|
| 1 | +## 1. 链表简介 |
| 2 | + |
| 3 | +### 1.1 链表定义 |
| 4 | + |
| 5 | +> **链表(Linked List)**:一种线性表数据结构。它使用一组任意的存储单元(可以是连续的,也可以是不连续的),来存储一组具有相同类型的数据。 |
| 6 | +
|
| 7 | +简单来说,**「链表」** 是实现线性表的链式存储结构的基础。 |
| 8 | + |
| 9 | +以单链表为例,链表的存储方式如下图所示。 |
| 10 | + |
| 11 | + |
| 12 | + |
| 13 | +如上图所示,链表通过将一组任意的存储单元串联在一起。其中,每个数据元素占用若干存储单元的组合称为一个「链节点」。为了将所有的节点串起来,每个链节点不仅要存放一个数据元素的数据信息,还要存放一个指出这个数据元素在逻辑关系上的直接后继元素所在链节点的地址,该地址被称为「后继指针 `next`」。 |
| 14 | + |
| 15 | +在链表中,数据元素之间的逻辑关系是通过指针来间接反映的。逻辑上相邻的数据元素在物理地址上可能相邻,可也能不相邻。其在物理地址上的表现是随机的。 |
| 16 | + |
| 17 | +我们先来简单介绍一下链表结构的优缺点: |
| 18 | + |
| 19 | +- 优点:存储空间不必事先分配,在需要存储空间的时候可以临时申请,不会造成空间的浪费;一些操作的时间效率远比数组高(插入、移动、删除元素等)。 |
| 20 | + |
| 21 | +- 缺点:不仅数据元素本身的数据信息要占用存储空间,指针也需要占用存储空间,链表结构比数组结构的空间开销大。 |
| 22 | + |
| 23 | +接下来先来介绍一下除了单链表之外,链表的其他几种类型。 |
| 24 | + |
| 25 | +### 1.2 双向链表 |
| 26 | + |
| 27 | +> **双向链表(Doubly Linked List)**:链表的一种,也叫做双链表。它的每个链节点中有两个指针,分别指向直接后继和直接前驱。 |
| 28 | +
|
| 29 | +从双链表的任意一个节点开始,都可以很方便的访问它的前驱节点和后继节点。 |
| 30 | + |
| 31 | +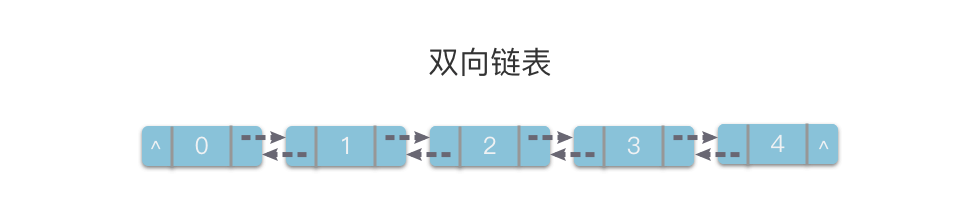 |
| 32 | + |
| 33 | +### 1.3 循环链表 |
| 34 | + |
| 35 | +> 循环链表(Circular linked list):链表的一种。它的最后一个链节点指向头节点,形成一个环。 |
| 36 | +
|
| 37 | +从循环链表的任何一个节点出发都能找到任何其他节点。 |
| 38 | + |
| 39 | + |
| 40 | + |
| 41 | +接下来我们以单链表为例,介绍一下链表的基本操作。 |
| 42 | + |
| 43 | +## 2. 链表的基本操作 |
| 44 | + |
| 45 | +数据结构的操作一般涉及到增、删、改、查 4 种情况,链表的操作也基本上是这 4 种情况。下面我们一起来看一下链表的基本操作。 |
| 46 | + |
| 47 | +### 2.1 链表的结构定义 |
| 48 | + |
| 49 | +链表是由链节点通过 `next` 链接而构成的,所以先来定义一个简单的链节点类,即 `ListNode` 类。`ListNode` 类使用成员变量 `val` 表示数据元素的值,`next` 表示后继指针。然后再定义链表类,即 `LinkedList` 类。`ListkedList` 类中只有一个链节点变量 `head` 用来表示链表的头节点。 |
| 50 | + |
| 51 | +我们在创建空链表时,只需要把相应的链表头节点变量设置为空链接即可。在 `Python` 里可以将其设置为 `None`,其他语言也有类似的惯用值,比如 `NULL`、`nil`、`0` 等。 |
| 52 | + |
| 53 | +**「链节点以及链表的结构定义」** 代码如下: |
| 54 | + |
| 55 | +```Python |
| 56 | +# 链节点类 |
| 57 | +class ListNode: |
| 58 | + def __init__(self, val=0, next=None): |
| 59 | + self.val = val |
| 60 | + self.next = next |
| 61 | + |
| 62 | +# 链表类 |
| 63 | +class LinkedList: |
| 64 | + def __init__(self): |
