| title | date |
|---|---|
Java基础 |
2019-10-08 17:33:50 -0700 |
自用的一些笔记,P35之前都是一些用处不大,没必要进行记录的部分,坚持每周一次内容更新。以下所有记录的都是个人认为有必要注意,了解透彻的部分,如有错误还望读者及时指出、批评。
2019年10月9日凌晨创
byte b = 10;
short s = 20;
int i = 30;
long x = 8888888L;
/*
*byte占一个字节 -128 - 127
*short 2 bytes
*int 4 bytes
*long的话要在最后用 L 声明 8 bytes
*不用小写小写L因为小写L很像数字一
*/
//浮点类型
float f = 12.3; // 4 bytes
double d = 33.4; // 8 bytes 默认数据类型
//float要末尾加F或者f 否则会把数字12.3看成double类型,大数据类型装进小数据类型中,损失精度
//字符类型 2 bytes
char c = "1";
//布尔类型 1 bit
boolean b1 = true;
boolean b2 = false;
声明变量之后,如果要使用的话,一定要先赋值。
int a; // 这里只是declare了但是没assign value
System.out.println(a);
//会报错
//但是输出去掉的话就不会//隐式转换
int x = 3;
byte b = 4;
x = x + b;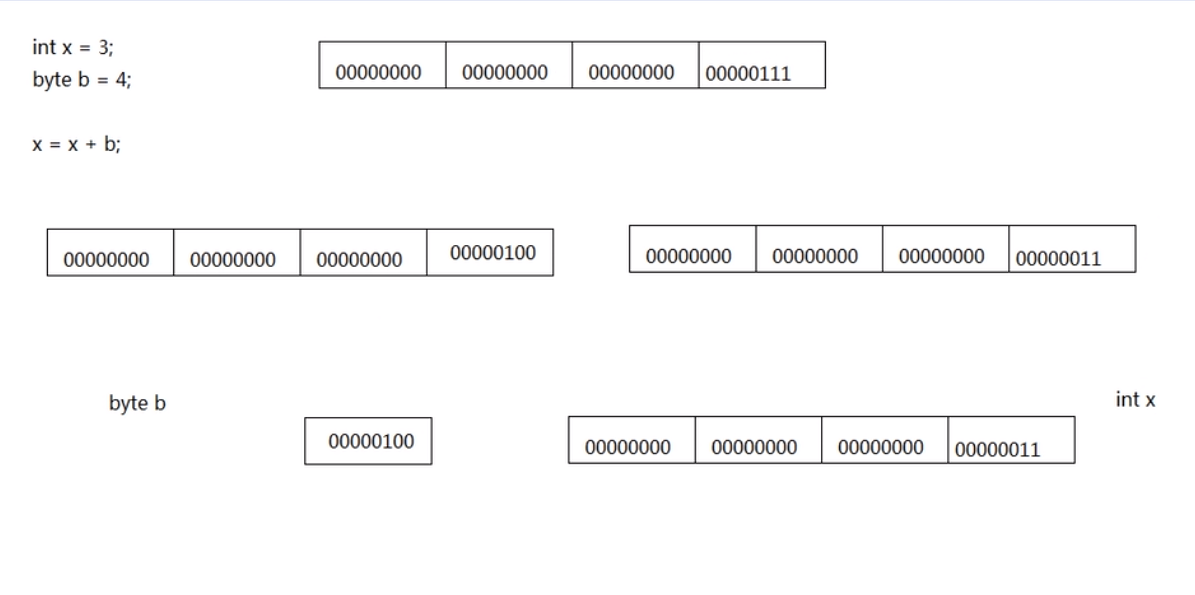
这里会先把byte类型转成int类型(在计算机底层)
int x = 3;
byte b = 4;
b = (byte)(x + b); //这里是大的(int)往小的(byte)里装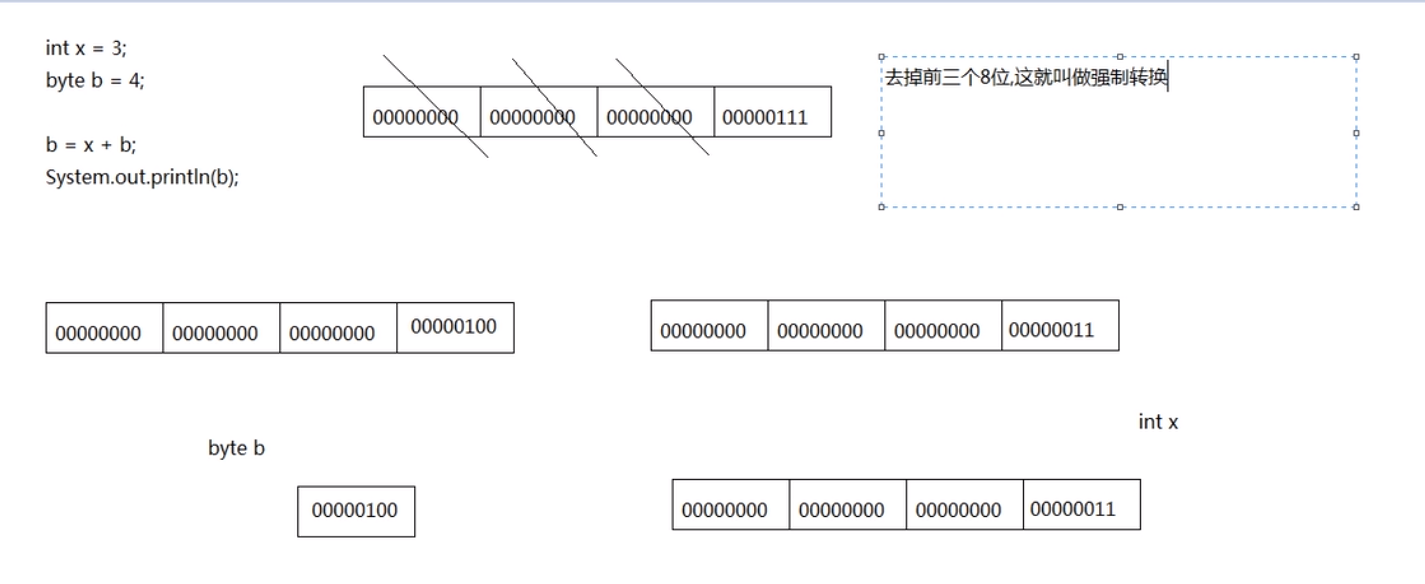
/* ### 注意事项 1 ###
* 如果出现赋值超出数据类型最大限度
* 还要进行强制转换的话会出现结果
