059 "Found array with dim %d. %s expected <= 2."
+ 1060 % (array.ndim, estimator_name)
+ 1061 )
+ 1063 if force_all_finite:
+-> 1064 _assert_all_finite(
+ 1065 array,
+ 1066 input_name=input_name,
+ 1067 estimator_name=estimator_name,
+ 1068 allow_nan=force_all_finite == "allow-nan",
+ 1069 )
+ 1071 if copy:
+ 1072 if _is_numpy_namespace(xp):
+ 1073 # only make a copy if `array` and `array_orig` may share memory`
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py:123, in _assert_all_finite(X, allow_nan, msg_dtype, estimator_name, input_name)
+ 120 if first_pass_isfinite:
+ 121 return
+--> 123 _assert_all_finite_element_wise(
+ 124 X,
+ 125 xp=xp,
+ 126 allow_nan=allow_nan,
+ 127 msg_dtype=msg_dtype,
+ 128 estimator_name=estimator_name,
+ 129 input_name=input_name,
+ 130 )
+
+File ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py:172, in _assert_all_finite_element_wise(X, xp, allow_nan, msg_dtype, estimator_name, input_name)
+ 155 if estimator_name and input_name == "X" and has_nan_error:
+ 156 # Improve the error message on how to handle missing values in
+ 157 # scikit-learn.
+ 158 msg_err += (
+ 159 f"\n{estimator_name} does not accept missing values"
+ 160 " encoded as NaN natively. For supervised learning, you might want"
+ (...)
+ 170 "#estimators-that-handle-nan-values"
+ 171 )
+--> 172 raise ValueError(msg_err)
+
+ValueError: Input y contains NaN.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[53]:
+
+
Make 49
+Colour 50
+Odometer (KM) 50
+Doors 50
+Price 50
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[57]:
+
+
Make 0
+Colour 0
+Odometer (KM) 50
+Doors 50
+Price 50
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[58]:
+
+
Doors
+4.0 811
+5.0 75
+3.0 64
+Name: count, dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[61]:
+
+
Make 0
+Colour 0
+Odometer (KM) 0
+Doors 0
+Price 50
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[63]:
+
+
Make 0
+Colour 0
+Odometer (KM) 0
+Doors 0
+Price 0
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Number of missing X values:
+Make 0
+Colour 0
+Odometer (KM) 0
+Doors 0
+dtype: int64
+Number of missing y values: 0
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[66]:
+
+
array([[0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,
+ 0.00000e+00, 3.54310e+04],
+ [1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
+ 1.00000e+00, 1.92714e+05],
+ [0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,
+ 0.00000e+00, 8.47140e+04],
+ ...,
+ [0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 1.00000e+00,
+ 0.00000e+00, 6.66040e+04],
+ [0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,
+ 0.00000e+00, 2.15883e+05],
+ [0.00000e+00, 0.00000e+00, 0.00000e+00, ..., 1.00000e+00,
+ 0.00000e+00, 2.48360e+05]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[68]:
+
+
Make 0
+Colour 0
+Odometer (KM) 0
+Doors 0
+Price 0
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[69]:
+
+
Make 49
+Colour 50
+Odometer (KM) 50
+Doors 50
+Price 50
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[71]:
+
+
Make 47
+Colour 46
+Odometer (KM) 48
+Doors 47
+Price 0
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[76]:
+
+
array([['Honda', 'White', 4.0, 71934.0],
+ ['Toyota', 'Red', 4.0, 162665.0],
+ ['Honda', 'White', 4.0, 42844.0],
+ ...,
+ ['Toyota', 'White', 4.0, 196225.0],
+ ['Honda', 'Blue', 4.0, 133117.0],
+ ['Honda', 'missing', 4.0, 150582.0]], dtype=object)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[77]:
+
+
Make 0
+Colour 0
+Doors 0
+Odometer (KM) 0
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[78]:
+
+
Make 0
+Colour 0
+Doors 0
+Odometer (KM) 0
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[79]:
+
+
Make 47
+Colour 46
+Odometer (KM) 48
+Doors 47
+Price 0
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[80]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Doors |
+Odometer (KM) |
+
+
+
+
+| 0 |
+Honda |
+White |
+4.0 |
+71934.0 |
+
+
+| 1 |
+Toyota |
+Red |
+4.0 |
+162665.0 |
+
+
+| 2 |
+Honda |
+White |
+4.0 |
+42844.0 |
+
+
+| 3 |
+Honda |
+White |
+4.0 |
+195829.0 |
+
+
+| 4 |
+Honda |
+Blue |
+4.0 |
+219217.0 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[81]:
+
+
array([[0.0, 1.0, 0.0, ..., 1.0, 0.0, 71934.0],
+ [0.0, 0.0, 0.0, ..., 1.0, 0.0, 162665.0],
+ [0.0, 1.0, 0.0, ..., 1.0, 0.0, 42844.0],
+ ...,
+ [0.0, 0.0, 0.0, ..., 1.0, 0.0, 196225.0],
+ [0.0, 1.0, 0.0, ..., 1.0, 0.0, 133117.0],
+ [0.0, 1.0, 0.0, ..., 1.0, 0.0, 150582.0]], dtype=object)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[84]:
+
+
+
+
+
+
+ |
+MedInc |
+HouseAge |
+AveRooms |
+AveBedrms |
+Population |
+AveOccup |
+Latitude |
+Longitude |
+target |
+
+
+
+
+| 0 |
+8.3252 |
+41.0 |
+6.984127 |
+1.023810 |
+322.0 |
+2.555556 |
+37.88 |
+-122.23 |
+4.526 |
+
+
+| 1 |
+8.3014 |
+21.0 |
+6.238137 |
+0.971880 |
+2401.0 |
+2.109842 |
+37.86 |
+-122.22 |
+3.585 |
+
+
+| 2 |
+7.2574 |
+52.0 |
+8.288136 |
+1.073446 |
+496.0 |
+2.802260 |
+37.85 |
+-122.24 |
+3.521 |
+
+
+| 3 |
+5.6431 |
+52.0 |
+5.817352 |
+1.073059 |
+558.0 |
+2.547945 |
+37.85 |
+-122.25 |
+3.413 |
+
+
+| 4 |
+3.8462 |
+52.0 |
+6.281853 |
+1.081081 |
+565.0 |
+2.181467 |
+37.85 |
+-122.25 |
+3.422 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[90]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+target |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+1 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+1 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+1 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[95]:
+
+
+
+
+
+
+ |
+age |
+sex |
+cp |
+trestbps |
+chol |
+fbs |
+restecg |
+thalach |
+exang |
+oldpeak |
+slope |
+ca |
+thal |
+
+
+
+
+| 0 |
+63 |
+1 |
+3 |
+145 |
+233 |
+1 |
+0 |
+150 |
+0 |
+2.3 |
+0 |
+0 |
+1 |
+
+
+| 1 |
+37 |
+1 |
+2 |
+130 |
+250 |
+0 |
+1 |
+187 |
+0 |
+3.5 |
+0 |
+0 |
+2 |
+
+
+| 2 |
+41 |
+0 |
+1 |
+130 |
+204 |
+0 |
+0 |
+172 |
+0 |
+1.4 |
+2 |
+0 |
+2 |
+
+
+| 3 |
+56 |
+1 |
+1 |
+120 |
+236 |
+0 |
+1 |
+178 |
+0 |
+0.8 |
+2 |
+0 |
+2 |
+
+
+| 4 |
+57 |
+0 |
+0 |
+120 |
+354 |
+0 |
+1 |
+163 |
+1 |
+0.6 |
+2 |
+0 |
+2 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[96]:
+
+
0 1
+1 1
+2 1
+3 1
+4 1
+Name: target, dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[97]:
+
+
array([0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0,
+ 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[98]:
+
+
np.float64(0.8524590163934426)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[101]:
+
+
array([[0.89, 0.11],
+ [0.49, 0.51],
+ [0.43, 0.57],
+ [0.84, 0.16],
+ [0.18, 0.82]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[102]:
+
+
array([0, 1, 1, 0, 1])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[106]:
+
+
np.float64(0.3270458119670544)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[113]:
+
+
array([0.81967213, 0.86885246, 0.81967213, 0.78333333, 0.76666667])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[114]:
+
+
array([0.83606557, 0.8852459 , 0.7704918 , 0.8 , 0.8 ])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[115]:
+
+
(0.8524590163934426, np.float64(0.8248087431693989))
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[116]:
+
+
array([0.78688525, 0.86885246, 0.80327869, 0.78333333, 0.76666667])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Heart Disease Classifier Accuracy: 85.25%
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[119]:
+
+
array([0. , 0. , 0. , 0. , 0. ,
+ 0.03448276, 0.03448276, 0.03448276, 0.03448276, 0.06896552,
+ 0.06896552, 0.10344828, 0.13793103, 0.13793103, 0.17241379,
+ 0.17241379, 0.27586207, 0.4137931 , 0.48275862, 0.55172414,
+ 0.65517241, 0.72413793, 0.72413793, 0.82758621, 1. ])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[122]:
+
+
np.float64(0.9304956896551724)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[126]:
+
+
array([[24, 5],
+ [ 4, 28]])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[127]:
+
+
+
+
+
+
+| Predicted Label |
+0 |
+1 |
+
+
+| Actual Label |
+ |
+ |
+
+
+
+
+| 0 |
+24 |
+5 |
+
+
+| 1 |
+4 |
+28 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
precision recall f1-score support
+
+ 0 0.86 0.83 0.84 29
+ 1 0.85 0.88 0.86 32
+
+ accuracy 0.85 61
+ macro avg 0.85 0.85 0.85 61
+weighted avg 0.85 0.85 0.85 61
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[131]:
+
+
+
+
+
+
+ |
+0.0 |
+1.0 |
+accuracy |
+macro avg |
+weighted avg |
+
+
+
+
+| precision |
+0.99990 |
+0.0 |
+0.9999 |
+0.499950 |
+0.99980 |
+
+
+| recall |
+1.00000 |
+0.0 |
+0.9999 |
+0.500000 |
+0.99990 |
+
+
+| f1-score |
+0.99995 |
+0.0 |
+0.9999 |
+0.499975 |
+0.99985 |
+
+
+| support |
+9999.00000 |
+1.0 |
+0.9999 |
+10000.000000 |
+10000.00000 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[136]:
+
+
np.float64(0.3270458119670544)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[137]:
+
+
+
+
+
+
+ |
+actual values |
+predictions |
+
+
+
+
+| 20046 |
+0.47700 |
+0.490580 |
+
+
+| 3024 |
+0.45800 |
+0.759890 |
+
+
+| 15663 |
+5.00001 |
+4.935016 |
+
+
+| 20484 |
+2.18600 |
+2.558640 |
+
+
+| 9814 |
+2.78000 |
+2.334610 |
+
+
+| ... |
+... |
+... |
+
+
+| 15362 |
+2.63300 |
+2.225000 |
+
+
+| 16623 |
+2.66800 |
+1.972540 |
+
+
+| 18086 |
+5.00001 |
+4.853989 |
+
+
+| 2144 |
+0.72300 |
+0.714910 |
+
+
+| 3665 |
+1.51500 |
+1.665680 |
+
+
+
+
4128 rows × 2 columns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[139]:
+
+
np.float64(0.2542443610174998)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[141]:
+
+
array([0.81967213, 0.90163934, 0.83606557, 0.78333333, 0.78333333])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
The cross-validated accuracy is: 82.48%
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
The cross-validated accuracy is: 82.48%
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
The cross-validated precision is: 0.83
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
The cross-validated recall is: 0.85
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
The cross-validated F1 score is: 0.84
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
The cross-validated R^2 score is: 0.65
+CPU times: user 40.5 s, sys: 286 ms, total: 40.8 s
+Wall time: 41.6 s
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
The cross-validated MAE score is: -0.47
+CPU times: user 40.4 s, sys: 246 ms, total: 40.7 s
+Wall time: 41.6 s
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
The cross-validated MSE score is: -0.43
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Classifier metrics on the test set:
+Accuracy: 85.25%
+Precision: 0.85
+Recall: 0.88
+F1: 0.86
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Regression model metrics on the test set:
+R^2: 0.81
+MAE: 0.33
+MSE: 0.25
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[163]:
+
+
{'bootstrap': True,
+ 'ccp_alpha': 0.0,
+ 'class_weight': None,
+ 'criterion': 'gini',
+ 'max_depth': None,
+ 'max_features': 'sqrt',
+ 'max_leaf_nodes': None,
+ 'max_samples': None,
+ 'min_impurity_decrease': 0.0,
+ 'min_samples_leaf': 1,
+ 'min_samples_split': 2,
+ 'min_weight_fraction_leaf': 0.0,
+ 'monotonic_cst': None,
+ 'n_estimators': 100,
+ 'n_jobs': None,
+ 'oob_score': False,
+ 'random_state': None,
+ 'verbose': 0,
+ 'warm_start': False}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[164]:
+
+
{'bootstrap': True,
+ 'ccp_alpha': 0.0,
+ 'class_weight': None,
+ 'criterion': 'gini',
+ 'max_depth': None,
+ 'max_features': 'sqrt',
+ 'max_leaf_nodes': None,
+ 'max_samples': None,
+ 'min_impurity_decrease': 0.0,
+ 'min_samples_leaf': 1,
+ 'min_samples_split': 2,
+ 'min_weight_fraction_leaf': 0.0,
+ 'monotonic_cst': None,
+ 'n_estimators': 100,
+ 'n_jobs': None,
+ 'oob_score': False,
+ 'random_state': None,
+ 'verbose': 0,
+ 'warm_start': False}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Acc: 80.00%
+Precision: 0.78
+Recall: 0.88
+F1 score: 0.82
+
+
+
+
+
Out[166]:
+
+
{'accuracy': 0.8,
+ 'precision': np.float64(0.78),
+ 'recall': np.float64(0.88),
+ 'f1': np.float64(0.82)}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Training data: 212 samples, 212 labels
+Validation data: 45 samples, 45 labels
+Testing data: 46 samples, 46 labels
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Acc: 77.78%
+Precision: 0.77
+Recall: 0.83
+F1 score: 0.80
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
There are 1440 potential combinations of hyperparameters to test.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Fitting 5 folds for each of 30 candidates, totalling 150 fits
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=10, max_features=None, min_samples_leaf=8, min_samples_split=2, n_estimators=500; total time= 0.3s
+[CV] END max_depth=10, max_features=None, min_samples_leaf=8, min_samples_split=2, n_estimators=500; total time= 0.3s
+[CV] END max_depth=10, max_features=None, min_samples_leaf=8, min_samples_split=2, n_estimators=500; total time= 0.3s
+[CV] END max_depth=10, max_features=None, min_samples_leaf=8, min_samples_split=2, n_estimators=500; total time= 0.3s
+[CV] END max_depth=10, max_features=None, min_samples_leaf=8, min_samples_split=2, n_estimators=500; total time= 0.3s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=5, max_features=log2, min_samples_leaf=2, min_samples_split=8, n_estimators=100; total time= 0.1s
+[CV] END max_depth=5, max_features=log2, min_samples_leaf=2, min_samples_split=8, n_estimators=100; total time= 0.1s
+[CV] END max_depth=5, max_features=log2, min_samples_leaf=2, min_samples_split=8, n_estimators=100; total time= 0.1s
+[CV] END max_depth=5, max_features=log2, min_samples_leaf=2, min_samples_split=8, n_estimators=100; total time= 0.1s
+[CV] END max_depth=5, max_features=log2, min_samples_leaf=2, min_samples_split=8, n_estimators=100; total time= 0.1s
+[CV] END max_depth=10, max_features=log2, min_samples_leaf=2, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=10, max_features=log2, min_samples_leaf=2, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=10, max_features=log2, min_samples_leaf=2, min_samples_split=4, n_estimators=200; total time= 0.2s
+[CV] END max_depth=10, max_features=log2, min_samples_leaf=2, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=10, max_features=log2, min_samples_leaf=2, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=8, min_samples_split=4, n_estimators=1200; total time= 0.7s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=8, min_samples_split=4, n_estimators=1200; total time= 0.7s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=8, min_samples_split=4, n_estimators=1200; total time= 0.7s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=8, min_samples_split=4, n_estimators=1200; total time= 0.8s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=8, min_samples_split=4, n_estimators=1200; total time= 0.7s
+[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=20, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=100; total time= 0.1s
+[CV] END max_depth=20, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=100; total time= 0.1s
+[CV] END max_depth=20, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=100; total time= 0.1s
+[CV] END max_depth=20, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=100; total time= 0.1s
+[CV] END max_depth=20, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=100; total time= 0.1s
+[CV] END max_depth=5, max_features=log2, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=5, max_features=log2, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=5, max_features=log2, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=5, max_features=log2, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=5, max_features=log2, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=4, min_samples_split=4, n_estimators=1200; total time= 0.7s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=4, min_samples_split=4, n_estimators=1200; total time= 0.7s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=4, min_samples_split=4, n_estimators=1200; total time= 0.8s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=4, min_samples_split=4, n_estimators=1200; total time= 0.8s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=4, min_samples_split=4, n_estimators=1200; total time= 0.7s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=5, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=5, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=5, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=5, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=5, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1200; total time= 0.8s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1200; total time= 0.7s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1200; total time= 0.8s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1200; total time= 0.7s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1200; total time= 0.7s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=8, min_samples_split=2, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=8, min_samples_split=2, n_estimators=1000; total time= 0.7s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=8, min_samples_split=2, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=8, min_samples_split=2, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=8, min_samples_split=2, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=4, min_samples_split=6, n_estimators=100; total time= 0.1s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=4, min_samples_split=6, n_estimators=100; total time= 0.1s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=4, min_samples_split=6, n_estimators=100; total time= 0.1s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=4, min_samples_split=6, n_estimators=100; total time= 0.1s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=4, min_samples_split=6, n_estimators=100; total time= 0.1s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=8, n_estimators=500; total time= 0.3s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=8, n_estimators=500; total time= 0.3s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=8, n_estimators=500; total time= 0.3s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=8, n_estimators=500; total time= 0.3s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=8, n_estimators=500; total time= 0.3s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=6, n_estimators=500; total time= 0.3s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=6, n_estimators=500; total time= 0.3s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=6, n_estimators=500; total time= 0.3s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=6, n_estimators=500; total time= 0.3s
+[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=6, n_estimators=500; total time= 0.3s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=1, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=1, min_samples_split=8, n_estimators=200; total time= 0.2s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=1, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=1, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=1, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=20, max_features=log2, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=20, max_features=log2, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=20, max_features=log2, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=20, max_features=log2, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=20, max_features=log2, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=None, max_features=log2, min_samples_leaf=2, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=None, max_features=log2, min_samples_leaf=2, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=None, max_features=log2, min_samples_leaf=2, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=None, max_features=log2, min_samples_leaf=2, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=None, max_features=log2, min_samples_leaf=2, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=100; total time= 0.1s
+[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=100; total time= 0.1s
+[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=100; total time= 0.1s
+[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=100; total time= 0.1s
+[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=100; total time= 0.1s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=2, min_samples_split=2, n_estimators=500; total time= 0.3s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=2, min_samples_split=2, n_estimators=500; total time= 0.3s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=2, min_samples_split=2, n_estimators=500; total time= 0.3s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=2, min_samples_split=2, n_estimators=500; total time= 0.3s
+[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=2, min_samples_split=2, n_estimators=500; total time= 0.4s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=None, max_features=None, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s
+[CV] END max_depth=None, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=None, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=None, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=None, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=10; total time= 0.0s
+[CV] END max_depth=None, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=10; total time= 0.0s
+[INFO] Total time taken for 30 random combinations of hyperparameters: 36.02 seconds.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[174]:
+
+
{'n_estimators': 200,
+ 'min_samples_split': 6,
+ 'min_samples_leaf': 4,
+ 'max_features': 'log2',
+ 'max_depth': 30}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Acc: 85.25%
+Precision: 0.85
+Recall: 0.88
+F1 score: 0.86
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[176]:
+
+
{'n_estimators': [10, 100, 200, 500, 1000, 1200],
+ 'max_depth': [None, 5, 10, 20, 30],
+ 'max_features': ['sqrt', 'log2', None],
+ 'min_samples_split': [2, 4, 6, 8],
+ 'min_samples_leaf': [1, 2, 4, 8]}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
There are 24 combinations of hyperparameters to test.
+This is 60.0 times less than before (previous: 1440).
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Fitting 5 folds for each of 24 candidates, totalling 120 fits
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.2s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.2s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.7s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.7s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.2s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.2s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.2s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.7s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.5s
+[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.5s
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[INFO] The total running time for running GridSearchCV was 41.95 seconds.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[182]:
+
+
{'max_depth': 30,
+ 'max_features': 'log2',
+ 'min_samples_leaf': 4,
+ 'min_samples_split': 2,
+ 'n_estimators': 200}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Acc: 88.52%
+Precision: 0.88
+Recall: 0.91
+F1 score: 0.89
+
+
+
+
+
Out[183]:
+
+
{'accuracy': 0.89,
+ 'precision': np.float64(0.88),
+ 'recall': np.float64(0.91),
+ 'f1': np.float64(0.89)}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Acc: 88.52%
+Precision: 0.88
+Recall: 0.91
+F1 score: 0.89
+
+
+
+
+
Out[187]:
+
+
{'accuracy': 0.89,
+ 'precision': np.float64(0.88),
+ 'recall': np.float64(0.91),
+ 'f1': np.float64(0.89)}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[189]:
+
+
['gs_random_forest_model_1.joblib']
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Acc: 88.52%
+Precision: 0.88
+Recall: 0.91
+F1 score: 0.89
+
+
+
+
+
Out[191]:
+
+
{'accuracy': 0.89,
+ 'precision': np.float64(0.88),
+ 'recall': np.float64(0.91),
+ 'f1': np.float64(0.89)}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[193]:
+
+
+
+
+
+
+ |
+Make |
+Colour |
+Odometer (KM) |
+Doors |
+Price |
+
+
+
+
+| 0 |
+Honda |
+White |
+35431.0 |
+4.0 |
+15323.0 |
+
+
+| 1 |
+BMW |
+Blue |
+192714.0 |
+5.0 |
+19943.0 |
+
+
+| 2 |
+Honda |
+White |
+84714.0 |
+4.0 |
+28343.0 |
+
+
+| 3 |
+Toyota |
+White |
+154365.0 |
+4.0 |
+13434.0 |
+
+
+| 4 |
+Nissan |
+Blue |
+181577.0 |
+3.0 |
+14043.0 |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[194]:
+
+
Make object
+Colour object
+Odometer (KM) float64
+Doors float64
+Price float64
+dtype: object
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Out[195]:
+
+
Make 49
+Colour 50
+Odometer (KM) 50
+Doors 50
+Price 50
+dtype: int64
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Fitting 5 folds for each of 16 candidates, totalling 80 fits
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s
+[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.7s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s
+[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s
+
+
+
+
+
Out[200]:
+
+
GridSearchCV(cv=5,
+ estimator=Pipeline(steps=[('preprocessor',
+ ColumnTransformer(transformers=[('cat',
+ Pipeline(steps=[('imputer',
+ SimpleImputer(fill_value='missing',
+ strategy='constant')),
+ ('onehot',
+ OneHotEncoder(handle_unknown='ignore'))]),
+ ['Make',
+ 'Colour']),
+ ('door',
+ Pipeline(steps=[('imputer',
+ SimpleImputer(fill_value=4,
+ strategy='constant'))]),
+ ['Doors']),
+ ('num',
+ Pipeline(steps=[('imputer',
+ SimpleImputer())]),
+ ['Odometer '
+ '(KM)'])])),
+ ('model',
+ RandomForestRegressor(n_jobs=-1))]),
+ param_grid={'model__max_depth': [None, 5],
+ 'model__max_features': ['sqrt'],
+ 'model__min_samples_split': [2, 4],
+ 'model__n_estimators': [100, 1000],
+ 'preprocessor__num__imputer__strategy': ['mean',
+ 'median']},
+ verbose=2)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.GridSearchCV(cv=5,
+ estimator=Pipeline(steps=[('preprocessor',
+ ColumnTransformer(transformers=[('cat',
+ Pipeline(steps=[('imputer',
+ SimpleImputer(fill_value='missing',
+ strategy='constant')),
+ ('onehot',
+ OneHotEncoder(handle_unknown='ignore'))]),
+ ['Make',
+ 'Colour']),
+ ('door',
+ Pipeline(steps=[('imputer',
+ SimpleImputer(fill_value=4,
+ strategy='constant'))]),
+ ['Doors']),
+ ('num',
+ Pipeline(steps=[('imputer',
+ SimpleImputer())]),
+ ['Odometer '
+ '(KM)'])])),
+ ('model',
+ RandomForestRegressor(n_jobs=-1))]),
+ param_grid={'model__max_depth': [None, 5],
+ 'model__max_features': ['sqrt'],
+ 'model__min_samples_split': [2, 4],
+ 'model__n_estimators': [100, 1000],
+ 'preprocessor__num__imputer__strategy': ['mean',
+ 'median']},
+ verbose=2)Pipeline(steps=[('preprocessor',
+ ColumnTransformer(transformers=[('cat',
+ Pipeline(steps=[('imputer',
+ SimpleImputer(fill_value='missing',
+ strategy='constant')),
+ ('onehot',
+ OneHotEncoder(handle_unknown='ignore'))]),
+ ['Make', 'Colour']),
+ ('door',
+ Pipeline(steps=[('imputer',
+ SimpleImputer(fill_value=4,
+ strategy='constant'))]),
+ ['Doors']),
+ ('num',
+ Pipeline(steps=[('imputer',
+ SimpleImputer())]),
+ ['Odometer (KM)'])])),
+ ('model',
+ RandomForestRegressor(max_depth=5, max_features='sqrt',
+ n_jobs=-1))])ColumnTransformer(transformers=[('cat',
+ Pipeline(steps=[('imputer',
+ SimpleImputer(fill_value='missing',
+ strategy='constant')),
+ ('onehot',
+ OneHotEncoder(handle_unknown='ignore'))]),
+ ['Make', 'Colour']),
+ ('door',
+ Pipeline(steps=[('imputer',
+ SimpleImputer(fill_value=4,
+ strategy='constant'))]),
+ ['Doors']),
+ ('num',
+ Pipeline(steps=[('imputer', SimpleImputer())]),
+ ['Odometer (KM)'])])
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
This webpage contains all of the materials for the Zero to Mastery Data Science and Machine Learning Bootcamp.
"},{"location":"#quick-links","title":"Quick Links","text":" - \ud83d\udcda Get the course materials on the course GitHub
- \ud83c\udfa5 Watch the first 10 hours of the course on YouTube
- \ud83e\udd13 Read more on the course page
- \ud83d\udcbb Sign up to the course on Zero to Mastery and start coding
"},{"location":"#contents","title":"Contents","text":"The following contents are listed in suggested chronological order.
But feel free to mix in match in anyway you feel fit.
Section Resource Description 00 A 6 step framework for approaching machine learning projects A guideline for different kinds of machine learning projects and how to break them down into smaller steps. 01 Introduction to NumPy NumPy stands for Numerical Python. It's one of the most used Python libraries for numerical processing (which is what much of data science and machine learning is). 02 Introduction to pandas pandas is a Python library for manipulating and analysing data. You can imagine pandas as a programmatic form of an Excel spreadsheet. 03 Introduction to Matplotlib Matplotlib helps to visualize data. You can create plots and graphs programmatically based on various data sources. 04 Introduction to Scikit-Learn Scikit-Learn or sklearn is full of data processing techniques as well as pre-built machine learning algorithms for many different tasks. 05 Milestone Project 1: End-to-end Heart Disease Classification Here we'll put together everything we've gone through in the previous sections to create a machine learning model that is capable of classifying if someone has heart disease or not based on their health characteristics. We'll start with a raw dataset and work through performing an exploratory data analysis (EDA) on it before trying out several different machine learning models to see which performs best. 06 Introduction to TensorFlow/Keras and Deep Learning TensorFlow/Keras are deep learning frameworks written in Python. Originally created by Google and are now open-source. These frameworks allow you to build and train neural networks, one of the most powerful kinds of machine learning models. In this section we'll learn about deep learning and TensorFlow/Keras by building Dog Vision \ud83d\udc36\ud83d\udc41\ufe0f, a neural network to identify dog breeds in images. 07 Communicating your work One of the most important parts of machine learning and any software project is communicating what you've found/done. This module takes the learnings from the previous sections and gives tips and tricks on how you can communicate your work to others. If you have any questions, leave an issue/discussion on the course GitHub.
"},{"location":"#author","title":"Author","text":"Daniel Bourke
Last update: 24 September 2024
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/","title":"A 6 Step Framework for Approaching Machine Learning Projects","text":"Machine learning is broad. The media makes it sound like magic. Reading this article will change that. It will give you an overview of the most common types of problems machine learning can be used for. And at the same time give you a framework to approach your future machine learning proof of concept projects.
First, we\u2019ll clear up some definitions.
How is machine learning, artificial intelligence and data science different?
These three topics can be hard to understand because there are no formal definitions. Even after being a machine learning engineer for over a year, I don\u2019t have a good answer to this question. I\u2019d be suspicious of anyone who claims they do.
To avoid confusion, we\u2019ll keep it simple. For this article, you can consider machine learning the process of finding patterns in data to understand something more or to predict some kind of future event.
The following steps have a bias towards building something and seeing how it works. Learning by doing.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#6-steps-for-your-next-machine-learning-project","title":"6 steps for your next machine learning project","text":"A machine learning pipeline can be broken down into three major steps. Data collection, data modelling and deployment. All influence one another.
You may start a project by collecting data, model it, realise the data you collected was poor, go back to collecting data, model it again, find a good model, deploy it, find it doesn\u2019t work, make another model, deploy it, find it doesn\u2019t work again, go back to data collection. It\u2019s a cycle.
Wait, what does model mean? What\u2019s does deploy mean? How do I collect data?
Great questions.
How you collect data will depend on your problem. We will look at examples in a minute. But one way could be your customer purchases in a spreadsheet.
Modelling refers to using a machine learning algorithm to find insights within your collected data.
What\u2019s the difference between a normal algorithm and a machine learning algorithm?
Like a cooking recipe for your favourite chicken dish, a normal algorithm is a set of instructions on how to turn a set of ingredients into that honey mustard masterpiece.
What makes a machine learning algorithm different is instead of having the set of instructions, you start with the ingredients and the final dish ready to go. The machine learning algorithm then looks at the ingredients and the final dish and works out the set of instructions.
There are many different types of machine learning algorithms and some perform better than others on different problems. But the premise remains, they all have the goal of finding patterns or sets of instructions in data.
Deployment is taking your set of instructions and using it in an application. This application could be anything from recommending products to customers on your online store to a hospital trying to better predict disease presence.
The specifics of these steps will be different for each project. But the principles within each remain similar.
This article focuses on data modelling. It assumes you have already collected data, and are looking to build a machine learning proof of concept with it. Let\u2019s break down how you might approach it.
Machine learning projects can be broken into three steps, data collection, data modelling and deployment. This article focuses on steps within the data modelling phase and assumes you already have data. Full version on Whimsical. - Problem definition\u200a\u2014\u200aWhat business problem are we trying to solve? How can it be phrased as a machine learning problem?
- Data\u200a\u2014\u200aIf machine learning is getting insights out of data, what data we have? How does it match the problem definition? Is our data structured or unstructured? Static or streaming?
- Evaluation\u200a\u2014\u200aWhat defines success? Is a 95% accurate machine learning model good enough?
- Features\u200a\u2014\u200aWhat parts of our data are we going to use for our model? How can what we already know influence this?
- Modelling\u200a\u2014\u200aWhich model should you choose? How can you improve it? How do you compare it with other models?
- Experimentation\u200a\u2014\u200aWhat else could we try? Does our deployed model do as we expected? How do the other steps change based on what we\u2019ve found?
Let\u2019s dive a little deeper in each.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#1-problem-definition-rephrase-your-business-problem-as-a-machine-learning-problem","title":"1. Problem definition\u200a\u2014\u200aRephrase your business problem as a machine learning problem","text":"To help decide whether or not your business could use machine learning, the first step is to match the business problem you\u2019re trying to solve a machine learning problem.
The four major types of machine learning are supervised learning, unsupervised learning, transfer learning and reinforcement learning (there\u2019s semi-supervised as well but I\u2019ve left it out for brevity). The three most used in business applications are supervised learning, unsupervised learning and transfer learning.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#supervised-learning","title":"Supervised learning","text":"Supervised learning, is called supervised because you have data and labels. A machine learning algorithm tries to learn what patterns in the data lead to the labels. The supervised part happens during training. If the algorithm guesses a wrong label, it tries to correct itself.
For example, if you were trying to predict heart disease in a new patient. You may have the anonymised medical records of 100 patients as the data and whether or not they had heart disease as the label.
A machine learning algorithm could look at the medical records (inputs) and whether or not a patient had heart disease (outputs) and then figure out what patterns in the medical records lead to heart disease.
Once you\u2019ve got a trained algorithm, you could pass through the medical records (input) of a new patient through it and get a prediction of whether or not they have heart disease (output). It\u2019s important to remember this prediction isn\u2019t certain. It comes back as a probability.
The algorithm says, \u201cbased on what I\u2019ve seen before, it looks like this new patients medical records are 70% aligned to those who have heart disease.\u201d
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#unsupervised-learning","title":"Unsupervised learning","text":"Unsupervised learning is when you have data but no labels. The data could be the purchase history of your online video game store customers. Using this data, you may want to group similar customers together so you can offer them specialised deals. You could use a machine learning algorithm to group your customers by purchase history.
After inspecting the groups, you provide the labels. There may be a group interested in computer games, another group who prefer console games and another which only buy discounted older games. This is called clustering.
What\u2019s important to remember here is the algorithm did not provide these labels. It found the patterns between similar customers and using your domain knowledge, you provided the labels.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#transfer-learning","title":"Transfer learning","text":"Transfer learning is when you take the information an existing machine learning model has learned and adjust it to your own problem.
Training a machine learning model from scratch can be expensive and time-consuming. The good news is, you don\u2019t always have to. When machine learning algorithms find patterns in one kind of data, these patterns can be used in another type of data.
Let\u2019s say you\u2019re a car insurance company and wanted to build a text classification model to classify whether or not someone submitting an insurance claim for a car accident is at fault (caused the accident) or not at fault (didn\u2019t cause the accident).
You could start with an existing text model, one which has read all of Wikipedia and has remembered all the patterns between different words, such as, which word is more likely to come next after another. Then using your car insurance claims (data) along with their outcomes (labels), you could tweak the existing text model to your own problem.
If machine learning can be used in your business, it\u2019s likely it\u2019ll fall under one of these three types of learning. But let\u2019s break them down further into classification, regression and recommendation.
- Classification\u200a\u2014\u200aDo you want to predict whether something is one thing or another? Such as whether a customer will churn or not churn? Or whether a patient has heart disease or not? Note, there can be more than two things. Two classes is called binary classification, more than two classes is called multi-class classification. Multi-label is when an item can belong to more than one class.
- Regression\u200a\u2014\u200aDo you want to predict a specific number of something? Such as how much a house will sell for? Or how many customers will visit your site next month?
- Recommendation\u200a\u2014\u200aDo you want to recommend something to someone? Such as products to buy based on their previous purchases? Or articles to read based on their reading history?
Now you know these things, your next step is to define your business problem in machine learning terms.
Let\u2019s use the car insurance example from before. You receive thousands of claims per day which your staff read and decide whether or not the person sending in the claim is at fault or not.
But now the number of claims are starting to come in faster than your staff can handle them. You\u2019ve got thousands of examples of past claims which are labelled at fault or not at fault.
Can machine learning help?
You already know the answer. But let\u2019s see. Does this problem fit into any of the three above? Classification, regression or recommendation?
Let\u2019s rephrase it.
We\u2019re a car insurance company who want to classify incoming car insurance claims into at fault or not at fault.
See the keyword? Classify.
It turns out, this could potentially be a machine learning classification problem. I say potentially because there\u2019s a chance it might not work.
When it comes to defining your business problem as a machine learning problem, start simple, more than one sentence is too much. Add complexity when required.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#2-data-if-machine-learning-is-getting-insights-out-of-data-what-data-do-you-have","title":"2. Data\u200a\u2014\u200aIf machine learning is getting insights out of data, what data do you have?","text":"The data you have or need to collect will depend on the problem you want to solve.
If you already have data, it\u2019s likely it will be in one of two forms. Structured or unstructured. Within each of these, you have static or streaming data.
- Structured data\u200a\u2014\u200aThink a table of rows and columns, an Excel spreadsheet of customer transactions, a database of patient records. Columns can be numerical, such as average heart rate, categorical, such as sex, or ordinal, such as chest pain intensity.
- Unstructured data\u200a\u2014\u200aAnything not immediately able to be put into row and column format, images, audio files, natural language text.
- Static data\u200a\u2014\u200aExisting historical data which is unlikely to change. Your companies customer purchase history is a good example.
- Streaming data\u200a\u2014\u200aData which is constantly updated, older records may be changed, newer records are constantly being added.
There are overlaps.
Your static structured table of information may have columns which contain natural language text and photos and be updated constantly.
For predicting heart disease, one column may be sex, another average heart rate, another average blood pressure, another chest pain intensity.
For the insurance claim example, one column may be the text a customer has sent in for the claim, another may be the image they\u2019ve sent in along with the text and a final a column being the outcome of the claim. This table gets updated with new claims or altered results of old claims daily.
Two examples of structured data with different kinds of data within it. Table 1.0 has numerical and categorical data. Table 2.0 has unstructured data with images and natural language text but is presented in a structured manner. The principle remains. You want to use the data you have to gains insights or predict something.
For supervised learning, this involves using the feature variable(s) to predict the target variable(s). A feature variable for predicting heart disease could be sex with the target variable being whether or not the patient has heart disease.
Table 1.0 broken into ID column (yellow, not used for building machine learning model), feature variables (orange) and target variables (green). A machine learning model finds the patterns in the feature variables and predicts the target variables. For unsupervised learning, you won\u2019t have labels. But you\u2019ll still want to find patterns. Meaning, grouping together similar samples and finding samples which are outliers.
For transfer learning, your problem stays a supervised learning problem, except you\u2019re leveraging the patterns machine learning algorithms have learned from other data sources separate from your own.
Remember, if you\u2019re using a customers data to improve your business or to offer them a better service, it\u2019s important to let them know. This is why you see \u201cthis site uses cookies\u201d popups everywhere. The website uses how you browse the site, likely along with some kind of machine learning to improve their offering.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#3-evaluation-what-defines-success-is-a-95-accurate-machine-learning-model-good-enough","title":"3. Evaluation\u200a\u2014\u200aWhat defines success? Is a 95% accurate machine learning model good enough?","text":"You\u2019ve defined your business problem in machine learning terms and you have data. Now define what defines success. There are different evaluation metrics for classification, regression and recommendation problems. Which one you choose will depend on your goal.
For this project to be successful, the model needs to be over 95% accurate at whether someone is at fault or not at fault.
A 95% accurate model may sound pretty good for predicting who\u2019s at fault in an insurance claim. But for predicting heart disease, you\u2019ll likely want better results.
Other things you should take into consideration for classification problems.
- False negatives\u200a\u2014\u200aModel predicts negative, actually positive. In some cases, like email spam prediction, false negatives aren\u2019t too much to worry about. But if a self-driving cars computer vision system predicts no pedestrian when there was one, this is not good.
- False positives\u200a\u2014\u200aModel predicts positive, actually negative. Predicting someone has heart disease when they don\u2019t, might seem okay. Better to be safe right? Not if it negatively affects the person\u2019s lifestyle or sets them on a treatment plan they don\u2019t need.
- True negatives\u200a\u2014\u200aModel predicts negative, actually negative. This is good.
- True positives\u200a\u2014\u200aModel predicts positive, actually positive. This is good.
- Precision\u200a\u2014\u200aWhat proportion of positive predictions were actually correct? A model that produces no false positives has a precision of 1.0.
- Recall\u200a\u2014\u200aWhat proportion of actual positives were predicted correctly? A model that produces no false negatives has a recall of 1.0.
- F1 score\u200a\u2014\u200aA combination of precision and recall. The closer to 1.0, the better.
- Receiver operating characteristic (ROC) curve & Area under the curve (AUC)\u200a\u2014\u200aThe ROC curve is a plot comparing true positive and false positive rate. The AUC metric is the area under the ROC curve. A model whose predictions are 100% wrong has an AUC of 0.0, one whose predictions are 100% right has an AUC of 1.0.
For regression problems (where you want to predict a number), you\u2019ll want to minimise the difference between what your model predicts and what the actual value is. If you\u2019re trying to predict the price a house will sell for, you\u2019ll want your model to get as close as possible to the actual price. To do this, use MAE or RMSE.
- Mean absolute error (MAE)\u200a\u2014\u200aThe average difference between your model's predictions and the actual numbers.
- Root mean square error (RMSE)\u200a\u2014\u200aThe square root of the average of squared differences between your model's predictions and the actual numbers.
Use RMSE if you want large errors to be more significant. Such as, predicting a house to be sold at $300,000 instead of $200,000 and being off by $100,000 is more than twice as bad as being off by $50,000. Or MAE if being off by $100,000 is twice as bad as being off by $50,000.
Recommendation problems are harder to test in experimentation. One way to do so is to take a portion of your data and hide it away. When your model is built, use it to predict recommendations for the hidden data and see how it lines up.
Let\u2019s say you\u2019re trying to recommend customers products on your online store. You have historical purchase data from 2010\u20132019. You could build a model on the 2010\u20132018 data and then use it to predict 2019 purchases. Then it becomes a classification problem because you\u2019re trying to classify whether or not someone is likely to buy an item.
However, traditional classification metrics aren\u2019t the best for recommendation problems. Precision and recall have no concept of ordering.
If your machine learning model returned back a list of 10 recommendations to be displayed to a customer on your website, you\u2019d want the best ones to be displayed first right?
- Precision @ k (precision up to k)\u200a\u2014\u200aSame as regular precision, however, you choose the cutoff, k. For example, precision at 5, means we only care about the top 5 recommendations. You may have 10,000 products. But you can\u2019t recommend them all to your customers.
To begin with, you may not have an exact figure for each of these. But knowing what metrics you should be paying attention to gives you an idea of how to evaluate your machine learning project.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#4-features-what-features-does-your-data-have-and-which-can-you-use-to-build-your-model","title":"4. Features\u200a\u2014\u200aWhat features does your data have and which can you use to build your model?","text":"Not all data is the same. And when you hear someone referring to features, they\u2019re referring to different kinds of data within data.
The three main types of features are categorical, continuous (or numerical) and derived.
-
Categorical features\u200a\u2014\u200aOne or the other(s). For example, in our heart disease problem, the sex of the patient. Or for an online store, whether or not someone has made a purchase or not.
-
Continuous (or numerical) features\u200a\u2014\u200aA numerical value such as average heart rate or the number of times logged in. Derived features\u200a\u2014\u200aFeatures you create from the data. Often referred to as feature engineering. Feature engineering is how a subject matter expert takes their knowledge and encodes it into the data. You might combine the number of times logged in with timestamps to make a feature called time since last login. Or turn dates from numbers into \u201cis a weekday (yes)\u201d and \u201cis a weekday (no)\u201d.
Text, images and almost anything you can imagine can also be a feature. Regardless, they all get turned into numbers before a machine learning algorithm can model them.
Some important things to remember when it comes to features.
- Keep them the same during experimentation (training) and production (testing)\u200a\u2014\u200aA machine learning model should be trained on features which represent as close as possible to what it will be used for in a real system.
- Work with subject matter experts\u200a\u2014\u200aWhat do you already know about the problem, how can that influence what features you use? Let your machine learning engineers and data scientists know this.
- Are they worth it?\u200a\u2014\u200aIf only 10% of your samples have a feature, is it worth incorporating it in a model? Have a preference for features with the most coverage. The ones where lots of samples have data for.
- Perfect equals broken\u200a\u2014\u200aIf your model is achieving perfect performance, you\u2019ve likely got feature leakage somewhere. Which means the data your model has trained on is being used to test it. No model is perfect.
You can use features to create a simple baseline metric. A subject matter expert on customer churn may know someone is 80% likely to cancel their membership after 3 weeks of not logging in.
Or a real estate agent who knows the sale prices of houses might know houses with over 5 bedrooms and 4 bathrooms sell for over $500,000.
These are simplified and don\u2019t have to be exact. But it\u2019s what you\u2019re going to use to see whether machine learning can improve upon or not.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#5-modelling-which-model-should-you-choose-how-can-you-improve-it-how-do-you-compare-it-with-other-models","title":"5. Modelling\u200a\u2014\u200aWhich model should you choose? How can you improve it? How do you compare it with other models?","text":"Once you\u2019ve defined your problem, prepared your data, evaluation criteria and features it\u2019s time to model.
Modelling breaks into three parts, choosing a model, improving a model, comparing it with others.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#choosing-a-model","title":"Choosing a model","text":"When choosing a model, you\u2019ll want to take into consideration, interpretability and ease to debug, amount of data, training and prediction limitations.
- Interpretability and ease to debug\u200a\u2014\u200aWhy did a model make a decision it made? How can the errors be fixed?
- Amount of data\u200a\u2014\u200aHow much data do you have? Will this change?
- Training and prediction limitations\u200a\u2014\u200aThis ties in with the above, how much time and resources do you have for training and prediction?
To address these, start simple. A state of the art model can be tempting to reach for. But if it requires 10x the compute resources to train and prediction times are 5x longer for a 2% boost in your evaluation metric, it might not be the best choice.
Linear models such as logistic regression are usually easier to interpret, are very fast for training and predict faster than deeper models such as neural networks.
But it\u2019s likely your data is from the real world. Data from the real world isn\u2019t always linear.
What then?
Ensembles of decision trees and gradient boosted algorithms (fancy words, definitions not important for now) usually work best on structured data, like Excel tables and dataframes. Look into random forests, XGBoost and CatBoost.
A non-exhaustive example of all the different tools you can use for machine learning/data science. Deep models such as neural networks generally work best on unstructured data like images, audio files and natural language text. However, the trade-off is they usually take longer to train, are harder to debug and prediction time takes longer. But this doesn\u2019t mean you shouldn\u2019t use them.
Transfer learning is an approach which takes advantage of deep models and linear models. It involves taking a pre-trained deep model and using the patterns it has learned as the inputs to your linear model. This saves dramatically on training time and allows you to experiment faster.
Where do I find pre-trained models?
Pre-trained models are available on PyTorch hub, TensorFlow hub, model zoo and within the fast.ai framework. This is a good place to look first for building any kind of proof of concept.
What about the other kinds of models?
For building a proof of concept, it\u2019s unlikely you\u2019ll have to ever build your own machine learning model. People have already written code for these.
What you\u2019ll be focused on is preparing your inputs and outputs in a way they can be used with an existing model. This means having your data and labels strictly defined and understanding what problem you\u2019re trying to solve.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#tuning-and-improving-a-model","title":"Tuning and improving a model","text":"A model's first results isn\u2019t its last. Like tuning a car, machine learning models can be tuned to improve performance.
Tuning a model involves changing hyperparameters such as learning rate or optimizer. Or model-specific architecture factors such as number of trees for random forests and number of and type of layers for neural networks.
These used to be something a practitioner would have to tune by hand but are increasingly becoming automated. And should be wherever possible.
Using a pre-trained model through transfer learning often has the added benefit of all of these steps been done.
The priority for tuning and improving models should be reproducibility and efficiency. Someone should be able to reproduce the steps you\u2019ve taken to improve performance. And because your main bottleneck will be model training time, not new ideas to improve, your efforts should be dedicated towards efficiency.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#comparing-models","title":"Comparing models","text":"Compare apples to apples.
- Model 1, trained on data X, evaluated on data Y.
- Model 2, trained on data X, evaluated on data Y.
Where model 1 and 2 can vary but not data X or data Y.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#6-experimentation-what-else-could-we-try-how-do-the-other-steps-change-based-on-what-weve-found-does-our-deployed-model-do-as-we-expected","title":"6. Experimentation\u200a\u2014\u200aWhat else could we try? How do the other steps change based on what we\u2019ve found? Does our deployed model do as we expected?","text":"This step involves all the other steps. Because machine learning is a highly iterative process, you\u2019ll want to make sure your experiments are actionable.
Your biggest goal should be minimising the time between offline experiments and online experiments.
Offline experiments are steps you take when your project isn\u2019t customer-facing yet. Online experiments happen when your machine learning model is in production.
All experiments should be conducted on different portions of your data.
- Training data set\u200a\u2014\u200aUse this set for model training, 70\u201380% of your data is the standard.
- Validation/development data set\u200a\u2014\u200aUse this set for model tuning, 10\u201315% of your data is the standard.
- Test data set\u200a\u2014\u200aUse this set for model testing and comparison, 10\u201315% of your data is the standard.
These amounts can fluctuate slightly, depending on your problem and the data you have.
Poor performance on training data means the model hasn\u2019t learned properly. Try a different model, improve the existing one, collect more data, collect better data.
Poor performance on test data means your model doesn\u2019t generalise well. Your model may be overfitting the training data. Use a simpler model or collect more data.
Poor performance once deployed (in the real world) means there\u2019s a difference in what you trained and tested your model on and what is actually happening. Revisit step 1 & 2. Ensure your data matches up with the problem you\u2019re trying to solve.
When you implement a large experimental change, document what and why. Remember, like model tuning, someone, including your future self, should be able to reproduce what you\u2019ve done.
This means saving updated models and updated datasets regularly.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#putting-it-together-in-a-proof-of-concept","title":"Putting it together in a proof of concept","text":"Many businesses have heard of machine learning but aren\u2019t sure where to start. One of the best places to start is to use the six steps above to build a proof of concept.
A proof of concept should not be seen as something to fundamentally change how your business operates but as an exploration into whether machine learning can bring your business value.
After all, you\u2019re not after fancy solutions to keep up with the hype. You\u2019re after solutions which add value.
Put a timeline on a proof of concept, 2, 6 and 12 weeks are good amounts. With good data, a good machine learning and data science practitioner can get 80\u201390% of the final modelling results in a relatively small timeframe.
Have your subject matter experts and machine learning engineers and data scientists work together. There is nothing worse than a machine learning engineer building a great model which models the wrong thing.
If a web designer could improve the layout of an online store to help a machine learning experiment, they should know.
Remember, due to the nature of proof of concepts, it may turn out machine learning isn\u2019t something your business can take advantage of (unlikely). As a project manager, ensure you\u2019re aware of this. If you are a machine learning engineer or data scientist, be willing to accept your conclusions lead nowhere.
But all is not lost.
The value in something not working is now you know what doesn\u2019t work and can direct your efforts elsewhere. This is why setting a timeframe for experiments is helpful. There is never enough time but deadlines work wonders.
If a machine learning proof of concept turns out well, take another step, if not, step back. Learning by doing is a faster process than thinking about something.
"},{"location":"a-6-step-framework-for-approaching-machine-learning-projects/#things-this-article-has-missed","title":"Things this article has missed","text":"Each of these steps could deserve an article on their own. I\u2019ll work on it.
In the meantime, there are some things to note.
It\u2019s always about the data. Without good data to begin with, no machine learning model will help you. If you want to use machine learning in your business, it starts with good data collection.
Deployment changes everything. A good model offline doesn\u2019t always mean a good model online. This article has focused on data modelling. Once you deploy a model, there\u2019s infrastructure management, data verification, model retraining, analysis and more. Any cloud provider has services for these but putting them together is still a bit of a dark art. Pay your data engineers well. If you\u2019re data engineer, share what you know.
Data collection and model deployment are the longest parts of a machine learning pipeline. This article has only focused on modelling. And even then, it misses specifics on how to get your data ready to be modelled (other sections in this repo cover that).
Tools of the trade vary. Machine learning is big tool comprised of many other tools. From code libraries and frameworks to different deployment architectures. There\u2019s usually several different ways to do the same thing. Best practice is continually being changed. This article focuses on things which don\u2019t.
"},{"location":"communicating-your-work/","title":"Communicating and Sharing Your Work as a Data Scientist/Machine Learning Engineer","text":"This article is nearly 3000 words long but you can summarise it in 3.
3 words in the form of a question.
Whenever you're communicating your work, ask yourself, \"Who's it for?\".
That's your start. Build upon it. Dig deeper. Got an idea of who your work is for? What questions will they have? What needs do they have? What concerns can you address before they arise?
You'll never be able to fully answer these questions but it pays to think about them in advance.
Having a conversation with your potential audience is a warm up for the actual conversation.
Communicating your work is an unsolved challenge. But that's what makes it fun. What may make complete sense in your head could be a complete mystery to someone else.
If you want your message to be heard, it's not enough for you to deliver it in a way someone can hear it. You have to deliver it in a way it can be understood.
Imagine a man yelling in the middle of the street. His message can be heard. But no matter what he's talking about, it's unlikely it'll be understood.
Let's break this down.
After asking yourself, \"Who's it for?\", you'll start to realise there are two main audiences for your work. Those on your team, your boss, your manager, the people you sit next to and those who aren't, your clients, your customers, your fans. These can be broken down further and have plenty of overlaps but they're where we'll start.
You'll also start to realise, your work isn't for everyone. A beginner's mistake is thinking too broadly. A message which appeals to everyone may convey information but it'll lack substance. You want the gut punch reaction.
To begin, let's pretend you've asked yourself, \"Who's it for?\", and your answer is someone you work with, your teammates, your manager, someone on the internet reading about your latest technical project.
"},{"location":"communicating-your-work/#communicating-with-people-on-your-team","title":"Communicating with people on your team","text":"All non-technical problems are communication problems. Often, you'll find these harder to solve than the technical problems. Technical problems, unless bounded by the laws of physics, have a finite solution. Communication problems don't.
"},{"location":"communicating-your-work/#what-do-they-need-to-know","title":"What do they need to know?","text":"After asking yourself, \"Who's it for?\", a question you should follow up with is, \"What do they need to know?\".
What your teammate may need to know might be different to what your manager needs to know.
When answering this for yourself, lean on the side of excess. Write it down for later. The worst case is, you figure out what's not needed.
Start with \"Who's it for?\" and follow it up with \"What do they need to know?\". When answering these questions, write your questions and answers down. Writing helps to clear your thinking. It also gives you a resource you can refer to later."},{"location":"communicating-your-work/#the-project-manager-boss-senior-lead","title":"The Project Manager, Boss, Senior, Lead","text":"Your project manager, Amber, has a mission. Aside from taking care of you and the team, she's determined to keep the project running on time and on budget.
This translates to: keeping obstacles out of your way.
So her questions will often come in some form of \"What's holding you back?\".
It should go without saying, honesty is your best friend here. Life happens. When challenges come up, Amber should know about them.
That's what Amber is there for. She's there to help oversee and figure out the challenges, she's there to connect you with people who might be able to help.
When preparing a report, align it to the questions and concerns Amber may have. If you\u2019ve asked yourself, \u201cWhat does Amber need to know?\u201d, start with the answers.
Your bosses primary job is to take care of you and challenging you (if not, get a new boss). After this, it's in their best interest for projects to run on budget and time. This means keeping obstacles out of your way. If something is holding you back, you should let them know."},{"location":"communicating-your-work/#the-people-youre-working-with-sitting-next-to-in-the-group-chat","title":"The People You're Working With, Sitting Next to, in the Group Chat","text":"It saddens me how many communication channels there are now. Most of them encourage communicating too often. Unless it's an emergency, \"Now\" is often never the best time.
Projects you work on will have arbitrarily long timelines, with many milestones, plans and steps. Keep in mind the longer the timescale, the worse humans are at dealing with them.
Break it down. Days and weeks are much easier units of time to understand.
Example of how a 6-month project becomes a day-by-day project. What are you working on this week? Write it down, share it with the team. This not only consolidates your thinking, it gives your team an opportunity to ask questions and offer advice.
Set a reminder for the end of each day. Have it ask, \"What did you work on today?\". Your response doesn't have to be long but it should be written down.
You could use the following template.
What I worked on today (1-3 points on what you did):
- What's working?
- What's not working?
- What could be improved?
What I'm working on next:
- What's your next course of action? (based on the above)
- Why?
- What's holding you back?
After you've written down answers, you should share them with your team.
The beauty of a daily reflection like this is you've got a history, a playbook, a thought process. Plus, this style of communication is far better than little bits and pieces scattered throughout the day.
You may be tempted to hold something back because it's not perfect, not fully thought out, but that's what your teammates are for. To help you figure it out. The same goes for the reverse. Help each other.
Relate these daily and weekly communications back to the overall project goal. A 6-month project seems like a lot to begin with but breaking it down week by week, day by day, helps you and the people around you know what's going on.
Take note of questions which arise. If a question gets asked more than 3 times, it should be documented somewhere for others to reference.
You'll see some of the communication points for the people you're sitting with crossover with your project manager and vice versa. You're smart enough to figure out when to use each.
"},{"location":"communicating-your-work/#start-the-job-before-you-have-it","title":"Start the job before you have it","text":"It can be hard to communicate with a project manager, boss or teammates if you don't have a job. And if you've recently learned some skills through an online course, it can be tempting to jump straight into the next one.
But what are you really chasing?
Are you after more certificates or more skills?
No matter how good the course, you can assume the skills you learn there will be commoditised. That means, many other people will have gone through the same course, acquired the skills and then will be looking for similar jobs to what you are.
If Janet posts a job vacancy and receives 673 applicants through an online form, you can imagine how hard it is for your resume to stand out.
This isn't to say you shouldn't apply through an online form but if you're really serious about getting a role somewhere, start the job before you have it.
How?
By working on and sharing your own projects which relate to the role you're applying for.
I call this the weekend project principle. During the week you're building foundational skills through various courses. But on the weekend, you design your own projects, projects inline with the role you're after and work on them.
Let\u2019s see it in practice.
Melissa and Henry apply for a data scientist role. They both make it through to interviews and are sitting with Janet. Janet looks at both their resumes and notices they've both done similar style courses.
She asks Joe if he's worked on any of his own projects and he tells her, no he's only had a chance to work on coursework but has plenty of ideas.
She asks Melissa the same. She pulls out her phone and tells Janet she's built a small app to help read food labels. Her daughter can't have gluten and got confused every time she tried to figure out what was in the food she was eating. The app isn't perfect but Melissa tells the story of how her daughter has figured out a few foods she should avoid and a few others which are fine.
If you were Janet, who would you lean towards?
Working on your own projects helps you build specific knowledge, they're what compound knowledge into skill, skill which can't be taught in courses.
What should you work on?
The hard part is you've unlimited options. The best part is you've got unlimited options.
One method is to find the ideal company and ideal role you're going for. And then do your research.
What does a person in that position day-to-day? Figure it out and then replicate it. Design yourself a 6-week project based on what you find.
Why 6-weeks? The worst case is, if it doesn't work out, it's only 6 weeks. The best case is, you'll surprise yourself at what you can accomplish in 42-days.
If you're still stuck, follow your interests. Use the same timeline except this time, choose something which excites you and see where it goes. Remember, the worst case is, after 6-weeks, you'll know whether to pursue it (another 6 weeks) or move onto the next thing.
Now instead of only having a collection of certificates, you've got a story to tell. You've got evidence of you trying to put what you've learned into practice (exactly what you'll be doing in a job).
And if you're wondering where the evidence comes from, it comes from you documenting your work.
Where?
On your own blog.
Why a blog?
We've discussed this before but it's worth repeating. Writing down what you're working on, helps solidify your thinking. It also helps others learn what you\u2019ve figured out.
You could start with a post per week detailing how your 6-week project is going, what you've figured out, what you're doing next. Again, your project doesn't have to be perfect, none are, and your writing doesn't have to be perfect either.
By the end of the 6-weeks, you'll have a series of articles detailing your work.
Something you can point to and say, \"This is what I've done.\"
If you're looking for resources to start a blog, Devblog by Hashnode and fast_template by the fast.ai team are both free and require almost zero setup. Medium is the next best place.
Share your articles on Twitter, LinkedIn or even better, send them directly to the person in charge of hiring for the role you're after. You're crafty enough to find them.
"},{"location":"communicating-your-work/#communicating-with-those-outside-your-team","title":"Communicating with those outside your team","text":"When answering \"Who's it for?\u201d results in someone who doesn't think like you, customers, clients, fans, it's also important to follow up with \"What do they need to know?\".
A reminder: The line between people on your team and outside your team isn\u2019t set in stone. The goal of these exercises and techniques are to get you thinking from the perspective of the person you are trying to communicate with.
"},{"location":"communicating-your-work/#clients-customers-fans","title":"Clients, Customers & Fans","text":"I made a presentation for a board meeting once. We were there to present our results on a recent software proof of concept to some executives. Being an engineer, my presentation slides were clogged with detailed text, barely large enough to read. It contained every detail of the project, the techniques used, theories, code, acronyms with no definition. The presentation looked great to other engineers but caused the executives to squint, lean in and ignore everything being said in an attempt to read them.
Once we made it through to the end, a slide with a visual appeared, to which, I palmed off as unnecessary but immediately sparked the interest of the executives.
\"What's that?\", one asked.
We spent the next 45-minutes discussing that one slide in detail. The slide which to me, didn\u2019t matter.
The lesson here is what you think is important may be the opposite to others. And what's obvious to you could be amazing to others.
Knowing this, you'll start to realise, unless they directly tell you, figuring out what your clients, customers and fans want to know is a challenge.
There's a simple solution to this.
Ask.
Most people have a lot to offer but rarely volunteer it. Ask if what you're saying is clear, ask if there is anything else they'd like to see.
You may get something left of field or things you're not sure of. In these cases, it's up to you to address them before they become larger issues.
Don't forget, sometimes the best answer is \"I don't know, but I'll figure it out and get back to you,\" or \"that's not what we're focused on for now...\" (then bringing it back to what you are focused on).
"},{"location":"communicating-your-work/#what-story-are-you-telling","title":"What story are you telling?","text":"You're going to underestimate and overestimate your work at the same time. This is a good thing. No one is going to care as much about your work as you. It's up to you to be your own biggest fan and harshest critique at the same time.
The first step of any creation is to make something you're proud of. The next step is to figure out how you could improve it. In other words, being your own biggest fan and harshest critique at the same time. When sharing your work, you could drop the facts in. Nothing but a list of exactly what you did. But everyone else can do that too.
Working what you've done into a story, sharing what worked, what didn't, why you went one direction and not another is hard. But that's exactly why it's worth it.
I will say it until I go hoarse, how you deliver your message will depend on who your audience is.
"},{"location":"communicating-your-work/#being-specific-is-brave-put-it-in-writing-and-heres-what-ive-done","title":"Being specific is brave, put it in writing and here's what I've done","text":"Starting with \"Who's it for?\", and following up with, \"What do they need to know?\", means you're going to have to be specific. And being specific means having to say, \u201cIt's not for you\" to a lot of people. Doing this takes courage but it also means the ones who do receive your message will engage with it more.
You'll get lost in thought but found in the words. Writing is nature's way of showing how sloppy your thinking is. Break your larger projects down into a series of sub projects.
What's on today? What's on this week? Tell yourself, tell your team.
Take advantage of Cunningham's Law: Sometimes the best way to figure out the right answer isn't to ask a question, it's to put the wrong answer out there.
Finally, remind yourself, you're not going for perfection. You're going for progress. Going for perfection gets in the way of progress.
You know you should have your own blog, you know you should be building specific knowledge by working on your own your projects, you know you should be documenting what you've been working on.
The upside of being able to say, \"Here's what I've done\", far outweighs the downside of potentially being wrong.
"},{"location":"communicating-your-work/#recommended-further-reading-and-resources","title":"Recommended Further Reading and Resources","text":"This article was inspired by experience and a handful of other resources worth your time.
- Basecamp\u2019s guide to internal communication \u2013 if you're working on a team, this should be required reading for everyone.
- You Should Blog by Jeremy Howard from fast.ai \u2013 The fast.ai team not only teach amazing artificial intelligence and other technical skills, they teach you how to communicate them. The best thing is, they live and breath what they teach.
- How to Start Your Own Machine Learning Projects by Daniel Bourke \u2013 After learning foundational skills using courses, one of the hardest things to do next is to use the skills you've learned in your own projects. This article by yours truly gives a deeper breakdown into how to approach your own projects.
- Why you (yes, you) should blog by Rachel Thomas from fast.ai \u2013 Rachel Thomas not only has incredible technical skills, she's a phenomenal communicator. If you aren't convinced to start your own blog yet, this article will have you writing in no time.
- Fast Template by fast.ai \u2013 Starting a blog should be required for everyone learning some kind of skill. Fast Template by the fast.ai team makes it free and easy.
- Devblog by Hasnode \u2013 Your own blog, your own domain, readers ready to go, you own your content (automatic backups on GitHub), all ready to go. Start writing.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/","title":"End-to-End Bulldozer Price Regression","text":"View source code | Read notebook in online book format
In\u00a0[8]: Copied! # Timestamp\nimport datetime\n\nimport datetime\nprint(f\"Notebook last run (end-to-end): {datetime.datetime.now()}\")\n # Timestamp import datetime import datetime print(f\"Notebook last run (end-to-end): {datetime.datetime.now()}\") Notebook last run (end-to-end): 2024-10-30 11:54:38.504966\n
In\u00a0[9]: Copied! # Import data analysis tools \nimport pandas as pd\nimport numpy as np\nimport matplotlib\nimport matplotlib.pyplot as plt\n\n# Print the versions we're using (as long as your versions are equal or higher than these, the code should work)\nprint(f\"pandas version: {pd.__version__}\")\nprint(f\"NumPy version: {np.__version__}\")\nprint(f\"matplotlib version: {matplotlib.__version__}\")\n # Import data analysis tools import pandas as pd import numpy as np import matplotlib import matplotlib.pyplot as plt # Print the versions we're using (as long as your versions are equal or higher than these, the code should work) print(f\"pandas version: {pd.__version__}\") print(f\"NumPy version: {np.__version__}\") print(f\"matplotlib version: {matplotlib.__version__}\") pandas version: 2.2.2\nNumPy version: 2.1.1\nmatplotlib version: 3.9.2\n
Now we've got our tools for data analysis ready, we can import the data and start to explore it.
For this project, I've downloaded the data from Kaggle and stored it on the course GitHub under the file path ../data/bluebook-for-bulldozers.
We can write some code to check if the files are available locally (on our computer) and if not, we can download them.
Note: If you're running this notebook on Google Colab, the code below will enable you to download the dataset programmatically. Just beware that each time Google Colab shuts down, the data will have to be redownloaded. There's also an example Google Colab notebook showing how to download the data programmatically.
In\u00a0[10]: Copied! from pathlib import Path\n\n# Check if 'bluebook-for-bulldozers' exists in the current or parent directory\n# Link to data (see the file \"bluebook-for-bulldozers\"): https://github.com/mrdbourke/zero-to-mastery-ml/tree/master/data\ndataset_dir = Path(\"../data/bluebook-for-bulldozers\")\nif not (dataset_dir.is_dir()):\n print(f\"[INFO] Can't find existing 'bluebook-for-bulldozers' dataset in current directory or parent directory, downloading...\")\n\n # Download and unzip the bluebook for bulldozers dataset\n !wget https://github.com/mrdbourke/zero-to-mastery-ml/raw/refs/heads/master/data/bluebook-for-bulldozers.zip\n !unzip bluebook-for-bulldozers.zip\n\n # Ensure a data directory exists and move the downloaded dataset there\n !mkdir ../data/\n !mv bluebook-for-bulldozers ../data/\n print(f\"[INFO] Current dataset dir: {dataset_dir}\")\n\n # Remove .zip file from notebook directory\n !rm -rf bluebook-for-bulldozers.zip\nelse:\n # If the target dataset directory exists, we don't need to download it\n print(f\"[INFO] 'bluebook-for-bulldozers' dataset exists, feel free to proceed!\")\n print(f\"[INFO] Current dataset dir: {dataset_dir}\")\n from pathlib import Path # Check if 'bluebook-for-bulldozers' exists in the current or parent directory # Link to data (see the file \"bluebook-for-bulldozers\"): https://github.com/mrdbourke/zero-to-mastery-ml/tree/master/data dataset_dir = Path(\"../data/bluebook-for-bulldozers\") if not (dataset_dir.is_dir()): print(f\"[INFO] Can't find existing 'bluebook-for-bulldozers' dataset in current directory or parent directory, downloading...\") # Download and unzip the bluebook for bulldozers dataset !wget https://github.com/mrdbourke/zero-to-mastery-ml/raw/refs/heads/master/data/bluebook-for-bulldozers.zip !unzip bluebook-for-bulldozers.zip # Ensure a data directory exists and move the downloaded dataset there !mkdir ../data/ !mv bluebook-for-bulldozers ../data/ print(f\"[INFO] Current dataset dir: {dataset_dir}\") # Remove .zip file from notebook directory !rm -rf bluebook-for-bulldozers.zip else: # If the target dataset directory exists, we don't need to download it print(f\"[INFO] 'bluebook-for-bulldozers' dataset exists, feel free to proceed!\") print(f\"[INFO] Current dataset dir: {dataset_dir}\") [INFO] 'bluebook-for-bulldozers' dataset exists, feel free to proceed!\n[INFO] Current dataset dir: ../data/bluebook-for-bulldozers\n
Dataset downloaded!
Let's check what files are available.
In\u00a0[11]: Copied! import os\n\nprint(f\"[INFO] Files/folders available in {dataset_dir}:\")\nos.listdir(dataset_dir)\n import os print(f\"[INFO] Files/folders available in {dataset_dir}:\") os.listdir(dataset_dir) [INFO] Files/folders available in ../data/bluebook-for-bulldozers:\n
Out[11]: ['random_forest_benchmark_test.csv',\n 'Valid.csv',\n 'median_benchmark.csv',\n 'Valid.zip',\n 'TrainAndValid.7z',\n 'Test.csv',\n 'predictions.csv',\n 'Train.7z',\n 'TrainAndValid_object_values_as_categories.parquet',\n 'test_predictions.csv',\n 'ValidSolution.csv',\n 'train_tmp.csv',\n 'Machine_Appendix.csv',\n 'Train.csv',\n 'Valid.7z',\n 'TrainAndValid_object_values_as_categories.csv',\n 'TrainAndValid_object_values_as_categories_and_missing_values_filled.parquet',\n 'Data Dictionary.xlsx',\n 'TrainAndValid.csv',\n 'Train.zip',\n 'TrainAndValid.zip']
You can explore each of these files individually or read about them on the Kaggle Competition page.
For now, the main file we're interested in is TrainAndValid.csv (this is also a combination of Train.csv and Valid.csv), this is a combination of the training and validation datasets.
- The training data (
Train.csv) contains sale data from 1989 up to the end of 2011. - The validation data (
Valid.csv) contains sale data from January 1, 2012 - April 30, 2012. - The test data (
Test.csv) contains sale data from May 1, 2012 - November 2012.
We'll use the training data to train our model to predict the sale price of bulldozers, we'll then validate its performance on the validation data to see if our model can be improved in any way. Finally, we'll evaluate our best model on the test dataset.
But more on this later on.
Let's import the TrainAndValid.csv file and turn it into a pandas DataFrame.
In\u00a0[12]: Copied! # Import the training and validation set\ndf = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/TrainAndValid.csv\")\n
# Import the training and validation set df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/TrainAndValid.csv\") /var/folders/c4/qj4gdk190td18bqvjjh0p3p00000gn/T/ipykernel_20423/1127193594.py:2: DtypeWarning: Columns (13,39,40,41) have mixed types. Specify dtype option on import or set low_memory=False.\n df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/TrainAndValid.csv\")\n
Wonderful! We've got our DataFrame ready to explore.
You might see a warning appear in the form:
DtypeWarning: Columns (13,39,40,41) have mixed types. Specify dtype option on import or set low_memory=False. df = pd.read_csv(\"../data/bluebook-for-bulldozers/TrainAndValid.csv\")
This is just saying that some of our columns have multiple/mixed data types. For example, a column may contain strings but also contain integers. This is okay for now and can be addressed later on if necessary.
How about we get some information about our DataFrame?
In\u00a0[13]: Copied! # Get info about DataFrame\ndf.info()\n
# Get info about DataFrame df.info() <class 'pandas.core.frame.DataFrame'>\nRangeIndex: 412698 entries, 0 to 412697\nData columns (total 53 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 SalesID 412698 non-null int64 \n 1 SalePrice 412698 non-null float64\n 2 MachineID 412698 non-null int64 \n 3 ModelID 412698 non-null int64 \n 4 datasource 412698 non-null int64 \n 5 auctioneerID 392562 non-null float64\n 6 YearMade 412698 non-null int64 \n 7 MachineHoursCurrentMeter 147504 non-null float64\n 8 UsageBand 73670 non-null object \n 9 saledate 412698 non-null object \n 10 fiModelDesc 412698 non-null object \n 11 fiBaseModel 412698 non-null object \n 12 fiSecondaryDesc 271971 non-null object \n 13 fiModelSeries 58667 non-null object \n 14 fiModelDescriptor 74816 non-null object \n 15 ProductSize 196093 non-null object \n 16 fiProductClassDesc 412698 non-null object \n 17 state 412698 non-null object \n 18 ProductGroup 412698 non-null object \n 19 ProductGroupDesc 412698 non-null object \n 20 Drive_System 107087 non-null object \n 21 Enclosure 412364 non-null object \n 22 Forks 197715 non-null object \n 23 Pad_Type 81096 non-null object \n 24 Ride_Control 152728 non-null object \n 25 Stick 81096 non-null object \n 26 Transmission 188007 non-null object \n 27 Turbocharged 81096 non-null object \n 28 Blade_Extension 25983 non-null object \n 29 Blade_Width 25983 non-null object \n 30 Enclosure_Type 25983 non-null object \n 31 Engine_Horsepower 25983 non-null object \n 32 Hydraulics 330133 non-null object \n 33 Pushblock 25983 non-null object \n 34 Ripper 106945 non-null object \n 35 Scarifier 25994 non-null object \n 36 Tip_Control 25983 non-null object \n 37 Tire_Size 97638 non-null object \n 38 Coupler 220679 non-null object \n 39 Coupler_System 44974 non-null object \n 40 Grouser_Tracks 44875 non-null object \n 41 Hydraulics_Flow 44875 non-null object \n 42 Track_Type 102193 non-null object \n 43 Undercarriage_Pad_Width 102916 non-null object \n 44 Stick_Length 102261 non-null object \n 45 Thumb 102332 non-null object \n 46 Pattern_Changer 102261 non-null object \n 47 Grouser_Type 102193 non-null object \n 48 Backhoe_Mounting 80712 non-null object \n 49 Blade_Type 81875 non-null object \n 50 Travel_Controls 81877 non-null object \n 51 Differential_Type 71564 non-null object \n 52 Steering_Controls 71522 non-null object \ndtypes: float64(3), int64(5), object(45)\nmemory usage: 166.9+ MB\n
Woah! Over 400,000 entries!
That's a much larger dataset than what we've worked with before.
One thing you might have noticed is that the saledate column value is being treated as a Python object (it's okay if you didn't notice, these things take practice).
When the Dtype is object, it's saying that it's a string.
However, when we look at it...
In\u00a0[15]: Copied! df[\"saledate\"][:10]\n
df[\"saledate\"][:10] Out[15]: 0 11/16/2006 0:00\n1 3/26/2004 0:00\n2 2/26/2004 0:00\n3 5/19/2011 0:00\n4 7/23/2009 0:00\n5 12/18/2008 0:00\n6 8/26/2004 0:00\n7 11/17/2005 0:00\n8 8/27/2009 0:00\n9 8/9/2007 0:00\nName: saledate, dtype: object
We can see that these object's are in the form of dates.
Since we're working on a time series problem (a machine learning problem with a time component), it's probably worth it to turn these strings into Python datetime objects.
Before we do, let's try visualize our saledate column against our SalePrice column.
To do so, we can create a scatter plot.
And to prevent our plot from being too big, how about we visualize the first 1000 values?
In\u00a0[16]: Copied! fig, ax = plt.subplots()\nax.scatter(x=df[\"saledate\"][:1000], # visualize the first 1000 values\n y=df[\"SalePrice\"][:1000])\nax.set_xlabel(\"Sale Date\")\nax.set_ylabel(\"Sale Price ($)\");\n
fig, ax = plt.subplots() ax.scatter(x=df[\"saledate\"][:1000], # visualize the first 1000 values y=df[\"SalePrice\"][:1000]) ax.set_xlabel(\"Sale Date\") ax.set_ylabel(\"Sale Price ($)\"); Hmm... looks like the x-axis is quite crowded.
Maybe we can fix this by turning the saledate column into datetime format.
Good news is that is looks like our SalePrice column is already in float64 format so we can view its distribution directly from the DataFrame using a histogram plot.
In\u00a0[17]: Copied! # View SalePrice distribution \ndf.SalePrice.plot.hist(xlabel=\"Sale Price ($)\");\n
# View SalePrice distribution df.SalePrice.plot.hist(xlabel=\"Sale Price ($)\"); In\u00a0[18]: Copied! df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/TrainAndValid.csv\",\n low_memory=False, # set low_memory=False to prevent mixed data types warning \n parse_dates=[\"saledate\"]) # can use the parse_dates parameter and specify which column to treat as a date column\n\n# With parse_dates... check dtype of \"saledate\"\ndf.info()\n
df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/TrainAndValid.csv\", low_memory=False, # set low_memory=False to prevent mixed data types warning parse_dates=[\"saledate\"]) # can use the parse_dates parameter and specify which column to treat as a date column # With parse_dates... check dtype of \"saledate\" df.info() <class 'pandas.core.frame.DataFrame'>\nRangeIndex: 412698 entries, 0 to 412697\nData columns (total 53 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 SalesID 412698 non-null int64 \n 1 SalePrice 412698 non-null float64 \n 2 MachineID 412698 non-null int64 \n 3 ModelID 412698 non-null int64 \n 4 datasource 412698 non-null int64 \n 5 auctioneerID 392562 non-null float64 \n 6 YearMade 412698 non-null int64 \n 7 MachineHoursCurrentMeter 147504 non-null float64 \n 8 UsageBand 73670 non-null object \n 9 saledate 412698 non-null datetime64[ns]\n 10 fiModelDesc 412698 non-null object \n 11 fiBaseModel 412698 non-null object \n 12 fiSecondaryDesc 271971 non-null object \n 13 fiModelSeries 58667 non-null object \n 14 fiModelDescriptor 74816 non-null object \n 15 ProductSize 196093 non-null object \n 16 fiProductClassDesc 412698 non-null object \n 17 state 412698 non-null object \n 18 ProductGroup 412698 non-null object \n 19 ProductGroupDesc 412698 non-null object \n 20 Drive_System 107087 non-null object \n 21 Enclosure 412364 non-null object \n 22 Forks 197715 non-null object \n 23 Pad_Type 81096 non-null object \n 24 Ride_Control 152728 non-null object \n 25 Stick 81096 non-null object \n 26 Transmission 188007 non-null object \n 27 Turbocharged 81096 non-null object \n 28 Blade_Extension 25983 non-null object \n 29 Blade_Width 25983 non-null object \n 30 Enclosure_Type 25983 non-null object \n 31 Engine_Horsepower 25983 non-null object \n 32 Hydraulics 330133 non-null object \n 33 Pushblock 25983 non-null object \n 34 Ripper 106945 non-null object \n 35 Scarifier 25994 non-null object \n 36 Tip_Control 25983 non-null object \n 37 Tire_Size 97638 non-null object \n 38 Coupler 220679 non-null object \n 39 Coupler_System 44974 non-null object \n 40 Grouser_Tracks 44875 non-null object \n 41 Hydraulics_Flow 44875 non-null object \n 42 Track_Type 102193 non-null object \n 43 Undercarriage_Pad_Width 102916 non-null object \n 44 Stick_Length 102261 non-null object \n 45 Thumb 102332 non-null object \n 46 Pattern_Changer 102261 non-null object \n 47 Grouser_Type 102193 non-null object \n 48 Backhoe_Mounting 80712 non-null object \n 49 Blade_Type 81875 non-null object \n 50 Travel_Controls 81877 non-null object \n 51 Differential_Type 71564 non-null object \n 52 Steering_Controls 71522 non-null object \ndtypes: datetime64[ns](1), float64(3), int64(5), object(44)\nmemory usage: 166.9+ MB\n
Nice!
Looks like our saledate column is now of type datetime64[ns], a NumPy-specific datetime format with high precision.
Since pandas works well with NumPy, we can keep it in this format.
How about we view a few samples from our SaleDate column again?
In\u00a0[19]: Copied! df[\"saledate\"][:10]\n
df[\"saledate\"][:10] Out[19]: 0 2006-11-16\n1 2004-03-26\n2 2004-02-26\n3 2011-05-19\n4 2009-07-23\n5 2008-12-18\n6 2004-08-26\n7 2005-11-17\n8 2009-08-27\n9 2007-08-09\nName: saledate, dtype: datetime64[ns]
Beautiful! That's looking much better already.
We'll see how having our dates in this format is really helpful later on.
For now, how about we visualize our saledate column against our SalePrice column again?
In\u00a0[20]: Copied! fig, ax = plt.subplots()\nax.scatter(x=df[\"saledate\"][:1000], # visualize the first 1000 values\n y=df[\"SalePrice\"][:1000])\nax.set_xlabel(\"Sale Date\")\nax.set_ylabel(\"Sale Price ($)\");\n
fig, ax = plt.subplots() ax.scatter(x=df[\"saledate\"][:1000], # visualize the first 1000 values y=df[\"SalePrice\"][:1000]) ax.set_xlabel(\"Sale Date\") ax.set_ylabel(\"Sale Price ($)\"); In\u00a0[21]: Copied! # Sort DataFrame in date order\ndf.sort_values(by=[\"saledate\"], inplace=True, ascending=True)\ndf.saledate.head(10), df.saledate.tail(10)\n
# Sort DataFrame in date order df.sort_values(by=[\"saledate\"], inplace=True, ascending=True) df.saledate.head(10), df.saledate.tail(10) Out[21]: (205615 1989-01-17\n 274835 1989-01-31\n 141296 1989-01-31\n 212552 1989-01-31\n 62755 1989-01-31\n 54653 1989-01-31\n 81383 1989-01-31\n 204924 1989-01-31\n 135376 1989-01-31\n 113390 1989-01-31\n Name: saledate, dtype: datetime64[ns],\n 409202 2012-04-28\n 408976 2012-04-28\n 411695 2012-04-28\n 411319 2012-04-28\n 408889 2012-04-28\n 410879 2012-04-28\n 412476 2012-04-28\n 411927 2012-04-28\n 407124 2012-04-28\n 409203 2012-04-28\n Name: saledate, dtype: datetime64[ns])
Nice!
Looks like our older samples are now coming first and the newer samples are towards the end of the DataFrame.
In\u00a0[22]: Copied! # Make a copy of the original DataFrame to perform edits on\ndf_tmp = df.copy()\n
# Make a copy of the original DataFrame to perform edits on df_tmp = df.copy() Because we imported the data using read_csv() and we asked pandas to parse the dates using parase_dates=[\"saledate\"], we can now access the different datetime attributes of the saledate column.
Let's use these attributes to add a series of different feature columns to our dataset.
After we've added these extra columns, we can remove the original saledate column as its information will be dispersed across these new columns.
In\u00a0[23]: Copied! # Add datetime parameters for saledate\ndf_tmp[\"saleYear\"] = df_tmp.saledate.dt.year\ndf_tmp[\"saleMonth\"] = df_tmp.saledate.dt.month\ndf_tmp[\"saleDay\"] = df_tmp.saledate.dt.day\ndf_tmp[\"saleDayofweek\"] = df_tmp.saledate.dt.dayofweek\ndf_tmp[\"saleDayofyear\"] = df_tmp.saledate.dt.dayofyear\n\n# Drop original saledate column\ndf_tmp.drop(\"saledate\", axis=1, inplace=True)\n
# Add datetime parameters for saledate df_tmp[\"saleYear\"] = df_tmp.saledate.dt.year df_tmp[\"saleMonth\"] = df_tmp.saledate.dt.month df_tmp[\"saleDay\"] = df_tmp.saledate.dt.day df_tmp[\"saleDayofweek\"] = df_tmp.saledate.dt.dayofweek df_tmp[\"saleDayofyear\"] = df_tmp.saledate.dt.dayofyear # Drop original saledate column df_tmp.drop(\"saledate\", axis=1, inplace=True) We could add more of these style of columns, such as, whether it was the start or end of a quarter (the sale being at the end of a quarter may bye influenced by things such as quarterly budgets) but these will do for now.
Challenge: See what other datetime attributes you can add to df_tmp using a similar technique to what we've used above. Hint: check the bottom of the pandas.DatetimeIndex docs.
How about we view some of our newly created columns?
In\u00a0[24]: Copied! # View newly created columns\ndf_tmp[[\"SalePrice\", \"saleYear\", \"saleMonth\", \"saleDay\", \"saleDayofweek\", \"saleDayofyear\"]].head()\n
# View newly created columns df_tmp[[\"SalePrice\", \"saleYear\", \"saleMonth\", \"saleDay\", \"saleDayofweek\", \"saleDayofyear\"]].head() Out[24]: SalePrice saleYear saleMonth saleDay saleDayofweek saleDayofyear 205615 9500.0 1989 1 17 1 17 274835 14000.0 1989 1 31 1 31 141296 50000.0 1989 1 31 1 31 212552 16000.0 1989 1 31 1 31 62755 22000.0 1989 1 31 1 31 Cool!
Now we've broken our saledate column into columns/features, we can perform further exploratory analysis such as visualizing the SalePrice against the saleMonth.
How about we view the first 10,000 samples (we could also randomly select 10,000 samples too) to see if reveals anything about which month has the highest sales?
In\u00a0[25]: Copied! # View 10,000 samples SalePrice against saleMonth\nfig, ax = plt.subplots()\nax.scatter(x=df_tmp[\"saleMonth\"][:10000], # visualize the first 10000 values\n y=df_tmp[\"SalePrice\"][:10000])\nax.set_xlabel(\"Sale Month\")\nax.set_ylabel(\"Sale Price ($)\");\n
# View 10,000 samples SalePrice against saleMonth fig, ax = plt.subplots() ax.scatter(x=df_tmp[\"saleMonth\"][:10000], # visualize the first 10000 values y=df_tmp[\"SalePrice\"][:10000]) ax.set_xlabel(\"Sale Month\") ax.set_ylabel(\"Sale Price ($)\"); Hmm... doesn't look like there's too much conclusive evidence here about which month has the highest sales value.
How about we plot the median sale price of each month?
We can do so by grouping on the saleMonth column with pandas.DataFrame.groupby and then getting the median of the SalePrice column.
In\u00a0[26]: Copied! # Group DataFrame by saleMonth and then find the median SalePrice\ndf_tmp.groupby([\"saleMonth\"])[\"SalePrice\"].median().plot()\nplt.xlabel(\"Month\")\nplt.ylabel(\"Median Sale Price ($)\");\n
# Group DataFrame by saleMonth and then find the median SalePrice df_tmp.groupby([\"saleMonth\"])[\"SalePrice\"].median().plot() plt.xlabel(\"Month\") plt.ylabel(\"Median Sale Price ($)\"); Ohhh it looks like the median sale prices of January and February (months 1 and 2) are quite a bit higher than the other months of the year.
Could this be because of New Year budget spending?
Perhaps... but this would take a bit more investigation.
In the meantime, there are many other values we could look further into.
In\u00a0[27]: Copied! # Check the different values of different columns\ndf_tmp.state.value_counts()[:10]\n
# Check the different values of different columns df_tmp.state.value_counts()[:10] Out[27]: state\nFlorida 67320\nTexas 53110\nCalifornia 29761\nWashington 16222\nGeorgia 14633\nMaryland 13322\nMississippi 13240\nOhio 12369\nIllinois 11540\nColorado 11529\nName: count, dtype: int64
Woah! Looks like Flordia sells a fair few bulldozers.
How about we go even further and group our samples by state and then find the median SalePrice per state?
We also compare this to the median SalePrice for all samples.
In\u00a0[28]: Copied! # Group DataFrame by saleMonth and then find the median SalePrice per state as well as across the whole dataset\nmedian_prices_by_state = df_tmp.groupby([\"state\"])[\"SalePrice\"].median() # this will return a pandas Series rather than a DataFrame\nmedian_sale_price = df_tmp[\"SalePrice\"].median()\n\n# Create a plot comparing median sale price per state to median sale price overall\nplt.figure(figsize=(10, 7))\nplt.bar(x=median_prices_by_state.index, # Because we're working with a Series, we can use the index (state names) as the x values\n height=median_prices_by_state.values)\nplt.xlabel(\"State\")\nplt.ylabel(\"Median Sale Price ($)\")\nplt.xticks(rotation=90, fontsize=7);\nplt.axhline(y=median_sale_price, \n color=\"red\", \n linestyle=\"--\", \n label=f\"Median Sale Price: ${median_sale_price:,.0f}\")\nplt.legend();\n # Group DataFrame by saleMonth and then find the median SalePrice per state as well as across the whole dataset median_prices_by_state = df_tmp.groupby([\"state\"])[\"SalePrice\"].median() # this will return a pandas Series rather than a DataFrame median_sale_price = df_tmp[\"SalePrice\"].median() # Create a plot comparing median sale price per state to median sale price overall plt.figure(figsize=(10, 7)) plt.bar(x=median_prices_by_state.index, # Because we're working with a Series, we can use the index (state names) as the x values height=median_prices_by_state.values) plt.xlabel(\"State\") plt.ylabel(\"Median Sale Price ($)\") plt.xticks(rotation=90, fontsize=7); plt.axhline(y=median_sale_price, color=\"red\", linestyle=\"--\", label=f\"Median Sale Price: ${median_sale_price:,.0f}\") plt.legend(); Now that's a nice looking figure!
Interestingly Florida has the most sales and the median sale price is above the overall median of all other states.
And if you had a bulldozer and were chasing the highest sale price, the data would reveal that perhaps selling in South Dakota would be your best bet.
Perhaps bulldozers are in higher demand in South Dakota because of a building or mining boom?
Answering this would require a bit more research.
But what we're doing here is slowly building up a mental model of our data.
So that if we saw an example in the future, we could compare its values to the ones we've already seen.
In\u00a0[29]: Copied! # This won't work since we've got missing numbers and categories\nfrom sklearn.ensemble import RandomForestRegressor\n\nmodel = RandomForestRegressor(n_jobs=-1)\nmodel.fit(X=df_tmp.drop(\"SalePrice\", axis=1), # use all columns except SalePrice as X input\n y=df_tmp.SalePrice) # use SalePrice column as y input\n
# This won't work since we've got missing numbers and categories from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor(n_jobs=-1) model.fit(X=df_tmp.drop(\"SalePrice\", axis=1), # use all columns except SalePrice as X input y=df_tmp.SalePrice) # use SalePrice column as y input \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\n/var/folders/c4/qj4gdk190td18bqvjjh0p3p00000gn/T/ipykernel_20423/2824176890.py in ?()\n 1 # This won't work since we've got missing numbers and categories\n 2 from sklearn.ensemble import RandomForestRegressor\n 3 \n 4 model = RandomForestRegressor(n_jobs=-1)\n----> 5 model.fit(X=df_tmp.drop(\"SalePrice\", axis=1), # use all columns except SalePrice as X input\n 6 y=df_tmp.SalePrice) # use SalePrice column as y input\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(estimator, *args, **kwargs)\n 1469 skip_parameter_validation=(\n 1470 prefer_skip_nested_validation or global_skip_validation\n 1471 )\n 1472 ):\n-> 1473 return fit_method(estimator, *args, **kwargs)\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X, y, sample_weight)\n 359 # Validate or convert input data\n 360 if issparse(y):\n 361 raise ValueError(\"sparse multilabel-indicator for y is not supported.\")\n 362 \n--> 363 X, y = self._validate_data(\n 364 X,\n 365 y,\n 366 multi_output=True,\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)\n 646 if \"estimator\" not in check_y_params:\n 647 check_y_params = {**default_check_params, **check_y_params}\n 648 y = check_array(y, input_name=\"y\", **check_y_params)\n 649 else:\n--> 650 X, y = check_X_y(X, y, **check_params)\n 651 out = X, y\n 652 \n 653 if not no_val_X and check_params.get(\"ensure_2d\", True):\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(X, y, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, estimator)\n 1297 raise ValueError(\n 1298 f\"{estimator_name} requires y to be passed, but the target y is None\"\n 1299 )\n 1300 \n-> 1301 X = check_array(\n 1302 X,\n 1303 accept_sparse=accept_sparse,\n 1304 accept_large_sparse=accept_large_sparse,\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)\n 1009 )\n 1010 array = xp.astype(array, dtype, copy=False)\n 1011 else:\n 1012 array = _asarray_with_order(array, order=order, dtype=dtype, xp=xp)\n-> 1013 except ComplexWarning as complex_warning:\n 1014 raise ValueError(\n 1015 \"Complex data not supported\\n{}\\n\".format(array)\n 1016 ) from complex_warning\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/_array_api.py in ?(array, dtype, order, copy, xp, device)\n 747 # Use NumPy API to support order\n 748 if copy is True:\n 749 array = numpy.array(array, order=order, dtype=dtype)\n 750 else:\n--> 751 array = numpy.asarray(array, order=order, dtype=dtype)\n 752 \n 753 # At this point array is a NumPy ndarray. We convert it to an array\n 754 # container that is consistent with the input's namespace.\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/core/generic.py in ?(self, dtype, copy)\n 2149 def __array__(\n 2150 self, dtype: npt.DTypeLike | None = None, copy: bool_t | None = None\n 2151 ) -> np.ndarray:\n 2152 values = self._values\n-> 2153 arr = np.asarray(values, dtype=dtype)\n 2154 if (\n 2155 astype_is_view(values.dtype, arr.dtype)\n 2156 and using_copy_on_write()\n\nValueError: could not convert string to float: 'Low' Oh no!
When we try to fit our model to the data, we get a value error similar to:
ValueError: could not convert string to float: 'Low'
The problem here is that some of the features of our data are in string format and machine learning models love numbers.
Not to mention some of our samples have missing values.
And typically, machine learning models require all data to be in numerical format as well as all missing values to be filled.
Let's start to fix this by inspecting the different datatypes in our DataFrame.
We can do so using the pandas.DataFrame.info() method, this will give us the different datatypes as well as how many non-null (a null value is generally a missing value) in our df_tmp DataFrame.
Note: There are some ML models such as sklearn.ensemble.HistGradientBoostingRegressor, CatBoost and XGBoost which can handle missing values, however, I'll leave exploring each of these as extra-curriculum/extensions.
In\u00a0[30]: Copied! # Check for missing values and different datatypes \ndf_tmp.info();\n
# Check for missing values and different datatypes df_tmp.info(); <class 'pandas.core.frame.DataFrame'>\nIndex: 412698 entries, 205615 to 409203\nData columns (total 57 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 SalesID 412698 non-null int64 \n 1 SalePrice 412698 non-null float64\n 2 MachineID 412698 non-null int64 \n 3 ModelID 412698 non-null int64 \n 4 datasource 412698 non-null int64 \n 5 auctioneerID 392562 non-null float64\n 6 YearMade 412698 non-null int64 \n 7 MachineHoursCurrentMeter 147504 non-null float64\n 8 UsageBand 73670 non-null object \n 9 fiModelDesc 412698 non-null object \n 10 fiBaseModel 412698 non-null object \n 11 fiSecondaryDesc 271971 non-null object \n 12 fiModelSeries 58667 non-null object \n 13 fiModelDescriptor 74816 non-null object \n 14 ProductSize 196093 non-null object \n 15 fiProductClassDesc 412698 non-null object \n 16 state 412698 non-null object \n 17 ProductGroup 412698 non-null object \n 18 ProductGroupDesc 412698 non-null object \n 19 Drive_System 107087 non-null object \n 20 Enclosure 412364 non-null object \n 21 Forks 197715 non-null object \n 22 Pad_Type 81096 non-null object \n 23 Ride_Control 152728 non-null object \n 24 Stick 81096 non-null object \n 25 Transmission 188007 non-null object \n 26 Turbocharged 81096 non-null object \n 27 Blade_Extension 25983 non-null object \n 28 Blade_Width 25983 non-null object \n 29 Enclosure_Type 25983 non-null object \n 30 Engine_Horsepower 25983 non-null object \n 31 Hydraulics 330133 non-null object \n 32 Pushblock 25983 non-null object \n 33 Ripper 106945 non-null object \n 34 Scarifier 25994 non-null object \n 35 Tip_Control 25983 non-null object \n 36 Tire_Size 97638 non-null object \n 37 Coupler 220679 non-null object \n 38 Coupler_System 44974 non-null object \n 39 Grouser_Tracks 44875 non-null object \n 40 Hydraulics_Flow 44875 non-null object \n 41 Track_Type 102193 non-null object \n 42 Undercarriage_Pad_Width 102916 non-null object \n 43 Stick_Length 102261 non-null object \n 44 Thumb 102332 non-null object \n 45 Pattern_Changer 102261 non-null object \n 46 Grouser_Type 102193 non-null object \n 47 Backhoe_Mounting 80712 non-null object \n 48 Blade_Type 81875 non-null object \n 49 Travel_Controls 81877 non-null object \n 50 Differential_Type 71564 non-null object \n 51 Steering_Controls 71522 non-null object \n 52 saleYear 412698 non-null int32 \n 53 saleMonth 412698 non-null int32 \n 54 saleDay 412698 non-null int32 \n 55 saleDayofweek 412698 non-null int32 \n 56 saleDayofyear 412698 non-null int32 \ndtypes: float64(3), int32(5), int64(5), object(44)\nmemory usage: 174.7+ MB\n
Ok, it seems as though we've got a fair few different datatypes.
There are int64 types such as MachineID.
There are float64 types such as SalePrice.
And there are object (the object dtype can hold any Python object, including strings) types such as UseageBand.
Resource: You can see a list of all the pandas dtypes in the pandas user guide.
How about we find out how many missing values are in each column?
We can do so using pandas.DataFrame.isna() (isna stands for 'is null or NaN') which will return a boolean True/False if a value is missing (True if missing, False if not).
Let's start by checking the missing values in the head of our DataFrame.
In\u00a0[31]: Copied! # Find missing values in the head of our DataFrame \ndf_tmp.head().isna()\n
# Find missing values in the head of our DataFrame df_tmp.head().isna() Out[31]: SalesID SalePrice MachineID ModelID datasource auctioneerID YearMade MachineHoursCurrentMeter UsageBand fiModelDesc ... Backhoe_Mounting Blade_Type Travel_Controls Differential_Type Steering_Controls saleYear saleMonth saleDay saleDayofweek saleDayofyear 205615 False False False False False False False True True False ... False False False True True False False False False False 274835 False False False False False False False True True False ... True True True False False False False False False False 141296 False False False False False False False True True False ... False False False True True False False False False False 212552 False False False False False False False True True False ... True True True False False False False False False False 62755 False False False False False False False True True False ... False False False True True False False False False False 5 rows \u00d7 57 columns
Alright it seems as though we've got some missing values in the MachineHoursCurrentMeter as well as the UsageBand and a few other columns.
But so far we've only viewed the first few rows.
It'll be very time consuming to go through each row one by one so how about we get the total missing values per column?
We can do so by calling .isna() on the whole DataFrame and then chaining it together with .sum().
Doing so will give us the total True/False values in a given column (when summing, True = 1, False = 0).
In\u00a0[32]: Copied! # Check for total missing values per column\ndf_tmp.isna().sum()\n
# Check for total missing values per column df_tmp.isna().sum() Out[32]: SalesID 0\nSalePrice 0\nMachineID 0\nModelID 0\ndatasource 0\nauctioneerID 20136\nYearMade 0\nMachineHoursCurrentMeter 265194\nUsageBand 339028\nfiModelDesc 0\nfiBaseModel 0\nfiSecondaryDesc 140727\nfiModelSeries 354031\nfiModelDescriptor 337882\nProductSize 216605\nfiProductClassDesc 0\nstate 0\nProductGroup 0\nProductGroupDesc 0\nDrive_System 305611\nEnclosure 334\nForks 214983\nPad_Type 331602\nRide_Control 259970\nStick 331602\nTransmission 224691\nTurbocharged 331602\nBlade_Extension 386715\nBlade_Width 386715\nEnclosure_Type 386715\nEngine_Horsepower 386715\nHydraulics 82565\nPushblock 386715\nRipper 305753\nScarifier 386704\nTip_Control 386715\nTire_Size 315060\nCoupler 192019\nCoupler_System 367724\nGrouser_Tracks 367823\nHydraulics_Flow 367823\nTrack_Type 310505\nUndercarriage_Pad_Width 309782\nStick_Length 310437\nThumb 310366\nPattern_Changer 310437\nGrouser_Type 310505\nBackhoe_Mounting 331986\nBlade_Type 330823\nTravel_Controls 330821\nDifferential_Type 341134\nSteering_Controls 341176\nsaleYear 0\nsaleMonth 0\nsaleDay 0\nsaleDayofweek 0\nsaleDayofyear 0\ndtype: int64
Woah! It looks like our DataFrame has quite a few missing values.
Not to worry, we can work on fixing this later on.
How about we start by tring to turn all of our data in numbers?
In\u00a0[33]: Copied! # Get the dtype of a given column\ndf_tmp[\"UsageBand\"].dtype, df_tmp[\"UsageBand\"].dtype.name\n
# Get the dtype of a given column df_tmp[\"UsageBand\"].dtype, df_tmp[\"UsageBand\"].dtype.name Out[33]: (dtype('O'), 'object') Beautiful!
Now we've got a way to check a column's datatype individually.
There's also another group of methods to check a column's datatype directly.
For example, using pd.api.types.is_object_dtype(arr_or_dtype) we can get a boolean response as to whether the input is an object or not.
Note: There are many more of these checks you can perform for other datatypes such as strings under a similar name space pd.api.types.is_XYZ_dtype. See the pandas documentation for more.
Let's see how it works on our df_tmp[\"UsageBand\"] column.
In\u00a0[34]: Copied! # Check whether a column is an object\npd.api.types.is_object_dtype(df_tmp[\"UsageBand\"])\n
# Check whether a column is an object pd.api.types.is_object_dtype(df_tmp[\"UsageBand\"]) Out[34]: True
We can also check whether a column is a string with pd.api.types.is_string_dtype(arr_or_dtype).
In\u00a0[35]: Copied! # Check whether a column is a string\npd.api.types.is_string_dtype(df_tmp[\"state\"])\n
# Check whether a column is a string pd.api.types.is_string_dtype(df_tmp[\"state\"]) Out[35]: True
Nice!
We can even loop through the items (columns and their labels) in our DataFrame using pandas.DataFrame.items() (in Python dictionary terms, calling .items() on a DataFrame will treat the column names as the keys and the column values as the values) and print out samples of columns which have the string datatype.
As an extra check, passing the sample to pd.api.types.infer_dtype() will return the datatype of the sample.
This will be a good way to keep exploring our data.
In\u00a0[36]: Copied! # Quick exampke of calling .items() on a dictionary\nrandom_dict = {\"key1\": \"hello\",\n \"key2\": \"world!\"}\n\nfor key, value in random_dict.items():\n print(f\"This is a key: {key}\")\n print(f\"This is a value: {value}\")\n # Quick exampke of calling .items() on a dictionary random_dict = {\"key1\": \"hello\", \"key2\": \"world!\"} for key, value in random_dict.items(): print(f\"This is a key: {key}\") print(f\"This is a value: {value}\") This is a key: key1\nThis is a value: hello\nThis is a key: key2\nThis is a value: world!\n
In\u00a0[37]: Copied! # Print column names and example content of columns which contain strings\nfor label, content in df_tmp.items():\n if pd.api.types.is_string_dtype(content):\n # Check datatype of target column\n column_datatype = df_tmp[label].dtype.name\n\n # Get random sample from column values\n example_value = content.sample(1).values\n\n # Infer random sample datatype\n example_value_dtype = pd.api.types.infer_dtype(example_value)\n print(f\"Column name: {label} | Column dtype: {column_datatype} | Example value: {example_value} | Example value dtype: {example_value_dtype}\")\n # Print column names and example content of columns which contain strings for label, content in df_tmp.items(): if pd.api.types.is_string_dtype(content): # Check datatype of target column column_datatype = df_tmp[label].dtype.name # Get random sample from column values example_value = content.sample(1).values # Infer random sample datatype example_value_dtype = pd.api.types.infer_dtype(example_value) print(f\"Column name: {label} | Column dtype: {column_datatype} | Example value: {example_value} | Example value dtype: {example_value_dtype}\") Column name: fiModelDesc | Column dtype: object | Example value: ['35ZTS'] | Example value dtype: string\nColumn name: fiBaseModel | Column dtype: object | Example value: ['PC75'] | Example value dtype: string\nColumn name: fiProductClassDesc | Column dtype: object | Example value: ['Backhoe Loader - 14.0 to 15.0 Ft Standard Digging Depth'] | Example value dtype: string\nColumn name: state | Column dtype: object | Example value: ['Florida'] | Example value dtype: string\nColumn name: ProductGroup | Column dtype: object | Example value: ['TTT'] | Example value dtype: string\nColumn name: ProductGroupDesc | Column dtype: object | Example value: ['Track Excavators'] | Example value dtype: string\n
Hmm... it seems that there are many more columns in the df_tmp with the object type that didn't display when checking for the string datatype (we know there are many object datatype columns in our DataFrame from using df_tmp.info()).
How about we try the same as above, except this time instead of pd.api.types.is_string_dtype, we use pd.api.types.is_object_dtype?
Let's try it.
In\u00a0[38]: Copied! # Start a count of how many object type columns there are\nnumber_of_object_type_columns = 0\n\nfor label, content in df_tmp.items():\n # Check to see if column is of object type (this will include the string columns)\n if pd.api.types.is_object_dtype(content): \n # Check datatype of target column\n column_datatype = df_tmp[label].dtype.name\n\n # Get random sample from column values\n example_value = content.sample(1).values\n\n # Infer random sample datatype\n example_value_dtype = pd.api.types.infer_dtype(example_value)\n print(f\"Column name: {label} | Column dtype: {column_datatype} | Example value: {example_value} | Example value dtype: {example_value_dtype}\")\n\n number_of_object_type_columns += 1\n\nprint(f\"\\n[INFO] Total number of object type columns: {number_of_object_type_columns}\")\n # Start a count of how many object type columns there are number_of_object_type_columns = 0 for label, content in df_tmp.items(): # Check to see if column is of object type (this will include the string columns) if pd.api.types.is_object_dtype(content): # Check datatype of target column column_datatype = df_tmp[label].dtype.name # Get random sample from column values example_value = content.sample(1).values # Infer random sample datatype example_value_dtype = pd.api.types.infer_dtype(example_value) print(f\"Column name: {label} | Column dtype: {column_datatype} | Example value: {example_value} | Example value dtype: {example_value_dtype}\") number_of_object_type_columns += 1 print(f\"\\n[INFO] Total number of object type columns: {number_of_object_type_columns}\") Column name: UsageBand | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: fiModelDesc | Column dtype: object | Example value: ['590SUPER MII'] | Example value dtype: string\nColumn name: fiBaseModel | Column dtype: object | Example value: ['580'] | Example value dtype: string\nColumn name: fiSecondaryDesc | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: fiModelSeries | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: fiModelDescriptor | Column dtype: object | Example value: ['H'] | Example value dtype: string\nColumn name: ProductSize | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: fiProductClassDesc | Column dtype: object | Example value: ['Track Type Tractor, Dozer - 75.0 to 85.0 Horsepower'] | Example value dtype: string\nColumn name: state | Column dtype: object | Example value: ['Florida'] | Example value dtype: string\nColumn name: ProductGroup | Column dtype: object | Example value: ['TEX'] | Example value dtype: string\nColumn name: ProductGroupDesc | Column dtype: object | Example value: ['Skid Steer Loaders'] | Example value dtype: string\nColumn name: Drive_System | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Enclosure | Column dtype: object | Example value: ['EROPS'] | Example value dtype: string\nColumn name: Forks | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Pad_Type | Column dtype: object | Example value: ['None or Unspecified'] | Example value dtype: string\nColumn name: Ride_Control | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Stick | Column dtype: object | Example value: ['Extended'] | Example value dtype: string\nColumn name: Transmission | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Turbocharged | Column dtype: object | Example value: ['None or Unspecified'] | Example value dtype: string\nColumn name: Blade_Extension | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Blade_Width | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Enclosure_Type | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Engine_Horsepower | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Hydraulics | Column dtype: object | Example value: ['Standard'] | Example value dtype: string\nColumn name: Pushblock | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Ripper | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Scarifier | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Tip_Control | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Tire_Size | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Coupler | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Coupler_System | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Grouser_Tracks | Column dtype: object | Example value: ['None or Unspecified'] | Example value dtype: string\nColumn name: Hydraulics_Flow | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Track_Type | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Undercarriage_Pad_Width | Column dtype: object | Example value: ['20 inch'] | Example value dtype: string\nColumn name: Stick_Length | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Thumb | Column dtype: object | Example value: ['None or Unspecified'] | Example value dtype: string\nColumn name: Pattern_Changer | Column dtype: object | Example value: ['None or Unspecified'] | Example value dtype: string\nColumn name: Grouser_Type | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Backhoe_Mounting | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Blade_Type | Column dtype: object | Example value: ['Straight'] | Example value dtype: string\nColumn name: Travel_Controls | Column dtype: object | Example value: ['None or Unspecified'] | Example value dtype: string\nColumn name: Differential_Type | Column dtype: object | Example value: [nan] | Example value dtype: empty\nColumn name: Steering_Controls | Column dtype: object | Example value: [nan] | Example value dtype: empty\n\n[INFO] Total number of object type columns: 44\n
Wonderful, looks like we've got sample outputs from all of the columns with the object datatype.
It also looks like that many of random samples are missing values.
In\u00a0[39]: Copied! # This will turn all of the object columns into category values\nfor label, content in df_tmp.items(): \n if pd.api.types.is_object_dtype(content):\n df_tmp[label] = df_tmp[label].astype(\"category\")\n
# This will turn all of the object columns into category values for label, content in df_tmp.items(): if pd.api.types.is_object_dtype(content): df_tmp[label] = df_tmp[label].astype(\"category\") Wonderful!
Now let's check if it worked by calling .info() on our DataFrame.
In\u00a0[40]: Copied! df_tmp.info()\n
df_tmp.info() <class 'pandas.core.frame.DataFrame'>\nIndex: 412698 entries, 205615 to 409203\nData columns (total 57 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 SalesID 412698 non-null int64 \n 1 SalePrice 412698 non-null float64 \n 2 MachineID 412698 non-null int64 \n 3 ModelID 412698 non-null int64 \n 4 datasource 412698 non-null int64 \n 5 auctioneerID 392562 non-null float64 \n 6 YearMade 412698 non-null int64 \n 7 MachineHoursCurrentMeter 147504 non-null float64 \n 8 UsageBand 73670 non-null category\n 9 fiModelDesc 412698 non-null category\n 10 fiBaseModel 412698 non-null category\n 11 fiSecondaryDesc 271971 non-null category\n 12 fiModelSeries 58667 non-null category\n 13 fiModelDescriptor 74816 non-null category\n 14 ProductSize 196093 non-null category\n 15 fiProductClassDesc 412698 non-null category\n 16 state 412698 non-null category\n 17 ProductGroup 412698 non-null category\n 18 ProductGroupDesc 412698 non-null category\n 19 Drive_System 107087 non-null category\n 20 Enclosure 412364 non-null category\n 21 Forks 197715 non-null category\n 22 Pad_Type 81096 non-null category\n 23 Ride_Control 152728 non-null category\n 24 Stick 81096 non-null category\n 25 Transmission 188007 non-null category\n 26 Turbocharged 81096 non-null category\n 27 Blade_Extension 25983 non-null category\n 28 Blade_Width 25983 non-null category\n 29 Enclosure_Type 25983 non-null category\n 30 Engine_Horsepower 25983 non-null category\n 31 Hydraulics 330133 non-null category\n 32 Pushblock 25983 non-null category\n 33 Ripper 106945 non-null category\n 34 Scarifier 25994 non-null category\n 35 Tip_Control 25983 non-null category\n 36 Tire_Size 97638 non-null category\n 37 Coupler 220679 non-null category\n 38 Coupler_System 44974 non-null category\n 39 Grouser_Tracks 44875 non-null category\n 40 Hydraulics_Flow 44875 non-null category\n 41 Track_Type 102193 non-null category\n 42 Undercarriage_Pad_Width 102916 non-null category\n 43 Stick_Length 102261 non-null category\n 44 Thumb 102332 non-null category\n 45 Pattern_Changer 102261 non-null category\n 46 Grouser_Type 102193 non-null category\n 47 Backhoe_Mounting 80712 non-null category\n 48 Blade_Type 81875 non-null category\n 49 Travel_Controls 81877 non-null category\n 50 Differential_Type 71564 non-null category\n 51 Steering_Controls 71522 non-null category\n 52 saleYear 412698 non-null int32 \n 53 saleMonth 412698 non-null int32 \n 54 saleDay 412698 non-null int32 \n 55 saleDayofweek 412698 non-null int32 \n 56 saleDayofyear 412698 non-null int32 \ndtypes: category(44), float64(3), int32(5), int64(5)\nmemory usage: 55.4 MB\n
It looks like it worked!
All of the object datatype columns now have the category datatype.
We can inspect this on a single column using pandas.Series.dtype.
In\u00a0[41]: Copied! # Check the datatype of a single column\ndf_tmp.state.dtype\n
# Check the datatype of a single column df_tmp.state.dtype Out[41]: CategoricalDtype(categories=['Alabama', 'Alaska', 'Arizona', 'Arkansas', 'California',\n 'Colorado', 'Connecticut', 'Delaware', 'Florida', 'Georgia',\n 'Hawaii', 'Idaho', 'Illinois', 'Indiana', 'Iowa', 'Kansas',\n 'Kentucky', 'Louisiana', 'Maine', 'Maryland',\n 'Massachusetts', 'Michigan', 'Minnesota', 'Mississippi',\n 'Missouri', 'Montana', 'Nebraska', 'Nevada', 'New Hampshire',\n 'New Jersey', 'New Mexico', 'New York', 'North Carolina',\n 'North Dakota', 'Ohio', 'Oklahoma', 'Oregon', 'Pennsylvania',\n 'Puerto Rico', 'Rhode Island', 'South Carolina',\n 'South Dakota', 'Tennessee', 'Texas', 'Unspecified', 'Utah',\n 'Vermont', 'Virginia', 'Washington', 'Washington DC',\n 'West Virginia', 'Wisconsin', 'Wyoming'],\n, ordered=False, categories_dtype=object)
Excellent, notice how the column is now of type pd.CategoricalDtype.
We can also access these categories using pandas.Series.cat.categories.
In\u00a0[42]: Copied! # Get the category names of a given column\ndf_tmp.state.cat.categories\n
# Get the category names of a given column df_tmp.state.cat.categories Out[42]: Index(['Alabama', 'Alaska', 'Arizona', 'Arkansas', 'California', 'Colorado',\n 'Connecticut', 'Delaware', 'Florida', 'Georgia', 'Hawaii', 'Idaho',\n 'Illinois', 'Indiana', 'Iowa', 'Kansas', 'Kentucky', 'Louisiana',\n 'Maine', 'Maryland', 'Massachusetts', 'Michigan', 'Minnesota',\n 'Mississippi', 'Missouri', 'Montana', 'Nebraska', 'Nevada',\n 'New Hampshire', 'New Jersey', 'New Mexico', 'New York',\n 'North Carolina', 'North Dakota', 'Ohio', 'Oklahoma', 'Oregon',\n 'Pennsylvania', 'Puerto Rico', 'Rhode Island', 'South Carolina',\n 'South Dakota', 'Tennessee', 'Texas', 'Unspecified', 'Utah', 'Vermont',\n 'Virginia', 'Washington', 'Washington DC', 'West Virginia', 'Wisconsin',\n 'Wyoming'],\n dtype='object')
Finally, we can get the category codes (the numeric values representing the category) using pandas.Series.cat.codes.
In\u00a0[43]: Copied! # Inspect the category codes\ndf_tmp.state.cat.codes\n
# Inspect the category codes df_tmp.state.cat.codes Out[43]: 205615 43\n274835 8\n141296 8\n212552 8\n62755 8\n ..\n410879 4\n412476 4\n411927 4\n407124 4\n409203 4\nLength: 412698, dtype: int8
This gives us a numeric representation of our object/string datatype columns.
In\u00a0[44]: Copied! # Get example string using category number\ntarget_state_cat_number = 43\ntarget_state_cat_value = df_tmp.state.cat.categories[target_state_cat_number] \nprint(f\"[INFO] Target state category number {target_state_cat_number} maps to: {target_state_cat_value}\")\n # Get example string using category number target_state_cat_number = 43 target_state_cat_value = df_tmp.state.cat.categories[target_state_cat_number] print(f\"[INFO] Target state category number {target_state_cat_number} maps to: {target_state_cat_value}\") [INFO] Target state category number 43 maps to: Texas\n
Epic!
All of our data is categorical and thus we can now turn the categories into numbers, however it's still missing values, not to worry though, we'll get to these shortly.
In\u00a0[45]: Copied! # Save preprocessed data to file\ndf_tmp.to_csv(\"../data/bluebook-for-bulldozers/TrainAndValid_object_values_as_categories.csv\",\n index=False)\n
# Save preprocessed data to file df_tmp.to_csv(\"../data/bluebook-for-bulldozers/TrainAndValid_object_values_as_categories.csv\", index=False) Now we've saved our preprocessed data to file, we can re-import it and make sure it's in the same format.
In\u00a0[46]: Copied! # Import preprocessed data to file\ndf_tmp = pd.read_csv(\"../data/bluebook-for-bulldozers/TrainAndValid_object_values_as_categories.csv\",\n low_memory=False)\n\ndf_tmp.head()\n
# Import preprocessed data to file df_tmp = pd.read_csv(\"../data/bluebook-for-bulldozers/TrainAndValid_object_values_as_categories.csv\", low_memory=False) df_tmp.head() Out[46]: SalesID SalePrice MachineID ModelID datasource auctioneerID YearMade MachineHoursCurrentMeter UsageBand fiModelDesc ... Backhoe_Mounting Blade_Type Travel_Controls Differential_Type Steering_Controls saleYear saleMonth saleDay saleDayofweek saleDayofyear 0 1646770 9500.0 1126363 8434 132 18.0 1974 NaN NaN TD20 ... None or Unspecified Straight None or Unspecified NaN NaN 1989 1 17 1 17 1 1821514 14000.0 1194089 10150 132 99.0 1980 NaN NaN A66 ... NaN NaN NaN Standard Conventional 1989 1 31 1 31 2 1505138 50000.0 1473654 4139 132 99.0 1978 NaN NaN D7G ... None or Unspecified Straight None or Unspecified NaN NaN 1989 1 31 1 31 3 1671174 16000.0 1327630 8591 132 99.0 1980 NaN NaN A62 ... NaN NaN NaN Standard Conventional 1989 1 31 1 31 4 1329056 22000.0 1336053 4089 132 99.0 1984 NaN NaN D3B ... None or Unspecified PAT Lever NaN NaN 1989 1 31 1 31 5 rows \u00d7 57 columns
Excellent, looking at the tale end (the far right side) our processed DataFrame has the columns we added to it (the extra data features) but it's still missing values.
But if we check df_tmp.info()...
In\u00a0[47]: Copied! df_tmp.info()\n
df_tmp.info() <class 'pandas.core.frame.DataFrame'>\nRangeIndex: 412698 entries, 0 to 412697\nData columns (total 57 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 SalesID 412698 non-null int64 \n 1 SalePrice 412698 non-null float64\n 2 MachineID 412698 non-null int64 \n 3 ModelID 412698 non-null int64 \n 4 datasource 412698 non-null int64 \n 5 auctioneerID 392562 non-null float64\n 6 YearMade 412698 non-null int64 \n 7 MachineHoursCurrentMeter 147504 non-null float64\n 8 UsageBand 73670 non-null object \n 9 fiModelDesc 412698 non-null object \n 10 fiBaseModel 412698 non-null object \n 11 fiSecondaryDesc 271971 non-null object \n 12 fiModelSeries 58667 non-null object \n 13 fiModelDescriptor 74816 non-null object \n 14 ProductSize 196093 non-null object \n 15 fiProductClassDesc 412698 non-null object \n 16 state 412698 non-null object \n 17 ProductGroup 412698 non-null object \n 18 ProductGroupDesc 412698 non-null object \n 19 Drive_System 107087 non-null object \n 20 Enclosure 412364 non-null object \n 21 Forks 197715 non-null object \n 22 Pad_Type 81096 non-null object \n 23 Ride_Control 152728 non-null object \n 24 Stick 81096 non-null object \n 25 Transmission 188007 non-null object \n 26 Turbocharged 81096 non-null object \n 27 Blade_Extension 25983 non-null object \n 28 Blade_Width 25983 non-null object \n 29 Enclosure_Type 25983 non-null object \n 30 Engine_Horsepower 25983 non-null object \n 31 Hydraulics 330133 non-null object \n 32 Pushblock 25983 non-null object \n 33 Ripper 106945 non-null object \n 34 Scarifier 25994 non-null object \n 35 Tip_Control 25983 non-null object \n 36 Tire_Size 97638 non-null object \n 37 Coupler 220679 non-null object \n 38 Coupler_System 44974 non-null object \n 39 Grouser_Tracks 44875 non-null object \n 40 Hydraulics_Flow 44875 non-null object \n 41 Track_Type 102193 non-null object \n 42 Undercarriage_Pad_Width 102916 non-null object \n 43 Stick_Length 102261 non-null object \n 44 Thumb 102332 non-null object \n 45 Pattern_Changer 102261 non-null object \n 46 Grouser_Type 102193 non-null object \n 47 Backhoe_Mounting 80712 non-null object \n 48 Blade_Type 81875 non-null object \n 49 Travel_Controls 81877 non-null object \n 50 Differential_Type 71564 non-null object \n 51 Steering_Controls 71522 non-null object \n 52 saleYear 412698 non-null int64 \n 53 saleMonth 412698 non-null int64 \n 54 saleDay 412698 non-null int64 \n 55 saleDayofweek 412698 non-null int64 \n 56 saleDayofyear 412698 non-null int64 \ndtypes: float64(3), int64(10), object(44)\nmemory usage: 179.5+ MB\n
Hmm... what happened here?
Notice that all of the category datatype columns are back to the object datatype.
This is strange since we already converted the object datatype columns to category.
Well then why did they change back?
This happens because of the limitations of the CSV (.csv) file format, it doesn't preserve data types, rather it stores all the values as strings.
So when we read in a CSV, pandas defaults to interpreting strings as object datatypes.
Not to worry though, we can easily convert them to the category datatype as we did before.
Note: If you'd like to retain the datatypes when saving your data, you can use file formats such as parquet (Apache Parquet) and feather. These filetypes have several advantages over CSV in terms of processing speeds and storage size. However, data stored in these formats is not human-readable so you won't be able to open the files and inspect them without specific tools. For more on different file formats in pandas, see the IO tools documentation page.
In\u00a0[48]: Copied! for label, content in df_tmp.items():\n if pd.api.types.is_object_dtype(content):\n # Turn object columns into category datatype\n df_tmp[label] = df_tmp[label].astype(\"category\")\n
for label, content in df_tmp.items(): if pd.api.types.is_object_dtype(content): # Turn object columns into category datatype df_tmp[label] = df_tmp[label].astype(\"category\") Now if we wanted to preserve the datatypes of our data, we can save to parquet or feather format.
Let's try using parquet format.
To do so, we can use the pandas.DataFrame.to_parquet() method.
Files in the parquet format typically have the file extension of .parquet.
In\u00a0[49]: Copied! # To save to parquet format requires pyarrow or fastparquet (or both)\n# Can install via `pip install pyarrow fastparquet`\ndf_tmp.to_parquet(path=\"../data/bluebook-for-bulldozers/TrainAndValid_object_values_as_categories.parquet\", \n engine=\"auto\") # \"auto\" will automatically use pyarrow or fastparquet, defaulting to pyarrow first\n
# To save to parquet format requires pyarrow or fastparquet (or both) # Can install via `pip install pyarrow fastparquet` df_tmp.to_parquet(path=\"../data/bluebook-for-bulldozers/TrainAndValid_object_values_as_categories.parquet\", engine=\"auto\") # \"auto\" will automatically use pyarrow or fastparquet, defaulting to pyarrow first Wonderful! Now let's try importing our DataFrame from the parquet format and check it using df_tmp.info().
In\u00a0[50]: Copied! # Read in df_tmp from parquet format\ndf_tmp = pd.read_parquet(path=\"../data/bluebook-for-bulldozers/TrainAndValid_object_values_as_categories.parquet\",\n engine=\"auto\")\n\n# Using parquet format, datatypes are preserved\ndf_tmp.info()\n
# Read in df_tmp from parquet format df_tmp = pd.read_parquet(path=\"../data/bluebook-for-bulldozers/TrainAndValid_object_values_as_categories.parquet\", engine=\"auto\") # Using parquet format, datatypes are preserved df_tmp.info() <class 'pandas.core.frame.DataFrame'>\nRangeIndex: 412698 entries, 0 to 412697\nData columns (total 57 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 SalesID 412698 non-null int64 \n 1 SalePrice 412698 non-null float64 \n 2 MachineID 412698 non-null int64 \n 3 ModelID 412698 non-null int64 \n 4 datasource 412698 non-null int64 \n 5 auctioneerID 392562 non-null float64 \n 6 YearMade 412698 non-null int64 \n 7 MachineHoursCurrentMeter 147504 non-null float64 \n 8 UsageBand 73670 non-null category\n 9 fiModelDesc 412698 non-null category\n 10 fiBaseModel 412698 non-null category\n 11 fiSecondaryDesc 271971 non-null category\n 12 fiModelSeries 58667 non-null category\n 13 fiModelDescriptor 74816 non-null category\n 14 ProductSize 196093 non-null category\n 15 fiProductClassDesc 412698 non-null category\n 16 state 412698 non-null category\n 17 ProductGroup 412698 non-null category\n 18 ProductGroupDesc 412698 non-null category\n 19 Drive_System 107087 non-null category\n 20 Enclosure 412364 non-null category\n 21 Forks 197715 non-null category\n 22 Pad_Type 81096 non-null category\n 23 Ride_Control 152728 non-null category\n 24 Stick 81096 non-null category\n 25 Transmission 188007 non-null category\n 26 Turbocharged 81096 non-null category\n 27 Blade_Extension 25983 non-null category\n 28 Blade_Width 25983 non-null category\n 29 Enclosure_Type 25983 non-null category\n 30 Engine_Horsepower 25983 non-null category\n 31 Hydraulics 330133 non-null category\n 32 Pushblock 25983 non-null category\n 33 Ripper 106945 non-null category\n 34 Scarifier 25994 non-null category\n 35 Tip_Control 25983 non-null category\n 36 Tire_Size 97638 non-null category\n 37 Coupler 220679 non-null category\n 38 Coupler_System 44974 non-null category\n 39 Grouser_Tracks 44875 non-null category\n 40 Hydraulics_Flow 44875 non-null category\n 41 Track_Type 102193 non-null category\n 42 Undercarriage_Pad_Width 102916 non-null category\n 43 Stick_Length 102261 non-null category\n 44 Thumb 102332 non-null category\n 45 Pattern_Changer 102261 non-null category\n 46 Grouser_Type 102193 non-null category\n 47 Backhoe_Mounting 80712 non-null category\n 48 Blade_Type 81875 non-null category\n 49 Travel_Controls 81877 non-null category\n 50 Differential_Type 71564 non-null category\n 51 Steering_Controls 71522 non-null category\n 52 saleYear 412698 non-null int64 \n 53 saleMonth 412698 non-null int64 \n 54 saleDay 412698 non-null int64 \n 55 saleDayofweek 412698 non-null int64 \n 56 saleDayofyear 412698 non-null int64 \ndtypes: category(44), float64(3), int64(10)\nmemory usage: 60.1 MB\n
Nice! Looks like using the parquet format preserved all of our datatypes.
For more on the parquet and feather formats, be sure to check out the pandas IO (input/output) documentation.
In\u00a0[51]: Copied! # Check missing values\ndf_tmp.isna().sum().sort_values(ascending=False)[:20]\n
# Check missing values df_tmp.isna().sum().sort_values(ascending=False)[:20] Out[51]: Blade_Width 386715\nEngine_Horsepower 386715\nTip_Control 386715\nPushblock 386715\nBlade_Extension 386715\nEnclosure_Type 386715\nScarifier 386704\nHydraulics_Flow 367823\nGrouser_Tracks 367823\nCoupler_System 367724\nfiModelSeries 354031\nSteering_Controls 341176\nDifferential_Type 341134\nUsageBand 339028\nfiModelDescriptor 337882\nBackhoe_Mounting 331986\nStick 331602\nTurbocharged 331602\nPad_Type 331602\nBlade_Type 330823\ndtype: int64
Ok, it seems like there are a fair few columns with missing values and there are several datatypes across these columns (numerical, categorical).
How about we break the problem down and work on filling each datatype separately?
In\u00a0[52]: Copied! # Find numeric columns \nfor label, content in df_tmp.items():\n if pd.api.types.is_numeric_dtype(content):\n # Check datatype of target column\n column_datatype = df_tmp[label].dtype.name\n\n # Get random sample from column values\n example_value = content.sample(1).values\n\n # Infer random sample datatype\n example_value_dtype = pd.api.types.infer_dtype(example_value)\n print(f\"Column name: {label} | Column dtype: {column_datatype} | Example value: {example_value} | Example value dtype: {example_value_dtype}\")\n # Find numeric columns for label, content in df_tmp.items(): if pd.api.types.is_numeric_dtype(content): # Check datatype of target column column_datatype = df_tmp[label].dtype.name # Get random sample from column values example_value = content.sample(1).values # Infer random sample datatype example_value_dtype = pd.api.types.infer_dtype(example_value) print(f\"Column name: {label} | Column dtype: {column_datatype} | Example value: {example_value} | Example value dtype: {example_value_dtype}\") Column name: SalesID | Column dtype: int64 | Example value: [1748586] | Example value dtype: integer\nColumn name: SalePrice | Column dtype: float64 | Example value: [13000.] | Example value dtype: floating\nColumn name: MachineID | Column dtype: int64 | Example value: [1441940] | Example value dtype: integer\nColumn name: ModelID | Column dtype: int64 | Example value: [1333] | Example value dtype: integer\nColumn name: datasource | Column dtype: int64 | Example value: [132] | Example value dtype: integer\nColumn name: auctioneerID | Column dtype: float64 | Example value: [2.] | Example value dtype: floating\nColumn name: YearMade | Column dtype: int64 | Example value: [1000] | Example value dtype: integer\nColumn name: MachineHoursCurrentMeter | Column dtype: float64 | Example value: [nan] | Example value dtype: floating\nColumn name: saleYear | Column dtype: int64 | Example value: [2010] | Example value dtype: integer\nColumn name: saleMonth | Column dtype: int64 | Example value: [6] | Example value dtype: integer\nColumn name: saleDay | Column dtype: int64 | Example value: [16] | Example value dtype: integer\nColumn name: saleDayofweek | Column dtype: int64 | Example value: [3] | Example value dtype: integer\nColumn name: saleDayofyear | Column dtype: int64 | Example value: [285] | Example value dtype: integer\n
Beautiful! Looks like we've got a mixture of int64 and float64 numerical datatypes.
Now how about we find out which numeric columns are missing values?
We can do so by using pandas.isnull(obj).sum() to detect and sum the missing values in a given array-like object (in our case, the data in a target column).
Let's loop through our DataFrame columns, find the numeric datatypes and check if they have any missing values.
