wandb FileNotFoundError(2, 'No such file or directory') #10097
-
|
Hi Team, trying to replicate https://github.com/explosion/projects/tree/v3/integrations/wandb approach here by using my config and also doing "python API" approach I am getting this Here is my config: [paths]
train = "spacy/train.spacy"
dev = "spacy/dev.spacy"
vectors = null
init_tok2vec = null
[system]
gpu_allocator = null
seed = 0
[nlp]
lang = "en"
pipeline = ["tok2vec","tagger","parser","attribute_ruler","lemmatizer","ner"]
disabled = ["senter"]
before_creation = null
after_creation = null
after_pipeline_creation = null
batch_size = 256
tokenizer = {"@tokenizers":"spacy.Tokenizer.v1"}
[components]
[components.attribute_ruler]
source = "en_core_web_lg"
[components.lemmatizer]
source = "en_core_web_lg"
[components.ner]
source = "en_core_web_lg"
[components.parser]
source = "en_core_web_lg"
replace_listeners = ["model.tok2vec"]
[components.tagger]
source = "en_core_web_lg"
replace_listeners = ["model.tok2vec"]
[components.tok2vec]
source = "en_core_web_lg"
[corpora]
[corpora.dev]
@readers = "spacy.Corpus.v1"
path = ${paths.dev}
max_length = 0
gold_preproc = false
limit = 0
augmenter = null
[corpora.train]
@readers = "spacy.Corpus.v1"
path = ${paths.train}
max_length = 0
gold_preproc = false
limit = 0
augmenter = null
[training]
train_corpus = "corpora.train"
dev_corpus = "corpora.dev"
seed = ${system:seed}
gpu_allocator = ${system:gpu_allocator}
dropout = 0.1
accumulate_gradient = 1
patience = 5000
max_epochs = 0
max_steps = 0
eval_frequency = 1000
frozen_components = ["tagger","parser","attribute_ruler","lemmatizer"]
before_to_disk = null
annotating_components = []
[training.batcher]
@batchers = "spacy.batch_by_words.v1"
discard_oversize = false
tolerance = 0.2
get_length = null
[training.batcher.size]
@schedules = "compounding.v1"
start = 100
stop = 1000
compound = 1.001
t = 0.0
[training.optimizer]
@optimizers = "Adam.v1"
beta1 = 0.9
beta2 = 0.999
L2_is_weight_decay = true
L2 = 0.01
grad_clip = 1.0
use_averages = true
eps = 0.00000001
learn_rate = 0.001
[training.score_weights]
tag_acc = null
dep_uas = null
dep_las = null
dep_las_per_type = null
sents_p = null
sents_r = null
sents_f = null
lemma_acc = null
ents_f = 0.16
ents_p = 0.0
ents_r = 0.0
ents_per_type = null
speed = 0.0
[training.logger]
@loggers = "spacy.WandbLogger.v2"
# Our W&B Project name
project_name = "registered-nurse"
# Any config data you do not want logged to W&B
remove_config_values = ["paths.train", "paths.dev", "corpora.train.path", "corpora.dev.path"]
# Optional, log the model every N steps to W&B Artifacts
model_log_interval = 100
[pretraining]
[initialize]
vectors = "en_core_web_lg"
init_tok2vec = ${paths.init_tok2vec}