* 与预期不相同
*/
//00000000 00000000 00000000 10000010
//10000010 -126补码 (-1求反码)
//11111110 -126源码
byte b = (byte)(126 + 4);
//输出的结果为-126
/* ### 注意事项 2 ###
* 变量相加和常量相加结果不一样
* 变量相加会直接转换成int类型
* 常量不变
*/
byte b1 = 3;
byte b2 = 4;
byte b3 = b1 + b2; //变量相加
//会报错 因为b1+b2已经上升到int层面
//从新赋值给b1会报错
byte b4 = 3 + 4; //java编译器自带常量优化机制,他会检测3+4在不在byte类型的取值范围float f = 12.3f;
long x = 12345;
f = x; //隐式转换 (装得下)
x = (long)f; //强制转换(砍掉小数点之后)解答:
float占4个字节
32个二进制位
1个位代表符号位
8个位代表指数位(2的指数位)
00000000 - 11111111
0 -255
IEEE754
0代表0
255代表无穷大
剩下1 - 254
规定还要回减127
-126 - 127
(Long最大值是2^63 - 1)
23个位代表尾数位
System.out.println('a' + 1);
//输出结果为98
System.out.println(char('a' + 1));
//输出结果为b
System.out.println("hello" + 'a' + 1);
//helloa1
System.out.println('a' + 1 + "hello");
//98hello
//与字符串用加号连接的数据类型之后都会产生一串新的字符串char的取值范围是 0 - 65535
char类型可以存储中文,因为java使用Unicode编码,char占两个字节,中文也是2个字节(一个char只能存一个中文)
// &, |, ^, !