In\u00a0[53]: Copied! # Check for which numeric columns have null values\nfor label, content in df_tmp.items():\n if pd.api.types.is_numeric_dtype(content):\n if pd.isnull(content).sum():\n print(f\"Column name: {label} | Has missing values: {True}\")\n else:\n print(f\"Column name: {label} | Has missing values: {False}\")\n # Check for which numeric columns have null values for label, content in df_tmp.items(): if pd.api.types.is_numeric_dtype(content): if pd.isnull(content).sum(): print(f\"Column name: {label} | Has missing values: {True}\") else: print(f\"Column name: {label} | Has missing values: {False}\") Column name: SalesID | Has missing values: False\nColumn name: SalePrice | Has missing values: False\nColumn name: MachineID | Has missing values: False\nColumn name: ModelID | Has missing values: False\nColumn name: datasource | Has missing values: False\nColumn name: auctioneerID | Has missing values: True\nColumn name: YearMade | Has missing values: False\nColumn name: MachineHoursCurrentMeter | Has missing values: True\nColumn name: saleYear | Has missing values: False\nColumn name: saleMonth | Has missing values: False\nColumn name: saleDay | Has missing values: False\nColumn name: saleDayofweek | Has missing values: False\nColumn name: saleDayofyear | Has missing values: False\n
Okay, it looks like our auctioneerID and MachineHoursCurrentMeter columns have missing numeric values.
Let's have a look at how we might handle these.
In\u00a0[54]: Copied! # Fill missing numeric values with the median of the target column\nfor label, content in df_tmp.items():\n if pd.api.types.is_numeric_dtype(content):\n if pd.isnull(content).sum():\n \n # Add a binary column which tells if the data was missing our not\n df_tmp[label+\"_is_missing\"] = pd.isnull(content).astype(int) # this will add a 0 or 1 value to rows with missing values (e.g. 0 = not missing, 1 = missing)\n\n # Fill missing numeric values with median since it's more robust than the mean\n df_tmp[label] = content.fillna(content.median())\n
# Fill missing numeric values with the median of the target column for label, content in df_tmp.items(): if pd.api.types.is_numeric_dtype(content): if pd.isnull(content).sum(): # Add a binary column which tells if the data was missing our not df_tmp[label+\"_is_missing\"] = pd.isnull(content).astype(int) # this will add a 0 or 1 value to rows with missing values (e.g. 0 = not missing, 1 = missing) # Fill missing numeric values with median since it's more robust than the mean df_tmp[label] = content.fillna(content.median()) Why add a binary column indicating whether the data was missing or not?
We can easily fill all of the missing numeric values in our dataset with the median.
However, a numeric value may be missing for a reason.
Adding a binary column which indicates whether the value was missing or not helps to retain this information. It also means we can inspect these rows later on.
In\u00a0[55]: Copied! # Show rows where MachineHoursCurrentMeter_is_missing == 1\ndf_tmp[df_tmp[\"MachineHoursCurrentMeter_is_missing\"] == 1].sample(5)\n
# Show rows where MachineHoursCurrentMeter_is_missing == 1 df_tmp[df_tmp[\"MachineHoursCurrentMeter_is_missing\"] == 1].sample(5) Out[55]: SalesID SalePrice MachineID ModelID datasource auctioneerID YearMade MachineHoursCurrentMeter UsageBand fiModelDesc ... Travel_Controls Differential_Type Steering_Controls saleYear saleMonth saleDay saleDayofweek saleDayofyear auctioneerID_is_missing MachineHoursCurrentMeter_is_missing 150110 1631531 35000.0 1267456 4794 132 2.0 1998 0.0 NaN 710D ... NaN NaN NaN 2003 9 11 3 254 0 1 111297 1327658 15000.0 1185021 4112 132 99.0 1980 0.0 NaN D5B ... None or Unspecified NaN NaN 2001 5 8 1 128 0 1 177121 1432179 52000.0 788654 1263 132 1.0 1997 0.0 NaN 330BL ... NaN NaN NaN 2005 2 15 1 46 0 1 138512 1440179 27000.0 790577 3547 132 7.0 1999 0.0 NaN 426C ... NaN NaN NaN 2002 12 6 4 340 0 1 69375 1473901 67500.0 196530 3823 132 6.0 1991 0.0 NaN 950F ... NaN Standard Conventional 1998 8 27 3 239 0 1 5 rows \u00d7 59 columns
Missing numeric values filled!
How about we check again whether or not the numeric columns have missing values?
In\u00a0[56]: Copied! # Check for which numeric columns have null values\nfor label, content in df_tmp.items():\n if pd.api.types.is_numeric_dtype(content):\n if pd.isnull(content).sum():\n print(f\"Column name: {label} | Has missing values: {True}\")\n else:\n print(f\"Column name: {label} | Has missing values: {False}\")\n # Check for which numeric columns have null values for label, content in df_tmp.items(): if pd.api.types.is_numeric_dtype(content): if pd.isnull(content).sum(): print(f\"Column name: {label} | Has missing values: {True}\") else: print(f\"Column name: {label} | Has missing values: {False}\") Column name: SalesID | Has missing values: False\nColumn name: SalePrice | Has missing values: False\nColumn name: MachineID | Has missing values: False\nColumn name: ModelID | Has missing values: False\nColumn name: datasource | Has missing values: False\nColumn name: auctioneerID | Has missing values: False\nColumn name: YearMade | Has missing values: False\nColumn name: MachineHoursCurrentMeter | Has missing values: False\nColumn name: saleYear | Has missing values: False\nColumn name: saleMonth | Has missing values: False\nColumn name: saleDay | Has missing values: False\nColumn name: saleDayofweek | Has missing values: False\nColumn name: saleDayofyear | Has missing values: False\nColumn name: auctioneerID_is_missing | Has missing values: False\nColumn name: MachineHoursCurrentMeter_is_missing | Has missing values: False\n
Woohoo! Numeric missing values filled!
And thanks to our binary _is_missing columns, we can even check how many were missing.
In\u00a0[57]: Copied! # Check to see how many examples in the auctioneerID were missing\ndf_tmp.auctioneerID_is_missing.value_counts()\n
# Check to see how many examples in the auctioneerID were missing df_tmp.auctioneerID_is_missing.value_counts() Out[57]: auctioneerID_is_missing\n0 392562\n1 20136\nName: count, dtype: int64
In\u00a0[58]: Copied! # Check columns which aren't numeric\nprint(f\"[INFO] Columns which are not numeric:\")\nfor label, content in df_tmp.items():\n if not pd.api.types.is_numeric_dtype(content):\n print(f\"Column name: {label} | Column dtype: {df_tmp[label].dtype.name}\")\n # Check columns which aren't numeric print(f\"[INFO] Columns which are not numeric:\") for label, content in df_tmp.items(): if not pd.api.types.is_numeric_dtype(content): print(f\"Column name: {label} | Column dtype: {df_tmp[label].dtype.name}\") [INFO] Columns which are not numeric:\nColumn name: UsageBand | Column dtype: category\nColumn name: fiModelDesc | Column dtype: category\nColumn name: fiBaseModel | Column dtype: category\nColumn name: fiSecondaryDesc | Column dtype: category\nColumn name: fiModelSeries | Column dtype: category\nColumn name: fiModelDescriptor | Column dtype: category\nColumn name: ProductSize | Column dtype: category\nColumn name: fiProductClassDesc | Column dtype: category\nColumn name: state | Column dtype: category\nColumn name: ProductGroup | Column dtype: category\nColumn name: ProductGroupDesc | Column dtype: category\nColumn name: Drive_System | Column dtype: category\nColumn name: Enclosure | Column dtype: category\nColumn name: Forks | Column dtype: category\nColumn name: Pad_Type | Column dtype: category\nColumn name: Ride_Control | Column dtype: category\nColumn name: Stick | Column dtype: category\nColumn name: Transmission | Column dtype: category\nColumn name: Turbocharged | Column dtype: category\nColumn name: Blade_Extension | Column dtype: category\nColumn name: Blade_Width | Column dtype: category\nColumn name: Enclosure_Type | Column dtype: category\nColumn name: Engine_Horsepower | Column dtype: category\nColumn name: Hydraulics | Column dtype: category\nColumn name: Pushblock | Column dtype: category\nColumn name: Ripper | Column dtype: category\nColumn name: Scarifier | Column dtype: category\nColumn name: Tip_Control | Column dtype: category\nColumn name: Tire_Size | Column dtype: category\nColumn name: Coupler | Column dtype: category\nColumn name: Coupler_System | Column dtype: category\nColumn name: Grouser_Tracks | Column dtype: category\nColumn name: Hydraulics_Flow | Column dtype: category\nColumn name: Track_Type | Column dtype: category\nColumn name: Undercarriage_Pad_Width | Column dtype: category\nColumn name: Stick_Length | Column dtype: category\nColumn name: Thumb | Column dtype: category\nColumn name: Pattern_Changer | Column dtype: category\nColumn name: Grouser_Type | Column dtype: category\nColumn name: Backhoe_Mounting | Column dtype: category\nColumn name: Blade_Type | Column dtype: category\nColumn name: Travel_Controls | Column dtype: category\nColumn name: Differential_Type | Column dtype: category\nColumn name: Steering_Controls | Column dtype: category\n
Okay, we've got plenty of category type columns.
Let's now write some code to fill the missing categorical values as well as ensure they are numerical (non-string).
To do so, we'll:
- Create a blank column to category dictionary, we'll use this to store categorical value names (e.g. their string name) as well as their categorical code. We'll end with a dictionary of dictionaries in the form
{\"column_name\": {category_code: \"category_value\"...}...}. - Loop through the items in the DataFrame.
- Check if the column is numeric or not.
- Add a binary column in the form
ORIGINAL_COLUMN_NAME_is_missing with a 0 or 1 value for if the row had a missing value. - Ensure the column values are in the
pd.Categorical datatype and get their category codes with pd.Series.cat.codes (we'll add 1 to these values since pandas defaults to assigning -1 to NaN values, we'll use 0 instead). - Turn the column categories and column category codes from 5 into a dictionary with Python's
dict(zip(category_names, category_codes)) and save this to the blank dictionary from 1 with the target column name as key. - Set the target column value to the numerical category values from 5.
Phew!
That's a fair few steps but nothing we can't handle.
Let's do it!
In\u00a0[59]: Copied! # 1. Create a dictionary to store column to category values (e.g. we turn our category types into numbers but we keep a record so we can go back)\ncolumn_to_category_dict = {} \n\n# 2. Turn categorical variables into numbers\nfor label, content in df_tmp.items():\n\n # 3. Check columns which *aren't* numeric\n if not pd.api.types.is_numeric_dtype(content):\n\n # 4. Add binary column to inidicate whether sample had missing value\n df_tmp[label+\"_is_missing\"] = pd.isnull(content).astype(int)\n\n # 5. Ensure content is categorical and get its category codes\n content_categories = pd.Categorical(content)\n content_category_codes = content_categories.codes + 1 # prevents -1 (the default for NaN values) from being used for missing values (we'll treat missing values as 0)\n\n # 6. Add column key to dictionary with code: category mapping per column\n column_to_category_dict[label] = dict(zip(content_category_codes, content_categories))\n \n # 7. Set the column to the numerical values (the category code value) \n df_tmp[label] = content_category_codes\n # 1. Create a dictionary to store column to category values (e.g. we turn our category types into numbers but we keep a record so we can go back) column_to_category_dict = {} # 2. Turn categorical variables into numbers for label, content in df_tmp.items(): # 3. Check columns which *aren't* numeric if not pd.api.types.is_numeric_dtype(content): # 4. Add binary column to inidicate whether sample had missing value df_tmp[label+\"_is_missing\"] = pd.isnull(content).astype(int) # 5. Ensure content is categorical and get its category codes content_categories = pd.Categorical(content) content_category_codes = content_categories.codes + 1 # prevents -1 (the default for NaN values) from being used for missing values (we'll treat missing values as 0) # 6. Add column key to dictionary with code: category mapping per column column_to_category_dict[label] = dict(zip(content_category_codes, content_categories)) # 7. Set the column to the numerical values (the category code value) df_tmp[label] = content_category_codes Ho ho! No errors!
Let's check out a few random samples of our DataFrame.
In\u00a0[60]: Copied! df_tmp.sample(5)\n
df_tmp.sample(5) Out[60]: SalesID SalePrice MachineID ModelID datasource auctioneerID YearMade MachineHoursCurrentMeter UsageBand fiModelDesc ... Undercarriage_Pad_Width_is_missing Stick_Length_is_missing Thumb_is_missing Pattern_Changer_is_missing Grouser_Type_is_missing Backhoe_Mounting_is_missing Blade_Type_is_missing Travel_Controls_is_missing Differential_Type_is_missing Steering_Controls_is_missing 232167 2412660 53000.0 1144729 607 136 1.0 2000 0.0 0 4823 ... 1 1 1 1 1 1 1 1 0 0 398100 1221746 18500.0 1047245 2759 121 3.0 1000 319.0 2 2224 ... 1 1 1 1 1 0 0 0 1 1 363820 2502559 31000.0 1333542 3172 149 1.0 2007 1149.0 3 1081 ... 1 1 1 1 1 1 1 1 1 1 322230 2432752 7500.0 1537457 36033 136 1.0 2003 0.0 0 4259 ... 1 1 1 1 1 1 1 1 1 1 10401 1356581 26000.0 1394933 4090 132 1.0 1988 0.0 0 2121 ... 1 1 1 1 1 0 0 0 1 1 5 rows \u00d7 103 columns
Beautiful! Looks like our data is all in numerical form.
How about we investigate an item from our column_to_category_dict?
This will show the mapping from numerical value to category (most likely a string) value.
In\u00a0[61]: Copied! # Check the UsageBand (measure of bulldozer usage)\nfor key, value in sorted(column_to_category_dict[\"UsageBand\"].items()): # note: calling sorted() on dictionary.items() sorts the dictionary by keys \n print(f\"{key} -> {value}\")\n # Check the UsageBand (measure of bulldozer usage) for key, value in sorted(column_to_category_dict[\"UsageBand\"].items()): # note: calling sorted() on dictionary.items() sorts the dictionary by keys print(f\"{key} -> {value}\") 0 -> nan\n1 -> High\n2 -> Low\n3 -> Medium\n
Note: Categorical values do not necessarily have order. They are strictly a mapping from number to value. In this case, our categorical values are mapped in numerical order. If you feel that the order of a value may influence a model in a negative way (e.g. 1 -> High is lower than 3 -> Medium but should be higher), you may want to look into ordering the values in a particular way or using a different numerical encoding technique such as one-hot encoding.
And we can do the same for the state column values.
In\u00a0[62]: Copied! # Check the first 10 state column values\nfor key, value in sorted(column_to_category_dict[\"state\"].items())[:10]:\n print(f\"{key} -> {value}\")\n # Check the first 10 state column values for key, value in sorted(column_to_category_dict[\"state\"].items())[:10]: print(f\"{key} -> {value}\") 1 -> Alabama\n2 -> Alaska\n3 -> Arizona\n4 -> Arkansas\n5 -> California\n6 -> Colorado\n7 -> Connecticut\n8 -> Delaware\n9 -> Florida\n10 -> Georgia\n
Beautiful!
How about we check to see all of the missing values have been filled?
In\u00a0[63]: Copied! # Check total number of missing values\ntotal_missing_values = df_tmp.isna().sum().sum()\n\nif total_missing_values == 0:\n print(f\"[INFO] Total missing values: {total_missing_values} - Woohoo! Let's build a model!\")\nelse:\n print(f\"[INFO] Uh ohh... total missing values: {total_missing_values} - Perhaps we might have to retrace our steps to fill the values?\")\n # Check total number of missing values total_missing_values = df_tmp.isna().sum().sum() if total_missing_values == 0: print(f\"[INFO] Total missing values: {total_missing_values} - Woohoo! Let's build a model!\") else: print(f\"[INFO] Uh ohh... total missing values: {total_missing_values} - Perhaps we might have to retrace our steps to fill the values?\") [INFO] Total missing values: 0 - Woohoo! Let's build a model!\n
In\u00a0[64]: Copied! # Save preprocessed data with object values as categories as well as missing values filled\ndf_tmp.to_parquet(path=\"../data/bluebook-for-bulldozers/TrainAndValid_object_values_as_categories_and_missing_values_filled.parquet\",\n engine=\"auto\")\n
# Save preprocessed data with object values as categories as well as missing values filled df_tmp.to_parquet(path=\"../data/bluebook-for-bulldozers/TrainAndValid_object_values_as_categories_and_missing_values_filled.parquet\", engine=\"auto\") And to make sure it worked, we can re-import it.
In\u00a0[65]: Copied! # Read in preprocessed dataset\ndf_tmp = pd.read_parquet(path=\"../data/bluebook-for-bulldozers/TrainAndValid_object_values_as_categories_and_missing_values_filled.parquet\",\n engine=\"auto\")\n
# Read in preprocessed dataset df_tmp = pd.read_parquet(path=\"../data/bluebook-for-bulldozers/TrainAndValid_object_values_as_categories_and_missing_values_filled.parquet\", engine=\"auto\") Does it have any missing values?
In\u00a0[66]: Copied! # Check total number of missing values\ntotal_missing_values = df_tmp.isna().sum().sum()\n\nif total_missing_values == 0:\n print(f\"[INFO] Total missing values: {total_missing_values} - Woohoo! Let's build a model!\")\nelse:\n print(f\"[INFO] Uh ohh... total missing values: {total_missing_values} - Perhaps we might have to retrace our steps to fill the values?\")\n # Check total number of missing values total_missing_values = df_tmp.isna().sum().sum() if total_missing_values == 0: print(f\"[INFO] Total missing values: {total_missing_values} - Woohoo! Let's build a model!\") else: print(f\"[INFO] Uh ohh... total missing values: {total_missing_values} - Perhaps we might have to retrace our steps to fill the values?\") [INFO] Total missing values: 0 - Woohoo! Let's build a model!\n
Checkpoint reached!
We've turned all of our data into numbers as well as filled the missing values, time to try fitting a model to it again.
In\u00a0[67]: Copied! %%time\n\n# Sample 1000 samples with random state 42 for reproducibility\ndf_tmp_sample_1k = df_tmp.sample(n=1000, random_state=42)\n\n# Instantiate a model\nmodel = RandomForestRegressor(n_jobs=-1) # use -1 to utilise all available processors\n\n# Create features and labels\nX_sample_1k = df_tmp_sample_1k.drop(\"SalePrice\", axis=1) # use all columns except SalePrice as X values\ny_sample_1k = df_tmp_sample_1k[\"SalePrice\"] # use SalePrice as y values (target variable)\n\n# Fit the model to the sample data\nmodel.fit(X=X_sample_1k, \n y=y_sample_1k)\n
%%time # Sample 1000 samples with random state 42 for reproducibility df_tmp_sample_1k = df_tmp.sample(n=1000, random_state=42) # Instantiate a model model = RandomForestRegressor(n_jobs=-1) # use -1 to utilise all available processors # Create features and labels X_sample_1k = df_tmp_sample_1k.drop(\"SalePrice\", axis=1) # use all columns except SalePrice as X values y_sample_1k = df_tmp_sample_1k[\"SalePrice\"] # use SalePrice as y values (target variable) # Fit the model to the sample data model.fit(X=X_sample_1k, y=y_sample_1k) CPU times: user 1.06 s, sys: 2.37 s, total: 3.43 s\nWall time: 976 ms\n
Out[67]: RandomForestRegressor(n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.\u00a0\u00a0RandomForestRegressor?Documentation for RandomForestRegressoriFittedRandomForestRegressor(n_jobs=-1)
Woah! It looks like things worked!
And quite quick too (since we're only using a relatively small number of rows).
How about we score our model?
We can do so using the built-in method score().
By default, sklearn.ensemble.RandomForestRegressor uses coefficient of determination ($R^2$ or R-squared) as the evaluation metric (higher is better, with a score of 1.0 being perfect).
In\u00a0[68]: Copied! # Evaluate the model\nmodel_sample_1k_score = model.score(X=X_sample_1k,\n y=y_sample_1k)\n\nprint(f\"[INFO] Model score on {len(df_tmp_sample_1k)} samples: {model_sample_1k_score}\")\n # Evaluate the model model_sample_1k_score = model.score(X=X_sample_1k, y=y_sample_1k) print(f\"[INFO] Model score on {len(df_tmp_sample_1k)} samples: {model_sample_1k_score}\") [INFO] Model score on 1000 samples: 0.9563062437082765\n
Wow, it looks like our model got a pretty good score on only 1000 samples (the best possible score it could achieve would've been 1.0).
How about we try our model on the whole dataset?
In\u00a0[69]: Copied! %%time\n\n# Instantiate model\nmodel = RandomForestRegressor(n_jobs=-1) # note: this could take quite a while depending on your machine (it took ~1.5 minutes on my MacBook Pro M1 Pro with 10 cores)\n\n# Create features and labels with entire dataset\nX_all = df_tmp.drop(\"SalePrice\", axis=1)\ny_all = df_tmp[\"SalePrice\"]\n\n# Fit the model\nmodel.fit(X=X_all, \n y=y_all)\n
%%time # Instantiate model model = RandomForestRegressor(n_jobs=-1) # note: this could take quite a while depending on your machine (it took ~1.5 minutes on my MacBook Pro M1 Pro with 10 cores) # Create features and labels with entire dataset X_all = df_tmp.drop(\"SalePrice\", axis=1) y_all = df_tmp[\"SalePrice\"] # Fit the model model.fit(X=X_all, y=y_all) CPU times: user 10min 21s, sys: 8min 31s, total: 18min 53s\nWall time: 3min 24s\n
Out[69]: RandomForestRegressor(n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.\u00a0\u00a0RandomForestRegressor?Documentation for RandomForestRegressoriFittedRandomForestRegressor(n_jobs=-1)
Ok, that took a little bit longer than fitting on 1000 samples (but that's too be expected, as many more calculations had to be made).
There's a reason we used n_jobs=-1 too.
If we stuck with the default of n_jobs=None (the same as n_jobs=1), it would've taken much longer.
Configuration (MacBook Pro M1 Pro, 10 Cores) CPU Times (User) CPU Times (Sys) CPU Times (Total) Wall Time n_jobs=-1 (all cores) 9min 14s 3.85s 9min 18s 1min 15s n_jobs=None (default) 7min 14s 1.75s 7min 16s 7min 25s And as we've discussed many times, one of the main goals when starting a machine learning project is to reduce your time between experiments.
How about we score the model trained on all of the data?
In\u00a0[70]: Copied! # Evaluate the model\nmodel_sample_all_score = model.score(X=X_all,\n y=y_all)\n\nprint(f\"[INFO] Model score on {len(df_tmp)} samples: {model_sample_all_score}\")\n # Evaluate the model model_sample_all_score = model.score(X=X_all, y=y_all) print(f\"[INFO] Model score on {len(df_tmp)} samples: {model_sample_all_score}\") [INFO] Model score on 412698 samples: 0.9875710658782831\n
An even better score!
Oh wait...
Oh no...
I think we've got an error... (you might've noticed it already)
Why might this metric be unreliable?
Hint: Compare the data we trained on versus the data we evaluated on.
In\u00a0[71]: Copied! # Import train samples (making sure to parse dates and then sort by them)\ntrain_df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/Train.csv\",\n parse_dates=[\"saledate\"],\n low_memory=False).sort_values(by=\"saledate\", ascending=True)\n\n# Import validation samples (making sure to parse dates and then sort by them)\nvalid_df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/Valid.csv\",\n parse_dates=[\"saledate\"])\n\n# The ValidSolution.csv contains the SalePrice values for the samples in Valid.csv\nvalid_solution = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/ValidSolution.csv\")\n\n# Map valid_solution to valid_df\nvalid_df[\"SalePrice\"] = valid_df[\"SalesID\"].map(valid_solution.set_index(\"SalesID\")[\"SalePrice\"])\n\n# Make sure valid_df is sorted by saledate still\nvalid_df = valid_df.sort_values(\"saledate\", ascending=True).reset_index(drop=True)\n\n# How many samples are in each DataFrame?\nprint(f\"[INFO] Number of samples in training DataFrame: {len(train_df)}\")\nprint(f\"[INFO] Number of samples in validation DataFrame: {len(valid_df)}\")\n # Import train samples (making sure to parse dates and then sort by them) train_df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/Train.csv\", parse_dates=[\"saledate\"], low_memory=False).sort_values(by=\"saledate\", ascending=True) # Import validation samples (making sure to parse dates and then sort by them) valid_df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/Valid.csv\", parse_dates=[\"saledate\"]) # The ValidSolution.csv contains the SalePrice values for the samples in Valid.csv valid_solution = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/ValidSolution.csv\") # Map valid_solution to valid_df valid_df[\"SalePrice\"] = valid_df[\"SalesID\"].map(valid_solution.set_index(\"SalesID\")[\"SalePrice\"]) # Make sure valid_df is sorted by saledate still valid_df = valid_df.sort_values(\"saledate\", ascending=True).reset_index(drop=True) # How many samples are in each DataFrame? print(f\"[INFO] Number of samples in training DataFrame: {len(train_df)}\") print(f\"[INFO] Number of samples in validation DataFrame: {len(valid_df)}\") [INFO] Number of samples in training DataFrame: 401125\n[INFO] Number of samples in validation DataFrame: 11573\n
In\u00a0[72]: Copied! # Let's check out the training DataFrame\ntrain_df.sample(5)\n
# Let's check out the training DataFrame train_df.sample(5) Out[72]: SalesID SalePrice MachineID ModelID datasource auctioneerID YearMade MachineHoursCurrentMeter UsageBand saledate ... Undercarriage_Pad_Width Stick_Length Thumb Pattern_Changer Grouser_Type Backhoe_Mounting Blade_Type Travel_Controls Differential_Type Steering_Controls 118276 1457333 58000 1434146 4147 132 1.0 1980 NaN NaN 1990-05-03 ... NaN NaN NaN NaN NaN None or Unspecified Straight None or Unspecified NaN NaN 149220 1522457 37000 1473616 4199 132 2.0 1992 NaN NaN 1996-11-16 ... None or Unspecified None or Unspecified None or Unspecified None or Unspecified Double NaN NaN NaN NaN NaN 118159 1457054 19250 1503681 4147 132 99.0 1979 NaN NaN 2009-10-01 ... NaN NaN NaN NaN NaN None or Unspecified Semi U None or Unspecified NaN NaN 28240 1258591 8250 1459934 6788 132 6.0 1971 NaN NaN 1990-04-18 ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 396348 6282780 41600 1916198 14272 149 99.0 2003 NaN NaN 2011-11-09 ... None or Unspecified None or Unspecified None or Unspecified None or Unspecified Double NaN NaN NaN NaN NaN 5 rows \u00d7 53 columns
In\u00a0[73]: Copied! # And how about the validation DataFrame?\nvalid_df.sample(5)\n
# And how about the validation DataFrame? valid_df.sample(5) Out[73]: SalesID MachineID ModelID datasource auctioneerID YearMade MachineHoursCurrentMeter UsageBand saledate fiModelDesc ... Stick_Length Thumb Pattern_Changer Grouser_Type Backhoe_Mounting Blade_Type Travel_Controls Differential_Type Steering_Controls SalePrice 7504 4325208 2306826 4840 172 1 1987 9540.0 Low 2012-03-22 850B ... NaN NaN NaN NaN None or Unspecified Straight None or Unspecified NaN NaN 10000.0 4853 6282223 1482307 28842 149 0 2004 NaN NaN 2012-02-23 80C ... None or Unspecified None or Unspecified None or Unspecified Double NaN NaN NaN NaN NaN 27000.0 28 6269818 1791122 7257 149 99 1978 48.0 Low 2012-01-11 910 ... NaN NaN NaN NaN NaN NaN NaN Standard Conventional 10600.0 7451 1226478 205898 1269 121 3 2004 9333.0 Medium 2012-03-22 330CL ... None or Unspecified Hydraulic Yes Double NaN NaN NaN NaN NaN 90000.0 693 1223479 143807 3538 121 3 1997 2154.0 Low 2012-01-27 416C ... NaN NaN NaN NaN NaN NaN NaN NaN NaN 19500.0 5 rows \u00d7 53 columns
Nice!
We've now got separate training and validation datasets imported.
In a previous section, we created a function to decompose the saledate column into multiple features such as saleYear, saleMonth, saleDay and more.
Let's now replicate that function here and apply it to our train_df and valid_df.
In\u00a0[74]: Copied! # Make a function to add date columns\ndef add_datetime_features_to_df(df, date_column=\"saledate\"):\n # Add datetime parameters for saledate\n df[\"saleYear\"] = df[date_column].dt.year\n df[\"saleMonth\"] = df[date_column].dt.month\n df[\"saleDay\"] = df[date_column].dt.day\n df[\"saleDayofweek\"] = df[date_column].dt.dayofweek\n df[\"saleDayofyear\"] = df[date_column].dt.dayofyear\n\n # Drop original saledate column\n df.drop(\"saledate\", axis=1, inplace=True)\n\n return df\n\ntrain_df = add_datetime_features_to_df(df=train_df)\nvalid_df = add_datetime_features_to_df(df=valid_df)\n
# Make a function to add date columns def add_datetime_features_to_df(df, date_column=\"saledate\"): # Add datetime parameters for saledate df[\"saleYear\"] = df[date_column].dt.year df[\"saleMonth\"] = df[date_column].dt.month df[\"saleDay\"] = df[date_column].dt.day df[\"saleDayofweek\"] = df[date_column].dt.dayofweek df[\"saleDayofyear\"] = df[date_column].dt.dayofyear # Drop original saledate column df.drop(\"saledate\", axis=1, inplace=True) return df train_df = add_datetime_features_to_df(df=train_df) valid_df = add_datetime_features_to_df(df=valid_df) Wonderful, now let's make sure it worked by inspecting the last 5 columns of train_df.
In\u00a0[75]: Copied! # Display the last 5 columns (the recently added datetime breakdowns)\ntrain_df.iloc[:, -5:].sample(5)\n
# Display the last 5 columns (the recently added datetime breakdowns) train_df.iloc[:, -5:].sample(5) Out[75]: saleYear saleMonth saleDay saleDayofweek saleDayofyear 319998 2010 4 22 3 112 133509 2003 2 20 3 51 291200 2008 5 23 4 144 280146 2006 3 18 5 77 335509 2008 4 29 1 120 Perfect! How about we try and fit a model?
In\u00a0[76]: Copied! # Split training data into features and labels\nX_train = train_df.drop(\"SalePrice\", axis=1)\ny_train = train_df[\"SalePrice\"]\n\n# Split validation data into features and labels\nX_valid = valid_df.drop(\"SalePrice\", axis=1)\ny_valid = valid_df[\"SalePrice\"]\n\n# Create a model\nmodel = RandomForestRegressor(n_jobs=-1)\n\n# Fit a model to the training data only\nmodel.fit(X=X_train,\n y=y_train)\n
# Split training data into features and labels X_train = train_df.drop(\"SalePrice\", axis=1) y_train = train_df[\"SalePrice\"] # Split validation data into features and labels X_valid = valid_df.drop(\"SalePrice\", axis=1) y_valid = valid_df[\"SalePrice\"] # Create a model model = RandomForestRegressor(n_jobs=-1) # Fit a model to the training data only model.fit(X=X_train, y=y_train) \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\n/var/folders/c4/qj4gdk190td18bqvjjh0p3p00000gn/T/ipykernel_20423/150598518.py in ?()\n 9 # Create a model\n 10 model = RandomForestRegressor(n_jobs=-1)\n 11 \n 12 # Fit a model to the training data only\n---> 13 model.fit(X=X_train,\n 14 y=y_train)\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(estimator, *args, **kwargs)\n 1469 skip_parameter_validation=(\n 1470 prefer_skip_nested_validation or global_skip_validation\n 1471 )\n 1472 ):\n-> 1473 return fit_method(estimator, *args, **kwargs)\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X, y, sample_weight)\n 359 # Validate or convert input data\n 360 if issparse(y):\n 361 raise ValueError(\"sparse multilabel-indicator for y is not supported.\")\n 362 \n--> 363 X, y = self._validate_data(\n 364 X,\n 365 y,\n 366 multi_output=True,\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)\n 646 if \"estimator\" not in check_y_params:\n 647 check_y_params = {**default_check_params, **check_y_params}\n 648 y = check_array(y, input_name=\"y\", **check_y_params)\n 649 else:\n--> 650 X, y = check_X_y(X, y, **check_params)\n 651 out = X, y\n 652 \n 653 if not no_val_X and check_params.get(\"ensure_2d\", True):\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(X, y, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, estimator)\n 1297 raise ValueError(\n 1298 f\"{estimator_name} requires y to be passed, but the target y is None\"\n 1299 )\n 1300 \n-> 1301 X = check_array(\n 1302 X,\n 1303 accept_sparse=accept_sparse,\n 1304 accept_large_sparse=accept_large_sparse,\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)\n 1009 )\n 1010 array = xp.astype(array, dtype, copy=False)\n 1011 else:\n 1012 array = _asarray_with_order(array, order=order, dtype=dtype, xp=xp)\n-> 1013 except ComplexWarning as complex_warning:\n 1014 raise ValueError(\n 1015 \"Complex data not supported\\n{}\\n\".format(array)\n 1016 ) from complex_warning\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/_array_api.py in ?(array, dtype, order, copy, xp, device)\n 747 # Use NumPy API to support order\n 748 if copy is True:\n 749 array = numpy.array(array, order=order, dtype=dtype)\n 750 else:\n--> 751 array = numpy.asarray(array, order=order, dtype=dtype)\n 752 \n 753 # At this point array is a NumPy ndarray. We convert it to an array\n 754 # container that is consistent with the input's namespace.\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/core/generic.py in ?(self, dtype, copy)\n 2149 def __array__(\n 2150 self, dtype: npt.DTypeLike | None = None, copy: bool_t | None = None\n 2151 ) -> np.ndarray:\n 2152 values = self._values\n-> 2153 arr = np.asarray(values, dtype=dtype)\n 2154 if (\n 2155 astype_is_view(values.dtype, arr.dtype)\n 2156 and using_copy_on_write()\n\nValueError: could not convert string to float: 'Medium' Oh no!
We run into the error:
ValueError: could not convert string to float: 'Medium'
Hmm...
Where have we seen this error before?
It looks like since we re-imported our training dataset (from Train.csv) its no longer all numerical (hence the ValueError above).
Not to worry, we can fix this!
In\u00a0[77]: Copied! # Define numerical and categorical features\nnumerical_features = [label for label, content in X_train.items() if pd.api.types.is_numeric_dtype(content)]\ncategorical_features = [label for label, content in X_train.items() if not pd.api.types.is_numeric_dtype(content)]\n\nprint(f\"[INFO] Numeric features: {numerical_features}\")\nprint(f\"[INFO] Categorical features: {categorical_features[:10]}...\")\n # Define numerical and categorical features numerical_features = [label for label, content in X_train.items() if pd.api.types.is_numeric_dtype(content)] categorical_features = [label for label, content in X_train.items() if not pd.api.types.is_numeric_dtype(content)] print(f\"[INFO] Numeric features: {numerical_features}\") print(f\"[INFO] Categorical features: {categorical_features[:10]}...\") [INFO] Numeric features: ['SalesID', 'MachineID', 'ModelID', 'datasource', 'auctioneerID', 'YearMade', 'MachineHoursCurrentMeter', 'saleYear', 'saleMonth', 'saleDay', 'saleDayofweek', 'saleDayofyear']\n[INFO] Categorical features: ['UsageBand', 'fiModelDesc', 'fiBaseModel', 'fiSecondaryDesc', 'fiModelSeries', 'fiModelDescriptor', 'ProductSize', 'fiProductClassDesc', 'state', 'ProductGroup']...\n
Nice!
We define our different feature types so we can use different preprocessing methods on each type.
Scikit-Learn has many built-in methods for preprocessing data under the sklearn.preprocessing module.
And I'd encourage you to spend some time reading the preprocessing data section of the Scikit-Learn user guide for more details.
For now, let's focus on turning our categorical features into numbers (from object/string datatype to numeric datatype).
The practice of turning non-numerical features into numerical features is often referred to as encoding.
There are several encoders available for different use cases.
Encoder Description Use case For use on LabelEncoder Encode target labels with values between 0 and n_classes-1. Useful for turning classification target values into numeric representations. Target labels. OneHotEncoder Encode categorical features as a one-hot numeric array. Turns every positive class of a unique category into a 1 and every negative class into a 0. Categorical variables/features. OrdinalEncoder Encode categorical features as an integer array. Turn unique categorical values into a range of integers, for example, 0 maps to 'cat', 1 maps to 'dog', etc. Categorical variables/features. TargetEncoder Encode regression and classification targets into a shrunk estimate of the average target values for observations of the category. Useful for converting targets into a certain range of values. Target variables. For our case, we're going to start with OrdinalEncoder.
When transforming/encoding values with Scikit-Learn, the steps as follows:
- Instantiate an encoder, for example,
sklearn.preprocessing.OrdinalEncoder. - Use the
sklearn.preprocessing.OrdinalEncoder.fit method on the training data (this helps the encoder learn a mapping of categorical to numeric values). - Use the
sklearn.preprocessing.OrdinalEncoder.transform method on the training data to apply the learned mapping from categorical to numeric values. - Note: The
sklearn.preprocessing.OrdinalEncoder.fit_transform method combines steps 1 & 2 into a single method.
- Apply the learned mapping to subsequent datasets such as validation and test splits using
sklearn.preprocessing.OrdinalEncoder.transform only.
Notice how the fit and fit_transform methods were reserved for the training dataset only.
This is because in practice the validation and testing datasets are meant to be unseen, meaning only information from the training dataset should be used to preprocess the validation/test datasets.
In short:
- Instantiate an encoder such as
sklearn.preprocessing.OrdinalEncoder. - Fit the encoder to and transform the training dataset categorical variables/features with
sklearn.preprocessing.OrdinalEncoder.fit_transform. - Transform categorical variables/features from subsequent datasets such as the validation and test datasets with the learned encoding from step 2 using
sklearn.preprocessing.OridinalEncoder.transform. - Note: Notice the use of the
transform method on validation/test datasets rather than fit_transform.
Let's do it!
We'll use the OrdinalEncoder class to fill any missing values with np.nan (NaN).
We'll also make sure to only use the OrdinalEncoder on the categorical features of our DataFrame.
Finally, the OrdinalEncoder expects all input variables to be of the same type (e.g. either numeric only or string only) so we'll make sure all the input variables are strings only using pandas.DataFrame.astype(str).
In\u00a0[78]: Copied! from sklearn.preprocessing import OrdinalEncoder\n\n# 1. Create an ordinal encoder (turns category items into numeric representation)\nordinal_encoder = OrdinalEncoder(categories=\"auto\",\n handle_unknown=\"use_encoded_value\",\n unknown_value=np.nan,\n encoded_missing_value=np.nan) # treat unknown categories as np.nan (or None)\n\n# 2. Fit and transform the categorical columns of X_train\nX_train_preprocessed = X_train.copy() # make copies of the oringal DataFrames so we can keep the original values in tact and view them later\nX_train_preprocessed[categorical_features] = ordinal_encoder.fit_transform(X_train_preprocessed[categorical_features].astype(str)) # OrdinalEncoder expects all values as the same type (e.g. string or numeric only)\n\n# 3. Transform the categorical columns of X_valid \nX_valid_preprocessed = X_valid.copy()\nX_valid_preprocessed[categorical_features] = ordinal_encoder.transform(X_valid_preprocessed[categorical_features].astype(str)) # only use `transform` on the validation data\n
from sklearn.preprocessing import OrdinalEncoder # 1. Create an ordinal encoder (turns category items into numeric representation) ordinal_encoder = OrdinalEncoder(categories=\"auto\", handle_unknown=\"use_encoded_value\", unknown_value=np.nan, encoded_missing_value=np.nan) # treat unknown categories as np.nan (or None) # 2. Fit and transform the categorical columns of X_train X_train_preprocessed = X_train.copy() # make copies of the oringal DataFrames so we can keep the original values in tact and view them later X_train_preprocessed[categorical_features] = ordinal_encoder.fit_transform(X_train_preprocessed[categorical_features].astype(str)) # OrdinalEncoder expects all values as the same type (e.g. string or numeric only) # 3. Transform the categorical columns of X_valid X_valid_preprocessed = X_valid.copy() X_valid_preprocessed[categorical_features] = ordinal_encoder.transform(X_valid_preprocessed[categorical_features].astype(str)) # only use `transform` on the validation data Wonderful!
Let's see if it worked.
First, we'll check out the original X_train DataFrame.
In\u00a0[79]: Copied! X_train.head()\n
X_train.head() Out[79]: SalesID MachineID ModelID datasource auctioneerID YearMade MachineHoursCurrentMeter UsageBand fiModelDesc fiBaseModel ... Backhoe_Mounting Blade_Type Travel_Controls Differential_Type Steering_Controls saleYear saleMonth saleDay saleDayofweek saleDayofyear 205615 1646770 1126363 8434 132 18.0 1974 NaN NaN TD20 TD20 ... None or Unspecified Straight None or Unspecified NaN NaN 1989 1 17 1 17 92803 1404019 1169900 7110 132 99.0 1986 NaN NaN 416 416 ... NaN NaN NaN NaN NaN 1989 1 31 1 31 98346 1415646 1262088 3357 132 99.0 1975 NaN NaN 12G 12 ... NaN NaN NaN NaN NaN 1989 1 31 1 31 169297 1596358 1433229 8247 132 99.0 1978 NaN NaN 644 644 ... NaN NaN NaN Standard Conventional 1989 1 31 1 31 274835 1821514 1194089 10150 132 99.0 1980 NaN NaN A66 A66 ... NaN NaN NaN Standard Conventional 1989 1 31 1 31 5 rows \u00d7 56 columns
And how about X_train_preprocessed?
In\u00a0[80]: Copied! X_train_preprocessed.head()\n
X_train_preprocessed.head() Out[80]: SalesID MachineID ModelID datasource auctioneerID YearMade MachineHoursCurrentMeter UsageBand fiModelDesc fiBaseModel ... Backhoe_Mounting Blade_Type Travel_Controls Differential_Type Steering_Controls saleYear saleMonth saleDay saleDayofweek saleDayofyear 205615 1646770 1126363 8434 132 18.0 1974 NaN 3.0 4536.0 1734.0 ... 0.0 7.0 5.0 4.0 5.0 1989 1 17 1 17 92803 1404019 1169900 7110 132 99.0 1986 NaN 3.0 734.0 242.0 ... 2.0 10.0 7.0 4.0 5.0 1989 1 31 1 31 98346 1415646 1262088 3357 132 99.0 1975 NaN 3.0 81.0 18.0 ... 2.0 10.0 7.0 4.0 5.0 1989 1 31 1 31 169297 1596358 1433229 8247 132 99.0 1978 NaN 3.0 1157.0 348.0 ... 2.0 10.0 7.0 3.0 1.0 1989 1 31 1 31 274835 1821514 1194089 10150 132 99.0 1980 NaN 3.0 1799.0 556.0 ... 2.0 10.0 7.0 3.0 1.0 1989 1 31 1 31 5 rows \u00d7 56 columns
Beautiful!
Notice all of the non-numerical values in X_train have been converted to numerical values in X_train_preprocessed.
Now how about missing values?
Let's see the top 10 columns with the highest number of missing values from X_train.
In\u00a0[81]: Copied! X_train[categorical_features].isna().sum().sort_values(ascending=False)[:10]\n
X_train[categorical_features].isna().sum().sort_values(ascending=False)[:10] Out[81]: Engine_Horsepower 375906\nBlade_Extension 375906\nTip_Control 375906\nPushblock 375906\nEnclosure_Type 375906\nBlade_Width 375906\nScarifier 375895\nHydraulics_Flow 357763\nGrouser_Tracks 357763\nCoupler_System 357667\ndtype: int64
Ok, plenty of missing values.
How about X_train_preprocessed?
In\u00a0[82]: Copied! X_train_preprocessed[categorical_features].isna().sum().sort_values(ascending=False)[:10]\n
X_train_preprocessed[categorical_features].isna().sum().sort_values(ascending=False)[:10] Out[82]: UsageBand 0\nfiModelDesc 0\nPushblock 0\nRipper 0\nScarifier 0\nTip_Control 0\nTire_Size 0\nCoupler 0\nCoupler_System 0\nGrouser_Tracks 0\ndtype: int64
Perfect! No missing values as well!
Now, what if we wanted to retrieve the original categorical values?
We can do using the OrdinalEncoder.categories_ attribute.
This will return the categories of each feature found during fit (or during fit_transform), the categories will be in the order of the features seen (same order as the columns of the DataFrame).
In\u00a0[83]: Copied! # Let's inspect the first three categories\nordinal_encoder.categories_[:3]\n
# Let's inspect the first three categories ordinal_encoder.categories_[:3] Out[83]: [array(['High', 'Low', 'Medium', 'nan'], dtype=object),\n array(['100C', '104', '1066', ..., 'ZX800LC', 'ZX80LCK', 'ZX850H'],\n dtype=object),\n array(['10', '100', '104', ..., 'ZX80', 'ZX800', 'ZX850'], dtype=object)]
Since these come in the order of the features seen, we can create a mapping of these using the categorical column names of our DataFrame.
In\u00a0[84]: Copied! # Create a dictionary of dictionaries mapping column names and their variables to their numerical encoding\ncolumn_to_category_mapping = {}\n\nfor column_name, category_values in zip(categorical_features, ordinal_encoder.categories_):\n int_to_category = {i: category for i, category in enumerate(category_values)}\n column_to_category_mapping[column_name] = int_to_category\n\n# Inspect an example column name to category mapping\ncolumn_to_category_mapping[\"UsageBand\"]\n # Create a dictionary of dictionaries mapping column names and their variables to their numerical encoding column_to_category_mapping = {} for column_name, category_values in zip(categorical_features, ordinal_encoder.categories_): int_to_category = {i: category for i, category in enumerate(category_values)} column_to_category_mapping[column_name] = int_to_category # Inspect an example column name to category mapping column_to_category_mapping[\"UsageBand\"] Out[84]: {0: 'High', 1: 'Low', 2: 'Medium', 3: 'nan'} We can also reverse our OrdinalEncoder values with the inverse_transform() method.
This is helpful for reversing a preprocessing step or viewing the original data again if necessary.
In\u00a0[85]: Copied! # Create a copy of the preprocessed DataFrame\nX_train_unprocessed = X_train_preprocessed[categorical_features].copy()\n\n# This will return an array of the original untransformed data\nX_train_unprocessed = ordinal_encoder.inverse_transform(X_train_unprocessed)\n\n# Turn back into a DataFrame for viewing pleasure\nX_train_unprocessed_df = pd.DataFrame(X_train_unprocessed, columns=categorical_features)\n\n# Check out a sample\nX_train_unprocessed_df.sample(5)\n
# Create a copy of the preprocessed DataFrame X_train_unprocessed = X_train_preprocessed[categorical_features].copy() # This will return an array of the original untransformed data X_train_unprocessed = ordinal_encoder.inverse_transform(X_train_unprocessed) # Turn back into a DataFrame for viewing pleasure X_train_unprocessed_df = pd.DataFrame(X_train_unprocessed, columns=categorical_features) # Check out a sample X_train_unprocessed_df.sample(5) Out[85]: UsageBand fiModelDesc fiBaseModel fiSecondaryDesc fiModelSeries fiModelDescriptor ProductSize fiProductClassDesc state ProductGroup ... Undercarriage_Pad_Width Stick_Length Thumb Pattern_Changer Grouser_Type Backhoe_Mounting Blade_Type Travel_Controls Differential_Type Steering_Controls 214315 nan 160CLC 160 C nan LC Small Hydraulic Excavator, Track - 14.0 to 16.0 Metr... Alabama TEX ... 28 inch None or Unspecified None or Unspecified None or Unspecified Triple nan nan nan nan nan 96782 nan D4H D4 H nan nan nan Track Type Tractor, Dozer - 85.0 to 105.0 Hors... California TTT ... nan nan nan nan nan None or Unspecified PAT None or Unspecified nan nan 224604 nan 140G 140 G nan nan nan Motorgrader - 145.0 to 170.0 Horsepower Missouri MG ... nan nan nan nan nan nan nan nan nan nan 310524 High 966E 966 E nan nan Medium Wheel Loader - 200.0 to 225.0 Horsepower Michigan WL ... nan nan nan nan nan nan nan nan Standard Conventional 156716 nan 650H 650 H nan nan nan Track Type Tractor, Dozer - 85.0 to 105.0 Hors... Florida TTT ... nan nan nan nan nan None or Unspecified PAT None or Unspecified nan nan 5 rows \u00d7 44 columns
Nice!
Now how about we try fitting a model again?
In\u00a0[86]: Copied! %%time\n\n# Instantiate a Random Forest Regression model\nmodel = RandomForestRegressor(n_jobs=-1)\n\n# Fit the model to the preprocessed training data\nmodel.fit(X=X_train_preprocessed,\n y=y_train)\n
%%time # Instantiate a Random Forest Regression model model = RandomForestRegressor(n_jobs=-1) # Fit the model to the preprocessed training data model.fit(X=X_train_preprocessed, y=y_train) CPU times: user 8min 54s, sys: 6min 26s, total: 15min 20s\nWall time: 2min 40s\n
Out[86]: RandomForestRegressor(n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.\u00a0\u00a0RandomForestRegressor?Documentation for RandomForestRegressoriFittedRandomForestRegressor(n_jobs=-1)
It worked!
Now you might be thinking, \"well if we could fit a model on a dataset with missing values, why did we bother filling them before?\"
And that's a great question.
The main reason is to practice, practice, practice.
While there are some models which can handle missing values, others can't.
So it's good to have experience with both of these scenarios.
Let's see how our model scores on the validation set, data our model has never seen.
In\u00a0[88]: Copied! %%time\n\n# Check model performance on the validation set\nmodel.score(X=X_valid,\n y=y_valid)\n
%%time # Check model performance on the validation set model.score(X=X_valid, y=y_valid) \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\n<timed eval> in ?()\n 1 'Could not get source, probably due dynamically evaluated source code.'\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(self, X, y, sample_weight)\n 844 \"\"\"\n 845 \n 846 from .metrics import r2_score\n 847 \n--> 848 y_pred = self.predict(X)\n 849 return r2_score(y, y_pred, sample_weight=sample_weight)\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X)\n 1059 The predicted values.\n 1060 \"\"\"\n 1061 check_is_fitted(self)\n 1062 # Check data\n-> 1063 X = self._validate_X_predict(X)\n 1064 \n 1065 # Assign chunk of trees to jobs\n 1066 n_jobs, _, _ = _partition_estimators(self.n_estimators, self.n_jobs)\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X)\n 637 force_all_finite = \"allow-nan\"\n 638 else:\n 639 force_all_finite = True\n 640 \n--> 641 X = self._validate_data(\n 642 X,\n 643 dtype=DTYPE,\n 644 accept_sparse=\"csr\",\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)\n 629 out = y\n 630 else:\n 631 out = X, y\n 632 elif not no_val_X and no_val_y:\n--> 633 out = check_array(X, input_name=\"X\", **check_params)\n 634 elif no_val_X and not no_val_y:\n 635 out = _check_y(y, **check_params)\n 636 else:\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)\n 1009 )\n 1010 array = xp.astype(array, dtype, copy=False)\n 1011 else:\n 1012 array = _asarray_with_order(array, order=order, dtype=dtype, xp=xp)\n-> 1013 except ComplexWarning as complex_warning:\n 1014 raise ValueError(\n 1015 \"Complex data not supported\\n{}\\n\".format(array)\n 1016 ) from complex_warning\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/_array_api.py in ?(array, dtype, order, copy, xp, device)\n 747 # Use NumPy API to support order\n 748 if copy is True:\n 749 array = numpy.array(array, order=order, dtype=dtype)\n 750 else:\n--> 751 array = numpy.asarray(array, order=order, dtype=dtype)\n 752 \n 753 # At this point array is a NumPy ndarray. We convert it to an array\n 754 # container that is consistent with the input's namespace.\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/core/generic.py in ?(self, dtype, copy)\n 2149 def __array__(\n 2150 self, dtype: npt.DTypeLike | None = None, copy: bool_t | None = None\n 2151 ) -> np.ndarray:\n 2152 values = self._values\n-> 2153 arr = np.asarray(values, dtype=dtype)\n 2154 if (\n 2155 astype_is_view(values.dtype, arr.dtype)\n 2156 and using_copy_on_write()\n\nValueError: could not convert string to float: 'Low' Oops!
Looks like we get an error:
ValueError: could not convert string to float: 'Low'
This is because we tried to evaluate our model on the original X_valid dataset which still contains strings rather than X_valid_preprocessed which contains all numerical values.
As we've discussed before, in machine learning problems, it's important to evaluate your models on data in the same format as they were trained on.
Knowing this, let's evaluate our model on our preprocessed validation dataset.
In\u00a0[89]: Copied! %%time\n\n# Check model performance on the validation set\nmodel.score(X=X_valid_preprocessed,\n y=y_valid)\n
%%time # Check model performance on the validation set model.score(X=X_valid_preprocessed, y=y_valid) CPU times: user 766 ms, sys: 3.54 s, total: 4.3 s\nWall time: 1.27 s\n
Out[89]: 0.8700295442271035
Excellent!
Now you might be wondering why this score ($R^2$ or R-squared by default) is lower than the previous score of ~0.9875.
That's because this score is based on a model that has only seen the training data and is being evaluated on an unseen dataset (training on Train.csv, evaluating on Valid.csv).
Our previous score was from a model that had all of the evaluation samples in the training data (training and evaluating on TrainAndValid.csv).
So in practice, we would consider the most recent score as a much more reliable metric of how well our model might perform on future unseen data.
Just for fun, let's see how our model scores on the training dataset.
In\u00a0[90]: Copied! %%time\n\n# Check model performance on the training set\nmodel.score(X=X_train_preprocessed,\n y=y_train)\n
%%time # Check model performance on the training set model.score(X=X_train_preprocessed, y=y_train) CPU times: user 17.6 s, sys: 19.2 s, total: 36.8 s\nWall time: 7.42 s\n
Out[90]: 0.9872786621410867
As expected our model performs better on the training set than the validation set.
It also scores much closer to the previous score of ~0.9875 we obtained when training and scoring on TrainAndValid.csv combined.
Note: It is common to see a model perform slightly worse on a validation/testing dataset than on a training set. This is because the model has seen all of the examples in the training set, where as, if done correctly, the validation and test sets are keep separate during training. So you would expect a model to do better on problems that it has seen before versus problems it hasn't. If you find your model scoring much higher on unseen data versus seen data (e.g. higher scores on the test set compared to the training set), you might want to inspect your data to make sure there isn't any leakage from the validation/test set into the training set.
In\u00a0[93]: Copied! # Create evaluation function (the competition uses Root Mean Square Log Error)\nfrom sklearn.metrics import mean_absolute_error, root_mean_squared_log_error\n\n# Create function to evaluate our model\ndef show_scores(model, \n train_features=X_train_preprocessed,\n train_labels=y_train,\n valid_features=X_valid_preprocessed,\n valid_labels=y_valid):\n \n # Make predictions on train and validation features\n train_preds = model.predict(X=train_features)\n val_preds = model.predict(X=valid_features)\n\n # Create a scores dictionary of different evaluation metrics\n scores = {\"Training MAE\": mean_absolute_error(y_true=train_labels, \n y_pred=train_preds),\n \"Valid MAE\": mean_absolute_error(y_true=valid_labels, \n y_pred=val_preds),\n \"Training RMSLE\": root_mean_squared_log_error(y_true=train_labels, \n y_pred=train_preds),\n \"Valid RMSLE\": root_mean_squared_log_error(y_true=valid_labels, \n y_pred=val_preds),\n \"Training R^2\": model.score(X=train_features, \n y=train_labels),\n \"Valid R^2\": model.score(X=valid_features, \n y=valid_labels)}\n return scores\n # Create evaluation function (the competition uses Root Mean Square Log Error) from sklearn.metrics import mean_absolute_error, root_mean_squared_log_error # Create function to evaluate our model def show_scores(model, train_features=X_train_preprocessed, train_labels=y_train, valid_features=X_valid_preprocessed, valid_labels=y_valid): # Make predictions on train and validation features train_preds = model.predict(X=train_features) val_preds = model.predict(X=valid_features) # Create a scores dictionary of different evaluation metrics scores = {\"Training MAE\": mean_absolute_error(y_true=train_labels, y_pred=train_preds), \"Valid MAE\": mean_absolute_error(y_true=valid_labels, y_pred=val_preds), \"Training RMSLE\": root_mean_squared_log_error(y_true=train_labels, y_pred=train_preds), \"Valid RMSLE\": root_mean_squared_log_error(y_true=valid_labels, y_pred=val_preds), \"Training R^2\": model.score(X=train_features, y=train_labels), \"Valid R^2\": model.score(X=valid_features, y=valid_labels)} return scores Now that's a nice looking function!
How about we test it out?
In\u00a0[94]: Copied! # Try our model scoring function out\nmodel_scores = show_scores(model=model)\nmodel_scores\n
# Try our model scoring function out model_scores = show_scores(model=model) model_scores Out[94]: {'Training MAE': np.float64(1596.4113176025767),\n 'Valid MAE': np.float64(6172.124644142976),\n 'Training RMSLE': np.float64(0.08546822305943352),\n 'Valid RMSLE': np.float64(0.2576977236694938),\n 'Training R^2': 0.9872786621410867,\n 'Valid R^2': 0.8700295442271035} Beautiful!
Now we can reuse this in the future for evaluating other models.
In\u00a0[95]: Copied! %%time\n\n# Change max samples in RandomForestRegressor\nmodel = RandomForestRegressor(n_estimators=100, # this is the default\n n_jobs=-1,\n max_samples=10000) # each estimator sees max_samples (the default is to see all available samples)\n\n# Cutting down the max number of samples each tree can see improves training time\nmodel.fit(X_train_preprocessed, \n y_train)\n
%%time # Change max samples in RandomForestRegressor model = RandomForestRegressor(n_estimators=100, # this is the default n_jobs=-1, max_samples=10000) # each estimator sees max_samples (the default is to see all available samples) # Cutting down the max number of samples each tree can see improves training time model.fit(X_train_preprocessed, y_train) CPU times: user 19.2 s, sys: 18.5 s, total: 37.6 s\nWall time: 7.53 s\n
Out[95]: RandomForestRegressor(max_samples=10000, n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.\u00a0\u00a0RandomForestRegressor?Documentation for RandomForestRegressoriFittedRandomForestRegressor(max_samples=10000, n_jobs=-1)
Nice! That worked much faster than training on the whole dataset.
Let's evaluate our model with our show_scores function.
In\u00a0[96]: Copied! # Get evaluation metrics from reduced sample model\nbase_model_scores = show_scores(model=model)\nbase_model_scores\n
# Get evaluation metrics from reduced sample model base_model_scores = show_scores(model=model) base_model_scores Out[96]: {'Training MAE': np.float64(5605.344206319725),\n 'Valid MAE': np.float64(7176.1651147786515),\n 'Training RMSLE': np.float64(0.26030112528907273),\n 'Valid RMSLE': np.float64(0.2935839690284876),\n 'Training R^2': 0.858111849057448,\n 'Valid R^2': 0.828549722372896} Excellent! Even though our new model saw far less data than the previous model, it still looks to be performing quite well.
With this faster model, we can start to run a series of different hyperparameter experiments.
In\u00a0[97]: Copied! %%time\n\nfrom sklearn.model_selection import RandomizedSearchCV\n\n# 1. Define a dictionary with different values for RandomForestRegressor hyperparameters\n# See documatation for potential different values - https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html \nrf_grid = {\"n_estimators\": np.arange(10, 200, 10),\n \"max_depth\": [None, 10, 20],\n \"min_samples_split\": np.arange(2, 10, 1), # min_samples_split must be an int in the range [2, inf) or a float in the range (0.0, 1.0]\n \"min_samples_leaf\": np.arange(1, 10, 1),\n \"max_features\": [0.5, 1.0, \"sqrt\"], # Note: \"max_features='auto'\" is equivalent to \"max_features=1.0\", as of Scikit-Learn version 1.1\n \"max_samples\": [10000]}\n\n# 2. Setup instance of RandomizedSearchCV to explore different parameters \nrs_model = RandomizedSearchCV(estimator=RandomForestRegressor(), # can pass new model instance directly, all settings will be taken from the rf_grid\n param_distributions=rf_grid,\n n_iter=20,\n # scoring=\"neg_root_mean_squared_log_error\", # want to optimize for RMSLE, though sometimes optimizing for the default metric (R^2) can lead to just as good results all round\n cv=3,\n verbose=3) # control how much output gets produced, higher number = more output\n\n# 3. Fit the model using a series of different hyperparameter values\nrs_model.fit(X=X_train_preprocessed, \n y=y_train)\n %%time from sklearn.model_selection import RandomizedSearchCV # 1. Define a dictionary with different values for RandomForestRegressor hyperparameters # See documatation for potential different values - https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html rf_grid = {\"n_estimators\": np.arange(10, 200, 10), \"max_depth\": [None, 10, 20], \"min_samples_split\": np.arange(2, 10, 1), # min_samples_split must be an int in the range [2, inf) or a float in the range (0.0, 1.0] \"min_samples_leaf\": np.arange(1, 10, 1), \"max_features\": [0.5, 1.0, \"sqrt\"], # Note: \"max_features='auto'\" is equivalent to \"max_features=1.0\", as of Scikit-Learn version 1.1 \"max_samples\": [10000]} # 2. Setup instance of RandomizedSearchCV to explore different parameters rs_model = RandomizedSearchCV(estimator=RandomForestRegressor(), # can pass new model instance directly, all settings will be taken from the rf_grid param_distributions=rf_grid, n_iter=20, # scoring=\"neg_root_mean_squared_log_error\", # want to optimize for RMSLE, though sometimes optimizing for the default metric (R^2) can lead to just as good results all round cv=3, verbose=3) # control how much output gets produced, higher number = more output # 3. Fit the model using a series of different hyperparameter values rs_model.fit(X=X_train_preprocessed, y=y_train) Fitting 3 folds for each of 20 candidates, totalling 60 fits\n[CV 1/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=1, min_samples_split=3, n_estimators=160;, score=0.539 total time= 21.6s\n[CV 2/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=1, min_samples_split=3, n_estimators=160;, score=0.720 total time= 23.0s\n[CV 3/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=1, min_samples_split=3, n_estimators=160;, score=0.596 total time= 22.2s\n[CV 1/3] END max_depth=10, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=60;, score=0.491 total time= 3.3s\n[CV 2/3] END max_depth=10, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=60;, score=0.655 total time= 3.4s\n[CV 3/3] END max_depth=10, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=60;, score=0.614 total time= 3.3s\n[CV 1/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=8, n_estimators=130;, score=0.520 total time= 6.7s\n[CV 2/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=8, n_estimators=130;, score=0.702 total time= 6.6s\n[CV 3/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=8, n_estimators=130;, score=0.636 total time= 6.6s\n[CV 1/3] END max_depth=20, max_features=sqrt, max_samples=10000, min_samples_leaf=8, min_samples_split=9, n_estimators=30;, score=0.512 total time= 3.0s\n[CV 2/3] END max_depth=20, max_features=sqrt, max_samples=10000, min_samples_leaf=8, min_samples_split=9, n_estimators=30;, score=0.703 total time= 2.7s\n[CV 3/3] END max_depth=20, max_features=sqrt, max_samples=10000, min_samples_leaf=8, min_samples_split=9, n_estimators=30;, score=0.636 total time= 2.7s\n[CV 1/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=3, n_estimators=100;, score=0.541 total time= 9.9s\n[CV 2/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=3, n_estimators=100;, score=0.745 total time= 11.1s\n[CV 3/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=3, n_estimators=100;, score=0.632 total time= 10.2s\n[CV 1/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=3, min_samples_split=8, n_estimators=50;, score=0.529 total time= 6.1s\n[CV 2/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=3, min_samples_split=8, n_estimators=50;, score=0.713 total time= 5.5s\n[CV 3/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=3, min_samples_split=8, n_estimators=50;, score=0.625 total time= 5.2s\n[CV 1/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=4, min_samples_split=6, n_estimators=170;, score=0.532 total time= 13.9s\n[CV 2/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=4, min_samples_split=6, n_estimators=170;, score=0.712 total time= 14.6s\n[CV 3/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=4, min_samples_split=6, n_estimators=170;, score=0.631 total time= 14.2s\n[CV 1/3] END max_depth=20, max_features=0.5, max_samples=10000, min_samples_leaf=1, min_samples_split=5, n_estimators=40;, score=0.545 total time= 6.6s\n[CV 2/3] END max_depth=20, max_features=0.5, max_samples=10000, min_samples_leaf=1, min_samples_split=5, n_estimators=40;, score=0.767 total time= 6.5s\n[CV 3/3] END max_depth=20, max_features=0.5, max_samples=10000, min_samples_leaf=1, min_samples_split=5, n_estimators=40;, score=0.619 total time= 6.2s\n[CV 1/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=120;, score=0.518 total time= 6.0s\n[CV 2/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=120;, score=0.703 total time= 6.4s\n[CV 3/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=120;, score=0.637 total time= 6.2s\n[CV 1/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=9, n_estimators=120;, score=0.533 total time= 10.7s\n[CV 2/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=9, n_estimators=120;, score=0.708 total time= 13.7s\n[CV 3/3] END max_depth=10, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=9, n_estimators=120;, score=0.628 total time= 10.5s\n[CV 1/3] END max_depth=20, max_features=1.0, max_samples=10000, min_samples_leaf=2, min_samples_split=7, n_estimators=90;, score=0.542 total time= 20.0s\n[CV 2/3] END max_depth=20, max_features=1.0, max_samples=10000, min_samples_leaf=2, min_samples_split=7, n_estimators=90;, score=0.756 total time= 19.9s\n[CV 3/3] END max_depth=20, max_features=1.0, max_samples=10000, min_samples_leaf=2, min_samples_split=7, n_estimators=90;, score=0.611 total time= 17.1s\n[CV 1/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=8, min_samples_split=8, n_estimators=190;, score=0.524 total time= 9.1s\n[CV 2/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=8, min_samples_split=8, n_estimators=190;, score=0.706 total time= 8.7s\n[CV 3/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=8, min_samples_split=8, n_estimators=190;, score=0.637 total time= 8.6s\n[CV 1/3] END max_depth=None, max_features=1.0, max_samples=10000, min_samples_leaf=5, min_samples_split=8, n_estimators=70;, score=0.539 total time= 16.0s\n[CV 2/3] END max_depth=None, max_features=1.0, max_samples=10000, min_samples_leaf=5, min_samples_split=8, n_estimators=70;, score=0.754 total time= 14.8s\n[CV 3/3] END max_depth=None, max_features=1.0, max_samples=10000, min_samples_leaf=5, min_samples_split=8, n_estimators=70;, score=0.615 total time= 14.2s\n[CV 1/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=1, min_samples_split=9, n_estimators=60;, score=0.548 total time= 9.3s\n[CV 2/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=1, min_samples_split=9, n_estimators=60;, score=0.766 total time= 8.6s\n[CV 3/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=1, min_samples_split=9, n_estimators=60;, score=0.623 total time= 9.0s\n[CV 1/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=170;, score=0.535 total time= 23.8s\n[CV 2/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=170;, score=0.715 total time= 25.5s\n[CV 3/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=170;, score=0.595 total time= 27.2s\n[CV 1/3] END max_depth=20, max_features=0.5, max_samples=10000, min_samples_leaf=2, min_samples_split=3, n_estimators=80;, score=0.544 total time= 12.0s\n[CV 2/3] END max_depth=20, max_features=0.5, max_samples=10000, min_samples_leaf=2, min_samples_split=3, n_estimators=80;, score=0.764 total time= 11.5s\n[CV 3/3] END max_depth=20, max_features=0.5, max_samples=10000, min_samples_leaf=2, min_samples_split=3, n_estimators=80;, score=0.642 total time= 10.4s\n[CV 1/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=6, min_samples_split=7, n_estimators=70;, score=0.538 total time= 8.2s\n[CV 2/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=6, min_samples_split=7, n_estimators=70;, score=0.752 total time= 8.4s\n[CV 3/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=6, min_samples_split=7, n_estimators=70;, score=0.640 total time= 8.5s\n[CV 1/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=90;, score=0.537 total time= 9.8s\n[CV 2/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=90;, score=0.747 total time= 9.5s\n[CV 3/3] END max_depth=None, max_features=0.5, max_samples=10000, min_samples_leaf=9, min_samples_split=5, n_estimators=90;, score=0.630 total time= 9.7s\n[CV 1/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=2, min_samples_split=8, n_estimators=180;, score=0.536 total time= 28.3s\n[CV 2/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=2, min_samples_split=8, n_estimators=180;, score=0.721 total time= 28.6s\n[CV 3/3] END max_depth=10, max_features=1.0, max_samples=10000, min_samples_leaf=2, min_samples_split=8, n_estimators=180;, score=0.597 total time= 28.1s\n[CV 1/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=2, min_samples_split=3, n_estimators=150;, score=0.539 total time= 9.0s\n[CV 2/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=2, min_samples_split=3, n_estimators=150;, score=0.733 total time= 10.7s\n[CV 3/3] END max_depth=None, max_features=sqrt, max_samples=10000, min_samples_leaf=2, min_samples_split=3, n_estimators=150;, score=0.643 total time= 8.9s\nCPU times: user 8min 6s, sys: 25min 58s, total: 34min 4s\nWall time: 11min 54s\n
Out[97]: RandomizedSearchCV(cv=3, estimator=RandomForestRegressor(), n_iter=20,\n param_distributions={'max_depth': [None, 10, 20],\n 'max_features': [0.5, 1.0, 'sqrt'],\n 'max_samples': [10000],\n 'min_samples_leaf': array([1, 2, 3, 4, 5, 6, 7, 8, 9]),\n 'min_samples_split': array([2, 3, 4, 5, 6, 7, 8, 9]),\n 'n_estimators': array([ 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130,\n 140, 150, 160, 170, 180, 190])},\n verbose=3)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.\u00a0\u00a0RandomizedSearchCV?Documentation for RandomizedSearchCViFittedRandomizedSearchCV(cv=3, estimator=RandomForestRegressor(), n_iter=20,\n param_distributions={'max_depth': [None, 10, 20],\n 'max_features': [0.5, 1.0, 'sqrt'],\n 'max_samples': [10000],\n 'min_samples_leaf': array([1, 2, 3, 4, 5, 6, 7, 8, 9]),\n 'min_samples_split': array([2, 3, 4, 5, 6, 7, 8, 9]),\n 'n_estimators': array([ 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130,\n 140, 150, 160, 170, 180, 190])},\n verbose=3) best_estimator_: RandomForestRegressorRandomForestRegressor(max_depth=20, max_features=0.5, max_samples=10000,\n min_samples_leaf=np.int64(2),\n min_samples_split=np.int64(3), n_estimators=np.int64(80))
\u00a0RandomForestRegressor?Documentation for RandomForestRegressorRandomForestRegressor(max_depth=20, max_features=0.5, max_samples=10000,\n min_samples_leaf=np.int64(2),\n min_samples_split=np.int64(3), n_estimators=np.int64(80))
Phew! That's quite a bit of testing!
Good news for us is that we can check the best hyperparameters with the best_params_ attribute.
In\u00a0[113]: Copied! # Find the best parameters from RandomizedSearchCV\nrs_model.best_params_\n
# Find the best parameters from RandomizedSearchCV rs_model.best_params_ Out[113]: {'n_estimators': np.int64(80),\n 'min_samples_split': np.int64(3),\n 'min_samples_leaf': np.int64(2),\n 'max_samples': 10000,\n 'max_features': 0.5,\n 'max_depth': 20} And we can evaluate this model with our show_scores function.
In\u00a0[114]: Copied! # Evaluate the RandomizedSearch model\nrs_model_scores = show_scores(rs_model)\nrs_model_scores\n
# Evaluate the RandomizedSearch model rs_model_scores = show_scores(rs_model) rs_model_scores Out[114]: {'Training MAE': np.float64(5804.886346446167),\n 'Valid MAE': np.float64(7271.010705137403),\n 'Training RMSLE': np.float64(0.2668477962708691),\n 'Valid RMSLE': np.float64(0.2985683128197976),\n 'Training R^2': 0.8494436266937344,\n 'Valid R^2': 0.8280568050158131} In\u00a0[115]: Copied! %%time\n\n# Create a model with best found hyperparameters \n# Note: There may be better values out there with longer searches but these are \n# the best I found with a ~2 hour search. A good challenge would be to see if you \n# can find better values.\nideal_model = RandomForestRegressor(n_estimators=90,\n max_depth=None,\n min_samples_leaf=1,\n min_samples_split=5,\n max_features=0.5,\n n_jobs=-1,\n max_samples=None)\n\n# Fit a model to the preprocessed data\nideal_model.fit(X=X_train_preprocessed, \n y=y_train)\n
%%time # Create a model with best found hyperparameters # Note: There may be better values out there with longer searches but these are # the best I found with a ~2 hour search. A good challenge would be to see if you # can find better values. ideal_model = RandomForestRegressor(n_estimators=90, max_depth=None, min_samples_leaf=1, min_samples_split=5, max_features=0.5, n_jobs=-1, max_samples=None) # Fit a model to the preprocessed data ideal_model.fit(X=X_train_preprocessed, y=y_train) CPU times: user 4min 6s, sys: 4min 34s, total: 8min 40s\nWall time: 2min\n
Out[115]: RandomForestRegressor(max_features=0.5, min_samples_split=5, n_estimators=90,\n n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.\u00a0\u00a0RandomForestRegressor?Documentation for RandomForestRegressoriFittedRandomForestRegressor(max_features=0.5, min_samples_split=5, n_estimators=90,\n n_jobs=-1)
And of course, we can evaluate our ideal_model with our show_scores function.
In\u00a0[116]: Copied! %%time\n\n# Evaluate ideal model\nideal_model_scores = show_scores(model=ideal_model)\nideal_model_scores\n
%%time # Evaluate ideal model ideal_model_scores = show_scores(model=ideal_model) ideal_model_scores CPU times: user 28.8 s, sys: 37.4 s, total: 1min 6s\nWall time: 14.5 s\n
Out[116]: {'Training MAE': np.float64(1955.980118634043),\n 'Valid MAE': np.float64(5979.47564414195),\n 'Training RMSLE': np.float64(0.10224456852444506),\n 'Valid RMSLE': np.float64(0.24733387014318542),\n 'Training R^2': 0.9809704227866279,\n 'Valid R^2': 0.8810497144604977} Woohoo!
With these new hyperparameters as well as using all the samples, we can see an improvement to our models performance.
One thing to keep in mind is that a larger model isn't always the best for a given problem even if it performs better.
For example, you may require a model that performs inference (makes predictions) very fast with a slight tradeoff to performance.
One way to a faster model is by altering some of the hyperparameters to create a smaller overall model.
Particularly by lowering n_estimators since each increase in n_estimators is basically building another small model.
Let's half our n_estimators value and see how it goes.
In\u00a0[117]: Copied! %%time\n\n# Halve the number of estimators\nfast_model = RandomForestRegressor(n_estimators=45,\n max_depth=None,\n min_samples_leaf=1,\n min_samples_split=5,\n max_features=0.5,\n n_jobs=-1,\n max_samples=None)\n\n# Fit the faster model to the data\nfast_model.fit(X=X_train_preprocessed, \n y=y_train)\n
%%time # Halve the number of estimators fast_model = RandomForestRegressor(n_estimators=45, max_depth=None, min_samples_leaf=1, min_samples_split=5, max_features=0.5, n_jobs=-1, max_samples=None) # Fit the faster model to the data fast_model.fit(X=X_train_preprocessed, y=y_train) CPU times: user 2min, sys: 1min 58s, total: 3min 58s\nWall time: 44.9 s\n
Out[117]: RandomForestRegressor(max_features=0.5, min_samples_split=5, n_estimators=45,\n n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.\u00a0\u00a0RandomForestRegressor?Documentation for RandomForestRegressoriFittedRandomForestRegressor(max_features=0.5, min_samples_split=5, n_estimators=45,\n n_jobs=-1)
Nice! The faster model fits to the training data in about half the time of the full model.
Now how does it go on performance?
In\u00a0[118]: Copied! %%time\n\n# Get results from the fast model\nfast_model_scores = show_scores(model=fast_model)\nfast_model_scores\n
%%time # Get results from the fast model fast_model_scores = show_scores(model=fast_model) fast_model_scores CPU times: user 14.6 s, sys: 23.7 s, total: 38.3 s\nWall time: 9.59 s\n
Out[118]: {'Training MAE': np.float64(1989.0544948757317),\n 'Valid MAE': np.float64(6029.137329100962),\n 'Training RMSLE': np.float64(0.10373049008046713),\n 'Valid RMSLE': np.float64(0.24897544966690316),\n 'Training R^2': 0.9802744452357592,\n 'Valid R^2': 0.8788749110488039} Woah! Looks like our faster model evaluates (performs inference/makes predictions) in about half the time too.
And only for a small tradeoff in validation RMSLE performance.
In\u00a0[119]: Copied! # Add names of models to dictionaries\nbase_model_scores[\"model_name\"] = \"default_model\"\nrs_model_scores[\"model_name\"] = \"random_search_model\"\nideal_model_scores[\"model_name\"] = \"ideal_model\" \nfast_model_scores[\"model_name\"] = \"fast_model\" \n\n# Turn all model score dictionaries into a list\nall_model_scores = [base_model_scores, \n rs_model_scores, \n ideal_model_scores,\n fast_model_scores]\n\n# Create DataFrame and sort model scores by validation RMSLE\nmodel_comparison_df = pd.DataFrame(all_model_scores).sort_values(by=\"Valid RMSLE\", ascending=False)\nmodel_comparison_df.head()\n
# Add names of models to dictionaries base_model_scores[\"model_name\"] = \"default_model\" rs_model_scores[\"model_name\"] = \"random_search_model\" ideal_model_scores[\"model_name\"] = \"ideal_model\" fast_model_scores[\"model_name\"] = \"fast_model\" # Turn all model score dictionaries into a list all_model_scores = [base_model_scores, rs_model_scores, ideal_model_scores, fast_model_scores] # Create DataFrame and sort model scores by validation RMSLE model_comparison_df = pd.DataFrame(all_model_scores).sort_values(by=\"Valid RMSLE\", ascending=False) model_comparison_df.head() Out[119]: Training MAE Valid MAE Training RMSLE Valid RMSLE Training R^2 Valid R^2 model_name 1 5804.886346 7271.010705 0.266848 0.298568 0.849444 0.828057 random_search_model 0 5605.344206 7176.165115 0.260301 0.293584 0.858112 0.828550 default_model 3 1989.054495 6029.137329 0.103730 0.248975 0.980274 0.878875 fast_model 2 1955.980119 5979.475644 0.102245 0.247334 0.980970 0.881050 ideal_model Now we've got our model result data in a DataFrame, let's turn it into a bar plot comparing the validation RMSLE of each model.
In\u00a0[120]: Copied! # Get mean RSMLE score of all models\nmean_rsmle_score = model_comparison_df[\"Valid RMSLE\"].mean()\n\n# Plot validation RMSLE against each other \nplt.figure(figsize=(10, 5))\nplt.bar(x=model_comparison_df[\"model_name\"],\n height=model_comparison_df[\"Valid RMSLE\"].values)\nplt.xlabel(\"Model\")\nplt.ylabel(\"Validation RMSLE (lower is better)\")\nplt.xticks(rotation=0, fontsize=10);\nplt.axhline(y=mean_rsmle_score, \n color=\"red\", \n linestyle=\"--\", \n label=f\"Mean RMSLE: {mean_rsmle_score:.4f}\")\nplt.legend();\n # Get mean RSMLE score of all models mean_rsmle_score = model_comparison_df[\"Valid RMSLE\"].mean() # Plot validation RMSLE against each other plt.figure(figsize=(10, 5)) plt.bar(x=model_comparison_df[\"model_name\"], height=model_comparison_df[\"Valid RMSLE\"].values) plt.xlabel(\"Model\") plt.ylabel(\"Validation RMSLE (lower is better)\") plt.xticks(rotation=0, fontsize=10); plt.axhline(y=mean_rsmle_score, color=\"red\", linestyle=\"--\", label=f\"Mean RMSLE: {mean_rsmle_score:.4f}\") plt.legend(); By the looks of the plot, our ideal_model is indeed the ideal model, slightly edging out fast_model in terms of validation RMSLE.
In\u00a0[121]: Copied! import joblib\n\nbulldozer_price_prediction_model_name = \"randomforest_regressor_best_RMSLE.pkl\"\n\n# Save model to file\njoblib.dump(value=ideal_model, \n filename=bulldozer_price_prediction_model_name)\n
import joblib bulldozer_price_prediction_model_name = \"randomforest_regressor_best_RMSLE.pkl\" # Save model to file joblib.dump(value=ideal_model, filename=bulldozer_price_prediction_model_name) Out[121]: ['randomforest_regressor_best_RMSLE.pkl']
And to load our model we can use the joblib.load method.
In\u00a0[122]: Copied! # Load the best model\nbest_model = joblib.load(filename=bulldozer_price_prediction_model_name)\nbest_model\n
# Load the best model best_model = joblib.load(filename=bulldozer_price_prediction_model_name) best_model Out[122]: RandomForestRegressor(max_features=0.5, min_samples_split=5, n_estimators=90,\n n_jobs=-1)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.\u00a0\u00a0RandomForestRegressor?Documentation for RandomForestRegressoriFittedRandomForestRegressor(max_features=0.5, min_samples_split=5, n_estimators=90,\n n_jobs=-1)
We can make sure our model saving and loading worked by evaluating our best_model with show_scores.
In\u00a0[123]: Copied! # Confirm that the model works\nbest_model_scores = show_scores(model=best_model)\nbest_model_scores\n
# Confirm that the model works best_model_scores = show_scores(model=best_model) best_model_scores Out[123]: {'Training MAE': np.float64(1955.9801186340424),\n 'Valid MAE': np.float64(5979.47564414195),\n 'Training RMSLE': np.float64(0.10224456852444506),\n 'Valid RMSLE': np.float64(0.24733387014318542),\n 'Training R^2': 0.9809704227866279,\n 'Valid R^2': 0.8810497144604977} And to confirm our ideal_model and best_model results are very close (if not the exact same), we can compare them with:
- The equality operator
==. np.iclose and setting the absolute tolerance (atol) to 1e-4.
In\u00a0[124]: Copied! # See if loaded model and pre-saved model results are the same\n# Note: these values may be very slightly different depending on how precise your computer stores values.\nbest_model_scores[\"Valid RMSLE\"] == ideal_model_scores[\"Valid RMSLE\"]\n
# See if loaded model and pre-saved model results are the same # Note: these values may be very slightly different depending on how precise your computer stores values. best_model_scores[\"Valid RMSLE\"] == ideal_model_scores[\"Valid RMSLE\"] Out[124]: np.True_
In\u00a0[125]: Copied! # Is the loaded model as good as the non-loaded model?\nif np.isclose(a=best_model_scores[\"Valid RMSLE\"], \n b=ideal_model_scores[\"Valid RMSLE\"],\n atol=1e-4): # Make sure values are within 0.0001 of each other\n print(f\"[INFO] Model results are close!\")\nelse:\n print(f\"[INFO] Model results aren't close, did something go wrong?\")\n
# Is the loaded model as good as the non-loaded model? if np.isclose(a=best_model_scores[\"Valid RMSLE\"], b=ideal_model_scores[\"Valid RMSLE\"], atol=1e-4): # Make sure values are within 0.0001 of each other print(f\"[INFO] Model results are close!\") else: print(f\"[INFO] Model results aren't close, did something go wrong?\") [INFO] Model results are close!\n
Note: When saving and loading a model, it is often the case to have very slightly different values at the extremes. For example, the pre-saved model may have an RMSLE of 0.24654150224930685 where as the loaded model may have an RMSLE of 0.24654150224930684 where in this case the values are off by 0.00000000000000001 (a very small number). This is due to the precision of computing) and the way computers store values, where numbers are exact but can be represented up to a certain amount of precision. This is why we generally compare results with many decimals using np.isclose rather than the == operator.
In\u00a0[126]: Copied! # Load the test data\ntest_df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/Test.csv\",\n parse_dates=[\"saledate\"])\ntest_df.head()\n
# Load the test data test_df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/Test.csv\", parse_dates=[\"saledate\"]) test_df.head() Out[126]: SalesID MachineID ModelID datasource auctioneerID YearMade MachineHoursCurrentMeter UsageBand saledate fiModelDesc ... Undercarriage_Pad_Width Stick_Length Thumb Pattern_Changer Grouser_Type Backhoe_Mounting Blade_Type Travel_Controls Differential_Type Steering_Controls 0 1227829 1006309 3168 121 3 1999 3688.0 Low 2012-05-03 580G ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 1 1227844 1022817 7271 121 3 1000 28555.0 High 2012-05-10 936 ... NaN NaN NaN NaN NaN NaN NaN NaN Standard Conventional 2 1227847 1031560 22805 121 3 2004 6038.0 Medium 2012-05-10 EC210BLC ... None or Unspecified 9' 6\" Manual None or Unspecified Double NaN NaN NaN NaN NaN 3 1227848 56204 1269 121 3 2006 8940.0 High 2012-05-10 330CL ... None or Unspecified None or Unspecified Manual Yes Triple NaN NaN NaN NaN NaN 4 1227863 1053887 22312 121 3 2005 2286.0 Low 2012-05-10 650K ... NaN NaN NaN NaN NaN None or Unspecified PAT None or Unspecified NaN NaN 5 rows \u00d7 52 columns
You might notice that the test_df is missing the SalePrice column.
That's because that's the variable we're trying to predict based on all of the other variables.
We can make predictions with our best_model using the predict method.
In\u00a0[127]: Copied! # Let's see how the model goes predicting on the test data\ntest_preds = best_model.predict(X=test_df)\n
# Let's see how the model goes predicting on the test data test_preds = best_model.predict(X=test_df) \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\nCell In[127], line 2\n 1 # Let's see how the model goes predicting on the test data\n----> 2 test_preds = best_model.predict(X=test_df)\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py:1063, in ForestRegressor.predict(self, X)\n 1061 check_is_fitted(self)\n 1062 # Check data\n-> 1063 X = self._validate_X_predict(X)\n 1065 # Assign chunk of trees to jobs\n 1066 n_jobs, _, _ = _partition_estimators(self.n_estimators, self.n_jobs)\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py:641, in BaseForest._validate_X_predict(self, X)\n 638 else:\n 639 force_all_finite = True\n--> 641 X = self._validate_data(\n 642 X,\n 643 dtype=DTYPE,\n 644 accept_sparse=\"csr\",\n 645 reset=False,\n 646 force_all_finite=force_all_finite,\n 647 )\n 648 if issparse(X) and (X.indices.dtype != np.intc or X.indptr.dtype != np.intc):\n 649 raise ValueError(\"No support for np.int64 index based sparse matrices\")\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py:608, in BaseEstimator._validate_data(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)\n 537 def _validate_data(\n 538 self,\n 539 X=\"no_validation\",\n (...)\n 544 **check_params,\n 545 ):\n 546 \"\"\"Validate input data and set or check the `n_features_in_` attribute.\n 547 \n 548 Parameters\n (...)\n 606 validated.\n 607 \"\"\"\n--> 608 self._check_feature_names(X, reset=reset)\n 610 if y is None and self._get_tags()[\"requires_y\"]:\n 611 raise ValueError(\n 612 f\"This {self.__class__.__name__} estimator \"\n 613 \"requires y to be passed, but the target y is None.\"\n 614 )\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py:535, in BaseEstimator._check_feature_names(self, X, reset)\n 530 if not missing_names and not unexpected_names:\n 531 message += (\n 532 \"Feature names must be in the same order as they were in fit.\\n\"\n 533 )\n--> 535 raise ValueError(message)\n\nValueError: The feature names should match those that were passed during fit.\nFeature names unseen at fit time:\n- saledate\nFeature names seen at fit time, yet now missing:\n- saleDay\n- saleDayofweek\n- saleDayofyear\n- saleMonth\n- saleYear\n Oh no!
We get an error:
ValueError: The feature names should match those that were passed during fit. Feature names unseen at fit time:
- saledate Feature names seen at fit time, yet now missing:
- saleDay
- saleDayofweek
- saleDayofyear
- saleMonth
- saleYear
Ahhh... the test data isn't in the same format of our other data, so we have to fix it.
In\u00a0[128]: Copied! # Make a function to add date columns\ndef add_datetime_features_to_df(df, date_column=\"saledate\"):\n # Add datetime parameters for saledate\n df[\"saleYear\"] = df[date_column].dt.year\n df[\"saleMonth\"] = df[date_column].dt.month\n df[\"saleDay\"] = df[date_column].dt.day\n df[\"saleDayofweek\"] = df[date_column].dt.dayofweek\n df[\"saleDayofyear\"] = df[date_column].dt.dayofyear\n\n # Drop original saledate column\n df.drop(\"saledate\", axis=1, inplace=True)\n\n return df\n\n# Preprocess test_df to have same columns as train_df (add the datetime features)\ntest_df = add_datetime_features_to_df(df=test_df)\ntest_df.head()\n
# Make a function to add date columns def add_datetime_features_to_df(df, date_column=\"saledate\"): # Add datetime parameters for saledate df[\"saleYear\"] = df[date_column].dt.year df[\"saleMonth\"] = df[date_column].dt.month df[\"saleDay\"] = df[date_column].dt.day df[\"saleDayofweek\"] = df[date_column].dt.dayofweek df[\"saleDayofyear\"] = df[date_column].dt.dayofyear # Drop original saledate column df.drop(\"saledate\", axis=1, inplace=True) return df # Preprocess test_df to have same columns as train_df (add the datetime features) test_df = add_datetime_features_to_df(df=test_df) test_df.head() Out[128]: SalesID MachineID ModelID datasource auctioneerID YearMade MachineHoursCurrentMeter UsageBand fiModelDesc fiBaseModel ... Backhoe_Mounting Blade_Type Travel_Controls Differential_Type Steering_Controls saleYear saleMonth saleDay saleDayofweek saleDayofyear 0 1227829 1006309 3168 121 3 1999 3688.0 Low 580G 580 ... NaN NaN NaN NaN NaN 2012 5 3 3 124 1 1227844 1022817 7271 121 3 1000 28555.0 High 936 936 ... NaN NaN NaN Standard Conventional 2012 5 10 3 131 2 1227847 1031560 22805 121 3 2004 6038.0 Medium EC210BLC EC210 ... NaN NaN NaN NaN NaN 2012 5 10 3 131 3 1227848 56204 1269 121 3 2006 8940.0 High 330CL 330 ... NaN NaN NaN NaN NaN 2012 5 10 3 131 4 1227863 1053887 22312 121 3 2005 2286.0 Low 650K 650 ... None or Unspecified PAT None or Unspecified NaN NaN 2012 5 10 3 131 5 rows \u00d7 56 columns
Date features added!
Now can we make predictions with our model on the test data?
In\u00a0[129]: Copied! # Try to predict with model\ntest_preds = best_model.predict(test_df)\n
# Try to predict with model test_preds = best_model.predict(test_df) \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\n/var/folders/c4/qj4gdk190td18bqvjjh0p3p00000gn/T/ipykernel_20423/2042912174.py in ?()\n 1 # Try to predict with model\n----> 2 test_preds = best_model.predict(test_df)\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X)\n 1059 The predicted values.\n 1060 \"\"\"\n 1061 check_is_fitted(self)\n 1062 # Check data\n-> 1063 X = self._validate_X_predict(X)\n 1064 \n 1065 # Assign chunk of trees to jobs\n 1066 n_jobs, _, _ = _partition_estimators(self.n_estimators, self.n_jobs)\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X)\n 637 force_all_finite = \"allow-nan\"\n 638 else:\n 639 force_all_finite = True\n 640 \n--> 641 X = self._validate_data(\n 642 X,\n 643 dtype=DTYPE,\n 644 accept_sparse=\"csr\",\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)\n 629 out = y\n 630 else:\n 631 out = X, y\n 632 elif not no_val_X and no_val_y:\n--> 633 out = check_array(X, input_name=\"X\", **check_params)\n 634 elif no_val_X and not no_val_y:\n 635 out = _check_y(y, **check_params)\n 636 else:\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)\n 1009 )\n 1010 array = xp.astype(array, dtype, copy=False)\n 1011 else:\n 1012 array = _asarray_with_order(array, order=order, dtype=dtype, xp=xp)\n-> 1013 except ComplexWarning as complex_warning:\n 1014 raise ValueError(\n 1015 \"Complex data not supported\\n{}\\n\".format(array)\n 1016 ) from complex_warning\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/_array_api.py in ?(array, dtype, order, copy, xp, device)\n 747 # Use NumPy API to support order\n 748 if copy is True:\n 749 array = numpy.array(array, order=order, dtype=dtype)\n 750 else:\n--> 751 array = numpy.asarray(array, order=order, dtype=dtype)\n 752 \n 753 # At this point array is a NumPy ndarray. We convert it to an array\n 754 # container that is consistent with the input's namespace.\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/core/generic.py in ?(self, dtype, copy)\n 2149 def __array__(\n 2150 self, dtype: npt.DTypeLike | None = None, copy: bool_t | None = None\n 2151 ) -> np.ndarray:\n 2152 values = self._values\n-> 2153 arr = np.asarray(values, dtype=dtype)\n 2154 if (\n 2155 astype_is_view(values.dtype, arr.dtype)\n 2156 and using_copy_on_write()\n\nValueError: could not convert string to float: 'Low' Another error...
ValueError: could not convert string to float: 'Low'
We can fix this by running our ordinal_encoder (that we used to preprocess the training data) on the categorical features in our test DataFrame.
In\u00a0[130]: Copied! # Create a copy of the test DataFrame to keep the original intact\ntest_df_preprocessed = test_df.copy()\n\n# Transform the categorical features of the test DataFrame into numbers\ntest_df_preprocessed[categorical_features] = ordinal_encoder.transform(test_df_preprocessed[categorical_features].astype(str))\ntest_df_preprocessed.info()\n
# Create a copy of the test DataFrame to keep the original intact test_df_preprocessed = test_df.copy() # Transform the categorical features of the test DataFrame into numbers test_df_preprocessed[categorical_features] = ordinal_encoder.transform(test_df_preprocessed[categorical_features].astype(str)) test_df_preprocessed.info() <class 'pandas.core.frame.DataFrame'>\nRangeIndex: 12457 entries, 0 to 12456\nData columns (total 56 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 SalesID 12457 non-null int64 \n 1 MachineID 12457 non-null int64 \n 2 ModelID 12457 non-null int64 \n 3 datasource 12457 non-null int64 \n 4 auctioneerID 12457 non-null int64 \n 5 YearMade 12457 non-null int64 \n 6 MachineHoursCurrentMeter 2129 non-null float64\n 7 UsageBand 12457 non-null float64\n 8 fiModelDesc 12349 non-null float64\n 9 fiBaseModel 12431 non-null float64\n 10 fiSecondaryDesc 12449 non-null float64\n 11 fiModelSeries 12456 non-null float64\n 12 fiModelDescriptor 12452 non-null float64\n 13 ProductSize 12457 non-null float64\n 14 fiProductClassDesc 12457 non-null float64\n 15 state 12457 non-null float64\n 16 ProductGroup 12457 non-null float64\n 17 ProductGroupDesc 12457 non-null float64\n 18 Drive_System 12457 non-null float64\n 19 Enclosure 12457 non-null float64\n 20 Forks 12457 non-null float64\n 21 Pad_Type 12457 non-null float64\n 22 Ride_Control 12457 non-null float64\n 23 Stick 12457 non-null float64\n 24 Transmission 12457 non-null float64\n 25 Turbocharged 12457 non-null float64\n 26 Blade_Extension 12457 non-null float64\n 27 Blade_Width 12457 non-null float64\n 28 Enclosure_Type 12457 non-null float64\n 29 Engine_Horsepower 12457 non-null float64\n 30 Hydraulics 12457 non-null float64\n 31 Pushblock 12457 non-null float64\n 32 Ripper 12457 non-null float64\n 33 Scarifier 12457 non-null float64\n 34 Tip_Control 12457 non-null float64\n 35 Tire_Size 12457 non-null float64\n 36 Coupler 12457 non-null float64\n 37 Coupler_System 12457 non-null float64\n 38 Grouser_Tracks 12457 non-null float64\n 39 Hydraulics_Flow 12457 non-null float64\n 40 Track_Type 12457 non-null float64\n 41 Undercarriage_Pad_Width 12457 non-null float64\n 42 Stick_Length 12457 non-null float64\n 43 Thumb 12457 non-null float64\n 44 Pattern_Changer 12457 non-null float64\n 45 Grouser_Type 12457 non-null float64\n 46 Backhoe_Mounting 12457 non-null float64\n 47 Blade_Type 12457 non-null float64\n 48 Travel_Controls 12457 non-null float64\n 49 Differential_Type 12457 non-null float64\n 50 Steering_Controls 12457 non-null float64\n 51 saleYear 12457 non-null int32 \n 52 saleMonth 12457 non-null int32 \n 53 saleDay 12457 non-null int32 \n 54 saleDayofweek 12457 non-null int32 \n 55 saleDayofyear 12457 non-null int32 \ndtypes: float64(45), int32(5), int64(6)\nmemory usage: 5.1 MB\n
Ok, date features created and categorical features turned into numbers, can we make predictions on the test data now?
In\u00a0[131]: Copied! # Make predictions on the preprocessed test data\ntest_preds = best_model.predict(test_df_preprocessed)\n
# Make predictions on the preprocessed test data test_preds = best_model.predict(test_df_preprocessed) Holy smokes! It worked!
Let's check out our test_preds.
In\u00a0[132]: Copied! # Check the first 10 test predictions\ntest_preds[:10]\n
# Check the first 10 test predictions test_preds[:10] Out[132]: array([14384.79497354, 31377.65862841, 48589.23540965, 95857.57194966,\n 26910.53992304, 29401.41534392, 27061.53819945, 20377.23364598,\n 17325.67857143, 33646.67768959])
Wonderful, looks like we're getting the price predictions of a given bulldozer.
How many predictions are there?
In\u00a0[133]: Copied! # Check number of test predictions\ntest_preds.shape, test_df.shape\n
# Check number of test predictions test_preds.shape, test_df.shape Out[133]: ((12457,), (12457, 56))
Perfect, looks like theres one prediction per sample in the test DataFrame.
Now how would we submit our predictions to Kaggle?
Well, when looking at the Kaggle submission requirements, we see that if we wanted to make a submission, the data is required to be in a certain format.
Namely, a DataFrame containing the SalesID and the predicted SalePrice of the bulldozer.
Let's make it.
In\u00a0[134]: Copied! # Create DataFrame compatible with Kaggle submission requirements\npred_df = pd.DataFrame()\npred_df[\"SalesID\"] = test_df[\"SalesID\"]\npred_df[\"SalePrice\"] = test_preds\npred_df.sample(5)\n
# Create DataFrame compatible with Kaggle submission requirements pred_df = pd.DataFrame() pred_df[\"SalesID\"] = test_df[\"SalesID\"] pred_df[\"SalePrice\"] = test_preds pred_df.sample(5) Out[134]: SalesID SalePrice 6517 6304619 78522.550705 922 1231204 13500.628307 6859 6311050 10891.180556 6634 6307731 28503.776455 8882 6447290 50641.411817 Excellent! We've got a SalePrice prediction for every SalesID in the test DataFrame.
Let's save this to CSV so we could upload it or share it with someone else if we had to.
In\u00a0[135]: Copied! # Export test dataset predictions to CSV\npred_df.to_csv(\"../data/bluebook-for-bulldozers/predictions.csv\",\n index=False)\n
# Export test dataset predictions to CSV pred_df.to_csv(\"../data/bluebook-for-bulldozers/predictions.csv\", index=False) In\u00a0[136]: Copied! # Get example from test_df\ntest_df_preprocessed_sample = test_df_preprocessed.sample(n=1, random_state=42)\n\n# Turn back into original format\ntest_df_unpreprocessed_sample = test_df_preprocessed_sample.copy() \ntest_df_unpreprocessed_sample[categorical_features] = ordinal_encoder.inverse_transform(test_df_unpreprocessed_sample[categorical_features])\ntest_df_unpreprocessed_sample.to_dict(orient=\"records\")\n
# Get example from test_df test_df_preprocessed_sample = test_df_preprocessed.sample(n=1, random_state=42) # Turn back into original format test_df_unpreprocessed_sample = test_df_preprocessed_sample.copy() test_df_unpreprocessed_sample[categorical_features] = ordinal_encoder.inverse_transform(test_df_unpreprocessed_sample[categorical_features]) test_df_unpreprocessed_sample.to_dict(orient=\"records\") Out[136]: [{'SalesID': 1229148,\n 'MachineID': 1042578,\n 'ModelID': 9579,\n 'datasource': 121,\n 'auctioneerID': 3,\n 'YearMade': 2004,\n 'MachineHoursCurrentMeter': 3290.0,\n 'UsageBand': 'Medium',\n 'fiModelDesc': 'S250',\n 'fiBaseModel': 'S250',\n 'fiSecondaryDesc': 'nan',\n 'fiModelSeries': 'nan',\n 'fiModelDescriptor': 'nan',\n 'ProductSize': 'nan',\n 'fiProductClassDesc': 'Skid Steer Loader - 2201.0 to 2701.0 Lb Operating Capacity',\n 'state': 'Missouri',\n 'ProductGroup': 'SSL',\n 'ProductGroupDesc': 'Skid Steer Loaders',\n 'Drive_System': 'nan',\n 'Enclosure': 'EROPS',\n 'Forks': 'None or Unspecified',\n 'Pad_Type': 'nan',\n 'Ride_Control': 'nan',\n 'Stick': 'nan',\n 'Transmission': 'nan',\n 'Turbocharged': 'nan',\n 'Blade_Extension': 'nan',\n 'Blade_Width': 'nan',\n 'Enclosure_Type': 'nan',\n 'Engine_Horsepower': 'nan',\n 'Hydraulics': 'Auxiliary',\n 'Pushblock': 'nan',\n 'Ripper': 'nan',\n 'Scarifier': 'nan',\n 'Tip_Control': 'nan',\n 'Tire_Size': 'nan',\n 'Coupler': 'Hydraulic',\n 'Coupler_System': 'Yes',\n 'Grouser_Tracks': 'None or Unspecified',\n 'Hydraulics_Flow': 'Standard',\n 'Track_Type': 'nan',\n 'Undercarriage_Pad_Width': 'nan',\n 'Stick_Length': 'nan',\n 'Thumb': 'nan',\n 'Pattern_Changer': 'nan',\n 'Grouser_Type': 'nan',\n 'Backhoe_Mounting': 'nan',\n 'Blade_Type': 'nan',\n 'Travel_Controls': 'nan',\n 'Differential_Type': 'nan',\n 'Steering_Controls': 'nan',\n 'saleYear': 2012,\n 'saleMonth': 6,\n 'saleDay': 15,\n 'saleDayofweek': 4,\n 'saleDayofyear': 167}] Wonderful, so if we're going to make a prediction on a custom sample, we'll need to fill out these details as much as we can.
Let's try and make a prediction on the example test sample.
In\u00a0[137]: Copied! # Make a prediction on the preprocessed test sample\nbest_model.predict(test_df_preprocessed_sample)\n
# Make a prediction on the preprocessed test sample best_model.predict(test_df_preprocessed_sample) Out[137]: array([13519.31657848])
Nice!
We get an output array containing a predicted SalePrice.
Let's now try it on a custom sample.
Again, like all good machine learning cooking shows, I've searched the internet for \"bulldozer sales in America\" and found a sale from 6th July 2024 (I'm writing these materials in mid 2024 so if it's many years in the future and the link doesn't work, check out the screenshot below).
Screenshot of a bulldozer sale advertisement. I took information from this advertisement to create our own custom sample for testing our machine learning model on data from the wild. Source. I went through the advertisement online and collected as much detail as I could and formatted the dictionary below with all of the related fields.
It may not be perfect but data in the real world is rarely perfect.
For values I couldn't find or were inconspicuous, I filled them with np.nan (or NaN).
Some values such as SalesID were unobtainable because they were part of the original collected dataset, for these I've also used np.nan.
Also notice how I've already created the extra date features saleYear, saleMonth, saleDay and more by manually breaking down the listed sale date of 6 July 2024.
In\u00a0[138]: Copied! # Create a dictionary of features and values from an internet-based bulldozer advertisement\n# See link: https://www.purplewave.com/auction/240606/item/EK8504/2004-Caterpillar-D6R_XL-Crawlers-Crawler_Dozer-Missouri (note: this link is/was valid as of October 2024 but may be invalid in the future)\ncustom_sample = {\n \"SalesID\": np.nan,\n \"MachineID\": 8504,\n \"ModelID\": np.nan,\n \"datasource\": np.nan,\n \"auctioneerID\": np.nan,\n \"YearMade\": 2004,\n \"MachineHoursCurrentMeter\": 11770.0,\n \"UsageBand\": \"High\",\n \"fiModelDesc\": \"D6RXL\",\n \"fiBaseModel\": \"D6\",\n \"fiSecondaryDesc\": \"XL\",\n \"fiModelSeries\": np.nan,\n \"fiModelDescriptor\": np.nan,\n \"ProductSize\": \"Medium\",\n \"fiProductClassDesc\": \"Track Type Tractor, Dozer - 130.0 to 160.0 Horsepower\",\n \"state\": \"Missouri\",\n \"ProductGroup\": \"TTT\",\n \"ProductGroupDesc\": \"Track Type Tractors\",\n \"Drive_System\": \"No\",\n \"Enclosure\": \"EROPS\",\n \"Forks\": \"None or Unspecified\",\n \"Pad_Type\": \"Grouser\",\n \"Ride_Control\": \"None or Unspecified\",\n \"Stick\": \"nan\",\n \"Transmission\": \"Powershift\",\n \"Turbocharged\": \"None or Unspecified\",\n \"Blade_Extension\": \"None or Unspecified\",\n \"Blade_Width\": np.nan,\n \"Enclosure_Type\": np.nan,\n \"Engine_Horsepower\": np.nan,\n \"Hydraulics\": np.nan,\n \"Pushblock\": \"None or Unspecified\",\n \"Ripper\": \"None or Unspecified\",\n \"Scarifier\": \"None or Unspecified\",\n \"Tip_Control\": \"Tip\",\n \"Tire_Size\": np.nan,\n \"Coupler\": np.nan,\n \"Coupler_System\": np.nan,\n \"Grouser_Tracks\": \"Yes\",\n \"Hydraulics_Flow\": np.nan,\n \"Track_Type\": \"Steel\",\n \"Undercarriage_Pad_Width\": \"22 inch\",\n \"Stick_Length\": np.nan,\n \"Thumb\": np.nan,\n \"Pattern_Changer\": np.nan,\n \"Grouser_Type\": \"Single\",\n \"Backhoe_Mounting\": \"None or Unspecified\",\n \"Blade_Type\": \"Semi U\",\n \"Travel_Controls\": np.nan,\n \"Differential_Type\": np.nan,\n \"Steering_Controls\": \"Command Control\",\n \"saleYear\": 2024,\n \"saleMonth\": 6,\n \"saleDay\": 7,\n \"saleDayofweek\": 5,\n \"saleDayofyear\": 159\n}\n # Create a dictionary of features and values from an internet-based bulldozer advertisement # See link: https://www.purplewave.com/auction/240606/item/EK8504/2004-Caterpillar-D6R_XL-Crawlers-Crawler_Dozer-Missouri (note: this link is/was valid as of October 2024 but may be invalid in the future) custom_sample = { \"SalesID\": np.nan, \"MachineID\": 8504, \"ModelID\": np.nan, \"datasource\": np.nan, \"auctioneerID\": np.nan, \"YearMade\": 2004, \"MachineHoursCurrentMeter\": 11770.0, \"UsageBand\": \"High\", \"fiModelDesc\": \"D6RXL\", \"fiBaseModel\": \"D6\", \"fiSecondaryDesc\": \"XL\", \"fiModelSeries\": np.nan, \"fiModelDescriptor\": np.nan, \"ProductSize\": \"Medium\", \"fiProductClassDesc\": \"Track Type Tractor, Dozer - 130.0 to 160.0 Horsepower\", \"state\": \"Missouri\", \"ProductGroup\": \"TTT\", \"ProductGroupDesc\": \"Track Type Tractors\", \"Drive_System\": \"No\", \"Enclosure\": \"EROPS\", \"Forks\": \"None or Unspecified\", \"Pad_Type\": \"Grouser\", \"Ride_Control\": \"None or Unspecified\", \"Stick\": \"nan\", \"Transmission\": \"Powershift\", \"Turbocharged\": \"None or Unspecified\", \"Blade_Extension\": \"None or Unspecified\", \"Blade_Width\": np.nan, \"Enclosure_Type\": np.nan, \"Engine_Horsepower\": np.nan, \"Hydraulics\": np.nan, \"Pushblock\": \"None or Unspecified\", \"Ripper\": \"None or Unspecified\", \"Scarifier\": \"None or Unspecified\", \"Tip_Control\": \"Tip\", \"Tire_Size\": np.nan, \"Coupler\": np.nan, \"Coupler_System\": np.nan, \"Grouser_Tracks\": \"Yes\", \"Hydraulics_Flow\": np.nan, \"Track_Type\": \"Steel\", \"Undercarriage_Pad_Width\": \"22 inch\", \"Stick_Length\": np.nan, \"Thumb\": np.nan, \"Pattern_Changer\": np.nan, \"Grouser_Type\": \"Single\", \"Backhoe_Mounting\": \"None or Unspecified\", \"Blade_Type\": \"Semi U\", \"Travel_Controls\": np.nan, \"Differential_Type\": np.nan, \"Steering_Controls\": \"Command Control\", \"saleYear\": 2024, \"saleMonth\": 6, \"saleDay\": 7, \"saleDayofweek\": 5, \"saleDayofyear\": 159 } Now we've got a single custom sample in the form of a dictionary, we can turn it into a DataFrame.
In\u00a0[139]: Copied! # Turn single sample in a DataFrame\ncustom_sample_df = pd.DataFrame(custom_sample, index=[0])\ncustom_sample_df.head()\n
# Turn single sample in a DataFrame custom_sample_df = pd.DataFrame(custom_sample, index=[0]) custom_sample_df.head() Out[139]: SalesID MachineID ModelID datasource auctioneerID YearMade MachineHoursCurrentMeter UsageBand fiModelDesc fiBaseModel ... Backhoe_Mounting Blade_Type Travel_Controls Differential_Type Steering_Controls saleYear saleMonth saleDay saleDayofweek saleDayofyear 0 NaN 8504 NaN NaN NaN 2004 11770.0 High D6RXL D6 ... None or Unspecified Semi U NaN NaN Command Control 2024 6 7 5 159 1 rows \u00d7 56 columns
And of course, we can preprocess the categoricial features using our ordinal_encoder (we use the same instance of OrdinalEncoder as we trained on the training dataset).
In\u00a0[140]: Copied! # Transform the categorical features of the custom sample\ncustom_sample_df[categorical_features] = ordinal_encoder.transform(custom_sample_df[categorical_features].astype(str))\ncustom_sample_df\n
# Transform the categorical features of the custom sample custom_sample_df[categorical_features] = ordinal_encoder.transform(custom_sample_df[categorical_features].astype(str)) custom_sample_df Out[140]: SalesID MachineID ModelID datasource auctioneerID YearMade MachineHoursCurrentMeter UsageBand fiModelDesc fiBaseModel ... Backhoe_Mounting Blade_Type Travel_Controls Differential_Type Steering_Controls saleYear saleMonth saleDay saleDayofweek saleDayofyear 0 NaN 8504 NaN NaN NaN 2004 11770.0 0.0 2308.0 703.0 ... 0.0 6.0 7.0 4.0 0.0 2024 6 7 5 159 1 rows \u00d7 56 columns
Custom sample preprocessed, let's make a prediction!
In\u00a0[141]: Copied! # Make a prediction on the preprocessed custom sample\ncustom_sample_pred = best_model.predict(custom_sample_df)\nprint(f\"[INFO] Predicted sale price of custom sample: ${round(custom_sample_pred[0], 2)}\")\n # Make a prediction on the preprocessed custom sample custom_sample_pred = best_model.predict(custom_sample_df) print(f\"[INFO] Predicted sale price of custom sample: ${round(custom_sample_pred[0], 2)}\") [INFO] Predicted sale price of custom sample: $51474.96\n
Now how close was this to the actual sale price (listed on the advertisement) of $72,600?
In\u00a0[142]: Copied! from sklearn.metrics import mean_absolute_error, root_mean_squared_log_error\n\n# Evaluate our model versus the actual sale price\ncustom_sample_actual_sale_price = [72600] # this is the sale price listed on the advertisement\n\nprint(f\"[INFO] Model MAE on custom sample: {mean_absolute_error(y_pred=custom_sample_pred, y_true=custom_sample_actual_sale_price)}\")\nprint(f\"[INFO] Model RMSLE on custom sample: {root_mean_squared_log_error(y_pred=custom_sample_pred, y_true=custom_sample_actual_sale_price)}\")\n from sklearn.metrics import mean_absolute_error, root_mean_squared_log_error # Evaluate our model versus the actual sale price custom_sample_actual_sale_price = [72600] # this is the sale price listed on the advertisement print(f\"[INFO] Model MAE on custom sample: {mean_absolute_error(y_pred=custom_sample_pred, y_true=custom_sample_actual_sale_price)}\") print(f\"[INFO] Model RMSLE on custom sample: {root_mean_squared_log_error(y_pred=custom_sample_pred, y_true=custom_sample_actual_sale_price)}\") [INFO] Model MAE on custom sample: 21125.040564373892\n[INFO] Model RMSLE on custom sample: 0.3438638042344433\n
Woah!
We get a quite high MAE value, however, it looks like our model's RMSLE performance on the custom sample was even better than the best_model on the validation dataset.
Not too bad for a model trained on sales data over 12 years older than our custom sample's sale date.
Note: In practice, to make this process easier, rather than manually typing out all of the feature values by hand, you might want to create an application capable of ingesting these values in a nice user interface. To create such machine learning applications, I'd practice by checking out Streamlit or Gradio.
In\u00a0[143]: Copied! # Find feature importance of our best model\nbest_model_feature_importances = best_model.feature_importances_\nbest_model_feature_importances\n
# Find feature importance of our best model best_model_feature_importances = best_model.feature_importances_ best_model_feature_importances Out[143]: array([3.78948522e-02, 2.70954102e-02, 5.85804002e-02, 1.79438322e-03,\n 5.25621132e-03, 1.92040831e-01, 6.71461619e-03, 1.42137572e-03,\n 4.79324438e-02, 4.73967258e-02, 4.12235661e-02, 4.75379381e-03,\n 2.55283197e-02, 1.60578799e-01, 5.08919397e-02, 8.34245434e-03,\n 3.43077232e-03, 4.16871935e-03, 1.45645185e-03, 6.32089976e-02,\n 1.93106853e-03, 7.91189110e-04, 2.16468186e-03, 2.42755109e-04,\n 1.44729959e-03, 1.10292279e-04, 4.69525167e-03, 4.70046399e-03,\n 2.18877572e-03, 4.03668217e-03, 4.46781002e-03, 2.86947732e-03,\n 5.20668987e-03, 3.50894384e-03, 1.75215277e-03, 1.16769900e-02,\n 1.84682779e-03, 2.08450645e-02, 1.17370327e-02, 5.26785421e-03,\n 2.07101299e-03, 1.36424627e-03, 1.60680297e-03, 9.71604299e-04,\n 7.85735364e-04, 7.29302663e-04, 6.74283032e-04, 3.28828690e-03,\n 2.83781098e-03, 3.92432694e-04, 4.73081800e-04, 7.26042221e-02,\n 5.42512552e-03, 8.54840059e-03, 4.42773246e-03, 1.26015531e-02])
Woah, looks like we get one value per feature in our dataset.
In\u00a0[144]: Copied! print(f\"[INFO] Number of feature importance values: {best_model_feature_importances.shape[0]}\") \nprint(f\"[INFO] Number of features in training dataset: {X_train_preprocessed.shape[1]}\")\n print(f\"[INFO] Number of feature importance values: {best_model_feature_importances.shape[0]}\") print(f\"[INFO] Number of features in training dataset: {X_train_preprocessed.shape[1]}\") [INFO] Number of feature importance values: 56\n[INFO] Number of features in training dataset: 56\n
We can inspect these further by turning them into a DataFrame.
We'll sort it descending order so we can see which feature our model is assigning the highest value.
In\u00a0[145]: Copied! # Create feature importance DataFrame\ncolumn_names = test_df.columns\nfeature_importance_df = pd.DataFrame({\"feature_names\": column_names,\n \"feature_importance\": best_model_feature_importances}).sort_values(by=\"feature_importance\",\n ascending=False)\nfeature_importance_df.head()\n # Create feature importance DataFrame column_names = test_df.columns feature_importance_df = pd.DataFrame({\"feature_names\": column_names, \"feature_importance\": best_model_feature_importances}).sort_values(by=\"feature_importance\", ascending=False) feature_importance_df.head() Out[145]: feature_names feature_importance 5 YearMade 0.192041 13 ProductSize 0.160579 51 saleYear 0.072604 19 Enclosure 0.063209 2 ModelID 0.058580 Hmmm... looks like YearMade may be contributing the most value in the model's eyes.
How about we turn our DataFrame into a plot to compare values?
In\u00a0[146]: Copied! # Plot the top feature importance values\ntop_n = 20\nplt.figure(figsize=(10, 5))\nplt.barh(y=feature_importance_df[\"feature_names\"][:top_n], # Plot the top_n feature importance values\n width=feature_importance_df[\"feature_importance\"][:top_n])\nplt.title(f\"Top {top_n} Feature Importance Values for Best RandomForestRegressor Model\")\nplt.xlabel(\"Feature importance value\")\nplt.ylabel(\"Feature name\")\nplt.gca().invert_yaxis();\n # Plot the top feature importance values top_n = 20 plt.figure(figsize=(10, 5)) plt.barh(y=feature_importance_df[\"feature_names\"][:top_n], # Plot the top_n feature importance values width=feature_importance_df[\"feature_importance\"][:top_n]) plt.title(f\"Top {top_n} Feature Importance Values for Best RandomForestRegressor Model\") plt.xlabel(\"Feature importance value\") plt.ylabel(\"Feature name\") plt.gca().invert_yaxis(); Ok, looks like the top 4 features contributing to our model's predictions are YearMade, ProductSize, Enclosure and saleYear.
Referring to the original data dictionary, do these values make sense to be contributing the most to the model?
YearMade - Year of manufacture of the machine.ProductSize - Size of the bulldozer.Enclosure - Type of bulldozer enclosure (e.g. OROPS = Open Rollover Protective Structures, EROPS = Enclosed Rollover Protective Structures).saleYear - The year the bulldozer was sold (this is one of our engineered features from saledate).
Now I've never sold a bulldozer but reading about each of these values seems to make sense that they would contribute significantly to the sale price.
I know when I've bought cars in the past, the year that is was made was an important part of my decision.
And it also makes sense that ProductSize be an important feature when deciding on the price of a bulldozer.
Let's check out the unique values for ProductSize and Enclosure.
In\u00a0[147]: Copied! print(f\"[INFO] Unique ProductSize values: {train_df['ProductSize'].unique()}\")\nprint(f\"[INFO] Unique Enclosure values: {train_df['Enclosure'].unique()}\")\n print(f\"[INFO] Unique ProductSize values: {train_df['ProductSize'].unique()}\") print(f\"[INFO] Unique Enclosure values: {train_df['Enclosure'].unique()}\") [INFO] Unique ProductSize values: ['Medium' nan 'Compact' 'Small' 'Large' 'Large / Medium' 'Mini']\n[INFO] Unique Enclosure values: ['OROPS' 'EROPS' 'EROPS w AC' nan 'EROPS AC' 'NO ROPS'\n 'None or Unspecified']\n
My guess is that a bulldozer with a ProductSize of 'Mini' would sell for less than a bulldozer with a size of 'Large'.
We could investigate this further in an extension to model driven data exploratory analysis or we could take this information to a colleague or client to discuss further.
Either way, we've now got a machine learning model capable of predicting the sale price of bulldozers given their features/attributes!
That's a huuuuuuge effort!
And you should be very proud of yourself for making it this far.
In\u00a0[244]: Copied! from sklearn.impute import SimpleImputer\nfrom sklearn.preprocessing import OrdinalEncoder\nfrom sklearn.metrics import mean_absolute_error, root_mean_squared_log_error\nfrom sklearn.ensemble import RandomForestRegressor\n\n# Import train samples (making sure to parse dates and then sort by them)\ntrain_df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/Train.csv\",\n parse_dates=[\"saledate\"],\n low_memory=False).sort_values(by=\"saledate\", ascending=True)\n\n# Import validation samples (making sure to parse dates and then sort by them)\nvalid_df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/Valid.csv\",\n parse_dates=[\"saledate\"])\n\n# The ValidSolution.csv contains the SalePrice values for the samples in Valid.csv\nvalid_solution = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/ValidSolution.csv\")\n\n# Map valid_solution to valid_df\nvalid_df[\"SalePrice\"] = valid_df[\"SalesID\"].map(valid_solution.set_index(\"SalesID\")[\"SalePrice\"])\n\n# Make sure valid_df is sorted by saledate still\nvalid_df = valid_df.sort_values(\"saledate\", ascending=True).reset_index(drop=True)\n\n# How many samples are in each DataFrame?\nprint(f\"[INFO] Number of samples in training DataFrame: {len(train_df)}\")\nprint(f\"[INFO] Number of samples in validation DataFrame: {len(valid_df)}\")\n\n# Make a function to add date columns\ndef add_datetime_features_to_df(df, date_column=\"saledate\"):\n # Add datetime parameters for saledate\n df[\"saleYear\"] = df[date_column].dt.year\n df[\"saleMonth\"] = df[date_column].dt.month\n df[\"saleDay\"] = df[date_column].dt.day\n df[\"saleDayofweek\"] = df[date_column].dt.dayofweek\n df[\"saleDayofyear\"] = df[date_column].dt.dayofyear\n\n # Drop original saledate column\n df.drop(\"saledate\", axis=1, inplace=True)\n\n return df\n\n# Add datetime features to DataFrames\ntrain_df = add_datetime_features_to_df(df=train_df)\nvalid_df = add_datetime_features_to_df(df=valid_df)\n\n# Split training data into features and labels\nX_train = train_df.drop(\"SalePrice\", axis=1)\ny_train = train_df[\"SalePrice\"]\n\n# Split validation data into features and labels\nX_valid = valid_df.drop(\"SalePrice\", axis=1)\ny_valid = valid_df[\"SalePrice\"]\n\n# Define numerical and categorical features\nnumeric_features = [label for label, content in X_train.items() if pd.api.types.is_numeric_dtype(content)]\ncategorical_features = [label for label, content in X_train.items() if not pd.api.types.is_numeric_dtype(content)]\n\n### Filling missing values ### \n\n# Create an ordinal encoder (turns category items into numeric representation)\nordinal_encoder = OrdinalEncoder(categories=\"auto\",\n handle_unknown=\"use_encoded_value\",\n unknown_value=np.nan,\n encoded_missing_value=np.nan) # treat unknown categories as np.nan (or None)\n\n# Create a simple imputer to fill missing values with median\nsimple_imputer_median = SimpleImputer(missing_values=np.nan,\n strategy=\"median\")\n\n# Fit and transform the categorical and numerical columns of X_train\nX_train_preprocessed = X_train.copy() # make copies of the oringal DataFrames so we can keep the original values in tact and view them later\nX_train_preprocessed[categorical_features] = ordinal_encoder.fit_transform(X_train_preprocessed[categorical_features].astype(str)) # OrdinalEncoder expects all values as the same type (e.g. string or numeric only)\nX_train_preprocessed[numerical_features] = simple_imputer_median.fit_transform(X_train_preprocessed[numerical_features])\n\n# Transform the categorical and numerical columns of X_valid \nX_valid_preprocessed = X_valid.copy()\nX_valid_preprocessed[categorical_features] = ordinal_encoder.transform(X_valid_preprocessed[categorical_features].astype(str)) # only use `transform` on the validation data\nX_valid_preprocessed[numerical_features] = simple_imputer_median.transform(X_valid_preprocessed[numerical_features])\n\n# Create function to evaluate our model\ndef show_scores(model, \n train_features=X_train_preprocessed,\n train_labels=y_train,\n valid_features=X_valid_preprocessed,\n valid_labels=y_valid):\n \n # Make predictions on train and validation features\n train_preds = model.predict(X=train_features)\n val_preds = model.predict(X=valid_features)\n\n # Create a scores dictionary of different evaluation metrics\n scores = {\"Training MAE\": mean_absolute_error(y_true=train_labels, \n y_pred=train_preds),\n \"Valid MAE\": mean_absolute_error(y_true=valid_labels, \n y_pred=val_preds),\n \"Training RMSLE\": root_mean_squared_log_error(y_true=train_labels, \n y_pred=train_preds),\n \"Valid RMSLE\": root_mean_squared_log_error(y_true=valid_labels, \n y_pred=val_preds),\n \"Training R^2\": model.score(X=train_features, \n y=train_labels),\n \"Valid R^2\": model.score(X=valid_features, \n y=valid_labels)}\n return scores\n\n# Instantiate a model with best hyperparameters \nideal_model_2 = RandomForestRegressor(n_estimators=90,\n max_depth=None,\n min_samples_leaf=1,\n min_samples_split=5,\n max_features=0.5,\n n_jobs=-1,\n max_samples=None)\n\n# Fit a model to the preprocessed data\nideal_model_2.fit(X=X_train_preprocessed, \n y=y_train)\n\n# Evalute the model\nideal_model_2_scores = show_scores(model=ideal_model_2)\nideal_model_2_scores\n from sklearn.impute import SimpleImputer from sklearn.preprocessing import OrdinalEncoder from sklearn.metrics import mean_absolute_error, root_mean_squared_log_error from sklearn.ensemble import RandomForestRegressor # Import train samples (making sure to parse dates and then sort by them) train_df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/Train.csv\", parse_dates=[\"saledate\"], low_memory=False).sort_values(by=\"saledate\", ascending=True) # Import validation samples (making sure to parse dates and then sort by them) valid_df = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/Valid.csv\", parse_dates=[\"saledate\"]) # The ValidSolution.csv contains the SalePrice values for the samples in Valid.csv valid_solution = pd.read_csv(filepath_or_buffer=\"../data/bluebook-for-bulldozers/ValidSolution.csv\") # Map valid_solution to valid_df valid_df[\"SalePrice\"] = valid_df[\"SalesID\"].map(valid_solution.set_index(\"SalesID\")[\"SalePrice\"]) # Make sure valid_df is sorted by saledate still valid_df = valid_df.sort_values(\"saledate\", ascending=True).reset_index(drop=True) # How many samples are in each DataFrame? print(f\"[INFO] Number of samples in training DataFrame: {len(train_df)}\") print(f\"[INFO] Number of samples in validation DataFrame: {len(valid_df)}\") # Make a function to add date columns def add_datetime_features_to_df(df, date_column=\"saledate\"): # Add datetime parameters for saledate df[\"saleYear\"] = df[date_column].dt.year df[\"saleMonth\"] = df[date_column].dt.month df[\"saleDay\"] = df[date_column].dt.day df[\"saleDayofweek\"] = df[date_column].dt.dayofweek df[\"saleDayofyear\"] = df[date_column].dt.dayofyear # Drop original saledate column df.drop(\"saledate\", axis=1, inplace=True) return df # Add datetime features to DataFrames train_df = add_datetime_features_to_df(df=train_df) valid_df = add_datetime_features_to_df(df=valid_df) # Split training data into features and labels X_train = train_df.drop(\"SalePrice\", axis=1) y_train = train_df[\"SalePrice\"] # Split validation data into features and labels X_valid = valid_df.drop(\"SalePrice\", axis=1) y_valid = valid_df[\"SalePrice\"] # Define numerical and categorical features numeric_features = [label for label, content in X_train.items() if pd.api.types.is_numeric_dtype(content)] categorical_features = [label for label, content in X_train.items() if not pd.api.types.is_numeric_dtype(content)] ### Filling missing values ### # Create an ordinal encoder (turns category items into numeric representation) ordinal_encoder = OrdinalEncoder(categories=\"auto\", handle_unknown=\"use_encoded_value\", unknown_value=np.nan, encoded_missing_value=np.nan) # treat unknown categories as np.nan (or None) # Create a simple imputer to fill missing values with median simple_imputer_median = SimpleImputer(missing_values=np.nan, strategy=\"median\") # Fit and transform the categorical and numerical columns of X_train X_train_preprocessed = X_train.copy() # make copies of the oringal DataFrames so we can keep the original values in tact and view them later X_train_preprocessed[categorical_features] = ordinal_encoder.fit_transform(X_train_preprocessed[categorical_features].astype(str)) # OrdinalEncoder expects all values as the same type (e.g. string or numeric only) X_train_preprocessed[numerical_features] = simple_imputer_median.fit_transform(X_train_preprocessed[numerical_features]) # Transform the categorical and numerical columns of X_valid X_valid_preprocessed = X_valid.copy() X_valid_preprocessed[categorical_features] = ordinal_encoder.transform(X_valid_preprocessed[categorical_features].astype(str)) # only use `transform` on the validation data X_valid_preprocessed[numerical_features] = simple_imputer_median.transform(X_valid_preprocessed[numerical_features]) # Create function to evaluate our model def show_scores(model, train_features=X_train_preprocessed, train_labels=y_train, valid_features=X_valid_preprocessed, valid_labels=y_valid): # Make predictions on train and validation features train_preds = model.predict(X=train_features) val_preds = model.predict(X=valid_features) # Create a scores dictionary of different evaluation metrics scores = {\"Training MAE\": mean_absolute_error(y_true=train_labels, y_pred=train_preds), \"Valid MAE\": mean_absolute_error(y_true=valid_labels, y_pred=val_preds), \"Training RMSLE\": root_mean_squared_log_error(y_true=train_labels, y_pred=train_preds), \"Valid RMSLE\": root_mean_squared_log_error(y_true=valid_labels, y_pred=val_preds), \"Training R^2\": model.score(X=train_features, y=train_labels), \"Valid R^2\": model.score(X=valid_features, y=valid_labels)} return scores # Instantiate a model with best hyperparameters ideal_model_2 = RandomForestRegressor(n_estimators=90, max_depth=None, min_samples_leaf=1, min_samples_split=5, max_features=0.5, n_jobs=-1, max_samples=None) # Fit a model to the preprocessed data ideal_model_2.fit(X=X_train_preprocessed, y=y_train) # Evalute the model ideal_model_2_scores = show_scores(model=ideal_model_2) ideal_model_2_scores [INFO] Number of samples in training DataFrame: 401125\n[INFO] Number of samples in validation DataFrame: 11573\n
Out[244]: {'Training MAE': np.float64(1951.2971558280735),\n 'Valid MAE': np.float64(5964.025764507629),\n 'Training RMSLE': np.float64(0.101909965049995),\n 'Valid RMSLE': np.float64(0.24697812443315573),\n 'Training R^2': 0.9810825663665007,\n 'Valid R^2': 0.8809697755766817} Looks like filling the missing numeric values made our ideal_model_2 perform slightly worse than our original ideal_model.
ideal_model_2 had a validation RMSLE of 0.24697812443315573 where as ideal_model had a validation RMSLE of 0.24654150224930685.
