Investigate why access performance isn't improved uniformly by repacking metadata #19
Description
On the files we tested over Antarctica, repacking the metadata with h5repack didn't improve access times in a dramatic way, specially for xarray and h5py. These granules contained a lot of data and each was around 6GB, with ~7MB of metadata. They were selected and processed using this notebook
e.g. ATL03_20181120182818_08110112_006_02.h5 ~7GB in size and 7MB of metadata
Note: The S3 bucket with the original data is gone but can be easily recreated.
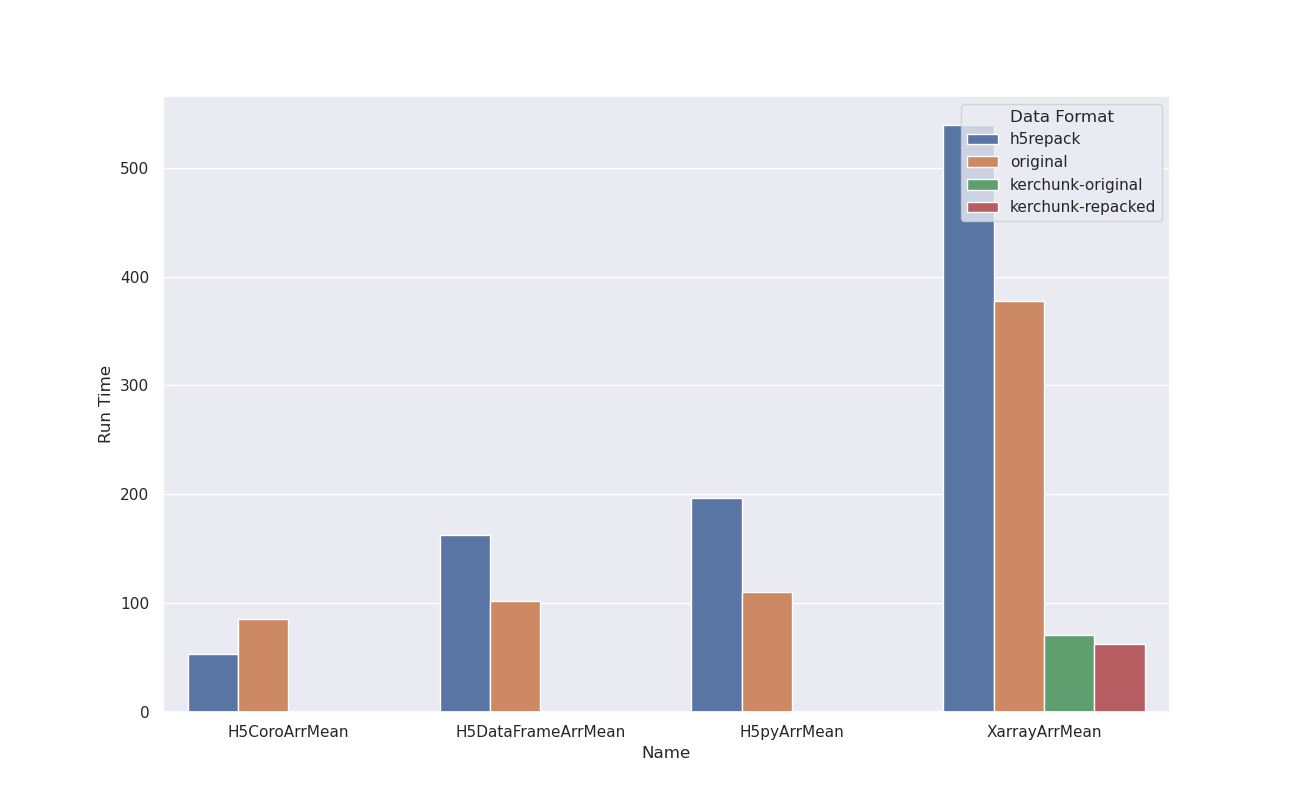
However for other granules with less data, repacking represented a 10X improvement for xarray
e.g. ATL03_20220201060852_06261401_005_01.h5 ~500MB in size and 3MB of metadata
After applying h5repack to both files the access time to the first one is not improved for xarray but it is improved from 1 minute to 5 seconds for the second granule, why?
group = '/gt2l/heights'
variable = 'h_ph'
with s3.open(file, 'rb') as file_stream:
ds = xr.open_dataset(file_stream, group=group, engine='h5netcdf')
variable_mean = ds[variable].mean()I'm going to repack the original files and put them on a more durable bucket, along with more examples from other NASA datasets.
Maybe @ajelenak has some clues on why this may be happening.
### Tasks
- [ ] https://github.com/ICESAT-2HackWeek/h5cloud/issues/28
- [ ] https://github.com/ICESAT-2HackWeek/h5cloud/issues/29
- [ ] https://github.com/ICESAT-2HackWeek/h5cloud/issues/27
- [ ] https://github.com/ICESAT-2HackWeek/h5cloud/issues/25
- [ ] https://github.com/ICESAT-2HackWeek/h5cloud/issues/24
- [ ] https://github.com/ICESAT-2HackWeek/h5cloud/issues/23
- [ ] https://github.com/ICESAT-2HackWeek/h5cloud/issues/26
### Tasks