//5 < x < 15不能再java中运行
//可以写成以下形式
//& : and
//| :or
x > 5 & x < 15;
//^ : exclusive& 和 && 的区别:&&具有短路效果,左面如果是false则右边不执行
| 和 || 的区别:||也具有短路效果,左面如果是true则右边不执行
++或--的使用注意事项:
a++ 和 ++a独立使用效果一样
但是涉及到赋值的时候或者运算的时候:
a++ 是当前a的值拿出去运算或者赋值,之后在进行自身+1的操作
++a 是先进行自身+1的操作然后再参与运算或赋值
//第一题
int x = 4;
int y = (x++) + (++x) + (x*10);
//结果为70 (4 + 6 +60)
//第二题 问哪句会报错
byte b = 10;
b++; // b = (byte)(b + 1)
//系统底层会进行这样的操作
b = b + 1;
//报错
//b + 1 虽然会提升为int进行相加
//但是b是byte 得到的结果是int 损失精度int x = 10;
int y = 5;
int z;
z = (x > y) ? x : y;
/* 如果x > y为true x的值赋给z
* 反之y赋给z
*/案例:
int a = 10;
int b = 20;
int c = 30;
//先比较任意两个数的大小,取大的
int temp = (a > b) ? a : b;
//用取得的大值和第三个比较
int max = (temp > c) ? temp : c;
System.out.println("max =" + max);以上为各种运算符的一个combination,有一些没加的默认成废话
//录入一个整数
import java.util.Scanner;
Class Demo2_Scanner {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("请输入一个整数:");
int x = sc.nextInt();
}
}//两个
import java.util.Scanner;
Class Demo2_Scanner {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("请输入第一个整数:");
int x = sc.nextInt();
System.out.println("请输入第二个整数:");
int y = sc.nextInt();
}
}从上往下(Sequence)(废话...)
注意事项:
条件语句的结果必须是boolean类型?
如果 if 语句控制的语句体是简单的一条语句,可以省略大括号(非常不建议!!!)
举例说明:
int age = 17;
if (age >= 18 && age <= 60) {
int x = 10;
}
/*
* 以上这个操作就会报错
* 因为int x = 10是两句话
* 第一句是 int x; 声明
* 第二句是x = 10; 赋值
*/好像也没什么要说的
也没什么要说的...
/* 基本格式
* switch(表达式) {
case 值1:
语句体1;
break;
case 值2:
语句体2;
break;
...
defaut;
语句体 N+1;
break;
}
*/- 基本数据类型 byte, short, char, int(能提升为int类型的都可以)
- 引用数据类型可以接受枚举(JDK 1.5) String字符串(JDK 1.7)
class Myclass {
public static void main(String[] args) {
int week = 5;
switch (week) {
case 1:
System.out.println("星期一");
break;
case 2:
System.out.println("星期二");
break;
case 3:
System.out.println("星期三");
break;
case 4:
System.out.println("星期四");
break;
case 5:
System.out.println("星期五");
break;
default:
System.out.println("没有该日期");
break;
}
}
}case之后只能跟常量不能是变量,而且case后的值不允许出现重复的情况
default就和else差不多,尽可能不要省略就完事了
break最后一个可以省略,但是其他的不建议省略,会出现case穿透
case穿透是指当表达式的那个值匹配上其中一个case的值之后,程序会一直向下(下方代码)执行语句,忽略case值,直到遇到break跳出为止。
default 可以放在任意为止,但是建议放在最后
//挺好玩的情况
int x = 2;
int y = 3;
switch(x) {
default:
y++;
case 3:
y++;
cese 4:
y++;
}
//以上代码中先判断case3和4,然后执行default,但是因为都没有break,
//所有3和4也都实行了(懒得打了...顺便看看图床还好用不)

switch 建议使用在判断固定值的时候使用
if 建议在在判断区间范围的时候使用
(switch 能做的 if 也都可以做)
循环的几个类别:for, while, do...while
这里只简单说一下do...while
int i = 1;
do {
System.out.println("i = " + i)
}
while (i <= 10);do...while至少要执行一次do中的循环体,即使判断条件不符合。
for语句和while语句的区别:
- for 语句执行后控制条件的变量会被释放,不能再使用。一般来说单纯的想起到循环功能的时候可以优先考虑。
- while 语句执行之后,判断条件的变量还可以继续使用(之前应该会有声明),最后这个变量的值可能会有其他的用途。
Mark标记:
我又偷懒了哈哈哈...
简单来说就是在循环的开头可以用一个合法的标识符加冒号,可以来指定特定的一个循环,然后即使是在最内部的一个循环,也可以通过break xxx的方式来终止任意一层循环。
基础的东西就不记录了,这里第一个记录的是 重载(Overload)
Definition:方法名相同,参数列表不同,与返回值类型无关
值得注意的一点是,方法中定义如果第一个是A类别,第二个是B类型,那么在传参的时候,如果把第一个填写成B类型,第二个是A类型的话会报错,所以注意让方法变得更加通用。
public static void main(String[] args) {
int sum1 = add(10, 20);
System.out.println(sum1);
int sum2 = add(10, 20, 30);
System.out.println(sum2);
}
public static int add(int a, int b) {
return a + b;
}
public static int add(int a, int b, int c) {
return a + b + c;
}
//以上,两个方法名字可以相同,所传递进去的数据个数或者类型可以不同,而且和他们返回的类型无关简单概述:数组是储存同一种数据量类型多个元素的集合,也可以看成是一个容器。
数组既可以储存基本数据类型,也可以储存引用数据类型。
//基本格式: 数据类型[] 数组名 = new 数组类型[数组长度];
int[] arr = new int[5]; //长度为5的整数数组
System.out.println(arr[0]);
System.out.println(arr); //输出结果一般长这样 [I@19bb25a以上值得注意的有三点
左边的"[]"代表的是数字,几个中括号就代表几维数组
初始化之后,不赋值的话
byte, short,int, long[]默认是0
String[]默认都是null
float, double[]默认都是0.0
char[]默认都是'\u0000'
char说一句,char在内存中占2 bytes,是16 bits
\u0000,每一个0代表的其实是16进制的0,(每一个16进制的单个位数可代表4位2进制)
所以这4个0也就代表的是16个二进制位
...
(有趣的是boolean[]默认的都是false)
[I@19bb25a 这个东西
最左面的 "[" 代表一维数组
"I" 代表 int 类型
"19bb25a" 代表hash code address (16进制)
int[] arr = new int[]{11, 22, 33, 44, 55, 66}; //不允许动静结合
//可以先声明再赋值(可以拆开)
int[] arr2 = {11, 22, 33, 44, 55, 66};
//必须写一起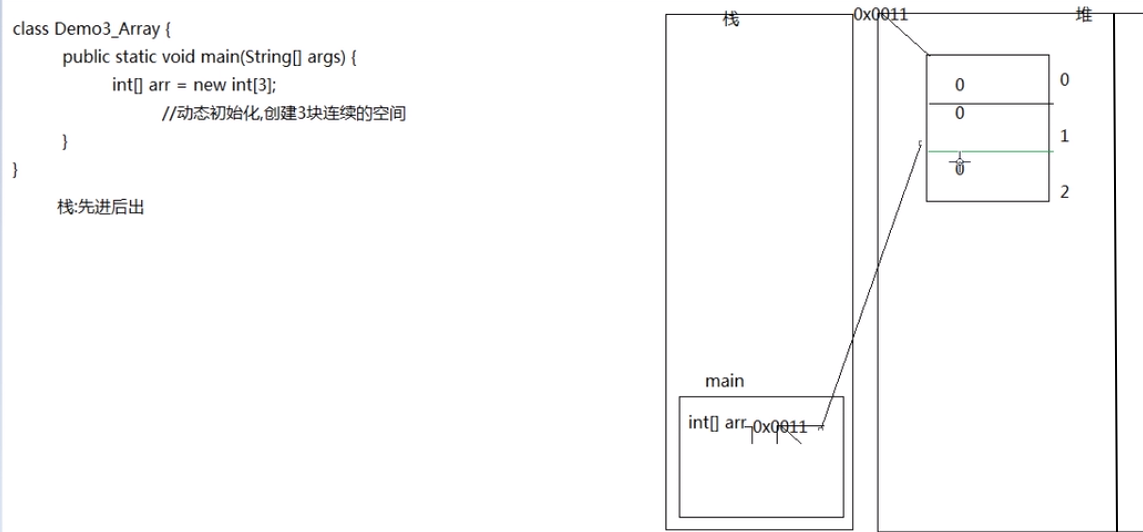
栈是先进后出(就和枪上子弹一样,先进的后出,后进的先出)
然后 int[] arr 语句会在栈里新的一块区域(虽然不确定但是感觉就和python里创造一个新的标签是一个意思),然后把实际的数据内容丢到堆里去创造,生成一个详细的地址,然后这个arr标签再指向这个地址。
public static void allElement(int[] arr) {
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}一般来说可以把这个先写好写成一个方法,然后直接去调用,看着好看简洁。
public static int getMax(int[] arr) {
int max = arr[0];
for (int i = 1; i < arr.length; i++) {
max = (max > arr[i]) ? max : arr[i];
}
return max;
}public static void reverseArray(int[] arr) {
for (int i = 0; i < arr.length / 2; i++) {
