Training of a Custom Object Cont. #137
Comments
|
The camera info published by the realsense camera looks correct. However, the dimensions are wrong. The config_pose.yaml file expects centimeters, and you chair is definitely not 2147 x 3258 x 2171 centimeters big. Maybe multiply it with the 0.03 value from the fixed_model_transform? By the way: Don't take photos from your mobile phone if possible.
|
|
I have updated my previous post with the images exported as you suggested, the phone pictures into direct text and the cuboid_dimensions multiplied by .03, but it is still shows detected_objects=[]. The size of the images ROS takes is 640x480 as per the exports by |
|
Can you look at the belief maps?
…On Tue, Aug 11, 2020 at 11:16 AM Franco Ribera ***@***.***> wrote:
I have updated my previous post with the images exported as you suggested,
the phone pictures into direct text and the cuboid_dimensions multiplied by
.03, but it is still shows detected_objects=[].
What would be the next debugging step?
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#137 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/ABK6JIAUIP23UEKBDB7NDXDSAGDJTANCNFSM4P26GEXQ>
.
|
|
I am not sure how to do this. |
|
I am working on a new version of DOPE and it includes this debug. |
|
I upgraded my dope to UE 4.24 and that's what I've been working with. Haven't finalized upgrading to 4.25... Related to the thread, I will export tomorrow first thing in the morning my dataset again with multi-colored materials and better camera angles and start training. While it does that I will add this function to the code so I can see the maps you are looking for... |
|
It's probably best to first show the belief maps before retraining. The belief maps are useful because there's a two-step process during inference:
Visualizing the belief maps helps narrow down the problem. If the belief maps look crappy, you know that you need to retrain the network. If the belief maps look ok, you know that the problem is elsewhere (camera_info, wrong bounding box dimensions, ...). I suspect your "dimensions" are still not correct. If you're going to export your dataset again, please make double sure that the scaling and bounding box center of your model is correct. I've always found it easiest to use meters (or centimeters) for the mesh and to move the mesh origin to the center of the bounding box. In meshlab, you can visualize this via "render -> show box corners". For example: Here's the corresponding {
"exported_object_classes": [
"getriebelager"
],
"exported_objects": [
{
"class": "getriebelager",
"segmentation_class_id": 155,
"segmentation_instance_id": 13841190,
"fixed_model_transform": [
[ 0, 0, 100, 0 ],
[ 0, -100, 0, 0 ],
[ 100, 0, 0, 0 ],
[ 0, 0, 0, 1 ]
],
"cuboid_dimensions": [ 10.569199562072754, 26.933900833129883, 14.880499839782715 ]
}
]
}And here's my topic_camera: "/ensenso/rgb/image_rect_color"
topic_camera_info: "/ensenso/rgb/camera_info"
topic_publishing: "dope"
input_is_rectified: True
downscale_height: 400
weights: {
"getriebelager":"package://hybrit_dope/weights/getriebelager_68.pth"
}
# Cuboid dimension in cm x,y,z
dimensions: {
"getriebelager": [10.569199562072754, 26.933900833129883, 14.880499839782715]
}
class_ids: {
"getriebelager": 1
}
draw_colors: {
"getriebelager": [228, 26 , 28]
}
# optional: provide a transform that is applied to the pose returned by DOPE
model_transforms: {
"getriebelager": [[ 0, 0, 1, 0],
[ 0, -1, 0, 0],
[ 1, 0, 0, 0],
[ 0, 0, 0, 1]],
}
# optional: if you provide a mesh of the object here, a mesh marker will be published for visualization in RViz
meshes: {
"getriebelager": "package://hybrit_objects/meshes/getriebelager/getriebelager.stl",
}
# Config params for DOPE
thresh_angle: 0.5
thresh_map: 0.01
sigma: 3
thresh_points: 0.1
# Depth image based post processing
# uncomment topic_depth to enable post processing
topic_depth: "/ensenso/depth/image_rect"
# maximum depth distance (in meters) between recognized pose and true pose in depth image
depth_tolerance: 0.30
# Minimum ratio between valid points (= not NaN, within depth_tolerance) in actual depth image and expected points in
# in rendered depth image. Detections below min_valid_points_ratio will be discarded. In practice, false positives
# almost always have 0 valid points, whereas true positives range between 0.02 and 0.70 (depending on object and
# camera).
min_valid_points_ratio: 0.01You can see that:
|