| 65 | + self.head = None |
| 66 | +``` |
| 67 | + |
| 68 | +### 2.2 建立一个线性链表 |
| 69 | + |
| 70 | +建立一个线性链表的过程是:根据线性表的数据元素动态生成链节点,并依次将其连接到链表中。其做法如下: |
| 71 | + |
| 72 | +- 从所给线性表的第 `1` 个数据元素开始依次获取表中的数据元素。 |
| 73 | +- 每获取一个数据元素,就为该数据元素生成一个新节点,将新节点插入到链表的尾部。 |
| 74 | +- 插入完毕之后返回第 `1` 个链节点的地址。 |
| 75 | + |
| 76 | +建立一个线性链表的时间复杂度为 $O(n)$,n 为线性表长度。 |
| 77 | + |
| 78 | +**「建立一个线性链表」** 的代码如下: |
| 79 | + |
| 80 | +```Python |
| 81 | +# 根据 data 初始化一个新链表 |
| 82 | +def create(self, data): |
| 83 | + self.head = ListNode(0) |
| 84 | + cur = self.head |
| 85 | + for i in range(len(data)): |
| 86 | + node = ListNode(data[i]) |
| 87 | + cur.next = node |
| 88 | + cur = cur.next |
| 89 | +``` |
| 90 | + |
| 91 | +### 2.3 求线性链表的长度 |
| 92 | + |
| 93 | +线性链表的长度被定义为链表中包含的链节点的个数。只需要使用一个可以顺着链表指针移动的指针变量 `cur` 和一个计数器 `count`。具体做法如下: |
| 94 | + |
| 95 | +- 让指针变量 `cur` 指向链表的第 `1` 个链节点。 |
| 96 | +- 然后顺着链节点的 `next` 指针遍历链表,指针变量 `cur` 每指向一个链节点,计数器就做一次计数。 |
| 97 | +- 等 ` cur` 指向为空时结束遍历,此时计数器的数值就是链表的长度,将其返回即可。 |
| 98 | + |
| 99 | +求线性链表的长度操作的问题规模是链表的链节点数 `n`,基本操作是 `cur` 指针的移动,操作的次数为 `n`,因此算法的时间复杂度为 $O(n)$。 |
| 100 | + |
| 101 | +**「求线性链表长度」** 的代码如下: |
| 102 | + |
| 103 | +```Python |
| 104 | +# 获取链表长度 |
| 105 | +def length(self): |
| 106 | + count = 0 |
| 107 | + cur = self.head |
| 108 | + while cur: |
| 109 | + count += 1 |
| 110 | + cur = cur.next |
| 111 | + return count |
| 112 | +``` |
| 113 | + |
| 114 | +### 2.4 查找元素 |
| 115 | + |
| 116 | +在链表中查找值为 `val` 的位置:链表不能像数组那样进行随机访问,只能从头节点 `head` 开始,沿着链表一个一个节点逐一进行查找。如果查找成功,返回被查找节点的地址。否则返回 `None`。 |
| 117 | + |
| 118 | +查找元素操作的问题规模是链表的长度 `n`,而基本操作是指针 `cur` 的移动操作,所以查找元素算法的时间复杂度为 $O(n)$。 |
| 119 | + |
| 120 | +**「在链表中查找元素」** 的代码如下: |
| 121 | + |
| 122 | +```Python |
| 123 | +# 查找元素 |
| 124 | +def find(self, val): |
| 125 | + cur = self.head |
| 126 | + while cur: |
| 127 | + if val == cur.val: |
| 128 | + return cur |
| 129 | + cur = cur.next |
| 130 | + |
| 131 | + return None |
| 132 | +``` |
| 133 | + |
| 134 | +### 2.5 插入元素 |
| 135 | + |
| 136 | +插入元素操作分为三种: |
| 137 | + |
| 138 | +- 头部插入元素:在链表第 `1` 个链节点之前插入值为 `val` 的链节点。 |
| 139 | +- 尾部插入元素:在链表尾部插入值为 `val` 的链节点。 |
| 140 | +- 中间插入元素:在链表第 `i` 个链节点之前插入值为 `val` 的链节点。 |
| 141 | + |
| 142 | +接下来我们分别讲解一下。 |
| 143 | + |
| 144 | +#### 2.5.1 头部插入元素 |
| 145 | + |
| 146 | +算法实现的步骤为: |
| 147 | + |
| 148 | +- 先创建一个值为 `val` 的链节点 `node`。 |
| 149 | +- 然后将 `node` 的 `next` 指针指向链表的头节点 `head`。 |
| 150 | +- 再将链表的头节点 `head ` 指向 `node`。 |
| 151 | + |
| 152 | +因为在链表头部插入链节点与链表的长度无关,所以该算法的时间复杂度为 $O(1)$。 |
| 153 | + |
| 154 | +**「在链表头部插入值为 `val` 元素」** 的代码如下: |
| 155 | + |
| 156 | +```Python |
| 157 | +# 头部插入元素 |
| 158 | +def insertFront(self, val): |
| 159 | + node = ListNode(val) |
| 160 | + node.next = self.head |
| 161 | + self.head = node |
| 162 | +``` |
| 163 | + |
| 164 | +#### 2.5.2 尾部插入元素 |
| 165 | + |
| 166 | +算法实现的步骤为: |
| 167 | + |
| 168 | +- 先创建一个值为 `val` 的链节点 `node`。 |
| 169 | +- 使用指针 `cur` 指向链表的头节点 `head`。 |
| 170 | +- 通过链节点的 `next` 指针移动 `cur` 指针,从而遍历链表,直到 `cur.next == None`。 |
| 171 | +- 令 `cur.next` 指向将新的链节点 `node`。 |
| 172 | + |
| 173 | +因为将 `cur` 从链表头部移动到尾部的操作次数是 `n` 次,所以该算法的时间复杂度是 $O(n)$。 |
| 174 | + |
| 175 | +**「在链表尾部插入值为 `val` 的元素」** 的代码如下: |
| 176 | + |
| 177 | +```Python |
| 178 | +# 尾部插入元素 |
| 179 | +def insertRear(self, val): |
| 180 | + node = ListNode(val) |
| 181 | + cur = self.head |
| 182 | + while cur.next: |
| 183 | + cur = cur.next |
| 184 | + cur.next = node |
| 185 | +``` |
| 186 | + |
| 187 | +#### 2.5.3 中间插入元素 |
| 188 | + |
| 189 | +算法的实现步骤如下: |
| 190 | + |
| 191 | +- 使用指针变量 `cur` 和一个计数器 `count`。令 `cur` 指向链表的头节点,`count` 初始值赋值为 `0`。 |
| 192 | +- 沿着链节点的 `next` 指针遍历链表,指针变量 `cur` 每指向一个链节点,计数器就做一次计数。 |
| 193 | +- 当 `count == index - 1` 时,说明遍历到了第 `index - 1` 个链节点,此时停止遍历。 |
| 194 | +- 将 `node.next` 指向 `cur.next`。 |
| 195 | +- 然后令 `cur.next` 指向 `node`。 |
| 196 | + |
| 197 | +因为将 `cur` 从链表头部移动到第 `i` 个链节点之前的操作平均时间复杂度是 $O(n)$,所以该算法的时间复杂度是 $O(n)$。 |
| 198 | + |
| 199 | +**「在链表第 `i` 个链节点之前插入值为 `val` 的元素」** 的代码如下: |
| 200 | + |
| 201 | +```Python |
| 202 | +# 中间插入元素 |
| 203 | +def insertInside(self, index, val): |
| 204 | + count = 0 |