int temp = arr[i];
arr[i] = arr[arr.length-1-i];
arr[arr.length-1-i] = temp;
}
}public static int getIndex(int[] arr, int value) {
foor (int i = 0; i < arr.length; i++) {
if (arr[i] == value) {
return i;
}
}
return -1;
}基本格式
int [][] arr = new int[3][2];第一个数字3表示,有三个一维数组(行)
第二个数字2表示,有两个元素(个/行)
区别:
int x;
int y;
int x, y;
int[] x; //一维数组x
int[] y[]; //二维数组y
int[] x, y[]; //此处x是一维数组,y是二维数组内存图:

二维数组输出
//其实和Python格式一个样
int [][] arr = {{1, 2, 3}, {4, 5}, {6, 7, 8, 9}};
for (int i = 0; i < arr.legth; i++) {
for (int j = 0; j < arr[i].length; j++) {
System.out.print(arr[i][j] + " ");
}
System.out.println();
}还是会涉及到内存的栈
不多bb直接上例子
基本数据类型,只会在栈里操作
public static void main(String[] args) {
int a = 10;
int b = 20;
System.out.println("a" + a + ",b" + b); //a = 10, b = 20
change(a,b);
System.out.println("a" + a + ",b" + b); //a = 10, b = 20
}
public static void change(int a, int b) {
System.out.println("a" + a + ",b" + b); //a = 10, b = 20
a = b; //a = 20
b = a + b; //b = 40
System.out.println("a" + a + ",b" + b); //a = 20, b = 40
}在main里的a和b是只在main里的,调用change把a和b丢进去只是会有一个传值的过程,并不是说把a和b本身传进去。

运行完change之后会弹栈(出栈),基本数据类型的值传递,不改变原值,因为调用后就会弹栈,局部变量随之消失。
这里涉及到了引用数据类型,会有堆(heap)参与进来
public static void main(String[] args) {
int [] arr = {1, 2, 3, 4, 5};
change(arr);
System.out.println(arr[1]); //输出结果:4
}
public static void change(int[] arr) {
for (int i = 0; i < arr.length; i++) {
if (arr[i] % 2 == 0) { //凡是偶数的都会乘二
arr[i] *= 2;
}
}
}简易图解

在语句int[]出现之后会在堆(heap)里产生对应的一块空间,然后调用change()方法的时候会压栈(进栈)并且吧刚才的arr传进来,这个操作是对堆(heap)内的数据进行操作,main中的arr和change中的arr都指向的是一个地址,所以这次会发生改变,里面的最后结果是[1,4,3,8,5] 而不是[1,2,3,4,5]
引用数据类型的值传递,会发生改变原值的情况,因为即使方法弹栈,但是堆内存的数组对象还是存在的,可以通过地址访问到。
Java中到底是值传递还是地址传递
- 既是传值,也是传地址;基本数据类型传递的值,而引用数据类型传递的是地址
- 只有传值,因为地址值也是值(面试用这种说法,支持者是高斯林,java之父)