kNN is a simple, instance-based unsupervised machine learning algorithm. kNN is a non-parametric and employs lazy-learning.
- Non-parametric means there is no assumption of the underlying data-distribution, meaning that the model structure is determined from the dataset.
- Lazy-learning implies that there is no need for a training data-points for model generation. This is because all training data is used during the testing phase.
When applied to the domain of anomaly detection kNN is a wonderful candidate, however it does come with the caveat of being somewhat costly during the testing phase (model.predict())
Our implementation is fully unsupervised, meaning it does not depend on labels, and is concerned only with X variables.
kNN algorithm can be broken into three high-level steps.
- Calculate distance between neighbors
- Find closest neighbors
- Vote for labels (normal/anomalous)
Our implementation relies on Manhattan Distance (Taxicab Geometry) for determining the distance between Zeek conn.log events.

The above formula simply calculates distance by using an absolute sum of difference between its cartesian co-ordinates
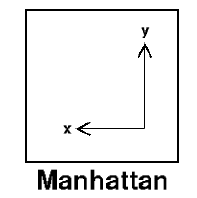
We chose this heuristic because it tends to work better on high-dimensional spaces compared to the more common Euclidean distance which excels in 2 dimensional space.
| Feature | Description |
|---|---|
| duration | The amount of time between the beginning and end of a connection. |
| orig_bytes | The number of bytes sent (not including header) |
| orig_ip_bytes | The number of bytes sent (including header) |
| resp_ip_bytes | The number of bytes received (including header) |
| resp_pkts | The number of packets received |
| id.resp_p | The port number that the recipient is listening on (more often than not this is a common service port) |
Once kNN returns the distance to the neighboring data points we calculate k-means which will return the distance to the centroids of clusters and you will have a general representation of your clusters.
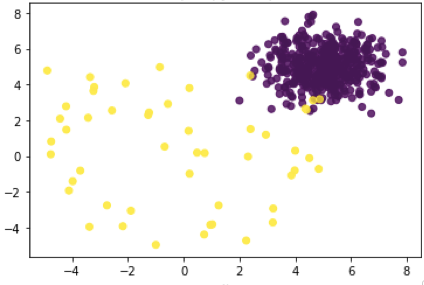
- Closely clustered - represent your "normal"
- Loosely clustered - represents your "anomalous"
Each object then "votes" for their class and the class with the most votes is taken as the prediction.
- Limit the dimensionality of your data, kNN can be very computationally expensive during the testing (prediction) phase. kNN performed significantly slower when additional features were introduced.
- Choose your features wisely. The algorithm is only as good as the data we "train" it on. We intentionally chose features that describe an application protocols "behaviors".
- This algorithm missed several events that, based on our criteria, were anomalous. For best results this algorithm should be used alongside other anomaly detectors which can help cut down on false-positives and false negatives.