| 205 | + cur = self.head |
| 206 | + while cur and count < index - 1: |
| 207 | + count += 1 |
| 208 | + cur = cur.next |
| 209 | + |
| 210 | + if not cur: |
| 211 | + return 'Error' |
| 212 | + |
| 213 | + node = ListNode(val) |
| 214 | + node.next = cur.next |
| 215 | + cur.next = node |
| 216 | +``` |
| 217 | + |
| 218 | +### 2.6 改变元素 |
| 219 | + |
| 220 | +将链表中第 `i` 个元素值改为 `val`:首先要先遍历到第 `i` 个链节点,然后直接更改第 `i` 个链节点的元素值。具体做法如下: |
| 221 | + |
| 222 | +- 使用指针变量 `cur` 和一个计数器 `count`。令 `cur` 指向链表的头节点,`count` 初始值赋值为 `0`。 |
| 223 | +- 沿着链节点的 `next` 指针遍历链表,指针变量 `cur` 每指向一个链节点,计数器就做一次计数。 |
| 224 | +- 当 `count == index` 时,说明遍历到了第 `index` 个链节点,此时停止遍历。 |
| 225 | +- 直接更改 `cur` 的值 `val`。 |
| 226 | + |
| 227 | +因为将 `cur` 从链表头部移动到第 `i` 个链节点的操作平均时间复杂度是 $O(n)$,所以该算法的时间复杂度是 $O(n)$。 |
| 228 | + |
| 229 | +**「将链表中第 `i` 个元素值改为 `val`」** 的代码如下: |
| 230 | + |
| 231 | +```Python |
| 232 | +# 改变元素 |
| 233 | +def change(self, index, val): |
| 234 | + count = 0 |
| 235 | + cur = self.head |
| 236 | + while cur and count < index: |
| 237 | + count += 1 |
| 238 | + cur = cur.next |
| 239 | + |
| 240 | + if not cur: |
| 241 | + return 'Error' |
| 242 | + |
| 243 | + cur.val = val |
| 244 | +``` |
| 245 | + |
| 246 | +### 2.7 删除元素 |
| 247 | + |
| 248 | +链表的删除元素操作同样分为三种情况: |
| 249 | + |
| 250 | +- 删除链表头部元素:删除链表的第 `1` 个链节点。 |
| 251 | +- 删除链表尾部元素:删除链表末尾最后 `1` 个链节点。 |
| 252 | +- 删除链表中间元素:删除链表第 `i` 个链节点。 |
| 253 | + |
| 254 | +接下来我们分别讲解一下。 |
| 255 | + |
| 256 | +#### 2.7.1 删除链表头部元素 |
| 257 | + |
| 258 | +删除链表头部元素的方法很简单,具体步骤如下: |
| 259 | + |
| 260 | +- 直接将 `self.head` 沿着 `next` 指针向右移动一步即可。 |
| 261 | + |
| 262 | +因为只涉及到一步移动操作,所以此算法的时间复杂度为 $O(1)$。 |
| 263 | + |
| 264 | +**「删除链表头部元素」** 的代码如下所示: |
| 265 | + |
| 266 | +```Python |
| 267 | +# 移除链表头部元素 |
| 268 | +def removeFront(self): |
| 269 | + if self.head: |
| 270 | + self.head = self.head.next |
| 271 | +``` |
| 272 | + |
| 273 | +#### 2.7.2 删除链表尾部元素 |
| 274 | + |
| 275 | +删除链表尾部元素的方法也比价简单,具体步骤如下: |
| 276 | + |
| 277 | +- 先使用指针变量 `cur` 沿着 `next` 指针移动到倒数第 `2` 个链节点。 |
| 278 | +- 然后将此节点的 `next` 指针指向 `None` 即可。 |