|
Thanks a lot for this reply! I clearly had some export discrepancies. The way it was: I had to modify the origin in blender to something else than 0 0 0 to get 0 0 0 in Meshlab interestingly (struggled 40min), even though my origin of the object is in the world origin. Now it looks like this: |



|
Now that looks much better! Did you re-measure if the dimensions fit your actual chair? Just to be sure. BTW, you can also center the object directly in Meshlab by using |
|
Thanks! I actually measured the chairs in the office this time to make a realistic object, not just "some 3D model", hehe! I am replacing the actors' meshes with the new chairs and then will reexport + retrain |
|
I have been training now for a day, it's at Crossing fingers so that by epoch 60 we see better results... My current question: is 13 epochs and such a low loss a good/bad sign, and 13 epochs too soon to test on ROS? |
Bad sign.
Not too soon. Looking forward to the belief maps! |
|
Hello guys What the camera sees: I don't know how to proceed from now on... I thought my dataset was well made. |


|
Could you please upload a small sample of your dataset (like 100 random images, your mesh + all the relevant yaml files) somewhere? |
|
Thanks! Could you also upload the chair STL model? |
|
Done! |
|
just the stl model of the chair would be enough |
|
It's all there 👍 |
|
Something is still seriously wrong with your With your fixed_model_transform in , nothing happens: I have fixed it: Now you can switch on and off the mesh:
However, I'm not sure if that's a problem. After all, your other json files look ok, particularly the Maybe better delete the *.cs.png files from your dataset, I'm not sure if that confuses DOPE. Also maybe try again without the color randomization. Other than that, I'm a bit lost. Maybe the problem is that most projected corners do not lie on (or near) the object (see my screenshot above). @TontonTremblay : Do you think that's the problem? |


|
Ok so I have learned that the way to "fix" the With this setup the fixed model transform looks like this Where the last row is for the coordinates of where in the world the object stands, I can manually modify that one I guess..? Since the network doesn't need to know the object is not in the "center" of the world/scene I will retrain then with these new setup you indicate and without color randomization (maybe subtle randomization black-dark gray colors). Edit: So the Do you think the Segmentation Class Id should be the same across all json files? |
|
By epoch 3, the loss is already very low.. I will wait a bit more, and then generate the feature maps again.. Maybe given the point you made about
I can try fixing it by training on the chair model without the recliner, so that it is at the level of the arm-rests, I will play around with this. I also will share a dropbox link with the new/current dataset sample and config again at the end of the day when I test. |
Maybe it's better if you only train on the black parts of the chair. The metal parts are very thin, so that's probably the bigger problem. |
|
I have been training and I think I found the error since the loss is looking a lot more normal (0.0025 is good?). Will test today after 20 epochs and show u results + belief maps. By the way do we have any kind of records of at which Hz speed does Dope work? |
|
So we have some progress this time, after 30 epochs!
These are my belief maps, they look good! (i think?)
|


|
Okay so i tracked down the error my openCV version is 4.2 and the error is in line I downgraded opencv to 3.4 and i got this:
Do you think its because im at home and i am playing from a rosbag? I missed a couple values DKG from the camera_info :/ will try this in a couple of days. I need to finish another task before thursday. Either way this is good news, im happy for all the patience and support, we will see how this ends up this week :) |