In\u00a0[247]: Copied! import pandas as pd\nimport numpy as np\n\nfrom sklearn.compose import ColumnTransformer\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.impute import SimpleImputer\nfrom sklearn.metrics import mean_absolute_error, root_mean_squared_log_error\nfrom sklearn.preprocessing import OrdinalEncoder, FunctionTransformer\nfrom sklearn.pipeline import Pipeline\n\n\n# Import and prepare data\ntrain_df = pd.read_csv(\"../data/bluebook-for-bulldozers/Train.csv\",\n parse_dates=[\"saledate\"],\n low_memory=False).sort_values(by=\"saledate\", ascending=True)\n\nvalid_df = pd.read_csv(\"../data/bluebook-for-bulldozers/Valid.csv\",\n parse_dates=[\"saledate\"])\n\nvalid_solution = pd.read_csv(\"../data/bluebook-for-bulldozers/ValidSolution.csv\")\nvalid_df[\"SalePrice\"] = valid_df[\"SalesID\"].map(valid_solution.set_index(\"SalesID\")[\"SalePrice\"])\nvalid_df = valid_df.sort_values(\"saledate\", ascending=True).reset_index(drop=True)\n\n# Add datetime features\ndef add_datetime_features_to_df(df, date_column=\"saledate\"):\n df = df.copy()\n df[\"saleYear\"] = df[date_column].dt.year\n df[\"saleMonth\"] = df[date_column].dt.month\n df[\"saleDay\"] = df[date_column].dt.day\n df[\"saleDayofweek\"] = df[date_column].dt.dayofweek\n df[\"saleDayofyear\"] = df[date_column].dt.dayofyear\n return df.drop(date_column, axis=1)\n\n# Apply datetime features\ntrain_df = add_datetime_features_to_df(train_df)\nvalid_df = add_datetime_features_to_df(valid_df)\n\n# Split data into features and labels\nX_train = train_df.drop(\"SalePrice\", axis=1)\ny_train = train_df[\"SalePrice\"]\nX_valid = valid_df.drop(\"SalePrice\", axis=1)\ny_valid = valid_df[\"SalePrice\"]\n\n# Define feature types\nnumeric_features = [label for label, content in X_train.items() \n if pd.api.types.is_numeric_dtype(content)]\ncategorical_features = [label for label, content in X_train.items() \n if not pd.api.types.is_numeric_dtype(content)]\n\n# Create preprocessing steps\nnumeric_transformer = Pipeline(steps=[\n ('imputer', SimpleImputer(strategy='median'))\n])\n\ncategorical_transformer = Pipeline(steps=[\n ('string_converter', FunctionTransformer(lambda x: x.astype(str))), # convert values to string\n ('ordinal', OrdinalEncoder(handle_unknown='use_encoded_value',\n unknown_value=np.nan,\n encoded_missing_value=np.nan)),\n])\n\n# Create preprocessor using ColumnTransformer\npreprocessor = ColumnTransformer(\n transformers=[\n ('numerical_transforms', numeric_transformer, numeric_features),\n ('categorical_transforms', categorical_transformer, categorical_features)\n ])\n\n# Create full pipeline\nmodel_pipeline = Pipeline([\n ('preprocessor', preprocessor),\n ('regressor', RandomForestRegressor(\n n_estimators=90,\n max_depth=None,\n min_samples_leaf=1,\n min_samples_split=5,\n max_features=0.5,\n n_jobs=-1,\n max_samples=None\n ))\n])\n\n# Function to evaluate the pipeline\ndef evaluate_pipeline(pipeline, X_train, y_train, X_valid, y_valid):\n # Make predictions\n train_preds = pipeline.predict(X_train)\n valid_preds = pipeline.predict(X_valid)\n \n # Calculate scores\n scores = {\n \"Training MAE\": mean_absolute_error(y_train, train_preds),\n \"Valid MAE\": mean_absolute_error(y_valid, valid_preds),\n \"Training RMSLE\": root_mean_squared_log_error(y_train, train_preds),\n \"Valid RMSLE\": root_mean_squared_log_error(y_valid, valid_preds),\n \"Training R^2\": pipeline.score(X_train, y_train),\n \"Valid R^2\": pipeline.score(X_valid, y_valid)\n }\n return scores\n\n# Fit and evaluate pipeline\nmodel_pipeline.fit(X_train, y_train)\npipeline_scores = evaluate_pipeline(model_pipeline, X_train, y_train, X_valid, y_valid)\nprint(\"\\nPipeline Scores:\")\npipeline_scores\n import pandas as pd import numpy as np from sklearn.compose import ColumnTransformer from sklearn.ensemble import RandomForestRegressor from sklearn.impute import SimpleImputer from sklearn.metrics import mean_absolute_error, root_mean_squared_log_error from sklearn.preprocessing import OrdinalEncoder, FunctionTransformer from sklearn.pipeline import Pipeline # Import and prepare data train_df = pd.read_csv(\"../data/bluebook-for-bulldozers/Train.csv\", parse_dates=[\"saledate\"], low_memory=False).sort_values(by=\"saledate\", ascending=True) valid_df = pd.read_csv(\"../data/bluebook-for-bulldozers/Valid.csv\", parse_dates=[\"saledate\"]) valid_solution = pd.read_csv(\"../data/bluebook-for-bulldozers/ValidSolution.csv\") valid_df[\"SalePrice\"] = valid_df[\"SalesID\"].map(valid_solution.set_index(\"SalesID\")[\"SalePrice\"]) valid_df = valid_df.sort_values(\"saledate\", ascending=True).reset_index(drop=True) # Add datetime features def add_datetime_features_to_df(df, date_column=\"saledate\"): df = df.copy() df[\"saleYear\"] = df[date_column].dt.year df[\"saleMonth\"] = df[date_column].dt.month df[\"saleDay\"] = df[date_column].dt.day df[\"saleDayofweek\"] = df[date_column].dt.dayofweek df[\"saleDayofyear\"] = df[date_column].dt.dayofyear return df.drop(date_column, axis=1) # Apply datetime features train_df = add_datetime_features_to_df(train_df) valid_df = add_datetime_features_to_df(valid_df) # Split data into features and labels X_train = train_df.drop(\"SalePrice\", axis=1) y_train = train_df[\"SalePrice\"] X_valid = valid_df.drop(\"SalePrice\", axis=1) y_valid = valid_df[\"SalePrice\"] # Define feature types numeric_features = [label for label, content in X_train.items() if pd.api.types.is_numeric_dtype(content)] categorical_features = [label for label, content in X_train.items() if not pd.api.types.is_numeric_dtype(content)] # Create preprocessing steps numeric_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='median')) ]) categorical_transformer = Pipeline(steps=[ ('string_converter', FunctionTransformer(lambda x: x.astype(str))), # convert values to string ('ordinal', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=np.nan, encoded_missing_value=np.nan)), ]) # Create preprocessor using ColumnTransformer preprocessor = ColumnTransformer( transformers=[ ('numerical_transforms', numeric_transformer, numeric_features), ('categorical_transforms', categorical_transformer, categorical_features) ]) # Create full pipeline model_pipeline = Pipeline([ ('preprocessor', preprocessor), ('regressor', RandomForestRegressor( n_estimators=90, max_depth=None, min_samples_leaf=1, min_samples_split=5, max_features=0.5, n_jobs=-1, max_samples=None )) ]) # Function to evaluate the pipeline def evaluate_pipeline(pipeline, X_train, y_train, X_valid, y_valid): # Make predictions train_preds = pipeline.predict(X_train) valid_preds = pipeline.predict(X_valid) # Calculate scores scores = { \"Training MAE\": mean_absolute_error(y_train, train_preds), \"Valid MAE\": mean_absolute_error(y_valid, valid_preds), \"Training RMSLE\": root_mean_squared_log_error(y_train, train_preds), \"Valid RMSLE\": root_mean_squared_log_error(y_valid, valid_preds), \"Training R^2\": pipeline.score(X_train, y_train), \"Valid R^2\": pipeline.score(X_valid, y_valid) } return scores # Fit and evaluate pipeline model_pipeline.fit(X_train, y_train) pipeline_scores = evaluate_pipeline(model_pipeline, X_train, y_train, X_valid, y_valid) print(\"\\nPipeline Scores:\") pipeline_scores \nPipeline Scores:\n
Out[247]: {'Training MAE': np.float64(1951.4776197781914),\n 'Valid MAE': np.float64(5974.931566226864),\n 'Training RMSLE': np.float64(0.10196097739473307),\n 'Valid RMSLE': np.float64(0.24760612684722114),\n 'Training R^2': 0.9811027965058758,\n 'Valid R^2': 0.8807288353268701} In\u00a0[148]: Copied! import pandas as pd\nimport numpy as np\n\nfrom sklearn.compose import ColumnTransformer\nfrom sklearn.ensemble import HistGradientBoostingRegressor\nfrom sklearn.impute import SimpleImputer\nfrom sklearn.metrics import mean_absolute_error, root_mean_squared_log_error\nfrom sklearn.preprocessing import OrdinalEncoder, FunctionTransformer, StandardScaler\nfrom sklearn.pipeline import Pipeline\n\n# Import and prepare data\ntrain_df = pd.read_csv(\"../data/bluebook-for-bulldozers/Train.csv\",\n parse_dates=[\"saledate\"],\n low_memory=False).sort_values(by=\"saledate\", ascending=True)\n\nvalid_df = pd.read_csv(\"../data/bluebook-for-bulldozers/Valid.csv\",\n parse_dates=[\"saledate\"])\n\nvalid_solution = pd.read_csv(\"../data/bluebook-for-bulldozers/ValidSolution.csv\")\nvalid_df[\"SalePrice\"] = valid_df[\"SalesID\"].map(valid_solution.set_index(\"SalesID\")[\"SalePrice\"])\nvalid_df = valid_df.sort_values(\"saledate\", ascending=True).reset_index(drop=True)\n\n# Add datetime features\ndef add_datetime_features_to_df(df, date_column=\"saledate\"):\n df = df.copy()\n df[\"saleYear\"] = df[date_column].dt.year\n df[\"saleMonth\"] = df[date_column].dt.month\n df[\"saleDay\"] = df[date_column].dt.day\n df[\"saleDayofweek\"] = df[date_column].dt.dayofweek\n df[\"saleDayofyear\"] = df[date_column].dt.dayofyear\n return df.drop(date_column, axis=1)\n\n# Apply datetime features\ntrain_df = add_datetime_features_to_df(train_df)\nvalid_df = add_datetime_features_to_df(valid_df)\n\n# Split data into features and labels\nX_train = train_df.drop(\"SalePrice\", axis=1)\ny_train = train_df[\"SalePrice\"]\nX_valid = valid_df.drop(\"SalePrice\", axis=1)\ny_valid = valid_df[\"SalePrice\"]\n\n# Define feature types\nnumeric_features = [label for label, content in X_train.items() \n if pd.api.types.is_numeric_dtype(content)]\ncategorical_features = [label for label, content in X_train.items() \n if not pd.api.types.is_numeric_dtype(content)]\n\n# Create preprocessing steps for different types of values\nnumeric_transformer = Pipeline(steps=[\n ('imputer', SimpleImputer(strategy='median')),\n])\n\ncategorical_transformer = Pipeline(steps=[\n ('string_converter', FunctionTransformer(lambda x: x.astype(str))), # convert values to string\n ('ordinal', OrdinalEncoder(categories='auto',\n handle_unknown='use_encoded_value',\n unknown_value=np.nan,\n encoded_missing_value=np.nan)), \n])\n\n# Create preprocessor using ColumnTransformer\npreprocessor = ColumnTransformer(\n transformers=[\n ('numerical_transforms', numeric_transformer, numeric_features),\n ('categorical_transforms', categorical_transformer, categorical_features)\n ])\n\n# Create full pipeline\nmodel_pipeline_hist_gradient_boosting_regressor = Pipeline([\n ('preprocessor', preprocessor),\n ('regressor', HistGradientBoostingRegressor()) # Change model to HistGradientBoostingRegressor\n])\n\n# Function to evaluate the pipeline\ndef evaluate_pipeline(pipeline, X_train, y_train, X_valid, y_valid):\n # Make predictions\n train_preds = pipeline.predict(X_train)\n valid_preds = pipeline.predict(X_valid)\n \n # Calculate scores\n scores = {\n \"Training MAE\": mean_absolute_error(y_train, train_preds),\n \"Valid MAE\": mean_absolute_error(y_valid, valid_preds),\n \"Training RMSLE\": root_mean_squared_log_error(y_train, train_preds),\n \"Valid RMSLE\": root_mean_squared_log_error(y_valid, valid_preds),\n \"Training R^2\": pipeline.score(X_train, y_train),\n \"Valid R^2\": pipeline.score(X_valid, y_valid)\n }\n return scores\n\n# Fit and evaluate pipeline\nprint(f\"[INFO] Fitting HistGradientBoostingRegressor model with pipeline...\")\nmodel_pipeline_hist_gradient_boosting_regressor.fit(X_train, y_train)\nprint(f\"[INFO] Evaluating HistGradientBoostingRegressor model with pipeline...\")\npipeline_hist_scores = evaluate_pipeline(model_pipeline_hist_gradient_boosting_regressor, X_train, y_train, X_valid, y_valid)\nprint(\"\\nPipeline HistGradientBoostingRegressor Scores:\")\npipeline_hist_scores\n import pandas as pd import numpy as np from sklearn.compose import ColumnTransformer from sklearn.ensemble import HistGradientBoostingRegressor from sklearn.impute import SimpleImputer from sklearn.metrics import mean_absolute_error, root_mean_squared_log_error from sklearn.preprocessing import OrdinalEncoder, FunctionTransformer, StandardScaler from sklearn.pipeline import Pipeline # Import and prepare data train_df = pd.read_csv(\"../data/bluebook-for-bulldozers/Train.csv\", parse_dates=[\"saledate\"], low_memory=False).sort_values(by=\"saledate\", ascending=True) valid_df = pd.read_csv(\"../data/bluebook-for-bulldozers/Valid.csv\", parse_dates=[\"saledate\"]) valid_solution = pd.read_csv(\"../data/bluebook-for-bulldozers/ValidSolution.csv\") valid_df[\"SalePrice\"] = valid_df[\"SalesID\"].map(valid_solution.set_index(\"SalesID\")[\"SalePrice\"]) valid_df = valid_df.sort_values(\"saledate\", ascending=True).reset_index(drop=True) # Add datetime features def add_datetime_features_to_df(df, date_column=\"saledate\"): df = df.copy() df[\"saleYear\"] = df[date_column].dt.year df[\"saleMonth\"] = df[date_column].dt.month df[\"saleDay\"] = df[date_column].dt.day df[\"saleDayofweek\"] = df[date_column].dt.dayofweek df[\"saleDayofyear\"] = df[date_column].dt.dayofyear return df.drop(date_column, axis=1) # Apply datetime features train_df = add_datetime_features_to_df(train_df) valid_df = add_datetime_features_to_df(valid_df) # Split data into features and labels X_train = train_df.drop(\"SalePrice\", axis=1) y_train = train_df[\"SalePrice\"] X_valid = valid_df.drop(\"SalePrice\", axis=1) y_valid = valid_df[\"SalePrice\"] # Define feature types numeric_features = [label for label, content in X_train.items() if pd.api.types.is_numeric_dtype(content)] categorical_features = [label for label, content in X_train.items() if not pd.api.types.is_numeric_dtype(content)] # Create preprocessing steps for different types of values numeric_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='median')), ]) categorical_transformer = Pipeline(steps=[ ('string_converter', FunctionTransformer(lambda x: x.astype(str))), # convert values to string ('ordinal', OrdinalEncoder(categories='auto', handle_unknown='use_encoded_value', unknown_value=np.nan, encoded_missing_value=np.nan)), ]) # Create preprocessor using ColumnTransformer preprocessor = ColumnTransformer( transformers=[ ('numerical_transforms', numeric_transformer, numeric_features), ('categorical_transforms', categorical_transformer, categorical_features) ]) # Create full pipeline model_pipeline_hist_gradient_boosting_regressor = Pipeline([ ('preprocessor', preprocessor), ('regressor', HistGradientBoostingRegressor()) # Change model to HistGradientBoostingRegressor ]) # Function to evaluate the pipeline def evaluate_pipeline(pipeline, X_train, y_train, X_valid, y_valid): # Make predictions train_preds = pipeline.predict(X_train) valid_preds = pipeline.predict(X_valid) # Calculate scores scores = { \"Training MAE\": mean_absolute_error(y_train, train_preds), \"Valid MAE\": mean_absolute_error(y_valid, valid_preds), \"Training RMSLE\": root_mean_squared_log_error(y_train, train_preds), \"Valid RMSLE\": root_mean_squared_log_error(y_valid, valid_preds), \"Training R^2\": pipeline.score(X_train, y_train), \"Valid R^2\": pipeline.score(X_valid, y_valid) } return scores # Fit and evaluate pipeline print(f\"[INFO] Fitting HistGradientBoostingRegressor model with pipeline...\") model_pipeline_hist_gradient_boosting_regressor.fit(X_train, y_train) print(f\"[INFO] Evaluating HistGradientBoostingRegressor model with pipeline...\") pipeline_hist_scores = evaluate_pipeline(model_pipeline_hist_gradient_boosting_regressor, X_train, y_train, X_valid, y_valid) print(\"\\nPipeline HistGradientBoostingRegressor Scores:\") pipeline_hist_scores [INFO] Fitting HistGradientBoostingRegressor model with pipeline...\n[INFO] Evaluating HistGradientBoostingRegressor model with pipeline...\n\nPipeline HistGradientBoostingRegressor Scores:\n
Out[148]: {'Training MAE': np.float64(5638.6121797753785),\n 'Valid MAE': np.float64(7264.258786098576),\n 'Training RMSLE': np.float64(0.2691456681483351),\n 'Valid RMSLE': np.float64(0.30482586120872424),\n 'Training R^2': 0.8646511348082063,\n 'Valid R^2': 0.8319021596407035} In\u00a0[7]: Copied! %%time\n\nimport pandas as pd\nimport numpy as np\nfrom sklearn.impute import SimpleImputer\nfrom sklearn.preprocessing import OneHotEncoder\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.metrics import mean_absolute_error, root_mean_squared_log_error\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.compose import ColumnTransformer\nfrom sklearn.preprocessing import FunctionTransformer\n\n# Import and prepare data\ntrain_df = pd.read_csv(\"../data/bluebook-for-bulldozers/Train.csv\",\n parse_dates=[\"saledate\"],\n low_memory=False).sort_values(by=\"saledate\", ascending=True)\n\nvalid_df = pd.read_csv(\"../data/bluebook-for-bulldozers/Valid.csv\",\n parse_dates=[\"saledate\"])\n\nvalid_solution = pd.read_csv(\"../data/bluebook-for-bulldozers/ValidSolution.csv\")\nvalid_df[\"SalePrice\"] = valid_df[\"SalesID\"].map(valid_solution.set_index(\"SalesID\")[\"SalePrice\"])\nvalid_df = valid_df.sort_values(\"saledate\", ascending=True).reset_index(drop=True)\n\n# Add datetime features\ndef add_datetime_features_to_df(df, date_column=\"saledate\"):\n df = df.copy()\n df[\"saleYear\"] = df[date_column].dt.year\n df[\"saleMonth\"] = df[date_column].dt.month\n df[\"saleDay\"] = df[date_column].dt.day\n df[\"saleDayofweek\"] = df[date_column].dt.dayofweek\n df[\"saleDayofyear\"] = df[date_column].dt.dayofyear\n return df.drop(date_column, axis=1)\n\n# Apply datetime features\ntrain_df = add_datetime_features_to_df(train_df)\nvalid_df = add_datetime_features_to_df(valid_df)\n\n# Split data\nX_train = train_df.drop(\"SalePrice\", axis=1)\ny_train = train_df[\"SalePrice\"]\nX_valid = valid_df.drop(\"SalePrice\", axis=1)\ny_valid = valid_df[\"SalePrice\"]\n\n# Define feature types\nnumeric_features = [label for label, content in X_train.items() \n if pd.api.types.is_numeric_dtype(content)]\ncategorical_features = [label for label, content in X_train.items() \n if not pd.api.types.is_numeric_dtype(content)]\n\n# Create preprocessing steps\nnumeric_transformer = Pipeline(steps=[\n ('imputer', SimpleImputer(strategy='median'))\n])\n\ncategorical_transformer = Pipeline(steps=[\n ('string_converter', FunctionTransformer(lambda x: x.astype(str))),\n ('imputer', SimpleImputer(strategy='constant', fill_value='missing')), # fill missing values with the term \"missing\"\n ('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=True)) # use OneHotEncoder instead of OrdinalEncoder\n])\n\n# Create preprocessor using ColumnTransformer\npreprocessor = ColumnTransformer(\n transformers=[\n ('num', numeric_transformer, numeric_features),\n ('cat', categorical_transformer, categorical_features)\n ],\n verbose_feature_names_out=False # Simplify feature names\n)\n\n# Create full pipeline\nmodel_one_hot_pipeline = Pipeline([\n ('preprocessor', preprocessor),\n ('regressor', RandomForestRegressor(\n n_estimators=10,\n max_depth=None,\n min_samples_leaf=1,\n min_samples_split=5,\n max_features=0.5,\n n_jobs=-1,\n max_samples=None\n ))\n])\n\n# Function to evaluate the pipeline\ndef evaluate_pipeline(pipeline, X_train, y_train, X_valid, y_valid):\n # Make predictions\n train_preds = pipeline.predict(X_train)\n valid_preds = pipeline.predict(X_valid)\n \n # Calculate scores\n scores = {\n \"Training MAE\": mean_absolute_error(y_train, train_preds),\n \"Valid MAE\": mean_absolute_error(y_valid, valid_preds),\n \"Training RMSLE\": root_mean_squared_log_error(y_train, train_preds),\n \"Valid RMSLE\": root_mean_squared_log_error(y_valid, valid_preds),\n \"Training R^2\": pipeline.score(X_train, y_train),\n \"Valid R^2\": pipeline.score(X_valid, y_valid)\n }\n return scores\n\n# Fit and evaluate pipeline\nprint(f\"[INFO] Fitting model with one hot encoded values...\")\nmodel_one_hot_pipeline.fit(X_train, y_train)\nprint(f\"[INFO] Evaluating model with one hot encoded values...\")\npipeline_one_hot_scores = evaluate_pipeline(model_one_hot_pipeline, X_train, y_train, X_valid, y_valid)\nprint(\"[INFO] Pipeline with one hot encoding scores:\")\npipeline_one_hot_scores\n %%time import pandas as pd import numpy as np from sklearn.impute import SimpleImputer from sklearn.preprocessing import OneHotEncoder from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_absolute_error, root_mean_squared_log_error from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformer from sklearn.preprocessing import FunctionTransformer # Import and prepare data train_df = pd.read_csv(\"../data/bluebook-for-bulldozers/Train.csv\", parse_dates=[\"saledate\"], low_memory=False).sort_values(by=\"saledate\", ascending=True) valid_df = pd.read_csv(\"../data/bluebook-for-bulldozers/Valid.csv\", parse_dates=[\"saledate\"]) valid_solution = pd.read_csv(\"../data/bluebook-for-bulldozers/ValidSolution.csv\") valid_df[\"SalePrice\"] = valid_df[\"SalesID\"].map(valid_solution.set_index(\"SalesID\")[\"SalePrice\"]) valid_df = valid_df.sort_values(\"saledate\", ascending=True).reset_index(drop=True) # Add datetime features def add_datetime_features_to_df(df, date_column=\"saledate\"): df = df.copy() df[\"saleYear\"] = df[date_column].dt.year df[\"saleMonth\"] = df[date_column].dt.month df[\"saleDay\"] = df[date_column].dt.day df[\"saleDayofweek\"] = df[date_column].dt.dayofweek df[\"saleDayofyear\"] = df[date_column].dt.dayofyear return df.drop(date_column, axis=1) # Apply datetime features train_df = add_datetime_features_to_df(train_df) valid_df = add_datetime_features_to_df(valid_df) # Split data X_train = train_df.drop(\"SalePrice\", axis=1) y_train = train_df[\"SalePrice\"] X_valid = valid_df.drop(\"SalePrice\", axis=1) y_valid = valid_df[\"SalePrice\"] # Define feature types numeric_features = [label for label, content in X_train.items() if pd.api.types.is_numeric_dtype(content)] categorical_features = [label for label, content in X_train.items() if not pd.api.types.is_numeric_dtype(content)] # Create preprocessing steps numeric_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='median')) ]) categorical_transformer = Pipeline(steps=[ ('string_converter', FunctionTransformer(lambda x: x.astype(str))), ('imputer', SimpleImputer(strategy='constant', fill_value='missing')), # fill missing values with the term \"missing\" ('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=True)) # use OneHotEncoder instead of OrdinalEncoder ]) # Create preprocessor using ColumnTransformer preprocessor = ColumnTransformer( transformers=[ ('num', numeric_transformer, numeric_features), ('cat', categorical_transformer, categorical_features) ], verbose_feature_names_out=False # Simplify feature names ) # Create full pipeline model_one_hot_pipeline = Pipeline([ ('preprocessor', preprocessor), ('regressor', RandomForestRegressor( n_estimators=10, max_depth=None, min_samples_leaf=1, min_samples_split=5, max_features=0.5, n_jobs=-1, max_samples=None )) ]) # Function to evaluate the pipeline def evaluate_pipeline(pipeline, X_train, y_train, X_valid, y_valid): # Make predictions train_preds = pipeline.predict(X_train) valid_preds = pipeline.predict(X_valid) # Calculate scores scores = { \"Training MAE\": mean_absolute_error(y_train, train_preds), \"Valid MAE\": mean_absolute_error(y_valid, valid_preds), \"Training RMSLE\": root_mean_squared_log_error(y_train, train_preds), \"Valid RMSLE\": root_mean_squared_log_error(y_valid, valid_preds), \"Training R^2\": pipeline.score(X_train, y_train), \"Valid R^2\": pipeline.score(X_valid, y_valid) } return scores # Fit and evaluate pipeline print(f\"[INFO] Fitting model with one hot encoded values...\") model_one_hot_pipeline.fit(X_train, y_train) print(f\"[INFO] Evaluating model with one hot encoded values...\") pipeline_one_hot_scores = evaluate_pipeline(model_one_hot_pipeline, X_train, y_train, X_valid, y_valid) print(\"[INFO] Pipeline with one hot encoding scores:\") pipeline_one_hot_scores [INFO] Fitting model with one hot encoded values...\n[INFO] Evaluating model with one hot encoded values...\n[INFO] Pipeline with one hot encoding scores:\nCPU times: user 29min, sys: 23min 12s, total: 52min 13s\nWall time: 9min 14s\n
Out[7]: {'Training MAE': np.float64(2133.748251811842),\n 'Valid MAE': np.float64(6176.810802667383),\n 'Training RMSLE': np.float64(0.11021214524792695),\n 'Valid RMSLE': np.float64(0.2539881442090813),\n 'Training R^2': 0.9759312990258391,\n 'Valid R^2': 0.870741470996933}"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#predicting-the-sale-price-of-bulldozers-using-machine-learning","title":"Predicting the Sale Price of Bulldozers using Machine Learning \ud83d\ude9c\u00b6","text":"In this notebook, we're going to go through an example machine learning project to use the characteristics of bulldozers and their past sales prices to predict the sale price of future bulldozers based on their characteristics.
- Inputs: Bulldozer characteristics such as make year, base model, model series, state of sale (e.g. which US state was it sold in), drive system and more.
- Outputs: Bulldozer sale price (in USD).
Since we're trying to predict a number, this kind of problem is known as a regression problem.
And since we're going to predicting results with a time component (predicting future sales based on past sales), this is also known as a time series or forecasting problem.
The data and evaluation metric we'll be using (root mean square log error or RMSLE) is from the Kaggle Bluebook for Bulldozers competition.
The techniques used in here have been inspired and adapted from the fast.ai machine learning course.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#overview","title":"Overview\u00b6","text":"Since we already have a dataset, we'll approach the problem with the following machine learning modelling framework.
6 Step Machine Learning Modelling Framework (read more) To work through these topics, we'll use pandas, Matplotlib and NumPy for data analysis, as well as, Scikit-Learn for machine learning and modelling tasks.
Tools that can be used for each step of the machine learning modelling process. We'll work through each step and by the end of the notebook, we'll have a trained machine learning model which predicts the sale price of a bulldozer given different characteristics about it.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#6-step-machine-learning-framework","title":"6 Step Machine Learning Framework\u00b6","text":""},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#1-problem-definition","title":"1. Problem Definition\u00b6","text":"For this dataset, the problem we're trying to solve, or better, the question we're trying to answer is,
How well can we predict the future sale price of a bulldozer, given its characteristics previous examples of how much similar bulldozers have been sold for?
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#2-data","title":"2. Data\u00b6","text":"Looking at the dataset from Kaggle we see that it contains historical sales data of bulldozers. Including things like, model type, size, sale date and more.
There are 3 datasets:
- Train.csv - Historical bulldozer sales examples up to 2011 (close to 400,000 examples with 50+ different attributes, including
SalePrice which is the target variable). - Valid.csv - Historical bulldozer sales examples from January 1 2012 to April 30 2012 (close to 12,000 examples with the same attributes as Train.csv).
- Test.csv - Historical bulldozer sales examples from May 1 2012 to November 2012 (close to 12,000 examples but missing the
SalePrice attribute, as this is what we'll be trying to predict).
Note: You can download the dataset bluebook-for-bulldozers dataset directly from Kaggle. Alternatively, you can also download it directly from the course GitHub.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#3-evaluation","title":"3. Evaluation\u00b6","text":"For this problem, Kaggle has set the evaluation metric to being root mean squared log error (RMSLE). As with many regression evaluations, the goal will be to get this value as low as possible (a low error value means our model's predictions are close to what the real values are).
To see how well our model is doing, we'll calculate the RMSLE and then compare our results to others on the Kaggle leaderboard.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#4-features","title":"4. Features\u00b6","text":"Features are different parts and attributes of the data.
During this step, you'll want to start finding out what you can about the data.
One of the most common ways to do this is to create a data dictionary.
For this dataset, Kaggle provides a data dictionary which contains information about what each attribute of the dataset means.
For example:
Variable Name Description Variable Type SalesID unique identifier of a particular sale of a machine at auction Independent variable MachineID identifier for a particular machine; machines may have multiple sales Independent variable ModelID identifier for a unique machine model (i.e. fiModelDesc) Independent variable datasource source of the sale record; some sources are more diligent about reporting attributes of the machine than others. Note that a particular datasource may report on multiple auctioneerIDs. Independent variable auctioneerID identifier of a particular auctioneer, i.e. company that sold the machine at auction. Not the same as datasource. Independent variable YearMade year of manufacturer of the Machine Independent variable MachineHoursCurrentMeter current usage of the machine in hours at time of sale (saledate); null or 0 means no hours have been reported for that sale Independent variable UsageBand value (low, medium, high) calculated comparing this particular Machine-Sale hours to average usage for the fiBaseModel; e.g. 'Low' means this machine has fewer hours given its lifespan relative to the average of fiBaseModel. Independent variable Saledate time of sale Independent variable fiModelDesc Description of a unique machine model (see ModelID); concatenation of fiBaseModel & fiSecondaryDesc & fiModelSeries & fiModelDescriptor Independent variable State US State in which sale occurred Independent variable Drive_System machine configuration; typically describes whether 2 or 4 wheel drive Independent variable Enclosure machine configuration - does the machine have an enclosed cab or not Independent variable Forks machine configuration - attachment used for lifting Independent variable Pad_Type machine configuration - type of treads a crawler machine uses Independent variable Ride_Control machine configuration - optional feature on loaders to make the ride smoother Independent variable Transmission machine configuration - describes type of transmission; typically automatic or manual Independent variable ... ... ... SalePrice cost of sale in USD Target/dependent variable You can download the full version of this file directly from the Kaggle competition page (Kaggle account required) or view it on Google Sheets.
With all of this being known, let's get started!
First, we'll import the dataset and start exploring.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#1-importing-the-data-and-preparing-it-for-modelling","title":"1. Importing the data and preparing it for modelling\u00b6","text":"First thing is first, let's get the libraries we need imported and the data we'll need for the project.
We'll start by importing pandas, NumPy and matplotlib.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#11-parsing-dates","title":"1.1 Parsing dates\u00b6","text":"When working with time series data, it's a good idea to make sure any date data is the format of a datetime object (a Python data type which encodes specific information about dates).
We can tell pandas which columns to read in as dates by setting the parse_dates parameter in pd.read_csv.
Once we've imported our CSV with the saledate column parsed, we can view information about our DataFrame again with df.info().
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#12-sorting-our-dataframe-by-saledate","title":"1.2 Sorting our DataFrame by saledate\u00b6","text":"Now we've formatted our saledate column to be NumPy datetime64[ns] objects, we can use built-in pandas methods such as sort_values to sort our DataFrame by date.
And considering this is a time series problem, sorting our DataFrame by date has the added benefit of making sure our data is sequential.
In other words, we want to use examples from the past (example sale prices from previous dates) to try and predict future bulldozer sale prices.
Let's use the pandas.DataFrame.sort_values method to sort our DataFrame by saledate in ascending order.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#13-adding-extra-features-to-our-dataframe","title":"1.3 Adding extra features to our DataFrame\u00b6","text":"One way to potentially increase the predictive power of our data is to enhance it with more features.
This practice is known as feature engineering, taking existing features and using them to create more/different features.
There is no set in stone way to do feature engineering and often it takes quite a bit of practice/exploration/experimentation to figure out what might work and what won't.
For now, we'll use our saledate column to add extra features such as:
- Year of sale
- Month of sale
- Day of sale
- Day of week sale (e.g. Monday = 1, Tuesday = 2)
- Day of year sale (e.g. January 1st = 1, January 2nd = 2)
Since we're going to be manipulating the data, we'll make a copy of the original DataFrame and perform our changes there.
This will keep the original DataFrame in tact if we need it again.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#14-inspect-values-of-other-columns","title":"1.4 Inspect values of other columns\u00b6","text":"When first exploring a new problem, it's often a good idea to become as familiar with the data as you can.
Of course, with a dataset that has over 400,000 samples, it's unlikely you'll ever get through every sample.
But that's where the power of data analysis and machine learning can help.
We can use pandas to aggregate thousands of samples into smaller more managable pieces.
And as we'll see later on, we can use machine learning models to model the data and then later inspect which features the model thought were most important.
How about we see which states sell the most bulldozers?
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#2-model-driven-data-exploration","title":"2. Model driven data exploration\u00b6","text":"We've performed a small Exploratory Data Analysis (EDA) as well as enriched it with some datetime attributes, now let's try to model it.
Why model so early?
Well, we know the evaluation metric (root mean squared log error or RMSLE) we're heading towards.
We could spend more time doing EDA, finding more out about the data ourselves but what we'll do instead is use a machine learning model to help us do EDA whilst simultaneously working towards the best evaluation metric we can get.
Remember, one of the biggest goals of starting any new machine learning project is reducing the time between experiments.
Following the Scikit-Learn machine learning map and taking into account the fact we've got over 100,000 examples, we find a sklearn.linear_model.SGDRegressor or a sklearn.ensemble.RandomForestRegressor model might be a good candidate.
Since we're worked with the Random Forest algorithm before (on the heart disease classification problem), let's try it out on our regression problem.
Note: We're trying just one model here for now. But you can try many other kinds of models from the Scikit-Learn library, they mostly work with a similar API. There are even libraries such as LazyPredict which will try many models simultaneously and return a table with the results.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#21-inspecting-the-datatypes-in-our-dataframe","title":"2.1 Inspecting the datatypes in our DataFrame\u00b6","text":"One way to help turn all of our data into numbers is to convert the columns with the object datatype into a category datatype using pandas.CategoricalDtype.
Note: There are many different ways to convert values into numbers. And often the best way will be specific to the value you're trying to convert. The method we're going to use, converting all objects (that are mostly strings) to categories is one of the faster methods as it makes a quick assumption that each unique value is its own number.
We can check the datatype of an individual column using the .dtype attribute and we can get its full name using .dtype.name.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#22-converting-strings-to-categories-with-pandas","title":"2.2 Converting strings to categories with pandas\u00b6","text":"In pandas, one way to convert object/string values to numerical values is to convert them to categories or more specifically, the pd.CategoricalDtype datatype.
This datatype keeps the underlying data the same (e.g. doesn't change the string) but enables easy conversion to a numeric code using .cat.codes.
For example, the column state might have the values 'Alabama', 'Alaska', 'Arizona'... and these could be mapped to numeric values 1, 2, 3... respectively.
To see this in action, let's first convert the object datatype columns to \"category\" datatype.
We can do so by looping through the .items() of our DataFrame and reassigning each object datatype column using pandas.Series.astype(dtype=\"category\").
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#23-saving-our-preprocessed-data-part-1","title":"2.3 Saving our preprocessed data (part 1)\u00b6","text":"Before we start doing any further preprocessing steps on our DataFrame, how about we save our current DataFrame to file so we could import it again later if necessary.
Saving and updating your dataset as you go is common practice in machine learning problems. As your problem changes and evolves, the dataset you're working with will likely change too.
Making checkpoints of your dataset is similar to making checkpoints of your code.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#24-finding-and-filling-missing-values","title":"2.4 Finding and filling missing values\u00b6","text":"Let's remind ourselves of the missing values by getting the top 20 columns with the most missing values.
We do so by summing the results of pandas.DataFrame.isna() and then using sort_values(ascending=False) to showcase the rows with the most missing.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#25-filling-missing-numerical-values","title":"2.5 Filling missing numerical values\u00b6","text":"There's no set way to fill missing values in your dataset.
And unless you're filling the missing samples with newly discovered actual data, every way you fill your dataset's missing values will introduce some sort of noise or bias.
We'll start by filling the missing numerical values in ourdataet.
To do this, we'll first find the numeric datatype columns.
We can do by looping through the columns in our DataFrame and calling pd.api.types.is_numeric_dtype(arr_or_dtype) on them.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#26-discussing-possible-ways-to-handle-missing-values","title":"2.6 Discussing possible ways to handle missing values\u00b6","text":"As previously discussed, there are many ways to fill missing values.
For missing numeric values, some potential options are:
Method Pros Cons Fill with mean of column - Easy to calculate/implement - Retains overall data distribution - Averages out variation - Affected by outliers (e.g. if one value is much higher/lower than others) Fill with median of column - Easy to calculate/implement - Robust to outliers - Preserves center of data - Ignores data distribution shape Fill with mode of column - Easy to calculate/implement - More useful for categorical-like data - May not make sense for continuous/numerical data Fill with 0 (or another constant) - Simple to implement - Useful in certain contexts like counts - Introduces bias (e.g. if 0 was a value that meant something) - Skews data (e.g. if many missing values, replacing all with 0 makes it look like that's the most common value) Forward/Backward fill (use previous/future values to fill future/previous values) - Maintains temporal continuity (for time series) - Assumes data is continuous, which may not be valid Use a calculation from other columns - Takes existing information and reinterprets it - Can result in unlikely outputs if calculations are not continuous Interpolate (e.g. like dragging a cell in Excel/Google Sheets) - Captures trends - Suitable for ordered data - Can introduce errors - May assume linearity (data continues in a straight line) Drop missing values - Ensures complete data (only use samples with all information) - Useful for small datasets - Can result in data loss (e.g. if many missing values are scattered across columns, data size can be dramatically reduced) - Reduces dataset size Which method you choose will be dataset and problem dependant and will likely require several phases of experimentation to see what works and what doesn't.
For now, we'll fill our missing numeric values with the median value of the target column.
We'll also add a binary column (0 or 1) with rows reflecting whether or not a value was missing.
For example, MachineHoursCurrentMeter_is_missing will be a column with rows which have a value of 0 if that row's MachineHoursCurrentMeter column was not missing and 1 if it was.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#27-filling-missing-categorical-values-with-pandas","title":"2.7 Filling missing categorical values with pandas\u00b6","text":"Now we've filled the numeric values, we'll do the same with the categorical values whilst ensuring that they are all numerical too.
Let's first investigate the columns which aren't numeric (we've already worked with these).
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#28-saving-our-preprocessed-data-part-2","title":"2.8 Saving our preprocessed data (part 2)\u00b6","text":"One more step before we train new model!
Let's save our work so far so we could re-import our preprocessed dataset if we wanted to.
We'll save it to the parquet format again, this time with a suffix to show we've filled the missing values.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#29-fitting-a-machine-learning-model-to-our-preprocessed-data","title":"2.9 Fitting a machine learning model to our preprocessed data\u00b6","text":"Now all of our data is numeric and there are no missing values, we should be able to fit a machine learning model to it!
Let's reinstantiate our trusty sklearn.ensemble.RandomForestRegressor model.
Since our dataset has a substantial amount of rows (~400k+), let's first make sure the model will work on a smaller sample of 1000 or so.
Note: It's common practice on machine learning problems to see if your experiments will work on smaller scale problems (e.g. smaller amounts of data) before scaling them up to the full dataset. This practice enables you to try many different kinds of experiments with faster runtimes. The benefit of this is that you can figure out what doesn't work before spending more time on what does.
Our X values (features) will be every column except the SalePrice column.
And our y values (labels) will be the entirety of the SalePrice column.
We'll time how long our smaller experiment takes using the magic function %%time and placing it at the top of the notebook cell.
Note: You can find out more about the %%time magic command by typing %%time? (note the question mark on the end) in a notebook cell.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#210-a-big-but-fixable-mistake","title":"2.10 A big (but fixable) mistake\u00b6","text":"One of the hard things about bugs in machine learning projects is that they are often silent.
For example, our model seems to have fit the data with no issues and then evaluated with a good score.
So what's wrong?
It seems we've stumbled across one of the most common bugs in machine learning and that's data leakage (data from the training set leaking into the validation/testing sets).
We've evaluated our model on the same data it was trained on.
This isn't the model's fault either.
It's our fault.
Right back at the start we imported a file called TrainAndValid.csv, this file contains both the training and validation data.
And while we preprocessed it to make sure there were no missing values and the samples were all numeric, we never split the data into separate training and validation splits.
The right workflow would've been to train the model on the training split and then evaluate it on the unseen and separate validation split.
Our evaluation scores above are quite good but they can't necessarily be trusted to be replicated on unseen data (data in the real world) because they've been obtained by evaluating the model on data its already seen during training.
This would be the equivalent of a final exam at university containing all of the same questions as the practice exam without any changes, you may get a good grade, but does that good grade translate to the real world?
Not to worry, we can fix this!
How?
We can import the training and validation datasets separately via Train.csv and Valid.csv respectively.
Or we could import TrainAndValid.csv and perform the appropriate splits according the original Kaggle competition page (training data includes all samples prior to 2012 and validation data includes samples from January 1 2012 to April 30 2012).
In both methods, we'll have to perform similar preprocessing steps we've done so far.
Except because the validation data is supposed to remain as unseen data, we'll only use information from the training set to preprocess the validation set (and not mix the two).
We'll work on this in the subsequent sections.
The takeaway?
Always (if possible) create appropriate data splits at the start of a project.
Because it's one thing to train a machine learning model but if you can't evaluate it properly (on unseen data), how can you know how it'll perform (or may perform) in the real world on new and unseen data?
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#3-splitting-data-into-the-right-trainvalidation-sets","title":"3. Splitting data into the right train/validation sets\u00b6","text":"The bad news is, we evaluated our model on the same data we trained it on.
The good news is, we get to practice importing and preprocessing our data again.
This time we'll make sure we've got separate training and validation splits.
Previously, we used pandas to ensure our data was all numeric and had no missing values.
And we can still use pandas for things such as creating/altering date-related columns.
But using pandas for all of our data preprocessing can be an issue with larger scale datasets or when new data is introduced.
How about this time we add Scikit-Learn to the mix and make a reproducible pipeline for our data preprocessing needs?
Note: Scikit-Learn has a fantastic guide on data transformations and in particular data preprocessing. I'd highly recommend spending an hour or so reading through this documentation, even if it doesn't make a lot of sense to begin with. Rest assured, with practice and experimentation you'll start to get the hang of it.
According to the Kaggle data page, the train, validation and test sets are split according to dates.
This makes sense since we're working on a time series problem (using past sale prices to try and predict future sale prices).
Knowing this, randomly splitting our data into train, validation and test sets using something like sklearn.model_selection.train_test_split() wouldn't work as this would mix samples from different dates in an unintended way.
Instead, we split our data into training, validation and test sets using the date each sample occured.
In our case:
- Training data (
Train.csv) = all samples up until 2011. - Validation data (
Valid.csv) = all samples form January 1, 2012 - April 30, 2012. - Testing data (
Test.csv) = all samples from May 1, 2012 - November 2012.
Previously we imported TrainAndValid.csv which is a combination of Train.csv and Valid.csv in one file.
We could split this based on the saledate column.
However, we could also import the Train.csv and Valid.csv files separately (we'll import Test.csv later on when we've trained a model).
We'll also import ValidSolution.csv which contains the SalePrice of Valid.csv and make sure we match the columns based on the SalesID key.
Note: For more on making good training, validation and test sets, check out the post How (and why) to create a good validation set by Rachel Thomas as well as The importance of a test set by Daniel Bourke.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#31-trying-to-fit-a-model-on-our-training-data","title":"3.1 Trying to fit a model on our training data\u00b6","text":"I'm a big fan of trying to fit a model on your dataset as early as possible.
If it works, you'll have to inspect and check its results.
And if it doesn't work, you'll get some insights into what you may have to do to your dataset to prepare it.
Let's turn our DataFrames into features (X) by dropping the SalePrice column (this is the value we're trying to predict) and labels (y) by extracting the SalePrice column.
Then we'll create a model using sklearn.ensemble.RandomForestRegressor and finally we'll try to fit it to only the training data.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#32-encoding-categorical-features-as-numbers-using-scikit-learn","title":"3.2 Encoding categorical features as numbers using Scikit-Learn\u00b6","text":"We've preprocessed our data previously with pandas.
And while this is a viable approach, how about we practice using another method?
This time we'll use Scikit-Learn's built-in preprocessing methods.
Why?
Because it's good exposure to different techniques.
And Scikit-Learn has many built-in helpful and well tested methods for preparing data.
You can also string together many of these methods and create a reusable pipeline (you can think of this pipeline as plumbing for data).
To preprocess our data with Scikit-Learn, we'll first define the numerical and categorical features of our dataset.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#33-fitting-a-model-to-our-preprocessed-training-data","title":"3.3 Fitting a model to our preprocessed training data\u00b6","text":"We've used Scikit-Learn to convert the categorical data in our training and validation sets into numbers.
But we haven't yet done anything with missing numerical values.
As it turns out, we can still try and fit a model.
Why?
Because there are several estimators/models in Scikit-Learn that can handle missing (NaN) values.
And our trusty sklearn.ensemble.RandomForestRegressor is one of them!
Let's try it out on our X_train_preprocessed DataFrame.
Note: For a list of all Scikit-Learn estimators that can handle NaN values, check out the Scikit-Learn imputation of missing values user guide.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#4-building-an-evaluation-function","title":"4. Building an evaluation function\u00b6","text":"Evaluating a machine learning model is just as important as training one.
And so because of this, let's create an evaluation function to make evaluation faster and reproducible.
According to Kaggle for the Bluebook for Bulldozers competition, the evaluation function they use is root mean squared log error (RMSLE).
$$ \\text{RMSLE} = \\sqrt{\\frac{1}{n} \\sum_{i=1}^{n} \\left( \\log(1 + \\hat{y}_i) - \\log(1 + y_i) \\right)^2} $$
Where:
- $ \\hat{y}_i $ is the predicted value,
- $ y_i $ is the actual value,
- $ n $ is the number of observations.
Contrast this with mean absolute error (MAE), another common regression metric.
$$ \\text{MAE} = \\frac{1}{n} \\sum_{i=1}^{n} \\left| \\hat{y}_i - y_i \\right| $$
With RMSLE, the relative error is more meaningful than the absolute error. You care more about ratios than absolute errors. For example, being off by $100 on a $1000 prediction (10% error) is more significant than being off by $100 on a $10,000 prediction (1% error). RMSLE is sensitive to large percentage errors.
Where as with MAE, is more about exact differences, a $100 prediction error is weighted the same regardless of the actual value.
In each of case, a lower value (closer to 0) is better.
For any problem, it's important to define the evaluation metric you're going to try and improve on.
In our case, let's create a function that calculates multiple evaluation metrics.
Namely, we'll use:
- MAE (mean absolute error) via
sklearn.metrics.mean_absolute_error - lower is better. - RMSLE (root mean squared log error) via
sklearn.metrics.root_mean_squared_log_error - lower is better. - $R^2$ (R-squared or coefficient of determination) via the
score method - higher is better.
For MAE and RMSLE we'll be comparing the model's predictions to the truth labels.
We can get an array of predicted values from our model using model.predict(X=features_to_predict_on).
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#5-tuning-our-models-hyperparameters","title":"5. Tuning our model's hyperparameters\u00b6","text":"Hyperparameters are the settings we can change on our model.
And tuning hyperparameters on a given model can often alter its performance on a given dataset.
Ideally, changing hyperparameters would lead to better results.
However, it's often hard to know what hyperparameter changes would improve a model ahead of time.
So what we can do is run several experiments across various different hyperparameter settings and record which lead to the best results.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#51-making-our-modelling-experiments-faster-to-speed-up-hyperparameter-tuning","title":"5.1 Making our modelling experiments faster (to speed up hyperparameter tuning)\u00b6","text":"Because of the size of our dataset (~400,000 rows), retraining an entire model (about 1-1.5 minutes on my MacBook Pro M1 Pro) for each new set of hyperparameters would take far too long to continuing experimenting as fast as we want to.
So what we'll do is take a sample of the training set and tune the hyperparameters on that before training a larger model.
Note: If you're experiments are taking longer than 10-seconds (or far longer than what you can interact with), you should be trying to speed things up. You can speed experiments up by sampling less data, using a faster computer or using a smaller model.
We can take a artificial sample of the training set by altering the number of samples seen by each n_estimator (an n_estimator is a decision tree a random forest will create during training, more trees generally leads to better performance but sacrifices compute time) in sklearn.ensemble.RandomForestRegressor using the max_samples parameter.
For example, setting max_samples to 10,000 means every n_estimator (default 100) in our RandomForestRegressor will only see 10,000 random samples from our DataFrame instead of the entire ~400,000.
In other words, we'll be looking at 40x less samples which means we should get faster computation speeds but we should also expect our results to worsen (because the model has less samples to learn patterns from).
Let's see if reducing the number samples speeds up our modelling time.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#52-hyperparameter-tuning-with-randomizedsearchcv","title":"5.2 Hyperparameter tuning with RandomizedSearchCV\u00b6","text":"The goal of hyperparameter tuning is to values for our model's settings which lead to better results.
We could sit there and do this by hand, adjusting parameters on sklearn.ensemble.RandomForestRegressor such as n_estimators, max_depth, min_samples_split and more.
However, this would quite tedious.
Instead, we can define a dictionary of hyperparametmer settings in the form {\"hyperparamter_name\": [values_to_test]} and then use sklearn.model_selection.RandomizedSearchCV (randomly search for best combination of hyperparameters) or sklearn.model_selection.GridSearchCV (exhaustively search for best combination of hyperparameters) to go through all of these settings for us on a given model and dataset and then record which perform best.
A general workflow is to start with a large number and wide range of potential settings and use RandomizedSearchCV to search across these randomly for a limited number of iterations (e.g. n_iter=10).
And then take the best results and narrow the search space down before exhaustively search for the best hyperparameters with GridSearchCV.
Let's start trying to find better hyperparameters by:
- Define a dictionary of hyperparameter values for our
RandomForestRegressor model. We'll keep max_samples=10000 so our experiments run faster. - Setup an instance of
RandomizedSearchCV to explore the parameter values defined in step 1. We can adjust how many sets of hyperparameters our model tries using the n_iter parameter as well as how many times our model performs cross-validation using the cv parameter. For example, setting n_iter=20 and cv=3 means there will be 3 cross-validation folds for each of the 20 different combinations of hyperparameters, a total of 60 (3*20) experiments. - Fit the instance of
RandomizedSearchCV to the data. This will automatically go through the defined number of iterations and record the results for each. The best model gets loaded at the end.
Note: You can read more about the tuning of hyperparameters of an esimator/model in the Scikit-Learn user guide.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#53-training-a-model-with-the-best-hyperparameters","title":"5.3 Training a model with the best hyperparameters\u00b6","text":"Like all good machine learning cooking shows, I prepared a model earlier.
I tried 100 different combinations of hyperparameters (setting n_iter=100 in RandomizedSearchCV) and found the best results came from the settings below.
n_estimators=90max_depth=Nonemin_samples_leaf=1min_samples_split=5max_features=0.5n_jobs=-1max_samples=None
Note: This search (n_iter=100) took ~2-hours on my MacBook Pro M1 Pro. So it's kind of a set and come back later experiment. That's one of the things you'll have to get used to as a machine learning engineer, figuring out what to do whilst your model trains. I like to go for long walks or to the gym (rule of thumb: while my model trains, I train).
We'll instantiate a new model with these discovered hyperparameters and reset the max_samples back to its original value.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#54-comparing-our-models-scores","title":"5.4 Comparing our model's scores\u00b6","text":"We've built four models so far with varying amounts of data and hyperparameters.
Let's compile the results into a DataFrame and then make a plot to compare them.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#6-saving-our-best-model-to-file","title":"6. Saving our best model to file\u00b6","text":"Since we've confirmed our best model as our ideal_model object, we can save it to file so we can load it in later and use it without having to retrain it.
Note: For more on model saving options with Scikit-Learn, see the documentation on model persistence.
To save our model we can use the joblib.dump method.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#7-making-predictions-on-test-data","title":"7. Making predictions on test data\u00b6","text":"Now we've got a trained model saved and loaded, it's time to make predictions on the test data.
Our model is trained on data prior to 2011, however, the test data is from May 1 2012 to November 2012.
So what we're doing is trying to use the patterns our model has learned from the training data to predict the sale price of a bulldozer with characteristics it's never seen before but are assumed to be similar to that of those in the training data.
Let's load in the test data from Test.csv, we'll make sure to parse the dates of the saledate column.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#71-preprocessing-the-test-data-to-be-in-the-same-format-as-the-training-data","title":"7.1 Preprocessing the test data (to be in the same format as the training data)\u00b6","text":"Our model has been trained on data preprocessed in a certain way.
This means in order to make predictions on the test data, we need to take the same steps we used to preprocess the training data to preprocess the test data.
Remember, whatever you do to preprocess the training data, you have to do to the test data.
Let's recreate the steps we used for preprocessing the training data except this time we'll do it on the test data.
First, we'll add the extra date features to breakdown the saledate column.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#8-making-a-prediction-on-a-custom-sample","title":"8. Making a prediction on a custom sample\u00b6","text":"We've made predictions on the test dataset which contains sale data from May to November 2012.
But how does our model go on a more recent bulldozer sale?
If we were to find an advertisement on a bulldozer sale, could we use our model on the information in the advertisement to predict the sale price?
In other words, how could we use our model on a single custom sample?
It's one thing to predict on data that has already been formatted but it's another thing to be able to predict a on a completely new and unseen sample.
Note: For predicting on a custom sample, the same rules apply as making predictions on the test dataset. The data you make predictions on should be in the same format that your model was trained on. For example, it should have all the same features and the numerical encodings should be in the same ballpark (e.g. preprocessed by the ordinal_encoder we fit to the training set). It's likely that samples you collect from the wild may not be as well formatted as samples in a pre-existing dataset. So it's the job of the machine learning engineer to be able to format/preprocess new samples in the same way a model was trained on.
If we're going to make a prediction on a custom sample, it'll need to be in the same format as our other datasets.
So let's remind ourselves of the columns/features in our test dataset.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#9-finding-the-most-important-predictive-features","title":"9. Finding the most important predictive features\u00b6","text":"Since we've built a model which is able to make predictions, the people you share these predictions with (or yourself) might be curious of what parts of the data led to these predictions.
This is where feature importance comes in.
Feature importance seeks to figure out which different attributes of the data were most important when it comes to predicting the target variable.
In our case, after our model learned the patterns in the data, which bulldozer sale attributes were most important for predicting its overall sale price?
We can do this for our sklearn.ensemble.RandomForestRegressor instance using the feature_importances_ attribute.
Let's check it out.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#summary","title":"Summary\u00b6","text":"We've covered a lot of ground.
But there are some main takeaways to go over.
- Every machine learning problem is different - Since machine learning is such a widespread technology, it can be used for a multitude of different problems. In saying this, there will often be many different ways to approach a problem. In this example, we've focused on predicting a number, which is a regression problem. And since our data had a time component, it could also be considered a time series problem.
- The machine learner's motto: Experiment, experiment, experiment! - Since there are many different ways to approach machine learning problems, one of the best habits you can develop is an experimental mindset. That means not being afraid to try new things over and over. Because the more things you try, the quicker you can figure what doesn't work and the quicker you can start to move towards what does.
- Always keep the test set separate - If you can't evaluate your model on unseen data, how would you know how it will perform in the real world on future unseen data? Of course, using a test set isn't a perfect replica of the real world but if it's done right, it can give you a good idea. Because evaluating a model is just as important as training a model.
- If you've trained a model on a data in a certain format, you'll have to make predictions in the same format - Any preprocessing you do to the training dataset, you'll have to do to the validation, test and custom data. Any computed values should happen on the training set only and then be used to update any subsequent datasets.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#exercises","title":"Exercises\u00b6","text":" - Fill the missing values in the numeric columns with the median using Scikit-Learn and see if that helps our best model's performance (hint: see
sklearn.impute.SimpleImputer for more). - Try putting multiple steps together (e.g. preprocessing -> modelling) with Scikit-Learn's
sklearn.pipeline.Pipeline features. - Try using another regression model/estimator on our preprocessed dataset and see how it goes. See the Scikit-Learn machine learning map for potential model options.
- Try replacing the
sklearn.preprocessing.OrdinalEncoder we used for the categorical variables with sklearn.preprocessing.OneHotEncoder (you may even want to do this within a pipeline) with the sklearn.ensemble.RandomForestRegressor model and see how it performs. Which is better for our specific dataset?
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#extra-curriculum","title":"Extra-curriculum\u00b6","text":"The following resources are suggested extra reading and activities to add backing to the materials we've covered in this project.
Reading documentation and knowing where to find information is one of the best skills you can develop as an engineer.
- Read the pandas IO tools documentation page for an idea of all the possible ways to get data in and out of pandas.
- See all of the available datatypes in the pandas user guide (knowing what type your data is in can help prevent a lot of future errors).
- Read the Scikit-Learn dataset transformations and data preprocessing guide for an overview of all the different ways you can preprocess and transform data.
- For more on saving and loading model objects with Scikit-Learn, see the documentation on model persistence.
- For more on the importance of creating good validation and test sets, I'd recommend reading How (and why) to create a good validation set by Rachel Thomas as well as The importance of a test set by Daniel Bourke.
- We've covered a handful of models in the Scikit-Learn library, however, there are some other ML models which are worth exploring such as CatBoost and XGBoost. Both of these models can handle missing values and are often touted as some of the most performant ML models on the market. A good extension would be to try get one of them working on our bulldozer data.
- Bonus: You can also see a list of models in Scikit-Learn which can handle missing/NaN values.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#example-exercise-solutions","title":"Example Exercise Solutions\u00b6","text":"The following are examples of how to solve the above exercises.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#1-fill-the-missing-values-in-the-numeric-columns-with-the-median-using-scikit-learn-and-see-if-that-helps-our-best-models-performance","title":"1. Fill the missing values in the numeric columns with the median using Scikit-Learn and see if that helps our best model's performance\u00b6","text":""},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#2-try-putting-multiple-steps-together-eg-preprocessing-modelling-with-scikit-learns-sklearnpipelinepipeline","title":"2. Try putting multiple steps together (e.g. preprocessing -> modelling) with Scikit-Learn's sklearn.pipeline.Pipeline\u00b6","text":""},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#3-try-using-another-regression-modelestimator-on-our-preprocessed-dataset-and-see-how-it-goes","title":"3. Try using another regression model/estimator on our preprocessed dataset and see how it goes\u00b6","text":"Going to use sklearn.linear_model.HistGradientBoostingRegressor.
"},{"location":"end-to-end-bluebook-bulldozer-price-regression-v2/#4-try-replacing-the-sklearnpreprocessingordinalencoder-we-used-for-the-categorical-variables-with-sklearnpreprocessingonehotencoder","title":"4. Try replacing the sklearn.preprocessing.OrdinalEncoder we used for the categorical variables with sklearn.preprocessing.OneHotEncoder\u00b6","text":"Note: This may take quite a long time depending on your machine. For example, on my MacBook Pro M1 Pro it took ~10 minutes with n_estimators=10 (9x lower than what we used for our best_model). This is because using sklearn.preprocessing.OneHotEncoder adds many more features to our dataset (each feature gets turned into an array of 0's and 1's for each unique value). And the more features, the longer it takes to compute and find patterns between them.
"},{"location":"end-to-end-dog-vision-v2/","title":"Introduction to TensorFlow, Deep Learning and Transfer Learning","text":"View source code | Read notebook in online book format
In\u00a0[1]: Copied! # Quick timestamp\nimport datetime\nprint(f\"Last updated: {datetime.datetime.now()}\")\n # Quick timestamp import datetime print(f\"Last updated: {datetime.datetime.now()}\") Last updated: 2024-04-26 01:26:48.838163\n
In\u00a0[2]: Copied! import tensorflow as tf\ntf.__version__\n
import tensorflow as tf tf.__version__ Out[2]: '2.15.0'
Nice!
Note: If you want to run TensorFlow locally, you can follow the TensorFlow installation guide.
Now let's check to see if TensorFlow has access to a GPU (this isn't 100% required to complete this project but will speed things up dramatically).
We can do so with the method tf.config.list_physical_devices().
In\u00a0[3]: Copied! # Do we have access to a GPU?\ndevice_list = tf.config.list_physical_devices()\nif \"GPU\" in [device.device_type for device in device_list]:\n print(f\"[INFO] TensorFlow has GPU available to use. Woohoo!! Computing will be sped up!\")\n print(f\"[INFO] Accessible devices:\\n{device_list}\")\nelse:\n print(f\"[INFO] TensorFlow does not have GPU available to use. Models may take a while to train.\")\n print(f\"[INFO] Accessible devices:\\n{device_list}\")\n # Do we have access to a GPU? device_list = tf.config.list_physical_devices() if \"GPU\" in [device.device_type for device in device_list]: print(f\"[INFO] TensorFlow has GPU available to use. Woohoo!! Computing will be sped up!\") print(f\"[INFO] Accessible devices:\\n{device_list}\") else: print(f\"[INFO] TensorFlow does not have GPU available to use. Models may take a while to train.\") print(f\"[INFO] Accessible devices:\\n{device_list}\") [INFO] TensorFlow has GPU available to use. Woohoo!! Computing will be sped up!\n[INFO] Accessible devices:\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]\n
In\u00a0[4]: Copied! # Download the dataset into train and test split using TensorFlow Datasets\n# import tensorflow_datasets as tfds\n# ds_train, ds_test = tfds.load('stanford_dogs', split=['train', 'test'])\n # Download the dataset into train and test split using TensorFlow Datasets # import tensorflow_datasets as tfds # ds_train, ds_test = tfds.load('stanford_dogs', split=['train', 'test']) In\u00a0[5]: Copied! from pathlib import Path\nfrom google.colab import drive\n\n# 1. Mount Google Drive (this will bring up a pop-up to sign-in/authenticate)\n# Note: This step is specifically for Google Colab, if you're working locally, you may need a different setup\ndrive.mount(\"/content/drive\")\n\n# 2. Setup constants\n# Note: For constants like this, you'll often see them created as variables with all capitals\nTARGET_DRIVE_PATH = Path(\"drive/MyDrive/tensorflow/dog_vision_data\")\nTARGET_FILES = [\"images.tar\", \"annotation.tar\", \"lists.tar\"]\nTARGET_URL = \"http://vision.stanford.edu/aditya86/ImageNetDogs\"\n\n# 3. Setup local path\nlocal_dir = Path(\"dog_vision_data\")\n\n# 4. Check if the target files exist in Google Drive, if so, copy them to Google Colab\nif all((TARGET_DRIVE_PATH / file).is_file() for file in TARGET_FILES):\n print(f\"[INFO] Copying Dog Vision files from Google Drive to local directory...\")\n print(f\"[INFO] Source dir: {TARGET_DRIVE_PATH} -> Target dir: {local_dir}\")\n !cp -r {TARGET_DRIVE_PATH} .\n print(\"[INFO] Good to go!\")\n\nelse:\n # 5. If the files don't exist in Google Drive, download them\n print(f\"[INFO] Target files not found in Google Drive.\")\n print(f\"[INFO] Downloading the target files... this shouldn't take too long...\")\n for file in TARGET_FILES:\n # wget is short for \"world wide web get\", as in \"get a file from the web\"\n # -nc or --no-clobber = don't download files that already exist locally\n # -P = save the target file to a specified prefix, in our case, local_dir\n !wget -nc {TARGET_URL}/{file} -P {local_dir} # the \"!\" means to execute the command on the command line rather than in Python\n\n print(f\"[INFO] Saving the target files to Google Drive, so they can be loaded later...\")\n\n # 6. Ensure target directory in Google Drive exists\n TARGET_DRIVE_PATH.mkdir(parents=True, exist_ok=True)\n\n # 7. Copy downloaded files to Google Drive (so we can use them later and not have to re-download them)\n !cp -r {local_dir}/* {TARGET_DRIVE_PATH}/\n from pathlib import Path from google.colab import drive # 1. Mount Google Drive (this will bring up a pop-up to sign-in/authenticate) # Note: This step is specifically for Google Colab, if you're working locally, you may need a different setup drive.mount(\"/content/drive\") # 2. Setup constants # Note: For constants like this, you'll often see them created as variables with all capitals TARGET_DRIVE_PATH = Path(\"drive/MyDrive/tensorflow/dog_vision_data\") TARGET_FILES = [\"images.tar\", \"annotation.tar\", \"lists.tar\"] TARGET_URL = \"http://vision.stanford.edu/aditya86/ImageNetDogs\" # 3. Setup local path local_dir = Path(\"dog_vision_data\") # 4. Check if the target files exist in Google Drive, if so, copy them to Google Colab if all((TARGET_DRIVE_PATH / file).is_file() for file in TARGET_FILES): print(f\"[INFO] Copying Dog Vision files from Google Drive to local directory...\") print(f\"[INFO] Source dir: {TARGET_DRIVE_PATH} -> Target dir: {local_dir}\") !cp -r {TARGET_DRIVE_PATH} . print(\"[INFO] Good to go!\") else: # 5. If the files don't exist in Google Drive, download them print(f\"[INFO] Target files not found in Google Drive.\") print(f\"[INFO] Downloading the target files... this shouldn't take too long...\") for file in TARGET_FILES: # wget is short for \"world wide web get\", as in \"get a file from the web\" # -nc or --no-clobber = don't download files that already exist locally # -P = save the target file to a specified prefix, in our case, local_dir !wget -nc {TARGET_URL}/{file} -P {local_dir} # the \"!\" means to execute the command on the command line rather than in Python print(f\"[INFO] Saving the target files to Google Drive, so they can be loaded later...\") # 6. Ensure target directory in Google Drive exists TARGET_DRIVE_PATH.mkdir(parents=True, exist_ok=True) # 7. Copy downloaded files to Google Drive (so we can use them later and not have to re-download them) !cp -r {local_dir}/* {TARGET_DRIVE_PATH}/ Mounted at /content/drive\n[INFO] Copying Dog Vision files from Google Drive to local directory...\n[INFO] Source dir: drive/MyDrive/tensorflow/dog_vision_data -> Target dir: dog_vision_data\n[INFO] Good to go!\n
Data downloaded!
Nice work! This may seem like a bit of work but it's an important step with any deep learning project. Getting data to work with.
Now if we get the contents of local_dir (dog_vision_data), what do we get?
We can first make sure it exists with Path.exists() and then we can iterate through its contents with Path.iterdir() and print out the .name attribute of each file.
In\u00a0[6]: Copied! if local_dir.exists():\n print(str(local_dir) + \"/\")\n for item in local_dir.iterdir():\n print(\" \", item.name)\n
if local_dir.exists(): print(str(local_dir) + \"/\") for item in local_dir.iterdir(): print(\" \", item.name) dog_vision_data/\n lists.tar\n images.tar\n annotation.tar\n
Excellent! That's exactly the format we wanted.
Now you might've noticed that each file ends in .tar.
What's this?
Searching \"what is .tar?\", I found:
In computing, tar is a computer software utility for collecting many files into one archive file, often referred to as a tarball, for distribution or backup purposes.
Source: Wikipedia tar page).
Exploring a bit more, I found that the .tar format is similar to .zip, however, .zip offers compression, where as .tar mostly combines many files into one.
So how do we \"untar\" the files in images.tar, annotation.tar and lists.tar?
We can use the !tar command (or just tar from outside of a Jupyter Cell)!
Doing this will expand all of the files within each of the .tar archives.
We'll also use a couple of flags to help us out:
- The
-x flag tells tar to extract files from an archive. - The
-f flag specifies that the following argument is the name of the archive file. - You can combine flags by putting them together
-xf.
Let's try it out!
In\u00a0[7]: Copied! # Untar images, notes/tags:\n# -x = extract files from the zipped file\n# -v = verbose\n# -z = decompress files\n# -f = tell tar which file to deal with\n!tar -xf dog_vision_data/images.tar\n!tar -xf dog_vision_data/annotation.tar\n!tar -xf dog_vision_data/lists.tar\n
# Untar images, notes/tags: # -x = extract files from the zipped file # -v = verbose # -z = decompress files # -f = tell tar which file to deal with !tar -xf dog_vision_data/images.tar !tar -xf dog_vision_data/annotation.tar !tar -xf dog_vision_data/lists.tar What new files did we get?
We can check in Google Colab by inspecting the \"Files\" tab on the left.
Or with Python by using os.listdir(\".\") where \".\" means \"the current directory\".
In\u00a0[8]: Copied! import os\n\nos.listdir(\".\") # \".\" stands for \"here\" or \"current directory\"\n
import os os.listdir(\".\") # \".\" stands for \"here\" or \"current directory\" Out[8]: ['.config',\n 'dog_vision_data',\n 'file_list.mat',\n 'drive',\n 'train_list.mat',\n 'Images',\n 'Annotation',\n 'test_list.mat',\n 'sample_data']
Ooooh!
Looks like we've got some new files!
Specifically:
train_list.mat - a list of all the training set images.test_list.mat - a list of all the testing set images.Images/ - a folder containing all of the images of dogs.Annotation/ - a folder containing all of the annotations for each image.file_list.mat - a list of all the files (training and test list combined).
Our next step is to go through them and see what we've got.
In\u00a0[9]: Copied! import scipy\n\n# Open lists of train and test .mat\ntrain_list = scipy.io.loadmat(\"train_list.mat\")\ntest_list = scipy.io.loadmat(\"test_list.mat\")\nfile_list = scipy.io.loadmat(\"file_list.mat\")\n\n# Let's inspect the output and type of the train_list\ntrain_list, type(train_list)\n
import scipy # Open lists of train and test .mat train_list = scipy.io.loadmat(\"train_list.mat\") test_list = scipy.io.loadmat(\"test_list.mat\") file_list = scipy.io.loadmat(\"file_list.mat\") # Let's inspect the output and type of the train_list train_list, type(train_list) Out[9]: ({'__header__': b'MATLAB 5.0 MAT-file, Platform: GLNXA64, Created on: Sun Oct 9 08:36:13 2011',\n '__version__': '1.0',\n '__globals__': [],\n 'file_list': array([[array(['n02085620-Chihuahua/n02085620_5927.jpg'], dtype='<U38')],\n [array(['n02085620-Chihuahua/n02085620_4441.jpg'], dtype='<U38')],\n [array(['n02085620-Chihuahua/n02085620_1502.jpg'], dtype='<U38')],\n ...,\n [array(['n02116738-African_hunting_dog/n02116738_6754.jpg'], dtype='<U48')],\n [array(['n02116738-African_hunting_dog/n02116738_9333.jpg'], dtype='<U48')],\n [array(['n02116738-African_hunting_dog/n02116738_2503.jpg'], dtype='<U48')]],\n dtype=object),\n 'annotation_list': array([[array(['n02085620-Chihuahua/n02085620_5927'], dtype='<U34')],\n [array(['n02085620-Chihuahua/n02085620_4441'], dtype='<U34')],\n [array(['n02085620-Chihuahua/n02085620_1502'], dtype='<U34')],\n ...,\n [array(['n02116738-African_hunting_dog/n02116738_6754'], dtype='<U44')],\n [array(['n02116738-African_hunting_dog/n02116738_9333'], dtype='<U44')],\n [array(['n02116738-African_hunting_dog/n02116738_2503'], dtype='<U44')]],\n dtype=object),\n 'labels': array([[ 1],\n [ 1],\n [ 1],\n ...,\n [120],\n [120],\n [120]], dtype=uint8)},\n dict) Okay, looks like we get a dictionary with several fields we may be interested in.
Let's check out the keys of the dictionary.
In\u00a0[10]: Copied! train_list.keys()\n
train_list.keys() Out[10]: dict_keys(['__header__', '__version__', '__globals__', 'file_list', 'annotation_list', 'labels'])
My guess is that the file_list key is what we're after, as this looks like a large array of image names (the files all end in .jpg).
How about we see how many files are in each file_list key?
In\u00a0[11]: Copied! # Check the length of the file_list key\nprint(f\"Number of files in training list: {len(train_list['file_list'])}\")\nprint(f\"Number of files in testing list: {len(test_list['file_list'])}\")\nprint(f\"Number of files in full list: {len(file_list['file_list'])}\")\n # Check the length of the file_list key print(f\"Number of files in training list: {len(train_list['file_list'])}\") print(f\"Number of files in testing list: {len(test_list['file_list'])}\") print(f\"Number of files in full list: {len(file_list['file_list'])}\") Number of files in training list: 12000\nNumber of files in testing list: 8580\nNumber of files in full list: 20580\n
Beautiful! Looks like these lists contain our training and test splits and the full list has a list of all the files in the dataset.
Let's inspect the train_list['file_list'] further.
In\u00a0[12]: Copied! train_list['file_list']\n
train_list['file_list'] Out[12]: array([[array(['n02085620-Chihuahua/n02085620_5927.jpg'], dtype='<U38')],\n [array(['n02085620-Chihuahua/n02085620_4441.jpg'], dtype='<U38')],\n [array(['n02085620-Chihuahua/n02085620_1502.jpg'], dtype='<U38')],\n ...,\n [array(['n02116738-African_hunting_dog/n02116738_6754.jpg'], dtype='<U48')],\n [array(['n02116738-African_hunting_dog/n02116738_9333.jpg'], dtype='<U48')],\n [array(['n02116738-African_hunting_dog/n02116738_2503.jpg'], dtype='<U48')]],\n dtype=object)
Looks like we've got an array of arrays.
How about we turn them into a Python list for easier handling?
We can do so by extracting each individual item via indexing and list comprehension.
Let's see what it's like to get a single file name.
In\u00a0[13]: Copied! # Get a single filename\ntrain_list['file_list'][0][0][0]\n
# Get a single filename train_list['file_list'][0][0][0] Out[13]: 'n02085620-Chihuahua/n02085620_5927.jpg'
Now let's get a Python list of all the individual file names (e.g. n02097130-giant_schnauzer/n02097130_2866.jpg) so we can use them later.
In\u00a0[14]: Copied! # Get a Python list of all file names for each list\ntrain_file_list = list([item[0][0] for item in train_list[\"file_list\"]])\ntest_file_list = list([item[0][0] for item in test_list[\"file_list\"]])\nfull_file_list = list([item[0][0] for item in file_list[\"file_list\"]])\n\nlen(train_file_list), len(test_file_list), len(full_file_list)\n
# Get a Python list of all file names for each list train_file_list = list([item[0][0] for item in train_list[\"file_list\"]]) test_file_list = list([item[0][0] for item in test_list[\"file_list\"]]) full_file_list = list([item[0][0] for item in file_list[\"file_list\"]]) len(train_file_list), len(test_file_list), len(full_file_list) Out[14]: (12000, 8580, 20580)
Wonderful!
How about we view a random sample of the filenames we extracted?
Note: One of my favourite things to do whilst exploring data is to continually view random samples of it. Whether it be file names or images or text snippets. Why? You can always view the first X number of samples, however, I find that continually viewing random samples of the data gives you a better of overview of the different kinds of data you're working with. It also gives you the small chance of stumbling upon a potential error.
We can view random samples of the data using Python's random.sample() method.
In\u00a0[15]: Copied! import random\n\nrandom.sample(train_file_list, k=10)\n
import random random.sample(train_file_list, k=10) Out[15]: ['n02094258-Norwich_terrier/n02094258_439.jpg',\n 'n02113624-toy_poodle/n02113624_3624.jpg',\n 'n02102973-Irish_water_spaniel/n02102973_3635.jpg',\n 'n02102318-cocker_spaniel/n02102318_2048.jpg',\n 'n02098286-West_Highland_white_terrier/n02098286_1261.jpg',\n 'n02088238-basset/n02088238_10095.jpg',\n 'n02108915-French_bulldog/n02108915_9457.jpg',\n 'n02098286-West_Highland_white_terrier/n02098286_5979.jpg',\n 'n02109047-Great_Dane/n02109047_31274.jpg',\n 'n02095889-Sealyham_terrier/n02095889_760.jpg']
Now let's do a quick check to make sure none of the training image file names appear in the testing image file names list.
This is important because the number 1 rule in machine learning is: always keep the test set separate from the training set.
We can check that there are no overlaps by turning train_file_list into a Python set() and using the intersection() method.
In\u00a0[16]: Copied! # How many files in the training set intersect with the testing set?\nlen(set(train_file_list).intersection(test_file_list))\n
# How many files in the training set intersect with the testing set? len(set(train_file_list).intersection(test_file_list)) Out[16]: 0
Excellent! Looks like there are no overlaps.
We could even put an assert check to raise an error if there are any overlaps (e.g. the length of the intersection is greater than 0).
assert works in the fashion: assert expression, message_if_expression_fails.
If the assert check doesn't output anything, we're good to go!
In\u00a0[17]: Copied! # Make an assertion statement to check there are no overlaps (try changing test_file_list to train_file_list to see how it works)\nassert len(set(train_file_list).intersection(test_file_list)) == 0, \"There are overlaps between the training and test set files, please check them.\"\n
# Make an assertion statement to check there are no overlaps (try changing test_file_list to train_file_list to see how it works) assert len(set(train_file_list).intersection(test_file_list)) == 0, \"There are overlaps between the training and test set files, please check them.\" Woohoo!
Looks like there's no overlaps, let's keep exploring the data.
In\u00a0[18]: Copied! os.listdir(\"Annotation\")[:10]\n
os.listdir(\"Annotation\")[:10] Out[18]: ['n02111129-Leonberg',\n 'n02102973-Irish_water_spaniel',\n 'n02110806-basenji',\n 'n02105251-briard',\n 'n02093991-Irish_terrier',\n 'n02099267-flat-coated_retriever',\n 'n02110627-affenpinscher',\n 'n02112137-chow',\n 'n02094114-Norfolk_terrier',\n 'n02095570-Lakeland_terrier']
Looks like there are files each with a dog breed name with several numbered files inside.
Each of the files contains a HTML version of an annotation relating to an image.
For example, Annotation/n02085620-Chihuahua/n02085620_10074:
<annotation>\n\t<folder>02085620</folder>\n\t<filename>n02085620_10074</filename>\n\t<source>\n\t\t<database>ImageNet database</database>\n\t</source>\n\t<size>\n\t\t<width>333</width>\n\t\t<height>500</height>\n\t\t<depth>3</depth>\n\t</size>\n\t<segment>0</segment>\n\t<object>\n\t\t<name>Chihuahua</name>\n\t\t<pose>Unspecified</pose>\n\t\t<truncated>0</truncated>\n\t\t<difficult>0</difficult>\n\t\t<bndbox>\n\t\t\t<xmin>25</xmin>\n\t\t\t<ymin>10</ymin>\n\t\t\t<xmax>276</xmax>\n\t\t\t<ymax>498</ymax>\n\t\t</bndbox>\n\t</object>\n</annotation>\n
The fields include the name of the image, the size of the image, the label of the object and where it is (bounding box coordinates).
If we were performing object detection (finding the location of a thing in an image), we'd pay attention to the <bndbox> coordinates.
However, since we're focused on classification, our main consideration is the mapping of image name to class name.
Since we're dealing with 120 classes of dog breed, let's write a function to check the number of subfolders in the Annotation directory (there should be 120 subfolders, one for each breed of dog).
To do so, we can use Python's pathlib.Path class, along with Path.iterdir() to loop over the contents of Annotation and Path.is_dir() to check if the target item is a directory.
In\u00a0[19]: Copied! from pathlib import Path\n\ndef count_subfolders(directory_path: str) -> int:\n \"\"\"\n Count the number of subfolders in a given directory.\n\n Args:\n directory_path (str): The path to the directory in which to count subfolders.\n\n Returns:\n int: The number of subfolders in the specified directory.\n\n Examples:\n >>> count_subfolders('/path/to/directory')\n 3 # if there are 3 subfolders in the specified directory\n \"\"\"\n return len([name for name in Path(directory_path).iterdir() if name.is_dir()])\n\n\ndirectory_path = \"Annotation\"\nfolder_count = count_subfolders(directory_path)\nprint(f\"Number of subfolders in {directory_path} directory: {folder_count}\")\n from pathlib import Path def count_subfolders(directory_path: str) -> int: \"\"\" Count the number of subfolders in a given directory. Args: directory_path (str): The path to the directory in which to count subfolders. Returns: int: The number of subfolders in the specified directory. Examples: >>> count_subfolders('/path/to/directory') 3 # if there are 3 subfolders in the specified directory \"\"\" return len([name for name in Path(directory_path).iterdir() if name.is_dir()]) directory_path = \"Annotation\" folder_count = count_subfolders(directory_path) print(f\"Number of subfolders in {directory_path} directory: {folder_count}\") Number of subfolders in Annotation directory: 120\n
Perfect!
There are 120 subfolders of annotations, one for each class of dog we'd like to identify.
But on further inspection of our file lists, it looks like the class name is already in the filepath.
In\u00a0[20]: Copied! # View a single training file pathname\ntrain_file_list[0]\n
# View a single training file pathname train_file_list[0] Out[20]: 'n02085620-Chihuahua/n02085620_5927.jpg'
With this information we know, that image n02085620_5927.jpg should contain a Chihuahua.
Let's check.
I searched \"how to display an image in Google Colab\" and found another answer on Stack Overflow.
Turns out you can use IPython.display.Image(), as Google Colab comes with IPython (Interactive Python) built-in.
In\u00a0[21]: Copied! from IPython.display import Image\nImage(Path(\"Images\", train_file_list[0]))\n
from IPython.display import Image Image(Path(\"Images\", train_file_list[0])) Out[21]: Woah!
We get an image of a dog!
In\u00a0[22]: Copied! # Get a list of all image folders\nimage_folders = os.listdir(\"Images\")\nimage_folders[:10]\n
# Get a list of all image folders image_folders = os.listdir(\"Images\") image_folders[:10] Out[22]: ['n02111129-Leonberg',\n 'n02102973-Irish_water_spaniel',\n 'n02110806-basenji',\n 'n02105251-briard',\n 'n02093991-Irish_terrier',\n 'n02099267-flat-coated_retriever',\n 'n02110627-affenpinscher',\n 'n02112137-chow',\n 'n02094114-Norfolk_terrier',\n 'n02095570-Lakeland_terrier']
Excellent!
Now let's make a dictionary which maps from the folder name to a simplified version of the class name, for example:
{'n02085782-Japanese_spaniel': 'japanese_spaniel',\n'n02106662-German_shepherd': 'german_shepherd',\n'n02093256-Staffordshire_bullterrier': 'staffordshire_bullterrier',\n...}\n
In\u00a0[23]: Copied! # Create folder name -> class name dict\nfolder_to_class_name_dict = {}\nfor folder_name in image_folders:\n # Turn folder name into class_name\n # E.g. \"n02089078-black-and-tan_coonhound\" -> \"black_and_tan_coonhound\"\n # We'll split on the first \"-\" and join the rest of the string with \"_\" and then lower it\n class_name = \"_\".join(folder_name.split(\"-\")[1:]).lower()\n folder_to_class_name_dict[folder_name] = class_name\n\n# Make sure there are 120 entries in the dictionary\nassert len(folder_to_class_name_dict) == 120\n # Create folder name -> class name dict folder_to_class_name_dict = {} for folder_name in image_folders: # Turn folder name into class_name # E.g. \"n02089078-black-and-tan_coonhound\" -> \"black_and_tan_coonhound\" # We'll split on the first \"-\" and join the rest of the string with \"_\" and then lower it class_name = \"_\".join(folder_name.split(\"-\")[1:]).lower() folder_to_class_name_dict[folder_name] = class_name # Make sure there are 120 entries in the dictionary assert len(folder_to_class_name_dict) == 120 Folder name to class name mapping created, let's view the first 10.
In\u00a0[24]: Copied! list(folder_to_class_name_dict.items())[:10]\n
list(folder_to_class_name_dict.items())[:10] Out[24]: [('n02111129-Leonberg', 'leonberg'),\n ('n02102973-Irish_water_spaniel', 'irish_water_spaniel'),\n ('n02110806-basenji', 'basenji'),\n ('n02105251-briard', 'briard'),\n ('n02093991-Irish_terrier', 'irish_terrier'),\n ('n02099267-flat-coated_retriever', 'flat_coated_retriever'),\n ('n02110627-affenpinscher', 'affenpinscher'),\n ('n02112137-chow', 'chow'),\n ('n02094114-Norfolk_terrier', 'norfolk_terrier'),\n ('n02095570-Lakeland_terrier', 'lakeland_terrier')] And we can get a list of unique dog names by getting the values() of the folder_to_class_name_dict and turning it into a list.
In\u00a0[25]: Copied! dog_names = sorted(list(folder_to_class_name_dict.values()))\ndog_names[:10]\n
dog_names = sorted(list(folder_to_class_name_dict.values())) dog_names[:10] Out[25]: ['affenpinscher',\n 'afghan_hound',\n 'african_hunting_dog',\n 'airedale',\n 'american_staffordshire_terrier',\n 'appenzeller',\n 'australian_terrier',\n 'basenji',\n 'basset',\n 'beagle']
Perfect!
Now we've got:
folder_to_class_name_dict - a mapping from the folder name to the class name.dog_names - a list of all the unique dog breeds we're working with.
In\u00a0[26]: Copied! import random\n\nfrom pathlib import Path\nfrom typing import List\n\nimport matplotlib.pyplot as plt\n\n# 1. Take in a select list of image paths\ndef plot_10_random_images_from_path_list(path_list: List[Path],\n extract_title: bool=True) -> None:\n # 2. Set up a grid of plots\n fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(20, 10))\n\n # 3. Randomly sample 10 paths from the list\n samples = random.sample(path_list, 10)\n\n # 4. Iterate through the flattened axes and corresponding sample paths\n for i, ax in enumerate(axes.flat):\n\n # 5. Get the target sample path (e.g. \"Images/n02087394-Rhodesian_ridgeback/n02087394_1161.jpg\")\n sample_path = samples[i]\n\n # 6. Extract the parent directory name to use as the title (if necessary)\n # (e.g. n02087394-Rhodesian_ridgeback/n02087394_1161.jpg -> n02087394-Rhodesian_ridgeback -> rhodesian_ridgeback)\n if extract_title:\n sample_title = folder_to_class_name_dict[sample_path.parent.stem]\n else:\n sample_title = sample_path.parent.stem\n\n # 7. Read the image file and plot it on the corresponding axis\n ax.imshow(plt.imread(sample_path))\n\n # 8. Set the title of the axis and turn of the axis (for pretty plots)\n ax.set_title(sample_title)\n ax.axis(\"off\")\n\n # 9. Display the plot\n plt.show()\n\nplot_10_random_images_from_path_list(path_list=[Path(\"Images\") / Path(file) for file in train_file_list])\n
import random from pathlib import Path from typing import List import matplotlib.pyplot as plt # 1. Take in a select list of image paths def plot_10_random_images_from_path_list(path_list: List[Path], extract_title: bool=True) -> None: # 2. Set up a grid of plots fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(20, 10)) # 3. Randomly sample 10 paths from the list samples = random.sample(path_list, 10) # 4. Iterate through the flattened axes and corresponding sample paths for i, ax in enumerate(axes.flat): # 5. Get the target sample path (e.g. \"Images/n02087394-Rhodesian_ridgeback/n02087394_1161.jpg\") sample_path = samples[i] # 6. Extract the parent directory name to use as the title (if necessary) # (e.g. n02087394-Rhodesian_ridgeback/n02087394_1161.jpg -> n02087394-Rhodesian_ridgeback -> rhodesian_ridgeback) if extract_title: sample_title = folder_to_class_name_dict[sample_path.parent.stem] else: sample_title = sample_path.parent.stem # 7. Read the image file and plot it on the corresponding axis ax.imshow(plt.imread(sample_path)) # 8. Set the title of the axis and turn of the axis (for pretty plots) ax.set_title(sample_title) ax.axis(\"off\") # 9. Display the plot plt.show() plot_10_random_images_from_path_list(path_list=[Path(\"Images\") / Path(file) for file in train_file_list]) Those are some nice looking dogs!
What I like to do here is rerun the random visualizations until I've seen 100+ samples so I've got an idea of the data we're working with.
Question: Here's something to think about, how would you code a system of rules to differentiate between all the different breeds of dogs? Perhaps you write an algorithm to look at the shapes or the colours? For example, if the dog had black fur, it's unlikely to be a golden retriever. You might be thinking \"that would take quite a long time...\" And you'd be right. Then how would we do it? With machine learning of course!
In\u00a0[27]: Copied! # Create a dictionary of image counts\nfrom pathlib import Path\nfrom typing import List, Dict\n\n# 1. Take in a target directory\ndef count_images_in_subdirs(target_directory: str) -> List[Dict[str, int]]:\n \"\"\"\n Counts the number of JPEG images in each subdirectory of the given directory.\n\n Each subdirectory is assumed to represent a class, and the function counts\n the number of '.jpg' files within each one. The result is a list of\n dictionaries with the class name and corresponding image count.\n\n Args:\n target_directory (str): The path to the directory containing subdirectories.\n\n Returns:\n List[Dict[str, int]]: A list of dictionaries with 'class_name' and 'image_count' for each subdirectory.\n\n Examples:\n >>> count_images_in_subdirs('/path/to/directory')\n [{'class_name': 'beagle', 'image_count': 50}, {'class_name': 'poodle', 'image_count': 60}]\n \"\"\"\n # 2. Create a list of all the subdirectoires in the target directory (these contain our images)\n images_dir = Path(target_directory)\n image_class_dirs = [directory for directory in images_dir.iterdir() if directory.is_dir()]\n\n # 3. Create an empty list to append image counts to\n image_class_counts = []\n\n # 4. Iterate through all of the subdirectories\n for image_class_dir in image_class_dirs:\n\n # 5. Get the class name from image directory (e.g. \"Images/n02116738-African_hunting_dog\" -> \"n02116738-African_hunting_dog\")\n class_name = image_class_dir.stem\n\n # 6. Count the number of images in the target subdirectory\n image_count = len(list(image_class_dir.rglob(\"*.jpg\"))) # get length all files with .jpg file extension\n\n # 7. Append a dictionary of class name and image count to count list\n image_class_counts.append({\"class_name\": class_name,\n \"image_count\": image_count})\n\n # 8. Return the list\n return image_class_counts\n # Create a dictionary of image counts from pathlib import Path from typing import List, Dict # 1. Take in a target directory def count_images_in_subdirs(target_directory: str) -> List[Dict[str, int]]: \"\"\" Counts the number of JPEG images in each subdirectory of the given directory. Each subdirectory is assumed to represent a class, and the function counts the number of '.jpg' files within each one. The result is a list of dictionaries with the class name and corresponding image count. Args: target_directory (str): The path to the directory containing subdirectories. Returns: List[Dict[str, int]]: A list of dictionaries with 'class_name' and 'image_count' for each subdirectory. Examples: >>> count_images_in_subdirs('/path/to/directory') [{'class_name': 'beagle', 'image_count': 50}, {'class_name': 'poodle', 'image_count': 60}] \"\"\" # 2. Create a list of all the subdirectoires in the target directory (these contain our images) images_dir = Path(target_directory) image_class_dirs = [directory for directory in images_dir.iterdir() if directory.is_dir()] # 3. Create an empty list to append image counts to image_class_counts = [] # 4. Iterate through all of the subdirectories for image_class_dir in image_class_dirs: # 5. Get the class name from image directory (e.g. \"Images/n02116738-African_hunting_dog\" -> \"n02116738-African_hunting_dog\") class_name = image_class_dir.stem # 6. Count the number of images in the target subdirectory image_count = len(list(image_class_dir.rglob(\"*.jpg\"))) # get length all files with .jpg file extension # 7. Append a dictionary of class name and image count to count list image_class_counts.append({\"class_name\": class_name, \"image_count\": image_count}) # 8. Return the list return image_class_counts Ho ho, what a function!
Let's run it on our target directory Images and view the first few indexes.
In\u00a0[28]: Copied! image_class_counts = count_images_in_subdirs(\"Images\")\nimage_class_counts[:3]\n
image_class_counts = count_images_in_subdirs(\"Images\") image_class_counts[:3] Out[28]: [{'class_name': 'n02111129-Leonberg', 'image_count': 210},\n {'class_name': 'n02102973-Irish_water_spaniel', 'image_count': 150},\n {'class_name': 'n02110806-basenji', 'image_count': 209}] Nice!
Since our image_class_counts variable is the form of a list of dictionaries, we can turn it into a pandas DataFrame.
Let's sort the DataFrame by \"image_count\" so the classes with the most images appear at the top, we can do so with DataFrame.sort_values().
In\u00a0[29]: Copied! # Create a DataFrame\nimport pandas as pd\nimage_counts_df = pd.DataFrame(image_class_counts).sort_values(by=\"image_count\", ascending=False)\nimage_counts_df.head()\n
# Create a DataFrame import pandas as pd image_counts_df = pd.DataFrame(image_class_counts).sort_values(by=\"image_count\", ascending=False) image_counts_df.head() Out[29]: class_name image_count 116 n02085936-Maltese_dog 252 53 n02088094-Afghan_hound 239 111 n02092002-Scottish_deerhound 232 103 n02112018-Pomeranian 219 54 n02107683-Bernese_mountain_dog 218 And let's cleanup the \"class_name\" column to be more readable by mapping the the values to our folder_to_class_name_dict.
In\u00a0[30]: Copied! # Make class name column easier to read\nimage_counts_df[\"class_name\"] = image_counts_df[\"class_name\"].map(folder_to_class_name_dict)\nimage_counts_df.head()\n
# Make class name column easier to read image_counts_df[\"class_name\"] = image_counts_df[\"class_name\"].map(folder_to_class_name_dict) image_counts_df.head() Out[30]: class_name image_count 116 maltese_dog 252 53 afghan_hound 239 111 scottish_deerhound 232 103 pomeranian 219 54 bernese_mountain_dog 218 Now we've got a DataFrame of image counts per class, we can make them more visual by turning them into a plot.
We covered plotting data directly from pandas DataFrame's in Section 3 of the Introduction to Matplotlib notebook: Plotting data directly with pandas.
To do so, we can use image_counts_df.plot(kind=\"bar\", ...) along with some other customization.
In\u00a0[31]: Copied! # Turn the image counts DataFrame into a graph\nimport matplotlib.pyplot as plt\nplt.figure(figsize=(14, 7))\nimage_counts_df.plot(kind=\"bar\",\n x=\"class_name\",\n y=\"image_count\",\n legend=False,\n ax=plt.gca()) # plt.gca() = \"get current axis\", get the plt we setup above and put the data there\n\n# Add customization\nplt.ylabel(\"Image Count\")\nplt.title(\"Total Image Counts by Class\")\nplt.xticks(rotation=90, # Rotate the x labels for better visibility\n fontsize=8) # Make the font size smaller for easier reading\nplt.tight_layout() # Ensure things fit nicely\nplt.show()\n
# Turn the image counts DataFrame into a graph import matplotlib.pyplot as plt plt.figure(figsize=(14, 7)) image_counts_df.plot(kind=\"bar\", x=\"class_name\", y=\"image_count\", legend=False, ax=plt.gca()) # plt.gca() = \"get current axis\", get the plt we setup above and put the data there # Add customization plt.ylabel(\"Image Count\") plt.title(\"Total Image Counts by Class\") plt.xticks(rotation=90, # Rotate the x labels for better visibility fontsize=8) # Make the font size smaller for easier reading plt.tight_layout() # Ensure things fit nicely plt.show() Beautiful! It looks like our classes are quite balanced. Each breed of dog has ~150 or more images.
We can find out some other quick stats about our data with DataFrame.describe().
In\u00a0[32]: Copied! # Get various statistics about our data distribution\nimage_counts_df.describe()\n
# Get various statistics about our data distribution image_counts_df.describe() Out[32]: image_count count 120.000000 mean 171.500000 std 23.220898 min 148.000000 25% 152.750000 50% 159.500000 75% 186.250000 max 252.000000 And the table shows a similar story to the plot. We can see the minimum number of images per class is 148, where as the maximum number of images is 252.
If one class had 10x less images than another class, we may look into collecting more data to improve the balance.
The main takeaway(s):
- When working on a classification problem, ideally, all classes have a similar number of samples (however, in some problems this may be unattainable, such as fraud detection, where you may have 1000x more \"not fraud\" samples to \"fraud\" samples.
- If you wanted to add a new class of dog breed to the existing 120, ideally, you'd have at least ~150 images for it (though as we'll see with transfer learning, the number of required images could be less as long as they're high quality).
In\u00a0[33]: Copied! from pathlib import Path\n\n# Define the target directory for image splits to go\nimages_split_dir = Path(\"images_split\")\n\n# Define the training and test directories\ntrain_dir = images_split_dir / \"train\"\ntest_dir = images_split_dir / \"test\"\n\n# Using Path.mkdir with exist_ok=True ensures the directory is created only if it doesn't exist\ntrain_dir.mkdir(parents=True, exist_ok=True)\ntest_dir.mkdir(parents=True, exist_ok=True)\nprint(f\"Directory {train_dir} is exists.\")\nprint(f\"Directory {test_dir} is exists.\")\n\n# Make a folder for each dog name\nfor dog_name in dog_names:\n # Make training dir folder\n train_class_dir = train_dir / dog_name\n train_class_dir.mkdir(parents=True, exist_ok=True)\n # print(f\"Making directory: {train_class_dir}\")\n\n # Make testing dir folder\n test_class_dir = test_dir / dog_name\n test_class_dir.mkdir(parents=True, exist_ok=True)\n # print(f\"Making directory: {test_class_dir}\")\n\n# Make sure there is 120 subfolders in each\nassert count_subfolders(train_dir) == len(dog_names)\nassert count_subfolders(test_dir) == len(dog_names)\n from pathlib import Path # Define the target directory for image splits to go images_split_dir = Path(\"images_split\") # Define the training and test directories train_dir = images_split_dir / \"train\" test_dir = images_split_dir / \"test\" # Using Path.mkdir with exist_ok=True ensures the directory is created only if it doesn't exist train_dir.mkdir(parents=True, exist_ok=True) test_dir.mkdir(parents=True, exist_ok=True) print(f\"Directory {train_dir} is exists.\") print(f\"Directory {test_dir} is exists.\") # Make a folder for each dog name for dog_name in dog_names: # Make training dir folder train_class_dir = train_dir / dog_name train_class_dir.mkdir(parents=True, exist_ok=True) # print(f\"Making directory: {train_class_dir}\") # Make testing dir folder test_class_dir = test_dir / dog_name test_class_dir.mkdir(parents=True, exist_ok=True) # print(f\"Making directory: {test_class_dir}\") # Make sure there is 120 subfolders in each assert count_subfolders(train_dir) == len(dog_names) assert count_subfolders(test_dir) == len(dog_names) Directory images_split/train is exists.\nDirectory images_split/test is exists.\n
Excellent!
We can check out the data split directories/folders we created by inspecting them in the files panel in Google Colab.
Alternatively, we can check the names of each by list the subdirectories inside them.
In\u00a0[34]: Copied! # See the first 10 directories in the training split dir\nsorted([str(dir_name) for dir_name in train_dir.iterdir() if dir_name.is_dir()])[:10]\n
# See the first 10 directories in the training split dir sorted([str(dir_name) for dir_name in train_dir.iterdir() if dir_name.is_dir()])[:10] Out[34]: ['images_split/train/affenpinscher',\n 'images_split/train/afghan_hound',\n 'images_split/train/african_hunting_dog',\n 'images_split/train/airedale',\n 'images_split/train/american_staffordshire_terrier',\n 'images_split/train/appenzeller',\n 'images_split/train/australian_terrier',\n 'images_split/train/basenji',\n 'images_split/train/basset',\n 'images_split/train/beagle']
You might've noticed that all of our dog breed directories are empty.
Let's change that by getting some images in there.
To do so, we'll create a function called copy_files_to_target_dir() which will copy images from the Images directory into their respective directories inside images/train and images/test.
More specifically, it will:
- Take in a list of source files to copy (e.g.
train_file_list) and a target directory to copy files to. - Iterate through the list of sources files to copy (we'll use
tqdm which comes installed with Google Colab to create a progress bar of how many files have been copied). - Convert the source file path to a
Path object. - Split the source file path and create a
Path object for the destination folder (e.g. \"n02112018-Pomeranian\" -> \"pomeranian\"). - Get the target file name (e.g. \"n02112018-Pomeranian/n02112018_6208.jpg\" -> \"n02112018_6208.jpg\").
- Create a destination path for the source file to be copied to (e.g.
images_split/train/pomeranian/n02112018_6208.jpg). - Ensure the destination directory exists, similar to the step we took in the previous section (you can't copy files to a directory that doesn't exist).
- Print out the progress of copying (if necessary).
- Copy the source file to the destination using Python's
shutil.copy2(src, dst).
In\u00a0[35]: Copied! from pathlib import Path\nfrom shutil import copy2\nfrom tqdm.auto import tqdm\n\n# 1. Take in a list of source files to copy and a target directory\ndef copy_files_to_target_dir(file_list: list[str],\n target_dir: str,\n images_dir: str = \"Images\",\n verbose: bool = False) -> None:\n \"\"\"\n Copies a list of files from the images directory to a target directory.\n\n Parameters:\n file_list (list[str]): A list of file paths to copy.\n target_dir (str): The destination directory path where files will be copied.\n images_dir (str, optional): The directory path where the images are currently stored. Defaults to 'Images'.\n verbose (bool, optional): If set to True, the function will print out the file paths as they are being copied. Defaults to False.\n\n Returns:\n None\n \"\"\"\n # 2. Iterate through source files\n for file in tqdm(file_list):\n\n # 3. Convert file path to a Path object\n source_file_path = Path(images_dir) / Path(file)\n\n # 4. Split the file path and create a Path object for the destination folder\n # e.g. \"n02112018-Pomeranian\" -> \"pomeranian\"\n file_class_name = folder_to_class_name_dict[Path(file).parts[0]]\n\n # 5. Get the name of the target image\n file_image_name = Path(file).name\n\n # 6. Create the destination path\n destination_file_path = Path(target_dir) / file_class_name / file_image_name\n\n # 7. Ensure the destination directory exists (this is a safety check, can't copy an image to a file that doesn't exist)\n destination_file_path.parent.mkdir(parents=True, exist_ok=True)\n\n # 8. Print out copy message if necessary\n if verbose:\n print(f\"[INFO] Copying: {source_file_path} to {destination_file_path}\")\n\n # 9. Copy the original path to the destination path\n copy2(src=source_file_path, dst=destination_file_path)\n from pathlib import Path from shutil import copy2 from tqdm.auto import tqdm # 1. Take in a list of source files to copy and a target directory def copy_files_to_target_dir(file_list: list[str], target_dir: str, images_dir: str = \"Images\", verbose: bool = False) -> None: \"\"\" Copies a list of files from the images directory to a target directory. Parameters: file_list (list[str]): A list of file paths to copy. target_dir (str): The destination directory path where files will be copied. images_dir (str, optional): The directory path where the images are currently stored. Defaults to 'Images'. verbose (bool, optional): If set to True, the function will print out the file paths as they are being copied. Defaults to False. Returns: None \"\"\" # 2. Iterate through source files for file in tqdm(file_list): # 3. Convert file path to a Path object source_file_path = Path(images_dir) / Path(file) # 4. Split the file path and create a Path object for the destination folder # e.g. \"n02112018-Pomeranian\" -> \"pomeranian\" file_class_name = folder_to_class_name_dict[Path(file).parts[0]] # 5. Get the name of the target image file_image_name = Path(file).name # 6. Create the destination path destination_file_path = Path(target_dir) / file_class_name / file_image_name # 7. Ensure the destination directory exists (this is a safety check, can't copy an image to a file that doesn't exist) destination_file_path.parent.mkdir(parents=True, exist_ok=True) # 8. Print out copy message if necessary if verbose: print(f\"[INFO] Copying: {source_file_path} to {destination_file_path}\") # 9. Copy the original path to the destination path copy2(src=source_file_path, dst=destination_file_path) Copying function created!
Let's test it out by copying the files in the train_file_list to train_dir.
In\u00a0[36]: Copied! # Copy training images from Images to images_split/train/...\ncopy_files_to_target_dir(file_list=train_file_list,\n target_dir=train_dir,\n verbose=False) # set this to True to get an output of the copy process\n # (warning: this will output a large amount of text)\n
# Copy training images from Images to images_split/train/... copy_files_to_target_dir(file_list=train_file_list, target_dir=train_dir, verbose=False) # set this to True to get an output of the copy process # (warning: this will output a large amount of text) 0%| | 0/12000 [00:00<?, ?it/s]
Woohoo!
Looks like our copying function copied 12000 training images in their respective directories inside images_split/train/.
How about we do the same for test_file_list and test_dir?
In\u00a0[37]: Copied! copy_files_to_target_dir(file_list=test_file_list,\n target_dir=test_dir,\n verbose=False)\n
copy_files_to_target_dir(file_list=test_file_list, target_dir=test_dir, verbose=False) 0%| | 0/8580 [00:00<?, ?it/s]
Nice! 8580 testing images copied from Images to images_split/test/.
Let's write some code to check that the number of files in the train_file_list is the same as the number of images files in train_dir (and the same for the test files).
In\u00a0[38]: Copied! # Get list of of all .jpg paths in train and test image directories\ntrain_image_paths = list(train_dir.rglob(\"*.jpg\"))\ntest_image_paths = list(test_dir.rglob(\"*.jpg\"))\n\n# Make sure the number of images in the training and test directories equals the number of files in their original lists\nassert len(train_image_paths) == len(train_file_list)\nassert len(test_image_paths) == len(test_file_list)\n\nprint(f\"Number of images in {train_dir}: {len(train_image_paths)}\")\nprint(f\"Number of images in {test_dir}: {len(test_image_paths)}\")\n # Get list of of all .jpg paths in train and test image directories train_image_paths = list(train_dir.rglob(\"*.jpg\")) test_image_paths = list(test_dir.rglob(\"*.jpg\")) # Make sure the number of images in the training and test directories equals the number of files in their original lists assert len(train_image_paths) == len(train_file_list) assert len(test_image_paths) == len(test_file_list) print(f\"Number of images in {train_dir}: {len(train_image_paths)}\") print(f\"Number of images in {test_dir}: {len(test_image_paths)}\") Number of images in images_split/train: 12000\nNumber of images in images_split/test: 8580\n
And adhering to the data explorers motto of visualize, visualize, visualize!, let's plot some random images from the train_image_paths list.
In\u00a0[39]: Copied! # Plot 10 random images from the train_image_paths\nplot_10_random_images_from_path_list(path_list=train_image_paths,\n extract_title=False) # don't need to extract the title since the image directories are already named simply\n
# Plot 10 random images from the train_image_paths plot_10_random_images_from_path_list(path_list=train_image_paths, extract_title=False) # don't need to extract the title since the image directories are already named simply In\u00a0[40]: Copied! # Create train_10_percent directory\ntrain_10_percent_dir = images_split_dir / \"train_10_percent\"\ntrain_10_percent_dir.mkdir(parents=True, exist_ok=True)\n
# Create train_10_percent directory train_10_percent_dir = images_split_dir / \"train_10_percent\" train_10_percent_dir.mkdir(parents=True, exist_ok=True) Now we should have 3 split folders inside images_split.
In\u00a0[41]: Copied! os.listdir(images_split_dir)\n
os.listdir(images_split_dir) Out[41]: ['test', 'train_10_percent', 'train']
Beautiful!
Now let's create a list of random training sample filepaths using Python's random.sample(), we'll want the total length of the list to equal 10% of the original training split.
To make things reproducible, we'll use a random seed (this is not 100% necessary, it just makes it so we get the same 10% of training image paths each time).
In\u00a0[42]: Copied! import random\n\n# Set a random seed\nrandom.seed(42)\n\n# Get a 10% sample of the training image paths\ntrain_image_paths_random_10_percent = random.sample(population=train_image_paths,\n k=int(0.1*len(train_image_paths)))\n\n# Check how many image paths we got\nprint(f\"Original number of training image paths: {len(train_image_paths)}\")\nprint(f\"Number of 10% training image paths: {len(train_image_paths_random_10_percent)}\")\nprint(\"First 5 random 10% training image paths:\")\ntrain_image_paths_random_10_percent[:5]\n import random # Set a random seed random.seed(42) # Get a 10% sample of the training image paths train_image_paths_random_10_percent = random.sample(population=train_image_paths, k=int(0.1*len(train_image_paths))) # Check how many image paths we got print(f\"Original number of training image paths: {len(train_image_paths)}\") print(f\"Number of 10% training image paths: {len(train_image_paths_random_10_percent)}\") print(\"First 5 random 10% training image paths:\") train_image_paths_random_10_percent[:5] Original number of training image paths: 12000\nNumber of 10% training image paths: 1200\nFirst 5 random 10% training image paths:\n
Out[42]: [PosixPath('images_split/train/miniature_pinscher/n02107312_2706.jpg'),\n PosixPath('images_split/train/irish_wolfhound/n02090721_272.jpg'),\n PosixPath('images_split/train/greater_swiss_mountain_dog/n02107574_3274.jpg'),\n PosixPath('images_split/train/italian_greyhound/n02091032_3763.jpg'),\n PosixPath('images_split/train/bloodhound/n02088466_7962.jpg')] Random 10% training image paths acquired!
Let's copy them to the images_split/train_10_percent directory using similar code to our copy_files_to_target_dir() function.
In\u00a0[43]: Copied! # Copy training 10% split images from images_split/train/ to images_split/train_10_percent/...\nfor source_file_path in tqdm(train_image_paths_random_10_percent):\n\n # Create the destination file path\n destination_file_and_image_name = Path(*source_file_path.parts[-2:]) # \"images_split/train/yorkshire_terrier/n02094433_2223.jpg\" -> \"yorkshire_terrier/n02094433_2223.jpg\"\n destination_file_path = train_10_percent_dir / destination_file_and_image_name # \"yorkshire_terrier/n02094433_2223.jpg\" -> \"images_split/train_10_percent/yorkshire_terrier/n02094433_2223.jpg\"\n\n # If the target directory doesn't exist, make it\n target_class_dir = destination_file_path.parent\n if not target_class_dir.is_dir():\n # print(f\"Making directory: {target_class_dir}\")\n target_class_dir.mkdir(parents=True,\n exist_ok=True)\n\n # print(f\"Copying: {source_file_path} to {destination_file_path}\")\n copy2(src=source_file_path,\n dst=destination_file_path)\n # Copy training 10% split images from images_split/train/ to images_split/train_10_percent/... for source_file_path in tqdm(train_image_paths_random_10_percent): # Create the destination file path destination_file_and_image_name = Path(*source_file_path.parts[-2:]) # \"images_split/train/yorkshire_terrier/n02094433_2223.jpg\" -> \"yorkshire_terrier/n02094433_2223.jpg\" destination_file_path = train_10_percent_dir / destination_file_and_image_name # \"yorkshire_terrier/n02094433_2223.jpg\" -> \"images_split/train_10_percent/yorkshire_terrier/n02094433_2223.jpg\" # If the target directory doesn't exist, make it target_class_dir = destination_file_path.parent if not target_class_dir.is_dir(): # print(f\"Making directory: {target_class_dir}\") target_class_dir.mkdir(parents=True, exist_ok=True) # print(f\"Copying: {source_file_path} to {destination_file_path}\") copy2(src=source_file_path, dst=destination_file_path) 0%| | 0/1200 [00:00<?, ?it/s]
1200 images copied!
Let's check our training 10% set distribution and make sure we've got some images for each class.
We can use our count_images_in_subdirs() function to count the images in each of the dog breed folders in the train_10_percent_dir.
In\u00a0[44]: Copied! # Count images in train_10_percent_dir\ntrain_10_percent_image_class_counts = count_images_in_subdirs(train_10_percent_dir)\ntrain_10_percent_image_class_counts_df = pd.DataFrame(train_10_percent_image_class_counts).sort_values(\"image_count\", ascending=True)\ntrain_10_percent_image_class_counts_df.head()\n
# Count images in train_10_percent_dir train_10_percent_image_class_counts = count_images_in_subdirs(train_10_percent_dir) train_10_percent_image_class_counts_df = pd.DataFrame(train_10_percent_image_class_counts).sort_values(\"image_count\", ascending=True) train_10_percent_image_class_counts_df.head() Out[44]: class_name image_count 33 labrador_retriever 3 23 welsh_springer_spaniel 4 61 great_dane 4 64 curly_coated_retriever 4 100 sussex_spaniel 5 Okay, looks like a few classes have only a handful of images.
Let's make sure there's 120 subfolders by checking the length of the train_10_percent_image_class_counts_df.
In\u00a0[45]: Copied! # How many subfolders are there?\nprint(len(train_10_percent_image_class_counts_df))\n
# How many subfolders are there? print(len(train_10_percent_image_class_counts_df)) 120\n
Beautiful, our train 10% dataset split has a folder for each of the dog breed classes.
Note: Ideally our random 10% training set would have the same distribution per class as the original training set, however, for this example, we've taken a global random 10% rather than a random 10% per class. This is okay for now, however for more fine-grained tasks, you may want to make sure your smaller training set is better distributed.
For one last check, let's plot the distribution of our train 10% dataset.
In\u00a0[46]: Copied! # Plot distribution of train 10% dataset.\nplt.figure(figsize=(14, 7))\ntrain_10_percent_image_class_counts_df.plot(kind=\"bar\",\n x=\"class_name\",\n y=\"image_count\",\n legend=False,\n ax=plt.gca()) # plt.gca() = \"get current axis\", get the plt we setup above and put the data there\n\n# Add customization\nplt.title(\"Train 10 Percent Image Counts by Class\")\nplt.ylabel(\"Image Count\")\nplt.xticks(rotation=90, # Rotate the x labels for better visibility\n fontsize=8) # Make the font size smaller for easier reading\nplt.tight_layout() # Ensure things fit nicely\nplt.show()\n
# Plot distribution of train 10% dataset. plt.figure(figsize=(14, 7)) train_10_percent_image_class_counts_df.plot(kind=\"bar\", x=\"class_name\", y=\"image_count\", legend=False, ax=plt.gca()) # plt.gca() = \"get current axis\", get the plt we setup above and put the data there # Add customization plt.title(\"Train 10 Percent Image Counts by Class\") plt.ylabel(\"Image Count\") plt.xticks(rotation=90, # Rotate the x labels for better visibility fontsize=8) # Make the font size smaller for easier reading plt.tight_layout() # Ensure things fit nicely plt.show() Excellent! Our train 10% dataset distribution looks similar to the original training set distribution.
However, it could be better.
If we really wanted to, we could recreate the train 10% dataset with 10% of the images from each class rather than 10% of images globally.
Extension: How would you create the train_10_percent data split with 10% of the images from each class? For example, each folder would have at least 10 images of a particular dog breed.
In\u00a0[47]: Copied! import tensorflow as tf\n\n# Create constants\nIMG_SIZE = (224, 224)\nBATCH_SIZE = 32\nSEED = 42\n\n# Create train 10% dataset\ntrain_10_percent_ds = tf.keras.utils.image_dataset_from_directory(\n directory=train_10_percent_dir,\n label_mode=\"categorical\", # turns labels into one-hot representations (e.g. [0, 0, 1, ..., 0, 0])\n batch_size=BATCH_SIZE,\n image_size=IMG_SIZE,\n shuffle=True, # shuffle training datasets to prevent learning of order\n seed=SEED\n)\n\n# Create full train dataset\ntrain_ds = tf.keras.utils.image_dataset_from_directory(\n directory=train_dir,\n label_mode=\"categorical\",\n batch_size=BATCH_SIZE,\n image_size=IMG_SIZE,\n shuffle=True,\n seed=SEED\n)\n\n# Create test dataset\ntest_ds = tf.keras.utils.image_dataset_from_directory(\n directory=test_dir,\n label_mode=\"categorical\",\n batch_size=BATCH_SIZE,\n image_size=IMG_SIZE,\n shuffle=False, # don't need to shuffle the test dataset (this makes evaluations easier)\n seed=SEED\n)\n
import tensorflow as tf # Create constants IMG_SIZE = (224, 224) BATCH_SIZE = 32 SEED = 42 # Create train 10% dataset train_10_percent_ds = tf.keras.utils.image_dataset_from_directory( directory=train_10_percent_dir, label_mode=\"categorical\", # turns labels into one-hot representations (e.g. [0, 0, 1, ..., 0, 0]) batch_size=BATCH_SIZE, image_size=IMG_SIZE, shuffle=True, # shuffle training datasets to prevent learning of order seed=SEED ) # Create full train dataset train_ds = tf.keras.utils.image_dataset_from_directory( directory=train_dir, label_mode=\"categorical\", batch_size=BATCH_SIZE, image_size=IMG_SIZE, shuffle=True, seed=SEED ) # Create test dataset test_ds = tf.keras.utils.image_dataset_from_directory( directory=test_dir, label_mode=\"categorical\", batch_size=BATCH_SIZE, image_size=IMG_SIZE, shuffle=False, # don't need to shuffle the test dataset (this makes evaluations easier) seed=SEED ) Found 1200 files belonging to 120 classes.\nFound 12000 files belonging to 120 classes.\nFound 8580 files belonging to 120 classes.\n
Note: If you're working with similar styles of data (e.g. all dog photos), it's best practice to shuffle training datasets to prevent the model from learning any order in the data, no need to shuffle testing datasets (this makes for easier evaluation).
tf.data.Datasets created!
Let's check out one of them.
In\u00a0[48]: Copied! train_10_percent_ds\n
train_10_percent_ds Out[48]: <_PrefetchDataset element_spec=(TensorSpec(shape=(None, 224, 224, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 120), dtype=tf.float32, name=None))>
You'll notice a few things going on here.
Essentially, we've got a collection of tuples:
- The image tensor(s) -
TensorSpec(shape=(None, 224, 224, 3), dtype=tf.float32, name=None) where (None, 224, 224, 3) is the shape of the image tensor (None is the batch size, (224, 224) is the IMG_SIZE we set and 3 is the number of colour channels, as in, red, green, blue or RGB since our images are in colour). - The label tensor(s) -
TensorSpec(shape=(None, 120), dtype=tf.float32, name=None) where None is the batch size and 120 is the number of labels we're using.
The batch size often appears as None since it's flexible and can change on the fly.
Each batch of images is assosciated with a batch of labels.
Instead of talking about it, let's check out what a single batch looks like.
We can do so by turning the tf.data.Dataset into an iterable with Python's built-in iter() and then getting the \"next\" batch with next().
In\u00a0[49]: Copied! # What does a single batch look like?\nimage_batch, label_batch = next(iter(train_ds))\nimage_batch.shape, label_batch.shape\n
# What does a single batch look like? image_batch, label_batch = next(iter(train_ds)) image_batch.shape, label_batch.shape Out[49]: (TensorShape([32, 224, 224, 3]), TensorShape([32, 120]))
Nice!
We get back a single batch of images and labels.
Looks like a single image_batch has a shape of [32, 224, 224, 3] ([batch_size, height, width, colour_channels]).
And our labels have a shape of [32, 120] ([batch_size, labels]).
These are numerical representations of our data images and labels!
Note: The shape of a tensor does not necessarily reflect the values inside a tensor. The shape only reflects the dimensionality of a tensor. For example, [32, 224, 224, 3] is a 4-dimensional tensor. Values inside a tensor can be any number (positive, negative, 0, float, integer, etc) representing almost any kind of data.
We can further inspect our data by looking at a single sample.
In\u00a0[50]: Copied! # Get a single sample from a single batch\nprint(f\"Single image tensor:\\n{image_batch[0]}\\n\")\nprint(f\"Single label tensor: {label_batch[0]}\") # notice the 1 is the index of the target label (our labels are one-hot encoded)\nprint(f\"Single sample class name: {dog_names[tf.argmax(label_batch[0])]}\")\n # Get a single sample from a single batch print(f\"Single image tensor:\\n{image_batch[0]}\\n\") print(f\"Single label tensor: {label_batch[0]}\") # notice the 1 is the index of the target label (our labels are one-hot encoded) print(f\"Single sample class name: {dog_names[tf.argmax(label_batch[0])]}\") Single image tensor:\n[[[196.61607 174.61607 160.61607 ]\n [197.84822 175.84822 161.84822 ]\n [200. 178. 164. ]\n ...\n [ 60.095097 79.75804 45.769207]\n [ 61.83293 71.22575 63.288315]\n [ 77.65755 83.65755 81.65755 ]]\n\n [[196. 174. 160. ]\n [197.83876 175.83876 161.83876 ]\n [199.07945 177.07945 163.07945 ]\n ...\n [ 94.573715 110.55229 83.59694 ]\n [125.869865 135.26268 127.33472 ]\n [122.579605 128.5796 126.579605]]\n\n [[195.73691 173.73691 159.73691 ]\n [196.896 174.896 160.896 ]\n [199. 177. 163. ]\n ...\n [ 26.679413 38.759026 20.500835]\n [ 24.372307 31.440136 26.675896]\n [ 20.214453 26.214453 24.214453]]\n\n ...\n\n [[ 61.57369 70.18976 104.72547 ]\n [189.91965 199.61607 213.28572 ]\n [247.26637 255. 252.70387 ]\n ...\n [113.40158 83.40158 57.40158 ]\n [110.75214 78.75214 53.752136]\n [107.37048 75.37048 50.370483]]\n\n [[ 61.27007 69.88614 104.42185 ]\n [188.93079 198.62721 212.29686 ]\n [246.33257 255. 251.77007 ]\n ...\n [110.88623 80.88623 54.88623 ]\n [102.763245 70.763245 45.763245]\n [ 99.457634 67.457634 42.457638]]\n\n [[ 60.25893 68.875 103.41071 ]\n [188.58261 198.27904 211.94868 ]\n [245.93112 254.6097 251.36862 ]\n ...\n [105.02222 75.02222 49.022217]\n [109.11186 77.11186 52.111866]\n [106.56936 74.56936 49.56936 ]]]\n\nSingle label tensor: [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]\nSingle sample class name: schipperke\n
Woah!!
We've got a numerical representation of a dog image (in the form of red, green, blue pixel values)!
This is exactly the kind of format our model will want.
Can we do the reverse?
Instead of image -> numbers, can we go from numbers -> image?
You bet.
In\u00a0[51]: Copied! plt.imshow(image_batch[0].numpy().astype(\"uint8\")) # convert tensor to uint8 to avoid matplotlib colour range issues\nplt.title(dog_names[tf.argmax(label_batch[0])])\nplt.axis(\"off\");\n
plt.imshow(image_batch[0].numpy().astype(\"uint8\")) # convert tensor to uint8 to avoid matplotlib colour range issues plt.title(dog_names[tf.argmax(label_batch[0])]) plt.axis(\"off\"); How about we plot multiple images?
We can do so by first setting up a plot with multiple subplots.
And then we can iterate through our dataset with tf.data.Dataset.take(count=1) which will \"take\" 1 batch of data (in our case, one batch is 32 samples) which we can then index on for each subplot.
In\u00a0[52]: Copied! # Create multiple subplots\nfig, axes = plt.subplots(nrows=2, ncols=5, figsize=(20, 10))\n\n# Iterate through a single batch and plot images\nfor images, labels in train_ds.take(count=1): # note: because our training data is shuffled, each \"take\" will be different\n for i, ax in enumerate(axes.flat):\n ax.imshow(images[i].numpy().astype(\"uint8\"))\n ax.set_title(dog_names[tf.argmax(labels[i])])\n ax.axis(\"off\")\n
# Create multiple subplots fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(20, 10)) # Iterate through a single batch and plot images for images, labels in train_ds.take(count=1): # note: because our training data is shuffled, each \"take\" will be different for i, ax in enumerate(axes.flat): ax.imshow(images[i].numpy().astype(\"uint8\")) ax.set_title(dog_names[tf.argmax(labels[i])]) ax.axis(\"off\") Aren't those good looking dogs!
In\u00a0[53]: Copied! # Get the first 5 file paths of the training dataset\ntrain_ds.file_paths[:5]\n
# Get the first 5 file paths of the training dataset train_ds.file_paths[:5] Out[53]: ['images_split/train/boston_bull/n02096585_1753.jpg',\n 'images_split/train/kerry_blue_terrier/n02093859_855.jpg',\n 'images_split/train/border_terrier/n02093754_2281.jpg',\n 'images_split/train/rottweiler/n02106550_11823.jpg',\n 'images_split/train/airedale/n02096051_5884.jpg']
We can also get the class names assosciated with a dataset using .class_names (TensorFlow has read these from the names of our target folders in the images_split directory).
In\u00a0[54]: Copied! # Get the class names TensorFlow has read from the target directory\nclass_names = train_ds.class_names\nclass_names[:5]\n
# Get the class names TensorFlow has read from the target directory class_names = train_ds.class_names class_names[:5] Out[54]: ['affenpinscher',\n 'afghan_hound',\n 'african_hunting_dog',\n 'airedale',\n 'american_staffordshire_terrier']
And we can make sure the class names are the same across our datasets by comparing them.
In\u00a0[55]: Copied! assert set(train_10_percent_ds.class_names) == set(train_ds.class_names) == set(test_ds.class_names)\n
assert set(train_10_percent_ds.class_names) == set(train_ds.class_names) == set(test_ds.class_names) In\u00a0[56]: Copied! AUTOTUNE = tf.data.AUTOTUNE # let TensorFlow find the best values to use automatically\n\n# Shuffle and optimize performance on training datasets\n# Note: these methods can be chained together and will have the same effect as calling them individually\ntrain_10_percent_ds = train_10_percent_ds.cache().shuffle(buffer_size=10*BATCH_SIZE).prefetch(buffer_size=AUTOTUNE)\ntrain_ds = train_ds.cache().shuffle(buffer_size=100*BATCH_SIZE).prefetch(buffer_size=AUTOTUNE)\n\n# Don't need to shuffle test datasets (for easier evaluation)\ntest_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)\n
AUTOTUNE = tf.data.AUTOTUNE # let TensorFlow find the best values to use automatically # Shuffle and optimize performance on training datasets # Note: these methods can be chained together and will have the same effect as calling them individually train_10_percent_ds = train_10_percent_ds.cache().shuffle(buffer_size=10*BATCH_SIZE).prefetch(buffer_size=AUTOTUNE) train_ds = train_ds.cache().shuffle(buffer_size=100*BATCH_SIZE).prefetch(buffer_size=AUTOTUNE) # Don't need to shuffle test datasets (for easier evaluation) test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE) Dataset performance optimized!
We spent some extra time here because datasets are so important to machine learning and deep learning workflows, wherever you can make them faster, you should.
Time to create our first neural network with TensorFlow!
In\u00a0[57]: Copied! # Create the input shape to our model\nINPUT_SHAPE = (*IMG_SIZE, 3)\n\nbase_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(\n include_top=True, # do want to include the top layer? (ImageNet has 1000 classes, so the top layer is formulated for this, we want to create our own top layer)\n include_preprocessing=True, # do we want the network to preprocess our data into the right format for us? (yes)\n weights=\"imagenet\", # do we want the network to come with pretrained weights? (yes)\n input_shape=INPUT_SHAPE # what is the input shape of our data we're going to pass to the network? (224, 224, 3) -> (height, width, colour_channels)\n)\n
# Create the input shape to our model INPUT_SHAPE = (*IMG_SIZE, 3) base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0( include_top=True, # do want to include the top layer? (ImageNet has 1000 classes, so the top layer is formulated for this, we want to create our own top layer) include_preprocessing=True, # do we want the network to preprocess our data into the right format for us? (yes) weights=\"imagenet\", # do we want the network to come with pretrained weights? (yes) input_shape=INPUT_SHAPE # what is the input shape of our data we're going to pass to the network? (224, 224, 3) -> (height, width, colour_channels) ) Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/efficientnet_v2/efficientnetv2-b0.h5\n29403144/29403144 [==============================] - 0s 0us/step\n
Base model created!
We can find out information about our base model by calling base_model.summary().
In\u00a0[58]: Copied! # Note: Uncomment to see full output\n# base_model.summary()\n
# Note: Uncomment to see full output # base_model.summary() Truncated output of base_model.summary():
Woah! Look at all those layers... this is what the \"deep\" in deep learning means! A deep number of layers.
How about we count the number of layers?
In\u00a0[59]: Copied! # Count the number of layers\nprint(f\"Number of layers in base_model: {len(base_model.layers)}\")\n # Count the number of layers print(f\"Number of layers in base_model: {len(base_model.layers)}\") Number of layers in base_model: 273\n
273 layers!
Wow, there's a lot going on.
Rather than step through each layer and explain what's happening in each layer, I'll leave that for the curious mind to research on their own.
Just know that when starting out deep learning you don't need to know what's happening every layer in a model to be able to use a model.
For now, let's pay attention to a few things:
- The input layer (the first layer) input shape, this will tell us the shape of the data the model expects as input.
- The output layer (the last layer) output shape, this will tell us the shape of the data the model will output.
- The number of parameters of the model, these are \"learnable\" numbers (also called weights) that a model will use to derive patterns out of and represent the data. Generally, the more parameters a model has, the more learning capacity it has.
- The number of layers a model has. Generally, the more layers a model has, the more learning capacity it has (each layer will learn progressively deeper patterns from the data). However, this caps out at a certain range.
Let's step through each of these.
In\u00a0[60]: Copied! # Check the input shape of our model\nbase_model.input_shape\n
# Check the input shape of our model base_model.input_shape Out[60]: (None, 224, 224, 3)
Nice! Looks like our model's input shape is where we want it (remember None in this case is equivalent to a wild card dimension, meaning it could be any value, but we've set ours to 32).
This is because the model we chose, tf.keras.applications.efficientnet_v2.EfficientNetV2B0, has been trained on images the same size as our images.
If our model had a different input shape, we'd have to make sure we processed our images to be the same shape.
Now let's check the output shape.
In\u00a0[61]: Copied! # Check the model's output shape\nbase_model.output_shape\n
# Check the model's output shape base_model.output_shape Out[61]: (None, 1000)
Hmm, is this what we're after?
Since we have 120 dog classes, we'd like an output shape of (None, 120).
Why is it by default (None, 1000)?
This is because the model has been trained already on ImageNet, a dataset of 1,000,000+ images with 1000 classes (hence the 1000 in the output shape).
How can we change this?
Let's recreate a base_model instance, except this time we'll change the classes parameter to 120.
In\u00a0[62]: Copied! # Create a base model with 120 output classes\nbase_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(\n include_top=True,\n include_preprocessing=True,\n weights=\"imagenet\",\n input_shape=INPUT_SHAPE,\n classes=len(dog_names)\n)\n\nbase_model.output_shape\n
# Create a base model with 120 output classes base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0( include_top=True, include_preprocessing=True, weights=\"imagenet\", input_shape=INPUT_SHAPE, classes=len(dog_names) ) base_model.output_shape \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\n<ipython-input-62-5e9b29e6f858> in <cell line: 2>()\n 1 # Create a base model with 120 output classes\n----> 2 base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(\n 3 include_top=True,\n 4 include_preprocessing=True,\n 5 weights=\"imagenet\",\n\n/usr/local/lib/python3.10/dist-packages/keras/src/applications/efficientnet_v2.py in EfficientNetV2B0(include_top, weights, input_tensor, input_shape, pooling, classes, classifier_activation, include_preprocessing)\n 1128 include_preprocessing=True,\n 1129 ):\n-> 1130 return EfficientNetV2(\n 1131 width_coefficient=1.0,\n 1132 depth_coefficient=1.0,\n\n/usr/local/lib/python3.10/dist-packages/keras/src/applications/efficientnet_v2.py in EfficientNetV2(width_coefficient, depth_coefficient, default_size, dropout_rate, drop_connect_rate, depth_divisor, min_depth, bn_momentum, activation, blocks_args, model_name, include_top, weights, input_tensor, input_shape, pooling, classes, classifier_activation, include_preprocessing)\n 932 \n 933 if weights == \"imagenet\" and include_top and classes != 1000:\n--> 934 raise ValueError(\n 935 \"If using `weights` as `'imagenet'` with `include_top`\"\n 936 \" as true, `classes` should be 1000\"\n\nValueError: If using `weights` as `'imagenet'` with `include_top` as true, `classes` should be 1000Received: classes=120
Oh dam!
We get an error:
ValueError: If using weights as 'imagenet' with include_top as true, classes should be 1000 Received: classes=120
What this is saying is that if we want to using the pretrained 'imagenet' weights (which we do to leverage the visual patterns/features a model has already learned on ImageNet, we need to change the parameters to the base_model.
What we're going to do is create our own top layers.
We can do this by setting include_top=False.
What this means is we'll use most of the model's existing layers to extract features and patterns out of our images and then customize the final few layers to our own problem.
This kind of transfer learning is often called feature extraction.
A setup where you use an existing models pretrained weights to extract features (or patterns) from your own custom data.
You can then used those extracted features and further tailor them to your own use case.
Let's create an instance of base_model without a top layer.
In\u00a0[63]: Copied! # Create a base model with no top\nbase_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(\n include_top=False, # don't include the top layer (we want to make our own top layer)\n include_preprocessing=True,\n weights=\"imagenet\",\n input_shape=INPUT_SHAPE,\n)\n\n# Check the output shape\nbase_model.output_shape\n
# Create a base model with no top base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0( include_top=False, # don't include the top layer (we want to make our own top layer) include_preprocessing=True, weights=\"imagenet\", input_shape=INPUT_SHAPE, ) # Check the output shape base_model.output_shape Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/efficientnet_v2/efficientnetv2-b0_notop.h5\n24274472/24274472 [==============================] - 0s 0us/step\n
Out[63]: (None, 7, 7, 1280)
Hmm, what's this output shape?
This still isn't what we want (we're after (None, 120) for our number of dog classes).
How about we check the number of layers again?
In\u00a0[64]: Copied! # Count the number of layers\nprint(f\"Number of layers in base_model: {len(base_model.layers)}\")\n # Count the number of layers print(f\"Number of layers in base_model: {len(base_model.layers)}\") Number of layers in base_model: 270\n
Looks like our new base_model has less layers than our previous one.
This is because we used include_top=False.
This means we've still got 270 base layers to extract features and patterns from our images, however, it also means we get to customize the output layers to our liking.
We'll come back to this shortly.
In\u00a0[65]: Copied! # Check the number of parameters in our model\nbase_model.count_params()\n
# Check the number of parameters in our model base_model.count_params() Out[65]: 5919312
Holy smokes!
Our model has 5,919,312 parameters!
That means each time an image goes through our model, it will be influenced in some small way by 5,919,312 numbers.
Each one of these is a potential learning opportunity (except for parameters that are non-trainable but we'll get to that soon too).
Now, you may be thinking, 5 million+ parameters sounds like a lot.
And it is.
However, many modern large scale models, such as GPT-3 (175B) and GPT-4 (200B+? the actual number of parameters was never released) deal in the billions of parameters (note: this is written in 2024, so if you're reading this in future, parameter counts may be in the trillions).
Generally, more parameters leads to better models.
However, there are always tradeoffs.
More parameters means more compute power to run the models.
In practice, if you have limited compute power (e.g. a single GPU on Google Colab), it's best to start with smaller models and gradually increase the size when necessary.
We can get the trainable and non-trainable parameters from our model with the trainable_weights and non_trainable_weights attributes (remember, parameters are also referred to as weights).
Note: Trainable weights are parameters of the model which are updated by backpropagation during training (they are changed to better match the data) where as non-trainable weights are parameters of the model which are not updated by backpropagation during training (they are fixed in place).
Let's write a function to count the trainable, non-trainable and trainable parameters of a model.
In\u00a0[66]: Copied! import numpy as np\n\ndef count_parameters(model, print_output=True):\n \"\"\"\n Counts the number of trainable, non-trainable and total parameters of a given model.\n \"\"\"\n trainable_parameters = np.sum([np.prod(layer.shape) for layer in model.trainable_weights])\n non_trainable_parameters = np.sum([np.prod(layer.shape) for layer in model.non_trainable_weights])\n total_parameters = trainable_parameters + non_trainable_parameters\n if print_output:\n print(f\"Model {model.name} parameter counts:\")\n print(f\"Total parameters: {total_parameters}\")\n print(f\"Trainable parameters: {trainable_parameters}\")\n print(f\"Non-trainable parameters: {non_trainable_parameters}\")\n else:\n return total_parameters, trainable_parameters, non_trainable_parameters\n\ncount_parameters(model=base_model, print_output=True)\n import numpy as np def count_parameters(model, print_output=True): \"\"\" Counts the number of trainable, non-trainable and total parameters of a given model. \"\"\" trainable_parameters = np.sum([np.prod(layer.shape) for layer in model.trainable_weights]) non_trainable_parameters = np.sum([np.prod(layer.shape) for layer in model.non_trainable_weights]) total_parameters = trainable_parameters + non_trainable_parameters if print_output: print(f\"Model {model.name} parameter counts:\") print(f\"Total parameters: {total_parameters}\") print(f\"Trainable parameters: {trainable_parameters}\") print(f\"Non-trainable parameters: {non_trainable_parameters}\") else: return total_parameters, trainable_parameters, non_trainable_parameters count_parameters(model=base_model, print_output=True) Model efficientnetv2-b0 parameter counts:\nTotal parameters: 5919312\nTrainable parameters: 5858704\nNon-trainable parameters: 60608\n
Nice! It looks like our function worked.
Most of our model's parameters are trainable.
This means they will be tweaked as they see more images of dogs.
However, a standard practice in transfer learning is to freeze the base layers of a model and only train the custom top layers to suit your problem.
Example of how we can take a pretrained model and customize it to our own use case. This kind of transfer learning workflow is often referred to as a feature extracting workflow as the base layers are frozen (not changed during training) and only the top layers are trained. Note: In this image the EfficientNetB0 architecture is being demonstrated, however we're going to be using the EfficientNetV2B0 architecture which is slightly different. I've used the older architecture image from the research paper as a newer one wasn't available.
In other words, keep the patterns an existing model has learned on a similar problem (if they're good) to form a base representation of an input sample and then manipulate that base representation to suit our needs.
Why do this?
It's faster.
The less trainable parameters, the faster your model training will be, the faster your experiments will be.
But how will we know this works?
We're going to run experiments to test it.
Okay, so how do we freeze the parameters of our base_model?
We can set its .trainable attribute to False.
In\u00a0[67]: Copied! # Freeze the base model\nbase_model.trainable = False\nbase_model.trainable\n
# Freeze the base model base_model.trainable = False base_model.trainable Out[67]: False
base_model frozen!
Now let's check the number of trainable and non-trainable parameters.
In\u00a0[68]: Copied! count_parameters(model=base_model, print_output=True)\n
count_parameters(model=base_model, print_output=True) Model efficientnetv2-b0 parameter counts:\nTotal parameters: 5919312.0\nTrainable parameters: 0.0\nNon-trainable parameters: 5919312\n
Beautiful!
Looks like all of the parameters in our base_model are now non-trainable (frozen).
This means they won't be updated during training.
In\u00a0[69]: Copied! # Extract features from a single image using our base model\nfeature_extraction = base_model(image_batch[0])\nfeature_extraction\n
# Extract features from a single image using our base model feature_extraction = base_model(image_batch[0]) feature_extraction \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\n<ipython-input-69-957d897dc1dc> in <cell line: 2>()\n 1 # Extract features from a single image using our base model\n----> 2 feature_extraction = base_model(image_batch[0])\n 3 feature_extraction\n\n/usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py in error_handler(*args, **kwargs)\n 68 # To get the full stack trace, call:\n 69 # `tf.debugging.disable_traceback_filtering()`\n---> 70 raise e.with_traceback(filtered_tb) from None\n 71 finally:\n 72 del filtered_tb\n\n/usr/local/lib/python3.10/dist-packages/keras/src/engine/input_spec.py in assert_input_compatibility(input_spec, inputs, layer_name)\n 296 if spec_dim is not None and dim is not None:\n 297 if spec_dim != dim:\n--> 298 raise ValueError(\n 299 f'Input {input_index} of layer \"{layer_name}\" is '\n 300 \"incompatible with the layer: \"\n\nValueError: Input 0 of layer \"efficientnetv2-b0\" is incompatible with the layer: expected shape=(None, 224, 224, 3), found shape=(224, 224, 3) Oh no!
Another error...
ValueError: Input 0 of layer \"efficientnetv2-b0\" is incompatible with the layer: expected shape=(None, 224, 224, 3), found shape=(224, 224, 3)
We've stumbled upon one of the most common errors in machine learning, shape errors.
In our case, the shape of the data we're trying to put into the model doesn't match the input shape the model is expecting.
Our input data shape is (224, 224, 3) ((height, width, colour_channels)), however, our model is expecting (None, 224, 224, 3) ((batch_size, height, width, colour_channels)).
We can fix this error by adding a singluar batch_size dimension to our input and thus make it (1, 224, 224, 3) (a batch_size of 1 for a single sample).
To do so, we can use the tf.expand_dims(input=target_sample, axis=0) where target_sample is our input tensor and axis=0 means we want to expand the first dimension.
In\u00a0[70]: Copied! # Current image shape\nshape_of_image_without_batch = image_batch[0].shape\n\n# Add a batch dimension to our single image\nshape_of_image_with_batch = tf.expand_dims(input=image_batch[0], axis=0).shape\n\nprint(f\"Shape of image without batch: {shape_of_image_without_batch}\")\nprint(f\"Shape of image with batch: {shape_of_image_with_batch}\")\n # Current image shape shape_of_image_without_batch = image_batch[0].shape # Add a batch dimension to our single image shape_of_image_with_batch = tf.expand_dims(input=image_batch[0], axis=0).shape print(f\"Shape of image without batch: {shape_of_image_without_batch}\") print(f\"Shape of image with batch: {shape_of_image_with_batch}\") Shape of image without batch: (224, 224, 3)\nShape of image with batch: (1, 224, 224, 3)\n
Perfect!
Now let's pass this image with a batch dimension to our base_model.
In\u00a0[71]: Copied! # Extract features from a single image using our base model\nfeature_extraction = base_model(tf.expand_dims(image_batch[0], axis=0))\nfeature_extraction\n
# Extract features from a single image using our base model feature_extraction = base_model(tf.expand_dims(image_batch[0], axis=0)) feature_extraction Out[71]: <tf.Tensor: shape=(1, 7, 7, 1280), dtype=float32, numpy=\narray([[[[-2.19177201e-01, -3.44185606e-02, -1.40321642e-01, ...,\n -1.44454449e-01, -2.73809850e-01, -7.41252452e-02],\n [-8.69670734e-02, -6.48750067e-02, -2.14546964e-01, ...,\n -4.57209721e-02, -2.77900100e-01, -8.20885971e-02],\n [-2.76872963e-01, -8.26781020e-02, -3.85153107e-02, ...,\n -2.72128999e-01, -2.52802134e-01, -2.28105962e-01],\n ...,\n [-1.01604000e-01, -3.55145968e-02, -2.23027021e-01, ...,\n -2.26227805e-01, -8.61771777e-02, -1.60450727e-01],\n [-5.87608740e-02, -4.65543661e-03, -1.06193267e-01, ...,\n -2.87548676e-02, -9.06914026e-02, -1.82624385e-01],\n [-6.27618432e-02, -1.38620799e-03, 1.52704502e-02, ...,\n -7.85450079e-03, -1.84584558e-01, -2.62404829e-01]],\n\n [[-2.17334151e-01, -1.10280879e-01, -2.74605274e-01, ...,\n -2.22405165e-01, -2.74738282e-01, -1.01998925e-01],\n [-1.40700653e-01, -1.66820198e-01, -2.77449101e-01, ...,\n 2.40375683e-01, -2.77627349e-01, -9.07808691e-02],\n [-2.40916476e-01, -2.00582087e-01, -2.38370374e-01, ...,\n -8.27576742e-02, -2.78428614e-01, -1.23056054e-01],\n ...,\n [-2.67296195e-01, -5.43131726e-03, -6.44061863e-02, ...,\n -3.34720500e-02, -1.55141622e-01, -3.23073938e-02],\n [-2.66513556e-01, -2.09966358e-02, -1.50375053e-01, ...,\n -6.29274473e-02, -2.69798309e-01, -2.74081439e-01],\n [-8.39830115e-02, -1.58605091e-02, -2.78447241e-01, ...,\n -1.43555822e-02, -2.77474761e-01, 1.37483165e-01]],\n\n [[-2.15840712e-01, 4.50323820e-01, -7.51058161e-02, ...,\n -2.43637279e-01, -2.75048614e-01, -6.00421876e-02],\n [-2.39066556e-01, -2.25066260e-01, -4.89832312e-02, ...,\n -2.77957618e-01, -1.14677951e-01, -2.69968715e-02],\n [-1.60943881e-01, -2.12972730e-01, -1.08622171e-01, ...,\n -2.78464079e-01, -1.95970193e-01, -2.92074662e-02],\n ...,\n [-2.67642140e-01, -7.13412274e-10, -2.47387841e-01, ...,\n -1.27752789e-03, 1.69062471e+00, -1.07747754e-02],\n [-2.69456387e-01, -3.02123808e-05, -2.19904676e-01, ...,\n -1.19841937e-02, 6.54936790e-01, 4.92877871e-01],\n [-1.83339473e-02, -9.84105989e-02, -2.77752399e-01, ...,\n -9.53171253e-02, -2.76987553e-01, -1.81873620e-01]],\n\n ...,\n\n [[-6.59235120e-02, -1.64803467e-03, -1.58951283e-01, ...,\n -1.34164095e-01, -6.30896613e-02, -7.77927637e-02],\n [-1.83377475e-01, -4.98497509e-04, -1.57654762e-01, ...,\n -4.48885784e-02, -1.06884383e-01, -2.78372377e-01],\n [-2.45749369e-01, -9.95399058e-03, -1.79216102e-01, ...,\n -1.02837617e-02, -1.84168354e-01, -1.70697242e-01],\n ...,\n [ 2.22050592e-01, -2.04384560e-04, -1.46467671e-01, ...,\n -2.65387502e-02, -1.85434178e-01, -9.71652716e-02],\n [ 1.52228832e+00, -3.39617883e-03, -3.22414264e-02, ...,\n -1.19287046e-02, -1.46435276e-01, -8.73169452e-02],\n [-1.89164400e-01, -5.49114570e-02, -2.05218419e-01, ...,\n -1.32163316e-01, -1.48950770e-01, -1.18042991e-01]],\n\n [[-2.16520607e-01, -7.84920622e-03, -1.43650264e-01, ...,\n -1.73660204e-01, -4.83706780e-02, -3.76228467e-02],\n [-2.78293848e-01, -6.24539470e-03, -2.28590608e-01, ...,\n -2.06465453e-01, -1.93291768e-01, -9.23046917e-02],\n [-2.40500003e-01, -2.73558766e-01, -1.58736348e-01, ...,\n -4.13209312e-02, -2.64240265e-01, -3.26484852e-02],\n ...,\n [-2.31358394e-01, -2.72292078e-01, -6.80670887e-02, ...,\n -2.16453914e-02, -2.71368980e-01, -3.88960652e-02],\n [-2.45319903e-01, -2.78179497e-01, -6.18890636e-02, ...,\n -1.86282583e-02, -2.23804727e-01, -2.72233319e-02],\n [-2.31111392e-01, -2.37449735e-01, -5.13911694e-02, ...,\n -4.55225781e-02, -2.74753064e-01, -3.51530202e-02]],\n\n [[-3.96142267e-02, -1.39998682e-02, -9.56050456e-02, ...,\n -2.33392462e-01, -1.83407709e-01, -4.99856956e-02],\n [-2.60713607e-01, -3.96164991e-02, -1.29626304e-01, ...,\n -2.78417081e-01, -2.78285533e-01, -7.70441368e-02],\n [-8.02241415e-02, -2.30456606e-01, -1.13508031e-01, ...,\n -5.45607917e-02, -2.71063268e-01, -2.75666509e-02],\n ...,\n [-9.41052362e-02, -2.42691532e-01, -5.48249595e-02, ...,\n -2.13044193e-02, -2.63691694e-01, -9.28506851e-02],\n [-9.08804908e-02, -2.40457997e-01, -7.88932368e-02, ...,\n -3.80579121e-02, -2.71065891e-01, -4.05692160e-02],\n [-1.26358300e-01, -2.17053503e-01, -7.44825602e-02, ...,\n -5.66985942e-02, -2.75216103e-01, -6.91162944e-02]]]],\n dtype=float32)>
Woah! Look at all those numbers!
After passing through ~270 layers, this is the numerical representation our model has created of our input image.
You might be thinking, okay, there's a lot here, how can I possibly understand all of them?
Well, with enough effort, you might.
However, these numbers are more for a model/computer to understand than for a human to understand.
Let's not stop there, let's check the shape of our feature_extraction.
In\u00a0[72]: Copied! # Check shape of feature extraction\nfeature_extraction.shape\n
# Check shape of feature extraction feature_extraction.shape Out[72]: TensorShape([1, 7, 7, 1280])
Ok, looks like our model has compressed our input image into a lower dimensional feature space.
Note: Feature space (or latent space or embedding space) is a numerical region where pieces of data are represented by tensors of various dimensions. Feature space is hard for humans to imagine because it could be 1000s of dimensions (humans are only good at imagining 3-4 dimensions at max). But you can think of feature space as an area where numerical representations of similar items will be close to together. If feature space was a grocery store, one breed of dogs may be in one aisle (similar numbers) where as another breed of dogs may be in the next aisle. You can see an example of a large embedding space representation of 8M Stack Overflow questions on Nomic Atlas.
Let's compare the new shape to the input shape.
In\u00a0[73]: Copied! num_input_features = 224*224*3\nfeature_extraction_features = 1*7*7*1280\n\n# Calculate the compression ratio\nnum_input_features / feature_extraction_features\n
num_input_features = 224*224*3 feature_extraction_features = 1*7*7*1280 # Calculate the compression ratio num_input_features / feature_extraction_features Out[73]: 2.4
Looks like our model has compressed the numerical representation of our input image by 2.4x so far.
But you might've noticed our feature_extraction is still a tensor.
How about we take it further and turn it into a vector and compress the representation even further?
We can do so by taking our feature_extraction tensor and pooling together the inner dimensions.
By pooling, I mean taking the average or the maximum values.
Why?
Because a neural network often outputs a large amount of learned feature values but many of them can be insignificant compared to others.
So taking the average or the max across them helps us compress the representation further while stil preserving the most important features.
This process is often referred to as:
- Average pooling - Take the average across given dimensions of a tensor, can perform with
tf.keras.layers.GlobalAveragePooling2D(). - Max pooling - Take the maximum value across given dimensions of a tensor, can perform with
tf.keras.layers.MaxPooling2D().
Let's try apply average pooling to our feature extraction and see what happens.
In\u00a0[74]: Copied! # Turn feature extraction into a feature vector\nfeature_vector = tf.keras.layers.GlobalAveragePooling2D()(feature_extraction) # pass feature_extraction to the pooling layer\nfeature_vector\n
# Turn feature extraction into a feature vector feature_vector = tf.keras.layers.GlobalAveragePooling2D()(feature_extraction) # pass feature_extraction to the pooling layer feature_vector Out[74]: <tf.Tensor: shape=(1, 1280), dtype=float32, numpy=\narray([[-0.11521906, -0.04476562, -0.12476546, ..., -0.09118073,\n -0.08420841, -0.07769417]], dtype=float32)>
Ho, ho!
Looks like we've compressed our feature_extraction tensor into a feature vector (notice the new shape of (1, 1280)).
Now if you're not sure what all these numbers mean, that's okay. I don't either.
A feature vector (also called an embedding) is supposed to be a numerical representation that's meaningful to computers.
We'll perform a few more transforms on it before it's recognizable to us.
Let's check out its shape.
In\u00a0[75]: Copied! # Check out the feature vector shape\nfeature_vector.shape\n
# Check out the feature vector shape feature_vector.shape Out[75]: TensorShape([1, 1280])
We've reduced the shape of feature_extraction from (1, 7, 7, 1280) to (1, 1280) (we've gone from a tensor with multiple dimensions to a vector with one dimension of size 1280).
Our neural network has performed calculations on our image and it is now represented by 1280 numbers.
This is one of the main goals of deep learning, to reduce higher dimensional information into a lower dimensional but still representative space.
Let's calculate how much we've reduced the dimensionality of our single input image.
In\u00a0[76]: Copied! # Compare the reduction\nnum_input_features = 224*224*3\nfeature_extraction_features = 1*7*7*1280\nfeature_vector_features = 1*1280\n\nprint(f\"Input -> feature extraction reduction factor: {num_input_features / feature_extraction_features}\")\nprint(f\"Feature extraction -> feature vector reduction factor: {feature_extraction_features / feature_vector_features}\")\nprint(f\"Input -> feature extraction -> feature vector reduction factor: {num_input_features / feature_vector_features}\")\n # Compare the reduction num_input_features = 224*224*3 feature_extraction_features = 1*7*7*1280 feature_vector_features = 1*1280 print(f\"Input -> feature extraction reduction factor: {num_input_features / feature_extraction_features}\") print(f\"Feature extraction -> feature vector reduction factor: {feature_extraction_features / feature_vector_features}\") print(f\"Input -> feature extraction -> feature vector reduction factor: {num_input_features / feature_vector_features}\") Input -> feature extraction reduction factor: 2.4\nFeature extraction -> feature vector reduction factor: 49.0\nInput -> feature extraction -> feature vector reduction factor: 117.6\n
A 117.6x reduction from our original image to its feature vector representation!
Why compress the representation like this?
Because representing our data in a compressed format but still with meaningful numbers (to a computer) means that less computation is required to reuse the patterns.
For example, imagine you have to relearn how to spell words every time you use them.
Would this be efficient?
Not at all.
Instead, you take a while to learn them at the start and then continually reuse this knowledge over time.
This is the same with a deep learning model.
It learns representative patterns in data, figures out the ideal connections between inputs and outputs and then reuses them over time in the form of numerical weights.
In\u00a0[77]: Copied! # Create a base model with no top and a pooling layer built-in\nbase_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(\n include_top=False,\n weights=\"imagenet\",\n input_shape=INPUT_SHAPE,\n pooling=\"avg\", # can also use \"max\"\n include_preprocessing=True,\n)\n\n# Check the summary (optional)\n# base_model.summary()\n\n# Check the output shape\nbase_model.output_shape\n
# Create a base model with no top and a pooling layer built-in base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0( include_top=False, weights=\"imagenet\", input_shape=INPUT_SHAPE, pooling=\"avg\", # can also use \"max\" include_preprocessing=True, ) # Check the summary (optional) # base_model.summary() # Check the output shape base_model.output_shape Out[77]: (None, 1280)
Boom!
We get the same output shape from the base_model as we did when using it with a pooling layer thanks to using pooling=\"avg\".
Let's now freeze these base weights, so they're not trainable.
In\u00a0[78]: Copied! # Freeze the base weights\nbase_model.trainable = False\n\n# Count the parameters\ncount_parameters(model=base_model, print_output=True)\n
# Freeze the base weights base_model.trainable = False # Count the parameters count_parameters(model=base_model, print_output=True) Model efficientnetv2-b0 parameter counts:\nTotal parameters: 5919312.0\nTrainable parameters: 0.0\nNon-trainable parameters: 5919312\n
And now we can pass an image through our base model and get a feature vector from it.
In\u00a0[79]: Copied! # Get a feature vector of a single image (don't forget to add a batch dimension)\nfeature_vector_2 = base_model(tf.expand_dims(image_batch[0], axis=0))\nfeature_vector_2\n
# Get a feature vector of a single image (don't forget to add a batch dimension) feature_vector_2 = base_model(tf.expand_dims(image_batch[0], axis=0)) feature_vector_2 Out[79]: <tf.Tensor: shape=(1, 1280), dtype=float32, numpy=\narray([[-0.11521906, -0.04476562, -0.12476546, ..., -0.09118073,\n -0.08420841, -0.07769417]], dtype=float32)>
Wonderful!
Now is this the same as our original feature_vector?
We can find out by comparing feature_vector and feature_vector_2 and seeing if all of the values are the same with np.all().
In\u00a0[80]: Copied! # Compare the two feature vectors\nnp.all(feature_vector == feature_vector_2)\n
# Compare the two feature vectors np.all(feature_vector == feature_vector_2) Out[80]: True
Perfect!
Let's put it all together and create a full model for our dog vision problem.
In\u00a0[81]: Copied! # Create a sequential model\ntf.random.set_seed(42)\nsequential_model = tf.keras.Sequential([base_model, # input and middle layers\n tf.keras.layers.Dense(units=len(dog_names), # output layer\n activation=\"softmax\")])\nsequential_model.summary()\n
# Create a sequential model tf.random.set_seed(42) sequential_model = tf.keras.Sequential([base_model, # input and middle layers tf.keras.layers.Dense(units=len(dog_names), # output layer activation=\"softmax\")]) sequential_model.summary() Model: \"sequential\"\n_________________________________________________________________\n Layer (type) Output Shape Param # \n=================================================================\n efficientnetv2-b0 (Functio (None, 1280) 5919312 \n nal) \n \n dense (Dense) (None, 120) 153720 \n \n=================================================================\nTotal params: 6073032 (23.17 MB)\nTrainable params: 153720 (600.47 KB)\nNon-trainable params: 5919312 (22.58 MB)\n_________________________________________________________________\n
Wonderful!
We've now got a model with 6,073,032 parameters, however, only 153,720 of them (the ones in the dense layer) are trainable.
Our dense layer (also called a fully-connected layer or feed-forward layer) takes the outputs of the base_model and performs further calulations on them to map them to our required number of classes (120 for the number of dog breeds).
We use activation=\"softmax\" (the Softmax function) to get prediction probablities, values between 0 and 1 which represent how much our model \"thinks\" a specific image relates to a certain class.
There's another common activation function called Sigmoid. If we only had two classes, for example, \"dog\" or \"cat\", we'd lean towards using this function.
Confusing, yes, but you'll get used to different functions with practice.
The following table summarizes a few use cases.
Activation Function Use Cases Code Sigmoid - When you have two choices (like yes or no, true or false). - In binary classification, where you're deciding between one thing or another (like if an email is spam or not spam). - When you want the output to be a probability between 0 and 1. tf.keras.activations.sigmoid or activation=\"sigmoid\" Softmax - When you have more than two choices. - In multi-class classification, like if you're trying to decide if a picture is of a dog, a cat, a horse, or a bird. - When you want to compare the probabilities across different options and pick the most likely one. tf.keras.activations.softmax or activation=\"softmax\" Now our model is built, let's check our input and output shapes.
In\u00a0[82]: Copied! # Check the input shape\nsequential_model.input_shape\n
# Check the input shape sequential_model.input_shape Out[82]: (None, 224, 224, 3)
In\u00a0[83]: Copied! # Check the output shape\nsequential_model.output_shape\n
# Check the output shape sequential_model.output_shape Out[83]: (None, 120)
Beautiful!
Our sequential model takes in an image tensor of size [None, 224, 224, 3] and outputs a vector of shape [None, 120] where None is the batch size we specify.
Let's try our sequential model out with a single image input.
In\u00a0[84]: Copied! # Get a single image with a batch size of 1\nsingle_image_input = tf.expand_dims(image_batch[0], axis=0)\n\n# Pass the image through our model\nsingle_image_output_sequential = sequential_model(single_image_input)\n\n# Check the output\nsingle_image_output_sequential\n
# Get a single image with a batch size of 1 single_image_input = tf.expand_dims(image_batch[0], axis=0) # Pass the image through our model single_image_output_sequential = sequential_model(single_image_input) # Check the output single_image_output_sequential Out[84]: <tf.Tensor: shape=(1, 120), dtype=float32, numpy=\narray([[0.00783153, 0.01119391, 0.00476165, 0.0072348 , 0.00766934,\n 0.00753752, 0.00522398, 0.02337082, 0.00579716, 0.00539333,\n 0.00549823, 0.01011768, 0.00610076, 0.0109506 , 0.00540159,\n 0.0079683 , 0.01227358, 0.01056393, 0.00507148, 0.00996652,\n 0.00604106, 0.00729022, 0.0155036 , 0.00745004, 0.00628229,\n 0.00796217, 0.00905823, 0.00712278, 0.01243507, 0.006427 ,\n 0.00602891, 0.01276839, 0.00652441, 0.00842482, 0.01247454,\n 0.00749902, 0.01086363, 0.007803 , 0.0058652 , 0.00474356,\n 0.00902809, 0.00715358, 0.00981051, 0.00444271, 0.01031628,\n 0.00691859, 0.00699083, 0.0065892 , 0.00966169, 0.01177148,\n 0.00908043, 0.00729699, 0.00496712, 0.00509035, 0.00584058,\n 0.01068885, 0.00817651, 0.00602052, 0.00901201, 0.01008151,\n 0.00495409, 0.01285929, 0.00480146, 0.0108622 , 0.01421483,\n 0.00814719, 0.00910061, 0.00798947, 0.00789293, 0.00636969,\n 0.00656019, 0.01309155, 0.00754355, 0.00702062, 0.00485884,\n 0.00958675, 0.01086809, 0.00682202, 0.00923016, 0.00856321,\n 0.00482627, 0.01234931, 0.01140433, 0.00771413, 0.01140642,\n 0.00382939, 0.00891482, 0.00409833, 0.00771865, 0.00652135,\n 0.00668143, 0.00935989, 0.00784146, 0.00751913, 0.00785116,\n 0.00794632, 0.0079146 , 0.00798953, 0.01011222, 0.01318719,\n 0.00721227, 0.00736159, 0.01369175, 0.01087009, 0.00510072,\n 0.00843218, 0.00451756, 0.00966478, 0.01013771, 0.00715721,\n 0.00367131, 0.00825834, 0.00832634, 0.01225684, 0.00724481,\n 0.00670675, 0.00536995, 0.01070637, 0.00937007, 0.00998812]],\n dtype=float32)>
Nice!
Our model has output a tensor of prediction probabilities in shape [1, 120], one value for each our dog classes.
Thanks to the softmax function, all of these values are between 0 and 1 and they should all add up to 1 (or close to it).
In\u00a0[85]: Copied! # Sum the output\nnp.sum(single_image_output_sequential)\n
# Sum the output np.sum(single_image_output_sequential) Out[85]: 1.0
Beautiful!
Now how do we figure out which of the values our model thinks is most likely?
We take the index of the highest value!
We can find the index of the highest value using tf.argmax() or np.argmax().
We'll get the highest value (not the index) alongside it.
Let's try.
In\u00a0[86]: Copied! # Find the index with the highest value\nhighest_value_index_sequential_model_output = np.argmax(single_image_output_sequential)\nhighest_value_sequential_model_output = np.max(single_image_output_sequential)\n\nprint(f\"Highest value index: {highest_value_index_sequential_model_output} ({dog_names[highest_value_index_sequential_model_output]})\")\nprint(f\"Prediction probability: {highest_value_sequential_model_output}\")\n # Find the index with the highest value highest_value_index_sequential_model_output = np.argmax(single_image_output_sequential) highest_value_sequential_model_output = np.max(single_image_output_sequential) print(f\"Highest value index: {highest_value_index_sequential_model_output} ({dog_names[highest_value_index_sequential_model_output]})\") print(f\"Prediction probability: {highest_value_sequential_model_output}\") Highest value index: 7 (basenji)\nPrediction probability: 0.023370817303657532\n
Note: these values may change every time due to the model/data being randomly initalized, don't worry too much about them being different, in machine learning randomness is a good thing.
This prediction probability value is quite low.
With the highest potential value being 1.0, it means the model isn't very confident on its prediction.
Let's check the original label value of our single image.
In\u00a0[87]: Copied! # Check the original label value\nprint(f\"Predicted value: {highest_value_index_sequential_model_output}\")\nprint(f\"Actual value: {tf.argmax(label_batch[0]).numpy()}\")\n # Check the original label value print(f\"Predicted value: {highest_value_index_sequential_model_output}\") print(f\"Actual value: {tf.argmax(label_batch[0]).numpy()}\") Predicted value: 7\nActual value: 95\n
Oh no! Looks like our model predicted the wrong label (or if it got it right, it was by pure chance).
This is to be expected.
As although our model comes with pretrained parameters from ImageNet, the dense layer we added on the end is initialized with random parameters.
So in essence, our model is randomly guessing what the label should be.
How do we fix this?
We can train the model to adjust its trainable parameters to better suit the data we're working with.
For completeness let's check out the text-based label our model predicted versus the original label.
In\u00a0[88]: Copied! # Index on class_names with our model's highest prediction probability\nsequential_model_predicted_label = class_names[tf.argmax(sequential_model(tf.expand_dims(image_batch[0], axis=0)), axis=1).numpy()[0]]\n\n# Get the truth label\nsingle_image_ground_truth_label = class_names[tf.argmax(label_batch[0])]\n\n# Print predicted and ground truth labels\nprint(f\"Sequential model predicted label: {sequential_model_predicted_label}\")\nprint(f\"Ground truth label: {single_image_ground_truth_label}\")\n # Index on class_names with our model's highest prediction probability sequential_model_predicted_label = class_names[tf.argmax(sequential_model(tf.expand_dims(image_batch[0], axis=0)), axis=1).numpy()[0]] # Get the truth label single_image_ground_truth_label = class_names[tf.argmax(label_batch[0])] # Print predicted and ground truth labels print(f\"Sequential model predicted label: {sequential_model_predicted_label}\") print(f\"Ground truth label: {single_image_ground_truth_label}\") Sequential model predicted label: basenji\nGround truth label: schipperke\n
In\u00a0[89]: Copied! # 1. Create input layer\ninputs = tf.keras.Input(shape=INPUT_SHAPE)\n\n# 2. Create hidden layer\nx = base_model(inputs, training=False)\n\n# 3. Create the output layer\noutputs = tf.keras.layers.Dense(units=len(class_names), # one output per class\n activation=\"softmax\",\n name=\"output_layer\")(x)\n\n# 4. Connect the inputs and outputs together\nfunctional_model = tf.keras.Model(inputs=inputs,\n outputs=outputs,\n name=\"functional_model\")\n\n# Get a model summary\nfunctional_model.summary()\n
# 1. Create input layer inputs = tf.keras.Input(shape=INPUT_SHAPE) # 2. Create hidden layer x = base_model(inputs, training=False) # 3. Create the output layer outputs = tf.keras.layers.Dense(units=len(class_names), # one output per class activation=\"softmax\", name=\"output_layer\")(x) # 4. Connect the inputs and outputs together functional_model = tf.keras.Model(inputs=inputs, outputs=outputs, name=\"functional_model\") # Get a model summary functional_model.summary() Model: \"functional_model\"\n_________________________________________________________________\n Layer (type) Output Shape Param # \n=================================================================\n input_4 (InputLayer) [(None, 224, 224, 3)] 0 \n \n efficientnetv2-b0 (Functio (None, 1280) 5919312 \n nal) \n \n output_layer (Dense) (None, 120) 153720 \n \n=================================================================\nTotal params: 6073032 (23.17 MB)\nTrainable params: 153720 (600.47 KB)\nNon-trainable params: 5919312 (22.58 MB)\n_________________________________________________________________\n
Functional model created!
Let's try it out.
It works in the same fashion as our sequential_model.
In\u00a0[90]: Copied! # Pass a single image through our functional_model\nsingle_image_output_functional = functional_model(single_image_input)\n\n# Find the index with the highest value\nhighest_value_index_functional_model_output = np.argmax(single_image_output_functional)\nhighest_value_functional_model_output = np.max(single_image_output_functional)\n\nhighest_value_index_functional_model_output, highest_value_functional_model_output\n
# Pass a single image through our functional_model single_image_output_functional = functional_model(single_image_input) # Find the index with the highest value highest_value_index_functional_model_output = np.argmax(single_image_output_functional) highest_value_functional_model_output = np.max(single_image_output_functional) highest_value_index_functional_model_output, highest_value_functional_model_output Out[90]: (69, 0.017855722)
Nice!
Looks like we got a slightly different value to our sequential_model (or they may be the same if randomness wasn't so random).
Why is this?
Because our functional_model was initialized with a random tf.keras.layers.Dense layer as well.
So the outputs of our functional_model are essentially random as well (neural networks start with random numbers and adjust them to better represent patterns in data).
Not to fear, we'll fix this soon when we train our model.
Right now we've created our model with a few scattered lines of code.
How about we functionize the model creation so we can repeat it later on?
In\u00a0[91]: Copied! def create_model(include_top: bool = False,\n num_classes: int = 1000,\n input_shape: tuple[int, int, int] = (224, 224, 3),\n include_preprocessing: bool = True,\n trainable: bool = False,\n dropout: float = 0.2,\n model_name: str = \"model\") -> tf.keras.Model:\n \"\"\"\n Create an EfficientNetV2 B0 feature extractor model with a custom classifier layer.\n\n Args:\n include_top (bool, optional): Whether to include the top (classifier) layers of the model.\n num_classes (int, optional): Number of output classes for the classifier layer.\n input_shape (tuple[int, int, int], optional): Input shape for the model's images (height, width, channels).\n include_preprocessing (bool, optional): Whether to include preprocessing layers for image normalization.\n trainable (bool, optional): Whether to make the base model trainable.\n dropout (float, optional): Dropout rate for the global average pooling layer.\n model_name (str, optional): Name for the created model.\n\n Returns:\n tf.keras.Model: A TensorFlow Keras model with the specified configuration.\n \"\"\"\n # Create base model\n base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(\n include_top=include_top,\n weights=\"imagenet\",\n input_shape=input_shape,\n include_preprocessing=include_preprocessing,\n pooling=\"avg\" # Can use this instead of adding tf.keras.layers.GlobalPooling2D() to the model\n # pooling=\"max\" # Can use this instead of adding tf.keras.layers.MaxPooling2D() to the model\n )\n\n # Freeze the base model (if necessary)\n base_model.trainable = trainable\n\n # Create input layer\n inputs = tf.keras.Input(shape=input_shape, name=\"input_layer\")\n\n # Create model backbone (middle/hidden layers)\n x = base_model(inputs, training=trainable)\n # x = tf.keras.layers.GlobalAveragePooling2D()(x) # note: you should include pooling here if not using `pooling=\"avg\"`\n # x = tf.keras.layers.Dropout(0.2)(x) # optional regularization layer (search \"dropout\" for more)\n\n # Create output layer (also known as \"classifier\" layer)\n outputs = tf.keras.layers.Dense(units=num_classes,\n activation=\"softmax\",\n name=\"output_layer\")(x)\n\n # Connect input and output layer\n model = tf.keras.Model(inputs=inputs,\n outputs=outputs,\n name=model_name)\n\n return model\n
def create_model(include_top: bool = False, num_classes: int = 1000, input_shape: tuple[int, int, int] = (224, 224, 3), include_preprocessing: bool = True, trainable: bool = False, dropout: float = 0.2, model_name: str = \"model\") -> tf.keras.Model: \"\"\" Create an EfficientNetV2 B0 feature extractor model with a custom classifier layer. Args: include_top (bool, optional): Whether to include the top (classifier) layers of the model. num_classes (int, optional): Number of output classes for the classifier layer. input_shape (tuple[int, int, int], optional): Input shape for the model's images (height, width, channels). include_preprocessing (bool, optional): Whether to include preprocessing layers for image normalization. trainable (bool, optional): Whether to make the base model trainable. dropout (float, optional): Dropout rate for the global average pooling layer. model_name (str, optional): Name for the created model. Returns: tf.keras.Model: A TensorFlow Keras model with the specified configuration. \"\"\" # Create base model base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0( include_top=include_top, weights=\"imagenet\", input_shape=input_shape, include_preprocessing=include_preprocessing, pooling=\"avg\" # Can use this instead of adding tf.keras.layers.GlobalPooling2D() to the model # pooling=\"max\" # Can use this instead of adding tf.keras.layers.MaxPooling2D() to the model ) # Freeze the base model (if necessary) base_model.trainable = trainable # Create input layer inputs = tf.keras.Input(shape=input_shape, name=\"input_layer\") # Create model backbone (middle/hidden layers) x = base_model(inputs, training=trainable) # x = tf.keras.layers.GlobalAveragePooling2D()(x) # note: you should include pooling here if not using `pooling=\"avg\"` # x = tf.keras.layers.Dropout(0.2)(x) # optional regularization layer (search \"dropout\" for more) # Create output layer (also known as \"classifier\" layer) outputs = tf.keras.layers.Dense(units=num_classes, activation=\"softmax\", name=\"output_layer\")(x) # Connect input and output layer model = tf.keras.Model(inputs=inputs, outputs=outputs, name=model_name) return model What a beautiful function!
Let's try it out.
In\u00a0[92]: Copied! # Create a model\nmodel_0 = create_model(num_classes=len(class_names))\nmodel_0.summary()\n
# Create a model model_0 = create_model(num_classes=len(class_names)) model_0.summary() Model: \"model\"\n_________________________________________________________________\n Layer (type) Output Shape Param # \n=================================================================\n input_layer (InputLayer) [(None, 224, 224, 3)] 0 \n \n efficientnetv2-b0 (Functio (None, 1280) 5919312 \n nal) \n \n output_layer (Dense) (None, 120) 153720 \n \n=================================================================\nTotal params: 6073032 (23.17 MB)\nTrainable params: 153720 (600.47 KB)\nNon-trainable params: 5919312 (22.58 MB)\n_________________________________________________________________\n
Woohoo! Looks like it worked!
Now how about we inspect each of the layers and whether they're trainable?
In\u00a0[93]: Copied! for layer in model_0.layers:\n print(layer.name, layer.trainable)\n
for layer in model_0.layers: print(layer.name, layer.trainable) input_layer True\nefficientnetv2-b0 False\noutput_layer True\n
Nice, looks like our base_model (efficientnetv2-b0) is frozen (it's not trainable).
And our output_layer is trainable.
This means we'll be reusing the patterns learned in the base_model to feed into our output_layer and then customizing those parameters to suit our own problem.
In\u00a0[94]: Copied! # 1. Create model\nmodel_0 = create_model(num_classes=len(class_names),\n model_name=\"model_0\")\n\nmodel_0.summary()\n
# 1. Create model model_0 = create_model(num_classes=len(class_names), model_name=\"model_0\") model_0.summary() Model: \"model_0\"\n_________________________________________________________________\n Layer (type) Output Shape Param # \n=================================================================\n input_layer (InputLayer) [(None, 224, 224, 3)] 0 \n \n efficientnetv2-b0 (Functio (None, 1280) 5919312 \n nal) \n \n output_layer (Dense) (None, 120) 153720 \n \n=================================================================\nTotal params: 6073032 (23.17 MB)\nTrainable params: 153720 (600.47 KB)\nNon-trainable params: 5919312 (22.58 MB)\n_________________________________________________________________\n
Model created!
How about we compile it?
In\u00a0[95]: Copied! # Create optimizer (short version)\noptimizer = \"adam\"\n\n# The above line is the same as below\noptimizer = tf.keras.optimizers.Adam(learning_rate=0.001)\noptimizer\n
# Create optimizer (short version) optimizer = \"adam\" # The above line is the same as below optimizer = tf.keras.optimizers.Adam(learning_rate=0.001) optimizer Out[95]: <keras.src.optimizers.adam.Adam at 0x7f3bb4107040>
In\u00a0[96]: Copied! # Check that our labels are one-hot encoded\nlabel_batch[0]\n
# Check that our labels are one-hot encoded label_batch[0] Out[96]: <tf.Tensor: shape=(120,), dtype=float32, numpy=\narray([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,\n 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,\n 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,\n 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,\n 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,\n 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,\n 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,\n 0.], dtype=float32)>
Excellent! Looks like our labels are indeed one-hot encoded.
Now let's create our loss function as tf.keras.losses.CategoricalCrossentropy(from_logits=False) or \"categorical_crossentropy\" for short.
We set from_logits=False (this is the default) because our model uses activation=\"softmax\" in the final layer so it's outputing prediction probabilities rather than logits (without activation=\"softmax\" the outputs of our model would be referred to as logits, I'll leave this for extra-curricula investigation).
In\u00a0[97]: Copied! # Create our loss function\nloss = tf.keras.losses.CategoricalCrossentropy(from_logits=False) # use from_logits=False if using an activation function in final layer of model (default)\nloss\n
# Create our loss function loss = tf.keras.losses.CategoricalCrossentropy(from_logits=False) # use from_logits=False if using an activation function in final layer of model (default) loss Out[97]: <keras.src.losses.CategoricalCrossentropy at 0x7f3bb4107430>
In\u00a0[98]: Copied! # Create list of evaluation metrics\nmetrics = [\"accuracy\"]\n
# Create list of evaluation metrics metrics = [\"accuracy\"] In\u00a0[99]: Copied! # Compile model with shortcuts (faster to write code but less customizable)\nmodel_0.compile(optimizer=\"adam\",\n loss=\"categorical_crossentropy\",\n metrics=[\"accuracy\"])\n\n# Compile model with classes (will do the same as above)\nmodel_0.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),\n loss=tf.keras.losses.CategoricalCrossentropy(from_logits=False),\n metrics=[\"accuracy\"])\n
# Compile model with shortcuts (faster to write code but less customizable) model_0.compile(optimizer=\"adam\", loss=\"categorical_crossentropy\", metrics=[\"accuracy\"]) # Compile model with classes (will do the same as above) model_0.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss=tf.keras.losses.CategoricalCrossentropy(from_logits=False), metrics=[\"accuracy\"]) In\u00a0[100]: Copied! # Fit model_0 for 5 epochs\nepochs = 5\nhistory_0 = model_0.fit(x=train_10_percent_ds,\n epochs=epochs,\n validation_data=test_ds)\n
# Fit model_0 for 5 epochs epochs = 5 history_0 = model_0.fit(x=train_10_percent_ds, epochs=epochs, validation_data=test_ds) Epoch 1/5\n38/38 [==============================] - 27s 482ms/step - loss: 3.9758 - accuracy: 0.3000 - val_loss: 3.0500 - val_accuracy: 0.5415\nEpoch 2/5\n38/38 [==============================] - 14s 379ms/step - loss: 2.0531 - accuracy: 0.8008 - val_loss: 1.8650 - val_accuracy: 0.7041\nEpoch 3/5\n38/38 [==============================] - 14s 375ms/step - loss: 1.0491 - accuracy: 0.9025 - val_loss: 1.3060 - val_accuracy: 0.7548\nEpoch 4/5\n38/38 [==============================] - 14s 373ms/step - loss: 0.6138 - accuracy: 0.9483 - val_loss: 1.0317 - val_accuracy: 0.7910\nEpoch 5/5\n38/38 [==============================] - 14s 373ms/step - loss: 0.4157 - accuracy: 0.9683 - val_loss: 0.8927 - val_accuracy: 0.8044\n
Woah!!!
Looks like our model performed outstandingly well!
Achieving a validation accuracy of ~80% after just 5 epochs of training.
That's far better than the original Stanford Dogs paper results of 22% accuracy.
How?
That's the power of transfer learning (and a series of modern updates to neural network architectures, hardware and training regimes)!
But these are just numbers on a page.
We'll get more in-depth on evaluations shortly.
For now, let's do a recap on the 3 steps we've practiced: create, compile, fit.
In\u00a0[101]: Copied! # 1. Create a model\nmodel_0 = create_model(num_classes=len(dog_names))\n\n# 2. Compile the model\nmodel_0.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),\n loss=\"categorical_crossentropy\",\n metrics=[\"accuracy\"])\n\n# 3. Fit the model\nepochs = 5\nhistory_0 = model_0.fit(x=train_10_percent_ds,\n epochs=epochs,\n validation_data=test_ds)\n
# 1. Create a model model_0 = create_model(num_classes=len(dog_names)) # 2. Compile the model model_0.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss=\"categorical_crossentropy\", metrics=[\"accuracy\"]) # 3. Fit the model epochs = 5 history_0 = model_0.fit(x=train_10_percent_ds, epochs=epochs, validation_data=test_ds) Epoch 1/5\n38/38 [==============================] - 22s 418ms/step - loss: 3.9263 - accuracy: 0.3225 - val_loss: 2.9969 - val_accuracy: 0.5549\nEpoch 2/5\n38/38 [==============================] - 14s 379ms/step - loss: 1.9899 - accuracy: 0.7900 - val_loss: 1.8436 - val_accuracy: 0.7063\nEpoch 3/5\n38/38 [==============================] - 14s 380ms/step - loss: 1.0152 - accuracy: 0.9058 - val_loss: 1.2817 - val_accuracy: 0.7702\nEpoch 4/5\n38/38 [==============================] - 14s 376ms/step - loss: 0.5997 - accuracy: 0.9483 - val_loss: 1.0173 - val_accuracy: 0.7945\nEpoch 5/5\n38/38 [==============================] - 14s 374ms/step - loss: 0.4040 - accuracy: 0.9708 - val_loss: 0.8792 - val_accuracy: 0.8107\n
Nice! We just trained our second neural network!
We practice these steps because they will be part of many of your future machine learning workflows.
As an extension, you could create a function called create_and_compile() which does the first two steps in one hit.
Now we've got a trained model, let's get to evaluating it.
In\u00a0[102]: Copied! # Inspect History.history attribute for model_0\nhistory_0.history\n
# Inspect History.history attribute for model_0 history_0.history Out[102]: {'loss': [3.926330089569092,\n 1.9898805618286133,\n 1.0152279138565063,\n 0.599678099155426,\n 0.4040333032608032],\n 'accuracy': [0.32249999046325684,\n 0.7900000214576721,\n 0.9058333039283752,\n 0.9483333230018616,\n 0.9708333611488342],\n 'val_loss': [2.996889591217041,\n 1.8436286449432373,\n 1.2817054986953735,\n 1.0173338651657104,\n 0.8792150616645813],\n 'val_accuracy': [0.5548951029777527,\n 0.7062937021255493,\n 0.7701631784439087,\n 0.7945221662521362,\n 0.8107225894927979]} Wonderful!
We've got a history of our model training over time.
It looks like everything is moving in the right direction.
Loss is going down whilst accuracy is going up.
How about we adhere to the data explorer's motto and write a function to visualize, visualize, visualize!
We'll call the function plot_model_loss_curves() and it'll take a History.history object as input and then plot loss and accuracy curves using matplotlib.
In\u00a0[103]: Copied! def plot_model_loss_curves(history: tf.keras.callbacks.History) -> None:\n \"\"\"Takes a History object and plots loss and accuracy curves.\"\"\"\n\n # Get the accuracy values\n acc = history.history[\"accuracy\"]\n val_acc = history.history[\"val_accuracy\"]\n\n # Get the loss values\n loss = history.history[\"loss\"]\n val_loss = history.history[\"val_loss\"]\n\n # Get the number of epochs\n epochs_range = range(len(acc))\n\n # Create accuracy curves plot\n plt.figure(figsize=(14, 7))\n plt.subplot(1, 2, 1)\n plt.plot(epochs_range, acc, label=\"Training Accuracy\")\n plt.plot(epochs_range, val_acc, label=\"Validation Accuracy\")\n plt.legend(loc=\"lower right\")\n plt.title(\"Training and Validation Accuracy\")\n plt.xlabel(\"Epoch\")\n plt.ylabel(\"Accuracy\")\n\n # Create loss curves plot\n plt.subplot(1, 2, 2)\n plt.plot(epochs_range, loss, label=\"Training Loss\")\n plt.plot(epochs_range, val_loss, label=\"Validation Loss\")\n plt.legend(loc=\"upper right\")\n plt.title(\"Training and Validation Loss\")\n plt.xlabel(\"Epoch\")\n plt.ylabel(\"Loss\")\n\n plt.show()\n\nplot_model_loss_curves(history=history_0)\n
def plot_model_loss_curves(history: tf.keras.callbacks.History) -> None: \"\"\"Takes a History object and plots loss and accuracy curves.\"\"\" # Get the accuracy values acc = history.history[\"accuracy\"] val_acc = history.history[\"val_accuracy\"] # Get the loss values loss = history.history[\"loss\"] val_loss = history.history[\"val_loss\"] # Get the number of epochs epochs_range = range(len(acc)) # Create accuracy curves plot plt.figure(figsize=(14, 7)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=\"Training Accuracy\") plt.plot(epochs_range, val_acc, label=\"Validation Accuracy\") plt.legend(loc=\"lower right\") plt.title(\"Training and Validation Accuracy\") plt.xlabel(\"Epoch\") plt.ylabel(\"Accuracy\") # Create loss curves plot plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=\"Training Loss\") plt.plot(epochs_range, val_loss, label=\"Validation Loss\") plt.legend(loc=\"upper right\") plt.title(\"Training and Validation Loss\") plt.xlabel(\"Epoch\") plt.ylabel(\"Loss\") plt.show() plot_model_loss_curves(history=history_0) Woohoo! Now those are some nice looking curves.
Our model is doing exactly what we'd like it to do.
The accuracy is moving up while the loss is going down.
In\u00a0[104]: Copied! # Evaluate model_0, see: https://www.tensorflow.org/api_docs/python/tf/keras/Model#evaluate\nmodel_0_results = model_0.evaluate(x=test_ds)\nmodel_0_results\n
# Evaluate model_0, see: https://www.tensorflow.org/api_docs/python/tf/keras/Model#evaluate model_0_results = model_0.evaluate(x=test_ds) model_0_results 269/269 [==============================] - 13s 47ms/step - loss: 0.8792 - accuracy: 0.8107\n
Out[104]: [0.8792150616645813, 0.8107225894927979]
Beautiful!
Evaluating our model on the test data shows it's performing at ~80% accuracy despite only seeing 10% of the training data.
We can also get the metrics used by our model with the metrics_names attribute.
In\u00a0[105]: Copied! # Get our model's metrics names\nmodel_0.metrics_names\n
# Get our model's metrics names model_0.metrics_names Out[105]: ['loss', 'accuracy']
In\u00a0[106]: Copied! # 1. Create model_1 (the next iteration of model_0)\nmodel_1 = create_model(num_classes=len(class_names),\n model_name=\"model_1\")\n\n# 2. Compile model\nmodel_1.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),\n loss=\"categorical_crossentropy\",\n metrics=[\"accuracy\"])\n\n# 3. Fit model\nepochs=5\nhistory_1 = model_1.fit(x=train_ds,\n epochs=epochs,\n validation_data=test_ds)\n
# 1. Create model_1 (the next iteration of model_0) model_1 = create_model(num_classes=len(class_names), model_name=\"model_1\") # 2. Compile model model_1.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss=\"categorical_crossentropy\", metrics=[\"accuracy\"]) # 3. Fit model epochs=5 history_1 = model_1.fit(x=train_ds, epochs=epochs, validation_data=test_ds) Epoch 1/5\n375/375 [==============================] - 43s 84ms/step - loss: 1.2725 - accuracy: 0.7607 - val_loss: 0.4849 - val_accuracy: 0.8756\nEpoch 2/5\n375/375 [==============================] - 30s 80ms/step - loss: 0.3667 - accuracy: 0.9013 - val_loss: 0.4041 - val_accuracy: 0.8770\nEpoch 3/5\n375/375 [==============================] - 30s 79ms/step - loss: 0.2641 - accuracy: 0.9287 - val_loss: 0.3731 - val_accuracy: 0.8832\nEpoch 4/5\n375/375 [==============================] - 30s 80ms/step - loss: 0.2043 - accuracy: 0.9483 - val_loss: 0.3708 - val_accuracy: 0.8819\nEpoch 5/5\n375/375 [==============================] - 30s 80ms/step - loss: 0.1606 - accuracy: 0.9633 - val_loss: 0.3753 - val_accuracy: 0.8767\n
Woah!
Was your intuition correct?
Did what you thought would happen actually happen?
It looks like all that extra data helped our model quite a bit, it's now performing at close to ~90% accuracy on the test set!
Question: How many epochs should I fit for? Generally with transfer learning you can get pretty good results quite quickly, however, you may want to look into training for longer (more epochs) as an experiment to see whether your model improves or not. What we've performed is a transfer learning technique called feature extraction, however, you may want to look further into fine-tuning (training the whole model to your own dataset) whole model and using callbacks (functions that take place during model training) such as Early Stopping to prevent the model from training so long its performance begins to degrade.
In\u00a0[107]: Copied! # Plot model_1 loss curves\nplot_model_loss_curves(history=history_1)\n
# Plot model_1 loss curves plot_model_loss_curves(history=history_1) Hmm, looks like our model performed well, however the validation accuracy and loss seemed to flatten out.
Whereas, the training accuracy and loss seemed to keep improving.
This is a sign of overfitting (model performing much better on the training set than the validation/test set).
However, since our model looks to be performing quite well I'll leave this overfitting problem as a research project for extra-curriculum.
For now, let's evaluate our model on the test dataset using the evaluate() method.
In\u00a0[108]: Copied! # Evaluate model_1\nmodel_1_results = model_1.evaluate(test_ds)\n
# Evaluate model_1 model_1_results = model_1.evaluate(test_ds) 269/269 [==============================] - 12s 46ms/step - loss: 0.3753 - accuracy: 0.8767\n
Nice!
Looks like that extra data boosted our models performance from ~80% on the test set to ~90% on test set (note: exact numbers here may vary due to the inherit randomness in machine learning models).
Extension: Putting it all together As a potential extension, you may want to try practicing putting all of the steps we've been through so far together. As in, loading the data, creating the model, compiling the model, fitting the model and evaluating the model. That's what I've found is one of the best ways to learn ML problems, replicating a system end to end.
In\u00a0[109]: Copied! # This will output logits (as long as softmax activation isn't in the model)\ntest_preds = model_1.predict(test_ds)\n\n# Note: If not using activation=\"softmax\" in last layer of model, may need to turn them into prediction probabilities (easier to understand)\n# test_preds = tf.keras.activations.softmax(tf.constant(test_preds), axis=-1)\n
# This will output logits (as long as softmax activation isn't in the model) test_preds = model_1.predict(test_ds) # Note: If not using activation=\"softmax\" in last layer of model, may need to turn them into prediction probabilities (easier to understand) # test_preds = tf.keras.activations.softmax(tf.constant(test_preds), axis=-1) 269/269 [==============================] - 13s 44ms/step\n
Let's inspect our test_preds by first checking its shape.
In\u00a0[110]: Copied! test_preds.shape\n
test_preds.shape Out[110]: (8580, 120)
Okay, looks like our test_pred variable contains 8580 values (one for each test sample) with 120 elements (one value for each dog class).
Let's inspect a single test prediction and see what it looks like.
In\u00a0[111]: Copied! # Get a \"random\" variable between all of the test samples\nrandom.seed(42)\nrandom_test_index = random.randint(0, test_preds.shape[0] - 1)\nprint(f\"[INFO] Random test index: {random_test_index}\")\n\n# Inspect a single test prediction sample\nrandom_test_pred_sample = test_preds[random_test_index]\n\nprint(f\"[INFO] Random test pred sample shape: {random_test_pred_sample.shape}\")\nprint(f\"[INFO] Random test pred sample argmax: {tf.argmax(random_test_pred_sample)}\")\nprint(f\"[INFO] Random test pred sample label: {dog_names[tf.argmax(random_test_pred_sample)]}\")\nprint(f\"[INFO] Random test pred sample max prediction probability: {tf.reduce_max(random_test_pred_sample)}\")\nprint(f\"[INFO] Random test pred sample prediction probability values:\\n{random_test_pred_sample}\")\n # Get a \"random\" variable between all of the test samples random.seed(42) random_test_index = random.randint(0, test_preds.shape[0] - 1) print(f\"[INFO] Random test index: {random_test_index}\") # Inspect a single test prediction sample random_test_pred_sample = test_preds[random_test_index] print(f\"[INFO] Random test pred sample shape: {random_test_pred_sample.shape}\") print(f\"[INFO] Random test pred sample argmax: {tf.argmax(random_test_pred_sample)}\") print(f\"[INFO] Random test pred sample label: {dog_names[tf.argmax(random_test_pred_sample)]}\") print(f\"[INFO] Random test pred sample max prediction probability: {tf.reduce_max(random_test_pred_sample)}\") print(f\"[INFO] Random test pred sample prediction probability values:\\n{random_test_pred_sample}\") [INFO] Random test index: 1824\n[INFO] Random test pred sample shape: (120,)\n[INFO] Random test pred sample argmax: 24\n[INFO] Random test pred sample label: brittany_spaniel\n[INFO] Random test pred sample max prediction probability: 0.9248308539390564\n[INFO] Random test pred sample prediction probability values:\n[3.0155065e-06 4.2946940e-05 3.2878995e-06 3.1306336e-05 1.7298260e-06\n 1.3368123e-05 2.8498230e-06 6.8758955e-06 2.6828552e-06 4.6089318e-04\n 9.8374185e-06 1.9263330e-06 7.6487186e-07 6.1217276e-04 1.2198443e-06\n 5.9309714e-06 2.4797799e-05 2.5847612e-06 4.9912862e-05 3.1809162e-07\n 1.0326848e-06 2.7293386e-06 2.1035332e-06 5.2793930e-06 9.2483085e-01\n 2.6070888e-06 1.6410323e-06 1.4008251e-06 2.0515323e-05 2.1309786e-05\n 1.4602327e-06 3.8456672e-04 7.4974610e-05 4.4831428e-05 5.5091264e-06\n 2.1345174e-07 2.9732748e-06 5.5520386e-06 8.7954652e-07 1.6277906e-03\n 5.3978354e-02 9.6090174e-05 9.6672220e-06 4.4037843e-06 2.5557700e-05\n 6.3994042e-07 1.6738920e-06 4.6715216e-04 4.1448075e-06 6.4118845e-05\n 2.0398900e-06 3.6135450e-06 4.4963690e-05 2.8406910e-05 3.4689847e-07\n 6.2964758e-04 9.1336078e-05 5.2363583e-05 1.2731762e-06 2.4212743e-06\n 1.5872080e-06 6.3476455e-06 6.2880179e-07 6.6757898e-06 1.6635622e-06\n 4.3550008e-07 2.3698403e-05 1.4149221e-05 3.8156581e-05 1.0464001e-05\n 5.0107906e-06 1.7395665e-06 2.8848885e-07 4.2622072e-05 3.2712339e-07\n 1.8591476e-07 2.2874669e-05 7.9814470e-07 2.3121322e-05 1.6275973e-06\n 4.6186727e-07 7.6188849e-07 3.2468931e-06 3.1449999e-05 2.9600946e-05\n 3.8992380e-06 2.8564186e-06 4.1459539e-06 6.0877244e-07 2.5443229e-05\n 5.4467969e-06 5.4184858e-07 2.8361776e-04 9.0548929e-05 8.8840829e-07\n 9.1714105e-07 1.9990568e-07 1.7958368e-05 7.7042150e-06 2.4126435e-05\n 1.9759838e-05 8.2941342e-06 2.5857928e-05 6.1904398e-06 1.4601937e-06\n 1.5800337e-05 6.0928446e-06 5.0209674e-05 1.4067524e-05 2.3544631e-05\n 1.4134421e-06 9.8844721e-05 9.1535941e-05 2.4448002e-03 5.8540131e-06\n 1.2547853e-02 1.3779800e-05 8.0164841e-07 2.5093528e-05 3.7180773e-05]\n
Okay looks like each individual sample of our test predictions is a tensor of prediction probabilities.
In essence, each element is a probability between 0 and 1 as to how confident our model is whether the prediction is correct or not.
A prediction probability of 1 means the model is 100% confident the given sample belongs to that class.
A prediction probability of 0 means the model isn't assigning any value value to that class at all.
And then all the other values fill in between.
Note: Just because a model's prediction probability for a particular sample is closer to 1 on a certain class (e.g. 0.9999) doesn't mean it is correct. A prediction can have a high probability but still be incorrect. We'll see this later on in the \"most wrong\" section.
The maximum value of our prediction probabilities tensor is what the model considers is the most likely prediction given the specific sample.
We take the index of the maximum value (using tf.argmax) and index on the list of dog names to get the predicted class name.
Note: tf.argmax or \"argmax\" for short gets the index of where the maximum value occurs in a tensor along a specified dimension. We can use tf.reduce_max to get the maximum value itself.
To make our predictions easier to compare to the test dataset, let's unbundle our test_ds object into two separate arrays called test_ds_images and test_ds_labels.
We can do this by looping through the samples in our test_ds object and appending each to a list (we'll do this with a list comprehension).
Then we can join those lists together into an array with np.concatenate.
In\u00a0[112]: Copied! import numpy as np\n\n# Extract test images and labels from test_ds\ntest_ds_images = np.concatenate([images for images, labels in test_ds], axis=0)\ntest_ds_labels = np.concatenate([labels for images, labels in test_ds], axis=0)\n\n# How many images and labels do we have?\nlen(test_ds_images), len(test_ds_labels)\n
import numpy as np # Extract test images and labels from test_ds test_ds_images = np.concatenate([images for images, labels in test_ds], axis=0) test_ds_labels = np.concatenate([labels for images, labels in test_ds], axis=0) # How many images and labels do we have? len(test_ds_images), len(test_ds_labels) Out[112]: (8580, 8580)
Perfect!
Now we've got a way to compare our predictions on a given image (in test_ds_images) to its appropriate label in test_ds_labels.
This is one of the main reasons we didn't shuffle the test dataset.
Because now our predictions tensor has the same indexes as our test_ds_images and test_ds_labels arrays.
Meaning if we chose to compare sample number 42, everything would line up.
In fact, let's try just that.
In\u00a0[113]: Copied! # Set target index\ntarget_index = 42 # try changing this to another value and seeing how the model performs on other samples\n\n# Get test image\ntest_image = test_ds_images[target_index]\n\n# Get truth label (index of max in test label)\ntest_image_truth_label = class_names[tf.argmax(test_ds_labels[target_index])]\n\n# Get prediction probabilities\ntest_image_pred_probs = test_preds[target_index]\n\n# Get index of class with highest prediction probability\ntest_image_pred_class = class_names[tf.argmax(test_image_pred_probs)]\n\n# Plot the image\nplt.figure(figsize=(5, 4))\nplt.imshow(test_image.astype(\"uint8\"))\n\n# Create sample title with prediction probability value\ntitle = f\"\"\"True: {test_image_truth_label}\nPred: {test_image_pred_class}\nProb: {np.max(test_image_pred_probs):.2f}\"\"\"\n\n# Colour the title based on correctness of pred\nplt.title(title,\n color=\"green\" if test_image_truth_label == test_image_pred_class else \"red\")\nplt.axis(\"off\");\n # Set target index target_index = 42 # try changing this to another value and seeing how the model performs on other samples # Get test image test_image = test_ds_images[target_index] # Get truth label (index of max in test label) test_image_truth_label = class_names[tf.argmax(test_ds_labels[target_index])] # Get prediction probabilities test_image_pred_probs = test_preds[target_index] # Get index of class with highest prediction probability test_image_pred_class = class_names[tf.argmax(test_image_pred_probs)] # Plot the image plt.figure(figsize=(5, 4)) plt.imshow(test_image.astype(\"uint8\")) # Create sample title with prediction probability value title = f\"\"\"True: {test_image_truth_label} Pred: {test_image_pred_class} Prob: {np.max(test_image_pred_probs):.2f}\"\"\" # Colour the title based on correctness of pred plt.title(title, color=\"green\" if test_image_truth_label == test_image_pred_class else \"red\") plt.axis(\"off\"); Woohoo!!! Look at that!
Looks like our model got the prediction right, according to the test data, sample number 42 is in fact an Affenpinscher.
Doing a quick search on Google for Affenpinscher seems to return similar looking dogs too.
Our model is working!
For sample 42 at least...
As an exercise you could try to change the target index above, perhaps to your favourite number and see how the model goes.
But we could also write some code to test a number of different samples at a time.
In\u00a0[114]: Copied! # Choose a random 10 indexes from the test data and compare the values\nimport random\n\nrandom.seed(42) # try changing the random seed or commenting it out for different values\nrandom_indexes = random.sample(range(len(test_ds_images)), 10)\n\n# Create a plot with multiple subplots\nfig, axes = plt.subplots(2, 5, figsize=(15, 7))\n\n# Loop through the axes of the plot\nfor i, ax in enumerate(axes.flatten()):\n target_index = random_indexes[i] # get a random index (this is another reason we didn't shuffle the test set)\n\n # Get relevant target image, label, prediction and prediction probabilities\n test_image = test_ds_images[target_index]\n test_image_truth_label = class_names[tf.argmax(test_ds_labels[target_index])]\n test_image_pred_probs = test_preds[target_index]\n test_image_pred_class = class_names[tf.argmax(test_image_pred_probs)]\n\n # Plot the image\n ax.imshow(test_image.astype(\"uint8\"))\n\n # Create sample title\n title = f\"\"\"True: {test_image_truth_label}\n Pred: {test_image_pred_class}\n Prob: {np.max(test_image_pred_probs):.2f}\"\"\"\n\n # Colour the title based on correctness of pred\n ax.set_title(title,\n color=\"green\" if test_image_truth_label == test_image_pred_class else \"red\")\n ax.axis(\"off\")\n # Choose a random 10 indexes from the test data and compare the values import random random.seed(42) # try changing the random seed or commenting it out for different values random_indexes = random.sample(range(len(test_ds_images)), 10) # Create a plot with multiple subplots fig, axes = plt.subplots(2, 5, figsize=(15, 7)) # Loop through the axes of the plot for i, ax in enumerate(axes.flatten()): target_index = random_indexes[i] # get a random index (this is another reason we didn't shuffle the test set) # Get relevant target image, label, prediction and prediction probabilities test_image = test_ds_images[target_index] test_image_truth_label = class_names[tf.argmax(test_ds_labels[target_index])] test_image_pred_probs = test_preds[target_index] test_image_pred_class = class_names[tf.argmax(test_image_pred_probs)] # Plot the image ax.imshow(test_image.astype(\"uint8\")) # Create sample title title = f\"\"\"True: {test_image_truth_label} Pred: {test_image_pred_class} Prob: {np.max(test_image_pred_probs):.2f}\"\"\" # Colour the title based on correctness of pred ax.set_title(title, color=\"green\" if test_image_truth_label == test_image_pred_class else \"red\") ax.axis(\"off\") Woah, looks like our model does quite well!
Try commenting out the random.seed() line and inspecting a few more dog photos, you might notice that model doesn't get too many wrong!
In\u00a0[115]: Copied! # Get argmax labels of test predictions and test ground truth\ntest_preds_labels = test_preds.argmax(axis=-1)\ntest_ds_labels_argmax = test_ds_labels.argmax(axis=-1)\n\n# Get highest prediction probability of test predictions\ntest_pred_probs_max = tf.reduce_max(test_preds, axis=-1).numpy() # extract NumPy since pandas doesn't handle TensorFlow Tensors\n\n# Create DataFram of test results\ntest_results_df = pd.DataFrame({\"test_pred_label\": test_preds_labels,\n \"test_pred_prob\": test_pred_probs_max,\n \"test_pred_class_name\": [class_names[test_pred_label] for test_pred_label in test_preds_labels],\n \"test_truth_label\": test_ds_labels_argmax,\n \"test_truth_class_name\": [class_names[test_truth_label] for test_truth_label in test_ds_labels_argmax]})\n\n# Create a column whether or not the prediction matches the label\ntest_results_df[\"correct\"] = test_results_df[\"test_pred_class_name\"] == test_results_df[\"test_truth_class_name\"]\n\ntest_results_df.head()\n # Get argmax labels of test predictions and test ground truth test_preds_labels = test_preds.argmax(axis=-1) test_ds_labels_argmax = test_ds_labels.argmax(axis=-1) # Get highest prediction probability of test predictions test_pred_probs_max = tf.reduce_max(test_preds, axis=-1).numpy() # extract NumPy since pandas doesn't handle TensorFlow Tensors # Create DataFram of test results test_results_df = pd.DataFrame({\"test_pred_label\": test_preds_labels, \"test_pred_prob\": test_pred_probs_max, \"test_pred_class_name\": [class_names[test_pred_label] for test_pred_label in test_preds_labels], \"test_truth_label\": test_ds_labels_argmax, \"test_truth_class_name\": [class_names[test_truth_label] for test_truth_label in test_ds_labels_argmax]}) # Create a column whether or not the prediction matches the label test_results_df[\"correct\"] = test_results_df[\"test_pred_class_name\"] == test_results_df[\"test_truth_class_name\"] test_results_df.head() Out[115]: test_pred_label test_pred_prob test_pred_class_name test_truth_label test_truth_class_name correct 0 0 0.974350 affenpinscher 0 affenpinscher True 1 0 0.694450 affenpinscher 0 affenpinscher True 2 0 0.993829 affenpinscher 0 affenpinscher True 3 44 0.691742 flat_coated_retriever 0 affenpinscher False 4 0 0.989754 affenpinscher 0 affenpinscher True What a cool looking DataFrame!
Now we can perform some further analysis.
Such as getting the accuracy per class.
We can do so by grouping the test_results_df via the \"test_truth_class_name\" column and then taking the mean of the \"correct\" column.
We can then create a new DataFrame based on this view and sort the values by correctness (e.g. the classes with the highest performance should be up the top).
In\u00a0[116]: Copied! # Calculate accuracy per class\naccuracy_per_class = test_results_df.groupby(\"test_truth_class_name\")[\"correct\"].mean()\n\n# Create new DataFrame to sort classes by accuracy\naccuracy_per_class_df = pd.DataFrame(accuracy_per_class).reset_index().sort_values(\"correct\", ascending=False)\naccuracy_per_class_df.head()\n
# Calculate accuracy per class accuracy_per_class = test_results_df.groupby(\"test_truth_class_name\")[\"correct\"].mean() # Create new DataFrame to sort classes by accuracy accuracy_per_class_df = pd.DataFrame(accuracy_per_class).reset_index().sort_values(\"correct\", ascending=False) accuracy_per_class_df.head() Out[116]: test_truth_class_name correct 10 bedlington_terrier 1.000000 62 keeshond 1.000000 30 chow 0.989583 92 saint_bernard 0.985714 2 african_hunting_dog 0.985507 Woah! Looks like we've got a fair few dog classes with close to (or exactly) 100% accuracy!
That's outstanding!
Now let's recreate the horizontal bar plot used on the original Stanford Dogs research paper page.
In\u00a0[117]: Copied! # Let's create a horizontal bar chart to replicate a similar plot to the original Stanford Dogs page\nplt.figure(figsize=(10, 17))\nplt.barh(y=accuracy_per_class_df[\"test_truth_class_name\"],\n width=accuracy_per_class_df[\"correct\"])\nplt.xlabel(\"Accuracy\")\nplt.ylabel(\"Class Name\")\nplt.title(\"Dog Vision Accuracy per Class\")\nplt.ylim(-0.5, len(accuracy_per_class_df[\"test_truth_class_name\"]) - 0.5) # Adjust y-axis limits to reduce white space\nplt.gca().invert_yaxis() # This will display the first class at the top\nplt.tight_layout()\nplt.show()\n
# Let's create a horizontal bar chart to replicate a similar plot to the original Stanford Dogs page plt.figure(figsize=(10, 17)) plt.barh(y=accuracy_per_class_df[\"test_truth_class_name\"], width=accuracy_per_class_df[\"correct\"]) plt.xlabel(\"Accuracy\") plt.ylabel(\"Class Name\") plt.title(\"Dog Vision Accuracy per Class\") plt.ylim(-0.5, len(accuracy_per_class_df[\"test_truth_class_name\"]) - 0.5) # Adjust y-axis limits to reduce white space plt.gca().invert_yaxis() # This will display the first class at the top plt.tight_layout() plt.show() Goodness me!
Looks like our model performs incredibly well across all the vast majority of classes.
Comparing it to the original Stanford Dogs horizontal bar graph we can see that their best performing class got close to 60% accuracy.
However, it's only when we take a look at our worst performing classes do we see a handful of classes just under 60% accuracy.
In\u00a0[118]: Copied! # Inspecting our worst performing classes (note how only a couple of classes perform at ~55% accuracy or below)\naccuracy_per_class_df.tail()\n
# Inspecting our worst performing classes (note how only a couple of classes perform at ~55% accuracy or below) accuracy_per_class_df.tail() Out[118]: test_truth_class_name correct 104 staffordshire_bullterrier 0.672727 76 miniature_poodle 0.654545 90 rhodesian_ridgeback 0.638889 71 malamute 0.615385 101 siberian_husky 0.271739 What an awesome result!
We've now replicated and even vastly improved a Stanford research paper.
You should be proud!
Now we've seen how well our model performs, how about we check where its performed poorly?
In\u00a0[119]: Copied! # Get most wrong\ntop_100_most_wrong = test_results_df[test_results_df[\"correct\"] == 0].sort_values(\"test_pred_prob\", ascending=False)[:100]\ntop_100_most_wrong.head()\n
# Get most wrong top_100_most_wrong = test_results_df[test_results_df[\"correct\"] == 0].sort_values(\"test_pred_prob\", ascending=False)[:100] top_100_most_wrong.head() Out[119]: test_pred_label test_pred_prob test_pred_class_name test_truth_label test_truth_class_name correct 2727 75 0.997043 miniature_pinscher 38 doberman False 5480 44 0.995325 flat_coated_retriever 78 newfoundland False 6884 54 0.994142 groenendael 95 schipperke False 4155 55 0.987126 ibizan_hound 60 italian_greyhound False 1715 85 0.984834 pekinese 22 brabancon_griffon False One way would be to inspect these most wrong predictions would be to go through the different breeds one by one and see why the model would've confused them.
Such as comparing miniature_pinscher to doberman (two quite similar looking dog breeds).
Alternatively, we could get a random 10 samples and plot them to see what they look like.
Let's do the latter!
In\u00a0[120]: Copied! # Get 10 random indexes of \"most wrong\" predictions\ntop_100_most_wrong.sample(n=10).index\n
# Get 10 random indexes of \"most wrong\" predictions top_100_most_wrong.sample(n=10).index Out[120]: Index([2001, 1715, 8112, 1642, 5480, 6383, 7363, 4155, 7895, 4105], dtype='int64')
How about we plot these indexes?
In\u00a0[121]: Copied! # Choose a random 10 indexes from the test data and compare the values\nimport random\n\nrandom_most_wrong_indexes = top_100_most_wrong.sample(n=10).index\n\n# Iterate through test results and plot them\n# Note: This is why we don't shuffle the test data, so that it's in original order when we evaluate it.\nfig, axes = plt.subplots(2, 5, figsize=(15, 7))\nfor i, ax in enumerate(axes.flatten()):\n target_index = random_most_wrong_indexes[i]\n\n # Get relevant target image, label, prediction and prediction probabilities\n test_image = test_ds_images[target_index]\n test_image_truth_label = class_names[tf.argmax(test_ds_labels[target_index])]\n test_image_pred_probs = test_preds[target_index]\n test_image_pred_class = class_names[tf.argmax(test_image_pred_probs)]\n\n # Plot the image\n ax.imshow(test_image.astype(\"uint8\"))\n\n # Create sample title\n title = f\"\"\"True: {test_image_truth_label}\n Pred: {test_image_pred_class}\n Prob: {np.max(test_image_pred_probs):.2f}\"\"\"\n\n # Colour the title based on correctness of pred\n ax.set_title(title,\n color=\"green\" if test_image_truth_label == test_image_pred_class else \"red\",\n fontsize=10)\n ax.axis(\"off\")\n # Choose a random 10 indexes from the test data and compare the values import random random_most_wrong_indexes = top_100_most_wrong.sample(n=10).index # Iterate through test results and plot them # Note: This is why we don't shuffle the test data, so that it's in original order when we evaluate it. fig, axes = plt.subplots(2, 5, figsize=(15, 7)) for i, ax in enumerate(axes.flatten()): target_index = random_most_wrong_indexes[i] # Get relevant target image, label, prediction and prediction probabilities test_image = test_ds_images[target_index] test_image_truth_label = class_names[tf.argmax(test_ds_labels[target_index])] test_image_pred_probs = test_preds[target_index] test_image_pred_class = class_names[tf.argmax(test_image_pred_probs)] # Plot the image ax.imshow(test_image.astype(\"uint8\")) # Create sample title title = f\"\"\"True: {test_image_truth_label} Pred: {test_image_pred_class} Prob: {np.max(test_image_pred_probs):.2f}\"\"\" # Colour the title based on correctness of pred ax.set_title(title, color=\"green\" if test_image_truth_label == test_image_pred_class else \"red\", fontsize=10) ax.axis(\"off\") Inspecting the \"most wrong\" examples, it's easy to see where the model got confused.
These samples can show us where we might want to collect more data or correct our data's labels.
Speaking of confused, how about we make a confusion matrix for further evaluation?
In\u00a0[122]: Copied! from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay\n\n# Create a confusion matrix\nconfusion_matrix_dog_preds = confusion_matrix(y_true=test_ds_labels_argmax, # requires all labels to be in same format (e.g. not one-hot)\n y_pred=test_preds_labels)\n# Create a confusion matrix plot\nconfusion_matrix_display = ConfusionMatrixDisplay(confusion_matrix=confusion_matrix_dog_preds,\n display_labels=class_names)\nfig, ax = plt.subplots(figsize=(25, 25))\nax.set_title(\"Dog Vision Confusion Matrix\")\nconfusion_matrix_display.plot(xticks_rotation=\"vertical\",\n cmap=\"Blues\",\n colorbar=False,\n ax=ax);\n
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay # Create a confusion matrix confusion_matrix_dog_preds = confusion_matrix(y_true=test_ds_labels_argmax, # requires all labels to be in same format (e.g. not one-hot) y_pred=test_preds_labels) # Create a confusion matrix plot confusion_matrix_display = ConfusionMatrixDisplay(confusion_matrix=confusion_matrix_dog_preds, display_labels=class_names) fig, ax = plt.subplots(figsize=(25, 25)) ax.set_title(\"Dog Vision Confusion Matrix\") confusion_matrix_display.plot(xticks_rotation=\"vertical\", cmap=\"Blues\", colorbar=False, ax=ax); Now that's one big confusion matrix!
It looks like most of the darker blue boxes are down the middle diagonal (we we'd like them to be).
But there are a few instances where the model confuses classes such as scottish_deerhound and irish_wolfhound.
And looking up those two breeds we can see that they look visually similar.
In\u00a0[123]: Copied! # Save the model to .keras\nmodel_save_path = \"dog_vision_model.keras\"\nmodel_1.save(filepath=model_save_path,\n save_format=\"keras\")\n
# Save the model to .keras model_save_path = \"dog_vision_model.keras\" model_1.save(filepath=model_save_path, save_format=\"keras\") Model saved!
And we can load it back in using the tf.keras.models.load_model() method.
In\u00a0[124]: Copied! # Load the model\nloaded_model = tf.keras.models.load_model(filepath=model_save_path)\n
# Load the model loaded_model = tf.keras.models.load_model(filepath=model_save_path) And now we can evaluate our loaded_model to make sure it performs well on the test dataset.
In\u00a0[125]: Copied! # Evaluate the loaded model\nloaded_model_results = loaded_model.evaluate(test_ds)\n
# Evaluate the loaded model loaded_model_results = loaded_model.evaluate(test_ds) 269/269 [==============================] - 15s 47ms/step - loss: 0.3753 - accuracy: 0.8767\n
How about we check if the loaded_model_results are the same as the model_1_results?
In\u00a0[126]: Copied! assert model_1_results == loaded_model_results\n
assert model_1_results == loaded_model_results Our trained model and loaded model results are the same!
We could now use our dog_vision_model.keras file in an application to predict a dog breed based on an image.
Note: If you're using Google Colab, remember that after a period of time if you Google Colab instance gets disconnected, it will delete all local files. So if you want to keep your dog_vision_model.keras be sure to download it or copy it to Google Drive.
In\u00a0[127]: Copied! # Download a set of custom images from GitHub and unzip them\n!wget -nc https://github.com/mrdbourke/zero-to-mastery-ml/raw/master/images/dog-photos.zip\n!unzip dog-photos.zip\n
# Download a set of custom images from GitHub and unzip them !wget -nc https://github.com/mrdbourke/zero-to-mastery-ml/raw/master/images/dog-photos.zip !unzip dog-photos.zip --2024-04-26 01:43:26-- https://github.com/mrdbourke/zero-to-mastery-ml/raw/master/images/dog-photos.zip\nResolving github.com (github.com)... 140.82.113.4\nConnecting to github.com (github.com)|140.82.113.4|:443... connected.\nHTTP request sent, awaiting response... 302 Found\nLocation: https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/images/dog-photos.zip [following]\n--2024-04-26 01:43:26-- https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/images/dog-photos.zip\nResolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...\nConnecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 1091355 (1.0M) [application/zip]\nSaving to: \u2018dog-photos.zip\u2019\n\ndog-photos.zip 100%[===================>] 1.04M --.-KB/s in 0.05s \n\n2024-04-26 01:43:27 (21.6 MB/s) - \u2018dog-photos.zip\u2019 saved [1091355/1091355]\n\nArchive: dog-photos.zip\n inflating: dog-photo-4.jpeg \n inflating: dog-photo-1.jpeg \n inflating: dog-photo-2.jpeg \n inflating: dog-photo-3.jpeg \n
Wonderful! We can inspect our images in the file browser and see that they're under the name dog-photo-*.jpeg.
How about we iterate through them and visualize each one?
In\u00a0[128]: Copied! # Create list of paths for custom dog images\ncustom_image_paths = [\"dog-photo-1.jpeg\",\n \"dog-photo-2.jpeg\",\n \"dog-photo-3.jpeg\",\n \"dog-photo-4.jpeg\"]\n\n# Iterate through list of dog images and plot each one\nfig, axes = plt.subplots(1, 4, figsize=(15, 7))\nfor i, ax in enumerate(axes.flatten()):\n ax.imshow(plt.imread(custom_image_paths[i]))\n ax.axis(\"off\")\n ax.set_title(custom_image_paths[i])\n
# Create list of paths for custom dog images custom_image_paths = [\"dog-photo-1.jpeg\", \"dog-photo-2.jpeg\", \"dog-photo-3.jpeg\", \"dog-photo-4.jpeg\"] # Iterate through list of dog images and plot each one fig, axes = plt.subplots(1, 4, figsize=(15, 7)) for i, ax in enumerate(axes.flatten()): ax.imshow(plt.imread(custom_image_paths[i])) ax.axis(\"off\") ax.set_title(custom_image_paths[i]) What?
The first three photos look well and good but we can see dog-photo-4.jpeg is a photo of me in a black hoodie pulling a blue steel face.
We'll see why this is later.
For now, let's use our loaded_model to try and make a prediction on the first dog image (dog-photo-1.jpeg)!
We can do so with the predict() method.
In\u00a0[129]: Copied! # Try and make a prediction on the first dog image\nloaded_model.predict(\"dog-photo-1.jpeg\")\n
# Try and make a prediction on the first dog image loaded_model.predict(\"dog-photo-1.jpeg\") \n---------------------------------------------------------------------------\nIndexError Traceback (most recent call last)\n<ipython-input-129-336b90293288> in <cell line: 2>()\n 1 # Try and make a prediction on the first dog image\n----> 2 loaded_model.predict(\"dog-photo-1.jpeg\")\n\n/usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py in error_handler(*args, **kwargs)\n 68 # To get the full stack trace, call:\n 69 # `tf.debugging.disable_traceback_filtering()`\n---> 70 raise e.with_traceback(filtered_tb) from None\n 71 finally:\n 72 del filtered_tb\n\n/usr/local/lib/python3.10/dist-packages/tensorflow/python/framework/tensor_shape.py in __getitem__(self, key)\n 960 else:\n 961 if self._v2_behavior:\n--> 962 return self._dims[key]\n 963 else:\n 964 return self.dims[key]\n\nIndexError: tuple index out of range
Oh no!
We get an error:
IndexError: tuple index out of range
This is a little hard to understand. But we can see the code is trying to get the shape of our image.
However, we didn't pass an image to the predict() method.
We only passed a filepath.
Our model expects inputs in the same format it was trained on.
So let's load our image and resize it.
We can do so with tf.keras.utils.load_img().
In\u00a0[130]: Copied! # Load the image (into PIL format)\ncustom_image = tf.keras.utils.load_img(\n path=\"dog-photo-1.jpeg\",\n color_mode=\"rgb\",\n target_size=IMG_SIZE, # (224, 224) or (img_height, img_width)\n)\n\ntype(custom_image), custom_image\n
# Load the image (into PIL format) custom_image = tf.keras.utils.load_img( path=\"dog-photo-1.jpeg\", color_mode=\"rgb\", target_size=IMG_SIZE, # (224, 224) or (img_height, img_width) ) type(custom_image), custom_image Out[130]: (PIL.Image.Image, <PIL.Image.Image image mode=RGB size=224x224>)
Excellent, we've loaded our first custom image.
But now let's turn our image into a tensor (our model was trained on image tensors, so it expects image tensors as input).
We can convert our image from PIL format to array format with tf.keras.utils.img_to_array().
In\u00a0[131]: Copied! # Turn the image into a tensor\ncustom_image_tensor = tf.keras.utils.img_to_array(custom_image)\ncustom_image_tensor.shape\n
# Turn the image into a tensor custom_image_tensor = tf.keras.utils.img_to_array(custom_image) custom_image_tensor.shape Out[131]: (224, 224, 3)
Nice! We've got an image tensor of shape (224, 224, 3).
How about we make a prediction on it?
In\u00a0[132]: Copied! # Make a prediction on our custom image tensor\nloaded_model.predict(custom_image_tensor)\n
# Make a prediction on our custom image tensor loaded_model.predict(custom_image_tensor) \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\n<ipython-input-132-bd82d1e41fed> in <cell line: 2>()\n 1 # Make a prediction on our custom image tensor\n----> 2 loaded_model.predict(custom_image_tensor)\n\n/usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py in error_handler(*args, **kwargs)\n 68 # To get the full stack trace, call:\n 69 # `tf.debugging.disable_traceback_filtering()`\n---> 70 raise e.with_traceback(filtered_tb) from None\n 71 finally:\n 72 del filtered_tb\n\n/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py in tf__predict_function(iterator)\n 13 try:\n 14 do_return = True\n---> 15 retval_ = ag__.converted_call(ag__.ld(step_function), (ag__.ld(self), ag__.ld(iterator)), None, fscope)\n 16 except:\n 17 do_return = False\n\nValueError: in user code:\n\n File \"/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py\", line 2440, in predict_function *\n return step_function(self, iterator)\n File \"/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py\", line 2425, in step_function **\n outputs = model.distribute_strategy.run(run_step, args=(data,))\n File \"/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py\", line 2413, in run_step **\n outputs = model.predict_step(data)\n File \"/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py\", line 2381, in predict_step\n return self(x, training=False)\n File \"/usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py\", line 70, in error_handler\n raise e.with_traceback(filtered_tb) from None\n File \"/usr/local/lib/python3.10/dist-packages/keras/src/engine/input_spec.py\", line 298, in assert_input_compatibility\n raise ValueError(\n\n ValueError: Input 0 of layer \"model_1\" is incompatible with the layer: expected shape=(None, 224, 224, 3), found shape=(32, 224, 3)\n
What?!?
We get another error...
ValueError: Input 0 of layer \"model_1\" is incompatible with the layer: expected shape=(None, 224, 224, 3), found shape=(32, 224, 3)
Hmm.
Looks like our model is expecting a batch size dimension on our input tensor.
We can do this by either turning the input tensor into a single element array or by using tf.expand_dims(input, axis=0) to expand the dimenion of the tensor on 0th axis.
In\u00a0[133]: Copied! # Option 1: Add batch dimension to custom_image_tensor\nprint(f\"Shape of custom image tensor: {np.array([custom_image_tensor]).shape}\")\nprint(f\"Shape of custom image tensor: {tf.expand_dims(custom_image_tensor, axis=0).shape}\")\n # Option 1: Add batch dimension to custom_image_tensor print(f\"Shape of custom image tensor: {np.array([custom_image_tensor]).shape}\") print(f\"Shape of custom image tensor: {tf.expand_dims(custom_image_tensor, axis=0).shape}\") Shape of custom image tensor: (1, 224, 224, 3)\nShape of custom image tensor: (1, 224, 224, 3)\n
Wonderful! We've now got a custom image tensor of shape (1, 224, 224, 3) ((batch_size, img_height, img_width, colour_channels)).
Let's try and predict!
In\u00a0[134]: Copied! # Get prediction probabilities from our mdoel\npred_probs = loaded_model.predict(tf.expand_dims(custom_image_tensor, axis=0))\npred_probs\n
# Get prediction probabilities from our mdoel pred_probs = loaded_model.predict(tf.expand_dims(custom_image_tensor, axis=0)) pred_probs 1/1 [==============================] - 2s 2s/step\n
Out[134]: array([[1.83611644e-06, 3.09535017e-06, 3.86047805e-06, 3.19048486e-05,\n 1.66974694e-03, 1.27542022e-04, 7.03033629e-06, 1.19856362e-04,\n 1.01050091e-05, 3.87266744e-04, 6.44192414e-06, 1.67636438e-06,\n 8.94749770e-04, 5.01931618e-06, 1.60283549e-03, 9.41093604e-05,\n 4.67637838e-05, 8.51367513e-05, 5.67736897e-05, 6.14693909e-06,\n 2.67342989e-06, 1.47549901e-04, 4.17501433e-05, 3.90995192e-05,\n 9.50478498e-05, 1.47656752e-02, 3.08718845e-05, 1.58209339e-04,\n 8.39364156e-03, 1.17800606e-03, 2.69454729e-04, 1.02170045e-04,\n 7.42143384e-05, 8.22680071e-04, 1.73064705e-04, 8.98789040e-06,\n 6.77722392e-06, 2.46034167e-03, 1.21447938e-05, 3.06540052e-04,\n 1.12927992e-04, 1.30907722e-06, 1.19819895e-04, 3.28008295e-03,\n 4.22435085e-04, 2.56334723e-04, 6.35078293e-04, 6.96951101e-05,\n 1.82968670e-05, 6.66733533e-02, 1.65604251e-06, 4.85742465e-04,\n 3.82422912e-03, 4.36909148e-04, 1.34899176e-06, 4.04351122e-05,\n 2.30197293e-05, 7.29483800e-05, 1.31009811e-05, 1.30437169e-04,\n 1.27625071e-05, 3.21804691e-06, 6.78410470e-06, 3.72191658e-03,\n 9.23305777e-07, 4.05427454e-06, 1.32554891e-02, 8.34832132e-01,\n 1.84010264e-06, 5.39118366e-04, 2.44915718e-05, 1.35658804e-04,\n 9.53144918e-04, 3.80869096e-05, 3.43683018e-06, 3.57066506e-06,\n 2.41459438e-05, 2.93612948e-06, 1.27533756e-04, 2.15716864e-05,\n 3.21038242e-05, 7.87725276e-06, 1.70349504e-05, 4.27997729e-05,\n 5.72475437e-06, 1.81680916e-05, 1.28094471e-04, 7.12008550e-05,\n 8.24760180e-04, 6.14038622e-03, 4.27179504e-03, 3.55221750e-03,\n 1.20739173e-03, 4.15856484e-04, 1.61429329e-04, 1.58363022e-04,\n 3.78229856e-06, 1.03004022e-05, 2.00551622e-05, 1.21213234e-04,\n 2.68000053e-06, 1.00253812e-04, 4.04065868e-05, 9.84299404e-05,\n 1.29673525e-03, 3.07669543e-05, 1.62672077e-05, 1.17529435e-05,\n 3.74953932e-04, 4.74653389e-05, 1.00191637e-05, 1.36496616e-04,\n 3.76833777e-05, 1.55215133e-02, 2.33796614e-04, 1.01105807e-05,\n 8.56942424e-05, 1.37508148e-04, 3.79100857e-06, 1.04301716e-05]],\n dtype=float32)
It worked!!!
Our model output a tensor of prediction probabilities.
We can find the predicted label by taking the argmax of the pred_probs tensor.
And we get the predicted class name by indexing on the class_names list using the predicted label.
In\u00a0[135]: Copied! # Get the predicted class label\npred_label = tf.argmax(pred_probs, axis=-1).numpy()[0]\n\n# Get the predicted class name\npred_class_name = class_names[pred_label]\n\nprint(f\"Predicted class label: {pred_label}\")\nprint(f\"Predicted class name: {pred_class_name}\")\n # Get the predicted class label pred_label = tf.argmax(pred_probs, axis=-1).numpy()[0] # Get the predicted class name pred_class_name = class_names[pred_label] print(f\"Predicted class label: {pred_label}\") print(f\"Predicted class name: {pred_class_name}\") Predicted class label: 67\nPredicted class name: labrador_retriever\n
Ho ho! That's looking good!
In summary, a model wants to make predictions on data in the same shape and format it was trained on.
So if you trained a model on image tensors with a certain shape and datatype, your model will want to make predictions on the same kind of image tensors with the same shape and datatype.
How about we try make predictions on multiple images?
To do so, let's make a function which replicates the workflow from above.
In\u00a0[136]: Copied! def pred_on_custom_image(image_path: str, # Path to the image file\n model, # Trained TensorFlow model for prediction\n target_size: tuple[int, int] = (224, 224), # Desired size of the image for input to the model\n class_names: list = None, # List of class names (optional for plotting)\n plot: bool = True): # Whether to plot the image and predicted class\n \"\"\"\n Loads an image, preprocesses it, makes a prediction using a provided model,\n and optionally plots the image with the predicted class.\n\n Args:\n image_path (str): Path to the image file.\n model: Trained TensorFlow model for prediction.\n target_size (int, optional): Desired size of the image for input to the model. Defaults to 224.\n class_names (list, optional): List of class names for plotting. Defaults to None.\n plot (bool, optional): Whether to plot the image and predicted class. Defaults to True.\n\n Returns:\n str: The predicted class.\n \"\"\"\n\n # Prepare and load image\n custom_image = tf.keras.utils.load_img(\n path=image_path,\n color_mode=\"rgb\",\n target_size=target_size,\n )\n\n # Turn the image into a tensor\n custom_image_tensor = tf.keras.utils.img_to_array(custom_image)\n\n # Add a batch dimension to the target tensor (e.g. (224, 224, 3) -> (1, 224, 224, 3))\n custom_image_tensor = tf.expand_dims(custom_image_tensor, axis=0)\n\n # Make a prediction with the target model\n pred_probs = model.predict(custom_image_tensor)\n\n # pred_probs = tf.keras.activations.softmax(tf.constant(pred_probs))\n pred_class = class_names[tf.argmax(pred_probs, axis=-1).numpy()[0]]\n\n # Plot if we want\n if not plot:\n return pred_class, pred_probs\n else:\n plt.figure(figsize=(5, 3))\n plt.imshow(plt.imread(image_path))\n plt.title(f\"pred: {pred_class}\\nprob: {tf.reduce_max(pred_probs):.3f}\")\n plt.axis(\"off\")\n def pred_on_custom_image(image_path: str, # Path to the image file model, # Trained TensorFlow model for prediction target_size: tuple[int, int] = (224, 224), # Desired size of the image for input to the model class_names: list = None, # List of class names (optional for plotting) plot: bool = True): # Whether to plot the image and predicted class \"\"\" Loads an image, preprocesses it, makes a prediction using a provided model, and optionally plots the image with the predicted class. Args: image_path (str): Path to the image file. model: Trained TensorFlow model for prediction. target_size (int, optional): Desired size of the image for input to the model. Defaults to 224. class_names (list, optional): List of class names for plotting. Defaults to None. plot (bool, optional): Whether to plot the image and predicted class. Defaults to True. Returns: str: The predicted class. \"\"\" # Prepare and load image custom_image = tf.keras.utils.load_img( path=image_path, color_mode=\"rgb\", target_size=target_size, ) # Turn the image into a tensor custom_image_tensor = tf.keras.utils.img_to_array(custom_image) # Add a batch dimension to the target tensor (e.g. (224, 224, 3) -> (1, 224, 224, 3)) custom_image_tensor = tf.expand_dims(custom_image_tensor, axis=0) # Make a prediction with the target model pred_probs = model.predict(custom_image_tensor) # pred_probs = tf.keras.activations.softmax(tf.constant(pred_probs)) pred_class = class_names[tf.argmax(pred_probs, axis=-1).numpy()[0]] # Plot if we want if not plot: return pred_class, pred_probs else: plt.figure(figsize=(5, 3)) plt.imshow(plt.imread(image_path)) plt.title(f\"pred: {pred_class}\\nprob: {tf.reduce_max(pred_probs):.3f}\") plt.axis(\"off\") What a good looking function!
How about we try it out on dog-photo-2.jpeg?
In\u00a0[137]: Copied! # Make prediction on custom dog photo 2\npred_on_custom_image(image_path=\"dog-photo-2.jpeg\",\n model=loaded_model,\n class_names=class_names)\n
# Make prediction on custom dog photo 2 pred_on_custom_image(image_path=\"dog-photo-2.jpeg\", model=loaded_model, class_names=class_names) 1/1 [==============================] - 0s 27ms/step\n
Woohoo!!! Our model got it right!
Let's repeat the process for our other custom images.
In\u00a0[138]: Copied! # Predict on multiple images\nfig, axes = plt.subplots(1, 4, figsize=(15, 7))\nfor i, ax in enumerate(axes.flatten()):\n image_path = custom_image_paths[i]\n pred_class, pred_probs = pred_on_custom_image(image_path=image_path,\n model=loaded_model,\n class_names=class_names,\n plot=False)\n ax.imshow(plt.imread(image_path))\n ax.set_title(f\"pred: {pred_class}\\nprob: {tf.reduce_max(pred_probs):.3f}\")\n ax.axis(\"off\");\n # Predict on multiple images fig, axes = plt.subplots(1, 4, figsize=(15, 7)) for i, ax in enumerate(axes.flatten()): image_path = custom_image_paths[i] pred_class, pred_probs = pred_on_custom_image(image_path=image_path, model=loaded_model, class_names=class_names, plot=False) ax.imshow(plt.imread(image_path)) ax.set_title(f\"pred: {pred_class}\\nprob: {tf.reduce_max(pred_probs):.3f}\") ax.axis(\"off\"); 1/1 [==============================] - 0s 28ms/step\n1/1 [==============================] - 0s 26ms/step\n1/1 [==============================] - 0s 25ms/step\n1/1 [==============================] - 0s 28ms/step\n
Epic!!
Our Dog Vision \ud83d\udc36\ud83d\udc41 model has come to life!
Looks like our model got it right for 3/4 of our custom dog photos (my dogs Bella and Seven are labrador retrievers, with a potential mix of something else).
But the model seemed to also think the photo of me was a soft_coated_wheaten_terrier (note: due to the randomness of machine learning, your result may be different here, if so, please let me know, I'd love to see what other kinds of dogs the model thinks I am :D).
You might be wondering, why does it do this?
It's because our model has been strictly trained to always predict a dog breed no matter what image it recieves.
So no matter what image we pass to our model, it will always predict a certain dog breed.
You can try this with your own images.
How would you fix this?
One way would be to train another model to predict whether the input image is of a dog or is not of a dog.
And then only letting our Dog Vision \ud83d\udc36\ud83d\udc41 model predict on the images that are of dogs.
Example of combining multiple machine learning models to create a workflow. One model for detecting food (Food Not Food) and another model for identifying what food is in the image (FoodVision, similar to Dog Vision). If an app is designed to take photos of food, taking photos of objects that aren't food and having them identified as food can be a poor customer experience. Source: Nutrify.
These are some of the workflows you'll have to think about when you eventually deploy your own machine learning models.
Machine learning models are often very powerful.
But they aren't perfect.
Implementing guidelines and checks around them is still a very active area of research.
In\u00a0[139]: Copied! from tensorflow.keras import layers\n\n# Note: Could functionize all of this\n\n# Setup hyperparameters\nimg_size = 224\nnum_classes = 120\n\n# Create data augmentation layer\ndata_augmentation_layer = tf.keras.Sequential(\n [\n layers.RandomFlip(\"horizontal\"), # randomly flip image across horizontal axis\n layers.RandomRotation(factor=0.2), # randomly rotate image\n layers.RandomZoom(height_factor=0.2, width_factor=0.2) # randomly zoom into image\n # More augmentation can go here\n ],\n name=\"data_augmentation\"\n)\n\n# Setup base model\nbase_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(\n include_top=False,\n weights='imagenet',\n input_shape=(img_size, img_size, 3),\n include_preprocessing=True\n)\n\n# Freeze the base model\nbase_model.trainable = False\n\n# Create new model\ninputs = tf.keras.Input(shape=(224, 224, 3))\n\n# Create data augmentation\nx = data_augmentation_layer(inputs)\n\n# Craft model\nx = base_model(x, training=False)\nx = tf.keras.layers.GlobalAveragePooling2D()(x)\nx = tf.keras.layers.Dropout(0.2)(x)\noutputs = tf.keras.layers.Dense(num_classes,\n name=\"output_layer\",\n activation=\"softmax\")(x) # Note: If you have \"softmax\" activation, use from_logits=False in loss function\nmodel_2 = tf.keras.Model(inputs, outputs, name=\"model_2\")\n\n# Uncomment for full model summary with augmentation layers\n# model_2.summary()\n
from tensorflow.keras import layers # Note: Could functionize all of this # Setup hyperparameters img_size = 224 num_classes = 120 # Create data augmentation layer data_augmentation_layer = tf.keras.Sequential( [ layers.RandomFlip(\"horizontal\"), # randomly flip image across horizontal axis layers.RandomRotation(factor=0.2), # randomly rotate image layers.RandomZoom(height_factor=0.2, width_factor=0.2) # randomly zoom into image # More augmentation can go here ], name=\"data_augmentation\" ) # Setup base model base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0( include_top=False, weights='imagenet', input_shape=(img_size, img_size, 3), include_preprocessing=True ) # Freeze the base model base_model.trainable = False # Create new model inputs = tf.keras.Input(shape=(224, 224, 3)) # Create data augmentation x = data_augmentation_layer(inputs) # Craft model x = base_model(x, training=False) x = tf.keras.layers.GlobalAveragePooling2D()(x) x = tf.keras.layers.Dropout(0.2)(x) outputs = tf.keras.layers.Dense(num_classes, name=\"output_layer\", activation=\"softmax\")(x) # Note: If you have \"softmax\" activation, use from_logits=False in loss function model_2 = tf.keras.Model(inputs, outputs, name=\"model_2\") # Uncomment for full model summary with augmentation layers # model_2.summary() In\u00a0[140]: Copied! !pip install -q gradio\nimport gradio as gr\n
!pip install -q gradio import gradio as gr \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 12.2/12.2 MB 34.0 MB/s eta 0:00:00\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 91.9/91.9 kB 12.9 MB/s eta 0:00:00\n Preparing metadata (setup.py) ... done\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 314.4/314.4 kB 33.7 MB/s eta 0:00:00\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 75.6/75.6 kB 10.1 MB/s eta 0:00:00\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 141.1/141.1 kB 18.2 MB/s eta 0:00:00\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 8.8/8.8 MB 91.6 MB/s eta 0:00:00\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 47.2/47.2 kB 4.3 MB/s eta 0:00:00\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 60.8/60.8 kB 8.8 MB/s eta 0:00:00\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 129.9/129.9 kB 16.6 MB/s eta 0:00:00\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 77.9/77.9 kB 9.8 MB/s eta 0:00:00\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 58.3/58.3 kB 8.3 MB/s eta 0:00:00\n \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 71.9/71.9 kB 9.7 MB/s eta 0:00:00\n Building wheel for ffmpy (setup.py) ... done\nERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\nspacy 3.7.4 requires typer<0.10.0,>=0.3.0, but you have typer 0.12.3 which is incompatible.\nweasel 0.3.4 requires typer<0.10.0,>=0.3.0, but you have typer 0.12.3 which is incompatible.\n
Then we'll download the saved model (the same model we trained during the Dog Vision notebook) along with the assosciated labels.
I've stored my saved model as well as the Stanford Dogs class names on Hugging Face.
You can see my files at huggingface.co/spaces/mrdbourke/dog_vision.
In\u00a0[141]: Copied! import tensorflow as tf\n\n# Download saved model and labels from Hugging Face\n!wget -q https://huggingface.co/spaces/mrdbourke/dog_vision/resolve/main/dog_vision_model_demo.keras\n!wget -q https://huggingface.co/spaces/mrdbourke/dog_vision/resolve/main/stanford_dogs_class_names.txt\n\n# Load model\nmodel_save_path = \"dog_vision_model_demo.keras\"\nloaded_model_for_demo = tf.keras.models.load_model(model_save_path)\n\n# Load labels\nwith open(\"stanford_dogs_class_names.txt\", \"r\") as f:\n class_names = [line.strip() for line in f.readlines()]\n
import tensorflow as tf # Download saved model and labels from Hugging Face !wget -q https://huggingface.co/spaces/mrdbourke/dog_vision/resolve/main/dog_vision_model_demo.keras !wget -q https://huggingface.co/spaces/mrdbourke/dog_vision/resolve/main/stanford_dogs_class_names.txt # Load model model_save_path = \"dog_vision_model_demo.keras\" loaded_model_for_demo = tf.keras.models.load_model(model_save_path) # Load labels with open(\"stanford_dogs_class_names.txt\", \"r\") as f: class_names = [line.strip() for line in f.readlines()] The prediction function should take in an image and return a dictionary of classes and their prediction probabilities.
In\u00a0[142]: Copied! # Create prediction function\ndef pred_on_custom_image(image, # input image (preprocessed by Gradio's Image input to be numpy.array)\n model: tf.keras.Model = loaded_model_for_demo, # Trained TensorFlow model for prediction\n target_size: int = 224, # Desired size of the image for input to the model\n class_names: list = class_names): # List of class names\n \"\"\"\n Loads an image, preprocesses it, makes a prediction using a provided model,\n and returns a dictionary of prediction probabilities per class name.\n\n Args:\n image: Input image.\n model: Trained TensorFlow model for prediction.\n target_size (int, optional): Desired size of the image for input to the model. Defaults to 224.\n class_names (list, optional): List of class names for plotting. Defaults to None.\n\n Returns:\n Dict[str: float]: A dictionary of string class names and their respective prediction probability.\n \"\"\"\n\n # Note: gradio.inputs.Image handles opening the image\n # # Prepare and load image\n # custom_image = tf.keras.utils.load_img(\n # path=image_path,\n # color_mode=\"rgb\",\n # target_size=target_size,\n # )\n\n # Create resizing layer to resize the image\n resize = tf.keras.layers.Resizing(height=target_size,\n width=target_size)\n\n # Turn the image into a tensor and resize it\n custom_image_tensor = resize(tf.keras.utils.img_to_array(image))\n\n # Add a batch dimension to the target tensor (e.g. (224, 224, 3) -> (1, 224, 224, 3))\n custom_image_tensor = tf.expand_dims(custom_image_tensor, axis=0)\n\n # Make a prediction with the target model\n pred_probs = model.predict(custom_image_tensor)[0]\n\n # Predictions get returned as a dictionary of {label: pred_prob}\n pred_probs_dict = {class_names[i]: float(pred_probs[i]) for i in range(len(class_names))}\n\n return pred_probs_dict\n\ninterface_title = \"Dog Vision \ud83d\udc36\ud83d\udc41\ufe0f\"\ninterface_description = \"Identify different dogs in images with deep learning. Model trained with TensorFlow/Keras.\"\ninterface = gr.Interface(fn=pred_on_custom_image,\n inputs=gr.Image(),\n outputs=gr.Label(num_top_classes=3),\n examples=[\"dog-photo-1.jpeg\",\n \"dog-photo-2.jpeg\",\n \"dog-photo-3.jpeg\",\n \"dog-photo-4.jpeg\"],\n title=interface_title,\n description=interface_description)\n\n# Uncomment to launch the interface directly in a notebook\n# interface.launch(debug=True)\n # Create prediction function def pred_on_custom_image(image, # input image (preprocessed by Gradio's Image input to be numpy.array) model: tf.keras.Model = loaded_model_for_demo, # Trained TensorFlow model for prediction target_size: int = 224, # Desired size of the image for input to the model class_names: list = class_names): # List of class names \"\"\" Loads an image, preprocesses it, makes a prediction using a provided model, and returns a dictionary of prediction probabilities per class name. Args: image: Input image. model: Trained TensorFlow model for prediction. target_size (int, optional): Desired size of the image for input to the model. Defaults to 224. class_names (list, optional): List of class names for plotting. Defaults to None. Returns: Dict[str: float]: A dictionary of string class names and their respective prediction probability. \"\"\" # Note: gradio.inputs.Image handles opening the image # # Prepare and load image # custom_image = tf.keras.utils.load_img( # path=image_path, # color_mode=\"rgb\", # target_size=target_size, # ) # Create resizing layer to resize the image resize = tf.keras.layers.Resizing(height=target_size, width=target_size) # Turn the image into a tensor and resize it custom_image_tensor = resize(tf.keras.utils.img_to_array(image)) # Add a batch dimension to the target tensor (e.g. (224, 224, 3) -> (1, 224, 224, 3)) custom_image_tensor = tf.expand_dims(custom_image_tensor, axis=0) # Make a prediction with the target model pred_probs = model.predict(custom_image_tensor)[0] # Predictions get returned as a dictionary of {label: pred_prob} pred_probs_dict = {class_names[i]: float(pred_probs[i]) for i in range(len(class_names))} return pred_probs_dict interface_title = \"Dog Vision \ud83d\udc36\ud83d\udc41\ufe0f\" interface_description = \"Identify different dogs in images with deep learning. Model trained with TensorFlow/Keras.\" interface = gr.Interface(fn=pred_on_custom_image, inputs=gr.Image(), outputs=gr.Label(num_top_classes=3), examples=[\"dog-photo-1.jpeg\", \"dog-photo-2.jpeg\", \"dog-photo-3.jpeg\", \"dog-photo-4.jpeg\"], title=interface_title, description=interface_description) # Uncomment to launch the interface directly in a notebook # interface.launch(debug=True) Save the following code to an app.py file for running on Hugging Face spaces.
Finally, you can see the running demo on Hugging Face.
Try it out with your own images of dogs and see Dog Vision \ud83d\udc36\ud83d\udc41\ufe0f come to life!
In\u00a0[143]: Copied! from IPython.display import HTML\n\n# Embed the Hugging Face Space as an iframe\nhtml_string = \"\"\"\n<iframe src=\"https://mrdbourke-dog-vision.hf.space\" frameborder=\"0\" width=\"850\" height=\"850\"></iframe>\n\"\"\"\n\ndisplay(HTML(html_string))\n
from IPython.display import HTML # Embed the Hugging Face Space as an iframe html_string = \"\"\" \"\"\" display(HTML(html_string)) The following will write the whole cell to a Python file called app.py, this can uploaded to Hugging Face and run as a Space. As long as all available files (e.g. model file and class names file) are available.
In\u00a0[144]: Copied! # %%writefile app.py\n# import gradio as gr\n# import tensorflow as tf\n\n# # Load model\n# model_save_path = \"dog_vision_model_demo.keras\"\n# loaded_model_for_demo = tf.keras.models.load_model(model_save_path)\n\n# # Load labels\n# with open(\"stanford_dogs_class_names.txt\", \"r\") as f:\n# class_names = [line.strip() for line in f.readlines()]\n\n# # Create prediction function\n# def pred_on_custom_image(image, # input image (preprocessed by Gradio's Image input to be numpy.array)\n# model: tf.keras.Model =loaded_model_for_demo, # Trained TensorFlow model for prediction\n# target_size: int = 224, # Desired size of the image for input to the model\n# class_names: list = class_names): # List of class names\n# \"\"\"\n# Loads an image, preprocesses it, makes a prediction using a provided model,\n# and returns a dictionary of prediction probabilities per class name.\n\n# Args:\n# image: Input image.\n# model: Trained TensorFlow model for prediction.\n# target_size (int, optional): Desired size of the image for input to the model. Defaults to 224.\n# class_names (list, optional): List of class names for plotting. Defaults to None.\n\n# Returns:\n# Dict[str: float]: A dictionary of string class names and their respective prediction probability.\n# \"\"\"\n\n# # Note: gradio.inputs.Image handles opening the image\n# # # Prepare and load image\n# # custom_image = tf.keras.utils.load_img(\n# # path=image_path,\n# # color_mode=\"rgb\",\n# # target_size=target_size,\n# # )\n\n# # Create resizing layer to resize the image\n# resize = tf.keras.layers.Resizing(height=target_size,\n# width=target_size)\n\n# # Turn the image into a tensor and resize it\n# custom_image_tensor = resize(tf.keras.utils.img_to_array(image))\n\n# # Add a batch dimension to the target tensor (e.g. (224, 224, 3) -> (1, 224, 224, 3))\n# custom_image_tensor = tf.expand_dims(custom_image_tensor, axis=0)\n\n# # Make a prediction with the target model\n# pred_probs = model.predict(custom_image_tensor)[0]\n\n# # Predictions get returned as a dictionary of {label: pred_prob}\n# pred_probs_dict = {class_names[i]: float(pred_probs[i]) for i in range(len(class_names))}\n\n# return pred_probs_dict\n\n# # Create Gradio interface\n# interface_title = \"Dog Vision \ud83d\udc36\ud83d\udc41\ufe0f\"\n# interface_description = \"Identify different dogs in images with deep learning. Model trained with TensorFlow/Keras.\"\n# interface = gr.Interface(fn=pred_on_custom_image,\n# inputs=gr.Image(),\n# outputs=gr.Label(num_top_classes=3),\n# examples=[\"dog-photo-1.jpeg\",\n# \"dog-photo-2.jpeg\",\n# \"dog-photo-3.jpeg\",\n# \"dog-photo-4.jpeg\"],\n# title=interface_title,\n# description=interface_description)\n# interface.launch(debug=True)\n # %%writefile app.py # import gradio as gr # import tensorflow as tf # # Load model # model_save_path = \"dog_vision_model_demo.keras\" # loaded_model_for_demo = tf.keras.models.load_model(model_save_path) # # Load labels # with open(\"stanford_dogs_class_names.txt\", \"r\") as f: # class_names = [line.strip() for line in f.readlines()] # # Create prediction function # def pred_on_custom_image(image, # input image (preprocessed by Gradio's Image input to be numpy.array) # model: tf.keras.Model =loaded_model_for_demo, # Trained TensorFlow model for prediction # target_size: int = 224, # Desired size of the image for input to the model # class_names: list = class_names): # List of class names # \"\"\" # Loads an image, preprocesses it, makes a prediction using a provided model, # and returns a dictionary of prediction probabilities per class name. # Args: # image: Input image. # model: Trained TensorFlow model for prediction. # target_size (int, optional): Desired size of the image for input to the model. Defaults to 224. # class_names (list, optional): List of class names for plotting. Defaults to None. # Returns: # Dict[str: float]: A dictionary of string class names and their respective prediction probability. # \"\"\" # # Note: gradio.inputs.Image handles opening the image # # # Prepare and load image # # custom_image = tf.keras.utils.load_img( # # path=image_path, # # color_mode=\"rgb\", # # target_size=target_size, # # ) # # Create resizing layer to resize the image # resize = tf.keras.layers.Resizing(height=target_size, # width=target_size) # # Turn the image into a tensor and resize it # custom_image_tensor = resize(tf.keras.utils.img_to_array(image)) # # Add a batch dimension to the target tensor (e.g. (224, 224, 3) -> (1, 224, 224, 3)) # custom_image_tensor = tf.expand_dims(custom_image_tensor, axis=0) # # Make a prediction with the target model # pred_probs = model.predict(custom_image_tensor)[0] # # Predictions get returned as a dictionary of {label: pred_prob} # pred_probs_dict = {class_names[i]: float(pred_probs[i]) for i in range(len(class_names))} # return pred_probs_dict # # Create Gradio interface # interface_title = \"Dog Vision \ud83d\udc36\ud83d\udc41\ufe0f\" # interface_description = \"Identify different dogs in images with deep learning. Model trained with TensorFlow/Keras.\" # interface = gr.Interface(fn=pred_on_custom_image, # inputs=gr.Image(), # outputs=gr.Label(num_top_classes=3), # examples=[\"dog-photo-1.jpeg\", # \"dog-photo-2.jpeg\", # \"dog-photo-3.jpeg\", # \"dog-photo-4.jpeg\"], # title=interface_title, # description=interface_description) # interface.launch(debug=True)"},{"location":"end-to-end-dog-vision-v2/#introduction-to-tensorflow-deep-learning-and-transfer-learning-work-in-progress","title":"Introduction to TensorFlow, Deep Learning and Transfer Learning (work in progress)\u00b6","text":" - Project: Dog Vision \ud83d\udc36\ud83d\udc41 - Using computer vision to classify dog photos into different breeds.
- Goals: Learn TensorFlow, deep learning and transfer learning, beat the original research paper results (22% accuracy).
- Domain: Computer vision.
- Data: Images of dogs from Stanford Dogs Dataset (120 dog breeds, 20,000+ images).
- Problem type: Multi-class classification (120 different classes).
- Runtime: This project is designed to run end-to-end in Google Colab (for free GPU access and easy setup). If you'd like to run it locally, it will require environment setup.
- Demo: See a demo of the trained model running on Hugging Face Spaces.
Welcome, welcome!
The focus of this notebook is to give a quick overview of deep learning with TensorFlow/Keras.
How?
We're going to go through the machine learning workflow steps and build a computer vision project to classify photos of dogs into their respective dog breed (a Predictive AI task, see below for more).
What we're going to build: Dog Vision \ud83d\udc36\ud83d\udc41\ufe0f, a neural network capable of identifying different dog breeds in images. All the way from dataset preparation to model building, training and evaluation.
"},{"location":"end-to-end-dog-vision-v2/#what-were-going-to-cover","title":"What we're going to cover\u00b6","text":"In this project, we're going to be introduced to the power of deep learning and more specifically, transfer learning using TensorFlow/Keras.
We'll go through each of these in the context of the 6 step machine learning framework:
- Problem defintion - Use computer vision to classify photos of dogs into different dog breeds.
- Data - 20,000+ images of dogs from 120 different dog breeds from the Stanford Dogs dataset.
- Evaluation - We'd like to beat the original paper's results (22% mean accuracy across all classes, tip: A good way to practice your skills is to find some results online and try to beat them).
- Features - Because we're using deep learning, our model will learn the features on its own.
- Modelling - We're going to use a pretrained convolutional neural network (CNN) and transfer learning.
- Experiments - We'll try different amounts of data with the same model to see the effects on our results.
Note: It's okay not to know these exact steps ahead of time. When starting a new project, it's often the case you'll figure it out as you go. These steps are only filled out because I've had practice working on several machine learning projects. You'll pick up these ideas overtime.
"},{"location":"end-to-end-dog-vision-v2/#table-of-contents","title":"Table of contents\u00b6","text":" - Getting Setup
- Getting Data (dog images and their breeds)
- Exploring the data (exploratory data analysis)
- Creating training and test splits
- Turning our datasets into TensorFlow Dataset(s)
- Creating a neural network with TensorFlow
- Model 0 - Train a model on 10% of the training data
- Putting it all together: create, compile, fit
- Model 1 - Train a model on 100% of the training data
- Make and evaluate predictions of the best model
- Save and load the best model
- Make predictions on custom images with the best model (bringing Dog Vision \ud83d\udc36\ud83d\udc41\ufe0f to life!)
- Key takeaways
- Extensions & exercises
"},{"location":"end-to-end-dog-vision-v2/#where-can-can-you-get-help","title":"Where can can you get help?\u00b6","text":"All of the materials for this course are available on GitHub.
If you run into trouble, you can ask a question on the course GitHub Discussions page there too.
You can also:
- Search for questions online and end up at places such as Stack Overflow (a great resource of developer-focused Q&A).
- Ask AI Assistants such as ChatGPT, Gemini and Claude for help with various coding problems and errors.
"},{"location":"end-to-end-dog-vision-v2/#quick-definitions","title":"Quick definitions\u00b6","text":"Let's start by breaking down some of the most important topics we're going to go through.
"},{"location":"end-to-end-dog-vision-v2/#what-is-tensorflowkeras","title":"What is TensorFlow/Keras?\u00b6","text":"TensorFlow is an open source machine learning and deep learning framework originally developed by Google. Inside TensorFlow, you can also use Keras which is another very helpful machine learning framework known for its ease of use.
"},{"location":"end-to-end-dog-vision-v2/#why-use-tensorflow","title":"Why use TensorFlow?\u00b6","text":"TensorFlow allows you to manipulate data and write deep learning algorithms using Python code.
It also has several built-in capabilities to leverage accelerated computing hardware (e.g. GPUs, Graphics Processing Units and TPUs, Tensor Processing Units).
Many of world's largest companies power their machine learning workloads with TensorFlow.
"},{"location":"end-to-end-dog-vision-v2/#what-is-deep-learning","title":"What is deep learning?\u00b6","text":"Deep learning is a form of machine learning where data passes through a series of progressive layers which all contribute to learning an overall representation of that data.
Each layer performs a pre-defined operation.
The series of progressive layers combine to form what's referred to as a neural network.
For example, a photo may be turned into numbers (e.g. red, green and blue pixel values) and those numbers are then manipulated mathematically through each progressive layer to learn patterns in the photo.
The \"deep\" in deep learning comes from the number of layers used in the neural network.
So when someone says deep learning or (artificial neural networks), they're typically referring to same thing.
Note: Artificial intelligence (AI), machine learning (ML) and deep learning are all broad terms. You can think of AI as the overall technology, machine learning as a type of AI, and deep learning as a type of machine learning. So if someone refers to AI, you can often assume they are often talking about machine learning or deep learning.
"},{"location":"end-to-end-dog-vision-v2/#what-can-deep-learning-be-used-for","title":"What can deep learning be used for?\u00b6","text":"Deep learning is such a powerful technique that new use cases are being discovered everyday.
Most of the modern forms of artifical intelligence (AI) applications you see, are powered by deep learning.
Two of the most useful types of AI are predictive and generative.
Predictive AI learns the relationship between data and labels such as photos of dog and their breeds (supervised learning). So that when it sees a new photo of a dog, it can predict its breed based on what its learned.
Generative AI generates something new given an input such as creating new text given input text.
Some examples of Predictive AI problems include:
- Tesla's self-driving cars use deep learning use object detection models to power their computer vision systems.
- Apple's Photos app uses deep learning to recognize faces in images and create Photo Memories.
- Siri and Google Assistant use deep learning to transcribe speech and understand voice commands.
- Nutrify (an app my brother and I build) uses predictive AI to recognize food in images.
- Magika uses deep learning to classify a file into what type it is (e.g.
.jpeg, .py, .txt). - Text classification models such as DeBERTa use deep learning to classify text into different categories such as \"positive\" and \"negative\" or \"spam\" or \"not spam\".
Some examples of Generative AI problems include:
- Stable Diffusion uses generative AI to generate images given a text prompt.
- ChatGPT and other large language models (LLMs) such as Llama, Claude, Gemini and Mistral use deep learning to process text and return a response.
- GitHub Copilot uses generative AI to generate code snippets given surrounding context.
All of these AI use cases are powered by deep learning.
And more often than not, whenever you get started on a deep learning problem, you'll start with transfer learning.
Example of different every day problems where AI/machine learning gets used.
"},{"location":"end-to-end-dog-vision-v2/#what-is-transfer-learning","title":"What is transfer learning?\u00b6","text":"Transfer learning is one of the most powerful and useful techniques in modern AI and machine learning.
It involves taking what one model (or neural network) has learned in a similar domain and applying to your own.
In our case, we're going to use transfer learning to take the patterns a neural network has learned from the 1 million+ images and over 1000 classes in ImageNet (a gold standard computer vision benchmark) and apply them to our own problem of recognizing dog breeds.
However, this concept can be applied to many different domains.
You could take a large language model (LLM) that has been pre-trained on most of the text on the internet and learned very well the patterns in naturual language and customize it for your own specific chat use-case.
The biggest benefit of transfer learning is that it often allows you to get outstanding results with less data and time.
A transfer learning workflow. Many publicly available models have been pretrained on large datasets such as ImageNet (1 million+ images). These models can then be applied to similar tasks downstream. For example, we can take a model pretrained on ImageNet and apply it to our Dog Vision \ud83d\udc36\ud83d\udc41\ufe0f problem. This same process can be repeated for many different styles of data and problem.
"},{"location":"end-to-end-dog-vision-v2/#1-getting-setup","title":"1. Getting setup\u00b6","text":"This notebook is designed to run in Google Colab, an online Jupyter Notebook that provides free access to GPUs (Graphics Processing Units, we'll hear more on these later).
For a quick rundown on how to use Google Colab, see their introductory guide (it's quite similar to a Jupyter Notebook with a few different options).
Google Colab also comes with many data science and machine learning libraries pre-installed, including TensorFlow/Keras.
"},{"location":"end-to-end-dog-vision-v2/#getting-a-gpu-on-google-colab","title":"Getting a GPU on Google Colab\u00b6","text":"Before running any code, we'll make sure our Google Colab instance is connected to a GPU.
You can do this via going to Runtime -> Change runtime type -> GPU (this may restart your existing runtime).
Why use a GPU?
Since neural networks perform a large amount of calculations behind the scenes (the main one being matrix multiplication), you need a computer chip that perform these calculations quickly, otherwise you'll be waiting all day for a model to train.
And in short, GPUs are much faster at performing matrix multiplications than CPUs.
Why this is the case is behind the scope of this project (you can search \"why are GPUs faster than CPUs for machine learning?\" for more).
The main thing to remember is: generally, in deep learning, GPUs = faster than CPUs.
Note: A good experiment would be to run the neural networks we're going to build later on with and without a GPU and see the difference in their training times.
Ok, enough talking, let's start by importing TensorFlow!
We'll do so using the common abbreviation tf.
"},{"location":"end-to-end-dog-vision-v2/#2-getting-data","title":"2. Getting Data\u00b6","text":"All machine learning (and deep learning) projects start with data.
If you have no data, you have no project.
If you have no project, you have no cool models to show your friends or improve your business.
Not to worry!
There are several options and locations to get data for a deep learning project.
Resource Description Kaggle Datasets A collection of datasets across a wide range of topics. TensorFlow Datasets A collection of ready-to-use machine learning datasets ready for use under the tf.data.Datasets API. You can see a list of all available datasets in the TensorFlow documentation. Hugging Face Datasets A continually growing resource of datasets broken into several different kinds of topics. Google Dataset Search A search engine by Google specifically focused on searching online datasets. Original sources Datasets which are made available by researchers or companies with the release of a product or research paper (sources for these will vary, they could be a link on a website or a link to an application form). Custom datasets These are datasets comprised of your own custom source of data. You may build these from scratch on your own or have access to them from an existing product or service. For example, your entire photos library could be your own custom dataset or your entire notes and documents folder or your company's customer order history. In our case, the dataset we're going to use is called the Stanford Dogs dataset (or ImageNet dogs, as the images are dogs separated from ImageNet).
Because the Stanford Dogs dataset has been around for a while (since 2011, which as of writing this in 2024 is like a lifetime in deep learning), it's available from several resources:
- The original project website via link download.
- Inside TensorFlow datasets under
stanford_dogs. - On Kaggle as a downloadable dataset.
The point here is that when you're starting out with practicing deep learning projects, there's no shortage of datasets available.
However, when you start wanting to work on your own projects or within a company environment, you'll likely start to work on custom datasets (datasets you build yourself or aren't available publicly online).
The main difference between existing datasets and custom datasets is that existing datasets often come preformatted and ready to use.
Where as custom datasets often require some preprocessing before they're ready to use within a machine learning project.
To practice formatting a dataset for a machine learning problem, we're going to download the Stanford Dogs dataset from the original website.
Before we do so, the following code is an example of how we'd get the Stanford Dogs dataset from TensorFlow Datasets.
"},{"location":"end-to-end-dog-vision-v2/#download-data-directly-from-stanford-dogs-website","title":"Download data directly from Stanford Dogs website\u00b6","text":"Our overall project goal is to build a computer vision model which performs better than the original Stanford Dogs paper (average of 22% accuracy per class across 120 classes).
To do so, we need some data.
Let's download the original Stanford Dogs dataset from the project website.
The data comes in three main files:
- Images (757MB) -
images.tar - Annotations (21MB) -
annotation.tar - Lists with train/test splits (0.5MB) -
lists.tar
Our goal is to get a file structure like this:
Note: If you're using Google Colab for this project, remember that any data uploaded to the Google Colab session gets deleted if the session disconnects. So to save us redownloading the data every time, we're going to download it once and save it to Google Drive.
Resource: For a good guide on getting data in and out of Google Colab, see the Google Colab io.ipynb tutorial.
To make sure we don't have to keep redownloading the data every time we leave and come back to Google Colab, we're going to:
- Download the data if it doesn't already exist on Google Drive.
- Copy it to Google Drive (because Google Colab connects nicely with Google Drive) if it isn't already there.
- If the data already exists on Google Drive (we've been through steps 1 & 2), we'll import it instead.
There are two main options to connect Google Colab instances to Google Drive:
- Click \"Mount Drive\" in \"Files\" menu on the left.
- Mount programmatically with
from google.colab import drive -> drive.mount('/content/drive').
More specifically, we're going to follow the following steps:
- Mount Google Drive.
- Setup constants such as our base directory to save files to, the target files we'd like to download and target URL we'd like to download from.
- Setup our target local path to save to.
- Check if the target files all exist in Google Drive and if they do, copy them locally.
- If the target files don't exist in Google Drive, download them from the target URL with the
!wget command. - Create a file on Google Drive to store the download files.
- Copy the downloaded files to Google Drive for use later if needed.
A fair few steps, but nothing we can't handle!
Plus, this is all good practice for dealing with and manipulating data, a very important skill in the machine learning engineers toolbox.
Note: The following data download section is designed to run in Google Colab. If you are running locally, feel free to modify the code to save to a local directory instead of Google Drive.
"},{"location":"end-to-end-dog-vision-v2/#3-exploring-the-data","title":"3. Exploring the data\u00b6","text":"Once you've got a dataset, before building a model, it's wise to explore it for a bit to see what kind of data you're working with.
Exploring a dataset can mean many things.
But a few rules of thumb when exploring new data:
- View at least 100+ random samples for a \"vibe check\". For example, if you have a large dataset of images, randomly sample 10 images at a time and view them. Or if you have a large dataset of texts, what do some of them say? The same with audio. It will often be impossible to view all samples in your dataset, but you can start to get a good idea of what's inside by randomly inspecting samples.
- Visualize, viuslaize, visualize! This is the data explorer's motto. Use it often. As in, it's good to get statistics about your dataset but it's often even better to view 100s of samples with your own eyes (see the point above).
- Check the distributions and other various statistics. How many samples are there? If you're dealing with classification, how many classes and labels per class are there? Which classes don't you understand? If you don't have labels, investigate clustering methods to put similar samples close together.
As Abraham Lossfunction says...
A play on words of Abraham Lincoln's famous quote on sharpening an axe before cutting down a tree in theme of machine learning. Source: Daniel Bourke X/Twitter.
"},{"location":"end-to-end-dog-vision-v2/#our-target-data-format","title":"Our target data format\u00b6","text":"Since our goal is to build a computer vision model to classify dog breeds, we need a way to tell our model what breed of dog is in what image.
A common data format for a classification problem is to have samples stored in folders named after their class name.
For example:
In the case of dog images, we'd put all of the images labelled \"chihuahua\" in a folder called chihuahua/ (and so on for all the other classes and images).
We could split these folders so that training images go in train/chihuahua/ and testing images go in test/chihuahua/.
This is what we'll be working towards creating.
Note: This structure of folder format doesn't just work for only images, it can work for text, audio and other kind of classification data too.
"},{"location":"end-to-end-dog-vision-v2/#exploring-the-file-lists","title":"Exploring the file lists\u00b6","text":"How about we check out the train_list.mat, test_list.mat and full_list.mat files?
Searching online, for \"what is a .mat file?\", I found that it's a MATLAB file. Before Python became the default language for machine learning and deep learning, many models and datasets were built in MATLAB.
Then I searched, \"how to open a .mat file with Python?\" and found an answer on Stack Overflow saying I could use the scipy library (a scientific computing library).
The good news is, Google Colab comes with scipy preinstalled.
We can use the scipy.io.loadmat() method to open a .mat file.
"},{"location":"end-to-end-dog-vision-v2/#exploring-the-annotation-folder","title":"Exploring the Annotation folder\u00b6","text":"How about we look at the Annotation folder next?
We can click the folder on the file explorer on the left to see what's inside.
But we can also explore the contents of the folder with Python.
Let's use os.listdir() to see what's inside.
"},{"location":"end-to-end-dog-vision-v2/#exploring-the-images-folder","title":"Exploring the Images folder\u00b6","text":"We've explored the Annotations folder, now let's check out our Images folder.
We know that the image file names come in the format class_name/image_name, for example, n02085620-Chihuahua/n02085620_5927.jpg.
To make things a little simpler, let's create the following:
- A mapping from folder name -> class name in dictionary form, for example,
{'n02113712-miniature_poodle': 'miniature_poodle', 'n02092339-Weimaraner': 'weimaraner', 'n02093991-Irish_terrier': 'irish_terrier'...}. This will help us when visualizing our data from its original folder. - A list of all unique dog class names with simple formatting, for example,
['affenpinscher', 'afghan_hound', 'african_hunting_dog', 'airedale', 'american_staffordshire_terrier'...].
Let's start by getting a list of all the folders in the Images directory with os.listdir().
"},{"location":"end-to-end-dog-vision-v2/#visualize-a-group-of-random-images","title":"Visualize a group of random images\u00b6","text":"How about we follow the data explorers motto of visualize, visualize, visualize and view some random images?
To help us visualize, let's create a function that takes in a list of image paths and then randomly selects 10 of those paths to display.
The function will:
- Take in a select list of image paths.
- Create a grid of matplotlib plots (e.g. 2x5 = 10 plots to plot on).
- Randomly sample 10 image paths from the input image path list (using
random.sample()). - Iterate through the flattened axes via
axes.flat which is a reference to the attribute numpy.ndarray.flat. - Extract the sample path from the list of samples.
- Get the sample title from the parent folder of the path using
Path.parent.stem and then extract the formatted dog breed name by indexing folder_to_class_name_dict. - Read the image with
plt.imread() and show it on the target ax with ax.imshow(). - Set the title of the plot to the parent folder name with
ax.set_title() and turn the axis marks of with ax.axis(\"off\") (this makes for pretty plots). - Show the plot with
plt.show().
Woah!
A lot of steps! But nothing we can't handle, let's do it.
"},{"location":"end-to-end-dog-vision-v2/#exploring-the-distribution-of-our-data","title":"Exploring the distribution of our data\u00b6","text":"After visualization, another valuable way to explore the data is by checking the data distribution.
Distribution refers to the \"spread\" of data.
In our case, how many images of dogs do we have per breed?
A balanced distribution would mean having roughly the same number of images for each breed (e.g. 100 images per dog breed).
Note: There's a deeper level of distribution than just images per dog breed. Ideally, the images for each different breed are well distributed as well. For example, we wouldn't want to have 100 of the same image per dog breed. Not only would we like a similar number of images per breed, we'd like the images of each particular breed to be in different scenarios, different lighting, different angles. We want this because we want to our model to be able to recognize the correct dog breed no matter what angle the photo is taken from.
To figure out how many images we have per class, let's write a function count the number of images per subfolder in a given directory.
Specifically, we'll want the function to:
- Take in a target directory/folder.
- Create a list of all the subdirectories/subfolders in the target folder.
- Create an empty list,
image_class_counts to append subfolders and their counts to. - Iterate through all of the subdirectories.
- Get the class name of the target folder as the name of the folder.
- Count the number of images in the target folder using the length of the list of image paths (we can get these with
Path().rglob(*.jpg) where *.jpg means \"all files with the extension .jpg. - Append a dictionary of
{\"class_name\": class_name, \"image_count\": image_count} to the image_class_counts list (we create a list of dictionaries so we can turn this into a pandas DataFrame). - Return the
image_class_counts list.
"},{"location":"end-to-end-dog-vision-v2/#4-creating-training-and-test-data-split-directories","title":"4. Creating training and test data split directories\u00b6","text":"After exploring the data, one of the next best things you can do is create experimental data splits.
This includes:
Set Name Description Typical Percentage of Data Training Set A dataset for the model to learn on 70-80% Testing Set A dataset for the model to be evaluated on 20-30% (Optional) Validation Set A dataset to tune the model on 50% of the test data (Optional) Smaller Training Set A smaller size dataset to run quick experiments on 5-20% of the training set Our dog dataset already comes with specified training and test set splits.
So we'll stick with those.
But we'll also create a smaller training set (a random 10% of the training data) so we can stick to the machine learning engineers motto of experiment, experiment, experiment! and run quicker experiments.
Note: One of the most important things in machine learning is being able to experiment quickly. As in, try a new model, try a new set of hyperparameters or try a new training setup. When you start out, you want the time between your experiments to be as small as possible so you can quickly figure out what doesn't work so you can spend more time on and run larger experiments with what does work.
As previously discussed, we're working towards a directory structure of:
images_split/\n\u251c\u2500\u2500 train/\n\u2502 \u251c\u2500\u2500 class_1/\n\u2502 \u2502 \u251c\u2500\u2500 train_image1.jpg\n\u2502 \u2502 \u251c\u2500\u2500 train_image2.jpg\n\u2502 \u2502 \u2514\u2500\u2500 ...\n\u2502 \u251c\u2500\u2500 class_2/\n\u2502 \u2502 \u251c\u2500\u2500 train_image1.jpg\n\u2502 \u2502 \u251c\u2500\u2500 train_image2.jpg\n\u2502 \u2502 \u2514\u2500\u2500 ...\n\u2514\u2500\u2500 test/\n \u251c\u2500\u2500 class_1/\n \u2502 \u251c\u2500\u2500 test_image1.jpg\n \u2502 \u251c\u2500\u2500 test_image2.jpg\n \u2502 \u2514\u2500\u2500 ...\n \u251c\u2500\u2500 class_2/\n \u2502 \u251c\u2500\u2500 test_image1.jpg\n \u2502 \u251c\u2500\u2500 test_image2.jpg\n...\n
So let's write some code to create:
images/train/ directory to hold all of the training images.images/test/ directory to hold all of the testing images.- Make a directory inside each of
images/train/ and images/test/ for each of the dog breed classes.
We can make each of the directories we need using Path.mkdir().
For the dog breed directories, we'll loop through the list of dog_names and create a folder for each inside the images/train/ and images/test/ directories.
"},{"location":"end-to-end-dog-vision-v2/#making-a-10-training-dataset-split","title":"Making a 10% training dataset split\u00b6","text":"We've already split the data into training and test sets, so why might we want to make another split?
Well, remember the machine learners motto?
Experiment, experiment, experiment!
We're going to make another training split which contains a random 10% (approximately 1,200 images, since the original training set has 12,000 images) of the data from the original training split.
Why?
Because whilst machine learning models generally perform better with more data, having more data means longer computation times.
And longer computation times means the time between our experiments gets longer.
Which is not what we want in the beginning.
In the beginning of any new machine learning project, your focus should be to reduce the amount of time between experiments as much as possible.
Why?
Because running more experiments means you can figure out what doesn't work.
And if you figure out what doesn't work, you can start working closer towards what does.
Once you find something that does work, you can start to scale up your experiments (more data, bigger models, longer training times - we'll see these later on).
To make our 10% training dataset, let's copy a random 10% of the existing training set to a new folder called images_split/train_10_percent, so we've got the layout:
images_split/\n\u251c\u2500\u2500 train/\n\u2502 \u251c\u2500\u2500 class_1/\n\u2502 \u2502 \u251c\u2500\u2500 train_image1.jpg\n\u2502 \u2502 \u251c\u2500\u2500 train_image2.jpg\n\u2502 \u2502 \u2514\u2500\u2500 ...\n\u2502 \u251c\u2500\u2500 class_2/\n\u2502 \u2502 \u251c\u2500\u2500 train_image1.jpg\n\u2502 \u2502 \u251c\u2500\u2500 train_image2.jpg\n\u2502 \u2502 \u2514\u2500\u2500 ...\n\u251c\u2500\u2500 train_10_percent/ <--- NEW!\n\u2502 \u251c\u2500\u2500 class_1/\n\u2502 \u2502 \u251c\u2500\u2500 random_train_image42.jpg\n\u2502 \u2502 \u2514\u2500\u2500 ...\n\u2502 \u251c\u2500\u2500 class_2/\n\u2502 \u2502 \u251c\u2500\u2500 random_train_image106.jpg\n\u2502 \u2502 \u2514\u2500\u2500 ...\n\u2514\u2500\u2500 test/\n \u251c\u2500\u2500 class_1/\n \u2502 \u251c\u2500\u2500 test_image1.jpg\n \u2502 \u251c\u2500\u2500 test_image2.jpg\n \u2502 \u2514\u2500\u2500 ...\n \u251c\u2500\u2500 class_2/\n \u2502 \u251c\u2500\u2500 test_image1.jpg\n \u2502 \u251c\u2500\u2500 test_image2.jpg\n \u2502 \u2514\u2500\u2500 ...\n
Let's start by creating that folder.
"},{"location":"end-to-end-dog-vision-v2/#5-turning-datasets-into-tensorflow-datasets","title":"5. Turning datasets into TensorFlow Dataset(s)\u00b6","text":"Alright, we've spent a bunch of time getting our dog images into different folders.
But how do we get the images from different folders into a machine learning model?
Well, like the other machine learning models we've built throughout the course, we need a way to turn our images into numbers.
Specifically, we're going to turn our images into tensors.
That's where the \"Tensor\" comes from in \"TensorFlow\".
A tensor is a way to numerically represent something (where something can be almost anything you can think of, text, images, audio, rows and columns).
There are several different ways to load data into TensorFlow.
But the formula is the same across data types, have data -> use TensorFlow to turn it into tensors.
The reason why we spent time getting our data into the standard image classification format (where the class name is the folder name) is because TensorFlow includes several utility functions to load data from this directory format.
Function Description tf.keras.utils.image_dataset_from_directory() Creates a tf.data.Dataset from image files in a directory. tf.keras.utils.audio_dataset_from_directory() Creates a tf.data.Dataset from audio files in a directory. tf.keras.utils.text_dataset_from_directory() Creates a tf.data.Dataset from text files in a directory. tf.keras.utils.timeseries_dataset_from_array() Creates a dataset of sliding windows over a timeseries provided as array. What is a tf.data.Dataset?
It's TensorFlow's efficient way to store a potentially large set of elements.
As machine learning datasets can get quite large, you need an efficient way to store and load them.
This is what the tf.data.Dataset API provides.
And it's what we'd like to turn our dog images into.
Since we're working with images, we can do so with tf.keras.utils.image_dataset_from_directory().
We'll pass in the following parameters:
directory = the target directory we'd like to turn into a tf.data.Dataset.label_mode = the kind of labels we'd like to use, in our case it's \"categorical\" since we're dealing with a multi-class classification problem (we would use \"binary\" if we were working with binary classifcation problem).batch_size = the number of images we'd like our model to see at a time (due to computation limitations, our model won't be able to look at every image at once so we split them into small batches and the model looks at each batch individually), generally 32 is a good value to start, this means our model will look at 32 images at a time (this number is flexible).image_size = the size we'd like to shape our images to before we feed them to our model (height x width).shuffle = whether we'd like our dataset to be shuffled to randomize the order.seed = if we're shuffling the order in a random fashion, do we want that to be reproducible?
Note: Values such as batch_size and image_size are known as hyperparameters, meaning they're values that you can decide what to set them as. As for the best value for a given hyperparameter, that depends highly on the data you're working with, problem space and compute capabilities you've got avaiable. Best to experiment!
With all this being said, let's see it in practice!
We'll make 3 tf.data.Dataset's, train_10_percent_ds, train_ds and test_ds.
"},{"location":"end-to-end-dog-vision-v2/#visualizing-images-from-our-tensorflow-dataset","title":"Visualizing images from our TensorFlow Dataset\u00b6","text":"Let's follow the data explorer's motto once again and visualize, visualize, visualize!
How about we turn our single sample from tensor format to image format?
We can do so by passing the single sample image tensor to matplotlib's plt.imshow() (we'll also need to convert its datatype from float32 to uint8 to avoid matplotlib colour range issues).
"},{"location":"end-to-end-dog-vision-v2/#getting-labels-from-our-tensorflow-dataset","title":"Getting labels from our TensorFlow Dataset\u00b6","text":"Since our data is now in tf.data.Dataset format, there are a couple of important attributes we can pull from it if necessary.
The first is the collection of filepaths asosciated with a tf.data.Dataset.
These are accessible by the .file_paths attribute.
Note: You can often a see a list of assosciated methods and attributes of a variable/class in Google Colab (or other IDEs) by pressing TAB afterwards (e.g type variable_name. + TAB).
"},{"location":"end-to-end-dog-vision-v2/#configuring-our-datasets-for-performance","title":"Configuring our datasets for performance\u00b6","text":"There's one last step we're going to do before we build our first TensorFlow model.
And that's configure our datasets for performance.
More specifically, we're going to focus on following the TensorFlow guide for Better performance with the tf.data API.
Why?
Because data loading is one of the biggest bottlenecks in machine learning.
Modern GPUs can perform calculations (matrix multiplications) to find patterns in data quite quickly.
However, for the GPU to perform such calculations, the data needs to be there.
Good news for us is that if we follow the TensorFlow tf.data best practices, TensorFlow will take care of all these optimizations and hardware acceleration for us.
We're going to call three methods on our dataset to optimize it for performance:
cache() - Cache the elements in the dataset in memory or a target folder (speeds up loading.shuffle() - Shuffle a set number of samples in preparation for loading (this will mean our samples and batches of samples will be shuffled), for example, setting shuffle(buffer_size=1000) will prepare and shuffle 1000 elements of data at a time.prefetch() - Prefetch the next batch of data and prepare it for computation whilst the previous one is being computed on (can scale to multiple prefetches depending on hardware availability). TensorFlow can automatically configure how many elements/batches to prefetch by setting prefetch(buffer_size=tf.data.AUTOTUNE).
Resource: For more performance tips on loading dataset in TensorFlow, see the Datasets Performance tips guide.
In our case, let's start by calling cache() on our datasets to save the loaded samples to memory.
We'll then shuffle() the training splits with buffer_size=10*BATCH_SIZE for the training 10% split and buffer_size=100*BATCH_SIZE for the full training set.
Why these numbers?
That's how many I decided to use via experimentation, feel free to figure out a different number that may work better.
Ideally if your dataset isn't too large, you would shuffle all possible samples (TensorFlow has a method of finding the number of samples in a dataset called tf.data.Dataset.cardinality()).
We won't call shuffle() on the testing dataset since it isn't required.
And we'll call prefetch(buffer_size=tf.data.AUTOTUNE) on each of our datasets to automatically load and prepare a number of data batches.
"},{"location":"end-to-end-dog-vision-v2/#6-creating-a-neural-network-with-tensorflow","title":"6. Creating a neural network with TensorFlow\u00b6","text":"We've spent lots of time preparing the data.
This is because it's often the largest part of a machine learning problem, getting your data ready for a machine learning model.
Thanks to modern frameworks like TensorFlow, when you've got your data in order, building a deep learning model to find patterns in your data can be one of the easier steps of the process.
When you hear people talk about deep learning, they're often referring to neural networks.
Neural networks are one of the most flexible machine learning models there is.
You can create a neural network to fit almost any kind of data.
The \"deep\" in deep learning refers to the many layers that can be contained inside a neural network.
A neural network often follows the structure of:
Input layer -> Middle layer(s) -> Output layer.
General anatomy of a neural network. Neural networks are almost infinitely customisable. The main premise is that data goes in one end, gets manipulated by many small functions in an attempt to learn patterns/weights which represent the data to produce useful outputs. Note that \"patterns\" is an arbitrary term, you\u2019ll often hear \"embedding\", \"weights\", \"feature representation\", \"representation\" all referring to similar things.
Where the input layer takes in the data, the middle layer(s) perform calculations on the data and (hopefully) learn patterns (also called weights/biases) to represent the data and the output layer performs a final transformation on the learned patterns to make them usable in human applications.
What goes into the middle layer(s)?
That's an excellent question.
Because there are so many different options.
But two of the most popular modern kinds of neural network are Convolutional Neural Networks (CNNs) and Transformers (the Transformer is the \"T\" in GPT, Generative Pretrained Transformer).
Architecture Description Example Layers Problem Examples Transformer) A combination of fully connected layers as well as attention-based layers. tf.keras.layers.Attention, tf.keras.layers.Dense NLP, Machine Translation, Computer Vision Convolutional Neural Network A combination of fully connected layers as well as convolutional-based layers. tf.keras.layers.Conv2D, tf.keras.layers.Dense Computer Vision, Audio Processing Because our problem is in the computer space, we're going to use a CNN.
And instead of crafting our own CNN from scratch, we're going to take an existing CNN model and apply it to our own problem, harnessing the wonderful superpower of transfer learning.
Note: You can build and use working neural networks with TensorFlow without knowing the intricate details that's going on the behind the scenes (that's what we're focused on). For an idea of the mathematical operations that make neural networks work, I'd recommend going through 3Blue1Brown's YouTube series on Neural Networks.
"},{"location":"end-to-end-dog-vision-v2/#the-magic-of-transfer-learning","title":"The magic of transfer learning\u00b6","text":"Transfer learning is the process of getting an existing working model and adjusting it to your own problem.
This works particularly well for neural networks.
The main benefit of transfer learning is being able to get better results in less time with less data.
How?
An existing model may have the following features:
- Trained on lots of data (in the case of computer vision, existing models are often pretrained on ImageNet, a dataset of 1M+ images, this means they've already learned patterns across many different kinds of images).
- Crafted by expert researchers (large universities and companies such as Google and Meta often open-source their best models for others to try and use).
- Trained of lots of computing hardware (the larger the model and the larger the dataset, the more compute power you need, not everyone has access to 10s, 100s or 1000s of GPUs).
- Proven to perform well on a given task through several studies (this means it has a good chance on performing well on your task if it's similar).
You may be thinking, ok so, this all sounds incredible, where can I get pretrained models?
And the good news is, there are plenty of places to find pretrained models!
Resource Description tf.keras.applications A module built-in to TensorFlow and Keras with a series of pretrained models ready to use. KerasNLP and KerasCV Two dedicated libraries for NLP (natural language processing) and CV (computer vision) each of which includes many modality-specific APIs and is capable of running with TensorFlow, JAX or PyTorch. Hugging Face Models Hub A large collection of pretrained models on a wide range on tasks, from computer vision to natural language processing to audio processing. Kaggle Models A huge collection of different pretrained models for many different tasks. Different locations to find pretrained models. This list is consistantly expanding as machine learning becomes more and more open-source.
Note: For most new machine learning problems, if you're looking to get good results quickly, you should generally look for a pretrained model similar to your problem and use transfer learning to adapt it to your own domain.
Since we're focused on TensorFlow/Keras, we're going to be using a pretrained model from tf.keras.applications.
More specifically, we're going to take the tf.keras.applications.efficientnet_v2.EfficientNetV2B0() model from the 2021 machine learning paper EfficientNetV2: Smaller Models and Faster Training from Google Research and apply it to our own problem.
This model has been trained on ImageNet1k (1M+ images across 1000 different diverse classes, there is a version called ImageNet22k with 14M+ images across 22,000 categories) so it has a good baseline understanding of patterns in images across a wide domain.
We'll see if we can adjust those patterns slightly to our dog images.
Let's create an instance of it and call it base_model (I'll explain why next).
"},{"location":"end-to-end-dog-vision-v2/#model-input-and-output-shapes","title":"Model input and output shapes\u00b6","text":"One of the most important practical steps in using a deep learning model is input and output shapes.
Two questions to ask:
- What is the shape of my input data?
- What is the ideal shape of my output data?
We ask about shapes because in all deep learning models input and output data comes in the form of tensors.
This goes for text, audio, images and more.
The raw data gets converted to a numerical representation first before being passed to a model.
In our case, our input data has the shape of [(32, 224, 224, 3)] or [(batch_size, height, width, colour_channels)].
And our ideal output shape will be [(32, 120)] or [(batch_size, number_of_dog_classes).
Your input and output shapes will differ depending on the problem and data you're working with.
But as you get deeper into the world of machine learning (and deep learning), you'll find input and output shapes are one of the most common errors.
We can check our model's input and output shapes with the .input_shape and .output_shape attributes.
"},{"location":"end-to-end-dog-vision-v2/#model-parameters","title":"Model parameters\u00b6","text":"In traditional programming, you write a list of rules for inputs to go in, get manipulated in some predefined way and then outputs come out.
However, as we've discussed, machine learning switches the order.
Inputs and ideal outputs go in (for example, dog images and their corresponding labels) and rules come out.
A model's parameters are the learned rules.
And learned is the important point.
In an ideal setup, we never tell the model what parameters to learn, it learns them itself by connecting input data to labels in supervised learning and by grouping together similar samples in unsupervised learning.
Note: Parameters are values learned by a model where as hyperpameters (e.g. batch size) are values set by a human.
Parameters also get referred to as \"weights\" or \"patterns\" or \"learned features\" or \"learned representations\".
Generally, the more parameters a model has, the more capacity it has to learn.
Each layer in a deep learning model will have a specific number of parameters (these vary depending on which layer you use).
The benefit of using a preconstructed model and transfer learning is that someone else has done the hard work in finding what combination of layers leads to a good set of parameters (a big thank you to these wonderful people).
We can count the number of parameters in a model/layer via the the .count_params() method.
"},{"location":"end-to-end-dog-vision-v2/#passing-data-through-our-model","title":"Passing data through our model\u00b6","text":"We've spoken a couple of times how our base_model is a \"feature extractor\" or \"pattern extractor\".
But what does this mean?
It means that when a data sample goes through the base_model, its numbers get manipulated into a compressed set of features.
In other words, the layers of the model will each perform a calculation on the sample eventually leading to an output tensor with patterns the model has deemed most important.
This is often referred to a compressed feature space.
That's one of the central ideas of deep learning.
Take a large input (e.g. an image tensor of shape [224, 224, 3]) and compress it into a smaller output (e.g. a feature vector#Feature_vectors) of shape [1280]) that captures a useful representation of the input.
Example of how a model can take an input piece of data and compress its representation into a feature vector with much lower dimensionality than the original data.
Note: A feature vector is also referred to as an embedding, a compressed representation of a data sample that makes it useful. The concept of embeddings is not limited to images either, the concept of embeddings stretches across all data types (text, images, video, audio + more).
We can see this in action by passing a single image through our base_model.
"},{"location":"end-to-end-dog-vision-v2/#going-from-image-to-feature-vector-practice","title":"Going from image to feature vector (practice)\u00b6","text":"We've covered a fair bit in the past few sections.
So let's practice.
The important takeaway is that one of the main goals of deep learning is to create a model that is able to take some kind of high dimensional data (e.g. an image tensor, a text tensor, an audio tensor) and extract meaningful patterns in it whilst compressing it to a lower dimensional form (e.g. a feature vector or embedding).
We can then use this lower dimensional form for our specific use cases.
And one of the most powerful ways to do this is with transfer learning.
Taking an existing model from a similar domain to yours and applying it to your own problem.
To practice turning a data sample into a feature vector, let's start by recreating a base_model instance.
This time, we can add in a pooling layer automatically using pooling=\"avg\" or pooling=\"max\".
Note: I demonstrated the use of the tf.keras.layers.GlobalAveragePooling2D() layer because not all pretrained models have the functionality of a pooling layer being built-in.
"},{"location":"end-to-end-dog-vision-v2/#creating-a-custom-model-for-our-dog-vision-problem","title":"Creating a custom model for our dog vision problem\u00b6","text":"The main steps when creating any kind of deep learning model from scratch are:
- Define the input layer(s).
- Define the middle layer(s).
- Define the output layer(s).
These sound broad because they are. Deep learning models are almost infinitely customizable.
Good news is, thanks to transfer learning, all of our middle layers are defined by base_model (you could argue the input layer is created too).
So now it's up to us to define our input and output layers.
TensorFlow/Keras have two main ways of connecting layers to form a model.
- The Sequential model (
tf.keras.Sequential) - Useful for making simple models with one tensor in and one tensor out, not suited for complex models. - The Functional API - Useful for making more complex and multi-step models but can also be used for simple models.
Let's start with the Sequential model.
It takes a list of layers and will pass data through them sequentially.
Our base_model will be the input and middle layers and we'll use a tf.keras.layers.Dense() layer as the output (we'll discuss this shortly).
"},{"location":"end-to-end-dog-vision-v2/#creating-a-model-with-the-sequential-api","title":"Creating a model with the Sequential API\u00b6","text":"The Sequential API is the most straightforward way to create a model.
Your model comes in the form of a list of layers from input to middle layers to output.
Each layer is executed sequentially.
"},{"location":"end-to-end-dog-vision-v2/#creating-a-model-with-the-functional-api","title":"Creating a model with the Functional API\u00b6","text":"As mentioned before, the Keras Functional API is a way/design pattern for creating more complex models.
It can include multiple different modelling steps.
But it can also be used for simple models.
And it's the way we'll construct our Dog Vision models going forward.
Let's recreate our sequential_model using the Functional API.
We'll follow the same process as mentioned before:
- Define the input layer(s).
- Define the middle/hidden layer(s).
- Define the output layer(s).
- Bonus: Connect the inputs and outputs within an instance of
tf.keras.Model().
"},{"location":"end-to-end-dog-vision-v2/#functionizing-model-creation","title":"Functionizing model creation\u00b6","text":"We've created two different kinds of models so far.
Each of which use the same layers.
Except one was with the Keras Sequential API and the other was with the Keras Functional API.
However, it would be quite tedious to rewrite that modelling code every time we wanted to create a new model.
So let's create a function called create_model() to replicate the model creation step with the Functional API.
Note: We're focused on the Functional API since it takes a bit more practice than the Sequential API.
"},{"location":"end-to-end-dog-vision-v2/#7-model-0-train-a-model-on-10-of-the-training-data","title":"7. Model 0 - Train a model on 10% of the training data\u00b6","text":"We've seen our model make a couple of predictions on our data.
And so far it hasn't done so well.
This is expected though.
Our model is essentially predicting random class values given an image.
Let's change that.
How?
By training the final layer on our model to be customized to recognizing images of dogs.
We can do so via five steps:
- Creating the model - We've done this \u2705.
- Compiling the model - Here's where we'll tell the model how to improve itself and how to measure its performance.
- Fitting the model - Here's where we'll show the model examples of what we'd like it to learn (e.g. batches of samples containing pairs of dog images and their breed).
- Evaluating the model - Once our model is trained on the training data, we can evaluate it on the testing data (data the model has never seen).
- Making a custom prediction - Finally, the best way to test a machine learning model is by seeing how it goes on custom data. This is where we'll try to make a prediction on our own custom images of dogs.
We'll work through each of these over the next few sections.
To begin, let's create a model.
To do so, we can use our create_model() function that we made earlier.
"},{"location":"end-to-end-dog-vision-v2/#compiling-a-model","title":"Compiling a model\u00b6","text":"After we've created a model, the next step is to compile it.
If creating a model is putting together learning blocks, compiling a model is to getting those learning blocks ready to learn.
We can compile our model_0 using the tf.keras.Model.compile() method.
There are many options we can pass to the compile() method, however, the main ones we'll be focused on are:
- The optimizer - this tells the model how to improve based on the loss value.
- The loss function - this measures how wrong the model is (e.g. how far off are its predictions from the truth, an ideal loss value is 0, meaning the model is perfectly predicting the data).
- The metric(s) - this is a human-readable value that shows how your model is performing, for example, accuracy is often used as an evaluation metric.
These three settings work together to help improve a model.
"},{"location":"end-to-end-dog-vision-v2/#which-optimizer-should-i-use","title":"Which optimizer should I use?\u00b6","text":"An optimizer tells a model how to improve its internal parameters (weights) to hopefully improve a loss value.
In most cases, improving the loss means to minimize it (a loss value is a measure of how wrong your model's predictions are, a perfect model will have a loss value of 0).
It does this through a process called gradient descent.
The gradients needed for gradient descent are calculated through backpropagation, a method that computes the gradient of the loss function with respect to each weight in the model.
Once the gradients have been calculated, the optimizer then tries to update the model weights so that they move in the opposite direction of the gradient (if you go down the gradient of a function, you reduce its value).
If you've never heard of the above processes, that's okay.
TensorFlow implements many of them behind the scenes.
For now, the main takeaway is that neural networks learn in the following fashion:
Start with random patterns/weights -> Look at data (forward pass) -> Try to predict data (with current weights) -> Measure performance of predictions (loss function, backpropagation calculates gradients of loss with respect to weights) -> Update patterns/weights (optimizer, gradient descent adjusts weights in the opposite direction of the gradients to minimize loss) -> Look at data (forward pass) -> Try to predict data (with updated weights) -> Measure performance (loss function) -> Update patterns/weights (optimizer) -> Repeat all of the above X times.
Example of how a neural network learns (in brief). Note the cyclical nature of the learning. You can think of it as a big game of guess and check, where the guess (hopefully) get better over time.
I'll leave the intricacies of gradient descent and backpropagation to your own extra-curricula research.
We're going to focus on using the tools TensorFlow has to offer to implement this process.
As for optimizer functions, there are two main options to get started:
Optimizer Code Stochastic Gradient Descent (SGD) tf.keras.optimizers.SGD() or \"sgd\" for short. Adam tf.keras.optimizers.Adam() or \"adam\" for short. Why these two?
Because they're the most often used in practice (you can see this via the number of machine learning papers referencing each one on paperswithcode.com).
There are many more optimizers available in the tf.keras.optimizers module too.
The good thing about using a premade optimizer from tf.keras.optimizers is that they usually come with good starting settings.
One the main ones being the learning_rate value.
The learning_rate is one of the most important hyperparameters to set in a neural network training setup.
It determines how much of a step change the optimizer will adjust your models weights every iteration.
Too low and the model won't learn.
Too high and the model will try to take too big of steps.
By default, TensorFlow sets the learning rate of the Adam optimizer to 0.001 (tf.keras.optimizers.Adam(learning_rate=0.001)) which is a good setting for many problems to get started with.
We can also set this default with the shortcut optimizer=\"adam\".
For more on finding the optimal learning rate, try searching for \"finding the optimal learning rate for neural networks\".
"},{"location":"end-to-end-dog-vision-v2/#which-loss-function-should-i-use","title":"Which loss function should I use?\u00b6","text":"A loss function measures how wrong your model's predictions are.
A model with poor predictions in comparison to the truth data will have a high loss value.
Where as a model with perfect predictions (e.g. it gets every prediction correct) will have a loss value of 0.
Different problems have different loss functions.
Some of the most common ones include:
Loss Function Problem Type Code Mean Absolute Error (MAE) Regression (predicting a number) tf.keras.losses.MeanAbsoluteError or \"mae\" for short Mean Squared Error (MSE) Regression (predicting a number) tf.keras.losses.MeanSquaredError Binary Cross Entropy (BCE) Binary classification tf.keras.losses.BinaryCrossentropy Categorical Cross Entropy Multi-class classification tf.keras.losses.CategoricalCrossentropy if your labels are one-hot encoded (e.g. [0, 0, 0, 0, 1, 0...]) or tf.keras.losses.SparseCategoricalCrossentropy if your labels are integers (e.g. [[1], [23], [43], [16]...]) In our case, since we're working with multi-class classification (multiple different dog breeds) and our labels are one-hot encoded, we'll be using tf.keras.losses.CategoricalCrossentropy.
We can leave all of the default parameters as they are as well.
However, if we didn't have activation=\"softmax\" in the final layer of our model, we'd have to change from_logits=False to from_logits=True as the softmax activation function does this conversion for us.
There are more loss functions than the ones we've discussed and you can see many of them on paperswithcode.com.
TensorFlow also has many more loss function implementations available in tf.keras.losses.
Let's check out a single sample of our labels to make sure they're one-hot encoded.
"},{"location":"end-to-end-dog-vision-v2/#which-mertics-should-i-use","title":"Which mertics should I use?\u00b6","text":"The evaluation metric is a human-readable value which is used to see how well your model is performing.
A slightly confusing concept is that the evaluation metric and loss function can be the same equation.
However, the main difference between a loss function and an evaluation metric is that the loss function will typically be differentiable (there are some exceptions to the rule but in most cases, the loss function will be differentiable).
Whereas, the evaluation metric does not have to be differtiable.
In the case of regression (predicting a number), your loss function and evaluation metric could be mean squared error (MSE).
Whereas in the case of classification, your loss function will generally be binary crossentropy (for two classes) or categorical crossentropy (for multiple classes) and your evalaution metric(s) could be accuracy, F1-score, precision and/or recall.
TensorFlow provides many pre-built metrics in the tf.keras.metrics module.
Evaluation Metric Problem Type Code Accuracy Classification tf.keras.metrics.Accuracy or \"accuracy\" for short Precision Classification tf.keras.metrics.Precision Recall Classification tf.keras.metrics.Recall F1 Score Classification tf.keras.metrics.F1Score Mean Squared Error (MSE) Regression tf.keras.metrics.MeanSquaredError or \"mse\" for short Mean Absolute Error (MAE) Regression tf.keras.metrics.MeanAbsoluteError or \"mae\" Area Under the ROC Curve (AUC-ROC) Binary Classification tf.keras.metrics.AUC with curve='ROC' The tf.keras.Model.compile() method expects the metrics parameter input as a list.
Since we're working with a classification problem, let's setup our evaluation metric as accuracy.
"},{"location":"end-to-end-dog-vision-v2/#learn-more-on-how-a-model-learns","title":"Learn more on how a model learns\u00b6","text":"We've breifly touched on optimizers, loss functions, gradient descent and backpropagation, the backbone of neural network learning, however, for a more in-depth look at each of these, I'd check out the following:
- 3Blue1Brown's series on Neural Networks - a fantastic 4 part video series on how neural networks are built to how they learn through gradient descent and backpropagation.
- The Little Book of Deep Learning by Fran\u00e7ois Fleuret - a free ~150 page booklet on the ins and outs of deep learning. The notation may be intimidating at first but with practice you will begin to understand it.
"},{"location":"end-to-end-dog-vision-v2/#putting-it-all-together-and-compiling-our-model","title":"Putting it all together and compiling our model\u00b6","text":"Phew!
We've now been through all the main steps in compiling a model:
- Creating the optimizer.
- Creating the loss function.
- Creating the evaluation metrics.
Now let's put everything we've done together and compile our model_0.
First we'll do it with shortcuts (e.g. \"accuracy\") then we'll do it with specific classes.
"},{"location":"end-to-end-dog-vision-v2/#fitting-a-model-on-the-data","title":"Fitting a model on the data\u00b6","text":"Model created and compiled!
Time to fit it to the data.
This means we're going to pass all of the data we have (dog images and their assigned labels) through our model and ask it to try and learn the relationship between the images and the labels.
Fitting the model is step 3 in our list:
- Creating the model - We've done this \u2705.
- Compiling the model - We've done this \u2705.
- Fitting the model - Here's where we'll show the model examples of what we'd like it to learn (e.g. the relationship between an image of a dog and its breed).
- Evaluating the model - Once our model is trained on the training data, we can evaluate it on the testing data (data the model has never seen).
- Making a custom prediction - Finally, the best way to test a machine learning model is by seeing how it goes on custom data. This is where we'll try to make a prediction on our own custom images of dogs.
We can fit our model_0 instance with the tf.keras.Model.fit() method.
The main parameters of the fit() method we'll be paying attention to are:
x = What data do you want the model to train on?y = What labels do you want your model to learn the patterns from your data to?batch_size = The number of samples your model will look at per gradient update (e.g. 32 samples at a time before updating its internal patterns).epochs = How many times do you want the model to go through all samples (e.g. epochs=5 means looking at all of the data 5 times)?validation_data = What data do you want to evaluate your model's learning on?
There are plenty more options in the TensorFlow/Keras documentation for the fit() method.
However, these options will be more than enough for us.
In our case, let's keep our experiments quick and set the following:
x=train_10_percent_ds - Since we've crafted a tf.data.Dataset, our x and y values are combined into one. We'll also start by training on 10% of the data for quicker experimentation (if things work on a smaller subset of the data, we can always increase it).epochs=5 - The more epochs you do, the more opportunities your model has to learn patterns, however, it also prolongs training.validation_data=test_ds - We'll evaluate the model's learning on the test dataset (samples its never seen before).
Let's do it!
Time to train our first neural network and bring Dog Vision \ud83d\udc36\ud83d\udc41\ufe0f to life!
Note: If you don't have a GPU here, training will likely take a considerably long time. You can activate a GPU in Google Colab by going to Runtime -> Change runtime type -> Hardware accelerator -> GPU. Note that changing a runtime type will mean you will have to restart your runtime and rerun all of the cells above.
"},{"location":"end-to-end-dog-vision-v2/#8-putting-it-all-together-create-compile-fit","title":"8. Putting it all together: create, compile, fit\u00b6","text":"Let's practice what we've done so far to train our first neural network.
Specifically, we're going to:
- Create a model (using our
create_model()) function. - Compile our model (selecting our optimizer, loss function and evaluation metric).
- Fit our model (get it to figure out the patterns bettwen images and labels).
And later on, we'll get to the other steps of evaluation and making custom predictions.
"},{"location":"end-to-end-dog-vision-v2/#evaluate-model-0-on-the-test-data","title":"Evaluate Model 0 on the test data\u00b6","text":"Alright, the next step in our journey is to evaluate our trained model.
In fact, evaluating a model is just as important as training a model.
There are several ways to evaluate a model:
- Look at the metrics (such as accuracy).
- Plot the loss curves.
- Make predictions on the test set and compare them to the truth labels.
- Make predictions on custom samples (not contained in the training or test sets).
We've done the first one, as these metrics were the outputs of our model training.
Now we're going to focus on the next two.
Plotting loss curves and making predictions on the test set.
We'll get to custom images later on.
So what are loss curves?
Loss curves are a visualization of how your model's loss value performs overtime.
We say loss \"curves\" because you can have a loss curve for each dataset, training, validation and test.
An ideal loss curve will start high and move towards zero (a perfect model will have a loss value of zero).
How do we get a loss curve?
We could manually plot the loss values output from our model training.
Or we could programmatically get the values thanks to the History object.
This object is returned by the fit method of tf.keras.Model instances.
And we've already got one!
It's saved to history_0 (the model history for model_0).
The History.history attribute contains a record of the training loss values and evaluation metrics for each epoch.
Let's check it out.
"},{"location":"end-to-end-dog-vision-v2/#overfitting-and-underfitting-when-your-model-doesnt-perform-how-youd-like","title":"Overfitting and underfitting (when your model doesn't perform how you'd like)\u00b6","text":"You may be wondering why there's a gap between the training and validation loss curves.
Ideally, the two lines would closely follow each other.
In our case, the validation loss doesn't decrease as low as the training loss.
This is known as overfitting, a common problem in machine learning where a model learns the training data very well but doesn't generalize to other unseen data.
You can think of this as a university student memorizing the course materials but failing to apply that knowledge to problems that aren't in the course materials (real-world problems).
The reverse of overfitting is underfitting, which is when a model fails to learn anything useful. For example, it never manages to increase accuracy or decrease loss.
Good news is, our model isn't underfitting (it's performing at ~80% accuracy on unseen data).
I'll leave \"ways to fix overfitting\" as an extension.
But one of the best ways is to use more data.
And guess what?
We've got plenty more!
Reminder, these results were achieved using only 10% of the training data.
Before we train a model with more data, there's another way to quickly evaluate our model on a given dataset.
And that's using the tf.keras.Model.evaluate() method.
How about we try it on our model_0?
We'll save the outputs to a model_0_results variable so we can use them later.
"},{"location":"end-to-end-dog-vision-v2/#9-model-1-train-a-model-on-100-of-the-training-data","title":"9. Model 1 - Train a model on 100% of the training data\u00b6","text":"Time to step it up a notch!
We've trained a model on 10% of the training data (to see if it works and it did!), now let's train a model on 100% of the training data and see what happens.
But before we do...
What do you think will happen?
If our model was able to perform well on only 10% of the data, how do you think it will go on 100% of the data?
These types of questions are good to think about in the world of machine learning.
After all, that's why the machine learner's motto is experiment, experiment, experiment!
Let's follow our three steps from before:
- Create a model (using our
create_model()) function. - Compile our model (selecting our optimizer, loss function and evaluation metric).
- Fit our model (this time on 100% of the data for 5 epochs).
Note: Fitting our model on such a large amount of data will take a long time without a GPU. If you're using Google Colab, you can access a GPU via Runtime -> Change runtime type -> Hardware accelerator -> GPU.
"},{"location":"end-to-end-dog-vision-v2/#evaluate-model-1-on-the-test-data","title":"Evaluate Model 1 on the test data\u00b6","text":"How about we evaluate our model_1?
Let's first by plotting loss curves with the data contained within history_1.
"},{"location":"end-to-end-dog-vision-v2/#10-make-and-evaluate-predictions-of-the-best-model","title":"10. Make and evaluate predictions of the best model\u00b6","text":"Now we've trained a model, it's time to make predictions with it!
That's the whole goal of machine learning.
Train a model on existing data, to make predictions on new data.
Our test data is supposed to simulate new data, data our model has never seen before.
We can make predictions with the tf.keras.Model.predict() method, passing it our test_ds (short for test dataset) variable.
"},{"location":"end-to-end-dog-vision-v2/#visualizing-predictions-from-our-best-trained-model","title":"Visualizing predictions from our best trained model\u00b6","text":"We could sit there looking at single image predictions of dogs all day.
Or we could write code to look at multiple at a time...
Let's do the latter!
"},{"location":"end-to-end-dog-vision-v2/#finding-the-accruacy-per-class","title":"Finding the accruacy per class\u00b6","text":"Our model's overall accuracy is ~90%.
This is an outstanding result.
But what about the accuracy per class?
As in, how did the boxer class perform?
Or the australian_terrier?
You'll see on the original Stanford Dogs Dataset website that the authors reported the accuracy per class of each of the dog breeds. Their best performing class, african_hunting_dog achieved close to 60% accuracy (about ~58% if I'm reading the graph correctly).
Results from the original Stanford Dogs Dataset paper (2011). Let's see if the model we trained performs better than it.
How about we try and replicate the same plot with our own results?
First, let's create a DataFrame with information about our test predictions and test samples.
We'll start by getting the argmax of the test predictions as well as the test labels.
Then we'll get the maximum prediction probabilities for each sample.
And then we'll put it all into a DataFrame!
"},{"location":"end-to-end-dog-vision-v2/#finding-the-most-wrong-examples","title":"Finding the most wrong examples\u00b6","text":"A great way to inspect your models errors is to find the examples where the prediction had a high probability but the prediction was wrong.
This is often called the \"most wrong\" samples.
As in the model was very confident but wrong.
Let's filter for the top 100 most wrong by sorting the incorrect predictions by the \"test_pred_prob\" column.
"},{"location":"end-to-end-dog-vision-v2/#create-a-confusion-matrix","title":"Create a confusion matrix\u00b6","text":"A confusion matrix helps to visualize which classes a predicted compared to which classes it should've predicted (truth vs. predictions).
We can create one using Scikit-Learn's sklearn.metrics.confusion_matrix and passing in our y_true and y_pred values.
And then we can display it using sklearn.metrics.ConfusionMatrixDisplay.
Note: Since we have 120 different classes, running the code bellow to show the confusion matrix plot may take a minute or so to load (it's quite a big plot!).
"},{"location":"end-to-end-dog-vision-v2/#11-save-and-load-the-best-model","title":"11. Save and load the best model\u00b6","text":"We've covered a lot of ground from loading data to training and evaluating a model.
But what if you wanted to use that model somewhere else?
Such as on a website or in an application?
The first step is saving it to file.
We can save our model using the tf.keras.Model.save() method and specifying the filepath as well as the save_format parameters.
We'll use filepath=\"dog_vision_model.keras\" as well as save_format=\"keras' to save our model to the new and versatile .keras format.
Let's save our best performing model_1.
Note: You may also see models being saved with the SavedModel format as well as HDF5 formats, however, it's recommended to use the newer .keras format. See the TensorFlow documentation on saving and loading a model for more.
"},{"location":"end-to-end-dog-vision-v2/#12-make-predictions-on-custom-images-with-the-best-model","title":"12. Make predictions on custom images with the best model\u00b6","text":"Now what fun would it be if we only made predictions on the test dataset?
How about we see how our model goes on real world images?
That's the whole goal of machine learning right? To see how your model goes in the real world?
Well, let's make some predictions on custom images!
Specifically, let's try our best model on images of my dogs (Bella \ud83d\udc36 and Seven 7\ufe0f\u20e3, yes, Seven is her actual name) and an extra wildcard image.
We can download the photos from the course GitHub.
"},{"location":"end-to-end-dog-vision-v2/#13-key-takeaways","title":"13. Key Takeaways\u00b6","text":" - Data, data, data! In any machine learning problem, getting a dataset and preparing it so that it is in a usable format will likely be the first and often most important step (hence why we spent so much time getting the data ready). It will also be an ongoing process, as although we've worked with thousands of dog images, our models could still be improved. And as we saw going from training with 10% of the data to 100% of the data, one of the best ways to improve a model is with more data. Explore your data early and often.
- When starting out, use transfer learning where possible. For most new problems, you should generally look to see if a pretrained model exists and see if you can adapt it to your use case. Ask yourself: What format is my data in? What are my ideal inputs and outputs? Is there a pretrained model for my use case?
- TensorFlow and Keras provide building blocks for neural networks which are powerful machine learning models capable of learning patterns in a wide range of data from text to audio to images and more.
- Experiment, experiment, experiment! It's highly unlikely you'll ever get the best performing model on your first try. Machine learning is very experimental by nature. This includes experimenting on the data, the model, the training setup and the outputs (how does your model work in practice?). Always keep this front of mind in any machine learning project. Your results are never stationary and can often always be improved.
"},{"location":"end-to-end-dog-vision-v2/#extensions-exercises","title":"Extensions & Exercises\u00b6","text":"The following are a series of exercises and extensions which build on what we've covered throughout this module.
I'd highly recommend going thorugh each one and spending time practicing what you've learned.
This is where the real knowledge is built. Trying things out for yourself.
- Try a prediction with our trained model on your own images of dogs and see if the model is correct.
- Try training another model from
tf.keras.applications (e.g. ConvNeXt) and see if it performs better than EfficientNetV2. - Try training a model on your own images in different classes, for example, apple vs. banana vs. orange. You could download images from the internet and sort them into different folders and then load them how we've done in the data loading section. Or you could take photos of your own and build a model to differentiate between them.
- For more advanced model training, you may want to look into the concept of \"Callbacks\", these are functions which run during the model training. TensorFlow and Keras have a series of built-in callbacks which can be helpful for training. Have a read of the
tf.keras.callbacks.Callback documentation and see which ones may be useful to you. - We touched on the concept of overfitting when we trained our model. This is when a model performs far better on the training set than on the test set. The concept of trying to prevent overfitting is known as regularization. Spend 20-minutes researching \"ways to prevent overfitting\" and write a list of 2-3 techniques and how they might come into play with our model training. Tip: One of the most common regularization techniques in computer vision is data augmentation (also see the brief example below).
- One of the most important parts of machine learning is having good data. The next most important part is loading that data in a way that can used to train models as fast and efficiently as possible. For more on this, I'd highly recommend reading more about the
tf.data API (this API is TensorFlow focused, however, the concepts can be bridged to other dataloading needs) as well as reviewing the tf.data best practices (better performance with the tf.data API). - Right now our model works well, however, we have to write code to interact with it. You could turn it into a small machine learning app using Gradio so people can upload their own images of dogs and see what the model predicts. See the example for image classification with TensorFlow and Keras for an idea of what you could build. See an example of this below as well as a running demo of Dog Vision on Hugging Face.
In this project we've only really scratched the surface of what's possible with TensorFlow/Keras and deep learning.
For a more comprehensive overview of TensorFlow/Keras, see the following:
- 14-hour TensorFlow Tutorial on YouTube (this is the first 14 hours of the ZTM TensorFlow course).
- Zero to Mastery TensorFlow for Deep Learning course (a 50+ hour course diving into many applications of TensorFlow and deep learning).
"},{"location":"end-to-end-dog-vision-v2/#extension-example-data-augmentation","title":"Extension example: data augmentation\u00b6","text":"Data augmentation is a regularization technique to help prevent overfitting.
It's designed to alter training images to artifically increase the diversity of the training dataset and hopefully help to generalize better to test images as well as real-life images.
For example, we want our models to be able to identify the same breed of dog in an image regardless if the dog is facing left or right.
So one simple data augmentation technique is to randomly flip the image horizontally so the model learns to recognize the same dog from different points of view.
You can repeat this for many different types of image modifications such as rotation, zone, colour alterations and more.
The following code is a brief example of how to incorporate a data augmentation layer into a model (note that in practice data augmentation is only applied during training time and not during testing/prediction time, this is set automatically within layers aimed at data augmentation).
For more, see the TensorFlow guide on data augmentation.
"},{"location":"end-to-end-dog-vision-v2/#extension-example-gradio-app-demo","title":"Extension Example: Gradio App Demo\u00b6","text":"This is a modified version of the Gradio Image Classification Tutorial with TensorFlow and Keras.
You can see a guide on Hugging Face for how to host it on Hugging Face Spaces (a place where you can host and share your machine learning apps).
First we'll install Gradio.
"},{"location":"end-to-end-heart-disease-classification/","title":"End-to-End Heart Disease Classification","text":"View source code | Read notebook in online book format
In\u00a0[1]: Copied! # Regular EDA and plotting libraries\nimport numpy as np # np is short for numpy\n\nimport pandas as pd # pandas is so commonly used, it's shortened to pd\n\nimport matplotlib\nimport matplotlib.pyplot as plt\n\nimport seaborn as sns # seaborn gets shortened to sns, TK - can seaborn be removed for matplotlib (simpler)?\n\n## Models\nimport sklearn \nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.ensemble import RandomForestClassifier\n\n## Model evaluators\nfrom sklearn.model_selection import train_test_split, cross_val_score\nfrom sklearn.model_selection import RandomizedSearchCV, GridSearchCV\nfrom sklearn.metrics import confusion_matrix, classification_report\nfrom sklearn.metrics import precision_score, recall_score, f1_score\n# from sklearn.metrics import plot_roc_curve # note: this was changed in Scikit-Learn 1.2+ to be \"RocCurveDisplay\" (see below)\nfrom sklearn.metrics import RocCurveDisplay # new in Scikit-Learn 1.2+\n\n# Print last updated\nimport datetime\nprint(f\"Notebook last updated: {datetime.datetime.now()}\\n\")\n\n# Print versions of libraries we're using (as long as yours are equal or greater than these, your code should work)\nprint(f\"NumPy version: {np.__version__}\")\nprint(f\"pandas version: {pd.__version__}\")\nprint(f\"matplotlib version: {matplotlib.__version__}\")\nprint(f\"Scikit-Learn version: {sklearn.__version__}\")\n # Regular EDA and plotting libraries import numpy as np # np is short for numpy import pandas as pd # pandas is so commonly used, it's shortened to pd import matplotlib import matplotlib.pyplot as plt import seaborn as sns # seaborn gets shortened to sns, TK - can seaborn be removed for matplotlib (simpler)? ## Models import sklearn from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.ensemble import RandomForestClassifier ## Model evaluators from sklearn.model_selection import train_test_split, cross_val_score from sklearn.model_selection import RandomizedSearchCV, GridSearchCV from sklearn.metrics import confusion_matrix, classification_report from sklearn.metrics import precision_score, recall_score, f1_score # from sklearn.metrics import plot_roc_curve # note: this was changed in Scikit-Learn 1.2+ to be \"RocCurveDisplay\" (see below) from sklearn.metrics import RocCurveDisplay # new in Scikit-Learn 1.2+ # Print last updated import datetime print(f\"Notebook last updated: {datetime.datetime.now()}\\n\") # Print versions of libraries we're using (as long as yours are equal or greater than these, your code should work) print(f\"NumPy version: {np.__version__}\") print(f\"pandas version: {pd.__version__}\") print(f\"matplotlib version: {matplotlib.__version__}\") print(f\"Scikit-Learn version: {sklearn.__version__}\") Notebook last updated: 2024-09-24 13:29:26.771285\n\nNumPy version: 2.1.1\npandas version: 2.2.2\nmatplotlib version: 3.9.2\nScikit-Learn version: 1.5.1\n
In\u00a0[2]: Copied! df = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/heart-disease.csv\")\n# df = pd.read_csv(\"../data/heart-disease.csv\") # Read from local directory, 'DataFrame' shortened to 'df'\ndf.shape # (rows, columns)\n
df = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/heart-disease.csv\") # df = pd.read_csv(\"../data/heart-disease.csv\") # Read from local directory, 'DataFrame' shortened to 'df' df.shape # (rows, columns) Out[2]: (303, 14)
In\u00a0[3]: Copied! # Check the head of our DataFrame\ndf.head()\n
# Check the head of our DataFrame df.head() Out[3]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1 Wonderful! We've got some data to work with. Notice how all the column names reflect a field in our data dicitonary above.
In\u00a0[4]: Copied! # Let's check the top 5 rows of our dataframe\ndf.head()\n
# Let's check the top 5 rows of our dataframe df.head() Out[4]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1 In\u00a0[5]: Copied! # And the top 10\ndf.head(10)\n
# And the top 10 df.head(10) Out[5]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1 5 57 1 0 140 192 0 1 148 0 0.4 1 0 1 1 6 56 0 1 140 294 0 0 153 0 1.3 1 0 2 1 7 44 1 1 120 263 0 1 173 0 0.0 2 0 3 1 8 52 1 2 172 199 1 1 162 0 0.5 2 0 3 1 9 57 1 2 150 168 0 1 174 0 1.6 2 0 2 1 value_counts() allows you to show how many times each of the values of a categorical column appear.
In\u00a0[6]: Copied! # Let's see how many positive (1) and negative (0) samples we have in our DataFrame\ndf.target.value_counts()\n
# Let's see how many positive (1) and negative (0) samples we have in our DataFrame df.target.value_counts() Out[6]: target\n1 165\n0 138\nName: count, dtype: int64
Since these two values are close to even, our target column can be considered balanced.
An unbalanced target column, meaning some classes have far more samples, can be harder to model than a balanced set.
In an ideal world, all of your target classes have the same number of samples.
If you'd prefer these values in percentages, value_counts() takes a parameter, normalize which can be set to true.
In\u00a0[7]: Copied! # Normalized value counts\ndf.target.value_counts(normalize=True)\n
# Normalized value counts df.target.value_counts(normalize=True) Out[7]: target\n1 0.544554\n0 0.455446\nName: proportion, dtype: float64
We can plot the target column value counts by calling the plot() function and telling it what kind of plot we'd like, in this case, bar is good.
In\u00a0[8]: Copied! # Plot the value counts with a bar graph\ndf.target.value_counts().plot(kind=\"bar\", color=[\"salmon\", \"lightblue\"]);\n
# Plot the value counts with a bar graph df.target.value_counts().plot(kind=\"bar\", color=[\"salmon\", \"lightblue\"]); pd.DataFrame.info() shows a quick insight into the number of missing values you have and what type of data you're working with.
In our case, there are no missing values and all of our columns are numerical in nature.
In\u00a0[9]: Copied! df.info()\n
df.info() <class 'pandas.core.frame.DataFrame'>\nRangeIndex: 303 entries, 0 to 302\nData columns (total 14 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 age 303 non-null int64 \n 1 sex 303 non-null int64 \n 2 cp 303 non-null int64 \n 3 trestbps 303 non-null int64 \n 4 chol 303 non-null int64 \n 5 fbs 303 non-null int64 \n 6 restecg 303 non-null int64 \n 7 thalach 303 non-null int64 \n 8 exang 303 non-null int64 \n 9 oldpeak 303 non-null float64\n 10 slope 303 non-null int64 \n 11 ca 303 non-null int64 \n 12 thal 303 non-null int64 \n 13 target 303 non-null int64 \ndtypes: float64(1), int64(13)\nmemory usage: 33.3 KB\n
Another way to get quick insights on your DataFrame is to use pd.DataFrame.describe().
describe() shows a range of different metrics about your numerical columns such as mean, max and standard deviation.
In\u00a0[10]: Copied! df.describe()\n
df.describe() Out[10]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target count 303.000000 303.000000 303.000000 303.000000 303.000000 303.000000 303.000000 303.000000 303.000000 303.000000 303.000000 303.000000 303.000000 303.000000 mean 54.366337 0.683168 0.966997 131.623762 246.264026 0.148515 0.528053 149.646865 0.326733 1.039604 1.399340 0.729373 2.313531 0.544554 std 9.082101 0.466011 1.032052 17.538143 51.830751 0.356198 0.525860 22.905161 0.469794 1.161075 0.616226 1.022606 0.612277 0.498835 min 29.000000 0.000000 0.000000 94.000000 126.000000 0.000000 0.000000 71.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 25% 47.500000 0.000000 0.000000 120.000000 211.000000 0.000000 0.000000 133.500000 0.000000 0.000000 1.000000 0.000000 2.000000 0.000000 50% 55.000000 1.000000 1.000000 130.000000 240.000000 0.000000 1.000000 153.000000 0.000000 0.800000 1.000000 0.000000 2.000000 1.000000 75% 61.000000 1.000000 2.000000 140.000000 274.500000 0.000000 1.000000 166.000000 1.000000 1.600000 2.000000 1.000000 3.000000 1.000000 max 77.000000 1.000000 3.000000 200.000000 564.000000 1.000000 2.000000 202.000000 1.000000 6.200000 2.000000 4.000000 3.000000 1.000000 In\u00a0[11]: Copied! df.sex.value_counts()\n
df.sex.value_counts() Out[11]: sex\n1 207\n0 96\nName: count, dtype: int64
There are 207 males and 96 females in our study.
What if we compared the target column values with the sex column values?
In\u00a0[12]: Copied! # Compare target column with sex column\npd.crosstab(index=df.target, columns=df.sex)\n
# Compare target column with sex column pd.crosstab(index=df.target, columns=df.sex) Out[12]: sex 0 1 target 0 24 114 1 72 93 What can we infer from this? Let's make a simple heuristic.
Since there are about 100 women and 72 of them have a positive value of heart disease being present, we might infer, based on this one variable if the participant is a woman, there's a ~72% (72/96 women in our dataset are positive for heart disease) chance she has heart disease.
As for males, there's about 200 total with around half (93/207) indicating a presence of heart disease.
So we might predict, if the participant is male, 50% of the time he will have heart disease.
Averaging these two values, we can assume, based on no other parameters, if there's a person, there's a 62.5% chance they have heart disease.
This can be our very simple baseline, we'll try to beat it with machine learning.
Note: A baseline is a simple model or estimate you start with and try to beat/confirm throughout your experiments. It can be as simple as looking at the data as we've done and creating a predictive heuristic to move forward.
In\u00a0[13]: Copied! # Create a plot\npd.crosstab(df.target, df.sex).plot(kind=\"bar\", \n figsize=(10,6), \n color=[\"salmon\", \"lightblue\"]);\n
# Create a plot pd.crosstab(df.target, df.sex).plot(kind=\"bar\", figsize=(10,6), color=[\"salmon\", \"lightblue\"]); Nice! But our plot is looking pretty bare. Let's add some attributes.
We'll create the plot again with pd.crosstab() and the plot() method.
Then, since our plot is built with matplotlib, we can add some helpful labels to it with plt.title(), plt.xlabel(), plt.legend() and more.
In\u00a0[14]: Copied! # Create a plot\npd.crosstab(df.target, df.sex).plot(kind=\"bar\", figsize=(10,6), color=[\"salmon\", \"lightblue\"])\n\n# Add some attributes to it\nplt.title(\"Heart Disease Frequency vs Sex\")\nplt.xlabel(\"0 = No Disease, 1 = Disease\")\nplt.ylabel(\"Amount\")\nplt.legend([\"Female\", \"Male\"])\nplt.xticks(rotation=0); # keep the labels on the x-axis vertical\n
# Create a plot pd.crosstab(df.target, df.sex).plot(kind=\"bar\", figsize=(10,6), color=[\"salmon\", \"lightblue\"]) # Add some attributes to it plt.title(\"Heart Disease Frequency vs Sex\") plt.xlabel(\"0 = No Disease, 1 = Disease\") plt.ylabel(\"Amount\") plt.legend([\"Female\", \"Male\"]) plt.xticks(rotation=0); # keep the labels on the x-axis vertical In\u00a0[15]: Copied! # Create another figure\nplt.figure(figsize=(10,6))\n\n# Start with positve examples\nplt.scatter(df.age[df.target==1], \n df.thalach[df.target==1], \n c=\"salmon\") # define it as a scatter figure\n\n# Now for negative examples, we want them on the same plot, so we call plt again\nplt.scatter(df.age[df.target==0], \n df.thalach[df.target==0], \n c=\"lightblue\") # axis always come as (x, y)\n\n# Add some helpful info\nplt.title(\"Heart Disease in function of Age and Max Heart Rate\")\nplt.xlabel(\"Age\")\nplt.legend([\"Disease\", \"No Disease\"])\nplt.ylabel(\"Max Heart Rate\");\n
# Create another figure plt.figure(figsize=(10,6)) # Start with positve examples plt.scatter(df.age[df.target==1], df.thalach[df.target==1], c=\"salmon\") # define it as a scatter figure # Now for negative examples, we want them on the same plot, so we call plt again plt.scatter(df.age[df.target==0], df.thalach[df.target==0], c=\"lightblue\") # axis always come as (x, y) # Add some helpful info plt.title(\"Heart Disease in function of Age and Max Heart Rate\") plt.xlabel(\"Age\") plt.legend([\"Disease\", \"No Disease\"]) plt.ylabel(\"Max Heart Rate\"); What can we infer from this?
It seems the younger someone is, the higher their max heart rate (dots are higher on the left of the graph) and it seems there may be more heart disease in the younger population too (more orange dots).
Both of these are observational of course, but this is what we're trying to do, build an understanding of the data.
Let's check the age distribution.
Note: Distribution can considered as the spread of data. As in, when viewed as a whole, what different values appear in the data?
In\u00a0[16]: Copied! # Histograms are a great way to check the distribution of a variable\ndf.age.plot.hist();\n
# Histograms are a great way to check the distribution of a variable df.age.plot.hist(); We can see it's a normal distribution but slightly swaying to the right, which reflects in the scatter plot above.
Let's keep going.
In\u00a0[17]: Copied! pd.crosstab(index=df.cp, columns=df.target)\n
pd.crosstab(index=df.cp, columns=df.target) Out[17]: target 0 1 cp 0 104 39 1 9 41 2 18 69 3 7 16 In\u00a0[18]: Copied! # Create a new crosstab and base plot\npd.crosstab(df.cp, df.target).plot(kind=\"bar\", \n figsize=(10,6), \n color=[\"lightblue\", \"salmon\"])\n\n# Add attributes to the plot to make it more readable\nplt.title(\"Heart Disease Frequency Per Chest Pain Type\")\nplt.xlabel(\"Chest Pain Type\")\nplt.ylabel(\"Frequency\")\nplt.legend([\"No Disease\", \"Disease\"])\nplt.xticks(rotation = 0);\n
# Create a new crosstab and base plot pd.crosstab(df.cp, df.target).plot(kind=\"bar\", figsize=(10,6), color=[\"lightblue\", \"salmon\"]) # Add attributes to the plot to make it more readable plt.title(\"Heart Disease Frequency Per Chest Pain Type\") plt.xlabel(\"Chest Pain Type\") plt.ylabel(\"Frequency\") plt.legend([\"No Disease\", \"Disease\"]) plt.xticks(rotation = 0); What can we infer from this?
Remember from our data dictionary what the different levels of chest pain are.
Feature Description Example Values cp Chest pain type 0: Typical angina (chest pain), 1: Atypical angina (chest pain not related to heart), 2: Non-anginal pain (typically esophageal spasms (non heart related), 3: Asymptomatic (chest pain not showing signs of disease) It's interesting that atypical angina (value 1) states it's not related to the heart but seems to have a higher ratio of participants with heart disease than not.
Wait...?
What does atypical agina even mean?
At this point, it's important to remember, if your data dictionary doesn't supply you enough information, you may want to do further research on your values.
This research may come in the form of asking a subject matter expert (such as a cardiologist or the person who gave you the data) or Googling to find out more.
According to PubMed, it seems even some medical professionals are confused by the term.
Today, 23 years later, \u201catypical chest pain\u201d is still popular in medical circles. Its meaning, however, remains unclear. A few articles have the term in their title, but do not define or discuss it in their text. In other articles, the term refers to noncardiac causes of chest pain.
Although not conclusive, the plot above is a sign there may be a confusion of defintions being represented in data.
In\u00a0[19]: Copied! # Find the correlation between our independent variables\ncorr_matrix = df.corr()\ncorr_matrix\n
# Find the correlation between our independent variables corr_matrix = df.corr() corr_matrix Out[19]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target age 1.000000 -0.098447 -0.068653 0.279351 0.213678 0.121308 -0.116211 -0.398522 0.096801 0.210013 -0.168814 0.276326 0.068001 -0.225439 sex -0.098447 1.000000 -0.049353 -0.056769 -0.197912 0.045032 -0.058196 -0.044020 0.141664 0.096093 -0.030711 0.118261 0.210041 -0.280937 cp -0.068653 -0.049353 1.000000 0.047608 -0.076904 0.094444 0.044421 0.295762 -0.394280 -0.149230 0.119717 -0.181053 -0.161736 0.433798 trestbps 0.279351 -0.056769 0.047608 1.000000 0.123174 0.177531 -0.114103 -0.046698 0.067616 0.193216 -0.121475 0.101389 0.062210 -0.144931 chol 0.213678 -0.197912 -0.076904 0.123174 1.000000 0.013294 -0.151040 -0.009940 0.067023 0.053952 -0.004038 0.070511 0.098803 -0.085239 fbs 0.121308 0.045032 0.094444 0.177531 0.013294 1.000000 -0.084189 -0.008567 0.025665 0.005747 -0.059894 0.137979 -0.032019 -0.028046 restecg -0.116211 -0.058196 0.044421 -0.114103 -0.151040 -0.084189 1.000000 0.044123 -0.070733 -0.058770 0.093045 -0.072042 -0.011981 0.137230 thalach -0.398522 -0.044020 0.295762 -0.046698 -0.009940 -0.008567 0.044123 1.000000 -0.378812 -0.344187 0.386784 -0.213177 -0.096439 0.421741 exang 0.096801 0.141664 -0.394280 0.067616 0.067023 0.025665 -0.070733 -0.378812 1.000000 0.288223 -0.257748 0.115739 0.206754 -0.436757 oldpeak 0.210013 0.096093 -0.149230 0.193216 0.053952 0.005747 -0.058770 -0.344187 0.288223 1.000000 -0.577537 0.222682 0.210244 -0.430696 slope -0.168814 -0.030711 0.119717 -0.121475 -0.004038 -0.059894 0.093045 0.386784 -0.257748 -0.577537 1.000000 -0.080155 -0.104764 0.345877 ca 0.276326 0.118261 -0.181053 0.101389 0.070511 0.137979 -0.072042 -0.213177 0.115739 0.222682 -0.080155 1.000000 0.151832 -0.391724 thal 0.068001 0.210041 -0.161736 0.062210 0.098803 -0.032019 -0.011981 -0.096439 0.206754 0.210244 -0.104764 0.151832 1.000000 -0.344029 target -0.225439 -0.280937 0.433798 -0.144931 -0.085239 -0.028046 0.137230 0.421741 -0.436757 -0.430696 0.345877 -0.391724 -0.344029 1.000000 Following the data explorer's motto of visualize, visualize, visualize!, let's plot this matrix.
In\u00a0[20]: Copied! # Let's make it look a little prettier\ncorr_matrix = df.corr()\nplt.figure(figsize=(15, 10))\nsns.heatmap(corr_matrix, \n annot=True, \n linewidths=0.5, \n fmt= \".2f\", \n cmap=\"YlGnBu\");\n
# Let's make it look a little prettier corr_matrix = df.corr() plt.figure(figsize=(15, 10)) sns.heatmap(corr_matrix, annot=True, linewidths=0.5, fmt= \".2f\", cmap=\"YlGnBu\"); Much better. A higher positive value means a potential positive correlation (increase) and a higher negative value means a potential negative correlation (decrease).
In\u00a0[21]: Copied! df.head()\n
df.head() Out[21]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1 We're trying to predict our target variable using all of the other variables.
To do this, we'll split the target variable from the rest.
We can do this by creating:
X - Our features (all variables except the target column) using pd.DataFrame.drop(labels=\"target\").y - Our target variable using df.target.to_numpy() (this will extract the target column as a NumPy array).
In\u00a0[22]: Copied! # Everything except target variable\nX = df.drop(labels=\"target\", axis=1)\n\n# Target variable\ny = df.target.to_numpy()\n
# Everything except target variable X = df.drop(labels=\"target\", axis=1) # Target variable y = df.target.to_numpy() Let's see our new variables.
In\u00a0[23]: Copied! # Independent variables (no target column)\nX.head()\n
# Independent variables (no target column) X.head() Out[23]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 In\u00a0[24]: Copied! # Targets (in the form of a NumPy array)\ny, type(y)\n
# Targets (in the form of a NumPy array) y, type(y) Out[24]: (array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]),\n numpy.ndarray)
In\u00a0[25]: Copied! # Random seed for reproducibility (since train_test_split is random by default, setting the seed will create reproducible splits)\nnp.random.seed(42)\n\n# Split into train & test set\nX_train, X_test, y_train, y_test = train_test_split(X, # independent variables \n y, # dependent variable\n test_size = 0.2) # percentage of data to use for test set\n
# Random seed for reproducibility (since train_test_split is random by default, setting the seed will create reproducible splits) np.random.seed(42) # Split into train & test set X_train, X_test, y_train, y_test = train_test_split(X, # independent variables y, # dependent variable test_size = 0.2) # percentage of data to use for test set The test_size parameter is used to tell the train_test_split() function how much of our data we want in the test set.
A rule of thumb is to use 80% of your data to train on and the other 20% to test on.
For our problem, a train and test set are enough. But for other problems, you could also use a validation (train/validation/test) set or cross-validation (we'll see this later on).
But again, each problem will differ.
To learn more about the importance of validation and test sets, I'd recommend reading:
- How (and why) to create a good validation set by Rachel Thomas.
- The importance of a test set by Daniel Bourke.
Let's look at our training data.
In\u00a0[26]: Copied! X_train.head()\n
X_train.head() Out[26]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal 132 42 1 1 120 295 0 1 162 0 0.0 2 0 2 202 58 1 0 150 270 0 0 111 1 0.8 2 0 3 196 46 1 2 150 231 0 1 147 0 3.6 1 0 2 75 55 0 1 135 250 0 0 161 0 1.4 1 0 2 176 60 1 0 117 230 1 1 160 1 1.4 2 2 3 In\u00a0[27]: Copied! y_train, len(y_train)\n
y_train, len(y_train) Out[27]: (array([1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1,\n 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0,\n 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1,\n 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0,\n 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0,\n 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1,\n 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1,\n 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0,\n 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 1,\n 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1,\n 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1]),\n 242)
Beautiful, we can see we're using 242 samples to train on.
Let's look at our test data.
In\u00a0[28]: Copied! X_test.head()\n
X_test.head() Out[28]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal 179 57 1 0 150 276 0 0 112 1 0.6 1 1 1 228 59 1 3 170 288 0 0 159 0 0.2 1 0 3 111 57 1 2 150 126 1 1 173 0 0.2 2 1 3 246 56 0 0 134 409 0 0 150 1 1.9 1 2 3 60 71 0 2 110 265 1 0 130 0 0.0 2 1 2 In\u00a0[29]: Copied! y_test, len(y_test)\n
y_test, len(y_test) Out[29]: (array([0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0,\n 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1,\n 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0]),\n 61)
And we've got 61 examples we'll test our model(s) on.
Let's build some.
In\u00a0[30]: Copied! # Put models in a dictionary\nmodels = {\"KNN\": KNeighborsClassifier(),\n \"Logistic Regression\": LogisticRegression(max_iter=100), # Note: if you see a warning about \"convergence not reached\", you can increase `max_iter` until convergence is reached\n \"Random Forest\": RandomForestClassifier()}\n\n# Create function to fit and score models\ndef fit_and_score(models, X_train, X_test, y_train, y_test):\n \"\"\"\n Fits and evaluates given machine learning models.\n models : a dict of different Scikit-Learn machine learning models\n X_train : training data\n X_test : testing data\n y_train : labels assosciated with training data\n y_test : labels assosciated with test data\n \"\"\"\n # Random seed for reproducible results\n np.random.seed(42)\n # Make a list to keep model scores\n model_scores = {}\n # Loop through models\n for name, model in models.items():\n # Fit the model to the data\n model.fit(X_train, y_train)\n # Evaluate the model and append its score to model_scores\n model_scores[name] = model.score(X_test, y_test)\n return model_scores\n # Put models in a dictionary models = {\"KNN\": KNeighborsClassifier(), \"Logistic Regression\": LogisticRegression(max_iter=100), # Note: if you see a warning about \"convergence not reached\", you can increase `max_iter` until convergence is reached \"Random Forest\": RandomForestClassifier()} # Create function to fit and score models def fit_and_score(models, X_train, X_test, y_train, y_test): \"\"\" Fits and evaluates given machine learning models. models : a dict of different Scikit-Learn machine learning models X_train : training data X_test : testing data y_train : labels assosciated with training data y_test : labels assosciated with test data \"\"\" # Random seed for reproducible results np.random.seed(42) # Make a list to keep model scores model_scores = {} # Loop through models for name, model in models.items(): # Fit the model to the data model.fit(X_train, y_train) # Evaluate the model and append its score to model_scores model_scores[name] = model.score(X_test, y_test) return model_scores Function built!
Now let's see how our collection of models go on our data.
In\u00a0[31]: Copied! model_scores = fit_and_score(models=models,\n X_train=X_train,\n X_test=X_test,\n y_train=y_train,\n y_test=y_test)\nmodel_scores\n
model_scores = fit_and_score(models=models, X_train=X_train, X_test=X_test, y_train=y_train, y_test=y_test) model_scores /Users/daniel/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/linear_model/_logistic.py:469: ConvergenceWarning: lbfgs failed to converge (status=1):\nSTOP: TOTAL NO. of ITERATIONS REACHED LIMIT.\n\nIncrease the number of iterations (max_iter) or scale the data as shown in:\n https://scikit-learn.org/stable/modules/preprocessing.html\nPlease also refer to the documentation for alternative solver options:\n https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression\n n_iter_i = _check_optimize_result(\n
Out[31]: {'KNN': 0.6885245901639344,\n 'Logistic Regression': 0.8852459016393442,\n 'Random Forest': 0.8360655737704918} Beautiful!
It looks like each of our models was able to fit our data without any errors.
How about we compare them visually?
In\u00a0[32]: Copied! model_compare = pd.DataFrame(model_scores, index=['accuracy'])\nmodel_compare.T.plot.bar();\n
model_compare = pd.DataFrame(model_scores, index=['accuracy']) model_compare.T.plot.bar(); Beautiful!
From the plot it looks like the sklearn.linear_model.LogisticRegression() model performs best.
Now... since we've found the best model.
Let's take it to the boss and show her what we've found!
In\u00a0[33]: Copied! # Create a list of train scores\ntrain_scores = []\n\n# Create a list of test scores\ntest_scores = []\n\n# Create a list of different values for n_neighbors\nneighbors = range(1, 21) # 1 to 20\n\n# Setup algorithm\nknn = KNeighborsClassifier()\n\n# Loop through different neighbors values\nfor i in neighbors:\n knn.set_params(n_neighbors = i) # set neighbors value\n \n # Fit the algorithm\n knn.fit(X_train, y_train)\n \n # Update the training scores\n train_scores.append(knn.score(X_train, y_train))\n \n # Update the test scores\n test_scores.append(knn.score(X_test, y_test))\n
# Create a list of train scores train_scores = [] # Create a list of test scores test_scores = [] # Create a list of different values for n_neighbors neighbors = range(1, 21) # 1 to 20 # Setup algorithm knn = KNeighborsClassifier() # Loop through different neighbors values for i in neighbors: knn.set_params(n_neighbors = i) # set neighbors value # Fit the algorithm knn.fit(X_train, y_train) # Update the training scores train_scores.append(knn.score(X_train, y_train)) # Update the test scores test_scores.append(knn.score(X_test, y_test)) That was quick!
Now let's look at KNN's train scores.
In\u00a0[34]: Copied! train_scores\n
train_scores Out[34]: [1.0,\n 0.8099173553719008,\n 0.7727272727272727,\n 0.743801652892562,\n 0.7603305785123967,\n 0.7520661157024794,\n 0.743801652892562,\n 0.7231404958677686,\n 0.71900826446281,\n 0.6942148760330579,\n 0.7272727272727273,\n 0.6983471074380165,\n 0.6900826446280992,\n 0.6942148760330579,\n 0.6859504132231405,\n 0.6735537190082644,\n 0.6859504132231405,\n 0.6652892561983471,\n 0.6818181818181818,\n 0.6694214876033058]
Ok, these are a bit hard to understand, so let's follow the data explorer's motto and visualize, visualize, visualize! In other words, let's plot them.
In\u00a0[35]: Copied! plt.plot(neighbors, train_scores, label=\"Train score\")\nplt.plot(neighbors, test_scores, label=\"Test score\")\nplt.xticks(np.arange(1, 21, 1))\nplt.xlabel(\"Number of neighbors\")\nplt.ylabel(\"Model score\")\nplt.legend()\n\nprint(f\"Maximum KNN score on the test data: {max(test_scores)*100:.2f}%\")\n plt.plot(neighbors, train_scores, label=\"Train score\") plt.plot(neighbors, test_scores, label=\"Test score\") plt.xticks(np.arange(1, 21, 1)) plt.xlabel(\"Number of neighbors\") plt.ylabel(\"Model score\") plt.legend() print(f\"Maximum KNN score on the test data: {max(test_scores)*100:.2f}%\") Maximum KNN score on the test data: 75.41%\n
Looking at the graph, n_neighbors = 11 seems best.
Even knowing this, the KNN's model performance didn't get near what LogisticRegression or the RandomForestClassifier did.
Because of this, we'll discard KNN and focus on the other two.
We've tuned KNN by hand but let's see how we can LogisticsRegression and RandomForestClassifier using RandomizedSearchCV.
Instead of us having to manually try different hyperparameters by hand, RandomizedSearchCV tries a number of different combinations, evaluates them and saves the best.
In\u00a0[37]: Copied! # Different LogisticRegression hyperparameters\nlog_reg_grid = {\"C\": np.logspace(-4, 4, 20),\n \"solver\": [\"liblinear\"]}\n\n# Different RandomForestClassifier hyperparameters\nrf_grid = {\"n_estimators\": np.arange(10, 1000, 50),\n \"max_depth\": [None, 3, 5, 10],\n \"min_samples_split\": np.arange(2, 20, 2),\n \"min_samples_leaf\": np.arange(1, 20, 2)}\n # Different LogisticRegression hyperparameters log_reg_grid = {\"C\": np.logspace(-4, 4, 20), \"solver\": [\"liblinear\"]} # Different RandomForestClassifier hyperparameters rf_grid = {\"n_estimators\": np.arange(10, 1000, 50), \"max_depth\": [None, 3, 5, 10], \"min_samples_split\": np.arange(2, 20, 2), \"min_samples_leaf\": np.arange(1, 20, 2)} Now let's use sklearn.model_selection.RandomizedSearchCV to try and tune our LogisticRegression model.
We'll pass it the different hyperparameters from log_reg_grid as well as set n_iter=20. This means, RandomizedSearchCV will try 20 different combinations of hyperparameters from log_reg_grid and save the best ones.
In\u00a0[38]: Copied! %%time\n\n# Setup random seed\nnp.random.seed(42)\n\n# Setup random hyperparameter search for LogisticRegression\nrs_log_reg = RandomizedSearchCV(LogisticRegression(),\n param_distributions=log_reg_grid,\n cv=5,\n n_iter=20,\n verbose=True)\n\n# Fit random hyperparameter search model\nrs_log_reg.fit(X_train, y_train);\n
%%time # Setup random seed np.random.seed(42) # Setup random hyperparameter search for LogisticRegression rs_log_reg = RandomizedSearchCV(LogisticRegression(), param_distributions=log_reg_grid, cv=5, n_iter=20, verbose=True) # Fit random hyperparameter search model rs_log_reg.fit(X_train, y_train); Fitting 5 folds for each of 20 candidates, totalling 100 fits\nCPU times: user 160 ms, sys: 7.51 ms, total: 168 ms\nWall time: 193 ms\n
In\u00a0[39]: Copied! rs_log_reg.best_params_\n
rs_log_reg.best_params_ Out[39]: {'solver': 'liblinear', 'C': np.float64(0.23357214690901212)} In\u00a0[40]: Copied! rs_log_reg.score(X_test, y_test)\n
rs_log_reg.score(X_test, y_test) Out[40]: 0.8852459016393442
Nice! That seems on par with the result we got before without any hyperparameter tuning.
Note: Many of the algorithms in Scikit-Learn have pretty good default hyperparameter values so don't be surprised if they perform pretty good on your data straight out of the box. But don't take this as being true all the time. Just because the default hyperparameters perform pretty well on your data doesn't mean there aren't a better set of hyperparameter values out there.
Now we've tuned LogisticRegression using RandomizedSearchCV, we'll do the same for RandomForestClassifier.
In\u00a0[41]: Copied! %%time \n\n# Setup random seed\nnp.random.seed(42)\n\n# Setup random hyperparameter search for RandomForestClassifier\nrs_rf = RandomizedSearchCV(RandomForestClassifier(),\n param_distributions=rf_grid,\n cv=5,\n n_iter=20,\n verbose=True)\n\n# Fit random hyperparameter search model\nrs_rf.fit(X_train, y_train);\n
%%time # Setup random seed np.random.seed(42) # Setup random hyperparameter search for RandomForestClassifier rs_rf = RandomizedSearchCV(RandomForestClassifier(), param_distributions=rf_grid, cv=5, n_iter=20, verbose=True) # Fit random hyperparameter search model rs_rf.fit(X_train, y_train); Fitting 5 folds for each of 20 candidates, totalling 100 fits\nCPU times: user 21.6 s, sys: 144 ms, total: 21.8 s\nWall time: 22.1 s\n
In\u00a0[50]: Copied! # Find the best parameters\nrs_rf.best_params_\n
# Find the best parameters rs_rf.best_params_ Out[50]: {'n_estimators': np.int64(210),\n 'min_samples_split': np.int64(4),\n 'min_samples_leaf': np.int64(19),\n 'max_depth': 3} In\u00a0[42]: Copied! # Evaluate the randomized search random forest model\nrs_rf.score(X_test, y_test)\n
# Evaluate the randomized search random forest model rs_rf.score(X_test, y_test) Out[42]: 0.8688524590163934
Excellent! Tuning the hyperparameters for each model saw a slight performance boost in both the RandomForestClassifier and LogisticRegression.
This is akin to tuning the settings on your oven and getting it to cook your favourite dish just right.
But since LogisticRegression is pulling out in front, we'll try tuning it further with GridSearchCV.
In\u00a0[43]: Copied! %%time\n\n# Different LogisticRegression hyperparameters\nlog_reg_grid = {\"C\": np.logspace(-4, 4, 20),\n \"solver\": [\"liblinear\"]}\n\n# Setup grid hyperparameter search for LogisticRegression\ngs_log_reg = GridSearchCV(LogisticRegression(),\n param_grid=log_reg_grid,\n cv=5,\n verbose=True)\n\n# Fit grid hyperparameter search model\ngs_log_reg.fit(X_train, y_train);\n %%time # Different LogisticRegression hyperparameters log_reg_grid = {\"C\": np.logspace(-4, 4, 20), \"solver\": [\"liblinear\"]} # Setup grid hyperparameter search for LogisticRegression gs_log_reg = GridSearchCV(LogisticRegression(), param_grid=log_reg_grid, cv=5, verbose=True) # Fit grid hyperparameter search model gs_log_reg.fit(X_train, y_train); Fitting 5 folds for each of 20 candidates, totalling 100 fits\nCPU times: user 161 ms, sys: 2.41 ms, total: 163 ms\nWall time: 212 ms\n
In\u00a0[44]: Copied! # Check the best parameters\ngs_log_reg.best_params_\n
# Check the best parameters gs_log_reg.best_params_ Out[44]: {'C': np.float64(0.23357214690901212), 'solver': 'liblinear'} In\u00a0[45]: Copied! # Evaluate the model\ngs_log_reg.score(X_test, y_test)\n
# Evaluate the model gs_log_reg.score(X_test, y_test) Out[45]: 0.8852459016393442
In this case, we get the same results as before since our grid only has a maximum of 20 different hyperparameter combinations.
Note: If there are a large number of hyperparameter combinations in your grid, GridSearchCV may take a long time to try them all out. This is why it's a good idea to start with RandomizedSearchCV, try a certain amount of combinations and then use GridSearchCV to refine them.
In\u00a0[46]: Copied! # Make preidctions on test data\ny_preds = gs_log_reg.predict(X_test)\n
# Make preidctions on test data y_preds = gs_log_reg.predict(X_test) Let's see them.
In\u00a0[47]: Copied! y_preds\n
y_preds Out[47]: array([0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0,\n 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1,\n 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0])
They look like our original test data labels, except different where the model has predicred wrong.
In\u00a0[48]: Copied! y_test\n
y_test Out[48]: array([0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0,\n 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1,\n 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0])
Since we've got our prediction values we can find the metrics we want.
Let's start with the ROC curve and AUC scores.
In\u00a0[49]: Copied! # Before Scikit-Learn 1.2.0 (will error with versions 1.2+)\n# from sklearn.metrics import plot_roc_curve \n# plot_roc_curve(gs_log_reg, X_test, y_test);\n\n# Scikit-Learn 1.2.0 or later\nfrom sklearn.metrics import RocCurveDisplay \n\n# from_estimator() = use a model to plot ROC curve on data\nRocCurveDisplay.from_estimator(estimator=gs_log_reg, \n X=X_test, \n y=y_test);\n
# Before Scikit-Learn 1.2.0 (will error with versions 1.2+) # from sklearn.metrics import plot_roc_curve # plot_roc_curve(gs_log_reg, X_test, y_test); # Scikit-Learn 1.2.0 or later from sklearn.metrics import RocCurveDisplay # from_estimator() = use a model to plot ROC curve on data RocCurveDisplay.from_estimator(estimator=gs_log_reg, X=X_test, y=y_test); This is great, our model does far better than guessing which would be a line going from the bottom left corner to the top right corner, AUC = 0.5.
But a perfect model would achieve an AUC score of 1.0, so there's still room for improvement.
Let's move on to the next evaluation request, a confusion matrix.
In\u00a0[50]: Copied! # Display confusion matrix\nprint(confusion_matrix(y_test, y_preds))\n
# Display confusion matrix print(confusion_matrix(y_test, y_preds)) [[25 4]\n [ 3 29]]\n
As you can see, Scikit-Learn's built-in confusion matrix is a bit bland. For a presentation you'd probably want to make it visual.
Let's create a function which uses Seaborn's heatmap() for doing so.
In\u00a0[51]: Copied! # Import Seaborn\nimport seaborn as sns\nsns.set(font_scale=1.5) # Increase font size\n\ndef plot_conf_mat(y_test, y_preds):\n \"\"\"\n Plots a confusion matrix using Seaborn's heatmap().\n \"\"\"\n fig, ax = plt.subplots(figsize=(3, 3))\n ax = sns.heatmap(confusion_matrix(y_test, y_preds),\n annot=True, # Annotate the boxes\n cbar=False)\n plt.xlabel(\"true label\")\n plt.ylabel(\"predicted label\")\n \nplot_conf_mat(y_test, y_preds)\n
# Import Seaborn import seaborn as sns sns.set(font_scale=1.5) # Increase font size def plot_conf_mat(y_test, y_preds): \"\"\" Plots a confusion matrix using Seaborn's heatmap(). \"\"\" fig, ax = plt.subplots(figsize=(3, 3)) ax = sns.heatmap(confusion_matrix(y_test, y_preds), annot=True, # Annotate the boxes cbar=False) plt.xlabel(\"true label\") plt.ylabel(\"predicted label\") plot_conf_mat(y_test, y_preds) Beautiful! That looks much better.
You can see the model gets confused (predicts the wrong label) relatively the same across both classes.
In essence, there are 4 occasaions where the model predicted 0 when it should've been 1 (false negative) and 3 occasions where the model predicted 1 instead of 0 (false positive).
As further evaluation, we could look into these samples and see why this may be the case.
In\u00a0[68]: Copied! # Show classification report\nprint(classification_report(y_test, y_preds))\n
# Show classification report print(classification_report(y_test, y_preds)) precision recall f1-score support\n\n 0 0.89 0.86 0.88 29\n 1 0.88 0.91 0.89 32\n\n accuracy 0.89 61\n macro avg 0.89 0.88 0.88 61\nweighted avg 0.89 0.89 0.89 61\n\n
What's going on here?
Let's refresh ourselves on of the above metrics.
Metric/metadata Explanation Precision Indicates the proportion of positive identifications (model predicted class 1) which were actually correct. A model which produces no false positives has a precision of 1.0. Recall Indicates the proportion of actual positives which were correctly classified. A model which produces no false negatives has a recall of 1.0. F1 score A combination of precision and recall. A perfect model achieves an F1 score of 1.0. Support The number of samples each metric was calculated on. Accuracy The accuracy of the model in decimal form. Perfect accuracy is equal to 1.0. Macro avg Short for macro average, the average precision, recall and F1 score between classes. Macro avg doesn\u2019t class imbalance into effort, so if you do have class imbalances, pay attention to this metric. Weighted avg Short for weighted average, the weighted average precision, recall and F1 score between classes. Weighted means each metric is calculated with respect to how many samples there are in each class. This metric will favour the majority class (e.g. will give a high value when one class out performs another due to having more samples). Ok, now we've got a few deeper insights on our model.
But these were all calculated using a single training and test set.
What we'll do to make them more solid is calculate them using cross-validation.
How?
We'll take the best model along with the best hyperparameters and use cross_val_score() along with various scoring parameter values.
cross_val_score() works by taking an estimator (machine learning model) along with data and labels.
It then evaluates the machine learning model on the data and labels using cross-validation across cv=5 (the default number of splits) splits and a defined scoring parameter.
Let's remind ourselves of the best hyperparameters and then see them in action.
In\u00a0[52]: Copied! # Check best hyperparameters\ngs_log_reg.best_params_\n
# Check best hyperparameters gs_log_reg.best_params_ Out[52]: {'C': np.float64(0.23357214690901212), 'solver': 'liblinear'} In\u00a0[53]: Copied! # Import cross_val_score\nfrom sklearn.model_selection import cross_val_score\n\n# Instantiate best model with best hyperparameters (found with GridSearchCV)\nclf = LogisticRegression(C=0.23357214690901212,\n solver=\"liblinear\")\n
# Import cross_val_score from sklearn.model_selection import cross_val_score # Instantiate best model with best hyperparameters (found with GridSearchCV) clf = LogisticRegression(C=0.23357214690901212, solver=\"liblinear\") Now we've got an instantiated classifier, let's find some cross-validated metrics.
In\u00a0[54]: Copied! %%time\n\n# Cross-validated accuracy score\ncv_acc = cross_val_score(clf,\n X,\n y,\n cv=5, # 5-fold cross-validation, this is the default\n scoring=\"accuracy\") # accuracy as scoring\ncv_acc\n
%%time # Cross-validated accuracy score cv_acc = cross_val_score(clf, X, y, cv=5, # 5-fold cross-validation, this is the default scoring=\"accuracy\") # accuracy as scoring cv_acc CPU times: user 9.91 ms, sys: 1.35 ms, total: 11.3 ms\nWall time: 9.75 ms\n
Out[54]: array([0.81967213, 0.90163934, 0.8852459 , 0.88333333, 0.75 ])
Woah!
The output from cross_val_score() shows 5 different metrics across different splits of the data.
This goes to show the power of cross-validation.
If we had have only chosen to go with the results of one data split, we might be thinking our model is under performing or over performing.
Since there are 5 metrics here, we'll take the average.
In\u00a0[55]: Copied! cv_acc = np.mean(cv_acc)\ncv_acc\n
cv_acc = np.mean(cv_acc) cv_acc Out[55]: np.float64(0.8479781420765027)
Now we'll do the same for other classification metrics.
In\u00a0[56]: Copied! # Cross-validated precision score\ncv_precision = np.mean(cross_val_score(clf,\n X,\n y,\n cv=5, # 5-fold cross-validation\n scoring=\"precision\")) # precision as scoring\ncv_precision\n
# Cross-validated precision score cv_precision = np.mean(cross_val_score(clf, X, y, cv=5, # 5-fold cross-validation scoring=\"precision\")) # precision as scoring cv_precision Out[56]: np.float64(0.8215873015873015)
In\u00a0[57]: Copied! # Cross-validated recall score\ncv_recall = np.mean(cross_val_score(clf,\n X,\n y,\n cv=5, # 5-fold cross-validation\n scoring=\"recall\")) # recall as scoring\ncv_recall\n
# Cross-validated recall score cv_recall = np.mean(cross_val_score(clf, X, y, cv=5, # 5-fold cross-validation scoring=\"recall\")) # recall as scoring cv_recall Out[57]: np.float64(0.9272727272727274)
In\u00a0[58]: Copied! # Cross-validated F1 score\ncv_f1 = np.mean(cross_val_score(clf,\n X,\n y,\n cv=5, # 5-fold cross-validation\n scoring=\"f1\")) # f1 as scoring\ncv_f1\n
# Cross-validated F1 score cv_f1 = np.mean(cross_val_score(clf, X, y, cv=5, # 5-fold cross-validation scoring=\"f1\")) # f1 as scoring cv_f1 Out[58]: np.float64(0.8705403543192143)
Okay, we've got cross validated metrics, now what?
Let's visualize them.
In\u00a0[59]: Copied! # Visualizing cross-validated metrics\ncv_metrics = pd.DataFrame({\"Accuracy\": cv_acc,\n \"Precision\": cv_precision,\n \"Recall\": cv_recall,\n \"F1\": cv_f1},\n index=[0])\ncv_metrics.T.plot.bar(title=\"Cross-Validated Metrics\", legend=False);\n # Visualizing cross-validated metrics cv_metrics = pd.DataFrame({\"Accuracy\": cv_acc, \"Precision\": cv_precision, \"Recall\": cv_recall, \"F1\": cv_f1}, index=[0]) cv_metrics.T.plot.bar(title=\"Cross-Validated Metrics\", legend=False); Great! This looks like something we could share. An extension might be adding the metrics on top of each bar so someone can quickly tell what they were.
What now?
The final thing to check off the list of our model evaluation techniques is feature importance.
In\u00a0[60]: Copied! # Fit an instance of LogisticRegression (taken from above)\nclf.fit(X_train, y_train);\n
# Fit an instance of LogisticRegression (taken from above) clf.fit(X_train, y_train); In\u00a0[61]: Copied! # Check coef_\nclf.coef_\n
# Check coef_ clf.coef_ Out[61]: array([[ 0.00369922, -0.90424094, 0.67472825, -0.0116134 , -0.00170364,\n 0.04787688, 0.33490202, 0.02472938, -0.6312041 , -0.57590972,\n 0.47095153, -0.65165346, -0.69984212]])
Looking at this it might not make much sense. But these values are how much each feature contributes to how a model makes a decision on whether patterns in a sample of patients health data leans more towards having heart disease or not.
Even knowing this, in it's current form, this coef_ array still doesn't mean much. But it will if we combine it with the columns (features) of our dataframe.
In\u00a0[62]: Copied! # Match features to columns\nfeatures_dict = dict(zip(df.columns, list(clf.coef_[0])))\nfeatures_dict\n
# Match features to columns features_dict = dict(zip(df.columns, list(clf.coef_[0]))) features_dict Out[62]: {'age': np.float64(0.0036992219987868977),\n 'sex': np.float64(-0.9042409356586161),\n 'cp': np.float64(0.6747282473934053),\n 'trestbps': np.float64(-0.011613399733807518),\n 'chol': np.float64(-0.0017036437157196944),\n 'fbs': np.float64(0.0478768767697894),\n 'restecg': np.float64(0.3349020243959257),\n 'thalach': np.float64(0.02472938207178759),\n 'exang': np.float64(-0.6312040952883138),\n 'oldpeak': np.float64(-0.575909718275565),\n 'slope': np.float64(0.4709515257844554),\n 'ca': np.float64(-0.6516534575992304),\n 'thal': np.float64(-0.6998421177365038)} Now we've match the feature coefficients to different features, let's visualize them.
In\u00a0[63]: Copied! # Visualize feature importance\nfeatures_df = pd.DataFrame(features_dict, index=[0])\nfeatures_df.T.plot.bar(title=\"Feature Importance\", legend=False);\n
# Visualize feature importance features_df = pd.DataFrame(features_dict, index=[0]) features_df.T.plot.bar(title=\"Feature Importance\", legend=False); You'll notice some are negative and some are positive.
The larger the value (bigger bar), the more the feature contributes to the models decision.
If the value is negative, it means there's a negative correlation. And vice versa for positive values.
For example, the sex attribute has a negative value of -0.904, which means as the value for sex increases, the target value decreases.
We can see this by comparing the sex column to the target column.
In\u00a0[81]: Copied! pd.crosstab(df[\"sex\"], df[\"target\"])\n
pd.crosstab(df[\"sex\"], df[\"target\"]) Out[81]: target 0 1 sex 0 24 72 1 114 93 You can see, when sex is 0 (female), there are almost 3 times as many (72 vs. 24) people with heart disease (target = 1) than without.
And then as sex increases to 1 (male), the ratio goes down to almost 1 to 1 (114 vs. 93) of people who have heart disease and who don't.
What does this mean?
It means the model has found a pattern which reflects the data. Looking at these figures and this specific dataset, it seems if the patient is female, they're more likely to have heart disease.
How about a positive correlation?
In\u00a0[82]: Copied! # Contrast slope (positive coefficient) with target\npd.crosstab(df[\"slope\"], df[\"target\"])\n
# Contrast slope (positive coefficient) with target pd.crosstab(df[\"slope\"], df[\"target\"]) Out[82]: target 0 1 slope 0 12 9 1 91 49 2 35 107 Looking back the data dictionary, we see slope is the \"slope of the peak exercise ST segment\" where:
- 0: Upsloping: better heart rate with excercise (uncommon)
- 1: Flatsloping: minimal change (typical healthy heart)
- 2: Downslopins: signs of unhealthy heart
According to the model, there's a positive correlation of 0.470, not as strong as sex and target but still more than 0.
This positive correlation means our model is picking up the pattern that as slope increases, so does the target value.
Is this true?
When you look at the contrast (pd.crosstab(df[\"slope\"], df[\"target\"]) it is. As slope goes up, so does target.
What can you do with this information?
This is something you might want to talk to a subject matter expert about.
They may be interested in seeing where machine learning model is finding the most patterns (highest correlation) as well as where it's not (lowest correlation).
Doing this has a few benefits:
- Finding out more - If some of the correlations and feature importances are confusing, a subject matter expert may be able to shed some light on the situation and help you figure out more.
- Redirecting efforts - If some features offer far more value than others, this may change how you collect data for different problems. See point 3.
- Less but better - Similar to above, if some features are offering far more value than others, you could reduce the number of features your model tries to find patterns in as well as improve the ones which offer the most. This could potentially lead to saving on computation, by having a model find patterns across less features, whilst still achieving the same performance levels.
"},{"location":"end-to-end-heart-disease-classification/#predicting-heart-disease-using-machine-learning","title":"Predicting Heart Disease using Machine Learning\u00b6","text":"This notebook will introduce some foundation machine learning and data science concepts by exploring the problem of heart disease classification.
For example, given a person's health characteristics, we're going to build a model to predict whether or not they have heart disease.
It is intended to be an end-to-end example of what a data science and machine learning proof of concept might look like.
"},{"location":"end-to-end-heart-disease-classification/#what-is-classification","title":"What is classification?\u00b6","text":"Classification involves deciding whether a sample is part of one class or another (binary classification).
If there are multiple class options, it's referred to as multi-class classification.
"},{"location":"end-to-end-heart-disease-classification/#what-well-end-up-with","title":"What we'll end up with\u00b6","text":"We'll start with the heart disease dataset we've worked on in previous modules and we'll approach the problem following the machine learning modelling framework.
6 Step Machine Learning Modelling Framework More specifically, we'll look at the following topics.
Step What we'll cover Exploratory data analysis (EDA) The process of going through a dataset and discovering more about it. Model training Create model(s) to learn to predict a target variable based on other variables. Model evaluation Evaluating a model's predictions using problem-specific evaluation metrics. Model comparison Comparing several different models to find the best one. Model hyperparameter tuning Once we've found a good model, can we tweak its hyperparameters to improve it? Feature importance Since we're predicting the presence of heart disease, are there some features/characteristics that are more important for prediction? Cross-validation If we do build a good model, can we be sure it will work on unseen data? Reporting what we've found If we had to present our work, what would we show someone? To work through these topics, we'll use pandas, Matplotlib and NumPy for data anaylsis, as well as, Scikit-Learn for machine learning and modelling tasks.
Tools which can be used for each step of the machine learning modelling process. We'll work through each step and by the end of the notebook, we'll have a handful of models, all which can predict whether or not a person has heart disease based on a number of different parameters at a considerable accuracy.
You'll also be able to describe which parameters are more indicative than others, for example, sex may be more important than age.
"},{"location":"end-to-end-heart-disease-classification/#1-going-through-the-6-step-ml-framework","title":"1. Going through the 6 step ML framework\u00b6","text":""},{"location":"end-to-end-heart-disease-classification/#11-problem-definition","title":"1.1 Problem Definition\u00b6","text":"In our case, the problem we will be exploring is binary classification (a sample can only be one of two things).
This is because we're going to be using a number of differnet features (pieces of information such as health characteristics) about a person to predict whether they have heart disease or not.
In a statement,
Given clinical parameters about a patient, can we predict whether or not they have heart disease?
"},{"location":"end-to-end-heart-disease-classification/#12-what-data-are-we-using","title":"1.2 What data are we using?\u00b6","text":"What you'll want to do here is dive into the data your problem definition is based on.
This may involve, sourcing data (if it doesn't already exist), defining different parameters, talking to experts about it and finding out what you should expect.
The original data came from the Cleveland database from UCI Machine Learning Repository.
Howevever, we've downloaded it in a formatted way from Kaggle.
The original database contains 76 attributes, but here only 14 attributes will be used. Attributes (also called features) are the variables what we'll use to predict our target variable.
Attributes and features are also referred to as independent variables and a target variable can be referred to as a dependent variable.
Note: We use the independent variable(s)to predict our dependent variable(s).
In our case, the independent variables are a patient's different medical attributes and the dependent variable is whether or not they have heart disease.
"},{"location":"end-to-end-heart-disease-classification/#13-how-will-we-evaluate-our-model","title":"1.3 How will we evaluate our model?\u00b6","text":"An evaluation metric is something you usually define at the start of a project.
However, since machine learning is very experimental, it can change over time.
But to begin a project, you might say something like:
If we can reach 95% accuracy at predicting whether or not a patient has heart disease during the proof of concept, we'll pursure this project.
The reason this is helpful is it provides a rough goal for a machine learning engineer or data scientist to work towards.
Of course, as the project progresses and gets tested in the real world, you may have to adjust this goal/threshold.
"},{"location":"end-to-end-heart-disease-classification/#14-which-features-of-the-data-will-be-important-to-us","title":"1.4 Which features of the data will be important to us?\u00b6","text":"Features are different parts and characteristics of the data.
During this step, you'll want to start exploring what each portion of the data relates to and then create a reference you can use to look up later on.
One of the most common ways to do this is to create a data dictionary.
"},{"location":"end-to-end-heart-disease-classification/#heart-disease-data-dictionary","title":"Heart Disease Data Dictionary\u00b6","text":"A data dictionary describes the data you're dealing with.
Not all datasets come with them so this is where you may have to do your research or ask a subject matter expert (someone who knows about the data) for more.
The following are the features we'll use to predict our target variable (heart disease or no heart disease).
Feature Description Example Values age Age in years 29, 45, 60 sex 1 = male; 0 = female 0, 1 cp Chest pain type 0: Typical angina (chest pain), 1: Atypical angina (chest pain not related to heart), 2: Non-anginal pain (typically esophageal spasms (non heart related), 3: Asymptomatic (chest pain not showing signs of disease) trestbps Resting blood pressure (in mm Hg on admission to the hospital) 120, 140, 150 chol Serum cholesterol in mg/dl 180, 220, 250 fbs Fasting blood sugar > 120 mg/dl (1 = true; 0 = false) 0, 1 restecg Resting electrocardiographic results 0: Nothing to note, 1: ST-T Wave abnormality, 2: Left ventricular hypertrophy thalach Maximum heart rate achieved 160, 180, 190 exang Exercise induced angina (1 = yes; 0 = no) 0, 1 oldpeak ST depression (heart potentially not getting enough oxygen) induced by exercise relative to rest 0.5, 1.0, 2.0 slope The slope of the peak exercise ST segment 0: Upsloping, 1: Flatsloping, 2: Downsloping ca Number of major vessels (0-3) colored by fluoroscopy 0, 1, 2, 3 thal Thalium stress result 1: Normal, 3: Normal, 6: Fixed defect, 7: Reversible defect target Have disease or not (1 = yes; 0 = no) 0, 1 Note: No personal identifiable information (PPI) can be found in the dataset.
It's a good idea to save these to a Python dictionary or in an external file, so we can look at them later without coming back here.
"},{"location":"end-to-end-heart-disease-classification/#2-preparing-the-tools","title":"2. Preparing the tools\u00b6","text":"At the start of any project, it's custom to see the required libraries imported in a big chunk (as you can see in the code cell below).
However, in practice, when starting on new projects you may import libraries as you go (because you don't know what you need ahead of time).
After you've spent a couple of hours working on your problem, you'll probably want to do some tidying up.
This is where you may want to consolidate every library you've used at the top of your notebook.
The libraries you use will differ from project to project. But there are a few which will you'll likely take advantage of during almost every structured data project.
- pandas for data analysis.
- NumPy for numerical operations.
- Matplotlib/seaborn for plotting or data visualization.
- Scikit-Learn for machine learning modelling and evaluation.
"},{"location":"end-to-end-heart-disease-classification/#3-loading-data","title":"3. Loading Data\u00b6","text":"There are many different ways to store data.
One typical way of storing tabular data, data similar to what you'd see in an Excel file is in .csv format or CSV format.
CSV stands for comma-separated values.
Other common formats include JSON, SQL and parquet.
Pandas has a built-in function to read .csv files called read_csv() which takes the file pathname of your .csv file. You'll likely use this a lot.
Note: CSV format is good for smaller datasets but can face some speed issues when working with larger datasets. For more on different data formats pandas is compatible with, I'd check out the pandas guide on reading and writing data.
And there are many more read functions for different data formats in the Input/Output section of the pandas documentation.
"},{"location":"end-to-end-heart-disease-classification/#4-data-exploration-exploratory-data-analysis-or-eda","title":"4. Data Exploration (exploratory data analysis or EDA)\u00b6","text":"Once you've imported a dataset, the next step is to explore.
Or in formal terms, perform an Exploratory Data Analysis (EDA).
There's no set way of doing this.
But what you should be trying to do is become more and more familiar with the dataset.
Compare different columns to each other, compare them to the target variable.
Refer back to your data dictionary and remind yourself of what different columns mean.
One of my favourites is viewing 10-100 random samples of the data.
Our goal here is to become a subject matter expert on the dataset you're working with.
So if someone asks you a question about it, you can give them an explanation and when you start building models, you can sound check them to make sure they're not performing too well (overfitting and memorizing the data rather than learning generalizable patterns) or why they might be performing poorly (underfitting or not learning patterns in the data).
Since EDA has no real set methodolgy, the following is a short check list you might want to walk through:
- What question(s) are you trying to solve (or prove wrong)?
- What kind of data do you have and how do you treat different types?
- What\u2019s missing from the data and how do you deal with it?
- Where are the outliers and why should you care about them?
- How can you add, change or remove features to get more out of your data?
Once of the quickest and easiest ways to check your data is with the head() function.
Calling it on any dataframe will print the top 5 rows, tail() calls the bottom 5. You can also pass a number to them like head(10) to show the top 10 rows.
"},{"location":"end-to-end-heart-disease-classification/#41-comparing-one-feature-to-another","title":"4.1 Comparing one feature to another\u00b6","text":"If you want to compare two columns to each other, you can use the function pd.crosstab(index, columns).
This is helpful if you want to start gaining an intuition about how your independent variables interact with your dependent variables.
Let's compare our target column with the sex column.
Remember from our data dictionary, for the target column, 1 = heart disease present, 0 = no heart disease.
And for sex, 1 = male, 0 = female.
"},{"location":"end-to-end-heart-disease-classification/#42-making-our-comparison-visual","title":"4.2 Making our comparison visual\u00b6","text":"I'm going to introduce you to a motto I remind myself of whenever I'm exploring data.
Visualize, visualize, visualize! - The data explorer's motto.
This is because it's very helpful whenever you're dealing with a new dataset to visualize as much as you can to build up an idea of the dataset in your head.
And one of the best ways to create visualizations is to make plots (graphical representations of our data).
We can plot our pd.crosstab comparison by calling the plot() method and passing it a few parameters:
kind- The type of plot you want (e.g. \"bar\" for a bar plot).figsize=(length, width) - How big you want it to be.color=[colour_1, colour_2] - The different colours you'd like to use.
Different metrics are represented best with different kinds of plots.
In our case, a bar graph is great. We'll see examples of more later. And with a bit of practice, you'll gain an intuition of which plot to use with different variables.
"},{"location":"end-to-end-heart-disease-classification/#43-comparing-age-and-maximum-heart-rate","title":"4.3 Comparing age and maximum heart rate\u00b6","text":"Let's try combining a couple of independent variables, such as, age and thalach (maximum heart rate) and then comparing them to our target variable heart disease.
Because there are so many different values for age and thalach, we'll use a scatter plot.
"},{"location":"end-to-end-heart-disease-classification/#44-comparing-heart-disease-frequency-and-chest-pain-type","title":"4.4 Comparing heart disease frequency and chest pain type\u00b6","text":"Let's try comparing another independent variable with our target variable.
This time, we'll use cp (chest pain) as the independent variable.
We'll use the same process as we did before with sex.
"},{"location":"end-to-end-heart-disease-classification/#45-correlation-between-independent-variables","title":"4.5 Correlation between independent variables\u00b6","text":"Finally, we'll compare all of the independent variables in one hit.
Why?
Because this may give an idea of which independent variables may or may not have an impact on our target variable.
We can do this using pd.DataFrame.corr() which will create a correlation matrix for us, in other words, a big table of numbers telling us how related each variable is the other.
"},{"location":"end-to-end-heart-disease-classification/#46-enough-eda-lets-model","title":"4.6 Enough EDA, let's model\u00b6","text":"Remember, we do exploratory data analysis (EDA) to start building an intuition of the dataset.
What have we learned so far?
Aside from our baseline estimate using sex, the rest of the data seems to require a bit more exploration before we draw any conclusions.
So what we'll do next is model driven EDA, meaning, we'll use machine learning models to drive our next questions.
A few extra things to remember:
- Not every EDA will look the same, what we've seen here is an example of what you could do for structured, tabular dataset.
- You don't necessarily have to do the same plots as we've done here, there are many more ways to visualize data, I encourage you to look at more.
- Quite often, we'll want to find:
- Distributions - What's the spread of the data? We can do this with
pd.DataFrame.hist(column=\"target_column\"). - Missing values - Is our data missing anything? Why might this be the case and will this affect us going forward? We can do this with
pd.DataFrame.info() or pd.isnull(). - Outliers - Are there any samples that lay quite far outside the rest of our data's distributions? How might these affect the data going forward?
With this being said, let's build some models!
"},{"location":"end-to-end-heart-disease-classification/#5-modeling","title":"5. Modeling\u00b6","text":"We've explored the data, now we'll try to build a machine learning model to be able to predict our target variable based on the 13 independent variables.
Remember our problem?
Given clinical parameters about a patient, can we predict whether or not they have heart disease?
That's what we'll be trying to answer.
And remember our evaluation metric?
If we can reach 95% accuracy at predicting whether or not a patient has heart disease during the proof of concept, we'll pursure this project.
That's what we'll be aiming for.
But before we build a model, we have to get our dataset ready.
Let's look at it again.
"},{"location":"end-to-end-heart-disease-classification/#51-creating-a-training-and-test-split","title":"5.1 Creating a training and test split\u00b6","text":"Now comes one of the most important concepts in machine learning, creating a training/test split.
This is where we'll split our data into a training set and a test set.
We'll use our training set to train our model and our test set to evaluate it.
All the samples in the training set must be separate from those in the test set (and vice versa).
In short:
- Training set (often 70-80% of total data) - Model learns patterns on this dataset to hopefully be able to predict on similar but unseen samples.
- Testing set (often 20-30% of total data) - Trained model gets evaluated on these unseen samples to see how the patterns learned from the training set may perform on future unseen samples (e.g. when used in an application or production setting). However, performance on the test set is not guaranteed in the real world.
"},{"location":"end-to-end-heart-disease-classification/#why-not-use-all-the-data-to-train-a-model","title":"Why not use all the data to train a model?\u00b6","text":"Let's say you wanted to take your model into the hospital and start using it on patients.
How would you know how well your model goes on a new patient not included in the original full dataset you had?
This is where the test set comes in.
It's used to mimic taking your model to a real environment as much as possible.
And it's why it's important to never let your model learn from the test set, it should only be evaluated on it.
To split our data into a training and test set, we can use Scikit-Learn's sklearn.model_selection.train_test_split() and feed it our independent and dependent variables (X & y).
"},{"location":"end-to-end-heart-disease-classification/#52-choosing-a-model","title":"5.2 Choosing a model\u00b6","text":"Now we've got our data prepared, we can start to fit models.
In the modern world of machine learning, there are many potential models we can choose from.
Rather than trying every potential model, it's often good practice to try a handful and see how they go.
We'll start by trying the following models and comparing their results.
- Logistic Regression -
sklearn.linear_model.LogisticRegression() - K-Nearest Neighbors -
sklearn.neighbors.KNeighboursClassifier() - RandomForest -
sklearn.ensemble.RandomForestClassifier()
"},{"location":"end-to-end-heart-disease-classification/#why-these","title":"Why these?\u00b6","text":"If we look at the Scikit-Learn algorithm machine learning model map, we can see we're working on a classification problem and these are the algorithms it suggests (plus a few more).
An example path we can take using the Scikit-Learn Machine Learning Map \"Wait, I don't see Logistic Regression and why not use LinearSVC?\"
Good questions.
I was confused too when I didn't see Logistic Regression listed as well because when you read the Scikit-Learn documentation on it, you can see it's a model for classification.
And as for sklearn.svm.LinearSVC, let's pretend we've tried it (you can try it for yourself if you like), and it doesn't work, so we're following other options in the map.
For now, knowing each of these algorithms inside and out is not essential (however, this would be a fantastic extension to this project).
Machine learning and data science is an iterative practice.
These algorithms are tools in your toolbox.
In the beginning, on your way to becoming a practitioner, it's more important to understand your problem (such as, classification versus regression) and what tools you can use to solve it.
Since our dataset is relatively small, we can run some quick experiments to see which algorithm performs best and iteratively try to improve it.
Many of the algorithms in the Scikit-Learn library have similar APIs (Application Programming Interfaces).
For example, for training a model you can use model.fit(X_train, y_train).
And for scoring a model model.score(X_test, y_test) (scoring a model compares predictions to the ground truth labels).
For classification models, calling score() usually defaults to returning the ratio (accuracy) of correct predictions (1.0 = 100% correct).
Since the algorithms we've chosen implement the same methods for fitting them to the data as well as evaluating them, let's put them in a dictionary and create a which fits and scores them.
"},{"location":"end-to-end-heart-disease-classification/#53-comparing-the-results-of-several-models","title":"5.3 Comparing the results of several models\u00b6","text":"Since we've saved our models scores to a dictionary, we can plot them by first converting them to a DataFrame.
"},{"location":"end-to-end-heart-disease-classification/#54-taking-our-best-model-to-the-boss-and-learning-about-a-few-new-terms","title":"5.4 Taking our best model to the boss (and learning about a few new terms)\u00b6","text":"A conversation with the boss/senior engineer begins...
You: I've found it!
Her: Nice one! What did you find?
You: The best algorithm for predicting heart disease is a Logistic Regression!
Her: Excellent. I'm surprised the hyperparameter tuning is finished by now.
You: wonders what hyperparameter tuning is
You: Ummm yeah, me too, it went pretty quick.
Her: I'm very proud, how about you put together a classification report to show the team, and be sure to include a confusion matrix, and the cross-validated precision, recall and F1 scores. I'd also be curious to see what features are most important. Oh and don't forget to include a ROC curve.
You: asks self, \"what are those???\"
You: Of course! I'll have to you by tomorrow.
Alright, there were a few words in there that could sound made up to someone who's not a budding data scientist like us.
But being the budding data scientist we are, we also know data scientists make up words all the time.
Let's briefly go through each before we see them in action.
Term Definition Hyperparameter tuning Many machine learning models have a series of settings/dials you can turn to dictate how they perform. Changing these values may increase or decrease model performance. The practice of figuring out the best settings for a model is called hyperparameter tuning. Feature importance If there are a large amount of features we're using to make predictions, do some have more importance than others? For example, for predicting heart disease, which is more important, sex or age? Confusion matrix Compares the predicted values with the true values in a tabular way, if 100% correct, all values in the matrix will be top left to bottom right (diagnol line). Cross-validation Splits your dataset into multiple versions of training and test sets and trains/evaluations your model on each different version. This ensures that your evaluation metrics are across several different splits of data rather than a single split (if it was only a single split, you might get lucky and get better than usual results, the same for the reverse, if you get a poor split, you might find your metrics lower than they should be). Precision A common classification evaluation metric. Measures the proportion of true positives over total number of samples. Higher precision leads to fewer false positives. Recall | A common classification evaluation metric. Measures the proportion of true positives over total number of true positives and false negatives. Higher recall leads to fewer false negatives. | | F1 score | Combines precision and recall into one metric. 1 is best, 0 is worst. | | Classification report | Sklearn has a built-in function called classification_report() which returns some of the main classification metrics such as precision, recall and f1-score. | | ROC Curve | Receiver Operating Characterisitc is a plot of true positive rate versus false positive rate. A perfect curve will follow the left and top border of a plot. | | Area Under Curve (AUC) | The area underneath the ROC curve. A perfect model achieves a score of 1.0. |
Woah!
There are a fair few things going on here but nothing we can't handle.
We'll explore each of these further throughout the rest of the notebook.
In the meantime, feel free to read more at the linked resources.
"},{"location":"end-to-end-heart-disease-classification/#6-hyperparameter-tuning-and-cross-validation","title":"6. Hyperparameter tuning and cross-validation\u00b6","text":"To cook your favourite dish, you know to set the oven to 180 degrees and turn the grill on.
But when your roommate cooks their favourite dish, they use 200 degrees and the fan-forced mode.
Same oven, different settings, different outcomes.
The same can be done for machine learning algorithms. You can use the same algorithms but change the settings (hyperparameters) and get different results.
But just like turning the oven up too high can burn your food, the same can happen for machine learning algorithms.
You change the settings and it works so well, it overfits (does too well) the data.
We're looking for the Goldilocks model.
One which does well on our training dataset but also on unseen examples like in the testing dataset/real world.
To test different hyperparameters, you could use a validation set but since we don't have much data, we'll use cross-validation.
Note: A validation set is a third player in the training/test split game. It's designed to be used in between a training and test set. You can think of it as the practice exam before the final exam. As in, the training set is the course material to learn on, the validation set is the practice exam to practice and tweak your skills on and the test set is the final exam to push your skills. In machine learning, the model learns patterns on the training set and then you can tweak hyperparameters to improve results on the validation set before finally testing your model on the testing set. All samples in the training, validation and test sets should be kept exclusive of each other.
The most common type of cross-validation is k-fold.
It involves splitting your data into k-fold's or k-different splits of the data and then training and testing a model on each split.
For example, let's say we had 5 folds (k = 5).
This is what it might look like.
Normal train and test split versus 5-fold cross-validation You have 5 different versions of train and test splits.
This means you'll be able to train and test 5 different versions of your model on different data splits and calculate the average performance.
Why do this?
This prevents us from focusing too much on the metrics from one data split (imagine the data split we do contains all the easy samples and the performance metrics we use say that the model performs better than it does).
We'll be using this setup to tune the hyperparameters of some of our models and then evaluate them.
We'll also get a few more metrics like precision, recall, F1-score and ROC at the same time.
Here's the plan:
- Tune model hyperparameters, and see which performs best
- Perform cross-validation
- Plot ROC curves
- Make a confusion matrix
- Get precision, recall and F1-score metrics
- Find the most important model features
"},{"location":"end-to-end-heart-disease-classification/#61-tune-kneighborsclassifier-k-nearest-neighbors-or-knn-by-hand","title":"6.1 Tune KNeighborsClassifier (K-Nearest Neighbors or KNN) by hand\u00b6","text":"There are several hyperparameters we can tune for the K-Nearest Neighbors (KNN) algorithm (or sklearn.neighbors.KNeighborsClassifier).
But for now, let's start with one, the number of neighbors.
The default is 5 (n_neigbors=5).
What are neighbours?
Well, imagine all our different samples on one graph like the scatter graph several cells above.
KNN works by assuming dots which are closer together belong to the same class.
If n_neighbors=5 then it assume a dot with the 5 closest dots around it are in the same class.
We've left out some details here like what defines close or how distance is calculated but I encourage you to research them by going through the documentation.
For now, let's try a few different values of n_neighbors and test how the results go.
"},{"location":"end-to-end-heart-disease-classification/#62-tuning-models-with-with-randomizedsearchcv","title":"6.2 Tuning models with with RandomizedSearchCV\u00b6","text":"Reading the Scikit-Learn documentation for LogisticRegression, we find there's a number of different hyperparameters we can tune.
The same for RandomForestClassifier.
Let's create a hyperparameter grid (a dictionary of different hyperparameters) for each and then test them out.
Note: Be careful creating a hyperparameter dictionary for tuning as if there are typos in the keys of the dictionary, you will find that your code hyperparameter tuning code will produce errors.
"},{"location":"end-to-end-heart-disease-classification/#63-tuning-a-model-with-gridsearchcv","title":"6.3 Tuning a model with GridSearchCV\u00b6","text":"The difference between RandomizedSearchCV and GridSearchCV is:
sklearn.model_selection.RandomizedSearchCV searches over a grid of hyperparameters performing n_iter combinations (e.g. will explore random combinations of the hyperparameters for a defined number of iterations).sklearn.model_selection.GridSearchCV will test every single possible combination of hyperparameters in the grid (this is a thorough test but can take quite a long time).
Each class will save the best model at the end of testing.
Let's see it in action.
"},{"location":"end-to-end-heart-disease-classification/#7-evaluating-a-classification-model-beyond-accuracy","title":"7. Evaluating a classification model, beyond accuracy\u00b6","text":"Now we've got a tuned model, let's get some of the metrics we discussed before.
We want:
Metric/Evaluation Technique Scikit-Learn method/documentation ROC curve and AUC score sklearn.metrics.RocCurveDisplay(), Note: This was previously sklearn.metrics.plot_roc_curve(), as of Scikit-Learn version 1.2+, it is sklearn.metrics.RocCurveDisplay(). Confusion matrix sklearn.metrics.confusion_matrix() Classification report sklearn.metrics.classification_report() Precision sklearn.metrics.precision_score() Recall sklearn.metrics.recall_score() F1-score sklearn.metrics.f1_score() Luckily, Scikit-Learn has these all built-in.
What many evaluation metrics have in common is that they compare model predictions to ground truth data.
So we'll need some model predictions!
To access them, we'll have to use our model to make predictions on the test set.
We can make predictions by calling predict() on a trained model and passing it the data you'd like to predict on.
We'll make predictions on the test data.
Note: When making predictions with a trained model, the data you're trying to predict on must be in the same format your model was trained on. For example, if a model was trained with data formatted in a certain way, it's important to make future predictions on data formatted in that same way.
"},{"location":"end-to-end-heart-disease-classification/#71-roc-curve-and-auc-scores","title":"7.1 ROC Curve and AUC Scores\u00b6","text":"What's a ROC curve?
It's a way of understanding how your model is performing by comparing the true positive rate to the false positive rate.
In our case...
To get an appropriate example in a real-world problem, consider a diagnostic test that seeks to determine whether a person has a certain disease. A false positive in this case occurs when the person tests positive, but does not actually have the disease. A false negative, on the other hand, occurs when the person tests negative, suggesting they are healthy, when they actually do have the disease.
Scikit-Learn implements a function RocCurveDisplay (previously called plot_roc_curve in Scikit-Learn versions < 1.2) which can help us create a ROC curve as well as calculate the area under the curve (AUC) metric.
Reading the documentation on the RocCurveDisplay function we can see it has a class method called from_estimator(estimator, X, y) as inputs.
Where estimator is a fitted machine learning model and X and y are the data you'd like to test it on.
In our case, we'll use the GridSearchCV version of our LogisticRegression estimator, gs_log_reg as well as the test data, X_test and y_test.
"},{"location":"end-to-end-heart-disease-classification/#72-creating-a-confusion-matrix","title":"7.2 Creating a confusion matrix\u00b6","text":"A confusion matrix is a visual way to show where your model made the right predictions and where it made the wrong predictions (or in other words, got confused).
Scikit-Learn allows us to create a confusion matrix using sklearn.metrics.confusion_matrix() and passing it the true labels and predicted labels.
"},{"location":"end-to-end-heart-disease-classification/#73-classification-report","title":"7.3 Classification report\u00b6","text":"A classification report is a collection of different metrics and other details.
We can make a classification report using sklearn.metrics.classification_report(y_true, y_pred) and passing it the true labels as well as our models predicted labels.
A classification report will also give us information on the precision and recall of our model for each class.
"},{"location":"end-to-end-heart-disease-classification/#8-feature-importance","title":"8. Feature importance\u00b6","text":"Feature importance is another way of asking, \"Which features contribute most to the outcomes of the model?\"
For our problem, trying to predict heart disease using a patient's medical characteristics, getting the feature importance is like asking \"Which characteristics contribute most to a model predicting whether someone has heart disease or not?\"
Because how each model finds patterns in data is slightly different, how a model judges how important those patterns are is different as well.
This means for each model, there's a slightly different way of finding which features were most important and in turn, the feature importance of one model won't necessarily reflect the feature importance of another.
You can usually find an example via the Scikit-Learn documentation or via searching for something like \"MODEL TYPE feature importance\", such as, \"random forest feature importance\".
Since we're using LogisticRegression, we'll look at one way we can calculate feature importance for it.
To do so, we'll use the coef_ attribute. Looking at the Scikit-Learn documentation for LogisticRegression, the coef_ attribute is the coefficient of the features in the decision function.
We can access the coef_ attribute after we've fit an instance of LogisticRegression.
"},{"location":"end-to-end-heart-disease-classification/#9-experimentation","title":"9. Experimentation\u00b6","text":"We've completed all the metrics your boss requested!
You should be able to put together a great report containing a confusion matrix, and a handful of cross-validated metrics such as precision, recall and F1-score and you can even include which features contribute most to the model making a decision.
But after all this you might be wondering where step 6 in the framework is, experimentation.
Well the secret here is, as you might've guessed, the whole thing is experimentation.
From trying different models, to tuning different models to figuring out which hyperparameters were best.
What we've worked through so far has been a series of experiments.
And the truth is, we could keep going. But of course, things can't go on forever.
So by this stage, after trying a few different things, we'd ask ourselves did we meet the evaluation metric?
Remember we defined one in step 3.
If we can reach 95% accuracy at predicting whether or not a patient has heart disease during the proof of concept, we'll pursue this project.
In this case, we didn't.
The highest accuracy our model achieved was below 90%.
"},{"location":"end-to-end-heart-disease-classification/#what-next","title":"What next?\u00b6","text":"You might be wondering, what happens when the evaluation metric doesn't get hit?
Is everything we've done wasted?
No.
It means we know what doesn't work.
In this case, we know the current model we're using (a tuned version of sklearn.linear_model.LogisticRegression) along with our specific data set doesn't hit the target we set ourselves.
This is where step 6 comes into its own.
A good next step would be to discuss with your team or research on your own different options of going forward.
- Could you collect more data? Across more patients with more features? This may take a while but in machine learning, more data is generally better.
- Could you try a better model? If you're working with structured data, you might want to look into CatBoost or XGBoost.
- Could you improve the current models (beyond what we've done so far)?
- If your model is good enough, how would you export it and share it with others? (Hint: check out Scikit-Learn's documentation on model persistance)
The key here is to remember, your biggest restriction will be time.
Hence why it's paramount to minimise your time between experiments (if you can).
The more things you try, the more you figure out what doesn't work, the more you'll start to get a hang of what does.
And that's the whole nature of machine learning.
"},{"location":"introduction-to-matplotlib/","title":"Introduction to Matplotlib","text":"View source code | Read notebook in online book format
In\u00a0[1]: Copied! import datetime\nprint(f\"Last updated: {datetime.datetime.now()}\")\n import datetime print(f\"Last updated: {datetime.datetime.now()}\") Last updated: 2024-09-06 13:12:51.657220\n
In\u00a0[2]: Copied! # Older versions of Jupyter Notebooks and matplotlib required this magic command \n# %matplotlib inline\n\n# Import matplotlib and matplotlib.pyplot\nimport matplotlib\nimport matplotlib.pyplot as plt\n\nprint(f\"matplotlib version: {matplotlib.__version__}\")\n # Older versions of Jupyter Notebooks and matplotlib required this magic command # %matplotlib inline # Import matplotlib and matplotlib.pyplot import matplotlib import matplotlib.pyplot as plt print(f\"matplotlib version: {matplotlib.__version__}\") matplotlib version: 3.9.2\n
In\u00a0[3]: Copied! # Create a simple plot, without the semi-colon\nplt.plot()\n
# Create a simple plot, without the semi-colon plt.plot() Out[3]: []
In\u00a0[4]: Copied! # With the semi-colon\nplt.plot();\n
# With the semi-colon plt.plot(); In\u00a0[5]: Copied! # You could use plt.show() if you want\nplt.plot()\nplt.show()\n
# You could use plt.show() if you want plt.plot() plt.show() In\u00a0[6]: Copied! # Let's add some data\nplt.plot([1, 2, 3, 4]);\n
# Let's add some data plt.plot([1, 2, 3, 4]); In\u00a0[8]: Copied! # Create some data\nx = [1, 2, 3, 4]\ny = [11, 22, 33, 44]\n
# Create some data x = [1, 2, 3, 4] y = [11, 22, 33, 44] A few quick things about a plot:
x is the horizontal axis.y is the vertical axis.- In a data point,
x usually comes first, e.g. (3, 4) would be (x=3, y=4). - The same is happens in
matplotlib.pyplot.plot(), x comes before y, e.g. plt.plot(x, y).
In\u00a0[9]: Copied! # Now a y-value too!\nplt.plot(x, y);\n
# Now a y-value too! plt.plot(x, y); Now let's try using the object-orientated version.
We'll start by creating a figure with plt.figure().
And then we'll add an axes with add_subplot.
In\u00a0[10]: Copied! # Creating a plot with the object-orientated verison\nfig = plt.figure() # create a figure\nax = fig.add_subplot() # add an axes \nplt.show()\n
# Creating a plot with the object-orientated verison fig = plt.figure() # create a figure ax = fig.add_subplot() # add an axes plt.show() A note on the terminology:
- A
Figure (e.g. fig = plt.figure()) is the final image in matplotlib (and it may contain one or more Axes), often shortened to fig. - The
Axes are an individual plot (e.g. ax = fig.add_subplot()), often shorted to ax. - One
Figure can contain one or more Axes.
- The
Axis are x (horizontal), y (vertical), z (depth).
Now let's add some data to our pevious plot.
In\u00a0[11]: Copied! # Add some data to our previous plot \nfig = plt.figure()\nax = fig.add_axes([1, 1, 1, 1])\nax.plot(x, y)\nplt.show()\n
# Add some data to our previous plot fig = plt.figure() ax = fig.add_axes([1, 1, 1, 1]) ax.plot(x, y) plt.show() But there's an easier way we can use matplotlib.pyplot to help us create a Figure with multiple potential Axes.
And that's with plt.subplots().
In\u00a0[12]: Copied! # Create a Figure and multiple potential Axes and add some data\nfig, ax = plt.subplots()\nax.plot(x, y);\n
# Create a Figure and multiple potential Axes and add some data fig, ax = plt.subplots() ax.plot(x, y); In\u00a0[13]: Copied! # This is where the object orientated name comes from \ntype(fig), type(ax)\n
# This is where the object orientated name comes from type(fig), type(ax) Out[13]: (matplotlib.figure.Figure, matplotlib.axes._axes.Axes)
In\u00a0[14]: Copied! # A matplotlib workflow\n\n# 0. Import and get matplotlib ready\n# %matplotlib inline # Not necessary in newer versions of Jupyter (e.g. 2022 onwards)\nimport matplotlib.pyplot as plt\n\n# 1. Prepare data\nx = [1, 2, 3, 4]\ny = [11, 22, 33, 44]\n\n# 2. Setup plot (Figure and Axes)\nfig, ax = plt.subplots(figsize=(10,10))\n\n# 3. Plot data\nax.plot(x, y)\n\n# 4. Customize plot\nax.set(title=\"Sample Simple Plot\", xlabel=\"x-axis\", ylabel=\"y-axis\")\n\n# 5. Save & show\nfig.savefig(\"../images/simple-plot.png\")\n
# A matplotlib workflow # 0. Import and get matplotlib ready # %matplotlib inline # Not necessary in newer versions of Jupyter (e.g. 2022 onwards) import matplotlib.pyplot as plt # 1. Prepare data x = [1, 2, 3, 4] y = [11, 22, 33, 44] # 2. Setup plot (Figure and Axes) fig, ax = plt.subplots(figsize=(10,10)) # 3. Plot data ax.plot(x, y) # 4. Customize plot ax.set(title=\"Sample Simple Plot\", xlabel=\"x-axis\", ylabel=\"y-axis\") # 5. Save & show fig.savefig(\"../images/simple-plot.png\") In\u00a0[15]: Copied! import numpy as np\n
import numpy as np In\u00a0[16]: Copied! # Create an array\nx = np.linspace(0, 10, 100)\nx[:10]\n
# Create an array x = np.linspace(0, 10, 100) x[:10] Out[16]: array([0. , 0.1010101 , 0.2020202 , 0.3030303 , 0.4040404 ,\n 0.50505051, 0.60606061, 0.70707071, 0.80808081, 0.90909091])
In\u00a0[17]: Copied! # The default plot is line\nfig, ax = plt.subplots()\nax.plot(x, x**2);\n
# The default plot is line fig, ax = plt.subplots() ax.plot(x, x**2); In\u00a0[18]: Copied! # Need to recreate our figure and axis instances when we want a new figure\nfig, ax = plt.subplots()\nax.scatter(x, np.exp(x));\n
# Need to recreate our figure and axis instances when we want a new figure fig, ax = plt.subplots() ax.scatter(x, np.exp(x)); In\u00a0[19]: Copied! fig, ax = plt.subplots()\nax.scatter(x, np.sin(x));\n
fig, ax = plt.subplots() ax.scatter(x, np.sin(x)); In\u00a0[20]: Copied! # You can make plots from a dictionary\nnut_butter_prices = {\"Almond butter\": 10,\n \"Peanut butter\": 8,\n \"Cashew butter\": 12}\nfig, ax = plt.subplots()\nax.bar(nut_butter_prices.keys(), nut_butter_prices.values())\nax.set(title=\"Dan's Nut Butter Store\", ylabel=\"Price ($)\");\n # You can make plots from a dictionary nut_butter_prices = {\"Almond butter\": 10, \"Peanut butter\": 8, \"Cashew butter\": 12} fig, ax = plt.subplots() ax.bar(nut_butter_prices.keys(), nut_butter_prices.values()) ax.set(title=\"Dan's Nut Butter Store\", ylabel=\"Price ($)\"); In\u00a0[21]: Copied! fig, ax = plt.subplots()\nax.barh(list(nut_butter_prices.keys()), list(nut_butter_prices.values()));\n
fig, ax = plt.subplots() ax.barh(list(nut_butter_prices.keys()), list(nut_butter_prices.values())); In\u00a0[22]: Copied! # Make some data from a normal distribution\nx = np.random.randn(1000) # pulls data from a normal distribution\n\nfig, ax = plt.subplots()\nax.hist(x);\n
# Make some data from a normal distribution x = np.random.randn(1000) # pulls data from a normal distribution fig, ax = plt.subplots() ax.hist(x); In\u00a0[23]: Copied! x = np.random.random(1000) # random data from random distribution\n\nfig, ax = plt.subplots()\nax.hist(x);\n
x = np.random.random(1000) # random data from random distribution fig, ax = plt.subplots() ax.hist(x); In\u00a0[24]: Copied! # Option 1: Create 4 subplots with each Axes having its own variable name\nfig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, \n ncols=2, \n figsize=(10, 5))\n\n# Plot data to each axis\nax1.plot(x, x/2);\nax2.scatter(np.random.random(10), np.random.random(10));\nax3.bar(nut_butter_prices.keys(), nut_butter_prices.values());\nax4.hist(np.random.randn(1000));\n
# Option 1: Create 4 subplots with each Axes having its own variable name fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(10, 5)) # Plot data to each axis ax1.plot(x, x/2); ax2.scatter(np.random.random(10), np.random.random(10)); ax3.bar(nut_butter_prices.keys(), nut_butter_prices.values()); ax4.hist(np.random.randn(1000)); In\u00a0[25]: Copied! # Option 2: Create 4 subplots with a single ax variable\nfig, ax = plt.subplots(nrows=2, ncols=2, figsize=(10, 5))\n\n# Index the ax variable to plot data\nax[0, 0].plot(x, x/2);\nax[0, 1].scatter(np.random.random(10), np.random.random(10));\nax[1, 0].bar(nut_butter_prices.keys(), nut_butter_prices.values());\nax[1, 1].hist(np.random.randn(1000));\n
# Option 2: Create 4 subplots with a single ax variable fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(10, 5)) # Index the ax variable to plot data ax[0, 0].plot(x, x/2); ax[0, 1].scatter(np.random.random(10), np.random.random(10)); ax[1, 0].bar(nut_butter_prices.keys(), nut_butter_prices.values()); ax[1, 1].hist(np.random.randn(1000)); In\u00a0[26]: Copied! import pandas as pd\n
import pandas as pd Now we need some data to check out.
In\u00a0[28]: Copied! # Let's import the car_sales dataset \n# Note: The following two lines load the same data, one does it from a local file path, the other does it from a URL.\n# car_sales = pd.read_csv(\"../data/car-sales.csv\") # load data from local file\ncar_sales = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales.csv\") # load data from raw URL (original: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/car-sales.csv)\ncar_sales\n
# Let's import the car_sales dataset # Note: The following two lines load the same data, one does it from a local file path, the other does it from a URL. # car_sales = pd.read_csv(\"../data/car-sales.csv\") # load data from local file car_sales = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales.csv\") # load data from raw URL (original: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/car-sales.csv) car_sales Out[28]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 $4,000.00 1 Honda Red 87899 4 $5,000.00 2 Toyota Blue 32549 3 $7,000.00 3 BMW Black 11179 5 $22,000.00 4 Nissan White 213095 4 $3,500.00 5 Toyota Green 99213 4 $4,500.00 6 Honda Blue 45698 4 $7,500.00 7 Honda Blue 54738 4 $7,000.00 8 Toyota White 60000 4 $6,250.00 9 Nissan White 31600 4 $9,700.00 In\u00a0[29]: Copied! # Start with some dummy data\nts = pd.Series(np.random.randn(1000),\n index=pd.date_range('1/1/2025', periods=1000))\n\n# Note: ts = short for time series (data over time)\nts\n # Start with some dummy data ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2025', periods=1000)) # Note: ts = short for time series (data over time) ts Out[29]: 2025-01-01 1.724020\n2025-01-02 -0.530374\n2025-01-03 2.247190\n2025-01-04 0.077367\n2025-01-05 -1.035777\n ... \n2027-09-23 -1.467224\n2027-09-24 -0.588671\n2027-09-25 -0.394004\n2027-09-26 1.327045\n2027-09-27 -0.160190\nFreq: D, Length: 1000, dtype: float64
Great! We've got some random values across time.
Now let's add up the data cumulatively overtime with DataFrame.cumsum() (cumsum is short for cumulative sum or continaully adding one thing to the next and so on).
In\u00a0[30]: Copied! # Add up the values cumulatively\nts.cumsum()\n
# Add up the values cumulatively ts.cumsum() Out[30]: 2025-01-01 1.724020\n2025-01-02 1.193646\n2025-01-03 3.440836\n2025-01-04 3.518203\n2025-01-05 2.482426\n ... \n2027-09-23 32.888806\n2027-09-24 32.300135\n2027-09-25 31.906130\n2027-09-26 33.233175\n2027-09-27 33.072985\nFreq: D, Length: 1000, dtype: float64
We can now visualize the values by calling the plot() method on the DataFrame and specifying the kind of plot we'd like with the kind parameter.
In our case, the kind we'd like is a line plot, hence kind=\"line\" (this is the default for the plot() method).
In\u00a0[31]: Copied! # Plot the values over time with a line plot (note: both of these will return the same thing)\n# ts.cumsum().plot() # kind=\"line\" is set by default\nts.cumsum().plot(kind=\"line\");\n
# Plot the values over time with a line plot (note: both of these will return the same thing) # ts.cumsum().plot() # kind=\"line\" is set by default ts.cumsum().plot(kind=\"line\"); In\u00a0[32]: Copied! # Import the car sales data \ncar_sales = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales.csv\")\n\n# Remove price column symbols\ncar_sales[\"Price\"] = car_sales[\"Price\"].str.replace('[\\$\\,\\.]', '', \n regex=True) # Tell pandas to replace using regex\ncar_sales\n # Import the car sales data car_sales = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales.csv\") # Remove price column symbols car_sales[\"Price\"] = car_sales[\"Price\"].str.replace('[\\$\\,\\.]', '', regex=True) # Tell pandas to replace using regex car_sales Out[32]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 400000 1 Honda Red 87899 4 500000 2 Toyota Blue 32549 3 700000 3 BMW Black 11179 5 2200000 4 Nissan White 213095 4 350000 5 Toyota Green 99213 4 450000 6 Honda Blue 45698 4 750000 7 Honda Blue 54738 4 700000 8 Toyota White 60000 4 625000 9 Nissan White 31600 4 970000 In\u00a0[33]: Copied! # Remove last two zeros\ncar_sales[\"Price\"] = car_sales[\"Price\"].str[:-2]\ncar_sales\n
# Remove last two zeros car_sales[\"Price\"] = car_sales[\"Price\"].str[:-2] car_sales Out[33]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 4000 1 Honda Red 87899 4 5000 2 Toyota Blue 32549 3 7000 3 BMW Black 11179 5 22000 4 Nissan White 213095 4 3500 5 Toyota Green 99213 4 4500 6 Honda Blue 45698 4 7500 7 Honda Blue 54738 4 7000 8 Toyota White 60000 4 6250 9 Nissan White 31600 4 9700 In\u00a0[34]: Copied! # Add a date column\ncar_sales[\"Sale Date\"] = pd.date_range(\"1/1/2024\", periods=len(car_sales))\ncar_sales\n
# Add a date column car_sales[\"Sale Date\"] = pd.date_range(\"1/1/2024\", periods=len(car_sales)) car_sales Out[34]: Make Colour Odometer (KM) Doors Price Sale Date 0 Toyota White 150043 4 4000 2024-01-01 1 Honda Red 87899 4 5000 2024-01-02 2 Toyota Blue 32549 3 7000 2024-01-03 3 BMW Black 11179 5 22000 2024-01-04 4 Nissan White 213095 4 3500 2024-01-05 5 Toyota Green 99213 4 4500 2024-01-06 6 Honda Blue 45698 4 7500 2024-01-07 7 Honda Blue 54738 4 7000 2024-01-08 8 Toyota White 60000 4 6250 2024-01-09 9 Nissan White 31600 4 9700 2024-01-10 In\u00a0[35]: Copied! # Make total sales column (doesn't work, adds as string)\n#car_sales[\"Total Sales\"] = car_sales[\"Price\"].cumsum()\n\n# Oops... want them as int's not string\ncar_sales[\"Total Sales\"] = car_sales[\"Price\"].astype(int).cumsum()\ncar_sales\n
# Make total sales column (doesn't work, adds as string) #car_sales[\"Total Sales\"] = car_sales[\"Price\"].cumsum() # Oops... want them as int's not string car_sales[\"Total Sales\"] = car_sales[\"Price\"].astype(int).cumsum() car_sales Out[35]: Make Colour Odometer (KM) Doors Price Sale Date Total Sales 0 Toyota White 150043 4 4000 2024-01-01 4000 1 Honda Red 87899 4 5000 2024-01-02 9000 2 Toyota Blue 32549 3 7000 2024-01-03 16000 3 BMW Black 11179 5 22000 2024-01-04 38000 4 Nissan White 213095 4 3500 2024-01-05 41500 5 Toyota Green 99213 4 4500 2024-01-06 46000 6 Honda Blue 45698 4 7500 2024-01-07 53500 7 Honda Blue 54738 4 7000 2024-01-08 60500 8 Toyota White 60000 4 6250 2024-01-09 66750 9 Nissan White 31600 4 9700 2024-01-10 76450 In\u00a0[36]: Copied! car_sales.plot(x='Sale Date', y='Total Sales');\n
car_sales.plot(x='Sale Date', y='Total Sales'); In\u00a0[37]: Copied! # Note: In previous versions of matplotlib and pandas, have the \"Price\" column as a string would\n# return an error\ncar_sales[\"Price\"] = car_sales[\"Price\"].astype(str)\n\n# Plot a scatter plot\ncar_sales.plot(x=\"Odometer (KM)\", y=\"Price\", kind=\"scatter\");\n
# Note: In previous versions of matplotlib and pandas, have the \"Price\" column as a string would # return an error car_sales[\"Price\"] = car_sales[\"Price\"].astype(str) # Plot a scatter plot car_sales.plot(x=\"Odometer (KM)\", y=\"Price\", kind=\"scatter\"); Having the Price column as an int returns a much better looking y-axis.
In\u00a0[38]: Copied! # Convert Price to int\ncar_sales[\"Price\"] = car_sales[\"Price\"].astype(int)\n\n# Plot a scatter plot\ncar_sales.plot(x=\"Odometer (KM)\", y=\"Price\", kind='scatter');\n
# Convert Price to int car_sales[\"Price\"] = car_sales[\"Price\"].astype(int) # Plot a scatter plot car_sales.plot(x=\"Odometer (KM)\", y=\"Price\", kind='scatter'); In\u00a0[39]: Copied! # Create 10 random samples across 4 columns\nx = np.random.rand(10, 4)\nx\n
# Create 10 random samples across 4 columns x = np.random.rand(10, 4) x Out[39]: array([[0.63664747, 0.11886476, 0.96687683, 0.62490457],\n [0.9623542 , 0.75100119, 0.08098382, 0.83857796],\n [0.49430885, 0.00545069, 0.89374991, 0.99877205],\n [0.89788013, 0.15844467, 0.50083739, 0.72846574],\n [0.51719877, 0.00978263, 0.74440314, 0.70385373],\n [0.17211921, 0.42804418, 0.16401737, 0.66153094],\n [0.39768996, 0.00628579, 0.71681382, 0.83828817],\n [0.75507146, 0.73571561, 0.30901804, 0.4720662 ],\n [0.46070935, 0.93093698, 0.01335433, 0.91765471],\n [0.77798775, 0.70517195, 0.05298553, 0.68972541]])
In\u00a0[40]: Copied! # Turn the data into a DataFrame\ndf = pd.DataFrame(x, columns=['a', 'b', 'c', 'd'])\ndf\n
# Turn the data into a DataFrame df = pd.DataFrame(x, columns=['a', 'b', 'c', 'd']) df Out[40]: a b c d 0 0.636647 0.118865 0.966877 0.624905 1 0.962354 0.751001 0.080984 0.838578 2 0.494309 0.005451 0.893750 0.998772 3 0.897880 0.158445 0.500837 0.728466 4 0.517199 0.009783 0.744403 0.703854 5 0.172119 0.428044 0.164017 0.661531 6 0.397690 0.006286 0.716814 0.838288 7 0.755071 0.735716 0.309018 0.472066 8 0.460709 0.930937 0.013354 0.917655 9 0.777988 0.705172 0.052986 0.689725 We can plot a bar chart directly with the bar() method on the DataFrame.
In\u00a0[41]: Copied! # Plot a bar chart\ndf.plot.bar();\n
# Plot a bar chart df.plot.bar(); And we can also do the same thing passing the kind=\"bar\" parameter to DataFrame.plot().
In\u00a0[42]: Copied! # Plot a bar chart with the kind parameter\ndf.plot(kind='bar');\n
# Plot a bar chart with the kind parameter df.plot(kind='bar'); Let's try a bar plot on the car_sales DataFrame.
This time we'll specify the x and y axis values.
In\u00a0[43]: Copied! # Plot a bar chart from car_sales DataFrame\ncar_sales.plot(x=\"Make\", \n y=\"Odometer (KM)\", \n kind=\"bar\");\n
# Plot a bar chart from car_sales DataFrame car_sales.plot(x=\"Make\", y=\"Odometer (KM)\", kind=\"bar\"); In\u00a0[44]: Copied! car_sales[\"Odometer (KM)\"].plot.hist(bins=10); # default number of bins (or groups) is 10\n
car_sales[\"Odometer (KM)\"].plot.hist(bins=10); # default number of bins (or groups) is 10 In\u00a0[45]: Copied! car_sales[\"Odometer (KM)\"].plot(kind=\"hist\");\n
car_sales[\"Odometer (KM)\"].plot(kind=\"hist\"); Changing the bins parameter we can put our data into different numbers of collections.
For example, by default bins=10 (10 groups of data), let's see what happens when we change it to bins=20.
In\u00a0[46]: Copied! # Default number of bins is 10 \ncar_sales[\"Odometer (KM)\"].plot.hist(bins=20);\n
# Default number of bins is 10 car_sales[\"Odometer (KM)\"].plot.hist(bins=20); To practice, let's create a histogram of the Price column.
In\u00a0[47]: Copied! # Create a histogram of the Price column\ncar_sales[\"Price\"].plot.hist(bins=10);\n
# Create a histogram of the Price column car_sales[\"Price\"].plot.hist(bins=10); And to practice even further, how about we try another dataset?
Namely, let's create some plots using the heart disease dataset we've worked on before.
In\u00a0[48]: Copied! # Import the heart disease dataset\n# Note: The following two lines create the same DataFrame, one just loads data from a local filepath where as the other downloads it directly from a URL.\n\n# heart_disease = pd.read_csv(\"../data/heart-disease.csv\") # load from local file path (requires data to be downloaded)\nheart_disease = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/heart-disease.csv\") # load directly from raw URL (source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/heart-disease.csv)\nheart_disease.head()\n
# Import the heart disease dataset # Note: The following two lines create the same DataFrame, one just loads data from a local filepath where as the other downloads it directly from a URL. # heart_disease = pd.read_csv(\"../data/heart-disease.csv\") # load from local file path (requires data to be downloaded) heart_disease = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/heart-disease.csv\") # load directly from raw URL (source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/heart-disease.csv) heart_disease.head() Out[48]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1 In\u00a0[49]: Copied! # Create a histogram of the age column\nheart_disease[\"age\"].plot.hist(bins=50);\n
# Create a histogram of the age column heart_disease[\"age\"].plot.hist(bins=50); What does this tell you about the spread of heart disease data across different ages?
In\u00a0[50]: Copied! # Inspect the data\nheart_disease.head()\n
# Inspect the data heart_disease.head() Out[50]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1 Since all of our columns are numeric in value, let's try and create a histogram of each column.
In\u00a0[51]: Copied! heart_disease.plot.hist(figsize=(5, 20), \n subplots=True);\n
heart_disease.plot.hist(figsize=(5, 20), subplots=True); Hmmm... is this a very helpful plot?
Perhaps not.
Sometimes you can visualize too much on the one plot and it becomes confusing.
Best to start with less and gradually increase.
In\u00a0[52]: Copied! # Perform data analysis on patients over 50\nover_50 = heart_disease[heart_disease[\"age\"] > 50]\nover_50\n
# Perform data analysis on patients over 50 over_50 = heart_disease[heart_disease[\"age\"] > 50] over_50 Out[52]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1 5 57 1 0 140 192 0 1 148 0 0.4 1 0 1 1 6 56 0 1 140 294 0 0 153 0 1.3 1 0 2 1 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 297 59 1 0 164 176 1 0 90 0 1.0 1 2 1 0 298 57 0 0 140 241 0 1 123 1 0.2 1 0 3 0 300 68 1 0 144 193 1 1 141 0 3.4 1 2 3 0 301 57 1 0 130 131 0 1 115 1 1.2 1 1 3 0 302 57 0 1 130 236 0 0 174 0 0.0 1 1 2 0 208 rows \u00d7 14 columns
Now let's create a scatter plot directly from the pandas DataFrame.
This is quite easy to do but is a bit limited in terms of customization.
Let's visualize patients over 50 cholesterol levels.
We can visualize which patients have or don't have heart disease by colouring the samples to be in line with the target column (e.g. 0 = no heart disease, 1 = heart disease).
In\u00a0[53]: Copied! # Create a scatter plot directly from the pandas DataFrame\nover_50.plot(kind=\"scatter\",\n x=\"age\", \n y=\"chol\", \n c=\"target\", # colour the dots by target value\n figsize=(10, 6));\n
# Create a scatter plot directly from the pandas DataFrame over_50.plot(kind=\"scatter\", x=\"age\", y=\"chol\", c=\"target\", # colour the dots by target value figsize=(10, 6)); We can recreate the same plot using plt.subplots() and then passing the Axes variable (ax) to the pandas plot() method.
In\u00a0[54]: Copied! # Create a Figure and Axes instance\nfig, ax = plt.subplots(figsize=(10, 6))\n\n# Plot data from the DataFrame to the ax object\nover_50.plot(kind=\"scatter\", \n x=\"age\", \n y=\"chol\", \n c=\"target\", \n ax=ax); # set the target Axes\n\n# Customize the x-axis limits (to be within our target age ranges)\nax.set_xlim([45, 100]);\n
# Create a Figure and Axes instance fig, ax = plt.subplots(figsize=(10, 6)) # Plot data from the DataFrame to the ax object over_50.plot(kind=\"scatter\", x=\"age\", y=\"chol\", c=\"target\", ax=ax); # set the target Axes # Customize the x-axis limits (to be within our target age ranges) ax.set_xlim([45, 100]); Now instead of plotting directly from the pandas DataFrame, we can make a bit more of a comprehensive plot by plotting data directly to a target Axes instance.
In\u00a0[55]: Copied! # Create Figure and Axes instance\nfig, ax = plt.subplots(figsize=(10, 6))\n\n# Plot data directly to the Axes intance\nscatter = ax.scatter(over_50[\"age\"], \n over_50[\"chol\"], \n c=over_50[\"target\"]) # Colour the data with the \"target\" column\n\n# Customize the plot parameters \nax.set(title=\"Heart Disease and Cholesterol Levels\",\n xlabel=\"Age\",\n ylabel=\"Cholesterol\");\n\n# Setup the legend\nax.legend(*scatter.legend_elements(), \n title=\"Target\");\n
# Create Figure and Axes instance fig, ax = plt.subplots(figsize=(10, 6)) # Plot data directly to the Axes intance scatter = ax.scatter(over_50[\"age\"], over_50[\"chol\"], c=over_50[\"target\"]) # Colour the data with the \"target\" column # Customize the plot parameters ax.set(title=\"Heart Disease and Cholesterol Levels\", xlabel=\"Age\", ylabel=\"Cholesterol\"); # Setup the legend ax.legend(*scatter.legend_elements(), title=\"Target\"); What if we wanted a horizontal line going across with the mean of heart_disease[\"chol\"]?
We do so with the Axes.axhline() method.
In\u00a0[56]: Copied! # Create the plot\nfig, ax = plt.subplots(figsize=(10, 6))\n\n# Plot the data\nscatter = ax.scatter(over_50[\"age\"], \n over_50[\"chol\"], \n c=over_50[\"target\"])\n\n# Customize the plot\nax.set(title=\"Heart Disease and Cholesterol Levels\",\n xlabel=\"Age\",\n ylabel=\"Cholesterol\");\n\n# Add a legned\nax.legend(*scatter.legend_elements(), \n title=\"Target\")\n\n# Add a meanline\nax.axhline(over_50[\"chol\"].mean(),\n linestyle=\"--\"); # style the line to make it look nice\n
# Create the plot fig, ax = plt.subplots(figsize=(10, 6)) # Plot the data scatter = ax.scatter(over_50[\"age\"], over_50[\"chol\"], c=over_50[\"target\"]) # Customize the plot ax.set(title=\"Heart Disease and Cholesterol Levels\", xlabel=\"Age\", ylabel=\"Cholesterol\"); # Add a legned ax.legend(*scatter.legend_elements(), title=\"Target\") # Add a meanline ax.axhline(over_50[\"chol\"].mean(), linestyle=\"--\"); # style the line to make it look nice In\u00a0[57]: Copied! # Setup plot (2 rows, 1 column)\nfig, (ax0, ax1) = plt.subplots(nrows=2, # 2 rows\n ncols=1, # 1 column \n sharex=True, # both plots should use the same x-axis \n figsize=(10, 8))\n\n# ---------- Axis 0: Heart Disease and Cholesterol Levels ----------\n\n# Add data for ax0\nscatter = ax0.scatter(over_50[\"age\"], \n over_50[\"chol\"], \n c=over_50[\"target\"])\n# Customize ax0\nax0.set(title=\"Heart Disease and Cholesterol Levels\",\n ylabel=\"Cholesterol\")\nax0.legend(*scatter.legend_elements(), title=\"Target\")\n\n# Setup a mean line\nax0.axhline(y=over_50[\"chol\"].mean(), \n color='b', \n linestyle='--', \n label=\"Average\")\n\n# ---------- Axis 1: Heart Disease and Max Heart Rate Levels ----------\n\n# Add data for ax1\nscatter = ax1.scatter(over_50[\"age\"], \n over_50[\"thalach\"], \n c=over_50[\"target\"])\n\n# Customize ax1\nax1.set(title=\"Heart Disease and Max Heart Rate Levels\",\n xlabel=\"Age\",\n ylabel=\"Max Heart Rate\")\nax1.legend(*scatter.legend_elements(), title=\"Target\")\n\n# Setup a mean line\nax1.axhline(y=over_50[\"thalach\"].mean(), \n color='b', \n linestyle='--', \n label=\"Average\")\n\n# Title the figure\nfig.suptitle('Heart Disease Analysis', \n fontsize=16, \n fontweight='bold');\n # Setup plot (2 rows, 1 column) fig, (ax0, ax1) = plt.subplots(nrows=2, # 2 rows ncols=1, # 1 column sharex=True, # both plots should use the same x-axis figsize=(10, 8)) # ---------- Axis 0: Heart Disease and Cholesterol Levels ---------- # Add data for ax0 scatter = ax0.scatter(over_50[\"age\"], over_50[\"chol\"], c=over_50[\"target\"]) # Customize ax0 ax0.set(title=\"Heart Disease and Cholesterol Levels\", ylabel=\"Cholesterol\") ax0.legend(*scatter.legend_elements(), title=\"Target\") # Setup a mean line ax0.axhline(y=over_50[\"chol\"].mean(), color='b', linestyle='--', label=\"Average\") # ---------- Axis 1: Heart Disease and Max Heart Rate Levels ---------- # Add data for ax1 scatter = ax1.scatter(over_50[\"age\"], over_50[\"thalach\"], c=over_50[\"target\"]) # Customize ax1 ax1.set(title=\"Heart Disease and Max Heart Rate Levels\", xlabel=\"Age\", ylabel=\"Max Heart Rate\") ax1.legend(*scatter.legend_elements(), title=\"Target\") # Setup a mean line ax1.axhline(y=over_50[\"thalach\"].mean(), color='b', linestyle='--', label=\"Average\") # Title the figure fig.suptitle('Heart Disease Analysis', fontsize=16, fontweight='bold'); In\u00a0[60]: Copied! # Check the available styles\nplt.style.available\n
# Check the available styles plt.style.available Out[60]: ['Solarize_Light2',\n '_classic_test_patch',\n '_mpl-gallery',\n '_mpl-gallery-nogrid',\n 'bmh',\n 'classic',\n 'dark_background',\n 'fast',\n 'fivethirtyeight',\n 'ggplot',\n 'grayscale',\n 'seaborn-v0_8',\n 'seaborn-v0_8-bright',\n 'seaborn-v0_8-colorblind',\n 'seaborn-v0_8-dark',\n 'seaborn-v0_8-dark-palette',\n 'seaborn-v0_8-darkgrid',\n 'seaborn-v0_8-deep',\n 'seaborn-v0_8-muted',\n 'seaborn-v0_8-notebook',\n 'seaborn-v0_8-paper',\n 'seaborn-v0_8-pastel',\n 'seaborn-v0_8-poster',\n 'seaborn-v0_8-talk',\n 'seaborn-v0_8-ticks',\n 'seaborn-v0_8-white',\n 'seaborn-v0_8-whitegrid',\n 'tableau-colorblind10']
Before we change the style of a plot, let's remind ourselves what the default plot style looks like.
In\u00a0[61]: Copied! # Plot before changing style\ncar_sales[\"Price\"].plot();\n
# Plot before changing style car_sales[\"Price\"].plot(); Wonderful!
Now let's change the style of our future plots using the plt.style.use(style) method.
Where the style parameter is one of the available matplotlib styles.
How about we try \"seaborn-v0_8-whitegrid\" (seaborn is another common visualization library built on top of matplotlib)?
In\u00a0[62]: Copied! # Change the style of our future plots\nplt.style.use(\"seaborn-v0_8-whitegrid\")\n
# Change the style of our future plots plt.style.use(\"seaborn-v0_8-whitegrid\") In\u00a0[63]: Copied! # Plot the same plot as before\ncar_sales[\"Price\"].plot();\n
# Plot the same plot as before car_sales[\"Price\"].plot(); Wonderful!
Notice the slightly different styling of the plot?
Some styles change more than others.
How about we try \"fivethirtyeight\"?
In\u00a0[64]: Copied! # Change the plot style\nplt.style.use(\"fivethirtyeight\")\n
# Change the plot style plt.style.use(\"fivethirtyeight\") In\u00a0[65]: Copied! car_sales[\"Price\"].plot();\n
car_sales[\"Price\"].plot(); Ohhh that's a nice looking plot!
Does the style carry over for another type of plot?
How about we try a scatter plot?
In\u00a0[66]: Copied! car_sales.plot(x=\"Odometer (KM)\", \n y=\"Price\", \n kind=\"scatter\");\n
car_sales.plot(x=\"Odometer (KM)\", y=\"Price\", kind=\"scatter\"); It does!
Looks like we may need to adjust the spacing on our x-axis though.
What about another style?
Let's try \"ggplot\".
In\u00a0[67]: Copied! # Change the plot style\nplt.style.use(\"ggplot\")\n
# Change the plot style plt.style.use(\"ggplot\") In\u00a0[69]: Copied! car_sales[\"Price\"].plot.hist(bins=10);\n
car_sales[\"Price\"].plot.hist(bins=10); Cool!
Now how can we go back to the default style?
Hint: with \"default\".
In\u00a0[70]: Copied! # Change the plot style back to the default \nplt.style.use(\"default\")\n
# Change the plot style back to the default plt.style.use(\"default\") In\u00a0[71]: Copied! car_sales[\"Price\"].plot.hist();\n
car_sales[\"Price\"].plot.hist(); In\u00a0[72]: Copied! # Create random data\nx = np.random.randn(10, 4)\nx\n
# Create random data x = np.random.randn(10, 4) x Out[72]: array([[ 1.17212975, 0.46563975, -1.90589871, -1.19235958],\n [-0.63717099, -0.08598952, -0.14465387, 0.54449588],\n [-1.60294003, 0.96718789, -0.13203246, 0.37619322],\n [-1.08186882, -1.7225243 , -1.91029832, -1.42247578],\n [-0.22936709, 1.79289551, 0.24236151, -0.11114891],\n [-0.22966661, -0.04768414, 0.74157096, -1.71206472],\n [-0.15221366, -0.34325158, 0.96609502, -1.03521241],\n [ 1.09157697, -0.77361491, 0.35805583, 0.91628358],\n [ 0.15352594, -1.22128756, -0.45763768, -1.3302614 ],\n [-0.86535615, -0.4931282 , -0.43404157, 0.55973627]])
In\u00a0[73]: Copied! # Turn data into DataFrame with simple column names\ndf = pd.DataFrame(x, \n columns=['a', 'b', 'c', 'd'])\ndf\n
# Turn data into DataFrame with simple column names df = pd.DataFrame(x, columns=['a', 'b', 'c', 'd']) df Out[73]: a b c d 0 1.172130 0.465640 -1.905899 -1.192360 1 -0.637171 -0.085990 -0.144654 0.544496 2 -1.602940 0.967188 -0.132032 0.376193 3 -1.081869 -1.722524 -1.910298 -1.422476 4 -0.229367 1.792896 0.242362 -0.111149 5 -0.229667 -0.047684 0.741571 -1.712065 6 -0.152214 -0.343252 0.966095 -1.035212 7 1.091577 -0.773615 0.358056 0.916284 8 0.153526 -1.221288 -0.457638 -1.330261 9 -0.865356 -0.493128 -0.434042 0.559736 Now let's plot the data from the DataFrame in a bar chart.
This time we'll save the plot to a variable called ax (short for Axes).
In\u00a0[74]: Copied! # Create a bar plot\nax = df.plot(kind=\"bar\")\n\n# Check the type of the ax variable\ntype(ax)\n
# Create a bar plot ax = df.plot(kind=\"bar\") # Check the type of the ax variable type(ax) Out[74]: matplotlib.axes._axes.Axes
Excellent!
We can see the type of our ax variable is of AxesSubplot which allows us to use all of the methods available in matplotlib for Axes.
Let's set a few attributes of the plot with the set() method.
Namely, we'll change the title, xlabel and ylabel to communicate what's being displayed.
In\u00a0[75]: Copied! # Recreate the ax object\nax = df.plot(kind=\"bar\")\n\n# Set various attributes\nax.set(title=\"Random Number Bar Graph from DataFrame\", \n xlabel=\"Row number\", \n ylabel=\"Random number\");\n
# Recreate the ax object ax = df.plot(kind=\"bar\") # Set various attributes ax.set(title=\"Random Number Bar Graph from DataFrame\", xlabel=\"Row number\", ylabel=\"Random number\"); Notice the legend is up in the top left corner by default, we can change that if we like with the loc parameter of the legend() method.
loc can be set as a string to reflect where the legend should be.
By default it is set to loc=\"best\" which means matplotlib will try to figure out the best positioning for it.
Let's try changing it to \"loc=\"upper right\".
In\u00a0[76]: Copied! # Recreate the ax object\nax = df.plot(kind=\"bar\")\n\n# Set various attributes\nax.set(title=\"Random Number Bar Graph from DataFrame\", \n xlabel=\"Row number\", \n ylabel=\"Random number\")\n\n# Change the legend position\nax.legend(loc=\"upper right\");\n
# Recreate the ax object ax = df.plot(kind=\"bar\") # Set various attributes ax.set(title=\"Random Number Bar Graph from DataFrame\", xlabel=\"Row number\", ylabel=\"Random number\") # Change the legend position ax.legend(loc=\"upper right\"); Nice!
Is that a better fit?
Perhaps not, but it goes to show how you can change the legend position if needed.
In\u00a0[77]: Copied! # Setup the Figure and Axes\nfig, ax = plt.subplots(figsize=(10, 6))\n\n# Create a scatter plot with no cmap change (use default colormap)\nscatter = ax.scatter(over_50[\"age\"], \n over_50[\"chol\"], \n c=over_50[\"target\"],\n cmap=\"viridis\") # default cmap value\n\n# Add attributes to the plot\nax.set(title=\"Heart Disease and Cholesterol Levels\",\n xlabel=\"Age\",\n ylabel=\"Cholesterol\");\nax.axhline(y=over_50[\"chol\"].mean(), \n c='b', \n linestyle='--', \n label=\"Average\");\nax.legend(*scatter.legend_elements(), \n title=\"Target\");\n
# Setup the Figure and Axes fig, ax = plt.subplots(figsize=(10, 6)) # Create a scatter plot with no cmap change (use default colormap) scatter = ax.scatter(over_50[\"age\"], over_50[\"chol\"], c=over_50[\"target\"], cmap=\"viridis\") # default cmap value # Add attributes to the plot ax.set(title=\"Heart Disease and Cholesterol Levels\", xlabel=\"Age\", ylabel=\"Cholesterol\"); ax.axhline(y=over_50[\"chol\"].mean(), c='b', linestyle='--', label=\"Average\"); ax.legend(*scatter.legend_elements(), title=\"Target\"); Wonderful!
That plot doesn't look too bad.
But what if we wanted to change the colours?
There are many different cmap parameter options available in the colormap reference.
How about we try cmap=\"winter\"?
We can also change the colour of the horizontal line using the color parameter and setting it to a string of the colour we'd like (e.g. color=\"r\" for red).
In\u00a0[78]: Copied! fig, ax = plt.subplots(figsize=(10, 6))\n\n# Setup scatter plot with different cmap\nscatter = ax.scatter(over_50[\"age\"], \n over_50[\"chol\"], \n c=over_50[\"target\"], \n cmap=\"winter\") # Change cmap value \n\n# Add attributes to the plot with different color line\nax.set(title=\"Heart Disease and Cholesterol Levels\",\n xlabel=\"Age\",\n ylabel=\"Cholesterol\")\nax.axhline(y=over_50[\"chol\"].mean(), \n color=\"r\", # Change color of line to \"r\" (for red)\n linestyle='--', \n label=\"Average\");\nax.legend(*scatter.legend_elements(), \n title=\"Target\");\n
fig, ax = plt.subplots(figsize=(10, 6)) # Setup scatter plot with different cmap scatter = ax.scatter(over_50[\"age\"], over_50[\"chol\"], c=over_50[\"target\"], cmap=\"winter\") # Change cmap value # Add attributes to the plot with different color line ax.set(title=\"Heart Disease and Cholesterol Levels\", xlabel=\"Age\", ylabel=\"Cholesterol\") ax.axhline(y=over_50[\"chol\"].mean(), color=\"r\", # Change color of line to \"r\" (for red) linestyle='--', label=\"Average\"); ax.legend(*scatter.legend_elements(), title=\"Target\"); Woohoo!
The first plot looked nice, but I think I prefer the colours of this new plot better.
For more on choosing colormaps in matplotlib, there's a sensational and in-depth tutorial in the matplotlib documentation.
In\u00a0[79]: Copied! # Recreate double Axes plot from above with colour updates \nfig, (ax0, ax1) = plt.subplots(nrows=2, \n ncols=1, \n sharex=True, \n figsize=(10, 7))\n\n# ---------- Axis 0 ----------\nscatter = ax0.scatter(over_50[\"age\"], \n over_50[\"chol\"], \n c=over_50[\"target\"],\n cmap=\"winter\")\nax0.set(title=\"Heart Disease and Cholesterol Levels\",\n ylabel=\"Cholesterol\")\n\n# Setup a mean line\nax0.axhline(y=over_50[\"chol\"].mean(), \n color=\"r\", \n linestyle=\"--\", \n label=\"Average\");\nax0.legend(*scatter.legend_elements(), title=\"Target\")\n\n# ---------- Axis 1 ----------\nscatter = ax1.scatter(over_50[\"age\"], \n over_50[\"thalach\"], \n c=over_50[\"target\"],\n cmap=\"winter\")\nax1.set(title=\"Heart Disease and Max Heart Rate Levels\",\n xlabel=\"Age\",\n ylabel=\"Max Heart Rate\")\n\n# Setup a mean line\nax1.axhline(y=over_50[\"thalach\"].mean(), \n color=\"r\", \n linestyle=\"--\", \n label=\"Average\");\nax1.legend(*scatter.legend_elements(), \n title=\"Target\")\n\n# Title the figure\nfig.suptitle(\"Heart Disease Analysis\", \n fontsize=16, \n fontweight=\"bold\");\n
# Recreate double Axes plot from above with colour updates fig, (ax0, ax1) = plt.subplots(nrows=2, ncols=1, sharex=True, figsize=(10, 7)) # ---------- Axis 0 ---------- scatter = ax0.scatter(over_50[\"age\"], over_50[\"chol\"], c=over_50[\"target\"], cmap=\"winter\") ax0.set(title=\"Heart Disease and Cholesterol Levels\", ylabel=\"Cholesterol\") # Setup a mean line ax0.axhline(y=over_50[\"chol\"].mean(), color=\"r\", linestyle=\"--\", label=\"Average\"); ax0.legend(*scatter.legend_elements(), title=\"Target\") # ---------- Axis 1 ---------- scatter = ax1.scatter(over_50[\"age\"], over_50[\"thalach\"], c=over_50[\"target\"], cmap=\"winter\") ax1.set(title=\"Heart Disease and Max Heart Rate Levels\", xlabel=\"Age\", ylabel=\"Max Heart Rate\") # Setup a mean line ax1.axhline(y=over_50[\"thalach\"].mean(), color=\"r\", linestyle=\"--\", label=\"Average\"); ax1.legend(*scatter.legend_elements(), title=\"Target\") # Title the figure fig.suptitle(\"Heart Disease Analysis\", fontsize=16, fontweight=\"bold\"); Now let's recreate the plot from above but this time we'll change the axis limits.
We can do so by using Axes.set(xlim=[50, 80]) or Axes.set(ylim=[60, 220]) where the inputs to xlim and ylim are a list of integers defining a range of values.
For example, xlim=[50, 80] will set the x-axis values to start at 50 and end at 80.
In\u00a0[80]: Copied! # Recreate the plot from above with custom x and y axis ranges\nfig, (ax0, ax1) = plt.subplots(nrows=2, \n ncols=1, \n sharex=True, \n figsize=(10, 7))\nscatter = ax0.scatter(over_50[\"age\"], \n over_50[\"chol\"], \n c=over_50[\"target\"],\n cmap='winter')\nax0.set(title=\"Heart Disease and Cholesterol Levels\",\n ylabel=\"Cholesterol\",\n xlim=[50, 80]) # set the x-axis ranges \n\n# Setup a mean line\nax0.axhline(y=over_50[\"chol\"].mean(), \n color=\"r\", \n linestyle=\"--\", \n label=\"Average\");\nax0.legend(*scatter.legend_elements(), title=\"Target\")\n\n# Axis 1, 1 (row 1, column 1)\nscatter = ax1.scatter(over_50[\"age\"], \n over_50[\"thalach\"], \n c=over_50[\"target\"],\n cmap='winter')\nax1.set(title=\"Heart Disease and Max Heart Rate Levels\",\n xlabel=\"Age\",\n ylabel=\"Max Heart Rate\",\n ylim=[60, 220]) # change the y-axis range\n\n# Setup a mean line\nax1.axhline(y=over_50[\"thalach\"].mean(), \n color=\"r\", \n linestyle=\"--\", \n label=\"Average\");\nax1.legend(*scatter.legend_elements(), \n title=\"Target\")\n\n# Title the figure\nfig.suptitle(\"Heart Disease Analysis\", \n fontsize=16, \n fontweight=\"bold\");\n
# Recreate the plot from above with custom x and y axis ranges fig, (ax0, ax1) = plt.subplots(nrows=2, ncols=1, sharex=True, figsize=(10, 7)) scatter = ax0.scatter(over_50[\"age\"], over_50[\"chol\"], c=over_50[\"target\"], cmap='winter') ax0.set(title=\"Heart Disease and Cholesterol Levels\", ylabel=\"Cholesterol\", xlim=[50, 80]) # set the x-axis ranges # Setup a mean line ax0.axhline(y=over_50[\"chol\"].mean(), color=\"r\", linestyle=\"--\", label=\"Average\"); ax0.legend(*scatter.legend_elements(), title=\"Target\") # Axis 1, 1 (row 1, column 1) scatter = ax1.scatter(over_50[\"age\"], over_50[\"thalach\"], c=over_50[\"target\"], cmap='winter') ax1.set(title=\"Heart Disease and Max Heart Rate Levels\", xlabel=\"Age\", ylabel=\"Max Heart Rate\", ylim=[60, 220]) # change the y-axis range # Setup a mean line ax1.axhline(y=over_50[\"thalach\"].mean(), color=\"r\", linestyle=\"--\", label=\"Average\"); ax1.legend(*scatter.legend_elements(), title=\"Target\") # Title the figure fig.suptitle(\"Heart Disease Analysis\", fontsize=16, fontweight=\"bold\"); Now that's a nice looking plot!
Let's figure out how we'd save it.
In\u00a0[81]: Copied! # Recreate the plot from above with custom x and y axis ranges\nfig, (ax0, ax1) = plt.subplots(nrows=2, \n ncols=1, \n sharex=True, \n figsize=(10, 7))\nscatter = ax0.scatter(over_50[\"age\"], \n over_50[\"chol\"], \n c=over_50[\"target\"],\n cmap='winter')\nax0.set(title=\"Heart Disease and Cholesterol Levels\",\n ylabel=\"Cholesterol\",\n xlim=[50, 80]) # set the x-axis ranges \n\n# Setup a mean line\nax0.axhline(y=over_50[\"chol\"].mean(), \n color=\"r\", \n linestyle=\"--\", \n label=\"Average\");\nax0.legend(*scatter.legend_elements(), title=\"Target\")\n\n# Axis 1, 1 (row 1, column 1)\nscatter = ax1.scatter(over_50[\"age\"], \n over_50[\"thalach\"], \n c=over_50[\"target\"],\n cmap='winter')\nax1.set(title=\"Heart Disease and Max Heart Rate Levels\",\n xlabel=\"Age\",\n ylabel=\"Max Heart Rate\",\n ylim=[60, 220]) # change the y-axis range\n\n# Setup a mean line\nax1.axhline(y=over_50[\"thalach\"].mean(), \n color=\"r\", \n linestyle=\"--\", \n label=\"Average\");\nax1.legend(*scatter.legend_elements(), \n title=\"Target\")\n\n# Title the figure\nfig.suptitle(\"Heart Disease Analysis\", \n fontsize=16, \n fontweight=\"bold\");\n
# Recreate the plot from above with custom x and y axis ranges fig, (ax0, ax1) = plt.subplots(nrows=2, ncols=1, sharex=True, figsize=(10, 7)) scatter = ax0.scatter(over_50[\"age\"], over_50[\"chol\"], c=over_50[\"target\"], cmap='winter') ax0.set(title=\"Heart Disease and Cholesterol Levels\", ylabel=\"Cholesterol\", xlim=[50, 80]) # set the x-axis ranges # Setup a mean line ax0.axhline(y=over_50[\"chol\"].mean(), color=\"r\", linestyle=\"--\", label=\"Average\"); ax0.legend(*scatter.legend_elements(), title=\"Target\") # Axis 1, 1 (row 1, column 1) scatter = ax1.scatter(over_50[\"age\"], over_50[\"thalach\"], c=over_50[\"target\"], cmap='winter') ax1.set(title=\"Heart Disease and Max Heart Rate Levels\", xlabel=\"Age\", ylabel=\"Max Heart Rate\", ylim=[60, 220]) # change the y-axis range # Setup a mean line ax1.axhline(y=over_50[\"thalach\"].mean(), color=\"r\", linestyle=\"--\", label=\"Average\"); ax1.legend(*scatter.legend_elements(), title=\"Target\") # Title the figure fig.suptitle(\"Heart Disease Analysis\", fontsize=16, fontweight=\"bold\"); Nice!
We can save our plots to several different kinds of filetypes.
And we can check these filetypes with fig.canvas.get_supported_filetypes().
In\u00a0[82]: Copied! # Check the supported filetypes\nfig.canvas.get_supported_filetypes()\n
# Check the supported filetypes fig.canvas.get_supported_filetypes() Out[82]: {'eps': 'Encapsulated Postscript',\n 'jpg': 'Joint Photographic Experts Group',\n 'jpeg': 'Joint Photographic Experts Group',\n 'pdf': 'Portable Document Format',\n 'pgf': 'PGF code for LaTeX',\n 'png': 'Portable Network Graphics',\n 'ps': 'Postscript',\n 'raw': 'Raw RGBA bitmap',\n 'rgba': 'Raw RGBA bitmap',\n 'svg': 'Scalable Vector Graphics',\n 'svgz': 'Scalable Vector Graphics',\n 'tif': 'Tagged Image File Format',\n 'tiff': 'Tagged Image File Format',\n 'webp': 'WebP Image Format'} Image filetypes such as jpg and png are excellent for blog posts and presentations.
Where as the pgf or pdf filetypes may be better for reports and papers.
One last look at our Figure, which is saved to the fig variable.
In\u00a0[83]: Copied! fig\n
fig Out[83]: Beautiful!
Now let's save it to file.
In\u00a0[84]: Copied! # Save the file\nfig.savefig(fname=\"../images/heart-disease-analysis.png\",\n dpi=100)\n
# Save the file fig.savefig(fname=\"../images/heart-disease-analysis.png\", dpi=100) File saved!
Let's try and display it.
We can do so with the HTML code:
<img src=\"../images/heart-disease-analysis.png\" alt=\"a plot showing a heart disease analysis comparing the presense of heart disease, cholesterol levels and heart rate on patients over 50/>\n
And changing the cell below to markdown.
Note: Because the plot is highly visual, it's import to make sure there is an alt=\"some_text_here\" tag available when displaying the image, as this tag is used to make the plot more accessible to those with visual impairments. For more on displaying images with HTML, see the Mozzila documentation.
Finally, if we wanted to start making more and different Figures, we can reset our fig variable by creating another plot.
In\u00a0[85]: Copied! # Resets figure\nfig, ax = plt.subplots()\n
# Resets figure fig, ax = plt.subplots() If you're creating plots and saving them like this often, to save writing excess code, you might put it into a function.
A function which follows the Matplotlib workflow.
In\u00a0[86]: Copied! # Potential matplotlib workflow function\n\ndef plotting_workflow(data):\n # 1. Manipulate data\n \n # 2. Create plot\n \n # 3. Plot data\n \n # 4. Customize plot\n \n # 5. Save plot\n \n # 6. Return plot\n \n return plot\n
# Potential matplotlib workflow function def plotting_workflow(data): # 1. Manipulate data # 2. Create plot # 3. Plot data # 4. Customize plot # 5. Save plot # 6. Return plot return plot"},{"location":"introduction-to-matplotlib/#a-quick-introduction-to-matplotlib","title":"A Quick Introduction to Matplotlib\u00b6","text":""},{"location":"introduction-to-matplotlib/#what-is-matplotlib","title":"What is matplotlib?\u00b6","text":"Matplotlib is a visualization library for Python.
As in, if you want to display something in a chart or graph, matplotlib can help you do that programmatically.
Many of the graphics you'll see in machine learning research papers or presentations are made with matplotlib.
"},{"location":"introduction-to-matplotlib/#why-matplotlib","title":"Why matplotlib?\u00b6","text":"Matplotlib is part of the standard Python data stack (pandas, NumPy, matplotlib, Jupyter).
It has terrific integration with many other Python libraries.
pandas uses matplotlib as a backend to help visualize data in DataFrames.
"},{"location":"introduction-to-matplotlib/#what-does-this-notebook-cover","title":"What does this notebook cover?\u00b6","text":"A central idea in matplotlib is the concept of a \"plot\" (hence the name).
So we're going to practice making a series of different plots, which is a way to visually represent data.
Since there are basically limitless ways to create a plot, we're going to focus on a making and customizing (making them look pretty) a few common types of plots.
"},{"location":"introduction-to-matplotlib/#where-can-i-get-help","title":"Where can I get help?\u00b6","text":"If you get stuck or think of something you'd like to do which this notebook doesn't cover, don't fear!
The recommended steps you take are:
- Try it - Since matplotlib is very friendly, your first step should be to use what you know and try figure out the answer to your own question (getting it wrong is part of the process). If in doubt, run your code.
- Search for it - If trying it on your own doesn't work, since someone else has probably tried to do something similar, try searching for your problem in the following places (either via a search engine or direct):
- matplotlib documentation - the best place for learning all of the vast functionality of matplotlib. Bonus: You can see a series of matplotlib cheatsheets on the matplotlib website.
- Stack Overflow - this is the developers Q&A hub, it's full of questions and answers of different problems across a wide range of software development topics and chances are, there's one related to your problem.
- ChatGPT - ChatGPT is very good at explaining code, however, it can make mistakes. Best to verify the code it writes first before using it. Try asking \"Can you explain the following code for me? {your code here}\" and then continue with follow up questions from there. But always be careful using generated code. Avoid blindly copying something you couldn't reproduce yourself with enough effort.
An example of searching for a matplotlib feature might be:
\"how to colour the bars of a matplotlib plot\"
Searching this on Google leads to this documentation page on the matplotlib website: https://matplotlib.org/stable/gallery/lines_bars_and_markers/bar_colors.html
The next steps here are to read through the post and see if it relates to your problem. If it does, great, take the code/information you need and rewrite it to suit your own problem.
- Ask for help - If you've been through the above 2 steps and you're still stuck, you might want to ask your question on Stack Overflow or in the ZTM Discord chat. Remember to be specific as possible and provide details on what you've tried.
Remember, you don't have to learn all of these functions off by heart to begin with.
What's most important is remembering to continually ask yourself, \"what am I trying to visualize?\"
Start by answering that question and then practicing finding the code which does it.
Let's get to visualizing some data!
"},{"location":"introduction-to-matplotlib/#0-importing-matplotlib","title":"0. Importing matplotlib\u00b6","text":"We'll start by importing matplotlib.pyplot.
Why pyplot?
Because pyplot is a submodule for creating interactive plots programmatically.
pyplot is often imported as the alias plt.
Note: In older notebooks and tutorials of matplotlib, you may see the magic command %matplotlib inline. This was required to view plots inside a notebook, however, as of 2020 it is mostly no longer required.
"},{"location":"introduction-to-matplotlib/#1-2-ways-of-creating-plots","title":"1. 2 ways of creating plots\u00b6","text":"There are two main ways of creating plots in matplotlib.
matplotlib.pyplot.plot() - Recommended for simple plots (e.g. x and y).matplotlib.pyplot.XX (where XX can be one of many methods, this is known as the object-oriented API) - Recommended for more complex plots (for example plt.subplots() to create multiple plots on the same Figure, we'll get to this later).
Both of these methods are still often created by building off import matplotlib.pyplot as plt as a base.
Let's start simple.
"},{"location":"introduction-to-matplotlib/#anatomy-of-a-matplotlib-figure","title":"Anatomy of a Matplotlib Figure\u00b6","text":"Matplotlib offers almost unlimited options for creating plots.
However, let's break down some of the main terms.
- Figure - The base canvas of all matplotlib plots. The overall thing you're plotting is a Figure, often shortened to
fig. - Axes - One Figure can have one or multiple Axes, for example, a Figure with multiple suplots could have 4 Axes (2 rows and 2 columns). Often shortened to
ax. - Axis - A particular dimension of an Axes, for example, the x-axis or y-axis.
"},{"location":"introduction-to-matplotlib/#a-quick-matplotlib-workflow","title":"A quick Matplotlib Workflow\u00b6","text":"The following workflow is a standard practice when creating a matplotlib plot:
- Import matplotlib - For example,
import matplotlib.pyplot as plt). - Prepare data - This may be from an existing dataset (data analysis) or from the outputs of a machine learning model (data science).
- Setup the plot - In other words, create the Figure and various Axes.
- Plot data to the Axes - Send the relevant data to the target Axes.
- Cutomize the plot - Add a title, decorate the colours, label each Axis.
- Save (optional) and show - See what your masterpiece looks like and save it to file if necessary.
"},{"location":"introduction-to-matplotlib/#2-making-the-most-common-type-of-plots-using-numpy-arrays","title":"2. Making the most common type of plots using NumPy arrays\u00b6","text":"Most of figuring out what kind of plot to use is getting a feel for the data, then seeing what kind of plot suits it best.
Matplotlib visualizations are built on NumPy arrays. So in this section we'll build some of the most common types of plots using NumPy arrays.
- Line plot -
ax.plot() (this is the default plot in matplotlib) - Scatter plot -
ax.scatter() - Bar plot -
ax.bar() - Histogram plot -
ax.hist()
We'll see how all of these can be created as a method from matplotlob.pyplot.subplots().
Resource: Remember you can see many of the different kinds of matplotlib plot types in the documentation.
To make sure we have access to NumPy, we'll import it as np.
"},{"location":"introduction-to-matplotlib/#creating-a-line-plot","title":"Creating a line plot\u00b6","text":"Line is the default type of visualization in Matplotlib. Usually, unless specified otherwise, your plots will start out as lines.
Line plots are great for seeing trends over time.
"},{"location":"introduction-to-matplotlib/#creating-a-scatter-plot","title":"Creating a scatter plot\u00b6","text":"Scatter plots can be great for when you've got many different individual data points and you'd like to see how they interact with eachother without being connected.
"},{"location":"introduction-to-matplotlib/#creating-bar-plots","title":"Creating bar plots\u00b6","text":"Bar plots are great to visualize different amounts of similar themed items.
For example, the sales of items at a Nut Butter Store.
You can create vertical bar plots with ax.bar() and horizontal bar plots with ax.barh().
"},{"location":"introduction-to-matplotlib/#creating-a-histogram-plot","title":"Creating a histogram plot\u00b6","text":"Histogram plots are excellent for showing the distribution of data.
For example, you might want to show the distribution of ages of a population or wages of city.
"},{"location":"introduction-to-matplotlib/#creating-figures-with-multiple-axes-with-subplots","title":"Creating Figures with multiple Axes with Subplots\u00b6","text":"Subplots allow you to create multiple Axes on the same Figure (multiple plots within the same plot).
Subplots are helpful because you start with one plot per Figure but scale it up to more when necessary.
For example, let's create a subplot that shows many of the above datasets on the same Figure.
We can do so by creating multiple Axes with plt.subplots() and setting the nrows (number of rows) and ncols (number of columns) parameters to reflect how many Axes we'd like.
nrows and ncols parameters are multiplicative, meaning plt.subplots(nrows=2, ncols=2) will create 2*2=4 total Axes.
Resource: You can see a sensational number of examples for creating Subplots in the matplotlib documentation.
"},{"location":"introduction-to-matplotlib/#3-plotting-data-directly-with-pandas","title":"3. Plotting data directly with pandas\u00b6","text":"Matplotlib has a tight integration with pandas too.
You can directly plot from a pandas DataFrame with DataFrame.plot().
Let's see the following plots directly from a pandas DataFrame:
To plot data with pandas, we first have to import it as pd.
"},{"location":"introduction-to-matplotlib/#line-plot-from-a-pandas-dataframe","title":"Line plot from a pandas DataFrame\u00b6","text":"To understand examples, I often find I have to repeat them (code them myself) rather than just read them.
To begin understanding plotting with pandas, let's recreate the a section of the pandas Chart visualization documents.
"},{"location":"introduction-to-matplotlib/#working-with-actual-data","title":"Working with actual data\u00b6","text":"Let's do a little data manipulation on our car_sales DataFrame.
"},{"location":"introduction-to-matplotlib/#scatter-plot-from-a-pandas-dataframe","title":"Scatter plot from a pandas DataFrame\u00b6","text":"You can create scatter plots from a pandas DataFrame by using the kind=\"scatter\" parameter.
However, you'll often find that certain plots require certain kinds of data (e.g. some plots require certain columns to be numeric).
"},{"location":"introduction-to-matplotlib/#bar-plot-from-a-pandas-dataframe","title":"Bar plot from a pandas DataFrame\u00b6","text":"Let's see how we can plot a bar plot from a pandas DataFrame.
First, we'll create some data.
"},{"location":"introduction-to-matplotlib/#histogram-plot-from-a-pandas-dataframe","title":"Histogram plot from a pandas DataFrame\u00b6","text":"We can plot a histogram plot from our car_sales DataFrame using DataFrame.plot.hist() or DataFrame.plot(kind=\"hist\").
Histograms are great for seeing the distribution or the spread of data.
"},{"location":"introduction-to-matplotlib/#creating-a-plot-with-multiple-axes-from-a-pandas-dataframe","title":"Creating a plot with multiple Axes from a pandas DataFrame\u00b6","text":"We can also create a series of plots (multiple Axes on one Figure) from a DataFrame using the subplots=True parameter.
First, let's remind ourselves what the data looks like.
"},{"location":"introduction-to-matplotlib/#4-plotting-more-advanced-plots-from-a-pandas-dataframe","title":"4. Plotting more advanced plots from a pandas DataFrame\u00b6","text":"It's possible to achieve far more complicated and detailed plots from a pandas DataFrame.
Let's practice using the heart_disease DataFrame.
And as an example, let's do some analysis on people over 50 years of age.
To do so, let's start by creating a plot directly from pandas and then using the object-orientated API (plt.subplots()) to build upon it.
"},{"location":"introduction-to-matplotlib/#plotting-multiple-plots-on-the-same-figure-adding-another-plot-to-an-existing-one","title":"Plotting multiple plots on the same figure (adding another plot to an existing one)\u00b6","text":"Sometimes you'll want to visualize multiple features of a dataset or results of a model in one Figure.
You can achieve this by adding data to multiple Axes on the same Figure.
The plt.subplots() method helps you create Figures with a desired number of Axes in a desired figuration.
Using nrows (number of rows) and ncols (number of columns) parameters you can control the number of Axes on the Figure.
For example:
nrows=2, ncols=1 = 2x1 = a Figure with 2 Axesnrows=5, ncols=5 = 5x5 = a Figure with 25 Axes
Let's create a plot with 2 Axes.
One the first Axes (Axes 0), we'll plot heart disease against cholesterol levels (chol).
On the second Axes (Axis 1), we'll plot heart disease against max heart rate levels (thalach).
"},{"location":"introduction-to-matplotlib/#5-customizing-your-plots-making-them-look-pretty","title":"5. Customizing your plots (making them look pretty)\u00b6","text":"If you're not a fan of the default matplotlib styling, there are plenty of ways to make your plots look prettier.
The more visually appealing your plot, the higher the chance people are going to want to look at them.
However, be careful not to overdo the customizations, as they may hinder the information being conveyed.
Some of the things you can customize include:
- Axis limits - The range in which your data is displayed.
- Colors - That colors appear on the plot to represent different data.
- Overall style - Matplotlib has several different styles built-in which offer different overall themes for your plots, you can see examples of these in the matplotlib style sheets reference documentation.
- Legend - One of the most informative pieces of information on a Figure can be the legend, you can modify the legend of an Axes with the
plt.legend() method.
Let's start by exploring different styles built into matplotlib.
"},{"location":"introduction-to-matplotlib/#customizing-the-style-of-plots","title":"Customizing the style of plots\u00b6","text":"Matplotlib comes with several built-in styles that are all created with an overall theme.
You can see what styles are available by using plt.style.available.
Resources:
- To see what many of the available styles look like, you can refer to the matplotlib style sheets reference documentation.
- For a deeper guide on customizing, refer to the Customizing Matplotlib with style sheets and rcParams tutorial.
"},{"location":"introduction-to-matplotlib/#customizing-the-title-legend-and-axis-labels","title":"Customizing the title, legend and axis labels\u00b6","text":"When you have a matplotlib Figure or Axes object, you can customize many of the attributes by using the Axes.set() method.
For example, you can change the:
xlabel - Labels on the x-axis.ylim - Limits of the y-axis.xticks - Style of the x-ticks.- much more in the documentation.
Rather than talking about it, let's practice!
First, we'll create some random data and then put it into a DataFrame.
Then we'll make a plot from that DataFrame and see how to customize it.
"},{"location":"introduction-to-matplotlib/#customizing-the-colours-of-plots-with-colormaps-cmap","title":"Customizing the colours of plots with colormaps (cmap)\u00b6","text":"Colour is one of the most important features of a plot.
It can help to separate different kinds of information.
And with the right colours, plots can be fun to look at and try to learn more.
Matplotlib provides many different colour options through matplotlib.colormaps.
Let's see how we can change the colours of a matplotlib plot via the cmap parameter (cmap is short for colormaps).
We'll start by creating a scatter plot with the default cmap value (cmap=\"viridis\").
"},{"location":"introduction-to-matplotlib/#customizing-the-xlim-ylim","title":"Customizing the xlim & ylim\u00b6","text":"Matplotlib is pretty good at setting the ranges of values on the x-axis and the y-axis.
But as you might've guessed, you can customize these to suit your needs.
You can change the ranges of different axis values using the xlim and ylim parameters inside of the set() method.
To practice, let's recreate our double Axes plot from before with the default x-axis and y-axis values.
We'll add in the colour updates from the previous section too.
"},{"location":"introduction-to-matplotlib/#6-saving-plots","title":"6. Saving plots\u00b6","text":"Once you've got a nice looking plot that you're happy with, the next thing is going to be sharing it with someone else.
In a report, blog post, presentation or something similar.
You can save matplotlib Figures with plt.savefig(fname=\"your_plot_file_name\") where fname is the target filename you'd like to save the plot to.
Before we save our plot, let's recreate it.
"},{"location":"introduction-to-matplotlib/#extra-resources","title":"Extra resources\u00b6","text":"We've covered a fair bit here.
But really we've only scratched the surface of what's possible with matplotlib.
So for more, I'd recommend going through the following:
- Matplotlib quick start guide - Try rewriting all the code in this guide to get familiar with it.
- Matplotlib plot types guide - Inside you'll get an idea of just how many kinds of plots are possible with matplotlib.
- Matplotlib lifecycle of a plot guide - A sensational ground-up walkthrough of the many different things you can do with a plot.
"},{"location":"introduction-to-numpy/","title":"Introduction to NumPy","text":"View source code | Read notebook in online book format
In\u00a0[1]: Copied! import datetime\nprint(f\"Last updated: {datetime.datetime.now()}\")\n import datetime print(f\"Last updated: {datetime.datetime.now()}\") Last updated: 2024-09-05 13:15:36.894029\n
In\u00a0[2]: Copied! import numpy as np\n\n# Check the version\nprint(np.__version__)\n
import numpy as np # Check the version print(np.__version__) 2.1.1\n
In\u00a0[3]: Copied! # 1-dimensonal array, also referred to as a vector\na1 = np.array([1, 2, 3])\n\n# 2-dimensional array, also referred to as matrix\na2 = np.array([[1, 2.0, 3.3],\n [4, 5, 6.5]])\n\n# 3-dimensional array, also referred to as a matrix\na3 = np.array([[[1, 2, 3],\n [4, 5, 6],\n [7, 8, 9]],\n [[10, 11, 12],\n [13, 14, 15],\n [16, 17, 18]]])\n
# 1-dimensonal array, also referred to as a vector a1 = np.array([1, 2, 3]) # 2-dimensional array, also referred to as matrix a2 = np.array([[1, 2.0, 3.3], [4, 5, 6.5]]) # 3-dimensional array, also referred to as a matrix a3 = np.array([[[1, 2, 3], [4, 5, 6], [7, 8, 9]], [[10, 11, 12], [13, 14, 15], [16, 17, 18]]]) In\u00a0[4]: Copied! a1.shape, a1.ndim, a1.dtype, a1.size, type(a1)\n
a1.shape, a1.ndim, a1.dtype, a1.size, type(a1) Out[4]: ((3,), 1, dtype('int64'), 3, numpy.ndarray) In\u00a0[5]: Copied! a2.shape, a2.ndim, a2.dtype, a2.size, type(a2)\n
a2.shape, a2.ndim, a2.dtype, a2.size, type(a2) Out[5]: ((2, 3), 2, dtype('float64'), 6, numpy.ndarray) In\u00a0[6]: Copied! a3.shape, a3.ndim, a3.dtype, a3.size, type(a3)\n
a3.shape, a3.ndim, a3.dtype, a3.size, type(a3) Out[6]: ((2, 3, 3), 3, dtype('int64'), 18, numpy.ndarray) In\u00a0[7]: Copied! a1\n
a1 Out[7]: array([1, 2, 3])
In\u00a0[8]: Copied! a2\n
a2 Out[8]: array([[1. , 2. , 3.3],\n [4. , 5. , 6.5]])
In\u00a0[9]: Copied! a3\n
a3 Out[9]: array([[[ 1, 2, 3],\n [ 4, 5, 6],\n [ 7, 8, 9]],\n\n [[10, 11, 12],\n [13, 14, 15],\n [16, 17, 18]]])
In\u00a0[10]: Copied! import pandas as pd\ndf = pd.DataFrame(np.random.randint(10, size=(5, 3)), \n columns=['a', 'b', 'c'])\ndf\n
import pandas as pd df = pd.DataFrame(np.random.randint(10, size=(5, 3)), columns=['a', 'b', 'c']) df Out[10]: a b c 0 5 8 0 1 3 3 2 2 1 6 7 3 7 3 9 4 6 6 7 In\u00a0[11]: Copied! a2\n
a2 Out[11]: array([[1. , 2. , 3.3],\n [4. , 5. , 6.5]])
In\u00a0[12]: Copied! df2 = pd.DataFrame(a2)\ndf2\n
df2 = pd.DataFrame(a2) df2 Out[12]: 0 1 2 0 1.0 2.0 3.3 1 4.0 5.0 6.5 In\u00a0[13]: Copied! # Create a simple array\nsimple_array = np.array([1, 2, 3])\nsimple_array\n
# Create a simple array simple_array = np.array([1, 2, 3]) simple_array Out[13]: array([1, 2, 3])
In\u00a0[14]: Copied! simple_array = np.array((1, 2, 3))\nsimple_array, simple_array.dtype\n
simple_array = np.array((1, 2, 3)) simple_array, simple_array.dtype Out[14]: (array([1, 2, 3]), dtype('int64')) In\u00a0[15]: Copied! # Create an array of ones\nones = np.ones((10, 2))\nones\n
# Create an array of ones ones = np.ones((10, 2)) ones Out[15]: array([[1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.]])
In\u00a0[16]: Copied! # The default datatype is 'float64'\nones.dtype\n
# The default datatype is 'float64' ones.dtype Out[16]: dtype('float64') In\u00a0[17]: Copied! # You can change the datatype with .astype()\nones.astype(int)\n
# You can change the datatype with .astype() ones.astype(int) Out[17]: array([[1, 1],\n [1, 1],\n [1, 1],\n [1, 1],\n [1, 1],\n [1, 1],\n [1, 1],\n [1, 1],\n [1, 1],\n [1, 1]])
In\u00a0[18]: Copied! # Create an array of zeros\nzeros = np.zeros((5, 3, 3))\nzeros\n
# Create an array of zeros zeros = np.zeros((5, 3, 3)) zeros Out[18]: array([[[0., 0., 0.],\n [0., 0., 0.],\n [0., 0., 0.]],\n\n [[0., 0., 0.],\n [0., 0., 0.],\n [0., 0., 0.]],\n\n [[0., 0., 0.],\n [0., 0., 0.],\n [0., 0., 0.]],\n\n [[0., 0., 0.],\n [0., 0., 0.],\n [0., 0., 0.]],\n\n [[0., 0., 0.],\n [0., 0., 0.],\n [0., 0., 0.]]])
In\u00a0[19]: Copied! zeros.dtype\n
zeros.dtype Out[19]: dtype('float64') In\u00a0[20]: Copied! # Create an array within a range of values\nrange_array = np.arange(0, 10, 2)\nrange_array\n
# Create an array within a range of values range_array = np.arange(0, 10, 2) range_array Out[20]: array([0, 2, 4, 6, 8])
In\u00a0[21]: Copied! # Random array\nrandom_array = np.random.randint(10, size=(5, 3))\nrandom_array\n
# Random array random_array = np.random.randint(10, size=(5, 3)) random_array Out[21]: array([[8, 7, 6],\n [4, 2, 7],\n [6, 0, 6],\n [0, 8, 5],\n [6, 2, 9]])
In\u00a0[22]: Copied! # Random array of floats (between 0 & 1)\nnp.random.random((5, 3))\n
# Random array of floats (between 0 & 1) np.random.random((5, 3)) Out[22]: array([[0.47811645, 0.49437395, 0.09426995],\n [0.80062461, 0.41609157, 0.45268566],\n [0.24531914, 0.56982162, 0.36856519],\n [0.32292926, 0.03760924, 0.13312765],\n [0.66844485, 0.88781517, 0.21807957]])
In\u00a0[23]: Copied! np.random.random((5, 3))\n
np.random.random((5, 3)) Out[23]: array([[0.96868201, 0.87777028, 0.21900062],\n [0.88225041, 0.73815918, 0.83321165],\n [0.14038979, 0.79643185, 0.2741666 ],\n [0.48166491, 0.74364069, 0.75385132],\n [0.58920305, 0.43270563, 0.42922598]])
In\u00a0[24]: Copied! # Random 5x3 array of floats (between 0 & 1), similar to above\nnp.random.rand(5, 3)\n
# Random 5x3 array of floats (between 0 & 1), similar to above np.random.rand(5, 3) Out[24]: array([[0.90225603, 0.76253433, 0.84856067],\n [0.8961939 , 0.37019149, 0.00568981],\n [0.78797133, 0.07953581, 0.99870521],\n [0.07481087, 0.74846133, 0.0788899 ],\n [0.40156115, 0.80716411, 0.37204142]])
In\u00a0[25]: Copied! np.random.rand(5, 3)\n
np.random.rand(5, 3) Out[25]: array([[0.80767414, 0.62863218, 0.32492877],\n [0.71402148, 0.06601142, 0.16626604],\n [0.81986587, 0.75875945, 0.73266779],\n [0.4233863 , 0.52077358, 0.21571921],\n [0.75862881, 0.65817717, 0.74667541]])
NumPy uses pseudo-random numbers, which means, the numbers look random but aren't really, they're predetermined.
For consistency, you might want to keep the random numbers you generate similar throughout experiments.
To do this, you can use np.random.seed().
What this does is it tells NumPy, \"Hey, I want you to create random numbers but keep them aligned with the seed.\"
Let's see it.
In\u00a0[26]: Copied! # Set random seed to 0\nnp.random.seed(0)\n\n# Make 'random' numbers\nnp.random.randint(10, size=(5, 3))\n
# Set random seed to 0 np.random.seed(0) # Make 'random' numbers np.random.randint(10, size=(5, 3)) Out[26]: array([[5, 0, 3],\n [3, 7, 9],\n [3, 5, 2],\n [4, 7, 6],\n [8, 8, 1]])
With np.random.seed() set, every time you run the cell above, the same random numbers will be generated.
What if np.random.seed() wasn't set?
Every time you run the cell below, a new set of numbers will appear.
In\u00a0[27]: Copied! # Make more random numbers\nnp.random.randint(10, size=(5, 3))\n
# Make more random numbers np.random.randint(10, size=(5, 3)) Out[27]: array([[6, 7, 7],\n [8, 1, 5],\n [9, 8, 9],\n [4, 3, 0],\n [3, 5, 0]])
Let's see it in action again, we'll stay consistent and set the random seed to 0.
In\u00a0[28]: Copied! # Set random seed to same number as above\nnp.random.seed(0)\n\n# The same random numbers come out\nnp.random.randint(10, size=(5, 3))\n
# Set random seed to same number as above np.random.seed(0) # The same random numbers come out np.random.randint(10, size=(5, 3)) Out[28]: array([[5, 0, 3],\n [3, 7, 9],\n [3, 5, 2],\n [4, 7, 6],\n [8, 8, 1]])
Because np.random.seed() is set to 0, the random numbers are the same as the cell with np.random.seed() set to 0 as well.
Setting np.random.seed() is not 100% necessary but it's helpful to keep numbers the same throughout your experiments.
For example, say you wanted to split your data randomly into training and test sets.
Every time you randomly split, you might get different rows in each set.
If you shared your work with someone else, they'd get different rows in each set too.
Setting np.random.seed() ensures there's still randomness, it just makes the randomness repeatable. Hence the 'pseudo-random' numbers.
In\u00a0[29]: Copied! np.random.seed(0)\ndf = pd.DataFrame(np.random.randint(10, size=(5, 3)))\ndf\n
np.random.seed(0) df = pd.DataFrame(np.random.randint(10, size=(5, 3))) df Out[29]: 0 1 2 0 5 0 3 1 3 7 9 2 3 5 2 3 4 7 6 4 8 8 1 In\u00a0[30]: Copied! # Your code here\n
# Your code here In\u00a0[31]: Copied! a1\n
a1 Out[31]: array([1, 2, 3])
In\u00a0[32]: Copied! a2\n
a2 Out[32]: array([[1. , 2. , 3.3],\n [4. , 5. , 6.5]])
In\u00a0[33]: Copied! a3\n
a3 Out[33]: array([[[ 1, 2, 3],\n [ 4, 5, 6],\n [ 7, 8, 9]],\n\n [[10, 11, 12],\n [13, 14, 15],\n [16, 17, 18]]])
Array shapes are always listed in the format (row, column, n, n, n...) where n is optional extra dimensions.
In\u00a0[34]: Copied! a1[0]\n
a1[0] Out[34]: np.int64(1)
In\u00a0[35]: Copied! a2[0]\n
a2[0] Out[35]: array([1. , 2. , 3.3])
In\u00a0[36]: Copied! a3[0]\n
a3[0] Out[36]: array([[1, 2, 3],\n [4, 5, 6],\n [7, 8, 9]])
In\u00a0[37]: Copied! # Get 2nd row (index 1) of a2\na2[1]\n
# Get 2nd row (index 1) of a2 a2[1] Out[37]: array([4. , 5. , 6.5])
In\u00a0[38]: Copied! # Get the first 2 values of the first 2 rows of both arrays\na3[:2, :2, :2]\n
# Get the first 2 values of the first 2 rows of both arrays a3[:2, :2, :2] Out[38]: array([[[ 1, 2],\n [ 4, 5]],\n\n [[10, 11],\n [13, 14]]])
This takes a bit of practice, especially when the dimensions get higher. Usually, it takes me a little trial and error of trying to get certain values, viewing the output in the notebook and trying again.
NumPy arrays get printed from outside to inside. This means the number at the end of the shape comes first, and the number at the start of the shape comes last.
In\u00a0[39]: Copied! a4 = np.random.randint(10, size=(2, 3, 4, 5))\na4\n
a4 = np.random.randint(10, size=(2, 3, 4, 5)) a4 Out[39]: array([[[[6, 7, 7, 8, 1],\n [5, 9, 8, 9, 4],\n [3, 0, 3, 5, 0],\n [2, 3, 8, 1, 3]],\n\n [[3, 3, 7, 0, 1],\n [9, 9, 0, 4, 7],\n [3, 2, 7, 2, 0],\n [0, 4, 5, 5, 6]],\n\n [[8, 4, 1, 4, 9],\n [8, 1, 1, 7, 9],\n [9, 3, 6, 7, 2],\n [0, 3, 5, 9, 4]]],\n\n\n [[[4, 6, 4, 4, 3],\n [4, 4, 8, 4, 3],\n [7, 5, 5, 0, 1],\n [5, 9, 3, 0, 5]],\n\n [[0, 1, 2, 4, 2],\n [0, 3, 2, 0, 7],\n [5, 9, 0, 2, 7],\n [2, 9, 2, 3, 3]],\n\n [[2, 3, 4, 1, 2],\n [9, 1, 4, 6, 8],\n [2, 3, 0, 0, 6],\n [0, 6, 3, 3, 8]]]])
In\u00a0[40]: Copied! a4.shape\n
a4.shape Out[40]: (2, 3, 4, 5)
In\u00a0[41]: Copied! # Get only the first 4 numbers of each single vector\na4[:, :, :, :4]\n
# Get only the first 4 numbers of each single vector a4[:, :, :, :4] Out[41]: array([[[[6, 7, 7, 8],\n [5, 9, 8, 9],\n [3, 0, 3, 5],\n [2, 3, 8, 1]],\n\n [[3, 3, 7, 0],\n [9, 9, 0, 4],\n [3, 2, 7, 2],\n [0, 4, 5, 5]],\n\n [[8, 4, 1, 4],\n [8, 1, 1, 7],\n [9, 3, 6, 7],\n [0, 3, 5, 9]]],\n\n\n [[[4, 6, 4, 4],\n [4, 4, 8, 4],\n [7, 5, 5, 0],\n [5, 9, 3, 0]],\n\n [[0, 1, 2, 4],\n [0, 3, 2, 0],\n [5, 9, 0, 2],\n [2, 9, 2, 3]],\n\n [[2, 3, 4, 1],\n [9, 1, 4, 6],\n [2, 3, 0, 0],\n [0, 6, 3, 3]]]])
a4's shape is (2, 3, 4, 5), this means it gets displayed like so:
- Inner most array = size 5
- Next array = size 4
- Next array = size 3
- Outer most array = size 2
In\u00a0[42]: Copied! a1\n
a1 Out[42]: array([1, 2, 3])
In\u00a0[43]: Copied! ones = np.ones(3)\nones\n
ones = np.ones(3) ones Out[43]: array([1., 1., 1.])
In\u00a0[44]: Copied! # Add two arrays\na1 + ones\n
# Add two arrays a1 + ones Out[44]: array([2., 3., 4.])
In\u00a0[45]: Copied! # Subtract two arrays\na1 - ones\n
# Subtract two arrays a1 - ones Out[45]: array([0., 1., 2.])
In\u00a0[46]: Copied! # Multiply two arrays\na1 * ones\n
# Multiply two arrays a1 * ones Out[46]: array([1., 2., 3.])
In\u00a0[47]: Copied! # Multiply two arrays\na1 * a2\n
# Multiply two arrays a1 * a2 Out[47]: array([[ 1. , 4. , 9.9],\n [ 4. , 10. , 19.5]])
In\u00a0[48]: Copied! a1.shape, a2.shape\n
a1.shape, a2.shape Out[48]: ((3,), (2, 3))
In\u00a0[49]: Copied! # This will error as the arrays have a different number of dimensions (2, 3) vs. (2, 3, 3) \na2 * a3\n
# This will error as the arrays have a different number of dimensions (2, 3) vs. (2, 3, 3) a2 * a3 \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\nCell In[49], line 2\n 1 # This will error as the arrays have a different number of dimensions (2, 3) vs. (2, 3, 3) \n----> 2 a2 * a3\n\nValueError: operands could not be broadcast together with shapes (2,3) (2,3,3)
In\u00a0[50]: Copied! a3\n
a3 Out[50]: array([[[ 1, 2, 3],\n [ 4, 5, 6],\n [ 7, 8, 9]],\n\n [[10, 11, 12],\n [13, 14, 15],\n [16, 17, 18]]])
In\u00a0[51]: Copied! a1\n
a1 Out[51]: array([1, 2, 3])
In\u00a0[52]: Copied! a1.shape\n
a1.shape Out[52]: (3,)
In\u00a0[53]: Copied! a2.shape\n
a2.shape Out[53]: (2, 3)
In\u00a0[54]: Copied! a2\n
a2 Out[54]: array([[1. , 2. , 3.3],\n [4. , 5. , 6.5]])
In\u00a0[55]: Copied! a1 + a2\n
a1 + a2 Out[55]: array([[2. , 4. , 6.3],\n [5. , 7. , 9.5]])
In\u00a0[56]: Copied! a2 + 2\n
a2 + 2 Out[56]: array([[3. , 4. , 5.3],\n [6. , 7. , 8.5]])
In\u00a0[57]: Copied! # Raises an error because there's a shape mismatch (2, 3) vs. (2, 3, 3)\na2 + a3\n
# Raises an error because there's a shape mismatch (2, 3) vs. (2, 3, 3) a2 + a3 \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\nCell In[57], line 2\n 1 # Raises an error because there's a shape mismatch (2, 3) vs. (2, 3, 3)\n----> 2 a2 + a3\n\nValueError: operands could not be broadcast together with shapes (2,3) (2,3,3)
In\u00a0[58]: Copied! # Divide two arrays\na1 / ones\n
# Divide two arrays a1 / ones Out[58]: array([1., 2., 3.])
In\u00a0[59]: Copied! # Divide using floor division\na2 // a1\n
# Divide using floor division a2 // a1 Out[59]: array([[1., 1., 1.],\n [4., 2., 2.]])
In\u00a0[60]: Copied! # Take an array to a power\na1 ** 2\n
# Take an array to a power a1 ** 2 Out[60]: array([1, 4, 9])
In\u00a0[61]: Copied! # You can also use np.square()\nnp.square(a1)\n
# You can also use np.square() np.square(a1) Out[61]: array([1, 4, 9])
In\u00a0[62]: Copied! # Modulus divide (what's the remainder)\na1 % 2\n
# Modulus divide (what's the remainder) a1 % 2 Out[62]: array([1, 0, 1])
You can also find the log or exponential of an array using np.log() and np.exp().
In\u00a0[63]: Copied! # Find the log of an array\nnp.log(a1)\n
# Find the log of an array np.log(a1) Out[63]: array([0. , 0.69314718, 1.09861229])
In\u00a0[64]: Copied! # Find the exponential of an array\nnp.exp(a1)\n
# Find the exponential of an array np.exp(a1) Out[64]: array([ 2.71828183, 7.3890561 , 20.08553692])
In\u00a0[65]: Copied! sum(a1)\n
sum(a1) Out[65]: np.int64(6)
In\u00a0[66]: Copied! np.sum(a1)\n
np.sum(a1) Out[66]: np.int64(6)
Tip: Use NumPy's np.sum() on NumPy arrays and Python's sum() on Python lists.
In\u00a0[67]: Copied! massive_array = np.random.random(100000)\nmassive_array.size, type(massive_array)\n
massive_array = np.random.random(100000) massive_array.size, type(massive_array) Out[67]: (100000, numpy.ndarray)
In\u00a0[68]: Copied! %timeit sum(massive_array) # Python sum()\n%timeit np.sum(massive_array) # NumPy np.sum()\n
%timeit sum(massive_array) # Python sum() %timeit np.sum(massive_array) # NumPy np.sum() 3.93 ms \u00b1 145 \u03bcs per loop (mean \u00b1 std. dev. of 7 runs, 100 loops each)\n20.5 \u03bcs \u00b1 698 ns per loop (mean \u00b1 std. dev. of 7 runs, 10,000 loops each)\n
Notice np.sum() is faster on the Numpy array (numpy.ndarray) than Python's sum().
Now let's try it out on a Python list.
In\u00a0[69]: Copied! import random \nmassive_list = [random.randint(0, 10) for i in range(100000)]\nlen(massive_list), type(massive_list)\n
import random massive_list = [random.randint(0, 10) for i in range(100000)] len(massive_list), type(massive_list) Out[69]: (100000, list)
In\u00a0[70]: Copied! massive_list[:10]\n
massive_list[:10] Out[70]: [8, 9, 1, 0, 0, 6, 2, 8, 6, 3]
In\u00a0[71]: Copied! %timeit sum(massive_list)\n%timeit np.sum(massive_list)\n
%timeit sum(massive_list) %timeit np.sum(massive_list) 419 \u03bcs \u00b1 6.74 \u03bcs per loop (mean \u00b1 std. dev. of 7 runs, 1,000 loops each)\n2.72 ms \u00b1 118 \u03bcs per loop (mean \u00b1 std. dev. of 7 runs, 100 loops each)\n
NumPy's np.sum() is still fast but Python's sum() is faster on Python lists.
In\u00a0[72]: Copied! a2\n
a2 Out[72]: array([[1. , 2. , 3.3],\n [4. , 5. , 6.5]])
In\u00a0[73]: Copied! # Find the mean\nnp.mean(a2)\n
# Find the mean np.mean(a2) Out[73]: np.float64(3.6333333333333333)
In\u00a0[74]: Copied! # Find the max\nnp.max(a2)\n
# Find the max np.max(a2) Out[74]: np.float64(6.5)
In\u00a0[75]: Copied! # Find the min\nnp.min(a2)\n
# Find the min np.min(a2) Out[75]: np.float64(1.0)
In\u00a0[76]: Copied! # Find the standard deviation\nnp.std(a2)\n
# Find the standard deviation np.std(a2) Out[76]: np.float64(1.8226964152656422)
In\u00a0[77]: Copied! # Find the variance\nnp.var(a2)\n
# Find the variance np.var(a2) Out[77]: np.float64(3.3222222222222224)
In\u00a0[78]: Copied! # The standard deviation is the square root of the variance\nnp.sqrt(np.var(a2))\n
# The standard deviation is the square root of the variance np.sqrt(np.var(a2)) Out[78]: np.float64(1.8226964152656422)
What's mean?
Mean is the same as average. You can find the average of a set of numbers by adding them up and dividing them by how many there are.
What's standard deviation?
Standard deviation is a measure of how spread out numbers are.
What's variance?
The variance is the averaged squared differences of the mean.
To work it out, you:
- Work out the mean
- For each number, subtract the mean and square the result
- Find the average of the squared differences
In\u00a0[79]: Copied! # Demo of variance\nhigh_var_array = np.array([1, 100, 200, 300, 4000, 5000])\nlow_var_array = np.array([2, 4, 6, 8, 10])\n\nnp.var(high_var_array), np.var(low_var_array)\n
# Demo of variance high_var_array = np.array([1, 100, 200, 300, 4000, 5000]) low_var_array = np.array([2, 4, 6, 8, 10]) np.var(high_var_array), np.var(low_var_array) Out[79]: (np.float64(4296133.472222221), np.float64(8.0))
In\u00a0[80]: Copied! np.std(high_var_array), np.std(low_var_array)\n
np.std(high_var_array), np.std(low_var_array) Out[80]: (np.float64(2072.711623024829), np.float64(2.8284271247461903))
In\u00a0[81]: Copied! # The standard deviation is the square root of the variance\nnp.sqrt(np.var(high_var_array))\n
# The standard deviation is the square root of the variance np.sqrt(np.var(high_var_array)) Out[81]: np.float64(2072.711623024829)
In\u00a0[82]: Copied! %matplotlib inline\nimport matplotlib.pyplot as plt\nplt.hist(high_var_array)\nplt.show()\n
%matplotlib inline import matplotlib.pyplot as plt plt.hist(high_var_array) plt.show() In\u00a0[83]: Copied! plt.hist(low_var_array)\nplt.show()\n
plt.hist(low_var_array) plt.show() In\u00a0[84]: Copied! a2\n
a2 Out[84]: array([[1. , 2. , 3.3],\n [4. , 5. , 6.5]])
In\u00a0[85]: Copied! a2.shape\n
a2.shape Out[85]: (2, 3)
In\u00a0[86]: Copied! a2 + a3\n
a2 + a3 \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\nCell In[86], line 1\n----> 1 a2 + a3\n\nValueError: operands could not be broadcast together with shapes (2,3) (2,3,3)
In\u00a0[\u00a0]: Copied! a2.reshape(2, 3, 1)\n
a2.reshape(2, 3, 1) In\u00a0[87]: Copied! a2.reshape(2, 3, 1) + a3\n
a2.reshape(2, 3, 1) + a3 Out[87]: array([[[ 2. , 3. , 4. ],\n [ 6. , 7. , 8. ],\n [10.3, 11.3, 12.3]],\n\n [[14. , 15. , 16. ],\n [18. , 19. , 20. ],\n [22.5, 23.5, 24.5]]])
In\u00a0[88]: Copied! a2.shape\n
a2.shape Out[88]: (2, 3)
In\u00a0[89]: Copied! a2.T\n
a2.T Out[89]: array([[1. , 4. ],\n [2. , 5. ],\n [3.3, 6.5]])
In\u00a0[90]: Copied! a2.transpose()\n
a2.transpose() Out[90]: array([[1. , 4. ],\n [2. , 5. ],\n [3.3, 6.5]])
In\u00a0[91]: Copied! a2.T.shape\n
a2.T.shape Out[91]: (3, 2)
For larger arrays, the default value of a tranpose is to swap the first and last axes.
For example, (5, 3, 3) -> (3, 3, 5).
In\u00a0[92]: Copied! matrix = np.random.random(size=(5, 3, 3))\nmatrix\n
matrix = np.random.random(size=(5, 3, 3)) matrix Out[92]: array([[[0.59816399, 0.17370251, 0.49752936],\n [0.51231935, 0.41529741, 0.44150892],\n [0.96844105, 0.23242417, 0.90336451]],\n\n [[0.35172075, 0.56481088, 0.57771134],\n [0.73115238, 0.88762934, 0.37368847],\n [0.35104994, 0.11873224, 0.72324236]],\n\n [[0.93202688, 0.09600718, 0.4330638 ],\n [0.71979707, 0.06689016, 0.20815443],\n [0.55415679, 0.08416165, 0.88953996]],\n\n [[0.00301345, 0.30163886, 0.12337636],\n [0.13435611, 0.51987339, 0.05418991],\n [0.11426417, 0.19005404, 0.61364183]],\n\n [[0.23385887, 0.13555752, 0.32546415],\n [0.81922614, 0.94551446, 0.12975713],\n [0.35431267, 0.37758386, 0.07987885]]])
In\u00a0[93]: Copied! matrix.shape\n
matrix.shape Out[93]: (5, 3, 3)
In\u00a0[94]: Copied! matrix.T\n
matrix.T Out[94]: array([[[0.59816399, 0.35172075, 0.93202688, 0.00301345, 0.23385887],\n [0.51231935, 0.73115238, 0.71979707, 0.13435611, 0.81922614],\n [0.96844105, 0.35104994, 0.55415679, 0.11426417, 0.35431267]],\n\n [[0.17370251, 0.56481088, 0.09600718, 0.30163886, 0.13555752],\n [0.41529741, 0.88762934, 0.06689016, 0.51987339, 0.94551446],\n [0.23242417, 0.11873224, 0.08416165, 0.19005404, 0.37758386]],\n\n [[0.49752936, 0.57771134, 0.4330638 , 0.12337636, 0.32546415],\n [0.44150892, 0.37368847, 0.20815443, 0.05418991, 0.12975713],\n [0.90336451, 0.72324236, 0.88953996, 0.61364183, 0.07987885]]])
In\u00a0[95]: Copied! matrix.T.shape\n
matrix.T.shape Out[95]: (3, 3, 5)
In\u00a0[96]: Copied! # Check to see if the reverse shape is same as tranpose shape\nmatrix.T.shape == matrix.shape[::-1]\n
# Check to see if the reverse shape is same as tranpose shape matrix.T.shape == matrix.shape[::-1] Out[96]: True
In\u00a0[97]: Copied! # Check to see if the first and last axes are swapped\nmatrix.T == matrix.swapaxes(0, -1) # swap first (0) and last (-1) axes\n
# Check to see if the first and last axes are swapped matrix.T == matrix.swapaxes(0, -1) # swap first (0) and last (-1) axes Out[97]: array([[[ True, True, True, True, True],\n [ True, True, True, True, True],\n [ True, True, True, True, True]],\n\n [[ True, True, True, True, True],\n [ True, True, True, True, True],\n [ True, True, True, True, True]],\n\n [[ True, True, True, True, True],\n [ True, True, True, True, True],\n [ True, True, True, True, True]]])
You can see more advanced forms of tranposing in the NumPy documentation under numpy.transpose.
In\u00a0[98]: Copied! np.random.seed(0)\nmat1 = np.random.randint(10, size=(3, 3))\nmat2 = np.random.randint(10, size=(3, 2))\n\nmat1.shape, mat2.shape\n
np.random.seed(0) mat1 = np.random.randint(10, size=(3, 3)) mat2 = np.random.randint(10, size=(3, 2)) mat1.shape, mat2.shape Out[98]: ((3, 3), (3, 2))
In\u00a0[99]: Copied! mat1\n
mat1 Out[99]: array([[5, 0, 3],\n [3, 7, 9],\n [3, 5, 2]])
In\u00a0[100]: Copied! mat2\n
mat2 Out[100]: array([[4, 7],\n [6, 8],\n [8, 1]])
In\u00a0[101]: Copied! np.dot(mat1, mat2)\n
np.dot(mat1, mat2) Out[101]: array([[ 44, 38],\n [126, 86],\n [ 58, 63]])
In\u00a0[102]: Copied! # Can also achieve np.dot() with \"@\" \n# (however, they may behave differently at 3D+ arrays)\nmat1 @ mat2\n
# Can also achieve np.dot() with \"@\" # (however, they may behave differently at 3D+ arrays) mat1 @ mat2 Out[102]: array([[ 44, 38],\n [126, 86],\n [ 58, 63]])
In\u00a0[103]: Copied! np.random.seed(0)\nmat3 = np.random.randint(10, size=(4,3))\nmat4 = np.random.randint(10, size=(4,3))\nmat3\n
np.random.seed(0) mat3 = np.random.randint(10, size=(4,3)) mat4 = np.random.randint(10, size=(4,3)) mat3 Out[103]: array([[5, 0, 3],\n [3, 7, 9],\n [3, 5, 2],\n [4, 7, 6]])
In\u00a0[104]: Copied! mat4\n
mat4 Out[104]: array([[8, 8, 1],\n [6, 7, 7],\n [8, 1, 5],\n [9, 8, 9]])
In\u00a0[105]: Copied! # This will fail as the inner dimensions of the matrices do not match\nnp.dot(mat3, mat4)\n
# This will fail as the inner dimensions of the matrices do not match np.dot(mat3, mat4) \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\nCell In[105], line 2\n 1 # This will fail as the inner dimensions of the matrices do not match\n----> 2 np.dot(mat3, mat4)\n\nValueError: shapes (4,3) and (4,3) not aligned: 3 (dim 1) != 4 (dim 0)
In\u00a0[106]: Copied! mat3.T.shape\n
mat3.T.shape Out[106]: (3, 4)
In\u00a0[107]: Copied! # Dot product\nnp.dot(mat3.T, mat4)\n
# Dot product np.dot(mat3.T, mat4) Out[107]: array([[118, 96, 77],\n [145, 110, 137],\n [148, 137, 130]])
In\u00a0[108]: Copied! # Element-wise multiplication, also known as Hadamard product\nmat3 * mat4\n
# Element-wise multiplication, also known as Hadamard product mat3 * mat4 Out[108]: array([[40, 0, 3],\n [18, 49, 63],\n [24, 5, 10],\n [36, 56, 54]])
In\u00a0[109]: Copied! np.random.seed(0)\nsales_amounts = np.random.randint(20, size=(5, 3))\nsales_amounts\n
np.random.seed(0) sales_amounts = np.random.randint(20, size=(5, 3)) sales_amounts Out[109]: array([[12, 15, 0],\n [ 3, 3, 7],\n [ 9, 19, 18],\n [ 4, 6, 12],\n [ 1, 6, 7]])
In\u00a0[110]: Copied! weekly_sales = pd.DataFrame(sales_amounts,\n index=[\"Mon\", \"Tues\", \"Wed\", \"Thurs\", \"Fri\"],\n columns=[\"Almond butter\", \"Peanut butter\", \"Cashew butter\"])\nweekly_sales\n
weekly_sales = pd.DataFrame(sales_amounts, index=[\"Mon\", \"Tues\", \"Wed\", \"Thurs\", \"Fri\"], columns=[\"Almond butter\", \"Peanut butter\", \"Cashew butter\"]) weekly_sales Out[110]: Almond butter Peanut butter Cashew butter Mon 12 15 0 Tues 3 3 7 Wed 9 19 18 Thurs 4 6 12 Fri 1 6 7 In\u00a0[111]: Copied! prices = np.array([10, 8, 12])\nprices\n
prices = np.array([10, 8, 12]) prices Out[111]: array([10, 8, 12])
In\u00a0[112]: Copied! butter_prices = pd.DataFrame(prices.reshape(1, 3),\n index=[\"Price\"],\n columns=[\"Almond butter\", \"Peanut butter\", \"Cashew butter\"])\nbutter_prices.shape\n
butter_prices = pd.DataFrame(prices.reshape(1, 3), index=[\"Price\"], columns=[\"Almond butter\", \"Peanut butter\", \"Cashew butter\"]) butter_prices.shape Out[112]: (1, 3)
In\u00a0[113]: Copied! weekly_sales.shape\n
weekly_sales.shape Out[113]: (5, 3)
In\u00a0[114]: Copied! # Find the total amount of sales for a whole day\ntotal_sales = prices.dot(sales_amounts)\ntotal_sales\n
# Find the total amount of sales for a whole day total_sales = prices.dot(sales_amounts) total_sales \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\nCell In[114], line 2\n 1 # Find the total amount of sales for a whole day\n----> 2 total_sales = prices.dot(sales_amounts)\n 3 total_sales\n\nValueError: shapes (3,) and (5,3) not aligned: 3 (dim 0) != 5 (dim 0)
The shapes aren't aligned, we need the middle two numbers to be the same.
In\u00a0[115]: Copied! prices\n
prices Out[115]: array([10, 8, 12])
In\u00a0[116]: Copied! sales_amounts.T.shape\n
sales_amounts.T.shape Out[116]: (3, 5)
In\u00a0[117]: Copied! # To make the middle numbers the same, we can transpose\ntotal_sales = prices.dot(sales_amounts.T)\ntotal_sales\n
# To make the middle numbers the same, we can transpose total_sales = prices.dot(sales_amounts.T) total_sales Out[117]: array([240, 138, 458, 232, 142])
In\u00a0[118]: Copied! butter_prices.shape, weekly_sales.shape\n
butter_prices.shape, weekly_sales.shape Out[118]: ((1, 3), (5, 3))
In\u00a0[119]: Copied! daily_sales = butter_prices.dot(weekly_sales.T)\ndaily_sales\n
daily_sales = butter_prices.dot(weekly_sales.T) daily_sales Out[119]: Mon Tues Wed Thurs Fri Price 240 138 458 232 142 In\u00a0[120]: Copied! # Need to transpose again\nweekly_sales[\"Total\"] = daily_sales.T\nweekly_sales\n
# Need to transpose again weekly_sales[\"Total\"] = daily_sales.T weekly_sales Out[120]: Almond butter Peanut butter Cashew butter Total Mon 12 15 0 240 Tues 3 3 7 138 Wed 9 19 18 458 Thurs 4 6 12 232 Fri 1 6 7 142 In\u00a0[121]: Copied! a1\n
a1 Out[121]: array([1, 2, 3])
In\u00a0[122]: Copied! a2\n
a2 Out[122]: array([[1. , 2. , 3.3],\n [4. , 5. , 6.5]])
In\u00a0[123]: Copied! a1 > a2\n
a1 > a2 Out[123]: array([[False, False, False],\n [False, False, False]])
In\u00a0[124]: Copied! a1 >= a2\n
a1 >= a2 Out[124]: array([[ True, True, False],\n [False, False, False]])
In\u00a0[125]: Copied! a1 > 5\n
a1 > 5 Out[125]: array([False, False, False])
In\u00a0[126]: Copied! a1 == a1\n
a1 == a1 Out[126]: array([ True, True, True])
In\u00a0[127]: Copied! a1 == a2\n
a1 == a2 Out[127]: array([[ True, True, False],\n [False, False, False]])
In\u00a0[128]: Copied! random_array\n
random_array Out[128]: array([[8, 7, 6],\n [4, 2, 7],\n [6, 0, 6],\n [0, 8, 5],\n [6, 2, 9]])
In\u00a0[129]: Copied! np.sort(random_array)\n
np.sort(random_array) Out[129]: array([[6, 7, 8],\n [2, 4, 7],\n [0, 6, 6],\n [0, 5, 8],\n [2, 6, 9]])
In\u00a0[130]: Copied! np.argsort(random_array)\n
np.argsort(random_array) Out[130]: array([[2, 1, 0],\n [1, 0, 2],\n [1, 0, 2],\n [0, 2, 1],\n [1, 0, 2]])
In\u00a0[131]: Copied! a1\n
a1 Out[131]: array([1, 2, 3])
In\u00a0[132]: Copied! # Return the indices that would sort an array\nnp.argsort(a1)\n
# Return the indices that would sort an array np.argsort(a1) Out[132]: array([0, 1, 2])
In\u00a0[133]: Copied! # No axis\nnp.argmin(a1)\n
# No axis np.argmin(a1) Out[133]: np.int64(0)
In\u00a0[134]: Copied! random_array\n
random_array Out[134]: array([[8, 7, 6],\n [4, 2, 7],\n [6, 0, 6],\n [0, 8, 5],\n [6, 2, 9]])
In\u00a0[135]: Copied! # Down the vertical\nnp.argmax(random_array, axis=1)\n
# Down the vertical np.argmax(random_array, axis=1) Out[135]: array([0, 2, 0, 1, 2])
In\u00a0[136]: Copied! # Across the horizontal\nnp.argmin(random_array, axis=0)\n
# Across the horizontal np.argmin(random_array, axis=0) Out[136]: array([3, 2, 3])
In\u00a0[137]: Copied! from matplotlib.image import imread\n\npanda = imread('../images/numpy-panda.jpeg')\nprint(type(panda))\n from matplotlib.image import imread panda = imread('../images/numpy-panda.jpeg') print(type(panda)) <class 'numpy.ndarray'>\n
In\u00a0[138]: Copied! panda.shape\n
panda.shape Out[138]: (852, 1280, 3)
In\u00a0[139]: Copied! panda\n
panda Out[139]: array([[[14, 27, 17],\n [14, 27, 17],\n [12, 28, 17],\n ...,\n [42, 36, 24],\n [42, 35, 25],\n [41, 34, 24]],\n\n [[14, 27, 17],\n [14, 27, 17],\n [12, 28, 17],\n ...,\n [42, 36, 24],\n [42, 35, 25],\n [42, 35, 25]],\n\n [[13, 26, 16],\n [14, 27, 17],\n [12, 28, 17],\n ...,\n [42, 36, 24],\n [42, 35, 25],\n [42, 35, 25]],\n\n ...,\n\n [[47, 32, 27],\n [48, 33, 28],\n [48, 33, 26],\n ...,\n [ 6, 6, 8],\n [ 6, 6, 8],\n [ 6, 6, 8]],\n\n [[39, 24, 17],\n [40, 25, 18],\n [42, 27, 20],\n ...,\n [ 6, 6, 8],\n [ 6, 6, 8],\n [ 6, 6, 8]],\n\n [[32, 17, 10],\n [33, 18, 11],\n [36, 21, 14],\n ...,\n [ 6, 6, 8],\n [ 6, 6, 8],\n [ 6, 6, 8]]], dtype=uint8)
In\u00a0[140]: Copied! car = imread(\"../images/numpy-car-photo.png\")\ncar.shape\n
car = imread(\"../images/numpy-car-photo.png\") car.shape Out[140]: (431, 575, 4)
In\u00a0[141]: Copied! car[:,:,:3].shape\n
car[:,:,:3].shape Out[141]: (431, 575, 3)
In\u00a0[142]: Copied! dog = imread(\"../images/numpy-dog-photo.png\")\ndog.shape\n
dog = imread(\"../images/numpy-dog-photo.png\") dog.shape Out[142]: (432, 575, 4)
In\u00a0[143]: Copied! dog\n
dog Out[143]: array([[[0.70980394, 0.80784315, 0.88235295, 1. ],\n [0.72156864, 0.8117647 , 0.8862745 , 1. ],\n [0.7411765 , 0.8156863 , 0.8862745 , 1. ],\n ...,\n [0.49803922, 0.6862745 , 0.8392157 , 1. ],\n [0.49411765, 0.68235296, 0.8392157 , 1. ],\n [0.49411765, 0.68235296, 0.8352941 , 1. ]],\n\n [[0.69411767, 0.8039216 , 0.8862745 , 1. ],\n [0.7019608 , 0.8039216 , 0.88235295, 1. ],\n [0.7058824 , 0.80784315, 0.88235295, 1. ],\n ...,\n [0.5019608 , 0.6862745 , 0.84705883, 1. ],\n [0.49411765, 0.68235296, 0.84313726, 1. ],\n [0.49411765, 0.68235296, 0.8392157 , 1. ]],\n\n [[0.6901961 , 0.8 , 0.88235295, 1. ],\n [0.69803923, 0.8039216 , 0.88235295, 1. ],\n [0.7058824 , 0.80784315, 0.88235295, 1. ],\n ...,\n [0.5019608 , 0.6862745 , 0.84705883, 1. ],\n [0.49803922, 0.6862745 , 0.84313726, 1. ],\n [0.49803922, 0.6862745 , 0.84313726, 1. ]],\n\n ...,\n\n [[0.9098039 , 0.81960785, 0.654902 , 1. ],\n [0.8352941 , 0.7490196 , 0.6509804 , 1. ],\n [0.72156864, 0.6313726 , 0.5372549 , 1. ],\n ...,\n [0.01568628, 0.07058824, 0.02352941, 1. ],\n [0.03921569, 0.09411765, 0.03529412, 1. ],\n [0.03921569, 0.09019608, 0.05490196, 1. ]],\n\n [[0.9137255 , 0.83137256, 0.6784314 , 1. ],\n [0.8117647 , 0.7294118 , 0.627451 , 1. ],\n [0.65882355, 0.5686275 , 0.47843137, 1. ],\n ...,\n [0.00392157, 0.05490196, 0.03529412, 1. ],\n [0.03137255, 0.09019608, 0.05490196, 1. ],\n [0.04705882, 0.10588235, 0.06666667, 1. ]],\n\n [[0.9137255 , 0.83137256, 0.68235296, 1. ],\n [0.76862746, 0.68235296, 0.5882353 , 1. ],\n [0.59607846, 0.5058824 , 0.44313726, 1. ],\n ...,\n [0.03921569, 0.10196079, 0.07058824, 1. ],\n [0.02745098, 0.08235294, 0.05882353, 1. ],\n [0.05098039, 0.11372549, 0.07058824, 1. ]]], dtype=float32)
"},{"location":"introduction-to-numpy/#a-quick-introduction-to-numerical-data-manipulation-with-python-and-numpy","title":"A Quick Introduction to Numerical Data Manipulation with Python and NumPy\u00b6","text":""},{"location":"introduction-to-numpy/#what-is-numpy","title":"What is NumPy?\u00b6","text":"NumPy stands for numerical Python. It's the backbone of all kinds of scientific and numerical computing in Python.
And since machine learning is all about turning data into numbers and then figuring out the patterns, NumPy often comes into play.
"},{"location":"introduction-to-numpy/#why-numpy","title":"Why NumPy?\u00b6","text":"You can do numerical calculations using pure Python. In the beginning, you might think Python is fast but once your data gets large, you'll start to notice slow downs.
One of the main reasons you use NumPy is because it's fast. Behind the scenes, the code has been optimized to run using C. Which is another programming language, which can do things much faster than Python.
The benefit of this being behind the scenes is you don't need to know any C to take advantage of it. You can write your numerical computations in Python using NumPy and get the added speed benefits.
If your curious as to what causes this speed benefit, it's a process called vectorization. Vectorization aims to do calculations by avoiding loops as loops can create potential bottlenecks.
NumPy achieves vectorization through a process called broadcasting.
"},{"location":"introduction-to-numpy/#what-does-this-notebook-cover","title":"What does this notebook cover?\u00b6","text":"The NumPy library is very capable. However, learning everything off by heart isn't necessary. Instead, this notebook focuses on the main concepts of NumPy and the ndarray datatype.
You can think of the ndarray datatype as a very flexible array of numbers.
More specifically, we'll look at:
- NumPy datatypes & attributes
- Creating arrays
- Viewing arrays & matrices (indexing)
- Manipulating & comparing arrays
- Sorting arrays
- Use cases (examples of turning things into numbers)
After going through it, you'll have the base knolwedge of NumPy you need to keep moving forward.
"},{"location":"introduction-to-numpy/#where-can-i-get-help","title":"Where can I get help?\u00b6","text":"If you get stuck or think of something you'd like to do which this notebook doesn't cover, don't fear!
The recommended steps you take are:
- Try it - Since NumPy is very friendly, your first step should be to use what you know and try figure out the answer to your own question (getting it wrong is part of the process). If in doubt, run your code.
- Search for it - If trying it on your own doesn't work, since someone else has probably tried to do something similar, try searching for your problem in the following places (either via a search engine or direct):
- NumPy documentation - The ground truth for everything NumPy, this resource covers all of the NumPy functionality.
- Stack Overflow - This is the developers Q&A hub, it's full of questions and answers of different problems across a wide range of software development topics and chances are, there's one related to your problem.
- ChatGPT - ChatGPT is very good at explaining code, however, it can make mistakes. Best to verify the code it writes first before using it. Try asking \"Can you explain the following code for me? {your code here}\" and then continue with follow up questions from there. Avoid straight copying and pasting and instead, only use things that you could yourself reproduce with adequate effort.
An example of searching for a NumPy function might be:
\"how to find unique elements in a numpy array\"
Searching this on Google leads to the NumPy documentation for the np.unique() function: https://numpy.org/doc/stable/reference/generated/numpy.unique.html
The next steps here are to read through the documentation, check the examples and see if they line up to the problem you're trying to solve.
If they do, rewrite the code to suit your needs, run it, and see what the outcomes are.
- Ask for help - If you've been through the above 2 steps and you're still stuck, you might want to ask your question on Stack Overflow. Be as specific as possible and provide details on what you've tried.
Remember, you don't have to learn all of the functions off by heart to begin with.
What's most important is continually asking yourself, \"what am I trying to do with the data?\".
Start by answering that question and then practicing finding the code which does it.
Let's get started.
"},{"location":"introduction-to-numpy/#0-importing-numpy","title":"0. Importing NumPy\u00b6","text":"To get started using NumPy, the first step is to import it.
The most common way (and method you should use) is to import NumPy as the abbreviation np.
If you see the letters np used anywhere in machine learning or data science, it's probably referring to the NumPy library.
"},{"location":"introduction-to-numpy/#1-datatypes-and-attributes","title":"1. DataTypes and attributes\u00b6","text":"Note: Important to remember the main type in NumPy is ndarray, even seemingly different kinds of arrays are still ndarray's. This means an operation you do on one array, will work on another.
"},{"location":"introduction-to-numpy/#anatomy-of-an-array","title":"Anatomy of an array\u00b6","text":"Key terms:
- Array - A list of numbers, can be multi-dimensional.
- Scalar - A single number (e.g.
7). - Vector - A list of numbers with 1-dimension (e.g.
np.array([1, 2, 3])). - Matrix - A (usually) multi-dimensional list of numbers (e.g.
np.array([[1, 2, 3], [4, 5, 6]])).
"},{"location":"introduction-to-numpy/#pandas-dataframe-out-of-numpy-arrays","title":"pandas DataFrame out of NumPy arrays\u00b6","text":"This is to examplify how NumPy is the backbone of many other libraries.
"},{"location":"introduction-to-numpy/#2-creating-arrays","title":"2. Creating arrays\u00b6","text":" np.array()np.ones()np.zeros()np.random.rand(5, 3)np.random.randint(10, size=5)np.random.seed() - pseudo random numbers- Searching the documentation example (finding
np.unique() and using it)
"},{"location":"introduction-to-numpy/#what-unique-values-are-in-the-array-a3","title":"What unique values are in the array a3?\u00b6","text":"Now you've seen a few different ways to create arrays, as an exercise, try find out what NumPy function you could use to find the unique values are within the a3 array.
You might want to search some like, \"how to find the unqiue values in a numpy array\".
"},{"location":"introduction-to-numpy/#3-viewing-arrays-and-matrices-indexing","title":"3. Viewing arrays and matrices (indexing)\u00b6","text":"Remember, because arrays and matrices are both ndarray's, they can be viewed in similar ways.
Let's check out our 3 arrays again.
"},{"location":"introduction-to-numpy/#4-manipulating-and-comparing-arrays","title":"4. Manipulating and comparing arrays\u00b6","text":" - Arithmetic
+, -, *, /, //, **, %np.exp()np.log()- Dot product -
np.dot() - Broadcasting
- Aggregation
np.sum() - faster than Python's .sum() for NumPy arraysnp.mean()np.std()np.var()np.min()np.max()np.argmin() - find index of minimum valuenp.argmax() - find index of maximum value- These work on all
ndarray's a4.min(axis=0) -- you can use axis as well
- Reshaping
- Transposing
- Comparison operators
><<=>=x != 3x == 3np.sum(x > 3)
"},{"location":"introduction-to-numpy/#arithmetic","title":"Arithmetic\u00b6","text":""},{"location":"introduction-to-numpy/#broadcasting","title":"Broadcasting\u00b6","text":" What is broadcasting?
- Broadcasting is a feature of NumPy which performs an operation across multiple dimensions of data without replicating the data. This saves time and space. For example, if you have a 3x3 array (A) and want to add a 1x3 array (B), NumPy will add the row of (B) to every row of (A).
Rules of Broadcasting
- If the two arrays differ in their number of dimensions, the shape of the one with fewer dimensions is padded with ones on its leading (left) side.
- If the shape of the two arrays does not match in any dimension, the array with shape equal to 1 in that dimension is stretched to match the other shape.
- If in any dimension the sizes disagree and neither is equal to 1, an error is raised.
The broadcasting rule: In order to broadcast, the size of the trailing axes for both arrays in an operation must be either the same size or one of them must be one.
"},{"location":"introduction-to-numpy/#aggregation","title":"Aggregation\u00b6","text":"Aggregation - bringing things together, doing a similar thing on a number of things.
"},{"location":"introduction-to-numpy/#reshaping","title":"Reshaping\u00b6","text":""},{"location":"introduction-to-numpy/#transpose","title":"Transpose\u00b6","text":"A tranpose reverses the order of the axes.
For example, an array with shape (2, 3) becomes (3, 2).
"},{"location":"introduction-to-numpy/#dot-product","title":"Dot product\u00b6","text":"The main two rules for dot product to remember are:
- The inner dimensions must match:
(3, 2) @ (3, 2) won't work(2, 3) @ (3, 2) will work(3, 2) @ (2, 3) will work
- The resulting matrix has the shape of the outer dimensions:
(2, 3) @ (3, 2) -> (2, 2)(3, 2) @ (2, 3) -> (3, 3)
Note: In NumPy, np.dot() and @ can be used to acheive the same result for 1-2 dimension arrays. However, their behaviour begins to differ at arrays with 3+ dimensions.
"},{"location":"introduction-to-numpy/#dot-product-practical-example-nut-butter-sales","title":"Dot product practical example, nut butter sales\u00b6","text":""},{"location":"introduction-to-numpy/#comparison-operators","title":"Comparison operators\u00b6","text":"Finding out if one array is larger, smaller or equal to another.
"},{"location":"introduction-to-numpy/#5-sorting-arrays","title":"5. Sorting arrays\u00b6","text":" np.sort() - sort values in a specified dimension of an array.np.argsort() - return the indices to sort the array on a given axis.np.argmax() - return the index/indicies which gives the highest value(s) along an axis.np.argmin() - return the index/indices which gives the lowest value(s) along an axis.
"},{"location":"introduction-to-numpy/#6-use-case","title":"6. Use case\u00b6","text":"Turning an image into a NumPy array.
Why?
Because computers can use the numbers in the NumPy array to find patterns in the image and in turn use those patterns to figure out what's in the image.
This is what happens in modern computer vision algorithms.
Let's start with this beautiful image of a panda:
"},{"location":"introduction-to-pandas/","title":"Introduction to pandas","text":"View source code | Read notebook in online book format
In\u00a0[1]: Copied! import datetime\nprint(f\"Last updated: {datetime.datetime.now()}\")\n import datetime print(f\"Last updated: {datetime.datetime.now()}\") Last updated: 2024-09-04 16:09:35.139163\n
In\u00a0[2]: Copied! import pandas as pd\n\n# Print the version\nprint(f\"pandas version: {pd.__version__}\")\n import pandas as pd # Print the version print(f\"pandas version: {pd.__version__}\") pandas version: 2.2.2\n
In\u00a0[3]: Copied! # Creating a series of car types\ncars = pd.Series([\"BMW\", \"Toyota\", \"Honda\"])\ncars\n
# Creating a series of car types cars = pd.Series([\"BMW\", \"Toyota\", \"Honda\"]) cars Out[3]: 0 BMW\n1 Toyota\n2 Honda\ndtype: object
In\u00a0[4]: Copied! # Creating a series of colours\ncolours = pd.Series([\"Blue\", \"Red\", \"White\"])\ncolours\n
# Creating a series of colours colours = pd.Series([\"Blue\", \"Red\", \"White\"]) colours Out[4]: 0 Blue\n1 Red\n2 White\ndtype: object
You can create a DataFrame by using pd.DataFrame() and passing it a Python dictionary.
Let's use our two Series as the values.
In\u00a0[5]: Copied! # Creating a DataFrame of cars and colours\ncar_data = pd.DataFrame({\"Car type\": cars, \n \"Colour\": colours})\ncar_data\n # Creating a DataFrame of cars and colours car_data = pd.DataFrame({\"Car type\": cars, \"Colour\": colours}) car_data Out[5]: Car type Colour 0 BMW Blue 1 Toyota Red 2 Honda White You can see the keys of the dictionary became the column headings (text in bold) and the values of the two Series's became the values in the DataFrame.
It's important to note, many different types of data could go into the DataFrame.
Here we've used only text but you could use floats, integers, dates and more.
In\u00a0[6]: Copied! # Your code here\n
# Your code here In\u00a0[7]: Copied! # Example solution\n\n# Make a Series of different foods\nfoods = pd.Series([\"Almond butter\", \"Eggs\", \"Avocado\"])\n\n# Make a Series of different dollar values \nprices = pd.Series([9, 6, 2])\n\n# Combine your Series of foods and dollar values into a DataFrame\nfood_data = pd.DataFrame({\"Foods\": foods,\n \"Price\": prices})\n\nfood_data\n # Example solution # Make a Series of different foods foods = pd.Series([\"Almond butter\", \"Eggs\", \"Avocado\"]) # Make a Series of different dollar values prices = pd.Series([9, 6, 2]) # Combine your Series of foods and dollar values into a DataFrame food_data = pd.DataFrame({\"Foods\": foods, \"Price\": prices}) food_data Out[7]: Foods Price 0 Almond butter 9 1 Eggs 6 2 Avocado 2 In\u00a0[8]: Copied! # Import car sales data\ncar_sales = pd.read_csv(\"../data/car-sales.csv\") # takes a filename as string as input\n\n# Option 2: Read directly from a URL/Google Sheets\n# If you are reading from GitHub, be sure to use the \"raw\" link (original link: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/car-sales.csv)\ncar_sales = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales.csv\")\ncar_sales\n
# Import car sales data car_sales = pd.read_csv(\"../data/car-sales.csv\") # takes a filename as string as input # Option 2: Read directly from a URL/Google Sheets # If you are reading from GitHub, be sure to use the \"raw\" link (original link: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/car-sales.csv) car_sales = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales.csv\") car_sales Out[8]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 $4,000.00 1 Honda Red 87899 4 $5,000.00 2 Toyota Blue 32549 3 $7,000.00 3 BMW Black 11179 5 $22,000.00 4 Nissan White 213095 4 $3,500.00 5 Toyota Green 99213 4 $4,500.00 6 Honda Blue 45698 4 $7,500.00 7 Honda Blue 54738 4 $7,000.00 8 Toyota White 60000 4 $6,250.00 9 Nissan White 31600 4 $9,700.00 Now we've got the same data from the spreadsheet available in a pandas DataFrame called car_sales.
Having your data available in a DataFrame allows you to take advantage of all of pandas functionality on it.
Another common practice you'll see is data being imported to DataFrame called df (short for DataFrame).
In\u00a0[9]: Copied! # Import the car sales data and save it to df\n\n# Option 1: Read from a CSV file (stored on our local computer)\ndf = pd.read_csv(\"../data/car-sales.csv\")\n\n# Option 2: Read directly from a URL/Google Sheets (if the file is hosted online)\ndf = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales.csv\")\ndf\n
# Import the car sales data and save it to df # Option 1: Read from a CSV file (stored on our local computer) df = pd.read_csv(\"../data/car-sales.csv\") # Option 2: Read directly from a URL/Google Sheets (if the file is hosted online) df = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales.csv\") df Out[9]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 $4,000.00 1 Honda Red 87899 4 $5,000.00 2 Toyota Blue 32549 3 $7,000.00 3 BMW Black 11179 5 $22,000.00 4 Nissan White 213095 4 $3,500.00 5 Toyota Green 99213 4 $4,500.00 6 Honda Blue 45698 4 $7,500.00 7 Honda Blue 54738 4 $7,000.00 8 Toyota White 60000 4 $6,250.00 9 Nissan White 31600 4 $9,700.00 Now car_sales and df contain the exact same information, the only difference is the name. Like any other variable, you can name your DataFrame's whatever you want. But best to choose something simple.
In\u00a0[10]: Copied! # Export the car sales DataFrame to csv\ncar_sales.to_csv(\"../data/exported-car-sales.csv\")\n
# Export the car sales DataFrame to csv car_sales.to_csv(\"../data/exported-car-sales.csv\") Running this will save a file called export-car-sales.csv to the current folder.
In\u00a0[11]: Copied! # Your code here\n
# Your code here In\u00a0[12]: Copied! # Importing heart-disease.csv\npatient_data = pd.read_csv(\"../data/heart-disease.csv\")\npatient_data\n
# Importing heart-disease.csv patient_data = pd.read_csv(\"../data/heart-disease.csv\") patient_data Out[12]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 298 57 0 0 140 241 0 1 123 1 0.2 1 0 3 0 299 45 1 3 110 264 0 1 132 0 1.2 1 0 3 0 300 68 1 0 144 193 1 1 141 0 3.4 1 2 3 0 301 57 1 0 130 131 0 1 115 1 1.2 1 1 3 0 302 57 0 1 130 236 0 0 174 0 0.0 1 1 2 0 303 rows \u00d7 14 columns
In\u00a0[13]: Copied! # Exporting the patient_data DataFrame to csv\npatient_data.to_csv(\"../data/exported-patient-data.csv\")\n
# Exporting the patient_data DataFrame to csv patient_data.to_csv(\"../data/exported-patient-data.csv\") In\u00a0[14]: Copied! car_sales\n
car_sales Out[14]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 $4,000.00 1 Honda Red 87899 4 $5,000.00 2 Toyota Blue 32549 3 $7,000.00 3 BMW Black 11179 5 $22,000.00 4 Nissan White 213095 4 $3,500.00 5 Toyota Green 99213 4 $4,500.00 6 Honda Blue 45698 4 $7,500.00 7 Honda Blue 54738 4 $7,000.00 8 Toyota White 60000 4 $6,250.00 9 Nissan White 31600 4 $9,700.00 .dtypes shows us what datatype each column contains.