vocab_data = null
lookups = null
before_init = null
after_init = null
[initialize.components]
[initialize.components.ner]
[initialize.components.ner.labels]
@readers = "spacy.read_labels.v1"
path = "spacy/labels/ner.json"
[initialize.components.parser]
[initialize.components.parser.labels]
@readers = "spacy.read_labels.v1"
path = "spacy/labels/parser.json"
[initialize.components.tagger]
[initialize.components.tagger.labels]
@readers = "spacy.read_labels.v1"
path = "spacy/labels/tagger.json"
[initialize.tokenizer]which generated by prodigy sweep.py import typer
from pathlib import Path
from spacy.training.loop import train
from spacy.training.initialize import init_nlp
from spacy import util
from thinc.api import Config
import wandb
import os
os.environ["WANDB_CONSOLE"] = "off"
def main(default_config: Path, output_path: Path):
print(default_config, output_path)
def train_spacy():
loaded_local_config = util.load_config(default_config)
with wandb.init(dir=os.getcwd()) as run:
sweeps_config = Config(util.dot_to_dict(run.config))
merged_config = Config(loaded_local_config).merge(sweeps_config)
nlp = init_nlp(merged_config)
train(nlp, output_path, use_gpu=False)
sweep_config = {
'method': 'bayes'
}
metric = {
'name': 'ents_f',
'goal': 'maximize'
}
sweep_config['metric'] = metric
parameters_dict = {
"training.optimizer.learn_rate": {
"max": 0.002,
"min": 0.0005,
"distribution": "uniform"
},
"training.dropout": {
"max": 0.2,
"min": 0.05,
"distribution": "uniform"
},
}
sweep_config['parameters'] = parameters_dict
sweep_id = wandb.sweep(sweep_config, project="registered-nurse")
wandb.agent(sweep_id, train_spacy, count=20)
if __name__ == "__main__":
typer.run(main)the folder structure:
and I am running the sweep like this Any ideas what exactly triggers? Btw, I've validated that |

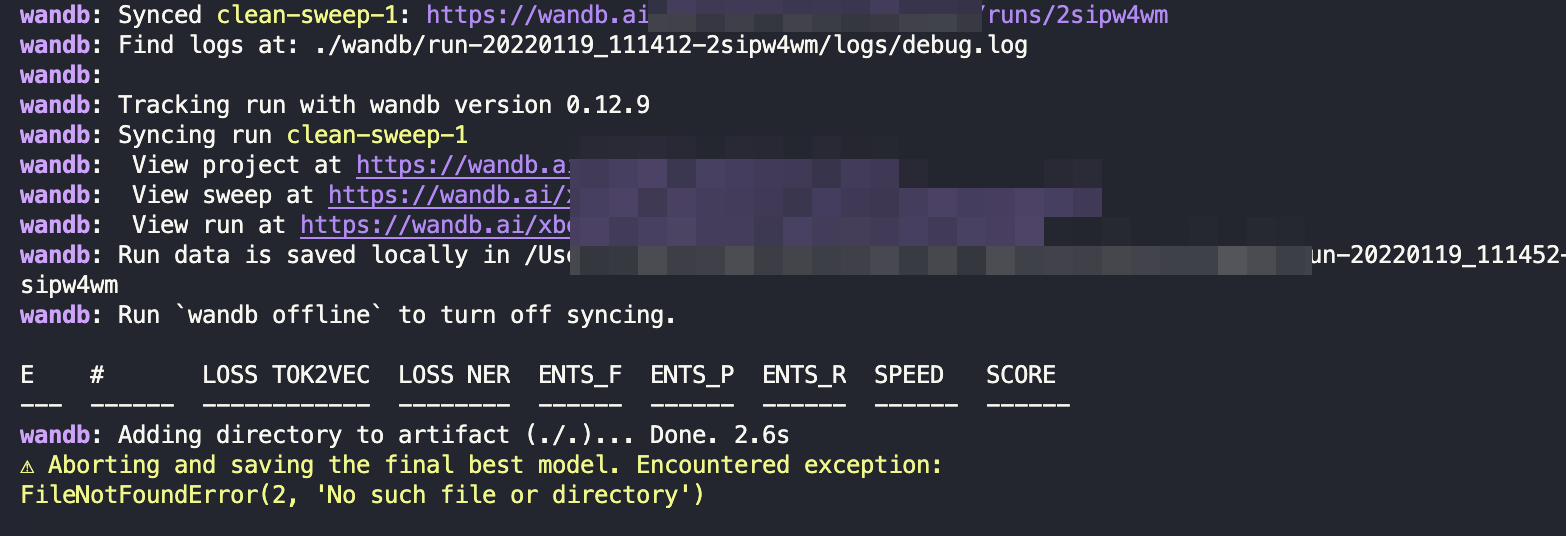
Beta Was this translation helpful? Give feedback.
Replies: 2 comments 3 replies
-
|
I generated a new config with |
Beta Was this translation helpful? Give feedback.
-
|
Hello, and running the same command |
Beta Was this translation helpful? Give feedback.
-
|
Yep, same issue :( |
Beta Was this translation helpful? Give feedback.
-
|
Maybe this issue is happening when the script tries to save the model and the output path |
Beta Was this translation helpful? Give feedback.
-
|
I can't believe it was it, need to take a break :) Thanks @thomashacker As you said, I'm used to spaCy creating of folders, so I was not expecting it. |
Beta Was this translation helpful? Give feedback.
Hello,
At the moment I can only guess. Have you tried changing the paths to:
and running the same command
python sweep.py spacy/config.cfg training/?