Yes, that looks good. Also your belief maps look perfect! How did you fix the problem?
That should still work in OpenCV 4, so you could try changing that line to elif CuboidPNPSolver.cv2majorversion >= 3:
That still looks like the solvePnP step failed for some reason. DOPE is tested with OpenCV 3.3.1. It's probably best if you just use the Docker image, at least for now. |
|
I did that but still gave me an error. Related to how I made it work... I falsely assumed from the documentation that the class name given in TagActor is something independent. I assumed that the folder name would be the class name given in the --object parameter. Before (assumed it was folder name) After (or just skip the whole parameter since I'm only feeding one object in the folders) I have been using the docker image to train (cluster), and testing the network directly on a separate laptop (host, not container) which has ROS, etc. |
|
So I have been able to log in to my machine (not in the office yet) and the network has trained nicely and always returns something :) here are the belief maps, i dont know why v4 and v5 always look a bit funny but the rest look good right? |

|
Yes, this looks good. Probably v4 and v5 are the two bbox corners that are "in the air" furthest away from the chair, so they are the hardest to predict. But I believe these results should be more than good enough for object detection. |
|
Hello! |

That's easy: In your config_pose, provide the scaling factor to meters: # optional: If the specified meshes are not in meters, provide a scale here (e.g. if the mesh is in centimeters, scale should be 0.01). default scale: 1.0.
mesh_scales: {
"cracker": 0.01,
"gelatin": 0.01,
"meat": 0.01,
"mustard": 0.01,
"soup": 0.01,
"sugar": 0.01,
"bleach": 0.01,
} |
|
Good news! only thing now is that it is rotated, i will find the axis...
|

|
Congratulations! When you have found the transformation, you should put it into your Do you mind uploading the trained weights and your mesh file somewhere? We have the same chairs in our office and I would love to try it out myself. |
|
Hello! Of course! Here is the dropbox with the videos of my performance and the weights + config: https://www.dropbox.com/sh/dz5wybaqf2evzco/AABBMsfJXeLK46FUBzra5KzUa?dl=0 Let me know if you have any feedback. Is the visualization where it tries to fit the mesh with the real model always blinking like this? It would be cool if there was some post-processing step. Do you know if can I enable the |
|
Also with two chairs (multiple objects), is it supposed to show multiple poses at the same time? since it only shows one at a time (second video). |
|
Additionally, sometimes the mask export doesn't work for me, some 3d models are properly exported with a white mask, and the others, for example the base models (this is a cylinder) from UE4, do not export a mask (as shown below, they export black and merge with background == no mask?) Edit: The only way I got this to work 👍 and to export me a mask is to go back to blender and merge the "new" object with an "old" object, then export the .fbx and import to UE4, then the model has "some property i dont know about which old objects have and new ones dont" and the mask shows when exporting (but then the cylinder model inside UE4 should have it...). Made an issue to ask about it in the meantime at: NVIDIA/Dataset_Synthesizer#86 but I am not very hopeful they will answer. |




|
@thangt Hey thang have you seen this problem before? Very cool results. This is very cool to see things come together like this :P |
|
Very nice! Could you please also upload your chair.stl (or even better, a mesh with colors)?
I fixed that in #120, but @TontonTremblay still has to merge that PR. (@TontonTremblay: could you please also merge #121 while you're at it?).
That's not merged into master yet, and I haven't opened a pull request since it's a rather large change and I don't know if @TontonTremblay wants it here. So for now, you'll have to use the "hybrit" branch of my fork: https://github.com/mintar/Deep_Object_Pose/tree/hybrit This will mainly correct the depth value of the objects and remove some false positives (like the huge chair around 0:30 of 20200908_205148.mp4):
Yes, it's supposed to detect both. You can see that it briefly detects both at around 0:58:
DOPE can definitely work better than in your videos with tabletop objects, but I guess your objects are quite hard to detect by DOPE, so I'm happy it works as well as it does. |