| 279 | + |
| 280 | +因为移动到链表尾部的操作次数为`n` 次,所以该算法的时间复杂度为 $O(n)$。 |
| 281 | + |
| 282 | +**「删除链表尾部元素」** 的代码如下所示: |
| 283 | + |
| 284 | +```Python |
| 285 | +# 移除链表尾部元素 |
| 286 | +def removeRear(self): |
| 287 | + if not self.head.next: |
| 288 | + return 'Error' |
| 289 | + |
| 290 | + cur = self.head |
| 291 | + while cur.next.next: |
| 292 | + cur = cur.next |
| 293 | + cur.next = None |
| 294 | +``` |
| 295 | + |
| 296 | +#### 2.7.3 删除链表中间元素 |
| 297 | + |
| 298 | +删除链表中第 `i` 个元素的算法具体步骤如下: |
| 299 | + |
| 300 | +- 先使用指针变量 `cur` 移动到第 `i - 1` 个位置的链节点。 |
| 301 | +- 然后将 `cur` 的 `next` 指针,指向要第 `i` 个元素的下一个节点即可。 |
| 302 | + |
| 303 | +**「删除链表中第 `i` 个元素」** 的代码如下所示: |
| 304 | + |
| 305 | +```Python |
| 306 | +# 移除链表中间元素 |
| 307 | +def removeInside(self, index): |
| 308 | + count = 0 |
| 309 | + cur = self.head |
| 310 | + |
| 311 | + while cur.next and count < index - 1: |
| 312 | + count += 1 |
| 313 | + cur = cur.next |
| 314 | + |
| 315 | + if not cur: |
| 316 | + return 'Error' |
| 317 | + |
| 318 | + del_node = cur.next |
| 319 | + cur.next = del_node.next |
| 320 | +``` |
| 321 | + |
| 322 | +--- |
| 323 | + |
| 324 | +到这里,有关链表的基础知识就介绍完了。下面进行一下总结。 |
| 325 | + |
| 326 | +## 3. 链表总结 |
| 327 | + |
| 328 | +链表是最基础、最简单的数据结构。**「链表」** 是实现线性表的链式存储结构的基础。它使用一组任意的存储单元(可以是连续的,也可以是不连续的),来存储一组具有相同类型的数据。 |
| 329 | + |
| 330 | +链表最大的优点在可以灵活的添加和删除元素。链表进行访问元素、改变元素操作的时间复杂度为 $O(n)$,进行头部插入、尾部插入、头部删除、尾部删除元素操作的时间复杂度是 $O(1)$,普通情况下进行插入、删除元素进行的时间复杂度为 $O(n)$。 |
| 331 | + |
| 332 | +## 参考资料 |
| 333 | + |
| 334 | +- 【文章】[链表理论基础 - 代码随想录](https://programmercarl.com/链表理论基础.html#链表理论基础) |
| 335 | + |
| 336 | +- 【文章】[Python 与 Java 中容器对比:List - 知乎](https://zhuanlan.zhihu.com/p/120312437) |
| 337 | + |
| 338 | +- 【文章】[什么是链表 - 漫画算法 - 小灰的算法之旅 - 力扣](https://leetcode-cn.com/leetbook/read/journey-of-algorithm/5ozchs/) |
| 339 | + |
| 340 | +- 【文章】[链表 - 数据结构与算法之美 - 极客时间](https://time.geekbang.org/column/article/41013) |
| 341 | + |
| 342 | +- 【书籍】数据结构教程 第 2 版 - 唐发根 著 |
| 343 | + |
| 344 | +- 【书籍】数据结构与算法 Python 语言描述 - 裘宗燕 著 |
0 commit comments