In\u00a0[15]: Copied! car_sales.dtypes\n
car_sales.dtypes Out[15]: Make object\nColour object\nOdometer (KM) int64\nDoors int64\nPrice object\ndtype: object
Notice how the Price column isn't an integer like Odometer or Doors. Don't worry, pandas makes this easy to fix.
.describe() gives you a quick statistical overview of the numerical columns.
In\u00a0[16]: Copied! car_sales.describe()\n
car_sales.describe() Out[16]: Odometer (KM) Doors count 10.000000 10.000000 mean 78601.400000 4.000000 std 61983.471735 0.471405 min 11179.000000 3.000000 25% 35836.250000 4.000000 50% 57369.000000 4.000000 75% 96384.500000 4.000000 max 213095.000000 5.000000 .info() shows a handful of useful information about a DataFrame such as:
- How many entries (rows) there are
- Whether there are missing values (if a columns non-null value is less than the number of entries, it has missing values)
- The datatypes of each column
In\u00a0[17]: Copied! car_sales.info()\n
car_sales.info() <class 'pandas.core.frame.DataFrame'>\nRangeIndex: 10 entries, 0 to 9\nData columns (total 5 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Make 10 non-null object\n 1 Colour 10 non-null object\n 2 Odometer (KM) 10 non-null int64 \n 3 Doors 10 non-null int64 \n 4 Price 10 non-null object\ndtypes: int64(2), object(3)\nmemory usage: 532.0+ bytes\n
You can also call various statistical and mathematical methods such as .mean() or .sum() directly on a DataFrame or Series.
In\u00a0[18]: Copied! # Calling .mean() on a DataFrame\ncar_sales.mean(numeric_only=True) # numeric_only = get mean values of numeric columnns only\n
# Calling .mean() on a DataFrame car_sales.mean(numeric_only=True) # numeric_only = get mean values of numeric columnns only Out[18]: Odometer (KM) 78601.4\nDoors 4.0\ndtype: float64
In\u00a0[19]: Copied! # Calling .mean() on a Series\ncar_prices = pd.Series([3000, 3500, 11250])\ncar_prices.mean()\n
# Calling .mean() on a Series car_prices = pd.Series([3000, 3500, 11250]) car_prices.mean() Out[19]: np.float64(5916.666666666667)
In\u00a0[20]: Copied! # Calling .sum() on a DataFrame with numeric_only=False (default)\ncar_sales.sum(numeric_only=False)\n
# Calling .sum() on a DataFrame with numeric_only=False (default) car_sales.sum(numeric_only=False) Out[20]: Make ToyotaHondaToyotaBMWNissanToyotaHondaHondaToyo...\nColour WhiteRedBlueBlackWhiteGreenBlueBlueWhiteWhite\nOdometer (KM) 786014\nDoors 40\nPrice $4,000.00$5,000.00$7,000.00$22,000.00$3,500.00...\ndtype: object
In\u00a0[21]: Copied! # Calling .sum() on a DataFrame with numeric_only=True\ncar_sales.sum(numeric_only=True)\n
# Calling .sum() on a DataFrame with numeric_only=True car_sales.sum(numeric_only=True) Out[21]: Odometer (KM) 786014\nDoors 40\ndtype: int64
In\u00a0[22]: Copied! # Calling .sum() on a Series\ncar_prices.sum()\n
# Calling .sum() on a Series car_prices.sum() Out[22]: np.int64(17750)
Calling these on a whole DataFrame may not be as helpful as targeting an individual column. But it's helpful to know they're there.
.columns will show you all the columns of a DataFrame.
In\u00a0[23]: Copied! car_sales.columns\n
car_sales.columns Out[23]: Index(['Make', 'Colour', 'Odometer (KM)', 'Doors', 'Price'], dtype='object')
You can save them to a list which you could use later.
In\u00a0[24]: Copied! # Save car_sales columns to a list \ncar_columns = car_sales.columns\ncar_columns[0]\n
# Save car_sales columns to a list car_columns = car_sales.columns car_columns[0] Out[24]: 'Make'
.index will show you the values in a DataFrame's index (the column on the far left).
In\u00a0[25]: Copied! car_sales.index\n
car_sales.index Out[25]: RangeIndex(start=0, stop=10, step=1)
pandas DataFrame's, like Python lists, are 0-indexed (unless otherwise changed). This means they start at 0.
In\u00a0[26]: Copied! # Show the length of a DataFrame\nlen(car_sales)\n
# Show the length of a DataFrame len(car_sales) Out[26]: 10
So even though the length of our car_sales dataframe is 10, this means the indexes go from 0-9.
In\u00a0[27]: Copied! # Show the first 5 rows of car_sales\ncar_sales.head()\n
# Show the first 5 rows of car_sales car_sales.head() Out[27]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 $4,000.00 1 Honda Red 87899 4 $5,000.00 2 Toyota Blue 32549 3 $7,000.00 3 BMW Black 11179 5 $22,000.00 4 Nissan White 213095 4 $3,500.00 Why 5 rows? Good question. I don't know the answer. But 5 seems like a good amount.
Want more than 5?
No worries, you can pass .head() an integer to display more than or less than 5 rows.
In\u00a0[28]: Copied! # Show the first 7 rows of car_sales\ncar_sales.head(7)\n
# Show the first 7 rows of car_sales car_sales.head(7) Out[28]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 $4,000.00 1 Honda Red 87899 4 $5,000.00 2 Toyota Blue 32549 3 $7,000.00 3 BMW Black 11179 5 $22,000.00 4 Nissan White 213095 4 $3,500.00 5 Toyota Green 99213 4 $4,500.00 6 Honda Blue 45698 4 $7,500.00 .tail() allows you to see the bottom 5 rows of your DataFrame. This is helpful if your changes are influencing the bottom rows of your data.
In\u00a0[29]: Copied! # Show bottom 5 rows of car_sales\ncar_sales.tail()\n
# Show bottom 5 rows of car_sales car_sales.tail() Out[29]: Make Colour Odometer (KM) Doors Price 5 Toyota Green 99213 4 $4,500.00 6 Honda Blue 45698 4 $7,500.00 7 Honda Blue 54738 4 $7,000.00 8 Toyota White 60000 4 $6,250.00 9 Nissan White 31600 4 $9,700.00 You can use .loc[] and .iloc[] to select data from your Series and DataFrame's.
Let's see.
In\u00a0[30]: Copied! # Create a sample series\nanimals = pd.Series([\"cat\", \"dog\", \"bird\", \"snake\", \"ox\", \"lion\"], \n index=[0, 3, 9, 8, 67, 3])\nanimals\n
# Create a sample series animals = pd.Series([\"cat\", \"dog\", \"bird\", \"snake\", \"ox\", \"lion\"], index=[0, 3, 9, 8, 67, 3]) animals Out[30]: 0 cat\n3 dog\n9 bird\n8 snake\n67 ox\n3 lion\ndtype: object
.loc[] takes an integer or label as input. And it chooses from your Series or DataFrame whichever index matches the number.
In\u00a0[31]: Copied! # Select all indexes with 3\nanimals.loc[3]\n
# Select all indexes with 3 animals.loc[3] Out[31]: 3 dog\n3 lion\ndtype: object
In\u00a0[32]: Copied! # Select index 9\nanimals.loc[9]\n
# Select index 9 animals.loc[9] Out[32]: 'bird'
Let's try with our car_sales DataFrame.
In\u00a0[33]: Copied! car_sales\n
car_sales Out[33]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 $4,000.00 1 Honda Red 87899 4 $5,000.00 2 Toyota Blue 32549 3 $7,000.00 3 BMW Black 11179 5 $22,000.00 4 Nissan White 213095 4 $3,500.00 5 Toyota Green 99213 4 $4,500.00 6 Honda Blue 45698 4 $7,500.00 7 Honda Blue 54738 4 $7,000.00 8 Toyota White 60000 4 $6,250.00 9 Nissan White 31600 4 $9,700.00 In\u00a0[34]: Copied! # Select row at index 3\ncar_sales.loc[3]\n
# Select row at index 3 car_sales.loc[3] Out[34]: Make BMW\nColour Black\nOdometer (KM) 11179\nDoors 5\nPrice $22,000.00\nName: 3, dtype: object
iloc[] does a similar thing but works with exact positions.
In\u00a0[35]: Copied! animals\n
animals Out[35]: 0 cat\n3 dog\n9 bird\n8 snake\n67 ox\n3 lion\ndtype: object
In\u00a0[36]: Copied! # Select row at position 3\nanimals.iloc[3]\n
# Select row at position 3 animals.iloc[3] Out[36]: 'snake'
Even though 'snake' appears at index 8 in the series, it's shown using .iloc[3] because it's at the 3rd (starting from 0) position.
Let's try with the car_sales DataFrame.
In\u00a0[37]: Copied! # Select row at position 3\ncar_sales.iloc[3]\n
# Select row at position 3 car_sales.iloc[3] Out[37]: Make BMW\nColour Black\nOdometer (KM) 11179\nDoors 5\nPrice $22,000.00\nName: 3, dtype: object
You can see it's the same as .loc[] because the index is in order, position 3 is the same as index 3.
You can also use slicing with .loc[] and .iloc[].
In\u00a0[38]: Copied! # Get all rows up to position 3\nanimals.iloc[:3]\n
# Get all rows up to position 3 animals.iloc[:3] Out[38]: 0 cat\n3 dog\n9 bird\ndtype: object
In\u00a0[39]: Copied! # Get all rows up to (and including) index 3\ncar_sales.loc[:3]\n
# Get all rows up to (and including) index 3 car_sales.loc[:3] Out[39]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 $4,000.00 1 Honda Red 87899 4 $5,000.00 2 Toyota Blue 32549 3 $7,000.00 3 BMW Black 11179 5 $22,000.00 In\u00a0[40]: Copied! # Get all rows of the \"Colour\" column\ncar_sales.loc[:, \"Colour\"] # note: \":\" stands for \"all\", e.g. \"all indices in the first axis\"\n
# Get all rows of the \"Colour\" column car_sales.loc[:, \"Colour\"] # note: \":\" stands for \"all\", e.g. \"all indices in the first axis\" Out[40]: 0 White\n1 Red\n2 Blue\n3 Black\n4 White\n5 Green\n6 Blue\n7 Blue\n8 White\n9 White\nName: Colour, dtype: object
When should you use .loc[] or .iloc[]?
- Use
.loc[] when you're selecting rows and columns based on their lables or a condition (e.g. retrieving data for specific columns). - Use
.iloc[] when you're selecting rows and columns based on their integer index positions (e.g. extracting the first ten rows regardless of the labels).
However, in saying this, it will often take a bit of practice with each of the methods before you figure out which you'd like to use.
If you want to select a particular column, you can use DataFrame.['COLUMN_NAME'].
In\u00a0[41]: Copied! # Select Make column\ncar_sales['Make']\n
# Select Make column car_sales['Make'] Out[41]: 0 Toyota\n1 Honda\n2 Toyota\n3 BMW\n4 Nissan\n5 Toyota\n6 Honda\n7 Honda\n8 Toyota\n9 Nissan\nName: Make, dtype: object
In\u00a0[42]: Copied! # Select Colour column\ncar_sales['Colour']\n
# Select Colour column car_sales['Colour'] Out[42]: 0 White\n1 Red\n2 Blue\n3 Black\n4 White\n5 Green\n6 Blue\n7 Blue\n8 White\n9 White\nName: Colour, dtype: object
Boolean indexing works with column selection too. Using it will select the rows which fulfill the condition in the brackets.
In\u00a0[43]: Copied! # Select cars with over 100,000 on the Odometer\ncar_sales[car_sales[\"Odometer (KM)\"] > 100000]\n
# Select cars with over 100,000 on the Odometer car_sales[car_sales[\"Odometer (KM)\"] > 100000] Out[43]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 $4,000.00 4 Nissan White 213095 4 $3,500.00 In\u00a0[44]: Copied! # Select cars which are made by Toyota\ncar_sales[car_sales[\"Make\"] == \"Toyota\"]\n
# Select cars which are made by Toyota car_sales[car_sales[\"Make\"] == \"Toyota\"] Out[44]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 $4,000.00 2 Toyota Blue 32549 3 $7,000.00 5 Toyota Green 99213 4 $4,500.00 8 Toyota White 60000 4 $6,250.00 pd.crosstab() is a great way to view two different columns together and compare them.
In\u00a0[45]: Copied! # Compare car Make with number of Doors\npd.crosstab(car_sales[\"Make\"], car_sales[\"Doors\"])\n
# Compare car Make with number of Doors pd.crosstab(car_sales[\"Make\"], car_sales[\"Doors\"]) Out[45]: Doors 3 4 5 Make BMW 0 0 1 Honda 0 3 0 Nissan 0 2 0 Toyota 1 3 0 If you want to compare more columns in the context of another column, you can use .groupby().
In\u00a0[46]: Copied! car_sales\n
car_sales Out[46]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 $4,000.00 1 Honda Red 87899 4 $5,000.00 2 Toyota Blue 32549 3 $7,000.00 3 BMW Black 11179 5 $22,000.00 4 Nissan White 213095 4 $3,500.00 5 Toyota Green 99213 4 $4,500.00 6 Honda Blue 45698 4 $7,500.00 7 Honda Blue 54738 4 $7,000.00 8 Toyota White 60000 4 $6,250.00 9 Nissan White 31600 4 $9,700.00 In\u00a0[47]: Copied! # Group by the Make column and find the mean of the other columns \ncar_sales.groupby([\"Make\"]).mean(numeric_only=True)\n
# Group by the Make column and find the mean of the other columns car_sales.groupby([\"Make\"]).mean(numeric_only=True) Out[47]: Odometer (KM) Doors Make BMW 11179.000000 5.00 Honda 62778.333333 4.00 Nissan 122347.500000 4.00 Toyota 85451.250000 3.75 pandas even allows for quick plotting of columns so you can see your data visualling. To plot, you'll have to import matplotlib. If your plots aren't showing, try running the two lines of code below.
%matplotlib inline is a special command which tells Jupyter to show your plots. Commands with % at the front are called magic commands.
In\u00a0[52]: Copied! # Import matplotlib and tell Jupyter to show plots\nimport matplotlib.pyplot as plt\n%matplotlib inline\n
# Import matplotlib and tell Jupyter to show plots import matplotlib.pyplot as plt %matplotlib inline You can visualize a column by calling .plot() on it.
In\u00a0[53]: Copied! car_sales[\"Odometer (KM)\"].plot(); # tip: the \";\" on the end prevents matplotlib from outputing the plot class\n
car_sales[\"Odometer (KM)\"].plot(); # tip: the \";\" on the end prevents matplotlib from outputing the plot class Or compare two columns by passing them as x and y to plot().
In\u00a0[54]: Copied! car_sales.plot(x=\"Make\", y=\"Odometer (KM)\");\n
car_sales.plot(x=\"Make\", y=\"Odometer (KM)\"); You can see the distribution of a column by calling .hist() on you.
The distribution of something is a way of describing the spread of different values.
In\u00a0[55]: Copied! car_sales[\"Odometer (KM)\"].hist()\n
car_sales[\"Odometer (KM)\"].hist() Out[55]: <Axes: >
In this case, the majority of the distribution (spread) of the \"Odometer (KM)\" column is more towards the left of the graph. And there are two values which are more to the right. These two values to the right could be considered outliers (not part of the majority).
Now what if we wanted to plot our \"Price\" column?
Let's try.
In\u00a0[56]: Copied! car_sales[\"Price\"].plot()\n
car_sales[\"Price\"].plot() \n---------------------------------------------------------------------------\nTypeError Traceback (most recent call last)\nCell In[56], line 1\n----> 1 car_sales[\"Price\"].plot()\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/plotting/_core.py:1030, in PlotAccessor.__call__(self, *args, **kwargs)\n 1027 label_name = label_kw or data.columns\n 1028 data.columns = label_name\n-> 1030 return plot_backend.plot(data, kind=kind, **kwargs)\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/plotting/_matplotlib/__init__.py:71, in plot(data, kind, **kwargs)\n 69 kwargs[\"ax\"] = getattr(ax, \"left_ax\", ax)\n 70 plot_obj = PLOT_CLASSES[kind](data, **kwargs)\n---> 71 plot_obj.generate()\n 72 plot_obj.draw()\n 73 return plot_obj.result\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/plotting/_matplotlib/core.py:499, in MPLPlot.generate(self)\n 497 @final\n 498 def generate(self) -> None:\n--> 499 self._compute_plot_data()\n 500 fig = self.fig\n 501 self._make_plot(fig)\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/plotting/_matplotlib/core.py:698, in MPLPlot._compute_plot_data(self)\n 696 # no non-numeric frames or series allowed\n 697 if is_empty:\n--> 698 raise TypeError(\"no numeric data to plot\")\n 700 self.data = numeric_data.apply(type(self)._convert_to_ndarray)\n\nTypeError: no numeric data to plot
Trying to run it leaves us with an error. This is because the \"Price\" column of car_sales isn't in numeric form. We can tell this because of the TypeError: no numeric data to plot at the bottom of the cell.
We can check this with .info().
In\u00a0[57]: Copied! car_sales.info()\n
car_sales.info() <class 'pandas.core.frame.DataFrame'>\nRangeIndex: 10 entries, 0 to 9\nData columns (total 5 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Make 10 non-null object\n 1 Colour 10 non-null object\n 2 Odometer (KM) 10 non-null int64 \n 3 Doors 10 non-null int64 \n 4 Price 10 non-null object\ndtypes: int64(2), object(3)\nmemory usage: 532.0+ bytes\n
So what can we do?
We need to convert the \"Price\" column to a numeric type.
How?
We could try a few different things on our own. But let's practice researching.
1. Open up a search engine and type in something like \"how to convert a pandas column price to integer\".
In the first result, I found this Stack Overflow question and answer . Where someone has had the same problem as us and someone else has provided an answer.
Note: Sometimes the answer you're looking for won't be in the first result, or the 2nd or the 3rd. You may have to combine a few different solutions. Or, if possible, you can try and ask ChatGPT to help you out.
2. In practice, you'd read through this and see if it relates to your problem.
3. If it does, you can adjust the code from what's given in the Stack Overflow answer(s) to your own problem.
4. If you're still stuck, you can try and converse with ChatGPT to help you with your problem (as long as the data/problem you're working on is okay to share - never share private data with anyone on the internet, including AI chatbots).
What's important in the beginning is not to remember every single detail off by heart but to know where to look. Remember, if in doubt, write code, run it, see what happens.
Let's copy the answer code here and see how it relates to our problem.
Answer code: dataframe['amount'] = dataframe['amount'].str.replace('[\\$\\,\\.]', '').astype(int)
There's a lot going on here but what we can do is change the parts which aren't in our problem and keep the rest the same.
Our DataFrame is called car_sales not dataframe.
car_sales['amount'] = car_sales['amount'].str.replace('[\\$\\,\\.]', '').astype(int)
And our 'amount' column is called \"Price\".
car_sales[\"Price\"] = car_sales[\"Price\"].str.replace('[\\$\\,\\.]', '').astype(int)
That looks better. What the code on the right of car_sales[\"Price\"] is saying is \"remove the $ sign and comma and change the type of the cell to int\".
Let's see what happens.
In\u00a0[58]: Copied! # Change Price column to integers\ncar_sales[\"Price\"] = car_sales[\"Price\"].str.replace('[\\$\\,\\.]', '', regex=True)\ncar_sales\n # Change Price column to integers car_sales[\"Price\"] = car_sales[\"Price\"].str.replace('[\\$\\,\\.]', '', regex=True) car_sales Out[58]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 400000 1 Honda Red 87899 4 500000 2 Toyota Blue 32549 3 700000 3 BMW Black 11179 5 2200000 4 Nissan White 213095 4 350000 5 Toyota Green 99213 4 450000 6 Honda Blue 45698 4 750000 7 Honda Blue 54738 4 700000 8 Toyota White 60000 4 625000 9 Nissan White 31600 4 970000 Cool! but there are extra zeros in the Price column.
Let's remove it.
In\u00a0[59]: Copied! # Remove 2 extra zeros from the price column (2200000 -> 22000) by indexing all but the last two digits\ncar_sales[\"Price\"] = car_sales[\"Price\"].str[:-2].astype(int)\ncar_sales\n
# Remove 2 extra zeros from the price column (2200000 -> 22000) by indexing all but the last two digits car_sales[\"Price\"] = car_sales[\"Price\"].str[:-2].astype(int) car_sales Out[59]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 4000 1 Honda Red 87899 4 5000 2 Toyota Blue 32549 3 7000 3 BMW Black 11179 5 22000 4 Nissan White 213095 4 3500 5 Toyota Green 99213 4 4500 6 Honda Blue 45698 4 7500 7 Honda Blue 54738 4 7000 8 Toyota White 60000 4 6250 9 Nissan White 31600 4 9700 In\u00a0[60]: Copied! car_sales.dtypes\n
car_sales.dtypes Out[60]: Make object\nColour object\nOdometer (KM) int64\nDoors int64\nPrice int64\ndtype: object
Beautiful! Now let's try to plot it agian.
In\u00a0[61]: Copied! car_sales[\"Price\"].plot();\n
car_sales[\"Price\"].plot(); This is one of the many ways you can manipulate data using pandas.
When you see a number of different functions in a row, it's referred to as chaining. This means you add together a series of functions all to do one overall task.
Let's see a few more ways of manipulating data.
In\u00a0[62]: Copied! # Lower the Make column\ncar_sales[\"Make\"].str.lower()\n
# Lower the Make column car_sales[\"Make\"].str.lower() Out[62]: 0 toyota\n1 honda\n2 toyota\n3 bmw\n4 nissan\n5 toyota\n6 honda\n7 honda\n8 toyota\n9 nissan\nName: Make, dtype: object
Notice how it doesn't change the values of the original car_sales DataFrame unless we set it equal to.
In\u00a0[63]: Copied! # View top 5 rows, Make column not lowered\ncar_sales.head()\n
# View top 5 rows, Make column not lowered car_sales.head() Out[63]: Make Colour Odometer (KM) Doors Price 0 Toyota White 150043 4 4000 1 Honda Red 87899 4 5000 2 Toyota Blue 32549 3 7000 3 BMW Black 11179 5 22000 4 Nissan White 213095 4 3500 In\u00a0[64]: Copied! # Set Make column to be lowered\ncar_sales[\"Make\"] = car_sales[\"Make\"].str.lower()\ncar_sales.head()\n
# Set Make column to be lowered car_sales[\"Make\"] = car_sales[\"Make\"].str.lower() car_sales.head() Out[64]: Make Colour Odometer (KM) Doors Price 0 toyota White 150043 4 4000 1 honda Red 87899 4 5000 2 toyota Blue 32549 3 7000 3 bmw Black 11179 5 22000 4 nissan White 213095 4 3500 Reassigning the column changes it in the original DataFrame. This trend occurs throughout all kinds of data manipulation with pandas.
Some functions have a parameter called inplace which means a DataFrame is updated in place without having to reassign it.
Let's see what it looks like in combination with .fillna(), a function which fills missing data. But the thing is, our table isn't missing any data.
In practice, it's likely you'll work with datasets which aren't complete. What this means is you'll have to decide whether how to fill the missing data or remove the rows which have data missing.
Let's check out what a version of our car_sales DataFrame might look like with missing values.
In\u00a0[65]: Copied! # Option 1: Import car sales data with missing values from local file (stored on our computer)\ncar_sales_missing = pd.read_csv(\"../data/car-sales-missing-data.csv\")\n\n# Option 2: Import car sales data with missing values from GitHub (if the file is hosted online)\ncar_sales_missing = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales-missing-data.csv\")\ncar_sales_missing\n
# Option 1: Import car sales data with missing values from local file (stored on our computer) car_sales_missing = pd.read_csv(\"../data/car-sales-missing-data.csv\") # Option 2: Import car sales data with missing values from GitHub (if the file is hosted online) car_sales_missing = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales-missing-data.csv\") car_sales_missing Out[65]: Make Colour Odometer Doors Price 0 Toyota White 150043.0 4.0 $4,000 1 Honda Red 87899.0 4.0 $5,000 2 Toyota Blue NaN 3.0 $7,000 3 BMW Black 11179.0 5.0 $22,000 4 Nissan White 213095.0 4.0 $3,500 5 Toyota Green NaN 4.0 $4,500 6 Honda NaN NaN 4.0 $7,500 7 Honda Blue NaN 4.0 NaN 8 Toyota White 60000.0 NaN NaN 9 NaN White 31600.0 4.0 $9,700 Missing values are shown by NaN in pandas. This can be considered the equivalent of None in Python.
Let's use the .fillna() function to fill the Odometer column with the average of the other values in the same column.
In\u00a0[66]: Copied! # Fill Odometer column missing values with mean\ncar_sales_missing[\"Odometer\"].fillna(car_sales_missing[\"Odometer\"].mean(), \n inplace=False) # inplace is set to False by default\n
# Fill Odometer column missing values with mean car_sales_missing[\"Odometer\"].fillna(car_sales_missing[\"Odometer\"].mean(), inplace=False) # inplace is set to False by default Out[66]: 0 150043.000000\n1 87899.000000\n2 92302.666667\n3 11179.000000\n4 213095.000000\n5 92302.666667\n6 92302.666667\n7 92302.666667\n8 60000.000000\n9 31600.000000\nName: Odometer, dtype: float64
Now let's check the original car_sales_missing DataFrame.
In\u00a0[67]: Copied! car_sales_missing\n
car_sales_missing Out[67]: Make Colour Odometer Doors Price 0 Toyota White 150043.0 4.0 $4,000 1 Honda Red 87899.0 4.0 $5,000 2 Toyota Blue NaN 3.0 $7,000 3 BMW Black 11179.0 5.0 $22,000 4 Nissan White 213095.0 4.0 $3,500 5 Toyota Green NaN 4.0 $4,500 6 Honda NaN NaN 4.0 $7,500 7 Honda Blue NaN 4.0 NaN 8 Toyota White 60000.0 NaN NaN 9 NaN White 31600.0 4.0 $9,700 Because inplace is set to False (default), there's still missing values in the \"Odometer\" column.
Instead of using inplace, let's resassign the column to the filled version.
We'll use the syntax df[col] = df[col].fillna(value) to fill the missing values in the \"Odometer\" column with the average of the other values in the same column.
In\u00a0[68]: Copied! # Fill the Odometer missing values to the mean with inplace=True\ncar_sales_missing[\"Odometer\"] = car_sales_missing[\"Odometer\"].fillna(car_sales_missing[\"Odometer\"].mean())\n
# Fill the Odometer missing values to the mean with inplace=True car_sales_missing[\"Odometer\"] = car_sales_missing[\"Odometer\"].fillna(car_sales_missing[\"Odometer\"].mean()) Now let's check the car_sales_missing DataFrame again.
In\u00a0[69]: Copied! car_sales_missing\n
car_sales_missing Out[69]: Make Colour Odometer Doors Price 0 Toyota White 150043.000000 4.0 $4,000 1 Honda Red 87899.000000 4.0 $5,000 2 Toyota Blue 92302.666667 3.0 $7,000 3 BMW Black 11179.000000 5.0 $22,000 4 Nissan White 213095.000000 4.0 $3,500 5 Toyota Green 92302.666667 4.0 $4,500 6 Honda NaN 92302.666667 4.0 $7,500 7 Honda Blue 92302.666667 4.0 NaN 8 Toyota White 60000.000000 NaN NaN 9 NaN White 31600.000000 4.0 $9,700 The missing values in the Odometer column have been filled with the mean value of the same column.
In practice, you might not want to fill a column's missing values with the mean, but this example was to show the difference between inplace=False (default) and inplace=True.
Whichever you choose to use will depend on how you structure your code.
All you have to remember is inplace=False returns a copy of the DataFrame you're working with.
This is helpful if you want to make a duplicate of your current DataFrame and save it to another variable.
Where as, inplace=True makes all the changes directly to the target DataFrame.
We've filled some values but there's still missing values in car_sales_missing. Let's say you wanted to remove any rows which had missing data and only work with rows which had complete coverage.
You can do this using .dropna().
In\u00a0[70]: Copied! # Remove missing data\ncar_sales_missing.dropna()\n
# Remove missing data car_sales_missing.dropna() Out[70]: Make Colour Odometer Doors Price 0 Toyota White 150043.000000 4.0 $4,000 1 Honda Red 87899.000000 4.0 $5,000 2 Toyota Blue 92302.666667 3.0 $7,000 3 BMW Black 11179.000000 5.0 $22,000 4 Nissan White 213095.000000 4.0 $3,500 5 Toyota Green 92302.666667 4.0 $4,500 It appears the rows with missing values have been removed, now let's check to make sure.
In\u00a0[71]: Copied! car_sales_missing\n
car_sales_missing Out[71]: Make Colour Odometer Doors Price 0 Toyota White 150043.000000 4.0 $4,000 1 Honda Red 87899.000000 4.0 $5,000 2 Toyota Blue 92302.666667 3.0 $7,000 3 BMW Black 11179.000000 5.0 $22,000 4 Nissan White 213095.000000 4.0 $3,500 5 Toyota Green 92302.666667 4.0 $4,500 6 Honda NaN 92302.666667 4.0 $7,500 7 Honda Blue 92302.666667 4.0 NaN 8 Toyota White 60000.000000 NaN NaN 9 NaN White 31600.000000 4.0 $9,700 Hmm, they're still there, can you guess why?
It's because .dropna() has inplace=False as default. We can either set inplace=True or reassign the car_sales_missing DataFrame.
In\u00a0[72]: Copied! # The following two lines do the same thing\ncar_sales_missing.dropna(inplace=True) # Operation happens inplace without reassignment\ncar_sales_missing = car_sales_missing.dropna() # car_sales_missing gets reassigned to same DataFrame but with dropped values\n
# The following two lines do the same thing car_sales_missing.dropna(inplace=True) # Operation happens inplace without reassignment car_sales_missing = car_sales_missing.dropna() # car_sales_missing gets reassigned to same DataFrame but with dropped values Now if check again, the rows with missing values are gone and the index numbers have been updated.
In\u00a0[73]: Copied! car_sales_missing\n
car_sales_missing Out[73]: Make Colour Odometer Doors Price 0 Toyota White 150043.000000 4.0 $4,000 1 Honda Red 87899.000000 4.0 $5,000 2 Toyota Blue 92302.666667 3.0 $7,000 3 BMW Black 11179.000000 5.0 $22,000 4 Nissan White 213095.000000 4.0 $3,500 5 Toyota Green 92302.666667 4.0 $4,500 Instead of removing or filling data, what if you wanted to create it?
For example, creating a column called Seats for number of seats.
pandas allows for simple extra column creation on DataFrame's.
Three common ways are:
- Adding a
pandas.Series as a column. - Adding a Python list as a column.
- By using existing columns to create a new column.
In\u00a0[74]: Copied! # Create a column from a pandas Series\nseats_column = pd.Series([5, 5, 5, 5, 5, 5, 5, 5, 5, 5])\ncar_sales[\"Seats\"] = seats_column\ncar_sales\n
# Create a column from a pandas Series seats_column = pd.Series([5, 5, 5, 5, 5, 5, 5, 5, 5, 5]) car_sales[\"Seats\"] = seats_column car_sales Out[74]: Make Colour Odometer (KM) Doors Price Seats 0 toyota White 150043 4 4000 5 1 honda Red 87899 4 5000 5 2 toyota Blue 32549 3 7000 5 3 bmw Black 11179 5 22000 5 4 nissan White 213095 4 3500 5 5 toyota Green 99213 4 4500 5 6 honda Blue 45698 4 7500 5 7 honda Blue 54738 4 7000 5 8 toyota White 60000 4 6250 5 9 nissan White 31600 4 9700 5 Creating a column is similar to selecting a column, you pass the target DataFrame along with a new column name in brackets.
In\u00a0[75]: Copied! # Create a column from a Python list\nengine_sizes = [1.3, 2.0, 3.0, 4.2, 1.6, 1, 2.0, 2.3, 2.0, 3.0]\ncar_sales[\"Engine Size\"] = engine_sizes\ncar_sales\n
# Create a column from a Python list engine_sizes = [1.3, 2.0, 3.0, 4.2, 1.6, 1, 2.0, 2.3, 2.0, 3.0] car_sales[\"Engine Size\"] = engine_sizes car_sales Out[75]: Make Colour Odometer (KM) Doors Price Seats Engine Size 0 toyota White 150043 4 4000 5 1.3 1 honda Red 87899 4 5000 5 2.0 2 toyota Blue 32549 3 7000 5 3.0 3 bmw Black 11179 5 22000 5 4.2 4 nissan White 213095 4 3500 5 1.6 5 toyota Green 99213 4 4500 5 1.0 6 honda Blue 45698 4 7500 5 2.0 7 honda Blue 54738 4 7000 5 2.3 8 toyota White 60000 4 6250 5 2.0 9 nissan White 31600 4 9700 5 3.0 You can also make a column by directly combining the values of other columns. Such as, price per kilometre on the Odometer.
In\u00a0[76]: Copied! # Column from other columns\ncar_sales[\"Price per KM\"] = car_sales[\"Price\"] / car_sales[\"Odometer (KM)\"]\ncar_sales\n
# Column from other columns car_sales[\"Price per KM\"] = car_sales[\"Price\"] / car_sales[\"Odometer (KM)\"] car_sales Out[76]: Make Colour Odometer (KM) Doors Price Seats Engine Size Price per KM 0 toyota White 150043 4 4000 5 1.3 0.026659 1 honda Red 87899 4 5000 5 2.0 0.056883 2 toyota Blue 32549 3 7000 5 3.0 0.215060 3 bmw Black 11179 5 22000 5 4.2 1.967976 4 nissan White 213095 4 3500 5 1.6 0.016425 5 toyota Green 99213 4 4500 5 1.0 0.045357 6 honda Blue 45698 4 7500 5 2.0 0.164121 7 honda Blue 54738 4 7000 5 2.3 0.127882 8 toyota White 60000 4 6250 5 2.0 0.104167 9 nissan White 31600 4 9700 5 3.0 0.306962 Now can you think why this might not be a great column to add?
It could be confusing when a car with less kilometers on the odometer looks to cost more per kilometre than one with more.
When buying a car, usually less kilometres on the odometer is better.
This kind of column creation is called feature engineering, the practice of enriching your dataset with more information (either from it directly or elsewhere).
If Make, Colour, Doors are features of the data, creating Price per KM could be another. But in this case, not a very good one.
As for column creation, you can also create a new column setting all values to a one standard value.
In\u00a0[77]: Copied! # Column to all 1 value (number of wheels)\ncar_sales[\"Number of wheels\"] = 4\ncar_sales\n
# Column to all 1 value (number of wheels) car_sales[\"Number of wheels\"] = 4 car_sales Out[77]: Make Colour Odometer (KM) Doors Price Seats Engine Size Price per KM Number of wheels 0 toyota White 150043 4 4000 5 1.3 0.026659 4 1 honda Red 87899 4 5000 5 2.0 0.056883 4 2 toyota Blue 32549 3 7000 5 3.0 0.215060 4 3 bmw Black 11179 5 22000 5 4.2 1.967976 4 4 nissan White 213095 4 3500 5 1.6 0.016425 4 5 toyota Green 99213 4 4500 5 1.0 0.045357 4 6 honda Blue 45698 4 7500 5 2.0 0.164121 4 7 honda Blue 54738 4 7000 5 2.3 0.127882 4 8 toyota White 60000 4 6250 5 2.0 0.104167 4 9 nissan White 31600 4 9700 5 3.0 0.306962 4 In\u00a0[78]: Copied! car_sales[\"Passed road safety\"] = True\ncar_sales\n
car_sales[\"Passed road safety\"] = True car_sales Out[78]: Make Colour Odometer (KM) Doors Price Seats Engine Size Price per KM Number of wheels Passed road safety 0 toyota White 150043 4 4000 5 1.3 0.026659 4 True 1 honda Red 87899 4 5000 5 2.0 0.056883 4 True 2 toyota Blue 32549 3 7000 5 3.0 0.215060 4 True 3 bmw Black 11179 5 22000 5 4.2 1.967976 4 True 4 nissan White 213095 4 3500 5 1.6 0.016425 4 True 5 toyota Green 99213 4 4500 5 1.0 0.045357 4 True 6 honda Blue 45698 4 7500 5 2.0 0.164121 4 True 7 honda Blue 54738 4 7000 5 2.3 0.127882 4 True 8 toyota White 60000 4 6250 5 2.0 0.104167 4 True 9 nissan White 31600 4 9700 5 3.0 0.306962 4 True Now you've created some columns, you decide to show your colleague what you've done. When they ask about the Price per KM column, you tell them you're not really sure why it's there.
You decide you better remove it to prevent confusion.
You can remove a column using .drop('COLUMN_NAME', axis=1).
In\u00a0[79]: Copied! # Drop the Price per KM column\ncar_sales = car_sales.drop(\"Price per KM\", axis=1) # columns live on axis 1\ncar_sales\n
# Drop the Price per KM column car_sales = car_sales.drop(\"Price per KM\", axis=1) # columns live on axis 1 car_sales Out[79]: Make Colour Odometer (KM) Doors Price Seats Engine Size Number of wheels Passed road safety 0 toyota White 150043 4 4000 5 1.3 4 True 1 honda Red 87899 4 5000 5 2.0 4 True 2 toyota Blue 32549 3 7000 5 3.0 4 True 3 bmw Black 11179 5 22000 5 4.2 4 True 4 nissan White 213095 4 3500 5 1.6 4 True 5 toyota Green 99213 4 4500 5 1.0 4 True 6 honda Blue 45698 4 7500 5 2.0 4 True 7 honda Blue 54738 4 7000 5 2.3 4 True 8 toyota White 60000 4 6250 5 2.0 4 True 9 nissan White 31600 4 9700 5 3.0 4 True Why axis=1? Because that's the axis columns live on. Rows live on axis=0.
Let's say you wanted to shuffle the order of your DataFrame so you could split it into train, validation and test sets. And even though the order of your samples was random, you wanted to make sure.
To do so you could use .sample(frac=1).
.sample() randomly samples different rows from a DataFrame.
The frac parameter dictates the fraction, where 1 = 100% of rows, 0.5 = 50% of rows, 0.01 = 1% of rows.
You can also use .sample(n=1) where n is the number of rows to sample.
In\u00a0[80]: Copied! # Sample car_sales\ncar_sales_sampled = car_sales.sample(frac=1)\ncar_sales_sampled\n
# Sample car_sales car_sales_sampled = car_sales.sample(frac=1) car_sales_sampled Out[80]: Make Colour Odometer (KM) Doors Price Seats Engine Size Number of wheels Passed road safety 2 toyota Blue 32549 3 7000 5 3.0 4 True 4 nissan White 213095 4 3500 5 1.6 4 True 9 nissan White 31600 4 9700 5 3.0 4 True 1 honda Red 87899 4 5000 5 2.0 4 True 0 toyota White 150043 4 4000 5 1.3 4 True 8 toyota White 60000 4 6250 5 2.0 4 True 3 bmw Black 11179 5 22000 5 4.2 4 True 5 toyota Green 99213 4 4500 5 1.0 4 True 6 honda Blue 45698 4 7500 5 2.0 4 True 7 honda Blue 54738 4 7000 5 2.3 4 True Notice how the rows remain intact but their order is mixed (check the indexes).
.sample(frac=X) is also helpful when you're working with a large DataFrame.
Say you had 2,000,000 rows.
Running tests, analysis and machine learning algorithms on 2,000,000 rows could take a long time. And since being a data scientist or machine learning engineer is about reducing the time between experiments, you might begin with a sample of rows first.
For example, you could use 40k_rows = 2_mil_rows.sample(frac=0.05) to work on 40,000 rows from a DataFrame called 2_mil_rows containing 2,000,000 rows.
What if you wanted to get the indexes back in order?
You could do so using .reset_index().
In\u00a0[81]: Copied! # Reset the indexes of car_sales_sampled\ncar_sales_sampled.reset_index()\n
# Reset the indexes of car_sales_sampled car_sales_sampled.reset_index() Out[81]: index Make Colour Odometer (KM) Doors Price Seats Engine Size Number of wheels Passed road safety 0 2 toyota Blue 32549 3 7000 5 3.0 4 True 1 4 nissan White 213095 4 3500 5 1.6 4 True 2 9 nissan White 31600 4 9700 5 3.0 4 True 3 1 honda Red 87899 4 5000 5 2.0 4 True 4 0 toyota White 150043 4 4000 5 1.3 4 True 5 8 toyota White 60000 4 6250 5 2.0 4 True 6 3 bmw Black 11179 5 22000 5 4.2 4 True 7 5 toyota Green 99213 4 4500 5 1.0 4 True 8 6 honda Blue 45698 4 7500 5 2.0 4 True 9 7 honda Blue 54738 4 7000 5 2.3 4 True Calling .reset_index() on a DataFrame resets the index numbers to their defaults. It also creates a new Index column by default which contains the previous index values.
Finally, what if you wanted to apply a function to a column. Such as, converting the Odometer column from kilometers to miles.
You can do so using the .apply() function and passing it a Python lambda function. We know there's about 1.6 kilometers in a mile, so if you divide the value in the Odometer column by 1.6, it should convert it to miles.
In\u00a0[82]: Copied! # Change the Odometer values from kilometres to miles\ncar_sales[\"Odometer (KM)\"].apply(lambda x: x / 1.6)\n
# Change the Odometer values from kilometres to miles car_sales[\"Odometer (KM)\"].apply(lambda x: x / 1.6) Out[82]: 0 93776.875\n1 54936.875\n2 20343.125\n3 6986.875\n4 133184.375\n5 62008.125\n6 28561.250\n7 34211.250\n8 37500.000\n9 19750.000\nName: Odometer (KM), dtype: float64
Now let's check our car_sales DataFrame.
In\u00a0[83]: Copied! car_sales\n
car_sales Out[83]: Make Colour Odometer (KM) Doors Price Seats Engine Size Number of wheels Passed road safety 0 toyota White 150043 4 4000 5 1.3 4 True 1 honda Red 87899 4 5000 5 2.0 4 True 2 toyota Blue 32549 3 7000 5 3.0 4 True 3 bmw Black 11179 5 22000 5 4.2 4 True 4 nissan White 213095 4 3500 5 1.6 4 True 5 toyota Green 99213 4 4500 5 1.0 4 True 6 honda Blue 45698 4 7500 5 2.0 4 True 7 honda Blue 54738 4 7000 5 2.3 4 True 8 toyota White 60000 4 6250 5 2.0 4 True 9 nissan White 31600 4 9700 5 3.0 4 True The Odometer column didn't change. Can you guess why?
We didn't reassign it.
In\u00a0[84]: Copied! # Reassign the Odometer column to be miles instead of kilometers\ncar_sales[\"Odometer (KM)\"] = car_sales[\"Odometer (KM)\"].apply(lambda x: x / 1.6)\ncar_sales\n
# Reassign the Odometer column to be miles instead of kilometers car_sales[\"Odometer (KM)\"] = car_sales[\"Odometer (KM)\"].apply(lambda x: x / 1.6) car_sales Out[84]: Make Colour Odometer (KM) Doors Price Seats Engine Size Number of wheels Passed road safety 0 toyota White 93776.875 4 4000 5 1.3 4 True 1 honda Red 54936.875 4 5000 5 2.0 4 True 2 toyota Blue 20343.125 3 7000 5 3.0 4 True 3 bmw Black 6986.875 5 22000 5 4.2 4 True 4 nissan White 133184.375 4 3500 5 1.6 4 True 5 toyota Green 62008.125 4 4500 5 1.0 4 True 6 honda Blue 28561.250 4 7500 5 2.0 4 True 7 honda Blue 34211.250 4 7000 5 2.3 4 True 8 toyota White 37500.000 4 6250 5 2.0 4 True 9 nissan White 19750.000 4 9700 5 3.0 4 True If you've never seen a lambda function they can be tricky. What the line above is saying is \"take the value in the Odometer (KM) column (x) and set it to be itself divided by 1.6\".
"},{"location":"introduction-to-pandas/#a-quick-introduction-to-data-analysis-and-manipulation-with-python-and-pandas","title":"A Quick Introduction to Data Analysis and Manipulation with Python and pandas\u00b6","text":""},{"location":"introduction-to-pandas/#what-is-pandas","title":"What is pandas?\u00b6","text":"If you're getting into machine learning and data science and you're using Python, you're going to use pandas.
pandas is an open source library which helps you analyse and manipulate data.
"},{"location":"introduction-to-pandas/#why-pandas","title":"Why pandas?\u00b6","text":"pandas provides a simple to use but very capable set of functions you can use to on your data.
It's integrated with many other data science and machine learning tools which use Python so having an understanding of it will be helpful throughout your journey.
One of the main use cases you'll come across is using pandas to transform your data in a way which makes it usable with machine learning algorithms.
"},{"location":"introduction-to-pandas/#what-does-this-notebook-cover","title":"What does this notebook cover?\u00b6","text":"Because the pandas library is vast, there's often many ways to do the same thing. This notebook covers some of the most fundamental functions of the library, which are more than enough to get started.
"},{"location":"introduction-to-pandas/#where-can-i-get-help","title":"Where can I get help?\u00b6","text":"If you get stuck or think of something you'd like to do which this notebook doesn't cover, don't fear!
The recommended steps you take are:
- Try it - Since pandas is very friendly, your first step should be to use what you know and try figure out the answer to your own question (getting it wrong is part of the process). If in doubt, run your code.
- Search for it - If trying it on your own doesn't work, since someone else has probably tried to do something similar, try searching for your problem in the following places (either via a search engine or direct):
- pandas documentation - the best place for learning pandas, this resource covers all of the pandas functionality.
- Stack Overflow - this is the developers Q&A hub, it's full of questions and answers of different problems across a wide range of software development topics and chances are, there's one related to your problem.
- ChatGPT - ChatGPT is very good at explaining code, however, it can make mistakes. Best to verify the code it writes first before using it. Try asking \"Can you explain the following code for me? {your code here}\" and then continue with follow up questions from there.
An example of searching for a pandas function might be:
\"how to fill all the missing values of two columns using pandas\"
Searching this on Google leads to this post on Stack Overflow: https://stackoverflow.com/questions/36556256/how-do-i-fill-na-values-in-multiple-columns-in-pandas
The next steps here are to read through the post and see if it relates to your problem. If it does, great, take the code/information you need and rewrite it to suit your own problem.
- Ask for help - If you've been through the above 2 steps and you're still stuck, you might want to ask your question on Stack Overflow. Remember to be specific as possible and provide details on what you've tried.
Remember, you don't have to learn all of these functions off by heart to begin with.
What's most important is remembering to continually ask yourself, \"what am I trying to do with the data?\".
Start by answering that question and then practicing finding the code which does it.
Let's get started.
"},{"location":"introduction-to-pandas/#0-importing-pandas","title":"0. Importing pandas\u00b6","text":"To get started using pandas, the first step is to import it.
The most common way (and method you should use) is to import pandas as the abbreviation pd (e.g. pandas -> pd).
If you see the letters pd used anywhere in machine learning or data science, it's probably referring to the pandas library.
"},{"location":"introduction-to-pandas/#1-datatypes","title":"1. Datatypes\u00b6","text":"pandas has two main datatypes, Series and DataFrame.
pandas.Series - a 1-dimensional column of data.pandas.DataFrame (most common) - a 2-dimesional table of data with rows and columns.
You can create a Series using pd.Series() and passing it a Python list.
"},{"location":"introduction-to-pandas/#exercises","title":"Exercises\u00b6","text":" - Make a
Series of different foods. - Make a
Series of different dollar values (these can be integers). - Combine your
Series's of foods and dollar values into a DataFrame.
Try it out for yourself first, then see how your code goes against the solution.
Note: Make sure your two Series are the same size before combining them in a DataFrame.
"},{"location":"introduction-to-pandas/#2-importing-data","title":"2. Importing data\u00b6","text":"Creating Series and DataFrame's from scratch is nice but what you'll usually be doing is importing your data in the form of a .csv (comma separated value), spreadsheet file or something similar such as an SQL database.
pandas allows for easy importing of data like this through functions such as pd.read_csv() and pd.read_excel() (for Microsoft Excel files).
Say you wanted to get this information from this Google Sheet document into a pandas DataFrame.
You could export it as a .csv file and then import it using pd.read_csv().
Tip: If the Google Sheet is public, pd.read_csv() can read it via URL, try searching for \"pandas read Google Sheet with URL\".
In this case, the exported .csv file is called car-sales.csv.
"},{"location":"introduction-to-pandas/#anatomy-of-a-dataframe","title":"Anatomy of a DataFrame\u00b6","text":"Different functions use different labels for different things. This graphic sums up some of the main components of DataFrame's and their different names.
"},{"location":"introduction-to-pandas/#3-exporting-data","title":"3. Exporting data\u00b6","text":"After you've made a few changes to your data, you might want to export it and save it so someone else can access the changes.
pandas allows you to export DataFrame's to .csv format using .to_csv() or spreadsheet format using .to_excel().
We haven't made any changes yet to the car_sales DataFrame but let's try export it.
"},{"location":"introduction-to-pandas/#exercises","title":"Exercises\u00b6","text":" - Practice importing a
.csv file using pd.read_csv(), you can download heart-disease.csv. This file contains annonymous patient medical records and whether or not they have heart disease. - Practice exporting a
DataFrame using .to_csv(). You could export the heart disease DataFrame after you've imported it.
Note:
- Make sure the
heart-disease.csv file is in the same folder as your notebook orbe sure to use the filepath where the file is. - You can name the variables and exported files whatever you like but make sure they're readable.
"},{"location":"introduction-to-pandas/#example-solution","title":"Example solution\u00b6","text":""},{"location":"introduction-to-pandas/#4-describing-data","title":"4. Describing data\u00b6","text":"One of the first things you'll want to do after you import some data into a pandas DataFrame is to start exploring it.
pandas has many built in functions which allow you to quickly get information about a DataFrame.
Let's explore some using the car_sales DataFrame.
"},{"location":"introduction-to-pandas/#5-viewing-and-selecting-data","title":"5. Viewing and selecting data\u00b6","text":"Some common methods for viewing and selecting data in a pandas DataFrame include:
DataFrame.head(n=5) - Displays the first n rows of a DataFrame (e.g. car_sales.head() will show the first 5 rows of the car_sales DataFrame).DataFrame.tail(n=5) - Displays the last n rows of a DataFrame.DataFrame.loc[] - Accesses a group of rows and columns by labels or a boolean array.DataFrame.iloc[] - Accesses a group of rows and columns by integer indices (e.g. car_sales.iloc[0] shows all the columns from index 0.DataFrame.columns - Lists the column labels of the DataFrame.DataFrame['A'] - Selects the column named 'A' from the DataFrame.DataFrame[DataFrame['A'] > 5] - Boolean indexing filters rows based on column values meeting a condition (e.g. all rows from column 'A' greater than 5.DataFrame.plot() - Creates a line plot of a DataFrame's columns (e.g. plot Make vs. Odometer (KM) columns with car_sales[[\"Make\", \"Odometer (KM)\"]].plot();).DataFrame.hist() - Generates histograms for columns in a DataFrame.pandas.crosstab() - Computes a cross-tabulation of two or more factors.
In practice, you'll constantly be making changes to your data, and viewing it. Changing it, viewing it, changing it, viewing it.
You won't always want to change all of the data in your DataFrame's either. So there are just as many different ways to select data as there is to view it.
.head() allows you to view the first 5 rows of your DataFrame. You'll likely be using this one a lot.
"},{"location":"introduction-to-pandas/#6-manipulating-data","title":"6. Manipulating data\u00b6","text":"You've seen an example of one way to manipulate data but pandas has many more.
How many more?
Put it this way, if you can imagine it, chances are, pandas can do it.
Let's start with string methods. Because pandas is based on Python, however you can manipulate strings in Python, you can do the same in pandas.
You can access the string value of a column using .str. Knowing this, how do you think you'd set a column to lowercase?
"},{"location":"introduction-to-pandas/#summary","title":"Summary\u00b6","text":""},{"location":"introduction-to-pandas/#main-topics-we-covered","title":"Main topics we covered\u00b6","text":" - Series - a single column (can be multiple rows) of values.
- DataFrame - multiple columns/rows of values (a DataFrame is comprised of multiple Series).
- Importing data - we used
pd.read_csv() to read in a CSV (comma-separated values) file but there are multiple options for reading data. - Exporting data - we exported our data using
to_csv(), however there are multiple methods of exporting data. - Describing data
df.dtypes - find the datatypes present in a dataframe.df.describe() - find various numerical features of a dataframe.df.info() - find the number of rows and whether or not any of them are empty.
- Viewing and selecting data
df.head() - view the first 5 rows of df.df.loc & df.iloc - select specific parts of a dataframe.df['A'] - select column A of df.df[df['A'] > 1000] - selection column A rows with values over 1000 of df.df['A'] - plot values from column A using matplotlib (defaults to line graph).
- Manipulating data and performing operations - pandas has many built-in functions you can use to manipulate data, also many of the Python operators (e.g.
+, -, >, ==) work with pandas.
"},{"location":"introduction-to-pandas/#further-reading","title":"Further reading\u00b6","text":"Since pandas is such a large library, it would be impossible to cover it all in one go.
The following are some resources you might want to look into for more.
- Python for Data Analysis by Wes McKinney - possibly the most complete text of the pandas library (apart from the documentation itself) written by the creator of pandas.
- Data Manipulation with Pandas (section of Python Data Science Handbook by Jake VanderPlas) - a very hands-on approach to many of the main functions in the pandas library.
"},{"location":"introduction-to-pandas/#exercises","title":"Exercises\u00b6","text":"After completing this notebook, you next thing should be to try out some more pandas code of your own.
I'd suggest at least going through number 1 (write out all the code yourself), a couple from number 2 (again, write out the code yourself) and spend an hour reading number 3 (this is vast but keep it in mind).
- 10-minute introduction to pandas - go through all the functions here and be sure to write out the code yourself.
- Pandas getting started tutorial - pick a couple from here which spark your interest and go through them both writing out the code for your self.
- Pandas essential basic functionality - spend an hour reading this and bookmark it for whenever you need to come back for an overview of pandas.
"},{"location":"introduction-to-scikit-learn/","title":"Introduction to Scikit-Learn","text":"View source code | Read notebook in online book format
In\u00a0[1]: Copied! import datetime\nprint(f\"Last updated: {datetime.datetime.now()}\")\n import datetime print(f\"Last updated: {datetime.datetime.now()}\") Last updated: 2024-09-06 13:30:34.743560\n
In\u00a0[2]: Copied! # Standard imports\n# %matplotlib inline # No longer required in newer versions of Jupyter (2022+)\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\n\nimport sklearn\nprint(f\"Using Scikit-Learn version: {sklearn.__version__} (materials in this notebook require this version or newer).\")\n # Standard imports # %matplotlib inline # No longer required in newer versions of Jupyter (2022+) import matplotlib.pyplot as plt import numpy as np import pandas as pd import sklearn print(f\"Using Scikit-Learn version: {sklearn.__version__} (materials in this notebook require this version or newer).\") Using Scikit-Learn version: 1.5.1 (materials in this notebook require this version or newer).\n
In\u00a0[3]: Copied! import pandas as pd\n\n# heart_disease = pd.read_csv(\"../data/heart-disease.csv\") # load data from local directory\nheart_disease = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/heart-disease.csv\") # load data directly from URL (requires raw form on GitHub, source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/heart-disease.csv)\nheart_disease.head()\n
import pandas as pd # heart_disease = pd.read_csv(\"../data/heart-disease.csv\") # load data from local directory heart_disease = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/heart-disease.csv\") # load data directly from URL (requires raw form on GitHub, source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/heart-disease.csv) heart_disease.head() Out[3]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1 Here, each row is a different patient and all columns except target are different patient characteristics.
The target column indicates whether the patient has heart disease (target=1) or not (target=0), this is our \"label\" columnm, the variable we're going to try and predict.
The rest of the columns (often called features) are what we'll be using to predict the target value.
Note: It's a common custom to save features to a varialbe X and labels to a variable y. In practice, we'd like to use the X (features) to build a predictive algorithm to predict the y (labels).
In\u00a0[4]: Copied! # Create X (all the feature columns)\nX = heart_disease.drop(\"target\", axis=1)\n\n# Create y (the target column)\ny = heart_disease[\"target\"]\n\n# Check the head of the features DataFrame\nX.head()\n
# Create X (all the feature columns) X = heart_disease.drop(\"target\", axis=1) # Create y (the target column) y = heart_disease[\"target\"] # Check the head of the features DataFrame X.head() Out[4]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 In\u00a0[5]: Copied! # Check the head and the value counts of the labels \ny.head(), y.value_counts()\n
# Check the head and the value counts of the labels y.head(), y.value_counts() Out[5]: (0 1\n 1 1\n 2 1\n 3 1\n 4 1\n Name: target, dtype: int64,\n target\n 1 165\n 0 138\n Name: count, dtype: int64)
One of the most important practices in machine learning is to split datasets into training and test sets.
As in, a model will train on the training set to learn patterns and then those patterns can be evaluated on the test set.
Crucially, a model should never see testing data during training.
This is equivalent to a student studying course materials during the semester (training set) and then testing their abilities on the following exam (testing set).
Scikit-learn provides the sklearn.model_selection.train_test_split method to split datasets in training and test sets.
Note: A common practice to use an 80/20 or 70/30 or 75/25 split for training/testing data. There is also a third set, known as a validation set (e.g. 70/15/15 for training/validation/test) for hyperparamter tuning on but for now we'll focus on training and test sets.
In\u00a0[6]: Copied! # Split the data into training and test sets\nfrom sklearn.model_selection import train_test_split\n\nX_train, X_test, y_train, y_test = train_test_split(X, \n y,\n test_size=0.25) # by default train_test_split uses 25% of the data for the test set\n\nX_train.shape, X_test.shape, y_train.shape, y_test.shape\n
# Split the data into training and test sets from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25) # by default train_test_split uses 25% of the data for the test set X_train.shape, X_test.shape, y_train.shape, y_test.shape Out[6]: ((227, 13), (76, 13), (227,), (76,))
In\u00a0[7]: Copied! # Since we're working on a classification problem, we'll start with a RandomForestClassifier\nfrom sklearn.ensemble import RandomForestClassifier\n\nclf = RandomForestClassifier()\n
# Since we're working on a classification problem, we'll start with a RandomForestClassifier from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier() We can see the current hyperparameters of a model with the get_params() method.
In\u00a0[8]: Copied! # View the current hyperparameters\nclf.get_params()\n
# View the current hyperparameters clf.get_params() Out[8]: {'bootstrap': True,\n 'ccp_alpha': 0.0,\n 'class_weight': None,\n 'criterion': 'gini',\n 'max_depth': None,\n 'max_features': 'sqrt',\n 'max_leaf_nodes': None,\n 'max_samples': None,\n 'min_impurity_decrease': 0.0,\n 'min_samples_leaf': 1,\n 'min_samples_split': 2,\n 'min_weight_fraction_leaf': 0.0,\n 'monotonic_cst': None,\n 'n_estimators': 100,\n 'n_jobs': None,\n 'oob_score': False,\n 'random_state': None,\n 'verbose': 0,\n 'warm_start': False} We'll leave this as is for now, as Scikit-Learn models generally have good default settings.
In\u00a0[9]: Copied! clf.fit(X=X_train, y=y_train)\n
clf.fit(X=X_train, y=y_train) Out[9]: RandomForestClassifier()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.\u00a0\u00a0RandomForestClassifier?Documentation for RandomForestClassifieriFittedRandomForestClassifier()
In\u00a0[10]: Copied! # This doesn't work... incorrect shapes\ny_label = clf.predict(np.array([0, 2, 3, 4]))\n
# This doesn't work... incorrect shapes y_label = clf.predict(np.array([0, 2, 3, 4])) /Users/daniel/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py:493: UserWarning: X does not have valid feature names, but RandomForestClassifier was fitted with feature names\n warnings.warn(\n
\n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\nCell In[10], line 2\n 1 # This doesn't work... incorrect shapes\n----> 2 y_label = clf.predict(np.array([0, 2, 3, 4]))\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py:904, in ForestClassifier.predict(self, X)\n 883 def predict(self, X):\n 884 \"\"\"\n 885 Predict class for X.\n 886 \n (...)\n 902 The predicted classes.\n 903 \"\"\"\n--> 904 proba = self.predict_proba(X)\n 906 if self.n_outputs_ == 1:\n 907 return self.classes_.take(np.argmax(proba, axis=1), axis=0)\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py:946, in ForestClassifier.predict_proba(self, X)\n 944 check_is_fitted(self)\n 945 # Check data\n--> 946 X = self._validate_X_predict(X)\n 948 # Assign chunk of trees to jobs\n 949 n_jobs, _, _ = _partition_estimators(self.n_estimators, self.n_jobs)\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py:641, in BaseForest._validate_X_predict(self, X)\n 638 else:\n 639 force_all_finite = True\n--> 641 X = self._validate_data(\n 642 X,\n 643 dtype=DTYPE,\n 644 accept_sparse=\"csr\",\n 645 reset=False,\n 646 force_all_finite=force_all_finite,\n 647 )\n 648 if issparse(X) and (X.indices.dtype != np.intc or X.indptr.dtype != np.intc):\n 649 raise ValueError(\"No support for np.int64 index based sparse matrices\")\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py:633, in BaseEstimator._validate_data(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)\n 631 out = X, y\n 632 elif not no_val_X and no_val_y:\n--> 633 out = check_array(X, input_name=\"X\", **check_params)\n 634 elif no_val_X and not no_val_y:\n 635 out = _check_y(y, **check_params)\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py:1050, in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)\n 1043 else:\n 1044 msg = (\n 1045 f\"Expected 2D array, got 1D array instead:\\narray={array}.\\n\"\n 1046 \"Reshape your data either using array.reshape(-1, 1) if \"\n 1047 \"your data has a single feature or array.reshape(1, -1) \"\n 1048 \"if it contains a single sample.\"\n 1049 )\n-> 1050 raise ValueError(msg)\n 1052 if dtype_numeric and hasattr(array.dtype, \"kind\") and array.dtype.kind in \"USV\":\n 1053 raise ValueError(\n 1054 \"dtype='numeric' is not compatible with arrays of bytes/strings.\"\n 1055 \"Convert your data to numeric values explicitly instead.\"\n 1056 )\n\nValueError: Expected 2D array, got 1D array instead:\narray=[0. 2. 3. 4.].\nReshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample. Oh no!
We get a ValueError (mismatched shapes):
ValueError: Expected 2D array, got 1D array instead:\narray=[0. 2. 3. 4.].\nReshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.\n
This happens because we're trying to make predictions on data that is in a different format to the data our model was trained on.
Since our model was trained on data from X_train, predictions should be made on data in the same format and shape as X_train.
Our goal in many machine learning problems is to use patterns learned from the training data to make predictions on the test data (or future unseen data).
In\u00a0[11]: Copied! # In order to predict a label, data has to be in the same shape as X_train\nX_test.head()\n
# In order to predict a label, data has to be in the same shape as X_train X_test.head() Out[11]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal 165 67 1 0 160 286 0 0 108 1 1.5 1 3 2 71 51 1 2 94 227 0 1 154 1 0.0 2 1 3 24 40 1 3 140 199 0 1 178 1 1.4 2 0 3 19 69 0 3 140 239 0 1 151 0 1.8 2 2 2 258 62 0 0 150 244 0 1 154 1 1.4 1 0 2 In\u00a0[12]: Copied! # Use the model to make a prediction on the test data (further evaluation)\ny_preds = clf.predict(X=X_test)\n
# Use the model to make a prediction on the test data (further evaluation) y_preds = clf.predict(X=X_test) In\u00a0[13]: Copied! # Evaluate the model on the training set\ntrain_acc = clf.score(X=X_train, y=y_train)\nprint(f\"The model's accuracy on the training dataset is: {train_acc*100}%\")\n # Evaluate the model on the training set train_acc = clf.score(X=X_train, y=y_train) print(f\"The model's accuracy on the training dataset is: {train_acc*100}%\") The model's accuracy on the training dataset is: 100.0%\n
Woah! Looks like our model does pretty well on the training datset.
This is because it has a chance to see both data and labels.
How about the test dataset?
In\u00a0[14]: Copied! # Evaluate the model on the test set\ntest_acc = clf.score(X=X_test, y=y_test)\nprint(f\"The model's accuracy on the testing dataset is: {test_acc*100:.2f}%\")\n # Evaluate the model on the test set test_acc = clf.score(X=X_test, y=y_test) print(f\"The model's accuracy on the testing dataset is: {test_acc*100:.2f}%\") The model's accuracy on the testing dataset is: 88.16%\n
Hmm, looks like our model's accuracy is a bit less on the test dataset than the training dataset.
This is quite often the case, because remember, a model has never seen the testing examples before.
There are also a number of other evaluation methods we can use for our classification models.
All of the following classification metrics come from the sklearn.metrics module:
classification_report(y_true, y_true) - Builds a text report showing various classification metrics such as precision, recall and F1-score.confusion_matrix(y_true, y_pred) - Create a confusion matrix to compare predictions to truth labels.accuracy_score(y_true, y_pred) - Find the accuracy score (the default metric) for a classifier.
All metrics have the following in common: they compare a model's predictions (y_pred) to truth labels (y_true).
In\u00a0[15]: Copied! from sklearn.metrics import classification_report, confusion_matrix, accuracy_score\n\n# Create a classification report\nprint(classification_report(y_test, y_preds))\n
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score # Create a classification report print(classification_report(y_test, y_preds)) precision recall f1-score support\n\n 0 0.87 0.84 0.85 31\n 1 0.89 0.91 0.90 45\n\n accuracy 0.88 76\n macro avg 0.88 0.87 0.88 76\nweighted avg 0.88 0.88 0.88 76\n\n
In\u00a0[16]: Copied! # Create a confusion matrix\nconf_mat = confusion_matrix(y_test, y_preds)\nconf_mat\n
# Create a confusion matrix conf_mat = confusion_matrix(y_test, y_preds) conf_mat Out[16]: array([[26, 5],\n [ 4, 41]])
In\u00a0[17]: Copied! # Compute the accuracy score (same as the score() method for classifiers) \naccuracy_score(y_test, y_preds)\n
# Compute the accuracy score (same as the score() method for classifiers) accuracy_score(y_test, y_preds) Out[17]: 0.881578947368421
In\u00a0[18]: Copied! # Try different numbers of estimators (trees)... (no cross-validation)\nnp.random.seed(42)\nfor i in range(100, 200, 10):\n print(f\"Trying model with {i} estimators...\")\n model = RandomForestClassifier(n_estimators=i).fit(X_train, y_train)\n print(f\"Model accuracy on test set: {model.score(X_test, y_test) * 100:.2f}%\")\n print(\"\")\n # Try different numbers of estimators (trees)... (no cross-validation) np.random.seed(42) for i in range(100, 200, 10): print(f\"Trying model with {i} estimators...\") model = RandomForestClassifier(n_estimators=i).fit(X_train, y_train) print(f\"Model accuracy on test set: {model.score(X_test, y_test) * 100:.2f}%\") print(\"\") Trying model with 100 estimators...\nModel accuracy on test set: 88.16%\n\nTrying model with 110 estimators...\nModel accuracy on test set: 90.79%\n\nTrying model with 120 estimators...\nModel accuracy on test set: 90.79%\n\nTrying model with 130 estimators...\nModel accuracy on test set: 89.47%\n\nTrying model with 140 estimators...\nModel accuracy on test set: 88.16%\n\nTrying model with 150 estimators...\nModel accuracy on test set: 94.74%\n\nTrying model with 160 estimators...\nModel accuracy on test set: 92.11%\n\nTrying model with 170 estimators...\nModel accuracy on test set: 92.11%\n\nTrying model with 180 estimators...\nModel accuracy on test set: 92.11%\n\nTrying model with 190 estimators...\nModel accuracy on test set: 89.47%\n\n
The metrics above were measured on a single train and test split.
Let's use sklearn.model_selection.cross_val_score to measure the results across 5 different train and test sets.
We can achieve this by setting cross_val_score(X, y, cv=5).
Where X is the full feature set and y is the full label set and cv is the number of train and test splits cross_val_score will automatically create from the data (in our case, 5 different splits, this is known as 5-fold cross-validation).
In\u00a0[19]: Copied! from sklearn.model_selection import cross_val_score\n\n# With cross-validation\nnp.random.seed(42)\nfor i in range(100, 200, 10):\n print(f\"Trying model with {i} estimators...\")\n model = RandomForestClassifier(n_estimators=i).fit(X_train, y_train)\n\n # Measure the model score on a single train/test split\n model_score = model.score(X_test, y_test)\n print(f\"Model accuracy on single test set split: {model_score * 100:.2f}%\")\n \n # Measure the mean cross-validation score across 5 different train and test splits\n cross_val_mean = np.mean(cross_val_score(model, X, y, cv=5))\n print(f\"5-fold cross-validation score: {cross_val_mean * 100:.2f}%\")\n \n print(\"\")\n from sklearn.model_selection import cross_val_score # With cross-validation np.random.seed(42) for i in range(100, 200, 10): print(f\"Trying model with {i} estimators...\") model = RandomForestClassifier(n_estimators=i).fit(X_train, y_train) # Measure the model score on a single train/test split model_score = model.score(X_test, y_test) print(f\"Model accuracy on single test set split: {model_score * 100:.2f}%\") # Measure the mean cross-validation score across 5 different train and test splits cross_val_mean = np.mean(cross_val_score(model, X, y, cv=5)) print(f\"5-fold cross-validation score: {cross_val_mean * 100:.2f}%\") print(\"\") Trying model with 100 estimators...\nModel accuracy on single test set split: 88.16%\n5-fold cross-validation score: 82.15%\n\nTrying model with 110 estimators...\nModel accuracy on single test set split: 94.74%\n5-fold cross-validation score: 81.17%\n\nTrying model with 120 estimators...\nModel accuracy on single test set split: 88.16%\n5-fold cross-validation score: 83.49%\n\nTrying model with 130 estimators...\nModel accuracy on single test set split: 89.47%\n5-fold cross-validation score: 83.14%\n\nTrying model with 140 estimators...\nModel accuracy on single test set split: 88.16%\n5-fold cross-validation score: 82.48%\n\nTrying model with 150 estimators...\nModel accuracy on single test set split: 90.79%\n5-fold cross-validation score: 80.17%\n\nTrying model with 160 estimators...\nModel accuracy on single test set split: 89.47%\n5-fold cross-validation score: 80.83%\n\nTrying model with 170 estimators...\nModel accuracy on single test set split: 86.84%\n5-fold cross-validation score: 82.16%\n\nTrying model with 180 estimators...\nModel accuracy on single test set split: 92.11%\n5-fold cross-validation score: 81.50%\n\nTrying model with 190 estimators...\nModel accuracy on single test set split: 88.16%\n5-fold cross-validation score: 81.83%\n\n
Which model had the best cross-validation score?
This is usually a better indicator of a quality model than a single split accuracy score.
Rather than set up and track the results of these experiments manually, we can get Scikit-Learn to do the exploration for us.
Scikit-Learn's sklearn.model_selection.GridSearchCV is a way to search over a set of different hyperparameter values and automatically track which perform the best.
Let's test it!
In\u00a0[20]: Copied! # Another way to do it with GridSearchCV...\nnp.random.seed(42)\nfrom sklearn.model_selection import GridSearchCV\n\n# Define the parameters to search over in dictionary form \n# (these can be any of your target model's hyperparameters) \nparam_grid = {'n_estimators': [i for i in range(100, 200, 10)]}\n\n# Setup the grid search\ngrid = GridSearchCV(estimator=RandomForestClassifier(),\n param_grid=param_grid,\n cv=5,\n verbose=1) \n\n# Fit the grid search to the data\ngrid.fit(X, y)\n\n# Find the best parameters\nprint(f\"The best parameter values are: {grid.best_params_}\")\nprint(f\"With a score of: {grid.best_score_*100:.2f}%\")\n # Another way to do it with GridSearchCV... np.random.seed(42) from sklearn.model_selection import GridSearchCV # Define the parameters to search over in dictionary form # (these can be any of your target model's hyperparameters) param_grid = {'n_estimators': [i for i in range(100, 200, 10)]} # Setup the grid search grid = GridSearchCV(estimator=RandomForestClassifier(), param_grid=param_grid, cv=5, verbose=1) # Fit the grid search to the data grid.fit(X, y) # Find the best parameters print(f\"The best parameter values are: {grid.best_params_}\") print(f\"With a score of: {grid.best_score_*100:.2f}%\") Fitting 5 folds for each of 10 candidates, totalling 50 fits\nThe best parameter values are: {'n_estimators': 120}\nWith a score of: 82.82%\n We can extract the best model/estimator with the best_estimator_ attribute.
In\u00a0[21]: Copied! # Set the model to be the best estimator\nclf = grid.best_estimator_\nclf\n
# Set the model to be the best estimator clf = grid.best_estimator_ clf Out[21]: RandomForestClassifier(n_estimators=120)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.\u00a0\u00a0RandomForestClassifier?Documentation for RandomForestClassifieriFittedRandomForestClassifier(n_estimators=120)
And now we've got the best cross-validated model, we can fit and score it on our original single train/test split of the data.
In\u00a0[22]: Copied! # Fit the best model\nclf = clf.fit(X_train, y_train)\n\n# Find the best model scores on our single test split\n# (note: this may be lower than the cross-validation score since it's only on one split of the data)\nprint(f\"Best model score on single split of the data: {clf.score(X_test, y_test)*100:.2f}%\")\n # Fit the best model clf = clf.fit(X_train, y_train) # Find the best model scores on our single test split # (note: this may be lower than the cross-validation score since it's only on one split of the data) print(f\"Best model score on single split of the data: {clf.score(X_test, y_test)*100:.2f}%\") Best model score on single split of the data: 85.53%\n
In\u00a0[23]: Copied! import pickle\n\n# Save an existing model to file\npickle.dump(model, open(\"random_forest_model_1.pkl\", \"wb\"))\n
import pickle # Save an existing model to file pickle.dump(model, open(\"random_forest_model_1.pkl\", \"wb\")) In\u00a0[24]: Copied! # Load a saved pickle model and evaluate it\nloaded_pickle_model = pickle.load(open(\"random_forest_model_1.pkl\", \"rb\"))\nprint(f\"Loaded pickle model prediction score: {loaded_pickle_model.score(X_test, y_test) * 100:.2f}%\")\n # Load a saved pickle model and evaluate it loaded_pickle_model = pickle.load(open(\"random_forest_model_1.pkl\", \"rb\")) print(f\"Loaded pickle model prediction score: {loaded_pickle_model.score(X_test, y_test) * 100:.2f}%\") Loaded pickle model prediction score: 88.16%\n
For larger models, it may be more efficient to use Joblib.
In\u00a0[25]: Copied! from joblib import dump, load\n\n# Save a model using joblib\ndump(model, \"random_forest_model_1.joblib\")\n
from joblib import dump, load # Save a model using joblib dump(model, \"random_forest_model_1.joblib\") Out[25]: ['random_forest_model_1.joblib']
In\u00a0[26]: Copied! # Load a saved joblib model and evaluate it\nloaded_joblib_model = load(\"random_forest_model_1.joblib\")\nprint(f\"Loaded joblib model prediction score: {loaded_joblib_model.score(X_test, y_test) * 100:.2f}%\")\n # Load a saved joblib model and evaluate it loaded_joblib_model = load(\"random_forest_model_1.joblib\") print(f\"Loaded joblib model prediction score: {loaded_joblib_model.score(X_test, y_test) * 100:.2f}%\") Loaded joblib model prediction score: 88.16%\n
Woah!
We've covered a lot of ground fast...
Let's break things down a bit more by revisting each section.
In\u00a0[27]: Copied! # Splitting the data into X & y\nheart_disease.head()\n
# Splitting the data into X & y heart_disease.head() Out[27]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1 In\u00a0[28]: Copied! # Splitting the data into features (X) and labels (y)\nX = heart_disease.drop('target', axis=1)\nX\n # Splitting the data into features (X) and labels (y) X = heart_disease.drop('target', axis=1) X Out[28]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 ... ... ... ... ... ... ... ... ... ... ... ... ... ... 298 57 0 0 140 241 0 1 123 1 0.2 1 0 3 299 45 1 3 110 264 0 1 132 0 1.2 1 0 3 300 68 1 0 144 193 1 1 141 0 3.4 1 2 3 301 57 1 0 130 131 0 1 115 1 1.2 1 1 3 302 57 0 1 130 236 0 0 174 0 0.0 1 1 2 303 rows \u00d7 13 columns
Nice! Looks like our dataset has 303 samples with 13 features (13 columns).
Let's check out the labels.
In\u00a0[29]: Copied! y = heart_disease['target']\ny\n
y = heart_disease['target'] y Out[29]: 0 1\n1 1\n2 1\n3 1\n4 1\n ..\n298 0\n299 0\n300 0\n301 0\n302 0\nName: target, Length: 303, dtype: int64
Beautiful, 303 labels with values of 0 (no heart disease) and 1 (heart disease).
Now let's split our data into training and test sets, we'll use an 80/20 split (80% of samples for training and 20% of samples for testing).
In\u00a0[30]: Copied! # Splitting the data into training and test sets\nfrom sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(X, \n y, \n test_size=0.2) # you can change the test size\n\n# Check the shapes of different data splits\nX_train.shape, X_test.shape, y_train.shape, y_test.shape\n
# Splitting the data into training and test sets from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # you can change the test size # Check the shapes of different data splits X_train.shape, X_test.shape, y_train.shape, y_test.shape Out[30]: ((242, 13), (61, 13), (242,), (61,))
In\u00a0[31]: Copied! # 80% of data is being used for the training set (the model will learn patterns on these samples)\nX.shape[0] * 0.8\n
# 80% of data is being used for the training set (the model will learn patterns on these samples) X.shape[0] * 0.8 Out[31]: 242.4
In\u00a0[32]: Copied! # And 20% of the data is being used for the testing set (the model will be evaluated on these samples)\nX.shape[0] * 0.2\n
# And 20% of the data is being used for the testing set (the model will be evaluated on these samples) X.shape[0] * 0.2 Out[32]: 60.6
In\u00a0[33]: Copied! # Import car-sales-extended.csv\n# car_sales = pd.read_csv(\"../data/car-sales-extended.csv\") # load data from local directory \ncar_sales = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales-extended.csv\") # load data directly from raw URL (source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/car-sales-extended.csv)\ncar_sales\n
# Import car-sales-extended.csv # car_sales = pd.read_csv(\"../data/car-sales-extended.csv\") # load data from local directory car_sales = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales-extended.csv\") # load data directly from raw URL (source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/car-sales-extended.csv) car_sales Out[33]: Make Colour Odometer (KM) Doors Price 0 Honda White 35431 4 15323 1 BMW Blue 192714 5 19943 2 Honda White 84714 4 28343 3 Toyota White 154365 4 13434 4 Nissan Blue 181577 3 14043 ... ... ... ... ... ... 995 Toyota Black 35820 4 32042 996 Nissan White 155144 3 5716 997 Nissan Blue 66604 4 31570 998 Honda White 215883 4 4001 999 Toyota Blue 248360 4 12732 1000 rows \u00d7 5 columns
We can check the dataset types with .dtypes.
In\u00a0[34]: Copied! car_sales.dtypes\n
car_sales.dtypes Out[34]: Make object\nColour object\nOdometer (KM) int64\nDoors int64\nPrice int64\ndtype: object
Notice the Make and Colour features are of dtype=object (they're strings) where as the rest of the columns are of dtype=int64.
If we want to use the Make and Colour features in our model, we'll need to figure out how to turn them into numerical form.
In\u00a0[35]: Copied! # Split into X & y and train/test\nX = car_sales.drop(\"Price\", axis=1)\ny = car_sales[\"Price\"]\n\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n
# Split into X & y and train/test X = car_sales.drop(\"Price\", axis=1) y = car_sales[\"Price\"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) Now let's try and build a model on our car_sales data.
In\u00a0[36]: Copied! # Try to predict with random forest on price column (doesn't work)\nfrom sklearn.ensemble import RandomForestRegressor\n\nmodel = RandomForestRegressor()\nmodel.fit(X_train, y_train)\nmodel.score(X_test, y_test)\n
# Try to predict with random forest on price column (doesn't work) from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor() model.fit(X_train, y_train) model.score(X_test, y_test) \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\n/var/folders/c4/qj4gdk190td18bqvjjh0p3p00000gn/T/ipykernel_23180/1044518071.py in ?()\n 1 # Try to predict with random forest on price column (doesn't work)\n 2 from sklearn.ensemble import RandomForestRegressor\n 3 \n 4 model = RandomForestRegressor()\n----> 5 model.fit(X_train, y_train)\n 6 model.score(X_test, y_test)\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(estimator, *args, **kwargs)\n 1469 skip_parameter_validation=(\n 1470 prefer_skip_nested_validation or global_skip_validation\n 1471 )\n 1472 ):\n-> 1473 return fit_method(estimator, *args, **kwargs)\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py in ?(self, X, y, sample_weight)\n 359 # Validate or convert input data\n 360 if issparse(y):\n 361 raise ValueError(\"sparse multilabel-indicator for y is not supported.\")\n 362 \n--> 363 X, y = self._validate_data(\n 364 X,\n 365 y,\n 366 multi_output=True,\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py in ?(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)\n 646 if \"estimator\" not in check_y_params:\n 647 check_y_params = {**default_check_params, **check_y_params}\n 648 y = check_array(y, input_name=\"y\", **check_y_params)\n 649 else:\n--> 650 X, y = check_X_y(X, y, **check_params)\n 651 out = X, y\n 652 \n 653 if not no_val_X and check_params.get(\"ensure_2d\", True):\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(X, y, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, estimator)\n 1297 raise ValueError(\n 1298 f\"{estimator_name} requires y to be passed, but the target y is None\"\n 1299 )\n 1300 \n-> 1301 X = check_array(\n 1302 X,\n 1303 accept_sparse=accept_sparse,\n 1304 accept_large_sparse=accept_large_sparse,\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py in ?(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)\n 1009 )\n 1010 array = xp.astype(array, dtype, copy=False)\n 1011 else:\n 1012 array = _asarray_with_order(array, order=order, dtype=dtype, xp=xp)\n-> 1013 except ComplexWarning as complex_warning:\n 1014 raise ValueError(\n 1015 \"Complex data not supported\\n{}\\n\".format(array)\n 1016 ) from complex_warning\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/_array_api.py in ?(array, dtype, order, copy, xp, device)\n 747 # Use NumPy API to support order\n 748 if copy is True:\n 749 array = numpy.array(array, order=order, dtype=dtype)\n 750 else:\n--> 751 array = numpy.asarray(array, order=order, dtype=dtype)\n 752 \n 753 # At this point array is a NumPy ndarray. We convert it to an array\n 754 # container that is consistent with the input's namespace.\n\n~/miniforge3/envs/ai/lib/python3.11/site-packages/pandas/core/generic.py in ?(self, dtype, copy)\n 2149 def __array__(\n 2150 self, dtype: npt.DTypeLike | None = None, copy: bool_t | None = None\n 2151 ) -> np.ndarray:\n 2152 values = self._values\n-> 2153 arr = np.asarray(values, dtype=dtype)\n 2154 if (\n 2155 astype_is_view(values.dtype, arr.dtype)\n 2156 and using_copy_on_write()\n\nValueError: could not convert string to float: 'Honda' Oh no! We get a another ValueError (some of data is in string format rather than numerical format).
ValueError: could not convert string to float: 'Honda'\n
Machine learning models prefer to work with numbers than text.
So we'll have to convert the non-numerical features into numbers first.
The process of turning categorical features into numbers is often referred to as encoding.
Scikit-Learn has a fantastic in-depth guide on Encoding categorical features.
But let's look at one of the most straightforward ways to turn categorical features into numbers, one-hot encoding.
In machine learning, one-hot encoding gives a value of 1 to the target value and a value of 0 to the other values.
For example, let's say we had five samples and three car make options, Honda, Toyota, BMW.
And our samples were:
- Honda
- BMW
- BMW
- Toyota
- Toyota
If we were to one-hot encode these, it would look like:
Sample Honda Toyota BMW 1 1 0 0 2 0 0 1 3 0 0 1 4 0 1 0 5 0 1 0 Notice how there's a 1 for each target value but a 0 for each other value.
We can use the following steps to one-hot encode our dataset:
- Import
sklearn.preprocessing.OneHotEncoder to one-hot encode our features and sklearn.compose.ColumnTransformer to target the specific columns of our DataFrame to transform. - Define the categorical features we'd like to transform.
- Create an instance of the
OneHotEncoder. - Create an instance of
ColumnTransformer and feed it the transforms we'd like to make. - Fit the instance of the
ColumnTransformer to our data and transform it with the fit_transform(X) method.
Note: In Scikit-Learn, the term \"transformer\" is often used to refer to something that transforms data.
In\u00a0[37]: Copied! # 1. Import OneHotEncoder and ColumnTransformer\nfrom sklearn.preprocessing import OneHotEncoder\nfrom sklearn.compose import ColumnTransformer\n\n# 2. Define the categorical features to transform\ncategorical_features = [\"Make\", \"Colour\", \"Doors\"]\n\n# 3. Create an instance of OneHotEncoder\none_hot = OneHotEncoder()\n\n# 4. Create an instance of ColumnTransformer\ntransformer = ColumnTransformer([(\"one_hot\", # name\n one_hot, # transformer\n categorical_features)], # columns to transform\n remainder=\"passthrough\") # what to do with the rest of the columns? (\"passthrough\" = leave unchanged) \n\n# 5. Turn the categorical features into numbers (this will return an array-like sparse matrix, not a DataFrame)\ntransformed_X = transformer.fit_transform(X)\ntransformed_X\n
# 1. Import OneHotEncoder and ColumnTransformer from sklearn.preprocessing import OneHotEncoder from sklearn.compose import ColumnTransformer # 2. Define the categorical features to transform categorical_features = [\"Make\", \"Colour\", \"Doors\"] # 3. Create an instance of OneHotEncoder one_hot = OneHotEncoder() # 4. Create an instance of ColumnTransformer transformer = ColumnTransformer([(\"one_hot\", # name one_hot, # transformer categorical_features)], # columns to transform remainder=\"passthrough\") # what to do with the rest of the columns? (\"passthrough\" = leave unchanged) # 5. Turn the categorical features into numbers (this will return an array-like sparse matrix, not a DataFrame) transformed_X = transformer.fit_transform(X) transformed_X Out[37]: array([[0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,\n 0.00000e+00, 3.54310e+04],\n [1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,\n 1.00000e+00, 1.92714e+05],\n [0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,\n 0.00000e+00, 8.47140e+04],\n ...,\n [0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 1.00000e+00,\n 0.00000e+00, 6.66040e+04],\n [0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,\n 0.00000e+00, 2.15883e+05],\n [0.00000e+00, 0.00000e+00, 0.00000e+00, ..., 1.00000e+00,\n 0.00000e+00, 2.48360e+05]])
Note: You might be thinking why we considered Doors as a categorical variable. Which is a good question considering Doors is already numerical. Well, the answer is that Doors could be either numerical or categorical. However, I've decided to go with categorical, since where I'm from, number of doors is often a different category of car. For example, you can shop for 4-door cars or shop for 5-door cars (which always confused me since where's the 5th door?). However, you could experiment with treating this value as numerical or categorical, training a model on each, and then see how each model performs.
Woah! Looks like our samples are all numerical, what did our data look like previously?
In\u00a0[38]: Copied! X.head()\n
X.head() Out[38]: Make Colour Odometer (KM) Doors 0 Honda White 35431 4 1 BMW Blue 192714 5 2 Honda White 84714 4 3 Toyota White 154365 4 4 Nissan Blue 181577 3 It seems OneHotEncoder and ColumnTransformer have turned all of our data samples into numbers.
Let's check out the first transformed sample.
In\u00a0[39]: Copied! # View first transformed sample\ntransformed_X[0]\n
# View first transformed sample transformed_X[0] Out[39]: array([0.0000e+00, 1.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,\n 0.0000e+00, 0.0000e+00, 0.0000e+00, 1.0000e+00, 0.0000e+00,\n 1.0000e+00, 0.0000e+00, 3.5431e+04])
And what were these values originally?
In\u00a0[40]: Copied! # View original first sample\nX.iloc[0]\n
# View original first sample X.iloc[0] Out[40]: Make Honda\nColour White\nOdometer (KM) 35431\nDoors 4\nName: 0, dtype: object
In\u00a0[41]: Copied! # View head of original DataFrame\ncar_sales.head()\n
# View head of original DataFrame car_sales.head() Out[41]: Make Colour Odometer (KM) Doors Price 0 Honda White 35431 4 15323 1 BMW Blue 192714 5 19943 2 Honda White 84714 4 28343 3 Toyota White 154365 4 13434 4 Nissan Blue 181577 3 14043 Wonderful, now let's use pd.get_dummies() to turn our categorical variables into one-hot encoded variables.
In\u00a0[42]: Copied! # One-hot encode categorical variables\ncategorical_variables = [\"Make\", \"Colour\", \"Doors\"]\ndummies = pd.get_dummies(data=car_sales[categorical_variables])\ndummies\n
# One-hot encode categorical variables categorical_variables = [\"Make\", \"Colour\", \"Doors\"] dummies = pd.get_dummies(data=car_sales[categorical_variables]) dummies Out[42]: Doors Make_BMW Make_Honda Make_Nissan Make_Toyota Colour_Black Colour_Blue Colour_Green Colour_Red Colour_White 0 4 False True False False False False False False True 1 5 True False False False False True False False False 2 4 False True False False False False False False True 3 4 False False False True False False False False True 4 3 False False True False False True False False False ... ... ... ... ... ... ... ... ... ... ... 995 4 False False False True True False False False False 996 3 False False True False False False False False True 997 4 False False True False False True False False False 998 4 False True False False False False False False True 999 4 False False False True False True False False False 1000 rows \u00d7 10 columns
Nice!
Notice how there's a new column for each categorical option (e.g. Make_BMW, Make_Honda, etc).
But also notice how it also missed the Doors column?
This is because Doors is already numeric, so for pd.get_dummies() to work on it, we can change it to type object.
By default, pd.get_dummies() also turns all of the values to bools (True or False).
We can get the returned values as 0 or 1 by setting dtype=float.
In\u00a0[43]: Copied! # Have to convert doors to object for dummies to work on it...\ncar_sales[\"Doors\"] = car_sales[\"Doors\"].astype(object)\ndummies = pd.get_dummies(data=car_sales[[\"Make\", \"Colour\", \"Doors\"]],\n dtype=float)\ndummies\n
# Have to convert doors to object for dummies to work on it... car_sales[\"Doors\"] = car_sales[\"Doors\"].astype(object) dummies = pd.get_dummies(data=car_sales[[\"Make\", \"Colour\", \"Doors\"]], dtype=float) dummies Out[43]: Make_BMW Make_Honda Make_Nissan Make_Toyota Colour_Black Colour_Blue Colour_Green Colour_Red Colour_White Doors_3 Doors_4 Doors_5 0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 1.0 0.0 1 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 2 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 1.0 0.0 3 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 1.0 0.0 4 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 0.0 0.0 ... ... ... ... ... ... ... ... ... ... ... ... ... 995 0.0 0.0 0.0 1.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 996 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 1.0 0.0 0.0 997 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 998 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 1.0 0.0 999 0.0 0.0 0.0 1.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 1000 rows \u00d7 12 columns
Woohoo!
We've now turned our data into fully numeric form using Scikit-Learn and pandas.
Now you might be wondering...
Should you use Scikit-Learn or pandas for turning data into numerical form?
And the answer is either.
But as a rule of thumb:
- If you're performing quick data analysis and running small modelling experiments, use
pandas as it's generally quite fast to get up and running. - If you're performing a larger scale modelling experiment or would like to put your data processing steps into a production pipeline, I'd recommend leaning towards Scikit-Learn, specifically a Scikit-Learn Pipeline (chaining together multiple estimator/modelling steps).
Since we've turned our data into numerical form, how about we try and fit our model again?
Let's recreate a train/test split except this time we'll use transformed_X instead of X.
In\u00a0[44]: Copied! np.random.seed(42)\n\n# Create train and test splits with transformed_X\nX_train, X_test, y_train, y_test = train_test_split(transformed_X,\n y,\n test_size=0.2)\n\n# Create the model instance\nmodel = RandomForestRegressor()\n\n# Fit the model on the numerical data (this errored before since our data wasn't fully numeric)\nmodel.fit(X_train, y_train)\n\n# Score the model (returns r^2 metric by default, also called coefficient of determination, higher is better)\nmodel.score(X_test, y_test)\n
np.random.seed(42) # Create train and test splits with transformed_X X_train, X_test, y_train, y_test = train_test_split(transformed_X, y, test_size=0.2) # Create the model instance model = RandomForestRegressor() # Fit the model on the numerical data (this errored before since our data wasn't fully numeric) model.fit(X_train, y_train) # Score the model (returns r^2 metric by default, also called coefficient of determination, higher is better) model.score(X_test, y_test) Out[44]: 0.3235867221569877
In\u00a0[47]: Copied! # Import car sales dataframe with missing values\n# car_sales_missing = pd.read_csv(\"../data/car-sales-extended-missing-data.csv\") # load from local directory\ncar_sales_missing = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales-extended-missing-data.csv\") # read directly from URL (source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/car-sales-extended-missing-data.csv)\ncar_sales_missing.head(10)\n
# Import car sales dataframe with missing values # car_sales_missing = pd.read_csv(\"../data/car-sales-extended-missing-data.csv\") # load from local directory car_sales_missing = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales-extended-missing-data.csv\") # read directly from URL (source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/car-sales-extended-missing-data.csv) car_sales_missing.head(10) Out[47]: Make Colour Odometer (KM) Doors Price 0 Honda White 35431.0 4.0 15323.0 1 BMW Blue 192714.0 5.0 19943.0 2 Honda White 84714.0 4.0 28343.0 3 Toyota White 154365.0 4.0 13434.0 4 Nissan Blue 181577.0 3.0 14043.0 5 Honda Red 42652.0 4.0 23883.0 6 Toyota Blue 163453.0 4.0 8473.0 7 Honda White NaN 4.0 20306.0 8 NaN White 130538.0 4.0 9374.0 9 Honda Blue 51029.0 4.0 26683.0 Notice the NaN value in row 7 for the Odometer (KM) column, that means pandas has detected a missing value there.
However, if you're dataset is large, it's likely you aren't going to go through it sample by sample to find the missing values.
Luckily, pandas has a method called pd.DataFrame.isna() which is able to detect missing values.
Let's try it on our DataFrame.
In\u00a0[48]: Copied! # Get the sum of all missing values\ncar_sales_missing.isna().sum()\n
# Get the sum of all missing values car_sales_missing.isna().sum() Out[48]: Make 49\nColour 50\nOdometer (KM) 50\nDoors 50\nPrice 50\ndtype: int64
Hmm... seems there's about 50 or so missing values per column.
How about we try and split the data into features and labels, then convert the categorical data to numbers, then split the data into training and test and then try and fit a model on it (just like we did before)?
In\u00a0[49]: Copied! # Create features\nX_missing = car_sales_missing.drop(\"Price\", axis=1)\nprint(f\"Number of missing X values:\\n{X_missing.isna().sum()}\")\n # Create features X_missing = car_sales_missing.drop(\"Price\", axis=1) print(f\"Number of missing X values:\\n{X_missing.isna().sum()}\") Number of missing X values:\nMake 49\nColour 50\nOdometer (KM) 50\nDoors 50\ndtype: int64\n
In\u00a0[50]: Copied! # Create labels\ny_missing = car_sales_missing[\"Price\"]\nprint(f\"Number of missing y values: {y_missing.isna().sum()}\")\n # Create labels y_missing = car_sales_missing[\"Price\"] print(f\"Number of missing y values: {y_missing.isna().sum()}\") Number of missing y values: 50\n
Now we can convert the categorical columns into one-hot encodings (just as before).
In\u00a0[51]: Copied! # Let's convert the categorical columns to one hot encoded (code copied from above)\n# Turn the categories (Make and Colour) into numbers\nfrom sklearn.preprocessing import OneHotEncoder\nfrom sklearn.compose import ColumnTransformer\n\ncategorical_features = [\"Make\", \"Colour\", \"Doors\"]\n\none_hot = OneHotEncoder()\n\ntransformer = ColumnTransformer([(\"one_hot\", \n one_hot, \n categorical_features)],\n remainder=\"passthrough\",\n sparse_threshold=0) # return a sparse matrix or not\n\ntransformed_X_missing = transformer.fit_transform(X_missing)\ntransformed_X_missing\n
# Let's convert the categorical columns to one hot encoded (code copied from above) # Turn the categories (Make and Colour) into numbers from sklearn.preprocessing import OneHotEncoder from sklearn.compose import ColumnTransformer categorical_features = [\"Make\", \"Colour\", \"Doors\"] one_hot = OneHotEncoder() transformer = ColumnTransformer([(\"one_hot\", one_hot, categorical_features)], remainder=\"passthrough\", sparse_threshold=0) # return a sparse matrix or not transformed_X_missing = transformer.fit_transform(X_missing) transformed_X_missing Out[51]: array([[0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 0.00000e+00,\n 0.00000e+00, 3.54310e+04],\n [1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 1.00000e+00,\n 0.00000e+00, 1.92714e+05],\n [0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 0.00000e+00,\n 0.00000e+00, 8.47140e+04],\n ...,\n [0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 0.00000e+00,\n 0.00000e+00, 6.66040e+04],\n [0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 0.00000e+00,\n 0.00000e+00, 2.15883e+05],\n [0.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,\n 0.00000e+00, 2.48360e+05]])
Finally, let's split the missing data samples into train and test sets and then try to fit and score a model on them.
In\u00a0[52]: Copied! # Split data into training and test sets\nX_train, X_test, y_train, y_test = train_test_split(transformed_X_missing,\n y_missing,\n test_size=0.2)\n\n# Fit and score a model\nmodel = RandomForestRegressor()\nmodel.fit(X_train, y_train)\nmodel.score(X_test, y_test)\n
# Split data into training and test sets X_train, X_test, y_train, y_test = train_test_split(transformed_X_missing, y_missing, test_size=0.2) # Fit and score a model model = RandomForestRegressor() model.fit(X_train, y_train) model.score(X_test, y_test) \n---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\nCell In[52], line 8\n 6 # Fit and score a model\n 7 model = RandomForestRegressor()\n----> 8 model.fit(X_train, y_train)\n 9 model.score(X_test, y_test)\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py:1473, in _fit_context.<locals>.decorator.<locals>.wrapper(estimator, *args, **kwargs)\n 1466 estimator._validate_params()\n 1468 with config_context(\n 1469 skip_parameter_validation=(\n 1470 prefer_skip_nested_validation or global_skip_validation\n 1471 )\n 1472 ):\n-> 1473 return fit_method(estimator, *args, **kwargs)\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/ensemble/_forest.py:363, in BaseForest.fit(self, X, y, sample_weight)\n 360 if issparse(y):\n 361 raise ValueError(\"sparse multilabel-indicator for y is not supported.\")\n--> 363 X, y = self._validate_data(\n 364 X,\n 365 y,\n 366 multi_output=True,\n 367 accept_sparse=\"csc\",\n 368 dtype=DTYPE,\n 369 force_all_finite=False,\n 370 )\n 371 # _compute_missing_values_in_feature_mask checks if X has missing values and\n 372 # will raise an error if the underlying tree base estimator can't handle missing\n 373 # values. Only the criterion is required to determine if the tree supports\n 374 # missing values.\n 375 estimator = type(self.estimator)(criterion=self.criterion)\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/base.py:650, in BaseEstimator._validate_data(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)\n 648 y = check_array(y, input_name=\"y\", **check_y_params)\n 649 else:\n--> 650 X, y = check_X_y(X, y, **check_params)\n 651 out = X, y\n 653 if not no_val_X and check_params.get(\"ensure_2d\", True):\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py:1318, in check_X_y(X, y, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, estimator)\n 1297 raise ValueError(\n 1298 f\"{estimator_name} requires y to be passed, but the target y is None\"\n 1299 )\n 1301 X = check_array(\n 1302 X,\n 1303 accept_sparse=accept_sparse,\n (...)\n 1315 input_name=\"X\",\n 1316 )\n-> 1318 y = _check_y(y, multi_output=multi_output, y_numeric=y_numeric, estimator=estimator)\n 1320 check_consistent_length(X, y)\n 1322 return X, y\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py:1328, in _check_y(y, multi_output, y_numeric, estimator)\n 1326 \"\"\"Isolated part of check_X_y dedicated to y validation\"\"\"\n 1327 if multi_output:\n-> 1328 y = check_array(\n 1329 y,\n 1330 accept_sparse=\"csr\",\n 1331 force_all_finite=True,\n 1332 ensure_2d=False,\n 1333 dtype=None,\n 1334 input_name=\"y\",\n 1335 estimator=estimator,\n 1336 )\n 1337 else:\n 1338 estimator_name = _check_estimator_name(estimator)\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py:1064, in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)\n 1058 raise ValueError(\n 1059 \"Found array with dim %d. %s expected <= 2.\"\n 1060 % (array.ndim, estimator_name)\n 1061 )\n 1063 if force_all_finite:\n-> 1064 _assert_all_finite(\n 1065 array,\n 1066 input_name=input_name,\n 1067 estimator_name=estimator_name,\n 1068 allow_nan=force_all_finite == \"allow-nan\",\n 1069 )\n 1071 if copy:\n 1072 if _is_numpy_namespace(xp):\n 1073 # only make a copy if `array` and `array_orig` may share memory`\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py:123, in _assert_all_finite(X, allow_nan, msg_dtype, estimator_name, input_name)\n 120 if first_pass_isfinite:\n 121 return\n--> 123 _assert_all_finite_element_wise(\n 124 X,\n 125 xp=xp,\n 126 allow_nan=allow_nan,\n 127 msg_dtype=msg_dtype,\n 128 estimator_name=estimator_name,\n 129 input_name=input_name,\n 130 )\n\nFile ~/miniforge3/envs/ai/lib/python3.11/site-packages/sklearn/utils/validation.py:172, in _assert_all_finite_element_wise(X, xp, allow_nan, msg_dtype, estimator_name, input_name)\n 155 if estimator_name and input_name == \"X\" and has_nan_error:\n 156 # Improve the error message on how to handle missing values in\n 157 # scikit-learn.\n 158 msg_err += (\n 159 f\"\\n{estimator_name} does not accept missing values\"\n 160 \" encoded as NaN natively. For supervised learning, you might want\"\n (...)\n 170 \"#estimators-that-handle-nan-values\"\n 171 )\n--> 172 raise ValueError(msg_err)\n\nValueError: Input y contains NaN. Ahh... dam! Another ValueError (our input data contains missing values).
ValueError: Input y contains NaN.
Looks like the model we're trying to use doesn't work with missing values.
When we try to fit it on a dataset with missing samples, Scikit-Learn produces an error similar to:
ValueError: Input X contains NaN. RandomForestRegressor does not accept missing values encoded as NaN natively...
Looks like if we want to use RandomForestRegressor, we'll have to either fill or remove the missing values.
Note: Scikit-Learn does have a list of models which can handle NaNs or missing values directly. Such as, sklearn.ensemble.HistGradientBoostingClassifier or sklearn.ensemble.HistGradientBoostingRegressor.
As an experiment, you may want to try the following:
\nfrom sklearn.ensemble import HistGradientBoostingRegressor\n\n# Try a model that can handle NaNs natively\nnan_model = HistGradientBoostingRegressor()\nnan_model.fit(X_train, y_train)\nnan_model.score(X_test, y_test)\n
Let's see what values are missing again. In\u00a0[53]: Copied! car_sales_missing.isna().sum()\n
car_sales_missing.isna().sum() Out[53]: Make 49\nColour 50\nOdometer (KM) 50\nDoors 50\nPrice 50\ndtype: int64
How can fill (impute) or remove these?
In\u00a0[55]: Copied! # Fill the missing values in the Make column\n# Note: In previous versions of pandas, inplace=True was possible, however this will be changed in a future version, can use reassignment instead.\n# car_sales_missing[\"Make\"].fillna(value=\"missing\", inplace=True)\n\ncar_sales_missing[\"Make\"] = car_sales_missing[\"Make\"].fillna(value=\"missing\")\n
# Fill the missing values in the Make column # Note: In previous versions of pandas, inplace=True was possible, however this will be changed in a future version, can use reassignment instead. # car_sales_missing[\"Make\"].fillna(value=\"missing\", inplace=True) car_sales_missing[\"Make\"] = car_sales_missing[\"Make\"].fillna(value=\"missing\") And we can do the same with the Colour column.
In\u00a0[56]: Copied! # Note: In previous versions of pandas, inplace=True was possible, however this will be changed in a future version, can use reassignment instead.\n# car_sales_missing[\"Colour\"].fillna(value=\"missing\", inplace=True)\n\n# Fill the Colour column\ncar_sales_missing[\"Colour\"] = car_sales_missing[\"Colour\"].fillna(value=\"missing\")\n
# Note: In previous versions of pandas, inplace=True was possible, however this will be changed in a future version, can use reassignment instead. # car_sales_missing[\"Colour\"].fillna(value=\"missing\", inplace=True) # Fill the Colour column car_sales_missing[\"Colour\"] = car_sales_missing[\"Colour\"].fillna(value=\"missing\") How many missing values do we have now?
In\u00a0[57]: Copied! car_sales_missing.isna().sum()\n
car_sales_missing.isna().sum() Out[57]: Make 0\nColour 0\nOdometer (KM) 50\nDoors 50\nPrice 50\ndtype: int64
Wonderful! We're making some progress.
Now let's fill the Doors column with 4 (the most common value), this is the same as filling it with the median or mode of the Doors column.
In\u00a0[58]: Copied! # Find the most common value of the Doors column\ncar_sales_missing[\"Doors\"].value_counts()\n
# Find the most common value of the Doors column car_sales_missing[\"Doors\"].value_counts() Out[58]: Doors\n4.0 811\n5.0 75\n3.0 64\nName: count, dtype: int64
In\u00a0[59]: Copied! # Fill the Doors column with the most common value\ncar_sales_missing[\"Doors\"] = car_sales_missing[\"Doors\"].fillna(value=4)\n
# Fill the Doors column with the most common value car_sales_missing[\"Doors\"] = car_sales_missing[\"Doors\"].fillna(value=4) Next, we'll fill the Odometer (KM) column with the mean value of itself.
In\u00a0[60]: Copied! # Fill the Odometer (KM) column\n# Old: car_sales_missing[\"Odometer (KM)\"].fillna(value=car_sales_missing[\"Odometer (KM)\"].mean(), inplace=True)\n\ncar_sales_missing[\"Odometer (KM)\"] = car_sales_missing[\"Odometer (KM)\"].fillna(value=car_sales_missing[\"Odometer (KM)\"].mean())\n
# Fill the Odometer (KM) column # Old: car_sales_missing[\"Odometer (KM)\"].fillna(value=car_sales_missing[\"Odometer (KM)\"].mean(), inplace=True) car_sales_missing[\"Odometer (KM)\"] = car_sales_missing[\"Odometer (KM)\"].fillna(value=car_sales_missing[\"Odometer (KM)\"].mean()) How many missing values do we have now?
In\u00a0[61]: Copied! # Check the number of missing values\ncar_sales_missing.isna().sum()\n
# Check the number of missing values car_sales_missing.isna().sum() Out[61]: Make 0\nColour 0\nOdometer (KM) 0\nDoors 0\nPrice 50\ndtype: int64
Woohoo! That's looking a lot better.
Finally, we can remove the rows which are missing the target value Price.
Note: Another option would be to impute the Price value with the mean or median or some other calculated value (such as by using similar cars to estimate the price), however, to keep things simple and prevent introducing too many fake labels to the data, we'll remove the samples missing a Price value.
We can remove rows with missing values in place from a pandas DataFrame with the pandas.DataFrame.dropna(inplace=True) method.
In\u00a0[62]: Copied! # Remove rows with missing Price labels\ncar_sales_missing.dropna(inplace=True)\n
# Remove rows with missing Price labels car_sales_missing.dropna(inplace=True) That should be no more missing values!
In\u00a0[63]: Copied! # Check the number of missing values\ncar_sales_missing.isna().sum()\n
# Check the number of missing values car_sales_missing.isna().sum() Out[63]: Make 0\nColour 0\nOdometer (KM) 0\nDoors 0\nPrice 0\ndtype: int64
Since we removed samples missing a Price value, there's now less overall samples but none of them have missing values.
In\u00a0[64]: Copied! # Check the number of total samples (previously was 1000)\nlen(car_sales_missing)\n
# Check the number of total samples (previously was 1000) len(car_sales_missing) Out[64]: 950
Can we fit a model now?
Let's try!
First we'll create the features and labels.
Then we'll convert categorical variables into numbers via one-hot encoding.
Then we'll split the data into training and test sets just like before.
Finally, we'll try to fit a RandomForestRegressor() model to the newly filled data.
In\u00a0[65]: Copied! # Create features\nX_missing = car_sales_missing.drop(\"Price\", axis=1)\nprint(f\"Number of missing X values:\\n{X_missing.isna().sum()}\")\n\n# Create labels\ny_missing = car_sales_missing[\"Price\"]\nprint(f\"Number of missing y values: {y_missing.isna().sum()}\")\n # Create features X_missing = car_sales_missing.drop(\"Price\", axis=1) print(f\"Number of missing X values:\\n{X_missing.isna().sum()}\") # Create labels y_missing = car_sales_missing[\"Price\"] print(f\"Number of missing y values: {y_missing.isna().sum()}\") Number of missing X values:\nMake 0\nColour 0\nOdometer (KM) 0\nDoors 0\ndtype: int64\nNumber of missing y values: 0\n
In\u00a0[66]: Copied! from sklearn.preprocessing import OneHotEncoder\nfrom sklearn.compose import ColumnTransformer\n\ncategorical_features = [\"Make\", \"Colour\", \"Doors\"]\n\none_hot = OneHotEncoder()\n\ntransformer = ColumnTransformer([(\"one_hot\", \n one_hot, \n categorical_features)],\n remainder=\"passthrough\",\n sparse_threshold=0) # return a sparse matrix or not\n\ntransformed_X_missing = transformer.fit_transform(X_missing)\ntransformed_X_missing\n
from sklearn.preprocessing import OneHotEncoder from sklearn.compose import ColumnTransformer categorical_features = [\"Make\", \"Colour\", \"Doors\"] one_hot = OneHotEncoder() transformer = ColumnTransformer([(\"one_hot\", one_hot, categorical_features)], remainder=\"passthrough\", sparse_threshold=0) # return a sparse matrix or not transformed_X_missing = transformer.fit_transform(X_missing) transformed_X_missing Out[66]: array([[0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,\n 0.00000e+00, 3.54310e+04],\n [1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,\n 1.00000e+00, 1.92714e+05],\n [0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,\n 0.00000e+00, 8.47140e+04],\n ...,\n [0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 1.00000e+00,\n 0.00000e+00, 6.66040e+04],\n [0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,\n 0.00000e+00, 2.15883e+05],\n [0.00000e+00, 0.00000e+00, 0.00000e+00, ..., 1.00000e+00,\n 0.00000e+00, 2.48360e+05]])
In\u00a0[67]: Copied! # Split data into training and test sets\nnp.random.seed(42)\nX_train, X_test, y_train, y_test = train_test_split(transformed_X_missing,\n y_missing,\n test_size=0.2)\n\n# Fit and score a model\nmodel = RandomForestRegressor()\nmodel.fit(X_train, y_train)\nmodel.score(X_test, y_test)\n
# Split data into training and test sets np.random.seed(42) X_train, X_test, y_train, y_test = train_test_split(transformed_X_missing, y_missing, test_size=0.2) # Fit and score a model model = RandomForestRegressor() model.fit(X_train, y_train) model.score(X_test, y_test) Out[67]: 0.22011714008302485
Fantastic!!!
Looks like filling the missing values with pandas worked!
Our model can be fit to the data without issues.
In\u00a0[68]: Copied! car_sales_missing.isna().sum()\n
car_sales_missing.isna().sum() Out[68]: Make 0\nColour 0\nOdometer (KM) 0\nDoors 0\nPrice 0\ndtype: int64
Let's reimport it so it has missing values and we can fill them with Scikit-Learn.
In\u00a0[69]: Copied! # Reimport the DataFrame (so that all the missing values are back)\n# car_sales_missing = pd.read_csv(\"../data/car-sales-extended-missing-data.csv\") # read from local directory\ncar_sales_missing = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales-extended-missing-data.csv\") # read directly from URL (source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/car-sales-extended-missing-data.csv)\ncar_sales_missing.isna().sum()\n
# Reimport the DataFrame (so that all the missing values are back) # car_sales_missing = pd.read_csv(\"../data/car-sales-extended-missing-data.csv\") # read from local directory car_sales_missing = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales-extended-missing-data.csv\") # read directly from URL (source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/car-sales-extended-missing-data.csv) car_sales_missing.isna().sum() Out[69]: Make 49\nColour 50\nOdometer (KM) 50\nDoors 50\nPrice 50\ndtype: int64
To begin, we'll remove the rows which are missing a Price value.
In\u00a0[70]: Copied! # Drop the rows with missing in the Price column\ncar_sales_missing.dropna(subset=[\"Price\"], inplace=True)\n
# Drop the rows with missing in the Price column car_sales_missing.dropna(subset=[\"Price\"], inplace=True) Now there are no rows missing a Price value.
In\u00a0[71]: Copied! car_sales_missing.isna().sum()\n
car_sales_missing.isna().sum() Out[71]: Make 47\nColour 46\nOdometer (KM) 48\nDoors 47\nPrice 0\ndtype: int64
Since we don't have to fill any Price values, let's split our data into features (X) and labels (y).
We'll also split the data into training and test sets.
In\u00a0[72]: Copied! # Split into X and y\nX = car_sales_missing.drop(\"Price\", axis=1)\ny = car_sales_missing[\"Price\"]\n\n# Split data into train and test\nnp.random.seed(42)\nX_train, X_test, y_train, y_test = train_test_split(X,\n y,\n test_size=0.2)\n
# Split into X and y X = car_sales_missing.drop(\"Price\", axis=1) y = car_sales_missing[\"Price\"] # Split data into train and test np.random.seed(42) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) Note: We've split the data into train & test sets here first to perform filling missing values on them separately. This is best practice as the test set is supposed to emulate data the model has never seen before. For categorical variables, it's generally okay to fill values across the whole dataset. However, for numerical vairables, you should only fill values on the test set that have been computed from the training set.
Training and test sets created!
Let's now setup a few instances of SimpleImputer() to fill various missing values.
We'll use the following strategies and fill values:
- For categorical columns (
Make, Colour), strategy=\"constant\", fill_value=\"missing\" (fill the missing samples with a consistent value of \"missing\". - For the
Door column, strategy=\"constant\", fill_value=4 (fill the missing samples with a consistent value of 4). - For the numerical column (
Odometer (KM)), strategy=\"mean\" (fill the missing samples with the mean of the target column). - Note: There are more
strategy and fill options in the SimpleImputer() documentation.
In\u00a0[73]: Copied! from sklearn.impute import SimpleImputer\n\n# Create categorical variable imputer\ncat_imputer = SimpleImputer(strategy=\"constant\", fill_value=\"missing\")\n\n# Create Door column imputer\ndoor_imputer = SimpleImputer(strategy=\"constant\", fill_value=4)\n\n# Create Odometer (KM) column imputer\nnum_imputer = SimpleImputer(strategy=\"mean\")\n
from sklearn.impute import SimpleImputer # Create categorical variable imputer cat_imputer = SimpleImputer(strategy=\"constant\", fill_value=\"missing\") # Create Door column imputer door_imputer = SimpleImputer(strategy=\"constant\", fill_value=4) # Create Odometer (KM) column imputer num_imputer = SimpleImputer(strategy=\"mean\") Imputers created!
Now let's define which columns we'd like to impute on.
Why?
Because we'll need these shortly (I'll explain in the next text cell).
In\u00a0[74]: Copied! # Define different column features\ncategorical_features = [\"Make\", \"Colour\"]\ndoor_feature = [\"Doors\"]\nnumerical_feature = [\"Odometer (KM)\"]\n
# Define different column features categorical_features = [\"Make\", \"Colour\"] door_feature = [\"Doors\"] numerical_feature = [\"Odometer (KM)\"] Columns defined!
Now how might we transform our columns?
Hint: we can use the sklearn.compose.ColumnTransformer class from Scikit-Learn, in a similar way to what we did before to get our data to all numeric values.
That's the reason we defined the columns we'd like to transform.
So we can use the ColumnTransformer() class.
ColumnTransformer() takes as input a list of tuples in the form (name_of_transform, transformer_to_use, columns_to_transform) specifying which columns to transform and how to transform them.
For example:
imputer = ColumnTransformer([\n (\"cat_imputer\", cat_imputer, categorical_features)\n])\n
In this case, the variables in the tuple are:
name_of_transform = \"cat_imputer\"transformer_to_use = cat_imputer (the instance of SimpleImputer() we defined above)columns_to_transform = categorical_features (the list of categorical features we defined above).
Let's exapnd upon this by extending the example.
In\u00a0[75]: Copied! from sklearn.compose import ColumnTransformer\n\n# Create series of column transforms to perform\nimputer = ColumnTransformer([\n (\"cat_imputer\", cat_imputer, categorical_features),\n (\"door_imputer\", door_imputer, door_feature),\n (\"num_imputer\", num_imputer, numerical_feature)])\n
from sklearn.compose import ColumnTransformer # Create series of column transforms to perform imputer = ColumnTransformer([ (\"cat_imputer\", cat_imputer, categorical_features), (\"door_imputer\", door_imputer, door_feature), (\"num_imputer\", num_imputer, numerical_feature)]) Nice!
The next step is to fit our ColumnTransformer() instance (imputer) to the training data and transform the testing data.
In other words we want to:
- Learn the imputation values from the training set.
- Fill the missing values in the training set with the values learned in 1.
- Fill the missing values in the testing set with the values learned in 1.
Why this way?
In our case, we're not calculating many variables (except the mean of the Odometer (KM) column), however, remember that the test set should always remain as unseen data.
So when filling values in the test set, they should only be with values calculated or imputed from the training sets.
We can achieve steps 1 & 2 simultaneously with the ColumnTransformer.fit_transform() method (fit = find the values to fill, transform = fill them).
And then we can perform step 3 with the ColumnTransformer.transform() method (we only want to transform the test set, not learn different values to fill).
In\u00a0[76]: Copied! # Find values to fill and transform training data\nfilled_X_train = imputer.fit_transform(X_train)\n\n# Fill values in to the test set with values learned from the training set\nfilled_X_test = imputer.transform(X_test)\n\n# Check filled X_train\nfilled_X_train\n
# Find values to fill and transform training data filled_X_train = imputer.fit_transform(X_train) # Fill values in to the test set with values learned from the training set filled_X_test = imputer.transform(X_test) # Check filled X_train filled_X_train Out[76]: array([['Honda', 'White', 4.0, 71934.0],\n ['Toyota', 'Red', 4.0, 162665.0],\n ['Honda', 'White', 4.0, 42844.0],\n ...,\n ['Toyota', 'White', 4.0, 196225.0],\n ['Honda', 'Blue', 4.0, 133117.0],\n ['Honda', 'missing', 4.0, 150582.0]], dtype=object)
Wonderful!
Let's now turn our filled_X_train and filled_X_test arrays into DataFrames to inspect their missing values.
In\u00a0[77]: Copied! # Get our transformed data array's back into DataFrame's\nfilled_X_train_df = pd.DataFrame(filled_X_train, \n columns=[\"Make\", \"Colour\", \"Doors\", \"Odometer (KM)\"])\n\nfilled_X_test_df = pd.DataFrame(filled_X_test, \n columns=[\"Make\", \"Colour\", \"Doors\", \"Odometer (KM)\"])\n\n# Check missing data in training set\nfilled_X_train_df.isna().sum()\n
# Get our transformed data array's back into DataFrame's filled_X_train_df = pd.DataFrame(filled_X_train, columns=[\"Make\", \"Colour\", \"Doors\", \"Odometer (KM)\"]) filled_X_test_df = pd.DataFrame(filled_X_test, columns=[\"Make\", \"Colour\", \"Doors\", \"Odometer (KM)\"]) # Check missing data in training set filled_X_train_df.isna().sum() Out[77]: Make 0\nColour 0\nDoors 0\nOdometer (KM) 0\ndtype: int64
And is there any missing data in the test set?
In\u00a0[78]: Copied! # Check missing data in the testing set\nfilled_X_test_df.isna().sum()\n
# Check missing data in the testing set filled_X_test_df.isna().sum() Out[78]: Make 0\nColour 0\nDoors 0\nOdometer (KM) 0\ndtype: int64
What about the original?
In\u00a0[79]: Copied! # Check to see the original... still missing values\ncar_sales_missing.isna().sum()\n
# Check to see the original... still missing values car_sales_missing.isna().sum() Out[79]: Make 47\nColour 46\nOdometer (KM) 48\nDoors 47\nPrice 0\ndtype: int64
Perfect!
No more missing values!
But wait...
Is our data all numerical?
In\u00a0[80]: Copied! filled_X_train_df.head()\n
filled_X_train_df.head() Out[80]: Make Colour Doors Odometer (KM) 0 Honda White 4.0 71934.0 1 Toyota Red 4.0 162665.0 2 Honda White 4.0 42844.0 3 Honda White 4.0 195829.0 4 Honda Blue 4.0 219217.0 Ahh... looks like our Make and Colour columns are still strings.
Let's one-hot encode them along with the Doors column to make sure they're numerical, just as we did previously.
In\u00a0[81]: Copied! # Now let's one hot encode the features with the same code as before \nfrom sklearn.preprocessing import OneHotEncoder\nfrom sklearn.compose import ColumnTransformer\n\ncategorical_features = [\"Make\", \"Colour\", \"Doors\"]\n\none_hot = OneHotEncoder()\n\ntransformer = ColumnTransformer([(\"one_hot\", \n one_hot, \n categorical_features)],\n remainder=\"passthrough\",\n sparse_threshold=0) # return a sparse matrix or not\n\n# Fill train and test values separately\ntransformed_X_train = transformer.fit_transform(filled_X_train_df)\ntransformed_X_test = transformer.transform(filled_X_test_df)\n\n# Check transformed and filled X_train\ntransformed_X_train\n
# Now let's one hot encode the features with the same code as before from sklearn.preprocessing import OneHotEncoder from sklearn.compose import ColumnTransformer categorical_features = [\"Make\", \"Colour\", \"Doors\"] one_hot = OneHotEncoder() transformer = ColumnTransformer([(\"one_hot\", one_hot, categorical_features)], remainder=\"passthrough\", sparse_threshold=0) # return a sparse matrix or not # Fill train and test values separately transformed_X_train = transformer.fit_transform(filled_X_train_df) transformed_X_test = transformer.transform(filled_X_test_df) # Check transformed and filled X_train transformed_X_train Out[81]: array([[0.0, 1.0, 0.0, ..., 1.0, 0.0, 71934.0],\n [0.0, 0.0, 0.0, ..., 1.0, 0.0, 162665.0],\n [0.0, 1.0, 0.0, ..., 1.0, 0.0, 42844.0],\n ...,\n [0.0, 0.0, 0.0, ..., 1.0, 0.0, 196225.0],\n [0.0, 1.0, 0.0, ..., 1.0, 0.0, 133117.0],\n [0.0, 1.0, 0.0, ..., 1.0, 0.0, 150582.0]], dtype=object)
Nice!
Now our data is:
- All numerical
- No missing values
Let's try and fit a model!
In\u00a0[82]: Copied! # Now we've transformed X, let's see if we can fit a model\nnp.random.seed(42)\nfrom sklearn.ensemble import RandomForestRegressor\n\nmodel = RandomForestRegressor()\n\n# Make sure to use the transformed data (filled and one-hot encoded X data)\nmodel.fit(transformed_X_train, y_train)\nmodel.score(transformed_X_test, y_test)\n
# Now we've transformed X, let's see if we can fit a model np.random.seed(42) from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor() # Make sure to use the transformed data (filled and one-hot encoded X data) model.fit(transformed_X_train, y_train) model.score(transformed_X_test, y_test) Out[82]: 0.21229043336119102
You might have noticed this result is slightly different to before.
Why do you think this is?
It's because we've created our training and testing sets differently.
We split the data into training and test sets before filling the missing values.
Previously, we did the reverse, filled missing values before splitting the data into training and test sets.
Doing this can lead to information from the training set leaking into the testing set.
Remember, one of the most important concepts in machine learning is making sure your model doesn't see any testing data before evaluation.
We'll keep practicing but for now, some of the main takeaways are:
- Keep your training and test sets separate.
- Most datasets you come across won't be in a form ready to immediately start using them with machine learning models. And some may take more preparation than others to get ready to use.
- For most machine learning models, your data has to be numerical. This will involve converting whatever you're working with into numbers. This process is often referred to as feature engineering or feature encoding.
- Some machine learning models aren't compatible with missing data. The process of filling missing data is referred to as data imputation.
In\u00a0[83]: Copied! # Get California Housing dataset\nfrom sklearn.datasets import fetch_california_housing\nhousing = fetch_california_housing()\nhousing; # gets downloaded as dictionary\n
# Get California Housing dataset from sklearn.datasets import fetch_california_housing housing = fetch_california_housing() housing; # gets downloaded as dictionary Since it's in a dictionary, let's turn it into a DataFrame so we can inspect it better.
In\u00a0[84]: Copied! housing_df = pd.DataFrame(housing[\"data\"], columns=housing[\"feature_names\"])\nhousing_df[\"target\"] = pd.Series(housing[\"target\"])\nhousing_df.head()\n
housing_df = pd.DataFrame(housing[\"data\"], columns=housing[\"feature_names\"]) housing_df[\"target\"] = pd.Series(housing[\"target\"]) housing_df.head() Out[84]: MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude Longitude target 0 8.3252 41.0 6.984127 1.023810 322.0 2.555556 37.88 -122.23 4.526 1 8.3014 21.0 6.238137 0.971880 2401.0 2.109842 37.86 -122.22 3.585 2 7.2574 52.0 8.288136 1.073446 496.0 2.802260 37.85 -122.24 3.521 3 5.6431 52.0 5.817352 1.073059 558.0 2.547945 37.85 -122.25 3.413 4 3.8462 52.0 6.281853 1.081081 565.0 2.181467 37.85 -122.25 3.422 In\u00a0[85]: Copied! # How many samples?\nlen(housing_df)\n
# How many samples? len(housing_df) Out[85]: 20640
Beautiful, our goal here is to use the feature columns, such as:
MedInc - median income in block groupHouseAge - median house age in block groupAveRooms - average number of rooms per householdAveBedrms - average number of bedrooms per household
To predict the target column which expresses the median house value for specfici California districts in hundreds of thousands of dollars (e.g. 4.526 = $452,600).
In essence, each row is a different district in California (the data) and we're trying to build a model to predict the median house value in that distract (the target/label) given a series of attributes about the houses in that district.
Since we have data and labels, this is a supervised learning problem.
And since we're trying to predict a number, it's a regression problem.
Knowing these two things, how do they line up on the Scikit-Learn machine learning algorithm cheat-sheet?
Following the map through, knowing what we know, it suggests we try RidgeRegression. Let's chek it out.
In\u00a0[86]: Copied! # Import the Ridge model class from the linear_model module\nfrom sklearn.linear_model import Ridge\n\n# Setup random seed\nnp.random.seed(42)\n\n# Split the data into features (X) and labels (y)\nX = housing_df.drop(\"target\", axis=1)\ny = housing_df[\"target\"]\n\n# Split into train and test sets\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\n# Institate and fit the model (on the training set)\nmodel = Ridge()\nmodel.fit(X_train, y_train)\n\n# Check the score of the model (on the test set)\n# The default score() metirc of regression aglorithms is R^2\nmodel.score(X_test, y_test)\n
# Import the Ridge model class from the linear_model module from sklearn.linear_model import Ridge # Setup random seed np.random.seed(42) # Split the data into features (X) and labels (y) X = housing_df.drop(\"target\", axis=1) y = housing_df[\"target\"] # Split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Institate and fit the model (on the training set) model = Ridge() model.fit(X_train, y_train) # Check the score of the model (on the test set) # The default score() metirc of regression aglorithms is R^2 model.score(X_test, y_test) Out[86]: 0.5758549611440125
What if RidgeRegression didn't work? Or what if we wanted to improve our results?
Following the diagram, the next step would be to try EnsembleRegressors.
Ensemble is another word for multiple models put together to make a decision.
One of the most common and useful ensemble methods is the Random Forest. Known for its fast training and prediction times and adaptibility to different problems.
The basic premise of the Random Forest is to combine a number of different decision trees, each one random from the other and make a prediction on a sample by averaging the result of each decision tree.
An in-depth discussion of the Random Forest algorithm is beyond the scope of this notebook but if you're interested in learning more, An Implementation and Explanation of the Random Forest in Python by Will Koehrsen is a great read.
Since we're working with regression, we'll use Scikit-Learn's RandomForestRegressor.
We can use the exact same workflow as above. Except for changing the model.
In\u00a0[87]: Copied! # Import the RandomForestRegressor model class from the ensemble module\nfrom sklearn.ensemble import RandomForestRegressor\n\n# Setup random seed\nnp.random.seed(42)\n\n# Split the data into features (X) and labels (y)\nX = housing_df.drop(\"target\", axis=1)\ny = housing_df[\"target\"]\n\n# Split into train and test sets\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\n# Institate and fit the model (on the training set)\nmodel = RandomForestRegressor()\nmodel.fit(X_train, y_train)\n\n# Check the score of the model (on the test set)\n# The default score metirc of regression aglorithms is R^2\nmodel.score(X_test, y_test)\n
# Import the RandomForestRegressor model class from the ensemble module from sklearn.ensemble import RandomForestRegressor # Setup random seed np.random.seed(42) # Split the data into features (X) and labels (y) X = housing_df.drop(\"target\", axis=1) y = housing_df[\"target\"] # Split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Institate and fit the model (on the training set) model = RandomForestRegressor() model.fit(X_train, y_train) # Check the score of the model (on the test set) # The default score metirc of regression aglorithms is R^2 model.score(X_test, y_test) Out[87]: 0.8059809073051385
Woah!
We get a good boost in score on the test set by changing the model.
This is another incredibly important concept in machine learning, if at first something doesn't achieve what you'd like, experiment, experiment, experiment!
At first, the Scikit-Learn algorithm diagram can seem confusing.
But once you get a little practice applying different models to different problems, you'll start to pick up which sorts of algorithms do better with different types of data.
In\u00a0[90]: Copied! # heart_disease = pd.read_csv(\"../data/heart-disease.csv\") # load from local directory\nheart_disease = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/heart-disease.csv\") # load directly from URL (source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/heart-disease.csv)\nheart_disease.head()\n
# heart_disease = pd.read_csv(\"../data/heart-disease.csv\") # load from local directory heart_disease = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/heart-disease.csv\") # load directly from URL (source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/heart-disease.csv) heart_disease.head() Out[90]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1 In\u00a0[91]: Copied! # How many samples are there?\nlen(heart_disease)\n
# How many samples are there? len(heart_disease) Out[91]: 303
Similar to the California Housing dataset, here we want to use all of the available data to predict the target column (1 for if a patient has heart disease and 0 for if they don't).
So what do we know?
We've got 303 samples (1 row = 1 sample) and we're trying to predict whether or not a patient has heart disease.
Because we're trying to predict whether each sample is one thing or another, we've got a classification problem.
Let's see how it lines up with our Scikit-Learn algorithm cheat-sheet.
Following the cheat-sheet we end up at LinearSVC which stands for Linear Support Vector Classifier. Let's try it on our data.