I have added an STL and an FBX into the dropbox link so you get both just in case, should be colored but they never arrived colored into UE4 (materials import was quite an adventure).
okay i will check this one out then, I guess it is a 4.22 version? I will have to update it to 4.24. Also, it would be cool to be able to test the results after training without ROS per se, I saw a related post but I am trying to implement a solution where a docker-compose file creates a container that replays a rosbag, and then another one which feeds from that and processes the feed (say, dope or some other network). |
It doesn't matter. The UE4 version is only relevant for generating the training data. Once you have the images, you can use any DOPE version you want with it. |
|
Ah, woops. |
|
Hello I measured the prediction time and it averages around 470-560 ms. This is a scary question but, is there a way to speed it up ? I am wondering if a prediction time of 100ish ms is possible... Edit: I might be testing on a CPU, i will double check. Python 3 timing: |
|
Also I see that there is an X11 mount on the run-with-docker, but I dont find how to VNC into the container? Should I install a vnc server myself etc? |
|
re: #137 (comment) I just merged the MR, I am sorry I did not do it ealier. Your problems with flickering should be solved now. |
|
I tried to mess around with NDDS and I am a bit confused about the GroupActorManager (GAM), and I can't find docs for it. Questions:
My settings:
|



|
Kind of to provide an update to everyone: Related to the question above, I ended up finding a way to modify the mesh of the objects generated but decided to not go into that direction, based on my doubts below. My dataset generation takeaways so far: 🔵 Setup1: static chairs + OrbitalMovement camera = DOPE worked 🔵 Setup2: RandomRotation, RandomMovement chairs+ OrbitalMovement camera = DOPE worked BUT the results come out as None None None None quaternions... 🔵 Setup3 (current): Mixed the RandomRotation+ static datasets generated and I am training again. I refuse strongly to believe that we cannot train with a RandomRotation. ❓ Question 1 ❓ Question 2 🔵 What losses have you achieved yourself on your previous trainings? |
I am trying to train on some chairs, for which I setup 4 different photorrealistic scenes in UE4.
My dataset is made of 20k images per location in the scene, being 20k x 5 x 4 = 400k images.
A sample of what my dataset looks like:







