interesting recent papers:
- theory
- compute and memory architectures
- meta-learning
- one-shot learning
- unsupervised learning
- generative models
- bayesian inference and learning
- reasoning
- program induction
- reinforcement learning
- dialog systems
- natural language processing
interesting papers:
- artificial intelligence
- knowledge representation and reasoning
- machine learning
- deep learning
- reinforcement learning
- bayesian inference and learning
- probabilistic programming
- natural language processing
- information retrieval
- personal assistants
Understanding Deep Learning Requires Rethinking Generalization (Google Brain)
"1. The effective capacity of neural networks is large enough for a brute-force memorization of the entire data set.
2. Even optimization on random labels remains easy. In fact, training time increases only by a small constant factor compared with training on the true labels.
3. Randomizing labels is solely a data transformation, leaving all other properties of the learning problem unchanged."
"It is likely that learning in the traditional sense still occurs in part, but it appears to be deeply intertwined with massive memorization. Classical approaches are therefore poorly suited for reasoning about why these models generalize well.""Deep Learning networks are just massive associative memory stores! Deep Learning networks are capable of good generalization even when fitting random data. This is indeed strange in that many arguments for the validity of Deep Learning is on the conjecture that ‘natural’ data tends to exists in a very narrow manifold in multi-dimensional space. Random data however does not have that sort of tendency."
"Large, unregularized deep nets outperform shallower nets with regularization."
"SOTA models can fit arbitrary label patterns, even on large data-sets like ImageNet."
"Popular models can fit structureless noise."
"In the case of one-pass SGD, where each training point is only visited at most once, the algorithm is essentially optimizing the expected loss directly. Therefore, there is no need to define generalization. However, in practice, unless one has access to infinite training samples, one-pass SGD is rarely used. Instead, it is almost always better to run many passes of SGD over the same training set. In this case, the algorithm is optimizing the empirical loss, and the deviation between the empirical loss and the expected loss (i.e. the generalization error) needs to be controlled. In statistical learning theory, the deviation is typically controlled by restricting the complexity of the hypothesis space. For example, in binary classification, for a hypothesis space with VC-dimension d and n i.i.d. training samples, the generalization error could be upper bounded by O(sqrt(d/n)). In the distribution-free setting, the VC dimension also provide a lower bound for the generalization error. For example, if we are highly over-parameterized, i.e. d >> n, then there is a data distribution under which the generalization error could be arbitrarily bad. This worst case behavior is recently demonstrated by a randomization test on large neural networks that have the full capability of shattering the whole training set. In those experiments, zero-error minimizers for the empirical loss are found by SGD. Since the test performance could be only at the level of chance, the worst possible generalization error is observed. On the other hand, those same networks are found to generalize very well on natural image classification datasets, achieving the state-of-the-art performance on some standard benchmarks. This create a puzzle as our traditional characterization of generalization no longer readily apply in this scenario."
- https://facebook.com/iclr.cc/videos/1710657292296663/ (18:25) (Recht)
- https://facebook.com/iclr.cc/videos/1710657292296663/ (53:40) (Zhang)
- https://blog.acolyer.org/2017/05/11/understanding-deep-learning-requires-re-thinking-generalization/
Deep Nets Don't Learn via Memorization
"We use empirical methods to argue that deep neural networks do not achieve their performance by memorizing training data, in spite of overlyexpressive model architectures. Instead, they learn a simple available hypothesis that fits the finite data samples. In support of this view, we establish that there are qualitative differences when learning noise vs. natural datasets, showing that: (1) more capacity is needed to fit noise, (2) time to convergence is longer for random labels, but shorter for random inputs, and (3) DNNs trained on real data examples learn simpler functions than when trained with noise data, as measured by the sharpness of the loss function at convergence. Finally, we demonstrate that for appropriately tuned explicit regularization, e.g. dropout, we can degrade DNN training performance on noise datasets without compromising generalization on real data."
Opening the Black Box of Deep Neural Networks via Information
"DNNs with SGD have two phases: error minimization, then representation compression"
Capacity and Trainability in Recurrent Neural Networks (Google Brain)
"RNNs can store an amount of task information which is linear in the number of parameters, and is approximately 5 bits per parameter.
RNNs can additionally store approximately one real number from their input history per hidden unit."
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
"Deep nets generalise better with smaller batch-size when no other form of regularisation is used. And it may be because SGD biases learning towards flat local minima, rather than sharp local minima."
- http://inference.vc/everything-that-works-works-because-its-bayesian-2/
- https://github.com/keskarnitish/large-batch-training
The Marginal Value of Adaptive Gradient Methods in Machine Learning (Recht)
"Despite the fact that our experimental evidence demonstrates that adaptive methods are not advantageous for machine learning, the Adam algorithm remains incredibly popular. We are not sure exactly as to why, but hope that our step-size tuning suggestions make it easier for practitioners to use standard stochastic gradient methods in their research. In our conversations with other researchers, we have surmised that adaptive gradient methods are particularly popular for training GANs and Q-learning with function approximation. Both of these applications stand out because they are not solving optimization problems. It is possible that the dynamics of Adam are accidentally well matched to these sorts of optimization-free iterative search procedures. It is also possible that carefully tuned stochastic gradient methods may work as well or better in both of these applications."
Learning Deep ResNet Blocks Sequentially using Boosting Theory (Schapire)
"We construct T weak module classifiers, each contains two of the T layers, such that the combined strong learner is a ResNet."
"We introduce an alternative Deep ResNet training algorithm, which is particularly suitable in non-differentiable architectures."
Hybrid Computing using a Neural Network with Dynamic External Memory (DeepMind)
- https://deepmind.com/blog/differentiable-neural-computers/
- https://youtube.com/watch?v=steioHoiEms (Graves)
- https://youtube.com/watch?v=PQrlOjj8gAc (Wayne)
- https://youtu.be/otRoAQtc5Dk?t=59m56s (Polykovskiy)
- https://github.com/deepmind/dnc
- https://github.com/yos1up/DNC
- https://github.com/Mostafa-Samir/DNC-tensorflow
- https://github.com/frownyface/dnc
- https://github.com/khaotik/dnc-theano
Scaling Memory-Augmented Neural Networks with Sparse Reads and Writes (DeepMind) # improved Differentiable Neural Computer
Dynamic Neural Turing Machine with Soft and Hard Addressing Schemes (Bengio)
Hierarchical Memory Networks (Bengio)
Learning Efficient Algorithms with Hierarchical Attentive Memory (DeepMind)
"We show that an LSTM network augmented with HAM can learn algorithms for problems like merging, sorting or binary searching from pure input-output examples."
"We also show that HAM can be trained to act like classic data structures: a stack, a FIFO queue and a priority queue."
"Our model may be seen as a special case of Gated Graph Neural Network"
Neural Random-Access Machines (Sutskever)
Associative Long Short-Term Memory (Graves)
- http://techtalks.tv/talks/associative-long-short-term-memory/62525/ (Danihelka)
- http://www.cogsci.ucsd.edu/~sereno/170/readings/06-Holographic.pdf
- https://github.com/mohammadpz/Associative_LSTM
Using Fast Weights to Attend to the Recent Past (Hinton) # alternative to LSTM
(Hinton) "It's a different approach to a Neural Turing Machine. It does not require any decisions about where to write stuff or where to read from. Anything that happened recently can automatically be retrieved associatively. Fast associative memory should allow neural network models of sequential human reasoning."
- https://drive.google.com/file/d/0B8i61jl8OE3XdHRCSkV1VFNqTWc (Hinton)
- https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Using-Fast-Weights-to-Attend-to-the-Recent-Past (Ba)
- http://www.fields.utoronto.ca/talks/title-tba-337 (Hinton)
- https://youtube.com/watch?v=mrj_hyH974o (Novikov, in russian)
- http://www.shortscience.org/paper?bibtexKey=journals/corr/1610.06258
- https://github.com/dennybritz/deeplearning-papernotes/blob/master/notes/fast-weight-to-attend.md
- https://reddit.com/r/MachineLearning/comments/58qjiw/research161006258_using_fast_weights_to_attend_to/d92kctk/
- https://theneuralperspective.com/2016/12/04/implementation-of-using-fast-weights-to-attend-to-the-recent-past/
- https://github.com/ajarai/fast-weights
- https://github.com/jxwufan/AssociativeRetrieval
Overcoming Catastrophic Forgetting in Neural Networks (DeepMind)
"The Mixture of Experts Layer is trained using back-propagation. The Gating Network outputs an (artificially made) sparse vector that acts as a chooser of which experts to consult. More than one expert can be consulted at once (although the paper doesn’t give any precision on the optimal number of experts). The Gating Network also decides on output weights for each expert."
Huszar:
"on-line sequential (diagonalized) Laplace approximation of Bayesian learning"
"EWC makes sense for any neural network (indeed, any parametric model, really), virtually any task. Doesn't have to be DQN and in fact the paper itself shows examples with way simpler tasks."
"The quadratic penalty/penalties prevent the network from forgetting what it has learnt from previous data - you can think of the quadratic penalty as a summary of the information from the data it has seen so far."
"You can apply it at the level of learning tasks sequentially, or you can even apply it to on-line learning in a single task (in case you can't loop over the same minibatches several time like you do in SGD)."
- http://www.pnas.org/content/early/2017/03/13/1611835114.abstract
- http://rylanschaeffer.github.io/content/research/overcoming_catastrophic_forgetting/main.html
- http://inference.vc/comment-on-overcoming-catastrophic-forgetting-in-nns-are-multiple-penalties-needed-2/
- https://github.com/ariseff/overcoming-catastrophic
Improved Multitask Learning Through Synaptic Intelligence
"The regularization penalty is similar to EWC. However, our approach computes the per-synapse consolidation strength in an online fashion, whereas for EWC synaptic importance is computed offline after training on a designated task."
PathNet: Evolution Channels Gradient Descent in Super Neural Networks (DeepMind)
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (Google Brain)
"The MoE with experts shows higher accuracy (or lower perplexity) than the state of the art using only 16% of the training time."
Adaptive Computation Time for Recurrent Neural Networks (Graves)
- https://youtu.be/nqiUFc52g78?t=58m45s (Graves)
- http://distill.pub/2016/augmented-rnns/
- https://www.evernote.com/shard/s189/sh/fd165646-b630-48b7-844c-86ad2f07fcda/c9ab960af967ef847097f21d94b0bff7
- https://github.com/DeNeutoy/act-tensorflow
Memory-Efficient Backpropagation Through Time (Graves)
Hierarchical Multiscale Recurrent Neural Networks (Bengio)
- https://github.com/dennybritz/deeplearning-papernotes/blob/master/notes/hm-rnn.md
- https://medium.com/@jimfleming/notes-on-hierarchical-multiscale-recurrent-neural-networks-7362532f3b64
Phased LSTM: Accelerating Recurrent Network Training for Long or Event-based Sequences
"If you take an LSTM and add a “time gate” that controls at what frequency to be open to new input and how long to be open each time, you can have different neurons that learn to look at a sequence with different frequencies, create a “wormhole” for gradients, save compute, and do better on long sequences and when you need to process inputs from multiple sensors that are sampled at different rates."
- https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Phased-LSTM-Accelerating-Recurrent-Network-Training-for-Long-or-Event-based-Sequences (Neil)
- https://github.com/dannyneil/public_plstm
Decoupled Neural Interfaces using Synthetic Gradients (DeepMind)
"At the very least it can allow individual modules to do gradient updates before waiting for the backward pass to reach them. So you could get better GPGPU utilization when the ordinary 'locked' mode of forward-then-backward doesn't always saturate the available compute units.
Put differently, if you consider the dependency DAG of tensor operations, using these DNI things reduces the depth of the parameter gradient nodes (which is the whole point of training) in the DAG. So for example, the gradient update for the layer at the beginning of a n-layer chain goes from depth ~2n to depth ~1, the layer at the end has depth n, which doesn't change. On average, the depth of the gradient computation nodes is about 40% of what it would be normally, for deep networks. So there is a lot more flexibility for scheduling nodes in time and space.
And for coarser-grained parallelism it could allow modules running on different devices to do updates before a final loss gradient is available to be distributed to all the devices. Synchronization still has to happen to update the gradient predictions, but that can happen later, and could even be opportunistic (asynchronous or stochastic)."
"I guess that the synthetic gradients conditioned on the labels and the synthetic layer inputs conditioned on the data work for the same reason why stochastic depth works: during training, at any given layer the networks before and after it can be approximated by simpler, shallower versions. In stochastic depth the approximation is performed by skipping layers, so the whole network is approximated by a shallower version of itself, which changes at each step. In this work, instead, the approximation is performed by separate networks.
- https://deepmind.com/blog/decoupled-neural-networks-using-synthetic-gradients/
- https://iamtrask.github.io/2017/03/21/synthetic-gradients/
- http://cnichkawde.github.io/SyntheticGradients.html
Understanding Synthetic Gradients and Decoupled Neural Interfaces (DeepMind)
Learning to Communicate with Deep Multi-Agent Reinforcement Learning (DeepMind)
- https://youtube.com/watch?v=cfsYBY4nd1c
- https://youtu.be/SAcHyzMdbXc?t=19m (de Freitas)
- https://youtube.com/watch?v=xL-GKD49FXs (Foerster)
- http://videolectures.net/deeplearning2016_foerster_learning_communicate/ (Foerster)
- http://www.shortscience.org/paper?bibtexKey=journals/corr/1605.07133
- https://github.com/iassael/learning-to-communicate
Learning Multiagent Communication with Backpropagation (Facebook)
- https://youtu.be/SAcHyzMdbXc?t=19m (de Freitas)
- https://youtu.be/_iVVXWkoEAs?t=30m6s (Fergus)
- https://github.com/facebookresearch/CommNet
Learning to Learn by Gradient Descent by Gradient Descent (DeepMind)
"Take some computation where you usually wouldn’t keep around intermediate states, such as a planning computation (say value iteration, where you only keep your most recent estimate of the value function) or stochastic gradient descent (where you only keep around your current best estimate of the parameters). Now keep around those intermediate states as well, perhaps reifying the unrolled computation in a neural net, and take gradients to optimize the entire computation with respect to some loss function. Instances: Value Iteration Networks, Learning to learn by gradient descent by gradient descent."
- https://youtu.be/SAcHyzMdbXc?t=10m24s (DeepMind)
- https://youtu.be/x1kf4Zojtb0?t=1h4m53s (DeepMind)
- https://blog.acolyer.org/2017/01/04/learning-to-learn-by-gradient-descent-by-gradient-descent/
- https://hackernoon.com/learning-to-learn-by-gradient-descent-by-gradient-descent-4da2273d64f2
- https://github.com/deepmind/learning-to-learn
Learning to Learn without Gradient Descent by Gradient Descent (DeepMind)
"Differentiable neural computers as alternatives to parallel Bayesian optimization for hyperparameter tuning of other networks."
Learned Optimizers that Scale and Generalize (DeepMind)
RL^2: Fast Reinforcement Learning via Slow Reinforcement Learning (OpenAI)
"outer episodes (sample a new bandit problem / MDP) and inner episodes (of sampled MDP)"
"use RNN policy with no state reset between inner episodes for outer POMDP""future directions:
- better outer-loop algorithms
- scaling RL^2 to 1M games
- model-based RL^2
- curriculum learning / universal RL^2
- RL^2 + one-shot imitation learning
- RL^2 for simulation -> real world transfer"
- http://www.fields.utoronto.ca/video-archive/2017/02/2267-16530 (19:00) (Abbeel)
- https://youtube.com/watch?v=SfCa1HQMkuw&t=1h16m56s (Schulman)
- https://youtu.be/BskhUBPRrqE?t=6m28s (Sutskever)
- https://youtu.be/19eNQ1CLt5A?t=7m52s (Sutskever)
- https://github.com/DanielTakeshi/Paper_Notes/blob/master/reinforcement_learning/RL2-Fast_Reinforcement_Learning_via_Slow_Reinforcement_Learning.md
Learning to Reinforcement Learn (DeepMind)
"outer episodes (sample a new bandit problem / MDP) and inner episodes (of sampled MDP)"
"use RNN policy with no state reset between inner episodes for outer POMDP"
- https://youtube.com/watch?v=SfCa1HQMkuw&t=1h16m56s (Schulman)
- https://hackernoon.com/learning-policies-for-learning-policies-meta-reinforcement-learning-rl²-in-tensorflow-b15b592a2ddf (Juliani)
- https://github.com/awjuliani/Meta-RL
HyperNetworks (Google Brain)
"Our main result is that hypernetworks can generate non-shared weights for LSTM and achieve near state-of-the-art results on a variety of sequence modelling tasks including character-level language modelling, handwriting generation and neural machine translation, challenging the weight-sharing paradigm for recurrent networks."
"Our results also show that hypernetworks applied to convolutional networks still achieve respectable results for image recognition tasks compared to state-of-the-art baseline models while requiring fewer learnable parameters."
Neural Architecture Search with Reinforcement Learning (Google Brain)
- https://youtube.com/watch?v=XDtFXBYpl1w (Le)
- https://facebook.com/iclr.cc/videos/1713144705381255/ (1:08:31) (Zoph)
- https://blog.acolyer.org/2017/05/10/neural-architecture-search-with-reinforcement-learning/
Designing Neural Network Architectures using Reinforcement Learning
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks (Abbeel, Levine)
"Unlike prior methods, the MAML learner’s weights are updated using the gradient, rather than a learned update rule. Our method does not introduce any additional parameters into the learning process and does not require a particular learner model architecture."
Optimization as a Model for Few-Shot Learning (Larochelle)
- https://facebook.com/iclr.cc/videos/1713144705381255/ (1:26:48) (Ravi)
Matching Networks for One Shot Learning (Vinyals)
"Given just a few, or even a single, examples of an unseen class, it is possible to attain high classification accuracy on ImageNet using Matching Networks. The core architecture is simple and straightforward to train and performant across a range of image and text classification tasks. Matching Networks are trained in the same way as they are tested: by presenting a series of instantaneous one shot learning training tasks, where each instance of the training set is fed into the network in parallel. Matching Networks are then trained to classify correctly over many different input training sets. The effect is to train a network that can classify on a novel data set without the need for a single step of gradient descent."
- https://pbs.twimg.com/media/Cy7Eyh5WgAAZIw2.jpg:large
- https://blog.acolyer.org/2017/01/03/matching-networks-for-one-shot-learning/
{kind=link}
Learning to Remember Rare Events (Google Brain)
Prototypical Networks for Few-shot Learning
One-shot Learning with Memory-Augmented Neural Networks
- http://techtalks.tv/talks/meta-learning-with-memory-augmented-neural-networks/62523/ + https://vk.com/wall-44016343_8782 (Santoro)
- https://youtube.com/watch?v=qos2CcviAuY (Bartunov, in russian)
- http://rylanschaeffer.github.io/content/research/one_shot_learning_with_memory_augmented_nn/main.html
- http://www.shortscience.org/paper?bibtexKey=journals/corr/1605.06065
- https://github.com/tristandeleu/ntm-one-shot
One-Shot Generalization in Deep Generative Models
"move over DRAW: deepmind's latest has spatial-transform attention and 1-shot generalization"
- http://youtube.com/watch?v=TpmoQ_j3Jv4 (demo)
- http://techtalks.tv/talks/one-shot-generalization-in-deep-generative-models/62365/
- https://youtu.be/XpIDCzwNe78?t=43m (Bartunov)
- http://techtalks.tv/talks/neural-statistician/63048/ (Edwards)
- https://youtu.be/XpIDCzwNe78?t=51m53s (Bartunov)
- http://www.shortscience.org/paper?bibtexKey=journals/corr/1606.02185
Fast Adaptation in Generative Models with Generative Matching Networks (Bartunov)
- https://youtu.be/XpIDCzwNe78 (Bartunov) + slides
- http://github.com/sbos/gmn
- https://youtube.com/watch?v=CzQSQ_0Z-QU (Woodward)
beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework (DeepMind)
"This paper proposes a modification of the variational ELBO in encourage 'disentangled' representations, and proposes a measure of disentanglement."
- http://tinyurl.com/jgbyzke (demo)
Early Visual Concept Learning with Unsupervised Deep Learning (DeepMind)
Towards Conceptual Compression (DeepMind)
{kind=link}
Attend, Infer, Repeat: Fast Scene Understanding with Generative Models (DeepMind)
"The latent variables can be a list or set of vectors."
"Consider the task of clearing a table after dinner. To plan your actions you will need to determine which objects are present, what classes they belong to and where each one is located on the table. In other words, for many interactions with the real world the perception problem goes far beyond just image classification. We would like to build intelligent systems that learn to parse the image of a scene into objects that are arranged in space, have visual and physical properties, and are in functional relationships with each other. And we would like to do so with as little supervision as possible. Starting from this notion our paper presents a framework for efficient inference in structured, generative image models that explicitly reason about objects. We achieve this by performing probabilistic inference using a recurrent neural network that attends to scene elements and processes them one at a time. Crucially, the model itself learns to choose the appropriate number of inference steps. We use this scheme to learn to perform inference in partially specified 2D models (variable-sized variational auto-encoders) and fully specified 3D models (probabilistic renderers). We show that such models learn to identify multiple objects - counting, locating and classifying the elements of a scene - without any supervision, e.g., decomposing 3D images with various numbers of objects in a single forward pass of a neural network."
- https://youtube.com/watch?v=4tc84kKdpY4 (demo)
- http://arkitus.com/attend-infer-repeat/
- http://www.shortscience.org/paper?bibtexKey=journals/corr/EslamiHWTKH16 (Larochelle)
Generative Temporal Models with Memory (DeepMind)
"A sufficiently powerful temporal model should separate predictable elements of the sequence from unpredictable elements, express uncertainty about those unpredictable elements, and rapidly identify novel elements that may help to predict the future. To create such models, we introduce Generative Temporal Models augmented with external memory systems."
Inducing Interpretable Representations with Variational Autoencoders (Goodman)
Learning Disentangled Representations with Semi-Supervised Deep Generative Models
Deep Unsupervised Clustering with Gaussian Mixture Variational Autoencoders (Arulkumaran)
Disentangling Factors of Variation in Deep Representations using Adversarial Training (LeCun)
- http://www.shortscience.org/paper?bibtexKey=journals%2Fcorr%2F1611.03383
- http://www.shortscience.org/paper?bibtexKey=conf%2Fnips%2FMathieuZZRSL16
Density Estimation using Real NVP
"Most interestingly, it is the only powerful generative model I know that combines A) a tractable likelihood, B) an efficient / one-pass sampling procedure and C) the explicit learning of a latent representation."
- http://www-etud.iro.umontreal.ca/~dinhlaur/real_nvp_visual/ (demo)
- https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Phased-LSTM-Accelerating-Recurrent-Network-Training-for-Long-or-Event-based-Sequences (08:19) (Dinh) + slides
- https://periscope.tv/hugo_larochelle/1ypKdAVmbEpGW (Dinh)
- http://www.shortscience.org/paper?bibtexKey=journals/corr/1605.08803
- https://github.com/tensorflow/models/tree/master/real_nvp
- https://github.com/taesung89/real-nvp
Unsupervised Learning by Predicting Noise
"The authors give a nice analogy: it's a SOM, but instead of mapping a latent vector to each input vector, the convolutional filters are learned in order to map each input vector to a fixed latent vector. In more words: each image is assigned a unique random latent vector as the label, and the mapping from image to label is taught in a supervised manner. Every few epochs, the label assignments are adjusted (but only within batches due to computational cost), so that an image might be assigned a different latent vector label which it is already close to in 'feature space'."
A Note on the Evaluation of Generative Models
- http://videolectures.net/iclr2016_theis_generative_models/ (Theis)
- https://pbs.twimg.com/media/CjA02jrWYAECWOZ.jpg:large ("The generative model on the left gets a better log-likelihood score.")
{kind=link}
On the Quantitative Analysis of Decoder-based Generative Models (Salakhutdinov)
"We propose to use Annealed Importance Sampling for evaluating log-likelihoods for decoder-based models and validate its accuracy using bidirectional Monte Carlo. Using this technique, we analyze the performance of decoder-based models, the effectiveness of existing log-likelihood estimators, the degree of overfitting, and the degree to which these models miss important modes of the data distribution."
"This paper introduces Annealed Importance Sampling to compute tighter lower bounds and upper bounds for any generative model (with a decoder)."
How (not) to train your generative model: schedule sampling, likelihood, adversary (Huszar)
NIPS 2016 Tutorial: Generative Adversarial Networks (Goodfellow)
- https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Generative-Adversarial-Networks (Goodfellow) + slides
A Connection Between Generative Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models (Abbeel, Levine)
- https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Deep-Learning-Symposium-Session-3 (33:17) (Levine)
- https://youtu.be/RZOKRFBtSh4?t=10m48s (Finn)
- http://pemami4911.github.io/paper-summaries/2017/02/12/gans-irl-ebm.html
On Unifying Deep Generative Models (Salakhutdinov)
"In this paper, we present a simple Bayesian formulation for end-to-end unsupervised and semi-supervised learning with generative adversarial networks. Within this framework, we marginalize the posteriors over the weights of the generator and discriminator using stochastic gradient Hamiltonian Monte Carlo. We interpret data samples from the generator, showing exploration across several distinct modes in the generator weights. We also show data and iteration efficient learning of the true distribution. We also demonstrate state of the art semi-supervised learning performance on several benchmarks, including SVHN, MNIST, CIFAR-10, and CelebA. The simplicity of the proposed approach is one of its greatest strengths: inference is straightforward, interpretable, and stable. Indeed all of the experimental results were obtained without feature matching, normalization, or any ad-hoc techniques."
Learning in Implicit Generative Models (Mohamed)
Variational Inference using Implicit Distributions (Huszar)
"This paper provides a unifying review of existing algorithms establishing connections between variational autoencoders, adversarially learned inference, operator VI, GAN-based image reconstruction, and more."
- http://inference.vc/variational-inference-with-implicit-probabilistic-models-part-1-2/
- http://inference.vc/variational-inference-with-implicit-models-part-ii-amortised-inference-2/
- http://inference.vc/variational-inference-using-implicit-models-part-iii-joint-contrastive-inference-ali-and-bigan/
- http://inference.vc/variational-inference-using-implicit-models-part-iv-denoisers-instead-of-discriminators/
Deep and Hierarchical Implicit Models (Blei)
"We develop likelihood-free variational inference (LFVI). Key to LFVI is specifying a variational family that is also implicit. This matches the model's flexibility and allows for accurate approximation of the posterior. Our work scales up implicit models to sizes previously not possible and advances their modeling design."
f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization
"Shows how to optimize many different objectives using adversarial training."
- https://youtube.com/watch?v=I1M_jGWp5n0
- https://youtube.com/watch?v=kQ1eEXgGsCU (Nowozin)
- https://youtube.com/watch?v=y7pUN2t5LrA (Nowozin)
- https://github.com/wiseodd/generative-models/tree/master/GAN/f_gan
Improved Generator Objectives for GANs (Google Brain)
"We present a framework to understand GAN training as alternating density ratio estimation and approximate divergence minimization. This provides an interpretation for the mismatched GAN generator and discriminator objectives often used in practice, and explains the problem of poor sample diversity. We also derive a family of generator objectives that target arbitrary f-divergences without minimizing a lower bound, and use them to train generative image models that target either improved sample quality or greater sample diversity."
Revisiting Classifier Two-Sample Tests for GAN Evaluation and Causal Discovery (Facebook)
Towards Principled Methods for Training Generative Adversarial Networks (Facebook)
Generalization and Equilibrium in Generative Adversarial Nets
Good Semi-supervised Learning That Requires a Bad GAN (Salakhutdinov)
Wasserstein GAN (Facebook)
"Paper uses Wasserstein distance instead of Jensen-Shannon divergence to compare distributions."
"Paper gets rid of a few unnecessary logarithms, and clips weights.""Loss curves that actually make sense and reflect sample quality."
Authors show how one can have meaningful and stable training process without having to cripple or undertrain the discriminator.
Authors show why original GAN formulations (using KL/JS divergence) are problematic and provide a solution for those problems.""There are two fundamental problems in doing image generation using GANs: 1) model structure 2) optimization instability. This paper makes no claims of improving model structure nor does it have experiments in that direction. To improve on imagenet generation, we need some work in (1) as well."
"Authors are not claiming that this directly improves image quality, but offers a host of other benefits like stability, the ability to make drastic architecture changes without loss of functionality, and, most importantly, a loss metric that actually appears to correlate with sample quality. That last one is a pretty big deal."
"Using Wasserstein objective reduces instability, but we still lack proof of existence of an equilibrium. Game theory doesn’t help because we need a so-called pure equilibrium, and simple counter-examples such as rock/paper/scissors show that it doesn’t exist in general. Such counterexamples are easily turned into toy GAN scenarios with generator and discriminator having finite capacity, and the game lacks a pure equilibrium."
- https://youtube.com/watch?v=DfJeaa--xO0&t=26m27s (Bottou)
- https://facebook.com/iclr.cc/videos/1710657292296663/ (1:30:02) (Arjowski)
- http://www.alexirpan.com/2017/02/22/wasserstein-gan.html
- https://paper.dropbox.com/doc/Wasserstein-GAN-GvU0p2V9ThzdwY3BbhoP7
- http://wiseodd.github.io/techblog/2017/02/04/wasserstein-gan/
- https://github.com/martinarjovsky/WassersteinGAN
- https://github.com/wiseodd/generative-models/tree/master/GAN/wasserstein_gan
- https://github.com/shekkizh/WassersteinGAN.tensorflow
- https://github.com/kuleshov/tf-wgan
- https://github.com/blei-lab/edward/blob/master/examples/gan_wasserstein.py
- https://github.com/tdeboissiere/DeepLearningImplementations/tree/master/WassersteinGAN
- https://github.com/igul222/improved_wgan_training
Improved Training of Wasserstein GANs (Facebook)
The Cramer Distance as a Solution to Biased Wasserstein Gradients (DeepMind)
BEGAN: Boundary Equilibrium Generative Adversarial Networks (Google Brain)
"We propose a new equilibrium enforcing method paired with a loss derived from the Wasserstein distance for training auto-encoder based Generative Adversarial Networks. This method balances the generator and discriminator during training. Additionally, it provides a new approximate convergence measure, fast and stable training and high visual quality. We also derive a way of controlling the trade-off between image diversity and visual quality. We focus on the image generation task, setting a new milestone in visual quality, even at higher resolutions. This is achieved while using a relatively simple model architecture and a standard training procedure."
"- A GAN with a simple yet robust architecture, standard training procedure with fast and stable convergence.
- An equilibrium concept that balances the power of the discriminator against the generator.
- A new way to control the trade-off between image diversity and visual quality.
- An approximate measure of convergence. To our knowledge the only other published measure is from Wasserstein GAN."
"There are still many unexplored avenues. Does the discriminator have to be an auto-encoder? Having pixel-level feedback seems to greatly help convergence, however using an auto-encoder has its drawbacks: what internal embedding size is best for a dataset? When should noise be added to the input and how much? What impact would using other varieties of auto-encoders such Variational Auto-Encoders have?"
- https://pbs.twimg.com/media/C8lYiYbW0AI4_yk.jpg:large + https://pbs.twimg.com/media/C8c6T2kXsAAI-BN.jpg (demo)
- https://blog.heuritech.com/2017/04/11/began-state-of-the-art-generation-of-faces-with-generative-adversarial-networks/
- https://reddit.com/r/MachineLearning/comments/633jal/r170310717_began_boundary_equilibrium_generative/dfrktje/
- https://github.com/carpedm20/BEGAN-tensorflow
- https://github.com/carpedm20/BEGAN-pytorch
{kind=link}
{kind=link}
Unrolled Generative Adversarial Networks
"We introduce a method to stabilize GANs by defining the generator objective with respect to an unrolled optimization of the discriminator. This allows training to be adjusted between using the optimal discriminator in the generator's objective, which is ideal but infeasible in practice, and using the current value of the discriminator, which is often unstable and leads to poor solutions. We show how this technique solves the common problem of mode collapse, stabilizes training of GANs with complex recurrent generators, and increases diversity and coverage of the data distribution by the generator."
Improved Techniques for Training GANs
"Our CIFAR-10 samples also look very sharp - Amazon Mechanical Turk workers can distinguish our samples from real data with an error rate of 21.3% (50% would be random guessing)"
"In addition to generating pretty pictures, we introduce an approach for semi-supervised learning with GANs that involves the discriminator producing an additional output indicating the label of the input. This approach allows us to obtain state of the art results on MNIST, SVHN, and CIFAR-10 in settings with very few labeled examples. On MNIST, for example, we achieve 99.14% accuracy with only 10 labeled examples per class with a fully connected neural network — a result that’s very close to the best known results with fully supervised approaches using all 60,000 labeled examples."
- https://youtu.be/RZOKRFBtSh4?t=26m18s (Metz)
- https://github.com/aleju/papers/blob/master/neural-nets/Improved_Techniques_for_Training_GANs.md
- http://www.shortscience.org/paper?bibtexKey=journals%2Fcorr%2FSalimansGZCRC16
- http://inference.vc/understanding-minibatch-discrimination-in-gans/
- https://github.com/openai/improved-gan
GANS for Sequences of Discrete Elements with the Gumbel-softmax Distribution
Maximum-Likelihood Augmented Discrete Generative Adversarial Networks (Bengio)
Boundary-Seeking Generative Adversarial Networks (Bengio)
"This approach can be used to train a generator with discrete output when the generator outputs a parametric conditional distribution. We demonstrate the effectiveness of the proposed algorithm with discrete image data. In contrary to the proposed algorithm, we observe that the recently proposed Gumbel-Softmax technique for re-parametrizing the discrete variables does not work for training a GAN with discrete data."
- http://wiseodd.github.io/techblog/2017/03/07/boundary-seeking-gan/
- https://github.com/wiseodd/generative-models/tree/master/GAN/boundary_seeking_gan
Task Specific Adversarial Cost Function
Stacked Generative Adversarial Networks
Alternating Back-Propagation for Generator Network
Generating Text via Adversarial Training
Learning to Protect Communications with Adversarial Neural Cryptography
- https://nlml.github.io/neural-networks/adversarial-neural-cryptography/
- https://blog.acolyer.org/2017/02/10/learning-to-protect-communications-with-adversarial-neural-cryptography/
Neural Photo Editing with Introspective Adversarial Networks
Generative Adversarial Text to Image Synthesis
Conditional Image Synthesis With Auxiliary Classifier GANs (Google Brain)
- https://pbs.twimg.com/media/CwM0BzjVUAAWTn4.jpg:large
- https://youtu.be/RZOKRFBtSh4?t=21m47s (Odena)
- https://github.com/buriburisuri/ac-gan
- https://github.com/wiseodd/generative-models/tree/master/GAN/auxiliary_classifier_gan
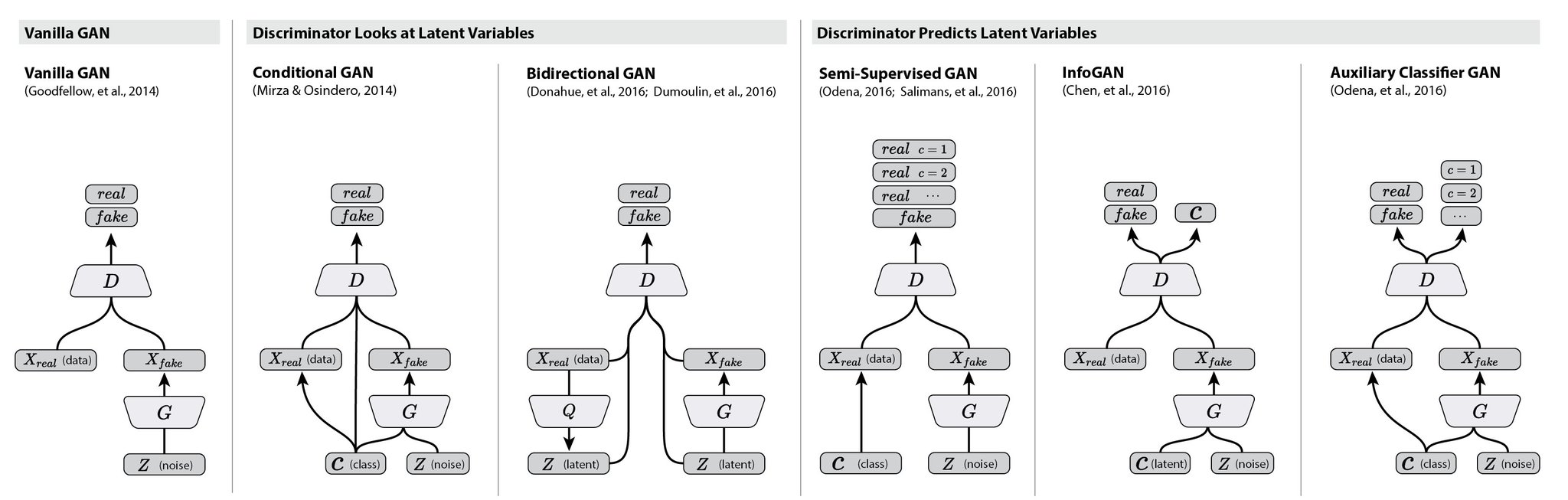{kind=link}
Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space
{kind=link}
Learning from Simulated and Unsupervised Images through Adversarial Training (Apple)
Unsupervised Pixel-Level Domain Adaptation with Generative Asversarial Networks (Google Brain)
Image-to-Image Translation with Conditional Adversarial Networks
Unsupervised Image-to-Image Translation Networks (NVIDIA)
DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
Towards a Deeper Understanding of Variational Autoencoding Models
"We provide a formal explanation for why VAEs generate blurry samples when trained on complex natural images. We show that under some conditions, blurry samples are not caused by the use of a maximum likelihood approach as previously thought, but rather they are caused by an inappropriate choice for the inference distribution. We specifically target this problem by proposing a sequential VAE model, where we gradually augment the the expressiveness of the inference distribution using a process inspired by the recent infusion training process. As a result, we are able to generate sharp samples on the LSUN bedroom dataset, even using 2-norm reconstruction loss in pixel space."
"We propose a new explanation of the VAE tendency to ignore the latent code. We show that this problem is specific to the original VAE objective function and does not apply to the more general family of VAE models we propose. We show experimentally that using our more general framework, we achieve comparable sample quality as the original VAE, while at the same time learning meaningful features through the latent code, even when the decoder is a powerful PixelCNN that can by itself model data."
Variational Lossy Autoencoder (OpenAI)
Adversarial Variational Bayes: Unifying Variational Autoencoders and Generative Adversarial Networks
- https://youtu.be/y7pUN2t5LrA?t=14m19s (Nowozin)
- https://github.com/wiseodd/generative-models/tree/master/VAE/adversarial_vb
- https://gist.github.com/poolio/b71eb943d6537d01f46e7b20e9225149
- http://inference.vc/variational-inference-with-implicit-models-part-ii-amortised-inference-2/
Importance Weighted Autoencoders (Salakhutdinov)
- http://dustintran.com/blog/importance-weighted-autoencoders/
- https://github.com/yburda/iwae
- https://github.com/arahuja/generative-tf
- https://github.com/blei-lab/edward/blob/master/examples/iwvi.py (DeepMind)
Variational Inference for Monte Carlo Objectives (DeepMind)
- http://techtalks.tv/talks/variational-inference-for-monte-carlo-objectives/62507/
- https://evernote.com/shard/s189/sh/54a9fb88-1a71-4e8a-b0e3-f13480a68b8d/0663de49b93d397f519c7d7f73b6a441
Discrete Variational Autoencoders (D-Wave)
- https://youtube.com/watch?v=c6GukeAkyVs (Struminsky)
The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables (DeepMind)
- http://youtube.com/watch?v=JFgXEbgcT7g (Jang)
- https://laurent-dinh.github.io/2016/11/22/gumbel-max.html
- https://casmls.github.io/general/2017/02/01/GumbelSoftmax.html
- http://timvieira.github.io/blog/post/2014/07/31/gumbel-max-trick/
- https://cmaddis.github.io/gumbel-machinery
- https://github.com/ericjang/gumbel-softmax/blob/master/gumbel_softmax_vae_v2.ipynb
- https://gist.github.com/gngdb/ef1999ce3a8e0c5cc2ed35f488e19748
Categorical Reparametrization with Gumbel-Softmax (Google Brain)
- http://youtube.com/watch?v=JFgXEbgcT7g (Jang)
- http://blog.evjang.com/2016/11/tutorial-categorical-variational.html
- https://laurent-dinh.github.io/2016/11/22/gumbel-max.html
- https://casmls.github.io/general/2017/02/01/GumbelSoftmax.html
- http://timvieira.github.io/blog/post/2014/07/31/gumbel-max-trick/
- https://cmaddis.github.io/gumbel-machinery
- https://github.com/ericjang/gumbel-softmax/blob/master/gumbel_softmax_vae_v2.ipynb
- https://github.com/EderSantana/gumbel
REBAR: Low-variance, unbiased gradient estimates for discrete latent variable models (Google Brain + DeepMind)
"Learning in models with discrete latent variables is challenging due to high variance gradient estimators. Generally, approaches have relied on control variates to reduce the variance of the REINFORCE estimator. Recent work (Jang et al. 2016, Maddison et al. 2016) has taken a different approach, introducing a continuous relaxation of discrete variables to produce low-variance, but biased, gradient estimates. In this work, we combine the two approaches through a novel control variate that produces low-variance, unbiased gradient estimates."
Multi-modal Variational Encoder-Decoders (Courville)
Stochastic Backpropagation through Mixture Density Distributions (DeepMind)
Variational Boosting: Iteratively Refining Posterior Approximations (Adams)
- http://andymiller.github.io/2016/11/23/vb.html
- https://youtu.be/Jh3D8Gi4N0I?t=1h9m52s (Nekludov, in russian)
Improving Variational Inference with Inverse Autoregressive Flow
"Most VAEs have so far been trained using crude approximate posteriors, where every latent variable is independent. Normalizing Flows have addressed this problem by conditioning each latent variable on the others before it in a chain, but this is computationally inefficient due to the introduced sequential dependencies. The core contribution of this work, termed inverse autoregressive flow (IAF), is a new approach that, unlike previous work, allows us to parallelize the computation of rich approximate posteriors, and make them almost arbitrarily flexible."
Normalizing Flows on Riemannian Manifolds (DeepMind)
{kind=link}
Auxiliary Deep Generative Models
- http://techtalks.tv/talks/auxiliary-deep-generative-models/62509/
- https://github.com/larsmaaloee/auxiliary-deep-generative-models
Composing graphical models with neural networks for structured representations and fast inference
- https://youtube.com/watch?v=btr1poCYIzw
- https://youtube.com/watch?v=vnO3w8OgTE8 (Duvenaud)
- http://www.cs.toronto.edu/~duvenaud/courses/csc2541/slides/svae-slides.pdf
- https://github.com/mattjj/svae
Rejection Sampling Variational Inference
The Generalized Reparameterization Gradient
- https://youtu.be/mrj_hyH974o?t=1h23m40s (Vetrov, in russian)
The Variational Fair Autoencoder
The Variational Gaussian Process
- http://videolectures.net/iclr2016_tran_variational_gaussian/ (Tran)
- http://github.com/blei-lab/edward
Stick-Breaking Variational Autoencoders # latent representation with stochastic dimensionality
Grammar Variational Autoencoder
Pixel Recurrent Neural Networks (DeepMind)
- http://techtalks.tv/talks/pixel-recurrent-neural-networks/62375/ (van den Oord)
- https://evernote.com/shard/s189/sh/fdf61a28-f4b6-491b-bef1-f3e148185b18/aba21367d1b3730d9334ed91d3250848 (Larochelle)
- https://github.com/tensorflow/magenta/blob/master/magenta/reviews/pixelrnn.md (Kastner)
- http://www.shortscience.org/paper?bibtexKey=journals%2Fcorr%2FOordKK16#shagunsodhani
- https://github.com/zhirongw/pixel-rnn
- https://github.com/igul222/pixel_rnn
- https://github.com/carpedm20/pixel-rnn-tensorflow
- https://github.com/shiretzet/PixelRNN
Conditional Image Generation with PixelCNN Decoders (DeepMind)
- https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Deep-Learning-Symposium-Session-1 (27:26) (van den Oord)
- http://www.shortscience.org/paper?bibtexKey=journals%2Fcorr%2F1606.05328#shagunsodhani
- http://sergeiturukin.com/2017/02/22/pixelcnn.html
- https://github.com/openai/pixel-cnn
- https://github.com/kundan2510/pixelCNN
- https://github.com/anantzoid/Conditional-PixelCNN-decoder
Parallel Multiscale Autoregressive Density Estimation (DeepMind)
"O(log N) sampling instead of O(N)"
WaveNet: A Generative Model for Raw Audio (DeepMind)
- https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Deep-Learning-Symposium-Session-1 (42:36) (van den Oord)
- https://github.com/ibab/tensorflow-wavenet
- https://github.com/basveeling/wavenet/
- https://github.com/usernaamee/keras-wavenet
- https://github.com/tomlepaine/fast-wavenet
Neural Machine Translation in Linear Time (ByteNet) (DeepMind)
"Generalizes LSTM seq2seq by preserving the resolution. Dynamic unfolding instead of attention. Linear time computation."
"The authors apply a WaveNet-like architecture to the task of Machine Translation. Encoder (Source Network) and Decoder (Target Network) are CNNs that use Dilated Convolutions and they are stacked on top of each other. The Target Network uses Masked Convolutions to ensure that it only relies on information from the past. Crucially, the time complexity of the network is c(|S| + |T|), which is cheaper than that of the common seq2seq attention architecture (|S|*|T|). Through dilated convolutions the network has constant path lengths between [source input -> target output] and [target inputs -> target output] nodes. This allows for efficient propagation of gradients."
Language Modeling with Gated Convolutional Networks (Facebook) # outperforming LSTM on language modelling
Tuning Recurrent Neural Networks with Reinforcement Learning (Google Brain)
"In contrast to relying solely on possibly biased data, our approach allows for encoding high-level domain knowledge into the RNN, providing a general, alternative tool for training sequence models."
- https://magenta.tensorflow.org/2016/11/09/tuning-recurrent-networks-with-reinforcement-learning/
- https://www.technologyreview.com/s/604010/google-brain-wants-creative-ai-to-help-humans-make-a-new-kind-of-art/ (10:45) (Eck)
- https://github.com/tensorflow/magenta/tree/master/magenta/models/rl_tuner
Learning to Decode for Future Success (Stanford)
An Actor-Critic Algorithm for Sequence Prediction (Bengio)
Professor Forcing: A New Algorithm for Training Recurrent Networks
"In professor forcing, G is simply an RNN that is trained to predict the next element in a sequence and D a discriminative bi-directional RNN. G is trained to fool D into thinking that the hidden states of G occupy the same state space at training (feeding ground truth inputs to the RNN) and inference time (feeding generated outputs as the next inputs). D, in turn, is trained to tell apart the hidden states of G at training and inference time. At the Nash equilibrium, D cannot tell apart the state spaces any better and G cannot make them any more similar. This is motivated by the problem that RNNs typically diverge to regions of the state space that were never observed during training and which are hence difficult to generalize to."
- https://youtube.com/watch?v=I7UFPBDLDIk
- http://videolectures.net/deeplearning2016_goyal_new_algorithm/ (Goyal)
- https://github.com/dennybritz/deeplearning-papernotes/blob/master/notes/professor-forcing.md
- http://www.shortscience.org/paper?bibtexKey=journals%2Fcorr%2F1610.09038
- https://github.com/anirudh9119/LM_GANS
Self-critical Sequence Training for Image Captioning
"REINFORCE with reward normalization but without baseline estimation"
- https://yadi.sk/i/-U5w4NpJ3H5TWD + https://yadi.sk/i/W3N7-6is3H5TWN (Ratnikov, in russian)
Sequence-to-Sequence Learning as Beam-Search Optimization
- https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Deep-Learning-Symposium-Session-2 (44:02) (Wiseman)
- http://shortscience.org/paper?bibtexKey=journals/corr/1606.02960
- https://medium.com/@sharaf/a-paper-a-day-2-sequence-to-sequence-learning-as-beam-search-optimization-92424b490350
Length Bias in Encoder Decoder Models and a Case for Global Conditioning (Google) # eliminating beam search
Order Matters: Sequence to Sequence for Sets (Vinyals)
Stochastic Gradient Descent as Approximate Bayesian Inference (Blei)
Bayesian Recurrent Neural Networks (DeepMind)
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles (DeepMind)
Dropout Inference in Bayesian Neural Networks with Alpha-divergences
"We demonstrate improved uncertainty estimates and accuracy compared to VI in dropout networks. We study our model’s epistemic uncertainty far away from the data using adversarial images, showing that these can be distinguished from non-adversarial images by examining our model’s uncertainty."
Sequential Neural Models with Stochastic Layers
- https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Sequential-Neural-Models-with-Stochastic-Layers (Fraccaro)
- https://youtu.be/mrj_hyH974o?t=32m49s (in russian)
- https://github.com/marcofraccaro/srnn
DISCO Nets: DISsimilarity COefficient Networks
Deep Probabilistic Programming (Blei)
Deep Amortized Inference for Probabilistic Programs (Goodman)
Inference Compilation and Universal Probabilistic Programming (Wood)
A Simple Neural Network Module for Relational Reasoning (DeepMind)
Text Understanding with the Attention Sum Reader Network (IBM Watson)
Gated-Attention Readers for Text Comprehension (Salakhutdinov)
- https://youtube.com/watch?v=ZSDrM-tuOiA (Salakhutdinov)
Question Answering on Knowledge Bases and Text using Universal Schema and Memory Networks (McCallum)
Key-Value Memory Networks for Directly Reading Documents (Weston)
- http://www.shortscience.org/paper?bibtexKey=journals/corr/1606.03126
- https://gist.github.com/shagunsodhani/a5e0baa075b4a917c0a69edc575772a8
- https://github.com/facebook/MemNN/blob/master/KVmemnn
Tracking the World State with Recurrent Entity Networks (Facebook)
"There's a bunch of memory slots that each can be used to represent a single entity. The first time an entity appears, it's written to a slot. Every time that something happens in the story that corresponds to a change in the state of an entity, the change in the state of that entity is combined with the entity's previous state via a modified GRU update equation and rewritten to the same slot."
Deep Compositional Question Answering with Neural Module Networks (Darrell)
- https://youtube.com/watch?v=gDXD3hYfBW8 (Andreas)
- http://research.microsoft.com/apps/video/default.aspx?id=260024 (10:45) (Darrell)
- http://blog.jacobandreas.net/programming-with-nns.html
- https://github.com/abhshkdz/papers/blob/master/reviews/deep-compositional-question-answering-with-neural-module-networks.md
- http://github.com/jacobandreas/nmn2
Learning to Compose Neural Networks for Question Answering (Darrell)
- https://youtube.com/watch?v=gDXD3hYfBW8 (Andreas)
- http://blog.jacobandreas.net/programming-with-nns.html
- http://github.com/jacobandreas/nmn2
Learning to Reason: End-to-End Module Networks for Visual Question Answering (Darrell)
Inferring and Executing Programs for Visual Reasoning (Stanford, Facebook)
Neural Enquirer: Learning to Query Tables with Natural Language
"Authors propose a fully distributed neural enquirer, comprising several neuralized execution layers of field attention, row annotation, etc. While the model is not efficient in execution because of intensive matrix/vector operation during neural information processing and lacks explicit interpretation of execution, it can be trained in an end-to-end fashion because all components in the neural enquirer are differentiable."
Learning a Natural Language Interface with Neural Programmer
Neural Symbolic Machines: Learning Semantic Parsers on Freebase with Weak Supervision (Google Brain)
"We propose the Manager-Programmer-Computer framework, which integrates neural networks with non-differentiable memory to support abstract, scalable and precise operations through a friendly neural computer interface. Specifically, we introduce a Neural Symbolic Machine, which contains a sequence-to-sequence neural "programmer", and a non-differentiable "computer" that is a Lisp interpreter with code assist."
The More You Know: Using Knowledge Graphs for Image Classification (Salakhutdinov) # evolution of Gated Graph Sequence Neural Networks
End-to-end Differentiable Proving (Rocktaschel)
"We introduce neural networks for end-to-end differentiable theorem proving that operate on dense vector representations of symbols. These neural networks are constructed recursively by taking inspiration from the backward chaining algorithm as used in Prolog. Specifically, we replace symbolic unification with a differentiable computation on vector representations of symbols using a radial basis function kernel, thereby combining symbolic reasoning with learning subsymbolic vector representations. By using gradient descent, the resulting neural network can be trained to infer facts from a given incomplete knowledge base. It learns to (i) place representations of similar symbols in close proximity in a vector space, (ii) make use of such similarities to prove facts, (iii) induce logical rules, and (iv) use provided and induced logical rules for complex multi-hop reasoning. We demonstrate that this architecture outperforms ComplEx, a state-of-the-art neural link prediction model, on four benchmark knowledge bases while at the same time inducing interpretable function-free first-order logic rules."
- http://aitp-conference.org/2017/slides/Tim_aitp.pdf (Rocktaschel)
- https://soundcloud.com/nlp-highlights/19a (Rocktaschel)
- Learning Knowledge Base Inference with Neural Theorem Provers by Rocktaschel and Riedel
TensorLog: A Differentiable Deductive Database (Cohen)
Differentiable Learning of Logical Rules for Knowledge Base Completion (Cohen)
WebNav: A New Large-Scale Task for Natural Language based Sequential Decision Making
Learning to Perform Physics Experiments via Deep Reinforcement Learning (DeepMind)
- https://youtu.be/SAcHyzMdbXc?t=16m6s (de Freitas)
Interaction Networks for Learning about Objects, Relations and Physics (DeepMind)
Learning Physical Intuition of Block Towers by Example (Facebook)
- https://youtu.be/oSAG57plHnI?t=19m48s (Tenenbaum)
RobustFill: Neural Program Learning under Noisy I/O (Microsoft)
Neuro-Symbolic Program Synthesis (Microsoft)
TerpreT: A Probabilistic Programming Language for Program Induction (Microsoft)
"These works raise questions of (a) whether new models can be designed specifically to synthesize interpretable source code that may contain looping and branching structures, and (b) whether searching over program space using techniques developed for training deep neural networks is a useful alternative to the combinatorial search methods used in traditional IPS. In this work, we make several contributions in both of these directions."
"Shows that differentiable interpreter-based program induction is inferior to discrete search-based techniques used by the programming languages community. We are then left with the question of how to make progress on program induction using machine learning techniques."
Making Neural Programming Architectures Generalize via Recursion # Neural Programmer-Interpreter with recursion
"We implement recursion in the Neural Programmer-Interpreter framework on four tasks: grade-school addition, bubble sort, topological sort, and quicksort."
- https://facebook.com/iclr.cc/videos/1713144705381255/ (49:59) (Cai)
Programming with a Differentiable Forth Interpreter (Riedel) # learning details of probabilistic program
Benchmarking Deep Reinforcement Learning for Continuous Control (Abbeel)
- http://techtalks.tv/talks/benchmarking-deep-reinforcement-learning-for-continuous-control/62380/ (Duan)
Evolution Strategies as a Scalable Alternative to Reinforcement Learning (OpenAI)
(Karpathy) "ES is much simpler than RL, and there's no need for backprop, it's highly parallelizable, has fewer hyperparams, needs no value functions."
"In our preliminary experiments we found that using ES to estimate the gradient on the MNIST digit recognition task can be as much as 1,000 times slower than using backpropagation. It is only in RL settings, where one has to estimate the gradient of the expected reward by sampling, where ES becomes competitive."
- https://blog.openai.com/evolution-strategies/
- https://www.technologyreview.com/s/603916/a-new-direction-for-artificial-intelligence/ (Sutskever)
- https://youtube.com/watch?v=Rd0UdJFYkqI (Temirchev, in russian)
- http://inference.vc/evolutionary-strategies-embarrassingly-parallelizable-optimization/ (Huszar)
- http://inference.vc/evolution-strategies-variational-optimisation-and-natural-es-2/ (Huszar)
- http://davidbarber.github.io/blog/2017/04/03/variational-optimisation/ (Barber)
- http://argmin.net/2017/04/03/evolution/ (Recht)
- https://github.com/openai/evolution-strategies-starter
- https://github.com/mdibaiee/flappy-es (demo)
- https://gist.github.com/kashif/5748e199a3bec164a867c9b654e5ffe5
- https://github.com/atgambardella/pytorch-es
RL^2: Fast Reinforcement Learning via Slow Reinforcement Learning (OpenAI)
"outer episodes (sample a new bandit problem / MDP) and inner episodes (of sampled MDP)"
"use RNN policy with no state reset between inner episodes for outer POMDP""future directions:
- better outer-loop algorithms
- scaling RL^2 to 1M games
- model-based RL^2
- curriculum learning / universal RL^2
- RL^2 + one-shot imitation learning
- RL^2 for simulation -> real world transfer"
- http://www.fields.utoronto.ca/video-archive/2017/02/2267-16530 (19:00) (Abbeel)
- https://youtube.com/watch?v=SfCa1HQMkuw&t=1h16m56s (Schulman)
- https://youtu.be/BskhUBPRrqE?t=6m28s (Sutskever)
- https://youtu.be/19eNQ1CLt5A?t=7m52s (Sutskever)
- https://github.com/DanielTakeshi/Paper_Notes/blob/master/reinforcement_learning/RL2-Fast_Reinforcement_Learning_via_Slow_Reinforcement_Learning.md
Learning to Reinforcement Learn (DeepMind)
"outer episodes (sample a new bandit problem / MDP) and inner episodes (of sampled MDP)"
"use RNN policy with no state reset between inner episodes for outer POMDP"
- https://youtube.com/watch?v=SfCa1HQMkuw&t=1h16m56s (Schulman)
- https://hackernoon.com/learning-policies-for-learning-policies-meta-reinforcement-learning-rl²-in-tensorflow-b15b592a2ddf (Juliani)
- https://github.com/awjuliani/Meta-RL
Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic (Lillicrap, Levine)
"We present Q-Prop, a policy gradient method that uses a Taylor expansion of the off-policy critic as a control variate. Q-Prop is both sample efficient and stable, and effectively combines the benefits of on-policy and off-policy methods."
"- unbiased gradient
- combine PG and AC gradients
- learns critic from off-policy data
- learns policy from on-policy data"
"Q-Prop works with smaller batch size than TRPO-GAE
Q-Prop is significantly more sample-efficient than TRPO-GAE"
"policy gradient algorithm that is as fast as value estimation"
"take off-policy algorithm and correct it with on-policy algorithm on residuals"
"can be understood as REINFORCE with state-action-dependent baseline with bias correction term instead of unbiased state-dependent baseline"
- https://facebook.com/iclr.cc/videos/1712224178806641/ (1:36:47) (Gu)
- https://youtu.be/M6nfipCxQBc?t=16m11s (Lillicrap)
- http://www.alexirpan.com/rl-derivations/#q-prop
- https://github.com/shaneshixiang/rllabplusplus
Sample Efficient Actor-Critic with Experience Replay (DeepMind) # ACER
- http://www.shortscience.org/paper?bibtexKey=journals%2Fcorr%2FWangBHMMKF16
- https://github.com/pfnet/chainerrl/blob/master/chainerrl/agents/acer.py
Combining policy gradient and Q-learning (DeepMind) # PGQ
"This connection allows us to estimate the Q-values from the action preferences of the policy, to which we apply Q-learning updates."
"We also establish an equivalency between action-value fitting techniques and actor-critic algorithms, showing that regularized policy gradient techniques can be interpreted as advantage function learning algorithms."
- http://www.shortscience.org/paper?bibtexKey=journals%2Fcorr%2FODonoghueMKM16
- https://github.com/Fritz449/Asynchronous-RL-agent
"REINFORCE, TRPO, Q-Prop, DDPG, SVG(0), PGQ, ACER are special limiting cases of IPG"
Bridging the Gap Between Value and Policy Reinforcement Learning (Google Brain) # PCL
- https://youtu.be/fZNyHoXgV7M?t=1h16m17s (Norouzi)
- https://github.com/ethancaballero/paper-notes/blob/master/Bridging%20the%20Gap%20Between%20Value%20and%20Policy%20Based%20Reinforcement%20Learning.md
- https://github.com/rarilurelo/pcl_keras
- https://github.com/pfnet/chainerrl/blob/master/chainerrl/agents/pcl.py
Equivalence Between Policy Gradients and Soft Q-Learning (OpenAI)
Asynchronous Methods for Deep Reinforcement Learning
- http://youtube.com/watch?v=0xo1Ldx3L5Q (TORCS demo)
- http://youtube.com/watch?v=nMR5mjCFZCw (3D Labyrinth demo)
- http://youtube.com/watch?v=Ajjc08-iPx8 (MuJoCo demo)
- http://youtube.com/watch?v=9sx1_u2qVhQ (Mnih)
- http://techtalks.tv/talks/asynchronous-methods-for-deep-reinforcement-learning/62475/ (Mnih)
- http://www.shortscience.org/paper?bibtexKey=journals%2Fcorr%2FMnihBMGLHSK16
- https://medium.com/@awjuliani/simple-reinforcement-learning-with-tensorflow-part-8-asynchronous-actor-critic-agents-a3c-c88f72a5e9f2
- https://github.com/Zeta36/Asynchronous-Methods-for-Deep-Reinforcement-Learning
- https://github.com/miyosuda/async_deep_reinforce
- https://github.com/muupan/async-rl
- https://github.com/yandexdataschool/AgentNet/blob/master/agentnet/learning/a2c_n_step.py
- https://github.com/coreylynch/async-rl
- https://github.com/carpedm20/deep-rl-tensorflow/blob/master/agents/async.py
- https://github.com/danijar/mindpark/blob/master/mindpark/algorithm/a3c.py
Continuous Deep Q-Learning with Model-based Acceleration (Sutskever)
- http://techtalks.tv/talks/continuous-deep-q-learning-with-model-based-acceleration/62474/
- https://youtu.be/M6nfipCxQBc?t=10m48s (Lillicrap)
- https://youtu.be/mrgJ53TIcQc?t=57m (Seleznev, in russian)
- http://www.bicv.org/?wpdmdl=1940
- https://github.com/carpedm20/NAF-tensorflow
- https://github.com/tambetm/gymexperiments
Learning to Play in a Day: Faster Deep Reinforcement Learning by Optimality Tightening # 10x faster Q-learning
- https://yadi.sk/i/yBO0q4mI3GAxYd (1:10:20) (Fritsler, in russian)
- https://youtu.be/mrj_hyH974o?t=16m13s (in russian)
Trust Region Policy Optimization (Schulman, Levine, Jordan, Abbeel)
High-Dimensional Continuous Control Using Generalized Advantage Estimation (Schulman)
- https://youtu.be/gb5Q2XL5c8A?t=21m2s + https://youtube.com/watch?v=ATvp0Hp7RUI + https://youtube.com/watch?v=Pvw28wPEWEo (demo)
- https://youtu.be/xe-z4i3l-iQ?t=30m35s (Abbeel)
- https://youtu.be/rO7Dx8pSJQw?t=40m20s (Schulman)
- https://danieltakeshi.github.io/2017/04/02/notes-on-the-generalized-advantage-estimation-paper/
- https://github.com/joschu/modular_rl
- https://github.com/rll/deeprlhw2/blob/master/ppo.py
Gradient Estimation Using Stochastic Computation Graphs (Schulman)
"Can mix and match likelihood ratio and path derivative. If black-box node: might need to place stochastic node in front of it and use likelihood ratio. This includes recurrent neural net policies."
Q(λ) with Off-Policy Corrections (DeepMind)
- https://youtube.com/watch?v=8hK0NnG_DhY&t=25m27s (Brunskill)
Safe and Efficient Off-Policy Reinforcement Learning (DeepMind) # Retrace
"Retrace(λ) is a new strategy to weight a sample for off-policy learning, it provides low-variance, safe and efficient updates."
"Our goal is to design a RL algorithm with two desired properties. Firstly, to use off-policy data, which is important for exploration, when we use memory replay, or observe log-data. Secondly, to use multi-steps returns in order to propagate rewards faster and avoid accumulation of approximation/estimation errors. Both properties are crucial in deep RL. We introduce the “Retrace” algorithm, which uses multi-steps returns and can safely and efficiently utilize any off-policy data."
"open issue: off policy unbiased, low variance estimators for long horizon delayed reward problems"
- https://youtube.com/watch?v=8hK0NnG_DhY&t=25m27s (Brunskill)
The Reactor: A Sample-Efficient Actor-Critic Architecture # Reactor = Retrace-actor
Data-Efficient Off-Policy Policy Evaluation for Reinforcement Learning (Brunskill)
- https://youtube.com/watch?v=8hK0NnG_DhY&t=15m44s (Brunskill)
Multi-step Reinforcement Learning: A Unifying Algorithm (Sutton)
Discrete Sequential Prediction of Continuous Actions for Deep RL (Google Brain)
Reinforcement Learning in Large Discrete Action Spaces
Deep Reinforcement Learning In Parameterized Action Space
Dual Learning for Machine Translation
"In the dual-learning mechanism, we use one agent to represent the model for the primal task and the other agent to represent the model for the dual task, then ask them to teach each other through a reinforcement learning process. Based on the feedback signals generated during this process (e.g., the language model likelihood of the output of a model, and the reconstruction error of the original sentence after the primal and dual translations), we can iteratively update the two models until convergence (e.g., using the policy gradient methods)."
"The basic idea of dual learning is generally applicable: as long as two tasks are in dual form, we can apply the dual-learning mechanism to simultaneously learn both tasks from unlabeled data using reinforcement learning algorithms. Actually, many AI tasks are naturally in dual form, for example, speech recognition versus text to speech, image caption versus image generation, question answering versus question generation (e.g., Jeopardy!), search (matching queries to documents) versus keyword extraction (extracting keywords/queries for documents), so on and so forth."
Automated Curriculum Learning for Neural Networks (DeepMind)
"We focus on variants of prediction gain, and also introduce a novel class of progress signals which we refer to as complexity gain. Derived from minimum description length principles, complexity gain equates acquisition of knowledge with an increase in effective information encoded in the network weights."
"VIME uses a reward signal that is closely related to variational complexity gain. The difference is that while VIME measures the KL between the posterior before and after a step in parameter space, we consider the change in KL between the posterior and prior induced by the step. Therefore, while VIME looks for any change to the posterior, we focus only on changes that alter the divergence from the prior. Further research will be needed to assess the relative merits of the two signals."
"For maximum likelihood training, we found prediction gain to be the most consistent signal, while for variational inference training, gradient variational complexity gain performed best. Importantly, both are instantaneous, in the sense that they can be evaluated using only the samples used for training."
Automatic Goal Generation for Reinforcement Learning Agents (Abbeel)
Intrinsic Motivation and Automatic Curricula via Asymmetric Self-Play (Facebook)
Deep Exploration via Randomized Value Functions (Osband)
"A very recent thread of work builds on count-based (or upper-confidence-bound-based) exploration schemes that operate with value function learning. These methods maintain a density over the state-action space of pseudo-counts, which represent the quantity of data gathered that is relevant to each state-action pair. Such algorithms may offer a viable approach to deep exploration with generalization. There are, however, some potential drawbacks. One is that a separate representation is required to generalize counts, and it's not clear how to design an effective approach to this. As opposed to the optimal value function, which is fixed by the environment, counts are generated by the agent’s choices, so there is no single target function to learn. Second, the count model generates reward bonuses that distort data used to fit the value function, so the value function representation needs to be designed to not only capture properties of the true optimal value function but also such distorted versions. Finally, these approaches treat uncertainties as uncoupled across state-action pairs, and this can incur a substantial negative impact on statistical efficiency."
- http://youtube.com/watch?v=ck4GixLs4ZQ (Osband) + slides
RL^2: Fast Reinforcement Learning via Slow Reinforcement Learning (OpenAI) # learning to explore
"outer episodes (sample a new bandit problem / MDP) and inner episodes (of sampled MDP)"
"use RNN policy for outer POMDP with no state reset between inner episodes""future directions:
- better outer-loop algorithms
- scaling RL^2 to 1M games
- model-based RL^2
- curriculum learning / universal RL^2
- RL^2 + one-shot imitation learning
- RL^2 for simulation -> real world transfer"
- http://www.fields.utoronto.ca/video-archive/2017/02/2267-16530 (Abbeel, 19:00)
- https://youtube.com/watch?v=SfCa1HQMkuw&t=1h16m56s (Schulman)
- https://youtu.be/BskhUBPRrqE?t=6m28s (Sutskever)
- https://youtu.be/19eNQ1CLt5A?t=7m52s (Sutskever)
- https://github.com/DanielTakeshi/Paper_Notes/blob/master/reinforcement_learning/RL2-Fast_Reinforcement_Learning_via_Slow_Reinforcement_Learning.md
Learning to Reinforcement Learn (DeepMind) # learning to explore
"outer episodes (sample a new bandit problem / MDP) and inner episodes (of sampled MDP)"
"use RNN policy with no state reset between inner episodes for outer POMDP"
- https://youtube.com/watch?v=SfCa1HQMkuw&t=1h16m56s (Schulman)
- https://hackernoon.com/learning-policies-for-learning-policies-meta-reinforcement-learning-rl²-in-tensorflow-b15b592a2ddf (Juliani)
- https://github.com/awjuliani/Meta-RL
Learning to Perform Physics Experiments via Deep Reinforcement Learning (DeepMind)
- https://youtu.be/SAcHyzMdbXc?t=16m6s (de Freitas)
Count-Based Exploration with Neural Density Models (DeepMind)
"PixelCNN for exploration, neural alternative to Context Tree Switching"
- http://youtube.com/watch?v=qSfd27AgcEk (Bellemare)
#Exploration: A Study of Count-Based Exploration for Deep Reinforcement Learning (Abbeel)
"The authors encourage exploration by adding a pseudo-reward of the form beta/sqrt(count(state)) for infrequently visited states. State visits are counted using Locality Sensitive Hashing (LSH) based on an environment-specific feature representation like raw pixels or autoencoder representations. The authors show that this simple technique achieves gains in various classic RL control tasks and several games in the ATARI domain. While the algorithm itself is simple there are now several more hyperaprameters to tune: The bonus coefficient beta, the LSH hashing granularity (how many bits to use for hashing) as well as the type of feature representation based on which the hash is computed, which itself may have more parameters. The experiments don't paint a consistent picture and different environments seem to need vastly different hyperparameter settings, which in my opinion will make this technique difficult to use in practice."
EX2: Exploration with Exemplar Models for Deep Reinforcement Learning (Levine)
"Many of the most effective exploration techniques rely on tabular representations, or on the ability to construct a generative model over states and actions. This paper introduces a novel approach, EX2, which approximates state visitation densities by training an ensemble of discriminators, and assigns reward bonuses to rarely visited states."
Curiosity-driven Exploration by Self-supervised Prediction (Darrell)
"Our main contribution is in designing an intrinsic reward signal based on prediction error of the agent’s knowledge about its environment that scales to high-dimensional continuous state spaces like images, bypasses the hard problem of predicting pixels and is unaffected by the unpredictable aspects of the environment that do not affect the agent."
"We introduce exploration potential, a quantity that measures how much a reinforcement learning agent has explored its environment class. In contrast to information gain, exploration potential takes the problem's reward structure into account."
Surprise-Based Intrinsic Motivation for Deep Reinforcement Learning
"Authors present two tractable approximations to their framework - one which ignores the stochasticity of the true environmental dynamics, and one which approximates the rate of information gain (somewhat similar to Schmidhuber's formal theory of creativity, fun and intrinsic motivation)."
"Stadie et al. learn deterministic dynamics models by minimizing Euclidean loss - whereas in our work, we learn stochastic dynamics with cross entropy loss - and use L2 prediction errors for intrinsic motivation."
"Our results suggest that surprisal is a viable alternative to VIME in terms of performance, and is highly favorable in terms of computational cost. In VIME, a backwards pass through the dynamics model must be computed for every transition tuple separately to compute the intrinsic rewards, whereas our surprisal bonus only requires forward passes through the dynamics model for intrinsic reward computation. Furthermore, our dynamics model is substantially simpler than the Bayesian neural network dynamics model of VIME. In our speed test, our bonus had a per-iteration speedup of a factor of 3 over VIME."
Variational Intrinsic Control (DeepMind)
"The second scenario is that in which the long-term goal of the agent is to get to a state with a maximal set of available intrinsic options – the objective of empowerment (Salge et al., 2014). This set o
f options consists of those that the agent knows how to use. Note that this is not the theoretical set of all options: it is of no use to the agent that it is possible to do something if it is unable to learn how to do it. Thus, to maximize empowerment, the agent needs to simultaneously learn how to control the environment as well – it needs to discover the options available to it. The agent should in fact not aim for st ates where it has the most control according to its current abilities, but for states where it expects it will achieve the most control after learning. Being able to learn available options is thus fundamental to becoming empowered."
"Let us compare this to the commonly used intrinsic motivation objective of maximizing the amount of model-learning progress, measured as the difference in compression of its experience before and after l
earning (Schmidhuber, 1991; 2010; Bellemare et al., 2016; Houthooft et al., 2016). The empowerment objective differs from this in a fundamental manner: the primary goal is not to understand or predict the observa tions but to control the environment. This is an important point – agents can often control an environment perfectly well without much understanding, as exemplified by canonical model-free reinforcement learning algorithms (Sutton & Barto, 1998), where agents only model action-conditioned expected returns. Focusing on such understanding might significantly distract and impair the agent, as such reducing the control it ac hieves."
Stochastic Neural Networks for Hierarchical Reinforcement Learning (Abbeel)
"Our SNN hierarchical approach outperforms state-of-the-art intrinsic motivation results like VIME (Houthooft et al., 2016)."
- https://youtube.com/playlist?list=PLEbdzN4PXRGVB8NsPffxsBSOCcWFBMQx3 (demo)
- https://github.com/florensacc/snn4hrl
Reinforcement Learning with Unsupervised Auxiliary Tasks (DeepMind) # UNREAL
"Auxiliary tasks:
- pixel changes: learn a policy for maximally changing the pixels in a grid of cells overlaid over the images
- network features: learn a policy for maximally activating units in a specific hidden layer
- reward prediction: predict the next reward given some historical context
- value function replay: value function regression for the base agent with varying window for n-step returns"
"By using these tasks we force the agent to learn about the controllability of its environment and the sorts of sequences which lead to rewards, and all of this shapes the features of the agent." "This approach exploits the multithreading capabilities of standard CPUs. The idea is to execute many instances of our agent in parallel, but using a shared model. This provides a viable alternative to experience replay, since parallelisation also diversifies and decorrelates the data. Our asynchronous actor-critic algorithm, A3C, combines a deep Q-network with a deep policy network for selecting actions. It achieves state-of-the-art results, using a fraction of the training time of DQN and a fraction of the resource consumption of Gorila."
- https://youtube.com/watch?v=Uz-zGYrYEjA (demo)
- https://youtube.com/watch?v=VVLYTqZJrXY (Jaderberg)
- https://facebook.com/iclr.cc/videos/1712224178806641/ (1:15:45) (Jaderberg)
- https://github.com/dennybritz/deeplearning-papernotes/blob/b097e313dc59c956575fb1bf23b64fa8d1d84057/notes/rl-auxiliary-tasks.md
- https://github.com/miyosuda/unreal
Learning to Navigate in Complex Environments (DeepMind)
- http://youtube.com/watch?v=5Rflbx8y7HY (Mirowski)
- http://pemami4911.github.io/paper-summaries/2016/12/20/learning-to-navigate-in-complex-envs.html
Loss is Its Own Reward: Self-Supervision for Reinforcement Learning (Darrell)
Feature Control as Intrinsic Motivation for Hierarchical Reinforcement Learning
Towards Information-Seeking Agents (Maluuba)
Variational Intrinsic Control (DeepMind)
A Laplacian Framework for Option Discovery in Reinforcement Learning (Bowling)
"Our algorithm can be seen as a bottom-up approach, in which we construct options before the agent observes any informative reward. Options discovered this way tend to be independent of an agent’s intention, and are potentially useful in many different tasks. Moreover, such options can also be seen as being useful for exploration by allowing agents to commit to a behavior for an extended period of time."
- https://youtube.com/watch?v=2BVicx4CDWA (demo)
- https://vimeo.com/220484541 (Machado)
Strategic Attentive Writer for Learning Macro-Actions (DeepMind)
"Learning temporally extended actions and temporal abstraction in general is a long standing problem in reinforcement learning. They facilitate learning by enabling structured exploration and economic computation. In this paper we present a novel deep recurrent neural network architecture that learns to build implicit plans in an end-to-end manner purely by interacting with an environment in a reinforcement learning setting. The network builds an internal plan, which is continuously updated upon observation of the next input from the environment. It can also partition this internal representation into contiguous sub-sequences by learning for how long the plan can be committed to – i.e. followed without replanning. Combining these properties, the proposed model, dubbed STRategic Attentive Writer (STRAW) can learn high-level, temporally abstracted macro-actions of varying lengths that are solely learnt from data without any prior information."
- https://youtube.com/watch?v=niMOdSu3yio (demo)
- https://blog.acolyer.org/2017/01/06/strategic-attentive-writer-for-learning-macro-actions/
- http://blog.shakirm.com/2016/07/learning-in-brains-and-machines-3-synergistic-and-modular-action/ (Mohamed)
The Option-Critic Architecture (Precup)
Options Discovery with Budgeted Reinforcement Learning
Modular Multitask Reinforcement Learning with Policy Sketches (Levine)
Stochastic Neural Networks for Hierarchical Reinforcement Learning (Abbeel)
"Our SNN hierarchical approach outperforms state-of-the-art intrinsic motivation results like VIME (Houthooft et al., 2016)."
FeUdal Networks for Hierarchical Reinforcement Learning (Silver)
Learning and Transfer of Modulated Locomotor Controllers (Silver)
A Deep Hierarchical Approach to Lifelong Learning in Minecraft
Principled Option Learning in Markov Decision Processes (Tishby)
"We suggest a mathematical characterization of good sets of options using tools from information theory. This characterization enables us to find conditions for a set of options to be optimal and an algorithm that outputs a useful set of options and illustrate the proposed algorithm in simulation."
Model-Based Planning in Discrete Action Spaces (LeCun)
Recurrent Environment Simulators (DeepMind)
- https://drive.google.com/file/d/0B_L2b7VHvBW2NEQ1djNjU25tWUE/view (TORCS demo)
- https://drive.google.com/file/d/0B_L2b7VHvBW2UjMwWVRoM3lTeFU/view (TORCS demo)
- https://drive.google.com/file/d/0B_L2b7VHvBW2UWl5YUtSMXdUbnc/view (3D Maze demo)
- https://sites.google.com/site/resvideos1729/ (demo)
Prediction and Control with Temporal Segment Models (Abbeel)
"variational autoencoder to learn the distribution over future state trajectories conditioned on past states, past actions, and planned future actions"
"latent action prior, another variational autoencoder that models a prior over action segments, and showed how it can be used to perform control using actions from the same distribution as a dynamics model’s training data"
QMDP-Net: Deep Learning for Planning under Partial Observability
"This paper introduces QMDP-net, a neural network architecture for planning under partial observability. The QMDP-net combines the strengths of model-free learning and model-based planning. It is a recurrent policy network, but it represents a policy by connecting a model with a planning algorithm that solves the model, thus embedding the solution structure of planning in the network architecture. The QMDP-net is fully differentiable and allows end-to-end training. We train a QMDP-net over a set of different environments so that it can generalize over new ones."
The Predictron: End-to-End Learning and Planning (Silver)
"value estimation in Markov reward processes"
"do not address the issue of decision making or planning"
- https://youtube.com/watch?v=BeaLdaN2C3Q
- https://github.com/zhongwen/predictron
- https://github.com/muupan/predictron
Reinforcement Learning via Recurrent Convolutional Neural Networks
"solving Markov Decision Processes and Reinforcement Learning problems using Recurrent Convolutional Neural Networks"
"1. Solving Value / Policy Iteration in a standard MDP using Feedforward passes of a Value Iteration RCNN.
2. Representing the Bayes Filter state belief update as feedforward passes of a Belief Propagation RCNN.
3. Learning the State Transition models in a POMDP setting, using backpropagation on the Belief Propagation RCNN.
4. Learning Reward Functions in an Inverse Reinforcement Learning framework from demonstrations, using a QMDP RCNN."
"addresses decision making under partial observability"
"focuses on learning a model rather than a policy"
"learning is restricted to a fixed environment and does not generalize to new environments"
Value Iteration Networks (Abbeel)
- https://youtube.com/watch?v=tXBHfbHHlKc (Tamar) + http://technion.ac.il/~danielm/icml_slides/Talk7.pdf
- https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Value-Iteration-Networks (Tamar)
- https://github.com/karpathy/paper-notes/blob/master/vin.md
- https://blog.acolyer.org/2017/02/09/value-iteration-networks/
- https://github.com/avivt/VIN
- https://github.com/TheAbhiKumar/tensorflow-value-iteration-networks
- https://github.com/zuoxingdong/VIN_TensorFlow
- https://github.com/zuoxingdong/VIN_PyTorch_Visdom
- https://github.com/onlytailei/Value-Iteration-Networks-PyTorch
- https://github.com/kentsommer/pytorch-value-iteration-networks
Metacontrol for Adaptive Imagination-Based Optimization (DeepMind)
"Rather than learning a single, fixed policy for solving all instances of a task, we introduce a metacontroller which learns to optimize a sequence of "imagined" internal simulations over predictive models of the world in order to construct a more informed, and more economical, solution. The metacontroller component is a model-free reinforcement learning agent, which decides both how many iterations of the optimization procedure to run, as well as which model to consult on each iteration. The models (which we call "experts") can be state transition models, action-value functions, or any other mechanism that provides information useful for solving the task, and can be learned on-policy or off-policy in parallel with the metacontroller."
Thinking Fast and Slow with Deep Learning and Tree Search (Barber)
Blazing the Trails before Beating the Path: Sample-efficient Monte-Carlo Planning (Munos)
"We study the sampling-based planning problem in Markov decision processes (MDPs) that we can access only through a generative model, usually referred to as Monte-Carlo planning."
"Our objective is to return a good estimate of the optimal value function at any state while minimizing the number of calls to the generative model, i.e. the sample complexity."
"TrailBlazer is an adaptive algorithm that exploits possible structures of the MDP by exploring only a subset of states reachable by following near-optimal policies."
Neural Episodic Control (DeepMind)
"Our agent uses a semi-tabular representation of the value function: a buffer of past experience containing slowly changing state representations and rapidly updated estimates of the value function."
"Greedy non-parametric tabular-memory agents like MFEC can outperform model-based agents when data are noisy or scarce.
NEC outperforms MFEC by creating an end-to-end trainable learning system using differentiable neural dictionaries and a convolutional neural network.
A representation of the environment as generated by the mammalian brain's ventral stream can be approximated with random projections, a variational autoencoder, or a convolutional neural network."
Model-Free Episodic Control (DeepMind)
"This might be achieved by a dual system (hippocampus vs neocortex http://wixtedlab.ucsd.edu/publications/Psych%20218/McClellandMcNaughtonOReilly95.pdf ) where information are stored in alternated way such that new nonstationary experience is rapidly encoded in the hippocampus (most flexible region of the brain with the highest amount of plasticity and neurogenesis); long term memory in the cortex is updated in a separate phase where what is updated (both in terms of samples and targets) can be controlled and does not put the system at risk of instabilities."
- https://sites.google.com/site/episodiccontrol/ (demo)
- http://blog.shakirm.com/2016/07/learning-in-brains-and-machines-4-episodic-and-interactive-memory/
- https://github.com/ShibiHe/Model-Free-Episodic-Control
- https://github.com/sudeepraja/Model-Free-Episodic-Control
Neural Map: Structured Memory for Deep Reinforcement Learning (Salakhutdinov)
size and computational cost doesn't grow with time horizon of environment
- https://yadi.sk/i/pMdw-_uI3Gke7Z (Shvechikov, in russian)
A Growing Long-term Episodic and Semantic Memory
Memory-based Control with Recurrent Neural Networks (Silver)
Generalizing Skills with Semi-Supervised Reinforcement Learning (Abbeel, Levine)
Deep Successor Reinforcement Learning
- https://youtube.com/watch?v=OCHwXxSW70o (Kulkarni)
- https://youtube.com/watch?v=kNqXCn7K-BM (Garipov)
- https://github.com/Ardavans/DSR
Learning to Act by Predicting the Future
"application of deep successor reinforcement learning"
- https://youtube.com/watch?v=947bSUtuSQ0 + https://youtube.com/watch?v=947bSUtuSQ0 (demo)
- https://youtube.com/watch?v=Q0ldKJbAwR8 (Dosovitskiy) (in russian)
- https://yadi.sk/i/pMdw-_uI3Gke7Z (1:02:03) (Shvechikov) (in russian)
- https://blog.acolyer.org/2017/05/12/learning-to-act-by-predicting-the-future/
- https://github.com/IntelVCL/DirectFuturePrediction
Successor Features for Transfer in Reinforcement Learning (Silver)
Learning Modular Neural Network Policies for Multi-Task and Multi-Robot Transfer (Abbeel, Levine)
Learning Invariant Feature Spaces to Transfer Skills with Reinforcement Learning (Abbeel, Levine)
Policy Distillation (DeepMind)
"Our new paper uses distillation to consolidate lots of policies into a single deep network. This works remarkably well, and can be applied online, during Q-learning, so that policies are compressed, distilled, and refined whilst being learned. Atari policies are actually improved through distillation and generalize better (with higher scores and lower variance) during novel starting state evaluation."
Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning (Salakhutdinov)
Progressive Neural Networks (DeepMind)
- https://youtube.com/watch?v=aWAP_CWEtSI (Hadsell)
- http://techtalks.tv/talks/progressive-nets-for-sim-to-real-transfer-learning/63043/ (Hadsell)
- https://blog.acolyer.org/2016/10/11/progressive-neural-networks/
- https://github.com/synpon/prog_nn
Learning from Demonstrations for Real World Reinforcement Learning
Deeply AggreVaTeD: Differentiable Imitation Learning for Sequential Prediction
Generative Adversarial Imitation Learning
"Uses a GAN framework to discriminate between teacher and student experience and force the student to behave close to the teacher."
- https://youtube.com/watch?v=bcnCo9RxhB8 (Ermon)
- https://github.com/openai/imitation
- https://github.com/DanielTakeshi/rl_algorithms/tree/master/il
Inferring The Latent Structure of Human Decision-Making from Raw Visual Inputs
Third Person Imitation Learning (OpenAI)
"The authors propose a new framework for learning a policy from third-person experience. This is different from standard imitation learning which assumes the same "viewpoint" for teacher and student. The authors build upon Generative Adversarial Imitation Learning, which uses a GAN framework to discriminate between teacher and student experience and force the student to behave close to the teacher. However, when using third-person experience from a different viewpoint the discriminator would simply learn to discriminate between viewpoints instead of behavior and the framework isn't easily applicable. The authors' solution is to add a second discriminator to maximize a domain confusion loss based on the same feature representation. The objective is to learn the same (viewpoint-independent) feature representation for both teacher and student experience while also learning to discriminate between teacher and student observations. In other words, the objective is to maximize domain confusion while minimizing class loss. In practice, this is another discriminator term in the GAN objective. The authors also found that they need to feed observations at time t+n (n=4 in experiments) to signal the direction of movement in the environment."
Model-based Adversarial Imitation Learning
One-Shot Imitation Learning (OpenAI)
Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization (Abbeel)
Unsupervised Perceptual Rewards for Imitation Learning (Levine)
"To our knowledge, these are the first results showing that complex robotic manipulation skills can be learned directly and without supervised labels from a video of a human performing the task."
Deep Reinforcement Learning: An Overview
DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker (Bowling)
- http://science.sciencemag.org/content/early/2017/03/01/science.aam6960
- https://youtube.com/watch?v=qndXrHcV1sM (Bowling)
- http://deepstack.ai
- http://twitter.com/DeepStackAI
Neural Combinatorial Optimization with Reinforcement Learning (Google Brain)
Learning Runtime Parameters in Computer Systems with Delayed Experience Injection
Coarse-to-Fine Question Answering for Long Documents (Google Research)
Improving Information Extraction by Acquiring External Evidence with Reinforcement Learning (Barzilay)
- https://youtu.be/k5KWUpqMO2U?t=47m37s (Narasimhan)
- https://github.com/karthikncode/DeepRL-InformationExtraction
Teaching Machines to Describe Images via Natural Language Feedback
Towards Deep Symbolic Reinforcement Learning
- https://youtube.com/watch?v=HOAVhPy6nrc (Shanahan)
A Paradigm for Situated and Goal-Driven Language Learning (OpenAI)
Multi-Agent Cooperation and the Emergence of (Natural) Language (Facebook)
- https://facebook.com/iclr.cc/videos/1712966538732405/ (Peysakhovich)
Emergence of Grounded Compositional Language in Multi-Agent Populations (OpenAI)
"Though the agents come up with words that we found to correspond to objects and other agents, as well as actions like 'Look at' or 'Go to', to the agents these words are abstract symbols represented by one-hot vector - we label these one-hot vectors with English words that capture their meaning for the sake of interpretability."
"One possible scenario is from goal oriented-dialog systems. Where one agent tries to transmit to another certain API call that it should perform (book restaurant, hotel, whatever). I think these models can make it more data efficient. At the first stage two agents have to communicate and discover their own language, then you can add regularization to make the language look more like natural language and on the final stage, you are adding a small amount of real data (dialog examples specific for your task). I bet that using additional communication loss will make the model more data efficient."
"The big outcome to hunt for in this space is a post-gradient descent learning algorithm. Of course you can make agents that play the symbol grounding game, but it's not a very big step from there to compression of data, and from there to compression of 'what you need to know to solve the problem you're about to encounter' - at which point you have a system which can learn by training or learn by receiving messages. It was pretty easy to get stuff like one agent learning a classifier, encoding it in a message, and transmitting it to a second agent who has to use it for zero-shot classification. But it's still single-task specific communication, so there's no benefit to the agent for receiving, say, the messages associated with the previous 100 tasks. The tricky thing is going from there to something more abstract and cumulative, so that you can actually use message generation as an iterative learning mechanism. I think a large part of that difficulty is actually designing the task ensemble, not just the network architecture."
- https://youtube.com/watch?v=liVFy7ZO4OA (demo)
- "A Paradigm for Situated and Goal-Driven Language Learning"
- https://blog.openai.com/learning-to-communicate/
- https://youtube.com/watch?v=f4gKhK8Q6mY&t=22m20s (Abbeel)
- http://videos.re-work.co/videos/366-learning-to-communicate (Lowe)
Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning
- https://visualdialog.org (demo)
Emergent Language in a Multi-Modal, Multi-Step Referential Game
A Deep Compositional Framework for Human-like Language Acquisition in Virtual Environment (Baidu)
On the Evaluation of Dialogue Systems with Next Utterance Classification
Towards an Automatic Turing Test: Learning to Evaluate Dialogue Responses
On-line Active Reward Learning for Policy Optimisation in Spoken Dialogue Systems (Young)
Continuously Learning Neural Dialogue Management (Young)
Online Sequence-to-Sequence Reinforcement Learning for Open-domain Conversational Agents
Generative Deep Neural Networks for Dialogue: A Short Review (Pineau)
Emulating Human Conversations using Convolutional Neural Network-based IR
Two are Better than One: An Ensemble of Retrieval- and Generation-Based Dialog Systems
Machine Comprehension by Text-to-Text Neural Question Generation (Maluuba)
Latent Intention Dialogue Models (Young)
"Learning an end-to-end dialogue system is appealing but challenging because of the credit assignment problem. Discrete latent variable dialogue models such as LIDM are attractive because the latent variable can serve as an interface for decomposing the learning of language and the internal dialogue decision-making. This decomposition can effectively help us resolve the credit assignment problem where different learning signals can be applied to different sub-modules to update the parameters. In variational inference for discrete latent variables, the latent distribution is basically updated by the reward from the variational lower bound. While in reinforcement learning, the latent distribution (i.e. policy network) is updated by the rewards from dialogue success and sentence BLEU score. Hence, the latent variable bridges the different learning paradigms such as Bayesian learning and reinforcement learning and brings them together under the same framework. This framework provides a more robust neural network-based approach than previous approaches because it does not depend solely on sequence-to-sequence learning but instead explicitly models the hidden dialogue intentions underlying the user’s utterances and allows the agent to directly learn a dialogue policy through interaction."
"End-to-end methods lack a general mechanism for injecting domain knowledge and constraints. For example, simple operations like sorting a list of database results or updating a dictionary of entities can expressed in a few lines of software, yet may take thousands of dialogs to learn. Moreover, in some practical settings, programmed constraints are essential – for example, a banking dialog system would require that a user is logged in before they can retrieve account information."
"In addition to learning an RNN, HCNs also allow a developer to express domain knowledge via software and action templates."
Adversarial Learning for Neural Dialogue Generation (Jurafsky)
End-to-End Reinforcement Learning of Dialogue Agents for Information Access (Deng)
Efficient Exploration for Dialog Policy Learning with Deep BBQ Networks & Replay Buffer Spiking (Deng)
Neural Belief Tracker: Data-Driven Dialogue State Tracking (Young)
Policy Networks with Two-Stage Training for Dialogue Systems (Maluuba)
Learning Language Games through Interaction (Manning)
Deep Reinforcement Learning for Dialogue Generation (Jurafsky)
End-to-End LSTM-based Dialog Control Optimized with Supervised and Reinforcement Learning (Zweig)
Learning End-to-End Goal-Oriented Dialog (Weston)
- https://facebook.com/iclr.cc/videos/1712966538732405/ (27:39) (Boureau)
A Network-based End-to-End Trainable Task-oriented Dialogue System (Young)
Towards Conversational Recommender Systems (Hoffman)
- https://periscope.tv/WiMLworkshop/1vAGRXDbvbkxl (Christakopoulou)
- https://youtube.com/watch?v=nLUfAJqXFUI (Christakopoulou)
A Copy-Augmented Sequence-to-Sequence Architecture Gives Good Performance on Task-Oriented Dialogue (Manning)
Multiresolution Recurrent Neural Networks: An Application to Dialogue Response Generation (Bengio)
An Attentional Neural Conversation Model with Improved Specificity (Zweig)
A Hierarchical Latent Variable Encoder-Decoder Model for Generating Dialogues (Bengio)
LSTM-based Mixture-of-Experts for Knowledge-Aware Dialogues
Multi-domain Neural Network Language Generation for Spoken Dialogue Systems
Sentence Level Recurrent Topic Model: Letting Topics Speak for Themselves
Context-aware Natural Language Generation with Recurrent Neural Networks
Data Distillation for Controlling Specificity in Dialogue Generation (Jurafsky)
A Persona-Based Neural Conversation Model
Conversational Contextual Cues: The Case of Personalization and History for Response Ranking (Kurzweil)
A Sequence-to-Sequence Model for User Simulation in Spoken Dialogue Systems (Maluuba)
Deep Contextual Language Understanding in Spoken Dialogue Systems
Improving Information Extraction by Acquiring External Evidence with Reinforcement Learning (Barzilay)
Improving Neural Language Models with a Continuous Cache (Facebook) # adaptive softmax
Learning to Compute Word Embeddings On the Fly
Pointer Sentinel Mixture Models (MetaMind)
"The authors combine a standard LSTM softmax with Pointer Networks in a mixture model called Pointer-Sentinel LSTM (PS-LSTM). The pointer networks helps with rare words and long-term dependencies but is unable to refer to words that are not in the input. The opposite is the case for the standard softmax."
Pointing the Unknown Words (Bengio)
Machine Comprehension Using Match-LSTM And Answer Pointer
Towards Universal Paraphrastic Sentence Embeddings # outperforming LSTM
Order-Embeddings of Images and Language
- http://videolectures.net/iclr2016_vendrov_order_embeddings/ (Vendrov)
- https://github.com/ivendrov/order-embedding
- https://github.com/ivendrov/order-embeddings-wordnet
- https://github.com/LeavesBreathe/tensorflow_with_latest_papers/blob/master/partial_ordering_embedding.py
Bag of Tricks for Efficient Text Classification (Facebook) # fastText
- http://www.shortscience.org/paper?bibtexKey=journals%2Fcorr%2F1607.01759#shagunsodhani
- https://github.com/fchollet/keras/blob/master/examples/imdb_fasttext.py
Globally Normalized Transition-Based Neural Networks # SyntaxNet, Parsey McParseface
"The parser uses a feed forward NN, which is much faster than the RNN usually used for parsing. Also the paper is using a global method to solve the label bias problem. This method can be used for many tasks and indeed in the paper it is used also to shorten sentences by throwing unnecessary words. The label bias problem arises when predicting each label in a sequence using a softmax over all possible label values in each step. This is a local approach but what we are really interested in is a global approach in which the sequence of all labels that appeared in a training example are normalized by all possible sequences. This is intractable so instead a beam search is performed to generate alternative sequences to the training sequence. The search is stopped when the training sequence drops from the beam or ends. The different beams with the training sequence are then used to compute the global loss."
- https://github.com/udibr/notes/raw/master/Talk%20by%20Sasha%20Rush%20-%20Interpreting%2C%20Training%2C%20and%20Distilling%20Seq2Seq%E2%80%A6.pdf
- http://www.shortscience.org/paper?bibtexKey=journals%2Fcorr%2F1603.06042
- https://github.com/tensorflow/models/tree/master/syntaxnet
Semantic Parsing with Semi-Supervised Sequential Autoencoders (DeepMind)
Open-Vocabulary Semantic Parsing with both Distributional Statistics and Formal Knowledge (Gardner)
Learning a Neural Semantic Parser from User Feedback
"We learn a semantic parser for an academic domain from scratch by deploying an online system using our interactive learning algorithm. After three train-deploy cycles, the system correctly answered 63.51% of user’s questions. To our knowledge, this is the first effort to learn a semantic parser using a live system, and is enabled by our models that can directly parse language to SQL without manual intervention."
Neural Variational Inference for Text Processing (Blunsom)
- http://dustintran.com/blog/neural-variational-inference-for-text-processing/
- https://github.com/carpedm20/variational-text-tensorflow
- https://github.com/cheng6076/NVDM
Discovering Discrete Latent Topics with Neural Variational Inference
Generating Sentences from a Continuous Space
- http://www.shortscience.org/paper?bibtexKey=journals/corr/1511.06349
- https://github.com/analvikingur/pytorch_RVAE
- https://github.com/cheng6076/Variational-LSTM-Autoencoder
A Hybrid Convolutional Variational Autoencoder for Text Generation
Improved Variational Autoencoders for Text Modeling using Dilated Convolutions (Salakhutdinov)
Controllable Text Generation (Salakhutdinov)
<brylevkirill (at) gmail.com>