In\u00a0[92]: Copied! # Import LinearSVC from the svm module\nfrom sklearn.svm import LinearSVC\n\n# Setup random seed\nnp.random.seed(42)\n\n# Split the data into X (features/data) and y (target/labels)\nX = heart_disease.drop(\"target\", axis=1)\ny = heart_disease[\"target\"]\n\n# Split into train and test sets\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\n# Instantiate and fit the model (on the training set)\nclf = LinearSVC(max_iter=1000, # iterations on the data, 1000 is the default\n dual=\"auto\") # dual=\"auto\" chooses best parameters for the model automatically\nclf.fit(X_train, y_train)\n\n# Check the score of the model (on the test set)\nclf.score(X_test, y_test)\n
# Import LinearSVC from the svm module from sklearn.svm import LinearSVC # Setup random seed np.random.seed(42) # Split the data into X (features/data) and y (target/labels) X = heart_disease.drop(\"target\", axis=1) y = heart_disease[\"target\"] # Split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Instantiate and fit the model (on the training set) clf = LinearSVC(max_iter=1000, # iterations on the data, 1000 is the default dual=\"auto\") # dual=\"auto\" chooses best parameters for the model automatically clf.fit(X_train, y_train) # Check the score of the model (on the test set) clf.score(X_test, y_test) Out[92]: 0.8688524590163934
Straight out of the box (with no tuning or improvements) our model achieves over 85% accruacy!
Although this is a sensational result to begin with, let's check out the diagram and see what other models we might use.
Following the path (and skipping a few, don't worry, we'll get to this) we come up to EnsembleMethods again.
Except this time, we'll be looking at ensemble classifiers instead of regressors.
Remember our RandomForestRegressor from above?
We'll it has a dance partner, RandomForestClassifier which is an ensemble based machine model learning model for classification.
You might be able to guess what we can use it for (hint: classification problems).
Let's try!
In\u00a0[93]: Copied! # Import the RandomForestClassifier model class from the ensemble module\nfrom sklearn.ensemble import RandomForestClassifier\n\n# Setup random seed\nnp.random.seed(42)\n\n# Split the data into X (features/data) and y (target/labels)\nX = heart_disease.drop(\"target\", axis=1)\ny = heart_disease[\"target\"]\n\n# Split into train and test sets\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\n# Instantiate and fit the model (on the training set)\nclf = RandomForestClassifier(n_estimators=100) # 100 is the default, but you could try 1000 and see what happens\nclf.fit(X_train, y_train)\n\n# Check the score of the model (on the test set)\nclf.score(X_test, y_test)\n
# Import the RandomForestClassifier model class from the ensemble module from sklearn.ensemble import RandomForestClassifier # Setup random seed np.random.seed(42) # Split the data into X (features/data) and y (target/labels) X = heart_disease.drop(\"target\", axis=1) y = heart_disease[\"target\"] # Split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Instantiate and fit the model (on the training set) clf = RandomForestClassifier(n_estimators=100) # 100 is the default, but you could try 1000 and see what happens clf.fit(X_train, y_train) # Check the score of the model (on the test set) clf.score(X_test, y_test) Out[93]: 0.8524590163934426
Hmmm, it looks like the default hyperparameters of RandomForestClassifier don't perform as well as LinearSVC.
Other than trying another classification model, we could start to run experiments to try and improve these models via hyperparameter tuning.
Hyperparameter tuning is fancy term for adjusting some settings on a model to try and make it better.
It usually happens once you've found a decent baseline model that you'd like to improve upon.
In this case, we could take either the RandomForestClassifier or the LinearSVC and try and improve it with hyperparameter tuning (which we'll see later on).
For example, you could try and take the n_estimators parameter (the number of trees in the forest) of RandomForestClassifier and change it from 100 (default) to 1000 and see what happens.
In\u00a0[94]: Copied! # Import the RandomForestClassifier model class from the ensemble module\nfrom sklearn.ensemble import RandomForestClassifier\n\n# Setup random seed\nnp.random.seed(42)\n\n# Split the data into X (features/data) and y (target/labels)\nX = heart_disease.drop(\"target\", axis=1)\ny = heart_disease[\"target\"]\n\n# Split into train and test sets\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\n# Instantiate the model (on the training set)\nclf = RandomForestClassifier(n_estimators=100)\n\n# Call the fit method on the model and pass it training data\nclf.fit(X_train, y_train)\n\n# Check the score of the model (on the test set)\nclf.score(X_test, y_test)\n
# Import the RandomForestClassifier model class from the ensemble module from sklearn.ensemble import RandomForestClassifier # Setup random seed np.random.seed(42) # Split the data into X (features/data) and y (target/labels) X = heart_disease.drop(\"target\", axis=1) y = heart_disease[\"target\"] # Split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Instantiate the model (on the training set) clf = RandomForestClassifier(n_estimators=100) # Call the fit method on the model and pass it training data clf.fit(X_train, y_train) # Check the score of the model (on the test set) clf.score(X_test, y_test) Out[94]: 0.8524590163934426
What's happening here?
Calling the fit() method will cause the machine learning algorithm to attempt to find patterns between X and y. Or if there's no y, it'll only find the patterns within X.
Let's see X.
In\u00a0[95]: Copied! X.head()\n
X.head() Out[95]: age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal 0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 And y.
In\u00a0[96]: Copied! y.head()\n
y.head() Out[96]: 0 1\n1 1\n2 1\n3 1\n4 1\nName: target, dtype: int64
Passing X and y to fit() will cause the model to go through all of the examples in X (data) and see what their corresponding y (label) is.
How the model does this is different depending on the model you use.
Explaining the details of each would take an entire textbook.
For now, you could imagine it similar to how you would figure out patterns if you had enough time.
You'd look at the feature variables, X, the age, sex, chol (cholesterol) and see what different values led to the labels, y, 1 for heart disease, 0 for not heart disease.
This concept, regardless of the problem, is similar throughout all of machine learning.
During training (finding patterns in data):
A machine learning algorithm looks at a dataset, finds patterns, tries to use those patterns to predict something and corrects itself as best it can with the available data and labels. It stores these patterns for later use.
During testing or in production (using learned patterns):
A machine learning algorithm uses the patterns its previously learned in a dataset to make a prediction on some unseen data.
In\u00a0[97]: Copied! # Use a trained model to make predictions\nclf.predict(X_test)\n
# Use a trained model to make predictions clf.predict(X_test) Out[97]: array([0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0,\n 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1,\n 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0])
Given data in the form of X, the predict() function returns labels in the form of y.
Note: For the predict() function to work, it must be passed X (data) in the same format the model was trained on. For example, if a model was trained on 10 features formatted in a certain way, predictions should be made on data with 10 features fortmatted in a certain way. Anything different and it will return an error.
It's standard practice to save these predictions to a variable named something like y_preds for later comparison to y_test or y_true (usually same as y_test just another name).
In\u00a0[98]: Copied! # Compare predictions to truth\ny_preds = clf.predict(X_test)\nnp.mean(y_preds == y_test)\n
# Compare predictions to truth y_preds = clf.predict(X_test) np.mean(y_preds == y_test) Out[98]: np.float64(0.8524590163934426)
Another way evaluating predictions (comparing them to the truth labels) is with Scikit-Learn's sklearn.metrics module.
Inside, you'll find method such as accuracy_score(), which is the default evaluation metric for classification problems.
In\u00a0[100]: Copied! from sklearn.metrics import accuracy_score\naccuracy_score(y_test, y_preds)\n
from sklearn.metrics import accuracy_score accuracy_score(y_test, y_preds) Out[100]: 0.8524590163934426
predict_proba() returns the probabilities (proba is short for probability) of a classification label.
In\u00a0[101]: Copied! # Return probabilities rather than labels\nclf.predict_proba(X_test[:5])\n
# Return probabilities rather than labels clf.predict_proba(X_test[:5]) Out[101]: array([[0.89, 0.11],\n [0.49, 0.51],\n [0.43, 0.57],\n [0.84, 0.16],\n [0.18, 0.82]])
Let's see the difference.
In\u00a0[102]: Copied! # Return labels\nclf.predict(X_test[:5])\n
# Return labels clf.predict(X_test[:5]) Out[102]: array([0, 1, 1, 0, 1])
predict_proba() returns an array of five arrays each containing two values.
Each number is the probability of a label given a sample.
In\u00a0[103]: Copied! # Find prediction probabilities for 1 sample\nclf.predict_proba(X_test[:1])\n
# Find prediction probabilities for 1 sample clf.predict_proba(X_test[:1]) Out[103]: array([[0.89, 0.11]])
This output means for the sample X_test[:1], the model is predicting label 0 (index 0) with a probability score of 0.9.
Because the highest probability score is at index 0 (and it's over 0.5), when using predict(), a label of 0 is assigned.
In\u00a0[104]: Copied! # Return the label for 1 sample\nclf.predict(X_test[:1])\n
# Return the label for 1 sample clf.predict(X_test[:1]) Out[104]: array([0])
Where does 0.5 come from?
Because our problem is a binary classification task (heart disease or not heart disease), predicting a label with 0.5 probability every time would be the same as a coin toss (guessing 50/50 every time).
Therefore, once the prediction probability of a sample passes 0.5 for a certain label, it's assigned that label.
predict() can also be used for regression models.
In\u00a0[105]: Copied! # Import the RandomForestRegressor model class from the ensemble module\nfrom sklearn.ensemble import RandomForestRegressor\n\n# Setup random seed\nnp.random.seed(42)\n\n# Split the data into features (X) and labels (y)\nX = housing_df.drop(\"target\", axis=1)\ny = housing_df[\"target\"]\n\n# Split into train and test sets\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\n# Institate and fit the model (on the training set)\nmodel = RandomForestRegressor()\nmodel.fit(X_train, y_train)\n\n# Make predictions\ny_preds = model.predict(X_test)\n
# Import the RandomForestRegressor model class from the ensemble module from sklearn.ensemble import RandomForestRegressor # Setup random seed np.random.seed(42) # Split the data into features (X) and labels (y) X = housing_df.drop(\"target\", axis=1) y = housing_df[\"target\"] # Split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Institate and fit the model (on the training set) model = RandomForestRegressor() model.fit(X_train, y_train) # Make predictions y_preds = model.predict(X_test) Now we can evaluate our regression model by using sklearn.metrics.mean_absolute_error which returns the average error across all samples.
In\u00a0[106]: Copied! # Compare the predictions to the truth\nfrom sklearn.metrics import mean_absolute_error\nmean_absolute_error(y_test, y_preds)\n
# Compare the predictions to the truth from sklearn.metrics import mean_absolute_error mean_absolute_error(y_test, y_preds) Out[106]: np.float64(0.3270458119670544)
Now we've seen how to get a model how to find patterns in data using the fit() function and make predictions using what its learned using the predict() and predict_proba() functions, it's time to evaluate those predictions.
In\u00a0[107]: Copied! # Import the RandomForestClassifier model class from the ensemble module\nfrom sklearn.ensemble import RandomForestClassifier\n\n# Setup random seed\nnp.random.seed(42)\n\n# Split the data into X (features/data) and y (target/labels)\nX = heart_disease.drop(\"target\", axis=1)\ny = heart_disease[\"target\"]\n\n# Split into train and test sets\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\n# Instantiate the model (on the training set)\nclf = RandomForestClassifier(n_estimators=100)\n\n# Call the fit method on the model and pass it training data\nclf.fit(X_train, y_train);\n
# Import the RandomForestClassifier model class from the ensemble module from sklearn.ensemble import RandomForestClassifier # Setup random seed np.random.seed(42) # Split the data into X (features/data) and y (target/labels) X = heart_disease.drop(\"target\", axis=1) y = heart_disease[\"target\"] # Split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Instantiate the model (on the training set) clf = RandomForestClassifier(n_estimators=100) # Call the fit method on the model and pass it training data clf.fit(X_train, y_train); Once the model has been fit on the training data (X_train, y_train), we can call the score() method on it and evaluate our model on the test data, data the model has never seen before (X_test, y_test).
In\u00a0[108]: Copied! # Check the score of the model (on the test set)\nclf.score(X_test, y_test)\n
# Check the score of the model (on the test set) clf.score(X_test, y_test) Out[108]: 0.8524590163934426
Each model in Scikit-Learn implements a default metric for score() which is suitable for the problem.
For example:
- Classifier models generally use
metrics.accuracy_score() as the default score() metric. - Regression models generally use
metrics.r2_score as the default score() metric. - There many more classification and regression specific metrics implemented in
sklearn.metrics.
Because clf is an instance of RandomForestClassifier, the score() method uses mean accuracy as its score method.
You can find this by pressing SHIFT + TAB (inside a Jupyter Notebook, may be different elsewhere) within the brackets of score() when called on a model instance.
Behind the scenes, score() makes predictions on X_test using the trained model and then compares those predictions to the actual labels y_test.
A classification model which predicts everything 100% correct would receive an accuracy score of 1.0 (or 100%).
Our model doesn't get everything correct, but at ~85% accuracy (0.85 * 100), it's still far better than guessing.
Let's do the same but with the regression code from above.
In\u00a0[109]: Copied! # Import the RandomForestRegressor model class from the ensemble module\nfrom sklearn.ensemble import RandomForestRegressor\n\n# Setup random seed\nnp.random.seed(42)\n\n# Split the data into features (X) and labels (y)\nX = housing_df.drop(\"target\", axis=1)\ny = housing_df[\"target\"]\n\n# Split into train and test sets\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\n# Institate and fit the model (on the training set)\nmodel = RandomForestRegressor()\nmodel.fit(X_train, y_train);\n
# Import the RandomForestRegressor model class from the ensemble module from sklearn.ensemble import RandomForestRegressor # Setup random seed np.random.seed(42) # Split the data into features (X) and labels (y) X = housing_df.drop(\"target\", axis=1) y = housing_df[\"target\"] # Split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Institate and fit the model (on the training set) model = RandomForestRegressor() model.fit(X_train, y_train); Due to the consistent design of the Scikit-Learn library, we can call the same score() method on model.
In\u00a0[110]: Copied! # Check the score of the model (on the test set)\nmodel.score(X_test, y_test)\n
# Check the score of the model (on the test set) model.score(X_test, y_test) Out[110]: 0.8059809073051385
Here, model is an instance of RandomForestRegressor.
And since it's a regression model, the default metric built into score() is the coefficient of determination or R^2 (pronounced R-sqaured).
Remember, you can find this by pressing SHIFT + TAB within the brackets of score() when called on a model instance.
The best possible value here is 1.0, this means the model predicts the target regression values exactly.
Calling the score() method on any model instance and passing it test data is a good quick way to see how your model is going.
However, when you get further into a problem, it's likely you'll want to start using more powerful metrics to evaluate your models performance.
In\u00a0[111]: Copied! # Import cross_val_score from the model_selection module\nfrom sklearn.model_selection import cross_val_score\n\n# Import the RandomForestClassifier model class from the ensemble module\nfrom sklearn.ensemble import RandomForestClassifier\n\n# Setup random seed\nnp.random.seed(42)\n\n# Split the data into X (features/data) and y (target/labels)\nX = heart_disease.drop(\"target\", axis=1)\ny = heart_disease[\"target\"]\n\n# Split into train and test sets\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\n# Instantiate the model (on the training set)\nclf = RandomForestClassifier(n_estimators=100)\n\n# Call the fit method on the model and pass it training data\nclf.fit(X_train, y_train);\n
# Import cross_val_score from the model_selection module from sklearn.model_selection import cross_val_score # Import the RandomForestClassifier model class from the ensemble module from sklearn.ensemble import RandomForestClassifier # Setup random seed np.random.seed(42) # Split the data into X (features/data) and y (target/labels) X = heart_disease.drop(\"target\", axis=1) y = heart_disease[\"target\"] # Split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Instantiate the model (on the training set) clf = RandomForestClassifier(n_estimators=100) # Call the fit method on the model and pass it training data clf.fit(X_train, y_train); Using cross_val_score() is slightly different to score().
Let's see a code example first and then we'll go through the details.
In\u00a0[112]: Copied! # Using score()\nclf.score(X_test, y_test)\n
# Using score() clf.score(X_test, y_test) Out[112]: 0.8524590163934426
In\u00a0[113]: Copied! # Using cross_val_score()\ncross_val_score(clf, X, y, cv=5) # cv = number of splits to test (5 by default)\n
# Using cross_val_score() cross_val_score(clf, X, y, cv=5) # cv = number of splits to test (5 by default) Out[113]: array([0.81967213, 0.86885246, 0.81967213, 0.78333333, 0.76666667])
What's happening here?
The first difference you might notice is cross_val_score() returns an array where as score() only returns a single number.
cross_val_score() returns an array because of a parameter called cv, which stands for cross-validation.
When cv isn't set, cross_val_score() will return an array of 5 numbers by default (cv=None is the same as setting cv=5).
Remember, you can see the parameters of a function using SHIFT + TAB (inside a Jupyter Notebook) from within the brackets.
But wait, you might be thinking, what even is cross-validation?
A visual might be able to help.
We've dealt with Figure 1.0 before using score(X_test, y_test).
But looking deeper into this, if a model is trained using the training data or 80% of samples, this means 20% of samples aren't used for the model to learn anything.
This also means depending on what 80% is used to train on and what 20% is used to evaluate the model, it may achieve a score which doesn't reflect the entire dataset.
For example, if a lot of easy examples are in the 80% training data, when it comes to test on the 20%, your model may perform poorly.
The same goes for the reverse.
Figure 2.0 shows 5-fold cross-validation, a method which tries to provide a solution to:
- Not training on all the data (always keeping training and test sets separate).
- Avoiding getting lucky scores on single splits of the data.
Instead of training only on 1 training split and evaluating on 1 testing split, 5-fold cross-validation does it 5 times.
On a different split each time, returning a score for each.
Why 5-fold?
The actual name of this setup K-fold cross-validation. Where K is an abitrary number. We've used 5 because it looks nice visually, and it is the default value in sklearn.model_selection.cross_val_score.
Figure 2.0 is what happens when we run the following.
In\u00a0[114]: Copied! # 5-fold cross-validation\ncross_val_score(clf, X, y, cv=5) # cv is equivalent to K\n
# 5-fold cross-validation cross_val_score(clf, X, y, cv=5) # cv is equivalent to K Out[114]: array([0.83606557, 0.8852459 , 0.7704918 , 0.8 , 0.8 ])
Since we set cv=5 (5-fold cross-validation), we get back 5 different scores instead of 1.
Taking the mean of this array gives us a more in-depth idea of how our model is performing by converting the 5 scores into one.
In\u00a0[115]: Copied! np.random.seed(42)\n\n# Single training and test split score\nclf_single_score = clf.score(X_test, y_test)\n\n# Take mean of 5-fold cross-validation\nclf_cross_val_score = np.mean(cross_val_score(clf, X, y, cv=5))\n\nclf_single_score, clf_cross_val_score\n
np.random.seed(42) # Single training and test split score clf_single_score = clf.score(X_test, y_test) # Take mean of 5-fold cross-validation clf_cross_val_score = np.mean(cross_val_score(clf, X, y, cv=5)) clf_single_score, clf_cross_val_score Out[115]: (0.8524590163934426, np.float64(0.8248087431693989))
Notice, the average cross_val_score() is slightly lower than single value returned by score().
In this case, if you were asked to report the accuracy of your model, even though it's lower, you'd prefer the cross-validated metric over the non-cross-validated metric.
Wait?
We haven't used the scoring parameter at all.
By default, it's set to None.
In\u00a0[116]: Copied! cross_val_score(clf, X, y, cv=5, scoring=None) # default scoring value, this can be set to other scoring metrics\n
cross_val_score(clf, X, y, cv=5, scoring=None) # default scoring value, this can be set to other scoring metrics Out[116]: array([0.78688525, 0.86885246, 0.80327869, 0.78333333, 0.76666667])
Note: If you notice different scores each time you call cross_val_score, this is because each data split is random every time. So the model may achieve higher/lower scores on different splits of the data. To get reproducible scores, you can set the random seed.
When scoring is set to None (by default), it uses the same metric as score() for whatever model is passed to cross_val_score().
In this case, our model is clf which is an instance of RandomForestClassifier which uses mean accuracy as the default score() metric.
You can change the evaluation score cross_val_score() uses by changing the scoring parameter.
And as you might have guessed, different problems call for different evaluation scores.
The Scikit-Learn documentation outlines a vast range of evaluation metrics for different problems but let's have a look at a few.
In\u00a0[117]: Copied! # Import cross_val_score from the model_selection module\nfrom sklearn.model_selection import cross_val_score\nfrom sklearn.ensemble import RandomForestClassifier\n\nnp.random.seed(42)\n\nX = heart_disease.drop(\"target\", axis=1)\ny = heart_disease[\"target\"]\n\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\nclf = RandomForestClassifier()\nclf.fit(X_train, y_train)\nclf.score(X_test, y_test)\n
# Import cross_val_score from the model_selection module from sklearn.model_selection import cross_val_score from sklearn.ensemble import RandomForestClassifier np.random.seed(42) X = heart_disease.drop(\"target\", axis=1) y = heart_disease[\"target\"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) clf = RandomForestClassifier() clf.fit(X_train, y_train) clf.score(X_test, y_test) Out[117]: 0.8524590163934426
In\u00a0[118]: Copied! # Accuracy as percentage\nprint(f\"Heart Disease Classifier Accuracy: {clf.score(X_test, y_test) * 100:.2f}%\")\n # Accuracy as percentage print(f\"Heart Disease Classifier Accuracy: {clf.score(X_test, y_test) * 100:.2f}%\") Heart Disease Classifier Accuracy: 85.25%\n
In\u00a0[119]: Copied! from sklearn.metrics import roc_curve\n\n# Make predictions with probabilities\ny_probs = clf.predict_proba(X_test)\n\n# Keep the probabilites of the positive class only\ny_probs = y_probs[:, 1]\n\n# Calculate fpr, tpr and thresholds\nfpr, tpr, thresholds = roc_curve(y_test, y_probs)\n\n# Check the false positive rate\nfpr\n
from sklearn.metrics import roc_curve # Make predictions with probabilities y_probs = clf.predict_proba(X_test) # Keep the probabilites of the positive class only y_probs = y_probs[:, 1] # Calculate fpr, tpr and thresholds fpr, tpr, thresholds = roc_curve(y_test, y_probs) # Check the false positive rate fpr Out[119]: array([0. , 0. , 0. , 0. , 0. ,\n 0.03448276, 0.03448276, 0.03448276, 0.03448276, 0.06896552,\n 0.06896552, 0.10344828, 0.13793103, 0.13793103, 0.17241379,\n 0.17241379, 0.27586207, 0.4137931 , 0.48275862, 0.55172414,\n 0.65517241, 0.72413793, 0.72413793, 0.82758621, 1. ])
Looking at these on their own doesn't make much sense. It's much easier to see their value visually.
Let's create a helper function to make a ROC curve given the false positive rates (fpr) and true positive rates (tpr).
Note: As of Scikit-Learn 1.2+, there is functionality of plotting a ROC curve. You can find this under sklearn.metrics.RocCurveDisplay.
In\u00a0[120]: Copied! import matplotlib.pyplot as plt\n\ndef plot_roc_curve(fpr, tpr):\n \"\"\"\n Plots a ROC curve given the false positve rate (fpr) and \n true postive rate (tpr) of a classifier.\n \"\"\"\n # Plot ROC curve\n plt.plot(fpr, tpr, color='orange', label='ROC')\n # Plot line with no predictive power (baseline)\n plt.plot([0, 1], [0, 1], color='darkblue', linestyle='--', label='Guessing')\n # Customize the plot\n plt.xlabel('False Positive Rate')\n plt.ylabel('True Positive Rate')\n plt.title('Receiver Operating Characteristic (ROC) Curve')\n plt.legend()\n plt.show()\n \nplot_roc_curve(fpr, tpr)\n import matplotlib.pyplot as plt def plot_roc_curve(fpr, tpr): \"\"\" Plots a ROC curve given the false positve rate (fpr) and true postive rate (tpr) of a classifier. \"\"\" # Plot ROC curve plt.plot(fpr, tpr, color='orange', label='ROC') # Plot line with no predictive power (baseline) plt.plot([0, 1], [0, 1], color='darkblue', linestyle='--', label='Guessing') # Customize the plot plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('Receiver Operating Characteristic (ROC) Curve') plt.legend() plt.show() plot_roc_curve(fpr, tpr) Looking at the plot for the first time, it might seem a bit confusing.
The main thing to take away here is our model is doing far better than guessing.
A metric you can use to quantify the ROC curve in a single number is AUC (Area Under Curve).
Scikit-Learn implements a function to caculate this called sklearn.metrics.roc_auc_score.
The maximum ROC AUC score you can achieve is 1.0 and generally, the closer to 1.0, the better the model.
In\u00a0[122]: Copied! from sklearn.metrics import roc_auc_score\n\nroc_auc_score_value = roc_auc_score(y_test, y_probs)\nroc_auc_score_value\n
from sklearn.metrics import roc_auc_score roc_auc_score_value = roc_auc_score(y_test, y_probs) roc_auc_score_value Out[122]: np.float64(0.9304956896551724)
I'll let you in a secret...
Although it was good practice, we didn't actually need to create our own plot_roc_curve function.
Scikit-Learn allows us to plot a ROC curve directly from our estimator/model by using the class method sklearn.metrics.RocCurveDisplay.from_estimator and passing it our estimator, X_test and y_test.
In\u00a0[123]: Copied! from sklearn.metrics import RocCurveDisplay\nroc_curve_display = RocCurveDisplay.from_estimator(estimator=clf, \n X=X_test, \n y=y_test)\n
from sklearn.metrics import RocCurveDisplay roc_curve_display = RocCurveDisplay.from_estimator(estimator=clf, X=X_test, y=y_test) The most ideal position for a ROC curve to run along the top left corner of the plot.
This would mean the model predicts only true positives and no false positives. And would result in a ROC AUC score of 1.0.
You can see this by creating a ROC curve using only the y_test labels.
In\u00a0[124]: Copied! # Plot perfect ROC curve\nfpr, tpr, thresholds = roc_curve(y_test, y_test)\nplot_roc_curve(fpr, tpr)\n
# Plot perfect ROC curve fpr, tpr, thresholds = roc_curve(y_test, y_test) plot_roc_curve(fpr, tpr) In\u00a0[125]: Copied! # Perfect ROC AUC score\nroc_auc_score(y_test, y_test)\n
# Perfect ROC AUC score roc_auc_score(y_test, y_test) Out[125]: np.float64(1.0)
In reality, a perfect ROC curve is unlikely.
In\u00a0[126]: Copied! from sklearn.metrics import confusion_matrix\n\ny_preds = clf.predict(X_test)\n\nconfusion_matrix(y_test, y_preds)\n
from sklearn.metrics import confusion_matrix y_preds = clf.predict(X_test) confusion_matrix(y_test, y_preds) Out[126]: array([[24, 5],\n [ 4, 28]])
Again, this is probably easier visualized.
One way to do it is with pd.crosstab().
In\u00a0[127]: Copied! pd.crosstab(y_test, \n y_preds, \n rownames=[\"Actual Label\"], \n colnames=[\"Predicted Label\"])\n
pd.crosstab(y_test, y_preds, rownames=[\"Actual Label\"], colnames=[\"Predicted Label\"]) Out[127]: Predicted Label 0 1 Actual Label 0 24 5 1 4 28 In\u00a0[128]: Copied! from sklearn.metrics import ConfusionMatrixDisplay\n\nConfusionMatrixDisplay.from_estimator(estimator=clf, X=X, y=y);\n
from sklearn.metrics import ConfusionMatrixDisplay ConfusionMatrixDisplay.from_estimator(estimator=clf, X=X, y=y); In\u00a0[129]: Copied! # Plot confusion matrix from predictions\nConfusionMatrixDisplay.from_predictions(y_true=y_test, \n y_pred=y_preds);\n
# Plot confusion matrix from predictions ConfusionMatrixDisplay.from_predictions(y_true=y_test, y_pred=y_preds); In\u00a0[130]: Copied! from sklearn.metrics import classification_report\n\nprint(classification_report(y_test, y_preds))\n
from sklearn.metrics import classification_report print(classification_report(y_test, y_preds)) precision recall f1-score support\n\n 0 0.86 0.83 0.84 29\n 1 0.85 0.88 0.86 32\n\n accuracy 0.85 61\n macro avg 0.85 0.85 0.85 61\nweighted avg 0.85 0.85 0.85 61\n\n
It returns four columns: precision, recall, f1-score and support.
The number of rows will depend on how many different classes there are. But there will always be three rows labell accuracy, macro avg and weighted avg.
Each term measures something slightly different:
- Precision - Indicates the proportion of positive identifications (model predicted class
1) which were actually correct. A model which produces no false positives has a precision of 1.0. - Recall - Indicates the proportion of actual positives which were correctly classified. A model which produces no false negatives has a recall of 1.0.
- F1 score - A combination of precision and recall. A perfect model achieves an F1 score of 1.0.
- Support - The number of samples each metric was calculated on.
- Accuracy - The accuracy of the model in decimal form. Perfect accuracy is equal to 1.0, in other words, getting the prediction right 100% of the time.
- Macro avg - Short for macro average, the average precision, recall and F1 score between classes. Macro avg doesn't take class imbalance into effect. So if you do have class imbalances (more examples of one class than another), you should pay attention to this.
- Weighted avg - Short for weighted average, the weighted average precision, recall and F1 score between classes. Weighted means each metric is calculated with respect to how many samples there are in each class. This metric will favour the majority class (e.g. it will give a high value when one class out performs another due to having more samples).
When should you use each?
It can be tempting to base your classification models perfomance only on accuracy. And accuracy is a good metric to report, except when you have very imbalanced classes.
For example, let's say there were 10,000 people. And 1 of them had a disease. You're asked to build a model to predict who has it.
You build the model and find your model to be 99.99% accurate. Which sounds great! ...until you realise, all its doing is predicting no one has the disease, in other words all 10,000 predictions are false.
In this case, you'd want to turn to metrics such as precision, recall and F1 score.
In\u00a0[131]: Copied! # Where precision and recall become valuable\ndisease_true = np.zeros(10000)\ndisease_true[0] = 1 # only one case\n\ndisease_preds = np.zeros(10000) # every prediction is 0\n\npd.DataFrame(classification_report(disease_true, \n disease_preds, \n output_dict=True,\n zero_division=0))\n
# Where precision and recall become valuable disease_true = np.zeros(10000) disease_true[0] = 1 # only one case disease_preds = np.zeros(10000) # every prediction is 0 pd.DataFrame(classification_report(disease_true, disease_preds, output_dict=True, zero_division=0)) Out[131]: 0.0 1.0 accuracy macro avg weighted avg precision 0.99990 0.0 0.9999 0.499950 0.99980 recall 1.00000 0.0 0.9999 0.500000 0.99990 f1-score 0.99995 0.0 0.9999 0.499975 0.99985 support 9999.00000 1.0 0.9999 10000.000000 10000.00000 You can see here, we've got an accuracy of 0.9999 (99.99%), great precision and recall on class 0.0 but nothing for class 1.0.
Ask yourself, although the model achieves 99.99% accuracy, is it useful?
To summarize:
- Accuracy is a good measure to start with if all classes are balanced (e.g. same amount of samples which are labelled with 0 or 1)
- Precision and recall become more important when classes are imbalanced.
- If false positive predictions are worse than false negatives, aim for higher precision.
- If false negative predictions are worse than false positives, aim for higher recall.
Resource: For more on precision and recall and the tradeoffs between them, I'd suggest going through the Scikit-Learn Precision-Recall guide.
In\u00a0[132]: Copied! # Import the RandomForestRegressor model class from the ensemble module\nfrom sklearn.ensemble import RandomForestRegressor\n\n# Setup random seed\nnp.random.seed(42)\n\n# Split data into features (X) and labels (y)\nX = housing_df.drop(\"target\", axis=1)\ny = housing_df[\"target\"]\n\n# Split into train and test sets\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\n# Institate and fit the model (on the training set)\nmodel = RandomForestRegressor()\nmodel.fit(X_train, y_train);\n
# Import the RandomForestRegressor model class from the ensemble module from sklearn.ensemble import RandomForestRegressor # Setup random seed np.random.seed(42) # Split data into features (X) and labels (y) X = housing_df.drop(\"target\", axis=1) y = housing_df[\"target\"] # Split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Institate and fit the model (on the training set) model = RandomForestRegressor() model.fit(X_train, y_train); R^2 Score (coefficient of determination)
Once you've got a trained regression model, the default evaluation metric in the score() function is R^2.
In\u00a0[133]: Copied! # Calculate the models R^2 score\nmodel.score(X_test, y_test)\n
# Calculate the models R^2 score model.score(X_test, y_test) Out[133]: 0.8059809073051385
Outside of the score() function, R^2 can be calculated using Scikit-Learn's r2_score() function.
A model which only predicted the mean would get a score of 0.
In\u00a0[134]: Copied! from sklearn.metrics import r2_score\n\n# Fill an array with y_test mean\ny_test_mean = np.full(len(y_test), y_test.mean())\n\nr2_score(y_test, y_test_mean)\n
from sklearn.metrics import r2_score # Fill an array with y_test mean y_test_mean = np.full(len(y_test), y_test.mean()) r2_score(y_test, y_test_mean) Out[134]: 0.0
And a perfect model would get a score of 1.
In\u00a0[135]: Copied! r2_score(y_test, y_test)\n
r2_score(y_test, y_test) Out[135]: 1.0
For your regression models, you'll want to maximise R^2, whilst minimising MAE and MSE.
Mean Absolute Error (MAE)
A model's mean absolute error can be calculated with Scikit-Learn's sklearn.metrics.mean_absolute_error method.
In\u00a0[136]: Copied! # Mean absolute error\nfrom sklearn.metrics import mean_absolute_error\n\ny_preds = model.predict(X_test)\nmae = mean_absolute_error(y_test, y_preds)\nmae\n
# Mean absolute error from sklearn.metrics import mean_absolute_error y_preds = model.predict(X_test) mae = mean_absolute_error(y_test, y_preds) mae Out[136]: np.float64(0.3270458119670544)
Our model achieves an MAE of 0.327.
This means, on average our models predictions are 0.327 units away from the actual value.
Let's make it a little more visual.
In\u00a0[137]: Copied! df = pd.DataFrame(data={\"actual values\": y_test, \n \"predictions\": y_preds})\n\ndf\n df = pd.DataFrame(data={\"actual values\": y_test, \"predictions\": y_preds}) df Out[137]: actual values predictions 20046 0.47700 0.490580 3024 0.45800 0.759890 15663 5.00001 4.935016 20484 2.18600 2.558640 9814 2.78000 2.334610 ... ... ... 15362 2.63300 2.225000 16623 2.66800 1.972540 18086 5.00001 4.853989 2144 0.72300 0.714910 3665 1.51500 1.665680 4128 rows \u00d7 2 columns
You can see the predictions are slightly different to the actual values.
Depending what problem you're working on, having a difference like we do now, might be okay. On the flip side, it may also not be okay, meaning the predictions would have to be closer.
In\u00a0[138]: Copied! fig, ax = plt.subplots()\nx = np.arange(0, len(df), 1)\nax.scatter(x, df[\"actual values\"], c='b', label=\"Acutual Values\")\nax.scatter(x, df[\"predictions\"], c='r', label=\"Predictions\")\nax.legend(loc=(1, 0.5));\n
fig, ax = plt.subplots() x = np.arange(0, len(df), 1) ax.scatter(x, df[\"actual values\"], c='b', label=\"Acutual Values\") ax.scatter(x, df[\"predictions\"], c='r', label=\"Predictions\") ax.legend(loc=(1, 0.5)); Mean Squared Error (MSE)
How about MSE?
We can calculate it with Scikit-Learn's sklearn.metrics.mean_squared_error.
In\u00a0[139]: Copied! # Mean squared error\nfrom sklearn.metrics import mean_squared_error\n\nmse = mean_squared_error(y_test, y_preds)\nmse\n
# Mean squared error from sklearn.metrics import mean_squared_error mse = mean_squared_error(y_test, y_preds) mse Out[139]: np.float64(0.2542443610174998)
MSE will often be higher than MAE because is squares the errors rather than only taking the absolute difference into account.
Now you might be thinking, which regression evaluation metric should you use?
- R^2 is similar to accuracy. It gives you a quick indication of how well your model might be doing. Generally, the closer your R^2 value is to 1.0, the better the model. But it doesn't really tell exactly how wrong your model is in terms of how far off each prediction is.
- MAE gives a better indication of how far off each of your model's predictions are on average.
- As for MAE or MSE, because of the way MSE is calculated, squaring the differences between predicted values and actual values, it amplifies larger differences. Let's say we're predicting the value of houses (which we are).
- Pay more attention to MAE: When being $10,000 off is twice as bad as being $5,000 off.
- Pay more attention to MSE: When being $10,000 off is more than twice as bad as being $5,000 off.
Note: What we've covered here is only a handful of potential metrics you can use to evaluate your models. If you're after a complete list, check out the Scikit-Learn metrics and scoring documentation.
In\u00a0[140]: Copied! from sklearn.model_selection import cross_val_score\nfrom sklearn.ensemble import RandomForestClassifier\n\nnp.random.seed(42)\n\nX = heart_disease.drop(\"target\", axis=1)\ny = heart_disease[\"target\"]\n\nclf = RandomForestClassifier(n_estimators=100)\n
from sklearn.model_selection import cross_val_score from sklearn.ensemble import RandomForestClassifier np.random.seed(42) X = heart_disease.drop(\"target\", axis=1) y = heart_disease[\"target\"] clf = RandomForestClassifier(n_estimators=100) First, we'll use the default, which is mean accuracy.
In\u00a0[141]: Copied! np.random.seed(42)\ncv_acc = cross_val_score(clf, X, y, cv=5)\ncv_acc\n
np.random.seed(42) cv_acc = cross_val_score(clf, X, y, cv=5) cv_acc Out[141]: array([0.81967213, 0.90163934, 0.83606557, 0.78333333, 0.78333333])
We've seen this before, now we got 5 different accuracy scores on different test splits of the data.
Averaging this gives the cross-validated accuracy.
In\u00a0[142]: Copied! # Cross-validated accuracy\nprint(f\"The cross-validated accuracy is: {np.mean(cv_acc)*100:.2f}%\")\n # Cross-validated accuracy print(f\"The cross-validated accuracy is: {np.mean(cv_acc)*100:.2f}%\") The cross-validated accuracy is: 82.48%\n
We can find the same using the scoring parameter and passing it \"accuracy\".
In\u00a0[143]: Copied! np.random.seed(42)\ncv_acc = cross_val_score(clf, X, y, cv=5, scoring=\"accuracy\")\nprint(f\"The cross-validated accuracy is: {np.mean(cv_acc)*100:.2f}%\")\n np.random.seed(42) cv_acc = cross_val_score(clf, X, y, cv=5, scoring=\"accuracy\") print(f\"The cross-validated accuracy is: {np.mean(cv_acc)*100:.2f}%\") The cross-validated accuracy is: 82.48%\n
The same goes for the other metrics we've been using for classification.
Let's try \"precision\".
In\u00a0[144]: Copied! np.random.seed(42)\ncv_precision = cross_val_score(clf, X, y, cv=5, scoring=\"precision\")\nprint(f\"The cross-validated precision is: {np.mean(cv_precision):.2f}\")\n np.random.seed(42) cv_precision = cross_val_score(clf, X, y, cv=5, scoring=\"precision\") print(f\"The cross-validated precision is: {np.mean(cv_precision):.2f}\") The cross-validated precision is: 0.83\n
How about \"recall\"?
In\u00a0[145]: Copied! np.random.seed(42)\ncv_recall = cross_val_score(clf, X, y, cv=5, scoring=\"recall\")\nprint(f\"The cross-validated recall is: {np.mean(cv_recall):.2f}\")\n np.random.seed(42) cv_recall = cross_val_score(clf, X, y, cv=5, scoring=\"recall\") print(f\"The cross-validated recall is: {np.mean(cv_recall):.2f}\") The cross-validated recall is: 0.85\n
And \"f1\" (for F1 score)?
In\u00a0[146]: Copied! np.random.seed(42)\ncv_f1 = cross_val_score(clf, X, y, cv=5, scoring=\"f1\")\nprint(f\"The cross-validated F1 score is: {np.mean(cv_f1):.2f}\")\n np.random.seed(42) cv_f1 = cross_val_score(clf, X, y, cv=5, scoring=\"f1\") print(f\"The cross-validated F1 score is: {np.mean(cv_f1):.2f}\") The cross-validated F1 score is: 0.84\n
We can repeat this process with our regression metrics.
Let's revisit our regression model.
In\u00a0[147]: Copied! from sklearn.model_selection import cross_val_score\nfrom sklearn.ensemble import RandomForestRegressor\n\nnp.random.seed(42)\n\nX = housing_df.drop(\"target\", axis=1)\ny = housing_df[\"target\"]\n\nmodel = RandomForestRegressor(n_estimators=100)\n
from sklearn.model_selection import cross_val_score from sklearn.ensemble import RandomForestRegressor np.random.seed(42) X = housing_df.drop(\"target\", axis=1) y = housing_df[\"target\"] model = RandomForestRegressor(n_estimators=100) The default is \"r2\".
Note: We can time how long a single cell of code takes to run using the %%time magic command.
In\u00a0[150]: Copied! %%time \nnp.random.seed(42)\ncv_r2 = cross_val_score(model, X, y, cv=5, scoring=\"r2\")\nprint(f\"The cross-validated R^2 score is: {np.mean(cv_r2):.2f}\")\n %%time np.random.seed(42) cv_r2 = cross_val_score(model, X, y, cv=5, scoring=\"r2\") print(f\"The cross-validated R^2 score is: {np.mean(cv_r2):.2f}\") The cross-validated R^2 score is: 0.65\nCPU times: user 40.5 s, sys: 286 ms, total: 40.8 s\nWall time: 41.6 s\n
But we can use \"neg_mean_absolute_error\" for MAE (mean absolute error).
In\u00a0[151]: Copied! %%time\nnp.random.seed(42)\ncv_mae = cross_val_score(model, X, y, cv=5, scoring=\"neg_mean_absolute_error\")\nprint(f\"The cross-validated MAE score is: {np.mean(cv_mae):.2f}\")\n %%time np.random.seed(42) cv_mae = cross_val_score(model, X, y, cv=5, scoring=\"neg_mean_absolute_error\") print(f\"The cross-validated MAE score is: {np.mean(cv_mae):.2f}\") The cross-validated MAE score is: -0.47\nCPU times: user 40.4 s, sys: 246 ms, total: 40.7 s\nWall time: 41.6 s\n
Why the \"neg_\"?
Because Scikit-Learn documentation states:
\"All scorer objects follow the convention that higher return values are better than lower return values.\"
Which in this case, means a lower negative value (closer to 0) is better.
What about \"neg_mean_squared_error\" for MSE (mean squared error)?
In\u00a0[159]: Copied! np.random.seed(42)\ncv_mse = cross_val_score(model, \n X, \n y, \n cv=5,\n scoring=\"neg_mean_squared_error\")\nprint(f\"The cross-validated MSE score is: {np.mean(cv_mse):.2f}\")\n np.random.seed(42) cv_mse = cross_val_score(model, X, y, cv=5, scoring=\"neg_mean_squared_error\") print(f\"The cross-validated MSE score is: {np.mean(cv_mse):.2f}\") The cross-validated MSE score is: -0.43\n
In\u00a0[160]: Copied! from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.model_selection import train_test_split\n\nnp.random.seed(42)\n\nX = heart_disease.drop(\"target\", axis=1)\ny = heart_disease[\"target\"]\n\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\nclf = RandomForestClassifier(n_estimators=100)\nclf.fit(X_train, y_train)\n\n# Make predictions\ny_preds = clf.predict(X_test)\n\n# Evaluate the classifier\nprint(\"Classifier metrics on the test set:\")\nprint(f\"Accuracy: {accuracy_score(y_test, y_preds) * 100:.2f}%\")\nprint(f\"Precision: {precision_score(y_test, y_preds):.2f}\")\nprint(f\"Recall: {recall_score(y_test, y_preds):.2f}\")\nprint(f\"F1: {f1_score(y_test, y_preds):.2f}\")\n from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split np.random.seed(42) X = heart_disease.drop(\"target\", axis=1) y = heart_disease[\"target\"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) clf = RandomForestClassifier(n_estimators=100) clf.fit(X_train, y_train) # Make predictions y_preds = clf.predict(X_test) # Evaluate the classifier print(\"Classifier metrics on the test set:\") print(f\"Accuracy: {accuracy_score(y_test, y_preds) * 100:.2f}%\") print(f\"Precision: {precision_score(y_test, y_preds):.2f}\") print(f\"Recall: {recall_score(y_test, y_preds):.2f}\") print(f\"F1: {f1_score(y_test, y_preds):.2f}\") Classifier metrics on the test set:\nAccuracy: 85.25%\nPrecision: 0.85\nRecall: 0.88\nF1: 0.86\n
In\u00a0[161]: Copied! from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.model_selection import train_test_split\n\nnp.random.seed(42)\n\nX = housing_df.drop(\"target\", axis=1)\ny = housing_df[\"target\"]\n\nX_train, X_test, y_train, y_test = train_test_split(X, \n y, \n test_size=0.2)\n\nmodel = RandomForestRegressor(n_estimators=100, \n n_jobs=-1)\nmodel.fit(X_train, y_train)\n\n# Make predictions\ny_preds = model.predict(X_test)\n\n# Evaluate the model\nprint(\"Regression model metrics on the test set:\")\nprint(f\"R^2: {r2_score(y_test, y_preds):.2f}\")\nprint(f\"MAE: {mean_absolute_error(y_test, y_preds):.2f}\")\nprint(f\"MSE: {mean_squared_error(y_test, y_preds):.2f}\")\n from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import train_test_split np.random.seed(42) X = housing_df.drop(\"target\", axis=1) y = housing_df[\"target\"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) model = RandomForestRegressor(n_estimators=100, n_jobs=-1) model.fit(X_train, y_train) # Make predictions y_preds = model.predict(X_test) # Evaluate the model print(\"Regression model metrics on the test set:\") print(f\"R^2: {r2_score(y_test, y_preds):.2f}\") print(f\"MAE: {mean_absolute_error(y_test, y_preds):.2f}\") print(f\"MSE: {mean_squared_error(y_test, y_preds):.2f}\") Regression model metrics on the test set:\nR^2: 0.81\nMAE: 0.33\nMSE: 0.25\n
Wow!
We've covered a lot!
But it's worth it.
Because evaluating a model's predictions is as important as training a model in any machine learning project.
There's nothing worse than training a machine learning model and optimizing for the wrong evaluation metric.
Keep the metrics and evaluation methods we've gone through when training your future models.
If you're after extra reading, I'd go through the Scikit-Learn guide for model evaluation.
Now we've seen some different metrics we can use to evaluate a model, let's see some ways we can improve those metrics.
In\u00a0[162]: Copied! from sklearn.ensemble import RandomForestClassifier\n\nclf = RandomForestClassifier()\n
from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier() When we instantiate a model like above, we're using the default hyperparameters.
These get printed out when you call the model instance and get_params().
In\u00a0[163]: Copied! clf.get_params()\n
clf.get_params() Out[163]: {'bootstrap': True,\n 'ccp_alpha': 0.0,\n 'class_weight': None,\n 'criterion': 'gini',\n 'max_depth': None,\n 'max_features': 'sqrt',\n 'max_leaf_nodes': None,\n 'max_samples': None,\n 'min_impurity_decrease': 0.0,\n 'min_samples_leaf': 1,\n 'min_samples_split': 2,\n 'min_weight_fraction_leaf': 0.0,\n 'monotonic_cst': None,\n 'n_estimators': 100,\n 'n_jobs': None,\n 'oob_score': False,\n 'random_state': None,\n 'verbose': 0,\n 'warm_start': False} You'll see things like max_depth, min_samples_split, n_estimators.
Each of these is a hyperparameter of the RandomForestClassifier you can adjust.
You can think of hyperparameters as being similar to dials on an oven.
On the default setting your oven might do an okay job cooking your favourite meal. But with a little experimentation, you find it does better when you adjust the settings.
The same goes for imporving a machine learning model by hyperparameter tuning.
The default hyperparameters on a machine learning model may find patterns in data well. But there's a chance a adjusting the hyperparameters may improve a models performance.
Every machine learning model will have different hyperparameters you can tune.
You might be thinking, \"how the hell do I remember all of these?\"
Another good question.
It's why we're focused on the Random Forest.
Instead of memorizing all of the hyperparameters for every model, we'll see how it's done with one.
And then knowing these principles, you can apply them to a different model if needed.
Reading the Scikit-Learn documentation for the Random Forest, you'll find they suggest trying to change n_estimators (the number of trees in the forest) and min_samples_split (the minimum number of samples required to split an internal node).
We'll try tuning these as well as:
max_features (the number of features to consider when looking for the best split)max_depth (the maximum depth of the tree)min_samples_leaf (the minimum number of samples required to be at a leaf node)
If this still sounds like a lot, the good news is, the process we're taking with the Random Forest and tuning its hyperparameters, can be used for other machine learning models in Scikit-Learn. The only difference is, with a different model, the hyperparameters you tune will be different.
Adjusting hyperparameters is usually an experimental process to figure out which are best. As there's no real way of knowing which hyperparameters will be best when starting out.
To get familar with hyparameter tuning, we'll take our RandomForestClassifier and adjust its hyperparameters in 3 ways.
- By hand
- Randomly with
sklearn.model_selection.RandomizedSearchCV - Exhaustively with
sklearn.model_selection.GridSearchCV
In\u00a0[164]: Copied! clf.get_params()\n
clf.get_params() Out[164]: {'bootstrap': True,\n 'ccp_alpha': 0.0,\n 'class_weight': None,\n 'criterion': 'gini',\n 'max_depth': None,\n 'max_features': 'sqrt',\n 'max_leaf_nodes': None,\n 'max_samples': None,\n 'min_impurity_decrease': 0.0,\n 'min_samples_leaf': 1,\n 'min_samples_split': 2,\n 'min_weight_fraction_leaf': 0.0,\n 'monotonic_cst': None,\n 'n_estimators': 100,\n 'n_jobs': None,\n 'oob_score': False,\n 'random_state': None,\n 'verbose': 0,\n 'warm_start': False} And we're going to adjust:
max_depthmax_featuresmin_samples_leafmin_samples_splitn_estimators
We'll use the same code as before, except this time we'll create a training, validation and test split.
With the training set containing 70% of the data and the validation and test sets each containing 15%.
Let's get some baseline results, then we'll tune the model.
And since we're going to be evaluating a few models, let's make an evaluation function.
In\u00a0[165]: Copied! def evaluate_preds(y_true: np.array, \n y_preds: np.array) -> dict:\n \"\"\"\n Performs evaluation comparison on y_true labels vs. y_pred labels.\n\n Returns several metrics in the form of a dictionary.\n \"\"\"\n accuracy = accuracy_score(y_true, y_preds)\n precision = precision_score(y_true, y_preds)\n recall = recall_score(y_true, y_preds)\n f1 = f1_score(y_true, y_preds)\n metric_dict = {\"accuracy\": round(accuracy, 2),\n \"precision\": round(precision, 2), \n \"recall\": round(recall, 2),\n \"f1\": round(f1, 2)}\n print(f\"Acc: {accuracy * 100:.2f}%\")\n print(f\"Precision: {precision:.2f}\")\n print(f\"Recall: {recall:.2f}\")\n print(f\"F1 score: {f1:.2f}\")\n\n return metric_dict\n def evaluate_preds(y_true: np.array, y_preds: np.array) -> dict: \"\"\" Performs evaluation comparison on y_true labels vs. y_pred labels. Returns several metrics in the form of a dictionary. \"\"\" accuracy = accuracy_score(y_true, y_preds) precision = precision_score(y_true, y_preds) recall = recall_score(y_true, y_preds) f1 = f1_score(y_true, y_preds) metric_dict = {\"accuracy\": round(accuracy, 2), \"precision\": round(precision, 2), \"recall\": round(recall, 2), \"f1\": round(f1, 2)} print(f\"Acc: {accuracy * 100:.2f}%\") print(f\"Precision: {precision:.2f}\") print(f\"Recall: {recall:.2f}\") print(f\"F1 score: {f1:.2f}\") return metric_dict Wonderful!
Now let's recreate a previous workflow, except we'll add in the creation of a validation set.
In\u00a0[166]: Copied! from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.ensemble import RandomForestClassifier\n\n# Set the seed\nnp.random.seed(42)\n\n# Read in the data\n# heart_disease = pd.read_csv(\"../data/heart-disease.csv\") # load in from local directory\nheart_disease = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/heart-disease.csv\") # load directly from URL (source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/heart-disease.csv)\n\n# Split into X (features) & y (labels)\nX = heart_disease.drop(\"target\", axis=1)\ny = heart_disease[\"target\"]\n\n# Training and test split (70% train, 30% test)\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)\n\n# Create validation and test split by spliting testing data in half (30% test -> 15% validation, 15% test)\nX_valid, X_test, y_valid, y_test = train_test_split(X_test, y_test, test_size=0.5)\n\nclf = RandomForestClassifier()\nclf.fit(X_train, y_train)\n\n# Make predictions\ny_preds = clf.predict(X_valid)\n\n# Evaluate the classifier\nbaseline_metrics = evaluate_preds(y_valid, y_preds)\nbaseline_metrics\n
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier # Set the seed np.random.seed(42) # Read in the data # heart_disease = pd.read_csv(\"../data/heart-disease.csv\") # load in from local directory heart_disease = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/heart-disease.csv\") # load directly from URL (source: https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/data/heart-disease.csv) # Split into X (features) & y (labels) X = heart_disease.drop(\"target\", axis=1) y = heart_disease[\"target\"] # Training and test split (70% train, 30% test) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # Create validation and test split by spliting testing data in half (30% test -> 15% validation, 15% test) X_valid, X_test, y_valid, y_test = train_test_split(X_test, y_test, test_size=0.5) clf = RandomForestClassifier() clf.fit(X_train, y_train) # Make predictions y_preds = clf.predict(X_valid) # Evaluate the classifier baseline_metrics = evaluate_preds(y_valid, y_preds) baseline_metrics Acc: 80.00%\nPrecision: 0.78\nRecall: 0.88\nF1 score: 0.82\n
Out[166]: {'accuracy': 0.8,\n 'precision': np.float64(0.78),\n 'recall': np.float64(0.88),\n 'f1': np.float64(0.82)} In\u00a0[167]: Copied! # Check the sizes of the splits\nprint(f\"Training data: {len(X_train)} samples, {len(y_train)} labels\")\nprint(f\"Validation data: {len(X_valid)} samples, {len(y_valid)} labels\")\nprint(f\"Testing data: {len(X_test)} samples, {len(y_test)} labels\")\n # Check the sizes of the splits print(f\"Training data: {len(X_train)} samples, {len(y_train)} labels\") print(f\"Validation data: {len(X_valid)} samples, {len(y_valid)} labels\") print(f\"Testing data: {len(X_test)} samples, {len(y_test)} labels\") Training data: 212 samples, 212 labels\nValidation data: 45 samples, 45 labels\nTesting data: 46 samples, 46 labels\n
Beautiful, now let's try and improve the results.
We'll change 1 of the hyperparameters, n_estimators=100 (default) to n_estimators=200 and see if it improves on the validation set.
In\u00a0[168]: Copied! np.random.seed(42)\n\n# Create a second classifier\nclf_2 = RandomForestClassifier(n_estimators=200)\nclf_2.fit(X_train, y_train)\n\n# Make predictions\ny_preds_2 = clf_2.predict(X_valid)\n\n# Evaluate the 2nd classifier\nclf_2_metrics = evaluate_preds(y_valid, y_preds_2)\n
np.random.seed(42) # Create a second classifier clf_2 = RandomForestClassifier(n_estimators=200) clf_2.fit(X_train, y_train) # Make predictions y_preds_2 = clf_2.predict(X_valid) # Evaluate the 2nd classifier clf_2_metrics = evaluate_preds(y_valid, y_preds_2) Acc: 77.78%\nPrecision: 0.77\nRecall: 0.83\nF1 score: 0.80\n
Hmm, it looks like doubling the n_estimators value performs worse than the default, perhaps there's a better value for n_estimators?
And what other hyperparameters could we change?
Wait...
This could take a while if all we're doing is building new models with new hyperparameters each time.
Surely there's a better way?
There is.
In\u00a0[169]: Copied! # Hyperparameter grid RandomizedSearchCV will search over\nparam_distributions = {\"n_estimators\": [10, 100, 200, 500, 1000, 1200],\n \"max_depth\": [None, 5, 10, 20, 30],\n \"max_features\": [\"sqrt\", \"log2\", None],\n \"min_samples_split\": [2, 4, 6, 8],\n \"min_samples_leaf\": [1, 2, 4, 8]}\n # Hyperparameter grid RandomizedSearchCV will search over param_distributions = {\"n_estimators\": [10, 100, 200, 500, 1000, 1200], \"max_depth\": [None, 5, 10, 20, 30], \"max_features\": [\"sqrt\", \"log2\", None], \"min_samples_split\": [2, 4, 6, 8], \"min_samples_leaf\": [1, 2, 4, 8]} Where did these values come from?
They're made up.
Made up?
Yes.
Not completely pulled out of the air but after reading the Scikit-Learn documentation on Random Forest's you'll see some of these values have certain values which usually perform well and certain hyperparameters take strings rather than integers.
Now we've got the parameter distribution dictionary setup, Scikit-Learn's RandomizedSearchCV will look at it, pick a random value from each, instantiate a model with those values and test each model.
How many models will it test?
As many as there are for each combination of hyperparameters to be tested. Let's add them up.
In\u00a0[170]: Copied! # Count the total number of hyperparameter combinations to test\ntotal_randomized_hyperparameter_combintions_to_test = np.prod([len(value) for value in param_distributions.values()])\nprint(f\"There are {total_randomized_hyperparameter_combintions_to_test} potential combinations of hyperparameters to test.\")\n # Count the total number of hyperparameter combinations to test total_randomized_hyperparameter_combintions_to_test = np.prod([len(value) for value in param_distributions.values()]) print(f\"There are {total_randomized_hyperparameter_combintions_to_test} potential combinations of hyperparameters to test.\") There are 1440 potential combinations of hyperparameters to test.\n
Woah!
That's a lot of combinations!
Or...
We can set the n_iter parameter to limit the number of models RandomizedSearchCV tests (e.g. n_iter=20 means to try 20 different random combintations of hyperparameters and will cross-validate each set, so if cv=5, 5x20 = 100 total fits).
The best thing?
The results we get will be cross-validated (hence the CV in RandomizedSearchCV) so we can use train_test_split().
And since we're going over so many different models, we'll set n_jobs=-1 in our RandomForestClassifier so Scikit-Learn takes advantage of all the cores (processors) on our computers.
Let's see it in action.
Note: Depending on n_iter (how many models you test), the different values in the hyperparameter grid, and the power of your computer, running the cell below may take a while (for reference, it took about ~1-minute on my M1 Pro MacBook Pro).
In\u00a0[171]: Copied! # Start the timer\nimport time\nstart_time = time.time()\n\nfrom sklearn.model_selection import RandomizedSearchCV, train_test_split\n\nnp.random.seed(42)\n\n# Split into X & y\nX = heart_disease.drop(\"target\", axis=1)\ny = heart_disease[\"target\"]\n\n# Split into train and test sets\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\n# Set n_jobs to -1 to use all available cores on your machine (if this causes errors, try n_jobs=1)\nclf = RandomForestClassifier(n_jobs=-1)\n\n# Setup RandomizedSearchCV \nn_iter = 30 # try 30 models total\nrs_clf = RandomizedSearchCV(estimator=clf,\n param_distributions=param_distributions,\n n_iter=n_iter, \n cv=5, # 5-fold cross-validation\n verbose=2) # print out results\n\n# Fit the RandomizedSearchCV version of clf (does cross-validation for us, so no need to use a validation set)\nrs_clf.fit(X_train, y_train);\n\n# Finish the timer\nend_time = time.time()\nprint(f\"[INFO] Total time taken for {n_iter} random combinations of hyperparameters: {end_time - start_time:.2f} seconds.\")\n # Start the timer import time start_time = time.time() from sklearn.model_selection import RandomizedSearchCV, train_test_split np.random.seed(42) # Split into X & y X = heart_disease.drop(\"target\", axis=1) y = heart_disease[\"target\"] # Split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Set n_jobs to -1 to use all available cores on your machine (if this causes errors, try n_jobs=1) clf = RandomForestClassifier(n_jobs=-1) # Setup RandomizedSearchCV n_iter = 30 # try 30 models total rs_clf = RandomizedSearchCV(estimator=clf, param_distributions=param_distributions, n_iter=n_iter, cv=5, # 5-fold cross-validation verbose=2) # print out results # Fit the RandomizedSearchCV version of clf (does cross-validation for us, so no need to use a validation set) rs_clf.fit(X_train, y_train); # Finish the timer end_time = time.time() print(f\"[INFO] Total time taken for {n_iter} random combinations of hyperparameters: {end_time - start_time:.2f} seconds.\") Fitting 5 folds for each of 30 candidates, totalling 150 fits\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=10, max_features=None, min_samples_leaf=8, min_samples_split=2, n_estimators=500; total time= 0.3s\n[CV] END max_depth=10, max_features=None, min_samples_leaf=8, min_samples_split=2, n_estimators=500; total time= 0.3s\n[CV] END max_depth=10, max_features=None, min_samples_leaf=8, min_samples_split=2, n_estimators=500; total time= 0.3s\n[CV] END max_depth=10, max_features=None, min_samples_leaf=8, min_samples_split=2, n_estimators=500; total time= 0.3s\n[CV] END max_depth=10, max_features=None, min_samples_leaf=8, min_samples_split=2, n_estimators=500; total time= 0.3s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=5, max_features=log2, min_samples_leaf=2, min_samples_split=8, n_estimators=100; total time= 0.1s\n[CV] END max_depth=5, max_features=log2, min_samples_leaf=2, min_samples_split=8, n_estimators=100; total time= 0.1s\n[CV] END max_depth=5, max_features=log2, min_samples_leaf=2, min_samples_split=8, n_estimators=100; total time= 0.1s\n[CV] END max_depth=5, max_features=log2, min_samples_leaf=2, min_samples_split=8, n_estimators=100; total time= 0.1s\n[CV] END max_depth=5, max_features=log2, min_samples_leaf=2, min_samples_split=8, n_estimators=100; total time= 0.1s\n[CV] END max_depth=10, max_features=log2, min_samples_leaf=2, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=10, max_features=log2, min_samples_leaf=2, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=10, max_features=log2, min_samples_leaf=2, min_samples_split=4, n_estimators=200; total time= 0.2s\n[CV] END max_depth=10, max_features=log2, min_samples_leaf=2, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=10, max_features=log2, min_samples_leaf=2, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=8, min_samples_split=4, n_estimators=1200; total time= 0.7s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=8, min_samples_split=4, n_estimators=1200; total time= 0.7s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=8, min_samples_split=4, n_estimators=1200; total time= 0.7s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=8, min_samples_split=4, n_estimators=1200; total time= 0.8s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=8, min_samples_split=4, n_estimators=1200; total time= 0.7s\n[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=20, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=100; total time= 0.1s\n[CV] END max_depth=20, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=100; total time= 0.1s\n[CV] END max_depth=20, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=100; total time= 0.1s\n[CV] END max_depth=20, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=100; total time= 0.1s\n[CV] END max_depth=20, max_features=log2, min_samples_leaf=8, min_samples_split=6, n_estimators=100; total time= 0.1s\n[CV] END max_depth=5, max_features=log2, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=5, max_features=log2, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=5, max_features=log2, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=5, max_features=log2, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=5, max_features=log2, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=4, min_samples_split=4, n_estimators=1200; total time= 0.7s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=4, min_samples_split=4, n_estimators=1200; total time= 0.7s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=4, min_samples_split=4, n_estimators=1200; total time= 0.8s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=4, min_samples_split=4, n_estimators=1200; total time= 0.8s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=4, min_samples_split=4, n_estimators=1200; total time= 0.7s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=5, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=5, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=5, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=5, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=5, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1200; total time= 0.8s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1200; total time= 0.7s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1200; total time= 0.8s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1200; total time= 0.7s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=2, min_samples_split=8, n_estimators=1200; total time= 0.7s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=8, min_samples_split=2, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=8, min_samples_split=2, n_estimators=1000; total time= 0.7s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=8, min_samples_split=2, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=8, min_samples_split=2, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=8, min_samples_split=2, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=2, min_samples_split=6, n_estimators=10; total time= 0.0s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=4, min_samples_split=6, n_estimators=100; total time= 0.1s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=4, min_samples_split=6, n_estimators=100; total time= 0.1s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=4, min_samples_split=6, n_estimators=100; total time= 0.1s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=4, min_samples_split=6, n_estimators=100; total time= 0.1s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=4, min_samples_split=6, n_estimators=100; total time= 0.1s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=8, n_estimators=500; total time= 0.3s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=8, n_estimators=500; total time= 0.3s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=8, n_estimators=500; total time= 0.3s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=8, n_estimators=500; total time= 0.3s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=4, min_samples_split=8, n_estimators=500; total time= 0.3s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=6, n_estimators=500; total time= 0.3s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=6, n_estimators=500; total time= 0.3s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=6, n_estimators=500; total time= 0.3s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=6, n_estimators=500; total time= 0.3s\n[CV] END max_depth=5, max_features=None, min_samples_leaf=1, min_samples_split=6, n_estimators=500; total time= 0.3s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=1, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=1, min_samples_split=8, n_estimators=200; total time= 0.2s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=1, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=1, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=sqrt, min_samples_leaf=1, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=20, max_features=log2, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=20, max_features=log2, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=20, max_features=log2, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=20, max_features=log2, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=20, max_features=log2, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=20, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=None, max_features=log2, min_samples_leaf=2, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=None, max_features=log2, min_samples_leaf=2, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=None, max_features=log2, min_samples_leaf=2, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=None, max_features=log2, min_samples_leaf=2, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=None, max_features=log2, min_samples_leaf=2, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=1, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=100; total time= 0.1s\n[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=100; total time= 0.1s\n[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=100; total time= 0.1s\n[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=100; total time= 0.1s\n[CV] END max_depth=10, max_features=sqrt, min_samples_leaf=1, min_samples_split=4, n_estimators=100; total time= 0.1s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=2, min_samples_split=2, n_estimators=500; total time= 0.3s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=2, min_samples_split=2, n_estimators=500; total time= 0.3s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=2, min_samples_split=2, n_estimators=500; total time= 0.3s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=2, min_samples_split=2, n_estimators=500; total time= 0.3s\n[CV] END max_depth=20, max_features=sqrt, min_samples_leaf=2, min_samples_split=2, n_estimators=500; total time= 0.4s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=None, max_features=None, min_samples_leaf=8, min_samples_split=4, n_estimators=10; total time= 0.0s\n[CV] END max_depth=None, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=None, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=None, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=None, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=10; total time= 0.0s\n[CV] END max_depth=None, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=10; total time= 0.0s\n[INFO] Total time taken for 30 random combinations of hyperparameters: 36.02 seconds.\n
When RandomizedSearchCV goes through n_iter combinations of of hyperparameter search space, it stores the best ones in the attribute best_params_.
In\u00a0[174]: Copied! # Find the best hyperparameters found by RandomizedSearchCV\nrs_clf.best_params_\n
# Find the best hyperparameters found by RandomizedSearchCV rs_clf.best_params_ Out[174]: {'n_estimators': 200,\n 'min_samples_split': 6,\n 'min_samples_leaf': 4,\n 'max_features': 'log2',\n 'max_depth': 30} Now when we call predict() on rs_clf (our RandomizedSearchCV version of our classifier), it'll use the best hyperparameters it found.
In\u00a0[175]: Copied! # Make predictions with the best hyperparameters\nrs_y_preds = rs_clf.predict(X_test)\n\n# Evaluate the predictions\nrs_metrics = evaluate_preds(y_test, rs_y_preds)\n
# Make predictions with the best hyperparameters rs_y_preds = rs_clf.predict(X_test) # Evaluate the predictions rs_metrics = evaluate_preds(y_test, rs_y_preds) Acc: 85.25%\nPrecision: 0.85\nRecall: 0.88\nF1 score: 0.86\n
Excellent!
Thanks to RandomizedSearchCV testing out a bunch of different hyperparameters, we get a nice boost to all of the evaluation metrics for our classification model.
In\u00a0[176]: Copied! param_distributions\n
param_distributions Out[176]: {'n_estimators': [10, 100, 200, 500, 1000, 1200],\n 'max_depth': [None, 5, 10, 20, 30],\n 'max_features': ['sqrt', 'log2', None],\n 'min_samples_split': [2, 4, 6, 8],\n 'min_samples_leaf': [1, 2, 4, 8]} RandomizedSearchCV tries n_iter combinations of different values.
Where as, GridSearchCV will try every single possible combination.
And if you remember from before when we did the calculation: max_depth has 4 values, max_features has 2, min_samples_leaf has 3, min_samples_split has 3, n_estimators has 5.
That's 4x2x3x3x5 = 360 models!
This could take a long time depending on the power of the computer you're using, the amount of data you have and the complexity of the hyperparamters (usually higher values means a more complex model).
In our case, the data we're using is relatively small (only ~300 samples).
Since we've already tried to find some ideal hyperparameters using RandomizedSearchCV, we'll create another hyperparameter grid based on the best_params_ of rs_clf with less options and then try to use GridSearchCV to find a more ideal set.
In essence, the workflow could be:
- Tune hyperparameters by hand to get a feel of the data/model.
- Create a large set of hyperparameter distributions and search across them randomly with
RandomizedSearchCV. - Find the best hyperparameters from 2 and reduce the search space before searching across a smaller subset exhaustively with
GridSearchCV.
Note: Based on the best_params_ of rs_clf implies the next set of hyperparameters we'll try are roughly in the same range of the best set found by RandomizedSearchCV.
In\u00a0[177]: Copied! # Create hyperparameter grid similar to rs_clf.best_params_\nparam_grid = {\"n_estimators\": [200, 1000],\n \"max_depth\": [30, 40, 50],\n \"max_features\": [\"log2\"],\n \"min_samples_split\": [2, 4, 6, 8],\n \"min_samples_leaf\": [4]}\n # Create hyperparameter grid similar to rs_clf.best_params_ param_grid = {\"n_estimators\": [200, 1000], \"max_depth\": [30, 40, 50], \"max_features\": [\"log2\"], \"min_samples_split\": [2, 4, 6, 8], \"min_samples_leaf\": [4]} We've created another grid of hyperparameters to search over, this time with less total.
In\u00a0[178]: Copied! # Count the total number of hyperparameter combinations to test\ntotal_grid_search_hyperparameter_combinations_to_test = np.prod([len(value) for value in param_grid.values()])\nprint(f\"There are {total_grid_search_hyperparameter_combinations_to_test} combinations of hyperparameters to test.\")\nprint(f\"This is {total_randomized_hyperparameter_combintions_to_test/total_grid_search_hyperparameter_combinations_to_test} times less\\\n than before (previous: {total_randomized_hyperparameter_combintions_to_test}).\")\n # Count the total number of hyperparameter combinations to test total_grid_search_hyperparameter_combinations_to_test = np.prod([len(value) for value in param_grid.values()]) print(f\"There are {total_grid_search_hyperparameter_combinations_to_test} combinations of hyperparameters to test.\") print(f\"This is {total_randomized_hyperparameter_combintions_to_test/total_grid_search_hyperparameter_combinations_to_test} times less\\ than before (previous: {total_randomized_hyperparameter_combintions_to_test}).\") There are 24 combinations of hyperparameters to test.\nThis is 60.0 times less than before (previous: 1440).\n
Now when we run GridSearchCV, passing it our classifier (clf), parameter grid (param_grid) and the number of cross-validation folds we'd like to use (cv=5), it'll create a model with every single combination of hyperparameters, and then cross-validate each 5 times (for example, 36 hyperparameter combinations * 5 = 135 fits in total) and check the results.
Note: Depending on the compute power of the machine you're using, the following cell may take a few minutes to run (for reference, it took ~60 seconds on my M1 Pro MacBook Pro).
In\u00a0[179]: Copied! # Start the timer\nimport time\nstart_time = time.time()\n\nfrom sklearn.model_selection import GridSearchCV, train_test_split\n\nnp.random.seed(42)\n\n# Split into X & y\nX = heart_disease.drop(\"target\", axis=1)\ny = heart_disease[\"target\"]\n\n# Split into train and test sets\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\n# Set n_jobs to -1 to use all available machine cores (if this produces errors, try n_jobs=1)\nclf = RandomForestClassifier(n_jobs=-1)\n\n# Setup GridSearchCV\ngs_clf = GridSearchCV(estimator=clf,\n param_grid=param_grid,\n cv=5, # 5-fold cross-validation\n verbose=2) # print out progress\n\n# Fit the RandomizedSearchCV version of clf\ngs_clf.fit(X_train, y_train);\n\n# Find the running time\nend_time = time.time()\n
# Start the timer import time start_time = time.time() from sklearn.model_selection import GridSearchCV, train_test_split np.random.seed(42) # Split into X & y X = heart_disease.drop(\"target\", axis=1) y = heart_disease[\"target\"] # Split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Set n_jobs to -1 to use all available machine cores (if this produces errors, try n_jobs=1) clf = RandomForestClassifier(n_jobs=-1) # Setup GridSearchCV gs_clf = GridSearchCV(estimator=clf, param_grid=param_grid, cv=5, # 5-fold cross-validation verbose=2) # print out progress # Fit the RandomizedSearchCV version of clf gs_clf.fit(X_train, y_train); # Find the running time end_time = time.time() Fitting 5 folds for each of 24 candidates, totalling 120 fits\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.2s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.2s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=30, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.7s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.7s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=40, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.2s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.2s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=2, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=4, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=200; total time= 0.2s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=6, n_estimators=1000; total time= 0.7s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=200; total time= 0.1s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.6s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.5s\n[CV] END max_depth=50, max_features=log2, min_samples_leaf=4, min_samples_split=8, n_estimators=1000; total time= 0.5s\n
In\u00a0[181]: Copied! # How long did it take? \ntotal_time = end_time - start_time\nprint(f\"[INFO] The total running time for running GridSearchCV was {total_time:.2f} seconds.\")\n # How long did it take? total_time = end_time - start_time print(f\"[INFO] The total running time for running GridSearchCV was {total_time:.2f} seconds.\") [INFO] The total running time for running GridSearchCV was 41.95 seconds.\n
Once it completes, we can check the best hyperparameter combinations it found using the best_params_ attribute.
In\u00a0[182]: Copied! # Check the best hyperparameters found with GridSearchCV\ngs_clf.best_params_\n
# Check the best hyperparameters found with GridSearchCV gs_clf.best_params_ Out[182]: {'max_depth': 30,\n 'max_features': 'log2',\n 'min_samples_leaf': 4,\n 'min_samples_split': 2,\n 'n_estimators': 200} And by default when we call the predict() function on gs_clf, it'll use the best hyperparameters.
In\u00a0[183]: Copied! # Max predictions with the GridSearchCV classifier\ngs_y_preds = gs_clf.predict(X_test)\n\n# Evaluate the predictions\ngs_metrics = evaluate_preds(y_test, gs_y_preds)\ngs_metrics\n
# Max predictions with the GridSearchCV classifier gs_y_preds = gs_clf.predict(X_test) # Evaluate the predictions gs_metrics = evaluate_preds(y_test, gs_y_preds) gs_metrics Acc: 88.52%\nPrecision: 0.88\nRecall: 0.91\nF1 score: 0.89\n
Out[183]: {'accuracy': 0.89,\n 'precision': np.float64(0.88),\n 'recall': np.float64(0.91),\n 'f1': np.float64(0.89)} Let's create a DataFrame to compare the different metrics.
In\u00a0[184]: Copied! compare_metrics = pd.DataFrame({\"baseline\": baseline_metrics,\n \"clf_2\": clf_2_metrics,\n \"random search\": rs_metrics,\n \"grid search\": gs_metrics})\ncompare_metrics.plot.bar(figsize=(10, 8));\n compare_metrics = pd.DataFrame({\"baseline\": baseline_metrics, \"clf_2\": clf_2_metrics, \"random search\": rs_metrics, \"grid search\": gs_metrics}) compare_metrics.plot.bar(figsize=(10, 8)); Nice!
After trying many different combinations of hyperparamters, we get a slight improvement in results.
However, sometimes you'll notice that your results don't change much.
These things might happen.
But it's important to remember, it's not over. There more things you can try.
In a hyperparameter tuning sense, there may be a better set we could find through more extensive searching with RandomizedSearchCV and GridSearchCV, this would require more experimentation.
Other techniques you could:
- Collecting more data - Based on the results our models are getting now, it seems like they're very capable of finding patterns. Collecting more data may improve a models ability to find patterns. However, your ability to do this will largely depend on the project you're working on.
- Try a more advanced model - Although our tuned Random Forest model is doing pretty well, a more advanced ensemble method such as XGBoost or CatBoost might perform better. I'll leave these for extra-curriculum.
Since machine learning is part engineering, part science, these kind of experiments are common place in any machine learning project.
Now we've got a tuned Random Forest model, let's find out how we might save it and export it so we can share it with others or potentially use it in an external application.
In\u00a0[185]: Copied! import pickle\n\n# Save an existing model to file\nbest_model_file_name_pickle = \"gs_random_forest_model_1.pkl\" # .pkl extension stands for \"pickle\"\npickle.dump(gs_clf, open(best_model_file_name_pickle, \"wb\"))\n
import pickle # Save an existing model to file best_model_file_name_pickle = \"gs_random_forest_model_1.pkl\" # .pkl extension stands for \"pickle\" pickle.dump(gs_clf, open(best_model_file_name_pickle, \"wb\")) Once it's saved, we can import it using pickle's load() function, passing it open() containing the filename as a string and \"rb\" standing for \"read binary\".
In\u00a0[186]: Copied! # Load a saved model\nloaded_pickle_model = pickle.load(open(best_model_file_name_pickle, \"rb\"))\n
# Load a saved model loaded_pickle_model = pickle.load(open(best_model_file_name_pickle, \"rb\")) Once you've reimported your trained model using pickle, you can use it to make predictions as usual.
In\u00a0[187]: Copied! # Make predictions and evaluate the loaded model\npickle_y_preds = loaded_pickle_model.predict(X_test)\nloaded_pickle_model_metrics = evaluate_preds(y_test, pickle_y_preds)\nloaded_pickle_model_metrics\n
# Make predictions and evaluate the loaded model pickle_y_preds = loaded_pickle_model.predict(X_test) loaded_pickle_model_metrics = evaluate_preds(y_test, pickle_y_preds) loaded_pickle_model_metrics Acc: 88.52%\nPrecision: 0.88\nRecall: 0.91\nF1 score: 0.89\n
Out[187]: {'accuracy': 0.89,\n 'precision': np.float64(0.88),\n 'recall': np.float64(0.91),\n 'f1': np.float64(0.89)} You'll notice the reimported model evaluation metrics are the same as the model before we exported it.
In\u00a0[188]: Copied! loaded_pickle_model_metrics == gs_metrics\n
loaded_pickle_model_metrics == gs_metrics Out[188]: True
In\u00a0[189]: Copied! from joblib import dump, load\n\n# Save a model to file\nbest_model_file_name_joblib = \"gs_random_forest_model_1.joblib\"\ndump(gs_clf, filename=best_model_file_name_joblib)\n
from joblib import dump, load # Save a model to file best_model_file_name_joblib = \"gs_random_forest_model_1.joblib\" dump(gs_clf, filename=best_model_file_name_joblib) Out[189]: ['gs_random_forest_model_1.joblib']
Once you've saved a model using dump(), you can import it using load() and passing it the filename of the model.
In\u00a0[190]: Copied! # Import a saved joblib model\nloaded_joblib_model = load(filename=best_model_file_name_joblib)\n
# Import a saved joblib model loaded_joblib_model = load(filename=best_model_file_name_joblib) Again, once imported, we can make predictions with our model.
In\u00a0[191]: Copied! # Make and evaluate joblib predictions \njoblib_y_preds = loaded_joblib_model.predict(X_test)\nloaded_joblib_model_metrics = evaluate_preds(y_test, joblib_y_preds)\nloaded_joblib_model_metrics\n
# Make and evaluate joblib predictions joblib_y_preds = loaded_joblib_model.predict(X_test) loaded_joblib_model_metrics = evaluate_preds(y_test, joblib_y_preds) loaded_joblib_model_metrics Acc: 88.52%\nPrecision: 0.88\nRecall: 0.91\nF1 score: 0.89\n
Out[191]: {'accuracy': 0.89,\n 'precision': np.float64(0.88),\n 'recall': np.float64(0.91),\n 'f1': np.float64(0.89)} And once again, you'll notice the evaluation metrics are the same as before.
In\u00a0[192]: Copied! loaded_joblib_model_metrics == gs_metrics\n
loaded_joblib_model_metrics == gs_metrics Out[192]: True
So which one should you use, pickle or joblib?
According to Scikit-Learn's model persistence documentation, they suggest it may be more efficient to use joblib as it's more efficient with large numpy arrays (which is what may be contained in trained/fitted Scikit-Learn models).
In\u00a0[193]: Copied! # data = pd.read_csv(\"../data/car-sales-extended-missing-data.csv\") # load from local directory\ndata = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales-extended-missing-data.csv\") # load directly from URL\ndata.head()\n
# data = pd.read_csv(\"../data/car-sales-extended-missing-data.csv\") # load from local directory data = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales-extended-missing-data.csv\") # load directly from URL data.head() Out[193]: Make Colour Odometer (KM) Doors Price 0 Honda White 35431.0 4.0 15323.0 1 BMW Blue 192714.0 5.0 19943.0 2 Honda White 84714.0 4.0 28343.0 3 Toyota White 154365.0 4.0 13434.0 4 Nissan Blue 181577.0 3.0 14043.0 In\u00a0[194]: Copied! data.dtypes\n
data.dtypes Out[194]: Make object\nColour object\nOdometer (KM) float64\nDoors float64\nPrice float64\ndtype: object
In\u00a0[195]: Copied! data.isna().sum()\n
data.isna().sum() Out[195]: Make 49\nColour 50\nOdometer (KM) 50\nDoors 50\nPrice 50\ndtype: int64
There's 1000 rows, three features are categorical (Make, Colour, Doors), the other two are numerical (Odometer (KM), Price) and there's 249 missing values.
We're going to have to turn the categorical features into numbers and fill the missing values before we can fit a model.
We'll build a Pipeline to do so.
Pipeline's main input parameter is steps which is a list of tuples ([(step_name, action_to_take)]) of the step name, plus the action you'd like it to perform.
In our case, you could think of the steps as:
- Fill missing data
- Convert data to numbers
- Build a model on the data
Let's do it!
In\u00a0[199]: Copied! # Getting data ready\nimport pandas as pd\nfrom sklearn.compose import ColumnTransformer\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.impute import SimpleImputer\nfrom sklearn.preprocessing import OneHotEncoder\n\n# Modelling\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.model_selection import train_test_split, GridSearchCV\n\n# Setup random seed\nimport numpy as np\nnp.random.seed(42)\n\n# Import data and drop the rows with missing labels\ndata = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales-extended-missing-data.csv\")\ndata.dropna(subset=[\"Price\"], inplace=True)\n\n# Define different features and transformer pipelines\ncategorical_features = [\"Make\", \"Colour\"]\ncategorical_transformer = Pipeline(steps=[\n (\"imputer\", SimpleImputer(strategy=\"constant\", fill_value=\"missing\")),\n (\"onehot\", OneHotEncoder(handle_unknown=\"ignore\"))])\n\ndoor_feature = [\"Doors\"]\ndoor_transformer = Pipeline(steps=[\n (\"imputer\", SimpleImputer(strategy=\"constant\", fill_value=4))])\n\nnumeric_features = [\"Odometer (KM)\"]\nnumeric_transformer = Pipeline(steps=[\n (\"imputer\", SimpleImputer(strategy=\"mean\"))\n])\n\n# Setup preprocessing steps (fill missing values, then convert to numbers)\npreprocessor = ColumnTransformer(\n transformers=[\n (\"cat\", categorical_transformer, categorical_features),\n (\"door\", door_transformer, door_feature),\n (\"num\", numeric_transformer, numeric_features)])\n\n# Create a preprocessing and modelling pipeline\nmodel = Pipeline(steps=[(\"preprocessor\", preprocessor),\n (\"model\", RandomForestRegressor(n_jobs=-1))])\n\n# Split data\nX = data.drop(\"Price\", axis=1)\ny = data[\"Price\"]\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)\n\n# Fit and score the model\nmodel.fit(X_train, y_train)\nmodel.score(X_test, y_test)\n
# Getting data ready import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline from sklearn.impute import SimpleImputer from sklearn.preprocessing import OneHotEncoder # Modelling from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import train_test_split, GridSearchCV # Setup random seed import numpy as np np.random.seed(42) # Import data and drop the rows with missing labels data = pd.read_csv(\"https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/data/car-sales-extended-missing-data.csv\") data.dropna(subset=[\"Price\"], inplace=True) # Define different features and transformer pipelines categorical_features = [\"Make\", \"Colour\"] categorical_transformer = Pipeline(steps=[ (\"imputer\", SimpleImputer(strategy=\"constant\", fill_value=\"missing\")), (\"onehot\", OneHotEncoder(handle_unknown=\"ignore\"))]) door_feature = [\"Doors\"] door_transformer = Pipeline(steps=[ (\"imputer\", SimpleImputer(strategy=\"constant\", fill_value=4))]) numeric_features = [\"Odometer (KM)\"] numeric_transformer = Pipeline(steps=[ (\"imputer\", SimpleImputer(strategy=\"mean\")) ]) # Setup preprocessing steps (fill missing values, then convert to numbers) preprocessor = ColumnTransformer( transformers=[ (\"cat\", categorical_transformer, categorical_features), (\"door\", door_transformer, door_feature), (\"num\", numeric_transformer, numeric_features)]) # Create a preprocessing and modelling pipeline model = Pipeline(steps=[(\"preprocessor\", preprocessor), (\"model\", RandomForestRegressor(n_jobs=-1))]) # Split data X = data.drop(\"Price\", axis=1) y = data[\"Price\"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Fit and score the model model.fit(X_train, y_train) model.score(X_test, y_test) Out[199]: 0.22188417408787875
What we've done is combine a series of data preprocessing steps (filling missing values, encoding numerical values) as well as a model into a Pipeline.
Doing so not only cleans up the code, it ensures the same steps are taken every time the code is run rather than having multiple different processing steps happening in different stages.
It's also possible to GridSearchCV or RandomizedSearchCV with a Pipeline.
The main difference is when creating a hyperparameter grid, you have to add a prefix to each hyperparameter (see the documentation for RandomForestRegressor for a full list of possible hyperparameters to tune).
The prefix is the name of the Pipeline step you'd like to alter, followed by two underscores.
For example, to adjust n_estimators of \"model\" in the Pipeline, you'd use: \"model__n_estimators\" (note the double underscore after model__ at the start).
Let's see it!
Note: Depending on your computer's processing power, the cell below may take a few minutes to run. For reference, it took about ~60 seconds on my M1 Pro MacBook Pro.
In\u00a0[200]: Copied! %%time\n\n# Using grid search with pipeline\npipe_grid = {\n \"preprocessor__num__imputer__strategy\": [\"mean\", \"median\"], # note the double underscore after each prefix \"preprocessor__\"\n \"model__n_estimators\": [100, 1000],\n \"model__max_depth\": [None, 5],\n \"model__max_features\": [\"sqrt\"],\n \"model__min_samples_split\": [2, 4]\n}\n\ngs_model = GridSearchCV(model, pipe_grid, cv=5, verbose=2)\ngs_model.fit(X_train, y_train)\n %%time # Using grid search with pipeline pipe_grid = { \"preprocessor__num__imputer__strategy\": [\"mean\", \"median\"], # note the double underscore after each prefix \"preprocessor__\" \"model__n_estimators\": [100, 1000], \"model__max_depth\": [None, 5], \"model__max_features\": [\"sqrt\"], \"model__min_samples_split\": [2, 4] } gs_model = GridSearchCV(model, pipe_grid, cv=5, verbose=2) gs_model.fit(X_train, y_train) Fitting 5 folds for each of 16 candidates, totalling 80 fits\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s\n[CV] END model__max_depth=None, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.7s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=2, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=mean; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=100, preprocessor__num__imputer__strategy=median; total time= 0.1s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.6s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=mean; total time= 0.5s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.6s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s\n[CV] END model__max_depth=5, model__max_features=sqrt, model__min_samples_split=4, model__n_estimators=1000, preprocessor__num__imputer__strategy=median; total time= 0.5s\n
Out[200]: GridSearchCV(cv=5,\n estimator=Pipeline(steps=[('preprocessor',\n ColumnTransformer(transformers=[('cat',\n Pipeline(steps=[('imputer',\n SimpleImputer(fill_value='missing',\n strategy='constant')),\n ('onehot',\n OneHotEncoder(handle_unknown='ignore'))]),\n ['Make',\n 'Colour']),\n ('door',\n Pipeline(steps=[('imputer',\n SimpleImputer(fill_value=4,\n strategy='constant'))]),\n ['Doors']),\n ('num',\n Pipeline(steps=[('imputer',\n SimpleImputer())]),\n ['Odometer '\n '(KM)'])])),\n ('model',\n RandomForestRegressor(n_jobs=-1))]),\n param_grid={'model__max_depth': [None, 5],\n 'model__max_features': ['sqrt'],\n 'model__min_samples_split': [2, 4],\n 'model__n_estimators': [100, 1000],\n 'preprocessor__num__imputer__strategy': ['mean',\n 'median']},\n verbose=2)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.\u00a0\u00a0GridSearchCV?Documentation for GridSearchCViFittedGridSearchCV(cv=5,\n estimator=Pipeline(steps=[('preprocessor',\n ColumnTransformer(transformers=[('cat',\n Pipeline(steps=[('imputer',\n SimpleImputer(fill_value='missing',\n strategy='constant')),\n ('onehot',\n OneHotEncoder(handle_unknown='ignore'))]),\n ['Make',\n 'Colour']),\n ('door',\n Pipeline(steps=[('imputer',\n SimpleImputer(fill_value=4,\n strategy='constant'))]),\n ['Doors']),\n ('num',\n Pipeline(steps=[('imputer',\n SimpleImputer())]),\n ['Odometer '\n '(KM)'])])),\n ('model',\n RandomForestRegressor(n_jobs=-1))]),\n param_grid={'model__max_depth': [None, 5],\n 'model__max_features': ['sqrt'],\n 'model__min_samples_split': [2, 4],\n 'model__n_estimators': [100, 1000],\n 'preprocessor__num__imputer__strategy': ['mean',\n 'median']},\n verbose=2) best_estimator_: PipelinePipeline(steps=[('preprocessor',\n ColumnTransformer(transformers=[('cat',\n Pipeline(steps=[('imputer',\n SimpleImputer(fill_value='missing',\n strategy='constant')),\n ('onehot',\n OneHotEncoder(handle_unknown='ignore'))]),\n ['Make', 'Colour']),\n ('door',\n Pipeline(steps=[('imputer',\n SimpleImputer(fill_value=4,\n strategy='constant'))]),\n ['Doors']),\n ('num',\n Pipeline(steps=[('imputer',\n SimpleImputer())]),\n ['Odometer (KM)'])])),\n ('model',\n RandomForestRegressor(max_depth=5, max_features='sqrt',\n n_jobs=-1))]) \u00a0preprocessor: ColumnTransformer?Documentation for preprocessor: ColumnTransformerColumnTransformer(transformers=[('cat',\n Pipeline(steps=[('imputer',\n SimpleImputer(fill_value='missing',\n strategy='constant')),\n ('onehot',\n OneHotEncoder(handle_unknown='ignore'))]),\n ['Make', 'Colour']),\n ('door',\n Pipeline(steps=[('imputer',\n SimpleImputer(fill_value=4,\n strategy='constant'))]),\n ['Doors']),\n ('num',\n Pipeline(steps=[('imputer', SimpleImputer())]),\n ['Odometer (KM)'])]) cat['Make', 'Colour']
\u00a0SimpleImputer?Documentation for SimpleImputerSimpleImputer(fill_value='missing', strategy='constant')
\u00a0OneHotEncoder?Documentation for OneHotEncoderOneHotEncoder(handle_unknown='ignore')
door['Doors']
\u00a0SimpleImputer?Documentation for SimpleImputerSimpleImputer(fill_value=4, strategy='constant')
num['Odometer (KM)']
\u00a0SimpleImputer?Documentation for SimpleImputerSimpleImputer()
\u00a0RandomForestRegressor?Documentation for RandomForestRegressorRandomForestRegressor(max_depth=5, max_features='sqrt', n_jobs=-1)
Now let's find the score of our model (by default GridSearchCV saves the best model to the gs_model object).
In\u00a0[201]: Copied! # Score the best model\ngs_model.score(X_test, y_test)\n
# Score the best model gs_model.score(X_test, y_test) Out[201]: 0.2848784564026805
Beautiful!
Using GridSearchCV we see a nice boost in our models score.
And the best thing is, because it's all in a Pipeline, we could easily replicate these results.
"},{"location":"introduction-to-scikit-learn/#a-quick-machine-learning-modelling-tutorial-with-python-and-scikit-learn","title":"A Quick Machine Learning Modelling Tutorial with Python and Scikit-Learn\u00b6","text":"This notebook goes through a range of common and useful featues of the Scikit-Learn library.
There's a bunch here but I'm calling it quick because of how vast the Scikit-Learn library is.
Covering everything requires a full-blown documentation, of which, if you ever get stuck, I'd highly recommend checking out.
"},{"location":"introduction-to-scikit-learn/#what-is-scikit-learn-sklearn","title":"What is Scikit-Learn (sklearn)?\u00b6","text":"Scikit-Learn, also referred to as sklearn, is an open-source Python machine learning library.
It's built on top on NumPy (Python library for numerical computing) and Matplotlib (Python library for data visualization).
"},{"location":"introduction-to-scikit-learn/#why-scikit-learn","title":"Why Scikit-Learn?\u00b6","text":"Although the fields of data science and machine learning are vast, the main goal is finding patterns within data and then using those patterns to make predictions.
And there are certain categories which a majority of problems fall into.
If you're trying to create a machine learning model to predict whether an email is spam and or not spam, you're working on a classification problem (whether something is one thing or another).
If you're trying to create a machine learning model to predict the price of houses given their characteristics, you're working on a regression problem (predicting a number).
If you're trying to get a machine learning algorithm to group together similar samples (that you don't necessarily know which should go together), you're working on a clustering problem.
Once you know what kind of problem you're working on, there are also similar steps you'll take for each.
Steps like splitting the data into different sets, one for your machine learning algorithms to learn on (the training set) and another to test them on (the testing set).
Choosing a machine learning model and then evaluating whether or not your model has learned anything.
Scikit-Learn offers Python implementations for doing all of these kinds of tasks (from preparing data to modelling data). Saving you from having to build them from scratch.
"},{"location":"introduction-to-scikit-learn/#what-does-this-notebook-cover","title":"What does this notebook cover?\u00b6","text":"The Scikit-Learn library is very capable. However, learning everything off by heart isn't necessary. Instead, this notebook focuses some of the main use cases of the library.
More specifically, we'll cover:
- An end-to-end Scikit-Learn worfklow
- Getting the data ready
- Choosing the right maching learning estimator/aglorithm/model for your problem
- Fitting your chosen machine learning model to data and using it to make a prediction
- Evaluting a machine learning model
- Improving predictions through experimentation (hyperparameter tuning)
- Saving and loading a pretrained model
- Putting it all together in a pipeline
Note: All of the steps in this notebook are focused on supervised learning (having data and labels). The other side of supervised learning is unsupervised learning (having data but no labels).
After going through it, you'll have the base knolwedge of Scikit-Learn you need to keep moving forward.
"},{"location":"introduction-to-scikit-learn/#where-can-i-get-help","title":"Where can I get help?\u00b6","text":"If you get stuck or think of something you'd like to do which this notebook doesn't cover, don't fear!
The recommended steps you take are:
- Try it - Since Scikit-Learn has been designed with usability in mind, your first step should be to use what you know and try figure out the answer to your own question (getting it wrong is part of the process). If in doubt, run your code.
- Press SHIFT+TAB - See you can the docstring of a function (information on what the function does) by pressing SHIFT + TAB inside it. Doing this is a good habit to develop. It'll improve your research skills and give you a better understanding of the library.
- Search for it - If trying it on your own doesn't work, since someone else has probably tried to do something similar, try searching for your problem. You'll likely end up in 1 of 2 places:
- Scikit-Learn documentation/user guide - the most extensive resource you'll find for Scikit-Learn information.
- Stack Overflow - this is the developers Q&A hub, it's full of questions and answers of different problems across a wide range of software development topics and chances are, there's one related to your problem.
- ChatGPT - ChatGPT is very good at explaining code, however, it can make mistakes. Best to verify the code it writes first before using it. Try asking \"Can you explain the following code for me? {your code here}\" and then continue with follow up questions from there. Avoid blindly trusting code you didn't write for yourself.
An example of searching for a Scikit-Learn solution might be:
\"how to tune the hyperparameters of a sklearn model\"
Searching this on Google leads to the Scikit-Learn documentation for the GridSearchCV function: http://scikit-learn.org/stable/modules/grid_search.html
The next steps here are to read through the documentation, check the examples and see if they line up to the problem you're trying to solve. If they do, rewrite the code to suit your needs, run it, and see what the outcomes are.
- Ask for help - If you've been through the above 3 steps and you're still stuck, you might want to ask your question on Stack Overflow or in the ZTM Machine Learning and AI Discord channel. Be as specific as possible and provide details on what you've tried.
Remember, you don't have to learn all of the functions off by heart to begin with.
What's most important is continually asking yourself, \"what am I trying to do with the data?\".
Start by answering that question and then practicing finding the code which does it.
Let's get started.
First we'll import the libraries we've been using previously.
We'll also check the version of sklearn we've got.
"},{"location":"introduction-to-scikit-learn/#0-an-end-to-end-scikit-learn-workflow","title":"0. An end-to-end Scikit-Learn workflow\u00b6","text":"Before we get in-depth, let's quickly check out what an end-to-end Scikit-Learn workflow might look like.
Once we've seen an end-to-end workflow, we'll dive into each step a little deeper.
Specifically, we'll get hands-on with the following steps:
- Getting data ready (split into features and labels, prepare train and test steps)
- Choosing a model for our problem
- Fit the model to the data and use it to make a prediction
- Evaluate the model
- Experiment to improve
- Save a model for someone else to use
Note: The following section is a bit information heavy but it is an end-to-end workflow. We'll go through it quite swiftly but we'll break it down more throughout the rest of the notebook. And since Scikit-Learn is such a vast library, capable of tackling many problems, the workflow we're using is only one example of how you can use it.
"},{"location":"introduction-to-scikit-learn/#random-forest-classifier-workflow-for-classifying-heart-disease","title":"Random Forest Classifier Workflow for Classifying Heart Disease\u00b6","text":""},{"location":"introduction-to-scikit-learn/#1-get-the-data-ready","title":"1. Get the data ready\u00b6","text":"As an example dataset, we'll import heart-disease.csv.
This file contains anonymised patient medical records and whether or not they have heart disease or not (this is a classification problem since we're trying to predict whether something is one thing or another).
"},{"location":"introduction-to-scikit-learn/#2-choose-the-model-and-hyperparameters","title":"2. Choose the model and hyperparameters\u00b6","text":"Choosing a model often depends on the type of problem you're working on.
For example, there are different models that Scikit-Learn recommends whether you're working on a classification or regression problem.
You can see a map breaking down the different kinds of model options and recommendations in the Scikit-Learn documentation.
Scikit-Learn refers to models as \"estimators\", however, they are often also referred to as model or clf (short for classifier).
A model's hyperparameters are settings you can change to adjust it for your problem, much like knobs on an oven you can tune to cook your favourite dish.
"},{"location":"introduction-to-scikit-learn/#3-fit-the-model-to-the-data-and-use-it-to-make-a-prediction","title":"3. Fit the model to the data and use it to make a prediction\u00b6","text":"Fitting a model a dataset involves passing it the data and asking it to figure out the patterns.
If there are labels (supervised learning), the model tries to work out the relationship between the data and the labels.
If there are no labels (unsupervised learning), the model tries to find patterns and group similar samples together.
Most Scikit-Learn models have the fit(X, y) method built-in, where the X parameter is the features and the y parameter is the labels.
In our case, we start by fitting a model on the training split (X_train, y_train).
"},{"location":"introduction-to-scikit-learn/#use-the-model-to-make-a-prediction","title":"Use the model to make a prediction\u00b6","text":"The whole point of training a machine learning model is to use it to make some kind of prediction in the future.
Once your model instance is trained, you can use the predict() method to predict a target value given a set of features.
In other words, use the model, along with some new, unseen and unlabelled data to predict the label.
Note: Data you predict on should be in the same shape and format as data you trained on.
"},{"location":"introduction-to-scikit-learn/#4-evaluate-the-model","title":"4. Evaluate the model\u00b6","text":"Now we've made some predictions, we can start to use some more Scikit-Learn methods to figure out how good our model is.
Each model or estimator has a built-in score() method.
This method compares how well the model was able to learn the patterns between the features and labels.
The score() method for each model uses a standard evaluation metric to measure your model's results.
In the case of a classifier (our model), one of the most common evaluation metrics is accuracy (the fraction of correct predictions out of total predictions).
Let's check out our model's accuracy on the training set.
"},{"location":"introduction-to-scikit-learn/#5-experiment-to-improve","title":"5. Experiment to improve\u00b6","text":"The first model you build is often referred to as a baseline (a baseline is often even simpler than the model we've used, a baseline could be \"let's just by default predict the most common value and then try to improve\").
Once you've got a baseline model, like we have here, it's important to remember, this is often not the final model you'll use.
The next step in the workflow is to try and improve upon your baseline model.
How?
With one of the most important mottos in machine learning...
Experiment, experiment, experiment!
Experiments can come in many different forms.
But let's break it into two.
- From a model perspective.
- From a data perspective.
From a model perspective may involve things such as using a more complex model or tuning your models hyperparameters.
From a data perspective may involve collecting more data or better quality data so your existing model has more of a chance to learn the patterns within.
If you're already working on an existing dataset, it's often easier try a series of model perspective experiments first and then turn to data perspective experiments if you aren't getting the results you're looking for.
One thing you should be aware of is if you're tuning a models hyperparameters in a series of experiments, your reuslts should always be cross-validated (we'll see this later on!).
Cross-validation is a way of making sure the results you're getting are consistent across your training and test datasets (because it uses multiple versions of training and test sets) rather than just luck because of the order the original training and test sets were created.
- Try different hyperparameters.
- All different parameters should be cross-validated.
- Note: Beware of cross-validation for time series problems (as for time series, you don't want to mix samples from the future with samples from the past).
Different models you use will have different hyperparameters you can tune.
For the case of our model, the RandomForestClassifier(), we'll start trying different values for n_estimators (a measure for the number of trees in the random forest).
By default, n_estimators=100, so how about we try values from 100 to 200 and see what happens (generally more is better)?
"},{"location":"introduction-to-scikit-learn/#6-save-a-model-for-someone-else-to-use","title":"6. Save a model for someone else to use\u00b6","text":"When you've done a few experiments and you're happy with how your model is doing, you'll likely want someone else to be able to use it.
This may come in the form of a teammate or colleague trying to replicate and validate your results or through a customer using your model as part of a service or application you offer.
Saving a model also allows you to reuse it later without having to go through retraining it. Which is helpful, especially when your training times start to increase.
You can save a Scikit-Learn model using Python's in-built pickle module.
"},{"location":"introduction-to-scikit-learn/#1-getting-the-data-ready","title":"1. Getting the data ready\u00b6","text":"Data doesn't always come ready to use with a Scikit-Learn machine learning model.
Three of the main steps you'll often have to take are:
- Splitting the data into features (usually
X) and labels (usually y). - Splitting the data into training and testing sets (and possibly a validation set).
- Filling (also called imputing) or disregarding missing values.
- Converting non-numerical values to numerical values (also call feature encoding).
Let's see an example.
"},{"location":"introduction-to-scikit-learn/#11-make-sure-its-all-numerical","title":"1.1 Make sure it's all numerical\u00b6","text":"Computers love numbers.
So one thing you'll often have to make sure of is that your datasets are in numerical form.
This even goes for datasets which contain non-numerical features that you may want to include in a model.
For example, if we were working with a car sales dataset, how might we turn features such as Make and Colour into numbers?
Let's figure it out.
First, we'll import the car-sales-extended.csv dataset.
"},{"location":"introduction-to-scikit-learn/#111-nuemrically-encoding-data-with-pandas","title":"1.1.1 Nuemrically encoding data with pandas\u00b6","text":"Another way we can numerically encode data is directly with pandas.
We can use the pandas.get_dummies() (or pd.get_dummies() for short) method and then pass it our target columns.
In return, we'll get a one-hot encoded version of our target columns.
Let's remind ourselves of what our DataFrame looks like.
"},{"location":"introduction-to-scikit-learn/#12-what-if-there-were-missing-values-in-the-data","title":"1.2 What if there were missing values in the data?\u00b6","text":"Holes in the data means holes in the patterns your machine learning model can learn.
Many machine learning models don't work well or produce errors when they're used on datasets with missing values.
A missing value can appear as a blank, as a NaN or something similar.
There are two main options when dealing with missing values:
- Fill them with some given or calculated value (imputation) - For example, you might fill missing values of a numerical column with the mean of all the other values. The practice of calculating or figuring out how to fill missing values in a dataset is called imputing. For a great resource on imputing missing values, I'd recommend refering to the Scikit-Learn user guide.
- Remove them - If a row or sample has missing values, you may opt to remove them from your dataset completely. However, this potentially results in using less data to build your model.
Note: Dealing with missing values differs from problem to problem, meaning there's no 100% best way to fill missing values across datasets and problem types. It will often take careful experimentation and practice to figure out the best way to deal with missing values in your own datasets.
To practice dealing with missing values, let's import a version of the car_sales dataset with several missing values (namely car-sales-extended-missing-data.csv).
"},{"location":"introduction-to-scikit-learn/#121-fill-missing-data-with-pandas","title":"1.2.1 Fill missing data with pandas\u00b6","text":"Let's see how we might fill missing values with pandas.
For categorical values, one of the simplest ways is to fill the missing fields with the string \"missing\".
We could do this for the Make and Colour features.
As for the Doors feature, we could use \"missing\" or we could fill it with the most common option of 4.
With the Odometer (KM) feature, we can use the mean value of all the other values in the column.
And finally, for those samples which are missing a Price value, we can remove them (since Price is the target value, removing probably causes less harm than imputing, however, you could design an experiment to test this).
In summary:
Column/Feature Fill missing value with Make \"missing\" Colour \"missing\" Doors 4 (most common value) Odometer (KM) mean of Odometer (KM) Price (target) NA, remove samples missing Price Note: The practice of filling missing data with given or calculated values is called imputation. And it's important to remember there's no perfect way to fill missing data (unless it's with data that should've actually been there in the first place). The methods we're using are only one of many. The techniques you use will depend heavily on your dataset. A good place to look would be searching for \"data imputation techniques\".
Let's start with the Make column.
We can use the pandas method fillna(value=\"missing\", inplace=True) to fill all the missing values with the string \"missing\".
"},{"location":"introduction-to-scikit-learn/#122-filling-missing-data-and-transforming-categorical-data-with-scikit-learn","title":"1.2.2 Filling missing data and transforming categorical data with Scikit-Learn\u00b6","text":"Now we've filled the missing columns using pandas functions, you might be thinking, \"Why pandas? I thought this was a Scikit-Learn introduction?\".
Not to worry, Scikit-Learn provides a class called sklearn.impute.SimpleImputer() which allows us to do a similar thing.
SimpleImputer() transforms data by filling missing values with a given strategy parameter.
And we can use it to fill the missing values in our DataFrame as above.
At the moment, our dataframe has no mising values.
"},{"location":"introduction-to-scikit-learn/#2-choosing-the-right-estimatoralgorithm-for-your-problem","title":"2. Choosing the right estimator/algorithm for your problem\u00b6","text":"Once you've got your data ready, the next step is to choose an appropriate machine learning algorithm or model to find patterns in your data.
Some things to note:
- Scikit-Learn refers to machine learning models and algorithms as estimators.
- Classification problem - predicting a category (heart disease or not).
- Sometimes you'll see
clf (short for classifier) used as a classification estimator instance's variable name.
- Regression problem - predicting a number (selling price of a car).
- Unsupervised problem (data with no labels) - clustering (grouping unlabelled samples with other similar unlabelled samples).
If you know what kind of problem you're working with, one of the next places you should look at is the Scikit-Learn algorithm cheatsheet.
This cheatsheet gives you a bit of an insight into the algorithm you might want to use for the problem you're working on.
It's important to remember, you don't have to explicitly know what each algorithm is doing on the inside to start using them.
If you start to apply different algorithms but they don't seem to be working (not performing as well as you'd like), that's when you'd start to look deeper into each one.
Let's check out the cheatsheet and follow it for some of the problems we're working on.
You can see it's split into four main categories. Regression, classification, clustering and dimensionality reduction. Each has their own different purpose but the Scikit-Learn team has designed the library so the workflows for each are relatively similar.
"},{"location":"introduction-to-scikit-learn/#21-picking-a-machine-learning-model-for-a-regression-problem","title":"2.1 Picking a machine learning model for a regression problem\u00b6","text":"Let's start with a regression problem (trying to predict a number). We'll use the California Housing dataset built into Scikit-Learn's datasets module.
The goal of the California Housing dataset is to predict a given district's median house value (in hundreds of thousands of dollars) on things like the age of the home, the number of rooms, the number of bedrooms, number of people living the home and more.
"},{"location":"introduction-to-scikit-learn/#22-picking-a-machine-learning-model-for-a-classification-problem","title":"2.2 Picking a machine learning model for a classification problem\u00b6","text":"Now, let's check out the choosing process for a classification problem.
Say you were trying to predict whether or not a patient had heart disease based on their medical records.
The dataset in ../data/heart-disease.csv (or at heart-disease.csv) contains data for just that problem.
"},{"location":"introduction-to-scikit-learn/#what-about-the-other-models","title":"What about the other models?\u00b6","text":"Looking at the Scikit-Learn aglorithm cheat-sheet and the examples above, you may have noticed we've skipped a few models.
Why?
The first reason is time.
Covering every single one would take a fair bit longer than what we've done here. And the second one is the effectiveness of ensemble methods.
A little tidbit for modelling in machine learning is:
- If you have structured data (tables, spreadsheets or dataframes), use ensemble methods, such as, a Random Forest.
- If you have unstructured data (text, images, audio, things not in tables), use deep learning or transfer learning (see the ZTM TensorFlow and PyTorch courses for more on deep learning).
For this notebook, we're focused on structured data, which is why the Random Forest has been our model of choice.
If you'd like to learn more about the Random Forest and why it's the war horse of machine learning, check out these resources:
- Random Forest Wikipedia
- An Implementation and Explanation of the Random Forest in Python by Will Koehrsen
"},{"location":"introduction-to-scikit-learn/#experiment-until-something-works","title":"Experiment until something works\u00b6","text":"The beautiful thing is, the way the Scikit-Learn API is designed, once you know the way with one model, using another is much the same.
And since a big part of being a machine learning engineer or data scientist is experimenting, you might want to try out some of the other models on the cheat-sheet and see how you go. The more you can reduce the time between experiments, the better.
"},{"location":"introduction-to-scikit-learn/#3-fit-the-model-to-data-and-using-it-to-make-predictions","title":"3. Fit the model to data and using it to make predictions\u00b6","text":"Now you've chosen a model, the next step is to have it learn from the data so it can be used for predictions in the future.
If you've followed through, you've seen a few examples of this already.
"},{"location":"introduction-to-scikit-learn/#31-fitting-a-model-to-data","title":"3.1 Fitting a model to data\u00b6","text":"In Scikit-Learn, the process of having a machine learning model learn patterns from a dataset involves calling the fit() method and passing it data, such as, fit(X, y).
Where X is a feature array and y is a target array.
Other names for X include:
- Data
- Feature variables
- Features
Other names for y include:
For supervised learning there is usually an X and y.
For unsupervised learning, there's no y (no labels).
Let's revisit the example of using patient data (X) to predict whether or not they have heart disease (y).
"},{"location":"introduction-to-scikit-learn/#32-making-predictions-using-a-machine-learning-model","title":"3.2 Making predictions using a machine learning model\u00b6","text":"Now we've got a trained model, one which has hoepfully learned patterns in the data, you'll want to use it to make predictions.
Scikit-Learn enables this in several ways.
Two of the most common and useful are predict() and predict_proba().
Let's see them in action.
"},{"location":"introduction-to-scikit-learn/#4-evaluating-a-model","title":"4. Evaluating a model\u00b6","text":"Once you've trained a model, you'll want a way to measure how trustworthy its predictions are.
Across the board, the main idea of evaluating a model is to compare the model's predictions to what they should've ideally been (the truth labels).
Scikit-Learn implements 3 different methods of evaluating models.
- The
score() method. Calling score() on a model instance will return a metric assosciated with the type of model you're using. The metric depends on which model you're using. - The
scoring parameter. This parameter can be passed to methods such as cross_val_score() or GridSearchCV() to tell Scikit-Learn to use a specific type of scoring metric. - Problem-specific metric functions available in
sklearn.metrics. Similar to how the scoring parameter can be passed different scoring functions, Scikit-Learn implements these as stand alone functions.
The scoring function you use will also depend on the problem you're working on.
Classification problems have different evaluation metrics and scoring functions to regression problems.
Let's look at some examples.
"},{"location":"introduction-to-scikit-learn/#41-general-model-evaluation-with-score","title":"4.1 General model evaluation with score()\u00b6","text":"If we bring down the code from our previous classification problem (building a classifier to predict whether or not someone has heart disease based on their medical records).
We can see the score() method come into play.
"},{"location":"introduction-to-scikit-learn/#42-evaluating-your-models-using-the-scoring-parameter","title":"4.2 Evaluating your models using the scoring parameter\u00b6","text":"The next step up from using score() is to use a custom scoring parameter with cross_val_score() or GridSearchCV.
As you may have guessed, the scoring parameter you set will be different depending on the problem you're working on.
We'll see some specific examples of different parameters in a moment but first let's check out cross_val_score().
To do so, we'll copy the heart disease classification code from above and then add another line at the top.
"},{"location":"introduction-to-scikit-learn/#421-classification-model-evaluation-metrics","title":"4.2.1 Classification model evaluation metrics\u00b6","text":"Four of the main evaluation metrics/methods you'll come across for classification models are:
- Accuracy
- Area under ROC curve (receiver operating characteristic curve)
- Confusion matrix
- Classification report
Let's have a look at each of these. We'll bring down the classification code from above to go through some examples.
"},{"location":"introduction-to-scikit-learn/#accuracy","title":"Accuracy\u00b6","text":"Accuracy is the default metric for the score() function within each of Scikit-Learn's classifier models. And it's probably the metric you'll see most often used for classification problems.
However, we'll see in a second how it may not always be the best metric to use.
Scikit-Learn returns accuracy as a decimal but you can easily convert it to a percentage.
"},{"location":"introduction-to-scikit-learn/#area-under-receiver-operating-characteristic-roc-curve","title":"Area Under Receiver Operating Characteristic (ROC) Curve\u00b6","text":"If this one sounds like a mouthful, its because reading the full name is.
It's usually referred to as AUC for Area Under Curve and the curve they're talking about is the Receiver Operating Characteristic or ROC for short.
So if hear someone talking about AUC or ROC, they're probably talking about what follows.
ROC curves are a comparison of true postive rate (tpr) versus false positive rate (fpr).
For clarity:
- True positive = model predicts 1 when truth is 1
- False positive = model predicts 1 when truth is 0
- True negative = model predicts 0 when truth is 0
- False negative = model predicts 0 when truth is 1
Now we know this, let's see one. Scikit-Learn lets you calculate the information required for a ROC curve using the roc_curve function.
"},{"location":"introduction-to-scikit-learn/#confusion-matrix","title":"Confusion matrix\u00b6","text":"Another fantastic way to evaluate a classification model is by using a confusion matrix.
A confusion matrix is a quick way to compare the labels a model predicts and the actual labels it was supposed to predict.
In essence, giving you an idea of where the model is getting confused.
"},{"location":"introduction-to-scikit-learn/#creating-a-confusion-matrix-using-scikit-learn","title":"Creating a confusion matrix using Scikit-Learn\u00b6","text":"Scikit-Learn has multiple different implementations of plotting confusion matrices:
sklearn.metrics.ConfusionMatrixDisplay.from_estimator(estimator, X, y) - this takes a fitted estimator (like our clf model), features (X) and labels (y), it then uses the trained estimator to make predictions on X and compares the predictions to y by displaying a confusion matrix.sklearn.metrics.ConfusionMatrixDisplay.from_predictions(y_true, y_pred) - this takes truth labels and predicted labels and compares them by displaying a confusion matrix.
Note: Both of these methods/classes require Scikit-Learn 1.0+. To check your version of Scikit-Learn run:
import sklearn\nsklearn.__version__\n
If you don't have 1.0+, you can upgrade at: https://scikit-learn.org/stable/install.html
"},{"location":"introduction-to-scikit-learn/#classification-report","title":"Classification report\u00b6","text":"The final major metric you should consider when evaluating a classification model is a classification report.
A classification report is more so a collection of metrics rather than a single one.
You can create a classification report using Scikit-Learn's sklearn.metrics.classification_report` method.
Let's see one.
"},{"location":"introduction-to-scikit-learn/#422-regression-model-evaluation-metrics","title":"4.2.2 Regression model evaluation metrics\u00b6","text":"Similar to classification, there are several metrics you can use to evaluate your regression models.
We'll check out the following.
- R^2 (pronounced r-squared) or coefficient of determination - Compares your models predictions to the mean of the targets. Values can range from negative infinity (a very poor model) to 1. For example, if all your model does is predict the mean of the targets, its R^2 value would be 0. And if your model perfectly predicts a range of numbers it's R^2 value would be 1. Higher is better.
- Mean absolute error (MAE) - The average of the absolute differences between predictions and actual values. It gives you an idea of how wrong your predictions were. Lower is better.
- Mean squared error (MSE) - The average squared differences between predictions and actual values. Squaring the errors removes negative errors. It also amplifies outliers (samples which have larger errors). Lower is better.
Let's see them in action. First, we'll bring down our regression model code again.
"},{"location":"introduction-to-scikit-learn/#423-evaluating-a-model-using-the-scoring-parameter","title":"4.2.3 Evaluating a model using the scoring parameter\u00b6","text":"We've covered a bunch of ways to evaluate a model's predictions but haven't even touched the scoring parameter...
Not to worry, it's very similar to what we've been doing!
As a refresh, the scoring parameter can be used with a function like cross_val_score() to tell Scikit-Learn what evaluation metric to return using cross-validation.
Let's check it out with our classification model and the heart disease dataset.
"},{"location":"introduction-to-scikit-learn/#43-using-different-evaluation-metrics-with-scikit-learn","title":"4.3 Using different evaluation metrics with Scikit-Learn\u00b6","text":"Remember the third way of evaluating Scikit-Learn functions?
- Problem-specific metric functions. Similar to how the
scoring parameter can be passed different scoring functions, Scikit-Learn implements these as stand alone functions.
Well, we've kind of covered this third way of using evaulation metrics with Scikit-Learn.
In essence, all of the metrics we've seen previously have their own function in Scikit-Learn.
They all work by comparing an array of predictions, usually called y_preds to an array of actual labels, usually called y_test or y_true.
"},{"location":"introduction-to-scikit-learn/#classification-functions","title":"Classification functions\u00b6","text":"For:
- Accuracy we can use
sklearn.metrics.accuracy_score - Precision we can use
sklearn.metrics.precision_score - Recall we can use
sklearn.metrics.recall_score - F1 we can use
sklearn.metrics.f1_score
"},{"location":"introduction-to-scikit-learn/#regression-metrics","title":"Regression metrics\u00b6","text":"We can use a similar setup for our regression problem, just with different methods.
For:
- R^2 we can use
sklearn.metrics.r2_score - MAE (mean absolute error) we can use
sklearn.metrics.mean_absolute_error - MSE (mean squared error) we can use
sklearn.metrics.mean_squared_error
"},{"location":"introduction-to-scikit-learn/#5-improving-model-predictions-through-experimentation-hyperparameter-tuning","title":"5. Improving model predictions through experimentation (hyperparameter tuning)\u00b6","text":"The first predictions you make with a model are generally referred to as baseline predictions.
It's similar for the first evaluation metrics you get. These are generally referred to as baseline metrics.
Your next goal is to improve upon these baseline metrics.
How?
Experiment, experiment, experiment!
Two of the main methods to improve baseline metrics are:
- From a data perspective.
- From a model perspective.
From a data perspective asks:
- Could we collect more data? In machine learning, more data is generally better, as it gives a model more opportunities to learn patterns.
- Could we improve our data? This could mean filling in misisng values or finding a better encoding (turning data into numbers) strategy.
From a model perspective asks:
- Is there a better model we could use? If you've started out with a simple model, could you use a more complex one? (we saw an example of this when looking at the Scikit-Learn machine learning map, ensemble methods are generally considered more complex models)
- Could we improve the current model? If the model you're using performs well straight out of the box, can the hyperparameters be tuned to make it even better?
Note: Patterns in data are also often referred to as data parameters. The difference between parameters and hyperparameters is a machine learning model seeks to find parameters in data on its own, where as, hyperparameters are settings on a model which a person (you) can adjust.
Since we have two existing datasets, we'll look at improving our results from a model perspective.
More specifically, we'll look at how we could improve our RandomForestClassifier and RandomForestRegressor models through hyperparameter tuning.
What even are hyperparameters?
Good question, let's check them out.
First, we'll instantiate a RandomForestClassifier.
"},{"location":"introduction-to-scikit-learn/#51-tuning-hyperparameters-by-hand","title":"5.1 Tuning hyperparameters by hand\u00b6","text":"So far we've worked with training and test datasets.
You train a model on a training set and evaluate it on a test dataset.
But hyperparameter tuning introduces a thrid set, a validation set.
Now the process becomes:
- Train a model on the training data.
- (Try to) improve the model's hyperparameters on the validation set.
- Evaluate the model on the test set.
If our starting dataset contained 100 different patient records labels indicating who had heart disease and who didn't and we wanted to build a machine learning model to predict who had heart disease and who didn't, it might look like this:
Since we know we're using a RandomForestClassifier and we know the hyperparameters we want to adjust, let's see what it looks like.
First, let's remind ourselves of the base parameters.
"},{"location":"introduction-to-scikit-learn/#52-hyperparameter-tuning-with-randomizedsearchcv","title":"5.2 Hyperparameter tuning with RandomizedSearchCV\u00b6","text":"Scikit-Learn's sklearn.model_selection.RandomizedSearchCV allows us to randomly search across different hyperparameters to see which work best.
It also stores details about the ones which work best!
Let's see it in action.
First, we create a dictionary of parameter distributions (collections of different values for specific hyperparamters) we'd like to search over.
This dictionary comes in the form:
param_distributions = {\"hyperparameter_name\": [values_to_randomly_try]}\n Where \"hyperparameter_name\" is the value of a specific hyperparameter for a model and [values_to_randomly_try] is a list of values for that specific hyperparamter to randomly try.
"},{"location":"introduction-to-scikit-learn/#53-hyperparameter-tuning-with-gridsearchcv","title":"5.3 Hyperparameter tuning with GridSearchCV\u00b6","text":"There's one more way we could try to improve our model's hyperparamters.
And it's with sklearn.model_selection.GridSearchCV.
The main difference between GridSearchCV and RandomizedSearchCV is GridSearchCV searches across a grid of hyperparamters exhaustively (it will try every combination possible), where as, RandomizedSearchCV searches across a grid of hyperparameters randomly (stopping after n_iter combinations).
GridSearchCV also refers to a dictionary of parameter distributions as a parameter grid (via the parameter param_grid).
For example, let's see our dictionary of hyperparameters.
"},{"location":"introduction-to-scikit-learn/#6-saving-and-loading-trained-machine-learning-models","title":"6. Saving and loading trained machine learning models\u00b6","text":"Our GridSearchCV model (gs_clf) has the best results so far, we'll export it and save it to file.
"},{"location":"introduction-to-scikit-learn/#61-saving-and-loading-a-model-with-pickle","title":"6.1 Saving and loading a model with pickle\u00b6","text":"We saw right at the start, one way to save a model is using Python's pickle module.
We'll use pickle's dump() method and pass it our model, gs_clf, along with the open() function containing a string for the filename we want to save our model as, along with the \"wb\" string which stands for \"write binary\", which is the file type open() will write our model as.
"},{"location":"introduction-to-scikit-learn/#62-saving-and-loading-a-model-with-joblib","title":"6.2 Saving and loading a model with joblib\u00b6","text":"The other way to load and save models is with joblib. Which works relatively the same as pickle.
To save a model, we can use joblib's dump() function, passing it the model (gs_clf) and the desired filename.
"},{"location":"introduction-to-scikit-learn/#7-revisiting-the-entire-pipeline","title":"7. Revisiting the entire pipeline\u00b6","text":"We've covered a lot. And so far, it seems to be all over the place, which it is.
But not to worry, machine learning projects often start out like this.
A whole bunch of experimenting and code all over the place at the start and then once you've found something which works, the refinement process begins.
What would this refinement process look like?
We'll use the car sales regression problem (predicting the sale price of cars) as an example.
To tidy things up, we'll be using Scikit-Learn's sklearn.pipeline.Pipeline class.
You can imagine Pipeline as being a way to string a number of different Scikit-Learn processes together.
"},{"location":"introduction-to-scikit-learn/#71-creating-a-regression-pipeline","title":"7.1 Creating a regression Pipeline\u00b6","text":"You might recall when, way back in Section 2: Getting Data Ready, we dealt with the car sales data, to build a regression model on it, we had to encode the categorical features into numbers and fill the missing data.
The code we used worked, but it was a bit all over the place.
Good news is, Pipeline can help us clean it up.
Let's remind ourselves what our car-sales-extended-missing-data.csv looks like in DataFrame form.
"},{"location":"introduction-to-scikit-learn/#where-to-next","title":"Where to next?\u00b6","text":"If you've made it this far, congratulations! We've covered a lot of ground in the Scikit-Learn library.
As you might've guessed, there's a lot more to be discovered.
But for the time being, you should be equipped with some of the most useful features of the library to start trying to apply them to your own problems.
Somewhere you might like to look next is to apply what you've learned above to a Kaggle competition.
Kaggle competitions are great places to practice your data science and machine learning skills and compare your results with others.
A great idea would be to try to combine the heart disease classification code, as well as the Pipeline code, to build a model for the Titanic dataset.
Otherwise, if you'd like to figure out what else the Scikit-Learn library is capable of I'd highly recommend browsing through the Scikit-Learn User Guide and seeing what sparks your interest.
Finally, as an extra-curriculum extension, you might want to look into trying out the CatBoost library for dealing with non-numerical data automatically.
The CatBoost algorithm is advanced version of a decision tree (like a Random Forest with superpowers) and is used in production at several large technology companies, including Cloudflare.
"}]}
\ No newline at end of file
diff --git a/sitemap.xml b/sitemap.xml
new file mode 100644
index 000000000..0f8724efd
--- /dev/null
+++ b/sitemap.xml
@@ -0,0 +1,3 @@
+
+
+
\ No newline at end of file
diff --git a/sitemap.xml.gz b/sitemap.xml.gz
new file mode 100644
index 000000000..059d349bb
Binary files /dev/null and b/sitemap.xml.gz differ
















![A visual representation of feature extraction from an input image using a neural network model. The process starts with an input image of a dog with dimensions 224 by 224 pixels and 3 color channels (totaling 150,528 data points). The image is processed by the model, symbolized by a network diagram, to produce a learned feature vector or embedding. The resulting tensor is displayed with a shape of [1, 1280], containing 1280 data points, which signifies an 117x reduction in the dimensionality from the original image data.](https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/images/unstructured-data-feature-vector-extraction.png?raw=true)
 +
+






 +
+

 +
+


 +
+






 +
+ +
+ +
+ +
+ +
+ +
+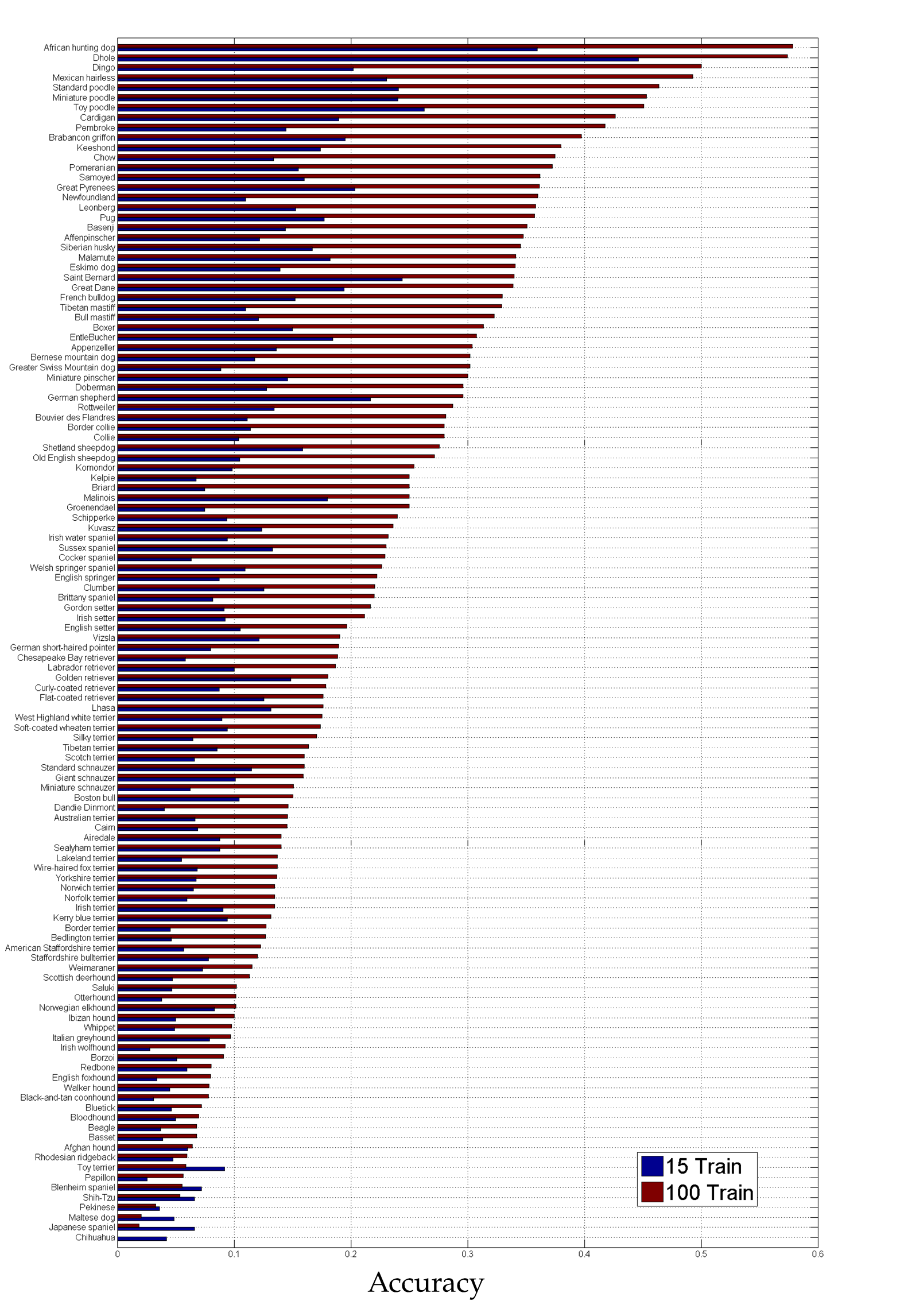{kind=link}