Right now the export size is 512x512. Should I be increasing the size of the pictures the Network takes in? I have an OrbitalMovement in the camera that goes from 200 to 500, so I get some really close up photos and some distant ones, as shown here:
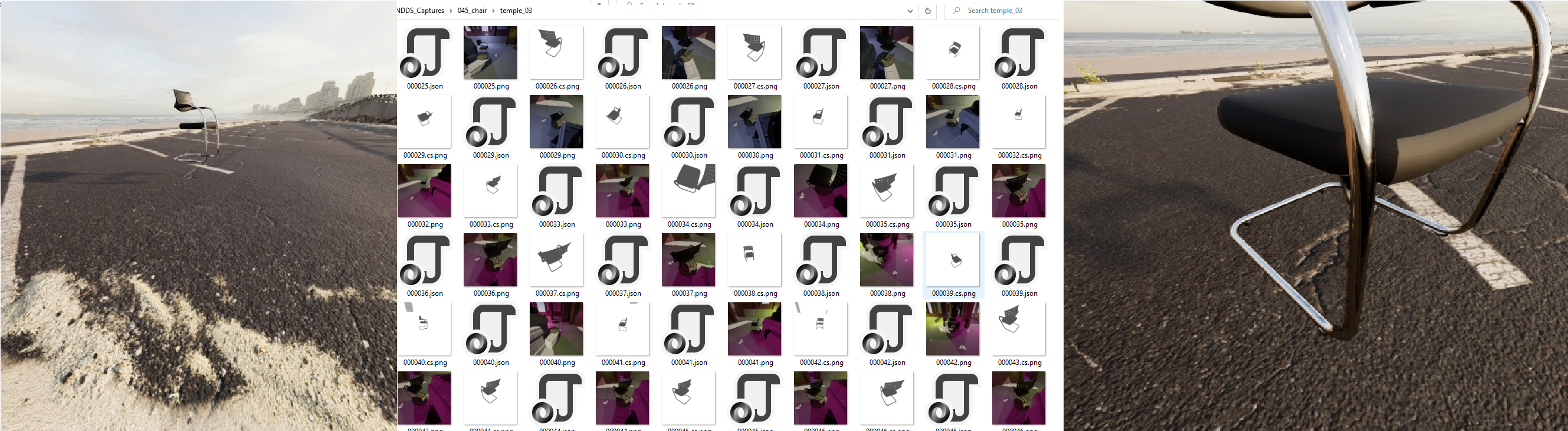
Examples of the pictures that ROS is seeing are:
Some questions that are cluttering my mind:
Additional Side info:
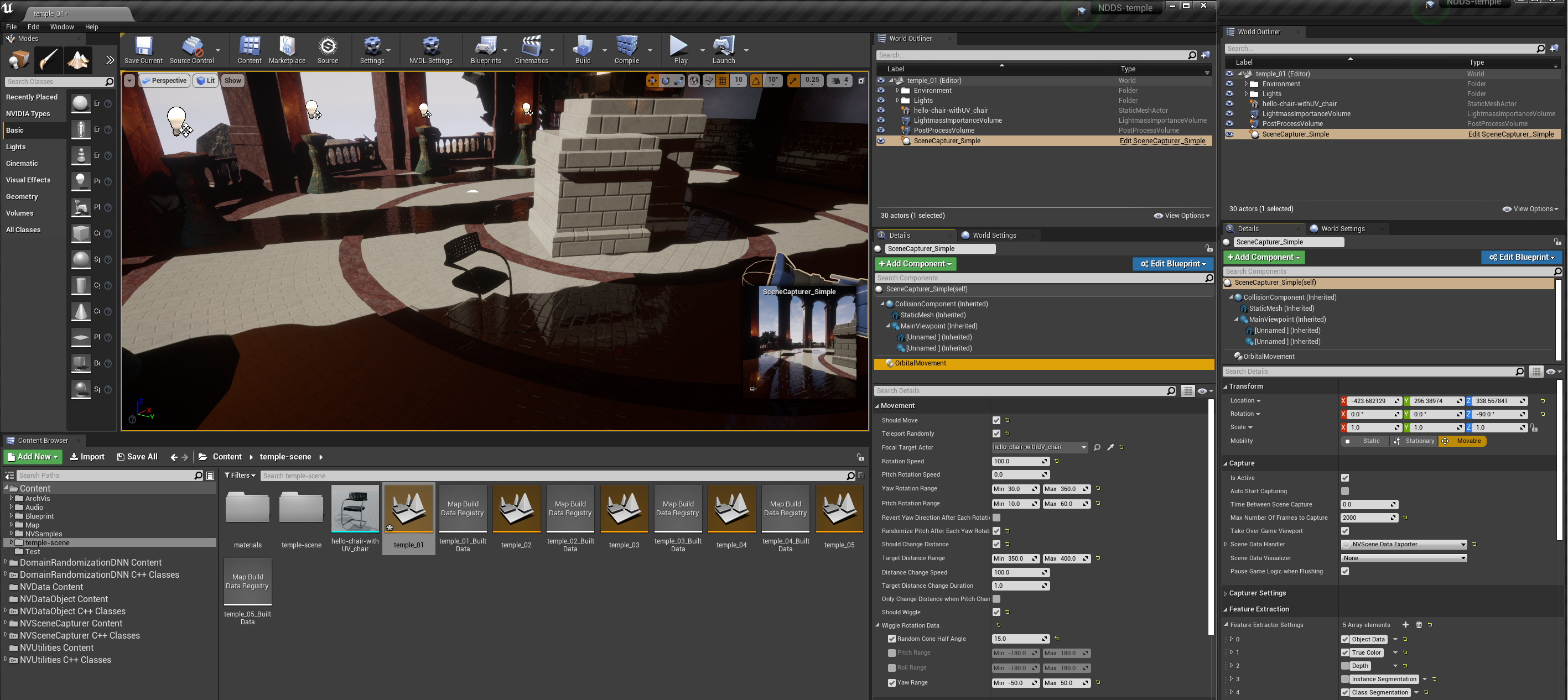
SceneCapturer info:
Thanks for taking the time to help me
Friendly regards,
The text was updated successfully, but these errors were encountered: