forked from elecrabbit/front-end-interview
-
Notifications
You must be signed in to change notification settings - Fork 1
/
Copy pathreact.md
300 lines (182 loc) · 22 KB
/
react.md
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
# React面试题
点击关注本[公众号](#公众号)获取文档最新更新,并可以领取配套于本指南的 **《前端面试手册》** 以及**最标准的简历模板**.
## React最新的生命周期是怎样的?
React 16之后有三个生命周期被废弃(但并未删除)
* componentWillMount
* componentWillReceiveProps
* componentWillUpdate
官方计划在17版本完全删除这三个函数,只保留UNSAVE_前缀的三个函数,目的是为了向下兼容,但是对于开发者而言应该尽量避免使用他们,而是使用新增的生命周期函数替代它们
目前React 16.8 +的生命周期分为三个阶段,分别是挂载阶段、更新阶段、卸载阶段
挂载阶段:
* constructor: 构造函数,最先被执行,我们通常在构造函数里初始化state对象或者给自定义方法绑定this
* getDerivedStateFromProps: `static getDerivedStateFromProps(nextProps, prevState)`,这是个静态方法,当我们接收到新的属性想去修改我们state,可以使用getDerivedStateFromProps
* render: render函数是纯函数,只返回需要渲染的东西,不应该包含其它的业务逻辑,可以返回原生的DOM、React组件、Fragment、Portals、字符串和数字、Boolean和null等内容
* componentDidMount: 组件装载之后调用,此时我们可以获取到DOM节点并操作,比如对canvas,svg的操作,服务器请求,订阅都可以写在这个里面,但是记得在componentWillUnmount中取消订阅
更新阶段:
* getDerivedStateFromProps: 此方法在更新个挂载阶段都可能会调用
* shouldComponentUpdate: `shouldComponentUpdate(nextProps, nextState)`,有两个参数nextProps和nextState,表示新的属性和变化之后的state,返回一个布尔值,true表示会触发重新渲染,false表示不会触发重新渲染,默认返回true,我们通常利用此生命周期来优化React程序性能
* render: 更新阶段也会触发此生命周期
* getSnapshotBeforeUpdate: `getSnapshotBeforeUpdate(prevProps, prevState)`,这个方法在render之后,componentDidUpdate之前调用,有两个参数prevProps和prevState,表示之前的属性和之前的state,这个函数有一个返回值,会作为第三个参数传给componentDidUpdate,如果你不想要返回值,可以返回null,此生命周期必须与componentDidUpdate搭配使用
* componentDidUpdate: `componentDidUpdate(prevProps, prevState, snapshot)`,该方法在getSnapshotBeforeUpdate方法之后被调用,有三个参数prevProps,prevState,snapshot,表示之前的props,之前的state,和snapshot。第三个参数是getSnapshotBeforeUpdate返回的,如果触发某些回调函数时需要用到 DOM 元素的状态,则将对比或计算的过程迁移至 getSnapshotBeforeUpdate,然后在 componentDidUpdate 中统一触发回调或更新状态。
卸载阶段:
* componentWillUnmount: 当我们的组件被卸载或者销毁了就会调用,我们可以在这个函数里去清除一些定时器,取消网络请求,清理无效的DOM元素等垃圾清理工作

> 一个查看react生命周期的[网站](http://projects.wojtekmaj.pl/react-lifecycle-methods-diagram/)
## React的请求应该放在哪个生命周期中?
React的异步请求到底应该放在哪个生命周期里,有人认为在`componentWillMount`中可以提前进行异步请求,避免白屏,其实这个观点是有问题的.
由于JavaScript中异步事件的性质,当您启动API调用时,浏览器会在此期间返回执行其他工作。当React渲染一个组件时,它不会等待componentWillMount它完成任何事情 - React继续前进并继续render,没有办法“暂停”渲染以等待数据到达。
而且在`componentWillMount`请求会有一系列潜在的问题,首先,在服务器渲染时,如果在 componentWillMount 里获取数据,fetch data会执行两次,一次在服务端一次在客户端,这造成了多余的请求,其次,在React 16进行React Fiber重写后,`componentWillMount`可能在一次渲染中多次调用.
目前官方推荐的异步请求是在`componentDidmount`中进行.
如果有特殊需求需要提前请求,也可以在特殊情况下在`constructor`中请求:[](https://gist.github.com/bvaughn/89700e525ff423a75ffb63b1b1e30a8f)
> react 17之后`componentWillMount`会被废弃,仅仅保留`UNSAFE_componentWillMount`
## setState到底是异步还是同步?
先给出答案: 有时表现出异步,有时表现出同步
1. **`setState `只在合成事件和钩子函数中是“异步”的,在原生事件和`setTimeout` 中都是同步的。**
2. **`setState` 的“异步”并不是说内部由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数的调用顺序在更新之前,导致在合成事件和钩子函数中没法立马拿到更新后的值,形成了所谓的“异步”,当然可以通过第二个参数 `setState(partialState, callback)` 中的`callback`拿到更新后的结果。**
3. **`setState` 的批量更新优化也是建立在“异步”(合成事件、钩子函数)之上的,在原生事件和setTimeout 中不会批量更新,在“异步”中如果对同一个值进行多次`setState`,`setState`的批量更新策略会对其进行覆盖,取最后一次的执行,如果是同时`setState`多个不同的值,在更新时会对其进行合并批量更新。**
## React组件通信如何实现?
React组件间通信方式:
* 父组件向子组件通讯: 父组件可以向子组件通过传 props 的方式,向子组件进行通讯
* 子组件向父组件通讯: props+回调的方式,父组件向子组件传递props进行通讯,此props为作用域为父组件自身的函数,子组件调用该函数,将子组件想要传递的信息,作为参数,传递到父组件的作用域中
* 兄弟组件通信: 找到这两个兄弟节点共同的父节点,结合上面两种方式由父节点转发信息进行通信
* 跨层级通信: `Context`设计目的是为了共享那些对于一个组件树而言是“全局”的数据,例如当前认证的用户、主题或首选语言,对于跨越多层的全局数据通过`Context`通信再适合不过
* 发布订阅模式: 发布者发布事件,订阅者监听事件并做出反应,我们可以通过引入event模块进行通信
* 全局状态管理工具: 借助Redux或者Mobx等全局状态管理工具进行通信,这种工具会维护一个全局状态中心Store,并根据不同的事件产生新的状态

## React有哪些优化性能是手段?
性能优化的手段很多时候是通用的详情见[前端性能优化加载篇](load.md)
## React如何进行组件/逻辑复用?
抛开已经被官方弃用的Mixin,组件抽象的技术目前有三种比较主流:
* 高阶组件:
- 属性代理
- 反向继承
* 渲染属性
* react-hooks
组件复用详解见[组件复用](abstract.md)
## mixin、hoc、render props、react-hooks的优劣如何?
Mixin的缺陷:
* 组件与 Mixin 之间存在隐式依赖(Mixin 经常依赖组件的特定方法,但在定义组件时并不知道这种依赖关系)
* 多个 Mixin 之间可能产生冲突(比如定义了相同的state字段)
* Mixin 倾向于增加更多状态,这降低了应用的可预测性(The more state in your application, the harder it is to reason about it.),导致复杂度剧增
* 隐式依赖导致依赖关系不透明,维护成本和理解成本迅速攀升:
- 难以快速理解组件行为,需要全盘了解所有依赖 Mixin 的扩展行为,及其之间的相互影响
- 组价自身的方法和state字段不敢轻易删改,因为难以确定有没有 Mixin 依赖它
- Mixin 也难以维护,因为 Mixin 逻辑最后会被打平合并到一起,很难搞清楚一个 Mixin 的输入输出
**HOC相比Mixin的优势:**
* HOC通过外层组件通过 Props 影响内层组件的状态,而不是直接改变其 State不存在冲突和互相干扰,这就降低了耦合度
* 不同于 Mixin 的打平+合并,HOC 具有天然的层级结构(组件树结构),这又降低了复杂度
**HOC的缺陷:**
* 扩展性限制: HOC 无法从外部访问子组件的 State因此无法通过shouldComponentUpdate滤掉不必要的更新,React 在支持 ES6 Class 之后提供了React.PureComponent来解决这个问题
* Ref 传递问题: Ref 被隔断,后来的React.forwardRef 来解决这个问题
* Wrapper Hell: HOC可能出现多层包裹组件的情况,多层抽象同样增加了复杂度和理解成本
* 命名冲突: 如果高阶组件多次嵌套,没有使用命名空间的话会产生冲突,然后覆盖老属性
* 不可见性: HOC相当于在原有组件外层再包装一个组件,你压根不知道外层的包装是啥,对于你是黑盒
**Render Props优点:**
* 上述HOC的缺点Render Props都可以解决
**Render Props缺陷:**
* 使用繁琐: HOC使用只需要借助装饰器语法通常一行代码就可以进行复用,Render Props无法做到如此简单
* 嵌套过深: Render Props虽然摆脱了组件多层嵌套的问题,但是转化为了函数回调的嵌套
**React Hooks优点:**
* 简洁: React Hooks解决了HOC和Render Props的嵌套问题,更加简洁
* 解耦: React Hooks可以更方便地把 UI 和状态分离,做到更彻底的解耦
* 组合: Hooks 中可以引用另外的 Hooks形成新的Hooks,组合变化万千
* 函数友好: React Hooks为函数组件而生,从而解决了类组件的几大问题:
- this 指向容易错误
- 分割在不同声明周期中的逻辑使得代码难以理解和维护
- 代码复用成本高(高阶组件容易使代码量剧增)
**React Hooks缺陷:**
* 额外的学习成本(Functional Component 与 Class Component 之间的困惑)
* 写法上有限制(不能出现在条件、循环中),并且写法限制增加了重构成本
* 破坏了PureComponent、React.memo浅比较的性能优化效果(为了取最新的props和state,每次render()都要重新创建事件处函数)
* 在闭包场景可能会引用到旧的state、props值
* 内部实现上不直观(依赖一份可变的全局状态,不再那么“纯”)
* React.memo并不能完全替代shouldComponentUpdate(因为拿不到 state change,只针对 props change)
> 关于react-hooks的评价来源于官方[react-hooks RFC](https://github.com/reactjs/rfcs/blob/master/text/0068-react-hooks.md#drawbacks)
## 你是如何理解fiber的?
React Fiber 是一种基于浏览器的**单线程调度算法**.
React 16之前 ,`reconcilation ` 算法实际上是递归,想要中断递归是很困难的,React 16 开始使用了循环来代替之前的递归.
`Fiber`:**一种将 `recocilation` (递归 diff),拆分成无数个小任务的算法;它随时能够停止,恢复。停止恢复的时机取决于当前的一帧(16ms)内,还有没有足够的时间允许计算。**
## 你对 Time Slice的理解?
**时间分片**
- React 在渲染(render)的时候,不会阻塞现在的线程
- 如果你的设备足够快,你会感觉渲染是同步的
- 如果你设备非常慢,你会感觉还算是灵敏的
- 虽然是异步渲染,但是你将会看到完整的渲染,而不是一个组件一行行的渲染出来
- 同样书写组件的方式
也就是说,这是React背后在做的事情,对于我们开发者来说,是透明的,具体是什么样的效果呢?
有图表三个图表,有一个输入框,以及上面的三种模式<br />**这个组件非常的巨大,而且在输入框**每次**输入东西的时候,就会进去一直在渲染。**为了更好的看到渲染的性能,Dan为我们做了一个表。
我们先看看,同步模式:<br /><br />同步模式下,我们都知道,我们没输入一个字符,React就开始渲染,当React渲染一颗巨大的树的时候,是非常卡的,所以才会有shouldUpdate的出现,在这里Dan也展示了,这种卡!
我们再来看看第二种(Debounced模式):<br /><br />Debounced模式简单的来说,就是延迟渲染,比如,当你输入完成以后,再开始渲染所有的变化。<br />这么做的坏处就是,至少不会阻塞用户的输入了,但是依然有非常严重的卡顿。
切换到异步模式:<br /><br />异步渲染模式就是不阻塞当前线程,继续跑。在视频里可以看到所有的输入,表上都会是原谅色的。
时间分片正是基于可随时打断、重启的Fiber架构,可打断当前任务,优先处理紧急且重要的任务,保证页面的流畅运行.
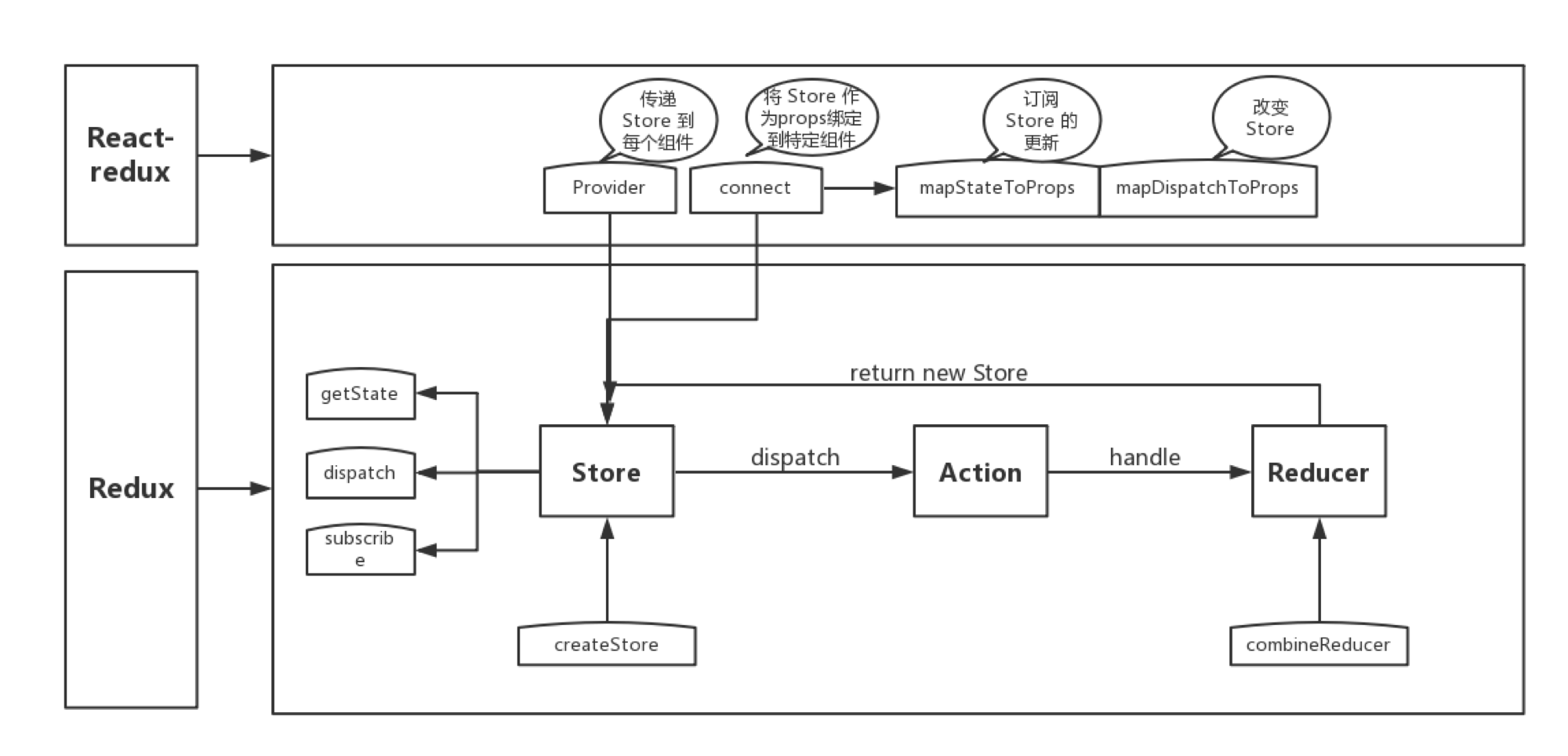
## redux的工作流程?
首先,我们看下几个核心概念:
* Store:保存数据的地方,你可以把它看成一个容器,整个应用只能有一个Store。
* State:Store对象包含所有数据,如果想得到某个时点的数据,就要对Store生成快照,这种时点的数据集合,就叫做State。
* Action:State的变化,会导致View的变化。但是,用户接触不到State,只能接触到View。所以,State的变化必须是View导致的。Action就是View发出的通知,表示State应该要发生变化了。
* Action Creator:View要发送多少种消息,就会有多少种Action。如果都手写,会很麻烦,所以我们定义一个函数来生成Action,这个函数就叫Action Creator。
* Reducer:Store收到Action以后,必须给出一个新的State,这样View才会发生变化。这种State的计算过程就叫做Reducer。Reducer是一个函数,它接受Action和当前State作为参数,返回一个新的State。
* dispatch:是View发出Action的唯一方法。
然后我们过下整个工作流程:
1. 首先,用户(通过View)发出Action,发出方式就用到了dispatch方法。
2. 然后,Store自动调用Reducer,并且传入两个参数:当前State和收到的Action,Reducer会返回新的State
3. State一旦有变化,Store就会调用监听函数,来更新View。
到这儿为止,一次用户交互流程结束。可以看到,在整个流程中数据都是单向流动的,这种方式保证了流程的清晰。

## react-redux是如何工作的?
* Provider: Provider的作用是从最外部封装了整个应用,并向connect模块传递store
* connect: 负责连接React和Redux
- 获取state: connect通过context获取Provider中的store,通过store.getState()获取整个store tree 上所有state
- 包装原组件: 将state和action通过props的方式传入到原组件内部wrapWithConnect返回一个ReactComponent对象Connect,Connect重新render外部传入的原组件WrappedComponent,并把connect中传入的mapStateToProps, mapDispatchToProps与组件上原有的props合并后,通过属性的方式传给WrappedComponent
- 监听store tree变化: connect缓存了store tree中state的状态,通过当前state状态和变更前state状态进行比较,从而确定是否调用`this.setState()`方法触发Connect及其子组件的重新渲染
## redux与mobx的区别?
**两者对比:**
* redux将数据保存在单一的store中,mobx将数据保存在分散的多个store中
* redux使用plain object保存数据,需要手动处理变化后的操作;mobx适用observable保存数据,数据变化后自动处理响应的操作
* redux使用不可变状态,这意味着状态是只读的,不能直接去修改它,而是应该返回一个新的状态,同时使用纯函数;mobx中的状态是可变的,可以直接对其进行修改
* mobx相对来说比较简单,在其中有很多的抽象,mobx更多的使用面向对象的编程思维;redux会比较复杂,因为其中的函数式编程思想掌握起来不是那么容易,同时需要借助一系列的中间件来处理异步和副作用
* mobx中有更多的抽象和封装,调试会比较困难,同时结果也难以预测;而redux提供能够进行时间回溯的开发工具,同时其纯函数以及更少的抽象,让调试变得更加的容易
**场景辨析:**
基于以上区别,我们可以简单得分析一下两者的不同使用场景.
mobx更适合数据不复杂的应用: mobx难以调试,很多状态无法回溯,面对复杂度高的应用时,往往力不从心.
redux适合有回溯需求的应用: 比如一个画板应用、一个表格应用,很多时候需要撤销、重做等操作,由于redux不可变的特性,天然支持这些操作.
mobx适合短平快的项目: mobx上手简单,样板代码少,可以很大程度上提高开发效率.
当然mobx和redux也并不一定是非此即彼的关系,你也可以在项目中用redux作为全局状态管理,用mobx作为组件局部状态管理器来用.
## redux中如何进行异步操作?
当然,我们可以在`componentDidmount`中直接进行请求无须借助redux.
但是在一定规模的项目中,上述方法很难进行异步流的管理,通常情况下我们会借助redux的异步中间件进行异步处理.
redux异步流中间件其实有很多,但是当下主流的异步中间件只有两种redux-thunk、redux-saga,当然redux-observable可能也有资格占据一席之地,其余的异步中间件不管是社区活跃度还是npm下载量都比较差了.
## redux异步中间件之间的优劣?
**redux-thunk优点:**
* 体积小: redux-thunk的实现方式很简单,只有不到20行代码
* 使用简单: redux-thunk没有引入像redux-saga或者redux-observable额外的范式,上手简单
**redux-thunk缺陷:**
* 样板代码过多: 与redux本身一样,通常一个请求需要大量的代码,而且很多都是重复性质的
* 耦合严重: 异步操作与redux的action偶合在一起,不方便管理
* 功能孱弱: 有一些实际开发中常用的功能需要自己进行封装
**redux-saga优点:**
* 异步解耦: 异步操作被被转移到单独 saga.js 中,不再是掺杂在 action.js 或 component.js 中
* action摆脱thunk function: dispatch 的参数依然是一个纯粹的 action (FSA),而不是充满 “黑魔法” thunk function
* 异常处理: 受益于 generator function 的 saga 实现,代码异常/请求失败 都可以直接通过 try/catch 语法直接捕获处理
* 功能强大: redux-saga提供了大量的Saga 辅助函数和Effect 创建器供开发者使用,开发者无须封装或者简单封装即可使用
* 灵活: redux-saga可以将多个Saga可以串行/并行组合起来,形成一个非常实用的异步flow
* 易测试,提供了各种case的测试方案,包括mock task,分支覆盖等等
**redux-saga缺陷:**
* 额外的学习成本: redux-saga不仅在使用难以理解的 generator function,而且有数十个API,学习成本远超redux-thunk,最重要的是你的额外学习成本是只服务于这个库的,与redux-observable不同,redux-observable虽然也有额外学习成本但是背后是rxjs和一整套思想
* 体积庞大: 体积略大,代码近2000行,min版25KB左右
* 功能过剩: 实际上并发控制等功能很难用到,但是我们依然需要引入这些代码
* ts支持不友好: yield无法返回TS类型
**redux-observable优点:**
* 功能最强: 由于背靠rxjs这个强大的响应式编程的库,借助rxjs的操作符,你可以几乎做任何你能想到的异步处理
* 背靠rxjs: 由于有rxjs的加持,如果你已经学习了rxjs,redux-observable的学习成本并不高,而且随着rxjs的升级redux-observable也会变得更强大
**redux-observable缺陷:**
* 学习成本奇高: 如果你不会rxjs,则需要额外学习两个复杂的库
* 社区一般: redux-observable的下载量只有redux-saga的1/5,社区也不够活跃,在复杂异步流中间件这个层面redux-saga仍处于领导地位
> 关于redux-saga与redux-observable的详细比较可见[此链接](https://hackmd.io/@2qVnJRlJRHCk20dvVxsySA/H1xLHUQ8e?type=view#side-by-side-**comparison**)
---
## 公众号
想要实时关注笔者最新的文章和最新的文档更新请关注公众号**程序员面试官**,后续的文章会优先在公众号更新.
**简历模板:** 关注公众号回复「模板」获取
**《前端面试手册》:** 配套于本指南的突击手册,关注公众号回复「fed」获取
